

Abstract
We propose a novel transformation called Lehmer transform and establish a theoretical framework used to compress and characterize large volumes of highly volatile time series data. The proposed method is a powerful data-driven approach for analyzing extreme events in non-stationary and highly oscillatory stochastic processes like biological signals. The proposed Lehmer transform decomposes the information contained in a function of the data sample into a domain of some statistical moments. The mentioned statistical moments, referred to as suddencies, can be perceived as the moments that generate all possible statistics when used as inputs of the transformation. Besides, the appealing analytical properties of Lehmer transform makes it a natural candidate to take on the role of a statistic-generating function, a notion that we define in this work for the first time. Possible connections of the proposed transformation to the frequency domain will be briefly discussed, while we extensively study various aspects of developing methodologies based on the time-suddency decomposition framework. In particular, we demonstrate several superior features of the Lehmer transform over the traditional time-frequency methods such as Fourier and Wavelet transforms by analyzing the challenging electroencephalogram signals of the patients suffering from the major depressive disorder. It is shown that our proposed transformation can successfully lead to more robust and accurate classifiers developed for discerning patients from healthy controls.
Subject terms: Neuroscience, Psychology, Mathematics and computing
Introduction
Analysis of the non-stationary spatiotemporal data is often a daunting task as it involves the mediation of the concepts, theories, and techniques often developed in several seemingly diverse areas of mathematical, statistical, engineering and computational sciences. Most notably, the non-stationarity of time series can be shown to have a subtle connection to the non-autonomous behavior of dynamical systems in which the oscillatory law governing the manifestation of a specific phenomenon itself undergoes various temporal changes. As a result, acquiring a relatively thorough understanding of any phenomenon that gives rise to the realization of highly oscillatory and complex time series data can only be accomplished simultaneously utilizing the instruments developed in statistical and dynamical systems theories.
Even though the concurrent use of the classical statistics framework alongside the dynamical systems theory can potentially encapsulate many valuable information about the observed time series data, little does it reveal the temporal nature of the laws governing widespread non-stationary processes. For instance, the non-autonomous behavior of the oscillatory systems is typically attributed to the influence of some external fields; in this respect, the dynamical systems theory could be a potential aid for analysis insofar as the external modulation source is known or strictly assumed to be deterministic, periodic, or stochastic. In a situation where the governing law of the external modulations itself may exhibit some sort of time-dependency, such approaches for studying the phenomena usually become less effective.
This work presents a data-driven model based on a new class of transformations to reliably infer the underlying laws of the non-stationary phenomena based on the time series data observed. The proposed mathematical model is shown to be a framework par excellence to exploit possible sources contributing to the occurrence of the extreme events in non-stationary stochastic processes and non-autonomous dynamics. To this end, we introduce, for the first time, the notions of the Lehmer transform and the so-called domain of suddency moments. Briefly stated, Lehmer transform decomposes the information contained in a function of the data sample into their constituting statistical moments. In other words, the Lehmer transformation can be perceived as domain representation on a space of certain statistical moments, which we refer to them as the suddency moments (or s-moments in short).
The domain of s-moments shares a number of similarities with the widely used frequency domain. However, unlike the frequency domain analysis whose focal point is the intrinsic periodicity of all phenomena observed in the nature, our proposed analytical framework frees the statistical moments domain from adhering to any restrictive assumptions such as the one mentioned above. We find it meritorious to mention that, the proposed Lehmer transform and its statistical moment domain can provide a set of complementary instruments for the traditional frequency-based frameworks, if not replace them entirely. In turn, this further enables one to construct parametric families of non-parametric statistical models, potentially bridging the existing gap between parametric and non-parametric areas of statistics.
Our proposed transform, named after the renowned number theorist Derrick H. Lehmer, has its mathematical roots in generalized means family. In particular, there exists a member of the mentioned family of functions known as the Lehmer mean, which has primarily been studied in specific branches of analytic number theory, to the best of our knowledge. Nevertheless, the appealing properties of this function have not received much attention from statistics, machine learning and data science communities in the past, leaving its wide range of potential applications largely unexploited in handling complex non-stationary time series such as biological signals.
Most existing works employing the Lehmer mean function for the purpose of data analysis, rely mainly on its special cases. For instance, Terziyan21 formulated a distance metric using the harmonic and contra-harmonic means and evaluated its effectiveness in geographic information systems. In a similar manner, Somasundaram et al.20 studied the disconnected graphs and their possible labeling schemes and Sluciak19 developed state-dependent consensus algorithms by resorting to applications of some special cases of the Lehmer mean function. Besides, Gomes11 successfully constructed a family of high-performance value at risk estimators through the use of this function and proved asymptotic normality of the constructed estimators.
On the other hand, being a generalization of the power mean function and having connections to other important classes of means, more attention has recently been geared towards the Lehmer mean function and its characterization. For instance, the function’s elementary properties like homogeneity, monotonicity and differentiability have been discussed in1,3, whereas its more advanced properties like Schur-convexity, Schur harmonic convexity and Schur power convexity have been the focus of more recent studies, e.g., see8–10,23,24 and references therein. Also, the inflection points of the function have been studied in18, and the results concerning its possible connections to Gini and Toader means have been provided in5–7,12,22,25.
In this article, we formally define the Lehmer transform and the domain of s-moments. Thereafter, we use the developed framework to study a benchmark electroencephalography (EEG) dataset of patients suffering from major depressive disorder (MDD), whose computational results are further provided and discussed in detail. Before that, however, we find it of great importance to clarify our motivations for introducing and laying out the theoretical foundations of this new transformation within the context of brain wave analysis and, in particular, the EEG analysis of MDD dataset.
Motivation
The proposed Lehmer transform is intrinsically a powerful method to summarize the information contained in any given set of data, whether sequential data like time series or unordered ones. More explicitly, this transform computes the ratio of two moments whose numeratorial and denumeratorial power difference is exactly one. Even though it might not be entirely clear at first glance, this mechanism leads to unraveling significant amount of salient information contained in the data that other transforms cannot capture.
On the one hand, from the statistical physics point of view, one would look at a given energy level through the use of various powers for the s-moments. On the other hand, from the classical statistics perspective, the Lehmer transform can be perceived as a statistic-generating function, i.e., one can generate all possible statistics such as sample mean, maximum, minimum, etc., by applying the Lehmer transform to specific values of the s-moments. Accordingly, all complex non-stationary signals can be formulated under one coherent and unified framework capable of concentrating on patterns that are difficult to capture otherwise by Wavelets or Fourier transforms.
More specifically, the main challenges and limitations confronted by analysts equipped with the frequency domain tools for analysis of EEG signals can be surmounted to a great extent by resorting to applications of our proposed framework:
-
Filtering the noise:
The raw EEG signals contain various artifacts arising from eye movements (horizontal and vertical), eye blinks as well as muscular and heart activities which require applying a set of suitable filtering techniques in the prepossessing step. However, the majority of the filtering techniques, in one way or another, require the data to satisfy certain number of conditions on stationarity. The EEG signals rarely meet such requirements in reality, rendering inefficacy of many filtering techniques used for noise removal.
The most common procedures used for removing noise from EEG signals are semi-automatic. That is, the subjective opinion of a well-trained operator plays a key role in selecting the types of artifacts to be corrected. As a result, the noise filtering techniques applied to a certain dataset become to some extent customized based on the choices made by the operator during artifact removal stage. Thus, the frameworks and methodologies borrowed from any other study should be incorporated with great caution on side of fully understanding the steps conducted by previous scholars. What we pointed out above can arguably be considered among the most substantial factors leading to lack of portability of the vast majority of the methods available from the literature, partially delineating the reasons as to why various inconsistencies are observed across different lines of study on psychiatric disorders and neuroscience areas.
-
Lack of interpretability:
Most of existing models which rely on frequency-domain properties, usually assemble a complex of advanced-level mathematical ideas and tools to solve the problems. However, this cannot be achieved without compromising the interpretability of the model and its subsequent results, whose impacts become even more pronounced for those researchers not already mastered the countless venues of Fourier and Wavelets analyses, who would face various impediments upon their attempt to build up an intuititive know-how of such approaches. After all, it is well-known that a thorough and insightful understanding of the brain and its underlying mechanisms is more likely to be obtained through devising interpretable mathematical models instead of convoluted ones.
-
Existence of various dependence relations:
In studying the brain by analyzing its EEG signals, it is essential to consider the fact that various clusters of neurons are spatially related to one another, especially the association and dependence being stronger in the neighboring clusters. However, the EEG signals quantify the local activities of the brain. As a result, the spatial relations among various clusters of neurons which reside on a three-dimensional space get mapped to the two-dimensional surface of the scalp through EEG recordings, rendering the loss of all spatial information previously-existing among the clusters and their connecting electrodes.
An important implication here is that the inter-cluster dependence relations which are apparent in the recorded EEG signals, do not necessarily reflect the true spatial relations among different regions of the brain. Omitting investigation of existing dependence relationships can make the outcomes of the analysis rather unreliable. The difficulty for exploiting those spatial relations become even more concerning when the non-stationary and temporal nature of the data are further taken into account.
-
Dealing with big volumes of data:
It is no secret that the data recorded by EEG electrodes can easily exceed terabytes of volume, especially when the brain waves are recorded for extensive periods of time in order to detect an anomalous behavior as a symptom of severe disease. Hence, incorporation of big data technologies such as cloud computing is inevitable. The main issue here is not lack of accessibility to adequate amount of memory for storing the data, rather it pertains to the fact that analysis of big volumes using current frequency-based methodologies are simply not feasible due to the fact that almost all those methods rely on subroutines for traversing over large number of variable-size frequency windows and their countless combinations during fine-tuning the parameters step. In other words, it is the lack of any just-in-time framework for analysis of EEG signals that demands for storage of big volumes of data.
-
Non-applicability of many theoretical frameworks:
Presence of large volumes of data naturally calls for the use of statistical theories in order to summarize the EEG data and reduce their dimensions. However, it is not straightforward at all to extend the results of the standard statistical theories to the situations where random variables involved in the system demonstrate strong evidence of dependence and they almost never are identically distributed. Even resorting to the asymptotic theories of statistics which allow violation of several restrictive constrains often renders impractical due to the extremely small sample sizes available, especially when the cases related to some rare diseases are studied whose number of participants is limited.
-
Handling the missing data:
The EEG studies often entail several experiments, but it is very common to have a dataset in which the recordings pertaining to some experiment(s) for a particular subject are entirely missing, i.e., the recordings related to all (or some) of the electrodes are missing for the entire period of the experiment(s). However, it is not always possible to remove that particular subject from the list of participants in order to handle the missing data, e.g., the number of participants might not be large enough for this purpose. More importantly, the missing data are often associated with some of the key participants of the study, whose removal can induce substantial bias in the final outcome of analysis. Various types of censoring and truncation are among the potential reasons behind missing data.
Besides, the nature of censorship or truncation can be of such a type that partial recordings are available for that particular person under the experimentation(s). In those cases, one cannot easily omit the participant from the dataset as those data, even not being complete, convey important information about the subject and can contribute to discovering various subtleties not apparent about the psychiatric disorder under study. The set of techniques prescribed by the survival analysis can prove useful in those situations, however most of the existing models, especially the ones developed in frequency domain, do not extend easily to accommodate applications of the survival analysis techniques.
Now, we briefly list out all the advantages that our proposed framework based on the Lehmer transform possesses as follows:
Performing the preprocessing step for noise filtering is entirely eliminated in the proposed framework due to the fact that s-moments capture all the noise polluting the EEG signal, regardless of the source which has generated the noisy data, further enabling one to bypass the filtering step of EEG signal analysis.
The model is easily interpretable by those lacking sufficient knowledge on technical details related to the areas of mathematics and physics since the proposed framework enables one to deal with the familiar and tangible notion of statistics such as the sample mean. Furthermore, the Lehmer transform directly works with the actual measurements recorded on the EEG electrodes (measured in mV) without requiring application of any transformation. More importantly, this facilitating feature of the model lends itself to our proposed action potential function that lets one study the brain activities on a true scale of the action potentials of neurons, which is the most intuitive approach and leads to many insightful observations and discoveries on brain functionality.
Since our model utilizes all possible summary statistics to describe the data, there is no need to store large volumes of data anymore. In other words, all the computations can be carried out online with almost negligible space and time complexities, making it one of the most suitable frameworks to utilize when the EEG experiments are designed to last for relatively longer periods of time.
Spatiotemporal-preserving structure of our model in the domain of s-moments makes it practical to apply a vast number of machine learning techniques for both supervised and unsupervised learning purposes. The reason is that many machine learning algorithms require large number of sample points with dimensions on feature space of the problem being as low as possible to guarantee their success, which can easily be accomplished through the use of our proposed statistical moments.
Being itself a statistical model in nature, our proposed framework allows incorporation of the tools developed in various areas of statistical sciences such as survival analysis in order to deal with the censored and missing data.
A great advantage of the proposed model is that it enables one to detect existence of possible sub-types, either by visual inspection or the use of algorithmic approaches. Our developed action potential probability distribution function will be the main gauge to visualize the multi-dimensional EEG data, which can prove extremely beneficial at both the preliminary stages of the study and during the algorithm design process.
Lehmer transform
Let and denote the sets of strictly positive and extended real numbers, respectively. Given a signal , the Lehmer transform is a mapping defined by
According to this definition, the Lehmer transform maps every point into some statistic contained within the range , where we refer to the point s as a suddency moment of the given signal . Table 1 reports some of the widely-encountered suddency moments in data analysis. The proposed transform is differentiable in P-probability and its nth order derivative could be proven using the mathematical induction to be as follows:
where
Table 1.
Some special cases of suddency moments.
| Suddency domain | Sample domain |
|---|---|
| Minimum () | |
| 0 | Harmonic mean () |
| 1/2 | Geometric mean () |
| 1 | Arithmetic mean () |
| 2 | Contra-harmonic mean () |
| Maximum () |
In particular, the first derivative of the Lehmer transform is derived as
Furthermore, for any statistic , the inverse image provides a set that contains the associated suddency moment(s) of the signal such that
Subsequently, given that the signal contains at least two unique elements, the Lehmer transform will be a monotonously increasing function, and its inverse transform can be obtained by resorting to the following theorem:
Theorem 1
Given the signal satisfying the condition for some such that , the inverse Lehmer transform is defined as
where
for some .
Proof
Under the compatibility condition imposed on the given signal, the monotonicity property of implies that the function is injective, which in turn guarantees the existence of some inverse function denoted by . By further noting that is analytic for every point , the Lagrange-Bürmann formula4,15 can be utilized to express the interior points of the inverse function as a Taylor expansion g(t) about some given point , hence yielding the presented result.
The following example employs the inversion theorem mentioned above and illustrates an application of the inverse Lehmer transform as a non-linear filter for detecting anomalous events.
Example 1
Let us assume that a time-indexed sample is given whose elements correspond to the EEG measurements recorded using sampling frequency for a time period of 10 seconds. Figure 1 depicts the plot for membrane potentials measured at every time index . Furthermore, Figs. 2 and 3 exhibit the plots corresponding to Lehmer transform and its inverse function, respectively. As revealed by Fig. 2, successfully perpetuates structure of the raw EEG signal. Besides, Fig. 3 shows that the majority of computed moments lie in a range , where the thresholds are indicated using dashed lines. Examining the EEG signal on a statistical moment domain, may then help one to detect the anomalous points and identify the time-dependent behavior of their underlying events.
Figure 1.

Plot of raw membrane potentials against time.
Figure 2.

Plot of Lehmer transform against time.
Figure 3.

Plot of inverse Lehmer transform against time.
Action potential distributions
In this section, we show that the Lehmer transform has a deep connection with potential functions. It is used to construct a general class of action potential functions that are suitable to characterize intrinsic patterns embedded in a non-stationary time series such as EEG signals.
Let us recall the principal branch of the Lambert-W function denoted by , which is defined for every real as the inverse function of , whose schematics are depicted in Fig. 4a. Here, denotes the Omega constant defined by The membrane voltage function (see Fig. 4b) may then be expressed as some transformation of the following functional (for a constant c):
Figure 4.

Schematics of , g(y) and V(t).
Inspired by the appealing properties of the membrane voltage function defined above, we propose a distribution function to account for the probabilistic phenomena that underlie the complex dynamics of the action potentials.
Theorem 2
Let us assume that a signal is given which has been transformed such that it would satisfy the following conditions:
Then, a real-valued random variable S is said to follow an action potential distribution if its probability density function is given by
where , and the normalization constant C is obtained using the following relation
Proof
Let us consider the following function
where
and
Then, it is straightforward to show that F(s) is right-continuous and nondecreasing in the domain of suddency moments, and further it satisfies the following properties
Thus, F(s) is a distribution function. As a result, we may resort to the Caratheodory extension theorem which asserts that there exists a unique Lebesgue-Stieltjes measure associated with the distribution function F(s). In turn, this enables us to define a real-valued random variable S on a support , whose cumulative probability distribution function, i.e., , coincides with F(s). The probability distribution function presented in the theorem is then derived by differentiating the .
The action potential distribution function is a general framework to analyze complex non-stationary time series such as brain waves, e.g., see Fig. 5 which depicts plots of action potential distribution function for an EEG signal with varying the parameters and . An important class of action potentials is referred to as the dendritic spikes, which plays a significant role in neuronal communication, memory and learning.
Figure 5.

Plots of action potential distributions for some EEG signal with varying the parameters and .
Theoretically speaking, the dendritic spike dynamics would involve a number of different phase transitions, typically starting out from an initialization phase upon allying a stimulus. The dynamical system would then enter a rising phase if the membrane voltage rises above some threshold value, which is then followed by a phase transition into a falling phase. The final transition would occur at a reestablishment phase through which the membrane potential would eventually reside at its resting state.
In reality, however, a large body of evidence in neurophysiology suggests that the variations in electro-physiological measurements may distort the actual action potentials, yielding a substantially different phase transition scheme as compared to the theoretical one mentioned above. That is, different types of undershoot and overshoot may be encountered in dendritic spikes dynamics. The key element which we incorporate in our analysis of dendritic spikes, pertains to the point that membrane voltages could effectively be modelled using the Lambert-W function and its variants.
Major depressive disorder
The data set we study in this work is comprised of EEG recordings of 34 patients suffering from MDD. This is one of the benchmark data sets to test classification algorithms designed for EEG recordings and extract knowledge on the underlying mechanisms and functionality of different areas of the brain in MDD patients. In this research, a sample of 34 MDD outpatients with 17 males and 17 females was recruited according to the experiment design at the Hospital University Sains Malaysia (HUSM), Kelantan, Malaysia. During each visit to the clinic, the MDD patients were assessed by experienced clinicians. Detailed information can be found in17.
Our primary goal is to investigate whether the patterns existing in the EEG recordings of the subjects can be used for discerning the MDD patients from healthy controls. To this end, EEG recordings of 30 control subjects are further taken into consideration as the control group of this study. Each subject undergoes 3 different types of experiments while his/her EEG signals are recorded. More precisely, the experiments are conducted in 3 different setups: eyes closed (EC), eyes open (EO), and while the subject performs a specific task (TASK). The duration for each of the experiments EC and EO is 5 minutes which comprises an average of 77000 signals per each channel (there exist 19 channel per each experiment). The experiment TASK, however, lasts for longer duration 10 minutes and its average number of signals sampled with frequency 256Hz is roughly 155000 on each channel; see17 for more details on the conducted experiments.
One of the challenges faced when studying the present problem pertains to the fact that a considerable number of data are missing from the provided dataset. Summary of the missing data for each of the experiments within control and MDD groups are presented in Table (2). Furthermore, let us use matrices to embed the experiment data by assigning their columns to different channels and populating their rows based on the EEG samples observed in the time domain (measured in ). In other words, the EEG recordings of the nth subject, , within the mth experiment, , is denoted using the following matrix
where and are total number of the subjects and experiments, respectively. Also, denotes total number of the active channels within each experiment where the recordings on each of these channels contain I samples points.
Table 2.
Summary of missing data for MDD dataset.
| Experiment | EC | EO | TASK | Total |
|---|---|---|---|---|
| Control | 6.7% | 3.3% | 6.7% | 5.5% |
| MDD | 11.8% | 5.9% | 2.9% | 6.9% |
| Total | 9.4% | 5.0% | 5.0% | 6.3% |
The key point in our developed methodology is to assign random variables to each channel using the action potential distribution. In this way, one would take an implicit approach in studying the set of random vectors which have spatiotemporal correlations and autocorrelations as well as various other types of dependence. That is, for each signal contained within the dataset corresponding to a single column of some matrix for the subject n and experiment m, parameters of the action potential distribution are estimated using the maximum likelihood method. Figure 6 depicts plots of 19 action potential probability density functions for EEG signals of a single healthy subject when performing the TASK, which are compared to 19 probability density function of a subject selected from the MDD group.
Figure 6.

Schematics of electrode placement and action potential distributions for control and MDD subjects.
Furthermore, Figs. 7, 8, 9 depict the heat maps constructed based on differential entropy values computed for the action potential distribution functions of all available EEG signals. It is observed that the overall brain activation of MDD patients rests at its lowest possible state across all three experiments, whereas their brain becomes relatively more active overall when they undergo the EC and EO experiments. It is also interesting to note the consistently low activation of the temporal regions of the brain, especially the right ones, across all experiments.
Figure 7.

Heat maps of the differential entropy of action potential distributions for experiments with EC.
Figure 8.

Heat maps of the differential entropy of action potential distributions for experiments with EO.
Figure 9.

Heat maps of the differential entropy of action potential distributions when performing TASK.
Next, the following quantities are computed for each available signal using its underlying action potential distribution function. That is, for the EEG signal recorded on the jth channel of experiment m associated to subject n, we compute:
where f and F represent and , respectively. Furthermore, we define and as follows:
These quantities are then utilized to train a classifier for biological signals such as EEG measurements. Thus, for each subject (instance), the total number of extracted features would be in our case.
At the final stage and to classify the subjects into binary classes, we propose an algorithm based on bootstrap-aggregated decision trees (BADT) where each tree has a structure as depicted in the following. To be more precise, in addition to “H” and “MDD” labels, we assume there exist a latent label called “Mixed”, i.e., a sub-type, whose consideration will significantly improve the performance and interpretability of the classification algorithm. Furthermore, two other classifiers based on Gaussian naive Bayes (GNB) and convolutionary neural networks (an Encoder-Decoder with FCN-8 architecture) were developed and tested alongside the BADT, whose performance are further reported in Table 3. 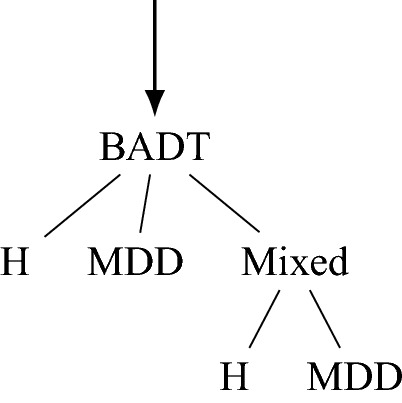
Table 3.
Comparisons with different incorporated classifiers.
| Classifier | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| Lehmer Transform + GNB | |||
| Lehmer Transform + CNN | |||
| Lehmer Transform + BADT |
Besides, the last row of the Table 4 reports computational results of the proposed algorithm for classification of the benchmark instances using 10-fold cross validation averaged over 100 replications. Table 4 further compares the performance of our proposed framework to other methods from the literature, including the prominent work of Mumtaz et al.17. It is noted that all the reported results pertain to the experiments conducted on the same benchmark EEG dataset and under identical settings 10-fold cross validation with 100 replications.
Table 4.
Comparisons with other algorithms from literature.
| Derived EEG measure | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| ATR Index13 | |||
| EEG Theta Coherence16 | |||
| Coherence, PSD, PSD ratio14 | |||
| P300 (amplitude and latencies)2 | |||
| PSD, PSD ratios14 | |||
| Wavelet Transform17 | |||
| Lehmer Transform |
Significant values are in bold.
On the basis of Table 4, it is seen that our proposed method achieves higher accuracy as compared to the method based on the wavelet transforms as well as other previously-proposed approaches for classifying the MDD and healthy subjects. A distinguishing aspect of our proposed Lehmer-based classifier is that it yields relatively lower standard errors when classifying the instances. In turn, this makes the results obtained by using the proposed classifier reliable to a great extent, and such reliability can potentially lead to an effective applications of the Lehmer-based classifiers by practitioners who monitor the possible impacts of prescribed antidepressants’ treatment on their patients.
By further noting that the classification algorithm proposed by Mumtaz et al., is mainly based on a logistic regression algorithm wherein the authors have used a combination of wavelet transforms (WT), short-time Fourier transforms (STFT) and empirical mode decomposition (EMD) as the feature extraction method and a rank-based algorithm for the purpose of feature selection, the superiority of Lehmer transform and its applications become more evident as compared to the frequency-based approaches.
Conclusion
We propose a new transform that is shown be suitable to handle highly oscillatory non-stationary time series. It can effectively summarize and extract features from multi-channel signals and form the basis for building a highly accurate classifier. Although our work is still exploratory in nature, we believe that the potential of this new transform can be utilized fully in order to discern subtle patterns that cannot be recognized by other traditional methods such as Fourier and Wavelets transforms.
Author contributions
M.A. developed the methodology and conceived, conducted and analyzed the experiments, X.W. developed the methodology and analyzed the experiments. All authors reviewed the manuscript.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Beliakov G, Sola HB, Sanchez TC. A Practical Guide to Averaging Functions. Springer; 2016. [Google Scholar]
- 2.Bruder GE, Tenke CE, Stewart JW, Towey JP, Leite P, Voglmaier M, Quitkin FM. Brain event-related potentials to complex tones in depressed patients: Relations to perceptual asymmetry and clinical features. Psychophysiology. 1995;32(4):373–381. doi: 10.1111/j.1469-8986.1995.tb01220.x. [DOI] [PubMed] [Google Scholar]
- 3.Bullen PS. Handbook of Means and Their Inequalities. Springer Science & Business Media; 2013. [Google Scholar]
- 4.Hans, H.B. Essai de calcul fonctionnaire aux constantes ad-libitum. In: Versuch einer vereinfachten Analysis; ein Auszug eines Auszuges von Herrn Burmann [Attempt at a Simplified Analysis; an Extract of an Abridgement by Mr. Burmann] 2 (1799), pp. 495.499.
- 5.Yu-Ming C, Weimao Q. Sharp Lehmer mean bounds for Neuman means with applications. J. Math. Inequal. 2016;10(2):583–596. [Google Scholar]
- 6.Yu-Ming, C. & Miao-Kun, W. Inequalities between arithmetic-geometric, Gini, and Toader means. Abstract Appl Anal. Vol. 2012. Hindawi. (2012).
- 7.Chu Y-M, Wang M-K. Optimal Lehmer mean bounds for the Toader mean. Results Math. 2012;61(3–4):223–229. doi: 10.1007/s00025-010-0090-9. [DOI] [Google Scholar]
- 8.Yu-Ming C, Tie-Hong Z. Convexity and concavity of the complete elliptic integrals with respect to Lehmer mean. J. Inequal. Appl. 2015;2015(1):396. doi: 10.1186/s13660-015-0926-7. [DOI] [Google Scholar]
- 9.Culjak V. Schur-convexity of the weighted Ceby.ev functional II. J. Math. Inequal. 2012;6(1):141–147. doi: 10.7153/jmi-06-14. [DOI] [Google Scholar]
- 10.Fub C-R, Wanga D, Shic H-N. Schur-convexity for Lehmer mean of n variables. J. Nonlin. Sci. Appl. (JNSA) 2016;9:10. [Google Scholar]
- 11.Ivette Gomes, M., Fernanda, F., L.egia, H.-R. Port value-at-risk estimation through generalized means. In: Proceedings 2nd ISI Regional Statistics Conference. (2017).
- 12.Yun H, Feng Q. A double inequality for bounding Toader mean by the centroidal mean. Proc. Math. Sci. 2014;124(4):527–531. doi: 10.1007/s12044-014-0183-6. [DOI] [Google Scholar]
- 13.Iosifescu DV, Greenwald S, Devlin P, Mischoulon D, Denninger JW, Alpert JE, Fava M. Frontal EEG predictors of treatment outcome in major depressive disorder. Eur. Neuropsychopharmacol. 2009;19(11):772–777. doi: 10.1016/j.euroneuro.2009.06.001. [DOI] [PubMed] [Google Scholar]
- 14.Khodayari-Rostamabad A, Hasey GM, MacCrimmon DJ, Reilly JP, de Bruin H. A pilot study to determine whether machine learning methodologies using pre-treatment electroencephalography can predict the symptomatic response to clozapine therapy. Clin. Neurophysiol. 2010;121(12):1998–2006. doi: 10.1016/j.clinph.2010.05.009. [DOI] [PubMed] [Google Scholar]
- 15.Joseph, L.L. Nouvelle methode pour resoudre les equations litterales par le moyen des series. Chez Haude et Spener, Libraires de la Cour & de l’Academie royale, 1770.
- 16.Leuchter AF, Cook IA, Lufkin RB, Dunkin J, Newton TF, Cummings JL, Kevin Mackey J, Walter DO. Cordance: a new method for assessment of cerebral perfusion and metabolism using quantitative electroencephalography. Neuroimage. 1994;1(3):208–219. doi: 10.1006/nimg.1994.1006. [DOI] [PubMed] [Google Scholar]
- 17.Mumtaz W, Xia L, Yasin MAM, Ali SSA, Malik AS. A wavelet-based technique to predict treatment outcome for major depressive disorder. PloS one. 2017;12(2):e0171409. doi: 10.1371/journal.pone.0171409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Ondrej, S. On Inflection Points of the Lehmer Mean Function. In: arXiv preprint arXiv:1509.09277 (2015).
- 19.Ondrej, S., & Markus, R. Consensus algorithms with state-dependent weights. Acoustics Speech Signal Process (ICASSP), 2014 IEEE International Conference on. IEEE. 2014, pp. 5462–5466.
- 20.Somasundaram S, Sandhya SS, Pavithra TS. Lehmer-3 mean labeling of some new disconnected graphs. Int. J. Math. Trends Technol. 2016;35:1. doi: 10.14445/22315373/IJMTT-V35P501. [DOI] [Google Scholar]
- 21.Terziyan V. Social Distance metric: from coordinates to neighborhoods. Int. J. Geogr. Inf. Sci. 2017;31(12):2401–2426. doi: 10.1080/13658816.2017.1367796. [DOI] [Google Scholar]
- 22.Trif T. Sharp inequalities involving the symmetric mean. Miskolc Math. 2002;3:157–164. doi: 10.18514/MMN.2002.59. [DOI] [Google Scholar]
- 23.Xia WF, Chu YM. The Schur harmonic convexity of Lehmer means. Int. Math. Forum. 2009;4:41–44. [Google Scholar]
- 24.Yang Z-H. Schur power convexity of Gini means. Bull. Korean Math. Soc. 2013;50(2):485–498. doi: 10.4134/BKMS.2013.50.2.485. [DOI] [Google Scholar]
- 25.Zhao T-H, Chu Y-M, Zhang W. Optimal inequalities for bounding Toader mean by arithmetic and quadratic means. J. Inequal. Appl. 2017;1:26. doi: 10.1186/s13660-017-1300-8. [DOI] [PMC free article] [PubMed] [Google Scholar]