

Abstract
We propose a new adaptive feedback cancellation (AFC) system in hearing aids (HAs) based on a well-posed optimization criterion that jointly considers both decorrelation of the signals and sparsity of the underlying channel. We show that the least squares criterion on subband errors regularized by a p-norm-like diversity measure can be used to simultaneously decorrelate the speech signals and exploit sparsity of the acoustic feedback path impulse response. Compared with traditional subband adaptive filters that are not appropriate for incorporating sparsity due to shorter sub-filters, our proposed framework is suitable for promoting sparse characteristics, as the update rule utilizing subband information actually operates in the fullband. Simulation results show that the normalized misalignment, added stable gain, and other objective metrics of the AFC are significantly improved by choosing a proper sparsity promoting factor and a suitable number of subbands. More importantly, the results indicate that the benefits of subband decomposition and sparsity promoting are complementary and additive for AFC in HAs.
Index Terms—: hearing aids, feedback cancellation, whitening, decorrelation, sparsity, adaptive filter
I. Introduction
The acoustic feedback or so-called howling effect induced by the strong coupling between the receiver (loudspeaker) and the microphone in hearing aids (HAs) deteriorates the intelligibility, quality and maximum stable gain of the input. To mitigate this feedback problem, adaptive feedback cancellation (AFC) is commonly employed to continuously identify or approximate the time-varying impulse response (IR) of the acoustic feedback path [1]. Due to the strong correlation between the microphone and the receiver signals [2], adaptive filters without decorrelation capability in AFC give biased estimates and result in degraded performance in convergence, e.g., the classic least mean square (LMS) and the well-known normalized LMS (NLMS) [3]–[5]. More importantly, adaptive filters without leveraging sparsity of the acoustic feedback path are prone to have slower initial convergence rate [6]–[8].
Therefore, to improve the performance of AFC, both decorrelation and sparsity may be jointly exploited. However, in the AFC literature, many works have been dedicated to either decorrelation [9]–[18] or promoting sparsity [7], [8]; a joint exploration on both is lacking. Recently, a sparsity promoting, subband AFC [19] was developed based on solving a constrained optimization problem with ℓ1 norm penalty. However, there are still several aspects that deserve further investigations. On the theoretical part, the cost function considered in [19] was based on the least perturbation principle which is not as straightforward as direct minimization on subband errors. On the experimental part, the effect of using different degrees of decorrelation and sparsity promoting on AFC was not studied (only evaluated on four subbands). Moreover, the additional benefit that the widely used prediction error method (PEM) [14]–[16] adding to the subband system for deccorrelation was not quantified.
Based on our previous work [20] which only studied a theoretical problem, in this paper, we extend the joint framework for leveraging decorrelation and sparsity to a real-world application in HAs. We propose and evaluate a new AFC system in HAs based on a well-posed optimization criterion that simultaneously explores decorrelation and sparsity. Using different speech input signals, feedback paths and amplifications, we extensively study the efficacy of AFC using different numbers of subbands and degrees of promoted sparsity. In addition, we study the benefits of using the PEM on top of our system. Both commonly used AFC evaluation criteria and objective evaluations on intelligibility and quality are presented on a large speech corpus to illustrate the effectiveness of the proposed AFC framework. We show that the benefits of decorrelation and sparsity promoting for AFC are additive and complementary.
II. Background
To address the bias issue in AFC systems, several methods have been proposed [9]–[16], [21]. One of the bias reduction methods in AFC is the usage of subband adaptive filters (SAFs) [6], [17], [18], [22]. A conventional SAF for AFC like that in [17] utilizes an independent adaptive filter for each subband. However, SAFs are known to suffer from the aliasing problem and band-edge effects [6]. To avoid these issues, a family of new SAFs or normalized subband adaptive filters (NSAFs) [23]–[25] which compute the gradient before the subband projection were proposed. For example, in [18], a delayless NSAF on top of the PEM was introduced to improve AFC. Besides, the acquisition of fullband filter taps in NSAFs is important since inducing sparsity on shorter sub-filters does not seem logical in conventional SAFs.
On the other hand, to achieve faster convergence rate of the AFC filter, the sparse characteristics of the acoustic feedback path may be taken into account [6]–[8]. This can be carried out by utilizing the proportionate adaptation scheme originated from the proportionate NLMS (PNLMS) [26] algorithm. In the adaptive filtering literature, the PNLMS [26] was introduced to improve convergence behavior by intuitively assigning a step size proportional to the magnitude of the estimated coefficient to each filter tap. Many proportionate-type NLMS (PtNLMS) algorithms [27] were later proposed to enhance PNLMS. Based on PtNLMS, a family of proportionate-type NSAFs (PtNSAFs) [28]–[30] have been proposed on top of NSAF to speed up convergence as they exploit the sparse structure of the fullband filter taps and reduce signal correlation. Finally, the update rule recently proposed in [20] is a generalization of PtNSAFs. The criterion is straightforward in a sense that it minimizes errors in each subband but penalizes a weighted norm in the fullband.
III. The Proposed AFC Framework
The proposed AFC framework is depicted in Fig. 1. The microphone signal d(n) is the sum of the speech signal x(n) and the feedback signal y(n), i.e., d(n) = x(n) + y(n). u(n) denotes the receiver signal which is given by passing the feedback-compensated signal e(n) through the HA processing G(z). Assuming that the acoustic feedback path is a finite impulse response (FIR) filter F(z), we have y(n) generated by filtering u(n) through F(z). The goal of AFC is to have the estimated feedback signal close to y(n) by continuously adapting the filter S(z). Together with a set of fixed analysis filters Hi(z), i = 1, 2, …, M, the prediction-error filter A(z) from PEM forms a time-varying analysis filter bank, i.e., A(z)Hi(z) where the coefficients in A(z) are adapted by using the linear prediction of e(n). Notice that the synthesis filters are not needed in our proposed framework. The subband error signals are computed and then aggregated together to update the fullband filter taps. The block of coefficient adaptation in Fig. 1 is the core of the AFC and a novel update rule in this block is discussed in the following paragraphs.
Fig. 1:

Block diagram of the proposed AFC framework.
We propose the following optimization criterion to jointly exploit sparsity and achieve decorrelation:
| (1) |
where τ → 0+ is a regularization parameter, is the ith subband error scalar; di(n) and ui(n) are the ith subband desired scalar and the ith subband input vector, respectively. M is the number of subbands and the optimization variable denotes the adaptive filter of length L. We have used the p-norm-like diversity measure for promoting sparsity where the parameter p ∈ (0, 2] controls the degree of sparsity promoting [31], [32]. By minimizing the cost function (1) using the reweighted ℓ2 framework [31], affine scaling transformation [32] and the regularized Newton’s method [20], the resulting LMS-like update rule is given by
| (2) |
where is the subband error vector and s(n) = [s1(n) s2(n) ⋯ sL(n)]T is the adaptive filter. The subband input data matrix is given by where the columns are subband signals.
For the proportionate matrix W(n) = diag{w1(n), w2(n), ⋯, wL(n)}, it is given by
| (3) |
where c > 0 is a regularization constant for avoiding stagnation and instability. The suggested range of the parameter p for sparse, compressible (quasi-sparse) and dispersive solutions are [1.0, 1.2], (1.2, 1.8) and [1.8, 2.0], respectively [7].
For the whitening matrix Φ(n), a time-varying diagonal regularization matrix Δ(n) can be employed as
| (4) |
where Δ(n) = diag{δ1(n), δ2(n), ⋯, δM(n)} and δi, i = 1, 2, …, M depends on the estimated time-varying variance of the subband error ei(n). However, the proper estimation of δi needs further investigations and empirical research. In this paper, we use Δ(n) = δI where δ > 0 is a samll constant.
In sum, (2), (3) and (4) give the proposed Sparsity-promoting Normalized Subband Adaptive Filter algorithm (S-NSAF). Indeed, the proposed update rule (2) is a generalized framework for some well-known adaptive filtering algorithms including NLMS, affine projection algorithm (APA), etc. We hereby summarize the behaviors in TABLE I.
TABLE I:
Different cases of S-NSAF. For the correspondence to NSAF and PtNSAF, Φ(n) needs to be approximated by a diagonal matrix using a proper analysis filter bank.
Different from the direct combination method, i.e., the PEM-based PtNLMS for AFC [35], our proposed AFC framework jointly combines decorrelation (first term in (1)) and tunable sparsity exploiting (second term in (1)) in one cost function and update rule. The PEM in our framework can be considered as a way to establish a time-varying analysis filter bank for better decorrelation.
IV. Simulation Results
In this section, we evaluate the performance of using S-NSAF for AFC in HAs. To be more specific, the effects of using different numbers of subbands M and different degrees of sparsity promoting, namely, the p value, are jointly investigated. In addition, the relationship between the PEM and the proposed method is studied.
Experimental Setup:
The experiments were conducted at 16 kHz with the input speech signal x(n) from the TIMIT dataset [36] and two feedback paths measured from the real-world setup as shown in Fig. 3. In order to get realistic simulations of human experiences, long speech signals (89.11 seconds) created by concatenating speech files were used.
Fig. 3:

The truncated FIR filters of different feedback paths were measured from a HA on a dummy head. (a) represents the IRs and (b) shows the magnitudes of the frequency responses.
The forward path, i.e., the HA processing, was simulated by G(z) = gz−d where g was the gain in the linear scale and d was the samples of delay corresponding to a fixed latency of 8 milliseconds. In the setting of the S-NSAF, the length L = 100 was set to the same size as the truncated FIR filter in Fig. 3 and all taps were initialized by 0. For PEM, the order of the prediction-error filter A(z) was 20 and the filter was updated every 10 milliseconds via Levinson-Durbin recursion with the window length of 160 samples [18]. The analysis filter bank H is a cosine-modulated pseudo-quadrature mirror filter (QMF) bank. M = 1, 2, 4 were chosen to be evaluated. We maintain the same length N = 16 of the analysis filters for M = 2 and M = 4. The p values which were chosen to be tested are 1.5 [7] and 2.0. For regularizations, we used δ = 10−5 and c = 10−3 for all simulations. The step size is given by so that the comparison is fair for adaptive filters using different M. All curves in Fig. 2 and Fig. 4 were ensemble averaged over 100 different speech signals. During all experiments, a sudden change of the feedback path was introduced at half time where this new path was given by the one with obstruction in Fig. 3.
Fig. 2:
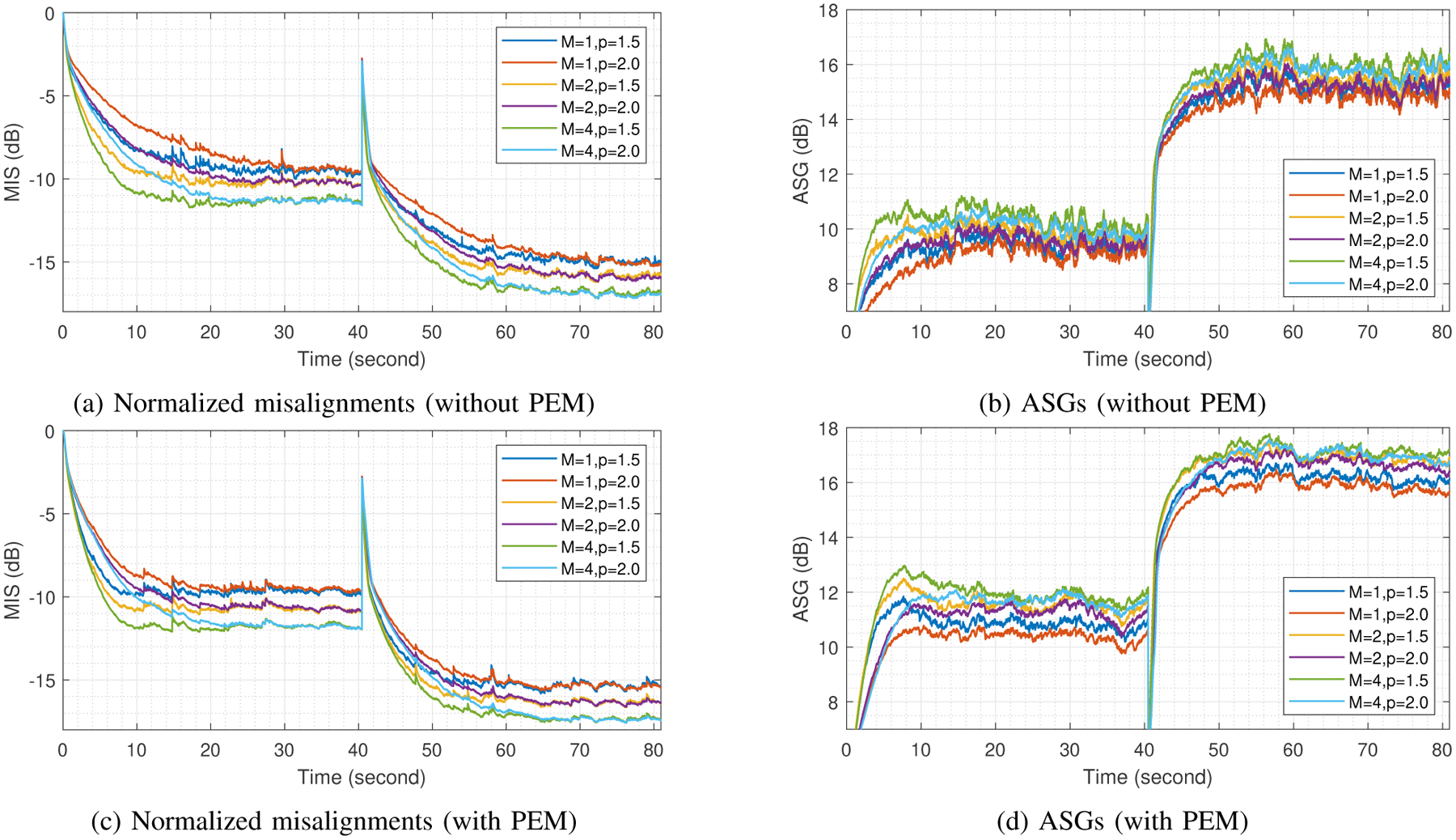
The performance of AFC is better with higher M for a given p; and p = 1.5 is better than p = 2.0 for a given M, in terms of normalized misalignment and ASG. Noticeably, the case of M = 4 and p = 1.5 outperforms all the other cases. If the PEM is used, the performance can be further enhanced; there is approximately ASG improvement of 2.0 dB in all cases.
Fig. 4:

In (a), the speech intelligibility is better with higher M for a given p; and p = 1.5 is better than p = 2.0 for a given M. In (b), the speech quality is improved by choosing higher M; and the p value seems to be irrelevant. If the PEM is used, the performance gaps between different M reduce in terms of STOI and HASQI.
Evaluation Metrics:
To evaluate the performance of the proposed AFC using S-NSAF, the normalized misalignment (MIS), added stable gain (ASG) [14], [37], short-time objective intelligibility (STOI) [38], [39] and hearing-aid speech quality index (HASQI) [40] were used. The normalized misalignment and ASG given by (5) were evaluated for a fixed HA processing G(z) with the gain value set to 20 in dB scale. On the other hand, the objective metrics including STOI and HASQI were used to quantify the performance of AFC for different values of gain g in the HA processing G(z). Measuring AFC performance in different gain values is critical since the gain in HAs is subject to change in real-world scenarios. The STOI and HASQI were computed via the comparison between the input speech signal x(n) and the feedback-compensated signal e(n). They both are scores of a single scalar which ranges from 0 to 1, where the higher the score, the better the intelligibility or quality.
| (5) |
Misalignments and ASGs under a fix gain:
We first consider the case where the PEM is not incorporated. In this case, increasing M is the only way to further decorrelate the signals. In Fig. 2(a) and Fig. 2(b), it is obvious that the performance of AFC is better with higher M for a given p; and p = 1.5 is better than p = 2.0 for a given M. Noticeably, the case of M = 4 and p = 1.5 outperforms all the other cases in terms of normalized misalignment and ASG. On the other hand, M = 1 and p = 2.0, i.e., the NLMS, is the worst case since it has nothing to do with decorrelation and sparsity promoting of the sparse feedback path. We observe that a better decorrelation scheme can be potentially achieved by choosing a larger M (here we have shown this up to M = 4). In addition, the benefits of subband decomposition and sparsity promoting are additive and complementary for AFC.
Now consider the situation where the PEM is incorporated. In Fig. 2(c) and Fig. 2(d), we observe the same conclusions we have drawn from Fig. 2(a) and Fig. 2(b). However, notice that the performance of AFC is further enhanced with PEM. Comparing Fig. 2(b) to Fig. 2(d), there is approximately ASG improvement of 2.0 dB in all cases if the PEM is used. This means that the decorrelation performed by subband decomposition can even be improved by employing PEM on top of it. To be more specific, the combination of the analysis filter bank and the prediction-error filter induces a time-varying analysis filter bank which gives a better approximation to the input spectrum; the bias reduction is then enhanced in AFC.
STOI and HASQI under different gains:
In Fig. 4(a), we observe that the speech intelligibility is better with higher M for a given p; and p = 1.5 is better than p = 2.0 for a given M. In Fig. 4(b), we find that the speech quality is improved by choosing higher M; and the p value seems to be irrelevant. When the PEM is incorporated as in Fig. 4(c) and Fig. 4(d), the performance gaps between different M reduce in terms of STOI and HASQI. However, the incorporation of the PEM does not seem to necessarily improve the performance for M = 4 here. According to Fig. 4(c), the p value has larger impact on speech intelligibility when the gain is increased.
V. Conclusion
Different from our previous work [20] which was only evaluated in a theoretical system identification setting, a new formulation of jointly exploring sparsity promoting and decorrelation is proposed for practical AFC applications. In the proposed method, the effectiveness of using different degrees of sparsity promoting and number of subbands are studied extensively with a large speech corpus and different feedback paths. The simulation results show that higher number of subbands (up to a certain level) and a proper degree of sparsity promoting give superior AFC performance in terms of commonly used metrics regardless of the incorporation of the PEM. Compared with the ordinary AFC using the NLMS, our proposed method improves ASG by 2 to 3 dB, STOI and HASQI from 0.91 to 0.94 and 0.76 to 0.81, respectively.
Acknowledgment
This work was supported by NIH/NIDCD under Grants R01DC015436 and R33DC015046, and NSF/IIS under Award 1838830.
References
- [1].van Waterschoot T and Moonen M, “Fifty years of acoustic feedback control: State of the art and future challenges,” Proceedings of the IEEE, vol. 99, no. 2, pp. 288–327, 2010. [Google Scholar]
- [2].Siqueira MG and Alwan A, “Steady-state analysis of continuous adaptation in acoustic feedback reduction systems for hearing-aids,” IEEE Transactions on Speech and Audio Processing, vol. 8, no. 4, pp. 443–453, 2000. [Google Scholar]
- [3].Widrow B and Stearns SD, Adaptive Signal Processing. Upper Saddle River, NJ, USA: Prentice-Hall, Inc., 1985. [Google Scholar]
- [4].Haykin SS, Adaptive Filter Theory. Pearson Education India, 2008. [Google Scholar]
- [5].Sayed AH, Adaptive Filters. John Wiley & Sons, 2011. [Google Scholar]
- [6].Lee K-A, Gan W-S, and Kuo SM, Subband Adaptive Filtering: Theory and Implementation. John Wiley & Sons, 2009. [Google Scholar]
- [7].Lee C-H, Rao BD, and Garudadri H, “Sparsity promoting LMS for adaptive feedback cancellation,” in European Signal Processing Conference (EUSIPCO). IEEE, 2017, pp. 226–230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Pradhan S, Patel V, Patel K, Maheshwari J, and George NV, “Acoustic feedback cancellation in digital hearing aids: A sparse adaptive filtering approach,” Applied Acoustics, vol. 122, pp. 138–145, 2017. [Google Scholar]
- [9].Hellgren J, “Analysis of feedback cancellation in hearing aids with Filtered-x LMS and the direct method of closed loop identification,” IEEE Transactions on Speech and Audio Processing, vol. 10, no. 2, pp. 119–131, 2002. [Google Scholar]
- [10].Chi H-F, Gao SX, Soli SD, and Alwan A, “Band-limited feedback cancellation with a modified filtered-X LMS algorithm for hearing aids,” Speech Communication, vol. 39, no. 1–2, pp. 147–161, 2003. [Google Scholar]
- [11].Guo M, Jensen SH, and Jensen J, “Novel acoustic feedback cancellation approaches in hearing aid applications using probe noise and probe noise enhancement,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 9, pp. 2549–2563, 2012. [Google Scholar]
- [12].Guo M, Jensen SH, Jensen J, and Grant SL, “On the use of a phase modulation method for decorrelation in acoustic feedback cancellation,” in European Signal Processing Conference (EUSIPCO). IEEE, 2012, pp. 2000–2004. [Google Scholar]
- [13].Strasser F and Puder H, “Adaptive feedback cancellation for realistic hearing aid applications,” IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 23, no. 12, pp. 2322–2333, 2015. [Google Scholar]
- [14].Spriet A, Proudler I, Moonen M, and Wouters J, “Adaptive feedback cancellation in hearing aids with linear prediction of the desired signal,” IEEE Transactions on Signal Processing, vol. 53, no. 10, pp. 3749–3763, 2005. [Google Scholar]
- [15].Spriet A, Rombouts G, Moonen M, and Wouters J, “Adaptive feedback cancellation in hearing aids,” Journal of the Franklin Institute, vol. 343, no. 6, pp. 545–573, 2006. [Google Scholar]
- [16].Spriet A, Doclo S, Moonen M, and Wouters J, “Feedback control in hearing aids,” in Springer Handbook of Speech Processing. Springer, 2008, pp. 979–1000. [Google Scholar]
- [17].Siqueira M, Speece R, Petsalis E, Alwan A, Soli S, and Gao S, “Subband adaptive filtering applied to acoustic feedback reduction in hearing aids,” in Asilomar Conference on Signals, Systems and Computers (ACSSC). IEEE, 1996, pp. 788–792. [Google Scholar]
- [18].Pradhan S, Patel V, Somani D, and George NV, “An improved proportionate delayless multiband-structured subband adaptive feedback canceller for digital hearing aids,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 8, pp. 1633–1643, 2017. [Google Scholar]
- [19].Vasundhara N. Puhan, and Panda G “Zero attracting proportionate normalized subband adaptive filtering technique for feedback cancellation in hearing aids,” Applied Acoustics, vol. 149, pp. 39–45, 2019. [Google Scholar]
- [20].Chen K-L, Lee C-H, Rao BD, and Garudadri H, “A generalized proportionate-type normalized subband adaptive filter,” in Asilomar Conference on Signals, Systems, and Computers (ACSSC). IEEE, 2019, pp. 749–753. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Schepker H, Tran LTT, Nordholm S, and Doclo S, “Improving adaptive feedback cancellation in hearing aids using an affine combination of filters,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016, pp. 231–235. [Google Scholar]
- [22].Lee K-A and Gan W-S, “Inherent decorrelating and least perturbation properties of the normalized subband adaptive filter,” IEEE Transactions on Signal Processing, vol. 54, no. 11, pp. 4475–4480, 2006. [Google Scholar]
- [23].De Courville M and Duhamel P, “Adaptive filtering in subbands using a weighted criterion,” IEEE Transactions on Signal Processing, vol. 46, no. 9, pp. 2359–2371, 1998. [Google Scholar]
- [24].Pradham SS and Reddy V, “A new approach to subband adaptive filtering,” IEEE Transactions on Signal Processing, vol. 47, no. 3, pp. 655–664, 1999. [Google Scholar]
- [25].Lee K-A and Gan W-S, “Improving convergence of the NLMS algorithm using constrained subband updates,” IEEE Signal Processing Letters, vol. 11, no. 9, pp. 736–739, 2004. [Google Scholar]
- [26].Duttweiler DL, “Proportionate normalized least-mean-squares adaptation in echo cancelers,” IEEE Transactions on Speech and Audio Processing, vol. 8, no. 5, pp. 508–518, 2000. [Google Scholar]
- [27].Wagner K and Doroslovački M, Proportionate-type normalized least mean square algorithms. John Wiley & Sons, 2013. [Google Scholar]
- [28].Abadi MSE, “Proportionate normalized subband adaptive filter algorithms for sparse system identification,” Signal Processing, vol. 89, no. 7, pp. 1467–1474, 2009. [Google Scholar]
- [29].Abadi MSE and Kadkhodazadeh S, “A family of proportionate normalized subband adaptive filter algorithms,” Journal of the Franklin Institute, vol. 348, no. 2, pp. 212–238, 2011. [Google Scholar]
- [30].See X, Lee K, Gan W, and Li H, “Proportionate subband adaptive filtering,” in International Conference on Audio, Language and Image Processing. IEEE, 2008, pp. 128–132. [Google Scholar]
- [31].Lee C-H, Rao BD, and Garudadri H, “Proportionate adaptive filters based on minimizing diversity measures for promoting sparsity,” in Asilomar Conference on Signals, Systems, and Computers (ACSSC). IEEE, 2019, pp. 769–773. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Rao BD and Kreutz-Delgado K, “An affine scaling methodology for best basis selection,” IEEE Transactions on Signal Processing, vol. 47, no. 1, pp. 187–200, 1999. [Google Scholar]
- [33].Gay SL and Tavathia S, “The fast affine projection algorithm,” in International Conference on Acoustics, Speech, and Signal Processing (ICASSP). IEEE, 1995, pp. 3023–3026. [Google Scholar]
- [34].Paleologu C, Ciochina S, and Benesty J, “An efficient proportionate affine projection algorithm for echo cancellation,” IEEE Signal Processing Letters, vol. 17, no. 2, pp. 165–168, 2009. [Google Scholar]
- [35].Tran LTT, Schepker H, Doclo S, Dam HH, and Nordholm S, “Proportionate NLMS for adaptive feedback control in hearing aids,” in International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 211–215. [Google Scholar]
- [36].Garofolo J, Lamel L, Fisher W, Fiscus J, Pallett D, Dahlgren N, and Zue V, “TIMIT acoustic-phonetic continuous speech corpus,” Linguistic Data Consortium, 1993. [Google Scholar]
- [37].Kates JM, “Room reverberation effects in hearing aid feedback cancellation,” The Journal of the Acoustical Society of America, vol. 109, no. 1, pp. 367–378, 2001. [DOI] [PubMed] [Google Scholar]
- [38].Taal CH, Hendriks RC, Heusdens R, and Jensen J, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2010, pp. 4214–4217. [Google Scholar]
- [39].Taal CH, Hendriks RC, Heusdens R, and Jensen J, “An algorithm for intelligibility prediction of time–frequency weighted noisy speech,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125–2136, Sep. 2011. [DOI] [PubMed] [Google Scholar]
- [40].Kates JM and Arehart KH, “The hearing-aid speech quality index (HASQI) version 2,” Journal of the Audio Engineering Society, vol. 62, no. 3, pp. 99–117, 2014. [Google Scholar]