

Abstract
In the cocktail party phenomenon, participants cannot attend to more than one stream of information but sometimes detect their own name being presented in the irrelevant message during a selective listening task. Here we present a preregistered replication of the phenomenon, in which we also tested whether semantically unexpected words have a similar effect, and whether individual differences in working memory capacity as measured by the operation and running span tasks are related to the ability to detect one’s own name or unexpected words in the irrelevant message. Twenty-nine percent of the participants reported noticing their own name, and those who did made more errors on relevant, to-be-shadowed words presented around the time of the name. Low span participants were more likely than high span participants to notice their names and to commit shadowing errors concurrently to the presentation of the name or shortly after. In contrast, semantically unexpected words were rarely detected, nor were they associated with shadowing errors in the relevant message. Our results demonstrate once again that highly relevant stimuli such as one’s own name are capable of attracting and capturing attention for a short period of time. Our results also demonstrate that unexpected words within sentences do not belong to this category of stimuli.
Keywords: Dichotic Listening, Selective Attention, Working Memory Capacity, Attentional Capture, Semantic Processing
The cocktail party phenomenon appears in almost every textbook on cognitive psychology, because it illustrates well the ability of the attentional system to detect highly relevant stimuli even though they are presented in an ignored auditory channel. The term has been used to refer to several inter-related phenomena. First, it includes the point that people cannot process multiple, complex streams of incoming acoustic information at once, but are able to select one stream based on its physical characteristics (such as voice or spatial location) and process it even in a multi-stream cacophony, such as a cocktail party with many people talking (Cherry, 1953). Second, most relevant to the present work, approximately one third of the participants report hearing their own name being presented in the irrelevant message during a selective listening task (Moray, 1959; Wood & Cowan, 1995). We sought to understand better the basis of this finding by examining individual differences in the detection not only of names, but also of spoken sentences with sometimes-unexpected last words. First, we sketch the background for this study.
In the selective listening paradigm, two messages are presented dichotically and the task for the participants is to shadow a message presented to one ear—repeating each word as soon as they hear it—while ignoring a second message that is simultaneously presented to the other ear. This task was developed and introduced to the literature by Cherry (1953), who asked the participants afterwards about the content of the irrelevant message and found out that physical features, such as whether it was a female or a male voice, could be recalled, whereas the specific ignored words or the language spoken were not recalled. In light of these and related findings (cf. Broadbent, 1958), it was initially assumed that the content of the irrelevant message is filtered out early, on the basis of acoustic features, without being processed semantically. The work of Moray (1959), however, challenged this assumption.
Moray used the standard selective listening task with dichotic presentation, in which a relevant, to-be-shadowed message was presented to one ear, and an irrelevant, to-be-ignored message was presented to the other. The irrelevant message contained short instructions, some of which were prefixed by the participant’s name (e.g., John Smith, you may stop now). In a retrospective questionnaire, four of the twelve participants (33 percent) reported noticing their own name. As influential as it is, there are only a few direct replications of the phenomenon (Conway, Cowan, & Bunting, 2001; Naveh-Benjamin et al., 2014; Wood & Cowan, 1995). Wood and Cowan (1995) were the first to examine shadowing errors in the relevant channel concurrently to the presentation of the name or shortly after. Consistent with Moray (1959), 35 percent of the participants reported hearing their own name, and those who did were more likely to commit an error on a relevant to-be-shadowed word location.
Conway et al. (2001) addressed the issue of the mechanism of the detection of one’s own name in the ignored message using an individual-differences procedure. It could be that the most capable participants were able to monitor both channels concurrently, or it could be that the most capable participants are best at concentrating on the relevant message and tuning out the irrelevant message. Strongly supporting the latter possibility, Conway et al. found that name detection is negatively related to working memory capacity as measured by the operation span task (Turner & Engle, 1989), consistent with the notion that operation span indexes the ability to control attention and to block out, or inhibit, task-irrelevant information (e.g., Unsworth, Schrock, & Engle, 2004).
Conway et al. (2001) showed that low span participants were not only more likely to detect their own name in the irrelevant message than were high span participants, but also were more likely to commit shadowing errors concurrent with and shortly after the presentation of the name. Further work on adult aging by Naveh-Benjamin et al. (2014) shows that it is not low span per se that drives the individual difference in noticing one’s own name, but span insofar as it relates to control of attention. Specifically, while two thirds of the younger participants noticed their own name in the irrelevant message, older participants rarely did, even though their average span was equivalent to low-span young adults.
The cocktail party phenomenon has often been taken to indicate that stimuli such as one’s name require less perceptual information than other stimuli to be recognized which allows the system to detect and react to highly relevant information even if it is presented in an unattended auditory channel (e.g., Treisman, 1969). Results from a cross-modal distraction paradigm seem to suggest that the presentation of one’s name in a task-irrelevant, to-be-ignored auditory message has a similar effect on a visual-verbal focal task. Participants make more errors in serial recall of to-be-remembered digits when sentences are played that contain their own name as opposed to that of a yoked-control participant (Röer, Bell, & Buchner, 2013). Moreover, recent findings suggest that words in the irrelevant auditory channel are not only processed at the level of their individual meaning, but also at the level of their match to the preceding semantic context (Röer, Bell, Körner, & Buchner, 2019; Röer, Buchner, & Bell, in press): Semantically unexpected endings (e.g., Today was a beautiful day without a single cloud in the error) were more disruptive to serial recall than sentences with expected endings (e.g., Today was a beautiful day without a single cloud in the sky). Unlike the disruptive effect of one’s name that of semantically unexpected words cannot be explained with occasional slips of attention to the irrelevant message, because the detection of a semantic expectation violation requires the integration of words into the sentence context. Instead, it seems that the irrelevant auditory channel is routinely processed semantically, but this processing may result in an observable disruption only if an unexpected or highly relevant signal is detected.
It remains an open question how widely applicable these findings are to a situation in which both relevant and irrelevant stimuli are presented in the auditory modality, which requires more effort devoted to selecting one channel and filtering out others based on physical cues (Johnston & Heinz, 1978). Wood, Stadler, and Cowan (1997) examined the ability of participants to process unattended, spoken phrases like taxi fare presented in an unattended channel during shadowing (based on lexical choice when asked to spell the second word, which could be fare or fair) and found that these spoken phrases left an observable mark on memory only if the shadowing stimuli were presented much more slowly than is the case for most selective listening procedures, leaving time for attention to shift to the channel to-be-ignored. Therefore, there are reasons to question whether, in a typical selective listening task, sentences can be processed to the point of differentiating between expected and unexpected endings. Here, we revisit the classic cocktail party phenomenon to address this question empirically.
The present study has three main purposes, (1) to examine whether semantically unexpected words in the irrelevant message are detected during a selective listening task, (2) to conduct a direct replication of the cocktail party phenomenon, and (3) to explore whether individual differences in working memory capacity are related to the ability to detect unexpected words or one’s own name in the irrelevant message. The study is the first to investigate whether semantically unexpected words are detected in the irrelevant auditory channel. Therefore, we used a straightforward approach with a standard selective listening task with dichotic presentation of the relevant and irrelevant channels. To minimize error variance associated with individual differences, we used a within-subject manipulation of self-relevance (own name, yoked-control name) and semantic expectation (unexpected, expected word) with Bayesian analyses to allow the interpretation of potential null results. Further, we used two working memory span tasks (i.e., the operation span task and a running span task) to provide a comprehensive measurement of individual differences in working memory capacity.
Previous relevant studies have relied on complex span tasks as the measures of working memory capacity (Conway et al., 2001; Naveh-Benjamin et al., 2014). It has often been assumed that, in order for a working memory task to correlate well with cognitive capabilities such as the control of attention and inhibition, it must be such tasks, like operation span, which require concurrent storage and processing. In contrast to that assumption is recent work showing that running digit span (Pollack, Johnson, & Knaff, 1959) also correlates about equally well with cognitive aptitudes (Broadway & Engle, 2010; Cowan et al., 2005; Gray et al., 2017). In running digit span, a long list of digits ends unpredictably and the participant must recall as many items as possible from the end of the list in the presented order. Because it is impossible to group or rehearse the items, participants must wait until the list ends and then focus attention on the items at the end of the list to transfer the representations quickly from a labile, acoustic or phonetic form to a capacity-limited working memory (Bunting, Cowan, & Colflesh, 2008; Bunting, Cowan, & Saults, 2006). This strategic use of attention in the task may be the reason that it correlates with cognitive aptitudes about as well as operation span, and we consequently found it suitable for our second measure of working memory capacity.
Method
Ethics and consent
Research was performed in accordance with the Declaration of Helsinki and received the approval of the first authors’ institutional ethics committee. Written informed consent was obtained from all participants prior to participation.
Preregistration Statement
A time stamped preregistration document was published prior to the start of data collection outlining in detail the method and planned analysis using the format provided by https://aspredicted.org. The preregistration document is available at the project page on OSF under https://osf.io/rgyv5/ (Röer & Cowan, 2020). A power analysis is included. Given a sample size of N = 80 and a scale r on the effect size of 0.707, a t-value of 1.44 or smaller would yield a Bayes factor greater than 3 in favor of the null hypothesis, and a t-value of 2.63 or greater would yield a Bayes factor greater than 3 in favor of the alternative hypothesis (Rouder, Speckman, Sun, Morey, & Iverson, 2009). Experimental materials are also included.
Participants
In two instances, the yoked-control partner of the participant did not show up. As specified in the preregistration, these data were removed prior to analysis. The remaining sample consisted of 80 participants (59 women; M age = 25, SD = 10). All participants were native German speakers with no known hearing impairments. Participants received course credit or a monetary compensation for participating. Only participants whose first names had one, two or three syllables could participate to allow the names to be synchronized with words to be shadowed. Participants whose first names had more than three syllables were given the opportunity to participate in another study.
Materials and Procedure
Participants were run individually. They wore headphones with high-insulation hearing protection covers (beyerdynamic DT-150) throughout the experiment, feeding into an Apple iMac computer. The experiment took approximately 24 min.
First, participants completed computerized versions of the operation span task (Turner & Engle, 1989) and the running span task (Pollack et al., 1959; see also Bunting et al., 2006; 2008). In the operation span task, participants evaluated the correctness of mathematical equations while maintaining lists of two, three, four, five, or six words. There were three trials for each list length, amounting to 15 trials which were presented in random order. Following the procedure from Conway et al. (2001), credit was given only to completely correct trials (i.e., trials in which all words were recalled in the correct serial position). Thus, the operation span score was the cumulative number of recalled words from completely correct trials. In the running span task, 12, 13, 14, 15, 16, 17, 18, 19, or 20 digits from the set 1-9 were presented over headphones. The task for the participants was to recall the last six digits from the list. Each compressed digit was presented for 250 ms. There were two trials for each list length, amounting to 18 trials, which were presented in random order. A response was only scored as correct, if a digit was recalled in the correct serial position relative to the end of the list. The running span score was the proportion of correctly recalled digits across all trials. The presentation order of the working memory span tasks was counterbalanced across participants.
Next, for our selective listening task with dichotic presentation, written instructions informed the participants that their task was to listen to the female voice presented to their right ear and repeat each word as soon as they heard it until the sound stopped. They were further instructed that they should ignore the male voice presented to their left ear. During shadowing, the experimenter, who was seated at a separate table, recorded shadowing errors. Stimuli were recorded digitally at 44.1 kHz with 16-bit encoding using the text-to-speech software of Mac OS. The relevant message was spoken by the female voice “Anna”, the irrelevant message by the male voice “Markus”. The relevant message contained 420 words with one, two, or three syllables that were presented at the rate of 60 words per minute. The presentation of the irrelevant message began 30 s after the relevant message to allow for a practice period without distraction. The irrelevant message contained sentences (e.g., excerpts from weather forecasts, cooking recipes, scientific textbooks, operating manuals) taken from previous auditory distraction experiments (Röer et al., 2013; Röer, Bell, & Buchner, 2014, 2015). Self-relevance (own name, yoked-control name) and semantic expectation (unexpected, expected) were manipulated within-subjects. A complete list of the sentences that were presented in the irrelevant channel is given in the Appendix.
For each participant, the semantically unexpected word was the semantically expected word for the yoked-control partner, and the same was true for their names. The critical words were presented after 3, 4, 5, and 6 minutes of shadowing. The onsets of the critical words in the irrelevant message were synchronized with the onsets of words in the relevant message with the same number of syllables. There were eight different orders in which the critical words could be presented. These orders were counterbalanced across participants. The relevant and irrelevant messages stopped after seven minutes.
Last, after the selective listening task, participants completed a questionnaire about the irrelevant message. Participants were instructed to fill out the questions in the order presented. They were asked to write down everything they could remember from the irrelevant message, and whether they noticed something unusual, whether they had noticed that a name was presented, and specifically whether they noticed that their own name or another name was presented. They were also asked whether they noticed that a well-known proverb was presented and specifically whether they noticed that a well-known proverb was presented with an unexpected last word.The order of the questions most relevant to the present purposes (self-relevance, semantic expectation) was counterbalanced across participants. The original version of the questionnaire and an English translation are available at the project page on OSF under https://osf.io/rgyv5/.
Results
Data Availability and Post-registration Revision
All data together with a data dictionary and analyses are available at the project page on OSF under https://osf.io/rgyv5/. Analyses were conducted with the computer software JASP (JASP Team, 2020) using a default Cauchy prior width of 1. For the sake of consistency, we decided to depart from the preregistered analyses in one way, by reporting Bayesian contingency table tests instead of Fisher's exact tests. The pattern of results is the same for both of these tests.
Questionnaire
According to the retrospective report immediately after the shadowing task, 23 participants (29%) reported hearing their name in the irrelevant message. Two participants reported hearing the yoked-control partner’s name, one participant reported hearing the semantically unexpected word, and two participants reported hearing the semantically expected word. Bayesian contingency table tests showed that task presentation order, condition presentation order, and test question order had no effect on the detection of one’s name (BF10 = 0.255, BF10 = 0.519, and, BF10 = 0.323, respectively) and no effect on the detection of unexpected words within sentences (BF10 = 0.096 in all three cases).
Following the procedure from Conway et al. (2001), we tested whether low span participants detected their names more often than high span participants. To this end, we compared the lower versus upper quartiles of operation span scores, running span scores, and both measures combined. Although low span participants detected their names more often than high span participants, Bayesian contingency table tests did not reveal any reliable differences (BF10 = 1.023, BF10 = 0.582, and, BF10 = 1.018, respectively). Table 1 gives a summary of name detection percentages and mean shadowing errors for each quartile. As specified in the preregistration, we also planned to test whether individual differences in working memory span are related to the detection of unexpected words, but only one participant reported noticing an unexpected word in the irrelevant message, thus rendering this test unnecessary.
Table 1.
Name detection percentages and mean shadowing errors (with standard errors of the means in parentheses) of each quartile for operation span scores, running span scores, and both measures combined into average z-scores
| Measure | Name detection | Shadowing Errors |
|---|---|---|
| Operation Span Scores | ||
| Q1 (M = 28.00, range 10 to 39) | 38 % (11) | 34.4 (4.0) |
| Q2 (M = 43.68, range 40 to 47) | 26 % (11) | 35.6 (5.6) |
| Q3 (M = 50.85, range 48 to 54) | 27 % (9) | 34.8 (5.1) |
| Q4 (M = 58.29, range 55 to 60) | 21 % (11) | 30.6 (5.4) |
| Running Span Scores | ||
| Q1 (M = 0.41, range 0.24 to 0.46) | 36 % (11) | 40.8 (5.3) |
| Q2 (M = 0.50, range 0.47 to 0.53) | 28 % (11) | 31.1 (4.7) |
| Q3 (M = 0.57, range 0.54 to 0.60) | 21 % (10) | 29.4 (4.0) |
| Q4 (M = 0.66, range 0.61 to 0.78) | 28 % (11) | 35.1 (6.2) |
| Combined Normalized Scores | ||
| Q1 (M = −1.10, range −1.86 to −0.78) | 37 % (11) | 35.5 (3.7) |
| Q2 (M = −0.13, range −0.44 to 0.07) | 33 % (11) | 36.3 (6.0) |
| Q3 (M = 0.31, range 0.09 to 0.57) | 25 % (10) | 31.1 (4.0) |
| Q4 (M = 0.92, range 0.58 to 1.66) | 21 % (10) | 34.1 (6.3) |
Shadowing Errors
The errors in shadowing after the presentation of the critical words confirm the results from the retrospective report. A 2x5 Bayesian repeated measures ANOVA with self-relevance (own name, yoked-control name) and position (word −1, word, word +1, word +2, word +3) as within-subjects variables yielded an effect of self-relevance, BF10 = 19.26 (i.e., strong evidence for the alternative hypothesis as defined by Jeffreys, 1968). A 2x5 Bayesian repeated measures ANOVA of sentence-final words with semantic expectation (unexpected, expected) and position (word −1, word, word +1, word +2, word +3) as factors yielded no effect of semantic expectation, BF10 = 0.060 (i.e., strong evidence for the null hypothesis as defined by Jeffreys, 1968).
Figure 1 shows the mean percentage of participants who made errors at a relevant to-be-shadowed word location. Clearly, a higher portion of participants who noticed their own name made shadowing errors concurrently with the presentation of the name, and on the two words following the name. On the word to-be-shadowed before the presentation of their own name, a Bayesian independent samples t-test indicated that there was no reliable difference in shadowing errors between participants who did and those who did not notice their own names, BF10 = 1.818, suggesting that participants did not notice the names merely because their attention wandered to the irrelevant message shortly before. On the word to-be-shadowed concurrently with the presentation of their own name, and on the two words following the name, there were reliable differences between participants who did and those who did not notice their own names, BF10 = 112.6, BF10 > 1000, and BF10 > 1000 (i.e., decisive evidence for the alternative hypothesis as defined by Jeffreys, 1968). On the word to-be-shadowed three words following their own name, no reliable difference in shadowing errors was found, BF10 = 2.171.
Figure 1.
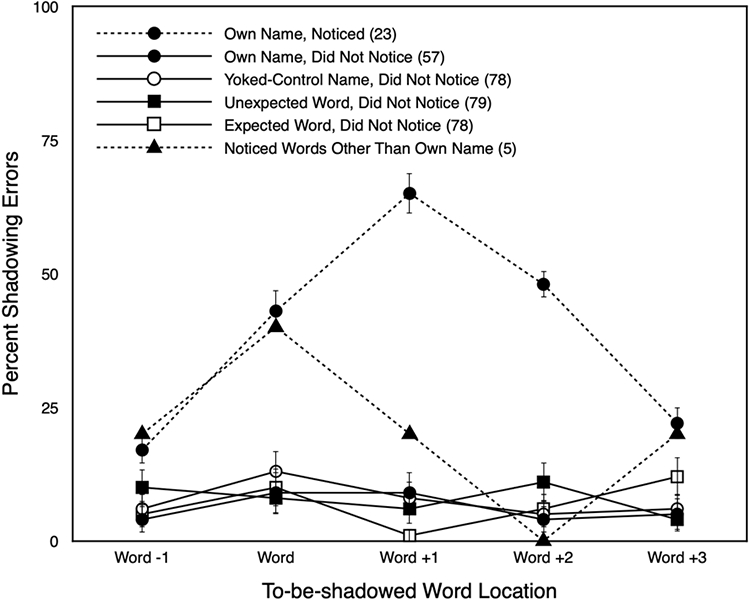
Mean percentage of participants who made errors in shadowing at different locations of the to-be-shadowed word (X axis): one position before the critical word was presented in the irrelevant channel, concurrently with its presentation, and one, two, and three positions after the critical word. Among critical-word conditions and participant reactions to them (graph parameter), the top, dashed line with filled circles shows the pattern for individuals who noticed their name according to the post-shadowing questionnaire. In parentheses is the number of participants for each situation. The error bars depict the standard errors of the means. Standard errors of the line for shadowing errors in 5 participants who noticed words other than their own name, omitted for clarity, are 20 (word −1), 25 (word), 20 (word +1), 0 (word +2), and 20 (word +3).
Figure 1 clearly shows that there was no increase in shadowing errors during the presentation of expected or unexpected final sentence words, or of the yoked control name. In an exploratory analysis, we combined the shadowing data for five individuals who reported noticing the unexpected word or another critical word. The pattern shown for these individuals at the point of the noticed word suggests that their attention may have wandered to the unattended channel when that word was presented, but there is no evidence of a more sustained effect comparable to what is seen when participants noticed their name. The latter has been taken as evidence of recruitment of attention to the channel to be ignored, for a short period after hearing the name.
We also tested whether low span participants were more likely than high span participants to commit shadowing errors at a relevant to-be-shadowed word location (i.e., word, word +1, word +2), similar to what Conway et al. (2001) observed. To this end, we compared the lower versus upper quartiles of operation span scores, running span scores, and both measures combined using Bayesian contingency table tests. When operation span scores and running span scores were compared separately, the Bayes Factors were BF10 = 6.487, and BF10 = 3.366, respectively (i.e., moderate evidence for the alternative hypothesis as defined by Jeffreys, 1968). When the combined span scores were compared, the Bayes factor was BF10 = 11.68 (i.e., strong evidence for the alternative hypothesis as defined by Jeffreys, 1968), indicating that low span participants were indeed more likely to commit a shadowing error at a relevant to-be-shadowed word location than high span participants. Thus, online processing proved more sensitive to individual differences than the retrospective report. There were no reliable differences in shadowing errors between low span and high span participants at the to-be-shadowed location one word before the presentation of the name (BF10 = 0.423, BF10 = 2.251, and, BF10 = 0.709, respectively), and three words following the name (BF10 = 0.422, BF10 = 0.220, and, BF10 = 0.192, respectively). Table 2 gives a summary of shadowing errors for each quartile.
Table 2.
Mean shadowing errors (with standard errors of the means in parentheses) of each quartile for operation span scores, running span scores, and both measures combined into average z-scores one position before the name was presented in the irrelevant channel, concurrently with the presentation, and one, two, and three positions after the name.
| Measure | Position | ||||
|---|---|---|---|---|---|
| name −1 | name | name +1 | name +2 | name +3 | |
| Operation Span Scores | |||||
| Q1 | 0.14 (0.08) | 0.29 (0.10) | 0.38 (0.11) | 0.33 (0.11) | 0.14 (0.08) |
| Q2 | 0.00 (0.00) | 0.16 (0.09) | 0.16 (0.09) | 0.11 (0.07) | 0.21 (0.10) |
| Q3 | 0.08 (0.05) | 0.19 (0.08) | 0.23 (0.08) | 0.12 (0.06) | 0.00 (0.00) |
| Q4 | 0.07 (0.07) | 0.07 (0.07) | 0.21 (0.11) | 0.07 (0.07) | 0.07 (0.07) |
| Running Span Scores | |||||
| Q1 | 0.18 (0.08) | 0.36 (0.11) | 0.23 (0.09) | 0.32 (0.10) | 0.14 (0.08) |
| Q2 | 0.06 (0.06) | 0.22 (0.10) | 0.44 (0.12) | 0.11 (0.08) | 0.06 (0.06) |
| Q3 | 0.05 (0.05) | 0.10 (0.07) | 0.19 (0.09) | 0.14 (0.08) | 0.05 (0.05) |
| Q4 | 0.00 (0.00) | 0.06 (0.06) | 0.17 (0.09) | 0.06 (0.06) | 0.17 (0.09) |
| Combined Normalized Scores | |||||
| Q1 | 0.11 (0.07) | 0.37 (0.11) | 0.26 (0.10) | 0.37 (0.11) | 0.05 (0.05) |
| Q2 | 0.10 (0.07) | 0.14 (0.08) | 0.33 (0.11) | 0.14 (0.08) | 0.19 (0.09) |
| Q3 | 0.10 (0.07) | 0.20 (0.09) | 0.30 (0.11) | 0.10 (0.07) | 0.10 (0.07) |
| Q4 | 0.00 (0.00) | 0.05 (0.05) | 0.11 (0.07) | 0.05 (0.05) | 0.05 (0.05) |
Discussion
In the present study, we replicated and extended the cocktail party phenomenon to examine whether semantically unexpected words in the irrelevant message have a similar effect as one’s own name. The results were fairly straightforward. One’s own name attracted and captured attention of some individuals when it was presented in the irrelevant auditory channel, whereas semantically unexpected words did not. According to the retrospective questionnaire, 29 percent of the participants reported hearing their own name in the irrelevant message during a selective listening task. This is fairly comparable to the 33 percent from Moray (1959) and the 35 percent from Wood and Cowan (1995), and somewhat lower as the 43 percent from Conway et al. (2001), for lowest and highest quartiles averaged, and the 58 and 48 percent of younger adults in Experiments 1 and 4 of Naveh-Benjamin et al. (2014). One participant reported that they noticed a sentence with a semantically unexpected word in the irrelevant message, but they only did so after being asked specifically about it, and they were not able to report the word. In short, there was no clear evidence that semantically unexpected words captured attention when they are presented in the irrelevant message during selective listening.
The results from the shadowing error analysis demonstrate that participants who noticed their name in the irrelevant message made more errors in shadowing concurrently to the presentation of the name or shortly after. There were no reliable differences in shadowing errors between participants who did and did not notice their name on the word to-be-shadowed just before the name. This shows that the errors in shadowing therefore did not result from persistent sampling of the channel with the name, and could have resulted partly or wholly from recruitment of attention by the name itself. Replicating earlier findings (Conway et al., 2001; Wood & Cowan, 1995), there were also no reliable differences on the word to-be-shadowed three words following the name, suggesting that the reallocation of attention to the name did not persist for longer than two words. Interestingly, the line in Figure 1 which shows shadowing errors for participants who noticed words other than their own name seems to indicate a similar response initially, which might be associated with the conscious identification of the stimulus. Although speculative, the identification of a highly relevant stimulus such as one’s own name may cause the attentional system to allocate further processing resources resulting in a full attention switch towards the irrelevant auditory channel. This could explain why the percentage of shadowing errors continued to increase after the name when one’s own name was detected, but decreased after the name when a word other than one’s own name was detected. The allocation of further processing resources should also result in a richer memory trace that is more likely to be remembered later, which could explain why participants reported hearing their own name in the irrelevant message more often than the name of their yoked-control partner.
Replicating the finding of Conway et al. (2001) that individual differences in working memory span are related to errors in shadowing after the presentation of one’s own name, low span participants were more likely than high span participants to commit shadowing errors on a relevant to-be-shadowed word location. While this was true regardless of whether participants were classified based on their operation span scores or based on their running span scores, the effect was largest when participants were classified based on both scores combined. Thus it seems the effect is most reliably detected when more than one measure of working memory span is used.
The retrospective questionnaire proved insensitive to individual differences in working memory, probably because our lowest quartile (M operation span = 28.00, range 10-39) was well above the lowest quartile of Conway et al. (M operation span = 8.22, range 6-12). Taken together, our findings suggest that errors in shadowing caused by attention recruitment may occur in some individuals without rising to the point of conscious memory of the event.
A priori, it seemed possible to speculate that unexpected words are also noticed during selective listening. Recent evidence from a cross-modal distraction task suggested that the extent of semantic processing in the irrelevant auditory channel tends to be underestimated, because the processing only results in an observable disruption if an unexpected or behaviorally relevant signal is detected (Röer et al., 2019; see also Vachon, Marsh & Labonté, in press). However, although the main aim is to understand the extent of analysis of the irrelevant message both in cross-modal distraction tasks, such as the irrelevant sound paradigm, and in the selective listening paradigm, there are also a number of differences between these paradigms. One difference is the time of presentation of the critical word. In the selective listening paradigm, the critical words are embedded in a continuous stream of words in the irrelevant channel. In the irrelevant sound paradigm, by contrast, a typical trial only lasts a few seconds, so that the critical word is much more salient in the irrelevant channel. Moreover, the critical word is often presented either at the beginning or at the end of the trial (e.g., Röer et al., 2013), which further increases its salience compared to in the selective listening paradigm. It is also worth noting that, when the critical word is presented at the beginning of the trial in the irrelevant sound paradigm, the task demands are still relatively low, which may increase the likelihood that words in the irrelevant auditory channel are processed semantically.
In the present study, the presentation of unexpected words was not associated with shadowing errors in the relevant message, and only one participant reported that they noticed a semantically unexpected word, but could not remember which one, indicating that findings from cross-modal distraction tasks cannot be generalized to a situation in which the relevant and irrelevant sources of information are both presented auditorily. Although the theoretical possibility exists that the unexpected words were noticed nevertheless, this obviously did not result in a conscious recollection of the presentation of the word, nor did it become apparent in the form of errors or increased lags in shadowing. Last, there is another relevant difference between the cross-modal and unimodal distraction tasks. In the irrelevant sound paradigm, 96 percent of the participants reported noticing their own name (Röer et al., 2013), which is a considerably higher level than what is typically found in the selective listening paradigm (Conway et al., 2001; Moray, 1959; Wood & Cowan, 1995). The results presented here thus seem to imply that the likelihood of detecting highly relevant stimuli is reduced in situations in which few attentional resources are available for the processing of the ignored auditory channel, either because the focal task is particularly demanding as is the case in the selective listening paradigm, or because participants have relatively high working memory capacity, which allows them to more effectively inhibit task-irrelevant information.
Acknowledgements
The research reported in this article was supported by grants from the Deutsche Forschungsgemeinschaft (RO 4972/1-1) to Röer and NIH R01 HD-21338 to Cowan. Correspondence concerning this article should be addressed to Jan Philipp Röer, Department of Psychology and Psychotherapy, Witten/Herdecke University, Alfred-Herrhausen-Straße 44, 58455 Witten. Electronic mail may be sent to jan.roeer@uni-wh.de. The preregistration document, the materials, and the data are available at the project page on OSF under https://osf.io/rgyv5/.
Appendix
Table A1.
List of sentences presented in the irrelevant channel.
| Sentences with critical words |
|---|
| Own name (yoked-control name) trinkt an heißen Tagen meistens Limonade. |
| Own name (yoked-control name) läuft beim Telefonieren oft in der Wohnung herum. |
| Erst die Arbeit, dann das Vergnügen (Späne). |
| Liebe geht durch den Magen (Kraft). |
| Sentences without critical words |
| Am Dienstag überwiegend sonnig, nur vereinzelt sind Schauer möglich. Es weht ein schwacher bis mäßiger Nordostwind. |
| Kanada hat die längste Küste von allen Staaten der Erde. |
| Pech im Spiel, Glück in der Liebe. |
| In Bolivien liegt der höchstgelegene Regierungssitz der Welt. |
| Die dümmsten Bauern ernten die dicksten Kartoffeln. |
| Deine eigenen Fehler sind es, die Du an anderen rügst, merke sie Dir, damit Du Dich nicht länger selbst betrügst. |
| Wer anderen eine Grube gräbt, fällt selbst hinein. |
| März und April sind die heißesten Monate auf den Malediven. |
| Wenn Zwei sich streiten, freut sich der Dritte. |
| Ohne auch nur den geringsten Moment zu zögern, griff sie zum Telefonhörer und wählte die Nummer des örtlichen Polizeireviers. |
| Morpheus ist der griechische Gott der Träume. |
| Zwiebeln schälen, vierteln und in Scheiben schneiden. Die Tomaten hinzu geben, dann einige Minuten bei mittlerer Hitze köcheln lassen. |
| Minerva ist die römische Göttin der Weisheit. |
| Was lange währt, wird endlich gut. |
| Ein neugeborenes Pandababy, ist kleiner als eine Maus. |
| Wenn mir mein Hund das Liebste ist, denk’ nicht, es wäre Sünde. Mein Hund blieb’ mir im Stürme treu, der Mensch nicht mal im Winde. |
| Das Jojo war ursprünglich eine philippinische Jagdwaffe. |
| Knapp daneben ist auch vorbei. |
| Frauen blinzeln fast doppelt so häufig wie Männer. |
| Die Patrone mit dem Klebestreifen über der Tintenaustrittsöffnung in den Drucker einsetzen und eine Druckkopfreinigung durchführen. |
| In Uganda ist die Amtssprache Englisch. |
| Alle Wege führen nach Rom. |
| Am Sonnabend wechselnde Bewölkung mit sonnigen Abschnitten. In der Nacht kühlt es ab auf Temperaturen um den Gefrierpunkt. |
| Hochmut kommt vor dem Fall. |
| Ebenso wie der Fingerabdruck ist auch der Zungenabdruck eines Menschen einzigartig. |
| Kleine Sünden bestraft der liebe Gott sofort. |
| Das erste Taschenbuch der Geschichte war Goethes "Faust". |
| Eine Hand wäscht die andere. |
| Das Autobahnkreuz Hilden ist in Richtung Düsseldorf wegen Bauarbeiten bis mittags gesperrt, eine örtliche Umleitung ist eingerichtet. |
| Mongolen geben Salz statt Zucker in ihren Tee. |
| Die Letzten werden die Ersten sein. |
| Nauru ist die kleinste souveräne Republik der Erde. |
| Betrunkene und Kinder sprechen die Wahrheit. |
| Blaue Augen werden im Alter immer heller. |
| Auf Höhe der Anschlussstelle Recklinghausen ist in beiden Fahrtrichtungen nach einem Unfall jeweils der linke Fahrstreifen blockiert. |
| Wie man sich bettet, so liegt man. |
| Kamele sind über kurze Distanzen schneller als ein Rennpferd. |
| Wer nicht wagt, der nicht gewinnt. |
| Die synaptischen Vesikel sind zum größten Teil über das Protein Synapsin an die Actinfäden des Zytoskeletts fixiert. |
| Die Luftpumpe ist eine französische Erfindung. |
| Der Zweck heiligt die Mittel. |
| Der erste Sinn, der im Alter nachlässt, ist das Hören. |
| Schweigsam und mit einem grimmigen Ausdruck auf dem vernarbten Gesicht schaute er beharrlich auf die rastlosen Zeiger der Wanduhr. |
| Der See Genezareth ist das tiefstgelegenste stehende Gewässer der Erde. |
| Kleine Geschenke erhalten die Freundschaft. |
| Die Tanne ist der Nadelbaum mit den längsten Nadeln. |
| Wo ein Wille ist, ist auch ein Weg. |
| Die Wüste Gobi ist eine Felswüste. |
| Hunde, die bellen, beißen nicht. |
| Kendo ist eine aus Japan stammende waffenlose Kampfsportart. |
| Wasser, Zitronensaft und Zucker in einen Topf geben. Unter Rühren zum Kochen bringen und nach und nach den Eischnee darunter heben. |
| Für jeden Topf gibt es den passenden Deckel. |
| Der Kilt stammt ursprünglich aus Irland, nicht aus Schottland. |
| Man muss die Feste feiern, wie sie fallen. |
| Die Stilrichtung des Impressionismus entwickelte sich in Spanien. |
| Einsam wandle Deine Bahnen, stilles Herz und unverzagt, viel erkennen, vieles ahnen wirst Du, was Dir keiner sagt. |
| Unter den Bären legt der Braunbär die größten Entfernungen zurück. |
| Man sollte das Eisen schmieden, solange es heiß ist. |
| Tuberkulose wird durch Viren übertragen. |
| Die Insel Ösel gehört zu Dänemark. |
| Verwenden Sie den horizontalen Rollbalken, wenn Sie durch die Vorschau von Seiten blättern möchten, die Sie heute besucht haben. |
| Nicht für die Schule lernt man, sondern für das Leben. |
| Der Philosoph Platon war einer der besten Speerwerfer seiner Zeit. |
| Was man nicht im Kopf hat, muss man in den Beinen haben. |
| Die ADH-unabhängige Wasserretention ist gewöhnlich die Folge einer akuten oder chronischen Niereninsuffizienz. |
| Die Aktivität einer radioaktiven Substanz wird in Sievert gemessen. |
| Nichts wird so heiß gegessen, wie es gekocht wird. |
| Von allen Staaten hat Singapur die höchste Einwohnerdichte. |
| Säume nicht, Dich zu erdreisten, wenn die Menge zaudernd schweift, alles kann der Edle leisten, der versteht und rasch ergreift. |
References
- Broadbent DE (1958). Perception and communication. New York: Pergamon. [Google Scholar]
- Broadway JM, & Engle RW (2010). Validating running memory span: Measurement of working memory capacity and links with fluid intelligence. Behavior Research Methods, 42, 563–570. [DOI] [PubMed] [Google Scholar]
- Bunting M, Cowan N, & Colflesh GH (2008). The deployment of attention in short-term memory tasks: Trade-offs between immediate and delayed deployment. Memory & Cognition, 36, 799–812. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bunting M, Cowan N, & Saults JS (2006). How does running memory span work? Quarterly Journal of Experimental Psychology, 59, 1691–1700. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cherry EC (1953). Some experiments on the recognition of speech, with one and with two ears. Journal of the Acoustical Society of America, 25, 975–979. [Google Scholar]
- Conway AR, Cowan N, & Bunting MF (2001). The cocktail party phenomenon revisited: The importance of working memory capacity. Psychonomic Bulletin & Review, 8, 331–335. [DOI] [PubMed] [Google Scholar]
- Cowan N, Elliott EM, Scott Saults J, Morey CC, Mattox S, Hismjatullina A, & Conway AR (2005). On the capacity of attention: Its estimation and its role in working memory and cognitive aptitudes. Cognitive Pychology, 51, 42–100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gray S, Green S, Alt M, Hogan TP, Kuo T, Brinkley S, & Cowan N (2017). The structure of working memory in young children and its relation to intelligence. Journal of Memory and Language, 92, 183–201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- JASP Team (2020). JASP (Version 0.12) [Computer software]. Retrieved from https://jasp-stats.org. [Google Scholar]
- Jeffreys H (1968). The Theory of Probability. Oxford: Oxford University Press. [Google Scholar]
- Johnston WA, & Heinz SP (1978). Flexibility and capacity demands of attention. Journal of Experimental Psychology: General, 107, 420–435. [Google Scholar]
- Moray N (1959). Attention in dichotic listening: Affective cues and the influence of instructions. The Quarterly Journal of Experimental Psychology, 11, 56–60. [Google Scholar]
- Naveh-Benjamin M, Kilb A, Maddox GB, Thomas J, Fine HC, Chen T, & Cowan N (2014). Older adults do not notice their names: A new twist to a classic attention task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40, 1540–1550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pollack I, Johnson LB, & Knaff PR (1959). Running memory span. Journal of Experimental Psychology: Learning, Memory, and Cognition, 57, 137–146. [DOI] [PubMed] [Google Scholar]
- Röer JP, Bell R, & Buchner A (2013). Self-relevance increases the irrelevant speech effect: Attentional disruption by one’s own name. Journal of Cognitive Psychology, 25, 925–931. [Google Scholar]
- Röer JP, Bell R, & Buchner A (2014). Evidence for habituation of the irrelevant sound effect on serial recall. Memory & Cognition, 42, 609–621. [DOI] [PubMed] [Google Scholar]
- Röer JP, Bell R, & Buchner A (2015). Specific foreknowledge reduces auditory distraction by irrelevant speech. Journal of Experimental Psychology: Human Perception and Performance, 41, 692–702. [DOI] [PubMed] [Google Scholar]
- Röer JP, Bell R, Körner U, & Buchner A (2019). A semantic mismatch effect on serial recall: Evidence for interlexical processing of irrelevant speech. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45, 515–525. [DOI] [PubMed] [Google Scholar]
- Röer JP, Buchner A, & Bell R (in press). Auditory distraction in short-term memory: Stable effects of semantic mismatches on serial recall. Auditory Perception & Cognition. [Google Scholar]
- Röer JP, & Cowan N (2020). A Preregistered Replication and Extension of the Cocktail Party Phenomenon. Retrieved from osf.io/rgyv5. doi: 10.17605/OSF.IO/RGYV5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rouder JN, Speckman PL, Sun D, Morey RD, & Iverson G (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16, 225–237. [DOI] [PubMed] [Google Scholar]
- Treisman AM (1969). Strategies and models of selective attention. Psychological Review, 76, 282–99. [DOI] [PubMed] [Google Scholar]
- Turner ML, & Engle RW (1989). Is working memory capacity task dependent? Journal of Memory & Language, 28, 127–154. [Google Scholar]
- Unsworth N, Schrock JC, & Engle RW (2004). Working memory capacity and the antisaccade task: Individual differences in voluntary saccade control. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30, 1302–1321. [DOI] [PubMed] [Google Scholar]
- Vachon F, Marsh JE, & Labonté K (in press). The automaticity of semantic processing revisited: Auditory distraction by a categorical deviation. Journal of Experimental Psychology: General. [DOI] [PubMed] [Google Scholar]
- Wood NL, & Cowan N (1995). The cocktail party phenomenon revisited: Attention and memory in the classic selective listening procedure of Cherry (1953). Journal of Experimental Psychology: General, 124, 243–262. [DOI] [PubMed] [Google Scholar]
- Wood NL, Stadler MA, & Cowan N (1997). Is there implicit memory without attention? A reexamination of task demands in Eich's (1984) procedure. Memory & Cognition, 25, 772–779. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All data together with a data dictionary and analyses are available at the project page on OSF under https://osf.io/rgyv5/. Analyses were conducted with the computer software JASP (JASP Team, 2020) using a default Cauchy prior width of 1. For the sake of consistency, we decided to depart from the preregistered analyses in one way, by reporting Bayesian contingency table tests instead of Fisher's exact tests. The pattern of results is the same for both of these tests.