

Abstract
Background
Eating disorders affect an increasing number of people. Social networks provide information that can help.
Objective
We aimed to find machine learning models capable of efficiently categorizing tweets about eating disorders domain.
Methods
We collected tweets related to eating disorders, for 3 consecutive months. After preprocessing, a subset of 2000 tweets was labeled: (1) messages written by people suffering from eating disorders or not, (2) messages promoting suffering from eating disorders or not, (3) informative messages or not, and (4) scientific or nonscientific messages. Traditional machine learning and deep learning models were used to classify tweets. We evaluated accuracy, F1 score, and computational time for each model.
Results
A total of 1,058,957 tweets related to eating disorders were collected. were obtained in the 4 categorizations, with The bidirectional encoder representations from transformer–based models had the best score among the machine learning and deep learning techniques applied to the 4 categorization tasks (F1 scores 71.1%-86.4%).
Conclusions
Bidirectional encoder representations from transformer–based models have better performance, although their computational cost is significantly higher than those of traditional techniques, in classifying eating disorder–related tweets.
Keywords: natural language processing, NLP, social media, data, bidirectional encoder representations from transformer, BERT, deep learning, machine learning, eating disorder, mental health, model, classification, Twitter, nutrition, diet, weight, disorder, performance
Introduction
Background
Physical appearance is an essential element for people in this society. Although many studies corroborate that moderate physical activity and proper nutrition help to maintain a healthy body [1] and mind [2], a large part of society continues to place more importance on physical appearance than on health. In recent years, trends have promoted a curvy physique [3,4] despite it being unhealthy, and most people associate having a slim body with being happy to have a slim body. These associations between physical appearance and happiness are the causes of illnesses such as eating disorders. These mental illnesses are complex and do not depend on a single factor [5,6]. Thus, messages relating being fat or skinny with aesthetics that are contained in some media—advertisements, magazines, and celebrity social media—can hurt people vulnerable to these types of illnesses.
The prevalence of eating disorders has been increasing [7]. In addition, since the start of the COVID-19 pandemic, there has been a more pronounced increase in eating disorders [7]. Therefore, any strategy that helps to combat this health problem may be of interest to society.
With the emergence of social media, studies [8-12] using social media data to propose solutions that can help combat this type of illness from different perspectives have also emerged. Artificial intelligence and machine learning techniques, mainly applied to text, have been used to find patterns that help in classifying text to explore eating disorder–related discourse shared on Twitter [8,9] and other studies [10-12] are making use of the data contained in social networks and offering solutions that can help in the field of public health. Among the social media currently available, the most widely used platform in scientific studies is Twitter [13].
Despite the increase in studies on eating disorders that have, for example, analyzed pro–eating disorder websites [14], performed sentiment analysis of pro–anorexia and antiproanorexia videos on YouTube [15], and that have used social media data and artificial intelligence techniques on pro–eating disorder and prorecovery text [16], none has identified (1) tweets that have been written by people who suffer or have suffered from eating disorders, (2) tweets that promote eating disorders, (3) informative or noninformative tweets related to eating disorders and, within the informative tweets, (4) which ones make use of scientific information and which ones do not.
Objectives
Our main objectives were to achieve accurate text classification in performing these 4 tasks, to compare the efficiency of text classification models using traditional machine learning techniques and those using novel techniques, such as pretrained bidirectional encoder representations from transformer (BERT)–based models, to determine which approach has the best combination of performance and computational cost and would be useful for future research.
In our previous research [17], in which 6 test-beds were conducted, the main objective was only to apply 6 pretrained bidirectional encoder representations from transformer–based models to classify a category in a data set. This time, we used a broader approach, by presenting the main problem as a comparison of the performance (accuracy and computational cost) of traditional machine learning models vs bidirectional encoder representations from transformer–based models on 4 different data categorization tasks. This meant increasing 6 test-beds to 40 different test-beds.
Literature Review
Social Media in Health Informatics
Social media, specifically social networks, have become very important sources of information within the field of health informatics. Health informatics includes the design and application of innovations based on information technologies to solve problems related to public health and health services [18]. In this branch of interdisciplinary science, it is possible to carry out complex research to manage information to improve efficiency and reduce costs in health care [19]. Health informatics includes information science, informatics, and health care.
Health-related research using social media is mainly focused on two areas. In real-time monitoring and the prediction of diseases (eg, influenza), it is possible to collect and use messages that have been geographically localized and that are on topics of interest. In this way, research tasks related to the user discussions are a simple task. Social media are also used to determine perspectives on different health problems and conditions. Thus, social media are useful, easy to use, and very important tools for observational studies.
Twitter is a very popular and widely used social network within the field of health and social health research. Some studies [9,14-16] make use of artificial intelligence techniques, such as social network data mining, to generate predictive models based on current knowledge. These techniques have been used, for example, in the context of the COVID-19 pandemic, to determine the public’s perceptions [20] and to examine communication behavior between health organizations and users [21].
Studies [8,9,17,22-24] in the field of health informatics have used Twitter to study user behaviors and characteristics such as location, frequency, most used hashtags, or the structure of user networks. This information, being public and anonymous, is typically exempt from requiring the approval of an ethics committee [25]. Other studies have analyzed the impact of content shared by users [21] and how Twitter is used to receive and provide emotional support [26] or to determine the best way raise public awareness (World Rare Disease Day [27]).
Social media facilitate a great deal of research in the field of health informatics, for example, sentiment analysis, behavioral analysis, or information dissemination analysis, which make use of techniques related to machine learning or deep learning techniques for the classification and prediction of content that has been prepared using natural language processing.
Classification Methods and Health Informatics
Supervised machine learning techniques are used to predict an outcome based on a given input by constructing an input–output pair. The main goal is to build a model that can then be used to make accurate predictions using new data.
Tasks in the field of supervised machine learning include regression—the prediction of a real number—and classification—the prediction of a class label [28]. Supervised classification tasks make use of a labeled training data set. This set allows the creation of classifiers or predictive models [28]. Text mining techniques are used to quantify text data (what is feature engineering) to represent the relationships between words as tokens.
Classification techniques make it possible to categorize large data sets efficiently to study text-based data. This approach has many advantages—more accurate predictions than those of humans and time savings [29-31]. Some commonly used classification techniques in health informatics are logistic regression, support vector machines, Naïve Bayes, random forest, gradient boosting trees, decision trees, and gradient boosted regression trees.
Naïve Bayes classifiers have been used to predict Zika and dengue diseases using data obtained from Twitter [32] and to test the classification of 4 conditions—influenza, depression, pregnancy, and eating disorders—and 2 locations—Portugal and Spain [33].
Other studies [34-36] have shown that good results can be obtained using support vector machine algorithms, such as, with a neural network to predict COVID-19 in chest x-ray images, a prediction model [35], and for sentiment analysis tasks on a Twitter data set related to the COVID-19 pandemic in Canada [36]. A gradient boosted regression tree classifier was used to identify tweets related to e-cigarettes [22], with accurate classification of 5 different user types, by manually labeling a sample of tweets and using feature engineering techniques based on the term frequency–inverse document frequency matrix.
It is also possible to combine different classification algorithms and compare their performance to use the best performing classifier for a given task [37], for example, gradient boosting tree, decision tree, logistic regression, and support vector machine models were used to predict patient needs at the level of informational support [23].
Social Media Research Related to Eating Disorders
There are a number of studies that make use of data related to eating disorders [8,14-16,24,38]. In one study [24], 123,977 tweets were collected and a subsample of 2219 was labeled; the efficiency of a convolutional neural network, with long short-term memory, in classifying tweets about eating disorders was demonstrated. Another study [8] statistically analyzed the effect of eating disorder awareness campaigns by obtaining information on tweets that mentioned 2 hashtags. A review [39] showed the importance of machine learning in advancing the prediction, prevention, and treatment of mental illness and eating disorders. Other studies [14-16,38] have demonstrated the importance of the use of data obtained from social networks in the field of eating disorders, by performing analysis from a social rather than computational perspective, which is known as social network analysis.
A previous social media study predicted depression from texts [40]; therefore, detecting texts written by people suffering from eating disorders can also be helpful. Studies on the detection of pro-ana and pro-recovery communities [41-43]—people in favor of and who promote anorexia and recovery from eating disorders, respectively—and reviews [44,45], have suggested this type of study may be useful. Furthermore, to the best of our knowledge, no studies having the same objectives as ours have been conducted.
Methods
Data Collection
Tweets
A tool (T-Hoarder [46]) was used to collect tweets (Figure 1). Tweets were obtained at the moment they were sent because the tool uses the Twitter streaming API, thus tweets that were subsequently removed from the platform for not complying with regulations were still obtained.
Figure 1.
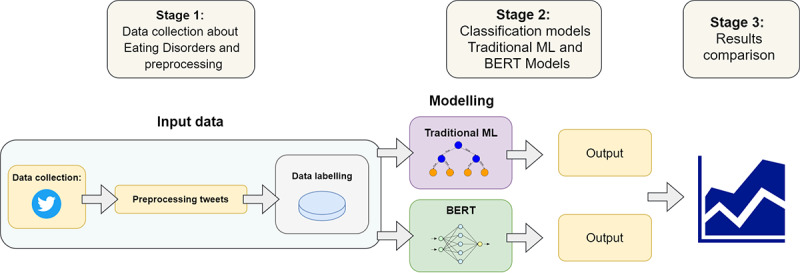
Study workflow: (A) data collection and preprocessing, (B) classification model training, and (C) evaluation. BERT: bidirectional encoder representations from transformer, ML: machine learning.
T-Hoarder allowed us to obtain additional information about tweets for further analysis, such as, ID, text, and author (among other fields). Tweets were identified by keywords [17]. In set 1 “anorexia,” “anorexic,” “dietary disorders,” “inappetence,” “feeding disorder,” “food problem,” “binge eating,” and “anorectic” we used. In set 2, “eating disorders,” “bulimia,” “food issues,” “loss of appetite,” “food issue,” “food hater,” “eat healthier,” “disturbed eating habits,” “abnormal eating habits,” and “abnormal eating habit” were used. In set 3, “binge-vomit syndrome,” “bingeing,” “bulimarexia,” “anorexic skinny,” and “eating healthy” were used.
By using a different Twitter accounts for each set, more tweets could be obtained without exceeding the Twitter platform's usage limit. English terms were used because more tweets are generated in English [46].
Preprocessing
Preprocessing was conducted in Python (version 3.6). Data were loaded from documents obtained through T-Hoarder, which generates a file up to 100 MB; therefore, 4 files were obtained for data set 1, 4 files were obtained for data set 2, and 2 files were obtained for data set 3. Some data, such as location, name, and biography, contained line breaks or tabs. To avoid conflicts with delimiters, tabs and line breaks were removed using a function. After preprocessing the data frames, they were concatenated into a single data frame. In order to be able to work in a more agile way with the data frame, the memory usage of the data frame was calculated and optimized by converting numeric columns into numbers, converting dates to datetime format, and converting the remaining objects into categories. These steps helped reduce the data frame from 2.7 GB to 1.1 GB. We removed all tweets that were retweets, duplicates (because we unified data sets that might contain common tweets), and non–English tweets.
To select the subset of 2000 tweets, manual filtering was performed to eliminate tweets that were not related to eating disorder issues. Some of our keywords were too generic and meant that the tweets collected were not about eating disorders. For example, some of these words that triggered the collection of tweets unrelated to eating disorders were “food problem,” “inappetence,” “food issue,” and “bingeing”; however, in order to generate predictive models with greater accuracy and less bias, we kept a small sample of tweets (n=286) that did not belong to any of the categories, but that did contain some of the keywords of interest.
Labeling
Tweets in 4 different categories in the subset were manually labeled (Table 1). Labeling was carried out by 2 people, labeling 1000 tweets each. The labels were then reviewed by 4 mental illness experts. This procedure took place over the course of 1 full month, with each person taking approximately a total of 70 hours in carrying out this work. In category 1, tweets written by people suffering from eating disorders were represented with a value of 1, and the rest were represented with a value of 0. To assess this, each user profile was accessed and user description and tweets published by the user were examined to determine if the user had publicly mentioned having an eating disorder. In category 2, tweets that promoted having an eating disorder were labeled with a value of 1, and all other tweets were labeled with a value of 0. There are communities of people who suffer from eating disorders who try to encourage other people to also suffer from it by promoting it as if it were something positive or fashionable. There are many studies [9] that talk about pro–eating disorders communities using the terms pro-ana or pro-anorexia. In category 3, informative tweets were represented with a value of 1, and noninformative tweets were represented with a value of 0. Informative tweets are those that show information with the aim of informing readers, while the rest were those in which the author expressed an opinion. In category 4, scientific tweets were labeled with a value of 1, and the rest were labeled with a value of 0. A tweet of an informative nature that had been written by a person belonging to the field of research, for example, a doctor of philosophy in different subjects, was labeled as a scientific tweet. Scientific tweets were also those that shared links to papers published in scientific journals. If a tweet did not belong to any of the 4 proposed categories, it was not eliminated from the data set, since having tweets with value of 0 was also necessary.
Table 1.
Categories of labeled tweets and examples.
| Category topics | Tweet | |
| Category 1 |
|
|
|
|
Written by someone who suffers from eating disorder | i was stressed and ate a whole bowl of pasta, where’s my badge for being the worst anorexic #edtwt |
|
|
Written by someone who does not have an eating disorder | Is your #teenager not eating or eating a lot less than normal? She might be suffering from #anorexia. We can help; please come see us https://t.co/GfStM1IVGz #weightloss #losingweight https://t.co/z5NK0tjNIt |
| Category 2 |
|
|
|
|
Promotes eating disorders | Currently feeling like the best anorexic #eating disordertwt https://t.co/1BZPMs8bGU #mentalhealth #diet #anorexia |
|
|
Not promotes eating disorders | Higher-calorie diets could lead to a speedier recovery in patients with anorexia nervosa, study shows https://t.co/mipX3nrhHN |
| Category 3 |
|
|
|
|
Informative |
#AnorexiaNervosa – A Father and Daughter Perspec- tive -Highlights from RCPsychIC 2019 # EatingDisorders #mentalhealth https://t.co/iq3GH5ce6C |
|
|
Noninformative | Binge eating makes me sad :( #eatingdisorder #bingeeating https://t.co/0jjf7YrVyc |
| Category 4 |
|
|
|
|
Scientific | The problem extends to Food and Drug Administration and National Institutes of Health data sets used in a recent study appearing in Reproductive Toxicology. #ai #technology #BigData #ML https://t.co/DFvh6gNA38 |
|
|
Nonscientific | Do not waste time thinking about what you could have done differently. Keep your eyes on the road ahead and do it differently now. #anorexia #eatingdis- order #recovery #nevergiveup #alwayskeepfighting https://t.co/YalYzclBDM |
Final Sample
Before training and validating the models, tweets in the labeled set with more than 80% similarity were eliminated. It was decided to apply this criterion for tweets containing the same text but using different hashtags. Remaining tweets were processed by removing the stop words (words that have no meaning on their own and that modify or accompany other words, for example, articles, pronouns, adverbs, prepositions, or some verbs) and punctuation or symbols, that hindered the application of machine learning techniques.
Classification Methods
General
We used random forest, recurrent neural networks, bidirectional long short-term memory networks (ClassificationModel; simpletransformers [47], version 0.62.2), and pretrained bidirectional encoder representations from transformer–based models (RoBERTa [48], BERT [49], CamemBERT [50], DistilBERT [51], FlauBERT [52], ALBERT [53], and RobBERT [54]). Bidirectional long short-term memory and bidirectional encoder representations from transformer–based methods were chosen because they seemed to be the most promising models for natural language processing [55-57]. In addition, random forest was used for comparison because it is a traditional machine learning technique.
Two models—CamemBERT [50] and FlauBERT [52]—were pretrained using French text, and RobBERT [54] was pretrained using Dutch text. We used these models to obtain performance data for with text not written in their initial language. Data were divided into 70% training and 30% testing sets (train_test_split function in scikit-learn). The evaluation metrics were accuracy and F1 score.
For the random forest model, 5-fold cross-validation was used. For the neural networks, 5 different iterations were performed, and the mean F1 score and accuracy were obtained.
Random Forest
Random forest models [58] are constructed from a set of decision trees, which are usually trained with a method called bagging, to take advantage of the independence between the simple algorithms, since error can be greatly reduced by averaging the outputs of the simple models. Several decision trees are built and fused in order to obtain a more stable and accurate prediction. Random forest models can be used for both regression and classification problems.
One of the advantages offered by this type of model is the additional randomness when more trees are included. The algorithm searches for the best feature as a node is split from a random set of features. This makes it possible to obtain models with better performance. When a node is split, only a random subset of features is considered. Random thresholds can also be used for each feature, instead of searching for the best possible threshold, which adds additional randomness.
Recurrent Neural Network
In this type of neural network, a temporal sequence that contains a directed graph made up of connections between different nodes is defined. These networks have the capacity to show a dynamic temporal behavior. These types of networks, which are derived from feedforward neural networks, have the ability to use memory (their internal state) to process input sequences of varying lengths. This feature makes recurrent neural networks useful for tasks such as unsegmented and connected handwriting recognition or speech recognition [55,59,60].
There are 2 classes of recurrent neural networks—finite-pulse and infinite-pulse. The former are made up of a directed acyclic graph that can be unrolled and replaced by a strictly feedforward neural network, whereas the latter are made of a directed cyclic graph, which does not allow the graph from being unrolled.
Bidirectional Long Short-Term Memory
Bidirectional long short-term memory networks [61] are constructed from 2 long short-term memory modules that, at each time step, take past and future states into account to produce the output.
Bidirectional Encoder Representations From Transformer–Based Models
The bidirectional encoder representations from transformer framework is not a model in itself. According to Devlin et al [49], it is a “language understanding” model.
In the bidirectional encoder representations from transformer–based method, a neural network is trained to learn a language, similar to transfer learning in computer vision neural networks, and follows the linguistic representation in a bidirectional way, looking at the words both after and before each words. It is the combination of these approaches that has made it a successful natural language processing method [62].
Configuration
We used Jupyter notebook and TensorFlow and Pytorch libraries. It was necessary to use both libraries because, currently, bidirectional encoder representations from transformer–based networks can only be generated through Pytorch, while TensorFlow is one of the most widely used libraries to generate random forest, recurrent neural network, and bidirectional long short-term memory models.
Hyperparameters
We used a grid search (GridSearchCV) to select the random forest parameters (Table 2).
Table 2.
Random forest hyperparameters.
| Category | criterion | max_depth | max_features | n_estimators |
| Category 1 | gini | 7 | log2 | 200 |
| Category 2 | gini | 8 | auto | 1000 |
| Category 3 | gini | 8 | sqrt | 800 |
| Category 4 | gini | 8 | auto | 1000 |
To train recurrent neural networks (sklearn; keras) to perform the binary categorization tasks, the sigmoid activation function used (Figure 2). We trained and validated the bidirectional long short-term memory models (sklearn and TensorFlow libraries) using the best-performing configuration (Figure 3), after carrying out different tests.
Figure 2.
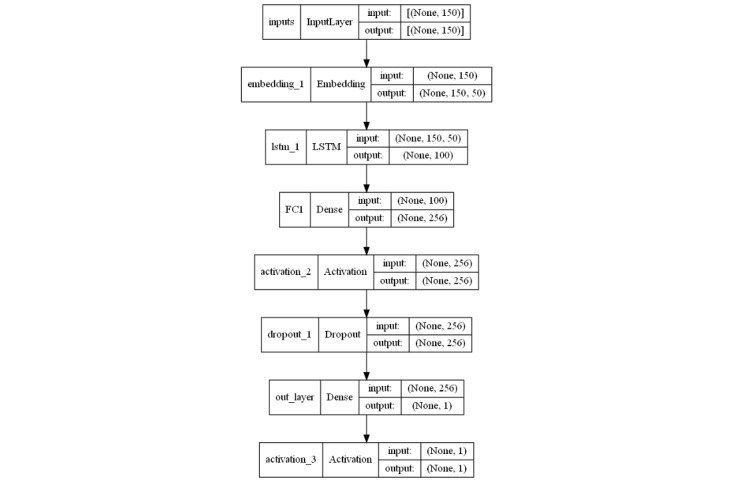
Architecture of the recurrent neural network network. LSTM: long short-term memory.
Figure 3.
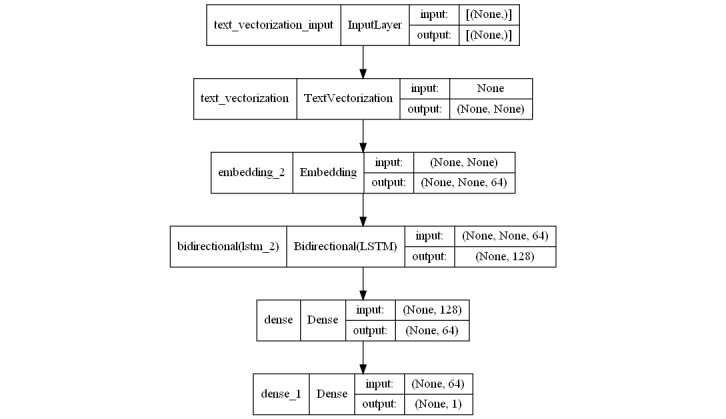
Architecture of the bidirectional long short-term memory (LSTM) network.
For the 7 pretrained bidirectional encoder representations from transformer–based models, the hyperparameters were reprocess_input_data=True; fp16=False; evaluate_during_training=False; evaluate_during_training_verbose=False; learning_rate=2e-5; train_batch_size=32; eval_batch_size=32; num_train_epochs=15; overwrite_output_dir=True; and evaluation_strategy='epochs'.
All experiments and data are published in a repository accessible to anyone [63].
Results
Preprocessing
A total of 1,085,957 tweets, written and posted on Twitter between October 20, 2020 and December 26, 2020, were collected. After preprocessing, a total of 494,025 valid tweets were obtained. These tweets are shared and publicly available on the Kaggle platform [64]. From the subset of 2000 tweets that was manually labeled, 1877 remained after the similarity criterion was applied. Table 3 shows the 10 most repeated terms in the full set of tweets and in the subset that was labeled.
Table 3.
Table of terms and frequencies of the 10 most repeated terms in the initial data set and in the labeled subset of data.
| Term | Frequency, n | ||
| Complete set (n=494,025) |
|
||
|
|
hey mp | 230,013 | |
|
|
healthy | 210,430 | |
|
|
pltpinkmonday | 209,330 | |
|
|
eat | 183,436 | |
|
|
covid19 | 156,541 | |
|
|
edtwt | 123,175 | |
|
|
anorexia | 112,864 | |
|
|
disorders | 102,063 | |
|
|
endsars | 99,844 | |
|
|
bachelorette | 48,370 | |
|
|
problem | 45,959 | |
| Subset (n=2000) |
|
||
|
|
eat | 1132 | |
|
|
disorder | 830 | |
|
|
food | 410 | |
|
|
recovery | 382 | |
|
|
edtwt | 301 | |
|
|
binge | 282 | |
|
|
people | 245 | |
|
|
anorexic | 244 | |
|
|
research | 226 | |
|
|
study | 202 | |
|
|
problem | 199 | |
Category
In category 1, 50.2% (942/1877) of tweets were written by a person with an eating disorder, and 49.8% (935/1877) of tweets were written by a person without an eating disorder. In category 2, 23.8% (447/1877) of tweets encourage people to suffer from an eating disorder, and 76.2% (1400/1877) of tweets do not encourage people to suffer from an eating disorder.
In category 3, 37% (694/1877) of the tweets were informative, 63% (1183/1877) of tweets were opinionated. In category 4, 23.3% (437/1877) of the tweets were scientific, 76.7% (1440/1877) of tweets were of a nonscientific nature.
Performance
Performance (Table 4) and implementation time (Table 5), which corresponds to the time invested in generating and validating the different models, for 4 different categorization tasks. The pretrained RoBERTa model was the most accurate for detecting tweets that had been written by people suffering from some type of eating disorder (accuracy 83.1%). Despite this, the more traditional recurrent neural network yielded an accuracy that was not much lower (accuracy 82.6%). The most accurate model for the detection of tweets that did or did not promote an eating disorder was the RoBERTa model (accuracy 88.5%); however, applying bidirectional long short-term memory improved performance (accuracy 86.7%). The most accurate model for the detection of informative or opinion-based tweets was RoBERTa model (accuracy 84.4%). Accuracy for all bidirectional encoder representations from transformer–based models, except ALBERT and FlauBERT, exceeded 80%; however, applying bidirectional long short-term memory resulted in an accuracy of 78.7%. The model with the highest accuracy for the detection of scientific or nonscientific tweets was the RoBERTa model (accuracy 94.2%). All bidirectional encoder representations from transformer–based models equaled or exceeded 92%; however, applying bidirectional long short-term memory yielded an accuracy of 85.8%.
Table 4.
Classification performance.
| Model | Having eating disorders or not | Encouraging eating disorders or not | Informative or not | Scientific or not | ||||
|
|
F1 score, % | Accuracy, % | F1 score, % | Accuracy, % | F1 score, % | Accuracy, % | F1 score, % | Accuracy, % |
| Random forest | 79.8 | 79.2 | 47 | 76.7 | 49.2 | 73.7 | 27.3 | 80.4 |
| Recurrent neural network | 83.2 | 82.6 | 61 | 82.1 | 67.3 | 70.7 | 67.3 | 70.7 |
| Bidirectional long short-term memory | 78.5 | 79.3 | 67.1 | 86.7 | 67.1 | 78.7 | 76.8 | 85.8 |
| Bidirectional encoder representations from transformer–baseda | 83.3 | 83 | 71.9 | 87.2 | 77.6 | 84.3 | 86 | 94.1 |
| RoBERTaa | 83.8 | 83.1 | 74.3 | 88.5 | 77.6 | 84.4 | 86.4 | 94.2 |
| DistilBERTa | 84 | 83.1 | 72.3 | 87.3 | 75 | 82.8 | 84.2 | 93.3 |
| CamemBERTa | 79.1 | 78.7 | 73.6 | 87.8 | 74.7 | 81.7 | 82.5 | 92.3 |
| ALBERTa | 81.2 | 80.4 | 74.3 | 88.2 | 73.8 | 81.5 | 83.3 | 93 |
| FlauBERTa | 82.6 | 81.7 | 72.9 | 87.5 | 72.2 | 80 | 83.4 | 92.7 |
| RobBERTa | 78.8 | 78.4 | 71.1 | 86.2 | 73.8 | 81.6 | 83 | 92.6 |
aA pretrained model was used: bert-based-multilingual-cased for BERT, roberta-base for RoBERTa, distilbert-base-cased for DistilBERT, camembert-base for CamemBERT, albert-base-v1 for ALBERT, flaubert-base-cased for FlauBERT, and robbert-v2-dutch-base for RobBERT.
Table 5.
Implementation time.
| Model | Time (seconds) | |||
|
|
Having eating disorders or not | Encouraging eating disorders or not | Informative or not | Scientific or not |
| Random forest | 1.74 | 12.8 | 10.4 | 12.9 |
| Recurrent neural network | 152.1 | 163.1 | 151.5 | 153.7 |
| Bidirectional long short-term memory | 163.2 | 175.3 | 164.8 | 167.9 |
| Bidirectional encoder representations from transformer–based | 1257.4 | 1232.1 | 1292.7 | 1311.4 |
| RoBERTa | 1116.2 | 1158.8 | 1142.5 | 1192.8 |
| DistilBERT | 1343.3 | 1327.8 | 1332.0 | 1362.3 |
| CamemBERT | 1472.3 | 1457.5 | 1462.0 | 1493.4 |
| ALBERT | 1372.7 | 1352.3 | 1331.3 | 1392.5 |
| FlauBERT | 1203.9 | 1207.1 | 1202.1 | 1235.1 |
| RobBERT | 1234.4 | 1215.4 | 1319.7 | 1123.5 |
For bidirectional encoder representations from transformer–based models, despite obtaining better performance metrics in terms of accuracy, the training and validation times of the models are much higher than those of random forest, recurrent neural network, and bidirectional long short-term memory models. For example, bidirectional encoder representations from transformer–based models take approximately 15 times longer than random forest models (Table 5).
The improvements between the accuracy of the best bidirectional encoder representations from transformer–based model (Categorization 1: DistilBERT 83.1%; Categorization 2: RoBERTa 88.5%; Categorization 3: RoBERTa 84.4%; Categorization 4: RoBERTa 94.2%) and that of the best model between random forest, recurrent neural network, or bidirectional long short-term memory models (Categorization 1: recurrent neural network 82.6%; Categorization 2: bidirectional long short-term memory 86.7%; Categorization 3: bidirectional long short-term memory 78.7%; Categorization 4: bidirectional long short-term memory 85.8%) were 0.61%, 2.08%, 7.24%, and 9.79%, respectively.
Discussion
Principal Results
Practitioners and researchers can benefit from the use of social media data in the field of eating disorder. Although the model with the best accuracy was always one of the pretrained bidirectional encoder representations from transformer–based models, the computational costs compared with those of simpler models may be excessive. The difference between the accuracy of the best bidirectional encoder representations from transformer–based model and the best of the 3 simpler models (random forest, recurrent neural network, and bidirectional long short-term memory) did not exceed 9.79%.
Given the high computational cost, use of bidirectional encoder representations from transformer–based models in this instance may not be essential. The accuracy for the 4 different categorization tasks is relatively high even in the simplest models.
Despite the fact that we used only 1877 tweets (which is similar to the amounts used in previous studies: 2219 [24] and 2095 [65]), the models classified the tweets with a high level of accuracy.
For the classification of tweets into informative or noninformative (categorization 3), our models obtained a higher accuracy (80%-84.4%) than those in previous studies (77.7% [44] and 81% [45]). Comparisons cannot be made for the other 3 categorization tasks because of a lack pf applicable eating disorder–related studies.
Limitations
This research has several limitations. (1) It was limited to a social media platform, (2) some categorization tasks were not balanced, which may lead to bias in the generated models, (3) the training set was sufficient but could be larger for better results in a real environment, and (4) when labeling tweets, it is possible that there was a bias in determining whether a tweet was written by someone with an eating disorder due to lack of information about the user.
Conclusions
Machine learning and deep learning models were used to classify eating disorder–related tweets into binary categories in 4 categorization tasks, with accuracies greater than 80%. The best performing models were RoBERTa and DistilBERT, both bidirectional encoder representations from transformer–based classification methods.
The computational cost was much higher for the bidirectional encoder representations from transformer–based models compared to those of the simpler models (random forest, recurrent neural network or traditional bidirectional long short-term memory), time invested in training and validation was greater by a factor of 10.
Future work will include (1) increasing the training and validation data set, (2) applying natural language processing techniques that make use of ontologies with which it is possible to include automation and logical reasoning, (3) integrating predictive models in a real-world development project, such as a Twitter bot, and (4) validating the model using texts written by patients with eating disorders and who are in treatment.
Footnotes
Conflicts of Interest: None declared.
References
- 1.Norris E, van Steen T, Direito A, Stamatakis E. Physically active lessons in schools and their impact on physical activity, educational, health and cognition outcomes: a systematic review and meta-analysis. Br J Sports Med. 2020 Jul 16;54(14):826–838. doi: 10.1136/bjsports-2018-100502.bjsports-2018-100502 [DOI] [PubMed] [Google Scholar]
- 2.Thomas J, Thirlaway K, Bowes N, Meyers R. Effects of combining physical activity with psychotherapy on mental health and well-being: a systematic review. J Affect Disord. 2020 Mar 15;265:475–485. doi: 10.1016/j.jad.2020.01.070.S0165-0327(19)32907-6 [DOI] [PubMed] [Google Scholar]
- 3.Izquierdo A, Plessow F, Becker KR, Mancuso CJ, Slattery M, Murray HB, Hartmann AS, Misra M, Lawson EA, Eddy KT, Thomas JJ. Implicit attitudes toward dieting and thinness distinguish fat-phobic and non-fat-phobic anorexia nervosa from avoidant/restrictive food intake disorder in adolescents. Int J Eat Disord. 2019 Apr 31;52(4):419–427. doi: 10.1002/eat.22981. http://europepmc.org/abstract/MED/30597579 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Urdapilleta I, Lahlou S, Demarchi S, Catheline J. Women with obesity are not as curvy as they think: consequences on their everyday life behavior. Front Psychol. 2019 Aug 16;10:1854. doi: 10.3389/fpsyg.2019.01854. doi: 10.3389/fpsyg.2019.01854. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Griffen TC, Naumann E, Hildebrandt T. Mirror exposure therapy for body image disturbances and eating disorders: a review. Clin Psychol Rev. 2018 Nov;65:163–174. doi: 10.1016/j.cpr.2018.08.006.S0272-7358(18)30057-6 [DOI] [PubMed] [Google Scholar]
- 6.Hoek H. Review of the worldwide epidemiology of eating disorders. Curr Opin Psychiatry. 2016 Nov;29(6):336–9. doi: 10.1097/YCO.0000000000000282. [DOI] [PubMed] [Google Scholar]
- 7.Qian J, Wu Y, Liu F, Zhu Y, Jin H, Zhang H, Wan Y, Li C, Yu D. An update on the prevalence of eating disorders in the general population: a systematic review and meta-analysis. Eat Weight Disord. 2021 Apr 08; doi: 10.1007/s40519-021-01162-z.10.1007/s40519-021-01162-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Viguria I, Alvarez-Mon MA, Llavero-Valero M, Asunsolo Del Barco Angel, Ortuño Felipe, Alvarez-Mon M. Eating disorder awareness campaigns: thematic and quantitative analysis using Twitter. J Med Internet Res. 2020 Jul 14;22(7):e17626. doi: 10.2196/17626. https://www.jmir.org/2020/7/e17626/ v22i7e17626 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Sukunesan S, Huynh M, Sharp G. Examining the pro-eating disorders community on Twitter via the hashtag #proana: statistical modeling approach. JMIR Ment Health. 2021 Jul 09;8(7):e24340. doi: 10.2196/24340. https://mental.jmir.org/2021/7/e24340/ v8i7e24340 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Fiumara G, Celesti A, Galletta A, Carnevale L, Villari M. Applying artificial intelligence in healthcare social networks to identity critical issues in patients' posts. Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies - Volume 5: AI4Health; International Joint Conference on Biomedical Engineering Systems and Technologies; January 19, 2018; Maderia, Portugal. 2018. pp. 680–687. https://www.scitepress.org/Link.aspx?doi=10.5220/0006750606800687 . [Google Scholar]
- 11.Musacchio N, Giancaterini A, Guaita G, Ozzello A, Pellegrini MA, Ponzani P, Russo GT, Zilich R, de Micheli A. Artificial intelligence and big data in diabetes care: a position statement of the Italian Association of Medical Diabetologists. J Med Internet Res. 2020 Jun 22;22(6):e16922. doi: 10.2196/16922. https://www.jmir.org/2020/6/e16922/ v22i6e16922 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Bauer GR, Lizotte DJ. Artificial intelligence, intersectionality, and the future of public health. Am J Public Health. 2021 Jan;111(1):98–100. doi: 10.2105/AJPH.2020.306006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Timmins KA, Green MA, Radley D, Morris MA, Pearce J. How has big data contributed to obesity research? a review of the literature. Int J Obes (Lond) 2018 Dec 18;42(12):1951–1962. doi: 10.1038/s41366-018-0153-7. http://europepmc.org/abstract/MED/30022056 .10.1038/s41366-018-0153-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Lewis SP, Arbuthnott AE. Searching for thinspiration: the nature of internet searches for pro-eating disorder websites. Cyberpsychol Behav Soc Netw. 2012 Apr;15(4):200–4. doi: 10.1089/cyber.2011.0453. [DOI] [PubMed] [Google Scholar]
- 15.Oksanen A, Garcia D, Sirola A, Näsi M, Kaakinen M, Keipi T, Räsänen P. Pro-anorexia and anti-pro-anorexia videos on YouTube: sentiment analysis of user responses. J Med Internet Res. 2015 Nov 12;17(11):e256. doi: 10.2196/jmir.5007. http://www.jmir.org/2015/11/e256/ v17i11e256 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Fettach Y, Benhiba L. Pro-eating disorders and pro-recovery communities on Reddit: text and network comparative analyses. 21st International Conference on Information Integration and Web-based Applications & Services; December 2, 2019; Munich, Germany. pp. 277–286. [DOI] [Google Scholar]
- 17.Benítez-Andrades J, Alija-Pérez J, García-Rodríguez I, Benavides Carmen, Alaiz-Moretón Héctor, Pastor-Vargas Rafael, García-Ordás María Teresa. BERT model-based approach for detecting categories of tweets in the field of eating disorders. IEEE 34th International Symposium on Computer-Based Medical Systems; June 7, 2021; Aveiro, Portugal. 2021. pp. 586–590. [DOI] [Google Scholar]
- 18.Gamache R, Kharrazi H, Weiner J. Public and population health informatics: the bridging of big data to benefit communities. Yearb Med Inform. 2018 Aug 29;27(1):199–206. doi: 10.1055/s-0038-1667081. http://www.thieme-connect.com/DOI/DOI?10.1055/s-0038-1667081 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Mei R. Health informatics and healthcare delivery: from the cost-effectiveness perspective. 7th International Conference on Information Management; March 27, 2021; London, United Kingdom. 2021. Apr 30, pp. 62–65. [DOI] [Google Scholar]
- 20.Mheidly N, Fares J. Leveraging media and health communication strategies to overcome the COVID-19 infodemic. J Public Health Policy. 2020 Dec 21;41(4):410–420. doi: 10.1057/s41271-020-00247-w. http://europepmc.org/abstract/MED/32826935 .10.1057/s41271-020-00247-w [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Zhang Z, Ahmed W. A comparison of information sharing behaviours across 379 health conditions on Twitter. Int J Public Health. 2019 Apr;64(3):431–440. doi: 10.1007/s00038-018-1192-5. http://europepmc.org/abstract/MED/30585297 .10.1007/s00038-018-1192-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Kim A, Miano T, Chew R, Eggers M, Nonnemaker J. Classification of Twitter users who tweet about e-cigarettes. JMIR Public Health Surveill. 2017 Sep 26;3(3):e63. doi: 10.2196/publichealth.8060. http://publichealth.jmir.org/2017/3/e63/ v3i3e63 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Choi M, Kim S, Lee S, Kwon BC, Yi JS, Choo J, Huh J. Toward predicting social support needs in online health social networks. J Med Internet Res. 2017 Aug 02;19(8):e272. doi: 10.2196/jmir.7660. https://www.jmir.org/2017/8/e272/ v19i8e272 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Zhou S, Zhao Y, Bian J, Haynos AF, Zhang R. Exploring eating disorder topics on Twitter: machine learning approach. JMIR Med Inform. 2020 Oct 30;8(10):e18273. doi: 10.2196/18273. https://medinform.jmir.org/2020/10/e18273/ v8i10e18273 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Eysenbach G, Till JE. Ethical issues in qualitative research on internet communities. BMJ. 2001 Nov 10;323(7321):1103–5. doi: 10.1136/bmj.323.7321.1103. http://europepmc.org/abstract/MED/11701577 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Liu L, Woo BKP. Twitter as a mental health support system for students and professionals in the medical field. JMIR Med Educ. 2021 Jan 19;7(1):e17598. doi: 10.2196/17598. https://mededu.jmir.org/2021/1/e17598/ v7i1e17598 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Weder F, Krainer L, Karmasin M. The Sustainability Communication Reader A Reflective Compendium. Wiesbaden: Springer VS; 2021. [Google Scholar]
- 28.Géron A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition. London, United Kingdom: O'Reilly Media; 2017. Concepts, tools, and techniques to build intelligent systems. [Google Scholar]
- 29.Van Der Walt E, Eloff J. Using machine learning to detect fake identities: bots vs humans. IEEE Access. 2018;6:6540–6549. doi: 10.1109/access.2018.2796018. [DOI] [Google Scholar]
- 30.Geirhos R, Meding K, Wichmann F. Beyond accuracy: quantifying trial-by-trial behaviour of CNNs and humans by measuring error consistency. 34th Conference on Neural Information Processing Systems (NeurIPS 2020); December 6, 2020; Vancouver, Canada. 2020. Dec 06, p. 200616736. http://arxiv.org/abs/2006.16736 . [Google Scholar]
- 31.Youyou W, Kosinski M, Stillwell D. Computer-based personality judgments are more accurate than those made by humans. Proc Natl Acad Sci U S A. 2015 Jan 27;112(4):1036–40. doi: 10.1073/pnas.1418680112. http://www.pnas.org/cgi/pmidlookup?view=long&pmid=25583507 .1418680112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.A.Jabbar Alkubaisi GA, Kamaruddin SS, Husni H. Stock market classification model using sentiment analysis on Twitter based on hybrid naive bayes classifiers. Comput Inf Sci. 2018 Jan 11;11(1):52. doi: 10.5539/cis.v11n1p52. [DOI] [Google Scholar]
- 33.Prieto VM, Matos S, Álvarez M, Cacheda F, Oliveira JL. Twitter: a good place to detect health conditions. PLoS One. 2014 Jan;9(1):e86191. doi: 10.1371/journal.pone.0086191. http://dx.plos.org/10.1371/journal.pone.0086191 .PONE-D-13-10567 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Dixit A, Mani A, Bansal R. CoV2-Detect-Net: design of COVID-19 prediction model based on hybrid DE-PSO with SVM using chest X-ray images. Inf Sci (N Y) 2021 Sep;571:676–692. doi: 10.1016/j.ins.2021.03.062. http://europepmc.org/abstract/MED/33840820 .S0020-0255(21)00313-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Singh V, Poonia RC, Kumar S, Dass P, Agarwal P, Bhatnagar V, Raja L. Prediction of COVID-19 corona virus pandemic based on time series data using support vector machine. J Discrete Math Sci Crypto. 2020 Dec 14;23(8):1583–1597. doi: 10.1080/09720529.2020.1784535. [DOI] [Google Scholar]
- 36.Shofiya C, Abidi S. Sentiment analysis on COVID-19-related social distancing in Canada using Twitter data. Int J Environ Res Public Health. 2021 Jun 03;18(11):5993. doi: 10.3390/ijerph18115993. https://www.mdpi.com/resolver?pii=ijerph18115993 .ijerph18115993 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Yeom H, Hwang M, Hwang M, Jung H. study of machine-learning classifier and feature set selection for intent classification of Korean tweets about food safety. J Inf Sci Theory Pract. 2014 Sep 30;2(3):29–39. doi: 10.1633/jistap.2014.2.3.3. [DOI] [Google Scholar]
- 38.Wang T, Brede M, Ianni A, Mentzakis E. Social interactions in online eating disorder communities: a network perspective. PLoS One. 2018 Jul 30;13(7):e0200800. doi: 10.1371/journal.pone.0200800. https://dx.plos.org/10.1371/journal.pone.0200800 .PONE-D-18-09835 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Wang Shirley B. Machine learning to advance the prediction, prevention and treatment of eating disorders. Eur Eat Disord Rev. 2021 Sep;29(5):683–691. doi: 10.1002/erv.2850. https://onlinelibrary.wiley.com/doi/10.1002/erv.2850 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Nadeem M. Identifying Depression on Twitter. arXiv. Preprint posted online on Jul 25, 2016. http://arxiv.org/abs/1607.07384 . [Google Scholar]
- 41.Arseniev-Koehler A, Lee H, McCormick T, Moreno MA. #Proana: pro-eating disorder socialization on Twitter. J Adolesc Health. 2016 Jun;58(6):659–64. doi: 10.1016/j.jadohealth.2016.02.012.S1054-139X(16)00059-8 [DOI] [PubMed] [Google Scholar]
- 42.Bert F, Gualano MR, Camussi E, Siliquini R. Risks and threats of social media websites: Twitter and the proana movement. Cyberpsychol Behav Soc Netw. 2016 Apr;19(4):233–8. doi: 10.1089/cyber.2015.0553. [DOI] [PubMed] [Google Scholar]
- 43.Branley DB, Covey J. Pro-ana versus pro-recovery: a content analytic comparison of social media users' communication about eating disorders on Twitter and Tumblr. Front Psychol. 2017 Aug 11;8:1356. doi: 10.3389/fpsyg.2017.01356. doi: 10.3389/fpsyg.2017.01356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Kumar A, Singh JP, Dwivedi YK, Rana NP. A deep multi-modal neural network for informative Twitter content classification during emergencies. Ann Oper Res. 2020 Jan 16; doi: 10.1007/s10479-020-03514-x. [DOI] [Google Scholar]
- 45.Madichetty S, Sridevi M. Classifying informative and non-informative tweets from the twitter by adapting image features during disaster. Multimed Tools Appl. 2020 Aug 07;79(39-40):28901–28923. doi: 10.1007/s11042-020-09343-1. [DOI] [Google Scholar]
- 46.Congosto M, Basanta-Val P, Sanchez-Fernandez L. T-Hoarder: a framework to process Twitter data streams. J Netw Comput Appl. 2017 Apr;83:28–39. doi: 10.1016/j.jnca.2017.01.029. [DOI] [Google Scholar]
- 47.simpletransformers. Github. [2021-10-26]. https://github.com/ThilinaRajapakse/simpletransformers .
- 48.Liu Y, Ott M, Goyal N. RoBERTa: a robustly optimized BERT pretraining approach. arXiv. Preprint posted online on Jul 26, 2019. http://arxiv.org/abs/1907.11692 . [Google Scholar]
- 49.Devlin J, Chang M, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. arXiv. Preprint posted online on May 24, 2019. https://arxiv.org/abs/1810.04805 . [Google Scholar]
- 50.Martin L, Muller B, Suárez P. CamemBERT: a tasty french language model. 58th Annual Meeting of the Association for Computational Linguistics; July 1, 2020; Online. 2020. pp. 7203–7219. [DOI] [Google Scholar]
- 51.Sanh V, Debut L, Chaumond J, Wolf T. DistilBERT, a distilled version of BERTmaller, faster, cheaper and lighter. Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing; December 13, 2019; Vancouver, BC. 2019. p. 191001108. https://www.emc2-ai.org/assets/docs/neurips-19/emc2-neurips19-paper-33.pdf . [Google Scholar]
- 52.Le H, Vial L, Frej J. FlauBERT: unsupervised language model pre-training for french. arXiv. Preprint posted online on December 11, 2019. http://arxiv.org/abs/1912.05372 . [Google Scholar]
- 53.Lan Z, Chen M, Goodman S, Gimpel K, Sharma P, Soricut R. ALBERT: a lite BERT for self-supervised learning of language representations. arXiv. Preprint posted online on Feb 9, 2020. http://arxiv.org/abs/1909.11942 . [Google Scholar]
- 54.Delobelle P, Winters T, Berendt B. RobBERT: a Dutch RoBERTa-based language model. Association for Computational Linguistics: EMNLP 2020; November 2020; Online. 2020. Nov 01, pp. 3255–3265. https://aclanthology.org/2020.findings-emnlp.292/ [DOI] [Google Scholar]
- 55.Saon G, Tüske Z, Bolanos D, Kingsbury B. Advancing RNN transducer technology for speech recognition. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing; June 6-11, 2021; Toronto, ON, Canada. 2021. [DOI] [Google Scholar]
- 56.Enhancing BERT for lexical normalization. HAL-Inria. [2022-02-18]. https://hal.inria.fr/hal-02294316/
- 57.Shahid Farah, Zameer Aneela, Muneeb Muhammad. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals. 2020 Nov;140:110212. doi: 10.1016/j.chaos.2020.110212. http://europepmc.org/abstract/MED/32839642 .S0960-0779(20)30608-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Breiman L. Random forests. Machine Learning. 2001;45:5–32. doi: 10.1023/A:1010933404324. https://link.springer.com/article/10.1023/a:1010933404324#citeas . [DOI] [Google Scholar]
- 59.Chen Xie, Wu Yu, Wang Zhenghao, Liu Shujie, Li Jinyu. Developing real-time streaming transformer transducer for speech recognition on large-scale dataset. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing; June 6-11, 2021; Toronto, Canada. 2021. [Google Scholar]
- 60.Hamdi Y, Boubaker H, Alimi A M. Online Arabic handwriting recognition using graphemes segmentation and deep learning recurrent neural networks. In: Hassanien A E, Darwish A, Abd El-Kader S M, Alboaneen D A, editors. Enabling Machine Learning Applications in Data Science. Algorithms for Intelligent Systems. Singapore: Springer; 2021. [Google Scholar]
- 61.Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997 Nov 15;9(8):1735–80. doi: 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- 62.Yates A, Nogueira R, Lin J. Pretrained transformers for text ranking: BERT and beyond. 14th ACM International Conference on Web Search and Data Mining; March 8-11; Israel (online). 2021. [DOI] [Google Scholar]
- 63.Benítez-Andrades J. jabenitez88/NLP-EatingDisordersBERT: Categorizing tweets about eating disorders using text mining: BERT models and machine learning techniques. Zenodo. 2021. Jul 31, [2022-02-22]. https://zenodo.org/record/5148631#.YhU1tJPMI_U .
- 64.Benítez-Andrades J A. Eating disorders tweets. Kaggle. [2021-12-26]. https://www.kaggle.com/jabenitez88/eating-disorders-tweets/activity .
- 65.Roitero K, Bozzato C, Mea V, Mizzaro S, Serra G. Twitter goes to the doctor: detecting medical tweets using machine learning and BERT. CEUR Workshop. 2020. Jan 01, [2022-02-22]. http://ceur-ws.org/Vol-2619/short1.pdf .