

Abstract
Background
Type 2 diabetes is a major health concern worldwide. The present study is aimed at discovering effective biomarkers for an efficient diagnosis of type 2 diabetes.
Methods
Differentially expressed genes (DEGs) between type 2 diabetes patients and normal controls were identified by analyses of integrated microarray data obtained from the Gene Expression Omnibus database using the Limma package. Functional analysis of genes was performed using the R software package clusterProfiler. Analyses of protein-protein interaction (PPI) performed using Cytoscape with the CytoHubba plugin were used to determine the most sensitive diagnostic gene biomarkers for type 2 diabetes in our study. The support vector machine (SVM) classification model was used to validate the gene biomarkers used for the diagnosis of type 2 diabetes.
Results
GSE164416 dataset analysis revealed 499 genes that were differentially expressed between type 2 diabetes patients and normal controls, and these DEGs were found to be enriched in the regulation of the immune effector pathway, type 1 diabetes mellitus, and fatty acid degradation. PPI analysis data showed that five MCODE clusters could be considered as clinically significant modules and that 10 genes (IL1B, ITGB2, ITGAX, COL1A1, CSF1, CXCL12, SPP1, FN1, C3, and MMP2) were identified as “real” hub genes in the PPI network using algorithms such as Degree, MNC, and Closeness. The sensitivity and specificity of the SVM model for identifying patients with type 2 diabetes were 100%, with an area under the curve of 1 in the training as well as the validation dataset.
Conclusion
Our results indicate that the SVM-based model developed by us can facilitate accurate diagnosis of type 2 diabetes.
1. Introduction
Diabetes mellitus (DM) is one of the top three major chronic noncommunicable diseases [1]. Over 90% of DM cases are those of type 2 diabetes. In recent years, the incidence of type 2 diabetes has been increasing significantly each year [2]. According to the latest survey released by the International Diabetes Federation in 2019, diabetes has a prevalence of 9.3%, and it affects approximately 463 million adults worldwide. It is expected that the number of affected individuals will reach 578 million (10.2%) by 2030 and 700 million (10.9%) by 2045 [3], making the prevention and treatment of type 2 diabetes a serious challenge that faces humanity.
The support vector machine (SVM) algorithm was first proposed by Vapnik et al. [4] in 1995 as a supervised learning method in machine learning, and it gradually developed and matured to have a wide range of applications in the mid-1990s. Later on, a series of improved and extended algorithms stemming from SVM were developed, such as multiclass SVM classification, support vector regression, least-squares SVM, support vector clustering, and semisupervised SVM [5].
Machine learning tools are used to detect key features from complex datasets. SVM is a machine learning tool that is widely used in disease research to build predictive models, and it is known to produce effective and predictable models [6–9]. The following are a few examples of efficient predictive models built using SVM: a study showing the application of an SVM-based approach to identify postmenopausal women with low bone density [10] and a gene signature associated with postmenopausal osteoporosis that was detected and validated using SVM [11].
The Gene Expression Omnibus (GEO) [12], an online public database made available by National Center for Biotechnology Information in 2000, is currently one of the most comprehensive gene expression databases. Based on data from this database, we systematically analyzed the expression patterns of genes associated with type 2 diabetes samples at a transcriptional level.
Based on the literature study [13, 14], we hypothesize that multigene panels may be more effective and comprehensive in predicting the prognosis of type 2 diabetes patients. Therefore, we attempted to identify and verify a robust prognostic feature that predicts survival rate by integrating multiple datasets of type 2 diabetes patients. In this study, we constructed a risk prediction model based on SVM at the transcription level for type 2 diabetes patients; this model may supplement traditional clinical prognostic factors and further provide more effective therapeutic intervention and personalized treatment for type 2 diabetes patients.
2. Materials and Methods
2.1. Data Acquisition
MINiML formatted family files of type 2 diabetes-related microarray datasets, GSE164416 [15], GSE156993 [16], GSE161355 [17], GSE163980, GSE76895 [18], GSE9006 [19], and GSE78721 [20], were downloaded from GEO. Those datasets we use are the processed data from the GEO database, which has been background processed and normalized.
Type 2 diabetes samples and control samples were retrieved from the GEO dataset, and the probe IDs were converted to gene symbols. Any single probe corresponding to multiple genes was removed, and for genes corresponding to multiple gene symbols, the median gene expression was considered.
The RNA-Seq dataset (GSE164416) was processed using the following steps.
Type 2 diabetes samples and control samples from the dataset were retrieved, and the expression spectrum was counted in terms of transcripts per million. ENSG IDs were converted into gene symbols, and the median value was considered for expression of genes corresponding to multiple gene symbols.
Clinical statistics of the processed samples are shown in Table 1. Clinical information of datasets is shown in Table 2.
Table 1.
Clinical sample information of datasets.
Table 2.
Clinical feature information of GEO datasets.
2.2. Identification of Differentially Expressed Genes (DEGs)
The “Limma” package [21] in the latest R language (version 4.2.2) was used to screen DEGs between the type 2 diabetes samples and the normal control samples, and the criteria for statistical significance were ∣log2FC | >1 and FDR < 0.05.
2.3. Functional Enrichment Analysis
Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway analysis and Gene Ontology (GO) functional enrichment analysis based on cellular components (CCs), biological processes (BPs), and molecular functions (MFs) were performed on the DEGs using the R software package clusterProfiler [22]. P < 0.05 was used as the significance threshold for enrichment.
2.4. Protein-Protein Interaction (PPI) Networks
PPI networks facilitate the study of the molecular mechanisms of a disease from a system perspective, for example, in the discovery of new drug targets. We constructed a PPI network using resources from the STRING database [23], a database of known and predicted protein-protein interactions. The PPI network of the modular gene was obtained by importing the module genes into the STRING database and processing them with the resources available on the database website. Generally, the importance of a network node is positively correlated with the node having more connections to the genes in the network, thus implying the node to have a greater connectivity across the network. Each point in the PPI network for screening the modular pivot genes was calculated using the Cytoscape (version 3.7.2) [24] software with the plugin CytoHubba [25] and using the following four algorithms: Degree, MCC (Maximal Clique Centrality), Closeness, and Betweenness.
2.5. Construction of a Support Vector Machine (SVM) Classifier
SVM is a supervised machine learning classification algorithm that distinguishes sample types by estimating the chance of a sample belonging to a certain class. For the training set, the SVM classifier was constructed using the SVM method based on the optimal mRNA set in the R package e1071 (version 1.6-8, http://cran.r-project.org/web/packages/e1071).
The performance of the SVM classifier was evaluated in the training and validation sets by the area under the curve (AUC) of the receiver operating characteristic (ROC) curve as an evaluation metric.
3. Results
3.1. Identification and Functional Annotation of DEGs
The analysis flowchart describing the methodology of this study is shown in Figure 1. A total of 499 DEGs were obtained, of which, 320 were upregulated and 179 were downregulated in the type 2 diabetes samples (Figures 2(a) and 2(b)). Furthermore, KEGG pathway analysis and GO functional enrichment analysis were performed on the 499 DEGs using the R software package clusterProfiler. For the 320 upregulated genes, the top 10 significantly enriched BPs, MFs, and CCs are shown in Figures 3(a)–3(c). Based on the KEGG annotation, 63 pathways were obtained, which included pathways associated with Epstein-Barr virus infection, type I diabetes mellitus, and Staphylococcus aureus infection (Figure 3(d)). For the 179 downregulated genes, the top 10 significantly enriched BPs, MFs, and CCs are shown in Figures 4(a)–4(c). Based on the KEGG annotation, three pathways were obtained, which included fatty acid degradation, carbohydrate digestion and absorption, and the citric acid cycle (Figure 4(d)).
Figure 1.
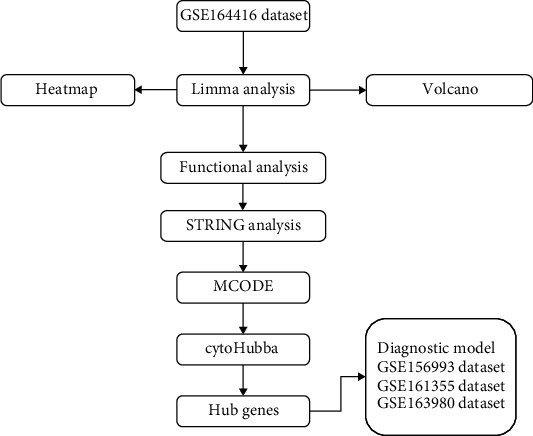
Workflow chart.
Figure 2.
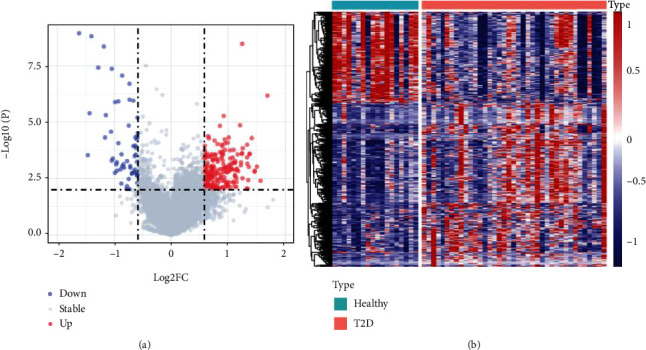
Identification of differentially expressed genes. (a) The volcano map of differentially expressed genes in the GSE164416 dataset. (b) The heat map of differentially expressed genes in the GSE164416 dataset. P < 0.01 and ∣log2FC | >1.5.
Figure 3.
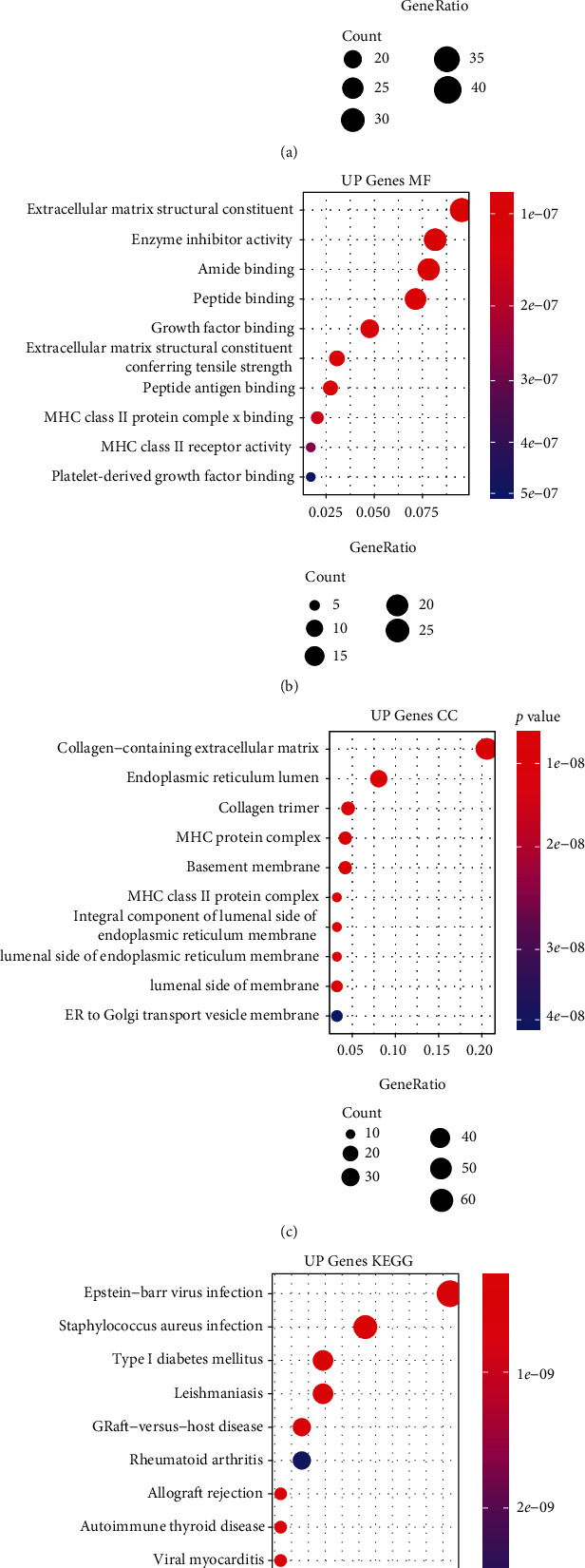
Functional enrichment analysis of differentially expressed upregulated genes. (a) The biological process annotation map of differentially expressed upregulated genes. (b) The cellular component annotation map of differentially expressed upregulated genes. (c) The molecular function annotation map of differentially expressed upregulated genes. (d) The Kyoto Encyclopedia of Genes and Genomes annotation map of differentially expressed upregulated genes.
Figure 4.
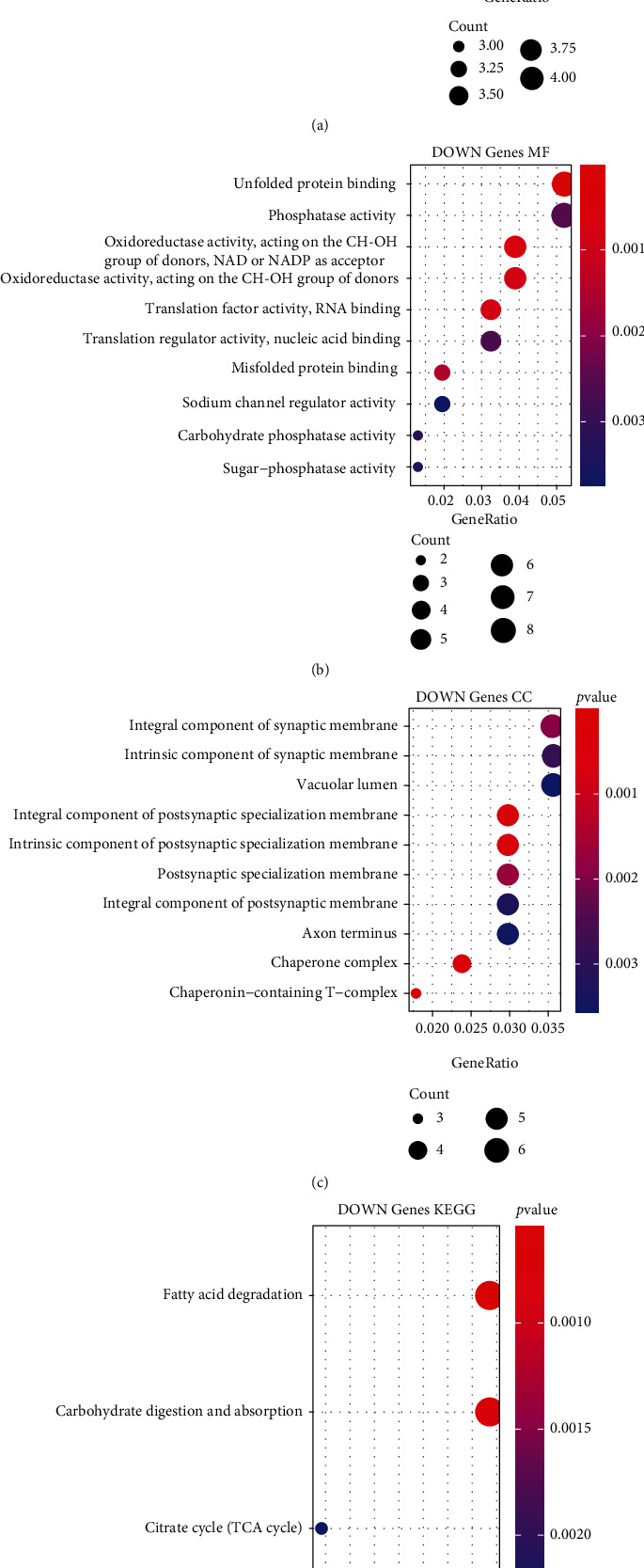
Functional enrichment analysis of differentially expressed downregulated genes. (a) The biological process annotation map of differentially expressed downregulated genes. (b) The cellular component annotation map of differentially expressed downregulated genes. (c) The molecular function annotation map of differentially expressed downregulated genes. (d) The Kyoto Encyclopedia of Genes and Genomes annotation map of differentially expressed downregulated genes.
3.2. Protein-Protein Interaction Networks
The PPI network of the 499 DEGs was constructed using the STRING database. Cytoscape (version 3.7.2) was used to filter the network modules, and the MCODE algorithm plugin found five clinically significant modules (Figure 5).
Figure 5.
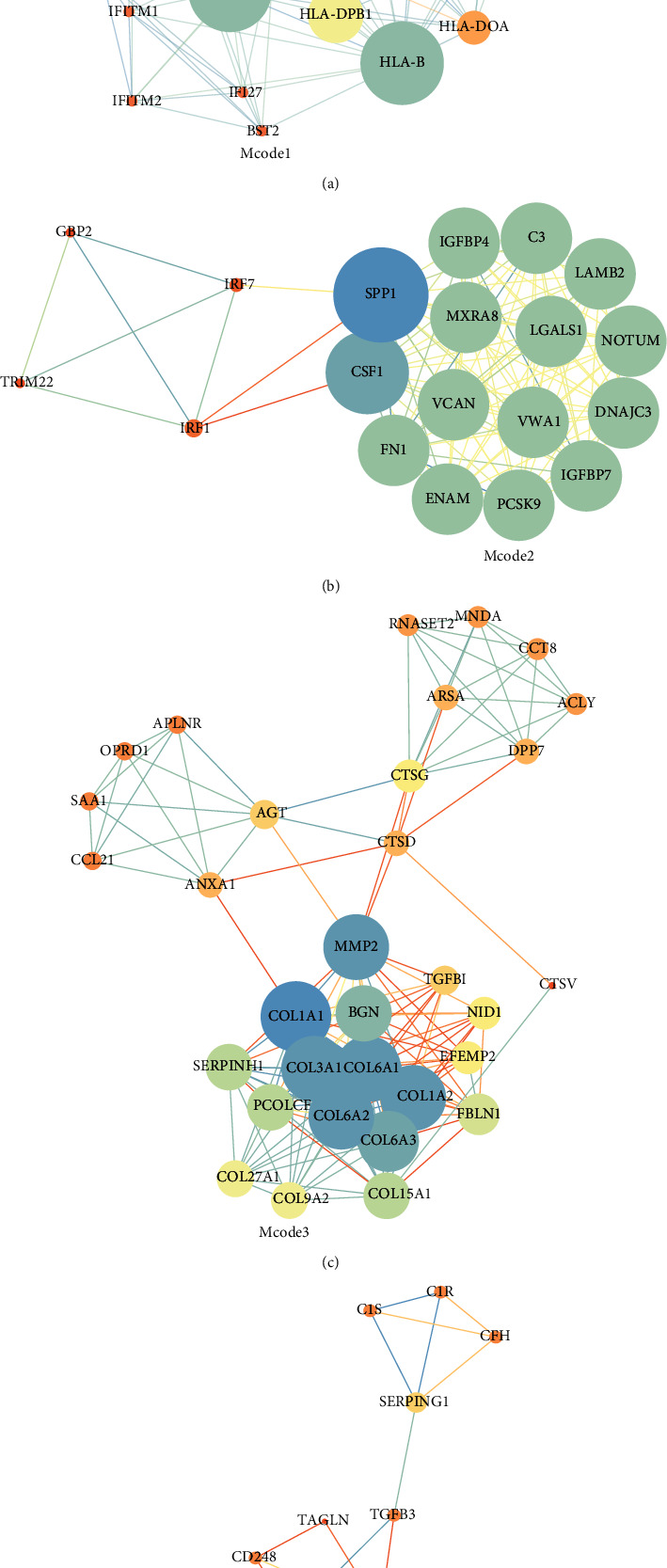
Gene protein-protein interaction maps of the functional modules mined by MCODE.
3.3. Identification of Hub Genes
Calculations were performed on the PPI network developed with the 499 DEGs using the three algorithms, Degree, MNC, and Closeness, available in CytoHubba, a plugin of the Cytoscape (version 3.7.2) software, to select the top 15 genes as the key genes (Figures 6(a)–6(c)). The intersection of the hub genes obtained by the three algorithms was considered to contain the ten “real” hub genes (IL1B, ITGB2, ITGAX, COL1A1, CSF1, CXCL12, SPP1, FN1, C3, and MMP2) (Figure 6(d)).
Figure 6.
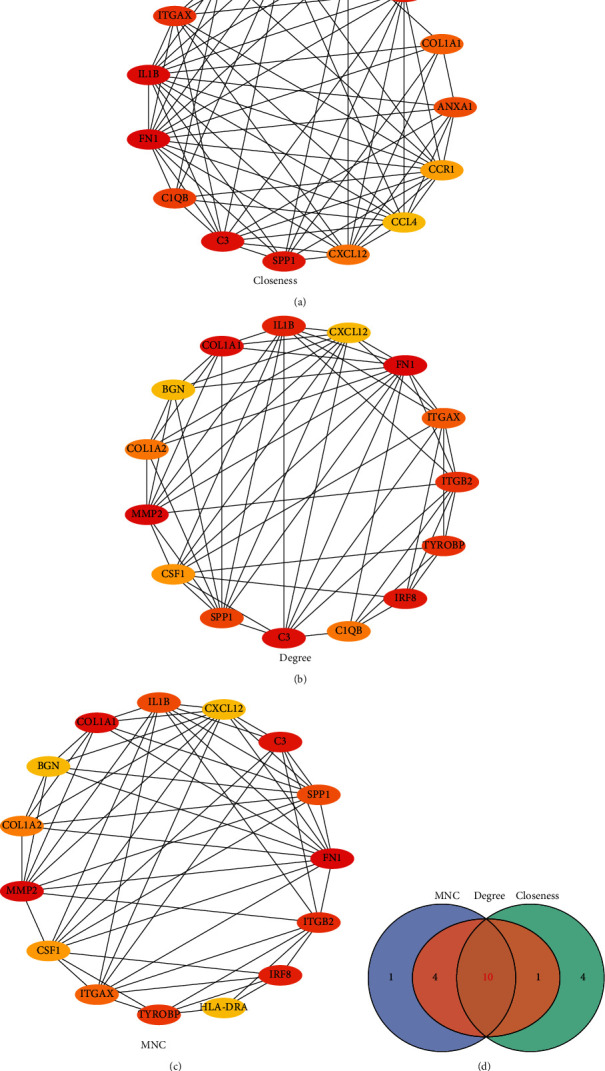
Identification of hub genes. (a) Protein-protein interaction network diagram of hub genes identified by the Closeness algorithm. (b) Protein-protein interaction network diagram of hub genes identified by the Degree algorithm. (c) Protein-protein interaction network diagram of hub genes identified by the MNC algorithm. (d) Venn diagram of genes obtained by the three algorithms.
3.4. Construction and Validation of the Diagnostic Model
The GSE164416 dataset was used as the training dataset, and the datasets GSE156993, GSE161355, and GSE163980 were used as validation datasets. The ten “real” hub genes served as features in the training dataset, and their corresponding expression profiles were obtained, according to which the SVM classification model was constructed (1000 iterations and 10-fold cross-validation). The classification accuracy of the GSE156993 dataset was 100%, as 57 out of 57 samples were correctly classified; the sensitivity and specificity of the model were both 100%, with an AUC of the ROC curve of 1 (Figure 7(a)). Furthermore, all samples in the GSE156993, GSE161355, and GSE163980 datasets were correctly classified, showing the model to have a high classification accuracy, with both the sensitivity and specificity being 100% and the AUC of the ROC curve being 1 (Figures 7(b)–7(e)). The three datasets (GSE76895, GSE9006, and GSE78721) were further verified by our diagnostic model. The results showed that in the GSE76895 dataset, 62 out of 68 samples were correctly classified, with a classification accuracy of 91.2%. The sensitivity is 88.9% and specificity is 93.8%, and the area under the ROC curve was 0.914 (Figure 7(e)). In the GSE9006 dataset, 36 of the 36 samples were correctly classified with a classification accuracy of 100%. The sensitivity and specificity of the model were 100%, and the area under the ROC curve was 1 (Figure 7(f)). In the GSE78721 dataset, 128 of the 130 samples were correctly classified, with a classification accuracy of 98.5%. The sensitivity and specificity of the model were 100% and 96.8%, and the area under the ROC curve was 0.988 (Figure 7(g)).
Figure 7.
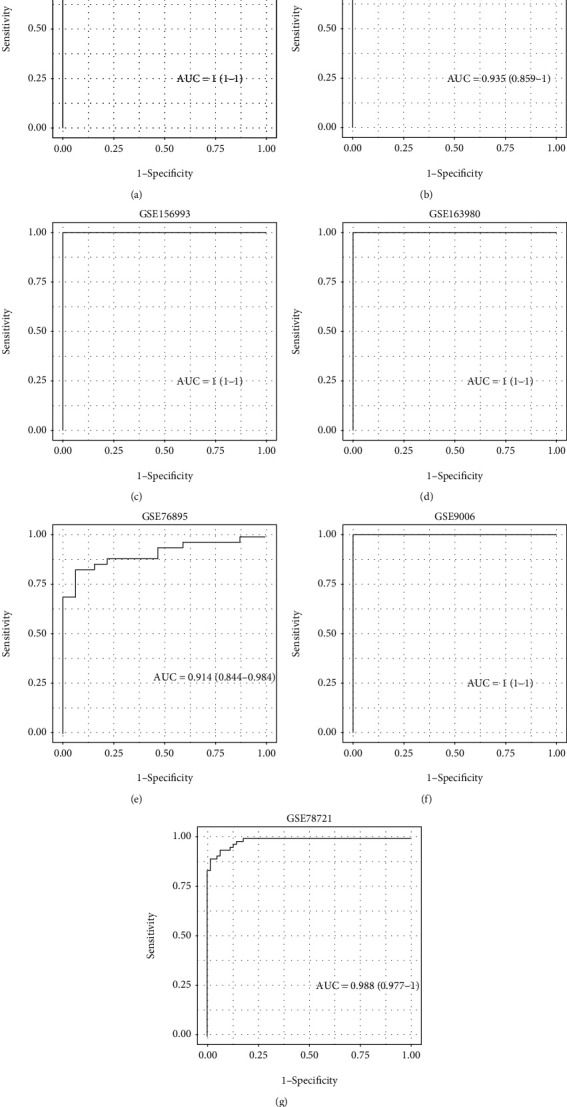
Construction and validation of diagnostic models. (a) Receiver operating characteristic curves of the classification results of the diagnostic model on the samples of the GSE164416 dataset. (b) Receiver operating characteristic curves of the classification results of the diagnostic model on the samples of the GSE161355 dataset. (c) Receiver operating characteristic curves of the classification results of the diagnostic model on the samples of the GSE156993 dataset. (d) Receiver operating characteristic curves of the classification results of the diagnostic model on the samples of the GSE163980 dataset. (e) Receiver operating characteristic curves of the classification results of the diagnostic model on the samples of the GSE76895 dataset. (f) Receiver operating characteristic curves of the classification results of the diagnostic model on the samples of the GSE9006 dataset. (g) Receiver operating characteristic curves of the classification results of the diagnostic model on the samples of the GSE78721 dataset.
4. Discussion
The present study identified 499 DEGs between type 2 diabetes patients and normal controls from the GSE164416 dataset. PPI analysis identified five modules as being clinically significant, and subsequent analysis revealed 10 genes (IL1B, ITGB2, ITGAX, COL1A1, CSF1, CXCL12, SPP1, FN1, C3, and MMP2) to be the “real” hub genes. The SVM-based classification involving the 10-gene signature achieved a 100% prediction accuracy in distinguishing patients with type 2 diabetes from normal controls with 100% sensitivity, 100% specificity, and an AUC of 1. The validation results obtained using the other three datasets (GSE156993, GSE161355, and GSE163980) further support the validity of our model.
Tyler et al. developed an inference method based on a general model of molecular, neuronal, and ecological oscillatory systems that merges the advantages of both model-based and model-free methods, namely, accuracy, broad applicability, and usability [26]. SVM methods have been widely used in classification and prediction owing to their feasibility of extracting higher order statistics. Abbas et al. discovered a type 2 diabetes prediction model based on the features derived only from the plasma glucose concentrations measured during an oral glucose tolerance test using SVM [27]. Cui et al. indicated that the proposed SVM-based method achieved an accuracy of 81.02%, a sensitivity of 82.89%, and a specificity of 79.23%, and it outperformed other popular algorithms in identifying diabetic patients who may be readmitted [28]. An SVM algorithm was used to classify osteoporosis in patients with type 2 diabetes by relying on several serological items and personal information with a diagnostic accuracy of 88% [29]. The present study shows the application of SVM based on a 10-gene signature to identify patients with type 2 diabetes by distinguishing positive type 2 diabetes samples from normal control samples with a high sensitivity.
Type 2 diabetes is a multifactorial, typical complex disease, which is associated with lifestyle and other environmental factors [30, 31]. In this research, a set of ten “real” hub genes, IL1B, ITGB2, ITGAX, COL1A1, CSF1, CXCL12, SPP1, FN1, C3, and MMP2, was integrated into a model to predict type 2 diabetes. Studies have shown these genes to be involved in the development of type 2 diabetes, for example, a study showing IL-1β-induced β cell dysfunction [32]. Glawe et al. showed that genetic deficiency of ITGB2 completely prevented the development of hyperglycemia and frank diabetes in NOD mice [33]. Some experiments have found that islet inflammation could promote beta cell dysfunction in type 2 diabetes with increased expression of ITGAX [34, 35]. COL1A1 was the most significant gene in the extracellular matrix-receptor interaction pathway and was linked to hypoglycemic activity for the first time. Thus, COL1A1 is a novel potential therapeutic target for alleviating type 2 diabetes. It is reported that CSF1 receptor dephosphorylation inhibits alveolar bone resorption in diabetic periodontitis [36]. Genetic variations of the CXCL12 gene might affect trafficking of inflammatory cells or defected precursors and hence induce tendencies toward diabetic complications. The SDF1-3′A genetic variation of CXCL12 influences the development of late vascular diabetic complications, and study reported that this genetic variation regulates the expression of CXCL12 [37]. SPP1 encodes osteopontin which has been shown to cause glomerular damage and interstitial fibrosis in diabetic kidney disease [38]. A study involving signaling pathway enrichment analysis reported that ECM-receptor interaction is one of the main pathways in the diabetic nephropathy extracellular matrix and that FN1 is involved in the ECM-receptor interaction pathway [39]. Human pancreatic islets highly express C3 and are associated with the donor status of type 2 diabetes. C3 may be upregulated as a cytoprotective factor during type 2 diabetes to combat β cell dysfunction caused by impaired autophagy [40]. Type 2 diabetes increases the activity of matrix metalloproteinases (MMPs) [41]. Clinical correlation studies suggest that high circulating MMP-2 levels may correlate with the severity of periodontitis in type 2 diabetes [42]. Further research is required to explore the roles of the 10 “real” hub genes identified in our study in type 2 diabetes.
In summary, the present study used PPI analysis to identify 10 hub genes associated with type 2 diabetes. In addition, the components of the combination of these 10 genes may serve as potential biomarkers for type 2 diabetes. However, the lack of a detailed biological investigation and the lack of validation with a larger sample size were considered as limitations of this study. Further studies are therefore needed before clinical application to verify the diagnostic ability of this 10-gene signature for type 2 diabetes.
5. Conclusion
In this study, we analyzed transcriptional level gene expression data using SVM to construct a risk prediction model for type 2 diabetes patients, which may supplement traditional clinical prognostic factors, enabling clinicians to provide more effective therapeutic intervention and personalized treatment for type 2 diabetes patients.
Contributor Information
Jiabin Li, Email: 6513077@zju.edu.cn.
Hui Wang, Email: wh@zcmu.edu.cn.
Data Availability
The analyzed datasets generated during the study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare that they have no competing interests.
References
- 1.Cloete L. Diabetes mellitus: an overview of the types, symptoms, complications and management. Nursing standard. Nursing Standard . 2022;37(1):61–66. doi: 10.7748/ns.2021.e11709. [DOI] [PubMed] [Google Scholar]
- 2.Jaacks L. M., Siegel K. R., Gujral U. P., Narayan K. M. Type 2 diabetes: a 21st century epidemic. Best Practice & Research Clinical Endocrinology & Metabolism. . 2016;30(3):331–343. doi: 10.1016/j.beem.2016.05.003. [DOI] [PubMed] [Google Scholar]
- 3.Saeedi P., Petersohn I., Salpea P., et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: results from the International Diabetes Federation Diabetes Atlas. Diabetes Research and Clinical Practice . 2019;157, article 107843 doi: 10.1016/j.diabres.2019.107843. [DOI] [PubMed] [Google Scholar]
- 4.Idicula-Thomas S., Kulkarni A. J., Kulkarni B. D., Jayaraman V. K., Balaji P. V. A support vector machine-based method for predicting the propensity of a protein to be soluble or to form inclusion body on overexpression in Escherichia coli. Bioinformatics . 2006;22(3):278–284. doi: 10.1093/bioinformatics/bti810. [DOI] [PubMed] [Google Scholar]
- 5.Hussein A. F., Hashim S. J., Rokhani F. Z., Wan Adnan W. A. An automated high-accuracy detection scheme for myocardial ischemia based on multi-lead long-interval ECG and Choi-Williams time-frequency analysis incorporating a multi-class SVM classifier. Sensors . 2021;21(7):p. 2311. doi: 10.3390/s21072311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Aswathy M. A., Jagannath M. An SVM approach towards breast cancer classification from H&E-stained histopathology images based on integrated features. Medical & Biological Engineering & Computing . 2021;59(9):1773–1783. doi: 10.1007/s11517-021-02403-0. [DOI] [PubMed] [Google Scholar]
- 7.Hussain S., Raza Z., Giacomini G., Goswami N. Support vector machine-based classification of vasovagal syncope using head-up tilt test. Biology . 2021;10(10):p. 1029. doi: 10.3390/biology10101029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Du Y., Han D., Liu S., et al. Raman spectroscopy-based adversarial network combined with SVM for detection of foodborne pathogenic bacteria. Talanta . 2022;237, article 122901 doi: 10.1016/j.talanta.2021.122901. [DOI] [PubMed] [Google Scholar]
- 9.Huang S., Cai N., Pacheco P. P., Narrandes S., Wang Y., Xu W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genomics & Proteomics . 2018;15(1):41–51. doi: 10.21873/cgp.20063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Kavitha M. S., Asano A., Taguchi A., Kurita T., Sanada M. Diagnosis of osteoporosis from dental panoramic radiographs using the support vector machine method in a computer-aided system. BMC Medical Imaging . 2012;12(1):p. 1. doi: 10.1186/1471-2342-12-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Yang C., Ren J., Li B., et al. Identification of gene biomarkers in patients with postmenopausal osteoporosis. Molecular Medicine Reports . 2019;19(2):1065–1073. doi: 10.3892/mmr.2018.9752. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Barrett T., Wilhite S. E., Ledoux P., et al. NCBI GEO: archive for functional genomics data sets--update. Nucleic acids research. . 2013;41(Database issue):D991–D995. doi: 10.1093/nar/gks1193. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Kolberg J. A., Gerwien R. W., Watkins S. M., Wuestehube L. J., Urdea M. Biomarkers in type 2 diabetes: improving risk stratification with the PreDx ® diabetes risk score. Expert Review of Molecular Diagnostics . 2011;11(8):775–792. doi: 10.1586/erm.11.63. [DOI] [PubMed] [Google Scholar]
- 14.Sale M. M., Rich S. S. Genetic contributions to type 2 diabetes: recent insights. Expert Review of Molecular Diagnostics . 2007;7(2):207–217. doi: 10.1586/14737159.7.2.207. [DOI] [PubMed] [Google Scholar]
- 15.Benisch P., Schilling T., Klein-Hitpass L., et al. The transcriptional profile of mesenchymal stem cell populations in primary osteoporosis is distinct and shows overexpression of osteogenic inhibitors. PLoS One . 2012;7(9, article e45142) doi: 10.1371/journal.pone.0045142. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Cheishvili D., Parashar S., Mahmood N., et al. Identification of an epigenetic signature of osteoporosis in blood DNA of postmenopausal women. Journal of Bone and Mineral Research . 2018;33(11):1980–1989. doi: 10.1002/jbmr.3527. [DOI] [PubMed] [Google Scholar]
- 17.Xiao P., Chen Y., Jiang H., et al. In vivo genome-wide expression study on human circulating B cells suggests a novel ESR1 and MAPK3 network for postmenopausal osteoporosis. Journal of Bone and Mineral Research . 2008;23(5):644–654. doi: 10.1359/jbmr.080105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Khamis A., Canouil M., Siddiq A., et al. Laser capture microdissection of human pancreatic islets reveals novel eQTLs associated with type 2 diabetes. Molecular Metabolism . 2019;24:98–107. doi: 10.1016/j.molmet.2019.03.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Kaizer E. C., Glaser C. L., Chaussabel D., Banchereau J., Pascual V., White P. C. Gene expression in peripheral blood mononuclear cells from children with diabetes. The Journal of Clinical Endocrinology and Metabolism . 2007;92(9):3705–3711. doi: 10.1210/jc.2007-0979. [DOI] [PubMed] [Google Scholar]
- 20.Kumar A., Tiwari P., Saxena A., et al. The transcriptomic evidence on the role of abdominal visceral vs. subcutaneous adipose tissue in the pathophysiology of diabetes in Asian Indians indicates the involvement of both. Biomolecules . 2020;10(9):p. 1230. doi: 10.3390/biom10091230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Ritchie M. E., Phipson B., Wu D., et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Research . 2015;43(7, article e47) doi: 10.1093/nar/gkv007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Yu G., Wang L. G., Han Y., He Q. Y. clusterProfiler: an R package for comparing biological themes among gene clusters. Omics: a Journal of Integrative Biology . 2012;16(5):284–287. doi: 10.1089/omi.2011.0118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Szklarczyk D., Gable A. L., Nastou K. C., et al. The STRING database in 2021: customizable protein-protein networks, and functional characterization of user-uploaded gene/measurement sets. Nucleic Acids Research . 2021;49(D1):D605–D612. doi: 10.1093/nar/gkaa1074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Shannon P., Markiel A., Ozier O., et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Research . 2003;13(11):2498–2504. doi: 10.1101/gr.1239303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Chin C. H., Chen S. H., Wu H. H., Ho C. W., Ko M. T., Lin C. Y. cytoHubba: identifying hub objects and sub-networks from complex interactome. BMC Systems Biology . 2014;8(4):1–7. doi: 10.1186/1752-0509-8-S4-S11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Tyler J., Forger D., Kim J. Inferring causality in biological oscillators. Bioinformatics . 2021;38(1):196–203. doi: 10.1093/bioinformatics/btab623. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Abbas H. T., Alic L., Erraguntla M., et al. Predicting long-term type 2 diabetes with support vector machine using oral glucose tolerance test. PLoS One . 2019;14(12, article e0219636) doi: 10.1371/journal.pone.0219636. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Cui S., Wang D., Wang Y., Yu P. W., Jin Y. An improved support vector machine-based diabetic readmission prediction. Computer Methods and Programs in Biomedicine. . 2018;166:123–135. doi: 10.1016/j.cmpb.2018.10.012. [DOI] [PubMed] [Google Scholar]
- 29.Wang C., Zhang T., Wang P., et al. Bone metabolic biomarker-based diagnosis of type 2 diabetes osteoporosis by support vector machine. Annals of Translational Medicine . 2021;9(4):p. 316. doi: 10.21037/atm-20-3388. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Vangipurapu J., Fernandes Silva L., Kuulasmaa T., Smith U., Laakso M. Microbiota-related metabolites and the risk of type 2 diabetes. Diabetes Care . 2020;43(6):1319–1325. doi: 10.2337/dc19-2533. [DOI] [PubMed] [Google Scholar]
- 31.Lu T., Forgetta V., Yu O. H. Y., et al. Polygenic risk for coronary heart disease acts through atherosclerosis in type 2 diabetes. Cardiovascular Diabetology. . 2020;19(1):p. 12. doi: 10.1186/s12933-020-0988-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Wang G., Liang R., Liu T., et al. Opposing effects of IL-1β/COX-2/PGE2 pathway loop on islets in type 2 diabetes mellitus. Endocrine Journal. . 2019;66(8):691–699. doi: 10.1507/endocrj.EJ19-0015. [DOI] [PubMed] [Google Scholar]
- 33.Glawe J. D., Patrick D. R., Huang M., Sharp C. D., Barlow S. C., Kevil C. G. Genetic deficiency of Itgb2 or ItgaL prevents autoimmune diabetes through distinctly different mechanisms in NOD/LtJ mice. Diabetes . 2009;58(6):1292–1301. doi: 10.2337/db08-0804. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Meier D. T., Morcos M., Samarasekera T., Zraika S., Hull R. L., Kahn S. E. Islet amyloid formation is an important determinant for inducing islet inflammation in high-fat-fed human IAPP transgenic mice. Diabetologia . 2014;57(9):1884–1888. doi: 10.1007/s00125-014-3304-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Hannibal T. D., Schmidt-Christensen A., Nilsson J., Fransén-Pettersson N., Hansen L., Holmberg D. Deficiency in plasmacytoid dendritic cells and type I interferon signalling prevents diet-induced obesity and insulin resistance in mice. Diabetologia . 2017;60(10):2033–2041. doi: 10.1007/s00125-017-4341-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Zhang D., Jiang Y., Song D., et al. Tyrosine-protein phosphatase non-receptor type 2 inhibits alveolar bone resorption in diabetic periodontitis via dephosphorylating CSF1 receptor. Journal of Cellular and Molecular Medicine . 2019;23(10):6690–6699. doi: 10.1111/jcmm.14545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Karimabad M. N., Hassanshahi G. Significance of CXCL12 in type 2 diabetes mellitus and its associated complications. Inflammation . 2015;38(2):710–717. doi: 10.1007/s10753-014-9981-3. [DOI] [PubMed] [Google Scholar]
- 38.Zhang Y., Li W., Zhou Y. Identification of hub genes in diabetic kidney disease via multiple-microarray analysis. Annals of Translational Medicine. . 2020;8(16):p. 997. doi: 10.21037/atm-20-5171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Geng X. D., Wang W. W., Feng Z., et al. Identification of key genes and pathways in diabetic nephropathy by bioinformatics analysis. Journal of Diabetes Investigation . 2019;10(4):972–984. doi: 10.1111/jdi.12986. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.King B. C., Kulak K., Krus U., et al. Complement component C3 is highly expressed in human pancreatic islets and prevents β cell death via ATG16L1 interaction and autophagy regulation. Cell Metabolism. . 2019;29(1):202–210. doi: 10.1016/j.cmet.2018.09.009. [DOI] [PubMed] [Google Scholar]
- 41.Arreguin-Cano J. A., Ayerdi-Nájera B., Tacuba-Saavedra A., et al. MMP-2 salivary activity in type 2 diabetes mellitus patients. Diabetology & Metabolic Syndrome . 2019;11(1):p. 113. doi: 10.1186/s13098-019-0510-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Kocher T., König J., Borgnakke W. S., Pink C., Meisel P. Periodontal complications of hyperglycemia/diabetes mellitus: epidemiologic complexity and clinical challenge. Periodontology . 2018;78(1):59–97. doi: 10.1111/prd.12235. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The analyzed datasets generated during the study are available from the corresponding author on reasonable request.