

Abstract
Pharmaceutical agents in oncology currently have high attrition rates from early to late phase clinical trials. Recent advances in computational methods, notably causal artificial intelligence, and availability of rich clinico-genomic databases have made it possible to simulate the efficacy of cancer drug protocols in diverse patient populations, which could inform and improve clinical trial design. Here, we review the current and potential use of in silico trials and causal AI to increase the efficacy and safety of traditional clinical trials. We conclude that in silico trials using causal AI approaches can simulate control and efficacy arms, inform patient recruitment and regimen titrations, and better enable subgroup analyses critical for precision medicine.
Keywords: AI, in silico clinical trials, disease modeling, systems biomedicine, efficacy arm, causal AI
Introduction
Clinical trial optimization is an unmet need in oncology. Oncology has one of the highest number of drugs in multi-million-dollar clinical trials while also having one of the lowest Phase I to market likelihoods at 5.1% (Thomas et al., 2016). Computational simulation of clinical trials, termed in silico trials (ISTs), can salvage the resources devoted to failed pharmacological studies by enabling better powered trials, simulating control and efficacy arms, and optimizing patient recruitment and drug protocols in efficacy arms. Here, we discuss the current challenges of traditional clinical trials in oncology, how ISTs can improve their efficacy and safety, and why causal artificial intelligence (AI) frameworks are uniquely poised to generate synthetic efficacy arms from multimodal clinico-genomic real-world data (RWD) in order to predict clinical intervention outcomes.
Cancer remains a leading cause of death across the globe, with a great urgency for more effective pharmacologic treatments. However, traditional pharmacological clinical trials are limited by expense, time, sample size, and scope. Oncology clinical trials from Phase I to III take an average of eight years with a mean cost of $56.3 million (Bianchi, 2013). A large percentage of these costs come from patient recruitment, as more participants are required at each incremental phase in the trial. Despite the greater demand for participants at each step, less than 10% of adult cancer patients partake in clinical trials, with even fewer children included as participants (Unger et al., 2019). Lack of patient heterogeneity in Phase I can lead to ungeneralizable conclusions of the benefits and risks of a drug. As a result, many of these drugs are no longer efficacious in Phase II. Additionally, the attrition rate between Phase II and III trials, when the drug is given to a greater number of patients with complex clinical profiles, is over 75% (Thomas et al., 2016).
Notably, phase III trials of pharmaceutical agents in oncology often rely on fixed doses and dosing schedules (Hui et al., 2013). However, minute changes to drug dosing, chemical structure, or pharmacokinetic/dynamic (drug action and metabolism) profile could lead to better patient outcomes (Manolis et al., 2013). But, traditional clinical trials with preset intervention and control arms often prevent exploration of heterogeneity of a drug’s effectiveness, instead leading to the premature dismissal of potentially promising drugs (Alqahtani, 2017). Furthermore, even in successful Phase II and III trials, there is still limited availability to study response variability and excluded subpopulations.
Recent “omics” studies that have started to appreciate this heterogeneity have facilitated more precise regimens tailored to individual patient’s tumor mutations or molecular expression profiles. Advances in patient data generation and integration; collection of genomic and real-world data from the EMR; and AI and cloud-based supercomputing are converging to allow for the creation of in silico patients and trials. These in silico methods offer a viable alternative that addresses the limitations of clinical trials as described above.
In silico trials
In silico clinical trials develop virtual cohorts or case studies from patient-specific and disease-specific computational models to test the safety and efficacy of medical interventions. The foundation of ISTs depends on the ability to recreate human physiology and pathology, including the impact of genetic variations on clinical outcomes. To do this, virtual platforms mine the growing real world clinico-genomic data collected from real patients to represent 3D anatomical shapes and/or clinical outcomes and the biochemical pathways and gene networks that drive them (Viceconti et al., 2016). Particular feature(s) of the patient models, like the concentration of biomolecules, known to be affected by a drug in preclinical studies, can be modulated to test the effects of an intervention. Statistical models then use this information to predict relevant health outcomes commonly measured in RCTs, like tumor size, heart rate, and 5-year survival.
ISTs address many of the challenges inherent in the design of RCTs and streamline the drug development process. The virtual platforms of ISTs reduce the cost of clinical trials by cutting the expense of patient recruitment and physical resources as well as the duration of the trial. Furthermore, a larger sample size can be included in the studies, improving the statistical reliability of the results. Provided that the underlying data are diverse, the increase in sample size can improve the likelihood that the participant pool includes health data from underrepresented high-risk subgroups (i.e. elderly patients, pregnant women) who are often excluded from clinical trials, ensuring the outcomes are more generalizable. As a result, they replicate scenarios that are difficult to study in real life and predict the long term or rare sequelae of interventions for diverse populations that RCTs are unlikely to reveal within a limited time frame.
Observations from ISTs inform patient selection and drug administration protocols for studies done in the clinic. The results from the simulations could stratify virtual participants by their predicted outcome measures to identify characteristics of patients at risk of complications. For example, in silico modeling groups have applied ISTs to predict which patients would benefit from immunomodulating cancer therapies, consequently improving numerous Phase II/III clinical trials (Auslander et al., 2018; Butner et al., 2020; Vanderman et al., 2020). In 2018, one company built a 200-patient IST to compare the efficacy of the novel combinations of four candidate therapies (platinum doublet chemotherapy, anti-PD1, anti-CDLA4, and EGFR inhibitors) for non-small cell lung cancer (NSCLC) with the standard-of-care anti-PD1 therapy (Vanderman et al., 2020). The study noted trends in immune cell composition, biomarker levels, and cytokine levels of an individual’s tumor that differentiate between responders and nonresponders for each regimen. Similarly, another group analyzed data from patients to find genetic markers that predict response to immunotherapy for melanoma (Auslander et al., 2018).
For individual patients or subgroups with poor outcomes, ISTs prompt further investigation into why the original intervention failed. For example, an in silico acute stroke model identified the ratio of astrocytes to neurons as a driver for why hundreds of compounds successful in animal models failed for many in clinical trials (Arquitectura et al., 2015). This effort could inform modifications in the dosing, scheduling, and interaction among co-interventions for the drug(s) of interest to optimize its efficacy.
While regularly adopted in various fields, including physics, mathematics, and epidemiology, to predict the behavior of complex systems, in silico simulations are still nascent in medicine. They have been most appreciated for the assessment of medical devices. In 2018, FDA’s VICTRE study analyzed computer simulated imaging of 2,986 in silico patients and predicted that breast tomosynthesis is more effective than standard-of-care digital mammography to detect lesions for various breast sizes and cancer types (Badano et al., 2018). The results corresponded with a prior clinical study conducted on this topic. The findings verified that in silico imaging trials and tools should be considered viable sources of evidence for the regulatory evaluation of imaging devices.
While underutilized in drug development, ISTs have also been instrumental for pharmaceutical trials, first in the form of synthetic control arms. This study design simulates the effects of placebo interventions on virtual patients and compares them to the experimental arm of RCTs. In addition to the benefits of ISTs listed above, synthetic control arms ensure that all participants of RCTs receive the experimental intervention, eliminating concerns about treatment assignment and the risk of unblinding (Thorlund et al., 2020). In 2015, a healthcare company conducted a synthetic control arm of 68 patients for alectinib, a drug for non-small-cell lung cancer, accelerating its FDA approval and advancing its coverage by 18 months in European countries (Thorlund et al., 2020). Similarly, another group used a synthetic control arm of 694 patients to accelerate the approval of blinatumomab for the treatment of a rare form of acute lymphoblastic leukemia (Thorlund et al., 2020).
Given the early success of synthetic control arms, companies have started to extend this approach for the simulation of intervention arm drug effects – in silico efficacy arms (Viceconti et al., 2016). Notably, in 2007, one company simulated a rheumatic joint to compare the effects of rituximab versus anti-TNF in preventing bone erosion in rheumatoid arthritis patients with severe disease (Viceconti et al., 2016; Schmidt et al., 2013). Their model predicted that rituximab was superior to anti-TNF therapies, findings confirmed by RCTs years later. More recently, a team of cancer researchers announced the success of its virtual trials in predicting the response to standard care therapies for AML and myelodysplastic syndromes and identifying patients unlikely to respond to prescribed therapies with high specificity and ~90% accuracy (Stein et al., 2020). These triumphs demonstrate the utility of ISTs in supporting drug development, prompting more groups to apply this paradigm in oncology (Alqahtani, 2017; Ouzounoglou et al., 2018) and health organizations to consider these virtual platforms in their evaluation of a pharmaceutical intervention.
Multimodal Clinico-genomic data and in silico trials
In silico trials have been recognized by the FDA as useful tools in advancing personalized treatment and streamlining RCTs (FDA, 2020; Morrison, 2018). In support, the FDA has been advocating for the collection of multimodal data sets and the development of bioinformatic infrastructures to analyze them. Advancements in data acquisition and sequencing technology have reinforced this goal.
Completed in 2003, The Human Genome Project mapped the genetic blueprint of the human body, generating vast amounts of information on genes that drive normal physiology and polygenic diseases like cancer. Insights from this project laid the groundwork for The Cancer Genome Atlas, which identified the complex heterogeneity of tumor molecular profiles between individuals (Wheeler & Wang, 2013). This finding prompted the need for personalized approaches to cancer therapy. However, such approaches required more feasible genomic sequencing for individual patients to generate in silico trials that predict combination therapies with high likelihood of success. Newer models of gene expression microarray chips and RNA sequencing technologies developed in the 2010s have bridged the gap between theory and practice, enabling scientists to extract high-throughput genomic data while concomitantly reducing the speed and cost of doing so (Navarro et al., 2019). In this new era of data accessibility, we envision the early successes of in silico trials for the study of simple or monogenic diseases to translate to the study of cancer subtypes with complex molecular features.
Current in silico trials have been integrating more nuanced forms of clinico-genomic real-world data (RWD), collected in the context of routine patient care. These data include diagnostic “omics” and radioimaging studies, electronic health records (EHR), socio-economic data, and mobile health technologies that continuously monitor patients’ lifestyles and medication compliance. The algorithms implemented for ISTs are evolving as well; artificial intelligence methods are better equipped to learn from the complexity and mere quantity of these new data sources.
AI and in silico trials
AI algorithms can offer distinct advantages over biomathematical models for in silico trials. RWD in healthcare is often incomplete and unstructured, lacking a standardized organization that is easily interpretable. While predictions from simpler linear statistical models are limited to the structured portions of RWD like numerical values in lab reports, AI-powered technologies can also mine and integrate information from variegated sources like physicians’ notes and MRI scans, and high-throughput molecular profiling of DNA sequencing, gene expression profiling, and proteomic profiling. These technologies include neural networks, deep learning, unsupervised machine learning, natural language processing, and computer vision. ISTs fueled by AI can undergo an iterative process, where each consecutive run of the same intervention incorporates new patient data and learns from error reports of prior simulations, to improve predictions. Finally, AI algorithms can increase the number of virtual patients included in a trial, while sparing the computational cost of doing so by running scenarios faster and in parallel.
Computational biology groups have started to utilize the added advantages of the AI models for pharmaceutical drug development. For example, some companies have been leveraging these tools to mine RWD from public databases like ClinicalTrials.gov to prescreen individuals eligible to participate in a clinical trial, with the ultimate goal of increasing cancer patient enrollment into RCTs (Nelson and Cross, 2019).
The promise of causal AI
Predictions from ISTs, particularly from those using AI platforms, have advanced drug development by inferring the effect of an intervention on complex patients. However, ISTs used for risk prediction are still limited in their ability to recognize the cause of an outcome. Why does an immunomodulating therapy work in patient A but not patient B? Identifying the causality of a treatment will unveil the underlying mechanism of an intervention, offering intelligent design of chemotherapies and personalized medicine regimens that optimize these causal relationships and improve patient outcomes (Hartnett, 2020; Properzi et al., 2020; Sgaier et al., 2020).
Causal AI algorithms can help ISTs determine the cause and effect of an intervention in individuals or populations using two frameworks: potential outcomes and causal graphs. The potential outcomes framework builds a control and experimental group on a retrospective dataset of exposures and outcomes. AI is used to mine the dataset to identify virtual participants for each group that are nearly identical except for the exposure of interest. While the potential outcomes method is useful to test the causal influence of one intervention at a time, causal graph models can test the cause and effect of changing multiple variables (Sgaier et al., 2020, Pearl, 2009).
Bayesian network models are one subset of causal graph models that use AI to estimate the probabilistic relationships between variables in a dataset in the causal discovery step (Glymour, Zhang, and Spirtes 2019; Sgaier et al., 2020). After building a baseline network of causal relationships, ISTs can simulate numerous “what if” scenarios to record the outcomes of systematic perturbations to the network (Hernan 2006). Because causal AI ISTs can process a large number of features and interventions at once, they could serve as a powerful tool to test precision medicine hypotheses in a virtual setting.
In multiple myeloma research, several groups have utilized the Multiple Myeloma Research Foundation CoMMPass clinico-genomic patient database to conduct ISTs. For example, Laganà et al. 2018 developed a causal network of modules of co-expressed genes from the CoMMPass IA7 dataset and found a module involved in cell cycle regulation and DNA damage response that correlates with early relapse and aggressive disease. This module also led to the development of a simple prognostic signature validated on independent datasets. Another example is the work by Liu et al. 2019 who developed a causal network from the Multiple Myeloma Research Consortium dataset that was validated on the CoMMPass dataset. Findings from this work include a 178-gene prognostic subnetwork enriched in cell cycle genes, a unification of previously published prognostic gene signatures as well as elucidation of the signature response of proteasome inhibitors and immunomodulatory drugs.
One company, GNS Healthcare, has used its causal AI simulatiton platform, Gemini — The in silico Patient™, to reverse-engineer an in silico patient population from 645 patient with approximately ~30,000 clinical and molecular features from the MMRF CoMMPass IA9 dataset. The technology reverse-engineered an approximation of the causal relationships among the variables in the data (Figure 1) and investigated the drivers of relevant outcomes like high risk, progression free survival (PFS), and overall survival (Gruber et al. 2016; Furchtgott et al. 2017; Bolomsky et al. 2018).
Figure 1.
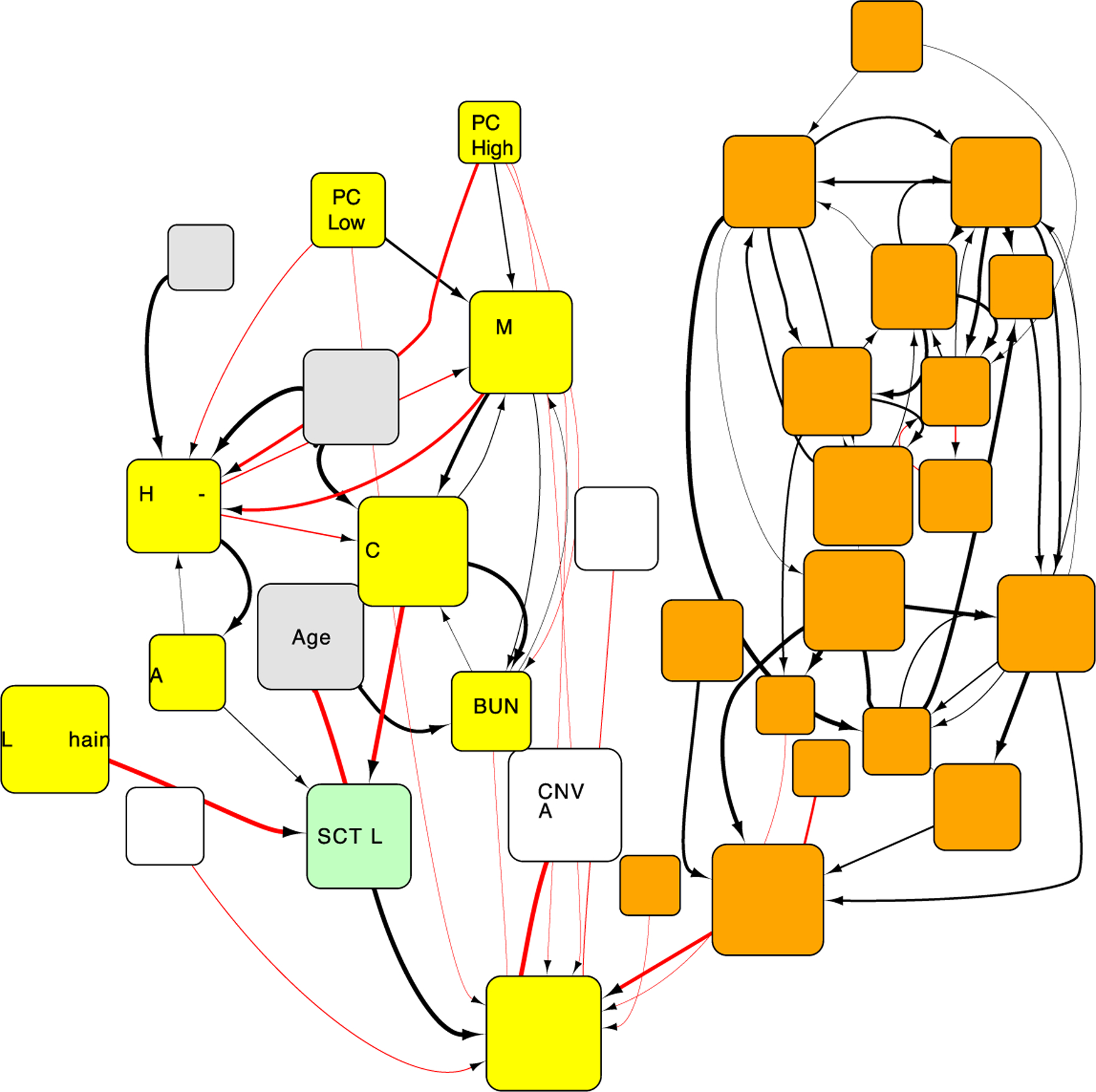
Fragment of causal network describing the relationship between variables in the CoMMPass IA9 dataset (Furchtgott et al. 2017). This network structure estimates the effect of interventions by simulating how changes in values of variables affects other variables downstream in the networks. Orange are genes, yellow are laboratories, gray are demographics, white are somatic variants, and green are treatment variables. The size of the nodes is relative to the estimated size of the effect from simulations, the width of the edges represents the confidence in the connection and the color represent whether the relationship between variables is direct or inverse.
This model was then simulated to answer one of the primary questions in multiple myeloma patient care: Which patients will respond to stem cell transplant? In order to estimate the effect of interventions, the ensemble of models representing the patient cohort is used to simulate the effect of treatments conditioned on the specific patient characteristics. This counterfactual simulation represents a new type of data-driven in silico trial that reveals the treatment response driven by the integrated impact of patient genomic and clinical profiles. Sub-populations of responder and non-responder patients were revealed, with high expression of CHEK1 appeared to have a smaller stem cell transplant effect on PFS (Gruber et al. 2016). An independent non-prospective clinical trial dataset confirmed this relationship and the corresponding significant impact on PFS, as shown in Figure 2 (Furchtgott et al. 2017). CHEK1 is involved in cell cycle regulation that drives PFS in high risk patients and the underlying mechanisms were preliminarily validated by drug inhibitor experiments (Bolomsky et al. 2018).
Figure 2.
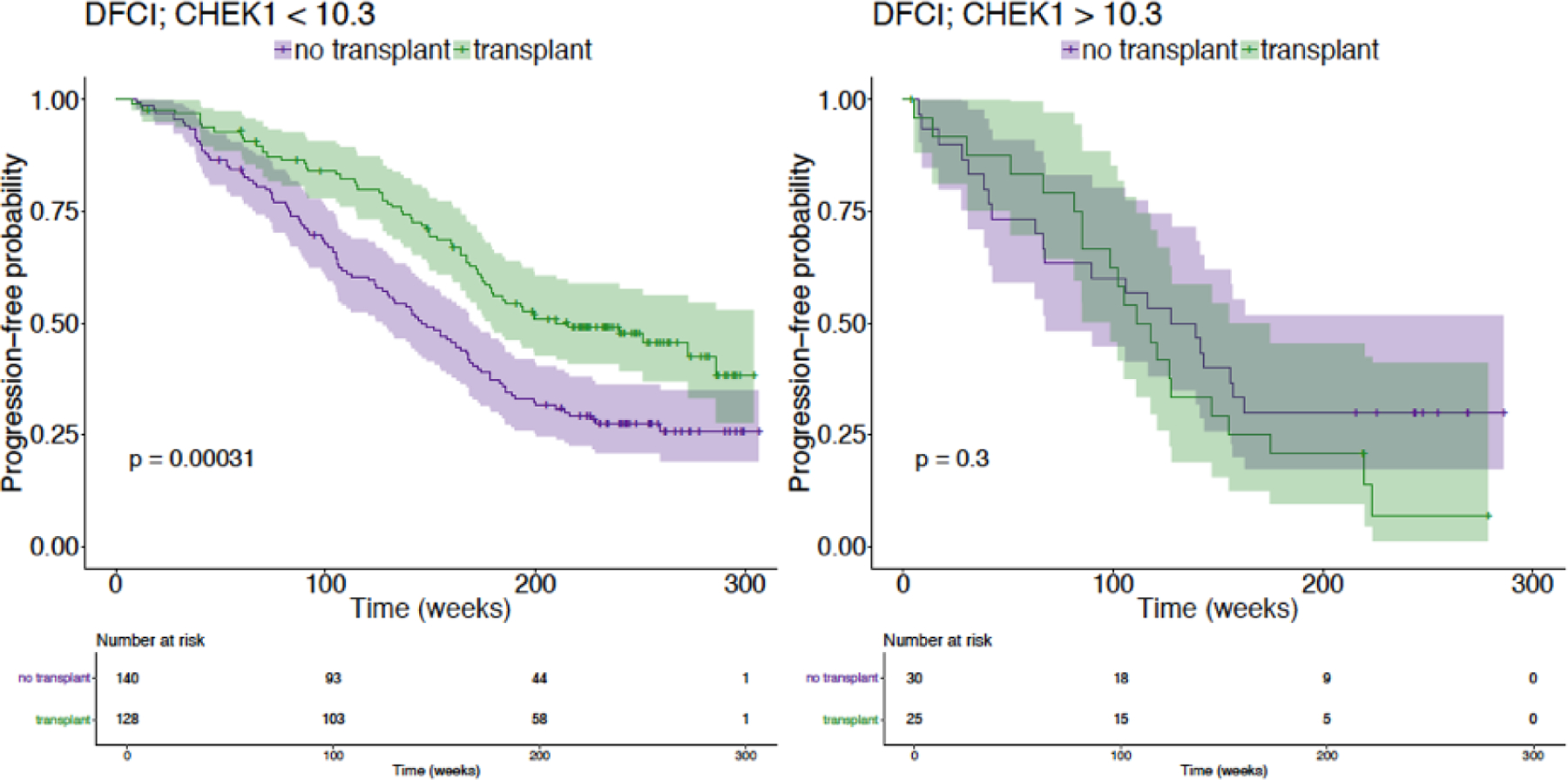
An independent non-prospective clinical trial dataset (DFCI) confirms a sub-population of responder and non-responder to SCT stratified by CHEK1. Patients with high expression of CHEK1 appeared to have a smaller stem cell transplant effect on PFS.
Conclusion
In silico trials provide rich opportunities to support the clinical trial process in oncology, ensuring that fewer interventions fail Phase II/III trials and more enter the market sooner. Here, we highlight the benefits of computer simulation of drug development trials, and in particular the utility of causal AI methods for ISTs. However, some limitations still need to be addressed for the widespread adoption of these methods.
The first and greatest limitation is the generation and curation of large clinico-genomic datasets. There remains a dearth of high-quality clinical datasets with corresponding multi-omic data generation from patient samples. In addition, the analytical workflow for these data need to expanded and standardized. Expanding real world data collection can isolate more social and biological factors that drive health behaviors, reducing the assumptions made in the models and improving their accuracy. Standardization will help to ensure data privacy, quality, and access. Furthermore, a uniformed workflow will encourage algorithmic transparency and replicability of results. Second, AI methods, especially causal AI methods based on Bayesian Networks need to be improved and more broadly applied to these emerging clinico-genomic data sets. Third, we need to build a rigorous criterion to evaluate ISTs for biases, errors, overfitting, and validity. This criterion should be developed collaboratively between academics, industry, and regulatory bodies (e.g., FDA). Finally, an interdisciplinary bridge between computer scientists, biologists, physicists, and clinicians should be constructed early to align the goals of both teams.
ISTs will never fully replace randomized clinical trials. But, as we reach a tipping point in greater availability of clinic-genomic data routinely collected in the clinic and with mobile health technologies, along with the development of more complex analytical structures, such as causal AI and almost unlimited cloud computing platforms, ISTs will serve as a powerful tool to proactively refine RCTs in oncology. This may not only reduce the cost and complexity of running a trial, but also enable discovery of many more treatment options for different patients.
Funding
The authors in this article were supported by the NIH Medical Scientist Training Program T32 GM07170 (to L.K.) and National Palliative Care Research Center (to R.B.P.)
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Declaration of Competing Interest
The authors declare that they have the following competing financial interests or personal relationships: RBP has received personal fees and equity from GNS Healthcare. FG and CH are employees of GNS Healthcare.
References
- Alqahtani S (2017). In silico ADME-Tox modeling: progress and prospects. Expert Opinion on Drug Metabolism and Toxicology, 13(11), 1147–1158. doi: 10.1080/17425255.2017.1389897 [DOI] [PubMed] [Google Scholar]
- Auslander N, Zhang G, Lee JS, Frederick DT, Miao B, Moll T, Tian T, Wei Z, Madan S, Sullivan RJ, Boland G, Flaherty K, Herlyn M, & Ruppin E (2018). Robust prediction of response to immune checkpoint blockade therapy in metastatic melanoma. Nature Medicine, 24(10), 1545–1549. doi: 10.1038/s41591-018-0157-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Badano A, Graff CG, Badal A, Sharma D, Zeng R, Samuelson FW, Glick SJ, & Myers KJ (2018). Evaluation of Digital Breast Tomosynthesis as Replacement of Full-Field Digital Mammography Using an In Silico Imaging Trial. JAMA Network Open, 1(7), e185474. doi: 10.1001/jamanetworkopen.2018.5474 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bianchi A (2013). Patient Recruitment Driving Length and Cost of Oncology Clinical Trials. International Pharmaceutical Industry, 5(2), 58–61. http://ipimediaworld.com/wp-content/uploads/2013/06/2-Patient-Recruitment-Driving-Lenght-and-Cost-of-Oncology-Clinical-Trials.pdf“ http://ipimediaworld.com/wp-content/uploads/2013/06/2-Patient-Recruitment-Driving-Lenght-and-Cost-of-Oncology-Clinical-Trials.pdf [Google Scholar]
- Bolomsky A, Gruber F, Stangelberger K, Furchtgott L, Arnold D, Raut P, Wuest D, Runge K, Khalil I, Zojer N, Munshi N, Hayete B, Ludwig H (2018). Preclinical Validation Studies Support Causal Machine Learning Based Identification of Novel Drug Targets for High-Risk Multiple Myeloma. Blood 132, 3210–3210. doi: 10.1182/blood-2018-99-117886 [DOI] [Google Scholar]
- Butner JD, Elganainy D, Wang CX, Wang Z, Chen SH, Esnaola NF, Pasqualini R, Arap W, Hong DS, Welsh J, Koay EJ, & Cristini V (2020). Mathematical prediction of clinical outcomes in advanced cancer patients treated with checkpoint inhibitor immunotherapy. Science Advances, 6(18), 1–12. doi: 10.1126/sciadv.aay6298 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Couturier CP, Ayyadhury S, Le PU, Nadaf J, Monlong J, Riva G, Allache R, Baig S, Yan X, Bourgey M, Lee C, Wang YCD, Wee Yong V, Guiot MC, Najafabadi H, Misic B, Antel J, Bourque G, Ragoussis J, & Petrecca K (2020). Single-cell RNA-seq reveals that glioblastoma recapitulates a normal neurodevelopmental hierarchy. Nature Communications, 11(1). doi: 10.1038/s41467-020-17186-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- FDA. (2020). Statement by FDA Commissioner Scott Gottlieb, M.D., on new strategies to modernize clinical trials to advance precision medicine, patient protections and more efficient product development. Fda, 1–5. https://www.fda.gov/news-events/press-announcements/statement-fda-commissioner-scott-gottlieb-md-new-strategies-modernize-clinical-trials-advance“ https://www.fda.gov/news-events/press-announcements/statement-fda-commissioner-scott-gottlieb-md-new-strategies-modernize-clinical-trials-advance
- Furchtgott L, Bolomsky A, Gruber F, Samur MK, Keats JJ, Yesil J, Stangelberger K, Attal M, Moreau P, Avet-Loiseau H, Runge K, Wuest D, Rich K, Khalil I, Hayete B, Ludwig H, Munshi N, Auclair D (2017). Multiple Myeloma Drivers of High Risk and Response to Stem Cell Transplantation Identified By Causal Machine Learning: Out-of-Cohort and Experimental Validation. Blood 130, 3029–3029. doi: 10.1182/blood.V130.Suppl_1.3029.3029 [DOI] [Google Scholar]
- Ginsburg GS, & Phillips KA (2018). Precision medicine: From science to value. Health Affairs, 37(5), 694–701. doi: 10.1377/hlthaff.2017.1624” doi: 10.1377/hlthaff.2017.1624 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glymour C, Zhang K, Spirtes P (2019). Review of Causal Discovery Methods Based on Graphical Models. Front. Genet 10. doi: 10.3389/fgene.2019.00524” doi: 10.3389/fgene.2019.00524 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gruber F, Keats JJ, McBride K, Runge K, Wuest D, Hadzi T, Derome M, Lonial S, Khalil I, Hayete B, Auclair D (2016). Bayesian Network Models of Multiple Myeloma: Drivers of High Risk and Durable Response. Blood 128, 4406–4406. doi: 10.1182/blood.V128.22.4406.4406 [DOI] [Google Scholar]
- Hartnett K (2018). To Build Truly Intelligent Machines, Teach Them Cause and Effect. Quanta Magazine https://www.quantamagazine.org/to-build-truly-intelligent-machines-teach-them-cause-and-effect-20180515“ https://www.quantamagazine.org/to-build-truly-intelligent-machines-teach-them-cause-and-effect-20180515
- Hernán MA, Robins JM (2006). Estimating causal effects from epidemiological data. Journal of Epidemiology & Community Health 60, 578–586. doi: 10.1136/jech.2004.029496 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hui D, Glitza I, Chisholm G, Yennu S and Bruera E (2013). Attrition rates, reasons, and predictive factors in supportive care and palliative oncology clinical trials. Cancer, 119(5), pp.1098–1105. doi: 10.1002/cncr.27854 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kirk R (2012). Genetics: Personalized medicine and tumour heterogeneity. Nature Reviews Clinical Oncology, 9(5), 250. doi: 10.1038/nrclinonc.2012.46” doi: 10.1038/nrclinonc.2012.46 [DOI] [PubMed] [Google Scholar]
- Laganà A, Perumal D, Melnekoff D, Readhead B, Kidd BA, Leshchenko V, Kuo P-Y, Keats J, DeRome M, Yesil J, Auclair D, Lonial S, Chari A, Cho HJ, Barlogie B, Jagannath S, Dudley JT, Parekh S (2018). Integrative network analysis identifies novel drivers of pathogenesis and progression in newly diagnosed multiple myeloma. Leukemia 32, 120–130. doi: 10.1038/leu.2017.197” doi: 10.1038/leu.2017.197 [DOI] [PubMed] [Google Scholar]
- Liu Y, Yu H, Yoo S, Lee E, Laganà A, Parekh S, Schadt EE, Wang L, Zhu J (2019). A Network Analysis of Multiple Myeloma Related Gene Signatures. Cancers 11, 1452. doi: 10.3390/cancers11101452 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Manolis E, Rohou S, Hemmings R, Salmonson T, Karlsson M, & Milligan PA (2013). The role of modeling and simulation in development and registration of medicinal products: Output from the efpia/ema modeling and simulation workshop. CPT: Pharmacometrics and Systems Pharmacology, 2(2). doi: 10.1038/psp.2013.7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Monteiro C, Bruezière L, Laheux S, Hommel M, Radreau P, Roy E, Darteil R, André P, Boissel J, Vonderscher J, & Scalfaro P (n.d.). An in silico disease model for the development of FXR agonist EYP001 as a therapy for HBV infection 1, 69009. [Google Scholar]
- Morrison T (2018). How simulation can transform regulatory pathways. In Food and Drug Administration (p. https://www.fda.gov/science-research/about-science“ https://www.fda.gov/science-research/about-science).
- Navarro FCP, Mohsen H, Yan C, Li S, Gu M, Meyerson W, & Gerstein M (2019). Genomics and data science: An application within an umbrella. Genome Biology, 20(1), 1–11. doi: 10.1186/s13059-019-1724-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nelson JR, and Cross S (2019). Health Quest Sets out to Boost Participation in Clinical Trials with IBM Watson: Use of IBM Watson for Clinical Trial Matching Expands Health Quest ‘ s Use of AI https://newsroom.ibm.com/2019-03-21-Health-Quest-Sets-out-to-Boost-Participation-in-Clinical-Trials-with-IBM-Watson
- Ouzounoglou E, Kolokotroni E, Stanulla M, & Stamatakos GS (2018). A study on the predictability of acute lymphoblastic leukaemia response to treatment using a hybrid oncosimulator. Interface Focus, 8(1). doi: 10.1098/rsfs.2016.0163 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Properzi F, Taylor K, Cruz M, Ronte H, & Haughey J (2020). Intelligent clinical trials 34. https://www2.deloitte.com/content/dam/insights/us/articles/22934_intelligent-clinical-trials/DI_Intelligent-clinical-trials.pdf
- Schmidt BJ, Casey FP, Paterson T, & Chan JR (2013). Alternate virtual populations elucidate the type I interferon signature predictive of the response to rituximab in rheumatoid arthritis. BMC Bioinformatics, 14(1). doi: 10.1186/1471-2105-14-221 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sgaier BSK, Huang V, & Charles G (2020). The Case for Causal AI. Stanford Social Innovation Review, Summer, 50–56. https://ssir.org/articles/entry/the_case_for_causal_ai#
- Stein AS, Watson D, Kapoor S, Ghosh Roy KG, Alam A, Sahu D, Basu K, Prakash A, Ullal Y, Raju KS, Suseela RP, Joseph V, Basu S, Kumar C, Mohapatra S, Kumari P, Birajdar S, Gopi R, Mitra U, & Marcucci G (2020). Superior therapy response predictions for patients with myelodysplastic syndrome (MDS) using Cellworks Singula: MyCare-009–02. Journal of Clinical Oncology, 38(15_suppl), e19528–e19528. doi: 10.1200/jco.2020.38.15_suppl.e19528 [DOI] [Google Scholar]
- Thomas DW, Burns J, Audette J, Carroll A, Dow-Hygelund C, & Hay M (2016). Clinical Development Success Rates. BioMedTracker, June(June), 22. https://www.bio.org/sites/default/files/Clinical Development Success Rates 2006-2015 - BIO, Biomedtracker, Amplion 2016.pdf
- Thorlund K, Dron L, Park JJH, & Mills EJ (2020). Synthetic and external controls in clinical trials – A primer for researchers. Clinical Epidemiology, 12, 457–467. doi: 10.2147/CLEP.S242097 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tronci E (n.d.). IN SILICO CLINICAL TRIALS Moving from In Vivo ….
- Unger JM, Vaidya R, Hershman DL, Minasian LM, & Fleury ME (2019). Systematic review and meta-analysis of the magnitude of structural, clinical, and physician and patient barriers to cancer clinical trial participation. Journal of the National Cancer Institute, 111(3), 245–255. doi: 10.1093/jnci/djy221 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vanderman K, Stine A, & Chang S (2020). Abstract A17: Predictions of comparative clinical outcomes for checkpoint inhibitor combo therapies and mechanistic targets in first-line NSCLC. Cancer Immunology Research, 8, 2–5. doi: 10.1158/2326-6074.TUMIMM18-A1731909728 [DOI] [Google Scholar]
- Viceconti M, Henney A and Morley-Fletcher E (2016). In silico clinical trials: how computer simulation will transform the biomedical industry. International Journal of Clinical Trials, 3(2), pp.37–46. 10.18203/2349-3259.ijct20161408 [DOI] [Google Scholar]
- Wheeler DA & Wang L (2013). From human genome to cancer genome: The first decade. Genome Research, 23(7), 1054. doi: 10.1101/gr.157602.113 [DOI] [PMC free article] [PubMed] [Google Scholar]