

Summary
Reinforcement learning models of the basal ganglia map the phasic dopamine signal to reward prediction errors (RPEs). Conventional models assert that, when a stimulus predicts a reward with fixed delay, dopamine activity during the delay should converge to baseline through learning. However, recent studies have found that dopamine ramps up before reward in certain conditions even after learning, thus challenging the conventional models. In this work, we show that sensory feedback causes an unbiased learner to produce RPE ramps. Our model predicts that, when feedback gradually decreases during a trial, dopamine activity should resemble a ‘bump,’ whose ramp-up phase should furthermore be greater than that of conditions where the feedback stays high. We trained mice on a virtual navigation task with varying brightness, and both predictions were empirically observed. In sum, our theoretical and experimental results reconcile the seemingly conflicting data on dopamine behaviors under the RPE hypothesis.
Keywords: dopamine, ramps, bumps, reinforcement learning, reward prediction error, state value, state uncertainty, sensory feedback
eTOC Blurb
Dopamine serves as a ‘reward prediction error’ (RPE) that facilitates learning. Mikhael et al. argue that, in the presence of sensory feedback, an unbiased learner will produce RPE ramps. This view predicts a previously unobserved dopamine behavior, a dopamine ‘bump,’ which is empirically validated using a virtual reality task in mice.
Introduction
Perhaps the most successful convergence of reinforcement learning theory with neuroscience has been the insight that the phasic activity of midbrain dopamine (DA) neurons tracks ‘reward prediction errors’ (RPEs), or the difference between received and expected reward 1–3. In reinforcement learning algorithms, RPEs serve as teaching signals that update an agent’s estimate of rewards until those rewards are well-predicted. In a seminal experiment, Schultz et al. 1 recorded from midbrain DA neurons in primates and found that the neurons responded with a burst of activity when an unexpected reward was delivered. However, if a reward-predicting cue was available, the DA neurons eventually stopped responding to the (now expected) reward and instead began to respond to the cue, much like an RPE (Results). This finding formed the basis for the RPE hypothesis of DA.
Over the past two decades, a large and compelling body of work has supported the view that phasic DA functions as a teaching signal 1,3–6. In particular, phasic DA activity has been shown to track the RPE term of temporal difference (TD) learning models, which we review below, remarkably well 2. However, recent results have called this model of DA into question. Using fast-scan cyclic voltammetry in rat striatum during a goal-directed spatial navigation task, Howe et al. 7 observed a ramping phenomenon—a steady increase in DA over the course of a single trial—that persisted even after extensive training. Since then, DA ramping has been observed during a two-armed bandit task 8, during the execution of self-initiated action sequences 9, and in the timing of movement initiation 10. At first glance, these findings appear to contradict the RPE hypothesis of DA. Indeed, why would error signals persist (and ramp) after a task has been well-learned? Perhaps, then, instead of reporting an RPE, DA should be reinterpreted as reflecting the value of the animal’s current state, such as its position during reward approach 8. Alternatively, perhaps DA signals different quantities in different tasks, e.g., value in operant tasks, in which the animal must act to receive reward, and RPE in classical conditioning tasks, in which the animal need not act to receive reward.
To distinguish among these possibilities, we recently devised an experimental paradigm that dissociates the value and RPE interpretations of DA 11. We began with the insight that, in the experiments considered above, RPEs can be approximated as the derivative of value under the TD learning framework (Gershman 12; STAR Methods). This implies that, to effectively arbitrate between the value and RPE interpretations, one only need devise experiments where value and its derivative are expected to behave very differently. Indeed, by training mice on a virtual reality environment and manipulating various properties of the task—namely, the speed of scene movement and the presence of forward teleportations and temporary pauses—we could make precise predictions about how value should change vs. how its derivative (RPE) should change. We found that the changes in DA behaviors were consistent with the RPE hypothesis and not with the value interpretation. The virtual reality task further allowed us to dissociate spatial navigation from locomotion (running), as one view of ramps had been that they are specific to operant tasks, and that DA conveys qualitatively different information in operant vs. classical conditioning tasks. However, we found that mice continued to display ramping DA signals during the task even without locomotion (i.e., when the mice did not run for reward). We confirmed these key results at the levels of somatic spiking of DA neurons, axonal calcium signals, and DA concentrations at neuronal terminals in striatum. Taken together, these findings strongly support the RPE hypothesis of DA.
The body of experimental studies outlined above produces a number of unanswered questions regarding the function of DA: First, why would an error signal persist once an association is well-learned? Second, why would it ramp over the duration of the trial? Third, why would this ramp occur in some tasks but not others? Does value (and thus RPE) take different functional forms in different tasks, and if so, what determines which forms result in a ramp and which do not? Here we address these questions from normative principles.
We begin this work by examining the influence of sensory feedback in guiding value estimation. Because of irreducible temporal uncertainty, animals not receiving sensory feedback (and therefore relying only on internal timekeeping mechanisms) will have corrupted value estimates regardless of how well a task is learned. In this case, value functions will be ‘blurred’ in proportion to the uncertainty at each point. Sensory feedback, however, reduces this blurring as each new timepoint is approached. Beginning with the normative principle that animals seek to best learn the value of each state, we show that unbiased learning, in the presence of feedback, requires RPEs that ramp. These ramps scale with the informativeness of the feedback (i.e., the reduction in uncertainty), and at the extreme, absence of feedback leads to flat RPEs. Thus we show that differences in a task’s feedback profile explain the puzzling collection of DA behaviors described above. To experimentally verify our hypothesis, we trained mice on a virtual navigation task in which the brightness of the virtual track was varied. As predicted by our framework, when the scene was darkened over the course of the trial (putatively decreasing the sensory feedback), DA exhibited a ‘bump,’ or a ramp-up followed by a ramp-down. Furthermore, the magnitude of signals during the ramp-up phase was globally greater than that of the corresponding ramp in conditions when the scene brightness remained high, as predicted by the theory.
We will begin the next section with a review of the TD learning algorithm, then examine the effect of state uncertainty on value learning. We will then show how, by reducing state uncertainty without biasing learning, sensory feedback causes the RPE to reproduce the experimentally observed behaviors of DA. Finally, we will specifically control the sensory feedback by manipulating the brightness of the track in a virtual navigation task, thereby uncovering DA bumps.
Results
Temporal difference learning
In TD learning, an agent transitions through a sequence of states according to a Markov process 13. The value associated with each state is defined as the expected discounted future return:
| (1) |
where t denotes time and indexes states, rt denotes the reward delivered at time t, and γ ∈ (0,1) is a discount factor. In the experiments we will examine, a single reward is presented at the end of each trial. For these cases, Equation (1) can be written simply as:
| (2) |
for all t ∈ [0,T], where r is the magnitude of reward delivered at time T. In words, value increases exponentially as reward time T is approached, peaking at a value of r at T (Figure 1D,F). Additionally, note that exponential functions are convex; the convex shape of the value function will be important in subsequent sections (see Kim et al. 11 for an experimental test of this property).
Figure 1: Sensory feedback biases value learning.
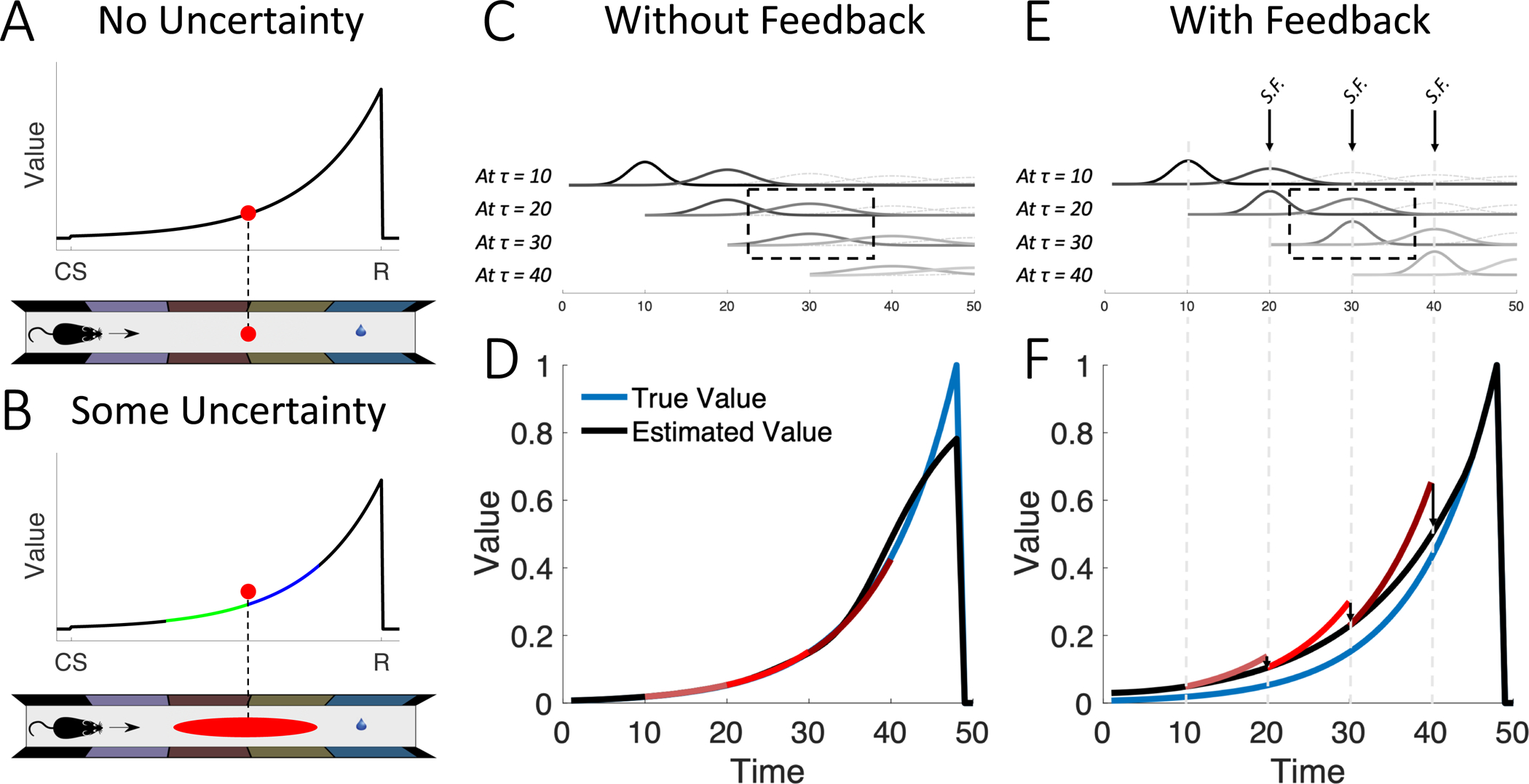
(A) In the absence of state uncertainty, each state (red dot on maze) is mapped to its value (red dot on value function). (B) On the other hand, when some state uncertainty is present (red ellipse on maze), the animal overestimates the value (red dot above value function). This is because convex functions are shallower to the left (green) and steeper to the right (blue), and the estimated value is a weighted average of the points on the green and blue segments. (C) Illustration of state uncertainty in the absence of sensory feedback. Each row includes the uncertainty kernels at the current state and the next state (solid curves). Lighter gray curves represent uncertainty kernels for later states. Thus, similarly colored kernels on different rows represent uncertainty kernels for the same state, but evaluated at different timepoints (e.g., dashed box). In the absence of feedback, state uncertainty for a single state does not acutely change across time (compare with E). (D) Without feedback, value is unbiased on average. Red curves illustrate the overestimated predicted increase in value between the current state and the next state (red curves; three examples extending over 10 states each for illustration only, as all 50 states are experienced on every trial). After learning, this roughly equals an increase by γ−1 on average. (E) Sensory feedback reduces state uncertainty. Three instances of partial feedback (incomplete reduction in kernel widths) are shown for illustration (S.F.; arrows). Note here that the kernels used to estimate value at the same state have different widths depending on whether they were evaluated before or after feedback. This results in different value estimates being used to compute the RPE at the current state and at the next state (Equations (8) and (9)). (F) As a result of sensory feedback, value at each state will be estimated based on an inflated version of value at the next state. Hence, after learning (when RPE is zero on average), estimated value will be systematically larger than true value. Red curves illustrate the overestimated value prediction. After learning, this roughly equals an increase by γ−1 on average. The illustration corresponds to a near-complete reduction in state uncertainty (lower kernel in the dashed box with near-zero width). See STAR Methods for simulation details.
How does the agent learn this value function? Under the Markov property, the value at any time t, defined in Equation (1), can be rewritten as a sum of the reward received at t and the discounted value at the next time step:
| (3) |
which is referred to as the Bellman equation 14. In words, value at time t is the sum of rewards received at t and the promise of future rewards. To learn Vt, the agent approximates it with , which is updated in the event of a mismatch between the estimated value and the reward actually received. By analogy with Equation (3), this mismatch (the RPE) can be written as:
| (4) |
When δt is zero, Equation (3) has been well-approximated. However, when δt is positive or negative, must be increased or decreased, respectively:
| (5) |
where α ∈ (0, 1) denotes the learning rate, and the superscript denotes the learning step. Learning will progress until δt = 0 on average. After this point, on average, which is precisely the true value. (See the STAR Methods for a more general description of TD learning and its neural implementation.)
Model overview
Having described TD learning in the simplified case where the agent has a perfect internal clock and thus no state uncertainty, let us now examine how state uncertainty and sensory feedback affect learning. Our extension of the TD model to account for this case will involve three key ingredients:
First, state uncertainty results in value overestimation. Intuitively, uncertainty about the state results in uncertainty about the value. However, the convexity of the value function creates a bias, as early portions of the function are shallower than later portions (Figure 1A,B). This overestimation is greater with (a) greater uncertainty, and (b) proximity to reward.
Second, sensory feedback that reduces this uncertainty biases learning. According to the TD algorithm, the agent takes a difference between two value estimates, one of the current state and another of the next state (Equation (4)). If the agent systematically receives new information (in the form of sensory feedback) to reduce the uncertainty about the next state upon transitioning to it, then the learned value will be systematically biased.
Third, the agent can correct this bias in the estimated value. In the TD algorithm, this can be written as a decay term that depends on the reduction in uncertainty due to sensory feedback, and results in a persistent, positive RPE. This RPE is greater with (a) a greater reduction in uncertainty, and (b) proximity to reward. In other words, the RPE ramps. For the special case of tasks without feedback, the correction is null and no ramps are observed.
Value learning under state uncertainty
Because animals do not have perfect internal clocks, they do not have complete access to the true time t 15–17. Instead, t is a latent state corrupted by timing noise, often modeled as follows:
| (6) |
where τ is subjective time, drawn from a distribution centered on objective time t, with some standard deviation σt. We take this distribution to be Gaussian for simplicity (an assumption we relax in the STAR Methods). Thus the subjective estimate of value is an average over the estimated values of each state t:
| (7) |
where p (t | τ) denotes the probability that t is the true state given the subjective measurement τ, and thus represents state uncertainty. We refer to this quantity as the uncertainty kernel (Figure 1C,E). Intuitively, is the result of blurring proportionally to the uncertainty kernel (STAR Methods).
After learning (i.e., when the RPE is zero on average), the estimated value at every state will be roughly the estimated value at the next state, discounted by γ, on average (black curve in Figure 1D). A key requirement for this unbiased learning can be discovered by writing the RPE equations for two successive states:
| (8) |
| (9) |
Notice here that is represented in both equations. In other words, must be computed at two separate timepoints: at τ (where it represents the value of the next state) and at τ + 1 (where it represents the value of the new, current state). The TD equations, in their standard form, require that remain the same regardless of when it is computed, to achieve unbiased value-learning. Said differently, for value to be well-learned, a requirement is that not acutely change during the interval after computing δτ and before computing δτ+1. This requirement extends to changes in the uncertainty kernels: By Equation (7), if the kernel p (t | τ + 1) were to be acutely updated due to information available at τ + 1 but not at τ, then will acutely change as well. This means that will be discounted based on before feedback (i.e., as estimated at τ; red curves in Figure 1F) rather than after feedback (i.e., as estimated at τ + 1; black curve). In the next section, we will examine this effect more precisely, and we will show that any such acute change (here, due to sensory feedback) will cause an unbiased agent to produce ramping RPEs.
Value learning in the presence of sensory feedback
How is value learning affected by sensory feedback? As each time τ is approached, state uncertainty is reduced due to sensory feedback (arrows in Figure 1E). This is because at timepoints preceding τ, the estimate of what the value will be at τ is corrupted by both temporal noise and the lower-resolution stimuli associated with τ. Approaching τ in the presence of sensory feedback reduces this corruption. This, however, means that will be estimated differently while computing δτ and δτ+1 (Equations (8) and (9); compare widths of similarly shaded kernels beneath each arrow in Figure 1E)—a violation of the requirement mentioned above, which in turn results in biased value learning.
To examine the nature of this bias, we note that averaging over a convex value function results in overestimation of value (Figure 1A,B). Intuitively, convex functions are steeper on the right (larger values; blue segment in Figure 1B) and shallower on the left (smaller values; green segment in Figure 1B), so averaging results in a bias toward larger values. Furthermore, wider kernels result in greater overestimation (STAR Methods). Thus upon entering each new state, the reduction of uncertainty via sensory feedback will acutely mitigate this overestimation, resulting in different estimates being used for δτ and δτ+1. Left uncorrected, the value estimate will be systematically biased, and in particular, value will be overestimated at every point (Figure 2A; STAR Methods). An intuitive way to see this is as follows: The objective of the TD algorithm (in this simplified task setting) is for the value at each state τ to be γ times smaller than the value at τ + 1 by the time the RPE converges to zero (Equation (2)). If an animal systematically overestimates value at the next state, then it will overestimate value at the current state as well (even if sensory feedback subsequently diminishes the next state’s overestimation). Thus the ‘wrong’ value function is learned (Figure 2A,B).
Figure 2: Unbiased learning in the presence of feedback leads to RPE ramps.

(A) In a hypothetical task with sensory feedback but in which correction does not occur, value at each state is learned according to an overestimated version of value at the next state. Thus, a biased (suboptimal) value function is learned (see Figure 1F). (B) After learning, the RPE converges to zero. (C) With a correction term, the correct value function is learned instead. (D) The cost of forcing an unbiased learning of value is a persistent RPE. Intuitively, value at the current state is not influenced by the overestimated version of value at the next state (compare with A,B). By Equation (13), this results in RPEs that ramp. See STAR Methods for simulation details.
To overcome this bias, an optimal agent must correct the just-computed RPE as sensory feedback becomes available. In the STAR Methods, we show that this correction can simply be written as:
| (10) |
| (11) |
where the approximate equality holds for sufficient reductions in state uncertainty due to feedback, and
| (12) |
Here, the uncertainty kernel of has some standard deviation l at τ and a smaller standard deviation s at τ + 1. In words, as the animal gains an improved estimate of , it corrects the previously computed δτ with a feedback term to ensure unbiased learning of value (Figure 2C). Notice here that the correction term is a function of the reduction in variance (l2 − s2) due to sensory feedback. In the absence of feedback, the reduction in variance is zero (the uncertainty kernel for τ + 1 cannot be reduced during the transition from τ to τ + 1), which means β = 0.
How does this correction affect the RPE? With enough learning, the RPE converges when the estimated value no longer changes on average, i.e.,. By Equation (10), the RPE will therefore converge to:
| (13) |
Therefore, with sensory feedback, the RPE ramps and tracks in shape (Figure 2D). In the absence of feedback, β = 0; thus, there is no ramp. Note here that the RPE is not a function of the learning rate α, as β itself is directly proportional to α (Equation (12)).
In summary, when feedback is provided with new states, value learning becomes miscalibrated, as each value point will be learned according to an overestimated version of the next (Figure 2A). With a subsequent correction of this bias, the agent will continue to overestimate the RPEs at each point (RPEs will ramp; Figure 2D), in exchange for learning the correct value function (Figure 2C).
Relationship with experimental data
In classical conditioning tasks without sensory feedback, DA ramping is not observed 1,6,18–25 (Figure 3A). On the other hand, in goal-directed navigation tasks, characterized by sensory feedback in the form of salient visual cues as well as locomotive cues (e.g., joint movement), DA ramping is present 7 (Figure 3C). DA ramping is also present in classical conditioning tasks that do not involve locomotion but that include either spatial or non-spatial feedback 11, as well as in two-armed bandit tasks 8, in the timing of movement initiation 10, and when executing self-initiated action sequences 9,26.
Figure 3: Differences in feedback result in different RPE behaviors.

(A) Schultz et al. 1 have found that after learning, phasic DA responses to a predicted reward (R) diminish, and instead begin to appear at the earliest reward-predicting cue (conditioned stimulus; CS). Figure from Schultz et al. 1. (B) Our derivations recapitulate this result. In the absence of sensory feedback, RPEs converge to zero. Note here the absence of an RPE at reward time in the experimental data. This is predicted by the model because the CS-R duration is very small (under 1.5 seconds) in the experimental paradigm, so temporal uncertainty is also small. Longer durations are predicted to result in an irreducible RPE response, as has been experimentally observed 18, a point we return to in the Discussion. (C) Howe et al. 7 have found that the DA signal ramps during a well-learned navigation task over the course of a single trial. Figure from Howe et al. 7. (D) Our derivations recapitulate this result. In the presence of sensory feedback, RPEs track the shape of the estimated value function. See STAR Methods for simulation details.
As described in the previous section, sensory feedback—due to external cues or to the animal’s own movement—can reconcile both types of DA behaviors with the RPE hypothesis: In the absence of feedback, there is no reduction in state uncertainty upon entering each new state (β = 0), and therefore no ramps (Equation (13); Figure 3B). On the other hand, when state uncertainty is reduced as each state is entered, ramps will occur (Figure 3D). Intuitively, information received after an RPE has already been computed (and hence, after a DA response has already occurred) biases the learning of value. To offset this bias, the RPE converges to be non-zero at the equilibrium state (when value is well-learned). Furthermore, because of the convexity of the value function, this non-zero RPE must increase as the reward is approached.
In a direct test of the competing views of DA, we recently devised a series of experiments to disentangle the value and RPE interpretations (Figure 4, top panels) 11. We trained mice on a virtual reality paradigm, in which the animals experience virtual spatial navigation toward a reward. Visual stimuli on the (virtual) walls on either side of the path afforded the animals information about their location at any given moment. We then introduced a number of experimental manipulations—changing the speed of virtual motion, introducing a forward ‘teleportation’ at various start and end points along the path, and pausing the navigation for 5 seconds before resuming virtual motion. We showed that the value interpretation of DA made starkly different predictions from the RPE hypothesis, and then demonstrated that DA behavior was consistent with RPEs and not values.
Figure 4: RPE behaviors match DA responses under various task manipulations.

We trained head-fixed mice on a visual virtual reality task, in which they virtually navigated a scene with a reward at the end 11. We then manipulated various aspects of the task. (A) When the mice were teleported from different locations to the same end point, a large DA response resulted, and scaled with the size of the teleport. When the navigation was paused for 5 seconds, the DA response dropped to baseline, with a large response occurring upon resuming navigation. (B) Our derivations recapitulate this result. With an instantaneous jump toward the reward, the RPE is very large, and increases with larger jumps. During a pause, the RPE drops to zero, but rapidly increases when navigation resumes. (C) When the mice were teleported from different locations but with the same magnitude, large DA responses resulted, and increased in size closer to the reward. (D) Our derivations recapitulate this result. Because of the convexity of the value function, an instantaneous teleportation of fixed magnitude will result in a larger RPE when it occurs closer to the reward. (E) When the scene was navigated through more quickly, the ramp was steeper. (F) Our derivations recapitulate this result. Faster navigation results in denser visual feedback per timepoint, i.e., the uncertainty kernels, defined by visual landmarks, become tighter with respect to true time. By Equations (12) and (13), this results in a greater reduction in uncertainty, and thus a steeper ramp. Panels (A,C,E) from Kim et al. 11. See STAR Methods for simulation details.
To show this difference, we noted that RPEs can be approximated as the derivative of value (Equation (4), where rt = 0 leading up to reward time, and γ is close to 1; note that this view ignores any contribution of state uncertainty). We then assumed that value is ‘sufficiently convex’ (STAR Methods), in order to produce a derivative that increases monotonically. The task, then, was to simply examine the expected effect of each experimental manipulation on value vs. its derivative.
This view is limited in a number of ways. Perhaps most importantly, the presented model—that RPEs are the approximate derivative of value—fails to capture the recursive effect of RPEs on value: Not only does a value estimate generate an RPE, but the RPE also modifies the value estimate. If RPEs ramp, then they are always positive. But how, then, can the agent settle on a single value estimate, if the RPE is always causing the estimate to increase? A second limitation of this model is that it had to assume a sufficiently convex value function, in order to achieve a monotonically increasing derivative (and hence a ramping RPE), leaving open the question of where this convexity originates from. Finally, this view cannot accommodate experiments where ramps are not observed. Instead, the model would seemingly predict ramping in all tasks, even though, as amply discussed above, this is not the case (e.g., 1,18). In Figure 4, we show that our uncertainty-based model, which is not subject to these limitations, predicts the entire range of experimental results in Kim et al. 11.
Manipulation of sensory feedback and DA bumps
We have shown that our framework captures an array of DA behaviors. However, the manipulations considered above do not isolate sensory feedback as the key contributor to ramping. We therefore sought to develop an experimental paradigm that can distinguish our uncertainty-based model from the conventional models.
By describing a relationship between sensory feedback and DA ramps, our model predicts that a wide variety of DA responses can be elicited under the appropriate uncertainty profiles. In particular, our model makes an interesting prediction about a third type of behavior that to our knowledge has not been previously observed: If state uncertainty rapidly increases over the course of a trial, then rather than a ramp, DA responses should exhibit a bump (Figure 5D). To see this intuitively, we can examine the RPE behaviors early and late in a trial in which the visual scene is gradually darkened, putatively decreasing the sensory feedback over the course of the trial. Initially, when the brightness is still high, the RPE should behave as in the constant-brightness condition (i.e., ramps). As the scene darkens, wider uncertainty kernels ‘blur’ the convex value function more. Thus the early ramp in the darkening condition will be higher than that of the constant condition. However, later in the trial, as the animal approaches the reward, wider uncertainty kernels serve to flatten the estimated value function (near the maximum value, averaging over a larger window decreases the value estimate). Thus the RPE will begin to decrease. Taken together, this results in an RPE bump that increases early on and decreases later. Furthermore, because of the lack of feedback near the reward time, the flatter estimated value function will result in a larger reward response than in the constant condition.
Figure 5: The state uncertainty model predicts DA responses in the darkening experiments.

(A) Images of the visual scene captured at four different locations. The floor patterns were intact to prevent animals from inferring that the trial was aborted. (B) Experimental design for fiber fluorometry. Adeno-associated virus (AAV) expressing a DA sensor (GRABDA2m) was injected into the ventral striatum (VS). DA signals were monitored through an optical fiber implanted into the VS. (C) Recording locations. A coronal section of the brain at Bregma, 1.10 mm. (D) Model predictions. Note three properties of the DA response in the darkening condition: the DA bump, the greater initial ramp compared to the constant condition, and the stronger reward response compared to the constant condition. Black, constant condition with standard speed; gray, darkening condition with standard speed; red, constant condition with fast speed (x1.7); yellow, darkening condition with fast speed. (E) DA responses. Shaded areas at the bottom depict time windows for the three epochs used in (F,G). (F) Average DA responses in the standard conditions. Three dots connected with lines represent individual animals (n = 11 mice). (G) Average DA responses in the fast conditions (n = 11 mice). Shadings and error bars represent standard errors of the mean. *p < 0.05, ** p < 0.01, ***p < 0.001, t-test. See also Figure S3.
In order to test these predictions explicitly, we dynamically modulated the reliability of sensory evidence by changing the brightness of the visual scene over the course of a single trial (‘darkening’ condition; Figure 5; Figure S3; Video S1). The darkening condition (25% of trials) was randomly interleaved with the constant-brightness condition (75% of trials). We independently interleaved the standard-speed and fast conditions (on 25% of trials, the scene moved 1.7 times faster than the standard-speed condition). Including a small portion of fast conditions appeared to help animals pay attention to the task. We monitored DA activity in the ventral striatum using fiber fluorometry (Figure 5B,C). Note that animals showed anticipatory licking in the darkening conditions (Figure S3B), suggesting that the animals did not think the trials were aborted.
As predicted, our manipulations of scene brightness—putatively manipulations of the sensory feedback—caused a DA bump, a signal that increases early on and decreases later (Figure 5E, gray and yellow curves). When the scene moved at standard speed, DA activity modestly ramped up in the constant condition (Figure 5F, left), whereas DA activity displayed a bump in the darkening condition (Figure 5F, right). The average responses in the middle epoch were significantly greater than those of either the start or end epoch (p < 0.01, t-test, n = 11 mice). Ramping in the constant condition became more evident when the scene moved fast (Figure 5G, left). Nevertheless, we still observed a bump in the middle when the visual scene was darkened (Figure 5G, right). Furthermore, because of the lack of feedback near the reward time, our model predicts that the flatter estimated value function will result in a larger (phasic) response to the reward, compared to the constant condition, for both the standard and fast conditions, as indeed observed (Figure S3C, left and right, respectively; p < 0.01, t-test, n = 11 mice).
Discussion
While a large body of work has established phasic DA as an error signal 1,3–6, more recent work has questioned this view 7–9,26. Indeed, in light of persistent DA ramps occurring in certain tasks even after extensive learning, some authors have proposed that DA may instead communicate value itself in these tasks 8. However, the determinants of DA ramps have remained unclear: Ramps are observed during goal-directed navigation, in which animals must run to receive reward (operant tasks 7), but can also be elicited in virtual reality tasks in which animals do not need to run for reward (classical conditioning tasks 11). Within classical conditioning, DA ramps can occur in the presence of navigational or non-navigational stimuli indicating time to reward 11. Within operant tasks, ramps can be observed in the period preceding the action 27 as well as during the action itself 7. These ramps are furthermore not specific to experimental techniques and measurements, and can be observed in cell body activities, axonal calcium signals, and in the DA concentrations 11.
We have shown in this work that, under the RPE hypothesis of DA, sensory feedback may control the different observed DA behaviors: In the presence of persistent sensory feedback, RPEs track the estimated value in shape (ramps), but they remain flat in the absence of feedback (no ramps). Thus DA ramps and phasic responses follow from common computational principles and may be generated by common neurobiological mechanisms. Moreover, a curious lemma of this result is that a measured DA signal whose shape tracks with estimated value need not be evidence against the RPE hypothesis of DA, contrary to some claims 8,28: Indeed, in the presence of persistent sensory feedback, δτ and have the same shape. Thus, our derivation is conceptually compatible with the value interpretation of DA under certain circumstances, but importantly, this derivation captures the experimental findings in other circumstances in which the value interpretation fails (see below for further discussion).
Our model implies that a variety of peculiar DA responses can be attained under the appropriate sensory feedback profiles. In particular, knowing that value increases monotonically over the course of a trial, our results imply that a rapidly decreasing sensory feedback profile will result in a previously unobserved DA bump. By testing animals on conditions in which the visual scenes gradually darkened over the course of a single trial, we found exactly this result: a DA response that ramps up early on and ramps down later.
Our work takes inspiration from previous studies that examined the role of state uncertainty in DA responses 18,29–34. For instance, temporal uncertainty increases with longer durations 15–17. This means that in a classical conditioning task, DA bursts at reward time will not be completely diminished, and will be larger for longer durations, as Kobayashi and Schultz 18 and Fiorillo et al. 30 have observed. Similarly, Starkweather et al. 33 have found that in tasks with uncertainty both in whether reward will be delivered as well as when it is delivered, DA exhibits a prolonged dip (i.e., a negative ramp) leading up to reward delivery. Here, value initially increases as expected reward time is approached, but then begins to slowly decrease as the probability of reward delivery during the present trial becomes less and less likely, resulting in persistently negative prediction errors (see also 25,35). As the authors of these studies note, both results are fully predicted by the RPE hypothesis of DA. Hence, state uncertainty, due to noise either in the internal circuitry or in the external environment, is reflected in the DA signal.
Alternative hypotheses
One might argue that state uncertainty is not necessary to explain the results in the darkening experiments. To address this issue, we considered the possibilities that the DA responses can be explained either by the value interpretation of DA or by an RPE hypothesis that does not account for state uncertainty (STAR Methods). Briefly, the non-monotonic behavior of the DA response is incompatible with the value interpretation of DA, as darkening the visual scene should not decrease the value. Indeed, the animals’ lick rates continued to increase in both the constant and darkening conditions (Figure S3). Second, the DA patterns are incompatible with the conventional, uncertainty-independent RPE view. To show this, we recovered the value functions from the putative RPE signals, and found that the value in the darkening condition would have to be globally greater than that in the constant condition. However, under the uncertainty-free RPE hypothesis, value in the darkening condition should either be the same as in the constant condition (value estimates unaffected by brightness) or smaller (if an inability to see the reward at the end of the trial leads to an assumed reward probability that is less than 1). We expand on these points in the STAR Methods.
Finally, we note that our results are based on the assumption that animals maintain the same value function across experimental conditions. Said differently, we have assumed here that animals learn the value function in the constant condition and subsequently apply this previously learned value function to probe trials in which the scene is gradually darkened. It is possible, however, that animals learn a separate value function for the darkening conditions. Because RPEs in our model increase with larger values and decrease with lower feedback, it remains possible that such an alternative model will still capture the observed effects (STAR Methods).
While we have derived RPE ramping from normative principles, it is important to note that a complete correction is not necessary to produce ramping. Furthermore, biases in value learning may also produce ramping. For instance, one earlier proposal by Gershman 12 was that value may take a fixed convex shape in spatial navigation tasks; the mismatch between this shape and the exponential shape in Equation (2) produces a ramp (see STAR Methods for a general derivation of the conditions for a ramp). Morita and Kato 36, on the other hand, posited that value updating involves a decay term, which is qualitatively similar to that in Equation (10), and thus RPE ramping (see also implementations in 37,38). Ramping can similarly be explained by assuming temporal or spatial bias that decreases with approach to the reward, by modulating the temporal discount term during task execution, or by other mechanisms (STAR Methods). In each of these proposals, ramps emerge as a ‘bug’ in the implementation, rather than as an optimal strategy for unbiased learning. These proposals furthermore do not explain the different DA patterns that emerge under different paradigms. Finally, it should be noted that we have not assumed any modality- or task-driven differences in learning (any differences in the shape of the RPE follow solely from the sensory feedback profile), although in principle, different value functions may certainly be learned in different types of tasks (STAR Methods).
Alternative accounts of DA ramping that deviate more significantly from our framework have also been proposed. In particular, Lloyd and Dayan 39 have provided three compelling theoretical accounts of ramping. In the first account, the authors show that within an actor-critic framework, uncertainty in the communicated information between actor and critic regarding the timing of action execution may result in a monotonically increasing RPE leading up to the action. In the second account, ramping modulates gain control for value accumulation within a drift-diffusion model (e.g., by modulating neuronal excitability 40). Under this framework, fluctuations in tonic and phasic DA produce average ramping. The third account extends the average reward rate model of tonic DA proposed by Niv et al. 41. In this extended view, ramping constitutes a ‘quasi-tonic’ signal that reflects discounted vigor. The authors show that the discounted average reward rate follows (1 − γ)V, and hence takes the shape of the value function in TD learning models. Ramps may also result from perceived control, i.e., they may only occur if the animal thinks it can control the outcome of the task. While the Kim et al. 11 virtual reality experiments strongly argue against this possibility, as the head-fixed animals who did not display running behavior during the task still exhibited ramps, it remains possible that these animals adopted some other, unmeasured superstitious behavior, thus resulting in perceived control. Finally, and relatedly, Howe et al. 7 have proposed that ramps may be necessary for sustained motivation in the operant tasks considered. Indeed, the notion that DA may serve multiple functions beyond the communication of RPEs is well-motivated and deeply ingrained 42–46. Our work does not necessarily invalidate these alternative interpretations, but rather shows how a single RPE interpretation can embrace a range of apparently inconsistent phenomena.
Lingering questions
A number of questions arise from our analysis. First, while our work examines learning with sensory feedback at the normative and algorithmic levels, how this uncertainty-guided update is implemented neurobiologically remains an open question. Our model predicts that RPEs depend on both the reduction in uncertainty and the estimated value. As the latter term develops with exposure to multiple trials, presumably via strengthening of synaptic weights 47,48, so too will the ramps. However, how the signal noise and resulting reduction in uncertainty are encoded, and how they evolve in parallel during the first few trials, remain a subject of active debate 49.
Second, is there any evidence to support the benefits of learning the ‘true’ value function as written in Equation (2) (Figure 2C) over the biased version of value (Figure 2A)? We note here that under the normative account, the agent seeks to learn some value function that maximizes its well-being, whose exact shape has been the subject of much interest (e.g., 50–53). Our key result is that this function—regardless of its exact shape—will not be learned well if feedback is delivered during learning, unless correction ensues. Beyond learning a suboptimal value function, the agent will furthermore be biased across options, as two equally rewarding options will generate different value functions if one was learned with feedback and the other was not (see STAR Methods for a similar case in which this bias is costly). Note also that, while we have chosen the exponential shape in Equation (2) after the conventional TD models, our ramping results extend to any convex value function.
Third, due to the presumed exponential shape, the ramping behaviors resulting from our analysis may also at times look exponential, rather than linear. We nonetheless have chosen to remain close to conventional TD models and purely exponential value functions for ease of comparison with the existing theoretical literature. Perhaps equally important, the relationship between RPE and its neural correlate need only be monotonic and not necessarily equal. In other words, a measured linear signal does not necessarily imply a linear RPE, and a convex neural signal need not communicate convex information. It remains an open question how best to bring abstract TD models into alignment with biophysically realistic assumptions about the signal-generating process.
STAR Methods
Resource availability
Lead contact
Further information and requests for resources and reagents should be directed to and will be fulfilled by the lead contact, John G. Mikhael (john_mikhael@hms.harvard.edu).
Materials availability
This study did not generate new unique reagents.
Data and code availability
Source code for all simulations can be found at www.github.com/jgmikhael/ramping.
Data for Figure 5 and S3 can be found at and https://doi.org/10.6084/m9.figshare.16706788.
Experimental model and subject details
In addition to the fifteen GCaMP mice used in the previous study 11, eleven adult C57/BL6J wild-type male mice were used for the scene darkening experiments using the DA sensor (DA2m). All mice were backcrossed for more than 5 generations with C57/BL6J mice. Animals were singly housed on a 12 hr dark/12 hr light cycle (dark from 07:00 to 19:00). All procedures were performed in accordance with the National Institutes of Health Guide for the Care and Use of Laboratory Animals and approved by the Harvard Animal Care and Use Committee.
Method details
Temporal difference learning and its neural correlates
Under TD learning, each state is determined by task-relevant contextual cues, referred to as features, that predict future rewards. For instance, a state might be determined by a subjective estimate of time or perceived distance from a reward. We model the agent as approximating Vt by taking a linear combination of the features 1,54,55:
| (14) |
where denotes the estimated value at time t, and xd,t denotes the dth feature at t. The learned relevance of each feature xd is reflected in its weight wd, and the weights are updated in the event of a mismatch between the estimated value and the rewards actually received. The update occurs in proportion to each weight’s contribution to the value estimate at t:
| (15) |
where α ∈ (0, 1) denotes the learning rate, and the superscript denotes the learning step. In words, when a feature xd does not contribute to the value estimate at t (xd,t = 0), its weight is not updated. On the other hand, weights corresponding to features that do contribute to will be updated in proportion to their activations at that time. This update rule is referred to as gradient ascent (xd,t is equal to the gradient of with respect to the weight wd), and it implements a form of credit assignment, in which the features most activated at t undergo the greatest modification to their weights.
In this formulation, the basal ganglia implements the TD algorithm termwise: Cortical inputs to striatum encode the features xd,t, corticostriatal synaptic strengths encode the weights wd 47,48, phasic activity of midbrain DA neurons encodes the error signal δt 1,3–6, and the output nuclei of the basal ganglia (substantia nigra pars reticulata and internal globus pallidus) encode estimated value 56. We have implicitly assumed in the Results a maximally flexible feature set, the complete serial compound representation 1,48,57,58, in which every time step following trial onset is represented as a separate feature. In other words, the feature xd,t is 1 when t = d and 0 otherwise. In this case, value at each timepoint is updated independently of the other timepoints, and each has its own weight. It follows that , and we can write Equation (15) directly in terms of , as in Equation (5).
Value learning under state uncertainty
The animal has access to subjective time τ, from which it forms a belief state p(t|τ), or, in Bayesian terms, a posterior distribution over true time. For simplicity, we have taken this distribution to be Gaussian, and we assume weak priors so that temporal estimates, though noisy, are accurate. In this case, the subjective time estimate is and is equal to the posterior mean. Note here that we are only concerned with capturing the noisy property of internal clocks. While a large literature has sought to establish the exact relationship between internal (‘psychological’) time and true time with varying degrees of success (e.g., linear vs. logarithmic relationship 59–63), our work is invariant to this exact relationship, and only depends on animals’ ability to reproduce time veridically on average, with some noise 15–17, which we take here to be Gaussian. Intuitively, animals only have access to subjective time, and compute values and RPEs with respect to subjective time. Because the mapping between subjective and objective time is monotonic, a ramp in subjective time will also be a ramp in objective time.
Given the subjective time τ, the RPE is then:
| (16) |
and this error signal is used to update the value estimates at each point t in proportion to its posterior probability p(t | τ):
| (17) |
Said differently, the effect of state uncertainty is that when the error signal δτ is computed, it updates the value estimate at a number of timepoints, in proportion to the uncertainty kernel 25,64.
Note here that, in the absence of uncertainty, our task structure obeys the Markov property: State transitions and rewards are independent of the animal’s history given its current state. An appeal of using belief states is that the task remains Markovian, but in the posterior distributions rather than in the signals, and the TD algorithm can be applied directly to our learning problem, as in Equations (16) and (17). This problem is a type of partially observable Markov decision process 65.
Acute changes in state uncertainty result in biased value learning
Averaging over a convex value function results in overestimation of value. For an exponential value function, we can derive this result analytically in the continuous time domain by computing the convolution of an exponential value function with a Gaussian kernel:
| (18) |
| (19) |
where σt is the standard deviation of the uncertainty kernel at t. The integral is evaluated over the entire temporal interval (i.e., the duration of a trial leading up to reward), but the contribution of distant timepoints is negligible when the Gaussian kernel width is small compared to the total temporal interval. Thus we can evaluate the integral from −∞ to +∞ for analytical convenience, representing points that far precede and far exceed τ relative to the kernel width, respectively:
| (20) |
| (21) |
| (22) |
The second term on the right-hand side is greater than one, so value is overestimated. Intuitively, because the function is steeper on the right side and shallower on the left side, the average will be overestimated. Importantly, however, the estimate will be a multiple of the true value, with a scaling factor that depends on the width of the kernel (second term on right-hand side of Equation (22); note also that while we have assumed a Gaussian distribution, our qualitative results hold for any distribution that results in overestimation of value). Thus, with sensory feedback that modifies the width of the kernel upon transitioning from one state (τ) to the next (τ + 1), there will be a mismatch in the value estimate when computing each RPE. More precisely, at τ, the learning rules are:
| (23) |
| (24) |
| (25) |
| (26) |
Notice that takes different values depending on the state: At τ, the agent computes according to Equation (25), whereas at τ + 1, it computes as:
| (27) |
How does this mismatch affect the learned value estimate? If averaging with kernels of different standard deviations can be written as multiples of true value, then they can be written as multiples of each other. The RPE is then
| (28) |
where we use the comma notation in the subscripts to denote that the two value estimates are evaluated with the same kernel width s, and a is a constant. By analogy with Equations (2) and (4), estimated value converges to . Here, a > 1, so value is systematically overestimated. By the learning rules in Equations (23) to (26), this is because δτ is inflated by
| (29) |
| (30) |
| (31) |
where β is defined in Equation (12).
An optimal agent will use the available sensory feedback to overcome this biased learning. Because averaging with a kernel of width l is simply a multiple of that with width s, it follows that a simple subtraction can achieve this correction (Equations (10) and (11)). Hence, sensory feedback can improve value learning with a correction term. It should be noted that with a complete correction to s as derived above, the bias is fully extinguished. For corrections to intermediate widths between s and l, the bias will be partially corrected but not eliminated. In both cases, because β > 0, ramps will occur.
In extension of the first STAR Methods section, we can posit an implementation of uncertainty kernels in which sensory information is relayed from cortical areas 47,48 and the uncertainty due to Weber’s law is based in fronto-striatal circuitry 66.
RPEs are approximately the derivative of value
Consider the formula for RPEs in Equation (4). In tasks where a single reward is delivered at T, rt = 0 for all t < T (no rewards delivered before T). Because γ ≃ 1, the RPE can be approximated as
| (32) |
which is the slope of the estimated value. To examine the relationship between value and RPEs more precisely, we can extend our analysis to the continuous domain:
| (33) |
| (34) |
| (35) |
| (36) |
where is the time derivative of , and the fifth equality follows from L’Hôpital’s Rule. Here, ln γ has units of inverse time. Because ln γ ≃ 0, RPE is approximately the derivative of value.
Sensory feedback in continuous time
In the complete absence of sensory feedback, σ1 is not constant, but rather increases linearly with time, a phenomenon referred to as scalar variability, a manifestation of Weber’s law in the domain of timing 15–17. In this case, we can write the standard deviation as σt = wt, where w is the Weber fraction, which is constant over the duration of the trial.
Set l = w(τ + Δτ) and s = wτ. Following the steps in the previous section,
| (37) |
Hence, as derived for the discrete case, RPEs are inflated, and value is systematically overestimated. RPE ramps result from sufficiently convex value functions
By Equation (36), the condition for ramping is , i.e., the estimated shape of the value function at any given point, before feedback, must obey
| (38) |
where is the second derivative of with respect to time. For an intuition of this relation, note that when γ ≃ 1, the inequality can be approximated as , which denotes any convex function. The exact inequality, however, has a tighter requirement on : Since for all t, ramping will only be observed if the contribution from (i.e., the convexity) outweighs the quantity (the scaled slope). For example, the function in Equation (2) does not satisfy the strict inequality even though it is convex, and therefore with this choice of , the RPE does not ramp. In other words, to produce an RPE ramp, has to be ‘sufficiently’ convex.
Biased value estimates and reward forfeiture
Let us illustrate here how a biased value function can lead to suboptimal choices. Imagine a two-armed bandit task in which the animal chooses between two options, A and B, yielding rewards rA and rB, respectively, after a fixed delay T.
Assume rA = 1 is learned under conditions with rich sensory feedback, and rB = 1.5 is learned without feedback. Assume, also, that the animal learns according to the TD algorithm without a correction term. Using the simulation parameters for Figure 2A, with a delay of T = 20, it follows that the values at the time of choice are (Figure 2A, black curve at t = 28) and (Figure 2A, approximated as blue curve at t = 28, scaled by rB). After learning, the animal will be more likely to select A. (Furthermore, a greedy animal will asymptotically only select A.) With each selection of A, the animal forfeits an additional of reward potential.
Alternative hypotheses and DA bumps
We have argued in the main text that DA bumps can be captured by an uncertainty-driven view of RPEs but not by the value interpretation or the standard, uncertainty-free RPE hypothesis. To rule out the alternative hypotheses, we begin by deconvolving the DA2m response, yielding a signal that we interpret as either pure value or uncertainty-free RPE.
The deconvolved signal is monotonic in the constant condition but non-monotonic in the darkening condition (Figure S1B). On the other hand, the licking data—putatively reflecting the animal’s estimate of value—increases monotonically in both conditions (Figure S3B, top panel). Taken together, these findings rule out the value interpretation of DA.
Next, we show that this signal is incompatible with an uncertainty-free RPE. To do so, we infer the value from the computed RPE (Figure S1C, using the derivation below). There is one free parameter, γ. We find that value is greater in the darkening condition than in the constant condition, even though under the uncertainty-free RPE hypothesis, it should either be the same (value estimate unaffected by brightness) or smaller (if an inability to see the reward location suggests a probability of receiving reward that is no longer equal to 1). Although γ is a free parameter, this result does not depend on γ, as , so γ simply amplifies or reduces existing differences, but does not reverse them.
To derive value from RPEs and γ, we use the relation:
| (39) |
To show that Equation (39) solves for Vt using Equation (4) leading up to reward (i.e., when rt = 0), we use proof by induction. First, for t = 1,
| (40) |
Thus Equation (39) holds for t = 1. Now assume it holds for t; let us show it also holds for t + 1:
| (41) |
as required.
DA bumps as a consequence of learning
In modeling the darkening manipulation, we have assumed that animals do not learn a separate value function for the probe trials in the darkening condition. We noted, however, that because of the opposite effects of the uncertainty profile and value on the RPE signal, bumps should still be observed when the manipulation occurs during learning (rather than only during performance). We show this analytically here.
Consider a manipulation in which the scene is gradually darkened, transitioning from perfect brightness to complete darkness over the course of a single trial. Using the terminology in the main text, the reduction in standard deviation (l − s) decreases monotonically over the course of the trial (less sensory feedback), eventually reaching zero. But value increases monotonically over the trial, starting at zero. By Equation (13), the RPE reflects a product of and β, which itself depends on (l2 − s2) = (l − s)(l + s). This means that the RPE should be zero at the beginning of the task and the end, but be positive in the middle. Because both V and β are continuous and differentiable, so is their product. Thus we predict that the RPE will gradually increase, reach some maximum, and subsequently decrease back to zero within a single trial (Figure S2).
Alternative causes of ramping
We have argued that ramping follows from normative principles. Here we illustrate that various types of biases (‘bugs’ in the implementation) may also lead to RPE ramps.
1. Ramping due to bias in state estimation
Assume the animal persistently overestimates the amount of time or distance remaining to reach its reward (or, equivalently, that it underestimates the time elapsed or the distance traversed so far), and that this overestimation decreases as the animal approaches the reward. For instance, since the receptive fields of place cells decrease as the animal approaches reward 67, the contribution of place cells immediately behind the approaching animal in its estimate of value may outweigh that from the place cells in front of it. It will simplify our analysis to set T = 0 without loss of generality, and allow time to progress from the negative domain (t < 0) toward T = 0. In the continuous domain and for the simple case of linear overestimation, we can write this as
| (42) |
where η > 1 is our overestimation factor. Therefore, by Equation (36),
| (43) |
which is monotonically increasing. Hence, the RPE should ramp. Equivalently, in the discrete domain,
| (44) |
Here, δt+1 > δt. Hence, the RPE should ramp.
2. Ramping due to state-dependent discounting of estimated value
Assume the animal underestimates by directly decreasing the temporal discount term γ. Then if , with η ∈ (0, 1), we can write in the continuous domain:
| (45) |
which is monotonically increasing. Hence, the RPE should ramp. Equivalently, in the discrete domain, if with η ∈ (0, 1), we can write
| (46) |
and
| (47) |
Here, δt+1 > δt. Hence, the RPE should ramp.
Simulation details
In all simulations, the agent updated its estimate of a value function according to the TD algorithm, implemented by Equations (7), (8), (10), and (12). Task-specific details and choices of parameters are described below.
Impulse response function:
To model experiments involving Ca 2+ and DA2m signals, we used the GCaMP impulse response function obtained in Kim et al. 11, and the DA2m impulse response function was obtained in the same manner, by averaging responses to unexpected reward. These functions were convolved with the computed RPEs to obtain simulated Ca 2+ signals (Figure 4) and DA2m signals (Figures 5D, S1, S2D).
Value learning under state uncertainty (Figure 1):
For our TD learning model, we have chosen γ = 0.9, α = 0.1, n = 50 states, and T = 48. In the absence of feedback, uncertainty kernels are determined by the Weber fraction, set to w = 0.15 68. In the presence of feedback, uncertainty kernels have a standard deviation of l = 3 before feedback and s = 0.1 after feedback. For the purposes of averaging with uncertainty kernels, value peaks at T and remains at its peak value after T, and the standard deviation at the last 4 states in the presence of feedback is fixed to 0.1. Intuitively, the agent expects reward to be delivered, and attributes any lack of reward delivery at τ = T to noise in its timing mechanism (uncertainty kernels have nonzero width) rather than to a reward omission. The agent iterated through all 50 states on every trial (three red curves on figure only to visually illustrate value overestimation). The agent experienced 1000 successive trials.
Value learning in the presence of sensory feedback (Figure 2):
For our TD learning model, we have chosen γ = 0.9, α = 0.1, n = 50 states, and T = 48. The agent experienced 1000 successive trials.
Relationship with experimental data (Figures 3 and 4):
For convolutions over negative RPEs, it is important to account for the low baseline firing rates of DA neurons, i.e., that negative RPEs cannot elicit phasic responses that equal those elicited by positive RPEs of similar magnitude. Thus, following previous experimental 69–71 and theoretical 72–74 work, we account for an asymmetry between positive and negative RPEs in the DA signal. We do so by scaling the RPEs by the maximum change in spiking activity in either the positive or negative direction. After Kim et al. 11, resting state spiking activity is approximately 5 spikes/second, the maximum spiking is 30 spikes/second, and the minimum spiking is 0 spikes/second. Thus one unit of positive RPE influences the DA response times as strongly as one unit of negative RPE.
Figure 3. For our TD learning model, we have chosen γ = 0.98, α = 0.1, and Weber fraction w = 0.15. For the navigation task, kernels have standard deviation l = 3 before feedback and s = 0.1 after feedback. For (B) and (D), we have set n = 10 and 70 states, respectively, between trial start and reward. RPEs were convolved with the GCaMP kernel, as described above, to produce simulated DA behaviors. The agent experienced 2000 successive trials.
Figure 4. For our TD learning model, we have chosen γ = 0.93, α = 0.1, and w = 0.15. The locomotion manipulations in the pause, teleport, and speed conditions all matched those in the experiments of Kim et al. 11. In particular, standard trials had length 7.6s from the CS to reward, and we set 10 states per second in our simulations. The agent was trained on the standard task and subsequently experienced either an unexpected pause, an unexpected teleport, or an unexpected change in navigation speed. In the pause condition, the agent experienced a 5-s pause at the 53 rd state (i.e., after navigating 70% of states between the CS and reward). In the short and long teleport conditions, states 59–62 and 40–62 were omitted, respectively, corresponding to 5% and 30% of states between the CS and reward. In the teleport conditions of equal magnitude, 25 states (30% of states between the CS and reward) were omitted, beginning at state 5, 25, or 45. Kernels have standard deviation l = 1 before feedback and s = 0.5 after feedback for the teleport and pause manipulations. In the speed conditions, the task was experienced at either 20 (fast), 10 (normal), or 5 (slow) states per second. Kernels have standard deviation l = 3 before feedback and s = 1 after feedback for the standard-speed manipulation. Experiencing the trial twice as fast corresponds to the kernels being stretched by a factor of 2, resulting in a greater reduction in uncertainty and a steeper ramp. Intuitively, navigating a track very quickly leads to lower precision about one’s exact location at any given moment. Similarly, experiencing the trial in the slow condition corresponds to a smaller reduction in uncertainty and a shallower ramp. In our simulation, the reduction in uncertainty is sufficiently weak that the shape of the value function dominates the RPE (see black curve in Figure 1D, corresponding to estimated value without feedback). Near reward time, the estimated value function may not be sufficiently convex (and may even be concave) with weak or absent feedback, so the RPE becomes negative. RPEs were convolved with the GCaMP kernel, as described above, to produce simulated DA behaviors. The agent experienced 2000 successive trials.
Manipulation of sensory feedback and DA bumps (Figure 5):
The TD model is identical to that in Figure 4. For both the constant and darkening conditions, we have chosen γ = 0.93, α = 0.1, w = 0.15, and n = 200 states. For the constant condition, the small kernel width is a constant, s = a. For the darkening condition, the width resembles that of the constant condition early on and resembles one without feedback later, (s − a)(s− wt − b) = c. The shape of this function is controlled by two parameters, c and b. The first determines how smoothly s transitions from resembling that of the constant condition to behaving according to Weber’s law, and the second determines when this occurs. The large uncertainty kernel width is l = s + z, where z is a constant in the constant condition, and z decreases smoothly to zero over the course of the trial in the darkening condition, which we model as . We set a = 8, b = 0.3, c = 3, d = 1, and e = 1. Because the reduction in uncertainty (l2 − s2) is constant in the constant condition and decreases in the darkening condition, it follows that β is constant in the constant condition and decreases in the darkening condition, as well. RPEs were convolved with the DA2m kernel, as described above, to produce simulated DA behaviors. The agent experienced 2000 successive trials.
Surgery and virus injections
Surgery for fiber fluorometry of DA sensor signals.
To prepare animals for recording, we performed a single surgery with three key components: (1) injection of a DA sensor into the ventral striatum, (2) head-plate installation, and (3) implantation of an optical fiber into the striatum 24,25. At the time of surgery, all mice were 2–4 months old. All surgeries were performed under aseptic conditions with animals anesthetized with isoflurane (1–2% at 0.5–1.0 L/min). Analgesia (ketoprofen for post-surgery treatment, 5 mg/kg, I.P.; buprenorphine for pre-operative treatment, 0.1 mg/kg, I.P.) was administered for 3 days following each surgery. We removed the skin above the surface of the brain and dried the skull using air. We injected 400 nL of AAV9-hSyn-DA2m (Vigene Biosciences) into the ventral striatum (bregma 1.0, lateral 1.1, depths 4.2 and 4.1 mm). Virus injection lasted several minutes, and then the injection pipette was slowly removed over the course of several minutes.
We then installed a head-plate for head-fixation by gluing a head-plate onto the top of the skull (C&B Metabond, Parkell). We used ring-shaped head-plates to ensure that the skull above the striatum would be accessible for fiber implants. Finally, during the same surgery, we also implanted optical fibers into the ventral striatum. To do this, we first slowly lowered optical fibers (200 μm diameter, Doric Lenses) into the striatum using a fiber holder (SCH_1.25, Doric Lenses). The coordinates we used for targeting were bregma 1.0, lateral 1.1, depth 4.1 mm. Once fibers were lowered, we first attached them to the skull with UV-curing epoxy (Thorlabs, NOA81), and then a layer of black Ortho-Jet dental adhesive (Lang Dental, IL). After waiting for fifteen minutes for this glue to dry, we applied a small amount of rapid-curing epoxy (A00254, Devcon) to attach the fiber cannulas to the underlying glue and head-plate. After waiting for fifteen minutes for the epoxy to cure, the surgery was completed.
Surgery for fiber fluorometry of GCaMP signals in the ventral striatum.
To examine axonal calcium signals of dopaminergic neurons in the ventral striatum, we injected AAV-FLEX-GCaMP into the midbrain of DAT-Cre mice 11. Surgical procedures up to virus injection were the same as the DA sensor injections described above. We unilaterally injected 250 nL of AAV5-CAG-FLEX-GCaMP6m (1 × 1012 particles/mL, Penn Vector Core) into both the ventral tegmental area (VTA) and substantia nigra pars compacta (SNc) (500 nL total). To target the VTA, we made a small craniotomy and injected the virus at bregma 3.1, lateral 0.6, depths 4.4 and 4.1 mm. To target SNc, we injected the virus at bregma 3.3, lateral 1.6, depths 3.8 and 3.6 mm.
Virtual reality setup
Virtual environments were displayed on three liquid crystal display (LCD) monitors with thin frames 11. VirMEn software 75 was used to generate virtual objects and render visual images using perspective projection. Mice were head-restrained at the center of three monitors. Mice were placed on a cylindrical styrofoam treadmill (diameter 20.3 cm, width 10.4 cm). The rotational velocity of the treadmill was encoded using a rotary encoder. The output pulses of the encoder were converted into continuous voltage signals using a customized Arduino program running on a microprocessor (Teensy 3.2). Water reward was given through a water spout located in front of the animal’s mouth. Licking tongue movements were monitored using an infrared sensor (OPB819Z, TT Electronics). Voltage signals from the rotary encoder and the lick sensor were digitized into a PCI-based data-acquisition system (PCIe-6323, National Instruments) installed on the visual stimulation computer. Timing and amount of water were controlled through a micro-solenoid valve (LHDA 1221111H, The Lee Company) and switch (2N7000, On Semiconductor). Analog output TTL pulse was generated from the visual stimulation computer to deliver reward to the animals.
Virtual linear track experiments
Animals were trained in a virtual linear track (see Kim et al. 11 for details). The maze was composed of a starting platform and a corridor with walls on both sides. We first trained animals on the standard approach-to-target task to learn the association between target location and reward. Once the animals learned the task, we ran a series of tasks with test trials to examine the nature of DA signals. In this paper, we simulated three main experiments in the previous study (Figure 4) 11. We typically ran each task for two consecutive days (with a zero- or one-day break). Unless otherwise noted, unexpected reward (5 μL) was given during the inter-trial interval on 3–6% of trials.
Scene darkening manipulation.
We dynamically modulated the reliability of sensory evidence by changing the brightness of the visual scene (Video S1). The brightness of the visual scene at each time point was determined by multiplying the original RGB color values with a time-varying multiplier. The multiplier k (t) is a function of the animal’s position as defined below (Figure S3A).
| (48) |
| (49) |
| (50) |
where kstart = 1.0, kend = 0.05, and P (t) is animal’s position at time t. The brightness of the floor pattern was intact to provide the animals a clue that trials were not aborted. We randomly interleaved four experimental conditions. On 25% of trials, the visual scene was darkened as described above. Brightness was kept constant (k (t) = 1) for the rest of the trials. Independent of the brightness manipulation, the speed of visual scene progression was increased by 1.7 times on 25% of trials. Since the darkening depends on the position of the animal, for each darkening condition, the brightness of the scene at the reward location is identical between the standard and fast conditions.
Fiber fluorometry (photometry)
Fluorescent signals from the brain were recorded using a custom-made fiber fluorometry (photometry) system as described in our previous studies 11,24,25. The blue light (473 nm) from a diode-pumped solid-state laser (DPSSL; 80–500 μW; Opto Engine LLC, UT, USA) was attenuated through a neutral density filter (4.0 optical density, Thorlabs, NJ, USA) and coupled into an optical fiber patchcord (400 μm, Doric Lenses) using a 0.65 NA microscope objective (Olympus). The patchcord connected to the implanted fiber was used to deliver excitation light to the brain and to collect the fluorescence emission signals from the brain. The fluorescent signal from the brain was spectrally separated from the excitation light using a dichroic mirror (T556lpxr, Chroma), passed through a bandpass filter (ET500/50, Chroma), focused onto a photodetector (FDS100, Thorlabs), and amplified using a current preamplifier (SR570, Stanford Research Systems). Acquisition from the red fluorophore (tdTomato) was simultaneously acquired (bandpass filter ET605/70 nm, Chroma) but was not used for further analyses. The voltage signal from the preamplifier was digitized through a data acquisition board (PCI-e6321, National Instruments) at 1 kHz and stored in a computer using a custom software written in LabVIEW (National Instruments).
Histology
Mice were perfused with phosphate buffered saline (PBS) followed by 4% paraformaldehyde in PBS. The brains were cut in 100-μm coronal sections using a vibratome (Leica). Brain sections were loaded on glass slides and stained with DAPI (Vectashield). The locations of fiber and tetrode tips were determined using the standard mouse brain atlas (Franklin and Paxinos, 2008).
Quantification and statistical analysis
Statistical analysis.
We used a t-test to compare between conditions (Figure 5; Figure S1). Kolmogorov-Smirnov test was used to check the normality assumption.
Fluorometry (photometry).
Power line noise in the raw voltage signals was removed by notch filter (MATLAB, Natick, MA, USA). A baseline of the voltage signal was defined by the lowest 10% of signals using a 2-min window. The baseline was subtracted from the raw signal, and the results were z-scored by a session-wide mean and standard deviation.
Licking and locomotion.
Lick timing was defined as deflection points (peaks) of the output signals above a threshold. To plot the time course of licks, instantaneous lick rate was computed by a moving average using a 200-ms window.
Session-averaged time course.
Licks, locomotion speed, and z-scored DA responses for individual trials were aligned by external events (e.g., trial start or teleport onset), and then smoothed using a moving average method. We did not smooth locomotion speed and fluorometry signals. The results were then averaged across trials for each experimental condition to generate a session-averaged time course.
Population-averaged time course.
For calcium recording experiments, we computed the mean of session-averaged time courses from the second session dataset (as the average of all session averages) along with the standard error (the total number of sessions being the sample size) for each experimental condition. Population-average time courses are used to summarize behavior and DA responses.
Quantification for the darkening experiments.
We quantified the z-scored DA sensor responses in the darkening experiment using three time windows (Figure 5E, shaded areas at the bottom). For the standard conditions, we used [0 s 0.4 s] from the trial start, [3.8 s 4.2 s] from the trial start, and [−0.4 s 0 s] from the reward onset. For the fast conditions, we used [0 s 0.4 s] from the trial start, [2.8 s 3.2 s] from the trial start, and [−0.4 s 0 s] from the reward onset.
Supplementary Material
Video S1: Visual stimulus in the standard darkening condition.
KEY RESOURCES TABLE.
| REAGENT or RESOURCE | SOURCE | IDENTIFIER |
|---|---|---|
| Bacterial and virus strains | ||
| AAV9-hSyn-DA2m | Vigene Biosciences | N/A |
| Experimental models: Organisms/strains | ||
| Mouse: C57BL/6J | The Jackson Laboratory | Jax # 000664; RRID: IMSR JAX:000664 |
| Software and algorithms | ||
| VirMEn | Dmitriy Aronov | https://pni.princeton.edu/pni-softwaretools/virmen |
| MATLAB | MathWorks | https://www.mathworks.com/ |
| Other | ||
| Isosol (Isourane, USP) | Vedco | N/A |
| LRS-0473 DPSS Laser System | LaserGlow Technologies | Cat #R471003FX |
| Mono Fiber-optic Cannulas | Doric Lenses | MFC 200/245–0.53 5mm MF1.25 FLT |
Highlights.
Dopamine (DA) ramps have challenged the reward prediction error (RPE) hypothesis
We provide a normative theory on how RPEs can ramp up in a task-dependent manner
Sensory feedback causes RPEs to ramp up over the course of a trial
Gradually weakening sensory feedback caused a DA ‘bump’ as our model predicts
Acknowledgments
The project described was supported by National Institutes of Health grants T32GM007753 and T32MH020017 (JGM), R01 MH110404 and MH095953 (NU), U19 NS113201-01 (SJG and NU), the Air Force Office of Scientific Research grant FA9550-20-1-0413 (SJG and NU), the Simons Collaboration on the Global Brain (NU), and a research fellowship from the Alfred P. Sloan Foundation (SJG). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health or the Simons Collaboration on the Global Brain. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Footnotes
Declaration of interests
The authors declare no competing interests.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- [1].Schultz Wolfram, Dayan Peter, and Montague P Read. A neural substrate of prediction and reward. Science, 275(5306):1593–1599, 1997. [DOI] [PubMed] [Google Scholar]
- [2].Schultz Wolfram. Behavioral dopamine signals. Trends in neurosciences, 30(5):203–210, 2007a. [DOI] [PubMed] [Google Scholar]
- [3].Glimcher Paul W. Understanding dopamine and reinforcement learning: the dopamine reward prediction error hypothesis. Proceedings of the National Academy of Sciences, 108(Supplement 3):15647–15654, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Niv Yael and Schoenbaum Geoffrey. Dialogues on prediction errors. Trends in cognitive sciences, 12(7):265–272, 2008. [DOI] [PubMed] [Google Scholar]
- [5].Steinberg Elizabeth E, Keiflin Ronald, Boivin Josiah R, Witten Ilana B, Deisseroth Karl, and Janak Patricia H. A causal link between prediction errors, dopamine neurons and learning. Nature neuroscience, 16(7):966–973, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Eshel Neir, Bukwich Michael, Rao Vinod, Hemmelder Vivian, Tian Ju, and Uchida Naoshige. Arithmetic and local circuitry underlying dopamine prediction errors. Nature, 525:243–246, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Howe Mark W, Tierney Patrick L, Sandberg Stefan G, Phillips Paul EM, and Graybiel Ann M. Prolonged dopamine signalling in striatum signals proximity and value of distant rewards. Nature, 500(7464):575, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Hamid Arif A, Pettibone Jeffrey R, Mabrouk Omar S, Hetrick Vaughn L, Schmidt Robert, Vander Weele Caitlin M, Kennedy Robert T, Aragona Brandon J, and Berke Joshua D. Mesolimbic dopamine signals the value of work. Nature Neuroscience, 19:117–126, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Collins Anne L, Greenfield Venuz Y, Bye Jeffrey K, Linker Kay E, Wang Alice S, and Wassum Kate M. Dynamic mesolimbic dopamine signaling during action sequence learning and expectation violation. Scientific reports, 6, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Hamilos Allison Elizabeth, Spedicato Giulia, Hong Ye, Sun Fangmiao, Li Yulong, and Assad John Abraham. Dynamic dopaminergic activity controls the timing of self-timed movement. bioRxiv, 2020. [Google Scholar]
- [11].Kim HyungGoo R, Malik Athar N, Mikhael John G, Bech Pol, Tsutsui-Kimura Iku, Sun Fangmiao, Zhang Yajun, Li Yulong, Watabe-Uchida Mitsuko, Gershman Samuel J, et al. A unified framework for dopamine signals across timescales. Cell, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Gershman Samuel J. Dopamine ramps are a consequence of reward prediction errors. Neural computation, 26(3):467–471, 2014. [DOI] [PubMed] [Google Scholar]
- [13].Sutton Richard S. Learning to predict by the methods of temporal differences. Machine learning, 3(1):9–44, 1988. [Google Scholar]
- [14].Bellman R. Dynamic programming. Princeton University Press, 1957. [Google Scholar]
- [15].Gibbon John. Scalar expectancy theory and Weber’s law in animal timing. Psychological review, 84(3):279, 1977. [Google Scholar]
- [16].Church Russell M and Meck W. A concise introduction to scalar timing theory. Functional and neural mechanisms of interval timing, pages 3–22, 2003. [Google Scholar]
- [17].Staddon JER. Some properties of spaced responding in pigeons. Journal of the Experimental Analysis of Behavior, 8(1):19–28, 1965. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Kobayashi Shunsuke and Schultz Wolfram. Influence of reward delays on responses of dopamine neurons. Journal of neuroscience, 28(31):7837–7846, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Stuber Garret D, Klanker Marianne, de Ridder Bram, Bowers M Scott, Joosten Ruud N, Feenstra Matthijs G, and Bonci Antonello. Reward-predictive cues enhance excitatory synaptic strength onto midbrain dopamine neurons. Science, 321(5896):1690–1692, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Flagel Shelly B, Clark Jeremy J, Robinson Terry E, Mayo Leah, Czuj Alayna, Willuhn Ingo, Akers Christina A, Clinton Sarah M, Phillips Paul EM, and Akil Huda. A selective role for dopamine in stimulus–reward learning. Nature, 469(7328):53, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Cohen Jeremiah Y, Haesler Sebastian, Vong Linh, Lowell Bradford B, and Uchida Naoshige. Neuron-type-specific signals for reward and punishment in the ventral tegmental area. Nature, 482(7383):85–88, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Hart Andrew S, Rutledge Robb B, Glimcher Paul W, and Phillips Paul EM. Phasic dopamine release in the rat nucleus accumbens symmetrically encodes a reward prediction error term. Journal of Neuroscience, 34(3):698–704, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Menegas William, Bergan Joseph F, Ogawa Sachie K, Isogai Yoh, Venkataraju Kannan Umadevi, Osten Pavel, Uchida Naoshige, and Watabe-Uchida Mitsuko. Dopamine neurons projecting to the posterior striatum form an anatomically distinct subclass. Elife, 4:e10032, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Menegas William, Babayan Benedicte M, Uchida Naoshige, and Watabe-Uchida Mitsuko. Opposite initialization to novel cues in dopamine signaling in ventral and posterior striatum in mice. Elife, 6:e21886, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Babayan Benedicte M, Uchida Naoshige, and Gershman Samuel J. Belief state representation in the dopamine system. Nature communications, 9(1):1891, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Wassum Kate M, Ostlund Sean B, and Maidment Nigel T. Phasic mesolimbic dopamine signaling precedes and predicts performance of a self-initiated action sequence task. Biological psychiatry, 71(10):846–854, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Totah Nelson KB, Kim Yunbok, and Moghaddam Bita. Distinct prestimulus and poststimulus activation of VTA neurons correlates with stimulus detection. Journal of neurophysiology, 110(1):75–85, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Berke Joshua D. What does dopamine mean? Nature neuroscience, page 1, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Kakade Sham and Dayan Peter. Dopamine: generalization and bonuses. Neural Networks, 15(4–6):549–559, 2002. [DOI] [PubMed] [Google Scholar]
- [30].Fiorillo Christopher D, Newsome William T, and Schultz Wolfram. The temporal precision of reward prediction in dopamine neurons. Nature neuroscience, 11(8):966, 2008. [DOI] [PubMed] [Google Scholar]
- [31].Rao Rajesh PN. Decision making under uncertainty: a neural model based on partially observable Markov decision processes. Frontiers in computational neuroscience, 4:146, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].de Lafuente Victor and Romo Ranulfo. Dopamine neurons code subjective sensory experience and uncertainty of perceptual decisions. Proceedings of the National Academy of Sciences, 108(49):19767–19771, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Starkweather Clara Kwon, Babayan Benedicte M, Uchida Naoshige, and Gershman Samuel J. Dopamine reward prediction errors reflect hidden-state inference across time. Nature Neuroscience, 20(4):581–589, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Lak Armin, Nomoto Kensaku, Keramati Mehdi, Sakagami Masamichi, and Kepecs Adam. Midbrain dopamine neurons signal belief in choice accuracy during a perceptual decision. Current Biology, 27(6):821–832, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Starkweather Clara Kwon, Gershman Samuel J, and Uchida Naoshige. The medial prefrontal cortex shapes dopamine reward prediction errors under state uncertainty. Neuron, 98:616–629, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Morita Kenji and Kato Ayaka. Striatal dopamine ramping may indicate flexible reinforcement learning with forgetting in the cortico-basal ganglia circuits. Frontiers in neural circuits, 8:36, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Mikhael John G and Bogacz Rafal. Learning reward uncertainty in the basal ganglia. PLoS computational biology, 12(9):e1005062, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Cinotti François, Fresno Virginie, Aklil Nassim, Coutureau Etienne, Girard Benoît, Marchand Alain R, and Khamassi Mehdi. Dopamine blockade impairs the exploration-exploitation trade-off in rats. Scientific reports, 9(1):6770, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Lloyd Kevin and Dayan Peter. Tamping ramping: Algorithmic, implementational, and computational explanations of phasic dopamine signals in the accumbens. PLoS computational biology, 11(12):e1004622, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Nicola Saleem M, Surmeier D James, and Malenka Robert C. Dopaminergic modulation of neuronal excitability in the striatum and nucleus accumbens. Annual review of neuroscience, 23(1):185–215, 2000. [DOI] [PubMed] [Google Scholar]
- [41].Niv Yael, Daw Nathaniel D, Joel Daphna, and Dayan Peter. Tonic dopamine: opportunity costs and the control of response vigor. Psychopharmacology, 191(3):507–520, 2007. [DOI] [PubMed] [Google Scholar]
- [42].Schultz Wolfram. Multiple dopamine functions at different time courses. Annu. Rev. Neurosci, 30:259–288, 2007. [DOI] [PubMed] [Google Scholar]
- [43].Schultz Wolfram. Review dopamine signals for reward value and risk: basic and recent data. Behav. Brain Funct, 6:24, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Berridge Kent C. The debate over dopamine’s role in reward: the case for incentive salience. Psychopharmacology, 191(3):391–431, 2007. [DOI] [PubMed] [Google Scholar]
- [45].Frank Michael J, Moustafa Ahmed A, Haughey Heather M, Curran Tim, and Hutchison Kent E. Genetic triple dissociation reveals multiple roles for dopamine in reinforcement learning. Proceedings of the National Academy of Sciences, 104(41):16311–16316, 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [46].Gardner Matthew PH, Schoenbaum Geoffrey, and Gershman Samuel J. Rethinking dopamine as generalized prediction error. Proceedings of the Royal Society B, 285(1891):20181645, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Houk James C., Adams James L., and Barto Andrew G.. A model of how the basal ganglia generate and use neural signals that predict reinforcement. In Houk James C., Davis Joel L., and Beiser David G., editors, Models of information processing in the basal ganglia. MIT Press, Cambridge, 1995. [Google Scholar]
- [48].Montague P Read, Dayan Peter, and Sejnowski Terrence J. A framework for mesencephalic dopamine systems based on predictive Hebbian learning. The Journal of neuroscience, 16(5):1936–1947, 1996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [49].Deneve Sophie. Making decisions with unknown sensory reliability. Frontiers in neuroscience, 6:75, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [50].Rachlin Howard and Green Leonard. Commitment, choice and self-control 1. Journal of the experimental analysis of behavior, 17(1):15–22, 1972. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Ainslie George. Specious reward: a behavioral theory of impulsiveness and impulse control. Psychological bulletin, 82(4):463, 1975. [DOI] [PubMed] [Google Scholar]
- [52].Tobin Henry and Logue Alexandra W. Self-control across species (Columba livia, Homo sapiens, and Rattus norvegicus). Journal of Comparative Psychology, 108(2):126, 1994. [DOI] [PubMed] [Google Scholar]
- [53].Rachlin Howard. The science of self-control. Harvard University Press, 2000. [Google Scholar]
- [54].Ludvig Elliot, Sutton Richard S, Kehoe E James, et al. Stimulus representation and the timing of reward-prediction errors in models of the dopamine system. 2008. [DOI] [PubMed]
- [55].Ludvig Elliot A, Sutton Richard S, and Kehoe E James. Evaluating the TD model of classical conditioning. Learning & behavior, 40(3):305–319, 2012. [DOI] [PubMed] [Google Scholar]
- [56].Ratcliff Roger and Frank Michael J. Reinforcement-based decision making in corticostriatal circuits: mutual constraints by neurocomputational and diffusion models. Neural computation, 24(5):1186–1229, 2012. [DOI] [PubMed] [Google Scholar]
- [57].Moore JW, Desmond JE, and Berthier NE. Adaptively timed conditioned responses and the cerebellum: a neural network approach. Biological cybernetics, 62(1):17–28, 1989. [DOI] [PubMed] [Google Scholar]
- [58].Sutton Richard S and Barto Andrew G. Time-derivative models of pavlovian reinforcement. 1990.
- [59].Allan Lorraine G. The location and interpretation of the bisection point. The Quarterly Journal of Experimental Psychology: Section B, 55(1):43–60, 2002. [DOI] [PubMed] [Google Scholar]
- [60].Wearden JH. Traveling in time: A time-left analogue for humans. Journal of Experimental Psychology: Animal Behavior Processes, 28(2):200, 2002. [PubMed] [Google Scholar]
- [61].Wearden John H and Jones Luke A. Is the growth of subjective time in humans a linear or nonlinear function of real time? The Quarterly Journal of Experimental Psychology, 60(9):1289–1302, 2007. [DOI] [PubMed] [Google Scholar]
- [62].Jozefowiez Jérémie, Gaudichon Clément, Mekkass Francis, and Machado Armando. Log versus linear timing in human temporal bisection: A signal detection theory study. Journal of Experimental Psychology: Animal Learning and Cognition, 44(4):396, 2018. [DOI] [PubMed] [Google Scholar]
- [63].Ren Yue, Müller Hermann J, and Shi Zhuanghua. Ensemble perception in the time domain: evidence in favor of logarithmic encoding of time intervals. bioRxiv, 2020. [Google Scholar]
- [64].Larsen T, Leslie DS, Collins EJ, and Bogacz R. Posterior weighted reinforcement learning with state uncertainty. Neural Computation, 22:1149–1179, 2010. [DOI] [PubMed] [Google Scholar]
- [65].Gershman Samuel J and Uchida Naoshige. Believing in dopamine. Nature Reviews Neuroscience, 20(11):703–714, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [66].Matell Matthew S, Meck Warren H, and Lustig Cindy. Not “just” a coincidence: Frontal-striatal interactions in working memory and interval timing. Memory, 13(3–4):441–448, 2005. [DOI] [PubMed] [Google Scholar]
- [67].O’Keefe John and Burgess Neil. Geometric determinants of the place fields of hippocampal neurons. Nature, 381(6581):425, 1996. [DOI] [PubMed] [Google Scholar]
- [68].Gallistel CR, King Adam, and McDonald Robert. Sources of variability and systematic error in mouse timing behavior. Journal of Experimental Psychology: Animal Behavior Processes, 30(1):3, 2004. [DOI] [PubMed] [Google Scholar]
- [69].Bayer Hannah M and Glimcher Paul W. Midbrain dopamine neurons encode a quantitative reward prediction error signal. Neuron, 47(1):129–141, 2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Morris Genela, Arkadir David, Nevet Alon, Vaadia Eilon, and Bergman Hagai. Coincident but distinct messages of midbrain dopamine and striatal tonically active neurons. Neuron, 43(1):133–143, 2004. [DOI] [PubMed] [Google Scholar]
- [71].Fiorillo Christopher D, Tobler Philippe N, and Schultz Wolfram. Discrete coding of reward probability and uncertainty by dopamine neurons. Science, 299(5614):1898–1902, 2003. [DOI] [PubMed] [Google Scholar]
- [72].Daw Nathaniel D, Courville Aaron C, and Touretzky David S. Representation and timing in theories of the dopamine system. Neural computation, 18(7):1637–1677, 2006. [DOI] [PubMed] [Google Scholar]
- [73].Nathaniel D Daw Sham Kakade, and Dayan Peter. Opponent interactions between serotonin and dopamine. Neural networks, 15(4–6):603–616, 2002. [DOI] [PubMed] [Google Scholar]
- [74].Niv Yael, Duff Michael O, and Dayan Peter. Dopamine, uncertainty and TD learning. Behavioral and brain Functions, 1(1):1–9, 2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [75].Aronov Dmitriy and Tank David W.. Engagement of Neural Circuits Underlying 2D Spatial Navigation in a Rodent Virtual Reality System. Neuron, 84(2):442–456, October 2014. ISSN 0896–6273. doi: 10.1016/j.neuron.2014.08.042. URL http://www.sciencedirect.com/science/article/pii/S0896627314007430. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Video S1: Visual stimulus in the standard darkening condition.
Data Availability Statement
Source code for all simulations can be found at www.github.com/jgmikhael/ramping.
Data for Figure 5 and S3 can be found at and https://doi.org/10.6084/m9.figshare.16706788.