

Abstract
Adaptive gradient methods (AGMs) have become popular in optimizing the nonconvex problems in deep learning area. We revisit AGMs and identify that the adaptive learning rate (A-LR) used by AGMs varies significantly across the dimensions of the problem over epochs (i.e., anisotropic scale), which may lead to issues in convergence and generalization. All existing modified AGMs actually represent efforts in revising the A-LR. Theoretically, we provide a new way to analyze the convergence of AGMs and prove that the convergence rate of Adam also depends on its hyper-parameter є, which has been overlooked previously. Based on these two facts, we propose a new AGM by calibrating the A-LR with an activation (softplus) function, resulting in the Sadam and SAMSGrad methods. We further prove that these algorithms enjoy better convergence speed under nonconvex, non-strongly convex, and Polyak-Łojasiewicz conditions compared with Adam. Empirical studies support our observation of the anisotropic A-LR and show that the proposed methods outperform existing AGMs and generalize even better than S-Momentum in multiple deep learning tasks.
Keywords: ADAM, Deep learning, Adaptive methods, Stochastic methods
1. Introduction
Many machine learning problems can be formulated as the minimization of an objective function f of the form: , where both f and fi maybe nonconvex in deep learning. Stochastic gradient descent (SGD), its variants such as SGD with momentum (S-Momentum) [1, 2, 3, 4], and adaptive gradient methods (AGMs) [5, 6, 7] play important roles in deep learning area due to simplicity and wide applicability. In particular, AGMs often exhibit fast initial progress in training and are easy to implement in solving large scale optimization problems. The updating rule of AGMs can be generally written as:
| (1) |
where ʘ calculates element-wise product of the first-order momentum mt and the learning rate . There is fairly an agreement on how to compute mt, which is a convex combination of previous mt−1 and current stochastic gradient gt, i.e., mt = β1mt−1 + (1 − β1)gt, β1 ∈ [0,1]. The LR consists of two parts: the base learning rate (B-LR) ηt is a scalar which can be constant or decay over iterations. In our convergence analysis, we consider the B-LR as constant η. The adaptive learning rate , varies adaptively across dimensions of the problem, where is the second-order momentum calculated as a combination of previous and current squared stochastic gradients. Unlike the first-order momentum, the formula to estimate the second-order momentum varies in different AGMs. As the core technique in AGMs, A-LR opens a new regime of controlling LR, and allows the algorithm to move with different step sizes along the search direction at different coordinates.
The first known AGM is Adagrad [5] where the second-order momentum is estimated as . It works well in sparse settings, but the A-LR often decays rapidly for dense gradients. To tackle this issue, Adadelta [7], Rmsprop [8], Adam [6] have been proposed to use exponential moving averages of past squared gradients, i.e., , β2 ∈ [0,1] and calculate the A-LR by where є > 0 is used in case that vt vanishes to zero. In particular, Adam has become the most popular optimizer in the deep learning area due to its effectiveness in early training stage. Nevertheless, it has been empirically shown that Adam generalizes worse than S-Momentum to unseen data and leaves a clear generalization gap [9, 10, 11], and even fails to converge in some cases [12, 13]. AGMs decrease the objective value rapidly in early iterations, and then stay at a plateau whereas SGD and S-Momentum continue to show dips in the training error curves, and thus continue to improve test accuracy over iterations. It is essential to understand what happens to Adam in the later learning process, so we can revise AGMs to enhance their generalization performance.
Recently, a few modified AGMs have been developed, such as, AMSGrad [12], Yogi [14], and AdaBound [13]. AMSGrad is the first method to theoretically address the non-convergence issue of Adam by taking the largest second-order momentum estimated in the past iterations, i.e., where , and proves its convergence in the convex case. The analysis is later extended to other AGMs (such as RMSProp and AMSGrad) in nonconvex settings [15, 16, 17, 18]. Yogi claims that the past ‘s are forgotten in a fairly fast manner in Adam and proposes to adjust the decay rate of the A-LR. However, the parameter in the A-LR is adjusted to 10−3, instead of 10−8 in the default setting of Adam, so ϵ dominates the A-LR in later iterations when vt becomes small and can be responsible for performance improvement. The hyper-parameter has rarely been discussed previously and our analysis shows that the convergence rate is closely related to є, which is further verified in our experiments. PAdam1 [19, 15] claims that the A-LR in Adam and AMSGrad are “overadapted”, and proposes to replace the A-LR updating formula by 1/((vt)p + є) where p ϵ (0,1/2] AdaBound confines the LR to a predefined range by applying), , where LR values outside the interval [ηl,ηr] are clipped to the interval edges. However, a more effective way is to softly and smoothly calibrate the A-LR rather than hard-thresholding the A-LR at all coordinates. Our main contributions are summarized as follows:
We study AGMs from a new perspective: the range of the A-LR. Through experimental studies, we find that the A-LR is always anisotropic. This anisotropy may lead the algorithm to focus on a few dimensions (those with large A-LR), which may exacerbate generalization performance. We analyze the existing modified AGMs to help explain how they close the generalization gap.
Theoretically, we are the first to include hyper-parameter є into the convergence analysis and clearly show that the convergence rate is upper bounded by a 1/є2 term, verifying prior observations that є affects performance of Adam empirically. We provide a new approach to convergence analysis of AGMs under the nonconvex, non-strongly convex, or Polyak-Łojasiewicz (P-L) condition.
Based on the above two results, we propose to calibrate the A-LR using an activation function, particularly we implement the softplus function with a hyper-parameter β, which can be combined with any AGM. In this work, we combine it with Adam and AMSGrad to form the SAdam and SAMSGrad methods.
We also provide theoretical guarantees of our methods, which enjoy better convergence speed than Adam and recover the same convergence rate as SGD in terms of the maximum iteration T as rather than the known result: in [16]. Empirical evaluations show that our methods obviously increase test accuracy, and outperform many AGMs and even S-Momentum in multiple deep learning models.
2. Preliminaries
Notations.
For any vectors , we use a ʘ b for element-wise product, a2 for element-wise square, for element-wise square root, for element-wise division; we use ak to denote element-wise power of k, and ǁaǁ to denote its l2-norm. We use 〈a,b〉 to denote their inner product, max{a,b} to compute element-wise maximum. e is the Euler number, log(·) denotes logarithm function with base e, and O(·) to hide constants which do not rely on the problem parameters.
Optimization Terminology.
In convex setting, the optimality gap, f(xt) − f∗, is examined where xt is the iterate at iteration t, and f∗ is the optimal value attained at x∗ assuming that f does have a minimum. When f(xt) − f∗ ≤ δ, it is said that the method reaches an optimal solution with δ-accuracy. However, in the study of AGMs, the average regret (where the maximum iteration number T is pre-specified) is used to approximate the optimality gap to define δ-accuracy. Our analysis moves one step further to examine if by applying Jensen’s inequality to the regret.
In nonconvex setting, finding the global minimum or even local minimum is NP-hard, so optimality gap is not examined. Rather, it is common to evaluate if a first-order stationary point has been achieved [20, 12, 14]. More precisely, we evaluate if (e.g., in the analysis of SGD [1]). The convergence rate of SGD is in both non-strongly convex and nonconvex settings. Requiring yields the maximum number of iterations T = O(1/δ2). Thus, SGD can obtain a δ-accurate solution in O(1/δ2) steps in non-strongly convex and nonconvex settings. Our results recover the rate of SGD and S-Momentum in terms of T.
Assumption 1. The loss fi and the objective f satisfy:
L-smoothness. , , .
Gradient bounded. , , .
Variance bounded. , , .
Definition 1. Suppose f has the global minimum, denoted as f∗ = f(x∗). Then for any ,
Non-strongly convex. .
Polyak-Łojasiewicz (P-L) condition. such that .
Strongly convex. such that .
3. Our New Analysis of Adam
First, we empirically observe that Adam has anisotropic A-LR caused by є, which may lead to poor generalization performance. Second, we theoretically show Adam method is sensitive to є, supporting observations in previous work.
3.1. Anisotropic A-LR.
We investigate how the A-LR in Adam varies over time and across problem dimensions, and plot four examples in Figure 1 (more figures in Appendix) where we run Adam to optimize a convolutional neural network (CNN) on the MNIST dataset, and ResNets or DenseNets on the CIFAR-10 dataset. The curves in Figure 1 exhibit very irregular shapes, and the median value is hardly placed in the middle of the range, the range of A-LR across the problem dimensions is anisotropic for AGMs. As a general trend, the A-LR becomes larger when vt approaches 0 over iterations. The elements in the A-LR vary significantly across dimensions and there are always some coordinates in the A-LR of AGMs that reach the maximum 108 determined by є (because we use є = 10−8 in Adam).
Figure 1:
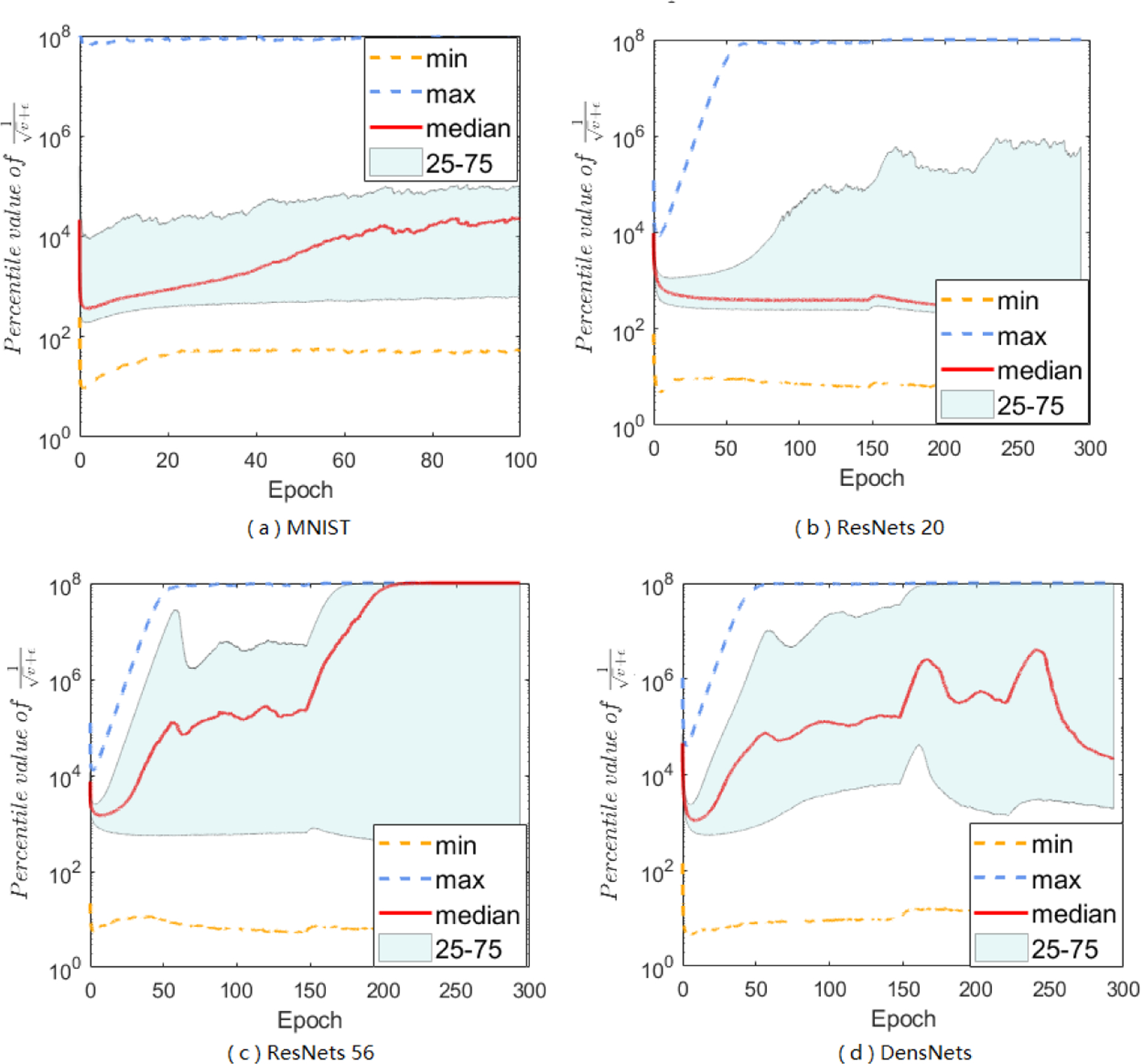
Range of the A-LR in Adam over iterations in four settings: (a) CNN on MNIST, (b) ResNet20 on CIFAR-10, (d) ResNet56 on CIFAR-10, (d) DenseNets on CIFAR-10. We plot the min, max, median, and the 25 and 75 percentiles of the A-LR across dimensions (the elements in )
This anisotropic scale of A-LR across dimensions makes it difficult to determine the B-LR, η. On the one hand, η should be set small enough so that the is appropriate, or otherwise some coordinates will have very large updates because the corresponding A-LR’s are big, likely resulting in performance oscillation [21]. This may be due to that exponential moving average of past gradients is different, hence the speed of mt diminishing to zero is different from the speed of diminishing to zero. Besides, noise generated in stochastic algorithms has nonnegligible influence to the learning process. On the other hand, very small η may harm the later stage of the learning process since the small magnitude of mt multiplying with a small step size (at some coordinates) will be too small to escape sharp local minimal, which has been shown to lead to poor generalization [22, 23, 24]. Further, in many deep learning tasks, stage-wise policies are often taken to decay the LR after several epochs, thus making the LR even smaller. To address the dilemma, it is essential to control the A-LR, especially when stochastic gradients get close to 0.
By analyzing previous modified AGMs that aim to close the generalization gap, we find that all these works can be summarized into one technique: constraining the A-LR, , to a reasonable range. Based on the observation of anisotropic A-LR, we propose a more effective way to calibrate the A-LR according to an activation function rather than hard-thresholding the A-LR at all coordinates, empirically improve generalization performance with theoretical guarantees of optimization.
3.2. Sensitive to є.
As a hyper-parameter in AGMs, ϵ is originally introduced to avoid the zero denominator issue when vt goes to 0, and has never been studied in the convergence analysis of AGMs. However, it has been empirically observed that AGMs can be sensitive to the choice of є in [17, 14]. As shown in Figure 1, a smaller є = 10−8 leads to a wide span of the A-LR across the different dimensions, whereas a bigger є = 10−3 as used in Yogi, reduces the span. To better learn the effect caused by sensitive є, we conduct experiments in multiple datasets and results are shown in Table 1 and 2. The setting of є is the main force causing anisotropy, unsatisfied, there has no theoretical result explains the effect of є on AGMs. Inspired by our observation, we believe that the current convergence analysis for Adam is not complete if omitting є.
Table 1:
Test Accuracy(%) of Adam for different є.
| є | ResNets 20 | ResNets 56 | DenseNets | ResNet 18 | VGG |
|---|---|---|---|---|---|
| 10−1 | 92.51 ± 0.13 | 94.29 ± 0.10 | 94.78 ± 0.19 | 77.21 ± 0.26 | 76.05 ± 0.27 |
| 10−2 | 92.88 ± 0.21 | 94.15 ± 0.17 | 94.35 ± 0.10 | 76.64 ± 0.24 | 75.69 ± 0.16 |
| 10−4 | 92.03 ± 0.21 | 93.62 ± 0.18 | 94.15 ± 0.12 | 76.19 ± 0.20 | 74.45 ± 0.19 |
| 10−6 | 92.99 ± 0.22 | 93.56 ± 0.15 | 94.24 ± 0.24 | 76.09 ± 0.20 | 74.20 ± 0.33 |
| 10−8 | 91.68 ± 0.12 | 92.82 ± 0.09 | 93.32 ± 0.06 | 76.14 ± 0.24 | 74.18 ± 0.15 |
Table 2:
Test Accuracy(%) of AMSGrad for different є.
| є | ResNets 20 | ResNets 56 | DenseNets | ResNet 18 | VGG |
|---|---|---|---|---|---|
| 10−1 | 92.80 ± 0.22 | 94.12 ± 0.07 | 94.92 ± 0.10 | 77.26 ± 0.30 | 75.84 ± 0.16 |
| 10−2 | 92.89 ± 0.07 | 94.20 ± 0.18 | 94.43 ± 0.22 | 76.23 ± 0.26 | 75.37 ± 0.18 |
| 10−4 | 91.85 ± 0.10 | 93.50 ± 0.14 | 94.02 ± 0.18 | 76.30 ± 0.31 | 74.44 ± 0.16 |
| 10−6 | 91.98 ± 0.23 | 93.54 ± 0.16 | 94.17 ± 0.10 | 76.14 ± 0.16 | 74.17 ± 0.28 |
| 10−8 | 91.70 ± 0.12 | 93.10 ± 0.11 | 93.71 ± 0.05 | 76.32 ± 0.11 | 74.26 ± 0.18 |
Most of the existing convergence analysis follows the line in [12] to first project the sequence of the iterates into a minimization problem as , and then examine if decreases over iterations. Hence, є is not discussed in this line of proof because it is not included in the step size. In our later convergence analysis section, we introduce an important lemma, bounded A-LR, and by using the bounds of the A-LR (specifically, the lower bound µ1 and upper bound µ2 both containing є for Adam), we give a new general framework of prove (details in Appendix) to show the convergence rate for reaching an x that satisfies in the nonconvex setting. Then, we also derive the optimality gap from the stationary point in the convex and P-L settings (strongly convex).
Theorem 3.1. [Nonconvex] Suppose f(x) is a nonconvex function that satisfies Assumption 1. Let , Adam has
Theorem 3.2. [Non-strongly Convex] Suppose f(x) is a convex function that satisfies Assumption 1. Assume that , , for any m ≠ n, , let , Adam has convergence rate , where .
Theorem 3.3. [P-L Condition] Suppose f(x) has P-L condition (with parameter λ) holds under convex case, satisfying Assumption 1. Let , Adam has the convergence rate: ,
The P-L condition is weaker than strongly convex, and for the strongly convex case, we also have:
Corollary 3.3.1. [Strongly Convex] Suppose f(x) is µ-strongly convex function that satisfies Assumption 1. Let , Adam has the convergence rate:
This is the first time to theoretically include є into analysis. As expected, the convergence rate of Adam is highly related with є. A bigger є will enjoy a better convergence rate since є will dominate the A-LR and behaves like SMomentum; A smaller є will preserve stronger “adaptivity”, we need to find a better way to control є.
4. The Proposed Algorithms
We propose to use activation functions to calibrate AGMs, and specifically focus on using softplus funciton on top of Adam and AMSGrad methods.
4.1. Activation Functions Help
Activation functions (such as sigmoid, ELU, tanh) transfer inputs to outputs are widely used in deep learning area. As a well-studied activation function, is known to keep large values unchanged (behaved like function y = x) while smoothing out small values (see Figure 2 (a)). The target magnitude to be smoothed out can be adjusted by a hyper-parameter . In our new algorithms, we introduce to smoothly calibrate the A-LR. This calibration brings the following benefits: (1) constraining extreme large-valued A-LR in some coordinates (corresponding to the small-values in vt) while keeping others untouched with appropriate β. For the undesirable large values in the A-LR, the softplus function condenses them smoothly instead of hard thresholding. For other coordinates, the A-LR largely remains unchanged; (2) removing the sensitive parameter є because the softplus function can be lower-bounded by a nonzero number when used on non-negative variables, .
Figure 2:
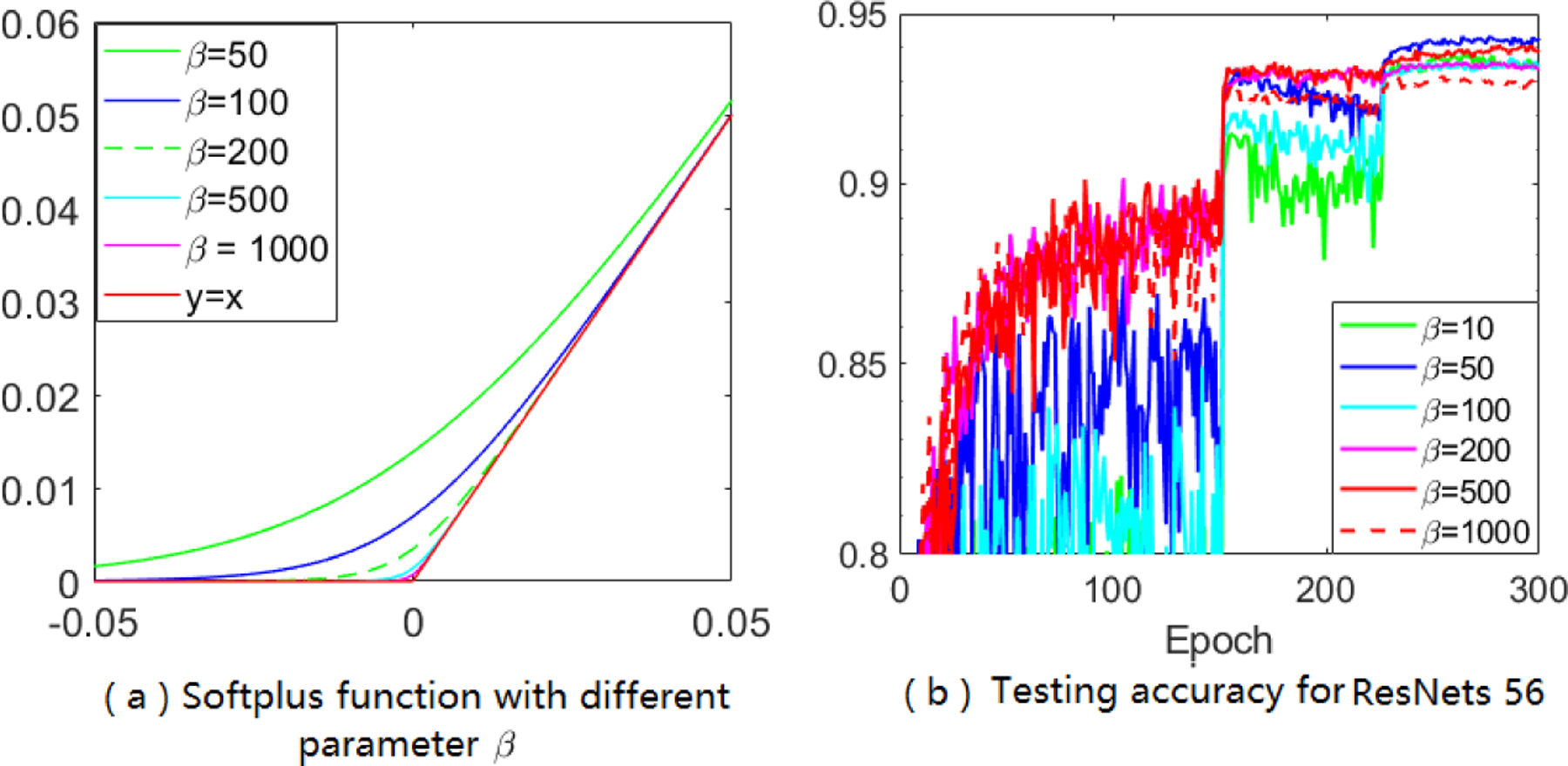
Behavior of the softplus function, and the test performance of our Sadam algorithm.
After calibrating with a softplus function, the anisotropic A-LR becomes much more regulated (see Figure 3 and Appendix), and we clearly observe improved test accuracy (Figure 2 (b) and more figures in Appendix). We name this method “Sadam” to represent the calibrated Adam with softplus function, here we recommend using softplus function but it is not limited to that, and the later theoretical analysis can be easily extended to other activation functions. More empirical evaluations have shown that the proposed methods significantly improve the generalization performance of Adam and AMSGrad.
Figure 3:
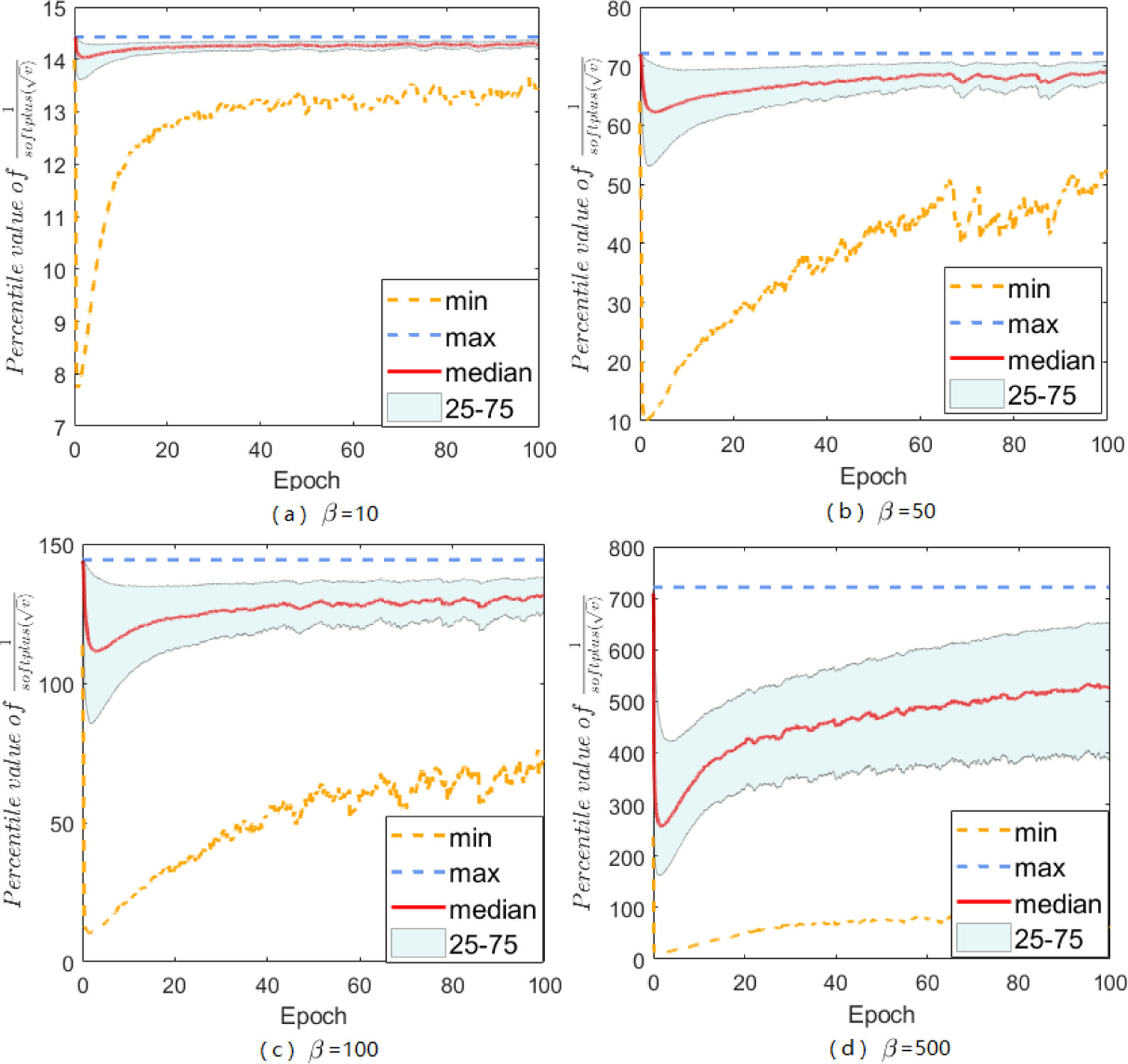
Behavior of the A-LR in the Sadam method with different choices of β (CNN on the MNIST data).
4.2. Calibrated AGMs
With activation function, we develop two new variants of AGMs: Sadam and SAMSGrad (Algorithms 1 and 2), which are developed based on Adam and AMSGrad respectively.
The key step lies in the way to design the adaptive functions, instead of using the generalized square root function only, we apply softplus(·) on top of the square root of the second-order momentum, which serves to regulate A-LR’s anisotropic behavior and replace the tolerance parameter є by the hyper-parameter β used in the softplus function.
In our algorithms, the hyper-parameters are recommended as β1 = 0.9, β2 = 0.999. For clarity, we omit the bias correction step proposed in the original Adam. However, our arguments and theoretical analysis are applicable to the bias correction version as well [6, 25, 14]. Using the softplus function, we introduce a new hyper-parameter β, which performs as a controller to smooth out anisotropic A-LR, and connect the Adam and S-Momentum methods automatically. When β is set to be small, Sadam and SAMSGrad perform similarly to S-Momentum; when β is set to be big, , and the updating formula becomes , which is degenerated into the original AGMs. The hyper-parameter β can be well tuned to achieve the best performance for different datasets and tasks. Based on our empirical observations, we recommend to use β = 50.
As a calibration method, the softplus function has better adaptive behavior than simply setting. More precisely, when є is large or β is small, Adam and AMSGrad amount to S-Momentum, but when є is small as commonly suggested 10−8 or β is taken large, the two methods are different because comparing Figure 1 and 3 yields that Sadam has more regulated A-LR distribution. The proposed calibration scheme regulates the massive range of A-LR back down to a moderate scale. The median of A-LR in different dimensions is now well positioned to the middle of the 25–75 percentile zone. Our approach opens up a new direction to examine other activation functions (not limited to the softplus function) to calibrate the A-LR.
The proposed Sadam and SAMSGrad can be treated as members of a class of AGMs that use the softplus (or another suitable activation) function to better adapt the step size. It can be readily combined with any other AGM, e.g., Rmsrop, Yogi, and PAdam. These methods may easily go back to the original ones by choosing a big β.
5. Convergence Analysis
We first demonstrate an important lemma to highlight that every coordinate in the A-LR is both upper and lower bounded at all iterations, which is consistent with empirical observations (Figure 1), and forms the foundation of our proof.
Lemma 5.1. [Bounded A-LR] With Assumption 1, for any t ≥ 1, j ∈ [1,d], β2 ∈ [0,1], and in Adam, β in Sadam, anisotropic A-LR is bounded in AGMs, Adam has (µ1,µ2)-bounded A-LR:
Sadam has (µ3,µ4)-bounded A-LR:
where 0 < µ1 ≤ µ2, and 0 < µ3 ≤ µ4
Remark 5.2. Besides the square root function and softplus function, the A-LR calibrated by any positive monotonically increasing function can be bounded. All of the bounds can be shown to be related to є or β (see Appendix). Bounded A-LR is an essential foundation in our analysis, we provide a different way of proof from previous works, and the proof procedure can be easily extended to other gradient methods as long as bounded LR is satisfied.
Remark 5.3. These bounds can be applied to all AGMs, including Adagrad. In fact, the lower bounds actually are not the same in Adam and Adagrad, because Adam will have smaller due to moment decay parameter β2. To achieve a unified result, we use the same relaxation to derive the fixed lower bound µ1.
We now describe our main results of Sadam (and SAMSGrad) in the nonconvex case, we clearly show that similar to Theorem 3.1, the convergence rate of Sadam is related to the bounds of the A-LR. Our methods have improved the convergence rate of Adam when comparing self-contained parameters є and β.
Theorem 5.4. [Nonconvex] Suppose f(x) is a nonconvex function that satisfies Assumption 1. Let , Sadam method has
Remark 5.5. Compared with the rate in Theorem 3.1, the convergence rate of Sadam relies on β, which can be a much smaller number (β = 50 as recommended) than (commonly є = 10−8 in AGMs), showing that our methods have a better convergence rate than Adam. When β is huge, Sadam’s rate is comparable to the classic Adam. When β is small, the convergence rate will be which recovers that of SGD [1].
Corollary 5.5.1. Treat є or β as a constant, then the Adam, Sadam (and SAMSGrad) methods with fixed L,σ,G,β1, and , have complexity of , and thus call for iterations to achieve δ-accurate solutions.
Theorem 5.6. [Non-strongly Convex] Suppose f(x) is a convex function that satisfies Assumption 1. Assume that , and , , let , Sadam has , where .
The accurate convergence rate will be for Adam and for Sadam with fixed L, σ, G, β1, D, D∞. Some works may specify additional sparsity assumptions on stochastic gradients, and in other words, require that [5, 12, 15, 19] to reduce the order from d to . Some works may use the element-wise bounds σj or Gj, and apply , and to hide d. In our work, we do not assume sparsity, so we use σ and G throughout the proof. Otherwise, those techniques can also be used to hide d from our convergence rate.
Corollary 5.6.1. If є or β is treated as constants, then Adam, Sadam (and SAMSGrad) methods with fixed L,σ,G,β1, and in the convex case will call for iterations to achieve δ-accurate solutions.
Theorem 5.7. [P-L Condition] Suppose f(x) satisfies the P-L condition (with parameter λ) and Assumption 1 in the convex case. Let , Sadam has:
Corollary 5.7.1. [Strongly Convex] Suppose f(x) is µ-strongly convex function that satisfies Assumption 1. Let , Sadam has the convergence rate:
In summary, our methods share the same convergence rate as Adam, and enjoy even better convergence speed if comparing the common values chosen for the parameters є and β. Our convergence rate recovers that of SGD and S-Momentum in terms of T for a small β.
6. Experiments
We compare Sadam and SAMSGrad against several state-of-the-art optimizers including S-Momentum, Adam, AMSGrad, Yogi, PAdam, PAMSGrad, Adabound, and Amsbound. More results and architecture details are in Appendix.
Experimental Setup.
We use three datasets for image classifications: MNIST, CIFAR-10 and CIFAR-100 and two datasets for LSTM language models: Penn Treebank dataset (PTB) and the WikiText-2 (WT2) dataset. The MNIST dataset is tested on a CNN with 5 hidden layers. The CIFAR-10 dataset is tested on Residual Neural Network with 20 layers (ResNets 20) and 56 layers (ResNets 56) [9], and DenseNets with 40 layers [11]. The CIFAR-100 dataset is tested on VGGNet [26] and Residual Neural Network with 18 layers (ResNets 18) [9]. The Penn Treebank dataset (PTB) and the WikiText-2 (WT2) dataset are tested on 3-layer LSTM models [27].
We train CNN on the MNIST data for 100 epochs, ResNets/DenseNets on CIFAR-10 for 300 epochs, with a weight decay factor of 5 × 10−4 and a batch size of 128, VGGNet/ResNets on CIFAR-100 for 300 epochs, with a weight decay factor of 0.025 and a batch size of 128 and LSTM language models on 200 epochs. For the CIFAR tasks, we use a fixed multi-stage LR decaying scheme: the B-LR decays by 0.1 at the 150-th epoch and 225-th epoch, which is a popular decaying scheme used in many works [28, 18]. For the language tasks, we use a fixed multi-stage LR decaying scheme: the B-LR decays by 0.1 at the 100-th epoch and 150-th epoch. All algorithms perform grid search for hyperparameters to choose from {10,1,0.1,0.01,0.001,0.0001} for B-LR, {0.9,0.99} for β1 and {0.99,0.999} for β2. For algorithm-specific hyper-parameters, they are tuned around the recommended values, such as in PAdam and PAMSGrad. For our algorithms, β is selected from {10,50,100} in Sadam and SAMSGrad, though we do observe fine-tuning β can achieve better test accuracy most of time. All experiments on CIFAR tasks are repeated for 6 times to obtain the mean and standard deviation for each algorithm.
Image Classification Tasks.
As a sanity check, experiment on MNIST has been done and its results are in Figure 4, which shows the learning curve for all baseline algorithms and our algorithms on both training and test datasets. As expected, all methods can reach the zero loss quickly, while for test accuracy, our SAMSGrad shows increase in test accuracy and outperforms competitors within 50 epochs.
Figure 4:
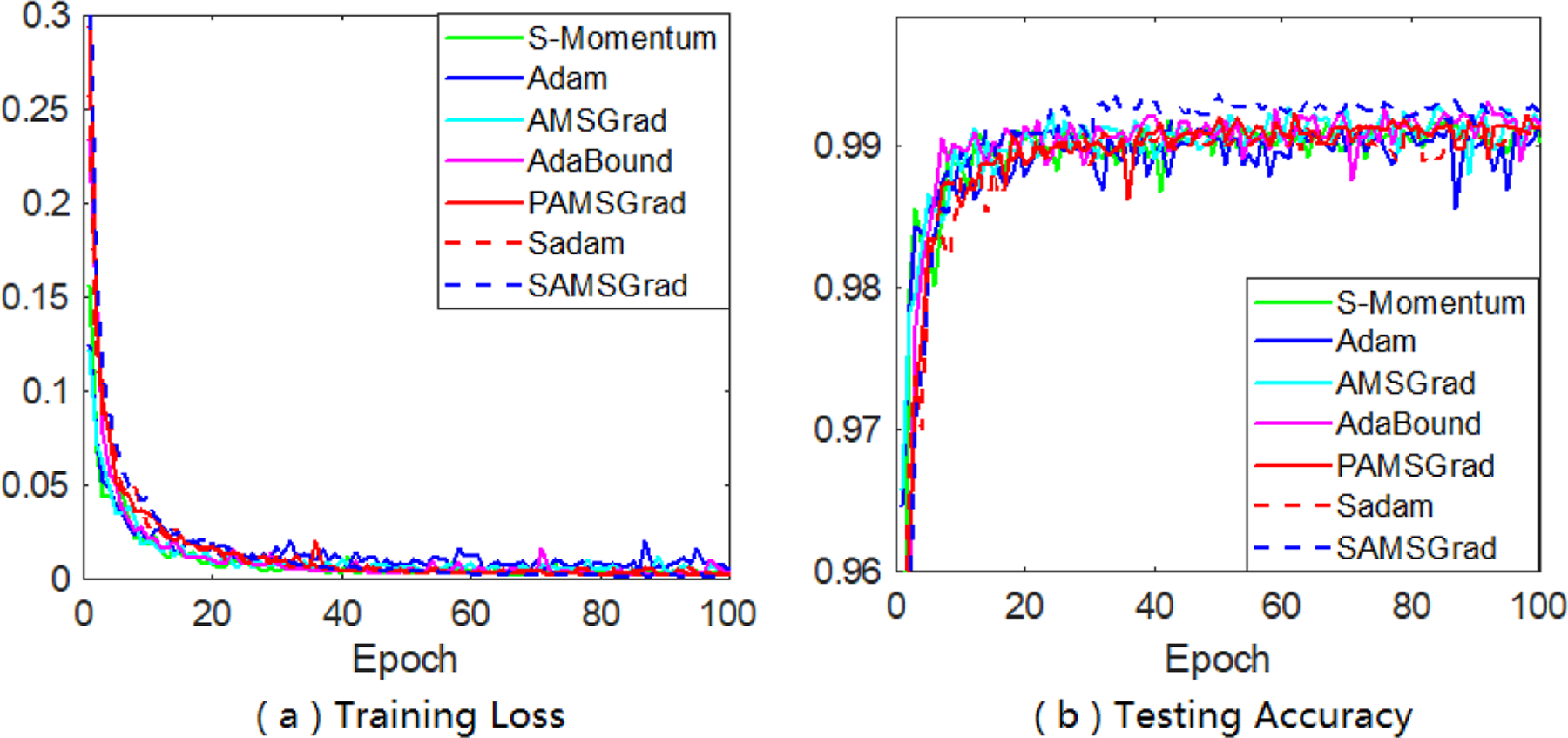
Training loss and test accuracy on MNIST.
Using the PyTorch framework, we first run the ResNets 20 model on CIFAR10 and results are shown in Table 3. The original Adam and AMSGrad have lower test accuracy in comparison with S-Momentum, leaving a clear generalization gap exactly same as what is previously reported. For our methods, Sadam and SAMSGrad clearly close the gap, and Sadam achieves the best test accuracy among competitors. We further test all methods with CIFAR10 on ResNets 56 with greater network depth, and the overall performance of each algorithm has been improved. For the experiments with DenseNets, we use a DenseNet with 40 layers and a growth rate k = 12 without bottleneck, channel reduction, or dropout. The results are reported in the last column of Table 3, SAMSGrad still achieves the best test performance, and the proposed two methods largely improve the performance of Adam and AMSGrad and close the gap with S-Momentum.
Table 3:
Test Accuracy(%) of CIFAR-10 for ResNets 20, ResNets 56 and DenseNets.
| Method | B-LR | є | β | ResNets 20 | ResNets 56 | DenseNets |
|---|---|---|---|---|---|---|
| S-Momentum [9, 11] | - | - | - | 91.25 | 93.03 | 94.76 |
| Adam [14] | 10−3 | 10−3 | - | 92.56 ± 0.14 | 93.42 ± 0.16 | 93.35 ± 0.21 |
| Yogi [14] | 10−2 | 10−3 | - | 92.62 ± 0.17 | 93.90 ± 0.21 | 94.38 ± 0.26 |
|
| ||||||
| S-Momentum | 10−1 | - | - | 92.73 ± 0.05 | 94.11 ± 0.15 | 95.03 ± 0.15 |
| Adam | 10−3 | 10−8 | - | 91.68 ± 0.12 | 92.82 ± 0.09 | 93.32 ± 0.06 |
| AMSGrad | 10−3 | 10−8 | - | 91.7 ± 0.12 | 93.10 ± 0.11 | 93.71 ± 0.05 |
| PAdam | 10−1 | 10−8 | - | 92.7 ± 0.10 | 94.12 ± 0.12 | 95.06 ± 0.06 |
| PAMSGrad | 10−1 | 10−8 | - | 92.74 ± 0.12 | 94.18 ± 0.06 | 95.21 ± 0.10 |
| AdaBound | 10−2 | 10−8 | - | 91.59 ± 0.24 | 93.09 ± 0.14 | 94.16 ± 0.10 |
| AmsBound | 10−2 | 10−8 | - | 91.76 ± 0.16 | 93.08 ± 0.09 | 94.03 ± 0.11 |
|
| ||||||
| Adam+ | 10−1 | 0.013 | - | 92.89 ± 0.13 | 92.24 ± 0.10 | 94.54 ± 0.13 |
| AMSGrad+ | 10−1 | 0.013 | - | 92.95 ± 0.17 | 94.32 ± 0.10 | 94.58 ± 0.18 |
| Sadam | 10−2 | - | 50 | 93.01 ± 0.16 | 94.26 ± 0.10 | 95.19 ± 0.18 |
| SAMSGrad | 10−2 | - | 50 | 92.88 ±0.10 | 94.32 ± 0.18 | 95.31 ± 0.15 |
Furthermore, two popular CNN architectures: VGGNet [26] and ResNets18 [9] are tested on CIFAR-100 dataset to compare different algorithms. Results can be found in Figure 5 and repeated results are in Appendix. Our proposed methods again perform slightly better than S-Momentum in terms of test accuracy.
Figure 5:
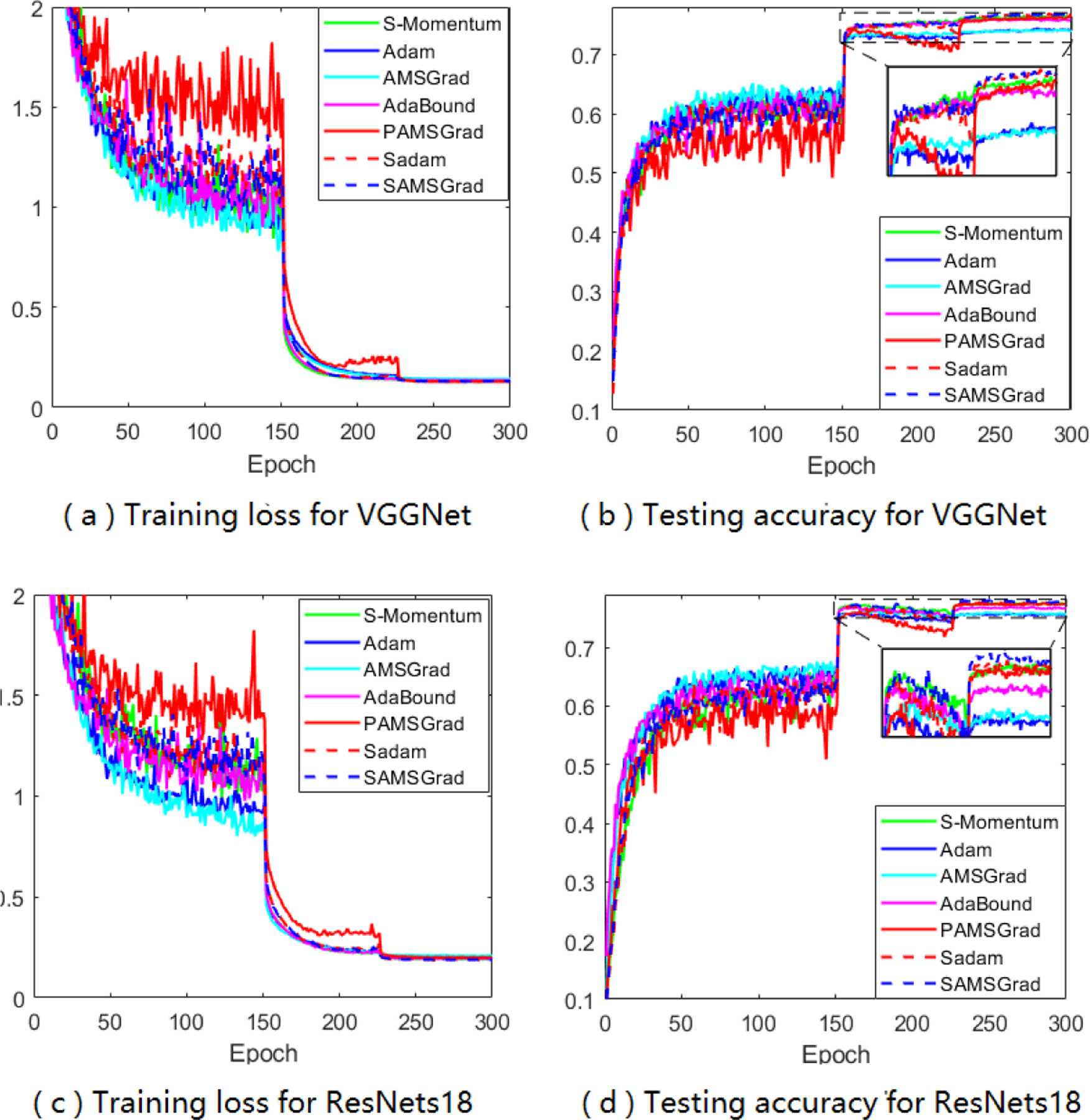
Training loss and test accuracy of two CNN architectures on CIFAR-100.
LSTM Language Models.
Observing the significant improvements in deep neural networks for image classification tasks, we further conduct experiments on the language models with LSTM. For comparing the efficiency of our proposed methods, two LSTM models over the Penn Treebank dataset (PTB) [29] and the WikiText-2 (WT2) dataset [30] are tested. We present the single-model perplexity results for both our proposed methods and other competitive methods in Figure 6 and our methods achieve both fast convergence and best generalization performance.
Figure 6:
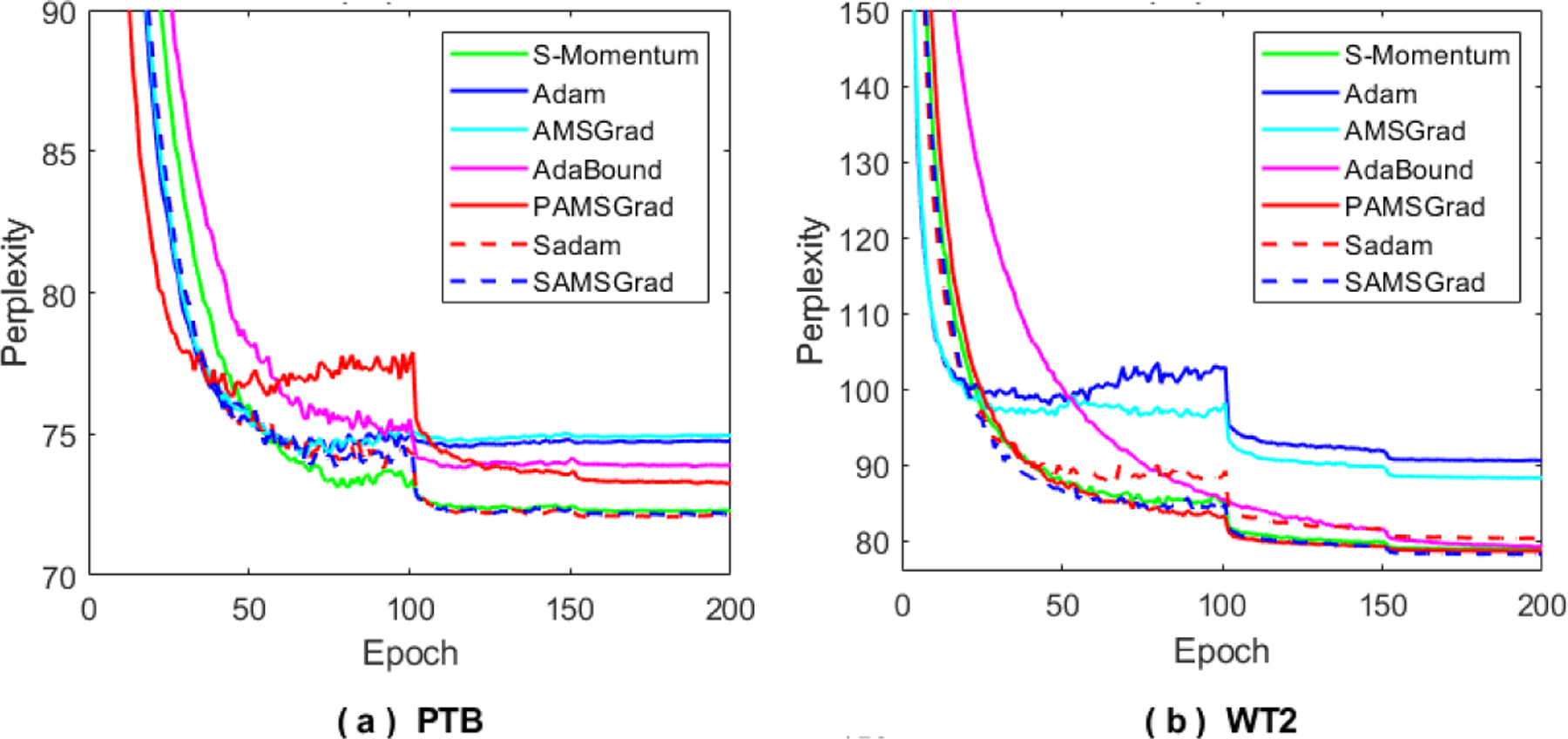
Perplexity curves on the test set on 3-layer LSTM models over PTB and WT2 datasets
In summary, our proposed methods show great efficacy on several standard benchmarks in both training and testing results, and outperform most optimizers in terms of generalization performance.
7. Conclusion
In this paper, we study adaptive gradient methods from a new perspective that is driven by the observation that the adaptive learning rates are anisotropic at each iteration. Inspired by this observation, we propose to calibrate the adaptive learning rates using an activation function, and in this work, we examine softplus function. We combine this calibration scheme with Adam and AMSGrad methods and empirical evaluations show obvious improvement on their generalization performance in multiple deep learning tasks. Using this calibration scheme, we replace the hyper-parameter є in the original methods by a new parameter β in the softplus function. A new mathematical model has been proposed to analyze the convergence of adaptive gradient methods. Our analysis shows that the convergence rate is related to є or β, which has not been previously revealed, and the dependence on є or β helps us justify the advantage of the proposed methods. In the future, the calibration scheme can be designed based on other suitable activation functions, and used in conjunction with any other adaptive gradient method to improve generalization performance.
Acknowledgments
This work was funded by NSF grants CCF-1514357, DBI-1356655, and IIS1718738 to Jinbo Bi, who was also supported by NIH grants K02-DA043063 and R01-DA037349.
Appendix
A.1. Architecture Used in Our Experiments
Here we mainly introduce the MNIST architecture with Pytorch used in our empirical study, ResNets and DenseNets are well-known architectures used in many works and we do not include details here.
| layer | layer setting |
|---|---|
| F.relu(self.conv1(x)) | self.conv1 = nn.Conv2d(1, 6, 5) |
| F.max pool2d(x, 2, 2) | |
| F.relu(self.conv2(x)) | self.conv2 = nn.Conv2d(6, 16, 5) |
| x.view(−1, 16*4) | |
| F.relu(self.fc1(x)) | self.fc1 = nn.Linear(16*4*4, 120) |
| x= F.relu(self.fc2(x)) | self.fc2 = nn.Linear(120, 84) |
| x = self.fc3(x) | self.fc3 = nn.Linear(84, 10) |
| F.log softmax(x, dim=1) |
B.2. More Empirical Results
In this section, we perform multiply experiments to study the property of anisotropic A-LR exsinting in AGMs and the performance of softplus function working on A-LR. We first show the A-LR range of popular Adam-type methods, then present how the parameter β in Sadam and SAMSGrad reduce the range of A-LR and improve both training and testing performance.
B.2.1. A-LR Range of AGMs
Besides the A-LR range of Adam method, which has shown in main paper, we further want to study more other Adam-type methods, and do experiments focus on AMSGrad, PAdam, and PAMSGrad on different tasks (Figure B.2.1, B.2.2, and B.2.3). AMSGrad also has extreme large-valued coordinates, and will encounter the “small learning rate dilemma” as well as Adam. With partial parameter p, the value range of A-LR can be largely narrow down, and the maximum range will be reduced around 102 with PAdam, and less than 102 with PAMSGrad. This reduced range, avoiding the “small learning rate dilemma”, may help us understand what “trick” works on Adam’s A-LR can indeed improve the generalization performance. Besides, the range of A-LR in Yogi, Adabound and Amsbound will be reduced or controlled by specific є or clip function, we don’t show more information here.
B.2.2. Parameter β Reduces the Range of A-LR
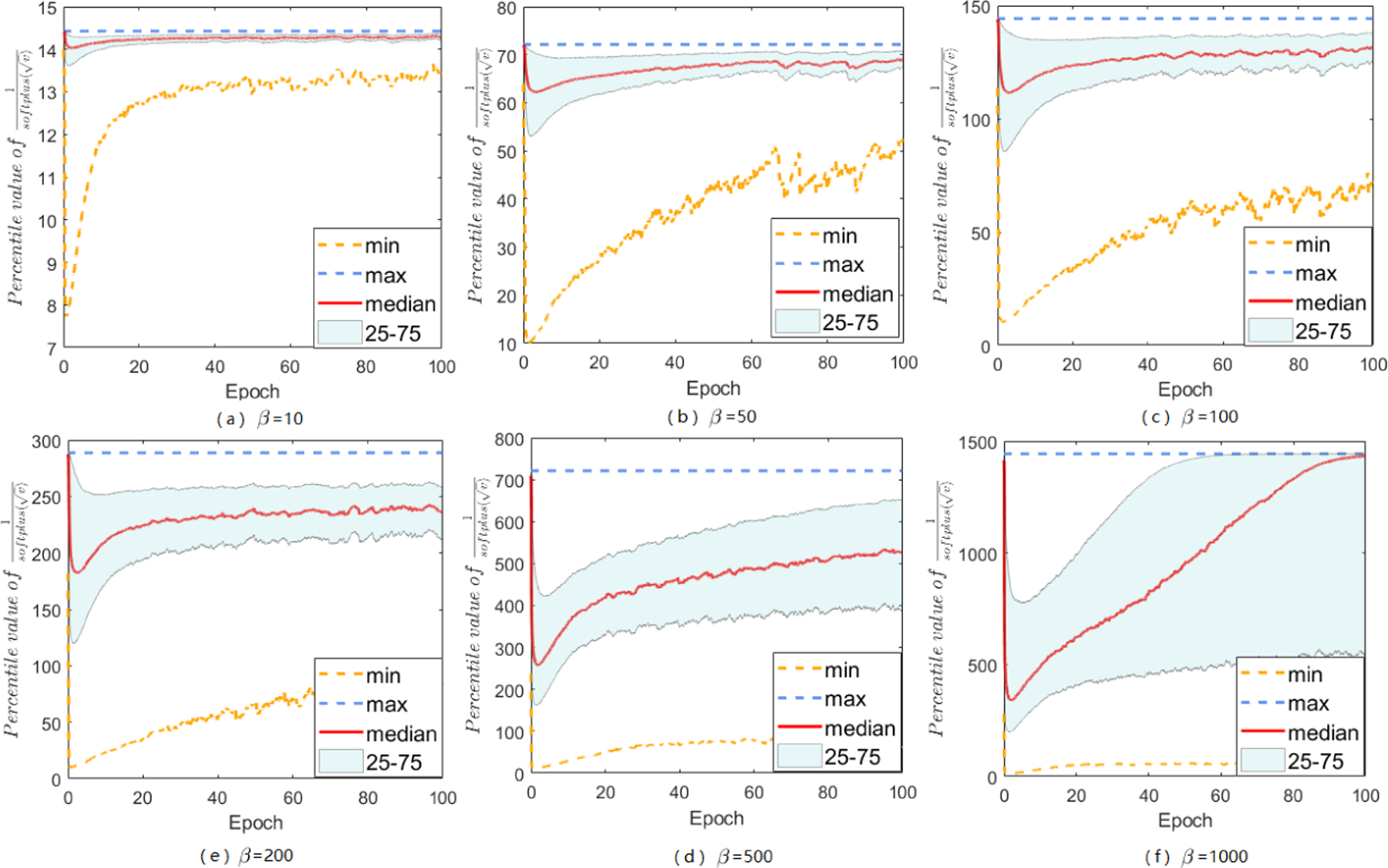
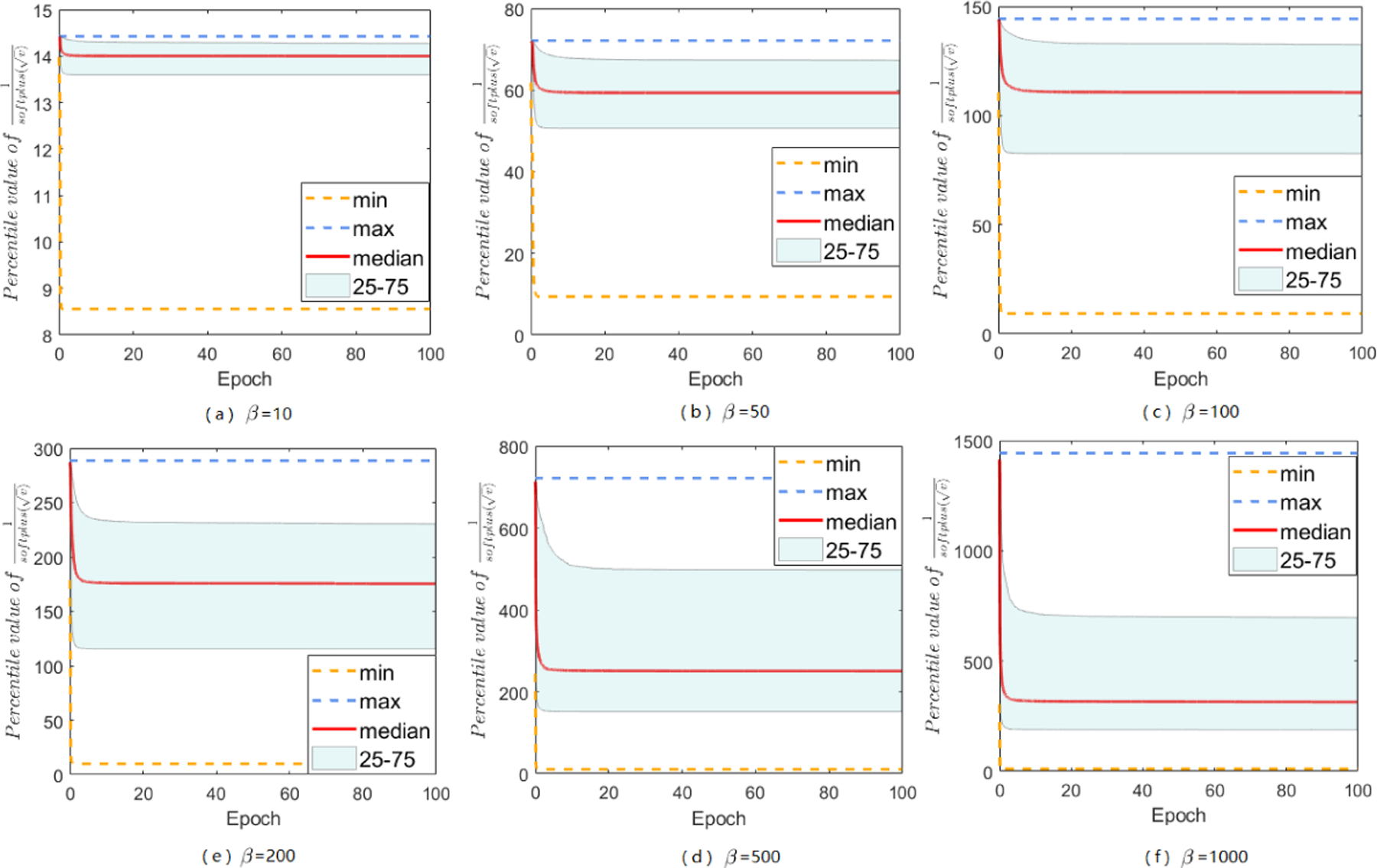
The main paper has discussed about softplus function, and mentions that it does help to constrain large-valued coordinates in A-LR while keep others untouched, here we give more empirical support. No matter how does β set, the modified A-LR will have a reduced range. By setting various β’s, we can find an appropriate β that performs the best for specific tasks on datasets. Besides the results of A-LR range of Sadam on MNIST with different choices of β, we also study Sadam and SAMSGrad on ResNets 20 and DenseNets.
Here we do grid search to choose appropriate β from {10,50,100,200,500,1000}. In summary, with softplus fuction, Sadam and SAMSGrad will narrow down the range of A-LR, make the A-LR vector more regular, avoiding ”small learning rate dilemma” and finally achieve better performance.
B.2.3. Parameter β Matters in Both Training and Testing
After studying existing Adam-type methods, and effect of different β in adjusting A-LR, we focus on the training and testing accuracy of our softplus framework, especially Sadam and SAMSGrad, with different choices of β.
Figure B.2.1:
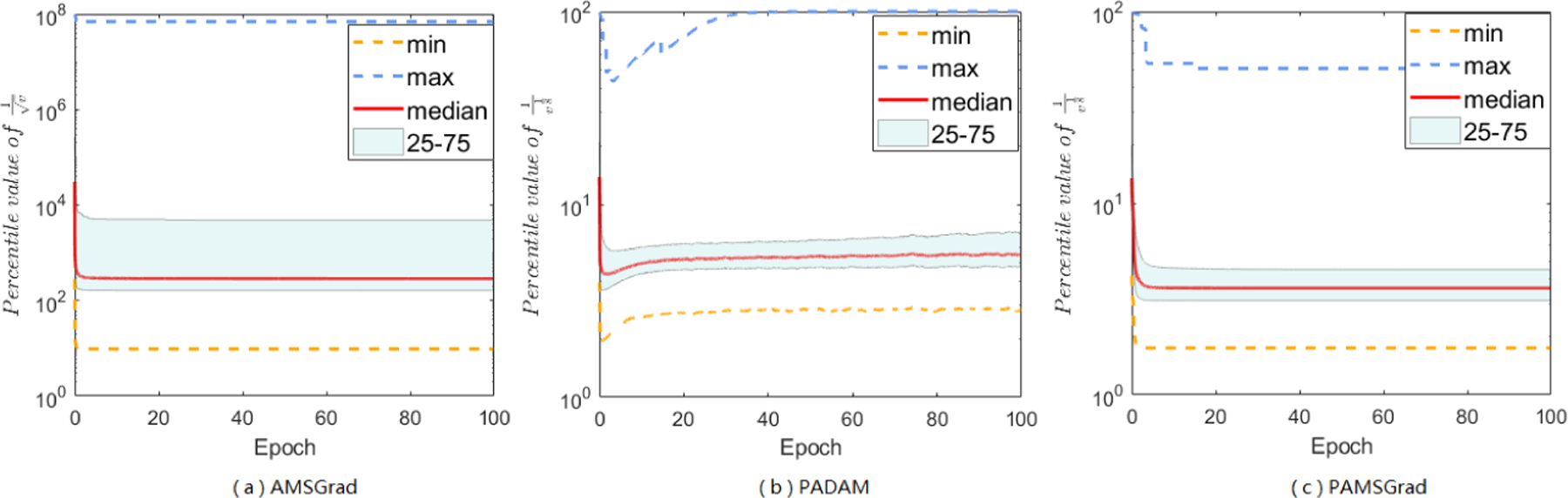
A-LR range of AMSGrad (a), PAdam (b), and PAMSGrad (c) on MNIST.
Figure B.2.2:
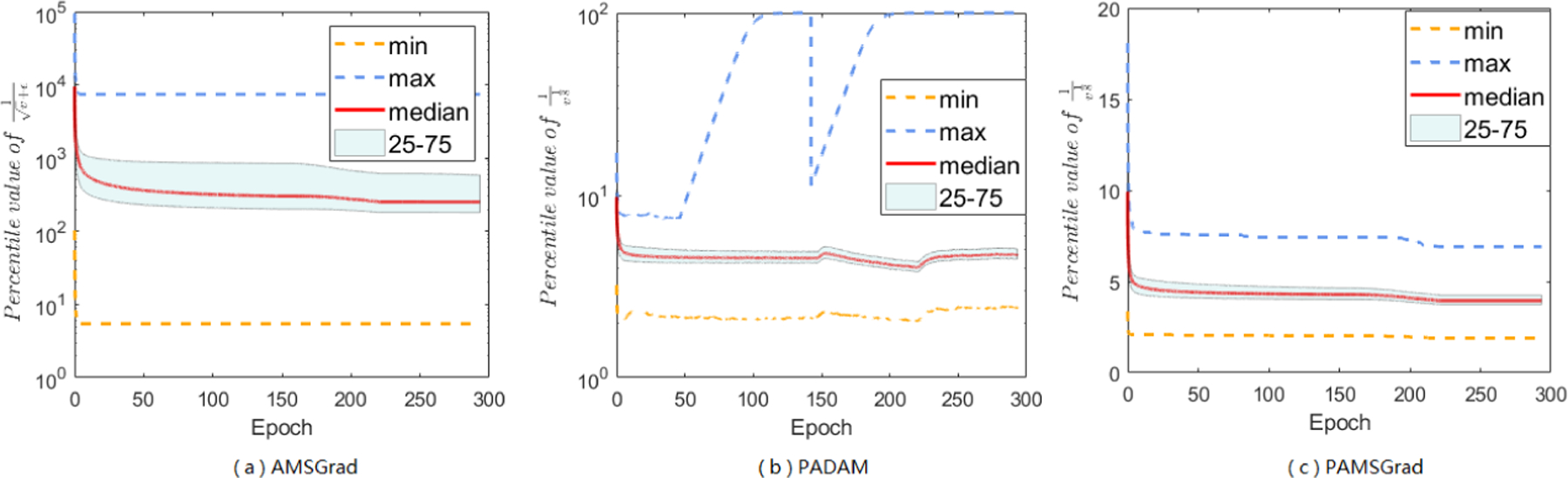
A-LR range of AMSGrad (a), PAdam (b), and PAMSGrad (c) on ResNets 20.
Figure B.2.3:
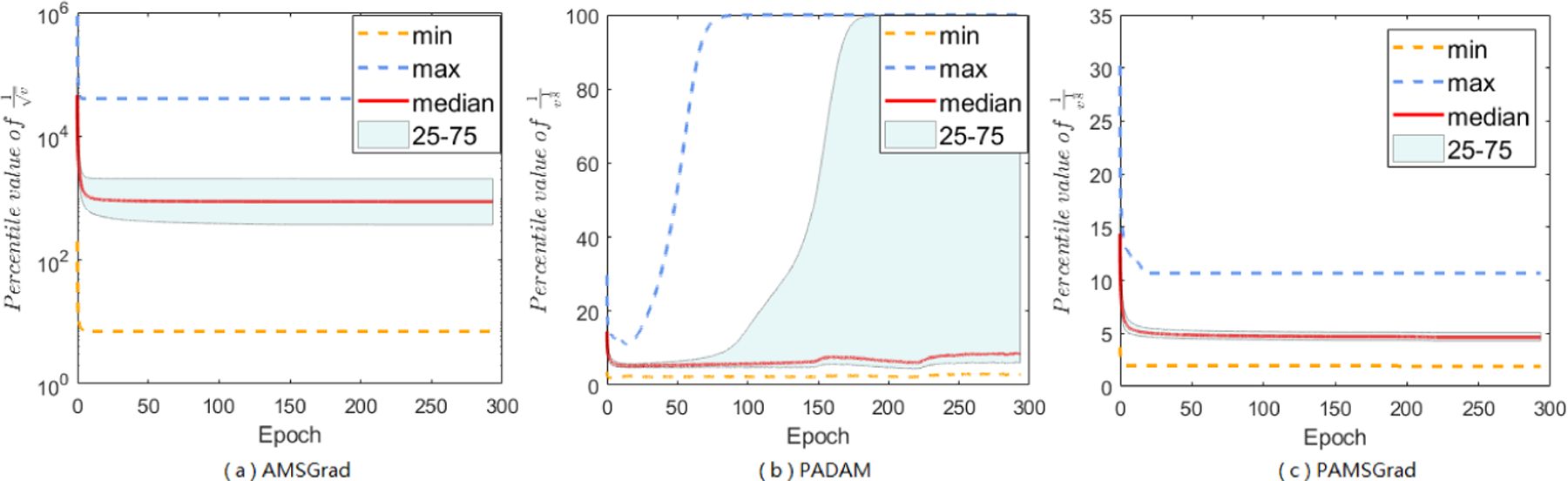
A-LR range of AMSGrad (a), PAdam (b), and PAMSGrad (c) on DenseNets.
Figure B.2.4:
The range of A-LR: over iterations for different choices of β. The maximum ranges in all figures are compressed to a reasonable smaller value compared with 108.
Figure B.2.5:
The range of A-LR: , over iterations for SAMSGrad on MNIST with different choice of β. The maximum ranges in all figures are compressed to a reasonable smaller value compared with those of AMSGrad on MNIST
Figure B.2.6:
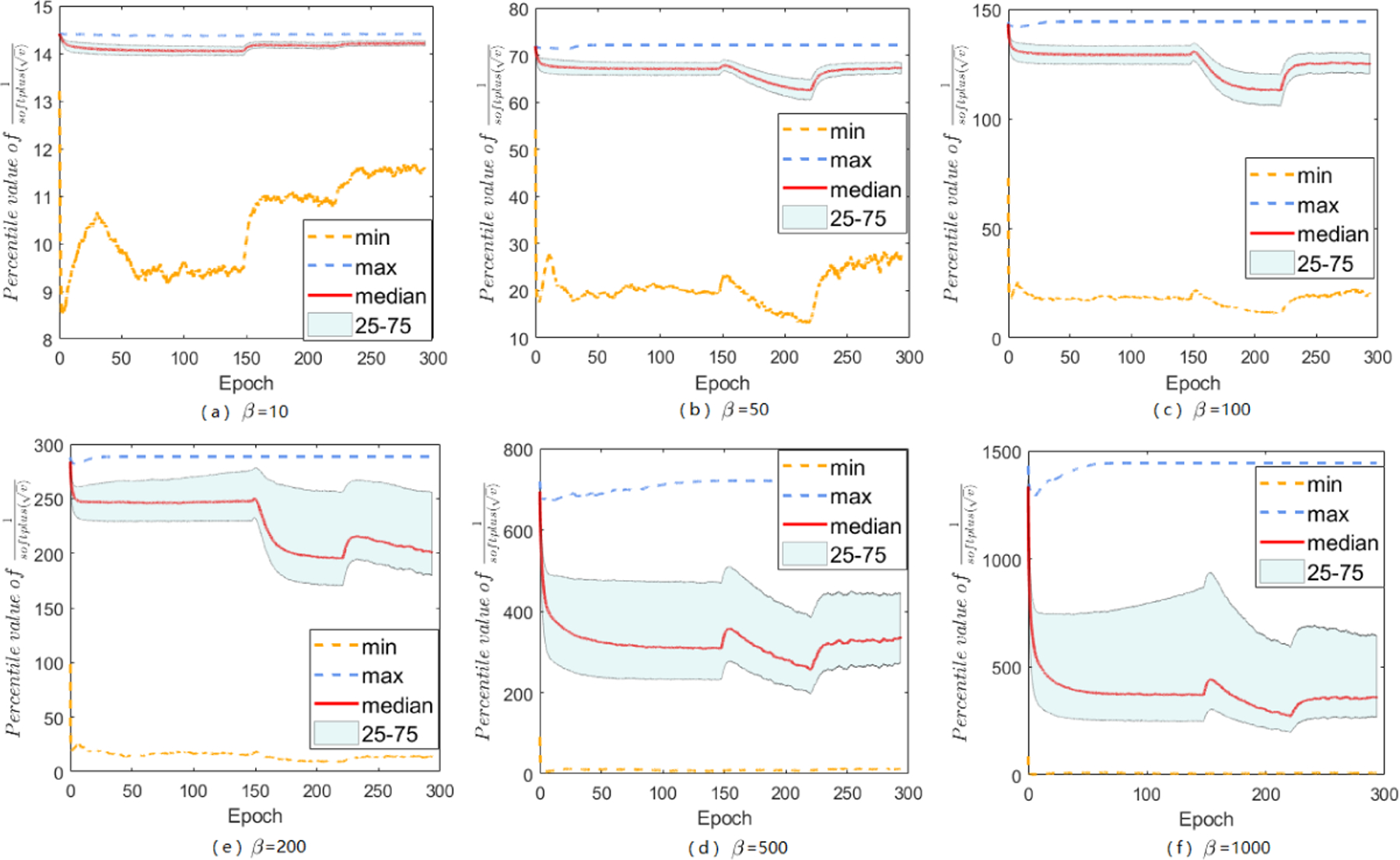
The range of A-LR: over iterations for Sadam on ResNets 20 with different choices of β.
Figure B.2.7:
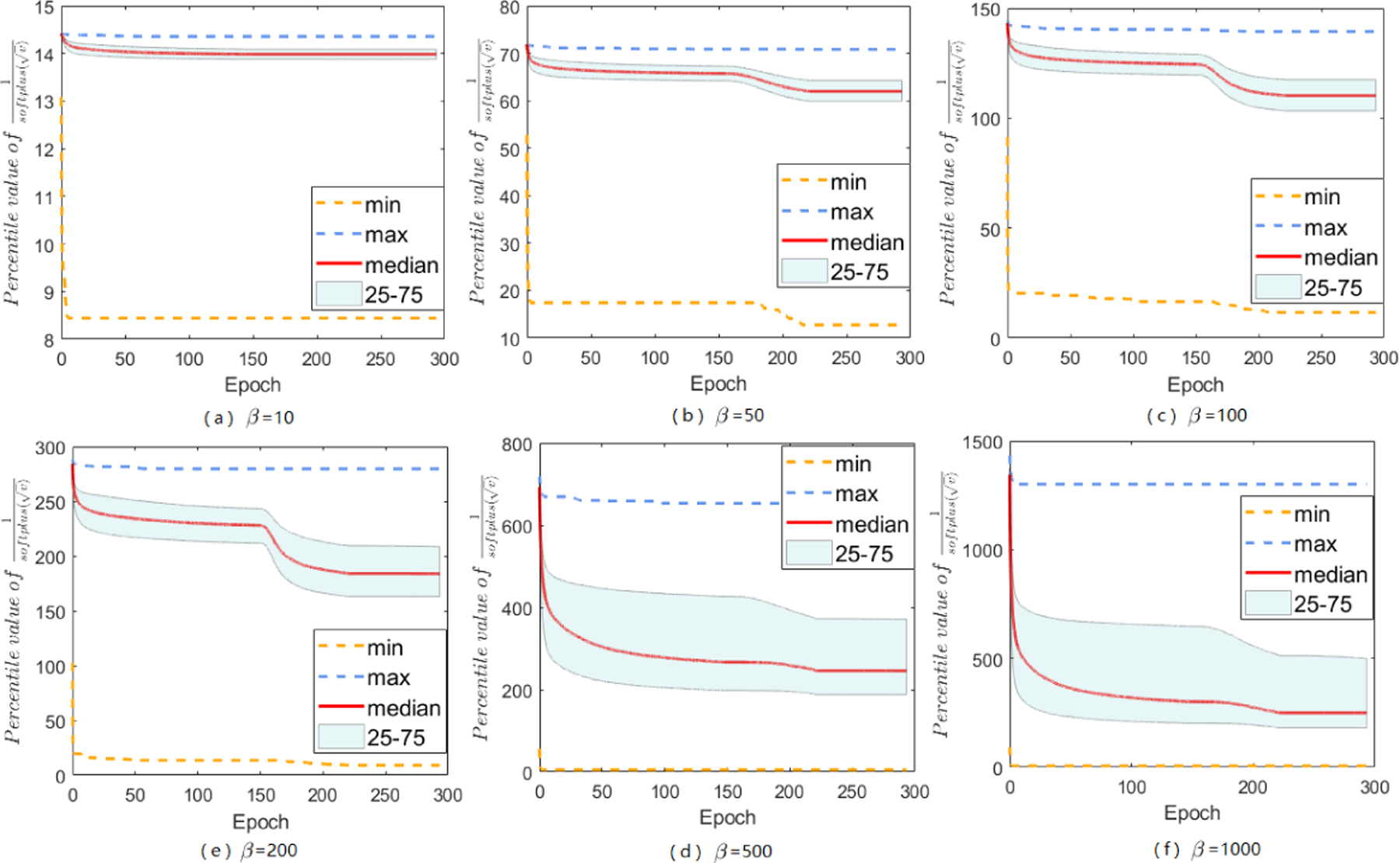
The range of A-LR: , over iterations for SAMSGrad on ResNets 20 with different choices of β.
Figure B.2.8:
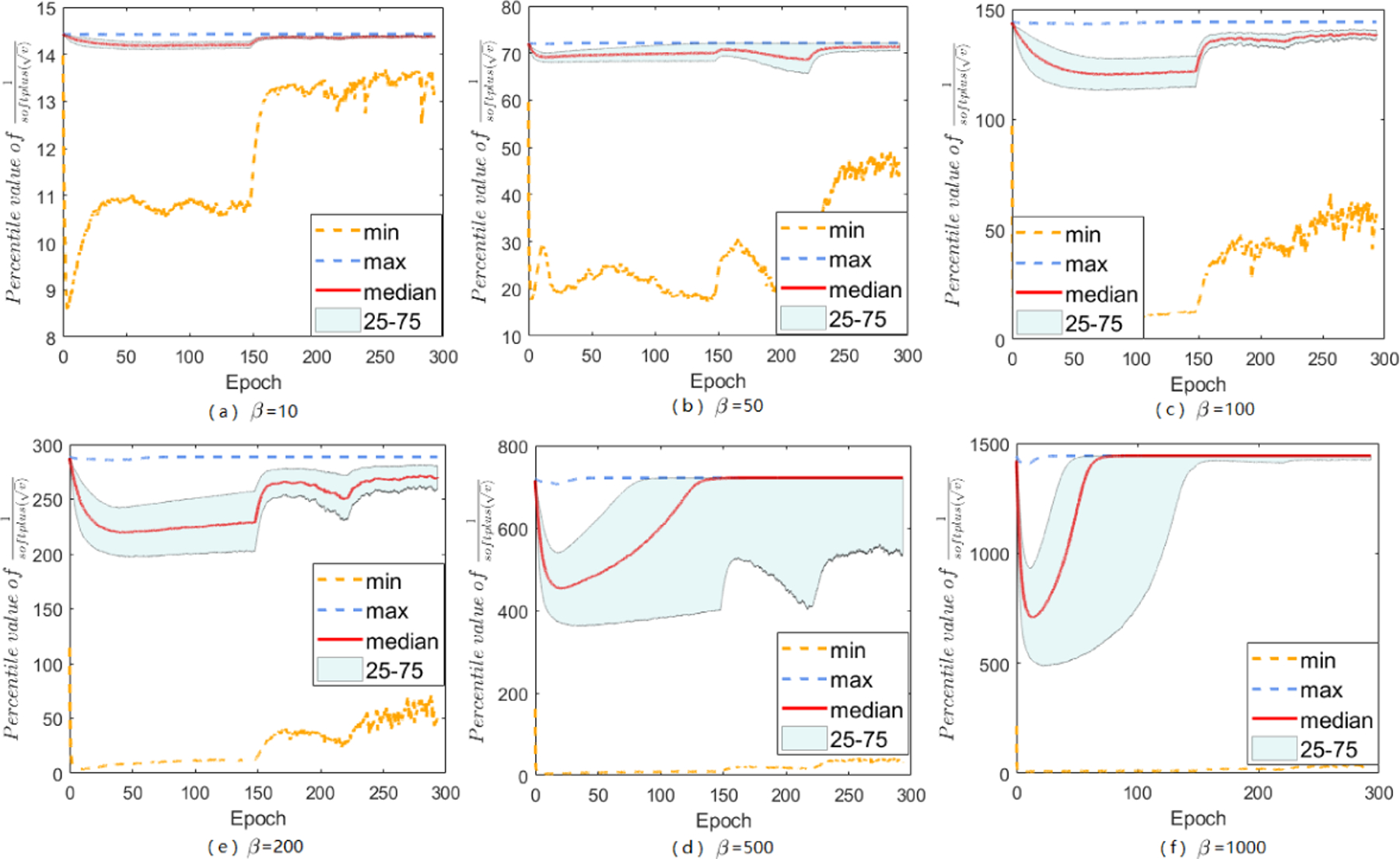
The range of A-LR: over iterations for Sadam on DenseNets with different choice of β.
Figure B.2.9:
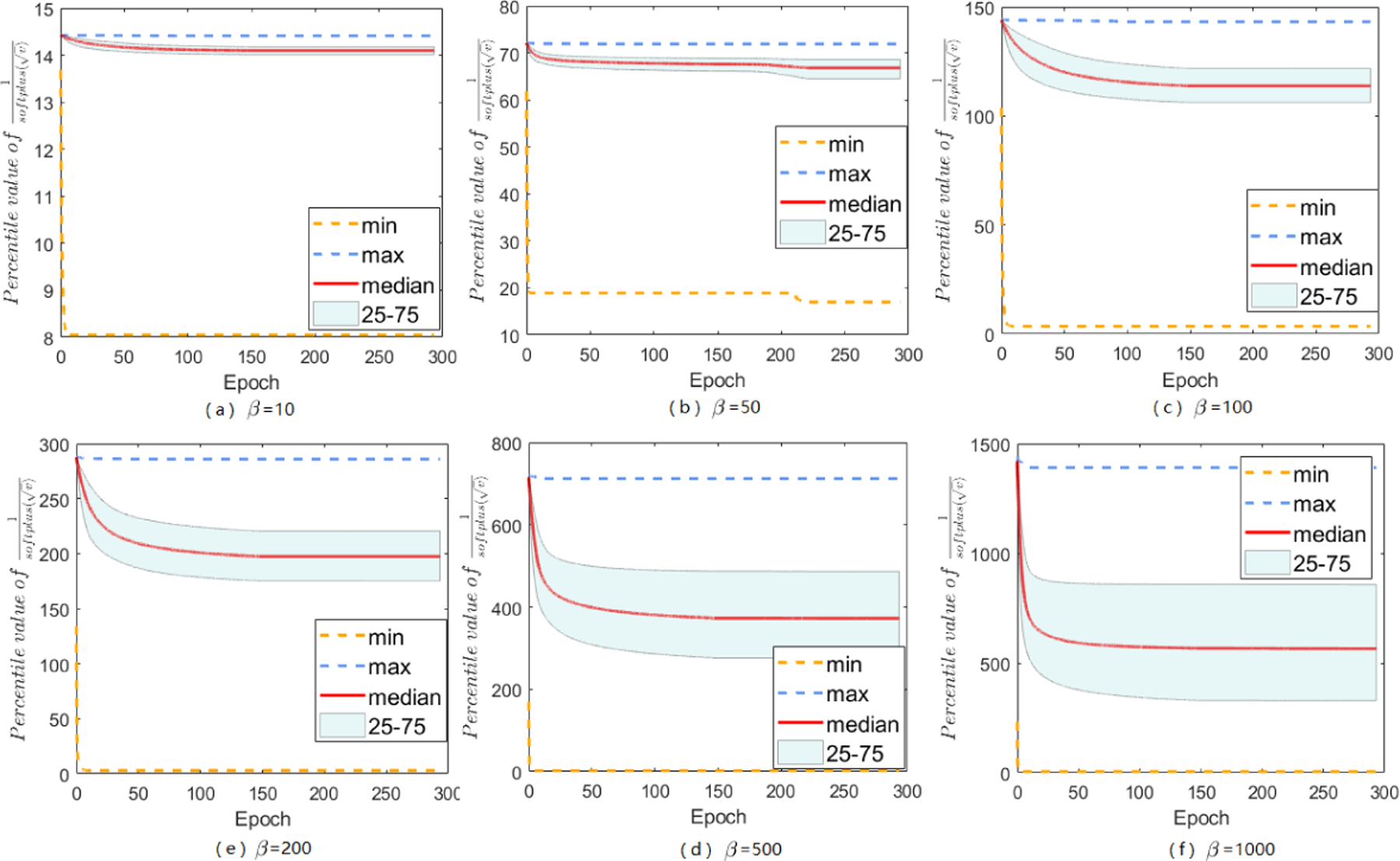
The range of A-LR: , over iterations for SAMSGrad on DenseNets with different choices of β.
Figure B.2.10:
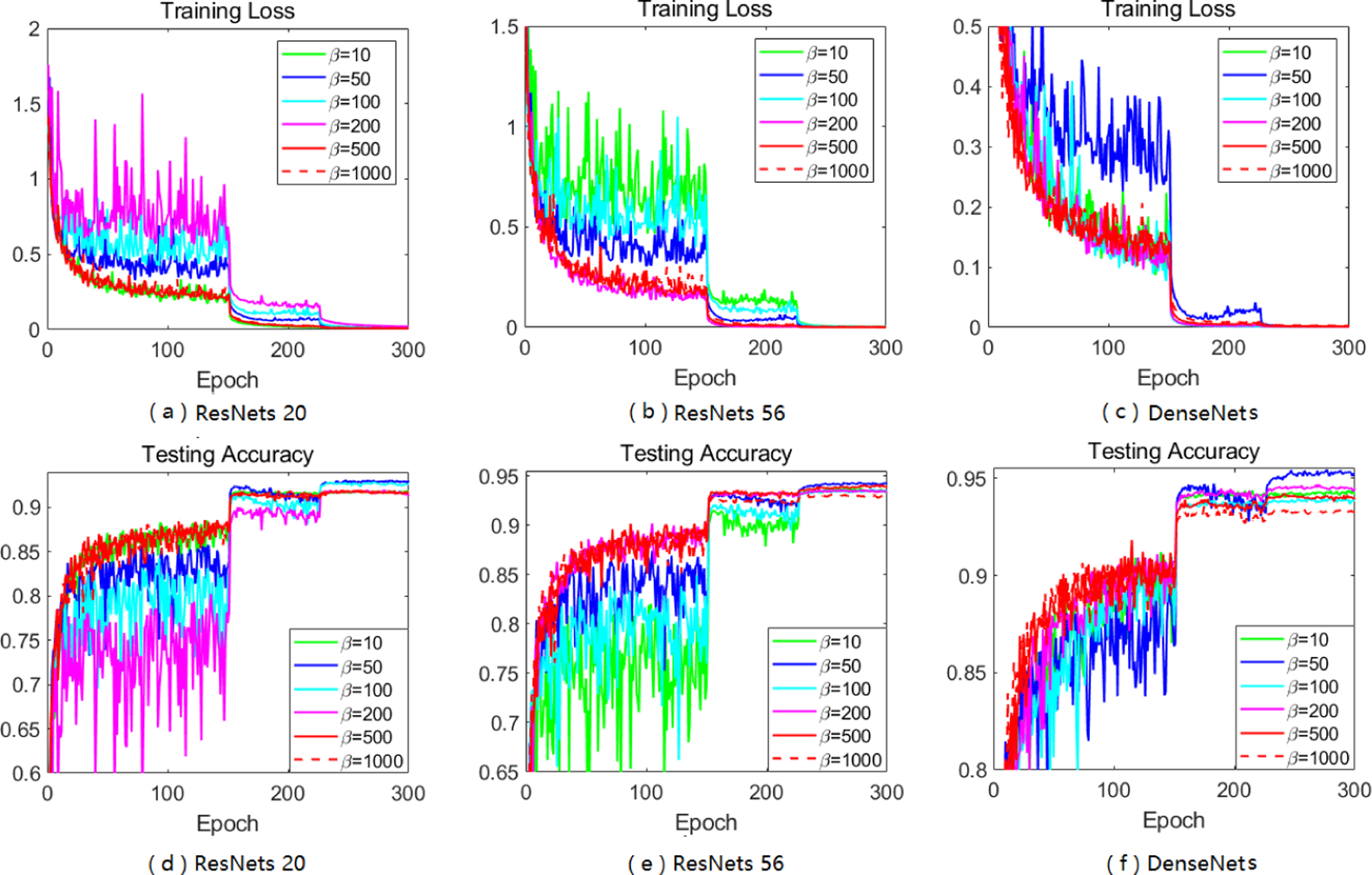
Performance of Sadam on CIFAR-10 with different choice of β.
Figure B.2.11:
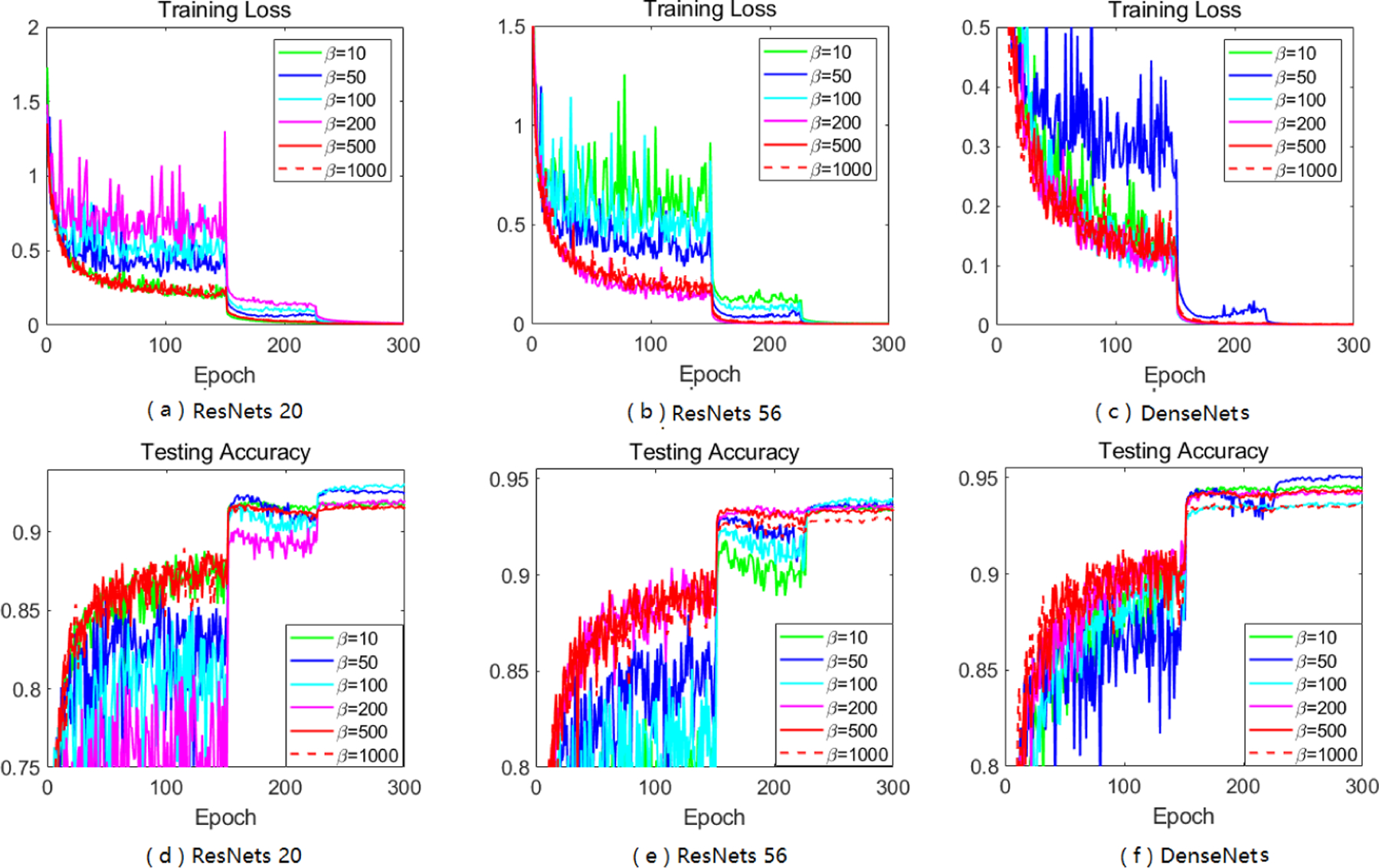
Performance of SAMSGrad on CIFAR-10 with different choice of β.
C.3. CIFAR100
Two popular CNN architectures are tested on CIFAR-100 dataset to compare different algorithms: VGGNet [26] and ResNets18 [9]. Besides the figures in main text, we have repeated experiments and show results as follows. Our proposed methods again perform slightly better than S-Momentum in terms of D.4. Theoretical Analysis Details
Table C.3.1:
Test Accuracy(%) of CIFAR100 for VGGNet.
| Method | 50th epoch | 150th epoch | 250th epoch | best perfomance |
|---|---|---|---|---|
| S-Momentum | 59.09 ± 2.09 | 61.25 ± 1.51 | 76.14 ± 0.12 | 76.43 ± 0.15 |
| Adam | 60.21 ± 0.81 | 62.98 ± 0.10 | 73.81 ± 0.17 | 74.18 ± 0.15 |
| AMSGrad | 61.00 ± 1.17 | 63.27 ± 1.18 | 74.04 ± 0.16 | 74.26 ± 0.18 |
| PAdam | 53.62 ± 1.70 | 56.02 ± 0.86 | 75.85 ± 0.20 | 76.36 ± 0.16 |
| PAMSGrad | 52.49 ± 3.07 | 57.39 ± 1.40 | 75.82 ± 0.31 | 76.26 ± 0.30 |
| AdaBound | 60.27 ± 0.99 | 60.36 ± 1.71 | 75.86 ± 0.23 | 76.10 ± 0.22 |
| AmsBound | 59.88 ± 0.56 | 60.11 ± 1.92 | 75.74 ± 0.23 | 75.99 ± 0.20 |
|
| ||||
| Adam+ | 43.59 ± 2.71 | 44.46 ± 4.39 | 74.91 ± 0.36 | 75.58 ± 0.33 |
| AMSGrad+ | 44.45 ± 2.83 | 45.61 ± 3.67 | 74.85 ± 0.08 | 75.56 ± 0.24 |
| Sadam | 58.59 ± 1.60 | 61.27 ± 1.67 | 76.35 ± 0.18 | 76.64 ± 0.18 |
| SAMSgrad | 59.16 ± 1.20 | 60.86 ± 0.39 | 76.27 ± 0.23 | 76.47 ± 0.26 |
Table C.3.2:
Test Accuracy(%) of CIFAR100 for ResNets18.
| Method | 50th epoch | 150th epoch | 250th epoch | best perfomance |
|---|---|---|---|---|
| S-Momentum | 59.98 ± 1.31 | 63.32 ± 1.61 | 77.19 ± 0.36 | 77.50 ± 0.25 |
| Adam | 63.40 ± 1.42 | 66.18 ± 1.02 | 75.68 ± 0.49 | 76.14 ± 0.24 |
| AMSGrad | 63.16 ± 0.47 | 66.59 ± 1.42 | 75.92 ± 0.26 | 76.32 ± 0.11 |
| PAdam | 56.28 ± 0.87 | 58.71 ± 1.66 | 77.18 ± 0.21 | 77.51 ± 0.19 |
| PAMSGrad | 54.34 ± 2.21 | 58.81 ± 1.95 | 77.41 ± 0.17 | 77.67 ± 0.14 |
| AdaBound | 61.13 ± 0.84 | 64.30 ± 1.84 | 77.18 ± 0.38 | 77.50 ± 0.29 |
| AmsBound | 61.05 ± 1.59 | 62.04 ± 2.10 | 77.08 ± 0.19 | 77.34 ± 0.13 |
|
| ||||
| Adam+ | 46.5 ± 2.12 | 48.68 ± 4.06 | 76.86 ± 0.36 | 77.19 ± 0.28 |
| AMSGrad+ | 49.06 ± 3.23 | 50.75 ± 2.45 | 76.58 ± 0.21 | 76.91 ± 0.12 |
| Sadam | 59.00 ± 1.09 | 62.75 ± 1.03 | 77.26 ± 0.30 | 77.61 ± 0.19 |
| SAMSgrad | 59.63 ± 1.27 | 63.44 ± 1.84 | 77.31 ± 0.40 | 77.70 ± 0.31 |
D.4. Theoretical Analysis Details
We analyze the convergence rate of Adam and Sadam under different cases, and derive competitive results of our methods. The following table gives an overview of stochastic gradient methods convergence rate under various conditions, in our work we provide a different way of proof compared with previous works and also associate the analysis with hyperparameters of Adam methods.
D.4.1. Prepared Lemmas
We have a series of prepared lemmas to help with optimization convergence rate analysis, and some of them maybe also used in generalization error bound analysis.
Lemma D.4.1. For any vectors , , , , here ʘ is element-wise product, is element-wise square root.
Proof.
◻
Lemma D.4.2. For any vector a, we have.
| (2) |
Lemma D.4.3. For unbiased stochastic gradient, we have
| (3) |
Proof. From gradient bounded assumption and variance bounded assumption,
◻
Lemma D.4.4. All momentum-based optimizers using first momentum mt = β1mt−1 + (1 − β1)gt will satisfy
| (4) |
Proof. From the updating rule of first momentum estimator, we can derive
| (5) |
Let , by Jensen inequality and Lemma D.4.3,
◻
Lemma D.4.5. Each coordinate of vector will satisfy
where j ∈ [1,d] is the coordinate index.
Proof. From the updating rule of second momentum estimator, we can derive
| (6) |
Since the decay parameter , . From Lemma D.4.3,
◻
And we can derive the following important lemma:
Lemma D.4.6. [Bounded A-LR] For any t ≥ 1, j ∈ [1,d], β2 ∈ [0,1], and fixed є in Adam and β defined in softplus function in Sadam, the following bounds always hold:
Adam has (µ1,µ2)− bounded A-LR:
| (7) |
Sadam has (µ3,µ4)− bounded A-LR:
| (8) |
where 0 < µ1 ≤ µ2, 0 < µ3 ≤ µ4. For brevity, we use µl,µu denoting the lower bound and upper bound respectively, and both Adam and Sadam will be analysis with the help of (µl,µu).
Proof. For Adam, let , , then we can get the result in (7).
For Sadam, notice that softplus (·) is a monotone increasing function, and is both upper-bounded and lower-bounded, then we have (8), where , .◻
Lemma D.4.7. Define , . Let ηt = η, then the following updating formulas hold: Gradient-based optimizer
| (9) |
Adam optimizer
| (10) |
Sadam optimizer
| (11) |
Proof. We consider the Adam optimizer and let β1 = 0, we can easily derive the gradient-based case.
Similarly, consider the Sadam optimizer:
◻
Lemma D.4.8. As defined in Lemma D.4.7, with the condition that vt ≥ vt−1, i.e., AMSGrad and SAMSGrad, we can derive the bound of distance of as follows:
Adam optimizer
| (12) |
Sadam optimizer
| (13) |
Proof. Adam case:
The first inequality holds because ǁa−bǁ2 ≤ 2ǁaǁ2 + 2ǁbǁ2, the second inequality holds because Lemma D.4.3 and D.4.4 and Lemma D.4.6, the third inequality holds because (a − b)2 ≤ a2 − b2 when a ≥ b, and in our assumption, we have vt ≥ vt−1 holds.
Sadam case:
Because the softplus function is monotone increasing function, therefore, the third inequality holds as well.◻
Lemma D.4.9. As defined in Lemma D.4.7, with the condition that vt ≥ vt−1, we can derive the bound of the inner product as follows:
Adam optimizer
| (14) |
Sadam optimizer
| (15) |
Proof. Since the stochastic gradient is unbiased, then we have E[gt] = ∇f(xt).
Adam case:
The first inequality holds because , the second inequality holds for L-smoothness, the last inequalities hold due to Lemma D.4.4 and D.4.6.
Similarly, for Sadam, we also have the following result:
◻
D.4.2. Adam Convergence in Nonconvex Setting
Proof. All the analyses hold true under the condition: vt ≥ vt−1. From L-smoothness and Lemma D.4.7, we have
Take expectation on both sides,
Plug in the results from prepared lemmas, then we have,
Applying the bound of mt and ∇f(zt),
By rearranging,
For the LHS above:
Then we obtain:
Divide ηµ1 on both sides:
Summing from t = 1 to T, where T is the maximum number of iteration,
Since v0 = 0, , we have
Divided by ,
The second inequality holds because .
Setting , let x0 = x1, then z1 = x1, f(z1) = f(x1) we derive the final result:
where
With fixed L,σ,G,β1, we have , , .
Therefore,
◻
Thus, we get the sublinear convergence rate of Adam in nonconvex setting, which recovers the well-known result of SGD ([1]) in nonconvex optimization in terms of T.
Remark D.4.10. The leading item from the above convergence is , є plays an essential role in the complexity, and we derive a more accurate order . At present, є is always underestimated and considered to be not associated with accuracy of the solution ([14]). However, it is closely related with complexity, and with bigger є, the computational complexity should be better. This also supports the analysis of of Adam in our main paper.
In some other works, people use σi or Gi to show all the element-wise bound, and then by applying , to hide d in the complexity. Here in our work, we didn’t specify write out σi or Gi, instead we use σ,G through all the procedure.
D.4.3. Sadam Convergence in Nonconvex Setting
As Sadam also has constrained bound pair (µ3,µ4), we can learn from the proof of Adam method, which provides us a general framework of such kind of adaptive methods.
Similar to the Adam proof, from L-smoothness and Lemma D.4.7, we have
Proof. All the analyses hold true under the condition: vt ≥ vt−1. From L-smoothness and Lemma D.4.7, we have
Taking expectation on both sides, and plug in the results from prepared lemmas, then we have,
By rearranging,
For the LHS above:
Then we obtain:
Divide ηµ3 on both sides and then sum from t = 1 to T, where T is the maximum number of iteration,
Since, v0 =0, , we have
Divided by ,
Setting , let x0 = x1, then z1 = x1, f(z1) = f(x1) we derive the final result for Sadam method:
where
With fixed L,σ,G,β1, we have C1 = O(β2), C2 = O(dβ), C3 = O(dβ2).
Therefore,
◻
Thus, we get the sublinear convergence rate of Sadam in nonconvex setting, which is the same order of Adam and recovers the well-known result of SGD [1] in nonconvex optimization in terms of T.
Remark D.4.11. The leading item from the above convergence is , β plays an essential role in the complexity, and a more accurate convergence should be . When β is chosen big, this will become , somehow behave like Adam’s case as , which also guides us to have a range of β; when β is chosen small, this will become , the computational complexity will get close to SGD case, and β is a much smaller number compared with 1/є, proving that Sadam converges faster. This also supports the analysis of range of A-LR: in our main paper.
D.4.4. Non-strongly Convex
In previous works, convex case has been well-studied in adaptive gradient methods. AMSGrad and later methods PAMSGrad both use a projection on minimizing objective function, here we want to show a different way of proof in non-strongly convex case. For consistency, we still follow the construction of sequence {zt}.
Starting from convexity:
Then, for any , ∀t ∈ [1,T],
| (16) |
where f∗ = f(x∗), x∗ is the optimal solution.
Proof. Adam case:
In the updating rule of Adam optimizer, , setting stepsize to be fixed, ηt = η, and assume vt ≥ vt−1 holds. Using previous results,
The first inequality holds due to ǁa−bǁ2 ≤ 2ǁaǁ2 +2ǁbǁ2, the second inequality holds due to Lemma D.4.3, D.4.4, D.4.6.
Since, ,
From the definition of zt and convexity,
Plugging in previous two inequalities:
By rearranging:
Divide 2ηµ1 on both sides,
Assume that , for any m ≠ n, hold, then E[ǁzt − x∗ǁ2] can be bounded.
| (17) |
| (18) |
Thus:
Summing from t = 1 to T,
The second inequality is based on the fact that, when iteration t reaches the maximum number T, xt is the optimal solution, zT = x∗.
By Jensen’s inequality,
where .
Then,
By plugging the stepsize , we complete the proof of Adam in non-strongly convex case.
◻
Remark D.4.12. The leading item of convergence order of Adam should be , where . With fixed , which also contains as well as dimension d, here with bigger є, the order should be better, this also supports the discussion in our main paper.
The analysis of Sadam is similar to Adam, by replacing the bounded pairs (µ1,µ2) with (µ3,µ4), we briefly give convergence result below.
Proof. Sadam case:
By plugging the stepsize , we get the convergence rate of Sadam in non-strongly convex case.
For brevity,
◻
Remark D.4.13. The leading item of convergence order of Sadam should be , where . With fixed L,σ,G,β1,D,D∞, , with small β, the Sadam will be similar to SGD convergence rate, and β is a much smaller number compared with 1/є, proving that Sadam method perfoms better than Adam in terms of convergence rate.
D.4.5. P-L Condition
Suppose that strongly convex assumption holds, we can easily deduce the P-L condition (see Lemma D.4.14), which shows that P-L condition is much weaker than strongly convex condition. And we further prove the convergence of Adam-type optimizer (Adam and Sadam) under the P-L condition in non-strongly convex case, which can be extended to the strongly convex case as well.
Lemma D.4.14. Suppose that f is continuously diffentiable and strongly convex with parameter γ. Then f has the unique minimizer, denoted as f∗ = f(x∗). Then for any , we have
Proof. From strongly convex assumption,
Letting ξ = x∗ − x, when , the quadratic function can achieve its minimum.◻
We restate our theorems under PL condition.
Theorem D.4.15. Suppose f(x) satisfies Assumption 1 and PL condition (with parameter λ) in non-strongly convex case and vt ≥ vt−1. Let ,
Adam and Sadam have convergence rate
Proof. Adam case:
Starting from L-smoothness, and borrowing the previous results we already have
Therefore, we get:
From P-L condition assumption,
From convexity,
From L-smoothness,
Then we can obtain
By rearranging,
From the fact , and Lemma D.4.1, D.4.4,
Similar,
Then,
The last inequality holds because .
Let
then we have
Let , then ,
Let t = T,
From the above inequality, η should be set less than to ensure all items in the RHS small enough.
Set , then
With appropriate η, we can derive the convergence rate under P-L condition (strongly convex) case.
The proof of Sadam is exactly same as Adam, by replacing the bounded pairs (µ1,µ2) with (µ3,µ4), and we can also get:
By setting appropriate η, we can also prove the Sadam converges under PL condition (and strongly convex).
Set ,
Overall, we have proved Adam algorithm and Sadam in all commonly used conditions, our designed algorithms always enjoy the same convergence rate compared with Adam, and even get better results with appropriate choice of β defined in softplus function. The proof procedure can be easily extended to other adaptive gradient algorithms, and theoretical results support the discussion and experiments in our main paper.
Footnotes
The PAdam in [19] actually used AMSGrad, and for clear comparison, we named it PAMSGrad. In our experiments, we also compared with the Adam that used the A-LR formula with p, which we named PAdam.
This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- [1].Ghadimi S, Lan G, Stochastic first-and zeroth-order methods for nonconvex stochastic programming, SIAM Journal on Optimization 23 (4) (2013) 2341–2368. [Google Scholar]
- [2].Wright SJ, Nocedal J, Numerical optimization, Springer Science 35 (6768) (1999) 7. [Google Scholar]
- [3].Wilson AC, Recht B, Jordan MI, A lyapunov analysis of momentum methods in optimization, arXiv preprint arXiv:1611.02635
- [4].Yang T, Lin Q, Li Z, Unified convergence analysis of stochastic momentum methods for convex and non-convex optimization, arXiv preprint arXiv:1604.03257
- [5].Duchi J, Hazan E, Singer Y, Adaptive subgradient methods for online learning and stochastic optimization, Journal of Machine Learning Research 12 (Jul) (2011) 2121–2159. [Google Scholar]
- [6].Kingma DP, Ba J, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980
- [7].Zeiler MD, Adadelta: an adaptive learning rate method, arXiv preprint arXiv:1212.5701
- [8].Tieleman T, Hinton G, Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude, COURSERA: Neural networks for machine learning 4 (2) (2012) 26–31. [Google Scholar]
- [9].He K, Zhang X, Ren S, Sun J, Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [10].Zagoruyko S, Komodakis N, Wide residual networks, arXiv preprint arXiv:1605.07146
- [11].Huang G, Liu Z, Van Der Maaten L, Weinberger KQ, Densely connected convolutional networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [12].Reddi SJ, Kale S, Kumar S, On the convergence of adam and beyond
- [13].Luo L, Xiong Y, Liu Y, Sun X, Adaptive gradient methods with dynamic bound of learning rate, arXiv preprint arXiv:1902.09843
- [14].Zaheer M, Reddi S, Sachan D, Kale S, Kumar S, Adaptive methods for nonconvex optimization, in: Advances in Neural Information Processing Systems, 2018, pp. 9815–9825.
- [15].Zhou D, Tang Y, Yang Z, Cao Y, Gu Q, On the convergence of adaptive gradient methods for nonconvex optimization, arXiv preprint arXiv:1808.05671
- [16].Chen X, Liu S, Sun R, Hong M, On the convergence of a class of adam-type algorithms for non-convex optimization, arXiv preprint arXiv:1808.02941
- [17].De S, Mukherjee A, Ullah E, Convergence guarantees for rmsprop and adam in non-convex optimization and an empirical comparison to nesterov acceleration
- [18].Staib M, Reddi SJ, Kale S, Kumar S, Sra S, Escaping saddle points with adaptive gradient methods, arXiv preprint arXiv:1901.09149
- [19].Chen J, Gu Q, Closing the generalization gap of adaptive gradient methods in training deep neural networks, arXiv preprint arXiv:1806.06763
- [20].Reddi SJ, Hefny A, Sra S, Poczos B, Smola AJ, On variance reduction in stochastic gradient descent and its asynchronous variants, in: Advances in Neural Information Processing Systems, 2015, pp. 2647–2655. [PMC free article] [PubMed]
- [21].Kleinberg R, Li Y, Yuan Y, An alternative view: When does sgd escape local minima?, in: International Conference on Machine Learning, 2018, pp. 2703–2712.
- [22].Keskar NS, Mudigere D, Nocedal J, Smelyanskiy M, Tang PTP, On large-batch training for deep learning: Generalization gap and sharp minima, arXiv preprint arXiv:1609.04836
- [23].Chaudhari P, Choromanska A, Soatto S, LeCun Y, Baldassi C, Borgs C, Chayes J, Sagun L, Zecchina R, Entropy-sgd: Biasing gradient descent into wide valleys, arXiv preprint arXiv:1611.01838
- [24].Li H, Xu Z, Taylor G, Studer C, Goldstein T, Visualizing the loss landscape of neural nets, in: Advances in Neural Information Processing Systems, 2018, pp. 6389–6399.
- [25].Dozat T, Incorporating nesterov momentum into adam
- [26].Simonyan K, Zisserman A, Very deep convolutional networks for largescale image recognition, arXiv preprint arXiv:1409.1556
- [27].Merity S, Keskar NS, Socher R, Regularizing and Optimizing LSTM Language Models, arXiv preprint arXiv:1708.02182
- [28].Keskar NS, Socher R, Improving generalization performance by switching from adam to sgd, arXiv preprint arXiv:1712.07628
- [29].Mikolov T, Karafiát M, Burget L, Černockỳ J, Khudanpur S, Recurrent neural network based language model, in: Eleventh annual conference of the international speech communication association, 2010.
- [30].Bradbury J, Merity S, Xiong C, Socher R, Quasi-recurrent neural networks, arXiv preprint arXiv:1611.01576