

Abstract
During the past decade, polygenic scores have become a fast-growing area of research in the behavioural sciences. The ability to directly assess people’s genetic propensities has transformed research by making it possible to add genetic predictors of traits to any study. The value of polygenic scores in the behavioural sciences rests on using inherited DNA differences to predict, from birth, common disorders and complex traits in unrelated individuals in the population. This predictive power of polygenic scores does not require knowing anything about the processes that lie between genes and behaviour. It also does not mandate disentangling the extent to which the prediction is due to assortative mating, genotype–environment correlation, or even population stratification. Although bottom-up explanation from genes to brain to behaviour will remain the long-term goal of the behavioural sciences, prediction is also a worthy achievement because it has immediate practical utility for identifying individuals at risk and is the necessary first step towards explanation. A high priority for research must be to increase the predictive power of polygenic scores to be able to use them as an early warning system to prevent problems.
Subject terms: Psychology, Genetics
Research using polygenic scores emerged as a fast-growing area in the behavioural sciences during the past decade. Polygenic scores consist of sums of thousands of single-nucleotide polymorphisms (SNPs) each weighted by the effect size of its association with a target trait derived from genome-wide association studies [1].
In 2009, the first paper was published reporting a polygenic score that predicted up to 3% of the liability to schizophrenia in independent case–control samples [2]. Since then, 2783 articles using polygenic scores have been listed on the Web of Science (search terms ‘polygenic score’ OR ‘polygenic risk score’ OR ‘polygenic risk’). The largest field of polygenic score research is the behavioural sciences (Web of Science categories: psychiatry, neuroscience, behavioural science, psychology, psychology multidisciplinary, psychological development and psychology clinical, with overlapping publications removed), which accounts for 45% (N = 1271) of the total publications. Figure 1 shows the dramatic rise of these 1271 polygenic score publications and their 14,228 citations, reaching 4636 citations in 2020.
Fig. 1. Polygenic score publications in the behavioural sciences per year since 2009.
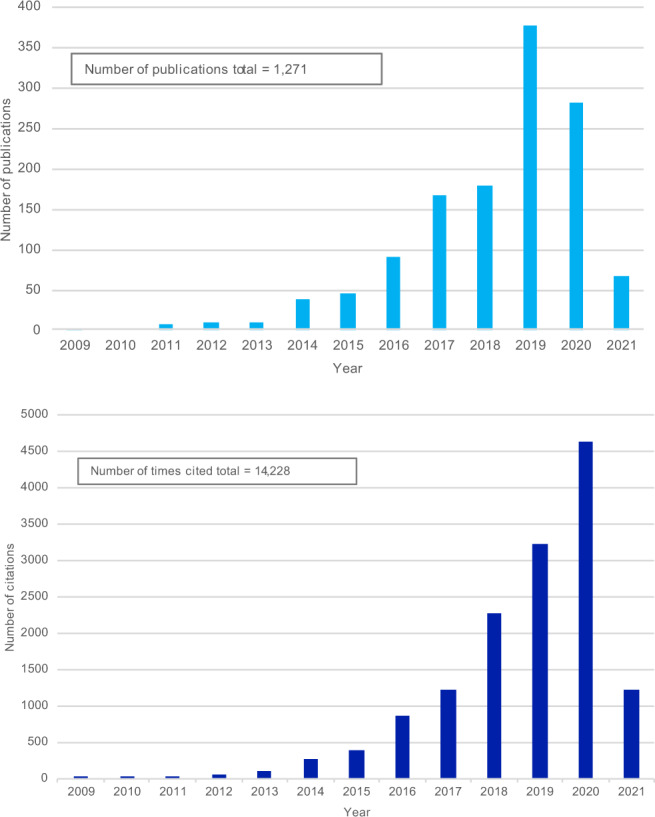
Top: number of publications. Bottom: Number of times cited. Data from Web of Science, April 2021.
Prediction
The predictive power of polygenic scores has increased steadily during the past decade for dozens of common disorders and complex traits. For example, the polygenic score for schizophrenia, which predicted up to 3% of the liability variance in 2009, can now predict 6% [3]. Polygenic scores can predict 2% of the liability variance for major depressive disorder [4], 5% for bipolar disorder [5], 3% for neuroticism [6], 6% for attention deficit hyperactivity disorder [7] and 10% for externalising behaviours [8]. In the cognitive realm, variance predicted by polygenic scores is 7% for general cognitive ability (intelligence) [9], 11% for years of schooling (educational attainment (EA)) [10] and 15% for tested school performance at age 16 [11], which is the most predictive polygenic score in the behavioural sciences.
Explain is the word used in statistical parlance to refer to effect sizes, but the word predict is more appropriate because polygenic scores do not explain how inherited DNA differences become associated with behavioural traits. Polygenic score predictions of behavioural traits are correlations and correlations do not imply causation. Causation is a complicated concept that generally refers to mechanisms that precede effects, often identified by experimental manipulation. Here, however, we refer to explanation in the more limited sense of statistical models of nonexperimental data that attempt to infer causation from correlational data [12, 13].
The purpose of this perspective is to contrast prediction and explanation. Prediction and explanation offer different scientific perspectives, and neither is right nor wrong, just more or less useful to achieve different research goals. The goal of prediction is to account for as much variance as possible, without regard for explanation. The goal of explanation is to deduce causality, without regard for prediction [14, 15]. These perspectives can be complementary, for example, if explanatory models are validated in terms of prediction, and if knowledge of causal processes leads to better prediction.
The value of explanation without prediction is seldom questioned but we argue here that prediction without explanation is also valuable. This point is widely acknowledged in some scientific disciplines, for example, in artificial intelligence where machine learning is an increasingly popular tool for prediction that explicitly eschews explanation. However, in the behavioural sciences, evidence for prediction has often been downplayed and devalued if it was devoid of explanation. This attitude seems especially paradoxical in the context of genomic research because success in identifying DNA differences came only after the search for candidate genes selected for their possible causal connection to a trait was superseded by a hypothesis-free approach that is agnostic about the specific function of DNA variants (i.e., genome-wide association).
The predictive power of polygenic scores is groundbreaking. Predicting 10% of the variance marks an important milestone because effect sizes of this magnitude are large enough to be ‘perceptible to the naked eye of a reasonably sensitive observer’ [16]. Nonetheless, 10% of the variance is equivalent to a correlation of only 0.32, and the resulting oval-shaped scatterplot between the polygenic score and a trait indicates the probabilistic nature of polygenic score prediction at the level of an individual [17, 18]. Even so, useful predictions can be made at the extremes. For example, the lowest and highest deciles for the polygenic score for IQ yield mean IQs of 92 and 108, respectively. For the polygenic score for EA, 25% of those in the lowest decile go to university as compared to 75% of those in the highest decile [18]. Being in the top decile of polygenic scores for schizophrenia is associated with an odds ratio of 4.6 for becoming diagnosed with schizophrenia as compared to the bottom decile; this is similar to the risk that either smoking or diabetes poses for experiencing coronary artery disease [19].
Polygenic score prediction compares favourably with other predictors in the behavioural sciences, which are rarely subjected to the same harsh spotlight of effect size. For example, in contrast to polygenic scores that predict 15% of the variance in tested school performance in the UK at age 16, ratings of school quality obtained by an independent body of evaluators (Ofsted) only predict 4% of the variance in the same tests of school performance [20]. Despite its modest effect size, school quality ratings are used by parents to decide which schools their children will attend [21].
Polygenic scores will never predict complex traits with perfect precision because heritabilities are about 50% for most behavioural traits [22]. Other limitations can be surmounted, most notably, the ‘missing heritability’ gap between variance predicted by polygenic scores and twin study estimates of heritability [23]. The missing heritability gap will be narrowed with bigger and better genome-wide association studies and with whole-genome sequencing that assesses all DNA differences in the genome rather than several hundred thousand SNPs assessed in current studies [24]. The only way is up for the predictive power of polygenic scores.
The ability to directly assess people’s genetic propensities has transformed research by enhancing the power and precision of genetic research on diagnoses and dimensions, heterogeneity and co-morbidity, developmental change and continuity and gene-environment correlation and interaction [25]. Polygenic scores make it possible to add genetic predictors of behavioural traits to any research without the need for samples of twins or adoptees. Although genome-wide association studies require huge sample sizes, a polygenic score that predicts 5% of the variance only needs a sample of 120 to detect its effect with 80% power (p = 0.05, one-tailed).
Polygenic score predictions are correlations, and correlations do not necessarily imply causation. However, polygenic scores have a unique causal status among predictors in one important sense: correlations between polygenic scores and traits can only be interpreted in one direction causally. That is, there can be no backward causation in the sense that the brain, behaviour or the environment cannot change inherited DNA variation. The unchanging nature of inherited DNA variation from the moment of conception also makes polygenic score predictions unique in that they are just as predictive of adult traits early in life as they are in adulthood.
Explanation
Causal models using genomic data are burgeoning [12]. Much of this work considers the extent to which assortative mating, genotype–environment (GE) correlation and population stratification contribute to polygenic score prediction. Assortative mating is an ingredient in polygenic score prediction because it increases genetic variance in a population when individuals inherit trait-relevant DNA variants from both parents that deviate in the same direction from the population mean. GE correlation can affect polygenic score prediction, for example, when the correlation between children’s polygenic scores and their school performance is mediated by their experiences at home or school. Population stratification, such as ancestral or regional differences within a population, also contributes to the total genetic variance in the population that is predicted by polygenic scores.
Quantitative genetic research that uses family, twin and adoption designs to disentangle nature and nurture provides a backdrop for genomic studies of these processes. For example, a clever combination of twin and partner data indicated that assortative mating is caused by social homogamy rather than genetic influence on choice or environmental convergence of spouses over time [26]. However, assortative mating increases genetic variance regardless of its causal mechanisms that drive assortative mating. Most twin studies ignore assortative mating and thus underestimate heritability by misattributing its variance to shared environmental influences. This is especially the case for cognitive traits, which show much greater assortative mating than personality or psychopathology [27].
Forty years of quantitative genetic research on GE correlation has revealed that most environmental measures widely used in the behavioural sciences show substantial genetic influence, about 25% heritability on average [28–30] and correlations between environmental measures and behavioural traits are substantially mediated genetically, about 50% on average [31, 32]. Three types of GE correlation have been investigated: passive, evocative and active [33]. Passive GE correlation occurs when children passively inherit environments correlated with their genetic propensities. For example, parents with high polygenic scores for EA not only transmit high EA scores to their children but also provide experiences such as tuition, aspirations and role models that foster EA-related traits in their children. Children with high EA scores might also evoke reactions from others such as teachers who enhance their school performance. Active GE correlation occurs when children select, modify or create environments correlated with their genetic propensities. For instance, children with high EA scores might select like-minded friends, extract more information from classroom instruction and read more. Passive GE correlation is limited to experiences provided by genetically related individuals, evocative GE correlation includes experiences with anyone and active GE correlation encompasses experiences with anything.
Twin studies commingle GE correlation in their estimates of heritability, but adoption designs [31] and combinations of twins and multi-generational families [34] are able to disentangle the three types of GE correlation. For example, comparing adoptive and nonadoptive families can assess passive GE correlation because it is absent in adoptive families. Results from such research point to the importance of passive GE correlation for cognitive traits [31] and evocative GE correlation for psychopathology [35]. It has been difficult to pin down active GE correlation in part because measures of the environment widely used in the behavioural sciences assess the environment that happens to us passively rather than the experiences that we actively choose and create.
Quantitative genetic research has had much less to say about population stratification. Because ancestral and regional groups are usually included in twin analyses, their effects, which are solely between-family effects, are read as shared environmental influence.
Genomic methods have created many new opportunities to investigate assortative mating [36, 37], population stratification [38, 39] and especially GE correlation [40–42]. Some genomic methods estimate the joint effect of all three mechanisms, most notably comparing polygenic score predictions between families; polygenic score predictions within families exclude the effects of assortative mating and population stratification [10, 41, 42].
All these methods indicate that assortative mating, passive GE correlation and population stratification can contribute to polygenic score predictions. The most notable finding is that they contribute much more to polygenic score predictions of cognitive traits than other behavioural domains. This seems likely to be part of the reason why polygenic scores are more predictive for cognitive traits.
Prediction versus explanation
Assortative mating, GE correlation and population stratification are interesting in their own right, and it is also reasonable to investigate the extent to which they contribute to polygenic score predictions. However, proclaiming that these processes make polygenic scores confounded, biased or inflated as predictors confuses explanation and prediction.
From the perspective of predicting individual differences in a particular population, that population’s assortative mating, GE correlation and population stratification are legitimate sources of genetic variance for polygenic score prediction. If our goal is prediction, we would not want to ‘correct’ the polygenic score to remove genetic variance that can be ascribed to assortative mating, GE correlation or population stratification. In contrast, in causal models such as Mendelian randomisation [41], these phenomena are viewed as confounds that need to be controlled, although it is inherently difficult to infer causality from correlational data [13].
Most controversial is population stratification, which is so assumed to be a confounder that its genetic variance is removed in the first step of genome-wide association studies by covarying principal component scores for groups that differ in SNP resemblance. Polygenic scores are corrected again for group principal components in analyses of their association with a phenotype. The chopsticks example [43] illustrates the issue: in a study of the use of chopsticks, any SNP differences between Asians and non-Asians would be incorporated in a polygenic score predicting chopstick use even though culture is the explanation for the use of chopsticks. However, it could be argued from a predictive perspective that once a phenotype and a population are defined, any inherited DNA differences that predict the phenotype in that population are legitimate sources of polygenic score prediction, whether due to ancestry, geography or culture. In addition, removing genetic variance due to ancestral differences raises the question of when to stop correcting polygenic scores because, in the end, all genetic variance is ancestral. The issue of whether population stratification confounds polygenic score prediction in a particular population is separate from the ability of polygenic scores to predict in different populations [44] or the need for greater ancestral diversity in genome-wide association studies [45, 46].
The long-term goal of the behavioural sciences is to map the explanatory pathways from DNA through the brain to behaviour [47]. Yet, prediction is the necessary first step towards explanation. Polygenic scores also have immediate impact on research, are of practical utility for identifying individuals at risk and serve as an early warning system to prevent problems before they occur.
From the prediction perspective, anything that improves the predictive power of polygenic scores is welcome, such as improved methodologies for creating polygenic scores from current genome-wide association data [48] or using multiple polygenic scores [49, 50]. However, a high priority for research must be to foster bigger and better genome-wide association studies that can create more powerful polygenic scores. These studies require enormous efforts because samples of unprecedented size are needed to pan for specks of gold from the sand of millions of SNPs. Denigrating polygenic scores because they are ‘only’ predictive undermines this effort.
Acknowledgements
RP is supported in part by the UK Medical Research Council (MR/M021475/1) with additional support from the US National Institutes of Health (AG04938). SvS is supported by a Jacobs Fellowship and a Nuffield award (EDO/44110).
Author contributions
RP and SvS contributed equally to the conceptualisation, design and writing of the article.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Wray NR, Lin T, Austin J, McGrath JJ, Hickie IB, Murray GK, et al. From basic science to clinical application of polygenic risk scores: a primer. JAMA Psychiatry. 2021;78:101. doi: 10.1001/jamapsychiatry.2020.3049. [DOI] [PubMed] [Google Scholar]
- 2.Purcell SM, Wray NR, Stone JL, Visscher PM, O’Donovan MC, Sullivan PF, et al. Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature. 2009;460:748–52. doi: 10.1038/nature08185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Pardiñas AF, Holmans P, Pocklington AJ, Escott-Price V, Ripke S, Carrera N, et al. Common schizophrenia alleles are enriched in mutation-intolerant genes and in regions under strong background selection. Nat Genet. 2018;50:381–9. doi: 10.1038/s41588-018-0059-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Wray NR, Ripke S, Mattheisen M, Trzaskowski M, Byrne EM, Abdellaoui A, et al. Genome-wide association analyses identify 44 risk variants and refine the genetic architecture of major depression. Nat Genet. 2018;50:668–81. doi: 10.1038/s41588-018-0090-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Mullins N, Forstner S, O’Connell KS, Coombes B, Coleman JRI, Qiao Z, et al. Genome-wide association study of over 40,000 bipolar disorder cases provides novel biological insights. Nat Genet. 2021;53:817–29. doi: 10.1038/s41588-021-00857-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Luciano M, Hagenaars SP, Davies G, Hill WD, Clarke T-K, Shirali M, et al. Association analysis in over 329,000 individuals identifies 116 independent variants influencing neuroticism. Nat Genet. 2018;50:6–11. doi: 10.1038/s41588-017-0013-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Demontis D, Walters RK, Martin J, Mattheisen M, Als TD, Agerbo E, et al. Discovery of the first genome-wide significant risk loci for attention deficit/hyperactivity disorder. Nat Genet. 2019;51:63–75. doi: 10.1038/s41588-018-0269-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Karlsson Linnér R, Mallard TT, Barr PB, Sanchez-Roige S, Madole JW, Driver MN, et al. Multivariate genomic analysis of 1.5 million people identifies genes related to addiction, antisocial behavior, and health. Nat Neuroscience. 2021;24:1367–76. doi: 10.1038/s41593-021-00908-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Savage JE, Jansen PR, Stringer S, Watanabe K, Bryois J, de Leeuw CA, et al. Genome-wide association meta-analysis in 269,867 individuals identifies new genetic and functional links to intelligence. Nat Genet. 2018;50:912–9. doi: 10.1038/s41588-018-0152-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Lee JJ, Wedow R, Okbay A, Kong E, Maghzian O, Zacher M, et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat Genet. 2018;50:1112–21. doi: 10.1038/s41588-018-0147-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Allegrini AG, Selzam S, Rimfeld K, von Stumm S, Pingault JB, Plomin R. Genomic prediction of cognitive traits in childhood and adolescence. Mol Psychiatry. 2019;24:819–27. doi: 10.1038/s41380-019-0394-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Pingault J-B, O’Reilly PF, Schoeler T, Ploubidis GB, Rijsdijk F, Dudbridge F. Using genetic data to strengthen causal inference in observational research. Nat Rev Genet. 2018;19:566–80. doi: 10.1038/s41576-018-0020-3. [DOI] [PubMed] [Google Scholar]
- 13.Rohrer JM. Thinking clearly about correlations and causation: graphical causal models for observational data. Adv Methods Pract Psychol Sci. 2018;1:27–42. [Google Scholar]
- 14.Shmueli G. To explain or to predict? Stat Sci. 2010;25:289–310. [Google Scholar]
- 15.Yarkoni T, Westfall J. Choosing prediction over explanation in psychology: lessons from machine learning. Perspect Psychol Sci. 2017;12:1100–22. doi: 10.1177/1745691617693393. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Cohen J. Statistical power analysis for the behavioral sciences. 2nd ed. Hillsdale, NJ: L. Erlbaum Associates; 1988. p. 26.
- 17.Lewis CM, Vassos E. Polygenic risk scores: from research tools to clinical instruments. Genome Med. 2020;12:44. doi: 10.1186/s13073-020-00742-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Plomin R, von Stumm S. The new genetics of intelligence. Nat Rev Genet. 2018;19:148–59. doi: 10.1038/nrg.2017.104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Zheutlin AB, Dennis J, Karlsson Linnér R, Moscati A, Restrepo N, Straub P, et al. Penetrance and pleiotropy of polygenic risk scores for schizophrenia in 106,160 patients across four health care systems. Am J Psychiatry. 2019;176:846–55. doi: 10.1176/appi.ajp.2019.18091085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.von Stumm S, Smith-Woolley E, Cheesman R, Pingault J-B, Asbury K, Dale PS, et al. School quality ratings are weak predictors of students’ achievement and well-being: Ofsted ratings and student outcomes. Child Psychol Psychiatry. 2020;62:339–48. doi: 10.1111/jcpp.13276. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Wespieser K, Durbin B, Sims D. School choice: the parent view. Slough: NFER; 2015.
- 22.Polderman TJC, Benyamin B, de Leeuw CA, Sullivan PF, van Bochoven A, Visscher PM, et al. Meta-analysis of the heritability of human traits based on fifty years of twin studies. Nat Genet. 2015;47:702–9. doi: 10.1038/ng.3285. [DOI] [PubMed] [Google Scholar]
- 23.Manolio TA, Collins FS, Cox NJ, Goldstein DB, Hindorff LA, Hunter DJ, et al. Finding the missing heritability of complex diseases. Nature. 2009;461:747–53. doi: 10.1038/nature08494. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Wainschtein P, Jain DP, Yengo L, Zheng Z. TOPMed Anthropometry Working Group, Trans-Omics for Precision Medicine Consortium, et al. Recovery of trait heritability from whole genome sequence data. bioRxiv 2019. 10.1101/588020.
- 25.Plomin R. Blueprint: how DNA makes us who we are. London: Penguin Books; 2019.
- 26.Zietsch BP, Verweij KJH, Heath AC, Martin NG. Variation in human mate choice: simultaneously investigating heritability, parental influence, sexual imprinting, and assortative mating. Am Nat. 2011;177:605–16. doi: 10.1086/659629. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Plomin R, Deary IJ. Genetics and intelligence differences: five special findings. Mol Psychiatry. 2015;20:98–108. doi: 10.1038/mp.2014.105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Plomin R, Bergeman CS. The nature of nurture: genetic influence on “environmental” measures. Behav Brain Sci. 1991;14:373–86. [Google Scholar]
- 29.Kendler KS, Baker JH. Genetic influences on measures of the environment: a systematic review. Psychol Med. 2007;37:615. doi: 10.1017/S0033291706009524. [DOI] [PubMed] [Google Scholar]
- 30.Avinun R, Knafo A. Parenting as a reaction evoked by children’s genotype: a Mmta-analysis of children-as-twins studies. Personal Soc Psychol Rev. 2014;18:87–102. doi: 10.1177/1088868313498308. [DOI] [PubMed] [Google Scholar]
- 31.Plomin R. Genetics and experience: the interplay between nature and nurture. Thousand Oaks: Sage Publications; 1994.
- 32.Ahmadzadeh YI, Schoeler T, Han M, Pingault J-B, Creswell C, McAdams TA, et al. Systematic review and meta-analysis of genetically informed research: associations between parent anxiety and offspring internalizing problems. J Am Acad Child Adolesc Psychiatry. 2021;60:823–40. doi: 10.1016/j.jaac.2020.12.037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Plomin R, DeFries JC, Loehlin JC. Genotype-environment interaction and correlation in the analysis of human behavior. Psychol Bull. 1977;84:309–22. [PubMed] [Google Scholar]
- 34.McAdams TA, Neiderhiser JM, Rijsdijk FV, Narusyte J, Lichtenstein P, Eley TC. Accounting for genetic and environmental confounds in associations between parent and child characteristics: a systematic review of children-of-twins studies. Psychol Bull. 2014;140:1138–73. doi: 10.1037/a0036416. [DOI] [PubMed] [Google Scholar]
- 35.Narusyte J, Neiderhiser JM, Andershed A-K, D’Onofrio BM, Reiss D, Spotts E, et al. Parental criticism and externalizing behavior problems in adolescents: the role of environment and genotype–environment correlation. J Abnorm Psychol. 2011;120:365–76. doi: 10.1037/a0021815. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Border R, O’Rourke S, de Candia T, Goddard ME, Visscher PM, Yengo L, et al. Assortative mating biases marker-based heritability estimators. bioRxiv 2021. 10.1101/2021.03.18.436091.
- 37.Yengo L, Robinson MR, Keller MC, Kemper KE, Yang Y, Trzaskowski M, et al. Imprint of assortative mating on the human genome. Nat Hum Behav. 2018;2:948–54. doi: 10.1038/s41562-018-0476-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Abdellaoui A, Verweij KJH, Nivard MG. Geographic confounding in genome-wide association studies. bioRxiv 2021. 10.1101/2021.03.18.435971.
- 39.Lawson DJ, Davies NM, Haworth S, Ashraf B, Howe L, Crawford A, et al. Is population structure in the genetic biobank era irrelevant, a challenge, or an opportunity? Hum Genet. 2020;139:23–41. doi: 10.1007/s00439-019-02014-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Allegrini AG, Karhunen V, Coleman JRI, Selzam S, Rimfeld K, von Stumm S, et al. Multivariable G-E interplay in the prediction of educational achievement. PLOS Genet. 2020;16:e1009153. [DOI] [PMC free article] [PubMed]
- 41.Brumpton B, Sanderson E, Heilbron K, Hartwig FP, Harrison S, Vie GÅ, et al. Avoiding dynastic, assortative mating, and population stratification biases in Mendelian randomization through within-family analyses. Nat Commun. 2020;11:3519. doi: 10.1038/s41467-020-17117-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Selzam S, Ritchie SJ, Pingault J-B, Reynolds CA, O’Reilly PF, Plomin R. Comparing within- and between-family polygenic score prediction. Am J Hum Genet. 2019;105:351–63. doi: 10.1016/j.ajhg.2019.06.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Lander E, Schork N. Genetic dissection of complex traits. Science. 1994;265:2037–48. doi: 10.1126/science.8091226. [DOI] [PubMed] [Google Scholar]
- 44.Martin AR, Daly MJ, Robinson EB, Hyman SE, Neale BM. Predicting polygenic risk of psychiatric disorders. Biol Psychiatry. 2019;86:97–109. doi: 10.1016/j.biopsych.2018.12.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Mills MC, Rahal C. A scientometric review of genome-wide association studies. Commun Biol. 2019;2:9. doi: 10.1038/s42003-018-0261-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Peterson RE, Kuchenbaecker K, Walters RK, Chen C-Y, Popejoy AB, Periyasamy S, et al. Genome-wide association studies in ancestrally diverse populations: opportunities, methods, pitfalls, and recommendations. Cell. 2019;179:589–603. doi: 10.1016/j.cell.2019.08.051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Abdellaoui A, Verweij KJH. Dissecting polygenic signals from genome-wide association studies on human behaviour. Nat Hum Behav. 2021;5:686–94. doi: 10.1038/s41562-021-01110-y. [DOI] [PubMed] [Google Scholar]
- 48.Márquez-Luna C, Gazal S, Loh P-R, Kim SS, Furlotte N, Auton A, et al. LDpred-funct: incorporating functional priors improves polygenic prediction accuracy in UK Biobank and 23andMe data sets. bioRxiv. 2020:375337. [DOI] [PMC free article] [PubMed]
- 49.Krapohl E, Patel H, Newhouse S, Curtis CJ, von Stumm S, Dale PS, et al. Multi-polygenic score approach to trait prediction. Mol Psychiatry. 2018;23:1368–74. doi: 10.1038/mp.2017.163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Grotzinger AD, Rhemtulla M, de Vlaming R, Ritchie SJ, Mallard TT, Hill WD, et al. Genomic structural equation modelling provides insights into the multivariate genetic architecture of complex traits. Nat Hum Behav. 2019;3:513–25. doi: 10.1038/s41562-019-0566-x. [DOI] [PMC free article] [PubMed] [Google Scholar]