

Abstract
Employing DNA as a high-density data storage medium has paved the way for next-generation digital storage and biosensing technologies. However, the multipart architecture of current DNA-based recording techniques renders them inherently slow and incapable of recording fluctuating signals with sub-hour frequencies. To address this limitation, we developed a simplified system employing a single enzyme, terminal deoxynucleotidyl transferase (TdT), to transduce environmental signals into DNA. TdT adds nucleotides to the 3’ ends of single-stranded DNA (ssDNA) in a template-independent manner, selecting bases according to inherent preferences and environmental conditions. By characterizing TdT nucleotide selectivity under different conditions, we show that TdT can encode various physiologically relevant signals like Co2+, Ca2+, Zn2+ concentrations and temperature changes in vitro. Further, by considering the average rate of nucleotide incorporation, we show that the resulting ssDNA functions as a molecular ticker tape. With this method we accurately encode a temporal record of fluctuations in Co2+ concentration to within 1 minute over a 60-minute period. Finally, we engineer TdT to allosterically turn off in the presence of physiologically relevant concentration of calcium. We use this engineered TdT in concert with a reference TdT to develop a two-polymerase system capable of recording a single step change in Ca2+ signal to within 1 minute over a 60-minute period. This work expands the repertoire of DNA-based recording techniques by developing a novel DNA synthesis-based system that can record temporal environmental signals into DNA with minutes resolution.
Keywords: DNA-based recording, enzymatic DNA synthesis, physiological signal recording, synthetic biology
Graphical Abstract
Introduction
DNA is an attractive medium for both long-term data storage and for in vitro recording molecular events due to its high information density (1–3) and long-term stability (4). Molecular recording strategies write information into DNA by altering existing DNA sequences (5) or adding new sequences (6). For example, systems have been developed that use methods including differential CRISPR spacer acquisition (5, 7, 8), enzymatic synthesis (9–11) and others (1, 8, 12). By connecting these DNA modifications to a user input (in the case of data storage) or environmental signal of interest (in the case of recording events), these strategies enable post hoc recovery of signal dynamics over time by DNA sequencing. To date, molecular recording systems, both in vitro and in vivo, have connected signals of interest to DNA recordings with transcriptional control, using signal-responsive promoters to drive the expression of molecular writers, such as base-editors, CRISPR-associated systems, or gene-circuits, to record changes in signal. These approaches have yielded accurate recordings, however the time required to transduce signals through a recording apparatus that includes transcription, translation, and DNA modification fundamentally constrains the application of these methods to events on the timescales of hours or days. A recording mechanism that relies only on post-translational elements would be inherently faster as signal transduction would only require sub-second conformational shifts in one enzyme.
In an effort to speed up DNA recording processes, we hypothesized that a DNA polymerase (DNAp), which continually incorporates bases (13), could serve as a candidate for post-translational molecular encoding. In such a system, a DNAp functions as a “ticker-tape” recorder, transforming changes in environmental signals into changes in the composition of the DNA it synthesizes (14) (Fig. 1A). Much faster than transcription and translation, nucleotide incorporation occurs on a timescale on the order of milliseconds to seconds (15), potentially enabling orders of magnitude improvements in the temporal accuracy and resolution of molecular recording. However, prototypical DNAp’s replicate the contents of an existing strand, which would prevent recording of new information. A DNAp that does not simply replicate DNA but rather creates a de novo sequence could allow for DNA recording.
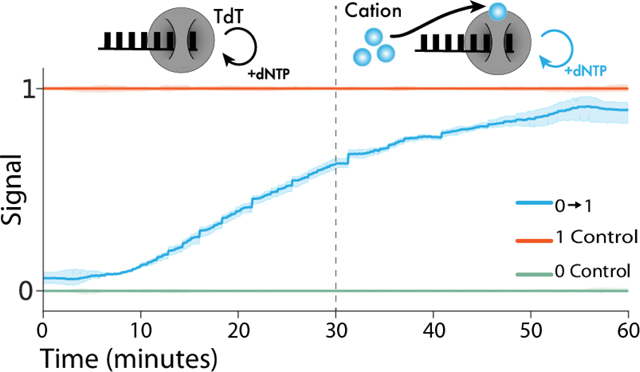
Figure 1: TURTLES device architecture and environmental signal responses.

(A.i) A representative time-varying input signal. (A.ii) TdT interacts directly with the signal of interest (small blue circles) (A.iii) resulting in different average DNA compositions in each condition. (B) Change in frequency of nucleotide selectivity by TdT in the presence of various environmental signals tested. Signal 0 is 10 mM Mg2+ at 37 °C for 1 hour. Signal 1 was: (i) 10 mM Mg2+ + 0.25 mM Co2+ at 37 °C for 1 hour, A incorporation increased by 12.4%, while G decreased by 8.0% and T and C decreased by 1.5% and 2.9% respectively; (ii) 10 mM Mg2+ + 1 mM Ca2+ at 37 °C for 1 hour A increased by 1.5%, G decrease by 1.2%, T increased by 0.4%, and C decreased by 0.8%; (iii) 10 mM Mg + 20 μM Zn2+ at 37 °C for 1 hour, A increased by 14.9%, G 8.8% decreased by, T decreased by 3.3%, and C decreased by 2.8%; and (iv) 10 mM Mg2+ at 20 °C for 1 hour, 0.4% increase in A, 3.8% decrease in G, 1.5 % increase in T and 1.8% increase in incorporation of C. Error bars show two standard deviations of the mean. Statistical significance was assessed after first transforming the data into Aitchison space which makes each dNTP frequency change statistically independent of the others (Fig. S2).
Terminal deoxynucleotidyl transferase (TdT) is a DNAp that can randomly incorporate bases to the 3’ of a DNA strand with biases toward particular bases (16, 17). Shifting the nucleotide bias of TdT could make it a prime candidate for post-translational control of DNA encoding. In fact, in vitro experiments have shown cations (e.g., Co2+) can shift the bias of TdT (16, 18). In addition, DNA is synthesized in a sequential manner which provides an estimate of the time a particular base is added. We therefore hypothesized that the environment in which a TdT extends a DNA strand might be encoded by the average base-composition of the extended DNA. Put another way, by combining the change in nucleotide bias in the presence of cations and the time bases are added inferred from sequence, a molecular ticker tape may be possible (13, 14).
Here, we introduce TdT-based Untemplated Recording of Temporal Local Environmental Signals (TURTLES), a polymerase-based molecular recording system that achieves high time resolution in vitro by utilizing post-translational control to change the bases incorporated. First, we describe methods to characterize DNA sequences synthesized by TdT and show that cation concentrations can be encoded in populations of TdT-synthesized DNA using an approach that analyzes the average composition of several bases added at similar times on the same or parallel strands of DNA. We next developed an algorithm to accurately estimate the times of signal changes and show that temporal information can be accurately recovered by using estimates of DNA synthesis rates to map DNA sequences to real time. We also describe an expanded TURTLES system that uses an engineered, allosterically modulated TdT to expand the generalizability and tunability of the system. By inserting an exogenous sensing domain, we show that TURTLES can be adapted to arbitrary signals of interest. Taken together, these results establish the feasibility of DNA synthesis-based encoding systems and demonstrate minutes resolution recording of cationic environmental signals for enhanced applications in DNA data storage and DNA recording.
Results:
TdT can encode environmental signals in vitro via changes in base selectivity:
The cations present in the reaction environment of TdT affect the rate of incorporation for specific nucleotides (16). For example, previous studies (18–20) and our experiments show that when only one nucleotide is present, the incorporation rates of pyrimidines, dCTP and dTTP, increase in the presence of Co2+ (Fig. S1).
We sought to examine if these Co2+-dependent changes in kinetics also occurred in the presence of all four nucleotides, dATP, dCTP, dGTP, and dTTP (hereafter referred to as A, C, G, and T). The nucleotide composition of ssDNA extended by bovine TdT in a Cobalt-free reaction buffer or with cobalt added was determined by next generation sequencing. In the presences of Co2+, A incorporation increased, while G, T and C incorporation decreased (Fig. 1B (i) and Fig. S2). Notably, the significant difference in the composition of DNA each condition effectively encodes information about the environmental Co2+ concentration at the time of DNA synthesis.
Next, we were interested in understanding which conditions could be encoded by TURTLES. We examined Ca2+, Zn2+, and temperature. Ca2+ signaling is biologically ubiquitous and functions in neural firing (21), fertilization (22, 23), and neurodevelopment (24); Zn2+ is an important signal in the development and differentiation of cells (25); and temperature is relevant in many situations.
Each signal altered both the particular dNTPs affected and the magnitude of the change in dNTP selectivity. We were able to encode 1 mM Ca2+, 20 μM Zn2+, and the temperature of 20 °C (Fig. 1B(ii-iv) and Fig. S2). Both cation addition and temperature change also altered the lengths of ssDNA strands synthesized (Fig. S3-8). For each environmental condition tested, we observed significant differences in the composition of TdT synthesized DNA. We conclude that input-dependent changes in TdT nucleotide selectivity can encode environmental information into DNA. For further analysis we chose to focus on Co2+ as the candidate cationic signal due to the large difference in TdT selectivity.
Recording a single step change in Co2+ concentration with minutes resolution:
Having shown nucleotide selectivity changes in the presence of Co2+, we attempted to identify the time at which Co2+ was added to a TdT-catalyzed ssDNA synthesis reaction based on the changes in the nucleotide composition of the synthesized ssDNA (Fig. 2A). During a 60-minute extension reaction, we created step transitions in cobalt concentration by adding 0.25 mM Co2+ at 10, 20, and 45 minutes (hereafter referred to as a input where ‘0’ is Co2+-free and ‘1’ is with 0.25 mM added Co2+) (Fig. 2B top). For each reaction, we analyzed approximately 500,000 DNA strands by deep sequencing and calculated the dNTP incorporation frequencies over all reads. Because the change in dNTP selectivity is a compositional data type (i.e., all changes in base frequency sum to 0%), they are not independent and do not satisfy the independence assumption required for most statistical tests. Therefore, to perform hypothesis testing, base composition was transformed into Aitchison space, where the proportion of each base becomes independent of the other three. The output signal for each reaction was calculated as the normalized distance in Aitchison space between the 0 and 1 controls.
Figure 2: Recording Co2+ fluctuations into ssDNA with minutes resolution in vitro.
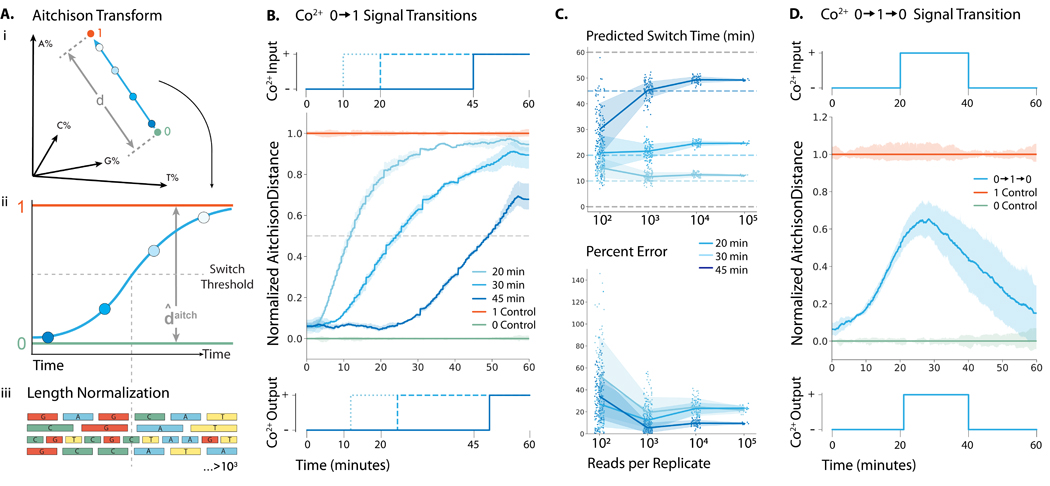
(A-i) Representation of how the percent incorporation of each nucleotide is dependent on each of the nucleotides incorporated. (A-ii) By transforming the percent incorporation of each nucleotide to the Aitchison distance, we can calculate the total “output signal”. (A-iii.) Sequences were normalized by length before the nucleotide composition at each time point was calculated. We plot the Aitchison distance for the recording experiment between the 0 (green) and 1 (orange) signals. (B) (top) 0.25 mM Co2+ was added at 10, 20, and 40 min to generate a transition. (center) Mean output signal across three biological replicates. Vertical lines are drawn at the inferred transition time. (bottom) Predicted output signal transition times were 11.9, 24.4, and 49.2 min. (C) (top) Predicted switch times for each transition calculated from randomly sampled subsets of sequences. (bottom) Time prediction error for each transition calculated from randomly sampled subsets of sequences. (D) (top) 0.25 mM Co2+ was added at 20 min and then removed at 40 min to generate a transition. (center) Mean output signal across three biological replicates. (bottom) Using the algorithm detailed by Glaser et al., (13) the signal was deconvoluted into a binary response, with vertical lines drawn at the predicted switch times of 21 and 41 min.
After normalizing each sequence by its own length, the Aitchison location along the extended strands showed that later addition of Co2+ resulted in dNTP selectivity changes farther down the extended strand (Fig. 2B center). To estimate the real time at which changes occurred, we calculated the average location along the strand for all sequences in each condition at which a distance halfway between the 0 and 1 control output signal was reached. To translate this location into a particular time in the experiment, we calculated the average rate of dNTP addition in each state (Fig. S9) and derived an equation that adjusted for the change in rate of DNA synthesis between the 0 and 1 controls (Equation 5, Supplementary Methods 3). Using this information, we estimated that the Co2+ additions were made at 11.9, 24.4 and 49.2 minutes (Fig. 2B bottom). We were also able to estimate the time within 4 minutes of the unit input step function for the reverse, a condition (Fig. S10).
While we were able to accurately estimate the times of Co2+ addition (01) and removal (10), simultaneously synthesizing ~500,000 strands of DNA will be infeasible for certain applications. To determine the number of strands needed for reasonable statistical certainty, we randomly sampled smaller groups of strands from the experiment and evaluated our ability to predict when Co2+ was added (Fig. 2C top and bottom). With about 1,000 strands, we still estimated the time of Co2+ additions to within 2 minutes of actual input times (Fig. 2C). Thus, TURTLES can be employed for recording temporal information even with a limited number of ssDNA substrates.
Recording multiple fluctuations in Co2+ concentration onto DNA with minutes resolution:
In contrast to current DNA-based recorders, which rely on time-integrated recording methods (i.e., accumulation of mutations) or slow signal transducing steps, DNA synthesis-based approaches can record the dynamics of multiple fluctuations in real time. While accumulation can tell what fraction of the time a signal was present in a time period, the ability to record multiple temporal changes would enable new levels of insight into dynamical processes such as physiologically signaling, which are poorly captured by time-integrated recording methods.
We used TURTLES to record a input cobalt signal. The 0 condition was maintained first 20 minutes, 1 for the next 20 minutes, and 0 for the last 20 minutes of the extension reaction (Fig. 2D top). Using the same methods as the single step transition, we calculated the output signal (Fig. 2D center). To account for the additional complexity of multiple fluctuations, we used an algorithm previously developed by Glaser et al. (13) (see Materials and Methods for details) to binarize the value of the output signal every 0.1 min. We were able to accurately reconstruct the input signal, estimating transitions between the 0 and 1 signals occurring at 21 and 41 minutes based on sequencing data (Fig. 2D bottom).
Based on the measured experimental parameters, we used in silico simulations to estimate the performance of TURTLES in more complex recording environments. We investigated how rapidly signals could change and still be detected and how many consecutive condition changes could be recorded accurately. By varying the length of time of each input condition (0 or 1) from 1 to 20 minutes (Fig. S12A), we estimated that TURTLES can record 6 consecutive signal changes with 1 minute between each with >75% accuracy from ≥ 2000 strands of 100bp ssDNA synthesized (>90% accuracy with ≥ 60,000 strands of ssDNA of 50 bp length each) (Fig. S12B). By keeping the duration of each input condition (0 or 1) constant at 10 minutes (Fig. S12C) and varying the total number of condition changes, we estimated that TURTLES would be capable of recording 10 sequential input signal changes with >80% accuracy (Fig. S12D). We thus show that TURTLES has the potential for high temporal precision and can decode signals across a range of frequencies.
TdT can be engineered to allosterically respond to and encode environmental signals:
Unlike Co2+ and Zn2+, we observed that Ca2+ only modestly altered the dNTP selectivity of TdT, precluding temporal recordings of Ca2+ concentration. To show that TURTLES could be expanded to signals to which TdT was unresponsive or weakly responsive, we attempted to engineer a TdT to allosterically respond to Ca2+. The structural determinants of base selectivity in TdT are poorly understood, which ruled out directly increasing the dynamic range of Ca2+-responsive dNTP selectivity changes (26). Accordingly, we conceived a modular recording system based on two distinct TdT species with different inherent dNTP selectivity.
The two-TdT system, TURTLES-2, uses a reference TdT whose catalytic rate is unaffected by inputs and a sensor TdT that is allosterically activated or deactivated in response to input signals. By choosing a pair of sensor and reference TdTs with distinct nucleotide selectivity, TURTLES-2 encodes environmental signals into changes in DNA composition based on the differential activity of the two TdTs (Fig. 3A). As the sensing and recording functions of the system are distributed between two TdT variants, TURTLES-2 is more accessible to tuning and engineering efforts.
Figure 3: Recording Ca2+ changes into ssDNA with TURTLES-2.
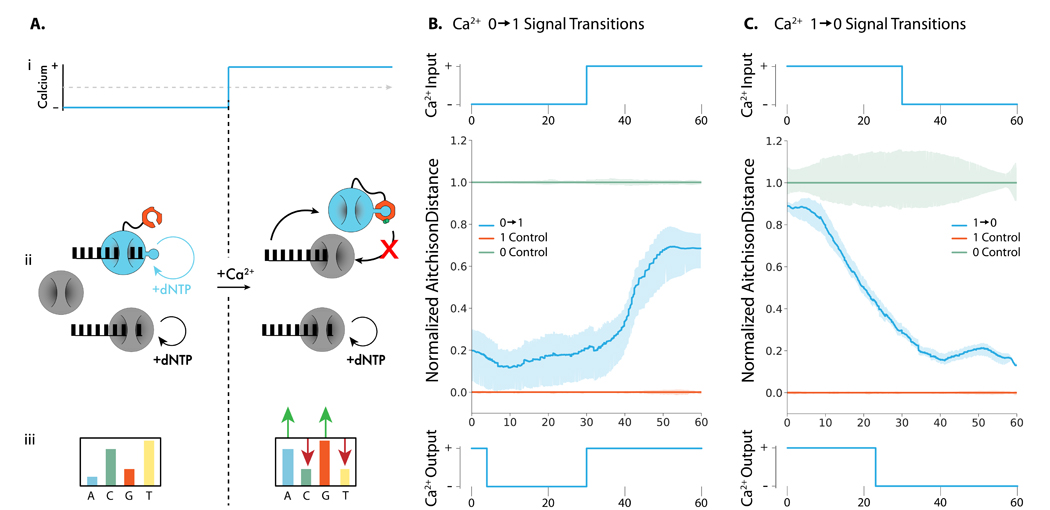
(A.i.) Representative calcium transition changing concentration from calcium-free to calcium-added conditions during a TdT-based DNA synthesis reaction. Mg2+ concentration and reaction temperature are held constant. (A.ii.) The CaM subunit (orange) of engineered TdT (teal) binds with the fused M13 peptide in the presence of Ca2+ to allosterically turn off DNA synthesis. The activity of the reference TdT (grey) is not affected by Ca2+. In the absence of Ca2+ both the engineered TdT and reference TdT are carrying out DNA synthesis. In the presence of Ca2+ only the reference TdT synthesizes DNA. (A.iii.) This results in a change in the overall nucleotide incorporation preference upon a change in Ca2+. (B) Top: 100 μM CaCl2 was added to the extension reaction at 30 minutes to generate a transition. Center: Mean output signal across 3 biological replicates. Bottom: Using a modified version of the algorithm detailed in Glaser et al. (13), the signal was deconvoluted into a binary response, with the predicted switch time of 30 minutes (C) Top: 50 μM EGTA was added to the extension reaction at 30 minutes to generate a transition. Center: Mean output signal across 3 biological replicates. Bottom: Using a modified version of the algorithm detailed in Glaser et al. (13), the signal was deconvoluted into a binary response, with the predicted switch time of 22 minutes.
We employed the natural calcium sensing protein, Calmodulin (CaM), and a cognate binding peptide, M13, to generate a TdT with allosterically modulated activity. The calcium-dependent interaction between CaM and M13 has been previously utilized to engineer allosteric calcium biosensors (27, 28) and as a platform for generalizable ligand biosensors (29, 30).
Here, we generated variants with M13 fused to one of 4 sites in mTdT that were predicted to minimize the structural disruption of inserting the M13 sequence using SCHEMA-RASPP(31) (Fig. S13, Table S2). After initial activity screening (Fig. S14) of the variants we observed that one variant, mTdT(M13–388), retained polymerase activity. CaM was subsequently fused to the N-terminus of mTdT(M13–388) via linker. Primer extension reactions showed that the resulting CaM-mTdT(m13–388) variant was active in calcium-free conditions and inactive in calcium-added conditions (Fig. S15). To confirm that the calcium-dependent interaction between CaM and M13 was responsible for the observed activity modulation, we mutated four essential Ca2+-binding residues in CaM, which ablated the calcium-sensitivity of CaM-mTdT(M13–388) (Fig. S15).
Depending on the application, sensor polymerases with different calcium affinities may be useful to selectively record Ca2+ fluctuations exceeding threshold concentrations. We anticipated that the modular design of CaM-mTdT(M13–388) would allow the properties of the fusion to be rationally modified with CaM variants with known differences in Ca2+ affinity. Polymerase activity was determined by the length distributions of primer extensions, CaM-mTdT(M13–388) variants containing the CaM mutants D96V, D130G, and D142L which reduce the calcium affinity of CaM (32). We observed that all variants exhibited greater activity than the unmodified CaM-mTdT(m13–388) in the presence of low concentrations of calcium (Fig. S16). Moreover, the increase in activity correlated with the reported effective Ca2+ KD of the variants, demonstrating that the calcium-sensitivity of CaM-mTdT(M13–388) can be rationally tuned.
Next, we tested if the TURTLES-2 system could encode the Ca2+ state into DNA. CaM-mTdT(M13–388) was purified and NGS analysis of extension reactions performed with the polymerase confirmed the calcium-sensitive phenotype (Fig. S17 & 18). We characterized CaM-mTdT(M13–388) in the context of the TURTLES-2 recording system by performing extensions with a mixture of purified bovine TdT and CaM-mTdT(M13–388) in calcium-free and calcium-added conditions. The two-polymerase system exhibited a significantly altered nucleotide selectivity in the calcium-added conditions (Fig. S19). As expected, in the calcium-free condition the overall base incorporation preference was approximately the average of the observed preferences of bovine TdT and CaM-mTdT(M13–388) whereas the overall base preference in the calcium added condition was nearly identical to that of bovine TdT (Fig. S20). We conclude that the differential overall base selectivity of the TURTLES-2 system is capable of encoding the environmental calcium state into DNA.
Recording a single step change in Ca2+ concentration with minutes resolution with two TdT system:
We next investigated if the differential calcium response of TURTLES-2 could be used to infer the time at which calcium concentrations changed in an extension reaction. During a 60 min extension we tested both and step transitions at 30 min, where 0 is calcium-free and 1 is calcium-added (Figure 3B, top, Figure 3C, top, Supplementary Note 6). Using a variation of the model developed by Glaser et al., (13) we inferred transition times of 22 min for the transition (Figure 3C, bottom) and 30 min for the transition (Figure 3B bottom). The decreased accuracy of the estimated time for the calcium transitions did not correspond to an increase in measurement variability. We speculate that the offset may be due to the different kinetics of holo calmodulin binding M13 and apo calmodulin releasing M13. Time estimations for transitions in TURTLES-2 would likely improve with more sophisticated decoding algorithms and a deeper characterization of the transition behavior of CaM-mTdT(M13-388). We conclude that TURTLES-2 serves as a promising proof of concept for developing high-resolution temporal calcium signal encoding systems.
Discussion
While many DNA-based biosensors have been deployed for studying physiological signals of interest (33–37), the scalability and spatial resolution of biosensors is intrinsically limiting in some applications (38). By leveraging post hoc recovery of biological data, optimized TURTLES systems may be capable of enabling otherwise inaccessible high-resolution spatial and temporal recordings of physiological signaling molecules that fluctuate on the timescale of 101–103 minutes. Such signals include slow calcium signaling that occurs in neurons (13, 14, 38, 39) and vertebrate development (22). Additional optimization of the TURTLES system will be required to enable the spatiotemporal resolution for characterizing systems with shorter timescales.
Beyond biological applications, there has been a sustained interest in biosensors for testing environmental parameters such as water quality. For longer term tracking of contaminating metal ions in water, one could use TURTLES to track cobalt concentration over time (40, 41). In concert with microfluidic reaction control, TURTLES can also serve as a competitive platform for enzymatic DNA synthesis for data archiving (9–11), which is an appealing alternative to phosphoramidite methods due to the low cost and reduced environmental impact (42). Although TURTLES was used in this work to record binary signals, it could also be used to record more than two signals in sequence. For example, in vitro addition of nucleotides via TdT with varied input nucleotide compositions could be used to encode data (Fig. S21). While the information density of such a system would be lower than those using base-specific DNA synthesis, it would not require specialized substrates or complex reaction cycling and would thus be a competitive application for digital data storage.
Going forward, more sophisticated computational methods will improve the recording accuracy of TURTLES. In this study we utilized simple, intuitive models of TdT activity to transform sequence data into temporal information. By incorporating kinetic models of TdT activity or machine learning to classify signal changes along individual DNA strands, the accuracy of temporal estimations could likely be increased. These methods would also improve the robustness of TURTLES recordings by reducing the required sequencing depth from thousands to hundreds of reads. In this work, both the inputs and outputs for TURTLES were binarized, however the underlying principle can be extended to record continuously varying analog signals with improved decoding algorithms.
The quality of TURTLES recordings may also be improved by engineering the properties of TdTs. In particular, the sequencing depth required to accurately decode recordings can be reduced by increasing the magnitude of changes in nucleotide selectivity in response to inputs. Likewise, reference TdTs that have a more distinct nucleotide selectivity from the CaM-mTdT(M13–388) sensor TdT can be engineered or identified among natural TdT diversity. Improvements to the temporal resolution of TURTLES systems can be accomplished by enhancing the nucleotide incorporation rate of TdT. In TURTLES-2, structural optimization of CaM-mTdT(M13–388) may improve temporal resolution by optimizing the kinetics of the CaM-M13 interaction. Notably, fluorescent biosensors based on CaM-M13 interactions can report calcium spikes on the order of seconds(43, 44), suggesting that calcium sensing will not be limiting with respect to temporal resolution in an optimized system. The functionality of TURTLES-2 may be further expanded by employing generalizable sensors based on the CaM-M13 interaction (29), or by probing TdT with sensing domains other than calmodulin such that new signals of interest can be encoded or recorded. In all, we have demonstrated a new methodology for recording dynamic, environmental information into DNA that relies only on allosteric regulation, enabling minutes resolution.
Conclusion
In this study, we demonstrated two DNA synthesis-based recording concepts that encode and record the temporal dynamics of fluctuating environmental signals with minutes accuracy. By coupling sensing and writing functions, TURTLES simplifies the recording apparatus to post-translational system. This gives TURTLES distinct advantages over the temporal constraints of existing tools paving the way towards development of tools with heretofore unprecedented temporal accuracy and resolution. While TURTLES can record several physiologically relevant signals, TURTLES-2 lends tunability to the recording system with simple rational engineering. Given the uncomplicated and genetically-encodable design of TURTLES systems, we anticipate that TURTLES can be further developed for both in vitro and in vivo biorecording applications.
Materials and Methods
Enzymes and ssDNA substrate:
Terminal deoxynucleotidyl polymerase, T4 RNA ligase I, Phusion High-Fidelity PCR Master Mix with HF Buffer were purchased through New England Biolabs (NEB). ssDNA substrates used for extension reactions were ordered from Integrated DNA Technologies (IDT) with standard desalting. dNTPs were obtained from Bioline.
CaM fusion design and screening
Four fusion proteins were designed that consisted of CaM fused to the N terminus of mTdT by a (GGGGS)4 linker and M13 inserted immediately following the fusion residue (see below) with flanking GS linkers. Fusion sites were selected from crossover sites identified with the SCHEMA/RASPP algorithm based on which sites were in catalytically essential regions and would be sterically available to CaM. SCHEMA crossover sites were calculated according to previously described protocols(31). Sets of crossover points were calculated for 3, 4, 5, 6, and 7 total crossovers. Calculations were performed with the following parameters: minimum fragment length = 4, bin width = 1, parent sequence = NP_001036693.1, parent structure = PDB 4i27 (all ligands, metals, and waters removed), homology sequences = NP_803461.1, AAH12920.1, NP_001012479.1, XP_021064401.1, XP_020136193.1. All sequences were trimmed to only include residues crystallized in the parent structure. Fusion sites were selected from crossover points that were in the DNA-binding region of mTdT (residues 282, 284, 287) or in Loop 1, a catalytically essential structure (residue 388). M13 fusions were screened for activity without N-terminal CaM to validate that the fusion was tolerated.
Cloning CaM-TdT(M13) variants
Molecular cloning of DNA constructs was completed under a contract research agreement with the lab of Dr. J. Andrew Jones at Miami University – Oxford, OH. The pET28a-M-CaM-cTdTS-M13-XXX (282, 284, 287, and 388) variants were constructed using a two-part Gibson Assembly method. The approximately 75bp M13 fragment was amplified from linear double stranded DNA template (gBlock-CaM-Linker-M13, IDT) using Accuzyme DNA polymerase (Bioline) using DNA primers P21 – P28 listed in Table S1. The amplicon was then purified using a Cycle Pure Kit (Omega Biotek). The vector backbone fragment was amplified from pET28a-M-CaM-cTdTS plasmid DNA constructed above using PfuUltra II Hotstart PCR Master Mix using DNA primers P29 – P36 listed in Table S1. The PCR product was then digested with DpnI to remove DNA template. The approximately 8100bp amplicon was purified using a gel extraction kit (Omega Biotek). DNA concentration of both linear fragments was measured using the Take3 plate coupled with a Biotek Cytation 5 plate reader. Corresponding backbone and M13 fragments were then assembled using the repliQa™ HiFi Assembly Kit (Quanta bio), transformed into chemically competent DH5α, and selected on LB-Kanamycin (50 μg/mL) plates. Individual colonies were then screened via restriction digestion and verified using Sanger sequencing (CBFG – Miami University) with primers S1 – S8, Table S1.
CaM-TdT(M13–388) expression and purification
Purification optimizations determined that N-terminal MBP was unnecessary for expression and purification and was not included in the final expression construct. The expression construct (pET28a-CaM-mTdT(m13–388)) was transformed into chemically competent NEB T7Express cells, plated on kanamycin selective plates, and incubated at 37°C. The following day, a single colony was selected and inoculated into 5mL of kanamycin supplemented LB. the culture was incubated for 20 hours at 37°C. Four flasks of 120mL kanamycin supplemented LB were inoculated 1:400 (v/v) with the overnight culture. The cultures were incubated with shaking at 250 RPM. Once the OD600 was between 0.5 and 0.6, the cultures were cooled to room temperature and induced with 1mM IPTG. Following induction, the cultures were incubated for 18 hours at 15°C. The cells were pelleted at 4°C and the supernatant was discarded. The decanted cell pellets were stored at −80°C.
The cell pellets were thawed on ice. Lysis and affinity chromatography were performed using the Takara Bio HisTALON gravity column purification kit; all steps were performed according to the manufacturer’s native protein extraction protocol. Note that the cell pellets were treated with optional DnaseI and lysozyme during lysis. 1mL of Takara Bio TALON metal affinity resin was used for affinity chromatography. All binding and wash steps were performed on ice with shaking at 250 RPM. 15 bed volumes of wash buffer were used for all washes. CaM-mTdT(M13–388) was eluted from the resin in 10, 500uL fractions. Each fraction was analyzed by SDS-PAGE, and the total protein concentration in each fraction was measured by absorbance at 280nm. The first five elution fractions, which contained the majority of eluted protein, were pooled.
The pooled fractions were diluted in binding buffer (20 mM Tris-HCl, pH 8.3) and further purified by anion exchange chromatography using a Cytiva HiTrap Q HP 5mL column and a 40 CV gradient from 0 mM to 1 mM NaCl in binding buffer with a GE Healthcare AKTAxpress FPLC. The protein eluted in two fractions.
Both elutions were buffer exchanged by dialysis into a storage buffer consisting of 200mM KH2PO4 and 100mM NaCl at pH 6.5 and concentrated using Vivaspin 20 columns to a final concentration of 0.37 mg/mL for the first fraction and 0.98 mg/mL for the second fraction. The fractions were aliquoted, and flash frozen on dry ice for storage at −80°C. Notably, PAGE analysis showed that the second elution contained a product at 25kDa in addition to the expected fusion protein at approximately 70kDa. Both CaM-mTdT(M13–388) elutions recapitulated the calcium-sensitive phenotype and exhibited similar nucleotide selectivity (Fig. S18-19). As significantly more protein was recovered in the second elution it was used for all subsequent experiments.
Cell free protein expression and primer extension assay
For initial activity screening of fusion variants and CaM-mTdT(M13–388) characterization, proteins were expressed in cell-free reactions. Variants were expressed using NEB PURExpress in 25 μL reactions containing 40% (v/v) PURExpress Solution A, 30% (v/v) PURExpress Solution B, 1.6 U/μL NEB Rnase I, 10 ng/μL expression vector DNA, and dH2O to volume. The expression reactions were incubated for 4 hours at 30°C.
Primer extension reactions were prepared on ice. Primer extensions were performed in 25 μL reactions containing 1X NEB TdT Reaction buffer, 0.8 μM single-stranded, FAM-labelled substrate DNA FAM_NB (Table S2), 1mM dNTPs, polymerase, and dH2O to 25 μL. For variants expressed in PUREexpress, 2.5 μL of the expression reaction was used immediately after expression; 20U (approximately 0.2 μg) of the NEB bovine TdT was used for positive control reactions; approximately 0.5 μg, of purified CaM-mTdT(M13–388) was used for activity validation reactions after purification. For calcium-added conditions, CaCl2 was added to the reactions to a final concentration of 1mM. Extension reactions were incubated for 2 hours at 37°C
Completed extensions were analyzed by urea-PAGE. 8 μL of each completed primer extension reaction was combined with 12 μL of BioRad 2x TBE urea sample buffer and boiled for 10 minutes. The boiled samples were loaded onto a 10% polyacrylamide TBE urea gel (bioRad 4566036), and 200V was applied to the gel for 40 minutes. The gels were imaged on a GE Healthcare Typhoon 9400 laser scanner using a 200um pixel size and λex=488nm, λem=520nm BP40. Imaging gain was adjusted for each experiment to avoid saturation.
Extension reaction for calculating effect of Co2+, Ca2+, Zn2+, and temperature on overall dNTP preference of TdT:
Each extension reaction consisted of a final concentration of 10 μM ssDNA substrate CS1 (Table S2), 1 mM dNTP mix (each dNTP at 1 mM final concentration), 1.4x NEB TdT reaction buffer, and 10 units of TdT to a final volume of 50 μL. When testing the effect of cations, CoCl2 was added at a final concentration of 0.25 mM, CaCl2 at 2 mM, or Zn(Ac)2 at 20 μM. It is important to note that reaction initiation was done by adding TdT to the ssDNA substrate mix (ssDNA substrate mix consisted of the ssDNA substrate, dNTPs and the cation). Prior to reaction initiation, the ssDNA substrate mix and TdT were stored in separate PCR strip tubes at 0 °C (on ice). The reaction was run for 1 hour at 37 °C in a Bio-Rad PCR block. When testing the effect of temperature, the same reaction mix was run on a Bio-Rad PCR block set at tested temperatures for 1 hour. Reactions were stopped by freezing at −20 °C. For initial testing, reactions were analyzed by urea-PAGE 2 μL of the reaction was mixed with 12 μL of TBE-Urea (Bio-Rad) loading dye and boiled for 10 minutes at 100 °C. All of the diluted extension reaction was then loaded onto 30 μL, 10 well 10% TBE-Urea Gel (Bio-Rad) and run for 40 minutes at 200 V. Immediately after the run was over, the gel was stained with Sybr Gold for 15 minutes and imaged on an ImageQuant BioRad.
TURTLES extension reactions:
Mg2+ only for 1 hour (signal 0) and Mg2++Co2+ for 1 hour (signal 1) were set up as regular extension reaction mentioned above. The reactions where the signal changed from 0 to 1 at various times during the 1 hour extension were run starting at a total volume of 45 μL with Mg2+ only. 5 μL 2.5 mM CoCl2 was added at the time we wanted the signal to change from 0 to 1. Reactions were all run for a total of 1 hour in triplicates. Fresh signal 0 and signal 1 controls were run with each set-up.
TURTLES-2 controls and and extension reactions:
TURTLES-2 extension reactions contained 1X NEB TdT reaction buffer, 0.1 μM ssDNA substrate CS1_5N (Table S2), 1 mM dNTP mixture, and 2.5 μL polymerase mixture. The polymerase mixture contained CaM-mTdT(M13–388) at a concentration of 0.45 mg/mL and NEB TdT at a concentration of 0.002 mg/mL (0.4U). Calcium-free reactions included EGTA at a final concentration of 50 μM. The high calcium control for reactions was supplemented with CaCl2 and EGTA to final concentrations of 100 μM and 50 μM, respectively. The high calcium control for reactions was neither supplemented with EGTA nor CaCl2 (supplementary text 6). Reactions were brought to a final volume of 25 μL with nuclease-free water. Reactions were assembled on ice and initiated by adding TdT to the substrate mixture. Reactions were incubated for 1 hour at 37 °C in a Bio-Rad PCR block and terminated by heating reactions to 80 °C for 10 minutes.
Signal transitions were performed by 1uL additions at 30 minutes. for reactions, the addition contained 1X NEB TdT buffer and 1.3 mM EGTA (50 mM EGTA in final reaction post- addition). for reactions, the addition contained 1X NEB TdT buffer and 2.6 mM CaCl2 (100 μM CaCl2 in final reaction post- addition).
Extension reactions for set-up:
Mg2+ only for 1 hour (signal 0) and Mg2++Co2+ for 1 hour (signal 1) were set up as regular extension reaction mentioned above. The reactions where the signal changed from 0 to 1 at 20 minutes and back to 0 at 40 minutes were run starting at a total volume of 45 μL with Mg2+ only. 5 μL 2.5 mM CoCl2 was added at the time we wanted the signal to change from . For changing the signal from 10, since the ssDNA was suspended in reaction buffer for these set-ups, we used a ssDNA clean up kit (methods mentioned below) to remove the reaction buffer, TdT, cation and dNTPs from each reaction. All of the ssDNA collected from the ssDNA clean up kit (20 μL) was then prepared for the last part of the extension reaction. Collected ssDNA was mixed with a dNTP mix at a final concentration of 1 mM (each dNTP at 1 mM final concentration), 1.4x TdT reaction buffer and 10 units of TdT to a final volume of 50 μL. All reactions were always initiated by adding TdT in the end. Signal 0 and signal 1 controls were run for 1 hour for each set-up in triplicates and also put through the ssDNA wash step at 40 minutes. Six replicates were run for reactions.
ssDNA wash for replacing buffers for reactions:
For changing cation concentration from 1 to 0 we utilized the ssDNA clean-up kit (ssDNA/RNA clean/concentrator D7010) from Zymo Research such that all the extended ssDNA synthesized in the initial part of the experiment was retained on the column and the TdT, reaction buffer, cation and dNTPs were washed away. Each 50 μL extension reaction was individually loaded into a separate column. Protocol was followed as mentioned in the kit. ssDNA was eluted into 20 μL ddH2O. We noticed in initial tests that after using the ssDNA clean-up kit, there was little to no TdT-based extension in some replicates (data not included). We presume this is due some ethanol getting carried forward into the eluted ssDNA. Thus, we extended the dry spin time based on suggestion from Zymo Research to 4 minutes. We also utilized two other ways to evaporate any remaining ethanol after the column dry spin step based on protocol mentioned in Cold Spring Harbor Protocols(45). We either kept the columns open in a biohood for 15 minutes to allow for evaporation, or after elution of ssDNA we kept the 1.5 mL eppendorf tubes containing the eluted ssDNA open at 45 °C for 3 minutes. Both methods gave better ethanol removal than just dry spin, and they were tried in triplicates and averaged and plotted for the time prediction analysis (Fig. 2D).
Illumina library preparation and sequencing:
Our sample preparation pipeline for NGS was adapted from a previous protocol(46),(47). After extension reaction, 2 μL of the product was utilized for a ligation reaction. 22 bp universal tag, common sequence 2 (CS2) of the Fluidigm Access Array Barcode Library for Illumina Sequencers (Fluidigm), synthesized as ssDNA with a 5’ phosphate modification and PAGE purified (Integrated DNA Technologies), was blunt-end ligated to the 3’ end of extended products using T4 RNA ligase. Ligation reactions were carried out in 20 μL volumes and consisted of 2 μL of extension reaction, 1 uM CS1 ssDNA, 1X T4 RNA Ligase Reaction Buffer (NEB), and 10 units of T4 RNA Ligase 1 (NEB). Ligation reactions were incubated at 25 °C for 16 hours. Ligated products were stored at −20 °C until PCR that was carried out on the same day. Ligation products were never stored at −20 °C for more than 24 hours.
PCR was performed with barcoded primer sets from the Access Array Barcode Library for Illumina Sequencers (Fluidigm) to label extension products from up to 96 individual reactions. Each PCR primer set contained a unique barcode in the reverse primer. From 5’−3’ the forward PCR primer (PE1 CS1) contained a 25-base paired-end Illumina adapter 1 sequence followed by CS1. The binding target of the forward PCR primer was the reverse complement of the CS1 tag that was used as the starting DNA substrate. From 5’−3’ the reverse PCR primer (PE2 BC CS2) consisted of a 24-base paired-end Illumina adapter 2 sequence (PE2), a 10-base Fluidigm barcode (BC), and the reverse complement of CS2. CS2 DNA that had been ligated onto the 3’ end of extended products served as the reverse PCR primer-binding site. Each PCR reaction consisted of 2 μL of ligation product, 1X Phusion High-Fidelity PCR Master Mix with HF Buffer (NEB), and 400 nM forward and reverse Fluidigm PCR primers in a 20 μL reaction volume. Products were initially denatured for 30 s at 98 °C, followed by 20 cycles of 10 s at 98 °C (denaturation), 30 s at 60 °C (annealing), and 30 s at 72 °C (extension). Final extensions were performed at 72 °C for 10 min. Amplified products were stored at −20 °C until clean up and pooling. QC for individual sequencing libraries was performed as follows. 2 μL of each library was pooled into a QC pool and the size and approximate concentration was determined using Agilent 4200 Tapestation. Pool concentration was further determined using Qubit and qPCR methods. Sequencing was performed on an Illumina MiniSeq Mid Output flow cell and sequencing was initiated using custom sequencing primers targeting the CS1 and CS2 conserved sites in the library linkers. Additionally, phiX control library was spiked into the run at 15–20% to increase diversity of the library clustering across the flow cell. After demultiplexing, the percent seen for each sample was used to calculate a new volume to pool for a final sequencing run with evenly balanced indexing across all samples. This pool was sequenced with metrics identical to the QC pool. Library preparation and sequencing were performed at the University of Illinois at Chicago Sequencing Core (UICSQC).
NGS Data Preprocessing:
For each sample, the NGS reads were first trimmed and filtered using cutadapt (v1.16). Only NGS read pairs with both Illumina Common Sequence adapters, CS1 and CS2, were kept. Of these, CS2 was trimmed off each R1 sequence and CS1 was trimmed off each R2 sequence. Cutadapt parameters were set as following: a minimum quality cutoff (-q) of 30, a maximum error rate (-e) of 0.05, a minimum overlap (-O) of 10, and a minimum extension length (-m) of 1. The minimum overlap was set to be higher than the default value of 3 because extended sequences in this case are random, and we did not want to filter out sequences where the final 1–10 bases just happen to look like the first 10 bases of CS2 (the read must still contain a full CS2 sequence for it to be kept and subsequently trimmed, however). The 3’ (-a) adapter trimmed from the R1 reads was 5’AGACCAAGTCTCTGCTACCGTA3’ (CS2 reverse complement), and the 5’ (-A) adapter trimmed from the R2 reads was 5’TGTAGAACCATGTCGTCAGTGT3’ (CS1 reverse complement). FastQC was used to quickly inspect the output trimmed .fastq files before downstream analysis. See filter_and_trim_TdT.sh at https://github.com/tyo-nu/turtles for an example preprocessing script. All runs were trimmed using this script. All initial preprocessing was done on Quest, Northwestern University’s high-performance computing facility, using a node running Red Hat Enterprise Linux Server release 7.5 (Maipo) with 4 cores and 4 GB of RAM, although only 1 core was used. Preprocessing took between 5 and 30 minutes depending on the number of conditions, replicates, and reads per replicate in a given run.
Finally, for each analysis, we did further preprocessing locally. We cut off bases that were still present in the reads but not added during the experiment. Degenerate bases (if any) that are part of the 5’ ssDNA substrate (at its 3’ end before the extension) were removed from the beginning of each sequence. Then, we cut off 5.8 bases off the end of every sequence because we found that, on average, 5.8 bases were being added after the extension reaction during the 16 hour ligation step (Fig. S9). Because 5.8 is not an integer value, we cut 5 bases off of 80% of the sequences and 6 bases off of 20% of the sequences. We also filtered out sequences with length less than 6 bases.
Timepoint prediction for single step change experiment:
All further analysis was done in python using Jupyter Notebooks. You can find all the Jupyter Notebooks used for this publication at https://github.com/tyo-nu/turtles. The following algorithm was applied in order to (1) read and normalize each sequence by its own length, (2) calculate a distance metric using the relative dATP, dCTP, dGTP, and dTTP percent incorporation changes between each condition and the 0 control, and (3) transform distances for all conditions into space based on the 0 and 1 control distance values.
We first normalize each sequence by length, such that all bases in each sequence are counted across 1000 bins. For example, for a sequence of length 10, the first base would get counted in the first 100 bins, the next base in bins 100–200, and so on.
We then calculate base composition, , in the sequence for condition, , at each bin with position, , using the formula for a closure (equation 1). Note that is unique for each (condition, replicate) pair if multiple replicates are present for a given experimental condition.
| (1) |
Here, is the total count of dATP, dCTP, dGTP, or dTTP depending on the value of across all sequences for condition, , at bin, .
To calculate distance between two compositions at a given bin location (e.g. between the 0 and 1 controls at every bin), we have to first transform the compositional data. We cannot simply take the L2 norm difference of each compositional element because the elements of a composition violate the principle of normality due to the total sum rule (all elements add up to 100%). Thus, the data is first transformed by using the center log-ratio (clr) transformation which maps this 4-component composition from a 3-dimensional space to a 4-dimensional space. We then take the L2 norm of these transformed normal elements. This distance metric is known as the Aitchison Distance, which is used here to calculate the base composition distance, , from the 0 control to each condition, , at each bin, (equation 2).
| (2) |
and is the geometric mean for condition, , and bin, , across all four bases in (equation 3).
| (3) |
For condition, , and bin , the output signal, , is calculated as
| (4) |
where is the Aitchison distance between the 0 control base composition and 1 control base composition at bin, for all . If there were multiple replicates for the 0 control, their average composition was used for in equation 2. If there were multiple replicates for the 1 control, their average composition was similarly used to calculate in equation 4.
Next, the switch times were estimated for each condition, , which contains a change in output signal, , (e.g. via addition of Co halfway through the reaction). For experiments with more than one change (e.g. ), a more sophisticated approach was used and is detailed below. However, the following simpler, more intuitive approach was used to predict switch times for and .
Switch times were estimated for a given condition, , by (1) finding , the average location across all the sequences (bin position, ) at which half the 1 control output signal is reached (i.e. ), (2) calculating , the ratio of the average rate of nucleotide addition for the 0 and 1 controls, and (3) using and to calculate the switch time, , using equations 5 and 6. For a derivation of equation 5, see supplementary methods.
| (5) |
where
| (6) |
is the average synthesis rate of the first environmental condition before the switch. For example, would be calculated using the 0 control for the condition, , but the 1 control for the condition, . The average synthesis rate is calculated by dividing the average extension length by the duration of the experiment. is the average synthesis rate for the second environmental condition (after the switch).
Timepoint estimation for multiple fluctuations experiment:
To predict the Co2+ condition in the experiment, we used the algorithm we developed in Glaser et al. for decoding continuous concentrations(13). The input to this algorithm is the amount of output signal on every nucleotide. Here, the output signal is from the previous section. The algorithm uses this information to predict continuous values of Co2+ between 0 and 1 for all time points that are most likely to produce the amount of output signal on the nucleotides. To binarize these predictions, we then set a threshold of 0.5. To be able to predict the values of Co2+, the algorithm requires knowledge of the expected amount of output signal in the 0 and 1 control conditions. Here, this is the average output signal across nucleotides in the 0 or 1 control experiments. The algorithm also requires knowledge of the rate of nucleotide addition. Here, we fit an inverse Gaussian distribution to the average experimental dNTP addition rate distribution (the distribution of the sequence lengths divided by the experiment time) from the control experiments. Note that this algorithm also assumes that the rate of dNTP addition is independent of the cation concentration. Thus, when making predictions in the experiment, we do not account for differences in the rate of dNTP addition distributions between the 0 and 1 conditions.
In silico simulations of recording faster and higher number of input signal changes:
Using the average dNTP incorporation rate from experiments, and the amount of output signal in the control conditions, we simulated additional experiments in silico. Each simulated experiment had at least 6 signal changes (instances of a single signal change from or ), where each condition was randomly chosen to be 0 or 1. All nucleotides that were added during the 0 or 1 condition had the signal associated with these control conditions. More specifically, to account for the experimental variability in signals within a given control condition, nucleotide signals were sampled from a Normal distribution determined by the experimental variability of nucleotide signals within the control conditions. We calculated the variability in two ways, corresponding to the two representative curves in Fig. S12A and S12C In one, the variability was calculated across the first 100 nucleotides, in which there were at least 2000 recordings of all base numbers. In the second, the variability was calculated across the first 50 nucleotides, in which there were at least 60000 recordings of all base numbers. Using the output signal of the simulated nucleotides, we used the algorithm we developed in Glaser et al. for decoding binary concentrations (13). Accuracy corresponds to the percentage of conditions correctly classified as 0 or 1 over the duration of the entire recording experiment.
Time point estimation for 01, 10 single step change for TURTLES-2 using an inverse model:
To predict the Co2+ condition in the experiment, we used a variation of the algorithm we developed in Glaser et al. for decoding continuous concentrations (13). This algorithm will predict continuous values of Co2+ between 0 and 1 for all time points that are most likely to produce the amount of signal. Here, instead of using the amount of signal on every nucleotide to predict the continuous concentrations, we use the normalized signal.
Let be the signal as a function of condition, , and normalized position, . Let be the probability that a nucleotide corresponding to normalized position was written at time t. Let be the normalized cation concentration for condition . Like in (13), our model is that . We use maximum likelihood estimation to find that minimizes subject to and given condition, . To binarize the predictions, we then set a threshold for of 0.5.
Here, for an experiment of duration (e.g. 60 minutes), we let , where renormalizes the probability distribution after values outside the domain of [0, ] are set to 0. We set for each experiment so that is equal to the frequency of strands with a single nucleotide divided by (because a normalized position of 1 would generally only be written in the th minute when there is a single nucleotide strand). Note that future work that more accurately models the kinetics of the polymerase to get a more accurate estimate of will provide improved results.
When running this algorithm on the Ca2+ data which has different rates when Ca2+ is or isn’t present, following the prediction of Ca2+ over time with the above algorithm, we used the ratio of incorporation rates between the 0 and 1 condition, as described by Equation 5 and 6, to rescale the results.
Supplementary Material
Acknowledgements
The authors would like to acknowledge Marija Milisavljevic for help with some experiments, and Bradley Biggs for helpful discussions and comments on the manuscript. This research was supported in part through the computational resources and staff contributions provided for the Quest high performance computing facility at Northwestern University, which is jointly supported by the Office of the Provost, the Office for Research, and Northwestern University Information Technology. All next generation sequencing was done with the help of the Next Generation Sequencing Core facility at University of Illinois at Chicago. Sanger sequencing was supported by the Northwestern University NUSeq Core Facility. Gel imaging was supported by the Northwestern University Keck Biophysics Facility and a Cancer Center Support Grant (NCI CA060553). The Keck Biophysics Facility’s Azure Sapphire Imager was funded by the 1S10OD026963-01 NIH grant. Protein purification was supported by the Northwestern University Recombinant Protein Production Core. This work was funded by the National Institutes of Health grants R01MH103910 (to KEJT, KPK, ESB and GMC), and UF1NS107697 (to KEJT, KPK, ESB) and National Institutes of Health Training Grant (T32GM008449) through Northwestern University’s Biotechnology Training Program (to JS and AC).
Footnotes
Classification: Biological Sciences/Applied Biological Sciences
Supplementary Information
The Supplementary Information includes an extended description of methods (Supplementary Text, sections 1-7) as well as supplementary figures (S1-S21) and tables (S1-S2) which are referred to in the main text.
Data and code availability
All data generated during this study are included in this published article and its Supplementary Information. NGS data are available from Sequence Read Archive https://www.ncbi.nlm.nih.gov/sra/PRJNA542184.
Competing Financial Interests
A utility patent application has been filed for some of the developments contained in this article by KT, NB, AC, JS, JG and KK.
References
- 1.Church GM, Gao Y, Kosuri S, Next-Generation Digital Information Storage in DNA. Science (80-. ). 337, 1628–1628 (2012). [DOI] [PubMed] [Google Scholar]
- 2.Goldman N, et al. , Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature 494, 77–80 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Erlich Y, Zielinski D, DNA Fountain enables a robust and efficient storage architecture. Science (80-. ). 355, 950–954 (2017). [DOI] [PubMed] [Google Scholar]
- 4.Grass RN, Heckel R, Puddu M, Paunescu D, Stark WJ, Robust Chemical Preservation of Digital Information on DNA in Silica with Error-Correcting Codes. Angew. Chemie Int. Ed. 54, 2552–2555 (2015). [DOI] [PubMed] [Google Scholar]
- 5.Sheth RU, Yim SS, Wu FL, Wang HH, Multiplex recording of cellular events over time on CRISPR biological tape. Science 358, 1457–1461 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Loveless TB, et al. , Lineage tracing and analog recording in mammalian cells by single-site DNA writing. Nat. Chem. Biol. 17, 739–747 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Shipman SL, Nivala J, Macklis JD, Church GM, Molecular recordings by directed CRISPR spacer acquisition. Science (80-. ). 353 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Shipman SL, Nivala J, Macklis JD, Church GM, CRISPR–Cas encoding of a digital movie into the genomes of a population of living bacteria. Nature 547, 345–349 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Palluk S, et al. , De novo DNA synthesis using polymerase-nucleotide conjugates. Nat. Biotechnol. 36, 645–650 (2018). [DOI] [PubMed] [Google Scholar]
- 10.Lee HH, Kalhor R, Goela N, Bolot J, Church GM, Terminator-free template-independent enzymatic DNA synthesis for digital information storage. Nat. Commun. 10 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lee H, et al. , Photon-directed multiplexed enzymatic DNA synthesis for molecular digital data storage. Nat. Commun. 11, 1–9 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Yim SS, et al. , Robust direct digital-to-biological data storage in living cells. Nat. Chem. Biol. 17, 246–253 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Glaser JI, et al. , Statistical Analysis of Molecular Signal Recording. PLoS Comput. Biol. 9 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Kording KP, Of toasters and molecular ticker tapes. PLoS Comput. Biol. 7, 1–5 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Kelman Z, O’Donnell M, DNA polymerase III holoenzyme: Structure and function of a chromosomal replicating machine. Annu. Rev. Biochem. 64, 171–200 (1995). [DOI] [PubMed] [Google Scholar]
- 16.and A EA Motea JB, Terminal Deoxynucleotidyl Transferase: The Story of a Misguided DNA Polymerase. 21, 253–260 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Boulé JB, Johnson E, Rougeon F, Papanicolaou C, High-level expression of murine terminal deoxynucleotidyl transferase in Escherichia coli grown at low temperature and overexpressing argU tRNA. Mol. Biotechnol. 10, 199–208 (1998). [DOI] [PubMed] [Google Scholar]
- 18.Chang MS, Bollum FJ, Multiple Roles of Divalent Deoxynucleotidyltransferase Cation in the Terminal Reaction *. 265, 17436–17440 (1990). [PubMed] [Google Scholar]
- 19.Fowler JD, Suo Z, Biochemical, Structural, and Physiological Characterization of Terminal Deoxynucleotidyl Transferase. 2092–2110 (2006). [DOI] [PubMed] [Google Scholar]
- 20.Deibel MR, Coleman MS, Biochemical properties of purified human terminal deoxynucleotidyltransferase. J. Biol. Chem. 255, 4206–12 (1980). [PubMed] [Google Scholar]
- 21.Grienberger C, Konnerth A, Imaging Calcium in Neurons. Neuron 73, 862–885 (2012). [DOI] [PubMed] [Google Scholar]
- 22.Whitaker M, Calcium at fertilization and in early development. Physiol. Rev. 86, 25–88 (2006). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Stricker SA, Comparative Biology of Calcium Signaling during Fertilization and Egg Activation in Animals. Dev. Biol. 211, 157–176 (1999). [DOI] [PubMed] [Google Scholar]
- 24.Rosenberg SS, Spitzer NC, Calcium Signaling in Neuronal Development 10.1101/cshperspect.a004259 (June 24, 2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Frederickson CJ, Koh J-Y, Bush AI, The neurobiology of zinc in health and disease. Nat. Rev. Neurosci. 6, 449–462 (2005). [DOI] [PubMed] [Google Scholar]
- 26.Motea EA, Berdis AJ, Terminal deoxynucleotidyl transferase: The story of a misguided DNA polymerase. Biochim. Biophys. Acta - Proteins Proteomics 1804, 1151–1166 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Nakai J, Ohkura M, Imoto K, A high signal-to-noise ca2+ probe composed of a single green fluorescent protein. Nat. Biotechnol. 19, 137–141 (2001). [DOI] [PubMed] [Google Scholar]
- 28.Palmer AE, et al. , Ca2+Indicators Based on Computationally Redesigned Calmodulin-Peptide Pairs. Chem. Biol. 13, 521–530 (2006). [DOI] [PubMed] [Google Scholar]
- 29.Edwardraja S, et al. , Caged activators of artificial allosteric protein biosensors (2020) 10.1021/acssynbio.9b00500. [DOI] [PubMed] [Google Scholar]
- 30.Guo Z, et al. , Generalizable Protein Biosensors Based on Synthetic Switch Modules. J. Am. Chem. Soc, jacs.8b12298 (2019). [DOI] [PubMed] [Google Scholar]
- 31.Smith MA, Arnold FH, Designing libraries of chimeric proteins using SCHEMA recombination and RASPP. Methods Mol. Biol. 1179, 335–343 (2014). [DOI] [PubMed] [Google Scholar]
- 32.Crotti L, et al. , Calmodulin mutations associated with recurrent cardiac arrest in infants. Circulation 127, 1009–1017 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Zulkifli SN, Rahim HA, Lau WJ, Detection of contaminants in water supply: A review on state-of-the-art monitoring technologies and their applications. Sensors Actuators, B Chem. 255, 2657–2689 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Slomovic S, Pardee K, Collins JJ, Synthetic biology devices for in vitro and in vivo diagnostics. Proc. Natl. Acad. Sci. U. S. A. 112, 14429–14435 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Liu X, et al. , Design of a transcriptional biosensor for the portable, on-demand detection of cyanuric acid. ACS Synth. Biol. 9, 84–94 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Jung JK, et al. , Cell-free biosensors for rapid detection of water contaminants HHS Public Access Author manuscript. Nat Biotechnol 38, 1451–1459 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Thavarajah W, et al. , Point-of-Use Detection of Environmental Fluoride via a Cell-Free Riboswitch-Based Biosensor. ACS Synth. Biol. 9, 10–18 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Marblestone AH, et al. , Physical principles for scalable neural recording. Front. Comput. Neurosci. 7, 1–34 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Marblestone AH, Daugharthy ER, Kalhor R, Peikon ID, Kebschull JM, Shipman SL, … Church GM Rosetta Brains: A Strategy for Molecularly-Annotated Connectomics. ArXiv: Neurons and Cognition, 1–18 (2014). [Google Scholar]
- 40.Vikesland PJ, Nanosensors for water quality monitoring. Nat. Nanotechnol. 13, 651–660 (2018). [DOI] [PubMed] [Google Scholar]
- 41.Long F, Zhu A, Shi H, Wang H, Liu J, Rapid on-site/in-situ detection of heavy metal ions in environmental water using a structure-switching DNA optical biosensor. Sci. Rep. 3, 2308 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Eisenstein M, Enzymatic DNA synthesis enters new phase. Nat. Biotechnol. 38, 1113–1115 (2020). [DOI] [PubMed] [Google Scholar]
- 43.Akerboom J, et al. , Optimization of a GCaMP Calcium Indicator for Neural Activity Imaging. J. Neurosci. 32, 13819–13840 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Chen T-W, et al. , Ultrasensitive fluorescent proteins for imaging neuronal activity. Nature 499, 295–300 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Green MR, Sambrook J, Precipitation of DNA with Ethanol. Cold Spring Harb. Protoc. 2016, pdb.prot093377 (2016). [DOI] [PubMed] [Google Scholar]
- 46.de Paz AM, et al. , High-resolution mapping of DNA polymerase fidelity using nucleotide imbalances and next-generation sequencing. Nucleic Acids Res. 46, e78–e78 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Zamft BM, et al. , Measuring cation dependent DNA polymerase fidelity landscapes by deep sequencing. PLoS One 7 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.