

Abstract
Patient-centered appointment access is of critical importance at community health centers (CHCs) and its optimal implementation entails the use of advanced data analytics. This study seeks to optimize patient-centered appointment scheduling through data mining of Electronic Health Record/Practice Management (EHR/PM) systems. Data was collected from different EHR/PM systems in use at three CHCs across the state of Indiana and integrated into a multidimensional data warehouse. Data mining was performed using decision tree modeling, logistic regression, and visual analytics combined with n-gram modeling to derive critical influential factors that guide implementation of patient-centered open-access scheduling. The analysis showed that appointment adherence was significantly correlated with the time dimension of scheduling, with lead time for an appointment being the most significant predictor. Other variables in the time dimension such as time of the day and season were important predictors as were variables tied to patient demographic and clinical characteristics. Operationalizing the findings for selection of open-access hours led to a 16% drop in missed appointment rates at the interventional health center. The study uncovered the variability in factors affecting patient appointment adherence and associated open-access interventions in different health care settings. It also shed light on the reasons for same-day appointment through n-gram-based text mining. Optimizing open-access scheduling methods require ongoing monitoring and mining of large-scale appointment data to uncover significant appointment variables that impact schedule utilization. The study also highlights the need for greater “in-CHC” data analytic capabilities to re-design care delivery processes for improving access and efficiency.
Keywords: Data mining, Decision tree modeling, Logistic regression, Visual analytics, Open-access scheduling, Community health centers
Introduction
The Institute of Medicine’s (IOM) landmark 2001 report “Crossing the Quality Chasm” [1] defined high-quality health care as care that is safe, effective, patient-centered, efficient, equitable, and timely. Considerable evidence exists that poor access and long wait times negatively impact patients and families, as well as providers, in terms of health outcomes, patient satisfaction with care, health care utilization, and organizational reputation [2, 3]. Efficient and effective scheduling is critical for optimal utilization of scarce medical staff resources.
Effective appointment scheduling has also become increasingly important in light of recent health care legislation, as health care organizations strive to achieve Patient-Centered Medical Home (PCMH) [4] recognition—a provision within the Affordable Care Act [5]. The very first standard within this PCMH model of care relates to “Enhancing Access and Continuity.” This standard calls for provisioning patient-preferred appointment access (including same-day appointments) and continuity of care—both of which are key elements of a patient-centered scheduling system [6].
The learning health system framework serves as the bed rock for health care transformation and is built around data capture and analysis with best practices seamlessly embedded in the delivery process [7]. In this study, we sought to guide the optimization of the appointment scheduling process in three Community Health Centers (CHCs, or health centers for short) using large-scale data mining from Electronic Health Record/Practice Management (EHR/PM) systems. Data mining in this context refers to the analysis step of the “knowledge discovery in databases” process, that is used to discover patterns in large data sets using methods at the intersection of machine learning, statistics, and database systems [8].
Background and Significance
Generally, two main classes of health care appointment scheduling are used in outpatient clinics [9]. One is the traditional scheduling system, where most, if not all the appointments are booked in advance, and the other is open access (also known as advanced access or same-day scheduling), where a majority of the appointment slots may be held open for patients who call that day, while the remainder are pre-booked [10]. Open-access scheduling in general has been shown to address the issues with traditional scheduling, such as high rates of missed appointments, high variability in staff workload [11], long appointment lead times [12], lack of continuity of care [13], and diversion to urgent care or emergency rooms [14, 15]. However, implementing open access has its own challenges, and requires a data-driven re-design of the clinic operations [16]. Additionally, per an IOM report on transforming healthcare access, the time dimension of scheduling was not as well studied or understood as other dimensions of scheduling [17].
When a clinic includes open-access hours in their schedule, it is important to understand the predictors of appointment adherence and also optimize the selection of the open-access hours. The difference in care settings has been known to greatly influence the factors (e.g., patient demographics, and appointment variables) that affect patient appointment [18]. CHCs are known to face unusually high no-show rates [19], stemming from low socio-economic status of the patient population, high provider turnover, and the inability (as safety-net providers) to penalize patients who no-show [11].
Predictive modeling of no-shows has been performed to improve clinic scheduling systems in multiple settings, including a pediatrics clinic [20], a pain clinic [21], a mental health center [22], Veteran Affairs Medical Centers [23, 24], and at a primary care center [25]. Notably, a study done at an outpatient academic practice found that lead time for an available appointment was not a significant factor in appointment keeping behavior [26]. This study looks at advanced data analytic methods to optimize open-access scheduling interventions within the unique community health center settings.
Method
Overview
This study is part of a larger systems-based research project funded by the Patient-Centered Outcomes Research Institute (PCORI) on improving efficiency and access to care at CHCs in Indiana. A multidimensional clinic data warehouse was developed based on the requirements gathered from the key stakeholders in seven participating CHCs and the prior work by the study investigators in this area [27–29]. The core patient-level data element categories included patient demographics, appointment data, date/time stamps of key events for patient and data flow, insurance information, provider information, medical problem list, encounter diagnoses, immunizations, medications, laboratory data, care plan, procedures, and healthcare referral information.
The multi-CHC data warehouse contained data from over 40 clinic delivery sites spanning more than 6 years [2010–2016], sourced from four different EHR vendors (eClinicalWorks, Athena Health, GE Centricity, and NextGen Healthcare) and representing 3.5 million encounters from 0.7 million unique patients. Details on the design and the development of that data warehouse and associated reporting have been documented in our prior publications [30, 31].
Data
Data for three health centers was extracted from the data warehouse and represented 130,000 encounters from 35,000 unique patients in 2015. The data used in this study was de-identified under the HIPAA privacy rule and was obtained under institutional IRB approval and a business associate agreement with the participating health centers.
Advanced Analytic Approaches
Machine learning, statistical analysis, and data visualization techniques were used to analyze the clinic appointment dataset. The first step of the data analysis was data cleaning and validation. In this case, the dataset was cleansed of any duplicates. As expected with database table normalization, there were several data dictionary and reference tables containing information on appointment types, patient profile, delivery of care, and providers.
The specific analyses include predictive modeling of appointment adherence based on the decision tree algorithm, Chi-square and logistic regression to quantify the impact of the predictor variables, and finally visual representations of the results. We also applied n-gram analysis of the appointment reasons, which is a free text field in the EHR systems.
To perform the modeling on the intervention CHCs in this study, we used RapidMiner 7 for machine learning (decision tree modeling) [32], R for statistical analysis/text mining (Chi-square test, logistic regression, n-gram modeling) [33], and Tableau 10 for data visualization [34].
Machine Learning
The decision tree was based on the C4.5 algorithm as implemented in Rapid Miner. For each tree node, the split attribute is chosen by iterating all attributes, finding the best split for each attribute based on the splitting criterion, and then selecting the attribute that maximizes the chosen criterion. The attribute selection criterion was based on either information gain or gain ratio. The gain ratio method, a variant of the information gain method, overcomes the bias towards selecting attributes with a large number of values by adjusting the information gain for each attribute to allow the breadth and uniformity of the attribute values. The depth of the tree (which restricts the number of tree nodes generated to a manageable number) was set to five. Pruning of the decision tree was applied to allow some branches to be replaced by leaves according to the chosen confidence parameter of 0.25 (the confidence level for the pessimistic error calculation of pruning). No pre-pruning was applied. The statistical performance of the model was assessed using 10-fold cross validation using different splitting criterion.
Statistical Analyses
Statistical analyses were performed after the decision tree to identify the significant predictors of appointment status (such as completed and missed appointments) and to obtain odds ratios of these predictors. Chi-square and binomial logistic regression were performed using R. The analysis steps included the following: (1) Read input data file; (2) Create classes for each of the time-dimension variables using factor functions; (3) Perform a Chi-square test of independence between the target label and the predictor variables and identify the significant attributes by their p values; (4) Perform binomial logistic regression to obtain the coefficients; and (5) Convert log odds to odds ratios.
During the statistical analysis, emphasis was on quantifying the associations, particularly on the variables in the time dimension of scheduling. The discovered predictors were then applied to optimize the selection of open-access scheduling hours at one of the health centers.
Results
This section first summarizes the clinic and patient characteristics of the three CHCs. Then, we present the analytical results of the patient appointment scheduling datasets and apply the analytical results to guide the optimization of same-day appointment access hours at a health center.
Clinic Data Characteristics
The CHC-level information was first gathered from the operational data stores and, in particular, from the annual Uniform Data Systems (UDS) reports. A clinic questionnaire was used to understand the appointment scheduling procedures. The combined information was analyzed and the critical characteristics for the health centers in the study year are presented in Table 1.
Table 1.
CHC-level characteristics for patient visits
| CHC Characteristic | CHC-1 | CHC-2 | CHC-3 |
|---|---|---|---|
| # of patients [for all sites of a CHC] | 9502 | 20,610 | 4989 |
| CHC care setting/location | Urban | Semi-urban | Rural |
| Services offered | Medical | Medical, Dental, Behavioral Health | Medical, Behavioral Health |
|
Number of visits [incl. physician, NP, nurse] |
54,344 | 63,108 | 13,110 |
|
Number of primary care sites [excl. mobile clinic] |
1 | 3 | 2 |
| Number of providers [MDs and NPs]; FTEs | 1 MD; 22 NP | 4.5 MD; 11.5 NP | No MDs; 8 NP |
|
Provider tenure [Avg. in mo., for MD/NPs] |
16 months; 11 months | 55 months; 32 months | 64 months |
| Ratio of number of visits to providers | 9502/23 = 413 | 20,610/16 = 1288 | 4989/8 = 624 |
|
Scheduling method [pre-booked and open access (OA)] |
AM: pre-booked PM: mostly OA | 1–2 pm and 6–7 pm are open access | 1 h/provider each day is OA |
| Average appointment adherence rates: no-show%; Cancelations% | 22%; 13% | 18%; 14% | 20%; 13% |
Significant characteristics include patient populations (5000 to 21,000 patients/year), care settings (urban, semi-urban, and rural), the range of medical services offered, the providers types and tenure, visits to provider ratios [413 to 1288], and appointment adherence rates. The relatively small number of providers in these health centers emphasizes the critical nature of provider stability in determining access and continuity of care. Furthermore, while modified open access makes it easier to accommodate acute care visits, the open-access hours were rather limited (1–2 h/day). Mornings were typically pre-booked ahead of time, while select hours in the afternoons were reserved for same-day/open-access hours. This limited number of open-access hours was not enough to mitigate the high no-show and cancelation rates at the participating CHCs.
After reviewing the practice characteristics, it was clear that both the number of open-access hours offered each day and the timing of the offerings could be improved to maximize provider utilization at the participating CHCs.
Decision Tree Modeling
Visit adherence was shown in terms of appointment and patient characteristics using a decision tree model. The target class of “show status” was binary: Completed (i.e., patients showed up for the appointment) or Missed (i.e., patients no-showed). For CHC-1 (the one having the highest no-show rates), there were 11 attributes, namely Appointment Lead Time, Appointment Duration, New/Established Patient, Visit Type, Patient Age Group, Ethnicity, Gender, Language, Race, Patient Web Portal Status, and Insurance. All of the above attributes are inherently categorical, except for lead time, which could belong to either category. When the decision tree was allowed to detect the numeric thresholds for the lead time, the split occurred at the “186 day” mark. Such a binary split was deemed to have little practical utility when scheduling patients out and hence three bins were created for the lead time. There were a total of 10,401 records over a 12-month period. The input characteristics (categories, counts, and %) are shown in Table 2.
Table 2.
Characteristics of the input data set for decision tree modeling
| Attribute | Categories | Count of Appt_IDs | % of total |
|---|---|---|---|
| Show_Status [Label] | Show | 7943 | 76 |
| No-show | 2458 | 24 | |
| Lead_Time | > 10 days | 3183 | 31 |
| 0 days | 2542 | 24 | |
| 1–10 days | 4676 | 45 | |
| Appt_Duration | > 30 min | 199 | 2 |
| 15 min | 6473 | 62 | |
| 30 min | 3729 | 36 | |
| New_Pt. | No | 9517 | 92 |
| Yes | 884 | 8 | |
| Visit_Type | Acute | 2743 | 26 |
| Routine | 7303 | 70 | |
| Wellness | 355 | 3 | |
| Age_Grp | <18 years | 3181 | 31 |
| ≥65 years | 364 | 3% | |
| 18–64 years | 6856 | 66 | |
| Ethnicity | Hispanic/Latino | 3241 | 31 |
| Not Hispanic/Latino | 7160 | 69 | |
| Gender | Female | 7046 | 68 |
| Male | 3355 | 32 | |
| Language | English | 7653 | 74 |
| Other | 372 | 4 | |
| Spanish | 2376 | 23 | |
| Race | Black | 4985 | 48 |
| Other | 585 | 6 | |
| White | 4831 | 46 | |
| Web_Enabled | No | 5044 | 48 |
| Yes | 5357 | 52 | |
| Insured | No | 1584 | 15 |
| Yes | 8817 | 85 |
The resulting accuracy based on 10-fold cross validation was approximately 76%. Replacing the Decision Tree Model with a logistic regression model produced a similar accuracy level. The use of different splitting criterion (be it information gain or gain ratio, but also others like Gini index and accuracy criterion) had no significant impact (± 0.5%) on the overall accuracy level. However, even though the overall accuracy was comparable between the information gain and gain ratio (76.59% and 76.26%), the former did have a much better precision (positive predictive value) for no-shows relative to gain ratio (53.20% vs. 35.14%).
Furthermore, the decision tree-based predictive model is more advantageous when compared to only relying on the base (pre-modeling) distribution of the data (Table 2). This is explained by analyzing the confusion matrix values and the corresponding labels (True Positive, False Positive, False Negative, True Negative, Positive Predictive Value, Negative Predictive Value, Sensitivity, and Specificity) as highlighted in Table 3.
Table 3.
Confusion matrix of the decision tree using the information gain criterion
| True no-show | True show | Class precision | |
|---|---|---|---|
| Pred. no-show | 191 [TP] | 168 [FP] | 53.20% [PPV] |
| Pred. show | 2267 [FN] | 7775 [TN] | 77.42% [NPV] |
| Class recall | 7.77% [Sensitivity] | 97.88% [Specificity] |
Of particular relevance is the false positive rate (0.6%) and false negative rate (92.2%) and their relative importance in health center settings when dealing with appointment adherence. If a patient was predicted to no-show but ended up showing up (False Positive), then this is of concern to the health center, since the operational workflow is disrupted leading to poor patient experience (long in-clinic wait times, rushed appointment) that end up reflecting poorly in the patient satisfaction results. Concurrently, the work overload and process variability leads to conflict and frustrations in the provider/care team members because of the need to accommodate unplanned patient appointments into their already tight schedule. These issues directly contravene the quadruple aim of healthcare [35], specifically improving the patient experience and care team well-being. The low false positive rate in the Decision Tree Model helps avoid both these issues. On the contrary, when a patient that is predicted to show up, ends up as a no-show (False Negative), this is not so much of a concern, since in most cases, the provider schedules have double bookings in place (particularly for specific visit types and/or times of the day) to limit the impact of missed appointments on schedule utilization. Secondly, clinics have no-show policies that prevent repeat no-showers from being allowed to have pre-booked appointments for up to a year or more. Such no-showers are only allowed to come in during same-day/walk-in hours during that disciplinary period. The high false negative rate in our results is therefore less of a concern to a health center.
In addition to the false positive and false negative rates, another measure of significance is the likelihood ratio (LR), which combines prevalence and sensitivity (and specificity) of a model while showing how the predicted result will improve on a guess using base probability. Specific to this model, LR is defined as the likelihood that a given predicted result is a “no-show” (= Sensitivity) compared to the likelihood that that same result would be expected in a patient who is a “show” (1-Specificity). In this case, the LR is equal to 3.71, which implies that a patient predicted to no-show will be 3.71 likely to be true no-show, compared to a patient who is predicted to show up.
The resulting decision tree graph based on the information gain criterion with a depth of 5 is shown in Fig. 1, while the decision tree with the same depth of 5 but with the gain ratio criterion is shown in Fig. 2. Even though the tree based on the information gain criterion is much more expansive than the one based on the gain ratio criterion, at the root of both the decision trees is the attribute: lead time (i.e., the time difference between the appointment creation date and the actual appointment date). Being at the root of the decision tree implies that the lead time is the most significant predictor variable determining appointment adherence. This finding supports the notion of a scheduling system based on making more same-day appointment slots available (since a smaller lead time will lead to higher appointment adherence) as well as avoiding scheduling appointments too far in the future. Other attributes that held significance (i.e., provided the highest information gain) included new patient vs. established patient, appointment duration, visit type, patient ethnicity, and race, age group, and gender.
Fig. 1.

Decision Tree Model to predict appointment adherence using information gain criteria
Fig. 2.

Decision Tree Model to predict appointment adherence using gain ratio criteria
Furthermore, visually tracing through the decision tree in Fig. 1 allowed for examining various scenarios. To give an example, using this method, we found that an African American patient, in the age group (18–64) for a wellness visit that is scheduled the same day, is highly likely to show up for a visit. A Spanish speaking uninsured patient has a high likelihood of no-show even when scheduled the same day. In another scenario, an appointment longer than 30 min for an under 18 patient of other race (i.e., either Caucasian or African American) scheduled greater than 10 days ahead of time is highly likely to miss their appointment. Thus, the Decision Tree Model helps demonstrate the importance of different variables and their linkage to others, in determining the outcome of interest (adherence).
A decision tree can also be converted into a set of if-then rules to separate the data into increasingly homogenous sub-sets. This visual representation with simple if-then constructs makes the decision tree technique a useful tool to guide open-access scheduling. For instance, patients with high likelihood to miss their appointments are good candidates for double booking or more intensive appointment reminder systems.
Results from Statistical Analysis
Following decision tree modeling, statistical approaches were applied to quantify the predictors for appointment adherence based on odd ratios from the logistic regression and also assess the strength of associations between a variable and the appointment adherence using Chi-square test of independence. The outcome variable of interest is “show status,” which is the binary values of 0 or 1. The show status of 0 indicates the patient missed the appointment (i.e., no-show), while a value of 1 means the patient showed up for the appointment.
The statistical analysis specifically focused on the predictor variables in the time dimension, given their importance for designing the optimal appointment schedules and the fact that knowledge of these variables would allow for deciding the hours allocated for open access. The specific variables in this dimension and possible classes were as follows: ApptLeadTime (same-day and not same-day), ApptHr (8:00 am–6:00 pm in 1-h blocks), ApptDay (Monday to Saturday), ApptMonth (January to December), and ApptSeason (Winter and non-Winter). The degrees of freedom is equal to n-1, where n is the number of classes for each of the variables. The number of classes varied among health centers. For example, CHC-1 was open only during the weekdays, while CHC-2 and -3 were open from Monday to Saturday).
The null hypothesis (H0) was that the “ShowStatus” is independent of these variables in the time dimension. The Pearson Chi-square test of independence revealed the dependence of the “show status” on the above time dimensions. The results are summarized in Table 4. The show status was dependent on each of the time dimensions (p value was < 0.05) for CHC-1. For both, CHC-2 and CHC-3, the show status was not significantly dependent on the Season (p value was > 0.05). For CHC-3, the dependence on ApptDay was not significant. The non-significant attributes are italicized in the table.
Table 4.
Results from Pearson’s Chi-square test of independence for “show status” prediction for Chi-square, degree of freedom (df), and p values.
| Pearson’s Chi-square test of independence [Format: Chi-square; df; p value] | |||
|---|---|---|---|
| CHC-1 | CHC-2 | CHC-3 | |
| Sample size | 17,449 | 25,008 | 5439 |
| Same day | 644.59; 1; < 2.2e-16 | 622.86; 1; < 2.2e-16 | 205.14; 1; < 2.2e-16 |
| ApptHr | 141.4; 10; < 2.2e-16 | 259.34; 12; < 2.2e-16 | 23.035; 10; 0.01062 |
| ApptDay | 31.916; 4; 1.99e-06 | 8.4465; 5; 0.1333 | 6.3706; 5; 0.2718 |
| ApptMonth | 79.725; 11; 1.668e-12 | 31.412; 11; 0.0009471 | 31.412; 11; 0.0009471 |
| Season | 15.831; 1; 6.924e-05 | 1.0535; 1; 0.3047 | 1.3806; 1; 0.24 |
For the logistic regression analysis, the log odds of the outcome were modeled as a linear combination of the predictor variables (i.e., the five time dimensions).
The change in the odds of the outcome is always with a reference value. The reference values for the different variables are 8:00 am for ApptHr, Fri for ApptDay, April for ApptMonth, non-Winter for ApptSeason, and Non-Same-Day appointment for the ApptLeadTime. The odds ratios from the logistic regression analysis for each of the CHC are shown in Table 5. Odd ratios that are greater than 1.1 and less than 0.9 are highlighted in italics and bold, respectively, showing their relative importance.
Table 5.
Odds ratios from logistic regression of the time dimension for “ShowStatus” prediction
| Logistic regression: odds ratios for show prediction | ||||
|---|---|---|---|---|
| Variable | Ref | CHC-1 | CHC-2 | CHC-3 |
| Same-day | Non-same day | 4.21 | 3.26 | 55.88 |
| Season | Non-winter | 1.01 | 1.07 | 0.73 |
| ApptHr | 8:00 AM | NA | NA | NA |
| 9:00 AM | 0.89 | 1.14 | 1.20 | |
| 10:00 AM | 0.92 | 1.17 | 1.01 | |
| 11:00 AM | 0.95 | 1.44 | 1.01 | |
| 12:00 PM | 0.78 | 1.31 | 0.95 | |
| 1:00 PM | 0.86 | 1.58 | 1.09 | |
| 2:00 PM | 1.05 | 1.70 | 1.34 | |
| 3:00 PM | 0.91 | 1.64 | 1.83 | |
| 4:00 PM | 0.88 | 1.68 | 1.19 | |
| 5:00 PM | 1.05 | 1.23 | 1.39 | |
| 6:00 PM | 0.83 | 1.14 | 1.65 | |
| ApptMonth | April | NA | NA | NA |
| Jan | 1.36 | 0.83 | 1.17 | |
| Feb | 1.14 | 0.93 | 0.81 | |
| Mar | 1.01 | |||
| May | 0.98 | 0.90 | 0.59 | |
| Jun | 1.03 | 0.68 | ||
| Jul | 0.98 | 0.70 | ||
| Aug | 0.99 | 1.30 | 0.65 | |
| Sep | 1.19 | 1.18 | 0.46 | |
| Oct | 1.17 | 1.00 | 0.63 | |
| Nov | 1.23 | 1.02 | 0.53 | |
| Dec | 1.11 | 0.98 | 0.83 | |
| ApptDay | Fri | NA | NA | NA |
| Mon | 0.70 | 1.03 | 1.12 | |
| Tue | 0.92 | 0.95 | 1.07 | |
| Wed | 0.88 | 1.07 | 1.08 | |
| Thu | 0.92 | 1.15 | 1.05 | |
| Sat | 1.05 | |||
The results also showed that even for the same predictor variable, the effect might be different for different clinical settings due to a unique attribute such as the characteristics of the patient population or the organizational variation in the clinic. The odds ratio for same-day vs. non-same-day, ranged from 3.26 to 55.88, showed that the ApptLeadTime was a strong determinant of appointment adherence. Thus, the likelihood of a patient showing up for their appointment scheduled on the same day is anywhere from 3 to 55 times higher than that for non-same-day appointments. It represents a significant impact and supports the implementation of more same-day appointments to improve appointment adherence. The odds ratio for winter vs. rest of the year was 0.73 (i.e., 27% lower likelihood of appointment adherence in winter months) for CHC-3. The odds ratio for the time of the day, the day of the week, and the month of the year varied significantly among the health centers. Notably, the odds ratios for 4:00 pm relative to 8:00 am were 0.88, 1.68, and 1.19 for the three CHCs respectively. Similarly, the odds ratios for Jan relative to April were 1.36, 0.83, and 1.17 for the three CHCs. These cases show the often opposing likelihood of patient adherence to appointments relative to certain times of the day and month of the year.
Visual Plots
The visit adherence patterns for the three CHCs were visually plotted (Fig. 3). The average rates for no-show vary from 15 to 23%, cancelations rates from 8 to 17%, and successful visit rates from 69 to 77%. There are distinct visit adherence patterns within the CHC hours of operation. For example, the no-show rates are consistently highest in the morning across each of the CHCs; the peak no-show rates vary from 7:00 am to 9:00 am among the CHCs. The lowest no-show rates occur in the early afternoon (1:00–2:00 pm) across all three CHCs. The patterns for cancelations rates are also relatively consistent, in that most of them occur late in the afternoon after 3:00 pm. Notably, appointments with high completion rates are in the early afternoon (1:00–3:00 pm) and in the evenings at 6:00 pm at all the three CHCs. In two out of the three CHCs, the 7:00 am time slot also has higher visit success rates.
Fig. 3.

Appointment adherence visualization by the time of the day across the 3 CHCs in the study
After identifying these patterns, we could recommend to all three health centers that they schedule same-day/open-access hours in the late morning [10:00 am–noon] because of the high no-show rates during those hours. It would also allow adequate time in the morning for patients to call in and schedule a same-day appointment. Offering more same-day appointment slots during this historically high no-show period should improve access for patients while reducing the no-show rate for the clinic.
Operationalizing the Findings
The findings from of our statistical analysis were applied to the clinical operations of CHC-1, which had the highest no-show rates relative to the other intervention clinics. CHC-1’s primary care site had recently achieved PCMH recognition. They were keen to optimize their same-day appointment scheduling, in particular, with a more sophisticated approach to selecting open-access hours. This CHC had been using a modified open-access scheduling system, where mornings were scheduled in advance and afternoons were being left open for walk-in appointments (although this was not strictly enforced).
We examined the appointment adherence pattern for CHC-1 to guide the selection of open-access hours. Our prior analysis had provided guidance on the relative importance of various predictors for appointment adherence (in particular the lead time), and the patterns are seen across a day. Specifically, based on the high missed appointments rates in the morning, we recommended that CHC-1 keep the early morning hours as scheduled, but have open-access hours in the late morning from 10:00 am to noon (to allow time for patients to call in for same-day appointments). For afternoons, we recommended CHC-1 have scheduled appointments until 2:00 pm and then open-access hours after that (to combat the higher canceled appointment rates occurring during that period).
CHC-1 implemented the schedule change in June 2016 based on the recommended changes. Their overall missed appointment rates (no-shows and cancelations) dropped from an average of 37% (during March–May) to 31% (during Jun–Sep)—a 16% relative reduction (Fig. 4).
Fig. 4.
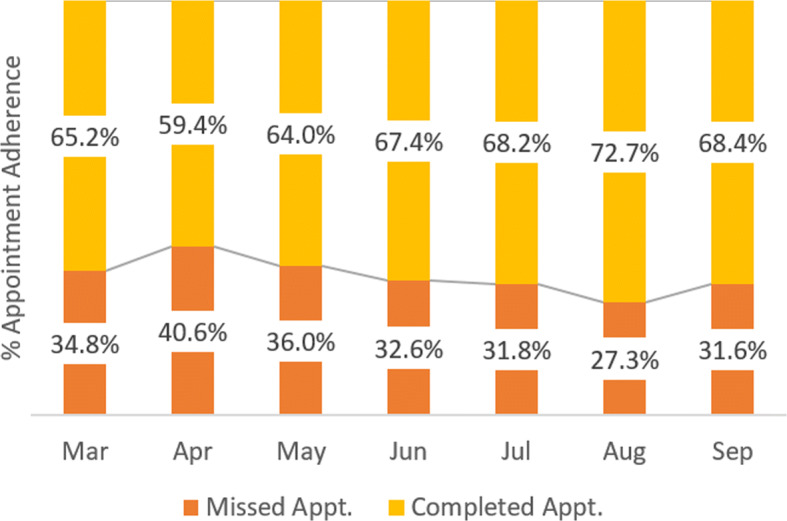
Appointment adherence trend for CHC-1 following implementation of same-day access hours starting in Jun 2016
CHC-1 was thus able to see an immediate benefit of modifying the open-access hours based on knowledge mined from their scheduling data. It may be pointed out here for the other CHCs (CHC-1 and -2), the intervention was not focused on increasing open-access hours. For CHC-2, all appointment durations were simplified to 20 min (in contrast to the prior practice of having 15- and 30-min appointment durations). Not surprisingly, there was no impact on missed appointment rates. For CHC-3, the intervention to increase open-access hours was not optimally implemented due to health center’s focus on opening two new care delivery sites during the intervention period.
n-Gram Modeling of Unstructured Text
To meet the PCMH requirement of measuring the percentage of appointments reserved for same-day access, CHC-1 found it easier to create “same-day” as an appointment type. However, unlike other appointment types—such as wellness, hospital follow-up, or chronic care management—an appointment type labeled “same-day” says nothing about the actual reason for appointment unless one were to analyze the free text entered in the “reason for appointment.” Not only is that information useful to understand the trend in appointment purpose, but it was also needed for reducing the number of appointment types, which in turn helps with implementing an open-access scheduling system.
We performed text mining of appointment reason (an unstructured text field) for CHC-1 to understand the reasons for those appointments categorized under “same-day”—they represent about 20% of the appointments for this CHC. n-Gram is a contiguous sequence of n items (typically words) from a given sequence of text and its use is common in the field of computational linguistics and probability. When n = 1, 2, 3, it referred to as a uni-gram, bi-gram, or tri-gram respectively. We applied uni-, bi-, and tri-gram analysis of the appointment reasons, which was a free text field in the EHR. The steps for n-gram analysis were as follows: Text Pre-Processing ➔ Tokenization ➔ Frequency Extraction ➔ Tag Cloud/Plot.
We found that the tri-gram (i.e., n = 3) analysis gave the most meaningful outcomes in the context of extracting the appointment reason. This is because a uni-gram analysis showed words, such as cough, sore, lower, pain, and pressure, which lack complete meaning. Bi-gram was better, but still had phrases that were not easy to interpret, such as “lower back,” “right knee,” and “high blood.” The tag cloud for the tri-gram analysis is shown in Fig. 5.
Fig. 5.
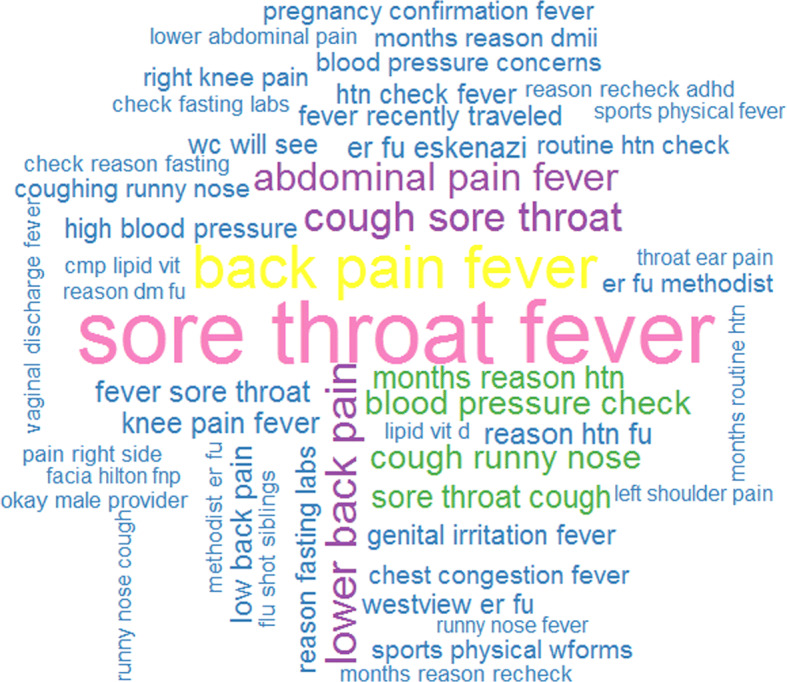
Tri-gram tag cloud of the appointment reason for same-day appointments
We can see that the most common reasons for visits include sore throat, cough, fever, and hypertension. They are non-urgent or chronic health conditions. This shows that same-day visits were not being used exclusively for acute conditions as one might expect. We also recommended CHC-1 (as well as to CHC-2 and -3) to avoid using same-day as an appointment type (to simplify and minimize the number of appointment types for easier scheduling). Instead, we suggested using a report generated from their EHR data that identified same-day appointments by comparing the “appointment creation date” and the “appointment scheduled date.”
Discussion
In this study, we sought to understand how clinic-specific modeling could guide appointment scheduling policies to improve access to care. Predictive modeling was applied to optimize appointment scheduling with a particular focus on the time dimension of appointments and appointment adherence, which was not well studied in prior studies.
A decision tree algorithm was first applied to predict appointment adherence. Interestingly, the lead time for the appointment was the most significant predictor of appointment adherence. Although this variable has not been widely studied, it is consistent with an article assessing the effectiveness of reminder systems to reduce the no-show rates [36]. Predictive analysis based on the Decision Tree Model also provided insights on multiple demographic (age, race, ethnicity, insurance status), clinical (new patient, visit type), and operational (visit duration, web-enabled) variables that are associated with appointment adherence.
Logistic regression was then applied to quantify the impact of lead time and other variables in the time dimension (such as time of the day, day of the week, month of the year, and season) on appointment adherence. This showed that patients scheduled for same-day appointments were at least three times more likely to show up when compared to patients who had scheduled non-same-day appointments. These among other factors (such as visit type, ethnicity, race, new vs. established patient, and appointment duration) were possible predictors of appointment adherence. There were differences in the statistical measures (odds ratios and p values) among the three participating CHCs, due to their differences in the structural, operational, and patient characteristics. Knowledge discovered from the decision tree and logistic regression regarding the patient appointment adherence can directly guide effective schedule utilization. They can be applied through appropriate scheduling (for example, double booking two patient appointments that are likely to be a no-show) and appointment reminder systems (targeting chronic no-show patients with more intensive reminder systems and asking for active confirmation of planned appointment keeping).
Visual modeling was used to assess the association between any scheduling time dimension and appointment adherence, which reaffirmed that the appointment adherence is significantly related to the time of day scheduled. These distinct patterns inform selection of pre-scheduled and open-access hours. Across each of the three CHC organizations, we consistently saw high no-show or cancelation rates in the morning from 8:00 to 9:00 am and in the late afternoon after 3:00 pm. Early afternoon and evenings have the lowest no-show rates across all of the CHCs. Based on these findings, clinics using a mix of pre-scheduled and open-access hours should consider having fewer booked appointments in the early morning, more in the early afternoon, and offer open-access hours during the late morning and late afternoon.
Graphical representation of these data in the form of decision trees and visualizations could be made available to anyone who schedules appointments. They can also be incorporated in electronic scheduling algorithms and tools to maximize provider utilization. As a use case, this pattern analysis was applied to one of the CHCs that was keen to optimize the selection of their open-access hours. The scheduling changes implemented as a result of the analysis led to a 16% relative reduction in missed appointment rates at this CHC. Finally, the tri-gram analysis was shown to be the most preferred route in discovering these reasons for an appointment and is likely generalizable when dealing with short phrases of clinical terms.
Strengths and Limitations of the Study
We designed and implemented a CHC data warehouse merging data from multiple CHCs across Indiana. It is a rich repository of data from seven participating CHCs for all clinical appointments from 2010 to 2016. The knowledge discovered from mining the EHR/PM data should be relevant to many CHCs in the state and across the country. It is due to the relative diversity of the patient populations served by CHC (specifically those with socio-economic challenges), and similar clinic operational and financial characteristics. The study findings, however, may not be generalizable to other ambulatory health centers.
Predictive modeling provides likelihood (probability) information, which may be difficult to interpret at times. Predicting the future using relations derived from historical data is inherently challenging when system involves people (i.e., patients and providers). There is also the possibility of not considering variables that may be critical to the predicted outcome due to unavailability of data, or failure to recognize the most significant variables. Additionally, modifying appointment hours requires flexibility in how the providers may be scheduled, which may pose challenges. These results should be considered as potentially valuable to providers but reconfirmed within a given clinic system before changes in scheduling are made.
Study Implications
The study has many implications in the area of knowledge discovery from health center EHR/PM databases, specifically when applied to designing patient-centered scheduling system. The current study utilizes advanced data modeling on a multidimensional CHC data warehouse to guide the design of unique scheduling interventions to improve access to care in three CHCs. Prior research has shown considerable variability in factors (e.g., patient demographics and appointment variables) that affect patient appointment adherence and potential interventions due to the difference in care settings [18].
This study provides further evidence of the predictive value of patient demographics and appointment variable through the application of multiple complementary analytic methods: machine learning, statistical analysis, and visualization techniques, which are easy to interpret and apply in clinical practice. Delivering the PCMH promise of improved access to healthcare requires that the health center provide for same-day appointments and monitor their effectiveness. This study adds to the evidence on implementing operational changes that support the open-access scheduling paradigm.
Further studies are needed to confirm these findings in other populations and determine how best to incorporate such factors in developing tools to optimize patient-centered scheduling. Scheduling methods may be optimized by appointment analysis and ongoing monitoring to derive the benefits associated with such an approach. Given the importance of efficiently utilizing scarce health care resources and appointments, there is a need for further research into models, strategies, and technological and organizational change solutions.
Conclusion
This study applied advanced exploratory and predictive modeling of EHR data to inform patient-centered scheduling, which uncovered factors that govern appointment adherence based on a multi-CHC EHR/PM data warehouse built for improving efficiency and access to care. Appointment adherence was significantly correlated with the time dimension (lead time, time of day, day of the week, month of the year, season) and there were distinct patterns identified in the data from participating health centers. These methods could be used to guide the selection of open-access hours and optimize the provider schedule utilization. Open-access scheduling methods require ongoing monitoring, and analysis for matching of supply (providers, staffing, open slots) and demand (appointment requests), to derive the benefits associated with such an approach. The study highlights the need for more significant “in-CHC” data analytic capabilities as well as additional research aimed at re-designing the care delivery process at CHCs for improving access and efficiency in an increasingly value-driven healthcare system.
Acknowledgements
The authors would like to thank and acknowledge PCORI (Patient-Centered Outcomes Research Institute), which has funded this project [IH-12-11-5488; “Improving Access to Care and Efficiency of Healthcare Systems for Underserved Patients”]. The authors would also like to acknowledge the staff at the collaborating health centers for their time and support, and the Indiana University School of Informatics and Computing (Indianapolis, IN) for providing the necessary technology infrastructure.
Funding
This study was funded by the Patient-Centered Outcomes Research Institute (Award IH-12-11-5488).
Compliance with Ethical Standards
Conflict of Interest
The authors declare that they have no conflict of interest.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Hurtado MP, Swift EK, Corrigan JM (2001) Crossing the quality chasm: a new health system for the 21st century. Institute of Medicine, Committee on the National Quality Report on Health Care Delivery
- 2. Pitkin Derose K, Varda DM (2009) Social capital and health care access: a systematic review. Med Care Res Rev 66(3):272–306 [DOI] [PMC free article] [PubMed]
- 3.Litaker D, Koroukian SM, Love TE. Context and health care access: looking beyond the individual. Med Care. 2005;43(6):531–540. doi: 10.1097/01.mlr.0000163642.88413.58. [DOI] [PubMed] [Google Scholar]
- 4.Patient-Centered Medical Home. https://pcmh.ahrq.gov/. Accessed 24 Jan 2017
- 5.Health care under the Affordable Care Act. http://www.hhs.gov/health care/. Accessed 24 Jan 2017
- 6.Carrier E, Gourevitch MN, Shah NR. Medical homes: challenges in translating theory into practice. Med Care. 2009;47(7):714–722. doi: 10.1097/MLR.0b013e3181a469b0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Friedman CP, Wong AK, Blumenthal D. Achieving a nationwide learning health system. Sci Transl Med. 2010;2(57):57cm29–57cm29. doi: 10.1126/scitranslmed.3001456. [DOI] [PubMed] [Google Scholar]
- 8.Fayyad U, Piatetsky-Shapiro G, Smyth P. From data mining to knowledge discovery in databases. AI Mag. 1996;17(3):37. [Google Scholar]
- 9.Phan K, Brown SR. Decreased continuity in a residency clinic: a consequence of open access scheduling. Fam Med. 2009;41(1):46–50. [PubMed] [Google Scholar]
- 10.Robinson LW, Chen RR (2010) A comparison of traditional and open-access policies for appointment scheduling. M&SOM 12(2):330–346
- 11.LaGanga LR, Lawrence SR. Clinic overbooking to improve patient access and increase provider productivity. Decis Sci. 2007;38(2):251–276. doi: 10.1111/j.1540-5915.2007.00158.x. [DOI] [Google Scholar]
- 12.Murray M, Berwick DM. Advanced access: reducing waiting and delays in primary care. JAMA. 2003;289(8):1035–1040. doi: 10.1001/jama.289.8.1035. [DOI] [PubMed] [Google Scholar]
- 13.Forjuoh SN, Averitt WM, Cauthen DB, Couchman GR, Symm B, Mitchell M. Open-access appointment scheduling in family practice: comparison of a demand prediction grid with actual appointments. J Am Board Fam Pract. 2001;14(4):259–265. [PubMed] [Google Scholar]
- 14.Ulmer T, Troxler C (2006) The economic cost of missed appointments and the open access system. Community Health Scholars
- 15.Murray M, Bodenheimer T, Rittenhouse D, Grumbach K. Improving timely access to primary care: case studies of the advanced access model. JAMA. 2003;289(8):1042–1046. doi: 10.1001/jama.289.8.1042. [DOI] [PubMed] [Google Scholar]
- 16.Parente DH, Pinto MB, Barber JC. A pre-post comparison of service operational efficiency and patient satisfaction under open access scheduling. Health Care Manag Rev. 2005;30(3):220–228. doi: 10.1097/00004010-200507000-00006. [DOI] [PubMed] [Google Scholar]
- 17.Kaplan G, Lopez MH, McGinnis JM (2015) Transforming health care scheduling and access: Getting to now. Washington DC: Institute of Medicine [PubMed]
- 18.Rose KD, Ross JS, Horwitz LI. Advanced access scheduling outcomes: a systematic review. Arch Intern Med. 2011;171(13):1150–1159. doi: 10.1001/archinternmed.2011.168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Cashman SB, Savageau JA, Lemay CA, Ferguson W. Patient health status and appointment keeping in an urban community health center. J Health Care Poor Underserved. 2004;15(3):474–488. doi: 10.1353/hpu.2004.0037. [DOI] [PubMed] [Google Scholar]
- 20.Huang Y, Hanauer DA. Patient no-show predictive model development using multiple data sources for an effective overbooking approach. Appl Clin Informatics. 2014;5(3):836–860. doi: 10.4338/ACI-2014-04-RA-0026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Odonkor CA, Christiansen S, Chen Y, Sathiyakumar A, Chaudhry H, Cinquegrana D, Lange J, He C, Cohen SP. Factors associated with missed appointments at an academic pain treatment center: a prospective year-long longitudinal study. Anesth Analg. 2017;125(2):562–570. doi: 10.1213/ANE.0000000000001794. [DOI] [PubMed] [Google Scholar]
- 22.Samorani M, LaGanga LR. Outpatient appointment scheduling given individual day-dependent no-show predictions. Eur J Oper Res. 2015;240(1):245–257. doi: 10.1016/j.ejor.2014.06.034. [DOI] [Google Scholar]
- 23.Daggy J, Lawley M, Willis D, Thayer D, Suelzer C, DeLaurentis PC, Turkcan A, Chakraborty S, Sands L. Using no-show modeling to improve clinic performance. Health Informatics J. 2010;16(4):246–259. doi: 10.1177/1460458210380521. [DOI] [PubMed] [Google Scholar]
- 24.Harris SL, May JH, Vargas LG. Predictive analytics model for healthcare planning and scheduling. Eur J Oper Res. 2016;253(1):121–131. doi: 10.1016/j.ejor.2016.02.017. [DOI] [Google Scholar]
- 25.Goldman L, Freidin R, Cook EF, Eigner J, Grich P. A multivariate approach to the prediction of no-show behavior in a primary care center. Arch Intern Med. 1982;142(3):563–567. doi: 10.1001/archinte.1982.00340160143026. [DOI] [PubMed] [Google Scholar]
- 26.Bennett KJ, Baxley EG. The effect of a carve-out advanced access scheduling system on no-show rates. Fam Med. 2009;41(1):51–56. [PubMed] [Google Scholar]
- 27.Wright MD, Flanagan ME, Kunjan K, Doebbeling BN, Toscos T (2016) Missing links: challenges in engaging the underserved with health information and communication technology. In Proceedings of the 10th EAI International Conference on Pervasive Computing Technologies for Healthcare (pp. 122–129). ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering)
- 28.Toscos T, Wright MD, Flanagan ME, Kunjan K, Olson-Miller A, Doebbeling BN (2017) Tailored, theory-based strategies for engaging lowincome populations with a personal health record. EAI Endorsed Transactions on Pervasive Health and Technology 3. 152885. 10.4108/eai.13-7-2017.152885
- 29.Toscos T, Carpenter M, Flanagan M, Kunjan K, Doebbeling BN (2018) Identifying successful practices to overcome access to care challenges in community health centers: a “positive deviance” approach. Health Serv Res Manag Epidemiol 5, 2333392817743406 [DOI] [PMC free article] [PubMed]
- 30.Kunjan K, Toscos T, Turkcan A, Doebbeling BN (2015) A multidimensional data warehouse for community health centers. In AMIA Annual Symposium Proceedings (Vol. 2015, p. 1976). American Medical Informatics Association [PMC free article] [PubMed]
- 31. Kunjan K, Doebbeling B, Toscos T (2018) Dashboards to support operational decision making in health centers: a case for role-specific design. Int J Hum Comput Interact 1–9.
- 32.RapidMiner Data Science Platform. https://rapidminer.com/. Accessed 15 Mar 2018
- 33.The R-Project for Statistical Computing. https://www.r-project.org/. Accessed 15 Mar 2018
- 34.Tableau Software for Business Intelligence and Analytics http://www.tableau.com/. Accessed 15 Mar 2018
- 35.Sikka R, Morath JM, Leape L (2015) The Quadruple Aim: care, health, cost and meaning in work BMJ Quality and Safety; 24:608–610 [DOI] [PubMed]
- 36.Parikh A, Gupta K, Wilson AC, Fields K, Cosgrove NM, Kostis JB. The effectiveness of outpatient appointment reminder systems in reducing no-show rates. Am J Med. 2010;123(6):542–548. doi: 10.1016/j.amjmed.2009.11.022. [DOI] [PubMed] [Google Scholar]