

Abstract
Human falls rarely occur; however, detecting falls is very important from the health and safety perspective. Due to the rarity of falls, it is difficult to employ supervised classification techniques to detect them. Moreover, in these highly skewed situations, it is also difficult to extract domain-specific features to identify falls. In this paper, we present a novel framework, DeepFall, which formulates the fall detection problem as an anomaly detection problem. The DeepFall framework presents the novel use of deep spatio-temporal convolutional autoencoders to learn spatial and temporal features from normal activities using non-invasive sensing modalities. We also present a new anomaly scoring method that combines the reconstruction score of frames across a temporal window to detect unseen falls. We tested the DeepFall framework on three publicly available datasets collected through non-invasive sensing modalities, thermal camera and depth cameras, and show superior results in comparison with traditional autoencoder methods to identify unseen falls.
Keywords: Fall detection, Convolutional autoencoders, Spatio-temporal, Anomaly detection
Introduction
Each year, one out of five falls that older adults incur causes a serious injury to them such as broken bones or a head injury [4]. Among nursing home residents, on an average, 2.6 falls per person per year occur [28]. Detecting falls is important from the perspective of health and safety; however, due to the infrequent occurrence of falls, it is difficult to collect sufficient training data for them [17]. Given this lack of training data, there may be no or little training data for falls, and it will be hard to employ supervised classification techniques. There are also concerns that the sensing devices for the task of fall detection may be invasive and breach the privacy of a person [22, 36]. Some non-invasive sensing devices, such as a thermal or depth camera, may not fully reveal the identity of a person, but it is difficult to extract discriminative features to identify unseen falls, especially in a highly skewed data scenario [31].
The research work discussed in this paper deals with identifying falls in video sequences captured from non-invasive sensing modalities, such as thermal and depth cameras, which may fully or partially protect the privacy of a person. We propose to address the problem of fall detection as an anomaly detection problem by considering the lack of fall data and the abundance of normal activities of daily living (ADL). The general idea explored in the paper is to train an autoencoder on normal activities and use their reconstruction error to identify unseen falls during testing. A deep autoencoder (DAE) can be used to learn features from normal ADL; however, it ignores the 2D structure of images and may force each feature to be global to span the entire visual field [21]. In visual recognition tasks, convolutional autoencoders (CAE) perform better because they can discover localized spatial features that repeat themselves over the input [21]. A video sequence embeds information in both space and time; therefore, spatio-temporal convolutional autoencoders are more relevant as they can learn a representation of local spatio-temporal patterns of frames in a video [1].
In this paper, we present a novel fall detection framework, DeepFall, which comprises (i) formulating fall detection as an anomaly detection problem, (ii) designing a deep spatio-temporal convolutional autoencoder (DSTCAE) and training it on only the normal ADL, and (iii) proposing a new anomaly score to detect unseen falls. The DSTCAE first encodes stacks of contiguous frames in a time window by performing 3D convolution/3D pooling. During the decoding phase, the DSTCAE uses 3D UpSampling, or 3D deconvolution to reconstruct the input window of frames. Reconstruction error for each frame within a window is then calculated. We then present a new method to compute anomaly score, termed as within-context score, which considers the reconstruction error of frames within a window and gives an anomaly score of a given window. The anomaly score can be used to identify an unseen fall during the testing phase of DSTCAE. To the best of our knowledge, this is the first time a DSTCAE has been used for fall detection problem. The present paper is an extension of our previous work [25] and differs from it in the following manner:
In the previous work, we employed convolutional LSTM–based autoencoder (CLSTMAE). By contrast, in this paper, we use a different 3D convolutional autoencoder, DSTCAE, for learning spatio-temporal features from the normal ADL. Our results show that DSTCAE gives better results than CLSTMAE for all the datasets.
The previous paper only tested CLSTMAE on thermal dataset, whereas in this paper we extend our experiments on two more depth camera–based fall detection datasets.
The previous paper presented a frame-based anomaly score. However, in this paper, we present a new anomaly scoring method that takes the decision at the level of a window (comprising contiguous frames) and not individual frames, which resulted in similar or higher area under the curve (AUC) across all the datasets.
In this paper, we did an additional experiment to understand the impact on AUC of designating an entire window as a fall by increasing the number of fall frames in it from 1 to the maximum size of the window. This experiment provided insights on choosing appropriate fall frames in a window before identifying it as a fall window using a given anomaly score.
In the present paper, we compare CLSTMAE with three variants of DSTCAE for all the three datasets and also added new results from one-class nearest neighbors on the features learned through the DAE.
Related Work
To the best of our knowledge, fall detection has not been addressed as an anomaly detection problem using unsupervised deep learning methods. Therefore, in this section, we present a review of literature on video anomaly detection, which is closer in concept to the work presented in this paper.
Ribeiro et al. [27] propose to use CAE for detecting anomalies in videos. They extract appearance and motion features from video frames and combine them to present different scenarios to the CAE. They train the CAE on only normal frames and use a regularized reconstruction error as a score to identify normal and anomalous frames. They extend their work by using reconstruction error from the CAE trained on normal video frames as an input to a one-class SVM and showed similar results [12]. Tran and Hogg [32] use CAE and one-class SVM for video anomaly detection. They first extract foreground optical flow patches using an empirical threshold, then train a convolutional autoencoder on these patches, which learn hierarchical sparse representations in an unsupervised manner. After training the model, sparse features are extracted and fed to a one-class SVM to learn the concept of normality. Their method shows competitive performance on two datasets in comparison with existing state-of-the-art methods. Chalapathy et al. [5] present a robust CAE that considers anomalies in the data and modify the objective function for training the model. They use the reconstruction error as a score and comment that their method is not over-sensitive to anomalies, can discover subtle anomalies, and can be potentially deployed in live settings. They show their results on a video activity detection dataset and other image datasets. Hasan et al. [13] use both hand-crafted spatio-temporal features and fully convolutional feed-forward autoencoder to learn regular motion patterns in videos. They introduce a regularity score that scales the reconstruction error of a frame between 0 and 1. They show a competitive performance of their method to other state-of-the-art anomaly detection methods. Munawar et al. [23] present a method to generate unbiased features by unsupervised learning for finding anomalies in industrial robot surveillance task. They cluster the input image data based on different image cues (such as color and gradient) to generate pseudo-class labels. Then, they simultaneously train the network on different pseudo-class labels to learn neutral feature representation using convolution neural networks. Finally, they use a deep long short term memory based recurrent neural network to predict the next video frame in the learned feature space. If it deviates significantly from the observed frame, it is identified as an anomaly in time and space. A fusion of appearance as well as motion features is used by Xu et al. [35] to detect anomalies in video. More precisely, stacked denoising DAE networks are applied separately to optical flow and raw image patches. Anomalies in video are then detected in a one-class SVM framework.
Zhao et al. [37] present a spatio-temporal autoencoder that uses 3D convolutions to extract spatio-temporal features from videos. They further introduce a weight-decreasing prediction loss for generating future frames to improve the learning of motion features in videos. They tested their method on a dataset comprising a set of real-world traffic surveillance videos along with other standard anomaly detection datasets and show superior performance on state-of-the-art approaches. Penttilä [26] proposes to use 3D CAE to learn spatial and temporal features to find anomalies in hyperspectral data. After training the network, they extract feature maps from the data and feed to standard anomaly detection algorithms. A two-stage cascade of autoencoders is used by Sabokrou et al. [29] to detect anomalies in video. In particular, spatio-temporal patches are fed to a 3D autoencoder, where regions of interest are detected. The proposed regions are then fed to a 3D convolutional neural network. The layers of the cascaded deep networks are designed as single-class Gaussian classifiers, which are used to detect anomalies in the video.
Chong and Tay [8] present a method to detect anomalies in videos that consists of a spatial feature extractor and a temporal encoder-decoder framework. The spatial feature extractor comprises convolutional and deconvolutional layers, whereas the temporal encoder-decoder is a three-layer convolutional long short term memory model. This model will be referred to as CLSTMAE. Their model is trained only on the videos with normal scenes. They use a regularity score [13] to identify anomalies. They show comparable performance in comparison with other standard methods; however, it may produce more false alarms.
The literature review suggests that spatio-temporal CAE are a good candidate to learn spatial and temporal features from normal activities and identify anomalies in videos. We expand on the previous works in the following ways:
None of the reviewed methods is used for fall detection problem. In DeepFall, we train a DSTCAE only on normal ADL and use a new anomaly scoring methods to identify a fall as an anomaly from non-invasive sensors with superior performance.
In the above-related works which use reconstruction error in videos (and thus regularity score), an anomaly score is given strictly on a per-frame basis. That is, a video sequence is reconstructed, and each reconstructed frame used as an anomaly score for that frame. It is not obvious that using this score is ideal for the fall detection problem. We thus explore alternatives through our novel anomaly scoring scheme, which allows aggregating anomaly scores across overlapping sliding windows. In this scheme, we can find an anomaly score per frame, and that incorporates information from adjacent windows. Further, in this scheme, we also find an anomaly score on a per-window basis.
The above authors use a regularity scoring system [13] as an anomaly score. The regularity score is a normalized reconstruction error. This normalization requires knowledge of the maximum and minimum reconstruction error for a video. Obtaining these maximum and minimum reconstruction error values requires reconstruction error for an entire video. This means that to give an anomaly score for a frame, we require reconstruction error values for all future frames of the video which this frame belongs to. Finding these future reconstruction error values is not practically feasible. We thus use the un-normalized reconstruction error in our anomaly scoring scheme.
The reader may consult other papers on general anomaly detection that may involve methods besides neural networks [6, 10, 18].
In the next section, we introduce the different components of the DeepFall framework, which consists of a DSTCAE and anomaly scoring methods (after formulating fall detection in an anomaly detection setting).
Deep Spatio-Temporal Convolutional Autoencoders
Traditional autoencoders consist of fully connected layers [19]. When passing an image to such a network, it is flattened into a 1D vector of pixels, and each pixel is connected to the units of the next layer. This results in a large number of network parameters and learns spatially global features [21]. A CAE exploits the 2D spatial structure of an image, by sharing a set of weights across the image, resulting in far fewer parameters than a traditional autoencoder, and allowing the extraction of local features from neighboring pixels [21]. A CAE may be a good choice to find spatial structures in images, but it cannot capture temporal information present in the contiguous frames of a video [37]. 3D convolutions can be used to extract both temporal and spatial features by convolving a 3D kernel with the cube formed by stacking temporally contiguous frames of a video (we refer it as a window). This allows information across these contiguous frames to be connected to form feature maps, thereby capturing spatio-temporal information encoded in these adjacent frames [15]. This idea can be used to construct a DSTCAE, where the encoding phase consists of dimensionality reduction both in space and time of a window of images that are joined contiguously. In the decoding phase, the network attempts to reconstruct the window.
Sliding Window Reconstruction
The inputs to DSTCAE are windows of contiguous video frames. These windows are generated by applying a temporal sliding window to video frames, with window length T, padding (or not), and stride B (which represents the amount of frames shifted from one window to the next). If a video contains V frames, and padding is not used, then the number of windows (D) generated is
| 1 |
In our implementation of DSTCAE, we chose T = 8 (this choice is explained in Section 5.2), no padding, and B = 1, which ensure that all the frames of the video are selected in forming windows. We re-size all the input frames to 64 × 64. The resulting network input (I) thus has dimensions of 8 × 64 × 64. DSTCAE encodes I into spatio-temporal features and then attempts to reconstruct it from the encoded representation. For training DSTCAE, we use mean squared error loss between I and reconstructed output window O (same dimensions as I), optimized on a per batch basis, giving the following cost function:
| 2 |
where N is the number of training samples in a batch, 𝜃 denotes the network parameters, and ∥⋅∥2 denotes the Euclidean norm.
3D Convolutions
The main component of a DSTCAE is the 3D convolutional layer, which is defined as follows: the value v at position (x,y,z) of the j th feature map in the i th 3D convolution layer, with bias bij, is given by the equation [15]
| 3 |
where Pi, Qi, and Si are the vertical (spatial), horizontal (spatial), and temporal extent of the filter cube wi in the i th layer. The set of feature maps from the (i − 1)th layer are indexed by m, and is the value of the filter cube at position pqs connected to the m th feature map in the previous layer. Multiple filter cubes will output multiple feature maps.
3D Encoding and Decoding
Encoding
The input I introduced in Section 3 in a DSTCAE is encoded by a sequence of 3D convolution and 3D-max-pooling layers. 3D convolutions operate as described in (3), with stride of 1 × 1 × 1 and padding. The max-pooling layers use padding, with stride and kernel dimensions of 2 × 2 × 2. This means that each dimension (temporal depth, height, and width) is reduced by a factor of 2 with every max-pooling layer. This process is repeated for 2 level of depth. For hidden layers (in both encoding and decoding), the activation function f in (3) is set to ReLU. We use Pi = Qi = 3 and Si = 5 for all convolutional and deconvolutional layers, as these values were found to produce the best results across all data sets. The specification of the encoding and decoding process is shown in Table 1 and described in detail below.
Table 1.
Configuration of the encoding and decoding of DSTCAE-UpSampling, DSTCAE-Deconv, and DSTCAE-C3D

Encoding is in blue and decoding in yellow
Decoding
For the decoding of DSTCAE, we explore two variants. The first method (DSTCAE-UpSampling) uses padded 3D convolutions with stride of 2 × 2 × 2, followed by a fixed UpSampling operation for increasing dimensions (as seen in Fig. 1). In particular, we use 3D UpSampling layers as defined in Keras [7], with UpSampling factors 2 × 2 × 2. That is, matrix elements are repeated across each dimension, such that the extent of all dimensions is doubled. The second method (DSTCAE-Deconv) uses 3D deconvolutions [7], with stride of 2 × 2 × 2 and padding [37] instead of UpSampling. This results in an increase in each dimension by a factor of 2, thus undoing a max-pooling operation. For both the decoding methods, the output layer activation function f is set to tanh, computed element-wise in both cases. We use tanh for the output layer to limit the reconstructed pixel values in the range [− 1,1], so that they are comparable to the input (see Section 5.2). In both decoding methods, outputs of the network (O) have the same dimensions as I and are generated by convolving a single filter cube with a final layer of feature maps. By proposing two methods for the decoding procedure in DSTCAE, we created two variants of the spatio-temporal autoencoder, whose performance are compared for detecting unseen falls in Section 5.4.
Fig. 1.
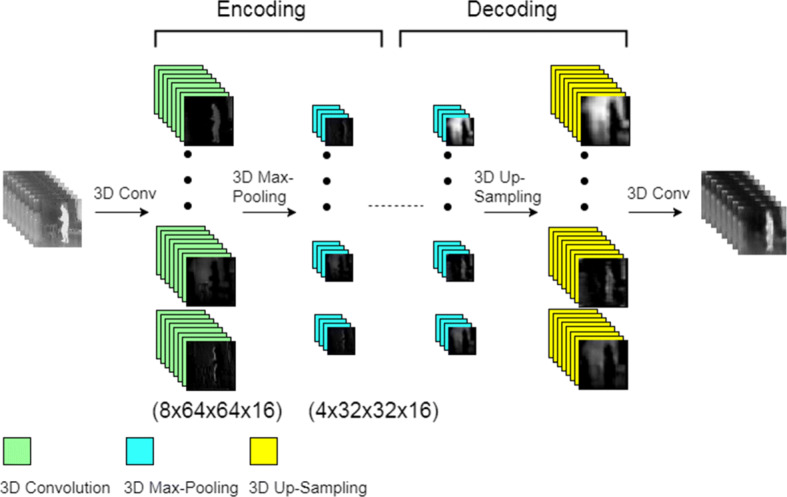
Out line of DSTCAE layers using fixed UpSampling (DSTCAE-UpSampling). Each layer has dimensions of temporal depth × height × width × number of feature maps
A diagram illustrating the DSTCAE-UpSampling structure is shown in Fig. 1. The first layer generates 16 feature maps (depicted in figure by vertical stacks), by convolving 16 different filter cubes with the input window of frames. This layer is followed by a 3D max-pooling layer. Convolution and pooling layers are repeated in this manner once more, resulting in an encoded dimension of 2 × 16 × 16 × 8. We choose to stop encoding at this point, in order to avoid collapsing the temporal dimension completely; a larger value of T would allow for a deeper network. Decoding then involves two UpSampling/3D convolution steps, bringing the hidden representation dimensions to 8 × 64 × 64 × 16. A final 3D convolution layer combines these 16 feature maps into the decoded reconstruction O.
We also test a third 3D convolutional autoencoder variant, based on Tran et al. [9], which we refer to as DSTCAE-C3D. The DSTCAE-C3D network has the same encoding and decoding as DSTCAE-UpSampling, but with an extra 3D Convolution/3D max-pooling layer in encoding (see Table 1) and extra 3D UpSampling/3D convolution in decoding. The extra 3D max-pooling has padding, with stride and kernel dimensions of 1 × 2 × 2. This results in spatial dimension reduction, but not temporal, allowing for greater network depth without collapsing the temporal dimension.
To summarize, we compare three variants of DSTCAE: (1) DSTCAE-UpSampling: uses UpSampling for decoding, (2) DSTCAE-Deconv: uses deconvolution for decoding (similar to [37]), and (3) DSTCAE-C3D: uses UpSampling for decoding, but contains additional spatial pooling/unpooling layer. These architectures are summarized in Table 1. In this table, encoding is highlighted in blue and decoding in yellow.
We compare these DSTCAE variants to 2D frame–based models CAE and DAE. Their specifications are shown in Table 2. This table only shows the configuration of the encoding phase of the autoencoder. The decoding configuration is the same, but using UpSampling, or deconvolution for CAE (referred to as CAE-UpSampling and CAE-Decconv respectively), and more fully connected layers for DAE. Also, dropout is applied to layer 1 for DAE. We also use dropout for layer 2 for all DSTCAE variants. In all cases, the dropout probability is set to 0.25. Dropout was not found to be beneficial for CAE models and so was not used.
Table 2.
Configuration of the encoding phase of CAE and DAE
| CAE | DAE |
|---|---|
| Input - (64, 64, 1) | Input - (64,64,1) |
| 2D Convolution - (64, 64, 16) | Fully Connected - (4096) |
| 2D Max-pooling - (32, 32, 16) | Fully Connected - (150) |
| 2D Convolution - (32, 32, 8) | Fully Connected - (100) |
| 2D Max-pooling - (16, 16, 8) | Fully Connected - (50) |
| 2D Convolution - (16, 16, 8) | – |
| 2D Max-pooling - (8, 8, 8) | – |
Anomaly Scores to Detect Unseen Falls
In this paper, we formulated fall detection in a one-class classification framework [19], where normal ADL are available in abundance and no fall data is present during training. However, during testing, both normal ADL and falls may be present. Therefore, we detect falls as an anomaly. In the DeepFall framework, the general process for detecting unseen falls is
Train a given type of autoencoder by minimizing reconstruction error on ADL
During testing, get reconstitution error of a frame (or a window comprising different frames); if the reconstruction error is “high,” then a fall is detected.
Previous anomaly scoring schemes involve using a regularity score [13], which is a normalized reconstruction error requiring future values from test frames, which is a major drawback in real-world deployment. We thus strictly use un-normalized reconstruction error.
Further, previous anomaly scoring schemes [8, 13, 37] etc. compute an anomaly score on a per-frame basis, using the reconstruction error of that frame. Such a scoring scheme may not be ideal for the fall detection problem, and so we propose to explore a new anomaly scoring scheme, presented in this section. In our novel anomaly scoring scheme, we compute an anomaly score per frame, while also incorporating information about reconstruction error in adjacent overlapping sliding windows. We also explore computing an anomaly score on a per-window basis. The details of this anomaly scoring scheme are as follows:
For CAE and DAE, the input to the network is a single frame; therefore, the reconstruction error is computed per frame. For all the variants of DSTCAE, the input to the network is a temporal window of T video frames. That is, given a test video sequence, we apply a sliding window as described in Section 3. For the i th window Ii, the network outputs a reconstruction of this window, Oi. The reconstruction error (Ri,j) between the j th frame of Ii and Oi can be calculated as
| 4 |
Figure 2 shows the sliding window approach for T = 8. The first window of T = 8 frames, I1 (Fr1 to Fr8) are reconstructed, and their corresponding reconstruction error is stored (R1,1:8). For the next window of frames, the input window is shifted forward in time by one frame. This process continues until all frames are used.
Fig. 2.
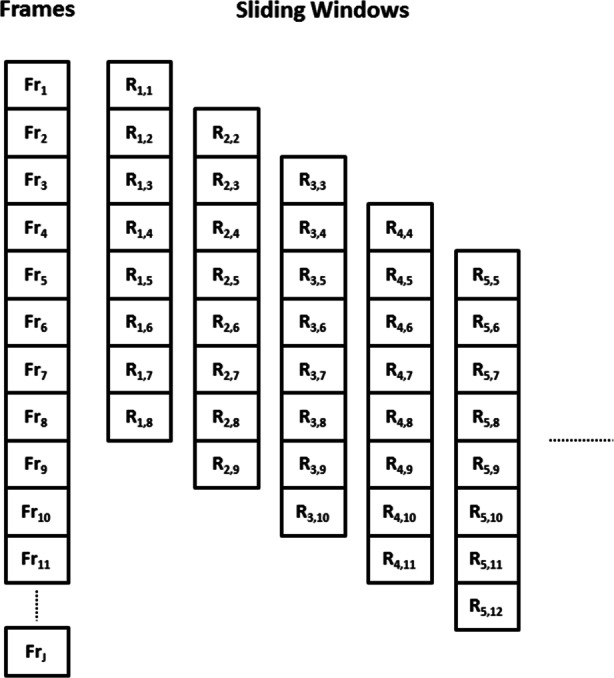
Temporal sliding window showing reconstruction error (Ri,j) per frame (Frj) with T = 8
Cross-Context Anomaly Score
To compare DSTCAE models with CAE and DAE, we must get a score per frame. A frame can appear in multiple windows. For instance, frame Fr2 (see Fig. 2) appears in two windows and thus gives two reconstruction errors: R1,2 and R2,2. The former is attained when frame Fr2 was the second frame in the window, and the latter case when frame Fr2 was the first frame of the input window. Each window that a frame appears in provides a different temporal context within which this frame can be viewed. The cross-context anomaly score gives scores on a per-frame basis, by considering all of the reconstruction errors obtained for a frame across different windows (temporal contexts) [25]. For a frame j, an anomaly score can be calculated based on the mean () or standard deviation () of the reconstruction errors (Ri,j) across different windows (or contexts):
| 5 |
and give an anomaly score per frame, while incorporating information from the past and future. A large value of or means that the j th frame, when appearing at different positions in subsequent windows, is reconstructed with a high average error or highly variable error. In a normal ADL case, the reconstruction error of a frame should not vary a lot with its position in subsequent windows; however, if it does, then this may indicate anomalous behavior, such as a fall.
Within-Context Anomaly Score
In a case when videos are considered as sequences of contiguous frames, we may want to designate the class of the whole window as fall or normal ADL, instead of deciding the class of every frame across different windows (or contexts). This way, all the frames present in a window will be used for predicting its class and they will have no influence on subsequent windows. Therefore, we call this method as within-context anomaly score. This method considers the reconstruction of frames within a context (or windows shown vertically in Fig. 2) and gives a single score. In particular, the mean () and standard deviation () of the reconstruction error of all the frames within a window Ii can be computed as an anomaly score to identify a fall,
| 6 |
A large value of means that the average reconstruction error of the T frames within the window is high. Similarly, a large value of means that the variation of reconstruction error among the T frames of a window is high. Both situations indicate that high reconstruction error may be happening due to one or more frames present within a window. Therefore, these situations represent the case when DSTCAE reconstructs the T frames in the window with high/variable reconstruction error, which may represent an anomalous behavior such as a fall.
In order to designate a whole window of frames as a fall or non fall, we set a threshold on the number of fall frames in the window. That is, if the sequence contains more fall frames than the threshold, the sequence is labeled as a fall. Otherwise, it is labeled as a non-fall window. If this threshold is too low then DeepFall may be very sensitive and may generate many false positives. Whereas, if this threshold is too high (for example all frames in the sequence are required to be fall frames), then our system may miss some falls. Therefore, this threshold, which is the number of fall frames that are required for a window of frames to be designated as a fall, is a hyper-parameter of the DeepFall framework and is discussed in detail in Section 5.4.
Experiments and Results
Datasets
We test the DeepFall framework on the following three publicly available data sets that collected normal ADL and falls using non-invasive sensing modalities.
Thermal Fall Dataset
This dataset consists of videos captured by a FLIR ONE thermal camera mounted on an Android phone in a room setting with a single view [33]. The videos have a frame rate of either 25 fps or 15 fps, which was obtained by observing the properties of each video. A total of 44 videos are collected; out of which, 35 videos contain a fall along with normal ADL and 9 videos contain only ADL. The spatial resolution of the thermal images is 640 × 480. The thermal dataset contains many empty frames; that is, scenes where no person is present. It also contains frames of people entering the scene from the left and from the right. Examples of thermal ADL and fall frames are given in Fig. 3.
Fig. 3.

Thermal dataset: ADL frames. a Empty scene. b Person entering the scene. c Person in the scene. d, e, and f Fall frames
The thermal dataset contains 22,116 ADL frames from 9 videos. After windowing the ADL videos individually, we generate 22,053 windows of contiguous frames (using (1)), which are used for training spatio-temporal autoencoders.
UR Fall Detection Dataset
The UR dataset (UR) [3] contains 70 depth videos collected using a Microsoft Kinect camera at 30 fps that was mounted parallel to the floor. Of these, 30 videos contain a fall and 40 videos contain various ADL, such as walking, sitting down, crouching down, and lying down in bed. Five persons performed two types of falls—from standing position and from sitting on the chair. The pixels in the depth frames indicate the calibrated depth in the scene. The depth map is provided in a 640 × 480 resolution. The UR dataset contains empty frames. It also contains frames of people entering the scene towards the camera. Samples of the original ADL and fall depth frame of the UR dataset are shown in Fig. 4. After applying the sliding window, we obtain 8661 windows of contiguous frames used for training different spatio-temporal autoencoders (Fig. 5).
Fig. 4.

UR dataset: original depth frames with holes. a Empty scene. b Person entering the scene. c Person in the scene. d Fall
Fig. 5.

UR dataset: depth frames after holes filling. a Empty scene. b Person entering the scene. c Person in the scene. d Fall
SDU Dataset
The SDU dataset [20] contains depth videos collected by a Microsoft Kinect camera. The data that was shared with us contains 1197 depth videos. Of these videos, 997 contain the following ADL: bending, squatting, sitting, lying, and walking. The remaining 200 videos contain a fall, as well as other various ADL. The activities are performed by 20 young men and women. Each person performs 10 trials, which consist of simulating a fall, as well as performing each of the above ADL. The videos are recorded at 30 fps, with a spatial resolution of 320 × 240, and an average length of 5 seconds. After applying the sliding window, we obtain 163,573 windows of contiguous frames used for training spatio-temporal autoencoders. The SDU dataset contains empty frames. It also contains frames of people entering the scene from the left and right. Samples of original ADL and fall depth frame from the SDU dataset are shown in Fig. 6.
Fig. 6.

SDU dataset: original depth frames with holes. a Empty scene. b Person entering the scene. c Person in the scene.d Fall
Data Preprocessing
The thermal dataset frames were extracted from mp4 video files. The UR dataset’s frames were already available in png format. The SDU dataset frames were extracted from AVI video files. All the frames in all the datasets are normalized by dividing the pixel values by 255 to keep them in the range [0,1] and subtracting the per-frame mean from each frame, resulting in pixel values in the range [− 1,1]. As discussed in Section 3.1, all the frames are also re-sized to 64 × 64.
In order to create windows of contiguous video frames to give as input to the DSTCAE for training and testing, we perform a sliding window on all video frames, as described in Section 3.1. We choose T = 8 because we do not want our window length to exceed the length of the shortest fall sequence, which is found to be 13 frames. We thus chose the largest power of 2 smaller than 13, which is 8. We use the same window length for all datasets for simplicity. Smaller window length may lead to higher false positives as the decision regarding a fall would have to be made on fewer reconstructed video frames. On the other hand, a greater window length may include non-fall frames because fall is a short term event. Therefore, some falls may be missed to be detected.
In both the UR dataset and the SDU dataset, there were many regions of missing pixels, termed as “holes.” Both of these datasets use the Microsoft Kinect depth sensor, which is a structured 3D scanner and light measurements from it can contain errors due to multiple reflections, transparent objects, occlusion, or scattering [34]. These holes can be seen as black regions in Figs. 4 and 6. These holes can be detrimental to learning useful spatio-temporal features using the DeepFall framework. Therefore, we employed hole-filling methods to fill in these regions. For the UR dataset, we used a method based on depth colorization [24]. Figure 5 shows the corresponding depth frame after filling holes in the frames shown in Fig. 4. For the SDU dataset, we did not have information of distance in the depth frames, since they were extracted from AVI formatted videos. That is, the depth images contain values in the range [0,255], where darker pixels correspond to a lesser distance from the camera; true distance is not known for these values. Distance information is required for using the depth colorization algorithm [24]. Thus, we used a simple inpainting technique, based on an OpenCV [14] implementation of the inpainting algorithm presented in [2]. Figure 7 shows the results of applying this inpainting technique on the frame shown in Fig. 6.
Fig. 7.

SDU dataset: depth frames after hole filling. a Empty scene. b Person entering the scene. c Person in the scene. d Fall
To evaluate the effectiveness of hole filling in detecting falls using different autoencoder methods, we created another version of the UR and SDU dataset in which the holes are filled for all the frames, we call them as UR-Filled and SDU-Filled.
Experimental Setup
Different types of autoencoders are trained on only the ADL videos, which only contain normal ADL / non-fall frames. The testing was carried out on fall videos, which contain fall activity as well as normal ADL. The video frames used for training the models were not annotated because they were all considered normal ADL. In order to test the models, fall videos are used that contained both fall and non-fall frames. The fall frames were manually annotated in these videos.
For comparing the performance of different variants of spatial-temporal autoencoder, DAE, CAE, all autoencoders are trained for 500 epochs. Adadelta optimizer was used in training these models. The training batch size is set to 32 for DAE and CAE models, and 16 for DSTCAE variants, where each batch consists of a stack of 8 frames. To train DAE and CAE variants, we augment the data by performing horizontal flipping. No data augmentation was performed when training DSTCAE variants, as it did not improve results. As noted in Section 3.3, dropout is applied to layer 1 for DAE and to layer 2 for all DSTCAE variants. In all cases, the dropout probability is set to 0.25.1
The within-context anomaly score can only be calculated for the DSTCAE variants, because it calculates a score for each window of T frames rather than individual frames. In this method, if there are α amount of fall frames, then the ground truth of the entire sequence of frames is labeled as a fall. The value of α is varied from α = 1 to α = T = 8. These anomaly scores are then used to compute the area under the curve (AUC) of the ROC with fall as the class of interest. The cross-context anomaly score gives a score per frame (for a given video); therefore, it can be directly compared with DAE and CAE variants. The anomaly scores obtained for every frame are used to calculate AUC of the ROC, with fall as the class of interest. For DAE and CAE variants, the reconstruction error of frames of a test video is considered as anomaly score. The reported AUC is the average of AUC across all test videos. As discussed in Section 3.3, we test three variants of DSTCAE: DSTCAE-UpSampling, DSTCAE-Deconv, DSTCAE-C3D.
Results
Cross-Context Anomaly Score
The results for all frame-based models, i.e., DAE, CAE variants, and DSTCAE variants using the cross-context score, are presented in Table 4. We also present the AUC values computed using an ensemble of one-class JK nearest neighbor method [16] trained over the features learned from DAE; features from the fourth fully connected layer were used. The nearest neighbors are set to 1 (JKNN-11) and 10 (JKNN-JK), and the ensemble sizes are fixed to 25. The results for UR and SDU using the one-class JK nearest neighbor method could not be obtained in a reasonable time because it calculates the euclidean distance for all pairs of input; thus, making the method very slow and impractical to work with large datasets. We also compare the results from our previous work of using CLSTMAE [25] over all the datasets with cross-context scores Cσ and Cμ. The first column of Table 4 indicates the model tested, and the other columns show the dataset. Each numerical value in the Table 4 represents the average ROC AUC across all videos for the model indicated by the row. The respective standard deviation of ROC AUC across all videos of the dataset is shown in small brackets. The results can be summarized as follows:
All the variants of spatio-temporal autoencoders outperforms spatial feature extraction methods (i.e., JKNN, DAE, and two CAE variants). This confirms the fact that extracting both spatial and temporal features are important in video-based fall detection approach.
All the variants of DSTCAE outperforms the CLSTM-based methods. This marks an improvement on our previous work [25]. This may be the case since LSTM-based models are tailored to long-term sequential modelling, but falls occur on short time scales. It further confirms that DSTCAE is better suited for such problems of short length sequences.
The autoencoders trained on holes filled versions of UR and SDU datasets performed better for all the classifiers (except for one CLSTMAE:Cσ for the SDU dataset, which is worse than the best AUC obtained for this dataset with holes-filled). This result shows that if the depth data contains holes or missing pixels, it must be filled with some technique for the autoencoder to detect falls appropriately.
The difference between DSTACE-Deconv and DSTCAE-UpSampling appears to be very small, but DSTCAE-C3D performs the best on two out of three datasets (excluding depth datasets without holes filled, which are degenerative cases).
We see that Cσ outperforms on Cμ on thermal and UR-Filled data. That is, DSTCAE-C3D:Cσ, and DSTCAE-UpSampling:Cσ perform the best on thermal and UR-Filled data respectively.
We also perform a significance test to compare the ROC AUC of these different algorithms on all the 5 datasets (i.e., thermal, UR, UR-Filled, SDU and SDU-Filled). In particular, we use Friedman’s post-hoc test with Bergmann and Hommel’s correction [4]. For simplicity, we choose to compare one variant from each type of algorithms (i.e., DAE and one each from JKNN, DAE, CAE, CLSTM, and DSTCAE variants). That is, we compare JKNN-JK, DAE, CAE-Deconv, CLSTMAE:Cμ, and DSTCAE-C3D:Cσ. The results of this significance test can be found in Table 3. The i th row and j th column compare the algorithm specified in the i th row of the table, to the algorithm specified in the j th column of the table. Significant differences are shown in bold. We see that the only algorithm with a significant difference from the others is DSTCAE-C3D:Cσ. This supports the above findings that spatio-temporal autoencoder (DSTCAE and variants) outperforms spatial feature extraction methods (Table 4).
Table 4.
ROC AUC values for different methods, for each dataset, based on cross-context anomaly score
| Models | Thermal | UR | UR-Filled | SDU | SDU-Filled |
|---|---|---|---|---|---|
| JKNN-11 | 0.53 | – | 0.5 | – | 0.72 |
| JKNN-JK | 0.53 | – | 0.5 | – | 0.86 |
| DAE | 0.65(0.14) | 0.38(0.14) | 0.75(0.15) | 0.72(0.16) | 0.94(0.05) |
| CAE-UpSampling | 0.73(0.12) | 0.38(0.14) | 0.67(0.19) | 0.64(0.16) | 0.89(0.06) |
| CAE-Deconv | 0.75(0.17) | 0.38(0.11) | 0.76(0.21) | 0.66(0.16) | 0.92(0.07) |
| CLSTMAE: Cσ | 0.64(0.16) | 0.49(0.09) | 0.67(0.20) | 0.66(0.10) | 0.56(0.11) |
| CLSTMAE: Cμ | 0.58(0.20) | 0.43(0.11) | 0.82(0.16) | 0.77(0.11) | 0.92(0.06) |
| DSTCAE-UpSampling:Cσ | 0.96(0.03) | 0.69(0.18) | 0.89(0.09) | 0.74(0.12) | 0.90(0.06) |
| DSTCAE-UpSampling:Cμ | 0.95(0.04) | 0.50(0.14) | 0.88(0.12) | 0.70(0.18) | 0.92(0.05) |
| DSTCAE-Deconv:Cσ | 0.96(0.02) | 0.72(0.17) | 0.88(0.10) | 0.70(0.13) | 0.92(0.05) |
| DSTCAE-Deconv:Cμ | 0.94(0.04) | 0.48(0.14) | 0.85(0.11) | 0.69(0.18) | 0.92(0.05) |
| DSTCAE-C3D:Cσ | 0.97(0.02) | 0.54(0.13) | 0.80(0.13) | 0.76(0.11) | 0.92(0.06) |
| DSTCAE-C3D:Cμ | 0.93(0.07) | 0.45(0.12) | 0.86(0.17 | 0.71(0.18) | 0.95(0.04) |
Table 3.
Friedman post-hoc test with Bergmann and Hommel’s correction
| JKNN-JK | DAE | CAE-Deconv | CLSTMAE:Cμ. | DSTCAE-C3D:Cμ | |
|---|---|---|---|---|---|
| JKNN-JK | n/a | 0.143 | 0.287 | 0.075 | 0.003 |
| DAE | 0.143 | n/a | 1.000 | 1.000 | 0.431 |
| CAE-Deconv | 0.287 | 1.000 | n/a | 1.000 | 0.431 |
| CLSTMAE:Cμ. | 0.075 | 1.000 | 1.000 | n/a | 0.543 |
| DSTCAE-C3D:Cμ | 0.003 | 0.431 | 0.431 | 0.543 | n/a |
It should be noted that these results may be misleading, firstly because we have a small sample size for conducting a significance test (only five datasets). We note that for the SDU and SDU-Filled dataset, the best performing model (DSTCAE-C3D:Cμ, 0.95(0.04) AUC) does not perform much better than the much simpler DAE model (0.94(0.05) AUC). The SDU dataset videos contain simple and organic activities; falls always happened from standing, besides having no furniture or background objects in the scene. We hypothesize that due to these reasons the DAE model may be able to learn global features to detect falls comparably to the spatio-temporal network. However, the activities in the thermal and UR datasets were complex; falls happened in various poses (e.g., falling from chair, falling from sitting, and falling from standing), and the scene involved different objects in the background (e.g., bed, chair). Besides that, in the thermal dataset, due to a person entering the scene, the pixel intensity would change values due to change in the heat in the environment. The proposed DSTCAE methods worked well under these diverse conditions to detect unseen falls.
Within-Context Anomaly Score
The results achieved using the within-context anomaly scores, Wμ and Wσ, for all the datasets are shown in Fig. 8. We do not show scores for SDU and UR with holes, because results were significantly worse than those with holes filled. We observe that increasing α increases the ROC AUC for thermal and SDU-Filled datasets, and to a lesser extent, UR-Filled dataset. This indicates that reducing false positives is effective in increasing the ROC AUC score, and thus the ability to detect falls.
Fig. 8.

Effect of changing fall frames in a stack of frames (α) on the ROC AUC
We also observe that the ROC AUC attained using Wμ and Wσ (with sufficiently high α) is at least as high, and in some cases higher than using frame-based scores Cσ and Cμ. That is, for thermal dataset, the highest ROC AUC remained consistent from within-context to cross-context scores. For UR-Filled, the ROC AUC improved from 0.89 (Cσ) to 0.91 (Wμ), and for SDU-Filled dataset, ROC AUC improved from 0.95 (Cσ) to 0.98 (Wμ). Scores for JKNN-11 and JKNN-JK are not shown in Fig. 8, because these methods do not give scores on a per-frame basis and do not give window-based scores.
Conclusions, Discussion, and Future Work
Detecting falls in a non-invasive manner is a challenging problem, especially, as falls occur rarely. In this paper, we formulated detecting falls as an anomaly detection problem and presented the DeepFall framework, which shows the development and comparison of three variants of DSTCAE. We tested the DeepFall framework on three datasets that captured ADL and falls in a non-invasive manner using thermal and depth camera. We presented a new anomaly scoring method—referred to as the within-context anomaly score. The results showed that the DeepFall framework outperforms the standard CAE, as well as traditional DAE. We also found that DSTCAE variants outperformed the convolutional LSTM autoencoder approach of detecting falls. It was also observed that the within-context anomaly score outperformed the per-frame-based anomaly scoring method (or cross-context anomaly score) on two out of three datasets (excluding depth data sets without hole filling).
The performance of the DeepFall method may be affected by the presence of multiple persons in a scene, occurrence of other anomalous behavior, or lighting conditions. We are planning to collect a new dataset on fall detection that will address some of these issues to build a robust fall detection system.
The main application of 3D convolutional spatio-temporal autoencoders investigated in this paper is fall detection. Higher performance is achieved because the concept of normal activities of daily living was clearly defined. This idea can be further extended to other possible applications, such as anomalous behavior in crowded scenes, violence detection in public places, and detecting security threats in open areas. In all of these applications, individual facial or body movements are not required, rather generic spatio-temporal features can be learned from normal behavior and anomalies may be flagged.
Explainability of deep learning- based methods is a challenge [30]. The advantage of spatio-temporal convolutional methods is that the filters learned during the training process can be visualized. This will improve our understanding of the mechanism of fall detection. In the future, we will explore the application of Generative Adversarial Networks [11] to the task of fall detection in an unsupervised setting.
Compliance with Ethical Standards
Conflict of interests
The authors declare that they have no conflict of interest.
Footnotes
The code for DSTCAE is available at https://github.com/JJN123/Fall-Detection.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Jacob Nogas, Email: jacob.nogas@mail.utoronto.ca.
Shehroz S. Khan, Email: alex.mihailidis@utoronto.ca
Alex Mihailidis, Email: shehroz.khan@uhn.ca.
References
- 1.Baccouche M, Mamalet F, Wolf C, Garcia C, Baskurt A (2012) Spatio-temporal convolutional sparse autoencoder for sequence classification. In: BMVC. Citeseer
- 2.Bertalmio M, Bertozzi AL, Sapiro G (2001) Navier-stokes, fluid dynamics, and image and video inpainting. In: Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001, vol 1, pp I–355–I–362, DOI 10.1109/CVPR.2001.990497
- 3.Bogdan Kwolek MK. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput Methods Programs Biomed. 2014;117:489–501. doi: 10.1016/j.cmpb.2014.09.005. [DOI] [PubMed] [Google Scholar]
- 4.CDC (2017) Enter of disease control and prevention – important facts about falls. https://www.cdc.gov/homeandrecreationalsafety/falls/adultfalls.html. [Online accessed 22-December-2017]
- 5.Chalapathy R, Menon AK, Chawla S (2017) Robust, deep and inductive anomaly detection. In: European conference on machine learning. Skopje
- 6.Chandola V, Banerjee A, Kumar V. Anomaly detection: a survey. ACM Comput Surv. 2009;41(3):15:1–15:58. doi: 10.1145/1541880.1541882. [DOI] [Google Scholar]
- 7.Chollet F., et al. (2015) Keras: the python deep learning library https://github.com/fchollet/keras. Online accessed 20-January-2018
- 8.Chong YS, Tay YH (2017) Abnormal event detection in videos using spatiotemporal autoencoder. In: International symposium on neural networks. Springer, pp 189–196
- 9.Du Tran Lubomir Bourdev RFLTMP (2015) Learning spatiotemporal features with 3d convolutional networks. In: IEEE International conference on computer vision (ICCV). IEEE, DOI 10.1109/ICCV.2015.510
- 10.Goldstein M, Uchida S. A comparative evaluation of unsupervised anomaly detection algorithms for multivariate data. PloS one 11. 2016;4:e0152173. doi: 10.1371/journal.pone.0152173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems, pp 2672–2680
- 12.Gutoski M, Aquino NMR, Ribeiro M, Lazzaretti AE, Lopes HS (2017) Detection of video anomalies using convolutional autoencoders and one-class support vector machines. In: Proc. XIII Brazilian congress on computational intelligence
- 13.Hasan M, Choi J, Neumann J, Roy-Chowdhury AK, Davis LS (2016) Learning temporal regularity in video sequences. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 733–742
- 14.Itseez (2015) Open source computer vision library. https://github.com/itseez/opencv
- 15.Ji S, Xu W, Yang M, Yu K. 3d convolutional neural networks for human action recognition. IEEE Trans Pattern Anal Mach Intell. 2013;35(1):221–231. doi: 10.1109/TPAMI.2012.59. [DOI] [PubMed] [Google Scholar]
- 16.Khan SS, Ahmad A. Relationship between variants of one-class nearest neighbors and creating their accurate ensembles. IEEE Trans Knowl Data Eng. 2018;30(9):1796–1809. doi: 10.1109/TKDE.2018.2806975. [DOI] [Google Scholar]
- 17.Khan SS, Karg ME, Kulić D, Hoey J. Detecting falls with x-factor hidden Markov models. Appl Soft Comput. 2017;55:168–177. doi: 10.1016/j.asoc.2017.01.034. [DOI] [Google Scholar]
- 18.Khan SS, Madden MG. One-class classification: taxonomy of study and review of techniques. Knowl Eng Rev. 2014;29(3):345–374. doi: 10.1017/S026988891300043X. [DOI] [Google Scholar]
- 19.Khan SS, Taati B (2017) Detecting unseen falls from wearable devices using channel-wise ensemble of autoencoders. Expert Systems with Applications
- 20.Ma X, Wang H, Xue B, Zhou M, Ji B, Li Y. Depth-based human fall detection via shape features and improved extreme learning machine. IEEE J Biomed Health Inform. 2014;18(6):1915–1922. doi: 10.1109/JBHI.2014.2304357. [DOI] [PubMed] [Google Scholar]
- 21.Masci J, Meier U, Cireşan D, Schmidhuber J (2011) Stacked convolutional auto-encoders for hierarchical feature extraction. In: International conference on artificial neural networks. Springer, pp 52–59
- 22.Mercuri M, Garripoli C, Karsmakers P, Soh PJ, Vandenbosch GA, Pace C, Leroux P, Schreurs D (2016) Healthcare system for non-invasive fall detection in indoor environment. In: Applications in electronics pervading industry, environment and society. Springer, pp 145–152
- 23.Munawar A, Vinayavekhin P, De Magistris G (2017) Spatio-temporal anomaly detection for industrial robots through prediction in unsupervised feature space. In: 2017 IEEE Winter conference on applications of computer vision (WACV). IEEE, pp 1017–1025
- 24.Nathan Silberman Derek Hoiem PK, Fergus R (2012) Indoor segmentation and support inference from rgbd images. In: ECCV
- 25.Nogas J, Khan SS, Mihailidis A (2018) Fall detection from thermal camera using convolutional lstm autoencoder. In: Proceedings of the 2nd workshop on aging, rehabilitation and independent assisted living. IJCAI Workshop
- 26.Penttilä J. A method for anomaly detection in hyperspectral images, using deep convolutional autoencoders. Master’s thesis. Finland: University of Jyväskylä; 2017. [Google Scholar]
- 27.Ribeiro M, Lazzaretti AE, Lopes HS (2017) A study of deep convolutional auto-encoders for anomaly detection in videos. Pattern Recognition Letters
- 28.Rubenstein LZ, Robbins AS, Josephson KR, Schulman BL, Osterweil D. The value of assessing falls in an elderly population: a randomized clinical trial. Ann Intern Med. 1990;113(4):308–316. doi: 10.7326/0003-4819-113-4-308. [DOI] [PubMed] [Google Scholar]
- 29.Sabokrou M, Fayyaz M, Fathy M, Klette R. Deep-cascade: cascading 3d deep neural networks for fast anomaly detection and localization in crowded scenes. IEEE Trans Image Process. 2017;26(4):1992–2004. doi: 10.1109/TIP.2017.2670780. [DOI] [PubMed] [Google Scholar]
- 30.Samek W, Wiegand T, Müller KR (2017) Explainable artificial intelligence: understanding, visualizing and interpreting deep learning models. arXiv:https://arxiv.org/abs/1708.08296
- 31.Skubic M, Harris BH, Stone E, Ho K, Su BY, Rantz M (2016) Testing non-wearable fall detection methods in the homes of older adults. In: 2016 IEEE 38th annual international conference of the engineering in medicine and biology society (EMBC). IEEE, pp 557–560 [DOI] [PubMed]
- 32.Tran HT, Hogg D (2017) Anomaly detection using a convolutional winner-take-all autoencoder. In: Proceedings of the British machine vision conference 2017. Leeds
- 33.Vadivelu S, Ganesan S, Murthy OR, Dhall A (2016) Thermal imaging based elderly fall detection. In: ACCV workshop. Springer, pp 541–553
- 34.Viacheslav V, Alexander F, Vladimir M, Svetlana T, Oksana L (2014) Kinect depth map restoration using modified exemplar-based inpainting. In: 2014 12th International conference on signal processing (ICSP). IEEE, pp 1175–1179
- 35.Xu D, Yan Y, Ricci E, Sebe N. Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput Vis Image Underst. 2017;156:117–127. doi: 10.1016/j.cviu.2016.10.010. [DOI] [Google Scholar]
- 36.Yusif S, Soar J, Hafeez-Baig A. Older people, assistive technologies, and the barriers to adoption: a systematic review. Int J Med Inform. 2016;94:112–116. doi: 10.1016/j.ijmedinf.2016.07.004. [DOI] [PubMed] [Google Scholar]
- 37.Zhao Y, Deng B, Shen C, Liu Y, Lu H, Hua XS (2017) Spatio-temporal autoencoder for video anomaly detection. In: Proceedings of the 2017 ACM on multimedia conference, MM ’17. ACM, New York