

Abstract
We present a diffeomorphic image registration algorithm to learn spatial transformations between pairs of images to be registered using fully convolutional networks (FCNs) under a self‐supervised learning setting. Particularly, a deep neural network is trained to estimate diffeomorphic spatial transformations between pairs of images by maximizing an image‐wise similarity metric between fixed and warped moving images, similar to those adopted in conventional image registration algorithms. The network is implemented in a multi‐resolution image registration framework to optimize and learn spatial transformations at different image resolutions jointly and incrementally with deep self‐supervision in order to better handle large deformation between images. A spatial Gaussian smoothing kernel is integrated with the FCNs to yield sufficiently smooth deformation fields for diffeomorphic image registration. The spatial transformations learned at coarser resolutions are utilized to warp the moving image, which is subsequently used as input to the network for learning incremental transformations at finer resolutions. This procedure proceeds recursively to the full image resolution and the accumulated transformations serve as the final transformation to warp the moving image at the finest resolution. Experimental results for registering high‐resolution 3D structural brain magnetic resonance (MR) images have demonstrated that image registration networks trained by our method obtain robust, diffeomorphic image registration results within seconds with improved accuracy compared with state‐of‐the‐art image registration algorithms.
Keywords: diffeomorphic image registration, fully convolutional networks, multi‐resolution, unsupervised learning
We present a diffeomorphic image registration algorithm to learn spatial transformations between pairs of images to be registered using fully convolutional networks under a self‐supervised learning setting. Experimental results have demonstrated our method could obtain robust, diffeomorphic image registration results within seconds with improved accuracy compared with state‐of‐the‐art image registration algorithms.
1. INTRODUCTION
Medical image registration plays an important role in many medical image analysis tasks (Sotiras, Davatzikos, & Paragios, 2013; Viergever et al., 2016). To solve the medical image registration problem, the most commonly used strategy is to seek a spatial transformation that establishes pixel/voxel correspondence between a pair of fixed and moving images in an optimization framework, by maximizing a surrogate measure of the spatial correspondence between images, such as image intensity correlation between the images to be registered (Ashburner, 2007; Avants et al., 2011; Fan, Jiang, & Evans, 2002; S. Klein, Staring, Murphy, Viergever, & Pluim, 2010; Rueckert et al., 1999). Conventional medical image registration algorithms typically solve the image registration optimization problem using iterative optimization algorithms, making the medical image registration computationally expensive and time‐consuming.
Recent medical image registration studies have leveraged deep learning techniques to improve the computational efficiency of conventional medical image registration algorithms, in addition to learning image features for the image registration using stacked autoencoders (Wu, Kim, Wang, Munsell, & Shen, 2016). In particular, deep learning techniques have been used to build prediction models of spatial transformations for achieving image registration under a supervised learning framework (Krebs et al., 2017; Rohé, Datar, Heimann, Sermesant, & Pennec, 2017; Sokooti et al., 2017; Yang, Kwitt, Styner, & Niethammer, 2017). Different from the conventional image registration algorithms, the deep learning‐based image registration algorithms formulate the image registration as a multi‐output regression problem (Krebs et al., 2017; Rohé et al., 2017; Sokooti et al., 2017; Yang et al., 2017). They are designed to predict a spatial relationship between image pixel/voxels from a pair of images based on their image patches. The learned prediction model can then be applied to images pixel/voxel‐wisely to achieve the image registration.
The prediction‐based image registration algorithms typically adopt convolutional neural networks (CNNs) to learn informative image features and a mapping between the learned image features and spatial transformations that register images in a training dataset, consisting of deformation fields and images that can be registered by the deformation fields (Krebs et al., 2017; Rohé et al., 2017; Sokooti et al., 2017; Yang et al., 2017). Similar to most deep learning tasks, the quality of training data plays an important role in the prediction‐based image registration, and a variety of strategies have been proposed to build training data, specifically the spatial transformations that register images in a training dataset (Krebs et al., 2017; Rohé et al., 2017; Sokooti et al., 2017; Yang et al., 2017). Particularly, synthetic deformation fields can be simulated and applied to a set of images to generate new images so that the synthetic deformation fields can be used as training data to build a prediction model (Sokooti et al., 2017). However, the synthetic deformation fields may not effectively capture spatial correspondences between real images. Spatial transformations that register pairs of images can also be estimated using conventional image registration algorithms (Krebs et al., 2017; Yang et al., 2017). However, a prediction‐based image registration model built upon such a training dataset is limited to estimating spatial transformations captured by the adopted conventional image registration algorithms. The estimation of spatial transformations that register pairs of images can also be guided by shape matching (Rohé et al., 2017). However, a large dataset of medical images with manual segmentation labels is often not available for training an image registration model.
The training data scarcity problem in deep learning‐based image registration could be overcome using unsupervised or self‐supervised learning techniques. A variety of deep learning algorithms have adopted deep CNNs, in conjunction with spatial transformer network (STN; Jaderberg, Simonyan, & Zisserman, 2015), to learn prediction models for image registration of pairs of fixed and moving images in an unsupervised learning fashion (A. V. Dalca, Balakrishnan, Guttag, & Sabuncu, 2019; de Vos et al., 2019; Eppenhof, Lafarge, Veta, & Pluim, 2019; Hering, van Ginneken, & Heldmann, 2019; Kim et al., 2019; Krebs, Delingette, Mailhé, Ayache, & Mansi, 2019; Kuang & Schmah, 2019; Lei et al., 2020; Li & Fan, 2017, 2018; Liu, Hu, Zhu, & Heng, 2019; Mansilla, Milone, & Ferrante, 2020; T. C. Mok & Chung, 2020a, 2020b; Yoo, Hildebrand, Tobin, Lee, & Jeong, 2017; Yu et al., 2020; Zhang, Liu, Zheng, & Shi, 2020; Zhao, Lau, Luo, Chang, & Xu, 2019). Particularly, fully convolutional networks (FCNs) that facilitate voxel‐to‐voxel learning (Long, Shelhamer, & Darrell, 2015) are adopted to predict the deformation field (A. V. Dalca et al., 2019; Kim et al., 2019; Kuang & Schmah, 2019; Li & Fan, 2017, 2018; Mansilla et al., 2020; Yoo et al., 2017; Zhao et al., 2019) using moving and fixed images as the input to deep learning networks. The optimization of the image registration networks is driven by image similarity measures between the fixed image and the warped moving image based on either image intensity (A. V. Dalca et al., 2019; Kim et al., 2019; Kuang & Schmah, 2019; Li & Fan, 2017, 2018; Mansilla et al., 2020; Zhao et al., 2019) or contextual features (Yoo et al., 2017). The deformation field can be modeled by sufficiently smooth velocity fields to facilitate diffeomorphic image registration (Ashburner, 2007; Avants et al., 2011), and such a strategy has been adopted in deep learning‐based image registration methods to favor diffeomorphic properties of the transformation including preservation of topology and invertible mapping (A. V. Dalca et al., 2019; T. C. Mok & Chung, 2020a; Zhang et al., 2020). Although physically plausible deformation and promising accuracy has been obtained, these registration methods are carried out at a single spatial scale and might be trapped by local optima, especially when registering images with large anatomical variability. Inspired by conventional image registration methods, multi‐stage and multi‐resolution registration techniques are incorporated into deep learning‐based registration methods using cascaded networks (de Vos et al., 2019; Hering et al., 2019; Kim et al., 2019; Zhao et al., 2019) and deep supervision (Eppenhof et al., 2019; Hering et al., 2019; Krebs et al., 2019; Lei et al., 2020; Liu et al., 2019), yielding improved performance compared with one‐stage or single‐scale image registration. However, they are not equipped to achieve diffeomorphic registration. A deep Laplacian pyramid image registration network (T. C. Mok & Chung, 2020b) has been recently proposed for diffeomorphic image registration in a multi‐resolution manner, demonstrating promising image registration performance.
In this study, we propose an end‐to‐end learning framework to optimize and learn diffeomorphic spatial transformations between pairs of images to be registered in a multi‐resolution diffeomorphic image registration framework, referred to as MDReg‐Net. In particular, our method trains FCNs to estimate voxel‐to‐voxel velocity fields of spatial transformations for registering images by maximizing their image‐wise similarity metric, similar to conventional image registration algorithms. To account for potential large deformations between images, a multi‐resolution strategy is adopted to jointly optimize and learn vocity fields for spatial transformations at different spatial resolutions progressively in an end‐to‐end learning framework. The velocity fields estimated at lower resolutions are used to warp the moving image and the warped moving image is used as the input to the subsequent sub‐network to estimate the residual velocity fields for spatial transformations at higher resolutions. The image similarity measures between the fixed and warped moving images are evaluated at different image resolutions to serve as deep self‐supervision so that FCNs at different spatial resolutions are jointly learned. A spatial Gaussian smoothing kernel is integrated with the FCNs to yield sufficiently smooth deformation fields to achieve diffeomorphic image registration. Our method has been evaluated based on 3D structural brain magnetic resonance (MR) images and obtained diffeomorphic image registration with better performance than state‐of‐the‐art image registration algorithms.
2. METHODS
2.1. Image registration by optimizing an image similarity metric
Given a pair of fixed image and moving image , the task of image registration is to seek a spatial transformation that establishes pixel/voxel‐wise spatial correspondence between the two images. The spatial correspondence can be gauged with a surrogate measure, such as an image intensity similarity measure between the fixed and transformed moving images, and therefore the image registration problem can be solved in an optimization framework by optimizing a spatial transformation that maximizes the image similarity measure between the fixed image and transformed moving image. For nonrigid image registration, the spatial transformation is often characterized by a dense deformation field that encodes displacement vectors between spatial coordinates of and their counterparts in . For mono‐modality image registration, mean squared intensity difference and normalized correlation coefficient (NCC) are often adopted as the surrogate measures of image similarity.
As the image registration problem is an ill‐posed problem, regularization techniques are usually adopted in image registration algorithms to obtain a spatially smooth and physically plausible deformation field (Sotiras et al., 2013; Viergever et al., 2016). In general, the optimization‐based image registration problem is formulated as
| (1) |
where is the deformation field to be optimized, represents spatial coordinates of pixel/voxels in , represents deformed spatial coordinates of pixel/voxels by in , is an image similarity measure, is a regularizer on the deformation field, and controls the trade‐off between the image similarity measure and the regularization on the deformation field.
The regularization is typically adopted to encourage the deformation field to be spatially smooth by minimizing magnitude of derivatives of the spatial transformation, such as square ‐norm, total variation, and learning‐based regularizer (Niethammer, Kwitt, & Vialard, 2019; Vishnevskiy, Gass, Szekely, Tanner, & Goksel, 2017). To facilitate diffeomorphic image registration, the deformation field can be represented by integration of velocity fields , that is, (Ashburner, 2007; Avants et al., 2011), and the regularization is directly applied to the velocity fields to obtain spatially smooth velocity fields and diffeomorphic deformation fields accordingly.
The image registration optimization problem can be solved by gradient descent based methods (Sotiras et al., 2013; Viergever et al., 2016). However, such an optimization‐based image registration task is typically computational expensive and time consuming. Instead of optimizing directly, the deformation field can be predicted using FCNs under an unsupervised setting (Li & Fan, 2017, 2018). However, the estimated deformation field may not be fold‐free or invertible even a large smooth regularization term is adopted (A. V. Dalca et al., 2019; T. C. Mok & Chung, 2020a; Zhang et al., 2020).
2.2. Multi‐resolution diffeomorphic image registration with deep self‐supervision
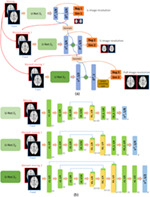
We adopt a multi‐resolution image registration procedure to estimate the velocity and deformation fields progressively from coarse to fine spatial resolutions for its effectiveness for handling large deformation between images, as demonstrated in conventional image registration algorithms (Sotiras et al., 2013; Viergever et al., 2016). The overall framework of our multi‐resolution image registration method is illustrated in Figure 1a, with three different resolutions involved. Particularly, the velocity fields are estimated incrementally from coarse to fine resolutions with levels ( and refer to the coarsest and finest spatial resolutions, respectively), which are optimized jointly and formulated as
| (2) |
where and denote fixed and moving images at resolution level , is the incremental velocity fields at level , and is the accumulated velocity fields of the deformation field at level , computed as
| (3) |
For the deformation field at the coarsest resolution (), a sub‐network with a U‐Net (Ronneberger, Fischer, & Brox, 2015) architecture is utilized to estimate velocity fields and a moving image to be registered to a fixed image are concatenated with the fixed image as a two‐channel input to sub‐network . For the deformation field at a finer resolution (), a dedicated sub‐network is adopted to estimate the velocity field increment using a concatenation of the warped moving image and the fixed image as an input to the sub‐network. Particularly, the moving image is warped by the deformation field obtained at its coarser resolution. The sub‐network is optimized to learn the deformation field that captures the residual variation between the warped moving image and the fixed image after deformation at all preceding coarser resolutions. Finally, the accumulated velocity fields over all the resolutions are utilized to obtain the deformation field at the finest resolution.
FIGURE 1.
Schematic illustration of the multi‐resolution diffeomorphic image registration based on FCNs. (a) Overall architecture of the multi‐resolution image registration framework and (b) detailed network structure for voxel‐to‐voxel multi‐output regression of velocity fields at different image resolutions. The number next to each network block denotes the number of its filters, and the number on each network block denotes the image resolution
Similar to the conventional multi‐resolution image registration algorithms, the similarity of registered images at different resolutions is maximized in our network to serve as deep supervision (Chen‐Yu, Saining, Patrick, Zhengyou, & Zhuowen, 2014), but without relying on any supervised information of the deformation fields. Such a supervised learning with surrogate supervised information is referred to as self‐supervision in this study. As it is capable of obtaining both deformation and inverse deformation fields for the moving and fixed images from the velocity fields under the diffeomorphic image registration setting, our multi‐resolution image registration model is formulated to optimize both the deformation and inverse deformation fields jointly
| (4) |
where normalized cross‐correlation (NCC) is adopted as the image similarity measure , , is the number of pixel/voxels in the velocity field, and is the hyper‐parameter to balance the image similarity and deformation regularization terms.
Different from conventional multi‐resolution image registration algorithms that perform multi‐stage optimization with their deformation fields at coarse resolutions used as initialization inputs to the image registration at a finer resolution, our deep learning‐based method jointly optimizes deformation fields at all spatial resolutions with an end‐to‐end deep learning setting. As the optimization of the loss function proceeds, the parameters within the network will be updated through the feedforward computation and backpropagation procedure, leading to improved prediction of deformation fields.
2.3. Network architecture for estimating the velocity fields
In our multi‐resolution image registration network, one dedicated sub‐network is designed to estimate the velocity fields or the velocity field increment at each spatial resolution. The sub‐network at the coarsest spatial resolution is optimized to learn the velocity fields to capture large deformation, while the sub‐networks at finer resolutions are optimized to learn residual deformation to achieve an accurate image registration.
In this study, stationary velocity fields (SVFs) are adopted to represent the deformation field as
| (5) |
where is the deformation field, is the identity transformation, and is time. The integration of SVFs using scaling and squaring method (Ashburner, 2007; A. V. Dalca et al., 2019) is adopted to compute the deformation field numerically. Particularly, the sub‐network used at each resolution in our study is specified as one U‐Net with both encoder and decoder paths, as illustrated in Figure 1b. The encoder path of all the sub‐networks share the same structure, consisting of one convolutional layer with 16 filters, followed by three convolutional layers with 32 filters, and all have a stride of 2. The decoder path of the sub‐networks from coarse to fine resolutions has one, two, and three deconvolutional layers, each with 32 filters and a stride of 2, followed by two convolution layers with 32 and 16 filters, respectively, and one output convolutional layer to predict the SVFs at three different spatial resolutions. For a particular sub‐net, the predicted SVF is integrated using the scaling and squaring operation to obtain the deformation field at different spatial resolutions. LeakyReLu activation is used for all the convolutional and deconvolutional layers except the output layer. The number of output channels is 3, corresponding to the spatial dimensionality of the input images. The kernel size in all layers are set to . The multi‐resolution images used for computing the image similarity in the loss function at different resolutions are obtained using average pooling. Specifically, the original image serves as the image at the finest (full) resolution, and images at reduced resolutions are obtained by applying average pooling to the original image recursively with a kernel size of and a stride of 2.
In the present study, SVFs are learned at , , and resolutions to reduce the computational memory consumption, and the SVFs at the full resolution are obtained from the output of the resolution using linear interpolation. The deformation field is computed from the SVFs with the number of time steps set to 7 (A. V. Dalca et al., 2019). A spatial smoothing layer, implemented as Gaussian kernel smoothing, is adopted as part of our deep learning network to smooth the deformation fields at the finest resolution in the end‐to‐end learning framework as illustrated in Figure 1a. The integration of the spatial smoothing in our deep learning model facilitates the interaction between the learning of deformation fields and spatial smoothing to favor the diffeomorphic image registration. The spatial smoothing operation is applied to the deformation field at the finest resolution, as used in ANTs (Avants et al., 2011).
Our image registration model is implemented using Tensorflow (Abadi et al., 2016). Adam optimization technique (Kingma & Ba, 2014) is adopted to train the networks. Once the training procedure is finished, the trained network can be directly used to register new images with feedforward computation.
3. EVALUATION AND EXPERIMENTAL SETTINGS
3.1. Image datasets
We evaluated our method based on two public brain imaging datasets with manual segmentations of fine‐grained brain structures, including (a) MICCAI 2012 Multi‐Atlas Labelling Challenge (MALC) dataset consisting of T1 brain MR images from 30 subjects with fine‐grained whole‐brain annotation for 134 structures (Landman & Warfield, 2012), and (b) Mindboggle‐101 dataset consisting of T1 brain MR images from 101 healthy subjects with 50 manual annotated cortical structures (A. Klein & Tourville, 2012). These images were used for testing only.
T1 brain MR images of 901 young subjects from PING dataset (Jernigan et al., 2016) were adopted to train our image registration model. Particular, images of 801 subjects were used for training, and images of the remaining 100 subjects were used for tuning the hyper‐parameter . In addition, T1 brain MR images of 809 old subjects from ADNI 1 cohort (http://adni.loni.usc.edu) were adopted for training a second image registration model from scratch to investigate the influences of different training data to the image registration performance. It is worth noting that our training and testing datasets were obtained from different cohorts and sites to evaluate our method's generalization performance.
All the images for model training and testing were preprocessed using FreeSurfer (Fischl, 2012), including skull‐stripping, intensity normalization and spatial alignment using affine registration. All the images were resampled with a spatial resolution of and cropped with a size of . Segmentation labels with 30 brain structures were also obtained using FreeSurfer for each subject from PING dataset, which were adopted to tune the hyper‐parameter .
3.2. Evaluation metrics
As it is nontrivial to obtain the ground truth deformation between any pair of images, we adopted the similarity of the anatomical segmentations of the fixed image and warped moving image as a surrogate metric of registration accuracy (Rohlfing, 2011). Particularly, the trained registration model was applied to register all the testing images to one random selected template image, and the generated deformation fields were used to warp their corresponding segmentation labels. Dice score between the warped segmentation and the template segmentation images was used to evaluate the registration performance. Although Dice score between anatomical structures is a reliable surrogate measure to quantify image registration accuracy, higher Dice score alone does not necessarily mean biologically plausible image registration as a deformation field with folding voxels could also lead to image registration with high regional Dice score. Therefore, we also evaluated the diffeomorphic property of the obtained deformation in addition to Dice score. Particularly, we calculated the Jacobian determinant of the deformation field obtained and counted all the voxels whose is non‐positive within the brain region. We have also evaluated the registration performance on images registered with the deformation fields computed in the opposite direction, that is, registering fixed images to moving images, based on the same velocity fields.
3.3. Network training
We trained pairwise registration models by randomly selecting one pair of images as the input to the network. Given a set of images, we obtained pairs of fixed and moving images, including pairs of the same images, such that every image can serve as the fixed image.
The learning rate was set to 0.0001 and batch size was set to 1. The networks were trained on one NVIDIA TITAN Xp GPU, and 150,000 iterations were adopted for the training. We have trained our registration model with different hyper‐parameter values () using the PING training dataset and selected the values that obtained the highest Dice score on the PING validation dataset using the FreeSurfer segmentation labels while no voxels with non‐positive existed in the obtained deformation fields. For the Gaussian kernel smoothing, the of the Gaussian kernel was set to 1.732 voxels and the kernel size was set to , according to the default value used in ANTs (Avants et al., 2011).
3.4. Comparison with state‐of‐the‐art image registration algorithms and ablation studies
We compared our method with representative medical image registration algorithms, including NiftyReg (Modat et al., 2010), ANTs (Avants et al., 2011), VoxelMorph (Adrian V Dalca, Balakrishnan, Guttag, & Sabuncu, 2018), ProbMultilayer network (Liu et al., 2019), and LapIRN (T. C. Mok & Chung, 2020b), based on the two testing datasets. Particularly, the default setting of NiftyReg was adopted. For ANTs based image registration, two configurations with different spatial smoothing regularization parameters were adopted with following command: ANTS 3 ‐m CC[fixed,moving,1,2] ‐t SyN[0.25] ‐r Gauss[9,0.2] (or ‐r Gauss[3,1.0]) ‐o output ‐i 201x201x201 ‐‐number‐of‐affine‐iterations 100x100x100 ‐‐use‐Histogram‐Matching 0. The configuration with the small smoothing size is referred to as ANTs‐c1, and the one with the larger smoothing size is referred to as ANTs‐c2. For the VoxelMorph model, bi‐directional image similarity based loss was adopted, and the number of time steps was set to 7 for computing the deformation field from the velocity field. The VoxelMorph model shared the same training strategy and setting as the proposed method, and its hyper‐parameters were also optimized to obtain the highest Dice scores based on the PING validation dataset. For the ProbMultilayer model and LapIRN model, the default setting was adopted, and they shared the same training strategy as the proposed method.
The comparison with VoxelMorph serves as an ablation study to evaluate if the multi‐resolution strategy could improve the image registration. As an additional ablation study, we also investigated the performance of our method without the spatial smoothing layer by optimizing to obtain the diffeomorphic image registration on the PING validation dataset.
4. EXPERIMENTAL RESULTS
4.1. Optimal parameter setting
Figure 2 shows the average Dice score and number of voxels with non‐positive in the obtained deformation fields for the PING validation dataset with different values of hyper‐parameter . It can be observed that the Dice scores reached the maximum when was around 0.35, while all the voxels had positive in the obtained deformation fields when was equal to or larger than 0.35. We adopted the registration model with for all the following evaluation unless specified otherwise.
FIGURE 2.
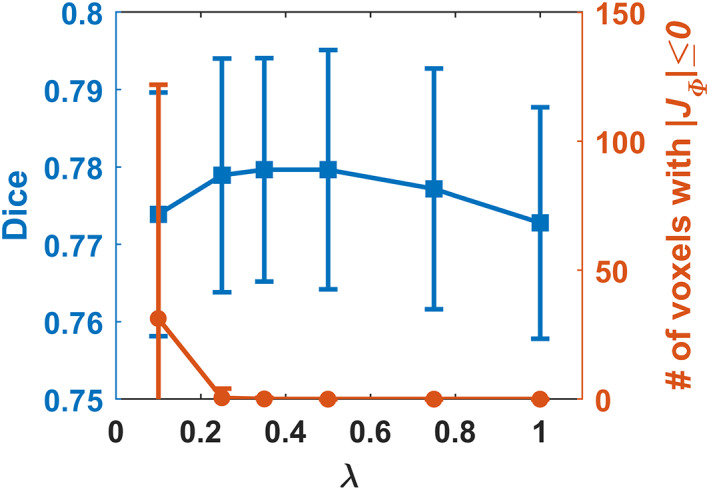
Dice score and number of voxels with non‐positive in the obtained deformation fields of the PING validation dataset for the proposed model with different values. The registration model with was adopted for all the evaluation
4.2. Quantitative performance of image registration algorithms under comparison
The average Dice scores calculated over all anatomical structures and subjects obtained by different registration methods for two testing datasets are summarized in Table 1. All the deformable registration methods obtained significantly higher Dice scores than the affine image registration (, Wilcoxon signed rank test), and our method obtained deformation fields with the minimal number of voxels with non‐positive Jacobian determinant among all the methods under comparison. Our method also obtained Dice scores close to those obtained by ANTs‐c1 and both of them ranked top in the deformable registration methods under comparison. Figures 3 and 4 show Dice scores of individual anatomical structures of MALC and Mindboggle‐101 datasets respectively, where the structures are presented in ascending order by their volumetric sizes (from small to large regions), and the Dice scores of the same anatomical structure from left and right brain hemispheres are combined. Our method was comparable to ANTs‐c1 in terms of Dice score for most structures and outperformed the VoxelMorph, LapIRN, and ProbMultilayer model for most structures across both data sets with either coarse‐grained (Mindboggle‐101 dataset) or fine‐grained (MALC dataset) structures. Example images before and after the image registration by different methods and their corresponding anatomical segmentations on two testing datasets are demonstrated in Figures 5a,b and 6a,b.
TABLE 1.
Average Dice score, number and percentage of voxels with non‐positive Jacobian determinant for affine alignment, NiftyReg, ANTs (SyN), VoxelMorph, ProbMultilayer, LapIRN, and the proposed method (referred to as MDReg‐Net) on different testing datasets
| Methods | MALC | Mindboggle‐101 | ||||
|---|---|---|---|---|---|---|
| Avg. Dice | (#) | (%) | Avg. Dice | (#) | (%) | |
| Affine | 0.429 (0.182) | – | – | 0.347 (0.093) | – | – |
| NiftyReg | 0.576 (0.184) | – | – | 0.471 (0.126) | – | – |
| ANTs‐c1 | 0.597 (0.187) | 9,571 (3,384) | 0.58 (0.21) | 0.538 (0.130) | 4,349 (1,081) | 0.74 (0.18) |
| ANTs‐c2 | 0.568 (0.188) | 126 (187.7) | 7.6e−3 (1.1e−2) | 0.482 (0.130) | 29 (49.1) | 4.9e−3 (8.3e−3) |
| VoxelMorph (PING) | 0.572 (0.182) | 3.68 (7.7) | 2.2e−4 (4.7e−4) | 0.472 (0.117) | 0.58 (1.98) | 9.8e−5 (3.3e−4) |
| VoxelMorph (ADNI1) | 0.568 (0.182) | 4.53 (9.8) | 2.7e−4 (6.0e−4) | 0.476 (0.113) | 0.32 (2.33) | 5.4e−5 (3.9e−4) |
| ProbMultilayer (PING) | 0.578 (0.181) | 0.26 (1.54) | 1.6e−5 (9.4e−5) | 0.486 (0.106) | 0.03 (0.3) | 5.1e−6 (5.1e−5) |
| ProbMultilayer (ADNI1) | 0.573 (0.181) | 0.35 (1.89) | 2.1e−5 (1.1e−4) | 0.482 (0.105) | 0 (0) | 0 (0) |
| LapIRN (PING) | 0.546 (0.186) | 2,642 (2,088) | 0.16 (0.13) | 0.475 (0.097) | 2,009 (920) | 0.34 (0.16) |
| LapIRN (ADNI1) | 0.547 (0.185) | 2,585 (2,074) | 0.16 (0.13) | 0.477 (0.097) | 1,533 (665) | 0.26 (0.11) |
| MDReg‐Net (PING) | 0.588 (0.180) | 0.089 (0.515) | 5.4e−6 (3.1e−5) | 0.534 (0.094) | 0 (0) | 0 (0) |
| MDReg‐Net (ADNI1) | 0.587 (0.172) | 0.029 (0.172) | 1.8e−6 (1.0e−5) | 0.530 (0.092) | 0.07 (0.7) | 1.2e−5 (1.2e−4) |
Note: The performance of VoxelMorph, ProbMultilayer, LapIRN, and MDReg‐Net trained using ADNI 1 dataset are also presented. The SDs are shown in parentheses. The average and standard deviation of Dice score were calculated over all anatomical structures and subjects. The statistics of voxels with non‐positive Jacobian determinant were calculated within brain region.
FIGURE 3.
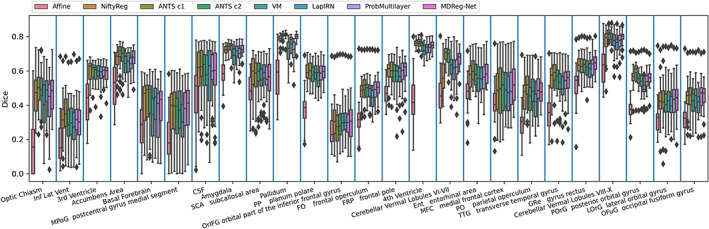
Boxplots of Dice score of 25 randomly selected anatomical structures for Affine, NiftyReg, ANTs (c1 and c2), VoxelMorph (VM), LapIRN, ProbMultilayer, and our method (MDReg‐Net) on the MALC dataset. Dice scores of the same structure from left and right brain hemispheres are combined. Brain structures are displayed in ascending order by their volumetric sizes from left to right
FIGURE 4.
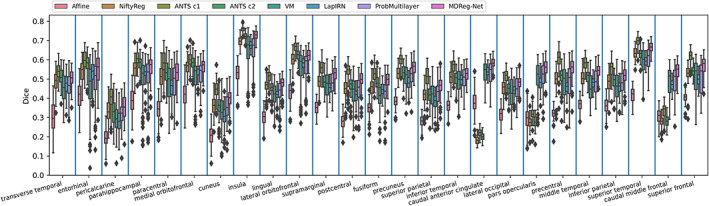
Boxplots of Dice score of anatomical structures for Affine, NiftyReg, ANTs (c1 and c2), VoxelMorph (VM), LapIRN, ProbMultilayer, and our method (MDReg‐Net) on the Mindboggle‐101 dataset. Dice scores of the same structure from left and right brain hemispheres are combined. Brain structures are displayed in ascending order by their volumetric sizes from left to right
FIGURE 5.
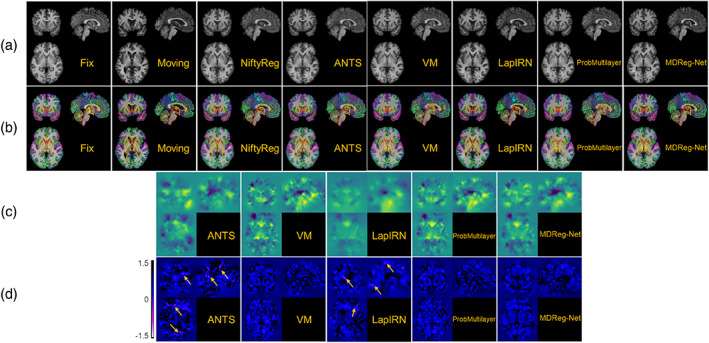
Example images before and after the image registration, obtained by the image registration algorithms under comparison on MALC dataset. (a) Fixed image, moving image, and warped moving images by NiftyReg, ANTs‐c1, VoxelMorph (VM), LapIRN, ProbMultilayer, and our method (MDReg‐Net). (b) Segmentations of fixed and moving image, and warped segmentation of moving image by different registration methods. (c) Deformation fields obtained by ANTs‐c1, VM, LapIRN, ProbMultilayer, and MDReg‐Net to register the moving image to the fixed image. Deformation in each spatial dimension is mapped to one of the RGB color channels for the visualization. (d) Jacobian determinant maps of the deformation fields shown in (c). Localized clusters of voxels with non‐positive Jacobian determinant are pointed out by the arrows. The average numbers of voxels with non‐positive Jacobian determinant obtained by ANTs‐c1, VM, LapIRN, ProbMultilayer, and MDReg‐Net were 9,571, 3.68, 2,585, 0.26, and 0.089, respectively
FIGURE 6.
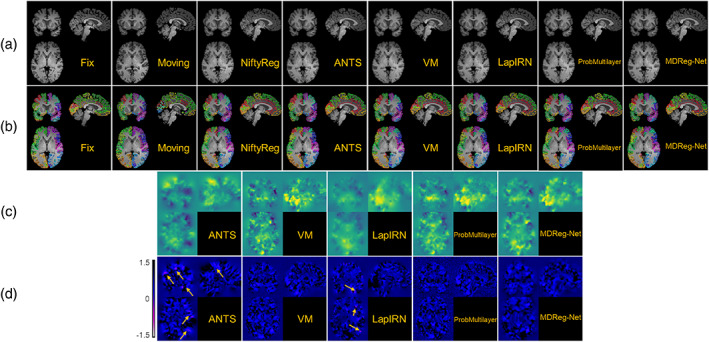
Example images before and after the image registration, obtained by the image registration algorithms under comparison on Mindboggle‐101 datasets. (a) Fixed image, moving image, and warped moving images by NiftyReg, ANTs‐c1, VoxelMorph (VM), LapIRN, ProbMultilayer, and our method (MDReg‐Net). (b) Segmentations of fixed and moving image, and warped segmentation of moving image by different registration methods. (c) Deformation fields obtained by ANTs‐c1, VM, LapIRN, ProbMultilayer, and MDReg‐Net to register the moving image to the fixed image. Deformation in each spatial dimension is mapped to one of the RGB color channels for the visualization. (d) Jacobian determinant maps of the deformation fields shown in (c). Localized clusters of voxels with non‐positive Jacobian determinant are pointed out by the arrows. The average numbers of voxels with non‐positive Jacobian determinant obtained by ANTs‐c1, VM, LapIRN, ProbMultilayer, and MDReg‐Net were 4,349, 0.58, 2,009, 0.03 and 0, respectively
Example deformation fields and their corresponding Jacobian determinant maps for each dataset obtained by ANTs‐c1, VoxelMorph, LapIRN, ProbMultilayer, and our method are shown in Figures 5c,d and 6c,d, respectively. While there were several localized clusters of voxels with non‐positive Jacobian determinant in the deformation fields obtained by ANTs‐c1 and LapIRN, nearly all voxels in the deformation fields obtained by VoxelMorph, ProbMultilayer, and our method were with positive Jacobian determinant, preserving good diffeomorphic property. As shown in Table 1, the average number of voxels with non‐positive Jacobian determinant in the deformation fields obtained by our method (~0.1) was substantially smaller than those obtained by all other methods under comparison, including ANTs‐c1 (~9,000), LapIRN (~3,000), VoxelMorph (~5), and ProbMultilayer (~0.4). These results indicate that incorporating the spatial smoothing layer in our method largely eliminated folding voxels in the deformation fields without sacrificing registration accuracy. Although the folding voxels in the deformation fields obtained by ANTs could be eliminated by increasing the spatial smoothing during the registration, over‐smoothing inevitably leads to degraded registration accuracy. As summarized in Table 1, ANTs‐c2 obtained image registration with a much smaller number of folding voxels compared with that obtained by ANTs‐c1, but its Dice score decreased dramatically.
The average time used to register one pair of images by different registration methods are presented in Table 2. Our method, ProbMultilayer, and VoxelMorph took about 4.67, 4.29, and 3.82 s respectively when run on an NIVIDIA TITAN Xp GPU, and LapIRN took about 6.46 s when run on an NVIDIA TITAN RTX GPU, much faster than NiftyReg and ANTs which took about 257 and 1,071 s on average when run on an Intel Xeon E5‐2660 CPU. On CPUs, our method took about 74.07 s to register one pair of images, faster than NiftyReg and ANTs.
TABLE 2.
Average runtime to register one pair of images by different registration methods
| Methods | NiftyReg | ANTs (SyN) | VoxelMorph | LapIRN | ProbMultilayer | MDReg‐Net (CPU) | MDReg‐Net |
|---|---|---|---|---|---|---|---|
| Avg. time (s) | 257 | 1,071 | 3.82 | 6.46 | 4.29 | 74.07 | 4.67 |
Note: NiftyReg, ANTs, and MDReg‐Net (CPU) run on one Intel Xeon E5‐2660 CPU, while VoxelMorph, ProbMultilayer, and our method (MDReg‐Net) run on one NVIDIA TITAN Xp GPU, and LapIRN run on one NVIDIA TITAN RTX GPU.
As a deep learning‐based image registration model, the performance of the proposed method might be affected by the datasets used for training the image registration model due to the anatomical variations in different datasets. Therefore, we further trained image registration models using the proposed method, VoxelMorph, LapIRN, and ProbMultilayer on an image dataset from ADNI 1 cohort with the same training procedure as described previously and evaluated their performance on the two testing datasets. As summarized in Table 1, the image registration models trained on different datasets by our method had more stable and better image registration performance than those trained by VoxelMorph, LapIRN, and ProbMultilayer, demonstrating that our method is robust and capable of learning anatomical variations from different images.
Without the spatial smoothing layer, larger regularization parameter was required to achieve diffeomorphic image registration. We trained image registration models without the spatial smoothing layer with different values on the PING training dataset to identify value capable of generating deformation fields free of voxels with non‐positive Jacobian determinant on the PING validation dataset. As shown in Figure 7a, produced an image registration model that registered the images of the PING validation dataset without any folding voxels, while produced an image registration model that registered the images of the PING validation dataset with the maximal Dice score that was estimated based on the brain structures labeled by FreeSurfer. Figure 7b shows numbers of voxels with non‐positive Jacobian determinant of the ADNI1 images that were registered by the image registration models trained on the PING dataset with and without the spatial smoothing layer, respectively. Specifically, the average number of voxels with non‐positive Jacobian determinant in the deformation fields obtained by MDReg‐Net with the spatial smoothing layer was significantly less than that obtained by MDReg‐Net without the spatial smoothing layer though a larger regularization parameter was used (, Wilcoxon signed rank test). At the subject level, the deformation fields of 31 out of 809 images obtained by MDReg‐Net with the spatial smoothing layer contained voxels with non‐positive Jacobian determinant, while 88 had deformation fields containing voxels with non‐positive Jacobian determinant out of 809 images registered by MDReg‐Net without the spatial smoothing layer. In terms of image registration accuracy measured by Dice scores on brain structures labeled by FreeSufer, MDReg‐Net with and without the spatial smoothing layer obtained Dice scores of (mean standard deviation) and , respectively (, Wilcoxon signed rank test).
FIGURE 7.
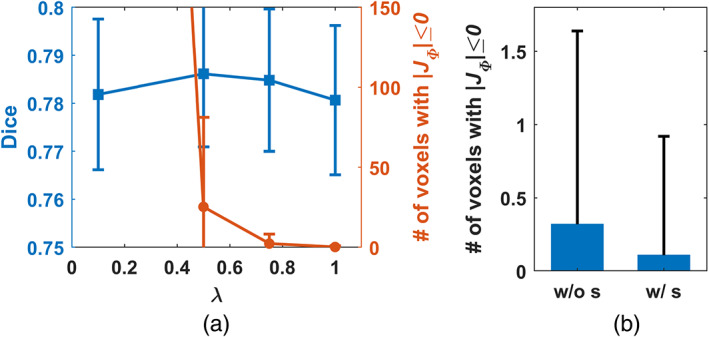
(a) Dice score and number of voxels with non‐positive in the obtained deformation fields of the PING validation dataset by MDReg‐Net without the spatial smoothing layer using different values. The registration model with was adopted for the following ablation evaluation. (b) Number of voxels with non‐positive in the obtained deformation fields of the ADNI 1 dataset using MDReg‐Net without and with the spatial smoothing layer, respectively
The image registration accuracy of MDReg‐Net image registration models with and without the spatial smoothing layer on the two testing datasets is summarized in Table 3. Particularly, two MDReg‐Net image registration models without the spatial smoothing layer were obtained with set to 0.5 and 1.0, respectively. Not surprisingly, MDReg‐Net without the spatial smoothing layer could obtain better image registration accuracy than MDReg‐Net with the spatial smoothing layer when at the cost of sacrificing the diffeomorphism. In contrast, MDReg‐Net with the spatial smoothing layer could achieve diffeomorphic, albeit not perfect, image registration without sacrificing the image registration accuracy too much, compared with MDReg‐Net without the spatial smoothing layer but with a larger regularization (when ). Moreover, the predicted velocity field performed well in the opposite direction‐based image registration. As summarized in Table 3, no significant differences were observed in the registration performance between the two opposite directions for registering images, demonstrating the good inverse consistency of our method.
TABLE 3.
Average dice score, number, and percentage of voxels with non‐positive Jacobian determinant for the proposed MDReg‐Net without/with spatial smoothing layer on two testing datasets
| Methods | MALC | Mindboggle‐101 | ||||
|---|---|---|---|---|---|---|
| Avg. Dice | (#) | (%) | Avg. Dice | (#) | (%) | |
| MDReg‐Net w/o s (, PING) | 0.592 (0.181) | 19.18 (20.85) | 1.2e−3 (1.3e−3) | 0.539 (0.099) | 2.59 (3.79) | 4.4e−4 (6.4e−4) |
| MDReg‐Net w/o s (, ADNI1) | 0.590 (0.181) | 15.5 (11.5) | 9.4e−4 (7.0e−4) | 0.543 (0.095) | 1.28 (2.17) | 2.2e−4 (3.7e−4) |
| MDReg‐Net w/o s (, PING) | 0.583 (0.181) | 0.029 (0.172) | 1.8e−6 (1.0e−5) | 0.527 (0.095) | 0.14 (1.14) | 2.4e−5 (1.9e−4) |
| MDReg‐Net w/o s (, ADNI1) | 0.580 (0.180) | 0.088 (0.515) | 5.4e−6 (3.1e−5) | 0.523 (0.094) | 0 (0) | 0 (0) |
| MDReg‐Net (PING) | 0.588 (0.180) | 0.089 (0.515) | 5.4e−6 (3.1e−5) | 0.534 (0.094) | 0 (0) | 0 (0) |
| MDReg‐Net (ADNI1) | 0.587 (0.172) | 0.029 (0.172) | 1.8e−6 (1.0e−5) | 0.530 (0.092) | 0.07 (0.7) | 1.2e−5 (1.2e−4) |
| MDReg‐Net (PING, inverse) | 0.586 (0.180) | 0.235 (0.855) | 1.4e−5 (5.2e−5) | 0.534 (0.092) | 0.05 (0.359) | 8.7e−6 (6.2e−5) |
| MDReg‐Net (ADNI1, inverse) | 0.585 (0.178) | 0.029 (0.172) | 1.8e−6 (1.0e−5) | 0.532 (0.091) | 0 (0) | 0 (0) |
Note: The registration performance on images registered with the deformation fields computed in the opposite direction based on the same velocity fields are referred as MDReg‐Net (inverse). The SDs are shown in parentheses. The average and standard deviation of Dice score were calculated over all anatomical structures and subjects. The statistics of voxels with non‐positive Jacobian determinant were calculated within brain region.
5. DISCUSSION AND CONCLUSIONS
We present an end‐to‐end deep learning framework for diffeomorphic image registration. Our method trains FCNs to estimate voxel‐to‐voxel velocity fields of diffeomorphic spatial transformations for registering images by maximizing their image‐wise similarity metric, similar to conventional image registration algorithms. To facilitate learning of large diffeomorphic deformations between images, a multi‐resolution strategy is adopted to jointly optimize and estimate velocity fields of spatial transformations at different spatial resolutions incrementally with an integrated spatial Gaussian smoothing kernel. The experimental results based on 3D structural brain MR images have demonstrated that our method could obtain diffeomorphic image registration with better performance than state‐of‐the‐art image registration algorithms, including those built upon multi‐stage and multi‐resolution image registration strategies (Avants et al., 2011; Liu et al., 2019; T. C. Mok & Chung, 2020b).
In order to achieve accurate image registration, multi‐stage and multi‐resolution image registration strategies have been adopted in deep learning‐based image registration methods. Particularly, deep learning methods have been developed to perform coarse‐to‐fine image registration to account for large anatomical variations (de Vos et al., 2019; Hering et al., 2019; Zhao et al., 2019). The multi‐stage and multi‐resolution image registration methods are typically implemented with multiple sub‐networks, each of them being trained separately with the preceding sub‐networks fixed (de Vos et al., 2019; Hering et al., 2019); Cascaded networks are utilized to achieve an end‐to‐end multi‐stage image registration, with all sub‐networks being focusing on images at a single image resolution (Zhao et al., 2019). Moreover, these deep learning‐based image registration methods are not equipped to achieve diffeomorphic image registration. To achieve the diffeomorphic image registration, deep supervision has been used to optimize image similarity at different spatial resolutions in recent studies (Krebs et al., 2019; Liu et al., 2019). However, these methods learn the deformations at different resolutions separately. In contrast, our method learns deformation velocity fields at multiple spatial resolutions jointly to optimize the image registration spatial transformations from coarse to fine resolutions incrementally, with the velocity fields estimated at a coarse resolution being used to warp the moving image to generate an input image for subsequent sub‐networks to estimate residual velocity fields for spatial transformations at finer resolutions. Comparison results have demonstrated that our method achieved better diffeomorphic image registration performance than the most successful conventional and deep learning‐based multi‐resolution image registration algorithms (Avants et al., 2011; Liu et al., 2019; T. C. Mok & Chung, 2020b), indicating that the incremental, multiple‐resolution image registration strategy creates a competitive advantage for multi‐resolution image registration.
We have evaluated our method using different brain structural image datasets with manually labeled anatomical segmentations available. These segmentations contains fine‐grained anatomical structures, which are favored over brain tissue segmentation or coarse‐grained segmentation for the evaluation of registration accuracy as suggested in literature (Rohlfing, 2011). Given that high region overlap‐based accuracy (such as Dice score) does not necessarily indicate biologically plausible deformations as folding voxels within regions could also result in high overlap index, we have also investigated the diffeomorphic property of the deformations obtained by different methods. As summarized in Table 1, our method obtained registration accuracy comparable to that obtained by ANTs, which is one top ranked diffeomorphic registration method, while our method obtained deformation fields with a much smaller number of folding voxels than those obtained by ANTs and other methods under comparison. As summarized in Table 2, deep learning methods on GPUs were much faster than conventional image registration algorithms on CPUs to register brain images, and our method was also faster than conventional registration algorithms when run on CPUs, attributed to its nature of learning‐based registration method. All these results indicated that deep learning‐based image registration methods can achieve faster image registration on GPUs than the conventional iterative optimization‐based image registration algorithms that are not optimized for GPU‐based computation. It merits further investigation to explore if the neural network architecture adopted in the deep learning‐based image registration algorithms can be optimized to improve both the image registration accuracy and the computational efficiency.
Our method obtained improved accuracy compared with VoxelMorph, which is a state‐of‐the‐art deep learning‐based diffeomorphic registration model with similar deformation regularity and computational efficiency. This indicates that our incremental learning strategy could facilitate a better characterization of deformation between images. Compared with VoxelMorph, our method obtained more stable and accurate image registration models based on different brain image datasets with substantially different age distributions (younger than 20 vs. older than 60 years), indicating that our method is not sensitive to the training data though the age distributions of the subjects from the PING cohort and the ADNI cohort are different. Our method also obtained improved accuracy compared with ProbMultilayer network that adopts a multi‐layer network structure to capture spatial transformation at different spatial resolutions, demonstrating the effectiveness of our incremental learning strategy. Our method also obtained improved accuracy compared with LapIRN that adopts a similar multi‐resolution strategy as our model. However, LapIRN's network architecture is quite different from ours and it also incorporates auto‐context and skip connections into its registration network, which makes it difficult to interpret what modules contribute to the performance gains without ablation results. LapIRN could obtain improved registration accuracy for brain subcortical structures, but not for those in cerebral cortex (T. C. Mok & Chung, 2020b), consistent with our findings in the present study (Figures 5b and 6b).
Due to anatomical differences between images to be registered, the diffeomorphic image registration is often achieved at the cost of sacrificing the image registration accuracy in the current image registration framework which relies on regularization to produce spatially smooth and plausible deformation fields (Sotiras et al., 2013; Viergever et al., 2016). Although larger regularization parameters produced image registration models that could register images with smoother deformation fields, those producing image registration models to achieve the diffeomorphic image registration for the training data did not necessarily yield diffeomorphic image registration for the testing data and the discrepancy was prominent for the models trained without the spatial smoothing layer, as indicated by the results shown in Figures 2 and 7a as well as in Tables 1 and 3. This is because the regularization parameter could adjust the network parameters during the network training to yield spatially smooth deformation fields but does not directly regularize the deformation fields for registering testing image pairs during inference. The regularization effect is likely to vanish when there exists large discrepancy in morphometry and appearance between the testing and training data. In contrast, the spatial smoothing layer always carries out the smoothing operation in the same way no matter when applied to training or testing images. As indicated by the results summarized in Table 1, the MDReg‐Net model with the spatial smoothing layer trained on the PING dataset achieved perfect diffeomorphic image registration on the Mindboggle‐101 dataset without sacrificing the image registration accuracy, compared with alternative state‐of‐the‐art image registration algorithms, including ANTs and VoxelMorph. Compared with the MDReg‐Net models without the spatial smoothing layer, the MDReg‐Net models with the spatial smoothing layer achieved better image registration accuracy and close to perfect diffeomorphic image registration, as indicated by the results summarized in Table 3. Moreover, the results summarized in Table 3 also demonstrated that the predicted velocity fields performed well in the opposite direction‐based image registration and no significant differences were observed in the registration performance between the two opposite directions for registering images, demonstrating the good inverse consistency of our method. All these results indicated that the spatial smoothing layer could enhance diffeomorphic image registration.
While registration accuracy (such as Dice score) and diffeomorphism reflect the registration performance in different aspects, their priorities may be dependent on different applications. Although a more accurate (measured in terms of Dice score) image registration is achievable without persevering the diffeomorphism as demonstrated in image registration results summarized in Table 3, the diffeomorphic image registration is desired for applications where image topology has to be preserved, such as accurately localizing cortical areas in neuroimaging studies of neuropsychiatric disorders that do not change the brain structures dramatically as tumors. Particularly, it is desired to register cortical structures of different subjects without folding or distortion, as the topological and geometrical properties of cortical structures may be inherently associated with behaviors and neuropsychiatric disorders (Luders et al., 2004; Madan & Kensinger, 2016; Nicastro et al., 2020). Our method achieved nearly perfect diffeomorphic brain image registration with comparable Dice scores to ANT‐c1. While loosening the constraint of absolute diffeomorphism, an image registration model trained with a smaller smooth regularization parameter obtained similar Dice scores as ANT‐c1, but with much less negative Jacobian voxels, as shown in Table 3. On the other hand, the Dice scores of ANTs decreased significantly with a larger regularization parameter (ANT‐c2), and the number of voxels with non‐positive Jacobian determinant were much larger than that obtained by our method, indicating that our method could achieve improved Dice scores when the diffeomorphic properties are at the same level. It has been demonstrated that surface‐based image registration methods achieved substantially better performance than conventional volume‐based image registration methods (Coalson, Van Essen, & Glasser, 2018). Our method provides an alternative means to achieve fast, accurate, and nearly perfect diffeomorphic brain image registration, facilitating computationally efficient brain image registration and brain mapping in large scale neuroimaging studies of brain development and neuropsychiatric disorders.
The present framework for diffeomorphic image registration could obtain image registration results within seconds with higher accuracy than state‐of‐the‐art image registration algorithms without diffeomorphism violation, however, potential refinements in the following aspects may further improve the registration performance. First, the architecture and parameter setting of the networks used could be further optimized. Second, stationary velocity fields were adopted to model spatial transformations currently, which may have inferior performance for charactering large deformations that are needed in certain scenarios, such as modeling morphology of developing and aging brains. Using time‐varying velocity fields (Beg, Miller, Trouvé, & Younes, 2005) to model spatial transformations merits investigation. Finally, the regularization‐based image registration framework may be replaced with a constrained optimization framework to train a deep learning model with diffeomorphic image registration constraints for gaining further improvement.
In summary, we have developed a deep learning method, referred to as MDReg‐Net, for diffeomorphic image registration, and experimental results have demonstrated MDReg‐Net could obtain robust, diffeomorphic, albeit not perfect, brain image registration for different datasets.
CONFLICT OF INTEREST
The authors have declared no conflicts of interest for this article.
ETHICS STATEMENT
This research study was conducted retrospectively using human subject data made available in open access. IRB approval was obtained to carry out the reported study.
ACKNOWLEDGMENTS
This work was supported in part by National Institutes of Health grants [grant numbers EB022573, and AG066650]. ADNI data collection and sharing for this project was funded by the Alzheimer's Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH‐12‐2‐0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer's Association; Alzheimer's Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol‐Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann‐La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer's Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
Li, H. , Fan, Y. , & for the Alzheimer's Disease Neuroimaging Initiative (2022). MDReg‐Net: Multi‐resolution diffeomorphic image registration using fully convolutional networks with deep self‐supervision. Human Brain Mapping, 43(7), 2218–2231. 10.1002/hbm.25782
Funding information National Institutes of Health, Grant/Award Numbers: AG066650, EB022573
DATA AVAILABILITY STATEMENT
Imaging data and source code are available upon request. Source code will be made publicly available at www.nitrc.org and GitHub.
REFERENCES
- Abadi, M. , Barham, P. , Chen, J. , Chen, Z. , Davis, A. , Dean, J. , … Isard, M. (2016). TensorFlow: A system for large‐scale machine learning.In Paper presented at the 12th USENIX symposium on operating systems design and implementation (OSDI ‘16), Savannah, GA . Retrieved from https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf.
- Ashburner, J. (2007). A fast diffeomorphic image registration algorithm. NeuroImage, 38(1), 95–113. 10.1016/j.neuroimage.2007.07.007 [DOI] [PubMed] [Google Scholar]
- Avants, B. B. , Tustison, N. J. , Song, G. , Cook, P. A. , Klein, A. , & Gee, J. C. (2011). A reproducible evaluation of ANTs similarity metric performance in brain image registration. NeuroImage, 54(3), 2033–2044. 10.1016/j.neuroimage.2010.09.025 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beg, M. F. , Miller, M. I. , Trouvé, A. , & Younes, L. (2005). Computing large deformation metric mappings via geodesic flows of diffeomorphisms. International Journal of Computer Vision, 61(2), 139–157. [Google Scholar]
- Chen‐Yu, L. , Saining, X. , Patrick, G. , Zhengyou, Z. , & Zhuowen, T. (2014). Deeply‐supervised nets. CoRR, 3(4), 93. [Google Scholar]
- Coalson, T. S. , Van Essen, D. C. , & Glasser, M. F. (2018). The impact of traditional neuroimaging methods on the spatial localization of cortical areas. Proceedings of the National Academy of Sciences of the United States of America, 115(27), E6356–E6365. 10.1073/pnas.1801582115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dalca, A. V. , Balakrishnan, G. , Guttag, J. , & Sabuncu, M. R. (2018). Unsupervised learning for fast probabilistic diffeomorphic registration. In Paper Presented at the International Conference on Medical Image Computing and Computer‐Assisted Intervention .
- Dalca, A. V. , Balakrishnan, G. , Guttag, J. , & Sabuncu, M. R. (2019). Unsupervised learning of probabilistic diffeomorphic registration for images and surfaces. Medical Image Analysis, 57, 226–236. 10.1016/j.media.2019.07.006 [DOI] [PubMed] [Google Scholar]
- de Vos, B. D. , Berendsen, F. F. , Viergever, M. A. , Sokooti, H. , Staring, M. , & Isgum, I. (2019). A deep learning framework for unsupervised affine and deformable image registration. Medical Image Analysis, 52, 128–143. 10.1016/j.media.2018.11.010 [DOI] [PubMed] [Google Scholar]
- Eppenhof, K. A. J. , Lafarge, M. W. , Veta, M. , & Pluim, J. P. W. (2019). Progressively trained convolutional neural networks for deformable image registration. IEEE Transactions on Medical Imaging, 39, 1594–1604. 10.1109/TMI.2019.2953788 [DOI] [PubMed] [Google Scholar]
- Fan, Y. , Jiang, T. , & Evans, D. J. (2002). Medical image registration using parallel genetic algorithms. Applications of Evolutionary Computing, 2279, 304–314. [Google Scholar]
- Fischl, B. (2012). FreeSurfer. NeuroImage, 62(2), 774–781. 10.1016/j.neuroimage.2012.01.021 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hering, A. , van Ginneken, B. , & Heldmann, S. (2019). mlVIRNET: Multilevel Variational image registration network. In Paper Presented at the International Conference on Medical Image Computing and Computer‐Assisted Intervention .
- Jaderberg, M. , Simonyan, K. , & Zisserman, A. (2015). Spatial transformer networks. In Paper Presented at the Advances in Neural Information Processing Systems .
- Jernigan, T. L. , Brown, T. T. , Hagler, D. J., Jr. , Akshoomoff, N. , Bartsch, H. , Newman, E. , … Schork, N. (2016). The pediatric imaging, neurocognition, and genetics (PING) data repository. NeuroImage, 124, 1149–1154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim, B. , Kim, J. , Lee, J.‐G. , Kim, D. H. , Park, S. H. , & Ye, J. C. (2019). Unsupervised deformable image registration using cycle‐consistent CNN. In Paper Presented at the International Conference on Medical Image Computing and Computer‐Assisted Intervention .
- Kingma, D. , & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv Preprint arXiv:1412.6980 .
- Klein, A. , & Tourville, J. (2012). 101 labeled brain images and a consistent human cortical labeling protocol. Frontiers in Neuroscience, 6, 171. 10.3389/fnins.2012.00171 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klein, S. , Staring, M. , Murphy, K. , Viergever, M. A. , & Pluim, J. P. W. (2010). Elastix: A toolbox for intensity‐based medical image registration. IEEE Transactions on Medical Imaging, 29(1), 196–205. 10.1109/TMI.2009.2035616 [DOI] [PubMed] [Google Scholar]
- Krebs, J. , Delingette, H. , Mailhé, B. , Ayache, N. , & Mansi, T. (2019). Learning a probabilistic model for diffeomorphic registration. IEEE Transactions on Medical Imaging, 38(9), 2165–2176. [DOI] [PubMed] [Google Scholar]
- Krebs, J. , Mansi, T. , Delingette, H. , Zhang, L. , Ghesu, F. , Miao, S. , … Kamen, A. (2017). Robust non‐rigid registration through agent‐based action learning. In Paper Presented at the Medical Image Computing and Computer Assisted Interventions (MICCAI) .
- Kuang, D. , & Schmah, T. (2019). Faim—a convnet method for unsupervised 3d medical image registration. In Paper Presented at the International Workshop on Machine Learning in Medical Imaging .
- Landman, B. , & Warfield, S. (2012). MICCAI 2012 workshop on multi‐atlas labeling. In Paper Presented at the Medical Image Computing and Computer Assisted Intervention Conference .
- Lei, Y. , Fu, Y. , Wang, T. , Liu, Y. , Patel, P. , Curran, W. J. , … Yang, X. (2020). 4D‐CT deformable image registration using multiscale unsupervised deep learning. Physics in Medicine & Biology, 65(8), 085003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li, H. , & Fan, Y. (2017). Non‐rigid image registration using fully convolutional networks with deep self‐supervision. arXiv Preprint arXiv:1709.00799 .
- Li, H. , & Fan, Y. (2018, 4–7 April). Non‐rigid image registration using self‐supervised fully convolutional networks without training data. In Paper Presented at the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) . [DOI] [PMC free article] [PubMed]
- Liu, L. , Hu, X. , Zhu, L. , & Heng, P.‐A. (2019). Probabilistic multilayer regularization network for unsupervised 3D brain image registration. In Paper Presented at the International Conference on Medical Image Computing and Computer‐Assisted Intervention .
- Long, J. , Shelhamer, E. , & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . [DOI] [PubMed]
- Luders, E. , Narr, K. L. , Thompson, P. M. , Rex, D. E. , Jancke, L. , Steinmetz, H. , & Toga, A. W. (2004). Gender differences in cortical complexity. Nature Neuroscience, 7(8), 799–800. 10.1038/nn1277 [DOI] [PubMed] [Google Scholar]
- Madan, C. R. , & Kensinger, E. A. (2016). Cortical complexity as a measure of age‐related brain atrophy. NeuroImage, 134, 617–629. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mansilla, L. , Milone, D. H. , & Ferrante, E. (2020). Learning deformable registration of medical images with anatomical constraints. Neural Networks, 124, 269–279. [DOI] [PubMed] [Google Scholar]
- Modat, M. , Ridgway, G. R. , Taylor, Z. A. , Lehmann, M. , Barnes, J. , Hawkes, D. J. , … Ourselin, S. (2010). Fast free‐form deformation using graphics processing units. Computer Methods and Programs in Biomedicine, 98(3), 278–284. [DOI] [PubMed] [Google Scholar]
- Mok, T. C. , & Chung, A. (2020a). Fast symmetric diffeomorphic image registration with convolutional neural networks. arXiv Preprint arXiv:2003.09514 .
- Mok, T. C. , & Chung, A. C. (2020b). Large deformation diffeomorphic image registration with Laplacian pyramid networks. In: Paper Presented at the International Conference on Medical Image Computing and Computer‐Assisted Intervention Placeholder Text.
- Nicastro, N. , Malpetti, M. , Cope, T. E. , Bevan‐Jones, W. R. , Mak, E. , Passamonti, L. , … O'Brien, J. T. (2020). Cortical complexity analyses and their cognitive correlate in Alzheimer's disease and frontotemporal dementia. Journal of Alzheimer's Disease, 76(1), 331–340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Niethammer, M. , Kwitt, R. , & Vialard, F.‐X. (2019). Metric learning for image registration. In: Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . [DOI] [PMC free article] [PubMed]
- Rohé, M.‐M. , Datar, M. , Heimann, T. , Sermesant, M. , & Pennec, X. (2017). SVF‐net: Learning deformable image registration using shape matching. In: Paper Presented at the MICCAI 2017‐the 20th International Conference on Medical Image Computing and Computer Assisted Intervention .
- Rohlfing, T. (2011). Image similarity and tissue overlaps as surrogates for image registration accuracy: Widely used but unreliable. IEEE Transactions on Medical Imaging, 31(2), 153–163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ronneberger, O. , Fischer, P. , & Brox, T. (2015). U‐net: Convolutional networks for biomedical image segmentation. In Paper Presented at the International Conference on Medical Image Computing and Computer‐Assisted Intervention .
- Rueckert, D. , Sonoda, L. I. , Hayes, C. , Hill, D. L. G. , Leach, M. O. , & Hawkes, D. J. (1999). Nonrigid registration using free‐form deformations: Application to breast MR images. IEEE Transactions on Medical Imaging, 18(8), 712–721. 10.1109/42.796284 [DOI] [PubMed] [Google Scholar]
- Sokooti, H. , Vos, B. , Berendsen, F. , Lelieveldt, B. P. F. , Išgum, I. , & Staring, M . (2017). Nonrigid image registration using multi‐scale 3D convolutional neural networks. In Paper Presented at the Medical Image Computing and Computer‐Assisted Intervention, Quebec,Canada .
- Sotiras, A. , Davatzikos, C. , & Paragios, N. (2013). Deformable medical image registration: A survey. IEEE Transactions on Medical Imaging, 32(7), 1153–1190. 10.1109/Tmi.2013.2265603 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Viergever, M. A. , Maintz, J. B. A. , Klein, S. , Murphy, K. , Staring, M. , & Pluim, J. P. W. (2016). A survey of medical image registration—Under review. Medical Image Analysis, 33, 140–144. 10.1016/j.media.2016.06.030 [DOI] [PubMed] [Google Scholar]
- Vishnevskiy, V. , Gass, T. , Szekely, G. , Tanner, C. , & Goksel, O. (2017). Isotropic Total variation regularization of displacements in parametric image registration. IEEE Transactions on Medical Imaging, 36(2), 385–395. 10.1109/TMI.2016.2610583 [DOI] [PubMed] [Google Scholar]
- Wu, G. , Kim, M. , Wang, Q. , Munsell, B. C. , & Shen, D. (2016). Scalable high‐performance image registration framework by unsupervised deep feature representations learning. IEEE Transactions on Biomedical Engineering, 63(7), 1505–1516. 10.1109/TBME.2015.2496253 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang, X. , Kwitt, R. , Styner, M. , & Niethammer, M. (2017). Quicksilver: Fast predictive image registration ‐ a deep learning approach. NeuroImage, 158, 378–396. 10.1016/j.neuroimage.2017.07.008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yoo, I. , Hildebrand, D. G. , Tobin, W. F. , Lee, W.‐C. A. , & Jeong, W.‐K. (2017). ssEMnet: Serial‐section electron microscopy image registration using a spatial transformer network with learned features. arXiv Preprint arXiv:1707.07833 .
- Yu, H. , Jiang, H. , Zhou, X. , Hara, T. , Yao, Y. , & Fujita, H. (2020). Unsupervised 3D PET‐CT image registration method using a metabolic constraint function and a multi‐domain similarity measure. IEEE Access, 8, 63077–63089. 10.1109/ACCESS.2020.2984804 [DOI] [Google Scholar]
- Zhang, S. , Liu, P. X. , Zheng, M. , & Shi, W. (2020). A diffeomorphic unsupervised method for deformable soft tissue image registration. Computers in Biology and Medicine, 120, 103708. [DOI] [PubMed] [Google Scholar]
- Zhao, S. , Lau, T. , Luo, J. , Chang, E. I. , & Xu, Y. (2019). Unsupervised 3D end‐to‐end medical image registration with volume Tweening network. IEEE Journal of Biomedical and Health Informatics, 24, 1394–1404. 10.1109/JBHI.2019.2951024 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Imaging data and source code are available upon request. Source code will be made publicly available at www.nitrc.org and GitHub.