

Abstract
The use of speech as a biomedical signal for diagnosing COVID-19 is investigated using statistical analysis of speech spectral features and classification algorithms based on machine learning. It is established that spectral features of speech, obtained by computing the short-time Fourier Transform (STFT), get altered in a statistical sense as a result of physiological changes. These spectral features are then used as input features to machine learning-based classification algorithms to classify them as coming from a COVID-19 positive individual or not. Speech samples from healthy as well as “asymptomatic” COVID-19 positive individuals have been used in this study. It is shown that the RMS error of statistical distribution fitting is higher in the case of speech samples of COVID-19 positive speech samples as compared to the speech samples of healthy individuals. Five state-of-the-art machine learning classification algorithms have also been analyzed, and the performance evaluation metrics of these algorithms are also presented. The tuning of machine learning model parameters is done so as to minimize the misclassification of COVID-19 positive individuals as being COVID-19 negative since the cost associated with this misclassification is higher than the opposite misclassification. The best performance in terms of the “recall” metric is observed for the Decision Forest algorithm which gives a recall value of 0.7892.
1. Introduction
The most basic functions of the human body are usually monitored by measuring the vital signs—temperature, heart (pulse) rate, respiratory (breathing rate), and blood pressure [1]. These are usually measured using medical devices, but nowadays, easy to use and low-cost devices and smart gadgets are available which allow measuring temperature, pulse rate, and blood pressure at home, even by nonmedical professionals. Various types of sensors, present in such devices, sense some signal generated by the human body, process the signal, and provide a reading of the vital sign in a simple and easy to interpret format. It is therefore necessary to connect the devices/sensors at appropriate points on the human body to obtain the desired measurements. The placement of such sensors on the body is invasive and intrusive and causes inconvenience to the patient/individual. This is particularly true when monitoring professional athletes and sports persons while they are performing intense exercise/training. Moreover, it does not allow measurement of body parameters without attaching the device/its sensors (probes) to the body or from a remote location; i.e., the patient has to be at the same location as the medical device. This article investigates the use of speech as a biomedical signal to detect COVID-19 based on a statistical analysis of speech and binary classification using machine learning. Speech characteristics of an individual get altered as a result of physiological and emotional changes [2–6]. Other factors that can cause physiological changes in the body are changes in health conditions, aging, stress, pollution exposure, and physical activity. There is significant evidence from the literature that clearly establishes a correlation between the characteristics of human speech and the physiological parameters of the speaker. A correlation between heart-related parameters such as heart rate, electrocardiogram (ECG) features, and the influence of heart function on speech characteristics has been shown in [7–13]. In [14], the variation of speech characteristics due to physical activity is demonstrated, and the effect of physical activity and fitness level on heart rate is shown in [15]. Physiological changes due to physical activity also depend on the regularity, duration, and intensity of the activity performed [16]. A correlation between speech and blood pressure is established in [17], and a method to detect emotions from speech is described in [15]. It is also established in the literature that tiredness can also affect an individual's speech and can cause speech to become slurred (dysarthria) [18]. Noncontact methods to measure physiological parameters based on image and video processing have also been investigated and reported in the literature [19,20]. Noncontact methods based on speech, images, and video can facilitate remote monitoring, telemedicine, and smart healthcare which are expected to play a major role in future healthcare infrastructures.
The COVID-19 pandemic era has necessitated and triggered an enormous amount of research into such noncontact-based diagnostic methods to detect COVID-19 using machine learning and deep learning [21–30]. A review of COVID-19 diagnostic methods along with prevention tools and policy decisions for COVID-19 management is provided in [31]. Artificial intelligence-based COVID-19 diagnosis tools are not without pitfalls. A critique of AI-based tools being given emergency authorization by regulatory bodies indicates that many such tools have been developed using small or low-quality datasets [32], concluding that AI could be useful in dealing with the COVID-19 pandemic but requires more detailed investigation and validation. Several research studies based on artificial intelligence are ongoing not only to detect COVID-19 but also to predict and understand the effects of the pandemic and be prepared for eventualities. A method to detect COVID-19 using machine learning on symptoms is proposed in [33]. COVID-19 detection based on the application of AI on X-ray and computerized tomography (CT) images is reported in [34–41]. In [42–44], detection of COVID-19 by applying machine learning to routine blood examination data has also been reported. AI-based systems to predict the deterioration of COVID-19 patients toward severe disease have been presented in [45–47], and prediction of mortality risk among COVID-19 infected individuals using AI is also available in the literature [48–50]. The COVID-19 pandemic has indeed necessitated and highlighted the need for interdisciplinary and transdisciplinary approaches to diagnose, treat, and manage not just COVID-19 patients but also to address medical problems in general [51]. The challenges involved in the use of AI for COVID-19 are elaborated in [52]. Several research groups [53–56] are actively investigating the use of speech sounds, cough sounds, and breathing/respiratory sounds to detect COVID-19 by analyzing these sounds using artificial intelligence algorithms.
2. Materials and Methods
2.1. Data Used in This Study
Speech recordings used in this study comprise two categories—speech from healthy individuals with no known preexisting medical conditions at resting heart rate and speech from asymptomatic COVID-19 positive individuals. Heart rate and blood oxygen saturation level (SpO2) are measured simultaneously at the time of recording the speech using an off-the-shelf pulse oximeter. It should be noted that the pulse rate measured by the pulse oximeter is exactly equal to the heart rate [57]. The total number of speech recordings of healthy individuals at resting heart rate is 84. All the healthy volunteers are in the age group of 25–45 years. Speech samples along with heart rate and SpO2 measurements were also obtained from 22 individuals who had tested COVID-19 positive following contact tracing, but with no conspicuous symptoms. The youngest in this category is 32 years and the oldest is 57 years. It should be noted that obtaining speech data of COVID-19 patients was challenging and hence the relatively small set of samples.
Speech recording was made using a Logitech headphone equipped with a noise cancellation microphone. While the samples of all the healthy individuals were recorded using the same microphone in the same environment, the speech samples of COVID-19 individuals were recorded with different microphones of the same make and model (Logitech H540) and under different ambient conditions for each. Hence, any variations in speech characteristics arising due to the difference in recording device and ambiance are not taken into consideration. It is reasonable to ignore these variations since the recordings were made in quiet rooms using microphones of the same make and model and therefore have the same technical specifications. Of course, the acoustic effects of the room and background noise, albeit small, are not taken into consideration as it was not possible to bring the COVID-19 patients to the laboratory settings where the recording of healthy individuals was made. Each individual was asked to read the sentence “A quick brown fox jumped over the lazy dogs” which was recorded by turning the microphone “ON”: for 5 seconds. The recording was made in stereo format at a sampling rate of 16000 samples per second (sps) which is the standard sampling rate for wideband representation of speech [58]. The recording is quantized using 216 quantization levels resulting in an audio bit rate of 256 kbps and stored on a computer in uncompressed .WAV format. Heart rate and SpO2 level are also concurrently measured at the time of speech recording using a pulse oximeter. The attributes of the data are highlighted in Table 1.
Table 1.
Attributes of data used in this study.
| Age group (years) | No. of recordings | Sampling rate (sps) | Quantization depth (bits) | Audio bit rate (kbps) | Audio format | Other parameters measured | |
|---|---|---|---|---|---|---|---|
| Healthy | 25–45 | 84 | 16000 | 16 | 256 | .wav | Heart rate, SpO2 |
| COVID+ | 32–57 | 22 |
2.2. Preprocessing of Speech Data
Unwanted components such as DC bias, which usually gets introduced by PC audio cards [59] and silence intervals due to pauses made by the speaker, are removed by preprocessing each of the speech recordings. DC bias is removed using a 1st-order infinite impulse response (IIR) filter, whereas silence intervals are removed by applying a voice activity detection (VAD) mechanism which extracts speech frames containing voice activity. VAD also mitigates noise effects by applying a posteriori signal to noise ratio (SNR) weighting to emphasize reliable segments of voice activity even at low SNR. DC bias removal and VAD are applied as per the implementation provided in [60]. A block diagram of preprocessing steps is shown in Figure 1.
Figure 1.

Speech preprocessing.
The features of speech that have been used in this study are the short-term Fourier Transform (STFT) coefficients. Features are defined as characteristics of a signal that enables some algorithm to detect an inherent pattern associated with the signal [61]. The premise of detecting COVID-19 from speech features stems from the fact that speech is produced by moving air from the lungs through the vocal cavity. Since there is an interaction between the lungs and heart for the oxygenation of the blood, cardiovascular responses are influenced by activities such as reading and speaking [62]. It is shown in [63] that breathing pattern is affected by the process of speech production. Changes in breathing patterns, in turn, have an effect on the heart rate, and this effect is termed respiratory sinus arrhythmia (RSA) [64]. Several techniques for feature extraction have been proposed in the literature for various applications but predominantly for speaker/speech recognition and speech enhancement. Linear prediction coefficients (LPC), linear prediction cepstral coefficients (LPCC), perceptual linear prediction (PLP), Mel frequency cepstral coefficients (MFCC), Mel frequency discrete wavelet coefficients (MFDWC), feature extraction using principal component analysis (PCA), and wavelets based features are some of the common features that have been reported in the literature [65–70]. STFT represents the time-varying spectral properties of a signal, and for this study, STFT coefficients with a high spectral resolution are used in order to capture subtle differences between closely spaced frequency components. The high spectral resolution is achieved by computing the STFT of long segments of speech, i.e., segment length greater than 500 ms. The high spectral resolution is achieved at the expense of temporal resolution. Since a correlation between physiological parameters and spectral features of speech is evident from existing literature, STFT coefficients with high spectral resolution have been used in this study. The STFT coefficients are used as input features to machine learning algorithms to classify the speech signal as that of COVID-19 positive or not.
2.3. Statistical Modeling of Speech Features
The most common symptoms of COVID-19 are fever, tiredness, and dry cough, and these may not be conspicuous until about 14 days after getting infected with an average of 5-6 days for the symptoms to become conspicuous. In this article, it is shown using statistical modeling of speech features that it is possible to detect COVID-19 from an individual's speech much before the symptoms become conspicuous so that the person can be quarantined, tested, and provided with medical support at an early stage. At their onset, while symptoms may not be conspicuous to the affected individual or to observers, physiological changes occur in the individual that cause variations in speech characteristics which can be analyzed by artificial intelligence (AI) algorithms. Signal processing and AI can be applied to speech to detect physiological changes which have a direct or indirect relation to one or more of the COVID-19 symptoms. The existence of a correlation between speech characteristics and physiological, psychological, and emotional conditions is well established in the literature. It is therefore possible to detect COVID-19 infection from speech samples of individuals and this possibility is investigated in this article. The relationship between the most common symptoms of COVID-19 and affected physiological parameters is illustrated in Figure 2.
Figure 2.
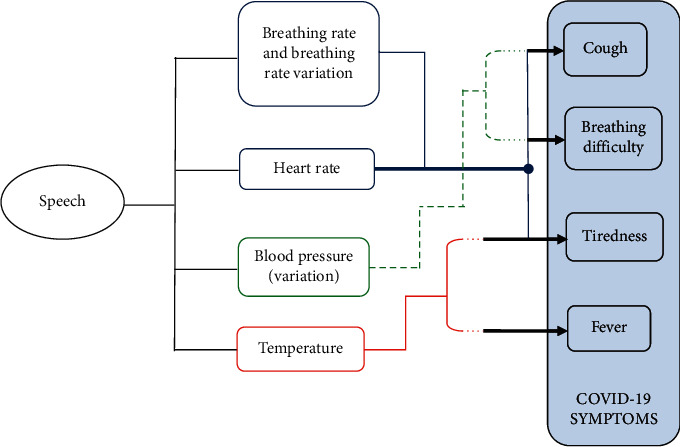
Biological parameters correlated to speech and COVID-19 symptoms.
A statistical analysis of speech spectral features is performed by applying maximum likelihood estimation (MLE) to obtain the best statistical distribution along with the distribution parameters that best characterize speech STFT coefficients, statistically. It has been shown in [58] that for speech samples at resting heart rate, STFT coefficients having high spectral resolution are accurately modeled by a Laplacian distribution (LD) with the estimated LD parameters exhibiting small RMS error. The Laplacian distribution is defined as
| (1) |
parameter and b > 0 is the scale parameter. The procedure to estimate μ and b, the RMS error associated with the estimation of b, and its lower bound defined as the Cramer-Rao bound (CRB) are provided in [58].
2.4. Binary Classification of Speech Samples Using Machine Learning
From the statistical analysis of speech STFT coefficients at the high spectral resolution, it is evident that the RMS error of fitted LD increases as a result of COVID-19 infection. Based on this finding, binary classification of speech signals as COVID-19 positive or COVID-19 negative is investigated by using STFT coefficients as input features to machine learning algorithms. In order to train and develop the AI models, speech samples of healthy as well as COVID-19 positive individuals are used. The trained AI model can then be incorporated into a mobile “app” for early detection of COVID-19, once the desired level of accuracy is achieved and regulatory approvals are obtained. If speech can be used to detect COVID-19, the functionality of the “smartphone” which already has wide proliferation and ubiquitous presence can be extended to alleviate the challenges posed by the pandemic. The results reported in the literature [71–78] are quite promising, providing exciting and interesting answers, giving confidence that research on this topic can lead to the development of mobile applications which can be used not only to detect COVID-19 from human sounds but also for other medical diagnostic/monitoring purposes. COVID-19 diagnosis using only cough recordings is presented in [71]. However, it uses biomarker information such as muscular degradation, vocal cords, sentiment, and lungs/respiratory tract function along with the cough recordings for diagnosis. The relation between COVID-19 symptoms and respiratory system function is highlighted in [72] along with a survey of AI-based COVID-19 diagnoses using human audio signals. Cough and respiratory sounds are used to classify COVID-19 and non-COVID-19 individuals in [73]. Furthermore, it is shown that cough from COVID-19 can be distinguished from healthy individuals' cough as well as cough of asthmatic patients. A project in progress [74] investigates the detection of COVID-19 from human audio sounds using AI. A news feature article in Nature [75] highlights research interest and progress among academic as well as commercial organizations to use the human voice for various diagnostic purposes including COVID-19. AI4COVID-19 is an app that runs an AI algorithm in the cloud to detect COVID-19 from cough sounds and reports promising results, encouraging further collection of labeled cough sounds [76]. An overview of the possibilities, challenges, and use cases of computer audition is presented in [77], which clearly highlights the potential of using sound analysis using AI for COVID-19 diagnosis. A support vector machine (SVM) based method to detect COVID-19 from speech signals is presented in [78] which combines voice signals and symptoms reported by the patient. In contrast to the research available in the literature, this article uses only speech signals without any side information such as symptoms or other biomarker information.
The STFT coefficients are labeled as coming from the speech of COVID-19 negative, i.e., healthy (Class 0) and COVID-19 positive (Class 1) individuals. Microsoft Azure Machine Learning Studio (MAMLS) cloud platform is used in this study to perform binary classification, and the performance of classification is analyzed and compared for five state-of-the-art classification algorithms available in MAMLS. Machine learning techniques produce a model for the data by learning the statistical relationship between input data (e.g., STFT coefficients extracted from speech signals) and output data (e.g., class label). The hyperparameters of the produced model are tuned optimally to minimize the classification error in an independent test dataset, resulting in a generalized model that can perform well on the test data set as well. The tuning is performed manually by adjusting the model hyperparameters until the highest value for the “recall” metric is achieved. Good performance on only the training dataset would result in an overfitting solution. A brief description of the five algorithms used for binary classification is provided here for completeness. The block diagram of the methodology used in the work is shown in Figure 3. An overview of the used ML algorithms follows.
Figure 3.
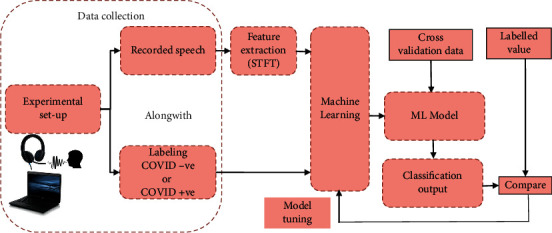
Block diagram of the methodology used.
Boosted Decision Tree (BDT) is an ensemble learning technique, wherein the succeeding tree corrects the errors of the previous tree to minimize classification error. The complete ensemble of trees is used for correctly predicting the binary class to which the input data belongs [79]. Another classification algorithm based on ensemble learning is the Decision Forest (DF) algorithm, wherein the most popular class is selected depending on the vote from each of the generated trees [80]. Neural Networks (NNs) are a network of interconnected layers of processing units called neurons. A typical NN consists of neurons aggregated into three layers. The first layer is formed by the input feature set which is linked to the output layer via an interconnection of several hidden layers in the middle. Each neuron processes its input variables and its output is passed to the neuron in the subsequent layer [81]. Logistic Regression (LoR) is a statistical technique for analyzing data when a dichotomous outcome is determined by one or more independent variables [82]. Support Vector Machines (SVMs) are based on the principle of recognizing patterns in a multidimensional hyperplane to estimate the maximum margin between samples of binary classes using a multidimensional input feature space [83].
These algorithms have relatively fast training and good performance and are robust to overfitting and have therefore been chosen in this study. The performance of classification models based on each of these algorithms is evaluated using the evaluation metrics listed in Table 2. These evaluation metrics are standard in machine learning literature [84].
Table 2.
Evaluation metrics for binary classification.
| Evaluation metric | Definition | Notations |
|---|---|---|
| Binary classification | ||
| Precision (PRE) | PRE = tp/tp+ fp | tp–Total no. of true positive samples |
| Recall (REC) | REC = tp/tp+ fn | tn–Total no. of true negative samples |
| Accuracy (ACC) | ACC = tp+ tn/tp + tn+ fp + fn | fp–Total no. of false positive samples |
| F1-score | F1=2∗PRE∗REC/PRE+REC | fn – Total no. of false negative samples |
| Area under RoC curve | (AUC) AUC =∫01RoC | RoC - receiver operating characteristic curve |
The input features used for binary classification are the STFT coefficients of speech from each of the 84 healthy individuals and the 22 COVID-19 positive individuals. Each individual's speech sample comprises 8 segments and STFT coefficients obtained from each speech segment are used as input features for binary classification. As mentioned in Section 4, STFT coefficients are complex numbers; hence, each speech segment comprises “real” and “imaginary” parts of STFT coefficients. The number of frequency points used in the computation of STFT coefficients is 8192, which is obtained as the next power of 2 greater than the segment length. Thus, for each individual speech sample, a matrix of 8192 rows × 8 columns is generated. The real and imaginary parts of the complex STFT coefficients are separated resulting in two separate matrices having dimensions of 8192 rows × 8 columns each. Class label is assigned to each row of these matrices as “Class 0” for healthy individuals' speech samples and “Class 1” for COVID-19 positive individuals. Thus, there are 8192 × 84 = 688,128 rows of STFT coefficients (real part) labeled as Class 0 and 8192 × 22 = 180,224 rows of STFT coefficients (real part) labeled as Class 1. Correspondingly, an equal number of rows are available under each class label containing the “imaginary part” of STFT coefficients.
Each row of the real/imaginary part of the STFT coefficients matrix corresponds to a frequency point in the STFT computation, and each column represents a segment of speech. The rows are treated as examples and columns as features since each column of the STFT matrix represents the time-localized spectral features of the speech signals. Every real and imaginary part “x” of STFT coefficients is normalized to lie in the interval [0,1] using a MinMax normalizer as follows:
| (2) |
Since the statistical distribution for both the real and imaginary parts of speech STFT coefficients is Laplacian, these are treated together without distinction in the context of this work. Thus, the entire dataset comprises 1,736,704 labeled rows, half of which comprise the real part of STFT coefficients and the other half comprise the imaginary part of STFT coefficients, which is saved in .csv format. For binary classification using machine learning, only the rows corresponding to the real part of STFT coefficients are utilized to reduce the time taken for training and cross-validation. The data is split in an 80 : 20 ratio; i.e., 80% of the rows are used for training and the remaining 20% are used for testing. Since the dataset used in this study is highly imbalanced—Class 0 constitutes nearly 80% of the dataset and Class 1 constitutes a little over 20% of the dataset—data splitting is performed with “stratification.” Stratification ensures that each subset of split data has the same class distribution as the entire dataset. The ratio of healthy: COVID-19 + samples in terms of speech recordings is 84 : 22 = 3.8181 : 1. In terms of the STFT coefficients also, this ratio remains the same. Since only the real part of STFT coefficients has been used for binary classification, the ratio healthy: COVID-19 + samples in terms of STFT coefficients is 688128:180224 = 3.8181 : 1. Since stratification has been used, both training and testing data contain STFT coefficients of “healthy” and “COVID+” individuals in the same proportion as 84 : 22 = 3.8181 : 1. Furthermore, the train-test split with stratification at the STFT level ensures permutation of the labeled STFT coefficients across all “individuals”—Class 0 as well as Class 1. Even though the number of speech samples used in this study is small, the number of frequency points (rows) of STFT is large due to the high spectral resolution adopted. The performance evaluation metrics are computed following a 10-fold cross-validation process. Furthermore, as in the data splitting process, stratification is used in the cross-validation process as well to ensure that the class distribution of the training data set is maintained in each fold of cross-validation.
3. Results
3.1. Classification of COVID-19 Samples Based on Statistical Distribution Fitting
LD fitting based on MLE is applied to all the speech samples used in this study—healthy individuals without COVID-19 as well as COVID-19 positive individuals. A comparison of statistical properties of speech STFT coefficients of the two categories of speech samples is performed. The statistical distribution of speech STFT coefficients of healthy individuals, i.e., not infected by COVID-19, is shown in Figure 4 and that of a COVID-19 positive individual is shown in Figure 5.
Figure 4.
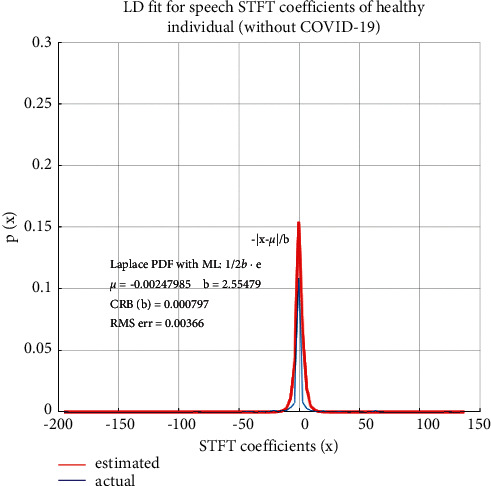
Statistical properties of speech STFT coefficients of a healthy person (without COVID-19).
Figure 5.
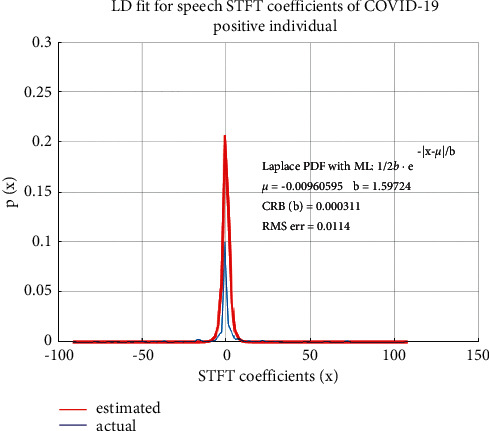
Statistical properties of speech STFT coefficients of an infected person (with COVID-19).
It is found from Figure 4 that spectral features of the speech of healthy individuals are accurately modeled by LD, with small RMS error as has been established in the literature [58]. In the case of speech samples of COVID-19 positive individuals without any conspicuous symptoms, while the statistical distribution of the STFT coefficients is still closely modeled by LD, the RMS error of the fitted distribution has a nearly 10-fold increase as compared to non-COVID-19 individuals. This increase in the RMS error of the fitted distribution indicates a variation of speech characteristics as a result of COVID-19 infection. The PDFs are obtained by plotting the envelope of histograms of STFT coefficients. The “estimated” PDF represents the fitted distribution based on estimated Laplacian distribution parameters “µ” and “b” and the “actual” PDF is the actual distribution of the STFT coefficients. The Laplacian distribution is therefore a suitable distribution for speech STFT coefficients as the RMS error between the actual and fitted distributions is small.
3.2. Performance Evaluation of Binary Classification
The model hyperparameters for each algorithm are tuned and optimized to achieve the best performance in binary classification in terms of the “Recall” metric. The performance evaluation metrics for the five binary classification algorithms used in this study, along with their optimal parameterization, are listed in Table 3. The best performance in terms of precision, recall, accuracy, and F1 score is achieved for the DF algorithm. For the classification application considered in this work, classifying speech spectral features as COVID-19 positive or not, the cost associated with misclassification is very high for “false negative” as compared to “false positive.”
Table 3.
Performance metrics for binary classification algorithms.
| Classification algorithms | Optimal Parameterization |
Performance metrics Mean value (standard deviation) |
||||
|---|---|---|---|---|---|---|
| ACC | PRE | REC | F1 score | AUC | ||
| BDT | No. of Leaves: 16 Learning rate: 0.05 No. of trees: 100 |
0.724 (0.048) | 0.714 (0.037) | 0.7037 (0.063) | 0.7088 (0.052) | 0.717 (0.053) |
| DF | Random split Count: 128 Maximum Depth: 32 No. of decision trees: 16 |
0.7317 (0.021) | 0.7421 (0.017) | 0.7892 (0.081) | 0.7649 (0.025) | 0.755 (0.017) |
| NN | Learning rate: 0.001 No. of hidden Nodes: 314 |
0.711 (0.031) | 0.7271 (0.043) | 0.7188 (0.018) | 0.7229 (0.029) | 0.7616 (0.095) |
| LoR | Optimization Tolerance: 1e-06 L1 regularization weight: 1 Memory size for L-BFGS: 18 |
0.6741 (0.019) | 0.6805 (0.024) | 0.6161 (0.027) | 0.6467 (0.019) | 0.6874 (0.065) |
| SVM | Lambda – 0.001 | 0.694 (0.017) | 0.673 (0.074) | 0.6027 (0.019) | 0.6359 (0.011) | 0.6619 (0.037) |
Since “recall” provides a measure of correctly predicted positives against the total number of positive examples, it is important for our classification problem to have a high value for this metric. This will minimize misclassifying a COVID-19 positive example as not being COVID-19 positive. While other evaluation metrics have also been determined, “recall” is the more important metric in the context of this work. In Table 3, the values within brackets are the standard deviations of the metrics. Small values for standard deviation indicate that the models are verified with an unbiased dataset which has been achieved by using stratification in the train-test split as well as in cross-validation.
4. Discussion
4.1. Statistical Distribution of COVID-19 Positive and COVID-19 Negative Speech Samples
The average RMS error for the fitted LD averaged over all the speech samples belonging to each of the two categories is shown in Table 4. This increase in RMS error of the fitted LD in COVID-19 positive samples is attributed to the physiological changes associated with COVID-19 infection which affect the characteristics of speech.
Table 4.
Average RMS error of the fitted LD distributions.
| Category | Average RMS error of fitted LD |
|---|---|
| Without COVID-19 | 0.00354 |
| With COVID-19 | 0.01271 |
Since the symptoms are not conspicuous among the samples used in this study, the distribution of STFT coefficients of speech is still Laplacian, albeit with a higher RMS error. STFT coefficients being complex numbers, the above findings are valid for both the “real” as well as “imaginary” parts of STFT coefficients and the same has also been shown in [58]. It remains to be seen if the distribution deviates significantly from being Laplacian or even ceases to be Laplacian when the symptoms become more pronounced and conspicuous. The increase in RMS error indicates such a trend. It should be noted that the data used in this study is unbalanced—the dataset from COVID-19 positive individuals is smaller than that of healthy individuals. The results discussed in this section clearly indicate that the statistical properties of speech spectral features are altered as a result of COVID-19 infection. However, as it was not possible to obtain samples of COVID-19 positive individuals whose symptoms are more pronounced and conspicuous, this shall be a subject of future investigation, once such samples are obtained. Due to the prevailing COVID-19 restrictions, access to such individuals has not been possible.
4.2. COVID-19 Detection on Test Data Using the Binary Classification Models
Finally, the optimally parameterized classification algorithms discussed in Section 2.4 have been tested on the test dataset. As discussed in Section 3.2, the algorithms have been parameterized to optimize the “recall” performance metric. The classification results of 20 samples (rows) from the test data are shown in Table 5 which contains the “actual” and “predicted” classes for the 20 test samples by each of the five classification algorithms. It can be observed from Table 5 that the misclassification of COVID-19 positive as “not positive”, i.e., class 1 being misclassified as Class 0, is the lowest for the DF algorithm. The misclassified values are highlighted in bold and underlined.
Table 5.
Test evaluation for binary classification
| Test sample | Actual class | Predicted class | ||||
|---|---|---|---|---|---|---|
| BDT | DF | NN | LoR | SVM | ||
| 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 2 | 1 | 1 | 1 | 0 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 0 | 0 |
| 4 | 0 | 1 | 0 | 1 | 1 | 1 |
| 5 | 1 | 1 | 1 | 0 | 1 | 1 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 1 | 0 | 0 | 1 | 1 | 1 |
| 8 | 1 | 1 | 1 | 1 | 0 | 0 |
| 9 | 1 | 0 | 0 | 0 | 1 | 1 |
| 10 | 0 | 1 | 0 | 0 | 1 | 1 |
| 11 | 1 | 0 | 1 | 1 | 1 | 1 |
| 12 | 0 | 0 | 1 | 1 | 0 | 0 |
| 13 | 0 | 1 | 0 | 1 | 1 | 0 |
| 14 | 1 | 1 | 1 | 1 | 0 | 1 |
| 15 | 0 | 0 | 0 | 0 | 0 | 1 |
| 16 | 0 | 1 | 1 | 0 | 0 | 1 |
| 17 | 1 | 1 | 1 | 0 | 0 | 0 |
| 18 | 1 | 0 | 1 | 1 | 1 | 1 |
| 19 | 0 | 0 | 0 | 1 | 0 | 1 |
| 20 | 1 | 1 | 1 | 1 | 0 | 1 |
For future investigation, concurrently at the time of recording speech samples of individuals, biomedical parameters such as heart rate (pulse oximeter), oxygen saturation (pulse oximeter), blood pressure (digital BP monitor), and temperature (infrared thermometer) have also been measured. These shall be used for future research to develop machine learning-based regression algorithms to predict these biomedical parameters from speech signals. The variations of these parameters among COVID-19 negative and COVID-19 positive individuals shall be analyzed to improve the accuracy of detecting COVID-19 from speech samples. The devices used to measure the biomedical parameters are shown in Figure 6. The e-health sensor platform shown in Figure 6 facilitates direct recording of the biomedical parameter to a PC, thus avoiding the manual entry of data.
Figure 6.
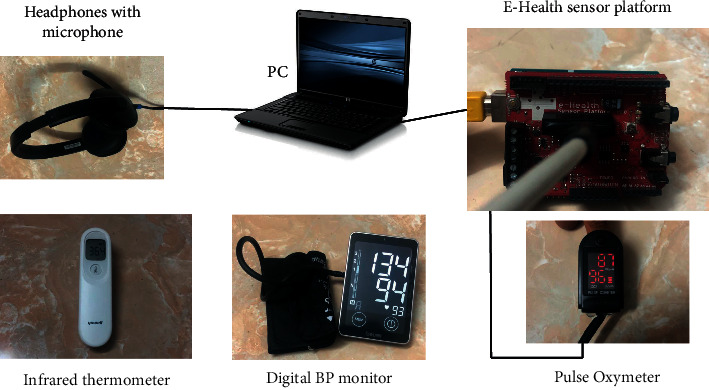
Devices used for measuring biomedical parameters along with speech for future analysis.
A limitation of the work presented in this article is that it cannot distinguish between similar symptoms which may appear due to multiple different causes such as influenza or myocarditis. It requires further research involving speech data from patients with various illnesses that have symptoms similar to COVID-19. This shall be a subject of future work.
5. Conclusions
This article investigates the statistical properties of speech spectral features for samples taken from healthy as well as asymptomatic COVID-19 positive individuals. While the statistical distribution for both is Laplacian, the RMS error of the fitted Laplace distribution is higher in the case of asymptomatic COVID-19 positive speech samples. This indicates that spectral properties of speech get altered as a result of physiological changes caused due to COVID-19 infection. It is therefore deduced that there is an associated entropy in speech which can be used to detect COVID-19. STFT coefficients of speech are then used as input features of machine learning-based classification algorithms and the classification performance of five state-of-the-art classification algorithms has been evaluated. All the five classification algorithms exhibit a moderate level of performance having their evaluation metrics values around 70% of their maximum values. The best performance is observed for the DF algorithm which has the highest value for the “recall” metric with a value of 0.7892. “Recall” is the metric used while training the model hyperparameters as a higher recall value means minimizing misclassification of the “false negative” category. The cost of misclassifying a COVID-19 positive sample as a COVID-19 negative is high and hence the choice of recall as the evaluation metric is to be maximized while tuning the model parameters. It is also noted from Table 5 that the misclassification of Class 1 (COVID-19 positive) as Class 0 (COVID-19 negative) is least for the DF algorithm when tested on previously unseen test data. The results obtained are promising and provide evidence that COVID-19 infection can be detected from speech signals of individuals.
Speech can be used as a biomedical signal to diagnose various physical and emotional disorders. It can be used to monitor the performance/health conditions of individuals while performing physical activity. The focus of this work, however, is to detect COVID-19 infection by analyzing a person's speech signal. This is possible because speech characteristics of individuals get altered by these conditions as depicted in Figure 7.
Figure 7.
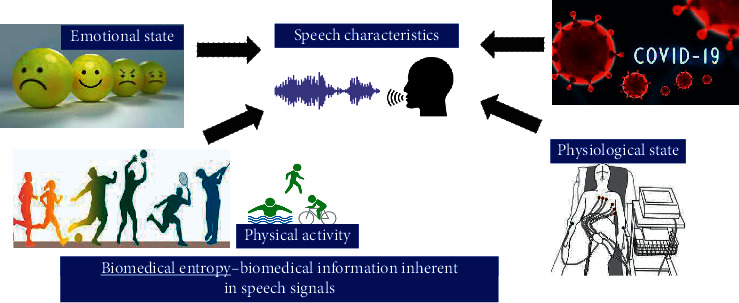
Possible applications of the proposed research.
The results presented are concurring with similar approaches available in published literature. For example, 100% sensitivity is reported in [71] for asymptomatic cases, but it uses additional biomarker information along with cough sounds. A maximum “recall” value of 0.72 is reported in [73,78] while, in [76], the highest accuracy of 92.85% is reported for binary classification using deep transfer learning.
The results presented in this work can be improved by using a larger dataset comprising different classes of human vocal sounds which should also include samples of individuals of different languages, dialects, and other health conditions. It was intended to collect large datasets by encouraging community participation but that could not be achieved due to regulatory procedures and limitations of funding. Hence, the results presented in this work are based on a small dataset but the findings are encouraging. Future work shall consider using the magnitude of STFT coefficients rather than just the real/imaginary part and also consider the use of other types of audio signal features such as MFCC as input features for ML-based classification. The detection of COVID-19 using speech can facilitate real-time, remote monitoring of infected yet asymptomatic individuals. This will allow early detection of COVID-19 symptoms and help manage the ongoing COVID-19 situation better. It should be noted that the fundamental idea presented in this article is not limited to detecting COVID-19 symptoms only but has broader applications in medical diagnosis and patient monitoring/care. AI can detect changes in human vocal sounds not discernible to the human ear. Smartphone apps that use AI algorithms to analyze human vocal sounds for diagnosis, screening, and monitoring can be extremely useful and are expected to play a vital role in future healthcare technologies.
Acknowledgments
The authors are thankful to the Institute of Research and Consulting Studies at King Khalid University for supporting this research through grant number # 33-91-S-2020.
Data Availability
The speech recordings and the features data used to support the findings of this study have not been made available because the participants have not consented to their data being shared with any third party.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- 1.Vital Signs (Body Temperature, Pulse Rate, Respiration Rate, Blood Pressure) [Internet] Johns Hopkins Medicine. 2021. https://www.hopkinsmedicine.org/health/conditions-and-diseases/vital-signs-body-temperature-pulse-rate-respiration-rate-blood-pressure .
- 2.Reynolds A., Paivio A. Cognitive and emotional determinants of speech. Canadian Journal of Psychology/Revue canadienne de psychologie . 1968;22(3):164–175. doi: 10.1037/h0082757. [DOI] [PubMed] [Google Scholar]
- 3.Ramig L. A. Effects of physiological aging on vowel spectral noise. Journal of Gerontology . 1983;38(2):223–225. doi: 10.1093/geronj/38.2.223. [DOI] [PubMed] [Google Scholar]
- 4.Trouvain J., Truong K. P. Prosodic Characteristics of Read Speech before and after Treadmill Running . Baixas, France: International Speech Communication Association (ISCA); 2015. [Google Scholar]
- 5.Borkovec T. D., Wall R. L., Stone N. M. False Physiological Feedback and the maintenance of speech anxiety. Journal of Abnormal Psychology . 1974;83(2):164–168. doi: 10.1037/h0036472. [DOI] [PubMed] [Google Scholar]
- 6.ScienceEncyclopedia. Speech - the Physiology of Speech - Air, Vocal, Words, and Sound - JRank Articles [Internet] 2019. https://science.jrank.org/pages/6371/Speech-physiology-speech.html .
- 7.Skopin D., Baglikov S. Heartbeat feature extraction from vowel speech signal using 2D spectrum representation. Proceedings of the 4th Inernational Conference Information Technology; June 2009; Doha, Qatarp. p. p. 6. [Google Scholar]
- 8.Schuller B., Friedmann F., Eyben F. Automatic recognition of physiological parameters in the human voice: heart rate and skin conductance. Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing; Vancover 2013; Vancouver, Canada. IEEE; pp. 7219–7223. [DOI] [Google Scholar]
- 9.Mesleh A., Skopin D., Baglikov S., Quteishat A. Heart rate extraction from vowel speech signals. Journal of Computer Science and Technology . 2012;27(6):1243–1251. doi: 10.1007/s11390-012-1300-6. [DOI] [Google Scholar]
- 10.Kaur J., Kaur R. Extraction of heart rate parameters using speech analysis. International Journal of Science and Research . 2014;3(10):1374–1376. [Google Scholar]
- 11.Sakai M. Modeling the relationship between heart rate and features of vocal frequency. International Journal of Computer Application . 2015;120(6):32–37. doi: 10.5120/21233-3986. [DOI] [Google Scholar]
- 12.Orlikoff R. F., Baken R. J. The effect of the heartbeat on vocal fundamental frequency perturbation. Journal of Speech, Language, and Hearing Research . 1989;32(3):576–582. doi: 10.1044/jshr.3203.576. [DOI] [PubMed] [Google Scholar]
- 13.Schuller B., Friedmann F., Eyben F. The munich biovoice corpus: effects of physical exercising, heart rate, and skin conductance on human speech production. Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC-2014); May 2014; Reykjavik, Iceland. Reykjavik: European Language Resources Association (ELRA); pp. 1506–1510. [Google Scholar]
- 14.Usman M. On the performance degradation of speaker recognition system due to variation in speech characteristics caused by physiological changes. International Journal of Computing and Digital Systemss . 2017;6(3):119–127. doi: 10.12785/IJCDS/060303. [DOI] [Google Scholar]
- 15.James A. P. Heart rate monitoring using human speech spectral features. Human-centric Computing and Information Sciences . 2015;5(1):1–12. doi: 10.1186/s13673-015-0052-z. [DOI] [Google Scholar]
- 16.Burton D. A., Stokes K., Hall G. M. Physiological effects of exercise. Continuing Education in Anaesthesia, Critical Care & Pain . 2004;4(6):185–188. doi: 10.1093/bjaceaccp/mkh050. [DOI] [Google Scholar]
- 17.Sakai M. Feasibility study on blood pressure estimations from voice spectrum analysis. International Journal of Computer Application . 2015;109(7):39–43. doi: 10.5120/19204-0848. [DOI] [Google Scholar]
- 18.Griswold D., Abraham M. Slurred Speech From Anxiety: Causes and Treatments [Internet]. CalmClinic. 2021. https://www.calmclinic.com/anxiety/symptoms/slurred-speech .
- 19.Scully C. G., Jinseok Lee J., Meyer J., et al. Physiological parameter monitoring from optical recordings with a mobile phone. IEEE Transactions on Biomedical Engineering . 2012;59(2):303–306. doi: 10.1109/TBME.2011.2163157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Poh M.-Z., McDuff D. J., Picard R. W. Advancements in noncontact, multiparameter physiological measurements using a webcam. IEEE Transactions on Biomedical Engineering . 2011;58(1):7–11. doi: 10.1109/TBME.2010.2086456. [DOI] [PubMed] [Google Scholar]
- 21.Mardian Y., Kosasih H., Karyana M., Neal A., Lau C.-Y. Review of current COVID-19 diagnostics and opportunities for further development. Frontiers of Medicine . 2021;8 doi: 10.3389/fmed.2021.615099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Tayarani N. M.-H. Applications of artificial intelligence in battling against covid-19: a literature review. Chaos, Solitons & Fractals . 2021;142 doi: 10.1016/j.chaos.2020.110338.110338 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Albahri A. S., Hamid R. A., Alwan J. k., et al. Role of biological data mining and machine learning techniques in detecting and diagnosing the novel coronavirus (COVID-19): a systematic review. Journal of Medical Systems . 2020;44(7):p. 122. doi: 10.1007/s10916-020-01582-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Alballa N., Al-Turaiki I. Machine learning approaches in COVID-19 diagnosis, mortality, and severity risk prediction: a review. Informatics in Medicine Unlocked . 2021;24 doi: 10.1016/j.imu.2021.100564.100564 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Bullock J., Luccioni A., Pham K. H., Sin Nga Lam C., Luengo-Oroz M. Mapping the landscape of artificial intelligence applications against COVID-19. Journal of Artificial Intelligence Research . 2020;69:807–845. doi: 10.1613/jair.1.12162. [DOI] [Google Scholar]
- 26.Agbehadji I. E., Awuzie B. O., Ngowi A. B., Millham R. C. Review of big data analytics, artificial intelligence and nature-inspired computing models towards accurate detection of COVID-19 pandemic cases and contact tracing. International Journal of Environmental Research and Public Health . 2020;17(15):p. 5330. doi: 10.3390/ijerph17155330. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Aishwarya T., Ravi Kumar V. Machine learning and deep learning approaches to analyze and detect COVID-19: a review. SN Computer Science . 2021;2(3):p. 226. doi: 10.1007/s42979-021-00605-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Swapnarekha H., Behera H. S., Nayak J., Naik B. Role of intelligent computing in COVID-19 prognosis: a state-of-the-art review. Chaos, Solitons & Fractals . 2020;138 doi: 10.1016/j.chaos.2020.109947.109947 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Wynants L., Van Calster B., Collins G. S., et al. Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal. BMJ . 2020;369 doi: 10.1136/bmj.m1328.m1328 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Li W. T., Ma J., Shende N., et al. Using machine learning of clinical data to diagnose COVID-19: a systematic review and meta-analysis. BMC Medical Informatics and Decision Making . 2020;20(1):p. 247. doi: 10.1186/s12911-020-01266-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Allam M., Cai S., Ganesh S., et al. COVID-19 diagnostics, tools, and prevention. Diagnostics . 2020;10(6):p. 409. doi: 10.3390/diagnostics10060409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.The Lancet Digital Health. Artificial intelligence for COVID-19: saviour or saboteur? Lancet Digit Heal . 2021;3:p. e1. doi: 10.1016/S2589-7500(20)30295-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Zoabi Y., Deri-Rozov S., Shomron N. Machine learning-based prediction of COVID-19 diagnosis based on symptoms. Npj Digital Medicine . 2021;4(1):p. 3. doi: 10.1038/s41746-020-00372-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Irfan M., Iftikhar M. A., Yasin S., et al. Role of hybrid deep neural networks (HDNNs), computed tomography, and chest X-rays for the detection of COVID-19. International Journal of Environmental Research and Public Health . 2021;18(6):p. 3056. doi: 10.3390/ijerph18063056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Masoud Rezaeijo S., Ghorvei M., Alaei M. A machine learning method based on lesion segmentation for quantitative analysis of CT radiomics to detect COVID-19. Proceedings of the 2020 6th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS); December 2020; Mashhad, Iran. IEEE; pp. 1–5. [DOI] [Google Scholar]
- 36.Rezaeijo S. M., Abedi-Firouzjah R., Ghorvei M., Sarnameh S. Screening of COVID-19 based on the extracted radiomics features from chest CT images. Journal of X-Ray Science and Technology . 2021;29(2):229–243. doi: 10.3233/XST-200831. [DOI] [PubMed] [Google Scholar]
- 37.Borkowski A. Using artificial intelligence for COVID-19 chest X-ray diagnosis. Federal Practitioner . 2020;37(9):398–404. doi: 10.12788/fp.0045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Brunese L., Martinelli F., Mercaldo F., Santone A. Machine learning for coronavirus covid-19 detection from chest x-rays. Procedia Computer Science . 2020;176:2212–2221. doi: 10.1016/j.procs.2020.09.258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Karbhari Y., Basu A., Geem Z. W., Han G.-T., Sarkar R. Generation of synthetic chest X-ray images and detection of COVID-19: a deep learning based approach. Diagnostics . 2021;11(5):p. 895. doi: 10.3390/diagnostics11050895. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Qiblawey Y., Tahir A., Chowdhury M. E. H., et al. Detection and severity classification of COVID-19 in CT images using deep learning. Diagnostics . 2021;11(5):p. 893. doi: 10.3390/diagnostics11050893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Chattopadhyay S., Dey A., Singh P. K., Geem Z. W., Sarkar R. COVID-19 detection by optimizing deep residual features with improved clustering-based golden ratio optimizer. Diagnostics . 2021;11(2):p. 315. doi: 10.3390/diagnostics11020315. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Kukar M., Gunčar G., Vovko T., et al. COVID-19 Diagnosis by Routine Blood Tests Using Machine Learning. Scientific Reports . 2020;11 doi: 10.1038/s41598-021-90265-9.10738 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Brinati D., Campagner A., Ferrari D., Locatelli M., Banfi G., Cabitza F. Detection of COVID-19 infection from routine blood exams with machine learning: a feasibility study. Journal of Medical Systems . 2020;44(8):p. 135. doi: 10.1007/s10916-020-01597-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.AlJame M., Ahmad I., Imtiaz A., Mohammed A. Ensemble learning model for diagnosing COVID-19 from routine blood tests. Informatics in Medicine Unlocked . 2020;21 doi: 10.1016/j.imu.2020.100449.100449 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Shamout F. E., Shen Y., Wu N., et al. An artificial intelligence system for predicting the deterioration of COVID-19 patients in the emergency department. Npj Digital Medicine . 2021;4(1):p. 80. doi: 10.1038/s41746-021-00453-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Dai Z., Zeng D., Cui D., et al. Prediction of COVID-19 patients at high risk of progression to severe disease. Frontiers in Public Health . 2020;8 doi: 10.3389/fpubh.2020.574915.574915 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Carlile M., Hurt B., Hsiao A., Hogarth M., Longhurst C. A., Dameff C. Deployment of artificial intelligence for radiographic diagnosis of COVID‐19 pneumonia in the emergency department. Journal of the American College of Emergency Physicians Open . 2020;1(6):1459–1464. doi: 10.1002/emp2.12297. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Hu C., Liu Z., Jiang Y., et al. Early prediction of mortality risk among patients with severe COVID-19, using machine learning. International Journal of Epidemiology . 2021;49(6):1918–1929. doi: 10.1093/ije/dyaa171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.López-Escobar A., Madurga R., Castellano J. M., et al. Risk score for predicting in-hospital mortality in COVID-19 (RIM score) Diagnostics . 2021;11(4):p. 596. doi: 10.3390/diagnostics11040596. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Gao Y., Cai G.-Y., Fang W., et al. Machine learning based early warning system enables accurate mortality risk prediction for COVID-19. Nature Communications . 2020;11(1):p. 5033. doi: 10.1038/s41467-020-18684-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Tretter F., Wolkenhauer O., Meyer-Hermann M., et al. The quest for system-theoretical medicine in the COVID-19 era. Frontiers of Medicine . 2021;8 doi: 10.3389/fmed.2021.640974. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Naudé W. Artificial intelligence vs COVID-19: limitations, constraints and pitfalls. AI & Society . 2020;35(3):761–765. doi: 10.1007/s00146-020-00978-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Tobias M. W. AI and Medical Diagnostics: Can A Smartphone App Detect Covid-19 from Speech or A Cough? Forbes. 2020.
- 54.Chu J. Artificial Intelligence Model Detects Asymptomatic Covid-19 Infections through Cellphone-Recorded Coughs . Cambridge, MA, USA: MIT News; 2020. [Google Scholar]
- 55.Scudellari M. AI Recognizes COVID-19 in the Sound of a Cough . USA: IEEE Spectrum - The Institute; 2020. [Google Scholar]
- 56.Coppock H., Gaskell A., Tzirakis P., Baird A., Jones L., Schuller B. End-to-end convolutional neural network enables COVID-19 detection from breath and cough audio: a pilot study. BMJ Innovations . 2021;7(2):356–362. doi: 10.1136/bmjinnov-2021-000668. [DOI] [PubMed] [Google Scholar]
- 57.MacGill M. Heart rate: What is a normal heart rate? [Internet] 2017. https://www.medicalnewstoday.com/articles/235710.php .
- 58.Usman M., Zubair M., Shiblee M., Rodrigues P., Jaffar S. Probabilistic modeling of speech in spectral domain using maximum likelihood estimation. Symmetry . 2018;10(12):p. 750. doi: 10.3390/sym10120750. [DOI] [Google Scholar]
- 59.Partila P., Voznak M., Mikulec M., Zdralek J. Fundamental frequency extraction method using central clipping and its importance for the classification of emotional state. Advances in Electrical and Electronic Engineering . 2012;10(4):270–275. doi: 10.15598/aeee.v10i4.738. [DOI] [Google Scholar]
- 60.Tan Z.-H., Lindberg B. Low-complexity variable frame rate analysis for speech recognition and voice activity detection. IEEE Journal of Selected Topics in Signal Processing . 2010;4(5):798–807. doi: 10.1109/JSTSP.2010.2057192. [DOI] [Google Scholar]
- 61.Wolf J. J. Spoken Language Generation and Understanding . Netherlands, Europe: Dordrecht: Springer; 1980. Speech signal processing and feature extraction. [Google Scholar]
- 62.Reilly K. J., Moore C. A. Respiratory sinus arrhythmia during speech production. Journal of Speech, Language, and Hearing Research . 2003;46(1):164–177. doi: 10.1044/1092-4388(2003/013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Von Euler C. Speech motor control. Proceedings of the International Symposium on Speech Motor Control, Wenner -Gren Center International Symposium Series; May 1981; Stockholm, Sweden. pp. 95–103. https://www.sciencedirect.com/science/article/pii/B978008028892550013X . [DOI] [Google Scholar]
- 64.Yasuma F., Hayano J.-i. Respiratory sinus arrhythmia. Chest . 2004;125(2):683–690. doi: 10.1378/chest.125.2.683. [DOI] [PubMed] [Google Scholar]
- 65.Magre S. B., Deshmukh R. R., Shrishrimal P. P. A comparative study on feature extraction techniques in speech recognition. Proceedings of the International Conference on Recent Advances in Statistics and Their Applications; December 2013; Maharashtra, India. Aurangabad; [Google Scholar]
- 66.Huang X., Acero A., Hon H.-W. Spoken Language Processing: A Guide to Theory, Algorithm, and System Development . Hoboken, NJ, USA: Prentice Hall PTR; 2001. [Google Scholar]
- 67.Davis S., Mermelstein P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech, & Signal Processing . 1980;28(4):357–366. doi: 10.1109/TASSP.1980.1163420. [DOI] [Google Scholar]
- 68.Hermansky H. Perceptual linear predictive (PLP) analysis of speech. Journal of the Acoustical Society of America . 1990;87(4):1738–1752. doi: 10.1121/1.399423. [DOI] [PubMed] [Google Scholar]
- 69.Tufekci Z., Gowdy J. N. Feature extraction using discrete wavelet transform for speech recognition. Proceedings of the IEEE SoutheastCon 2000 “Preparing for the New Millennium” (Cat No00CH37105); April 2000; Nashville, TN, USA. IEEE; pp. 116–123. [DOI] [Google Scholar]
- 70.Hermansky H., Morgan N. RASTA processing of speech. IEEE Transactions on Speech and Audio Processing . 1994;2(4):578–589. doi: 10.1109/89.326616. [DOI] [Google Scholar]
- 71.Laguarta J., Hueto F., Subirana B. COVID-19 artificial intelligence diagnosis using only cough recordings. IEEE Open Journal of Engineering in Medicine and Biology . 2020;1:275–281. doi: 10.1109/OJEMB.2020.3026928. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Deshpande G., Schuller B. W. Audio, Speech, Language, & Signal Processing for COVID-19: A Comprehensive Overview. Pattern Recognit . 2020;122 doi: 10.1016/j.patcog.2021.108289.108289 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Brown C., Chauhan J., Grammenos A., et al. Exploring automatic diagnosis of COVID-19 from crowdsourced respiratory sound data. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; August 2020; New York, NY, USA. ACM; pp. 3474–3484. [DOI] [Google Scholar]
- 74.Trancoso I. Project to Detect COVID-19 from Coughs and Speech. 2021. https://www.inesc-id.pt/project-to-detect-covid-19-from-coughs-and-speech/
- 75.Anthes E. Alexa, do I have COVID-19? Nature . 2020;586(7827):22–25. doi: 10.1038/d41586-020-02732-4. [DOI] [PubMed] [Google Scholar]
- 76.Imran A., Posokhova I., Qureshi H. N., et al. AI4COVID-19: AI enabled preliminary diagnosis for COVID-19 from cough samples via an app. Informatics in Medicine Unlocked . 2020;20 doi: 10.1016/j.imu.2020.100378.100378 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Schuller B. W., Schuller D. M., Qian K., Liu J., Zheng H., Li X. COVID-19 and Computer Audition: An Overview on what Speech & Sound Analysis Could Contribute in the SARS-CoV-2 Corona Crisis. Digit. Health . 2021;3 doi: 10.3389/fdgth.2021.564906. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Han J., Brown C., Chauhan J., et al. Exploring automatic COVID-19 diagnosis via voice and symptoms from crowdsourced data. Proceedings of the IEEE ICASSP 2021; June 2021; Toronto, Canada. [DOI] [Google Scholar]
- 79.Bühlmann P., Yu B. Boosting with theL2Loss. Journal of the American Statistical Association . 2003;98(462):324–339. doi: 10.1198/016214503000125. [DOI] [Google Scholar]
- 80.Criminisi A., Shotton J., Konukoglu E. Decision forests: a unified framework for classification, regression, density estimation, manifold learning and semi-supervised learning. Foundations and Trends® in Computer Graphics and Vision . 2011;7(2-3):81–227. doi: 10.1561/0600000035. [DOI] [Google Scholar]
- 81.Zhang G., Eddy Patuwo B., Hu M. Y. Forecasting with artificial neural networks: International Journal of Forecasting . 1998;14(1):35–62. doi: 10.1016/S0169-2070(97)00044-7. [DOI] [Google Scholar]
- 82.Dreiseitl S., Ohno-Machado L. Logistic regression and artificial neural network classification models: a methodology review. Journal of Biomedical Informatics . 2002;35(5–6):352–359. doi: 10.1016/S1532-0464(03)00034-0. [DOI] [PubMed] [Google Scholar]
- 83.Nasrabadi N. M. Pattern recognition and machine learning. Journal of Electronic Imaging . 2007;16(4) doi: 10.1117/1.2819119.049901 [DOI] [Google Scholar]
- 84.Roychowdhury S., Bihis M. AG-MIC: azure-based generalized flow for medical image classification. IEEE Access . 2016;4:5243–5257. doi: 10.1109/ACCESS.2016.2605641. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The speech recordings and the features data used to support the findings of this study have not been made available because the participants have not consented to their data being shared with any third party.