

Abstract
Pulmonary hypertension (PH) is a complex disease with multiple aetiologies, corresponding to phenotypic heterogeneity and variable therapeutic responses. Advancing understanding of PH pathogenesis is likely to hinge on integrated methods that leverage data from health records, imaging, novel molecular ‘-omics’ profiling, and other modalities. In this review, we summarize key datasets generated thus far in the field and describe analytical methods that hold promise for deciphering the molecular mechanisms that underpin pulmonary vascular remodeling, including machine learning, network medicine, and functional genetics. We also detail how genetic and sub-phenotyping approaches enable earlier diagnosis, refined prognostication, and optimized treatment prediction. We propose strategies that identify functionally important molecular pathways, bolstered by findings across multi-omics platforms, which are well-positioned to individualize drug therapy selection and advance precision medicine in this highly morbid disease.
Keywords: Big Data and Data Standards, Pulmonary Hypertension, Treatment
Introduction
A single unifying definition for big data is lacking, but in all instances involves expansive and centralized information of great variety, with potential for iterative modification and large impact on health and human disease. Indeed, the molecular era of medicine is defined, in part, by wider availability of economical multiplex assays that offer rapid throughput. This progress has, in turn, led to unanticipated obstacles in managing big data, including storage capacity, irregular (and heterogeneous) data structure across collections, challenges identifying data inaccuracy, and legal barriers among data sharing between nations (globalization), among others. Further, optimal methods for deciphering big data toward identifying biologically and clinically relevant information remain incompletely realized. Notwithstanding these challenges, immense opportunity exists to leverage big data for clarifying complex pathophenotypes and, ultimately, advance precision medicine. Substantial progress has already been reported utilizing big data in the context of pulmonary circulatory diseases, which include a series of highly morbid clinical phenotypes often lacking definitive therapeutic opportunities. Here, we review the state-of-the-art for big data in pulmonary hypertension (PH), with particular emphasis on strategies to abstract critical information from these resources for improving knowledge on pulmonary arterial hypertension (PAH) pathogenesis, pathobiology, and therapeutic discovery.
What are the ‘big data’ in PH?
Genomics
Next generation sequencing (NGS), inclusive of whole genome and exome coding regions, generates among the most voluminous outputs in medical research. These data require both analytic expertise and high-performance computing capabilities to analyse the millions of common DNA variants and numerous, but often patient-specific, rare genetic variants that directly alter an individual’s probability of developing disease. As many as 20% of idiopathic PAH cases are explained by a rare pathogenic genetic variant in known causal genes1. Four-fifths of these are in the bone morphogenetic protein receptor type II BMPR2 gene. Significant progress through NGS applied to thousands of patients2–4 has culminated in the discovery that novel, pathogenic variants in SOX175, ATP13A3, GDF26, AQP1, GGCX, KLK13 and KDR7 promote PAH.
Analysis of the common variation associated with PAH development identified variants in an enhancer upstream of SOX17 and variants associated with specific alleles of the major histocompatibility complex molecule HLA-DPB1 previously associated with beryllium-triggered lung disease8. HLA-DPB1 alleles were also associated with age of PAH onset and long-term survival outcomes, a finding mirroring the association of rare BMPR2 variants with more severe, early onset PAH9. As detailed further in the Functional Genetics article in this series [Guignabert et al.], one of the challenges going forward in PH genetics research will be understanding the pathobiology of these PAH genes in order to develop novel therapeutic strategies. This will take time (BMPR2 was discovered as the main PAH gene in 20001) but the importance of this approach is emphasised by the improved success rates associated with drugs developed to target biology supported by genetic disease associations10.
Epigenomics
Beyond the sequence of DNA, there are multiple chemical alterations to DNA-chromatin molecules that may be heritable or regulated dynamically through environmental perturbations through tissue- and disease-specific processes. One of the best studied and understood of these is DNA methylation, which occurs at CpG (5′-cytosine-phosphate-guanine-3′) dinucleotides and is most commonly associated with inhibition of gene expression when occurring in CpG-rich regions (islands) of promoters. An example of how this might be relevant to PAH was recently observed in BMPR2 variant carriers, in the context of incomplete penetrance as ~20% of mutation carriers express the PAH phenotype1. Hypermethylation of the BMPR2 promoter was observed recently to be associated with reduced gene expression in PAH probands compared to unaffected relatives in a cohort of 5 families11. Promoter methylation at granulysin has also been proposed to distinguish between PAH and pulmonary veno-occlusive disease12. Few large-scale epigenomic datasets in PH clinical samples have been generated but there is significant evidence for global alterations in histone modifications and non-coding RNAs which warrant further investigation13.
Transcriptomics
Microarray gene expression data in whole blood samples from PH patients represent some of the earliest large datasets generated and the public availability of these datasets through repositories such as the Gene Expression Omnibus has facilitated updated and more comprehensive analyses. These include a recent meta-analysis which accumulated seven studies generating 1,269 differentially expressed, unique gene transcripts14. While an interferon-associated signal was more strongly associated with systemic sclerosis-PAH perhaps the more remarkable finding was the similarity in profiles between PAH patients of differing aetiologies. Another study harnessing gene expression microarray data from 58 PAH and 25 control lung tissues15 again highlighted, among others, interferon signalling as well as beginning to tease apart potential sex-specific changes in Wnt signalling gene ontology pathways. The development of multiplexed high-throughput RNA sequencing (RNAseq) protocols has facilitated the analysis of large numbers of samples and comparison of 359 PAH patients with 72 healthy controls whole blood profiles identified 507 robustly PAH-associated genes16. Twenty-five of these genes were selected by Least Absolute Shrinkage and Selection Operator (LASSO)-driven logistic regression modelling to build a model capable of identifying PAH cases with 87% accuracy. The model was also associated with disease severity and poor outcomes, illustrating the potential clinical utility of scores derived from -omics datasets (data with large numbers of variables e.g. proteomics or transcriptomics representing 1000s of proteins or gene transcript values per sample) in PAH.
Another exciting technological development in transcriptomics is single-cell RNAseq which simultaneously allows the detailed characterisation of the individual cells being processed and identification of differentially expressed genes within defined cellular subsets. This has been applied to experimental PH;17 non-classical monocytes from Sugen-5416-hypoxia-PAH rats and conventional dendritic cells from monocrotaline-PAH rats both demonstrated NF-κB pathway activation. In three human idiopathic PAH (IPAH) lung explants and six control lungs18, comparative transcriptomic analyses of pulmonary artery endothelial cells (PAEC), pulmonary artery smooth muscle cells, lung pericytes, adventitial fibroblasts, and macrophages clusters identified multiple genes of interest. In particular, SOX18, which itself has not been found to harbour pathogenic variants unlike SOX17, was shown to be of significance in the endothelial transcriptome, suggesting broader dysfunction of this transcription factor family may be linked to PAH.
Proteomics
Protein profiles can be analyzed through untargeted (usually chromatography-mass spectrometry [LC-MS]-based) or targeted (antibody/aptamer-based) approaches, generating information on the expression pattern of ~103 targets per single sample. In-tandem LC-MS used on lobectomy homogenates from controls and PAH explants highlighted the importance of elevated levels of the chloride intracellular channel protein CLIC4 and depletion of key iron-regulating proteins, such as haptoglobin19. The SomaScan aptamer platform was used to measure >1,100 proteins in plasma samples from N=218 UK-based idiopathic/heritable PAH patients, identifying 20 that were strongly associated with survival20. Nine proteins combined to form a highly effective prognostic panel capable of predicting prognosis independent of established risk equations used in clinical practice21. The protein model was validated in patients from France, dividing them into low, medium and high-risk groups, and shown to change over time in line with clinical outcomes in patients from Germany, where increases in an individual patient’s score were associated with poorer survival20. These approaches demonstrate the potential of proteomic analyses to identify pathologic pathways and to contribute to clinical stratification of patients who may require more aggressive (e.g., triple) or specific (e.g., anti-inflammatory) therapies.
Metabolomics
Energy metabolism has for many years been of great interest in PAH particularly in light of detailed mechanistic studies demonstrating a switch from aerobic metabolism to a glycolytic phenotype (e.g., Warburg effect), as had been observed previously in selected solid tumor malignancies22. This recently culminated in the finding that dichloroacetate, a pyruvate dehydrogenase kinase inhibitor, may have salutary beneficial therapeutic effects in patients with a genetic predisposition to metabolic imbalance23.
Metabolomics approaches, using nuclear magnetic resonance (NMR) or LC-MS, have broadened our understanding of this aspect of PAH pathology. Lung tissue analysis demonstrated abnormal oxidation of metabolic intermediaries, reduced arginine and elevated sphingosine-1-phosphate and heme metabolites in 8 PAH lungs compared to 8 controls24 whereas analysis of PH right ventricular (RV) tissue identified altered acylcarnitine levels and ceramide accumulation, suggesting a defect in fatty acid oxidation25. Long-chain acylcarnitines were also elevated in blood samples from 11 PAH patients with normal creatinine compared to 22 healthy controls25 and a separate plasma metabolomic analysis further detailed circulating metabolites associated with RV dysfunction and pulmonary haemodynamics26. This study analysed 105 metabolites in N=101 individuals and identified novel associations between tryptophan metabolites, tricarboxylic acid intermediates, and purine metabolites with clinically relevant parameters, such as RV ejection fraction and pulmonary vascular resistance (PVR) on exercise26.
Another analysis measured 686 well-quantified biological metabolites in N=365 idiopathic/heritable PAH patients, N=121 healthy controls and N=139 disease controls (I.e., fully investigated symptomatic referrals to PH clinic). The study identified increased circulating levels of modified nucleosides originating from transfer RNAs, energy metabolism intermediates, polyamine, and tryptophan metabolites and decreased sphingomyelins, steroids and phosphatidylcholines both discriminated patients with PAH from control subjects (independent of confounders) and predicted survival in the PAH patients. Interestingly, patients defined by favorable cardiopulmonary hemodynamic response to calcium channel blockers, known to associate with lower overall clinical risk, had metabolic profiles more similar to controls than other PAH patients27. A recent extension of this study to patients with chronic thromboembolic PH (CTEPH) found very similar metabolic disturbances in CTEPH and PAH patients despite their distinct etiologies, and significant correction of profiles following curative pulmonary thromboendarterectomy surgery28. Both this and the earlier study by Lewis and colleagues26 performed sampling across different vascular compartments, allowing some characterisation of metabolites that may either originate from, or utilised by, pulmonary or cardiac tissues. These studies illustrate the concept that metabolomics may be useful in monitoring therapeutic outcomes and yield insight on tissue-specific mechanistic underpinnings in PAH.
Imaging data
The depth of information that can be gleaned from high resolution imaging methodologies such as cardiac magnetic resonance (CMR) render it ideal for machine learning approaches. Following the manual locating of six anatomical points on CMR images it was possible to create a reference ‘atlas’ of PH hearts allowing, from further scans, the automated generation of 30,000 data points per patient representing the motion of the heart from end-diastole to end-systole29. A supervised principal components analysis was then used to produce a 3-D motion score, which offered superior prognostication of N=256 PH patients compared to standard CMR measures, haemodynamics or exercise capacity (area under the receiver operating characteristic curve, AUC, 0.73 vs 0.60, P<0.001)29. Building on this approach, it is possible to calculate RV wall stress, which itself is prognostic, and also correlates with plasma levels of the prognostic metabolites including N2,N2-dimethylguanosine30. These advances identified a new link in the PAH pathobiology-phenotype relationship: maladaptive changes in RV geometric configuration with metabolic stress, in the context of elevated clinical risk. Given the recent change to the definition of PH from mean pulmonary artery pressure (mPAP) of ≥25 mmHg to >20 mmHg (plus pulmonary vascular resistance (PVR) ≥3 Woods units), and the association of the equivalent findings on echocardiography with mortality31 there is increased scope for the application of machine learning approaches to benefit the utility of imaging modalities for screening and diagnosis of PH.
Electronic health records
A data form which can certainly provide volume, complexity and follow-up data are electronic health records. While the disparity in systems deployed by various healthcare services represents a large data harmonisation challenge in this field centralised services such as the US Veterans Affairs or UK National Health Service (NHS) offer some early opportunities for assimilating data across very large samples of individuals. Kiely and colleagues used extreme gradient-boosting artificial intelligence (a method based on combining multiple decision trees) approach to build a model to predict IPAH from up to 5 years of hospital admission statistics (NHS HES data). In this study, 709 IPAH cases with data collected prior to attending specialist PH services distinct from 5630 confirmed non-IPAH patients who attended the PH service over the same period were modelled against N=2,812,458 UK non-IPAH patients with sufficient data who did not attend the PH service. The AI model, based on multiple variables such as number of visits to emergency wards, respiratory, haematology or cardiology clinics, was estimated to require screening of between 500–1000 high-risk patients to identify 100 PAH patients, which the authors noted was similar to the proportion of systemic sclerosis patients who develop PH, who undergo routine clinical screening for PH32. The automatic identification of patients who should be referred more rapidly to specialist services is a highly attractive approach, especially since a significant (~2.5 year) delay between initial presentation of symptoms and final PAH diagnosis is common33.
Wearables and ambulatory monitoring
Another potential source of huge volumes of individualised data collected in real time is the adoption of wearable devices, which can capture cardiovascular health indices including heart rate, rhythm, blood pressure, glucose and electrolytes34. Most devices are as yet unapproved for clinical uses and clear regulation and privacy concerns are significant hurdles for consideration. Nonetheless, there is enthusiasm for the potential ampliative value when integrating –omics with deep phenotyping, inclusive of implantable monitors for haemodynamics (e.g., CardioMEMS™ HF System reviewed in ref. 37) in PH35,36. Analytical methods, such as machine learning, are a natural fit to the density of data produced by constant monitoring and could potentially improve the accuracy and utility of device-based diagnoses centred on automated ‘biosignal’ detection37. Further important considerations with these approaches will be balancing the control of data and accessibility to the expert care providers since the comporting large amounts of data involving many patients poses practical challenges to clinical decision-making.
Registries and research networks
In contrast to purely clinical registries (e.g., REVEAL, COMPERA, others), research networks have been formed to address deep phenotyping priorities in PH. These multi-center networks include shared tissue biorepositories that allow paired analysis of molecular and clinical data. Examples of national omics-centered research networks include the PH Breakthrough Initiative (www.ipahresearch.org/services.html) and PAH Biobank (www.pahbiobank.org) (U.S.), the National Cohort Study of Idiopathic and Heritable PAH (www.ipahcohort.com) (U.K.), and the French Network on PAH. The PH Breakthrough Initiative uniquely harvests lung tissue from PAH transplant recipients, whereas blood samples serve as the primary tissue source in other biorepositories. PAH ICON (www.pahicon.com) is an international consortium of investigators from 10 countries focused on PAH genetics. Many of the landmark genomic, transcriptomic, proteomic, and metabolomic PAH studies we highlighted above are derivatives of these research networks. The more recent NHLBI-sponsored PVDOMICS initiative is an ongoing prospective multi-center study (7 U.S. academic institutions) which seeks to disrupt the existing PH clinical classification by identifying new phenotypes based on integrated clinical and molecular features38 (www.phassociation.org/pvdomics). Beyond this forward-thinking objective, PVDOMICS is distinct due to its highly-protocolized data collection, acquisition of comprehensive physiological and imaging data, inclusion of all forms of PH (Groups 1–5), and a diseased comparator group with PH risk factors. In all of these aforementioned network programs, adherence to FAIR guiding principles39 will help ensure that data are findable, accessible, interoperable, and reusable. To minimise error in data generation it is important to consider analysing samples in the smallest number of batches, with each batch containing representative subsets of samples (e.g. controls/patients/sex/age ranges). International omics collaborations will also depend on efforts to harmonize sample collection, sample processing, and molecular profiling protocols.
How to ‘harness’ big datasets in PH?
As high-throughput technologies advance and access to PH big data improves, it will be critical to prudently select approaches for data analysis, visualization, and interpretation. Rather than reflecting a simple genotype-phenotype relationship, PH is a complex disease encapsulating an amalgam of various genetic perturbations, epigenetic modifications from host exposures, multiple converging intermediate phenotypes (molecular/cellular endophenotypes), and significant clinical phenotypic heterogeneity40. Traditional reductionist research approaches, which focus on a specific biomarker/pathway of interest or anchor analysis to the existing clinical classification system, are not positioned to disentangle nuanced relationships between genotype, endophenotype, and clinical phenotype. Alternative strategies incorporating machine learning, systems-based network analysis, and multi-omics integration can be employed to avoid reductionism and address the complexity of PH.
Machine Learning (ML)
ML overview.
Within the wider purview of artificial intelligence computational methods that simulate human cognitive processes, machine learning (ML) refers to the family of algorithms used to make predictions and/or infer patterns in complex data. ML is utilized increasingly for a variety of research applications in pulmonary, critical care and cardiovascular medicine41–43. In contrast to the hypothesis-based and confirmatory nature of traditional statistics, ML is generally more exploratory and hypothesis-generating. Traditional statistical analyses (e.g., logistic regression) are less equipped than ML algorithms to handle high-dimensional datasets (where the number of input variables exceeds the number of observations/samples), as they require methods to adjust for multiple testing which may produce false negatives and hamper discovery. ML algorithms accommodate a broad range of input data types including continuous or discrete clinical data, images, tracings, and multiple omics features. Several ML approaches can simultaneously account for linear and complex non-linear interrelationships between variables, as they impose fewer assumptions about the underlying data than inferential statistical models. Positioned for big data discovery, traditional ML algorithms are sub-divided into supervised, unsupervised, and reinforcement learning methods. The ensuing sections will summarize these methods and highlight applications in PH.
Supervised ML.
Supervised ML algorithms rely on human-provided ground truth, as model training (“learning”) requires that all samples are ‘labeled’ with a known output feature (e.g., disease vs control, outcome, etc.). This trained model can be implemented to predict the output in an unseen and ‘unlabeled’ dataset. Most algorithms have the capacity to predict continuous or categorical features (regression or classification). Commonly deployed supervised algorithms include support vector machines, tree-based models (e.g. random forest, classification and regression trees), naïve or tree-augmented Bayesian models, k-nearest neighbor, and advanced regression methods (e.g. LASSO, partial least squares).
Each algorithm has inherent advantages and disadvantages which are beyond the scope of this review. Algorithm choice is typically tailored to the research objective, the particular dataset, and investigator expertise. Researchers building and interpreting supervised ML models must have awareness of the delicate trade-off between bias and variance error (underfitting vs. overfitting). Algorithms are inherently prone to overfitting to noise and outliers in high-dimensional data (“curse of dimensionality”). To strike a balance between underfitting and overfitting and train a model which will perform well in an independent dataset, researchers should tune user-defined algorithm input parameters (hyperparameters). This tuning can be accomplished by iteratively testing various hyperparameter combinations (e.g. grid search) or by more sophisticated approaches (e.g., Bayesian or evolutionary optimization). Other adjunctive methods that may minimize underfitting/overfitting include ‘boosting’ and ‘ensemble learning’. Boosting entails iteratively training ML models in series, where each added model learns from the prediction errors of preceding models (e.g., gradient boosted decision trees or adaptive boosting algorithms). In ensemble learning, multiple ML algorithms are executed in parallel to form a consensus model with improved performance.
Unsupervised ML.
Unsupervised learning is employed to infer patterns in ‘unlabeled’ datasets, an agnostic approach which does not require a priori knowledge of data structure. Unsupervised ML addresses dimensionality reduction or clustering tasks. Dimensionality reduction methods (principal component analysis, multidimensional scaling, t-SNE) transform data into lower-dimensional space to provide a simpler representation of high-dimensional data, permit structure detection, and facilitate graphical visualization Clustering algorithms aim to partition samples into subgroups possessing distinct input data profiles. For example, if one were interested in classifying new molecular phenotypes of a disease without initial guidance about phenotype characteristics, unsupervised clustering could be utilized to detect patient clusters with distinct omics signatures. Clustering approaches generally aim to maximize in-cluster similarity and between-cluster dissimilarity. Many clustering methods are available including partitional algorithms (e.g., k-means, k-medoids, DBSCAN), connectivity-based algorithms (e.g., hierarchal linkage), probabilistic algorithms (e.g., Gaussian mixture/expectation maximization, Bayesian), self-organizing maps, spectral clustering, and others. The selection of a clustering algorithm is typically project and investigator-specific. Heuristic data-driven strategies can be considered to help select the algorithm and optimize internal cluster validity, such as iterative clustering on resampled data subsets (e.g., consensus clustering) or ensemble clustering with parallel implementation of multiple algorithms (e.g., COMMUNAL clustering). Careful attention to cohort selection, data quality control and pre-processing is critical to reduce the chance that clusters partitioned by unsupervised ML reflect confounding sources of heterogeneity (e.g., comorbidities, medications, assay batch effects, etc.).
Reinforcement ML.
Reinforcement learning involves algorithms (e.g., Markov decision processes and Q learning) that learn by trial-and-error to make decisions maximizing some measure of cumulative reward. Reinforcement ML algorithms are autonomous, using continuous feedback to dynamically self-adjust decisions. To date, reinforcement learning has been primarily applied in robotics and gaming fields. Few biomedical research applications have been reported, as ethical concerns exist surrounding use of autonomous trial-and-error algorithms when human life is involved. Nonetheless, a prior study of protocolized sepsis care showed the potential of reinforcement ML to assimilate multifaceted time-series data and inform sequenced treatment interventions44, 45.
Deep learning.
Deep learning (DL) is a rapidly emerging and powerful sub-field of ML involving the use of artificial neural networks that process data by mimicking human brain connectivity. Artificial neural networks consist of information processing units (“neurons”) arranged in interconnected stacks. Data are transformed and mapped in non-linear fashion across network layers to aggregate sophisticated abstract feature representations (data patterns), which capture the most informative data components for the learning task. DL methods are available to support supervised or unsupervised learning goals. The data flow underlying DL is a departure from the imposed rules-based decision processes in traditional supervised, unsupervised, and reinforcement learning algorithms. DL has been shown to outperform traditional algorithms in higher-dimensional and unstructured datasets such as medical imaging and genomics46, 47. However, DL is sometimes perceived as “black box” (models can be difficult to explain/interpret) and less user-friendly (several hyperparameters must be set). DL algorithms also require extensive computational resources and are quite prone to overfitting with smaller training datasets.
Supervised learning in PH.
ML uptake is increasing within the PH research realm, where a range of opportunities exist for supervised and unsupervised learning approaches (Figure 1). To date, supervised learning methods have been primarily executed, specifically aiming to facilitate PH diagnosis and early detection using cardiac imaging, molecular or EHR claims data.
Figure 1. Overview of applied machine learning (ML) in pulmonary hypertension (PH).

Falling under the umbrella of artificial intelligence (AI), ML describes a family of algorithms used to make predictions or infer patterns in complex datasets. Supervised ML algorithms are trained to predict a known sample label (i.e. clinical feature or outcome), where a variety of data types can be input for prediction of a continuous or categorical feature (regression or classification). Unsupervised ML algorithms are most often applied for clustering, where patterns and structure are agnostically inferred in unlabeled datasets. Deep learning, an emerging sub-field of ML in which algorithms are built on artificial neural networks mimicking human brain connectivity, can be employed for supervised or unsupervised learning tasks. This figure summarizes potential high-yield applications of supervised and unsupervised ML methods in PH.
In an early cardiac imaging study, Leha et. al trained various supervised ML algorithms (support vector machine, random forest, boosted decision trees) with 27 echocardiogram features to identify confirmed PH cases among subjects who underwent paired diagnostic cardiac catheterization48. More recent ML-based studies focused on cardiac MRI data for PH diagnosis. ML can rapidly assimilate a massive number of 3D/4D cardiac MRI data points and extract representative features that are otherwise inaccessible. Leveraging sophisticated deep learning approaches, Swift et al. and Priya S et al. extracted informative cardiac MRI features which accurately discriminated patients with PAH (AUC 0.92)49 and PH due to heart failure with preserved ejection fraction (AUC 0.96)50. However, in the aforementioned cardiac imaging studies, evaluation of ML model performance was limited to resampling-based cross-validation in the training dataset without independent cohort assessment.
Supervised ML has also been exploited to detect circulating molecular signatures of PAH. For example, Errington et al. used an ensemble ML strategy (consensus predictions across random forest, regression partition trees, LASSO regression, and boosted decision trees algorithms) to uncover a microRNA signature of PAH51. Network-based pathway analyses identified the corresponding miRNA gene targets, which accurately discriminated PAH cases in public transcriptomic datasets. In another study centred on early PAH detection among at-risk patients with systemic sclerosis (SSc) from the DETECT cohort, Bauer et al. analyzed a platform of 313 proteins and built a random forest model which distinguished PAH cases according to 8 proteins52. This model demonstrated external validity in an independent cohort (81.1% accuracy, 77.3% sensitivity, 86.5% specificity).
Finally, researchers used supervised ML to pre-emptively “sniff out” PAH from EHR data32. Training a gradient boosted decision trees algorithm on patient-level resource utilization data, a model capable of classifying individuals most likely to later develop idiopathic PAH was developed. This type of approach could facilitate population-based screening.
Supervised ML offers an appealing methodological solution for PAH risk stratification. Kanwar and colleagues reported development of the Pulmonary Hypertension Outcomes Risk Assessment (PHORA) model, a tool built using the tree-augmented naïve Bayes ML algorithm53. PHORA was trained in the Registry to Evaluate Early and Long-Term PAH Management (REVEAL) cohort, using the same predictors included in the REVEAL 2.0 risk calculator54. PHORA outperformed REVEAL 2.0 for the prediction of one-year survival (AUC 0.80 vs 0.76). ML has similarly yielded greater risk prediction accuracy than conventional statistics in other disease contexts55, 56. In contrast to existing multi-dimensional PAH risk prediction tools which stratify risk categories, PHORA outputs the absolute probability of risk. This precise assessment along the continuum could help guide therapy decisions, as existing tools often misclassify the intermediate-risk stratum and many patients in this group fail to attain goal low-risk status with treatment57.
Supervised ML might help address the unmet need to identify predictors of treatment response which guide PAH therapy selection. In a recent phase 2 trial of rituximab for SSc-associated PAH58, Zamanian and colleagues conducted a ML-based analysis of exploratory molecular data (cytokines, chemokines, adhesion and growth factors, immunoglobulin subclasses, autoantibodies, and B-cell subsets). Supervised ML algorithms (random forest, gradient boosted decision trees, support vector machines) were trained in parallel to identify a baseline molecular signature predictive of rituximab clinical response. This algorithm ensemble identified a responder signature (low levels of rheumatoid factor, IL-12, and IL-17) achieving an AUC of 0.95 in training set cross-validation. Subjects in the rituximab arm with the responder signature had a placebo-corrected six-minute walk distance improvement of +101 m (vs. placebo subjects having the signature). Although prospective validation is required, this work highlights how ML might clear a path toward precision medicine. Drug responder profiles discovered through secondary analysis of clinical trial data could be utilized to enrich subsequent cohorts with predicted responders, and thereby improve study power. In a rare disease like PAH, extending ML-based drug response predictions to a “master protocol” trial could be considered. Master protocols, which have been implemented in oncology, either simultaneously study a single therapeutic in multiple diseases/subtypes (‘basket-type’) or multiple therapeutics in a single disease (‘umbrella-type’)59. Master protocol sub-studies efficiently share the same placebo arm. In a hypothetical umbrella-type protocol, established ML models could predict responses to each agent and assign patients to the sub-study where probability of benefit is the greatest. Supervised ML could also augment adaptive trial designs in which accruing data are re-analyzed at study intervals to inform protocol changes (e.g., reconfiguration of inclusion criteria, arm assignments, or treatment protocols)60. In theory, ML could be implemented to detect futility and safety signals in real-time. These unconventional trial designs might improve study efficiency, limit resource utilization, and reduce participant risk exposure.59, 61
Finally, PH epidemiological research could be empowered by supervised ML. Population-level studies are difficult to conduct, as PH cases are often mislabeled when diagnostic codes in claims-based databases are taken at face value. In a study of EHR-Medicare claims data from academic tertiary centers, Ong et al. compared two approaches for identifying PH cases: conventional decision rules (published human-guided methods) vs. supervised ML algorithms (random forest, gradient boosted decision trees, and LASSO regression)60. Claims data input to models included diagnosis, medication, and procedure codes. All three supervised ML algorithms more accurately classified PH cases than conventional decision rules approaches. This study provides evidence that ML may help accelerate epidemiologic PH research by permitting high-fidelity cohort ascertainment in large EHR databases.
Unsupervised learning in PH.
Unsupervised ML methods have been under-utilized for PH research. However, Sweatt et al. offered a proof-of-concept study showing that unsupervised ML can uncover novel PAH molecular phenotypes62. A targeted panel of 48 cytokines, chemokines, and growth factors was measured, as inflammation is a well-recognized feature of PAH pathogenesis and multiple immune modulating therapies are under investigation. Using a consensus clustering approach to classify patients based on their blood immune profiles without initial guidance from clinical features, the authors discovered 4 PAH immune phenotypes with distinct inflammatory signatures. These immune phenotypes are independent of demographic features, comorbidities, background therapies, and PAH clinical subtypes defined by underlying etiology. Although not intended to prognosticate, this sub-phenotyping strategy stratified groups with differing clinical disease severity and long-term outcomes. Parallel implementation of their ML analysis validated the immune phenotypes in an independent cohort. Similar but larger-scale unsupervised learning efforts may enable development of disease classification schemes that sit closer to pathobiology and identify therapeutically-targetable subsets63.
Researcher degrees of freedom in ML.
Conscientious human oversight will be crucial as ML is applied in our field. To exploit the advantages and maximize the yield of ML, PH researchers must be aware of common pitfalls and how to avoid them (Table 1).
Table 1: Machine Learning.
Advantages, challenges and pitfalls with avoidance strategies.
|
Machine Learning (ML) advantages
| |
| Effective task-specific algorithms are available for a wide range of research applications | |
| Allows for accurate prediction and detection of complex patterns/relationships in data | |
| Permits agnostic and unbiased exploratory research, freedom from assumptions about underlying data | |
| Well-suited for high dimensional “omics” datasets (where number of input variables exceeds observations) | |
| Able to accommodate several types of input variables (continuous, categorical, imaging features, etc.) | |
| Can simultaneously account for linear and non-linear relationships between variables | |
| Models can autonomously improve while learning in real-time from new data | |
|
| |
| ML challenges and pitfalls | Pitfall avoidance |
|
| |
| Models trained on small datasets often have poor generalizability in other datasets | Collaborative data sharing and harmonization (particularly important in PAH, a rare disease) |
| No gold standard approaches exist for algorithm selection or hyperparameter tuning | Apply heuristic data-driven methods to objectively select algorithm and set hyperparameters |
| Algorithms can be oversensitive to noise (mislabeled data, confounding signal, assay technical artifact) | Careful attention to data collection, quality control, and pre-processing (normalization, standardization, missing value handling, batch adjustment) |
| “Black box” models (difficult to interpret) | Explain model decision processes (graphically); delineate which input variables drive model decisions (feature selection methods, variable importance measures) |
| Model decisions can unfairly disadvantage certain patient subgroups (“algorithmic bias”) | Select a cohort representative of wider disease population; include socioeconomic input variables |
| Inadequate model validation | Independent cohort validation is critical (resampling-based cross-validation on training dataset is not adequate); compare model vs. existing gold standard |
| Lack of transparency in model reporting | Full disclosure of methods; share model code and anonymized data at publication; adhere to emerging ML reporting guidelines (e.g., TRIPOD-ML) |
Network Medicine
The discussed ‘omics’-based methods have been used effectively to identify genetic risk markers that associate with PAH and prognosticate at-risk patients8, 9, as well as profile the metabolic, transcriptomic, and proteomic pattern of varying disease-relevant cell types and other patient-derived biospecimens.64,65,66,20, 62. The reductionist format of results from these assays emphasizes individual gene mutations and quantitative differences in mRNA, protein, or metabolite expression. In turn, network medicine67 is useful for deciphering functionally relevant biological pathways or phenotypic patterns from robust datasets. For molecular studies, this approach uses centralized information on functional biological interactions that is derived from transcription factor-regulatory element binding partners, binary interaction from yeast two-hybrid high-throughput datasets, kinase-substrate pairs, and other similar datasets68. For clinical studies, correlation networks have been utilized to delineate physiological parameters that refine patient subgroup69. Emergent, integrative approaches linking biological networks to clinical characteristics, known as reticulotypes70, have also been described in patients at risk for PH.71 (Fig. 2).
Figure 2. Disrupting conventional risk stratification in PAH through networks.
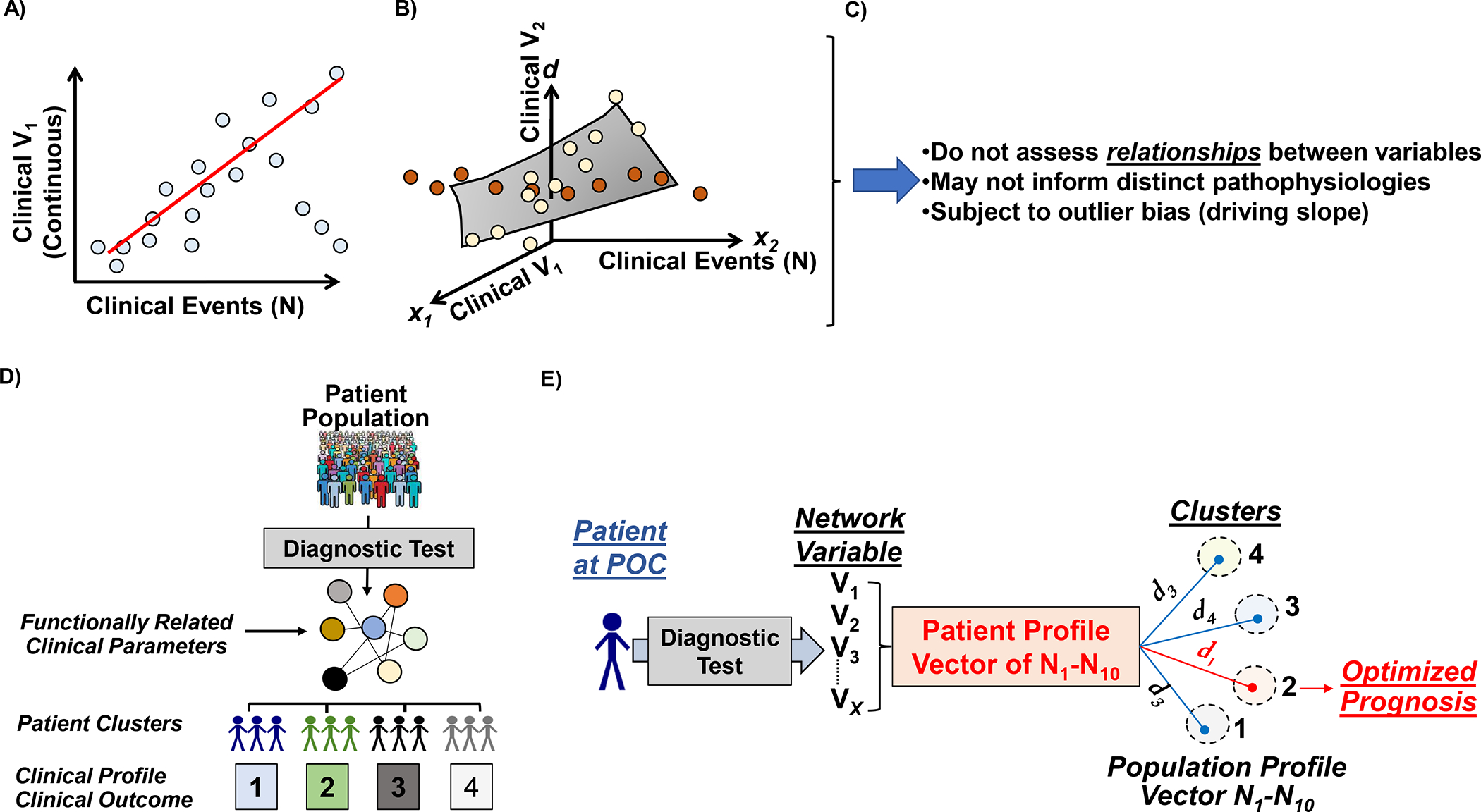
Classical strategies for risk stratification hinge on linear regression methods, including (A) univariate and (B) multivariate analyses, which estimate clinical risk based on the association individual parameters and outcomes. N, patient number. V, variable. (C) However, this approach does not inform clinical phenotypes based on functional relationships between variables and is also linked to over- and under-estimation of risk driven by extreme datapoints that alter regression slopes. (D) Phenotype networks offer an alternative approach to identifying patient subgroups, which relies on functional associations between clinical parameters as the starting point for cluster identification. (E) By focusing on a subset of functionally important clinical parameters to subgroup patients, Euclidian methods are accessible to match patients at point-of-care with similar patients for which outcome has been determined previously. This approach has been utilized to prognosticate cohorts at-risk for pulmonary arterial hypertension referred for invasive cardiopulmonary exercise testing. Panel E adapted from Oldham et al.80.
Biological networks, mechanistic studies, and network medicine in pulmonary vascular disease.
In 2012, Parikh and colleagues compiled a list from the curated literature of 131 genes directly implicated in the development of PH (that is, a PH disease module). The TargetScan 5 algorithm identified miRNA targets within the PH module, and focused on miRNA-protein pairs that were identified in the consolidated interactome that includes information on >14,000 proteins and >170,000 functional or physical protein-protein interactions (PPIs)68. From this approach, miR-21 emerged as hypoxia-sensitive and potentially relevant to PH in silico. Subsequent experiment data validated the functional importance of miR-21 to pulmonary vascular remodelling through repression of RhoB expression and Rho kinase activity that promotes angiogenesis72,73.
Samokhin and colleagues collated fibrosis genes from various repositories and segregated these by functionality (i.e., wound healing as physiologic vs. vascular fibrosis as pathogenic)74. The results were mapped to the consolidated interactome and analyzed in the context of gene targets regulated by aldosterone, which is increased in PAH and known to be pro-fibrotic75. Betweenness centrality, which leverages network distance to quantify the importance of a pathway, was used to rank ordered network features that were particularly important for delineating the two fibrosis functionalities. This approach identified the Cas protein NEDD9 as a novel pro-fibrotic intermediary in PAH in silico. Validation experiments identified a redox sensitive cysteinyl thiol at position 18 that regulates COL3A1 transcription and vascular fibrosis in PAH and, in convergent work, showed that NEDD9 is important in the pathogenesis of chronic thromboembolic PH76.
Recent mechanistic data suggesting that Csf2/GM-CSF drives inflammatory vascular injury in PAH raised the possibility that circulating levels of complement proteins may be important prognostically. Owing to the complexity of complement-regulating pathways as well as uncertainty as to the precise subsets of complement proteins that may be important to PAH, determining the most informative subset of intermediaries a priori required consideration to non-reductionist methods. To address this, investigators analyzed proteomic profiles associated with increased clinical risk in N=143 PAH patients20 to assemble a complement-PAH network, which included 13 proteins and 18 PPIs, populated heavily with complement intermediaries particularly within the alternative pathway77. The protein concentration of the intermediaries in this network defined two distinct patient subgroups (determined by a k-means analysis), which had vastly divergent outcomes profiles.
Phenotypic networks and pulmonary hypertension.
Variable outcome in PAH clinical trials and overlapping pathophysiologies across pulmonary hypertension subgroups have placed newfound importance on nuanced clinical phenotyping38. This is driven, in part, by the current approach to subgrouping patients, based largely on a narrow set of hemodynamic parameters analyzed using branch chain logic78. Approaches leveraging the integration of hemodynamic data, by contrast, have elucidated novel insight on inter-relatedness of pulmonary artery pressure, pulmonary vascular resistance, and pulmonary artery wedge pressure ranges that underlie extreme PH subphenotypes69,79.
In related work, an exercise network was assembled from N>750 patients referred for invasive cardiopulmonary exercise testing (iCPET) to clarify a diagnosis of undifferentiated dyspnea. Parameters from iCPET were assigned to one of 7 exercise functionalities (O2transport, exercise capacity, pulmonary function, invasive cardiac performance, ventilatory function, non-invasive cardiac performance, and hemodynamics)80. A pair-wise correlation network was then assembled that included only relationships between variables across different exercise functionalities to discover unexpected associations. As opposed to a direct cluster analysis, which relies solely on statistical variance among variables to determine patient subgroups, the network step permitted functional associations between clinical parameters to emerge. When focusing on the 9 variables connected in the network to peak volume of oxygen consumption (pVO2), inclusive of parameters across 5 functional domains, a cluster analysis was used to identify four discrete exercise subgroups. This approach established the framework for a novel risk assessment tool based on network medicine and Euclidean principles rather than linear regression to prognosticate patients with undifferentiated dyspnea and at risk for PH (Figure 3).
Figure 3. Leveraging networks to optimize phenotyping in pulmonary arterial hypertension.
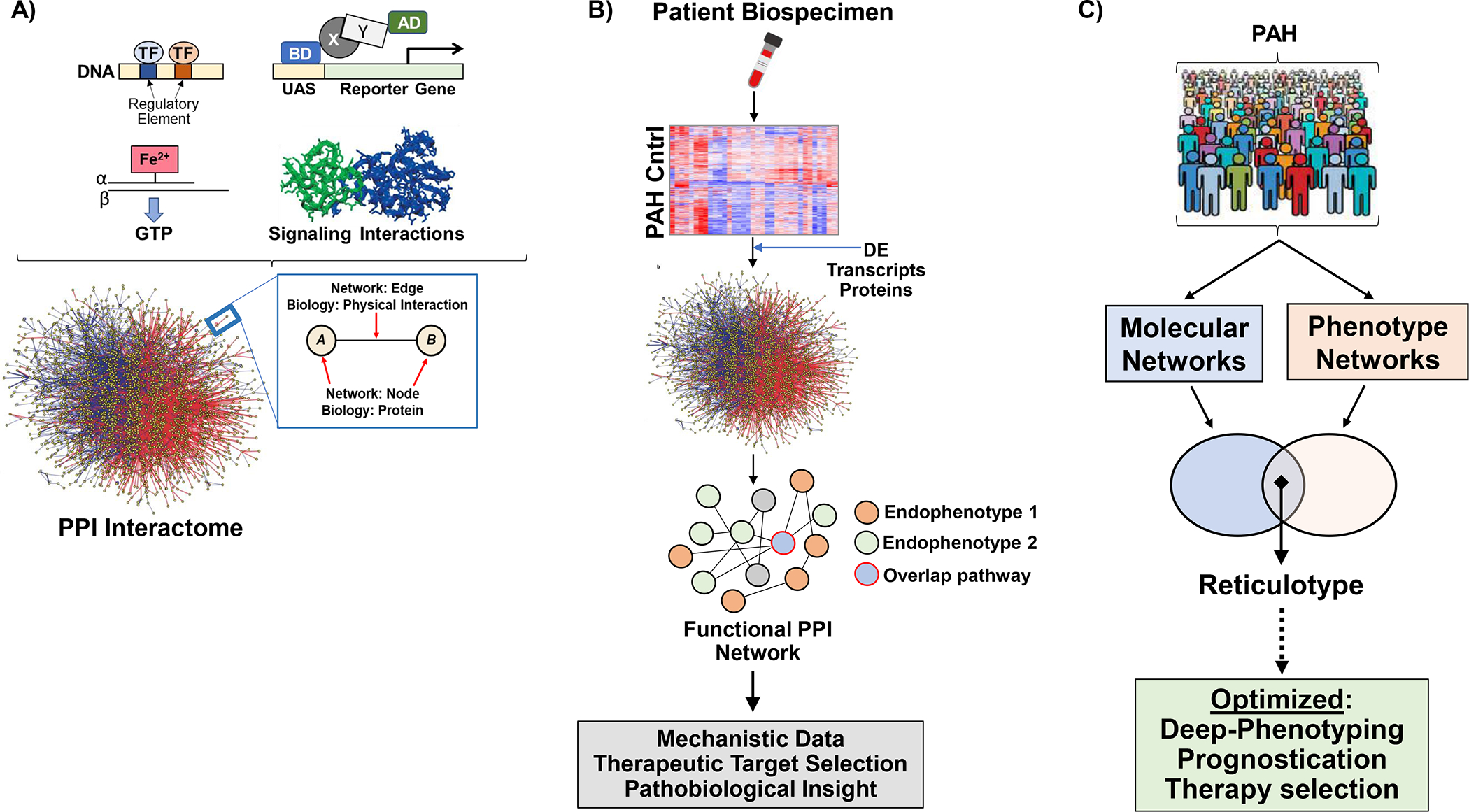
(A) Data from large scale screens profiling protein-protein interactions have been compiled from various sources to establish centralized protein-protein interactome. Thus, protein-protein interactions in the interactome reflect functional or physical associations between proteins and in this way generate a wiring map of molecular pathways inclusive of functionally relevant signaling pathways. (B) Multiplex data generating transcriptomic or proteomic signatures collected from PAH patients and controls can be analyzed further using networks. Differentially expressed data between groups is mapped to the interactome, and protein-protein interaction partners are carried forward to generate a PPI network. Thus, the network is based on biological data from patients, but transformed to a network output. Since, only valid functional- or physical- PPIs are in the interactome, the output is a wiring map of biological important PPIs informed from the patient samples. (C) The integration of PPIs with clinical phenotypic data defines reticulotypes, as reported previously for patients with World Symposium Pulmonary Hypertension Group 2 pulmonary hypertension due to cardiomyopathy71.
Drug repurposing and network medicine in pulmonary hypertension.
Owing to wide molecular target-promiscuity among approved therapeutics, drug repurposing has emerged as an important opportunity to advance care in patients with highly morbid and complex diseases. The role of network medicine to this endeavour is based on a need for emphasizing functional molecular pathways that underpin disease phenotypes, since an association between drug target and disease alone is often insufficient to predict efficacy81.
Wang and colleagues focused on 15 approved PAH therapies classified into six categories: endothelin receptor antagonists, phosphodiesterase type 5 inhibitors, parenteral prostanoids, soluble guanylyl cyclase stimulators, prostacyclin receptor agonists, and calcium channel blockers. Repositioned drug candidates were selected based on interactions with these approved PAH drugs (from DrugBank), based on shared molecular mechanisms, including drug-target, drug-enzyme, and drug-transporter associations82, resulting in 8199 drug interactions involving 1329 non-PAH drugs. The data were filtered further based on molecular/chemical structure overlap between non-PAH and PAH drugs, removal of experimental drugs, and proximity of non-PAH drug-target interactions to the PAH disease module within the consolidated interactome. Candidate drugs reinforced by supporting publications were considered, resulting in 15 drugs with biologically plausible repositioning for PAH (e.g., nintedanib, tamoxifen, pioglitazone, paclitaxel, others). Alternative approaches to drug repurposing include utilization of differential dependency networks (DDNs) to predict potential chemotherapeutics for pulmonary hypertension based on shared molecular reprogramming patterns, illustrated through networks, observed in response to drug treatment in cancer and as well as under conditions of hypoxia and inflammation83.
Defining pathogenic pathways: reticulotypes.
Recently, a method for individualizing PPI networks was applied it to a cohort of patients with heart failure from obstructive hypertrophic cardiomyopathy (HCM), which predisposes to Group 2 pulmonary hypertension84. Individualized PPI network data could be used to predict pathobiological and histopathophenotypic profiles that were unique to specific patients71. The individual patient network features also correlated with key parameters associated with pulmonary hypertension and adverse outcome in heart failure including indexed pulmonary vascular resistance. Orthogonal approaches to grouping patients via patient-patient networks (formulated by clinical, biological, or combined datasets) have been reported in cancer cohorts81, and hold promise for clarifying reticulotypes in pulmonary hypertension patients that could form the basis for personalized therapeutics.
Integrated omics
Prior deep phenotyping studies of PAH have been largely single-omic in nature, yet molecular profile alterations were observed within each domain. Viewing these alterations from the single-omic perspective offers only a partial glimpse of the overall pathobiological picture, ignoring a multitude of potentially important interdependencies. Integrated multi-omics analysis could yield a more complete understanding of relationships between genotype, environment, and converging endophenotypes that underlie observed clinical heterogeneity in PAH.
Examples of the simplest multi-omics approaches include verifying that an altered RNA expression profile is also reflected in proteomic measurements, or rather defining genetic variants responsible for alterations in levels of molecules (quantitative trait loci, QTL, see below). However, it can also be the case that one platform informs another without examining the same gene or its product. In general, multi-omics data can be integrated either sequentially, wherein omics domains are analyzed independently and the results are then correlated/aggregated downstream, or simultaneously, wherein sophisticated computational methods are used to conduct integrative analysis of pooled omics datasets85. Under the more basic sequential integration construct, single-omic analysis first selects the molecular features in a domain which are most informative for the research task (i.e. differentially expressed features, or a subset of features associated with a clinical variable or outcome). Selected features from each omics domain can then be correlated, or aggregated and mapped to public interaction networks, pathway databases, and other available knowledge sources to infer a shared biological context. In contrast, the simultaneous integration strategy reduces bias through a more holistic systems-based analysis of pooled multi-omics data85, 86. As further discussed below, a variety of computational methods have been increasingly implemented for simultaneous integration in oncology studies87. Simultaneous integration approaches are likely to power the future of multi-omics research in PH40. However, proof-of-concept for the use of multi-omics data in PH is currently limited to a few studies involving sequential integration.
In a study from Harbaum and colleagues88, PAH patients underwent NMR-based metabolomic profiling and paired proteomic analysis in blood. Patients with poor clinical outcomes were found to have a reduction of high-density lipoprotein (HDL-4) particles carrying pro-fibrinolytic proteins, such as alpha-2-antiplasmin. Lipoprotein subclasses were quantified by NMR, correlated with proteomic measurements, and presence of associated proteins ApoA1, prekallikrein and neuropilin-1 confirmed in the HDL-4 subfraction by ELISA assay of ultracentrifuged plasma.
Common genetic variants associated with risk of disease development identified by genome wide association studies (GWAS) are often located in non-coding genomic locations either intronic or intergenic. Understanding of the likely mechanistic importance commonly involves interpretation of multiple layers of public omics datasets including epigenomic and transcriptomic data. Histone modifications and DNA accessibility data indicate the likely presence of tissue-specific regulatory regions (promoters, enhancers) and chromatin immunoprecipitation-sequencing data identify potentially modified binding proteins (transcription factors/repressors). Chromatin conformation data, where DNA is cross-linked, sheared and sequenced to understand the 3-dimensional interactions of DNA segments (e.g. HiC data89), can inform on the potential target genes of distant regulatory elements. These analyses were applied to the PAH GWAS, where the chromosome 8 signal was characterised to alter activity of enhancer elements active in endothelial cells, in a topologically associated domain (TAD, based on HiC data) containing only the SOX17 gene. Functional studies in human PAEC confirmed that CRISPR-inhibition targeting the enhancer region specifically repressed Sox178. Another impressive example of interpreting a noncoding GWAS hit comes from coronary artery disease, where the 1p13 locus was characterised first by quantitative trait loci (QTL) analysis, where common genetic variants are associated with phenotypes for example gene expression (eQTL), determining 3 genes whose levels were associated with the variation. Overexpression of only one of these genes, SORT1, specifically affected murine metabolite profiles including hepatic very low-density lipoprotein (VLDL) secretion, defining a key role for this gene in coronary disease90.
The benchmark for integrated multi-omics analysis has been set by the oncology field, where studies exemplify that merging various combinations of omics data supplies more clear and holistic insights into pathobiology86. These successes have spurred the rapid development of numerous bioinformatics tools for simultaneous multi-omics data integration, analysis, and visualization87. Integrative methods are available to support either supervised prediction or unsupervised clustering efforts. These approaches could therefore be used in PH to identify multi-omics signatures that facilitate early diagnosis, prognosticate, predict treatment response, or discriminate new sub-phenotypes. There are theoretical benefits of multi-omics integration over single-omic analysis. Integration methods may reduce the effects of non-biological noise, and they are poised to capture lower-dimensional representations across omics domains that are reflective of cellular regulation. However, a recent benchmark analysis found that single-omic clustering methods sometimes yield better results than multi-omics approaches91. This signals that the integrated omics field remains in an early exploratory stage, and methods may rapidly evolve as experience accrues. However, several challenges will need to be addressed as integrated omics efforts materialize. Building multi-omics datasets will be costly and resource intensive. No standard methods are available for sample size determination, and securing an independent validation cohort with the same multi-omics data may be challenging in a rare disease like PH.
Fortunately, the PH research community appears ready to tackle these challenges, as evidenced by the formation of several collaborative networks focused on collecting multi-omics data (see ‘Registries and research networks’ section). Some of these networks, including the PVDOMICS initiative, are capturing longitudinal data. The Integrated Personal Omics Profiling (iPOP) project, which initially began with broad omics in a single individual and subsequently expanded to larger sub-cohort analyses, offers an exciting glimpse of how longitudinal multi-omics integration might lead to personalized precision medicine92. As part of this project, more than 100 patients in a cohort enriched for diabetes risk underwent deep integrated longitudinal profiling quarterly for up to 8 years (clinical measures, genome, immunome, transcriptome, proteome, metabolome, microbiome, and wearable monitoring). This produced innumerable discoveries including the characterization of inter- and intra-person variability in health, the identification of molecular pathways associated with multiple disease states, detection of distinct host and microbial alterations in response to immunization and viral infection, and the development of signatures predictive of diabetes prior to onset93, 94. Therefore, multi-omics analyses incorporating the dimension of time have the potential to detect health to disease transitions, determine how various perturbations directly impact a disease state and outcomes, and truly scrutinize the effects of environmental and genetic factors on clinical phenotype95.
Understanding PH through omics data
Genetic risk and Mendelian randomisation
The availability of genomic data in large populations with detailed phenotype data allows the interrogation of how common genetic variation drives changes in these phenotypes (i.e. QTL analyses). Through cataloguing and weighting of variants associated with phenotypes or diseases it is possible to calculated estimated genetics risks for development or worsening of conditions, or genetic risk models. These have become well-advertised for common conditions with commercial offerings garnering some popularity, but for rare conditions with few associated variants this is more restricted to rare variants which have greater impact and are more useful for understanding risk in families with heritable disease forms. Another use for the QTL of common phenotypes is the testing of likely causality for associations between a phenotype and an outcome such as disease development using methods known as Mendelian Randomisation (MR) analyses. MR analyses provide a summary of genetic evidence for causation by testing whether QTL for the phenotype are similarly associated with disease development (i.e. in disease GWAS data), based on the assumption that QTL act directly on the phenotype and cannot be affected by the disease secondarily unlike the phenotype itself which is often plastic. This also relies on the assumption that the variants act on the phenotype alone and could not be associated with the disease by another confounding mechanism.
In practice this requires GWAS summary data for both the QTL and the outcome and since the completion of the international PAH GWAS study, it is now possible to test phenotypes with QTL established by other studies (2-step MR). One recent example of this was the testing of likely causality of iron deficiency on development of PAH. Iron deficiency is common in PAH and is associated with poor clinical outcomes, but whether this is due to an effect of iron on pulmonary vasodilation or remodelling, or whether the development of PAH itself drives iron deficiency, was not established. Red cell distribution width (RDW) is a marker of iron deficiency, itself associated with poor outcomes in many conditions including PAH, and the genetic variation which drives variability in RDW has been well studied in large population analyses, making it an ideal candidate for an MR analysis. MR analysis demonstrated that variants strongly associated with higher RDW levels were not themselves associated with development of PAH to the extent that would be predicted by the observed association between iron deficiency and PAH96. This was subsequently backed up by results from studies utilising intravenous iron therapy to restore iron stores in PAH which demonstrated no improvement in PVR or exercise capacity associated with effective therapy97. This illustrates the potential for genetics data to inform pathogenesis beyond the single variants most strongly associated with disease development. Definition of therapeutic strategies most likely to fail is equally valuable to defining those most likely to succeed. The application of these approaches is dependent on the strength of the GWAS data on both QTL and disease and will inevitably become more powerful as phenotypes are better studied in populations, but most importantly, if PAH GWAS data can be expanded to a larger population of PAH patients more comparable with common disease GWAS studies.
Reclassifying PH into new sub-phenotypes
The clinical classification of PH, which organizes patient subgroups according to hemodynamic parameters and predisposing conditions98, has provided a practical framework for patient care and research. However, this system overlooks deeper pathobiological differences across patients which likely contribute to observed variability in disease progression and outcomes. Patients are commonly encountered who do not fit into only one bin of the PH clinical classification, due to a mixed hemodynamic profile or multiple predisposing conditions. Moreover, the framework does not inform PAH therapy selection or predict treatment responses. Although effective PAH therapies have been developed under this classification, no disease-modifying agents are available and prognosis remains poor with the current “one-size-fits-all” paradigm. Several emerging therapies have failed in PAH clinical trials after showing pre-clinical promise, yet these trials assumed a common pathophenotype across patients. For these reasons, experts call for discovery of novel PH sub-phenotypes through initiatives focused on deep omics profiling99–102. Identifying new subgroups with shared molecular features could help disentangle nuanced endophenotype-clinical phenotype relationships, uncover novel disease mechanisms and biomarkers, enhance clinical risk assessment, and foster therapeutic development. The vision is to identify PH sub-phenotypes responsive to specific therapies that could help enrich clinical trial cohorts and set the stage for precision medicine.
The study discussed from Sweatt et al.62, in which PAH was reclassified into immune phenotypes via unsupervised ML, serves as proof-of-concept for future sub-phenotyping initiatives. Despite a targeted single-omic platform and cross-sectional sampling at one time point, this study demonstrated immune profiling is a viable framework for PAH sub-phenotyping. Additional research is needed to prospectively validate these sub-phenotypes, elucidate the signalling pathways driving their circulating profiles (endotype refinement), and ultimately evaluate their responses to targeted therapies. The ongoing PVDOMICS initiative is well-positioned to advance sub-phenotype discovery through larger-scale profiling spanning multiple omics domains102.
Future PH sub-phenotyping efforts may rely heavily on unsupervised ML (Figure 4), which has uncovered sub-phenotypes in other cardiopulmonary diseases including heart failure with preserved ejection fraction103–105, asthma106, ARDS107–109, and sepsis110, 111. Unsupervised learning methods are well-suited for disease reclassification, allowing a cohort to be partitioned into subgroups/clusters in an agnostic data-driven manner. These methods permit a “birds-eye view” of heterogeneity in a population. However, many roads may “lead to Rome” in the quest to elucidate molecular sub-phenotypes. There is a parallel role for supervised learning or network-based strategies that anchor molecular data analysis to important clinical sub-traits or markers. For example, previous studies anchored supervised analyses of genomic and transcriptomic data to the vasoreactive clinical sub-phenotype of PAH 112, 113, a patient subset exhibiting a robust response to calcium channel blockers and prolonged survival. These studies refined the vasoreactive pathophenotype by characterizing underlying genetic variation and enriched signalling pathways. Similar strategies revealed molecular features of the maladaptive right heart phenotype in PAH. In these studies, echocardiogram and cardiac MRI parameters of right ventricular remodelling served as anchor points for supervised analyses of proteomic114 and metabolomic data30, respectively.
Figure 4. Translating PH sub-phenotype discovery into actionable knowledge and clinical applicability.

A blueprint is offered for possible investigations that may occur following initial unsupervised ML-based discovery of PH sub-phenotypes. First, independent cohort validation is required prior to additional follow-up studies. Because many initial sub-phenotyping studies may be limited to cross-sectional blood omics profiling, follow-up longitudinal analyses will be warranted to understand if and how phenotype-specific molecular profiles evolve during the disease course. To gain insight into the mechanistic underpinnings of a sub-phenotype, signaling pathways can be inferred in silico from public molecular interaction networks or enrichment databases. Implicated pathways can then be functionally validated in animal models of PH or examined in molecular studies of lung tissue from PH patients. To permit feasible sub-phenotype classification in the clinic or drug trial setting, parsimonious classifiers must be developed that require only a limited number of readily obtainable input variables. A classifier could be implemented for secondary analysis of data and samples from completed clinical trials. Data from this secondary analysis might provide the foundation for design of an innovative clinical trial (split-phase, master protocol, or adaptive design).
Important issues will emerge as the field of PH sub-phenotyping matures. With expanded access to paired omics data in PH, researchers will undoubtedly transition from single-omic to integrated multi-omics analysis. Integrated omics could enable more nuanced sub-phenotype characterization, yet it will require multi-disciplinary expertise, extensive analytical resources, and arduous validation studies (see ‘Integrated omics’ section). Regardless of the omics platform(s) utilized, linking detected sub-phenotype signatures to biological pathways will depend on in silico extraction of associations from existing knowledge sources (e.g., interaction networks, gene set/metabolite enrichment databases, etc.). Because these knowledge sources are not PH-specific, pathways implicated in silico should be validated in context-relevant mechanistic PH studies at the bench. Functionally validated pathways could be prioritized as candidate phenotype-specific therapeutic targets. PH sub-phenotyping initiatives will largely depend on “liquid biopsy”, as it is not feasible to obtain pulmonary vascular or right heart tissue from patients during their disease course. The extent to which blood molecular profiles correspond with lung pathobiology is unknown. Although explanted lungs from PAH transplant recipients are available to interrogate blood-derived sub-phenotype pathways of interest (e.g., PHBI research network), correlating early-disease blood profiles with end-stage molecular features in the lung is problematic. There is a need for innovative animal models of PH which permit multi-tissue omics studies and can somehow be linked to human profiles. Also, PH sub-phenotyping studies must expand from cross-sectional to longitudinal omics analysis. While resource-intensive and analytically complex, longitudinal studies will elucidate the constitutive dysregulated pathways of PH sub-phenotypes. Serial profiling will also delineate whether a sub-phenotype exhibits dynamic alterations with treatment interventions and disease progression. Moreover, longitudinal data could be utilized for trajectory-based sub-phenotyping, an approach recently exemplified in COVID-19 cohorts115. In PAH, this method might identify patients at high risk of deterioration who possess targetable early-warning signatures.
Finally, researchers will face the challenge of translating validated PH sub-phenotyping approaches into the clinic. Parsimonious models must be developed to allow feasible sub-phenotype detection in real-world practice. In such models, only a small number of readily available clinical and/or molecular features are required to accurately classify sub-phenotypes previously discovered based on more complex input data. This type of parsimonious classifier could be applied in the clinical trial setting to facilitate evaluation of sub-phenotype responses to investigated therapies. Given the rare nature of PAH, we must attempt to maximize use of data acquired from clinical trials. For example, data or stored samples from a completed trial could provide the input variables necessary for an established sub-phenotype classifier. An exploratory post-hoc analysis of sub-phenotype response to therapy might provide the basis for a subsequent dedicated phenotype-enriched trial. Secondary analyses of clinical trial data have previously uncovered therapy-responsive sub-phenotypes in ARDS108, 109 and heart failure with preserved ejection fraction105. The complex path to identifying therapy-responsive PH sub-phenotypes will require collaborative data sharing, careful planning, and the formation of large clinical trial networks.
Treatment strategies driven by large data in PH
Improved/early diagnosis
Patients typically experience a significant delay between onset of symptoms and eventual diagnosis of PH, due to the non-specific presentation and lack of simple non-invasive tests for early screening. Patients with PAH whose delay was over 2 years have demonstrated poorer outcomes, with an 11% increase in mortality risk after correcting for age, sex and diagnostic subgroup in a registry analysis of Australia and New Zealand’s PH services with little sign of change in delay times since 200433. Similarly, more advanced disease indicated by increased PAP in systemic sclerosis (SSc) associated-PAH leads to worse survival, suggesting earlier capture of patients could lead to improved outcomes116. Heritable PAH patients may have shorter diagnostic delays (median of 0.39 years in Khou et al33), perhaps reflecting progress in genetic screening programmes which are being informed by advances from next generation sequencing efforts as described above. As previously highlighted, supervised ML identified an eight-protein panel able to distinguish PAH from non-PAH within at-risk SSc patients in the DETECT study52. The specificity of the proteins is important to complement the sensitive but non-specific nature of the clinical algorithm. This study also identified combinations of proteins able to estimate PVR, although none were more accurate than NT-proBNP, illustrating the challenge of identifying early markers of disease progression. The ability of the metabolomics and transcriptomics datasets described above to distinguish PAH from controls suggest the potential for utility in these methodologies for screening strategies to reduce the delay in diagnosis from symptomatic presentation. The demonstration of clinical potential of these approaches will require prospective analysis of more representative populations at risk (such as breathlessness resistant to asthma therapies) enriched with PH cases of mixed aetiologies, in contrast to the well-defined, homogenous study populations which have provided proof-of-concept thus far.
Prognostic stratification
The improvement in risk stratification of PH would serve at least two purposes in identifying patients who could benefit most from aggressive therapy (triple therapy including intravenous prostacyclin analogue) and in defining populations of patients who stand to benefit most from the development of novel therapeutic strategies. As described above, omics approaches have defined panels of proteins, metabolites and genes associated with poorer outcomes and it remains to be established which are the most useful markers and which may further represent genuine therapeutic targets. One exciting example that may be both is the measurement of circulating neutrophil elastase or elafin levels for determining the likelihood to responding to elafin therapy, which is in phase 1 clinical trials117. The direct application of omics discovery approaches to PH populations is more likely to generate markers which truly reflect the disease process than borrowing/adapting markers developed in other, more common conditions. For example, NT-proBNP is a hard-to-beat prognostic marker in PH, but is not going to be useful for discriminating right from left ventricular dysfunction, as it is produced by stressed cardiomyocytes in either location. For novel prognostic markers to be useful in PH, they must perform better than or independently of established risk factors such as the REVEAL21, 118 or French119 risk equations, as was demonstrated for the protein panel and REVEAL20. Established clinical targets would be complemented by molecular targets derived from large data approaches focussed on independent predictors of progression and mortality (Figure 5). Until high-throughput omics methodologies become available in clinical pathology laboratories then it remains the case that the most useful specific molecules must be worked up into more practical targeted assays with a comparable cost to, for example, NT-proBNP measurements, and validated for utility in integrated clinical pathways.
Figure 5:
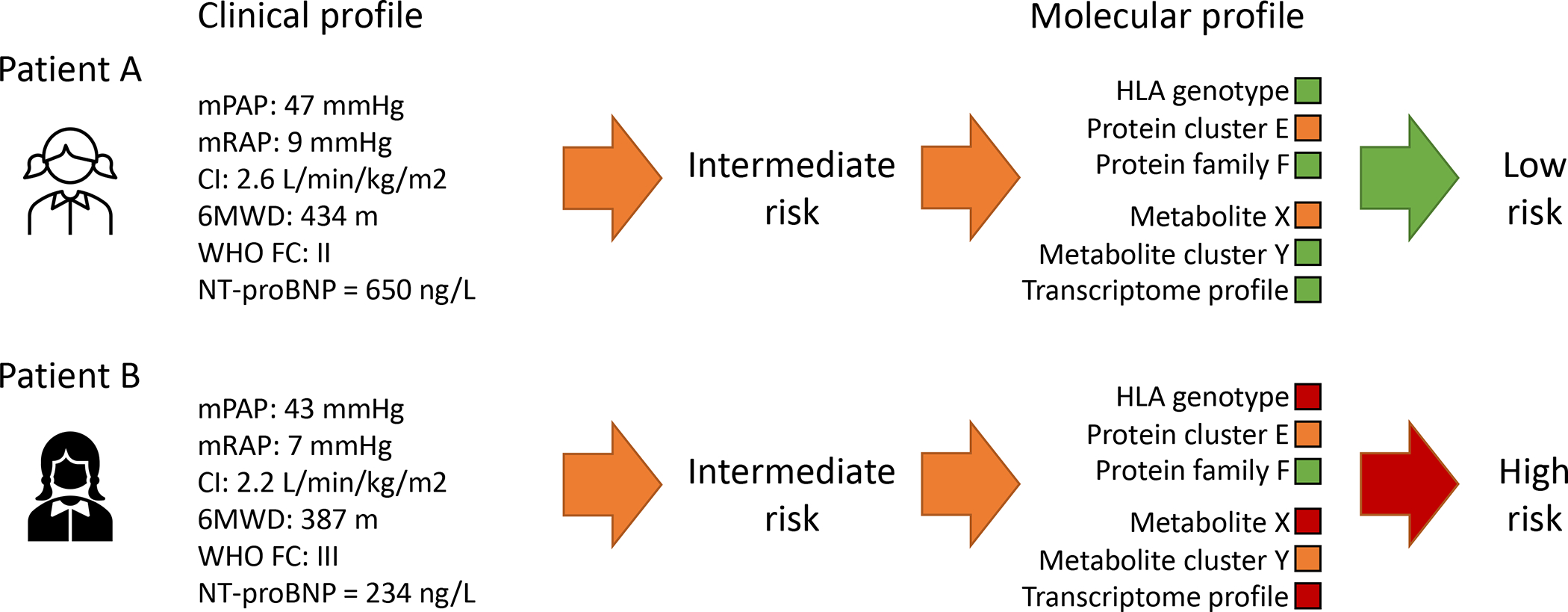
Illustrative example of how molecular profiles derived from understanding of large datasets could be integrated into standard clinical risk stratification to improve risk estimates. Established clinical risk factors enable identification of very high and very low risk patients but risk in more intermediate cases is harder to establish. Independent molecular stratifiers could provide additional information on whether a patient is considered to be higher or lower risk and therefore guide clinical decision making.
Prediction of therapeutics for repurposing
As the data on molecular profiles in PH continue to build there will be increased evidence for the requirement to develop therapeutic strategies to modify full profiles rather than representative single molecules. The establishment of databases of molecular responses to available drug libraries will also enable the prediction of drugs which might be suitable for re-purposing for use in treating PH on the basis of targets other than their defined or understood mechanism of action. An excellent example of this in action was recently published by the Rabinovitch lab120. Twenty candidate drug compounds identified from 4,500 by a screening strategy of reduced caspase activation in patient-derived endothelial cells were further narrowed down by comparison of drug signatures in the Library of Integrated Network-Based Cellular Signatures (LINCS) database to a PAH lung gene signature derived from public transcriptomic datasets. The LINCS database, containing gene expression responses of multiple screened cell lines to thousands of characterised drug compounds, enables prediction of matches between genes which change in disease and those that would be corrected by the drug therapy. This narrowed the candidate drugs from 20 to 2 and finally a lead compound (AG1296) was demonstrated to show efficacy in in vitro and in vivo disease models120. Testing all 20 compounds would not have been feasible or economically viable for a single research group and would most likely have ended up with few more than the one compound showing efficacy in the models. Expansion and improvement of both drug and disease molecular databases will facilitate future efforts for candidate drug screening and like the Mendelian Randomisation approaches will likely also show great value in de-prioritising compounds likely to show no or even opposing effects further down the development process before significant costs are incurred.
Summary and future perspectives
Early diagnosis and personalized drug therapy selection are two major unmet needs in PH. For the former, integrating electronic health records, artificial intelligence to unmask information hidden currently in screening tests, and genetic risk factors is an emerging path forward to offset delayed and inaccurate diagnosis. For the latter, strategies that identify functionally important molecular pathways and bolstered by findings across multi-omics platforms are well-positioned to individualize drug therapy selection. In these regards, novel advances in the next era of PAH stand to refocus attention on each critical aspect of the individual patient, processed as a collective, to administer optimal healthcare.
Central Illustration. Deep phenotyping in the next era of pulmonary hypertension.
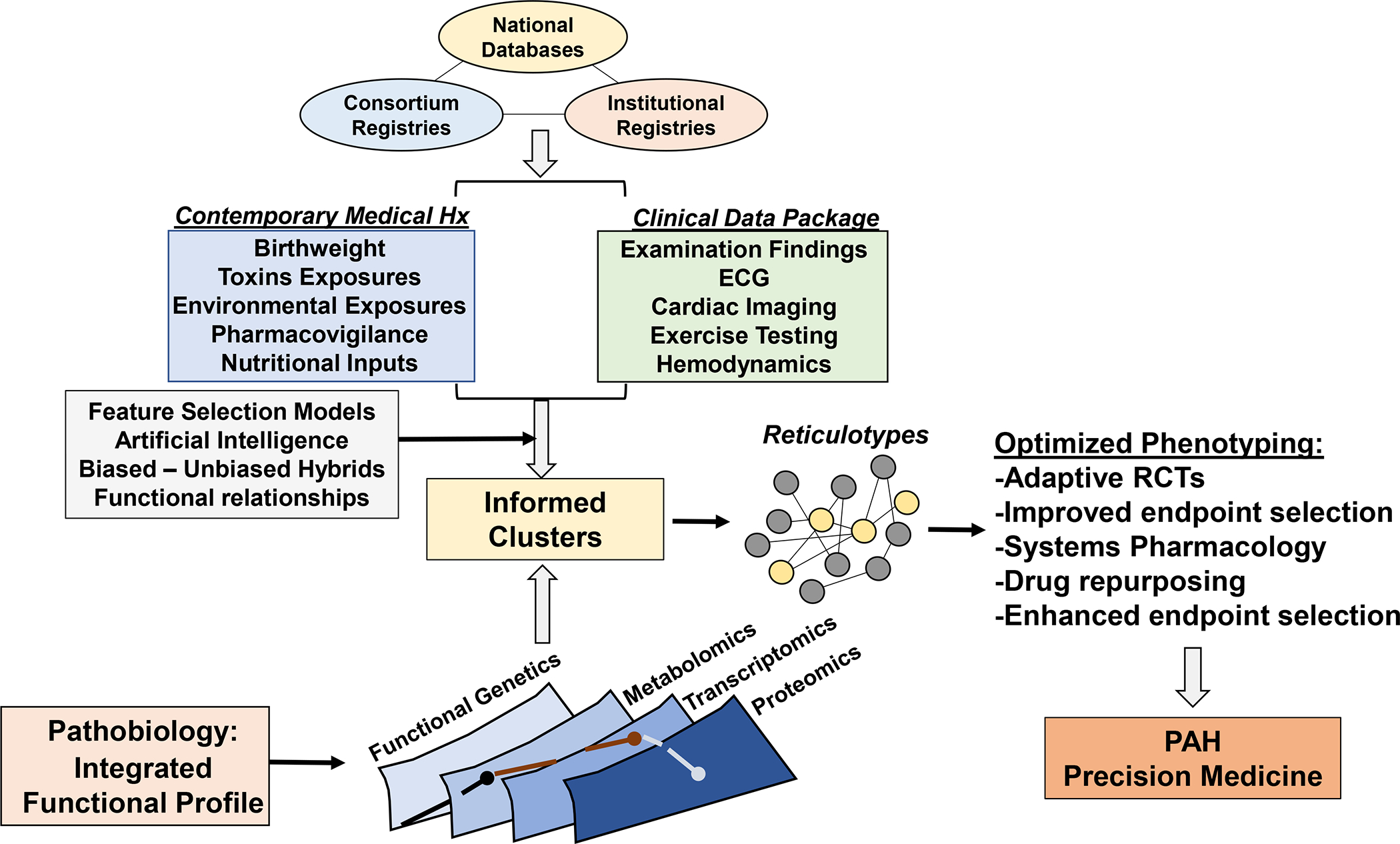
A substantiation number of large registries through foundation support, international collaborations, and institutional registries collecting clinical and biological data have emerged over the past 10 years. Integration of these data, coupled with unbiased and biased analytical methodologies, will be critical for clarifying the phenotypic profile of pulmonary hypertension. Expanding the range of collected data to non-conventional parameters, including perinatal events, nutritional patterns, toxic exposures, and pharmacovigilance programs (as already reported in France) via electronic medical record-based systems and other personalized device mechanisms will be critical for integrating genetic risk with acquired disease determinants. Ultimately, phenotyping patients will hinge on the identification of functionally important molecular pathways, inclusive of various –omics data, to generate reticulotypes. In turn, valid reticulocytes are well-positioned to optimize clinical trial design and establish a path toward individualized drug selection and, hence, precision medicine.
Source of funding statement:
Dr Rhodes is supported by a BHF Intermediate Basic Science Research fellowship (FS/15/59/31839) and Academy of Medical Sciences Springboard fellowship (SBF004\1095). Dr Sweatt is supported by a NIH/NHLBI Career Development award (grant # 1K23HL151892). Dr Maron is supported by NIH 1R01HL139613-01, R01HL153502, R01HL155096-01, 2021A007243 BWH/MIT-Broad Institute; McKenzie Family Charitable Trust.
Abbreviations
- AI
Artificial intelligence
- ARDS
Acute respiratory distress syndrome
- AUC
Area under the curve
- BNP
Brain natriuretic peptide
- CLIC4
Chloride intracellular channel protein 4
- CMR
Cardiac Magnetic resonance (imaging)
- CPET
Cardiopulmonary exercise testing
- CTEPH
Chronic thromboembolic PH
- DBSCAN
Density-Based Spatial Clustering of Applications with Noise
- DDN
Differential dependency networks
- EHR
Electronic health record
- GWAS
Genome wide association studies
- HCM
Hypertrophic cardiomyopathy
- HDL
High density lipoprotein
- HES
Hospital admission statistics
- ICON
International Consortium for Genetics (of PAH)
- IL
Interleukin
- IPAH
Idiopathic pulmonary arterial hypertension
- LASSO
Least absolute shrinkage and selection operator
- LC
Liquid chromatography
- ML
Machine learning
- MR(I)
Magnetic resonance (imaging)
- MS
Mass spectrometry
- NEDD9
Neural precursor cell expressed developmentally down-regulated protein
- NGS
Next generation sequencing
- NHS
National Health Service (UK)
- NMR
Nuclear Magnetic resonance
- PAEC
Pulmonary arterial endothelial cell
- PAH
Pulmonary arterial hypertension
- PAP
Pulmonary arterial pressure
- PH
Pulmonary hypertension
- PHBI
Pulmonary Hypertension Breakthrough Initiative
- PHORA
Pulmonary Hypertension Outcomes Risk Assessment
- PPI
Protein-protein interactions
- PVDOMICS
Pulmonary Vascular Disease ‘-omics’ Project
- PVR
Pulmonary vascular resistance
- QTL
Quantitative trait loci
- RDW
Red cell distribution width
- REVEAL
Registry to Evaluate Early and Long-Term PAH Management
- RV
Right ventricle
- SOX17
SRY-Box Transcription Factor 17
- TAD
Topologically associated domain
- t-SNE
t-Distributed Stochastic Neighbor Embedding
- VLDL
Very low-density lipoprotein
- VO2
Volume of oxygen consumption
Footnotes
Disclosures statement: The authors disclose no direct conflicts in this work. Dr Maron discloses Consultant roles for Actelion Pharmaceuticals and Tenax, and a Grant / Contract from Deerfield Company.
References
- 1.Southgate L, Machado RD, Graf S and Morrell NW. Molecular genetic framework underlying pulmonary arterial hypertension. Nature reviews Cardiology. 2019. [DOI] [PubMed] [Google Scholar]
- 2.Graf S, Haimel M, Bleda M, Hadinnapola C, Southgate L, Li W, Hodgson J, Liu B, Salmon RM, Southwood M, et al. Identification of rare sequence variation underlying heritable pulmonary arterial hypertension. Nature communications. 2018;9:1416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Zhu N, Pauciulo MW, Welch CL, Lutz KA, Coleman AW, Gonzaga-Jauregui C, Wang J, Grimes JM, Martin LJ, He H, et al. Novel risk genes and mechanisms implicated by exome sequencing of 2572 individuals with pulmonary arterial hypertension. Genome Med. 2019;11:69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Zhu N, Swietlik EM, Welch CL, Pauciulo MW, Hagen JJ, Zhou X, Guo Y, Karten J, Pandya D, Tilly T, et al. Rare variant analysis of 4241 pulmonary arterial hypertension cases from an international consortium implicates FBLN2, PDGFD, and rare de novo variants in PAH. Genome Med. 2021;13:80. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Wu Y, Wharton J, Walters R, Vasilaki E, Aman J, Zhao L, Wilkins MR and Rhodes CJ. The pathophysiological role of novel pulmonary arterial hypertension gene SOX17. Eur Respir J. 2021;58. [DOI] [PubMed] [Google Scholar]
- 6.Hodgson J, Swietlik EM, Salmon RM, Hadinnapola C, Nikolic I, Wharton J, Guo J, Liley J, Haimel M, Bleda M, et al. Characterization of GDF2 Mutations and Levels of BMP9 and BMP10 in Pulmonary Arterial Hypertension. American journal of respiratory and critical care medicine. 2020;201:575–585. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Swietlik EM, Greene D, Zhu N, Megy K, Cogliano M, Rajaram S, Pandya D, Tilly T, Lutz KA, Welch CCL, et al. Bayesian Inference Associates Rare KDR Variants with Specific Phenotypes in Pulmonary Arterial Hypertension. Circ Genom Precis Med. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Rhodes CJ, Batai K, Bleda M, Haimel M, Southgate L, Germain M, Pauciulo MW, Hadinnapola C, Aman J, Girerd B, et al. Genetic determinants of risk in pulmonary arterial hypertension: international genome-wide association studies and meta-analysis. The Lancet Respiratory medicine. 2019;7:227–238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Evans JD, Girerd B, Montani D, Wang XJ, Galie N, Austin ED, Elliott G, Asano K, Grunig E, Yan Y, et al. BMPR2 mutations and survival in pulmonary arterial hypertension: an individual participant data meta-analysis. The Lancet Respiratory medicine. 2016;4:129–37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.King EA, Davis JW and Degner JF. Are drug targets with genetic support twice as likely to be approved? Revised estimates of the impact of genetic support for drug mechanisms on the probability of drug approval. PLoS Genet. 2019;15:e1008489. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Liu D, Yan Y, Chen JW, Yuan P, Wang XJ, Jiang R, Wang L, Zhao QH, Wu WH, Simonneau G, et al. Hypermethylation of BMPR2 Promoter Occurs in Patients with Heritable Pulmonary Arterial Hypertension and Inhibits BMPR2 Expression. American journal of respiratory and critical care medicine. 2017;196:925–928. [DOI] [PubMed] [Google Scholar]
- 12.Perros F, Cohen-Kaminsky S, Gambaryan N, Girerd B, Raymond N, Klingelschmitt I, Huertas A, Mercier O, Fadel E, Simonneau G, et al. Cytotoxic cells and granulysin in pulmonary arterial hypertension and pulmonary veno-occlusive disease. American journal of respiratory and critical care medicine. 2013;187:189–96. [DOI] [PubMed] [Google Scholar]
- 13.Gamen E, Seeger W and Pullamsetti SS. The emerging role of epigenetics in pulmonary hypertension. Eur Respir J. 2016;48:903–17. [DOI] [PubMed] [Google Scholar]
- 14.Elinoff JM, Mazer AJ, Cai R, Lu M, Graninger G, Harper B, Ferreyra GA, Sun J, Solomon MA and Danner RL. Meta-analysis of blood genome-wide expression profiling studies in pulmonary arterial hypertension. Am J Physiol Lung Cell Mol Physiol. 2020;318:L98–L111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Stearman RS, Bui QM, Speyer G, Handen A, Cornelius AR, Graham BB, Kim S, Mickler EA, Tuder RM, Chan SY, et al. Systems Analysis of the Human Pulmonary Arterial Hypertension Lung Transcriptome. Am J Respir Cell Mol Biol. 2019;60:637–649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Rhodes CJ, Otero-Nunez P, Wharton J, Swietlik EM, Kariotis S, Harbaum L, Dunning MJ, Elinoff JM, Errington N, Thompson AAR, et al. Whole-Blood RNA Profiles Associated with Pulmonary Arterial Hypertension and Clinical Outcome. American journal of respiratory and critical care medicine. 2020;202:586–594. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Hong J, Arneson D, Umar S, Ruffenach G, Cunningham CM, Ahn IS, Diamante G, Bhetraratana M, Park JF, Said E, et al. Single-Cell Study of Two Rat Models of Pulmonary Arterial Hypertension Reveals Connections to Human Pathobiology and Drug Repositioning. American journal of respiratory and critical care medicine. 2021;203:1006–1022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Saygin D, Tabib T, Bittar HET, Valenzi E, Sembrat J, Chan SY, Rojas M and Lafyatis R. Transcriptional profiling of lung cell populations in idiopathic pulmonary arterial hypertension. Pulm Circ. 2020;10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Abdul-Salam VB, Wharton J, Cupitt J, Berryman M, Edwards RJ and Wilkins MR. Proteomic analysis of lung tissues from patients with pulmonary arterial hypertension. Circulation. 2010;122:2058–67. [DOI] [PubMed] [Google Scholar]
- 20.Rhodes CJ, Wharton J, Ghataorhe P, Watson G, Girerd B, Howard LS, Gibbs JSR, Condliffe R, Elliot CA, Kiely DG, et al. Plasma proteome analysis in patients with pulmonary arterial hypertension: an observational cohort study. The Lancet Respiratory medicine. 2017;5:717–726. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Benza RL, Miller DP, Gomberg-Maitland M, Frantz RP, Foreman AJ, Coffey CS, Frost A, Barst RJ, Badesch DB, Elliott CG, et al. Predicting survival in pulmonary arterial hypertension: insights from the Registry to Evaluate Early and Long-Term Pulmonary Arterial Hypertension Disease Management (REVEAL). Circulation. 2010;122:164–72. [DOI] [PubMed] [Google Scholar]
- 22.Rehman J and Archer SL. A proposed mitochondrial-metabolic mechanism for initiation and maintenance of pulmonary arterial hypertension in fawn-hooded rats: the Warburg model of pulmonary arterial hypertension. Adv Exp Med Biol. 2010;661:171–85. [DOI] [PubMed] [Google Scholar]
- 23.Michelakis ED, Gurtu V, Webster L, Barnes G, Watson G, Howard L, Cupitt J, Paterson I, Thompson RB, Chow K, et al. Inhibition of pyruvate dehydrogenase kinase improves pulmonary arterial hypertension in genetically susceptible patients. Science translational medicine. 2017;9. [DOI] [PubMed] [Google Scholar]
- 24.Zhao YD, Chu L, Lin K, Granton E, Yin L, Peng J, Hsin M, Wu L, Yu A, Waddell T, et al. A Biochemical Approach to Understand the Pathogenesis of Advanced Pulmonary Arterial Hypertension: Metabolomic Profiles of Arginine, Sphingosine-1-Phosphate, and Heme of Human Lung. PLoS One. 2015;10:e0134958. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Brittain EL, Talati M, Fessel JP, Zhu H, Penner N, Calcutt MW, West JD, Funke M, Lewis GD, Gerszten RE, et al. Fatty Acid Metabolic Defects and Right Ventricular Lipotoxicity in Human Pulmonary Arterial Hypertension. Circulation. 2016;133:1936–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Lewis GD, Ngo D, Hemnes AR, Farrell L, Domos C, Pappagianopoulos PP, Dhakal BP, Souza A, Shi X, Pugh ME, et al. Metabolic Profiling of Right Ventricular-Pulmonary Vascular Function Reveals Circulating Biomarkers of Pulmonary Hypertension. Journal of the American College of Cardiology. 2016;67:174–189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Rhodes CJ, Ghataorhe P, Wharton J, Rue-Albrecht KC, Hadinnapola C, Watson G, Bleda M, Haimel M, Coghlan G, Corris PA, et al. Plasma Metabolomics Implicates Modified Transfer RNAs and Altered Bioenergetics in the Outcomes of Pulmonary Arterial Hypertension. Circulation. 2017;135:460–475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Swietlik EM, Ghataorhe P, Zalewska KI, Wharton J, Howard LS, Taboada D, Cannon JE, PAH UKNCSo, Morrell NW, Wilkins MR, et al. Plasma metabolomics exhibit response to therapy in chronic thromboembolic pulmonary hypertension. Eur Respir J. 2021;57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Dawes TJW, de Marvao A, Shi W, Fletcher T, Watson GMJ, Wharton J, Rhodes CJ, Howard L, Gibbs JSR, Rueckert D, et al. Machine Learning of Three-dimensional Right Ventricular Motion Enables Outcome Prediction in Pulmonary Hypertension: A Cardiac MR Imaging Study. Radiology. 2017;283:381–390. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Attard MI, Dawes TJW, de Marvao A, Biffi C, Shi W, Wharton J, Rhodes CJ, Ghataorhe P, Gibbs JSR, Howard L, et al. Metabolic pathways associated with right ventricular adaptation to pulmonary hypertension: 3D analysis of cardiac magnetic resonance imaging. Eur Heart J Cardiovasc Imaging. 2019;20:668–676. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Huston JH, Maron BA, French J, Huang S, Thayer T, Farber-Eger EH, Wells QS, Choudhary G, Hemnes AR and Brittain EL. Association of Mild Echocardiographic Pulmonary Hypertension With Mortality and Right Ventricular Function. JAMA Cardiol. 2019;4:1112–1121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Kiely DG, Doyle O, Drage E, Jenner H, Salvatelli V, Daniels FA, Rigg J, Schmitt C, Samyshkin Y, Lawrie A, et al. Utilising artificial intelligence to determine patients at risk of a rare disease: idiopathic pulmonary arterial hypertension. Pulm Circ. 2019;9:2045894019890549. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Khou V, Anderson JJ, Strange G, Corrigan C, Collins N, Celermajer DS, Dwyer N, Feenstra J, Horrigan M, Keating D, et al. Diagnostic delay in pulmonary arterial hypertension: Insights from the Australian and New Zealand pulmonary hypertension registry. Respirology. 2020;25:863–871. [DOI] [PubMed] [Google Scholar]
- 34.Bayoumy K, Gaber M, Elshafeey A, Mhaimeed O, Dineen EH, Marvel FA, Martin SS, Muse ED, Turakhia MP, Tarakji KG, et al. Smart wearable devices in cardiovascular care: where we are and how to move forward. Nature reviews Cardiology. 2021;18:581–599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Elinoff JM and Solomon MA. The Road Toward Precision in PH: Personal Omics, Phenomics, and Wearables—Oh My! Advances in Pulmonary Hypertension. 2018;17:141–147. [Google Scholar]
- 36.Abraham WT, Adamson PB, Bourge RC, Aaron MF, Costanzo MR, Stevenson LW, Strickland W, Neelagaru S, Raval N, Krueger S, et al. Wireless pulmonary artery haemodynamic monitoring in chronic heart failure: a randomised controlled trial. Lancet. 2011;377:658–66. [DOI] [PubMed] [Google Scholar]
- 37.Krittanawong C, Rogers AJ, Johnson KW, Wang Z, Turakhia MP, Halperin JL and Narayan SM. Integration of novel monitoring devices with machine learning technology for scalable cardiovascular management. Nature reviews Cardiology. 2021;18:75–91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Hemnes AR, Beck GJ, Newman JH, Abidov A, Aldred MA, Barnard J, Berman Rosenzweig E, Borlaug BA, Chung WK, Comhair SAA, et al. PVDOMICS: A Multi-Center Study to Improve Understanding of Pulmonary Vascular Disease Through Phenomics. Circulation research. 2017;121:1136–1139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Wilkinson MD, Dumontier M, Aalbersberg IJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten JW, da Silva Santos LB, Bourne PE, et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data. 2016;3:160018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Leopold JA, Maron BA and Loscalzo J. The application of big data to cardiovascular disease: paths to precision medicine. J Clin Invest. 2020;130:29–38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Khemasuwan D, Sorensen JS and Colt HG. Artificial intelligence in pulmonary medicine: computer vision, predictive model and COVID-19. Eur Respir Rev. 2020;29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Angelini E, Dahan S and Shah A. Unravelling machine learning: insights in respiratory medicine. Eur Respir J. 2019;54. [DOI] [PubMed] [Google Scholar]
- 43.Krittanawong C, Zhang H, Wang Z, Aydar M and Kitai T. Artificial Intelligence in Precision Cardiovascular Medicine. Journal of the American College of Cardiology. 2017;69:2657–2664. [DOI] [PubMed] [Google Scholar]
- 44.Komorowski M, Celi LA, Badawi O, Gordon AC and Faisal AA. The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nat Med. 2018;24:1716–1720. [DOI] [PubMed] [Google Scholar]
- 45.Gottesman O, Johansson F, Komorowski M, Faisal A, Sontag D, Doshi-Velez F and Celi LA. Guidelines for reinforcement learning in healthcare. Nat Med. 2019;25:16–18. [DOI] [PubMed] [Google Scholar]
- 46.Bernard O, Lalande A, Zotti C, Cervenansky F, Yang X, Heng PA, Cetin I, Lekadir K, Camara O, Gonzalez Ballester MA, et al. Deep Learning Techniques for Automatic MRI Cardiac Multi-Structures Segmentation and Diagnosis: Is the Problem Solved? IEEE Trans Med Imaging. 2018;37:2514–2525. [DOI] [PubMed] [Google Scholar]
- 47.Alipanahi B, Delong A, Weirauch MT and Frey BJ. Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Nat Biotechnol. 2015;33:831–8. [DOI] [PubMed] [Google Scholar]
- 48.Leha A, Hellenkamp K, Unsold B, Mushemi-Blake S, Shah AM, Hasenfuss G and Seidler T. A machine learning approach for the prediction of pulmonary hypertension. PLoS One. 2019;14:e0224453. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Swift AJ, Lu H, Uthoff J, Garg P, Cogliano M, Taylor J, Metherall P, Zhou S, Johns CS, Alabed S, et al. A machine learning cardiac magnetic resonance approach to extract disease features and automate pulmonary arterial hypertension diagnosis. Eur Heart J Cardiovasc Imaging. 2021;22:236–245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Priya S, Aggarwal T, Ward C, Bathla G, Jacob M, Gerke A, Hoffman EA and Nagpal P. Radiomics side experiments and DAFIT approach in identifying pulmonary hypertension using Cardiac MRI derived radiomics based machine learning models. Sci Rep. 2021;11:12686. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Errington N, Iremonger J, Pickworth JA, Kariotis S, Rhodes CJ, Rothman AM, Condliffe R, Elliot CA, Kiely DG, Howard LS, et al. A diagnostic miRNA signature for pulmonary arterial hypertension using a consensus machine learning approach. EBioMedicine. 2021;69:103444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Bauer Y, de Bernard S, Hickey P, Ballard K, Cruz J, Cornelisse P, Chadha-Boreham H, Distler O, Rosenberg D, Doelberg M, et al. Identifying early pulmonary arterial hypertension biomarkers in systemic sclerosis: machine learning on proteomics from the DETECT cohort. Eur Respir J. 2021;57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Kanwar MK, Gomberg-Maitland M, Hoeper M, Pausch C, Pittrow D, Strange G, Anderson JJ, Zhao C, Scott JV, Druzdzel MJ, et al. Risk stratification in pulmonary arterial hypertension using Bayesian analysis. Eur Respir J. 2020;56. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Benza RL, Gomberg-Maitland M, Elliott CG, Farber HW, Foreman AJ, Frost AE, McGoon MD, Pasta DJ, Selej M, Burger CD, et al. Predicting Survival in Patients With Pulmonary Arterial Hypertension: The REVEAL Risk Score Calculator 2.0 and Comparison With ESC/ERS-Based Risk Assessment Strategies. Chest. 2019;156:323–337. [DOI] [PubMed] [Google Scholar]
- 55.Khanna NN, Jamthikar AD, Gupta D, Piga M, Saba L, Carcassi C, Giannopoulos AA, Nicolaides A, Laird JR, Suri HS, et al. Rheumatoid Arthritis: Atherosclerosis Imaging and Cardiovascular Risk Assessment Using Machine and Deep Learning-Based Tissue Characterization. Curr Atheroscler Rep. 2019;21:7. [DOI] [PubMed] [Google Scholar]
- 56.Loghmanpour NA, Kormos RL, Kanwar MK, Teuteberg JJ, Murali S and Antaki JF. A Bayesian Model to Predict Right Ventricular Failure Following Left Ventricular Assist Device Therapy. JACC Heart Fail. 2016;4:711–21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Galie N, Channick RN, Frantz RP, Grunig E, Jing ZC, Moiseeva O, Preston IR, Pulido T, Safdar Z, Tamura Y, et al. Risk stratification and medical therapy of pulmonary arterial hypertension. Eur Respir J. 2019;53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Zamanian RT, Badesch D, Chung L, Domsic RT, Medsger T, Pinckney A, Keyes-Elstein L, D’Aveta C, Spychala M, White RJ, et al. Safety and Efficacy of B-Cell Depletion with Rituximab for the Treatment of Systemic Sclerosis-associated Pulmonary Arterial Hypertension: A Multicenter, Double-Blind, Randomized, Placebo-controlled Trial. American journal of respiratory and critical care medicine. 2021;204:209–221. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Thorlund K, Haggstrom J, Park JJ and Mills EJ. Key design considerations for adaptive clinical trials: a primer for clinicians. BMJ. 2018;360:k698. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Ong MS, Klann JG, Lin KJ, Maron BA, Murphy SN, Natter MD and Mandl KD. Claims-Based Algorithms for Identifying Patients With Pulmonary Hypertension: A Comparison of Decision Rules and Machine-Learning Approaches. J Am Heart Assoc. 2020;9:e016648. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Bogin V Master protocols: New directions in drug discovery. Contemp Clin Trials Commun. 2020;18:100568. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Sweatt AJ, Hedlin HK, Balasubramanian V, Hsi A, Blum LK, Robinson WH, Haddad F, Hickey PM, Condliffe R, Lawrie A, et al. Discovery of Distinct Immune Phenotypes Using Machine Learning in Pulmonary Arterial Hypertension. Circulation research. 2019;124:904–919. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Leopold JA and Maron BA. Precision Medicine in Pulmonary Arterial Hypertension. Circulation research. 2019;124:832–833. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Reyes-Palomares A, Gu M, Grubert F, Berest I, Sa S, Kasowski M, Arnold C, Shuai M, Srivas R, Miao S, et al. Remodeling of active endothelial enhancers is associated with aberrant gene-regulatory networks in pulmonary arterial hypertension. Nature communications. 2020;11:1673. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Yuan K, Liu Y, Zhang Y, Nathan A, Tian W, Yu J, Sweatt AJ, Shamshou EA, Condon D, Chakraborty A, et al. Mural Cell SDF1 Signaling Is Associated with the Pathogenesis of Pulmonary Arterial Hypertension. Am J Respir Cell Mol Biol. 2020;62:747–759. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Zhang H, Wang D, Li M, Plecita-Hlavata L, D’Alessandro A, Tauber J, Riddle S, Kumar S, Flockton A, McKeon BA, et al. Metabolic and Proliferative State of Vascular Adventitial Fibroblasts in Pulmonary Hypertension Is Regulated Through a MicroRNA-124/PTBP1 (Polypyrimidine Tract Binding Protein 1)/Pyruvate Kinase Muscle Axis. Circulation. 2017;136:2468–2485. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Maron BA, Altucci L, Balligand JL, Baumbach J, Ferdinandy P, Filetti S, Parini P, Petrillo E, Silverman EK, Barabasi AL, et al. A global network for network medicine. NPJ Syst Biol Appl. 2020;6:29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Menche J, Sharma A, Kitsak M, Ghiassian SD, Vidal M, Loscalzo J and Barabasi AL. Disease networks. Uncovering disease-disease relationships through the incomplete interactome. Science. 2015;347:1257601. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Oldham WM, Hess E, Waldo SW, Humbert M, Choudhary G and Maron BA. Integrating haemodynamics identifies an extreme pulmonary hypertension phenotype. Eur Respir J. 2021;58. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Lee LY, Pandey AK, Maron BA and Loscalzo J. Network medicine in Cardiovascular Research. Cardiovasc Res. 2021;117:2186–2202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Maron BA, Wang RS, Shevtsov S, Drakos SG, Arons E, Wever-Pinzon O, Huggins GS, Samokhin AO, Oldham WM, Aguib Y, et al. Individualized interactomes for network-based precision medicine in hypertrophic cardiomyopathy with implications for other clinical pathophenotypes. Nature communications. 2021;12:873. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Parikh VN, Jin RC, Rabello S, Gulbahce N, White K, Hale A, Cottrill KA, Shaik RS, Waxman AB, Zhang YY, et al. MicroRNA-21 integrates pathogenic signaling to control pulmonary hypertension: results of a network bioinformatics approach. Circulation. 2012;125:1520–32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Bertero T, Cottrill K, Krauszman A, Lu Y, Annis S, Hale A, Bhat B, Waxman AB, Chau BN, Kuebler WM, et al. The microRNA-130/301 family controls vasoconstriction in pulmonary hypertension. J Biol Chem. 2015;290:2069–85. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Samokhin AO, Stephens T, Wertheim BM, Wang RS, Vargas SO, Yung LM, Cao M, Brown M, Arons E, Dieffenbach PB, et al. NEDD9 targets COL3A1 to promote endothelial fibrosis and pulmonary arterial hypertension. Science translational medicine. 2018;10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Maron BA, Opotowsky AR, Landzberg MJ, Loscalzo J, Waxman AB and Leopold JA. Plasma aldosterone levels are elevated in patients with pulmonary arterial hypertension in the absence of left ventricular heart failure: a pilot study. Eur J Heart Fail. 2013;15:277–83. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Alba GA, Samokhin AO, Wang RS, Zhang YY, Wertheim BM, Arons E, Greenfield EA, Lundberg Slingsby MH, Ceglowski JR, Haley KJ, et al. NEDD9 Is a Novel and Modifiable Mediator of Platelet-Endothelial Adhesion in the Pulmonary Circulation. American journal of respiratory and critical care medicine. 2021;203:1533–1545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Frid MG, McKeon BA, Thurman JM, Maron BA, Li M, Zhang H, Kumar S, Sullivan T, Laskowsky J, Fini MA, et al. Immunoglobulin-driven Complement Activation Regulates Proinflammatory Remodeling in Pulmonary Hypertension. American journal of respiratory and critical care medicine. 2020;201:224–239. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Maron BA, Abman SH, Elliott CG, Frantz RP, Hopper RK, Horn EM, Nicolls MR, Shlobin OA, Shah SJ, Kovacs G, et al. Pulmonary Arterial Hypertension: Diagnosis, Treatment, and Novel Advances. American journal of respiratory and critical care medicine. 2021;203:1472–1487. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Kovacs G, Avian A, Wutte N, Hafner F, Moazedi-Furst F, Kielhauser S, Aberer E, Brodmann M, Graninger W, Foris V, et al. Changes in pulmonary exercise haemodynamics in scleroderma: a 4-year prospective study. Eur Respir J. 2017;50. [DOI] [PubMed] [Google Scholar]
- 80.Oldham WM, Oliveira RKF, Wang RS, Opotowsky AR, Rubins DM, Hainer J, Wertheim BM, Alba GA, Choudhary G, Tornyos A, et al. Network Analysis to Risk Stratify Patients With Exercise Intolerance. Circulation research. 2018;122:864–876. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Hou Y, Zhou Y, Hussain M, Budd GT, Tang WHW, Abraham J, Xu B, Shah C, Moudgil R, Popovic Z, et al. Cardiac risk stratification in cancer patients: A longitudinal patient-patient network analysis. PLoS Med. 2021;18:e1003736. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Wang RS and Loscalzo J. Network module-based drug repositioning for pulmonary arterial hypertension. CPT Pharmacometrics Syst Pharmacol. 2021;10:994–1005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Negi V, Yang J, Speyer G, Pulgarin A, Handen A, Zhao J, Tai YY, Tang Y, Culley MK, Yu Q, et al. Computational repurposing of therapeutic small molecules from cancer to pulmonary hypertension. Sci Adv. 2021;7:eabh3794. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Covella M, Rowin EJ, Hill NS, Preston IR, Milan A, Opotowsky AR, Maron BJ, Maron MS and Maron BA. Mechanism of Progressive Heart Failure and Significance of Pulmonary Hypertension in Obstructive Hypertrophic Cardiomyopathy. Circ Heart Fail. 2017;10:e003689. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Pinu FR, Beale DJ, Paten AM, Kouremenos K, Swarup S, Schirra HJ and Wishart D. Systems Biology and Multi-Omics Integration: Viewpoints from the Metabolomics Research Community. Metabolites. 2019;9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Chakraborty S, Hosen MI, Ahmed M and Shekhar HU. Onco-Multi-OMICS Approach: A New Frontier in Cancer Research. Biomed Res Int. 2018;2018:9836256. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Subramanian I, Verma S, Kumar S, Jere A and Anamika K. Multi-omics Data Integration, Interpretation, and Its Application. Bioinform Biol Insights. 2020;14:1177932219899051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Harbaum L, Ghataorhe P, Wharton J, Jimenez B, Howard LSG, Gibbs JSR, Nicholson JK, Rhodes CJ and Wilkins MR. Reduced plasma levels of small HDL particles transporting fibrinolytic proteins in pulmonary arterial hypertension. Thorax. 2019;74:380–389. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Schofield EC, Carver T, Achuthan P, Freire-Pritchett P, Spivakov M, Todd JA and Burren OS. CHiCP: a web-based tool for the integrative and interactive visualization of promoter capture Hi-C datasets. Bioinformatics. 2016;32:2511–3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Musunuru K, Strong A, Frank-Kamenetsky M, Lee NE, Ahfeldt T, Sachs KV, Li X, Li H, Kuperwasser N, Ruda VM, et al. From noncoding variant to phenotype via SORT1 at the 1p13 cholesterol locus. Nature. 2010;466:714–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Rappoport N and Shamir R. Multi-omic and multi-view clustering algorithms: review and cancer benchmark. Nucleic Acids Res. 2019;47:1044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Stanberry L, Mias GI, Haynes W, Higdon R, Snyder M and Kolker E. Integrative analysis of longitudinal metabolomics data from a personal multi-omics profile. Metabolites. 2013;3:741–60. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93.Schussler-Fiorenza Rose SM, Contrepois K, Moneghetti KJ, Zhou W, Mishra T, Mataraso S, Dagan-Rosenfeld O, Ganz AB, Dunn J, Hornburg D, et al. A longitudinal big data approach for precision health. Nat Med. 2019;25:792–804. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Zhou W, Sailani MR, Contrepois K, Zhou Y, Ahadi S, Leopold SR, Zhang MJ, Rao V, Avina M, Mishra T, et al. Longitudinal multi-omics of host-microbe dynamics in prediabetes. Nature. 2019;569:663–671. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Kellogg RA, Dunn J and Snyder MP. Personal Omics for Precision Health. Circulation research. 2018;122:1169–1171. [DOI] [PubMed] [Google Scholar]
- 96.Ulrich A, Wharton J, Thayer TE, Swietlik EM, Assad TR, Desai AA, Graf S, Harbaum L, Humbert M, Morrell NW, et al. Mendelian randomisation analysis of red cell distribution width in pulmonary arterial hypertension. Eur Respir J. 2020;55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97.Howard L, He J, Watson GMJ, Huang L, Wharton J, Luo Q, Kiely DG, Condliffe R, Pepke-Zaba J, Morrell NW, et al. Supplementation with Iron in Pulmonary Arterial Hypertension. Two Randomized Crossover Trials. Ann Am Thorac Soc. 2021;18:981–988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Simonneau G, Montani D, Celermajer DS, Denton CP, Gatzoulis MA, Krowka M, Williams PG and Souza R. Haemodynamic definitions and updated clinical classification of pulmonary hypertension. Eur Respir J. 2019;53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Erzurum S, Rounds SI, Stevens T, Aldred M, Aliotta J, Archer SL, Asosingh K, Balaban R, Bauer N, Bhattacharya J, et al. Strategic plan for lung vascular research: An NHLBI-ORDR Workshop Report. American journal of respiratory and critical care medicine. 2010;182:1554–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 100.Robbins IM, Moore TM, Blaisdell CJ and Abman SH. National Heart, Lung, and Blood Institute Workshop: improving outcomes for pulmonary vascular disease. Circulation. 2012;125:2165–70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 101.Dweik RA, Rounds S, Erzurum SC, Archer S, Fagan K, Hassoun PM, Hill NS, Humbert M, Kawut SM, Krowka M, et al. An official American Thoracic Society Statement: pulmonary hypertension phenotypes. American journal of respiratory and critical care medicine. 2014;189:345–55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102.Oldham WM, Hemnes AR, Aldred MA, Barnard J, Brittain EL, Chan SY, Cheng F, Cho MH, Desai AA, Garcia JGN, et al. NHLBI-CMREF Workshop Report on Pulmonary Vascular Disease Classification: JACC State-of-the-Art Review. Journal of the American College of Cardiology. 2021;77:2040–2052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Shah SJ, Katz DH, Selvaraj S, Burke MA, Yancy CW, Gheorghiade M, Bonow RO, Huang CC and Deo RC. Phenomapping for novel classification of heart failure with preserved ejection fraction. Circulation. 2015;131:269–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Segar MW, Patel KV, Ayers C, Basit M, Tang WHW, Willett D, Berry J, Grodin JL and Pandey A. Phenomapping of patients with heart failure with preserved ejection fraction using machine learning-based unsupervised cluster analysis. Eur J Heart Fail. 2020;22:148–158. [DOI] [PubMed] [Google Scholar]
- 105.Cohen JB, Schrauben SJ, Zhao L, Basso MD, Cvijic ME, Li Z, Yarde M, Wang Z, Bhattacharya PT, Chirinos DA, et al. Clinical Phenogroups in Heart Failure With Preserved Ejection Fraction: Detailed Phenotypes, Prognosis, and Response to Spironolactone. JACC Heart Fail. 2020;8:172–184. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.Wu W, Bang S, Bleecker ER, Castro M, Denlinger L, Erzurum SC, Fahy JV, Fitzpatrick AM, Gaston BM, Hastie AT, et al. Multiview Cluster Analysis Identifies Variable Corticosteroid Response Phenotypes in Severe Asthma. American journal of respiratory and critical care medicine. 2019;199:1358–1367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107.Calfee CS, Delucchi K, Parsons PE, Thompson BT, Ware LB, Matthay MA and Network NA. Subphenotypes in acute respiratory distress syndrome: latent class analysis of data from two randomised controlled trials. The Lancet Respiratory medicine. 2014;2:611–20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 108.Famous KR, Delucchi K, Ware LB, Kangelaris KN, Liu KD, Thompson BT, Calfee CS and Network A. Acute Respiratory Distress Syndrome Subphenotypes Respond Differently to Randomized Fluid Management Strategy. American journal of respiratory and critical care medicine. 2017;195:331–338. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 109.Calfee CS, Delucchi KL, Sinha P, Matthay MA, Hackett J, Shankar-Hari M, McDowell C, Laffey JG, O’Kane CM, McAuley DF, et al. Acute respiratory distress syndrome subphenotypes and differential response to simvastatin: secondary analysis of a randomised controlled trial. The Lancet Respiratory medicine. 2018;6:691–698. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 110.Scicluna BP, van Vught LA, Zwinderman AH, Wiewel MA, Davenport EE, Burnham KL, Nurnberg P, Schultz MJ, Horn J, Cremer OL, et al. Classification of patients with sepsis according to blood genomic endotype: a prospective cohort study. The Lancet Respiratory medicine. 2017;5:816–826. [DOI] [PubMed] [Google Scholar]
- 111.Seymour CW, Kennedy JN, Wang S, Chang CH, Elliott CF, Xu Z, Berry S, Clermont G, Cooper G, Gomez H, et al. Derivation, Validation, and Potential Treatment Implications of Novel Clinical Phenotypes for Sepsis. JAMA. 2019;321:2003–2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Hemnes AR, Trammell AW, Archer SL, Rich S, Yu C, Nian H, Penner N, Funke M, Wheeler L, Robbins IM, et al. Peripheral blood signature of vasodilator-responsive pulmonary arterial hypertension. Circulation. 2015;131:401–9; discussion 409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 113.Hemnes AR, Zhao M, West J, Newman JH, Rich S, Archer SL, Robbins IM, Blackwell TS, Cogan J, Loyd JE, et al. Critical Genomic Networks and Vasoreactive Variants in Idiopathic Pulmonary Arterial Hypertension. American journal of respiratory and critical care medicine. 2016;194:464–75. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 114.Amsallem M, Sweatt AJ, Arthur Ataam J, Guihaire J, Lecerf F, Lambert M, Ghigna MR, Ali MK, Mao Y, Fadel E, et al. Targeted proteomics of right heart adaptation to pulmonary arterial hypertension. Eur Respir J. 2021;57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 115.Bos LDJ, Sjoding M, Sinha P, Bhavani SV, Lyons PG, Bewley AF, Botta M, Tsonas AM, Serpa Neto A, Schultz MJ, et al. Longitudinal respiratory subphenotypes in patients with COVID-19-related acute respiratory distress syndrome: results from three observational cohorts. The Lancet Respiratory medicine. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 116.Williams MH, Das C, Handler CE, Akram MR, Davar J, Denton CP, Smith CJ, Black CM and Coghlan JG. Systemic sclerosis associated pulmonary hypertension: improved survival in the current era. Heart. 2006;92:926–32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 117.Sweatt AJ, Miyagawa K, Rhodes CJ, Taylor S, Del Rosario PA, Hsi A, Haddad F, Spiekerkoetter E, Bental-Roof M, Bland RD, et al. Severe Pulmonary Arterial Hypertension Is Characterized by Increased Neutrophil Elastase and Relative Elafin Deficiency. Chest. 2021;160:1442–1458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 118.Benza RL, Kanwar MK, Raina A, Scott JV, Zhao CL, Selej M, Elliott CG and Farber HW. Development and Validation of an Abridged Version of the REVEAL 2.0 Risk Score Calculator, REVEAL Lite 2, for Use in Patients With Pulmonary Arterial Hypertension. Chest. 2021;159:337–346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 119.Sitbon O, Benza RL, Badesch DB, Barst RJ, Elliott CG, Gressin V, Lemarie JC, Miller DP, Muros-Le Rouzic E, Simonneau G, et al. Validation of two predictive models for survival in pulmonary arterial hypertension. Eur Respir J. 2015;46:152–64. [DOI] [PubMed] [Google Scholar]
- 120.Gu M, Donato M, Guo M, Wary N, Miao Y, Mao S, Saito T, Otsuki S, Wang L, Harper RL, et al. iPSC-endothelial cell phenotypic drug screening and in silico analyses identify tyrphostin-AG1296 for pulmonary arterial hypertension. Science translational medicine. 2021;13. [DOI] [PMC free article] [PubMed] [Google Scholar]