

Abstract
Replay is the reactivation of one or more neural patterns, which are similar to the activation patterns experienced during past waking experiences. Replay was first observed in biological neural networks during sleep, and it is now thought to play a critical role in memory formation, retrieval, and consolidation. Replay-like mechanisms have been incorporated into deep artificial neural networks that learn over time to avoid catastrophic forgetting of previous knowledge. Replay algorithms have been successfully used in a wide range of deep learning methods within supervised, unsupervised, and reinforcement learning paradigms. In this paper, we provide the first comprehensive comparison between replay in the mammalian brain and replay in artificial neural networks. We identify multiple aspects of biological replay that are missing in deep learning systems and hypothesize how they could be utilized to improve artificial neural networks.
Keywords: Replay, Sleep, Catastrophic Forgetting
1. Introduction
While artificial neural networks now rival human performance for many tasks, the dominant paradigm for training these networks is to train them once and then to re-train them from scratch if new data is acquired. This is wasteful of computational resources, and many tasks involve updating a network over time. However, standard training algorithms, i.e., online error backpropagation, produce catastrophic forgetting of past information when trained from a non-stationary input stream, e.g., incrementally learning new classes over time or most reinforcement learning problems (Abraham and Robins, 2005; Robins, 1995). The root cause of catastrophic forgetting is that learning requires the neural network’s weights to change, but changing weights critical to past learning results in forgetting. This is known as the stability-plasticity dilemma, which is an important problem in deep learning and neuroscience (Abraham and Robins, 2005).
In contrast, humans can continually learn and adapt to new experiences throughout their lifetimes and rarely does learning new information cause humans to catastrophically forget previous knowledge (French, 1999). In the mammalian brain, one mechanism used to combat forgetting and facilitate consolidation is replay - the reactivation of past neural activation patterns1 (McClelland et al., 1995; Kumaran et al., 2016; McClelland et al., 2020). Replay has primarily been observed in the hippocampus, which is a brain structure critical for consolidating short-term memory to long-term memory. Replay was first noted to occur during slow-wave sleep, but it also occurs during Rapid Eye Movement (REM) sleep (Louie and Wilson, 2001; Eckert et al., 2020; Kudrimoti et al., 1999) and while awake, potentially to facilitate the retrieval of recent memories (Walker and Stickgold, 2004).
In artificial networks, the catastrophic forgetting problem during continual learning has been successfully addressed by methods inspired by replay (Rebuffi et al., 2017; Castro et al., 2018; Wu et al., 2019a; Hou et al., 2019; Hayes et al., 2020). In the most common implementation, replay involves storing a subset of previous veridical inputs (e.g., RGB images) and mixing them with more recent inputs to update the networks (Rebuffi et al., 2017; Castro et al., 2018; Wu et al., 2019a; Hou et al., 2019; Andrychowicz et al., 2017; Schaul et al., 2016; Lesort et al., 2019; Wu et al., 2018; Draelos et al., 2017). This preserves representations for processing previous inputs while enabling new information to be learned. In contrast, the brain replays highly processed representations of past inputs, e.g., those stored within the hippocampus (Teyler and Rudy, 2007), and a similar approach has been used to enable continual learning for artificial networks in some recent works that replay high-level feature representations (Hayes et al., 2020; Iscen et al., 2020; Caccia et al., 2020; Pellegrini et al., 2019; van de Ven et al., 2020). While this is closer to biology, many facets of replay in biology have not been incorporated into artificial networks, but they could potentially improve generalization, abstraction, and data processing. A high-level depiction of the differences between biological and artificial replay is shown in Fig. 1.
Figure 1:
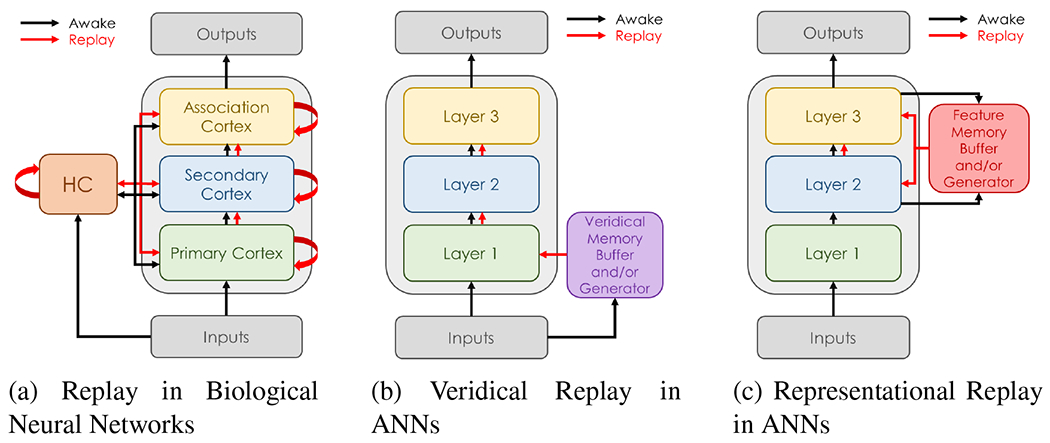
High-level overview of the flow of learning activity during awake and replay stages in biological networks versus artificial neural networks (ANNs). While replay occurs in several brain regions both independently and concurrently, replay in most artificial implementations occurs concurrently from a single layer. While the hippocampal complex (HC) can be used for both replay and inference in biological networks, the memory buffers in artificial replay implementations are mostly used to train the neural network that makes predictions. Figure (a) illustrates replay in biological networks. Figures (b) and (c) are examples of replay in an ANN with 3 hidden layers. For networks with more layers, the layer for representational replay can be chosen in a variety of ways (see text).
In this paper, we first describe replay’s theorized role in memory consolidation and retrieval in the brain, and provide supporting evidence from neuroscience and psychology studies. We also describe findings in biology that deviate from today’s theory. Subsequently, we discuss how replay is implemented to facilitate continual learning in artificial neural networks. While there have been multiple reviews of replay in the brain (Tingley and Peyrache, 2020; Ólafsdóttir et al., 2018; Pfeiffer, 2020; Foster, 2017; Robertson and Genzel, 2020) and reviews of continual learning in artificial networks (Kemker et al., 2018; Parisi et al., 2019; Delange et al., 2021; Belouadah et al., 2020), we provide the first comprehensive review that integrates and identifies the gaps between replay in these two fields. While it is beyond the scope of this paper to review everything known about the biology of replay, we highlight the salient differences between known biology and today’s machine learning systems to help biologists test hypotheses and help machine learning researchers improve algorithms. An overview of various replay mechanisms in the brain, their hypothesized functional role, and their implementation in deep neural networks is provided in Table 1.
Table 1:
High-level overview of replay mechanisms in the brain, their hypothesized functional role, and their implementation/use in deep learning.
| Replay Mechanism | Role in Brain | Use in Deep Learning |
|---|---|---|
| Replay includes contents from both new and old memories | Prevents forgetting | Interleave new data with old data to overcome forgetting |
| Only a few selected experiences are replayed | Increased efficiency, weighting experiences based on internal representation | Related to subset selection for what should be replayed |
| Replay can be partial (not entire experience) | Improves efficiency, allows for better integration of parts, generalization, and abstraction | Not explored in deep learning |
| Replay observed at sensory and association cortex (independent and coordinated) | Allows for vertical and horizontal integration in hierarchical memory structures | Some methods use representational replay of higher level inputs or feature maps |
| Replay modulated by reward | Allow reward to influence replay | Similar to reward functions in reinforcement learning |
| Replay is spontaneously generated (without external inputs) | Allows for all of the above features of replay without explicitly stored memories | Some methods replay samples from random inputs |
| Replay during NREM is different than replay during REM | Different states allow for different types of manipulation of memories | Deep learning currently focuses on NREM replay and ignores REM replay |
| Replay is temporally structured | Allows for more memory combinations and follows temporal waking experiences | Largely ignored by existing methods that replay static, uncorrelated inputs |
| Replay can happen in reverse | Allow reward mediated weighting of replay | Must have temporal correlations for reverse replay |
| Replay is different for novel versus non-novel inputs | Allows for selective replay to be weighted by novelty | Replay is largely the same independent of input novelty |
2. Replay in Biological Networks
Memory in the brain is the process of encoding, storing, and retrieving information. Encoding involves converting information into a format that can be stored in short-term memory, and then a subset of short-term memories are consolidated for long-term storage. Consolidation is a slow process that involves the integration of new memories with old (McGaugh, 2000). Splitting learning into short-term and long-term memory allows the brain to efficiently solve the stability-plasticity problem. The consolidation phase is used for long-term storage of declarative, semantic, and procedural memories (Rasch and Born, 2013; Born, 2010; Stickgold, 2005, 2012).
Consolidation occurs during periods of rest or sleep, where spiking activity during replay initiates long-term changes in synapses through activity dependent plasticity processes. Consolidation is well understood for declarative and semantic memory, which depend on the hippocampus. Bilateral removal of the hippocampus results in anterograde amnesia and the inability to form new semantic memories (Nadel and Moscovitch, 1997). The primary input to the hippocampus is the entorhinal cortex, which receives highly processed information from all sensory modalities and the prefrontal cortex. While the hippocampus allows for the quick assimilation of new information, medial prefrontal cortex is used for long-term storage of memories and generalization (Bontempi et al., 1999). These generalization capabilities are a result of medial prefrontal cortex using a slower learning rate and densely encoding memories with overlapping representations, whereas the hippocampus uses a faster learning rate in conjunction with sparsity and indexing mechanisms (Teyler and Rudy, 2007). Hebbian learning and error-driven schemes are used by both the hippocampus and medial prefrontal cortex (O’Reilly and Rudy, 2001). Initially, the hippocampus is used to retrieve new memories, but over time medial prefrontal cortex is instead used for retrieval (Kitamura et al., 2017). Results from (Kitamura et al., 2017) suggest that when new memories are created, neurons are allocated in both the hippocampus and medial prefrontal cortex, with unused neurons in the hippocampus engaged immediately for formation and neurons in medial prefrontal cortex being epigenetically ‘tagged’ for later storage (Lesburguères et al., 2011; Bero et al., 2014). This switch from hippocampus to cortex occurs over a period of several days with several episodes of sleep, however, it can take months or even years to make memories completely independent of the hippocampus. Replay during sleep determines which memories are formed for long-term storage. Moreover, while replay contributes to long-term memory consolidation, the associated retrieval processes have been shown to change memories qualitatively (Jonker et al., 2018). These qualitative changes are thought to strengthen the representations of episodically similar memories and have been underexplored in computational models.
The complementary learning systems (CLS) theory describes long-term memory consolidation based on the interplay between the hippocampus and the neocortex (McClelland et al., 1995; Kumaran et al., 2016). In this framework, the hippocampus and cortex act complimentary to one another. The hippocampus quickly learns short-term instance-level information, while the cortex learns much more slowly and is capable of better generalization. The CLS theory (McClelland et al., 1995; Kumaran et al., 2016) also suggests that the brain generalizes across a variety of experiences by retaining episodic memories in the hippocampal complex and consolidating this knowledge to the neocortex during sleep.
Consolidation of hippocampus independent short-term memory, such as emotional and procedural memory, is also enhanced by sleep (McGaugh, 2000; Hu et al., 2006; Payne et al., 2008; Wagner et al., 2001). Sleep improves motor sequence learning (Walker et al., 2005, 2002a), motor adaptation (Stickgold, 2005), and goal-related sequence tasks (Albouy et al., 2013; Cohen et al., 2005). Learning motor tasks involves many brain regions including motor cortex, basal ganglia, and hippocampus (Debas et al., 2010). While some improvement in sequential motor tasks may arise from the hippocampal contribution during sleep (King et al., 2017), improvement in motor adaptation tasks does not involve the hippocampus (Debas et al., 2010). Sleep has also been shown to prevent interference between procedural and declarative tasks (Brown and Robertson, 2007), suggesting a role for sleep in preventing interference during consolidation of different memory types.
Different sleep stages have distinct roles in memory consolidation. Non-rapid eye movement (NREM) sleep is strongly associated with consolidation of declarative memory (Diekelmann, 2014; Walker and Stickgold, 2010). In contrast, rapid eye movement (REM) sleep promotes the organization of internal representations (Dumay and Gaskell, 2007; Haskins et al., 2008; Bader et al., 2010; Tibon et al., 2014), abstraction (Gómez et al., 2006; Wagner et al., 2004; Smith and Smith, 2003; Djonlagic et al., 2009; Cai et al., 2009; Lewis et al., 2018; Durrant et al., 2015), and protects against interference between memories (McDevitt et al., 2015). In motor tasks, NREM is associated with the improvement of simple sequential tasks, while REM promotes the consolidation of complex motor tasks (King et al., 2017). REM also selectively promotes consolidation of emotional memories (Baran et al., 2012; Wagner et al., 2001). This collection of evidence suggests NREM is associated with transfer and storage of recent experiences and REM is associated with organizing internal representations. This also coincides with NREM occurring more during early parts of night sleep, when transfer occurs, followed by REM sleep occurring predominately during the later part of night sleep, when integration and higher order memory manipulations occur. This is illustrated in Fig. 2.
Figure 2:
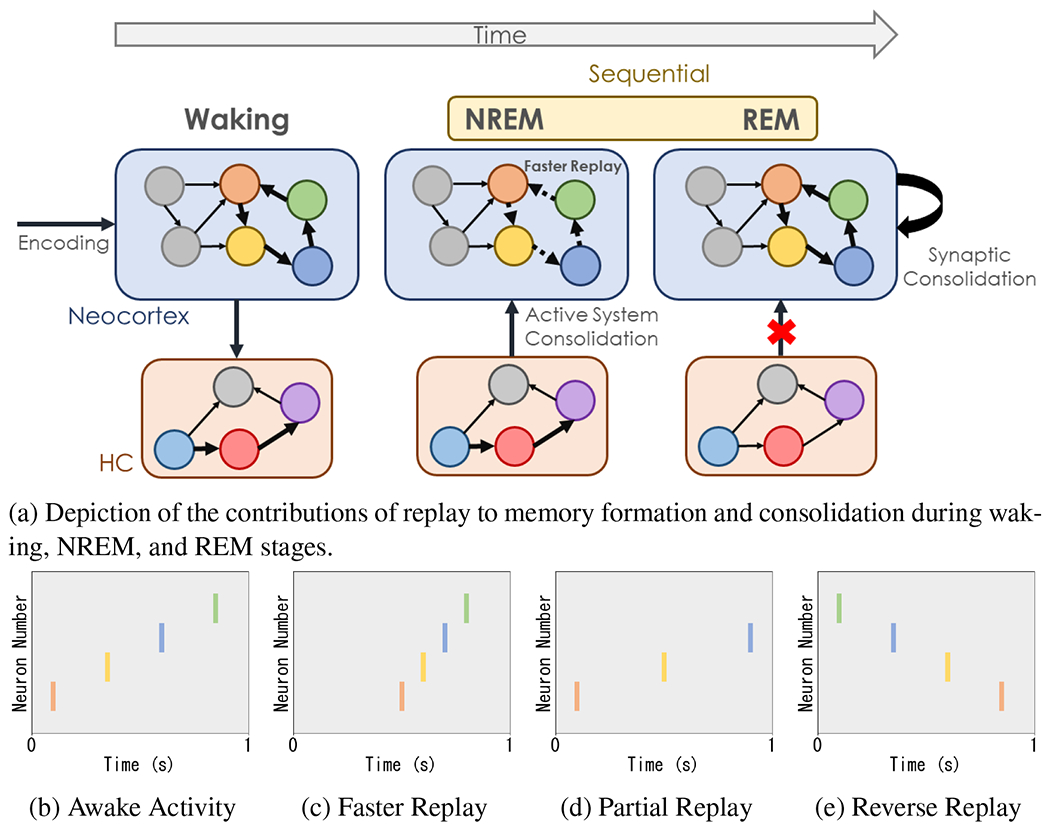
(a) Visualization of the contribution of replay in the hippocampal complex (HC) and the neocortex during different stages. Specifically, during waking hours, experiences are encoded in the HC and neocortex. While asleep, humans cycle between NREM and REM sleep stages, with NREM stages getting shorter and REM stages getting longer as the night progresses. In NREM, recent experiences are consolidated. In REM, internal experiences are organized. We also illustrate spike traces of neocortical outputs during (b) awake activity, (c) faster replay (NREM), (d) partial replay (NREM and REM), and (e) reverse replay (reinforcement learning). Note that activity during REM has been observed to be similar to that during waking experiences.
2.1. Replay Reflects Recent Memories
Since synaptic plasticity mechanisms that result in long-term changes are activity dependent (Bi and Poo, 1998; Markram et al., 1997; Abbott and Nelson, 2000), replay during sleep plays a critical role in long-term memory consolidation.
The first evidence of replay in the hippocampus was observed in the firing patterns of pairs of neurons (Pavlides and Winson, 1989; Wilson and McNaughton, 1994). In these studies, the firing patterns of ‘place cells’ in the hippocampus were measured during sleep. Since place cells are known to spike when the animal is in a particular location (O’Keefe and Nadel, 1978), it is possible to study neurons that are active during both sleep and recent waking experiences. A strong correlation was observed between the firing rates of place cell neurons during sleep to those observed during the waking task (Pavlides and Winson, 1989; Wilson and McNaughton, 1994). Such replay of recent learning has been replicated across several studies (Louie and Wilson, 2001; Davidson et al., 2009) and in other brain regions (Peyrache et al., 2009; Ji and Wilson, 2007). Subsequent studies focus on the relative timing of different neurons, and identified a similarity in the temporal order of spiking between awake experiences and sleep (Louie and Wilson, 2001; Ji and Wilson, 2007).
Replay of recent memories in hippocampus decays over time, with the progressive reduction of correlations in the firing of neurons with recent experience over several sleep cycles (Nádasdy et al., 1999). There is also a reduction in the strength of replay during awake rest across days (Karlsson and Frank, 2009). The decline in replay of recent experiences was shown to occur relatively fast in hippocampus and prefrontal cortex, i.e., within a matter of hours (Kudrimoti et al., 1999; Tatsuno et al., 2006). The decline of replay in recent experiences during sleep is followed by the resetting of hippocampal excitability during REM sleep (Grosmark et al., 2012), which may allow the hippocampus to encode new memories.
Replay of recent memories has also been observed in brain regions outside of the hippocampus. For example, the prefrontal cortex shows firing patterns similar to recent learning that are time-compressed (Euston et al., 2007; Peyrache et al., 2009). Coordinated replay between hippocampus and visual cortex has also been observed (Ji and Wilson, 2007), which provides direct evidence for the transfer of memories from hippocampus to cortex. Recent procedural memories also result in the replay of task related activity during sleep. Scalp recordings during sleep resemble activity during recently learned motor tasks (Schönauer et al., 2014). Spiking activity from motor cortex during NREM sleep has firing patterns that are similar to recent learning (Ramanathan et al., 2015; Gulati et al., 2017, 2014). Further, replay during sleep was essential for solving the credit assignment problem by selectively increasing task related neuron activity and decreasing task unrelated neuron activity following sleep (Gulati et al., 2017). Taken together, these findings suggest recent memories are replayed by many different brain regions during sleep, some of which may relate to hippocampus, while others appear to originate locally or through other brain regions.
2.2. Selective Replay Enables Better Memory Integration
Replay does not exactly replicate activity during waking experiences. An explicit demonstration of this effect was shown in a two choice maze task, where replay in rats corresponded to paths that were experienced and shortcuts that were never experienced (Gupta et al., 2010). More recently, replay during sleep in the hippocampus and prefrontal cortex corresponded to separate activation of movement related and movement independent representations (Yu et al., 2017). Likewise, commonly used methods for analyzing replay, e.g., template matching, principal component analysis, and independent component analysis, have shown high similarity, but not an exact match, between activation patterns during waking and sleep (Lee and Wilson, 2002; Louie and Wilson, 2001; Peyrache et al., 2009).
Selective and partial replay are, in part, responsible for why replay is not an exact reconstruction of waking experience. Since sleep is time limited as compared to the time required to replay all memories related to recent experiences, replaying only selected experiences can be more efficient for consolidation. Which experiences are selected for replay remains an open question. In (Schapiro et al., 2018), it was suggested that weakly learned information was replayed more frequently than other memories. Moreover, selective replay has also been shown to be motivated by fear (de Voogd et al., 2016) and reward (Gruber et al., 2016; Murty et al., 2017; Singer and Frank, 2009). In (McClelland et al., 2020), it was suggested that old experiences that overlap with new memories are in the most danger of being damaged by new learning and are preferentially replayed. Further, only certain sub-parts of the selected experiences are replayed. Such partial replay allows relevant memories with shared components to be blended, which could result in improved generalization. This was demonstrated in a recent experiment involving rats in various tasks, where coordinated partial replay of hippocampal and prefrontal cortical neurons represented generalization across different paths (Yu et al., 2018). Magnetoencephalography (MEG) studies in humans after training on tasks involving sequences with overlapping structure had activity evident of partial replays that resulted in generalization (Liu et al., 2019b). Partial replay has also been proposed to build cognitive schemata (Lewis and Durrant, 2011). Thus, partial replay provides a mechanism for higher order memory operations, which is not a simple repetition of past experience.
Rewards received during tasks are strong modulators of replay during sleep. The temporal order of replay can be reversed when it is associated with a reward, and the strength of this reversal is correlated with the reward magnitude (Ambrose et al., 2016). Reverse replay can be explained based on a form of spike time dependent synaptic plasticity (STDP), which allows for symmetric connections in both directions following sequential activation with rewards at the end of the sequence (Pfeiffer, 2020). A series of human experiments further suggest that selective and partial replay in tasks involving reward allow humans to perform generalization and model-based reinforcement learning (Momennejad, 2020), which has inspired several algorithms in machine learning (see (Cazé et al., 2018) for a review). Another important function of selective and partial replay is in planning. Replay is shown to include activity sampled from past experiences as well as novel activity that corresponds to future possibilities (Johnson and Redish, 2007) and random movements in place cells (Stella et al., 2019). Experimental and theoretical studies have identified partial replay as a potential mechanism for exploring possible routes or facilitating goal-directed navigation (Foster and Knierim, 2012; Pfeiffer and Foster, 2013). For example, partial replay corresponded to different locations in the environment that could facilitate the reconstruction of unexplored paths and novel future trajectories ((Ólafsdóttir et al., 2015, 2018).
Since reverse replay begins with the state of the reward and spike sequences trace backwards, it has been proposed to be similar to backward planning from the goal in Markov decision processes (Foster, 2017). Thus, reverse replay could be an efficient way of estimating state values, which are critical in reinforcement learning.
2.3. Replay Generation and Coordination Across Brain Regions
The exact mechanism for the spontaneous origin of replay during sleep and resting periods is not well understood. During sleep, there is a large change in the neuromodulatory tone for each sleep state across the entire brain (Brown et al., 2012; McCormick, 1992; Watson et al., 2010). Neuromodulatory levels determine a neuron’s excitability and the strength of its synaptic connections. During NREM sleep, due to a reduction in acetylcholine and monoamine levels, there is an overall reduction in neuron excitability and an increase in excitatory connections. Further, increased extracellular GABA during NREM suggests an increase in inhibition during this state. The reduced excitability and heightened synaptic connections result in spontaneous activity during sleep (Olcese et al., 2010; Krishnan et al., 2016). This reflects patterns of synaptic connectivity between neurons rather than the intrinsic state of neurons. Reactivation has also been observed in computational models of attractor networks (Shen and McNaughton, 1996), where random activations initiate attractor dynamics that result in the replay of activity that formed the attractor. If synaptic changes reflect previous learning, such as a particular group of neurons co-activating or a sequential activation of neurons, then the activity generated during sleep follows or replays the activity from learning. This has been demonstrated in several studies involving recurrently connected thalamocortical networks (Wei et al., 2016, 2018; González et al., 2020). The studies demonstrated that replay helps to avoid interference between competing memories and results in a synaptic connection that reflects the combination of previous tasks (Golden et al., 2020; González et al., 2020).
This mechanism is the basis of replay in computational models of attractor networks (Crick and Mitchison, 1983; Robins and McCallum, 1998, 1999). Specifically, in (Crick and Mitchison, 1983) attractors are randomly chosen for replay, facilitating the unlearning of them. Conversely, in (Robins and McCallum, 1998), attractors are replayed for re-learning (e.g., via replay or generative replay). Both of these studies use Hopfield networks and are directly compared in (Robins and McCallum, 1999).
An important characteristic of sleep is the synchronization of firing across neurons that leads to oscillations (e.g., oscillations in the local field potential or Electroencephalography (EEG) signals). Replay during sleep was shown to co-occur with sleep oscillations. NREM sleep is characterized by several well-defined types of oscillations, found across a wide range of species from reptiles to humans, including sharp wave ripples (100-200 Hz) in the hippocampus (Buzsáki et al., 1992), spindles (7-14 Hz) (Morison and Dempsey, 1941) and slow (< 1 Hz) oscillations (Steriade et al., 2001, 1993) in the thalamocortical network (Bazhenov and Timofeev, 2006). Numerous studies have demonstrated that replay in the hippocampus is linked to the occurrence of sharp-wave ripples (Nádasdy et al., 1999; Foster and Wilson, 2006; Davidson et al., 2009; Peyrache et al., 2009; Buzsáki, 2015). In the cortex, replay occurs during spindles and active states of slow oscillations (Ramanathan et al., 2015). Indeed, oscillatory activities during NREM stage 2 sleep, including sleep spindles and slow waves, are strongly correlated with motor sequence memory consolidation (Nishida and Walker, 2007; Barakat et al., 2013).
There is evidence for the coordination between oscillations across the cortex and hippocampus (Battaglia et al., 2004; Sirota et al., 2003; Mölle et al., 2006; Siapas and Wilson, 1998), suggesting that sleep rhythms can mediate the coordinated replay between brain regions. The nesting of ripples, spindles, and slow oscillations was reported in vivo (Staresina et al., 2015) and demonstrated in large-scale biophysical models (Sanda et al., 2021). Coordinated replay is supported by simultaneous recordings from hippocampus and neocortex (Ji and Wilson, 2007). Taken together, these evidences strongly suggest that replay in the neocortex is modulated by the hippocampus during sleep. Such coordination is critical for the transfer of recent memories from hippocampus to cortex and also across cortical regions. This coordination leads to the formation of long-range connections and promotes associations across memories and modalities.
Properties of sleep oscillations influence replay and synaptic plasticity during sleep. The frequency of spiking during spindles is well suited for initiating spike timing dependent synaptic plasticity (STDP) (Sejnowski and Destexhe, 2000). Both spindles and slow oscillations demonstrate characteristic spatio-temporal dynamics (Muller et al., 2016) and its properties determine synaptic changes during sleep (Wei et al., 2016).
2.4. Open Questions About Replay
There are several open questions about replay in biological networks that are far from being well understood. One of them is about the origin and functions of replay during REM sleep. REM sleep has been shown to play at least three intertwined roles (Walker and Stickgold, 2010): 1) it unitizes distinct memories for easier storage (Haskins et al., 2008; Bader et al., 2010; Tibon et al., 2014; Kuriyama et al., 2004; Ellenbogen et al., 2007), 2) it assimilates new memories into existing networks (Walker et al., 2002b; Stickgold et al., 1999; Dumay and Gaskell, 2007), and 3) it abstracts high-level schemas and generalizations to unlearn biased or irrelevant representations (Gómez et al., 2006; Wagner et al., 2004; Smith and Smith, 2003; Djonlagic et al., 2009; Cai et al., 2009; Lewis et al., 2018; Durrant et al., 2015). REM sleep also facilitates creative problem-solving (Lewis et al., 2018; Baird et al., 2012; Cai et al., 2009).
While the majority of replay studies are from NREM sleep, some studies have shown replay during REM sleep (Louie and Wilson, 2001; Eckert et al., 2020; Kudrimoti et al., 1999). Early studies did not find a correlation in firing patterns during REM, which had been found in NREM sleep (Kudrimoti et al., 1999). However, (Louie and Wilson, 2001) identified replay during REM in hippocampal place cells similar to NREM. In the case of motor skill learning, reactivation was observed during both REM and NREM sleep. Moreover, replays during REM and NREM are interlinked, since replay during REM is correlated with replay during NREM from the previous night (Eckert et al., 2020). REM sleep was implicated in pruning newly-formed postsynaptic dendritic spines in the mouse motor cortex during development and motor learning and was also shown to promote the survival of new, learning-induced, spines that are important for the improvement of motor skills (Li et al., 2017). Together, these studies point to the important but still poorly understood role of REM sleep in memory and learning and suggest that the repetition of NREM and REM stages with different neuromodulatory states are critical for memory consolidation.
What is the meaning of replayed activity? While in some cases the replay faithfully replicates activity learned during awake, many evidences suggest that the content of replay is more than just a simple combination of past activities. As the brain learns new memories that may potentially try to allocate synaptic resources belonging to the old memories, sleep may not simply replay previously learned memories to avoid forgetting. Instead, sleep may change representations of the old memories by re-assigning different subsets of neurons and synapses to effectively orthogonalize memory representations and allow for overlapping populations of neurons to store multiple competing memories (González et al., 2020). In fact, orthogonalizing network representations was one of the earliest attempted solutions to catastrophic forgetting in artificial networks (see (French, 1999) for an overview).
One of the outstanding questions about replay involves the selection of replayed activity. As highlighted in previous works (McClelland et al., 2020), given the limited time period of sleep, only a subset of memories are selected for replay during sleep. This suggests that the neural activity during sleep is selected to maximize consolidation, while simultaneously preventing forgetting. Machine learning algorithms could optimize directly for which old memories to be replayed during consolidation to long-term memory; these ideas could inform neuroscience research. While there are major differences between the nature of activity in artificial and spiking networks, machine learning inspired replay methods could still provide insights about neural activity selection during sleep replay.
3. Replay in Artificial Networks
When a deep neural network can be trained in an offline setting with fixed training and testing datasets, gradient descent can be used to learn a set of neural weights that minimize a loss function. However, when the training set evolves in a non-stationary manner or the agent learns from a sequence of experiences, gradient descent updates to the network cause catastrophic forgetting of previously learned knowledge (McCloskey and Cohen, 1989; Abraham and Robins, 2005). This forgetting occurs because parametric models, including neural networks, assume that data is independent and identically distributed (iid). In offline settings, models can simulate the notion of iid experiences by shuffling data. However, in continual learning settings, the data stream is evolving in a non-iid manner over time, which causes catastrophic forgetting of previous knowledge.
Further, offline machine learning setups are unable to continually learn new data since they assume there are distinct periods of training versus evaluation, that the training and testing data come from the same underlying data distribution, and that all of the training data is available at once. When these assumptions are violated, the performance of neural networks degrades. The broad field of lifelong machine learning seeks to overcome these challenges to continually train networks from evolving non-iid data streams. In addition to overcoming catastrophic forgetting, lifelong learning agents should be capable of using previous knowledge to learn similar information better and more quickly, which is known as forward knowledge transfer. This survey and much of the existing lifelong learning literature have focused on overcoming catastrophic forgetting using replay, however forward knowledge transfer is also an important aspect of lifelong learning that has received little attention (Chaudhry et al., 2018; Lopez-Paz and Ranzato, 2017), and should be studied in more detail.
Moreover, catastrophic forgetting occurs due to the stability-plasticity dilemma, which requires networks to keep weights of the network stable in order to preserve previous knowledge, but also keep weights plastic enough to learn new information. Three main types of methods for mitigating forgetting have been proposed (Parisi et al., 2019; Kemker et al., 2018; Delange et al., 2021): 1) regularization schemes for constraining weight updates with gradient descent (Kirkpatrick et al., 2017; Aljundi et al., 2018; Zenke et al., 2017; Chaudhry et al., 2018; Ritter et al., 2018; Serra et al., 2018; Dhar et al., 2019; Chaudhry et al., 2019; Lopez-Paz and Ranzato, 2017), 2) network expansion techniques for adding new parameters to a network to learn new information (Rusu et al., 2016; Yoon et al., 2018; Ostapenko et al., 2019; Hou et al., 2018), and 3) replay mechanisms for storing a representation of previous data to mix with new data when updating the network. Replay (or rehearsal) mechanisms have been shown to be the most effective of these approaches and are inspired by how the mammalian brain learns new information over time.
3.1. Replay in Supervised Learning
The ability of agents to learn over time from non-stationary data distributions without catastrophic forgetting is known as continual learning. Within continual learning, there are two major paradigms in which agents are trained (Parisi et al., 2019). The first paradigm, known as incremental batch learning, is the most common (Castro et al., 2018; Chaudhry et al., 2018; Fernando et al., 2017; Hou et al., 2019; Kemker and Kanan, 2018; Kemker et al., 2018; Rebuffi et al., 2017; Wu et al., 2019a; Zenke et al., 2017). In incremental batch learning, an agent is required to learn from a labelled dataset that is broken into T distinct batches. That is, , where each Bt is a batch of data consisting of Nt labelled training samples, i.e., with (xi, yi) denoting a training sample. At time t, the agent is required to learn from batch Bt by looping over the batch several times and making updates, before inference can be performed.
Although the incremental batch learning paradigm is popular in recent literature, it comes with caveats. Learning from batches is not biologically plausible and it is slow, which is not ideal for immediate learning. More specifically, mammals engage in resource constrained online learning from temporally correlated data streams, which is known as single pass online learning or streaming learning. Streaming learning is a special case of incremental batch learning where the batch size is set to one (Nt = 1) and the agent is only allowed a single epoch through the labelled training dataset (Gama, 2010; Gama et al., 2013). This paradigm closely resembles how humans and animals immediately learn from real-time data streams and can use new knowledge immediately.
Replay is one of the earliest (Hetherington, 1989; Ratcliff, 1990) and most effective mechanisms for overcoming forgetting in both the incremental batch (Castro et al., 2018; Rebuffi et al., 2017; Wu et al., 2019a; Hou et al., 2019; Kemker and Kanan, 2018; Kemker et al., 2018) and streaming (Hayes et al., 2019, 2020; Chaudhry et al., 2019; Lopez-Paz and Ranzato, 2017) paradigms. There are two ways in which replay has been used in artificial neural networks: partial replay and generative replay (pseudorehearsal). For partial replay, an agent will store either all or a subset of previously learned inputs in a replay buffer. It then mixes either all, or a subset of, these previous inputs with new samples and fine-tunes the network on this mixture. For example, several of the most successful models for incremental learning store a subset of previously learned raw inputs in a replay buffer (Gepperth and Karaoguz, 2016; Rebuffi et al., 2017; Lopez-Paz and Ranzato, 2017; Castro et al., 2018; Chaudhry et al., 2018; Nguyen et al., 2018; Hou et al., 2018; Hayes et al., 2019; Hou et al., 2019; Wu et al., 2019a; Lee et al., 2019; Belouadah and Popescu, 2019; Chaudhry et al., 2019; Riemer et al., 2019; Aljundi et al., 2019a,b; Belouadah and Popescu, 2020; He et al., 2020; Zhao et al., 2020; Kurle et al., 2020; Chrysakis and Moens, 2020; Kim et al., 2020; Tao et al., 2020; Douillard et al., 2020). However, replaying raw pixels is not biologically plausible. More recently, methods that store representations/features from the middle (latent) layers of a network for replay have been developed (Hayes et al., 2020; Iscen et al., 2020; Caccia et al., 2020; Pellegrini et al., 2019), which are more consistent with replay in the mammalian brain, as suggested by hippocampal indexing theory (Teyler and Rudy, 2007) (see Sec. 2). The challenge in using representational replay comes in choosing which hidden layer(s) to use replay features from. While choosing features from earlier layers in the network allows more of the network to be trained incrementally, early features usually have larger spatial dimensions and require more memory for storage. Choosing the ideal layer for representational replay remains an open question.
In contrast to storing previous examples explicitly, generative replay methods train a generative model such as an auto-encoder or a generative adversarial network (GAN) (Goodfellow et al., 2014) to generate samples from previously learned data (Draelos et al., 2017; Kemker and Kanan, 2018; Robins, 1995; Ostapenko et al., 2019; Shin et al., 2017; He et al., 2018; French, 1997; Atkinson et al., 2018; Robins, 1996). The first generative replay method was proposed in (Robins, 1995), where it was further suggested that these mechanisms might be related to memory consolidation during sleep in mammals. Similar to partial replay methods, generative replay methods can generate veridical inputs (Shin et al., 2017; Kemker and Kanan, 2018; Parisi et al., 2018; He et al., 2018; Wu et al., 2018; Ostapenko et al., 2019; Abati et al., 2020; Liu et al., 2020b; Titsias et al., 2020; von Oswald et al., 2020; Ye and Bors, 2020) or mid-level CNN feature representations (van de Ven et al., 2020; Lao et al., 2020). These generative approaches do not require the explicit storage of data samples, which could potentially reduce storage requirements and mitigate some concerns regarding privacy. However, the generator itself often contains as many parameters as the classification network, leading to large memory requirements. Additionally, generative models are notoriously difficult to train due to convergence issues and mode collapse, making these models less ideal for online learning. One advantage to using an unsupervised generative replay method is that the system could potentially be less susceptible to, but not completely unaffected by, catastrophic forgetting (Gillies, 1991). Additionally, generative replay is more biologically plausible as it is unrealistic to assume the human brain could store previous inputs explicitly, as is the case in partial replay. An overview of existing supervised replay methods for classification and their associated categorizations are in Fig. 3.
Figure 3:
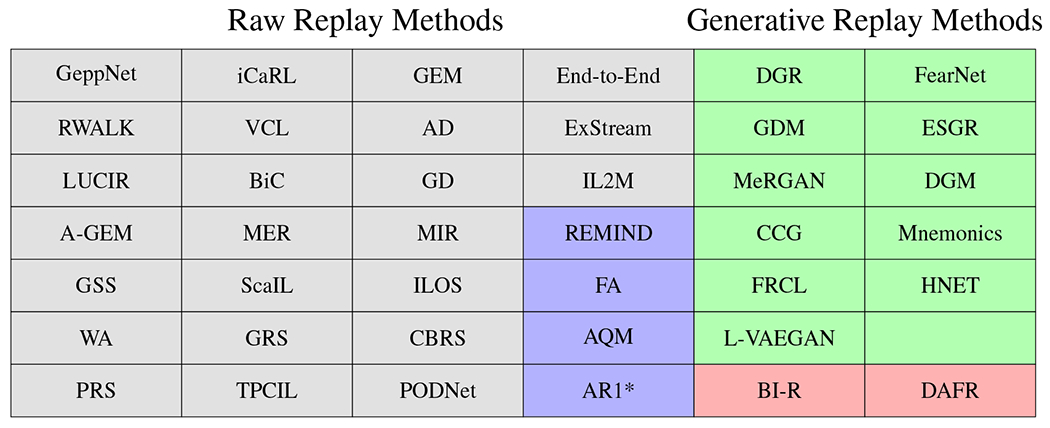
Categorizations of supervised artificial replay algorithms: Veridical Replay; Representational Replay; Generative Veridical Replay; Generative Representational Replay. See Appendix (Table 2) for algorithm citations.
In addition to the aforementioned models that perform replay by storing a subset of previous inputs, there have been several models that use replay in conjunction with other mechanisms to mitigate forgetting, such as regularizing parameter updates. For example, the Gradient Episodic Memory (GEM) (Lopez-Paz and Ranzato, 2017) and Averaged-GEM (Chaudhry et al., 2019) models store a subset of previous inputs to use with a gradient regularization loss. Similarly, the Meta-Experience Replay model (Riemer et al., 2019) and Variational Continual Learning model (Nguyen et al., 2018) use experience replay in conjunction with meta-learning and Bayesian regularization techniques, respectively.
For both partial replay and generative replay approaches, the agent must decide what to replay. In (Chaudhry et al., 2018), four selection strategies are compared for storing a small set of previous exemplars to use with a regularization approach. Namely, they compare uniform random sampling, storing examples closest to class decision boundaries, storing examples with the highest entropy, and storing a mean vector for each class in deep feature space. While they found storing a representative mean vector for each class performed the best, uniform random sampling performed nearly as well with less compute. In (Aljundi et al., 2019a), samples that would be the most interfered with after network updates are replayed to the network, i.e., those samples for which performance would be harmed the most by parameter updates. In their experiments, the authors found that replaying these interfered samples improved performance over randomly replaying samples. Similarly, in (Aljundi et al., 2019b) sample selection is formulated as a constrained optimization problem, which maximizes the chosen sample diversity. The authors of (Aljundi et al., 2019b) further propose a greedy sampling policy as an alternative to the optimization and find that both sample selection policies improve performance over random selection. Similarity scores have also been used to select replay samples (McClelland et al., 2020). While selective replay has demonstrated promising results in some small-scale settings, several large-scale studies have found that uniform random sampling works surprisingly well (Hayes et al., 2020; Wu et al., 2019a), achieving almost the same performance as more complicated techniques, while requiring less compute. The sample selection problem is also closely related to active learning strategies (Cohn et al., 1994; Lin and Parikh, 2017; Wang et al., 2016; Settles, 2009; Yoo and So Kweon, 2019; Wei et al., 2015), with the most common selection methods using uncertainty sampling (Lewis and Gale, 1994; Culotta and McCallum, 2005; Scheffer et al., 2001; Dagan and Engelson, 1995; Dasgupta and Hsu, 2008).
In addition to improving accuracy, selective replay can also facilitate better sample efficiency, i.e., the network requires fewer samples to learn new information. Sample efficiency has been studied for continual learning (Davidson and Mozer, 2020). In (Davidson and Mozer, 2020), the authors found that a convolutional neural network required fewer training epochs to reach a target accuracy on a new task after having learned other visually similar tasks. These findings are closely related to the multi-task learning literature, where the relationship between task similarity and network performance in terms of accuracy and time has been studied (Zhang and Yang, 2021; Ruder, 2017; Standley et al., 2020; Liu et al., 2019a; Kendall et al., 2018).
While the majority of supervised learning literature has focused on overcoming forgetting in feed-forward or convolutional neural networks, there has also been work focused on using replay to mitigate forgetting in recurrent neural networks (Parisi et al., 2018; Sodhani et al., 2020). In (Parisi et al., 2018), a self-organizing recurrent network architecture consisting of a semantic memory and an episodic memory is introduced to replay previous neural reactivations. In (Sodhani et al., 2020), a network expansion technique is combined with gradient regularization and replay in a recurrent neural network to mitigate forgetting.
Further, in (Hayes et al., 2020; Greco et al., 2019), replay is used as an effective mechanism to mitigate forgetting for the problem of visual question answering, where an agent must answer natural language questions about images. Similarly, replay has been used for continual language learning (de Masson d’Autume et al., 2019). Replay has also been used to perform continual semantic segmentation of medical images (Ozdemir et al., 2018; Ozdemir and Goksel, 2019), remote sensing data (Tasar et al., 2019; Wu et al., 2019b), and on standard computer vision benchmarks (Cermelli et al., 2020). In (Acharya et al., 2020; Liu et al., 2020a), replay is used to mitigate forgetting for a continual object detection approach. Replay approaches have also been explored in continual learning for robotics (Lesort et al., 2020; Feng et al., 2019).
3.2. Replay in Reinforcement Learning
Experience replay has also been widely used in reinforcement learning (Mnih et al., 2015, 2013; Van Hasselt et al., 2016; Lillicrap et al., 2016; Lin, 1992; Adam et al., 2011; Foerster et al., 2017; Kapturowski et al., 2019; Atkinson et al., 2021). As in supervised classification, experience replay in reinforcement learning is inspired by the interplay between memory systems in the mammalian brain and its biological plausibility has been discussed in (Schaul et al., 2016; Hassabis et al., 2017). The overall goal of reinforcement learning is to train an agent to appropriately take actions in an environment to maximize its reward, which is a naturally realistic setup as compared to existing supervised classification setups. In online reinforcement learning, an agent is required to learn from a temporally correlated stream of experiences. However, the temporal correlation of the input stream is not independent and identically distributed and violates the assumptions of conventional, gradient-based optimization algorithms typically used for updating agents, resulting in catastrophic forgetting. Lin (1992) proposed experience replay as a method for creating independent and identically distributed batches of data for an agent to learn from, while additionally allowing the agent to store and replay experiences that are rarely encountered. Specifically, the Deep Q-Network (DQN) (Mnih et al., 2013, 2015) performed experience replay using a sliding window approach where a uniformly selected set of previous transitions was replayed to the agent. While the random experience selection policy helped stabilize training of the DQN, prioritized experience replay (Schaul et al., 2016) has been shown to be more effective and efficient. Prioritized experience replay is based on the assumption that some transitions between experiences may be more surprising to the agent and additionally that some experiences might not be immediately relevant to an agent and should be replayed at a later point during training (Schmidhuber, 1991).
In (Schaul et al., 2016), prioritized experience replay was performed based on the magnitude of an experience’s temporal-difference (TD) error, which measures an agent’s learning progress and is consistent with biological findings (Singer and Frank, 2009; McNamara et al., 2014). However, using TD error alone can result in less diverse samples being replayed and must be combined with an importance-based sampling procedure. In (Isele and Cosgun, 2018), the authors compared four experience selection strategies to augment a first-in first-out queue, namely: TD error, absolute reward, distribution matching based on reservoir sampling, and state-space coverage maximization based on the nearest neighbors to an experience. They found that experience selection based on TD error and absolute reward did not work well in mitigating forgetting, while selection based on distribution matching and state-space coverage had comparable performance to an unlimited replay buffer. Although replay selection strategies have not shown as much benefit for the supervised learning scenario, they have significantly improved the performance and efficiency of training in reinforcement learning agents (Moore and Atkeson, 1993).
In standard prioritized experience replay, each experience is typically associated with a single goal (reward). In contrast, hindsight experience replay (Andrychowicz et al., 2017) allows experiences to be replayed with various rewards, which has several advantages. First, it allows learning when reward signals are sparse or binary, which is a common challenge in reinforcement learning agents. Overcoming sparse reward signals leads to sample efficiency. More interestingly, hindsight experience replay can serve as a form of curriculum learning (Bengio et al., 2009) by structuring the rewards such that they start off simple and grow increasingly more complex during training. Curriculum learning has been shown to speed up the training of neural networks, while also leading to better generalization (Bengio et al., 2009; Graves et al., 2017; Hunziker et al., 2019; Zhou and Bilmes, 2018; Fan et al., 2018; Achille et al., 2018). Additionally, curriculum learning is important for cognitive development in humans (Lenneberg, 1967; Senghas et al., 2004).
In addition to experience replay alone, several methods have also incorporated other brain-inspired mechanisms into their online reinforcement learning agents. For example, (Pritzel et al., 2017; Lengyel and Dayan, 2008; Blundell et al., 2016) take inspiration from the role the hippocampus plays in making decisions to develop agents that learn much faster than other approaches. In (Chen et al., 2019), the authors propose using only the raw environment pixel inputs for their agent in a trial-and-error scenario, which closely resembles how humans learn about and navigate their environments. In (Lake et al., 2017), it is argued that human brains are similar to model-free reinforcement learning agents for discrimination and associative learning tasks.
3.3. Replay in Unsupervised Learning
Although replay has been more extensively explored in supervised classification and reinforcement learning, it has also been explored in unsupervised learning settings (Lesort et al., 2019; Wu et al., 2018). For example, replay has been explored in continual learning of GANs for image and scene generation. Specifically, the Exemplar-Supported Generative Reproduction model (He et al., 2018) uses a GAN to generate pseudo-examples for replay during continual learning, while the Dynamic Generative Memory model (Ostapenko et al., 2019), the Deep Generative Replay model (Shin et al., 2017), the Memory Replay GAN model (Wu et al., 2018), and the Closed-Loop GAN model (Rios and Itti, 2019) are all used to continually learn to generate images and scenes. Continual learning with replay in GANs has also been used for reinforcement learning (Caselles-Dupré et al., 2019). Moreover, unsupervised learning techniques such as auto-encoders and GANs are widely used to generate replay samples in supervised learning algorithms (Draelos et al., 2017; Kemker and Kanan, 2018).
4. Juxtaposing Biological and Artificial Replay
Recently, machine learning researchers have tried to bridge some of the differences between biological replay and artificial replay. For example, several methods using representational replay (Hayes et al., 2020; Caccia et al., 2020; Pellegrini et al., 2019; Iscen et al., 2020) or generative representational replay (van de Ven et al., 2020; Lao et al., 2020), instead of veridical (raw pixel) replay, have been proposed to improve continual learning performance. Moreover, (McClelland et al., 2020) uses similarity scores in selecting which samples to replay based on evidence of replay in the hippocampus and cortex. Further, (Tadros et al., 2020b,a; Krishnan et al., 2019) implement a sleep-inspired mechanism in a converted spiking neural network to reduce catastrophic forgetting. More recently, (van de Ven et al., 2020) incorporated several brain-inspired mechanisms into their artificial network including feedback connections, context gating mechanisms, and generative representational replay.
However, many replay algorithms still differ from how humans learn and assimilate new information. For example, few existing techniques use Hebbian or error-based learning (Tao et al., 2020; Parisi et al., 2018) and most rely on supervised labels during training. Moreover, epigenetic tagging mechanisms in medial prefrontal cortex have largely been ignored by existing artificial network approaches and some approaches largely focus on replay during waking hours instead of replay during sleep (Hayes et al., 2019, 2020). In biological networks, replay happens both independently and concurrently in several different brain regions, whereas artificial replay implementations only perform replay at a single layer within the neural network. Furthermore, many existing artificial replay implementations 1) do not purge their memory buffer, which is not consistent with biology (Nádasdy et al., 1999; Karlsson and Frank, 2009) and 2) do not have a notion of waking (streaming/online) learning.
While selective experience replay has yielded significant performance gains in reinforcement learning, uniform random sampling still works well and is widely used in supervised classification, which is not consistent with how memories are selectively replayed in the brain. It is biologically infeasible to store everything a mammal encounters in its lifetime and likewise, it is not ideal for machine learning agents to store all previous data. In the case of partial replay, several different strategies have been explored for prioritizing what memories should be replayed (Chaudhry et al., 2018; Aljundi et al., 2019b,a; McClelland et al., 2020). While there have been several replay selection methods proposed, many existing works have found uniform random sampling of previous memories to work well, especially for large-scale problems (Chaudhry et al., 2018; Wu et al., 2019a; Hayes et al., 2020). While sampling strategies have not demonstrated significant success for supervised learning problems, the reinforcement learning community has seen more benefit from these approaches, e.g., prioritized experience replay (Schaul et al., 2016) and hindsight replay (Andrychowicz et al., 2017). Exploring selective replay strategies in machine learning could help inform biologists about what might be replayed in the brain. Further, the efficiency of selective replay in machine learning has largely been ignored with most researchers developing selective replay methods that only yield better performance. By studying selective replay techniques that are efficient, the agent could potentially learn information better and more quickly, which is closely related to forward knowledge transfer in humans. Moreover, humans generate novel memories that are not generated from external world inputs during REM sleep (Lewis et al., 2018). Exploring schemes to generate novel memories in machine learning could further improve performance.
In machine learning and computer vision, there have been several models inspired by CLS theory in biological networks (Gepperth and Karaoguz, 2016; French, 1997; Ans and Rousset, 1997; Kemker and Kanan, 2018; Robins, 1995, 1996). All of these models have, or presuppose, a fast-learning hippocampal-inspired network and consolidate knowledge to a medial prefrontal cortex network that learns more slowly. Further, (Gepperth and Karaoguz, 2016; Kemker and Kanan, 2018; Draelos et al., 2017) integrate neurogenesis into their models where new neurons are created to form new memories. Such neurogenesis-inspired mechanisms have been studied experimentally in biology (Kumar et al., 2020; Deng et al., 2010; Aimone et al., 2014, 2011). Several of these CLS-inspired models focus on using generative replay to generate new inputs during training (French, 1997; Ans and Rousset, 1997; Kemker and Kanan, 2018; Robins, 1995), instead of storing raw inputs explicitly (Gepperth and Karaoguz, 2016). However, the vast majority of existing replay approaches in artificial neural networks replay raw pixel inputs (Hou et al., 2019; Rebuffi et al., 2017; Castro et al., 2018; Wu et al., 2019a). There have been a few approaches that store high-level feature representations (feature maps) of inputs instead of using generative replay (Hayes et al., 2019, 2020; Pellegrini et al., 2019; Caccia et al., 2020), which is more biologically plausible than replay from raw pixels. While there have been several models inspired by CLS theory (Gepperth and Karaoguz, 2016; French, 1997; Ans and Rousset, 1997; Kemker and Kanan, 2018; Robins, 1995), many existing replay approaches have only focused on modeling medial prefrontal cortex directly and do not have a fast learning network. Moreover, (Kemker and Kanan, 2018) is the only CLS-inspired model that integrates a non-oracle basolateral amygdala network for decision-making during inference. Lastly, none of the aforementioned CLS-inspired models use information from the neocortex-inspired network to influence training of the hippocampal-inspired network, whereas the neocortex influences learning in the hippocampus and vice-versa in biological networks.
Further, CLS theory assumes that different awake and sleep states correspond to periods of encoding memories in hippocampus and the subsequent transfer of memories from hippocampus to cortex. This suggests that artificial neural networks could benefit from the inclusion of explicit awake and sleep states, inspired by the mammalian brain. Moreover, one open question in biology involves what happens to memories after they have been consolidated from the hippocampus to the neocortex. These memories in hippocampus could be erased entirely, or they could still be encoded in the hippocampus, but never reactivated again. While this is an open question in biology, its exploration in machine learning could inform the neuroscientific community and lead to new discoveries.
While the CLS memory model (i.e., fast learning in hippocampus followed by slow learning in the cortex) is widely accepted as a core principle of how the brain learns declarative memories, it is likely not the only memory model the brain uses. Indeed, procedural, presumably hippocampus-independent memories, e.g., some motor tasks (Fogel and Smith, 2006) can be learned without forgetting old skills and replayed during REM sleep when the hippocampus is effectively disconnected from the neocortex. Even if the hippocampus may be important for early phases of motor learning, subsequent training and replay rely on motor cortex and striatal networks (Lemke et al., 2019). Therefore, while typical machine learning replay approaches interleave new training data with old knowledge from hippocampus-like networks, the biological cortex is capable of replaying old traces on its own. For example, very few researchers have explored “self-generated” replay as a mechanism to protect old knowledge for continual learning (Tadros et al., 2020b,a; Krishnan et al., 2019). Another alternative to CLS theory is the idea of using both fast and slow weights between units for each connection in the network (Hinton and Plaut, 1987). While the fast weights are used to learn new information, the slow weights can be used for generative replay (Robins, 1997, 2004).
Beyond CLS theory, more interesting computational models of HC have been explored. For example, (Káli and Dayan, 2004) proposed a model where the HC and cortex were modelled as a lookup-table and a restricted-Boltzmann-machine, respectively. In this model, the HC network played a critical role in memory retrieval, beyond serving as an offline replay buffer, which is how HC is commonly modelled in modern neural network implementations. The authors further discuss index maintenance and extension. More recently, (Whittington et al., 2020) proposed the Tolman Eichenbaum Machine, where the HC network performs space and relational inference. Replay in the Tolman Eichenbaum Machine allowed for the organization of sequences into structures that could facilitate abstraction and generalization.
Another critical difference between biological and artificial implementations of replay is the notion of regularization. In biological networks, normalization and synaptic changes co-occur with replay (Chauvette et al., 2012; Tononi and Cirelli, 2014). However, in artificial networks, regularization and replay approaches for mitigating catastrophic forgetting have largely been explored independently. While some deep learning methods combine replay and regularization (Chaudhry et al., 2019; Lopez-Paz and Ranzato, 2017), each mechanism operates largely without informed knowledge of the other, unlike the co-occurrence and direct communication between the two mechanisms in biology. By integrating the two mechanisms with more communication in artificial networks, performance could be improved further and each mechanism could potentially strengthen the other component. For example, replay informed regularization could help strengthen connections specific to a particular memory, while regularization informed replay could help identify which samples to replay that will enable more transfer or less forgetting.
5. Conclusions
Although humans and animals are able to continuously acquire new information over their lifetimes without catastrophically forgetting prior knowledge, artificial neural networks lack these capabilities (Parisi et al., 2019; Kemker et al., 2018; Delange et al., 2021). Replay of previous experiences or memories in humans has been identified as the primary mechanism for overcoming forgetting and enabling continual knowledge acquisition (Walker and Stickgold, 2004). While replay-inspired mechanisms have enabled artificial networks to learn from non-stationary data distributions, these mechanisms differ from biological replay in several ways. Moreover, current artificial replay implementations are computationally expensive to deploy. In this paper, we have given an overview of the current state of research in both artificial and biological implementations of replay and further identified several gaps between the two fields. By incorporating more biological mechanisms into artificial replay implementations, we hope deep networks will exhibit better transfer, abstraction, and generalization. Further, we hope that advancing replay in artificial networks can inform future neuroscientifc studies of replay in biology.
Acknowledgments
TH and CK were supported in part by the DARPA/SRI Lifelong Learning Machines program [HR0011-18-C-0051], AFOSR grant [FA9550-18-1-0121], and NSF award #1909696. MB and GK were supported in part by the Lifelong Learning Machines program from DARPA/MTO [HR0011-18-2-0021], ONR grant [N000141310672], NSF award [IIS-1724405], and NIH grant [R01MH125557]. The views and conclusions contained herein are those of the authors and should not be interpreted as representing the official policies or endorsements of any sponsor. One author in this study, CK, was employed at a commercial company, Paige, New York during the preparation of this manuscript. This company played no role in the sponsorship, design, data collection and analysis, decision to publish, or preparation of the manuscript. We thank Anthony Robins and our anonymous reviewers and editors for their helpful comments and suggestions to improve this manuscript.
Appendix
Table 2:
Replay algorithm citations from Fig. 3.
Footnotes
For simplicity, we use replay to refer to both reactivation and replay. In the neuroscience literature, replay typically refers to the reactivation of a sequence of more than one neural patterns in the same sequence they occurred during waking experience, but here we define it as the reactivation of one or more neural patterns.
References
- Abati D, Tomczak J, Blankevoort T, Calderara S, Cucchiara R, and Bejnordi BE (2020). Conditional channel gated networks for task-aware continual learning. In CVPR, pages 3931–3940. [Google Scholar]
- Abbott LF and Nelson SB (2000). Synaptic plasticity: taming the beast. Nature neuroscience, 3(11):1178–1183. [DOI] [PubMed] [Google Scholar]
- Abraham WC and Robins A (2005). Memory retention – the synaptic stability versus plasticity dilemma. Trends in Neurosciences, 28(2):73–78. [DOI] [PubMed] [Google Scholar]
- Acharya M, Hayes TL, and Kanan C (2020). Rodeo: Replay for online object detection. In BMVC. [Google Scholar]
- Achille A, Rovere M, and Soatto S (2018). Critical learning periods in deep networks. In ICLR. [Google Scholar]
- Adam S, Busoniu L, and Babuska R (2011). Experience replay for real-time reinforcement learning control. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(2):201–212. [Google Scholar]
- Aimone JB, Deng W, and Gage FH (2011). Resolving new memories: a critical look at the dentate gyrus, adult neurogenesis, and pattern separation. Neuron, 70(4):589–596. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aimone JB, Li Y, Lee SW, Clemenson GD, Deng W, and Gage FH (2014). Regulation and function of adult neurogenesis: from genes to cognition. Physiological reviews, 94(4):991–1026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Albouy G, Fogel S, Pottiez H, Nguyen VA, Ray L, Lungu O, Carrier J, Robertson E, and Doyon J (2013). Daytime sleep enhances consolidation of the spatial but not motoric representation of motor sequence memory. PloS one, 8(1):e52805. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aljundi R, Babiloni F, Elhoseiny M, Rohrbach M, and Tuytelaars T (2018). Memory aware synapses: Learning what (not) to forget. In ECCV, pages 139–154. [Google Scholar]
- Aljundi R, Belilovsky E, Tuytelaars T, Charlin L, Caccia M, Lin M, and Page-Caccia L (2019a). Online continual learning with maximal interfered retrieval. In NeurIPS, pages 11849–11860. [Google Scholar]
- Aljundi R, Lin M, Goujaud B, and Bengio Y (2019b). Gradient based sample selection for online continual learning. In NeurIPS, pages 11816–11825. [Google Scholar]
- Ambrose RE, Pfeiffer BE, and Foster DJ (2016). Reverse Replay of Hippocampal Place Cells Is Uniquely Modulated by Changing Reward. Neuron, 91(5):1124–1136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Andrychowicz M, Wolski F, Ray A, Schneider J, Fong R, Welinder P, McGrew B, Tobin J, Abbeel OP, and Zaremba W (2017). Hindsight experience replay. In NeurIPS, pages 5048–5058. [Google Scholar]
- Ans B and Rousset S (1997). Avoiding catastrophic forgetting by coupling two reverberating neural networks. Comptes Rendus de l’Académie des Sciences-Series III-Sciences de la Vie, 320(12):989–997. [Google Scholar]
- Atkinson C, McCane B, Szymanski L, and Robins A (2018). Pseudo-recursal: Solving the catastrophic forgetting problem in deep neural networks. arxiv 2018. arXiv preprint arXiv:1802.03875. [Google Scholar]
- Atkinson C, McCane B, Szymanski L, and Robins A (2021). Pseudo-rehearsal: Achieving deep reinforcement learning without catastrophic forgetting. Neurocomputing, 428:291–307. [Google Scholar]
- Bader R, Mecklinger A, Hoppstädter M, and Meyer P (2010). Recognition memory for one-trial-unitized word pairs: Evidence from event-related potentials. NeuroImage, 50(2):772–781. [DOI] [PubMed] [Google Scholar]
- Baird B, Smallwood J, Mrazek MD, Kam JW, Franklin MS, and Schooler JW (2012). Inspired by distraction: Mind wandering facilitates creative incubation. Psychological science, 23(10):1117–1122. [DOI] [PubMed] [Google Scholar]
- Barakat M, Carrier J, Debas K, Lungu O, Fogel S, Vandewalle G, Hoge RD, Bellec P, Karni A, and Ungerleider LG (2013). Sleep spindles predict neural and behavioral changes in motor sequence consolidation. Human brain mapping, 34(11):2918–2928. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baran B, Pace-Schott EF, Ericson C, and Spencer RMC (2012). Processing of Emotional Reactivity and Emotional Memory over Sleep. Journal of Neuroscience, 32(3):1035–1042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Battaglia FP, Sutherland GR, and McNaughton BL (2004). Hippocampal sharp wave bursts coincide with neocortical “up-state” transitions. Learning & memory, 11(6):697–704. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bazhenov M and Timofeev I (2006). Thalamocortical oscillations. Scholarpedia, 1(6):1319. [Google Scholar]
- Belouadah E and Popescu A (2019). Il2m: Class incremental learning with dual memory. In ICCV, pages 583–592. [Google Scholar]
- Belouadah E and Popescu A (2020). Scail: Classifier weights scaling for class incremental learning. In WACV, pages 1266–1275. [Google Scholar]
- Belouadah E, Popescu A, and Kanellos I (2020). A comprehensive study of class incremental learning algorithms for visual tasks. Neural Networks. [DOI] [PubMed] [Google Scholar]
- Bengio Y, Louradour J, Collobert R, and Weston J (2009). Curriculum Learning. In ICML, pages 41–48. [Google Scholar]
- Bero AW, Meng J, Cho S, Shen AH, Canter RG, Ericsson M, and Tsai L-H (2014). Early remodeling of the neocortex upon episodic memory encoding. Proceedings of the National Academy of Sciences, 111(32):11852–11857. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bi G.-q. and Poo M.-m. (1998). Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, and postsynaptic cell type. Journal of Neuroscience, 18(24):10464–10472. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blundell C, Uria B, Pritzel A, Li Y, Ruderman A, Leibo JZ, Rae J, Wierstra D, and Hassabis D (2016). Model-free episodic control. arXiv preprint arXiv:1606.04460. [Google Scholar]
- Bontempi B, Laurent-Demir C, Destrade C, and Jaffard R (1999). Time-dependent reorganization of brain circuitry underlying long-term memory storage. Nature, 400(6745):671–675. [DOI] [PubMed] [Google Scholar]
- Born J (2010). Slow-Wave Sleep and the Consolidation of Long-Term Memory. The World Journal of Biological Psychiatry, 11(sup1):16–21. [DOI] [PubMed] [Google Scholar]
- Brown RE, Basheer R, McKenna JT, Strecker RE, and McCarley RW (2012). Control of Sleep and Wakefulness. Physiological reviews, 92(3):1087–1187. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown RM and Robertson EM (2007). Off-Line Processing: Reciprocal Interactions between Declarative and Procedural Memories. Journal of Neuroscience, 27(39):10468–10475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buzsaki G (2015). Hippocampal sharp wave-ripple: A cognitive biomarker for episodic memory and planning. Hippocampus, 25(10):1073–1188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buzsaki G, Horvath Z, Urioste R, Hetke J, and Wise K (1992). High-frequency network oscillation in the hippocampus. Science, 256(5059):1025–1027. [DOI] [PubMed] [Google Scholar]
- Caccia L, Belilovsky E, Caccia M, and Pineau J (2020). Online learned continual compression with adaptive quantization modules. In ICML, pages 1240–1250. [Google Scholar]
- Cai DJ, Mednick SA, Harrison EM, Kanady JC, and Mednick SC (2009). Rem, not incubation, improves creativity by priming associative networks. Proceedings of the National Academy of Sciences, 106(25):10130–10134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caselles-Dupré H, Garcia-Ortiz M, and Filliat D (2019). S-trigger: Continual state representation learning via self-triggered generative replay. arXiv preprint arXiv:1902.09434. [Google Scholar]
- Castro FM, Marín-Jiménez MJ, Guil N, Schmid C, and Alahari K (2018). End-to-end incremental learning. In ECCV, pages 233–248. [Google Scholar]
- Cazé R, Khamassi M, Aubin L, and Girard B (2018). Hippocampal replays under the scrutiny of reinforcement learning models. Journal of Neurophysiology, 120(6):2877–2896. [DOI] [PubMed] [Google Scholar]
- Cermelli F, Mancini M, Bulo SR, Ricci E, and Caputo B (2020). Modeling the background for incremental learning in semantic segmentation. In CVPR, pages 9233–9242. [DOI] [PubMed] [Google Scholar]
- Chaudhry A, Dokania PK, Ajanthan T, and Torr PH (2018). Riemannian walk for incremental learning: Understanding forgetting and intransigence. In ECCV, pages 532–547. [Google Scholar]
- Chaudhry A, Ranzato M, Rohrbach M, and Elhoseiny M (2019). Efficient lifelong learning with A-GEM. In ICLR. [Google Scholar]
- Chauvette S, Seigneur J, and Timofeev I (2012). Sleep oscillations in the thalamocortical system induce long-term neuronal plasticity. Neuron, 75(6):1105–1113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen J, Chen J, Zhang R, and Hu X (2019). Toward a brain-inspired system: Deep recurrent reinforcement learning for a simulated self-driving agent. Frontiers in Neurorobotics, 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chrysakis A and Moens M-F (2020). Online continual learning from imbalanced data. Proceedings of Machine Learning and Systems, pages 8303–8312. [Google Scholar]
- Cohen DA, Pascual-Leone A, Press DZ, and Robertson EM (2005). Off-line learning of motor skill memory: A double dissociation of goal and movement. Proceedings of the National Academy of Sciences, 102(50):18237–18241. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohn D, Atlas L, and Ladner R (1994). Improving generalization with active learning. Machine Learning, 15(2):201–221. [Google Scholar]
- Crick F and Mitchison G (1983). The function of dream sleep. Nature, 304(5922):111–114. [DOI] [PubMed] [Google Scholar]
- Culotta A and McCallum A (2005). Reducing labeling effort for structured prediction tasks. In AAAI, volume 5, pages 746–751. [Google Scholar]
- Dagan I and Engelson SP (1995). Committee-based sampling for training probabilistic classifiers. In Machine Learning Proceedings 1995, pages 150–157. Elsevier. [Google Scholar]
- Dasgupta S and Hsu D (2008). Hierarchical sampling for active learning. In ICML, pages 208–215. ACM. [Google Scholar]
- Davidson G and Mozer MC (2020). Sequential mastery of multiple visual tasks: Networks naturally learn to learn and forget to forget. In CVPR, pages 9282–9293. [Google Scholar]
- Davidson TJ, Kloosterman F, and Wilson MA (2009). Hippocampal Replay of Extended Experience. Neuron, 63(4):497–507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Masson d’Autume C, Ruder S, Kong L, and Yogatama D (2019). Episodic memory in lifelong language learning. In NeurIPS, pages 13122–13131. [Google Scholar]
- de Voogd LD, Fernández G, and Hermans EJ (2016). Awake reactivation of emotional memory traces through hippocampal–neocortical interactions. Neuroimage, 134:563–572. [DOI] [PubMed] [Google Scholar]
- Debas K, Carrier J, Orban P, Barakat M, Lungu O, Vandewalle G, Tahar AH, Bellec P, Karni A, and Ungerleider LG (2010). Brain plasticity related to the consolidation of motor sequence learning and motor adaptation. Proceedings of the National Academy of Sciences, 107(41):17839–17844. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Delange M, Aljundi R, Masana M, Parisot S, Jia X, Leonardis A, Slabaugh G, and Tuytelaars T (2021). A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence. [DOI] [PubMed] [Google Scholar]
- Deng W, Aimone JB, and Gage FH (2010). New neurons and new memories: how does adult hippocampal neurogenesis affect learning and memory? Nature Reviews Neuroscience, 11(5):339–350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dhar P, Singh RV, Peng K-C, Wu Z, and Chellappa R (2019). Learning without memorizing. In CVPR, pages 5138–5146. [Google Scholar]
- Diekelmann S (2014). Sleep for cognitive enhancement. Frontiers in Systems Neuroscience, 8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Djonlagic I, Rosenfeld A, Shohamy D, Myers C, Gluck M, and Stickgold R (2009). Sleep enhances category learning. Learning & Memory, 16(12):751–755. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Douillard A, Cord M, Ollion C, Robert T, and Valle E (2020). Podnet: Pooled outputs distillation for small-tasks incremental learning. In ECCV, pages 86–102. [Google Scholar]
- Draelos TJ, Miner NE, Lamb CC, Cox JA, Vineyard CM, Carlson KD, Severa WM, James CD, and Aimone JB (2017). Neurogenesis deep learning: Extending deep networks to accommodate new classes. In IJCNN, pages 526–533. IEEE. [Google Scholar]
- Dumay N and Gaskell MG (2007). Sleep-associated changes in the mental representation of spoken words. Psychological Science, 18(1):35–39. [DOI] [PubMed] [Google Scholar]
- Durrant SJ, Cairney SA, McDermott C, and Lewis PA (2015). Schema-conformant memories are preferentially consolidated during rem sleep. Neurobiology of Learning and Memory, 122:41–50. [DOI] [PubMed] [Google Scholar]
- Eckert M, McNaughton B, and Tatsuno M (2020). Neural ensemble reactivation in rapid eye movement and slow-wave sleep coordinate with muscle activity to promote rapid motor skill learning. Philosophical Transactions of the Royal Society B, 375(1799):20190655. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ellenbogen JM, Hu PT, Payne JD, Titone D, and Walker MP (2007). Human relational memory requires time and sleep. Proceedings of the National Academy of Sciences, 104(18):7723–7728. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Euston DR, Tatsuno M, and McNaughton BL (2007). Fast-forward playback of recent memory sequences in prefrontal cortex during sleep. Science, 318(5853):1147–1150. [DOI] [PubMed] [Google Scholar]
- Fan Y, Tian F, Qin T, Li X-Y, and Liu T-Y (2018). Learning to teach. In ICLR. [Google Scholar]
- Feng F, Chan RH, Shi X, Zhang Y, and She Q (2019). Challenges in task incremental learning for assistive robotics. IEEE Access. [Google Scholar]
- Fernando C, Banarse D, Blundell C, Zwols Y, Ha D, Rusu AA, Pritzel A, and Wierstra D (2017). Pathnet: Evolution channels gradient descent in super neural networks. arXiv:1701.08734. [Google Scholar]
- Foerster J, Nardelli N, Farquhar G, Afouras T, Torr PH, Kohli P, and Whiteson S (2017). Stabilising experience replay for deep multi-agent reinforcement learning. In ICML, pages 1146–1155. [Google Scholar]
- Fogel SM and Smith CT (2006). Learning-dependent changes in sleep spindles and stage 2 sleep. Journal of Sleep Research, 15(3):250–255. [DOI] [PubMed] [Google Scholar]
- Foster DJ (2017). Replay comes of age. Annual Review of Neuroscience, 40:581–602. [DOI] [PubMed] [Google Scholar]
- Foster DJ and Knierim JJ (2012). Sequence learning and the role of the hippocampus in rodent navigation. Current Opinion in Neurobiology, 22(2):294–300. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Foster DJ and Wilson MA (2006). Reverse replay of behavioural sequences in hippocampal place cells during the awake state. Nature, 440(7084):680–683. [DOI] [PubMed] [Google Scholar]
- French RM (1997). Pseudo-recurrent connectionist networks: An approach to the ‘sensitivity-stability’ dilemma. Connection Science, 9(4):353–380. [Google Scholar]
- French RM (1999). Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 3(4):128–135. [DOI] [PubMed] [Google Scholar]
- Gama J (2010). Knowledge discovery from data streams. Chapman and Hall/CRC. [Google Scholar]
- Gama J, Sebastião R, and Rodrigues PP (2013). On evaluating stream learning algorithms. Machine Learning, 90(3):317–346. [Google Scholar]
- Gepperth A and Karaoguz C (2016). A bio-inspired incremental learning architecture for applied perceptual problems. Cognitive Computation, 8(5):924–934. [Google Scholar]
- Gillies A (1991). The stability/plasticity dilemma in self-organising neural networks. Master’s thesis, Computer Science Department, University of Otago, New Zealand. [Google Scholar]
- Golden R, Delanois JE, Sanda P, and Bazhenov M (2020). Sleep prevents catastrophic forgetting in spiking neural networks by forming joint synaptic weight representations. bioRxiv, page 688622. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gómez RL, Bootzin RR, and Nadel L (2006). Naps promote abstraction in language-learning infants. Psychological Science, 17(8):670–674. [DOI] [PubMed] [Google Scholar]
- González OC, Sokolov Y, Krishnan GP, Delanois JE, and Bazhenov M (2020). Can sleep protect memories from catastrophic forgetting? Elife, 9:e51005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, and Bengio Y (2014). Generative adversarial nets. In NeurIPS, pages 2672–2680. [Google Scholar]
- Graves A, Bellemare MG, Menick J, Munos R, and Kavukcuoglu K (2017). Automated curriculum learning for neural networks. In ICML, pages 1311–1320. [Google Scholar]
- Greco C, Plank B, Fernández R, and Bernardi R (2019). Psycholinguistics meets continual learning: Measuring catastrophic forgetting in visual question answering. In Annual Meeting of the Association for Computational Linguistics, pages 3601–3605. [Google Scholar]
- Grosmark AD, Mizuseki K, Pastalkova E, Diba K, and Buzsáki G (2012). REM Sleep Reorganizes Hippocampal Excitability. Neuron, 75(6):1001–1007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gruber MJ, Ritchey M, Wang S-F, Doss MK, and Ranganath C (2016). Post-learning hippocampal dynamics promote preferential retention of rewarding events. Neuron, 89(5):1110–1120. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gulati T, Guo L, Ramanathan DS, Bodepudi A, and Ganguly K (2017). Neural reactivations during sleep determine network credit assignment. Nature, 201:7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gulati T, Ramanathan DS, Wong CC, and Ganguly K (2014). Reactivation of emergent task-related ensembles during slow-wave sleep after neuroprosthetic learning. Nature Neuroscience, 17(8):1107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gupta AS, van der Meer MA, Touretzky DS, and Redish AD (2010). Hippocampal Replay Is Not a Simple Function of Experience. Neuron, 65(5):695–705. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haskins AL, Yonelinas AP, Quamme JR, and Ranganath C (2008). Perirhinal cortex supports encoding and familiarity-based recognition of novel associations. Neuron, 59(4):554–560. [DOI] [PubMed] [Google Scholar]
- Hassabis D, Kumaran D, Summerfield C, and Botvinick M (2017). Neuroscience-inspired artificial intelligence. Neuron, 95(2):245–258. [DOI] [PubMed] [Google Scholar]
- Hayes TL, Cahill ND, and Kanan C (2019). Memory efficient experience replay for streaming learning. In ICRA, pages 9769–9776. [Google Scholar]
- Hayes TL, Kafle K, Shrestha R, Acharya M, and Kanan C (2020). Remind your neural network to prevent catastrophic forgetting. In ECCV, pages 466–483. [Google Scholar]
- He C, Wang R, Shan S, and Chen X (2018). Exemplar-supported generative reproduction for class incremental learning. In BMVC, page 98. [Google Scholar]
- He J, Mao R, Shao Z, and Zhu F (2020). Incremental learning in online scenario. In CVPR, pages 13926–13935. [Google Scholar]
- Hetherington P (1989). Is there ‘catastrophic interference’ in connectionist networks? In Annual Conference of the Cognitive Science Society, pages 26–33. [Google Scholar]
- Hinton GE and Plaut DC (1987). Using fast weights to deblur old memories. In Annual Conference of the Cognitive Science Society, pages 177–186. [Google Scholar]
- Hou S, Pan X, Change Loy C, Wang Z, and Lin D (2018). Lifelong learning via progressive distillation and retrospection. In ECCV, pages 437–452. [Google Scholar]
- Hou S, Pan X, Wang Z, Change Loy C, and Lin D (2019). Learning a unified classifier incrementally via rebalancing. In CVPR, pages 831–839. [Google Scholar]
- Hu P, Stylos-Allan M, and Walker MP (2006). Sleep Facilitates Consolidation of Emotional Declarative Memory. Psychological Science, 17(10):891–898. [DOI] [PubMed] [Google Scholar]
- Hunziker A, Chen Y, Mac Aodha O, Gomez Rodriguez M, Krause A, Perona P, Yue Y, and Singla A (2019). Teaching multiple concepts to a forgetful learner. In NeurIPS. [Google Scholar]
- Iscen A, Zhang J, Lazebnik S, and Schmid C (2020). Memory-efficient incremental learning through feature adaptation. In ECCV, pages 699–715. [Google Scholar]
- Isele D and Cosgun A (2018). Selective experience replay for lifelong learning. In AAAI, pages 3302–3309. [Google Scholar]
- Ji D and Wilson MA (2007). Coordinated Memory Replay in the Visual Cortex and Hippocampus during Sleep. Nature Neuroscience, 10(1):100–107. [DOI] [PubMed] [Google Scholar]
- Johnson A and Redish AD (2007). Neural ensembles in ca3 transiently encode paths forward of the animal at a decision point. Journal of Neuroscience, 27(45):12176–12189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jonker TR, Dimsdale-Zucker H, Ritchey M, Clarke A, and Ranganath C (2018). Neural reactivation in parietal cortex enhances memory for episodically linked information. Proceedings of the National Academy of Sciences, 115(43):11084–11089. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Káli S and Dayan P (2004). Off-line replay maintains declarative memories in a model of hippocampal-neocortical interactions. Nature Neuroscience, 7(3):286–294. [DOI] [PubMed] [Google Scholar]
- Kapturowski S, Ostrovski G, Dabney W, Quan J, and Munos R (2019). Recurrent experience replay in distributed reinforcement learning. In ICLR. [Google Scholar]
- Karlsson MP and Frank LM (2009). Awake Replay of Remote Experiences in the Hippocampus. Nature Neuroscience, 12(7):913–918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kemker R and Kanan C (2018). FearNet: Brain-inspired model for incremental learning. In ICLR. [Google Scholar]
- Kemker R, McClure M, Abitino A, Hayes TL, and Kanan C (2018). Measuring catastrophic forgetting in neural networks. In AAAI. [Google Scholar]
- Kendall A, Gal Y, and Cipolla R (2018). Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In CVPR, pages 7482–7491. [Google Scholar]
- Kim CD, Jeong J, and Kim G (2020). Imbalanced continual learning with partitioning reservoir sampling. In ECCV, pages 411–428. [Google Scholar]
- King BR, Hoedlmoser K, Hirschauer F, Dolfen N, and Albouy G (2017). Sleeping on the motor engram: The multifaceted nature of sleep-related motor memory consolidation. Neuroscience & Biobehavioral Reviews, 80:1–22. [DOI] [PubMed] [Google Scholar]
- Kirkpatrick J, Pascanu R, Rabinowitz N, Veness J, Desjardins G, Rusu AA, Milan K, Quan J, Ramalho T, Grabska-Barwinska A, Hassabis D, Clopath C, Kumaran D, and Hadsell R (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kitamura T, Ogawa SK, Roy DS, Okuyama T, Morrissey MD, Smith LM, Redondo RL, and Tonegawa S (2017). Engrams and circuits crucial for systems consolidation of a memory. Science, 356(6333):73–78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnan GP, Chauvette S, Shamie I, Soltani S, Timofeev I, Cash SS, Halgren E, and Bazhenov M (2016). Cellular and Neurochemical Basis of Sleep Stages in the Thalamocortical Network. eLife, 5:e18607. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnan GP, Tadros T, Ramyaa R, and Bazhenov M (2019). Biologically inspired sleep algorithm for artificial neural networks. arXiv preprint arXiv:1908.02240. [Google Scholar]
- Kudrimoti HS, Barnes CA, and McNaughton BL (1999). Reactivation of Hippocampal Cell Assemblies: Effects of Behavioral State, Experience, and EEG Dynamics. The Journal of Neuroscience, 19(10):4090–4101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kumar D, Koyanagi I, Carrier-Ruiz A, Vergara P, Srinivasan S, Sugaya Y, Kasuya M, Yu T-S, Vogt KE, Muratani M, et al. (2020). Sparse activity of hippocampal adult-born neurons during rem sleep is necessary for memory consolidation. Neuron, 107(3):552–565. [DOI] [PubMed] [Google Scholar]
- Kumaran D, Hassabis D, and McClelland JL (2016). What learning systems do intelligent agents need? complementary learning systems theory updated. Trends in Cognitive Sciences, 20(7):512–534. [DOI] [PubMed] [Google Scholar]
- Kuriyama K, Stickgold R, and Walker MP (2004). Sleep-dependent learning and motor-skill complexity. Learning & Memory, 11(6):705–713. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kurle R, Cseke B, Klushyn A, van der Smagt P, and Günnemann S (2020). Continual learning with bayesian neural networks for non-stationary data. In ICLR. [Google Scholar]
- Lake BM, Ullman TD, Tenenbaum JB, and Gershman SJ (2017). Building machines that learn and think like people. Behavioral and Brain Sciences, 40. [DOI] [PubMed] [Google Scholar]
- Lao Q, Jiang X, Havaei M, and Bengio Y (2020). Continuous domain adaptation with variational domain-agnostic feature replay. arXiv preprint arXiv:2003.04382. [DOI] [PubMed] [Google Scholar]
- Lee AK and Wilson MA (2002). Memory of Sequential Experience in the Hippocampus during Slow Wave Sleep. Neuron, 36(6):1183–1194. [DOI] [PubMed] [Google Scholar]
- Lee K, Lee K, Shin J, and Lee H (2019). Overcoming catastrophic forgetting with unlabeled data in the wild. In ICCV, pages 312–321. [Google Scholar]
- Lemke SM, Ramanathan DS, Guo L, Won SJ, and Ganguly K (2019). Emergent modular neural control drives coordinated motor actions. Nature Neuroscience, 22(7):1122–1131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lengyel M and Dayan P (2008). Hippocampal contributions to control: the third way. In NeurIPS, pages 889–896. [Google Scholar]
- Lenneberg EH (1967). The biological foundations of language. Hospital Practice, 2(12):59–67. [Google Scholar]
- Lesburguères E, Gobbo OL, Alaux-Cantin S, Hambucken A, Trifilieff P, and Bontempi B (2011). Early tagging of cortical networks is required for the formation of enduring associative memory. Science, 331(6019):924–928. [DOI] [PubMed] [Google Scholar]
- Lesort T, Caselles-Dupré H, Garcia-Ortiz M, Stoian A, and Filliat D (2019). Generative models from the perspective of continual learning. In IJCNN, pages 1–8. [Google Scholar]
- Lesort T, Lomonaco V, Stoian A, Maltoni D, Filliat D, and Díaz-Rodríguez N (2020). Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges. Information Fusion, 58:52–68. [Google Scholar]
- Lewis DD and Gale WA (1994). A sequential algorithm for training text classifiers. In SIGIR’94, pages 3–12. Springer. [Google Scholar]
- Lewis PA and Durrant SJ (2011). Overlapping memory replay during sleep builds cognitive schemata. Trends in Cognitive Sciences, 15(8):343–351. [DOI] [PubMed] [Google Scholar]
- Lewis PA, Knoblich G, and Poe G (2018). How Memory Replay in Sleep Boosts Creative Problem-Solving. Trends in Cognitive Sciences, 22(6):491–503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li W, Ma L, Yang G, and Gan W-B (2017). Rem sleep selectively prunes and maintains new synapses in development and learning. Nature Neuroscience, 20(3):427–437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lillicrap TP, Hunt JJ, Pritzel A, Heess N, Erez T, Tassa Y, Silver D, and Wierstra D (2016). Continuous control with deep reinforcement learning. In ICLR. [Google Scholar]
- Lin L-J (1992). Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning, 8(3-4):293–321. [Google Scholar]
- Lin X and Parikh D (2017). Active learning for visual question answering: An empirical study. arXiv:1711.01732. [Google Scholar]
- Liu S, Johns E, and Davison AJ (2019a). End-to-end multi-task learning with attention. In CVPR, pages 1871–1880. [Google Scholar]
- Liu X, Yang H, Ravichandran A, Bhotika R, and Soatto S (2020a). Continual universal object detection. arXiv preprint arXiv:2002.05347. [Google Scholar]
- Liu Y, Dolan RJ, Kurth-Nelson Z, and Behrens TE (2019b). Human replay spontaneously reorganizes experience. Cell, 178(3):640–652. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu Y, Su Y, Liu A-A, Schiele B, and Sun Q (2020b). Mnemonics training: Multi-class incremental learning without forgetting. In CVPR, pages 12245–12254. [Google Scholar]
- Lopez-Paz D and Ranzato M (2017). Gradient episodic memory for continual learning. In NeurIPS, pages 6467–6476. [Google Scholar]
- Louie K and Wilson MA (2001). Temporally Structured Replay of Awake Hippocampal Ensemble Activity during Rapid Eye Movement Sleep. Neuron, 29(1):145–156. [DOI] [PubMed] [Google Scholar]
- Markram H, Lübke J, Frotscher M, and Sakmann B (1997). Regulation of synaptic efficacy by coincidence of postsynaptic aps and epsps. Science, 275(5297):213–215. [DOI] [PubMed] [Google Scholar]
- McClelland JL, McNaughton BL, and Lampinen AK (2020). Integration of new information in memory: new insights from a complementary learning systems perspective. Philosophical Transactions of the Royal Society B, 375(1799):20190637. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McClelland JL, McNaughton BL, and O’reilly RC (1995). Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychological Review, page 419. [DOI] [PubMed] [Google Scholar]
- McCloskey M and Cohen NJ (1989). Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation, 24:109–165. [Google Scholar]
- McCormick DA (1992). Neurotransmitter actions in the thalamus and cerebral cortex and their role in neuromodulation of thalamocortical activity. Progress in Neurobiology, 39(4):337–388. [DOI] [PubMed] [Google Scholar]
- McDevitt EA, Duggan KA, and Mednick SC (2015). REM sleep rescues learning from interference. Neurobiology of Learning and Memory, 122:51–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McGaugh JL (2000). Memory-a Century of Consolidation. Science, 287(5451):248–251. [DOI] [PubMed] [Google Scholar]
- McNamara CG, Tejero-Cantero Á, Trouche S, Campo-Urriza N, and Dupret D (2014). Dopaminergic neurons promote hippocampal reactivation and spatial memory persistence. Nature Neuroscience, 17(12):1658–1660. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, and Riedmiller M (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602. [Google Scholar]
- Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G, et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540):529. [DOI] [PubMed] [Google Scholar]
- Mölle M, Yeshenko O, Marshall L, Sara SJ, and Born J (2006). Hippocampal sharp wave-ripples linked to slow oscillations in rat slow-wave sleep. Journal of Neurophysiology. [DOI] [PubMed] [Google Scholar]
- Momennejad I (2020). Learning Structures: Predictive Representations, Replay, and Generalization. Current Opinion in Behavioral Sciences, 32:155–166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore AW and Atkeson CG (1993). Prioritized sweeping: Reinforcement learning with less data and less time. Machine Learning, 13(1):103–130. [Google Scholar]
- Morison R and Dempsey E (1941). A study of thalamo-cortical relations. American Journal of Physiology-Legacy Content, 135(2):281–292. [Google Scholar]
- Muller L, Piantoni G, Koller D, Cash SS, Halgren E, and Sejnowski TJ (2016). Rotating Waves during Human Sleep Spindles Organize Global Patterns of Activity That Repeat Precisely through the Night. eLife, 5:e17267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murty VP, Tompary A, Adcock RA, and Davachi L (2017). Selectivity in postencoding connectivity with high-level visual cortex is associated with reward-motivated memory. Journal of Neuroscience, 37(3):537–545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nádasdy Z, Hirase H, Czurkó A, Csicsvari J, and Buzsáki G (1999). Replay and Time Compression of Recurring Spike Sequences in the Hippocampus. The Journal of Neuroscience, 19(21):9497–9507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nadel L and Moscovitch M (1997). Memory consolidation, retrograde amnesia and the hippocampal complex. Current Opinion in Neurobiology, 7(2):217–227. [DOI] [PubMed] [Google Scholar]
- Nguyen CV, Li Y, Bui TD, and Turner RE (2018). Variational continual learning. In ICLR. [Google Scholar]
- Nishida M and Walker MP (2007). Daytime Naps, Motor Memory Consolidation and Regionally Specific Sleep Spindles. PloS one, 2(4):e341. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Keefe J and Nadel L (1978). The Hippocampus as a Cognitive Map. Clarendon Press ; Oxford University Press, Oxford; : New York. [Google Scholar]
- Ólafsdóttir HF, Barry C, Saleem AB, Hassabis D, and Spiers HJ (2015). Hippocampal place cells construct reward related sequences through unexplored space. eLife, 4:e06063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ólafsdóttir HF, Bush D, and Barry C (2018). The role of hippocampal replay in memory and planning. Current Biology, 28(1):R37–R50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Olcese U, Esser SK, and Tononi G (2010). Sleep and synaptic renormalization: a computational study. Journal of Neurophysiology, 104(6):3476–3493. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Reilly RC and Rudy JW (2001). Conjunctive representations in learning and memory: principles of cortical and hippocampal function. Psychological Review, 108(2):311. [DOI] [PubMed] [Google Scholar]
- Ostapenko O, Puscas M, Klein T, Jähnichen P, and Nabi M (2019). Learning to remember: A synaptic plasticity driven framework for continual learning. In CVPR, pages 11321–11329. [Google Scholar]
- Ozdemir F, Fuernstahl P, and Goksel O (2018). Learn the new, keep the old: Extending pretrained models with new anatomy and images. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 361–369. Springer. [Google Scholar]
- Ozdemir F and Goksel O (2019). Extending pretrained segmentation networks with additional anatomical structures. International Journal of Computer Assisted Radiology and Surgery, 14(7):1187–1195. [DOI] [PubMed] [Google Scholar]
- Parisi GI, Kemker R, Part JL, Kanan C, and Wermter S (2019). Continual lifelong learning with neural networks: A review. Neural Networks. [DOI] [PubMed] [Google Scholar]
- Parisi GI, Tani J, Weber C, and Wermter S (2018). Lifelong learning of spatiotemporal representations with dual-memory recurrent self-organization. Frontiers in Neurorobotics, 12:78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pavlides C and Winson J (1989). Influences of hippocampal place cell firing in the awake state on the activity of these cells during subsequent sleep episodes. Journal of Neuroscience, 9(8):2907–2918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Payne JD, Stickgold R, Swanberg K, and Kensinger EA (2008). Sleep preferentially enhances memory for emotional components of scenes. Psychological Science, 19(8):781–788. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pellegrini L, Graffieti G, Lomonaco V, and Maltoni D (2019). Latent replay for real-time continual learning. arXiv preprint arXiv:1912.01100. [Google Scholar]
- Peyrache A, Khamassi M, Benchenane K, Wiener SI, and Battaglia FP (2009). Replay of Rule-Learning Related Neural Patterns in the Prefrontal Cortex during Sleep. Nature Neuroscience, 12(7):919–926. [DOI] [PubMed] [Google Scholar]
- Pfeiffer BE (2020). The content of hippocampal “replay”. Hippocampus, 30(1):6–18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pfeiffer BE and Foster DJ (2013). Hippocampal place-cell sequences depict future paths to remembered goals. Nature, 497(7447):74–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pritzel A, Uria B, Srinivasan S, Badia AP, Vinyals O, Hassabis D, Wierstra D, and Blundell C (2017). Neural episodic control. In ICML, pages 2827–2836. [Google Scholar]
- Ramanathan DS, Gulati T, and Ganguly K (2015). Sleep-Dependent Reactivation of Ensembles in Motor Cortex Promotes Skill Consolidation. PLoS Biol, 13(9):e1002263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rasch B and Born J (2013). About Sleep’s Role in Memory. Physiological Reviews, 93(2):681–766. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ratcliff R (1990). Connectionist models of recognition memory: constraints imposed by learning and forgetting functions. Psychological Review, 97(2):285. [DOI] [PubMed] [Google Scholar]
- Rebuffi S-A, Kolesnikov A, Sperl G, and Lampert CH (2017). icarl: Incremental classifier and representation learning. In CVPR, pages 2001–2010. [Google Scholar]
- Riemer M, Cases I, Ajemian R, Liu M, Rish I, Tu Y, , and Tesauro G (2019). Learning to learn without forgetting by maximizing transfer and minimizing interference. In ICLR. [Google Scholar]
- Rios A and Itti L (2019). Closed-loop memory gan for continual learning. IJCAI. [Google Scholar]
- Ritter H, Botev A, and Barber D (2018). Online structured laplace approximations for overcoming catastrophic forgetting. In NeurIPS, pages 3738–3748. [Google Scholar]
- Robertson EM and Genzel L (2020). Memories replayed: reactivating past successes and new dilemmas. Philosophical Transactions of the Royal Society B: Biological Sciences, 375(1799). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins A (1995). Catastrophic forgetting, rehearsal and pseudorehearsal. Connection Science, 7(2):123–146. [Google Scholar]
- Robins A (1996). Consolidation in neural networks and in the sleeping brain. Connection Science, 8(2):259–276. [Google Scholar]
- Robins A (1997). Maintaining stability during new learning in neural networks. In 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, volume 4, pages 3013–3018. IEEE. [Google Scholar]
- Robins A (2004). Sequential learning in neural networks: A review and a discussion of pseudorehearsal based methods. Intelligent Data Analysis, 8(3):301–322. [Google Scholar]
- Robins A and McCallum S (1998). Catastrophic forgetting and the pseudorehearsal solution in hopfield-type networks. Connection Science, 10(2):121–135. [Google Scholar]
- Robins A and McCallum S (1999). The consolidation of learning during sleep: comparing the pseudorehearsal and unlearning accounts. Neural Networks, 12(7-8):1191–1206. [DOI] [PubMed] [Google Scholar]
- Ruder S (2017). An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098. [Google Scholar]
- Rusu AA, Rabinowitz NC, Desjardins G, Soyer H, Kirkpatrick J, Kavukcuoglu K, Pascanu R, and Hadsell R (2016). Progressive neural networks. arXiv:1606.04671. [Google Scholar]
- Sanda P, Malerba P, Jiang X, Krishnan GP, Gonzalez-Martinez J, Halgren E, and Bazhenov M (2021). Bidirectional interaction of hippocampal ripples and cortical slow waves leads to coordinated spiking activity during nrem sleep. Cerebral Cortex, 31(1):324–340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schapiro AC, McDevitt EA, Rogers TT, Mednick SC, and Norman KA (2018). Human hippocampal replay during rest prioritizes weakly learned information and predicts memory performance. Nature Communications, 9(1):1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schaul T, Quan J, Antonoglou I, and Silver D (2016). Prioritized experience replay. In ICLR. [Google Scholar]
- Scheffer T, Decomain C, and Wrobel S (2001). Active hidden markov models for information extraction. In International Symposium on Intelligent Data Analysis, pages 309–318. Springer. [Google Scholar]
- Schmidhuber J (1991). Curious model-building control systems. In IJCNN, pages 1458–1463. [Google Scholar]
- Schönauer M, Geisler T, and Gais S (2014). Strengthening Procedural Memories by Reactivation in Sleep. Journal of Cognitive Neuroscience, 26(1):143–153. [DOI] [PubMed] [Google Scholar]
- Sejnowski TJ and Destexhe A (2000). Why do we sleep? Brain research, 886(1-2):208–223. [DOI] [PubMed] [Google Scholar]
- Senghas A, Kita S, and Özyürek A (2004). Children creating core properties of language: Evidence from an emerging sign language in nicaragua. Science, 305(5691):1779–1782. [DOI] [PubMed] [Google Scholar]
- Serra J, Suris D, Miron M, and Karatzoglou A (2018). Overcoming catastrophic forgetting with hard attention to the task. In ICML, pages 4555–4564. [Google Scholar]
- Settles B (2009). Active learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences. [Google Scholar]
- Shen B and McNaughton BL (1996). Modeling the spontaneous reactivation of experience-specific hippocampal cell assembles during sleep. Hippocampus, 6(6):685–692. [DOI] [PubMed] [Google Scholar]
- Shin H, Lee JK, Kim J, and Kim J (2017). Continual learning with deep generative replay. In NeurIPS, pages 2990–2999. [Google Scholar]
- Siapas AG and Wilson MA (1998). Coordinated interactions between hippocampal ripples and cortical spindles during slow-wave sleep. Neuron, 21(5):1123–1128. [DOI] [PubMed] [Google Scholar]
- Singer AC and Frank LM (2009). Rewarded outcomes enhance reactivation of experience in the hippocampus. Neuron, 64(6):910–921. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sirota A, Csicsvari J, Buhl D, and Buzsáki G (2003). Communication between neocortex and hippocampus during sleep in rodents. Proceedings of the National Academy of Sciences, 100(4):2065–2069. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith C and Smith D (2003). Ingestion of ethanol just prior to sleep onset impairs memory for procedural but not declarative tasks. Sleep, 26(2):185–191. [PubMed] [Google Scholar]
- Sodhani S, Chandar S, and Bengio Y (2020). Toward training recurrent neural networks for lifelong learning. Neural Computation, 32(1):1–35. [DOI] [PubMed] [Google Scholar]
- Standley T, Zamir A, Chen D, Guibas L, Malik J, and Savarese S (2020). Which tasks should be learned together in multi-task learning? In ICML, pages 9120–9132. [Google Scholar]
- Staresina BP, Bergmann TO, Bonnefond M, Van Der Meij R, Jensen O, Deuker L, Elger CE, Axmacher N, and Fell J (2015). Hierarchical nesting of slow oscillations, spindles and ripples in the human hippocampus during sleep. Nature Neuroscience, 18(11):1679–1686. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stella F, Baracskay P, O’Neill J, and Csicsvari J (2019). Hippocampal reactivation of random trajectories resembling brownian diffusion. Neuron, 102(2):450–461. [DOI] [PubMed] [Google Scholar]
- Steriade M, Nunez A, and Amzica F (1993). A novel slow (<1 hz) oscillation of neocortical neurons in vivo: depolarizing and hyperpolarizing components. Journal of Neuroscience, 13(8):3252–3265. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steriade M, Timofeev I, and Grenier F (2001). Natural waking and sleep states: a view from inside neocortical neurons. Journal of Neurophysiology, 85(5):1969–1985. [DOI] [PubMed] [Google Scholar]
- Stickgold R (2005). Sleep-Dependent Memory Consolidation. Nature, 437(7063):1272–1278. [DOI] [PubMed] [Google Scholar]
- Stickgold R (2012). To Sleep: Perchance to Learn. Nature Neuroscience, 15(10):1322–1323. [DOI] [PubMed] [Google Scholar]
- Stickgold R, Scott L, Rittenhouse C, and Hobson JA (1999). Sleep-induced changes in associative memory. Journal of Cognitive Neuroscience, 11(2):182–193. [DOI] [PubMed] [Google Scholar]
- Tadros T, Krishnan G, Ramyaa R, and Bazhenov M (2020a). Biologically inspired sleep algorithm for increased generalization and adversarial robustness in deep neural networks. In ICLR. [Google Scholar]
- Tadros T, Krishnan G, Ramyaa R, and Bazhenov M (2020b). Biologically inspired sleep algorithm for reducing catastrophic forgetting in neural networks. In AAAI, pages 13933–13934. [Google Scholar]
- Tao X, Chang X, Hong X, Wei X, and Gong Y (2020). Topology-preserving class-incremental learning. In ECCV, pages 254–270. [Google Scholar]
- Tasar O, Tarabalka Y, and Alliez P (2019). Incremental learning for semantic segmentation of large-scale remote sensing data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(9):3524–3537. [Google Scholar]
- Tatsuno M, Lipa P, and McNaughton BL (2006). Methodological Considerations on the Use of Template Matching to Study Long-Lasting Memory Trace Replay. Journal of Neuroscience, 26(42):10727–10742. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Teyler TJ and Rudy JW (2007). The hippocampal indexing theory and episodic memory: Updating the index. Hippocampus, 17(12):1158–1169. [DOI] [PubMed] [Google Scholar]
- Tibon R, Gronau N, Scheuplein A-L, Mecklinger A, and Levy DA (2014). Associative recognition processes are modulated by the semantic unitizability of memoranda. Brain and Cognition, 92:19–31. [DOI] [PubMed] [Google Scholar]
- Tingley D and Peyrache A (2020). On the methods for reactivation and replay analysis. Philosophical Transactions of the Royal Society B: Biological Sciences, 375(1799):20190231. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Titsias MK, Schwarz J, de G. Matthews AG, Pascanu R, and Teh YW (2020). Functional regularisation for continual learning with gaussian processes. In ICLR. [Google Scholar]
- Tononi G and Cirelli C (2014). Sleep and the Price of Plasticity: From Synaptic and Cellular Homeostasis to Memory Consolidation and Integration. Neuron, 81(1):12–34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van de Ven GM, Siegelmann HT, and Tolias AS (2020). Brain-inspired replay for continual learning with artificial neural networks. Nature Communications, 11(1):1–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Hasselt H, Guez A, and Silver D (2016). Deep reinforcement learning with double q-learning. In AAAI, pages 2094–2100. [Google Scholar]
- von Oswald J, Henning C, Sacramento J, and Grewe BF (2020). Continual learning with hypernetworks. In ICLR. [Google Scholar]
- Wagner U, Gais S, and Born J (2001). Emotional memory formation is enhanced across sleep intervals with high amounts of rapid eye movement sleep. Learning & Memory, 8(2):112–119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wagner U, Gais S, Haider H, Verleger R, and Born J (2004). Sleep inspires insight. Nature, 427(6972):352–355. [DOI] [PubMed] [Google Scholar]
- Walker M, Stickgold R, Alsop D, Gaab N, and Schlaug G (2005). Sleep-Dependent Motor Memory Plasticity in the Human Brain. Neuroscience, 133(4):911–917. [DOI] [PubMed] [Google Scholar]
- Walker MP, Brakefield T, Morgan A, Hobson JA, and Stickgold R (2002a). Practice with Sleep Makes Perfect: Sleep-Dependent Motor Skill Learning. Neuron, 35(1):205–211. [DOI] [PubMed] [Google Scholar]
- Walker MP, Liston C, Hobson JA, and Stickgold R (2002b). Cognitive flexibility across the sleep-wake cycle: Rem-sleep enhancement of anagram problem solving. Cognitive Brain Research, 14(3):317–324. [DOI] [PubMed] [Google Scholar]
- Walker MP and Stickgold R (2004). Sleep-dependent learning and memory consolidation. Neuron, 44(1):121–133. [DOI] [PubMed] [Google Scholar]
- Walker MP and Stickgold R (2010). Overnight alchemy: sleep-dependent memory evolution. Nature Reviews Neuroscience, 11(3):218. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang K, Zhang D, Li Y, Zhang R, and Lin L (2016). Cost-effective active learning for deep image classification. IEEE Transactions on Circuits and Systems for Video Technology, 27(12):2591–2600. [Google Scholar]
- Watson CJ, Baghdoyan HA, and Lydic R (2010). Neuropharmacology of Sleep and Wakefulness. Sleep Medicine Clinics, 5(4):513–528. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei K, Iyer R, and Bilmes J (2015). Submodularity in data subset selection and active learning. In ICML, pages 1954–1963. [Google Scholar]
- Wei Y, Krishnan GP, and Bazhenov M (2016). Synaptic Mechanisms of Memory Consolidation during Sleep Slow Oscillations. The Journal of Neuroscience, 36(15):4231–4247. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei Y, Krishnan GP, Komarov M, and Bazhenov M (2018). Differential roles of sleep spindles and sleep slow oscillations in memory consolidation. PLOS Computational Biology, 14(7):e1006322. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Whittington JC, Muller TH, Mark S, Chen G, Barry C, Burgess N, and Behrens TE (2020). The tolman-eichenbaum machine: Unifying space and relational memory through generalization in the hippocampal formation. Cell, 183(5):1249–1263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson MA and McNaughton BL (1994). Reactivation of hippocampal ensemble memories during sleep. Science, 265(5172):676–679. [DOI] [PubMed] [Google Scholar]
- Wu C, Herranz L, Liu X, Wang Y, van de Weijer J, and Raducanu B (2018). Memory replay gans: learning to generate images from new categories without forgetting. In NeurIPS, pages 5966–5976. [Google Scholar]
- Wu Y, Chen Y, Wang L, Ye Y, Liu Z, Guo Y, and Fu Y (2019a). Large scale incremental learning. In CVPR, pages 374–382. [Google Scholar]
- Wu Z, Wang X, Gonzalez JE, Goldstein T, and Davis LS (2019b). Ace: Adapting to changing environments for semantic segmentation. In ICCV, pages 2121–2130. [Google Scholar]
- Ye F and Bors AG (2020). Learning latent representations across multiple data domains using lifelong vaegan. In ECCV, pages 777–795. [Google Scholar]
- Yoo D and So Kweon I (2019). Learning loss for active learning. In CVPR, pages 93–102. [Google Scholar]
- Yoon J, Yang E, Lee J, and Hwang SJ (2018). Lifelong learning with dynamically expandable networks. In ICLR. [Google Scholar]
- Yu JY, Kay K, Liu DF, Grossrubatscher I, Loback A, Sosa M, Chung JE, Karlsson MP, Larkin MC, and Frank LM (2017). Distinct hippocampal-cortical memory representations for experiences associated with movement versus immobility. eLife, 6:e27621. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yu JY, Liu DF, Loback A, Grossrubatscher I, and Frank LM (2018). Specific hippocampal representations are linked to generalized cortical representations in memory. Nature Communications, 9(1):2209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zenke F, Poole B, and Ganguli S (2017). Continual learning through synaptic intelligence. In ICML, pages 3987–3995. [PMC free article] [PubMed] [Google Scholar]
- Zhang Y and Yang Q (2021). A survey on multi-task learning. IEEE Transactions on Knowledge and Data Engineering. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao B, Xiao X, Gan G, Zhang B, and Xia S-T (2020). Maintaining discrimination and fairness in class incremental learning. In CVPR, pages 13208–13217. [Google Scholar]
- Zhou T and Bilmes J (2018). Minimax curriculum learning: Machine teaching with desirable difficulties and scheduled diversity. In ICLR. [Google Scholar]