

Abstract
MicroRNAs (miRNAs) are a family of short non-coding RNAs that play significant roles as post-transcriptional regulators. Consequently, various methods have been proposed to identify precursor miRNAs (pre-miRNAs), among which the comparative studies of miRNA structures are the most important. To measure and classify the structural similarity of miRNAs, we propose a new three-dimensional (3D) graphical representation of the secondary structure of miRNAs, in which an miRNA secondary structure is initially transformed into a characteristic sequence based on physicochemical properties and frequency of base. A numerical characterization of the 3D graph is used to represent the miRNA secondary structure. We then utilize a novel Euclidean distance method based on this expression to compute the distance of different miRNA sequences for the sequence similarity analysis. Finally, we use this sequence similarity analysis method to identify plant pre-miRNAs among three commonly used datasets. Results show that the method is reasonable and effective.
MicroRNAs (miRNAs) are a family of short non-coding RNAs that play significant roles as post-transcriptional regulators.
Introduction
MicroRNAs (miRNAs) are a family of short noncoding RNAs that play significant roles as post-transcriptional regulators.1 With extracellular miRNAs, hypothalamic stem cells partially control the aging rate.2 As such, miRNA is an important noncoding RNA involved in many important biological processes, including plant development, signal transduction, and protein degradation.3,4 miRNA prediction has constantly been an important issue in the miRNA research domain. The bases of single-stranded miRNAs in live cells are constantly folded to form an miRNA secondary structure rather than a linear form. The three-dimensional (3D) structure and function of miRNAs are determined by their secondary structures,3 and their functions are mainly determined by their structures.5 Thus, studies on RNA sequences and their secondary structures are essential for identifying and understanding the functional similarities between plant miRNAs. Precursor miRNAs (pre-miRNAs) of plants generally have a more complex secondary structure than those of animals, and existing prediction methods on animal pre-miRNA classification cannot be effectively applied to predict plant pre-miRNAs.6 Experimental methods, such as ChIP-sequencing for pre-miRNA identification, are expensive and time consuming, thereby presenting the need for computational methods. Computational methods, including machine learning (ML) and sequence analysis methods, should be developed to predict, analyze, and provide reliable miRNA candidates for subsequent biological experiments.7
ML-based methods have been widely applied to identify plant miRNAs.1,8–15 ML-based methods have treated pre-miRNA identification as a binary classification task to discriminate between real and pseudo-pre-miRNAs. However, the performance of ML-based predictors mainly depends on ML algorithms or operation engines. Numerous classification prediction algorithms, which yield different results, have been utilized to recognize pre-miRNA. ML-based algorithms include support vector machines (SVM),1,8,16–26 back-propagation and self-organizing map (SOM) neural networks,27–29 and random forest (RF).30–32 Difficulties in using ML-based methods are attributed to the selection of representative samples that adequately describe the sample space of an entire positive dataset (pre-miRNA) and negative dataset counterexamples (pseudo pre-miRNA). Computational complexity in predicting large genome mass data is also high. These approaches involve a large number of false positive candidates. Therefore, miRNA classification prediction should be investigated and solved on the basis of ML prediction methods to improve sensitivity and specificity.
Sequence-based methods, including sequence alignment and distance analysis, are mainly used to analyze the similarities between miRNA sequences. T. Dezulian et al.33 used BLAST for sequence alignment to search for homologous sequences that are similar to known plant pre-miRNAs. The similarity of sequence distance is mainly transformed into the similarity between analysis sequences and secondary structures by graphical representation. Graphical representation has been widely applied to RNA sequence representation, especially for the analysis of RNA secondary structures. Y. H. Yao et al.34,35 proposed a graphical representation based on two-dimensionality (2D) to analyze the similarity of RNA secondary structures. On the basis of sequence and base physicochemical information, Jeffrey et al.36,37 proposed a 3D representation of RNA secondary structures. Liao et al.38,39 proposed four- to seven-dimensional graphical representation method for RNA secondary structures. This method can solve the problem of structural degradation and information loss of 2D graphical representation, but it is not conducive to graphic visualization. Zhang et al.40–42 developed a graphical representation for ncRNA secondary structures. To validate the aforementioned methods, researchers usually build phylogenetic trees based on the similarity between sequences to compare the reliability of the methods. In contrast to ML or other complex computing techniques, a graphical representation is an effective analysis method that can provide an intuitive and unique perspective in analyzing sequence similarity.
In this study, we propose a new 3D graphical representation of miRNA secondary structures. In this representation, an miRNA secondary structure is initially transformed into a characteristic sequence based on the frequency and physicochemical properties of nucleic acids. A numerical characterization of the 3D graph is then used to represent the miRNA secondary structure. On the basis of the proposed 3D graphical representation method, we utilize a novel Euclidean distance method to compute the distance of different miRNA secondary structures for similarity analysis. A small distance indicates a high similarity and vice versa. We use this similarity analysis method to identify plant pre-miRNAs among three commonly used datasets. Our results show that our method is reasonable, effective, simple to operate without training parameters, and more intuitive than several ML-methods.
Methods
Framework of the proposed method
Fig. 1 illustrates the overall framework of our method, which consists of two main phases, namely, pre-miRNA similarity analysis and prediction. In the similarity analysis phase, the initial pre-miRNA sequences are extracted from the raw data. Then, homology bias is avoided by using the CD-HIT software43 (threshold set to 0.8) to filter samples with a similarity greater than the threshold in the initial dataset, and the secondary structure of the given benchmark dataset is predicted with the RNAfold software.44 We design a new 3D graphical representation to represent the miRNA secondary structure. On the basis of the proposed method, we utilize a novel Euclidean distance method to compute the distance of different miRNA secondary structures for similarity analysis. In the pre-miRNA prediction phase, the distance between any two sequences in the benchmark datasets is calculated using the proposed method. The smaller the distance is, the more similar the two pre-miRNA sequences will be. The jackknife method is applied to traverse the entire benchmark datasets and to predict whether a given sequence is a plant pre-miRNA.
Fig. 1. Overall framework of the proposed method.

New 3D graphical representation of miRNA structure
The secondary structure of RNAs consists of a number of free bases (i.e., A, G, C, and U) and paired bases (i.e., A–U, G–C, and G–U). A total of 9 viral RNA base sequences are obtained from ref. 45. Fig. 2 shows the secondary structure of the RNA sequence of the obtained TSV-3 and AIMV-3 using the algorithm in ref. 46.
Fig. 2. The secondary structure of the RNA sequence of the TSV-3 and AIMV-3.

For research convenience, the base and unpaired bases should be distinguished. The bases of A, G, C, and U located in base pairs A–U, G–C, and G–U are denoted as a, g, c, and u, respectively. The RNA sequences of the 9 obtained viruses from ref. 45 are processed by RNAfold,44 and the RNA secondary structure sequence is shown in Table 1.
Information about the secondary structure of RNA sequences of 9 viruses.
| Species | RNA secondary structure | Length |
|---|---|---|
| AIMV-3 | AUGCucaugcaAAACugcaugaAUGCcccUAAgggAUGC | 39 |
| APMV-3 | AAUGCccacaacGUGAAguuguggAUGCcccGUUAgggAAGC | 42 |
| AVII | AUGCcuaaUacucucucuCAGggagagaguuuagAUGCcuccAAAggagAUGC | 53 |
| CILRV | AUGCcuauauuuucucUCCUgagaaaauauagAUGCcuccAAAggagAUGC | 51 |
| CVV-3 | AUGCccaAAcucucucuCAUggagagagAAuggAUGCcuccGAAggagAUGC | 52 |
| EMV-3 | CcuaauUcucucucuCACggagagagauuagAUGCcucCAAGgagAUGC | 49 |
| LRMV-3 | UUCcuauucucucucUCAGgagagGagaauagAUGCcuccAAAggagUCGC | 51 |
| PDV-3 | AUGCccucaccGUAAggugaggAUGCcccuUAAagggAUGC | 41 |
| TSV-3 | GUGCcaguaguauaUAAuauacuacugAUGCcuccuUUAUaggagAUGC | 49 |
Let s = s1, s2, s3, …, sn represent an RNA secondary structure sequence, where n is the length of the sequence. Let point coordinates si(xi, yi, zi) be the i-th base of the secondary structure sequence of miRNA, which corresponds to the eqn (1).
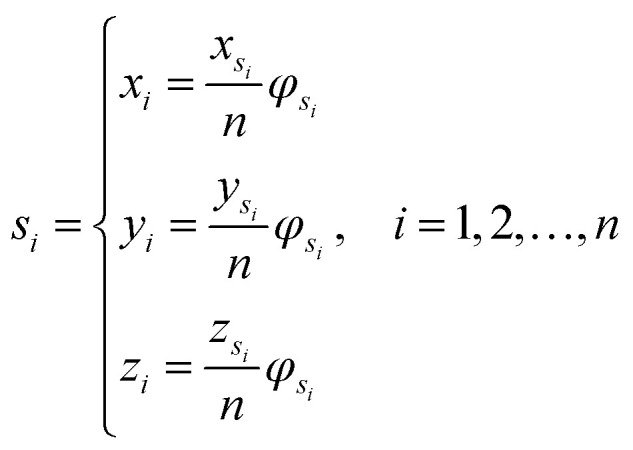 |
1 |
where φsi represents the accumulative occurrence frequency of the base at position i, and n is the length of the sequence. Ref. 35, 41 and 47 divided the bases in the pre-miRNA secondary structure sequence into three categories based on the physicochemical properties and obtained three representing graphs. Inspired by previous studies,35,41,47 in this study, xsi, ysi and zsi are represented as eqn (2)–(4).
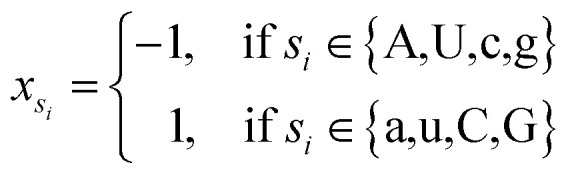 |
2 |
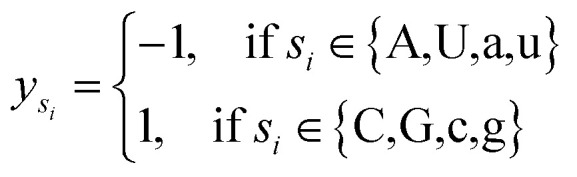 |
3 |
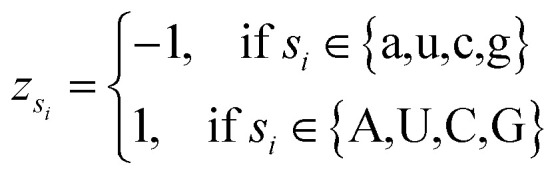 |
4 |
For every base in the RNA secondary structure, a new accumulative coordinate Si(Xi, Yi, Zi) can be obtained, which can be expressed as follows:
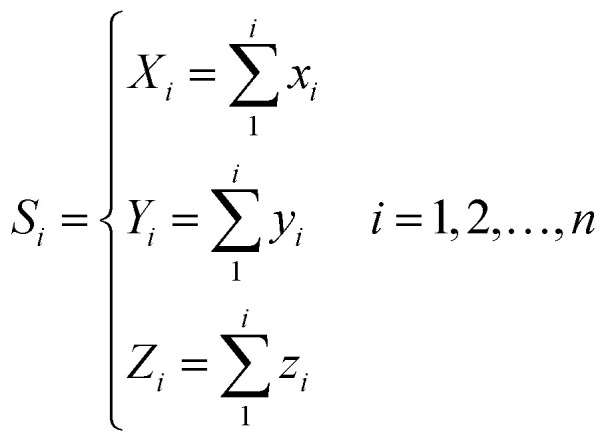 |
5 |
Thus, every base can obtain another point Si(Xi, Yi, Zi). The advantages of the accumulative coordinate depend on the calculation where it contains a large amount of information, and the accuracy is good and computing the distance between sequences with different lengths is convenient. The RNA secondary structure sequences of TSV-3 and AIMV-3 are used as examples. Table 2 shows the accumulative coordinates of the 20 bases in front of the RNA secondary structures of TSV-3 and AIMV-3. Fig. 3 shows the 3D graphical representation of the RNA secondary structures of TSV-3 and AIMV-3.
The cumulative coordinates of the first 20 bases in the RNA secondary structures of TSV-3 and AIMV-3. X, Y, and Z denote the cumulative coordinates of the X, Y, and Z coordinate axes of the base, respectively.
| TSV-3 | X | Y | Z | AIMV-3 | X | Y | Z |
|---|---|---|---|---|---|---|---|
| G | 0.02 | 0.02 | 0.02 | A | −0.03 | −0.03 | 0.03 |
| U | 0 | 0 | 0.04 | U | −0.05 | −0.05 | 0.05 |
| G | 0.04 | 0.04 | 0.08 | G | −0.03 | −0.03 | 0.08 |
| C | 0.06 | 0.06 | 0.1 | C | 0 | 0 | 0.1 |
| c | 0.08 | 0.08 | 0.12 | u | 0.03 | −0.03 | 0.08 |
| a | 0.06 | 0.06 | 0.1 | c | 0.05 | 0 | 0.1 |
| g | 0.04 | 0.08 | 0.08 | a | 0.03 | −0.03 | 0.08 |
| u | 0.06 | 0.06 | 0.06 | u | 0.08 | −0.08 | 0.03 |
| a | 0.02 | 0.02 | 0.02 | g | 0.05 | −0.05 | 0 |
| g | −0.02 | 0.06 | −0.02 | c | 0.1 | 0 | 0.05 |
| u | 0.02 | 0.02 | −0.06 | a | 0.05 | −0.05 | 0 |
| a | −0.04 | −0.04 | −0.12 | A | 0 | −0.1 | 0.05 |
| u | 0.02 | −0.1 | −0.18 | A | −0.08 | −0.18 | 0.13 |
| a | −0.06 | −0.18 | −0.27 | A | −0.18 | −0.28 | 0.23 |
| U | −0.1 | −0.22 | −0.22 | C | −0.13 | −0.23 | 0.28 |
| A | −0.12 | −0.24 | −0.2 | u | −0.05 | −0.31 | 0.21 |
| A | −0.16 | −0.29 | −0.16 | g | −0.1 | −0.26 | 0.15 |
| u | −0.08 | −0.37 | −0.24 | c | −0.03 | −0.18 | 0.23 |
| a | −0.18 | −0.47 | −0.35 | a | −0.1 | −0.26 | 0.15 |
| u | −0.08 | −0.57 | −0.45 | u | 0 | −0.36 | 0.05 |
Fig. 3. The 3D graphical representation of the RNA secondary structure of viruses TSV-3 and AIMV-3.

Cumulative coordinates or cumulative distances are widely used in many research areas because they show many advantages.48 However, the first residue may also be important, and the sequence space may be unbalanced. This study is different from the result of a previous cumulative coordinate study because the effects of sequence space imbalance are reduced in terms of the following aspects:
(1) The values of the cumulative coordinates are not monotonically increasing or decreasing. The coordinate value of each base may be positive or negative, and its positive and negative values depend on eqn (1)–(4). The cumulative coordinates are calculated by using eqn (5).
(2) The 3D coordinates of the constructed base are dynamically changed with the frequency of the base, reflecting the local characteristics of the sequence. For example, the initial sequence in Fig. 4 represents the first 20 bases of RNA “TSV-3”, which contains two g bases, and the coordinates of the two g bases are calculated using eqn (1). Re-routing from the beginning to the position of the base g is necessary to calculate the g base coordinate. Therefore, the coordinates of the base dynamically change with the position and number of bases, and the cumulative coordinates reflect the local characteristics of the pre-miRNA sequence to the base.
Fig. 4. Example of the base coordinate calculation.

(3) Table 2 shows that the coordinate values of the bases were not much different from the initial values, and the values gradually differed until the base position was about 10. Therefore, the cumulative coordinate values in this paper did not depend primarily on the first residue.
In summary, the cumulative coordinates are not monotonous, and they reflect the local characteristics of the sequence as the position and number of bases change dynamically. Therefore, the imbalance caused by the first residue in the sequence space has a slight effect.
A novel method for computing the distance of two sequences
To analyze the similarity between RNA sequences, a novel similarity calculation method for RNA secondary structure is proposed based on Euclidean distance. A smaller distance indicates more similarity, and vice versa.
Let the secondary structures of two arbitrary RNA sequences be represented by Sa and Sb, where Na and Nb denote the lengths of the two sequences. The distance between Sa and Sb is calculated as follows:
(1) If the lengths of two sequences Sa and Sb are equal, that is, Na = Nb, then D(Sa, Sb) represents the distance between sequences Sa and Sb, and is defined as eqn (6)
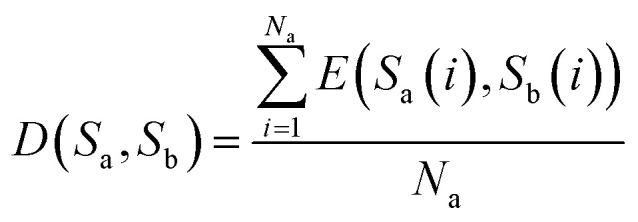 |
6 |
Here, E(Sa(i), Sb(i)) represents the Euclidean distance between the i-th bases of sequences Sa and Sb.
 |
7 |
(2) If the lengths of two sequences are not equal, then the distance between sequences Sa and Sb are computed as follows to obtain considerable information of the sequences:
Pattern 1
If Na > Nb, sequence Sb moves one base to the right each time, and the total times of sequences Sb needs to moves to the right is (Na − Nb). Eqn (6) is used to calculate the accumulative distance between subsequences Sa(1:Nb), Sa(2:Nb + 1), …, Sa(Na − Nb + 1:Na), and Sb successively, as shown in Fig. 5(a).
Fig. 5. Illustration of the steps of our method for calculating the distance between sequences. (A) shows the calculation steps for Pattern 1; (B) shows the calculation steps for Pattern 2.

Step 1: use eqn (6) to calculate the distance between sequence Sa(1:Nb) or sequence “GUGCcagu” and sequence Sb;
Step 2: sequence Sb moves on the right by a base character. Use eqn (6) to calculate the distance between sequences Sa(2:Nb) and Sb, as shown in Step 2 of Fig. 5(a).
…
Step (Na − Nb + 1): sequence Sb moves on the right by a base character. Use eqn (6) to calculate the distance between sequences Sa((Na − Nb + 1):Na) and Sb.
Then, the average distance of every step is calculated (by dividing Na − Nb) as shown in eqn (8).
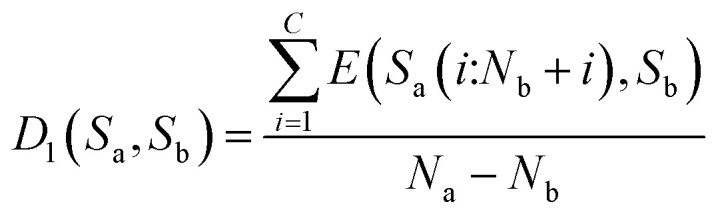 |
8 |
Pattern 2
If Na > Nb, then the subsequence whose length (Na − Nb) is used, and sequence Sa moves one base character to the right each time successively. Then, eqn (10) is used to calculate the accumulative distance between subsequences Sa − Sa(1:Na − Nb), Sa − Sa(2:Na − Nb + 1), …, Sa − Sa(Nb:Na), and Sb, and the average distance is calculated (by dividing Na), as shown in Fig. 5(b).
Step 1: exclude sequence Sa(1:Na − Nb), that is, sequence “GUGC”, and use eqn (6) to calculate the distance between Sa − Sa(1:Na − Nb) or sequence “caguagua” and sequence Sb, as shown in Step 1 of Fig. 5(b).
Step 2: use the sequence whose length is Na − Nb in sequence Sa, which moves one base character to the right. Use eqn (6) to calculate the distance between the remaining bases of sequences Sa and Sb, as shown in Step 2 of Fig. 5(b).
…
Step B: use eqn (6) to calculate the distance between Sa − Sa(Nb:Na) and Sb.
Then, calculate the average distance of each Step (B). The computational formula is demonstrated by eqn (9).
 |
9 |
After synthesizing the aforementioned scenarios, the distance between sequences Sa and Sb is expressed as shown in eqn (10).
 |
10 |
where, Na, Nb represent the lengths of the sequences Sa, Sb. E, D1 and D2 refer to eqn (7), (8) and (9), respectively.
We use the sequence similarity analysis method to compute the distances among 9 viruses.45Table 3 shows the distance matrix of 9 RNA virus sequences. From the table, the three smallest values correspond to the RNA sequence pairs, namely, (AVII, LRMV-3), (LRMV-3, EMV-3), and (AVII, EMV-3), which indicate that they are the most similar. In addition, the large values in the table appear in the rows of APMV-3, AIMV-3, and PDV-3, which indicates that obvious differences exist between APMV-3, AIMV-3, and PDV-3 and other RNA sequences. In addition, the distances between APMV-3, AIMV-3, and PDV-3 22 are small, which indicate that the similarity among them is higher than the similarity among the other sequences. These results show that our method successfully captures the apparent similarity among the 9 RNA sequences. The results are similar to those of Liao et al.37,38,40,41 Our 3D graphical representation and sequence similarity analysis method extract some essential information on RNA secondary structure and can effectively analyze the similarity of RNA sequences.
The distance matrix of the secondary structure of the 9 RNA virus sequences.
| APMV-3 | AVII | CILRV | CVV-3 | EMV-3 | LRMV-3 | PDV-3 | TSV-3 | |
|---|---|---|---|---|---|---|---|---|
| AIMV-3 | 0.97 | 1.64 | 2.70 | 1.17 | 2.16 | 1.75 | 1.42 | 1.89 |
| APMV-3 | 0.00 | 2.14 | 3.33 | 1.09 | 2.58 | 2.18 | 0.76 | 2.69 |
| AVII | 0.00 | 1.57 | 1.64 | 0.69 | 0.58 | 2.31 | 1.40 | |
| CILRV | 0.00 | 2.92 | 1.47 | 1.89 | 3.62 | 1.14 | ||
| CVV-3 | 0.00 | 2.01 | 1.53 | 1.21 | 2.45 | |||
| EMV-3 | 0.00 | 0.70 | 2.67 | 1.79 | ||||
| LRMV-3 | 0.00 | 2.32 | 1.49 | |||||
| PDV-3 | 0.00 | 3.01 |
Results and discussions
MiRNAs are involved in a large number of biological processes, such as plant development and metabolism by either translational repression, RNA degradation, or through an RNA-induced silencing complex. Here, we apply our method to predict plant pre-miRNAs based on the similarity of pre-miRNA sequences.
We divide the datasets of plant pre-miRNA sequences into sample and test datasets. In the test dataset, a test sequence can be classified as the category of the sequence in the sample dataset that has the smallest distance with the test sequence. For example, the sequence with the smallest distance from the sample dataset is the pseudo pre-miRNA (negative data), and this test sequence is also the pseudo pre-miRNA, and vice versa. We use the jackknife method to calculate the accuracy of our method.
Datasets
In this section, we use three datasets to evaluate the performance of the proposed method.
Dataset 1
A total of 1906 plant pre-miRNAs were obtained as positive samples from ref. 6. A total of 2122 pseudo pre-miRNA were used negative samples. The dataset processing using the same method of Liu et al.8,24–26,49 is expressed as follows. (1) To avoid redundancy and homologous bias, the threshold of CD-HIT software43 was set to 80% to filter those other similarity sequences of more than 80% samples in the same sample dataset. (2) Then, the sequences that contained non-U, -A, -G, and -C character bases were excluded. (3) The secondary structure of pre-miRNAs was predicted by RNAfold,44 and the pre-miRNAs that did not form a single-hairpin structure were removed. A total of 1204 plant pre-miRNAs were obtained as positive samples, and 1975 pseudo pre-miRNAs were obtained as negative samples. To avoid the imbalance between positive and negative samples, 1204 samples were selected from 1975 pseudo pre-miRNAs from front to back, and negative sample sets were constructed. Finally, 1204 plant pre-miRNAs were obtained as positive samples, and 1204 negative samples were obtained as dataset 1.
Dataset 2
In this study, we selected miRBase (19th edition),50,51 which has been proved by experiments as a positive sample dataset for pre-miRNA sequences. A similar screening process with that of dataset 1 was conducted, and a total of 1848 non-redundant pre-miRNAs with single-hairpin structure were obtained. The pseudo pre-miRNAs obtained from ref. 14 were subjected to a similar screening process with that of dataset 1, and 1848 samples were selected from front to back to construct the negative dataset 2.
Dataset 3
Arabidopsis thaliana, Oryza sativa, Populus trichocarpa, Physcomitrella patens, and Medicago truncatula are typical model plants. Sorghum bicolor, Zea mays, and Glycine max are important crops. Ten sets of species datasets were obtained from ref. 6 through the screening process of the above data. A total of 153 A. thaliana (ATH dataset), 256 O. sativa (OSA dataset), 133 P. trichocarpa (PTC dataset), 184 P. patens (PPT dataset), 67 M. truncatula (MTR dataset), S. bicolor (105 SBI dataset), 74 Z. mays (ZMA dataset), 69 G. max (GMA dataset), 167 A. lyrata (updated ALY dataset), and 105 G. max (updated GMA dataset) pre-miRNAs were obtained, as well as 1095 pseudo pre-miRNA negative samples. The negative sample set was selected from the 1095 pseudo pre-miRNAs to maintain the consistency between the positive and negative samples, thereby avoiding the imbalance between positive and negative samples. For example, the ATH dataset containing 153 pre-miRNAs selected 153 pseudo pre-miRNAs from the 1095 pseudo pre-miRNAs as the negative sample set.
Comparison of state-of-the-art algorithms
The following measures were used to assess the performance of the classifiers used in this study.
To measure the effectiveness of identifying plant pre-miRNAs, the following equations are used to measure the experiment results, including the overall accuracy (ACC), sensitivity (SE), specificity (SP), and Mathews coefficient (MCC). The expressions are shown as follows:
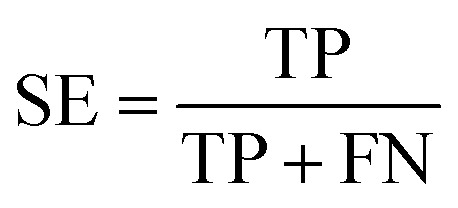 |
11 |
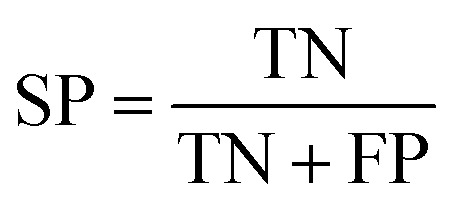 |
12 |
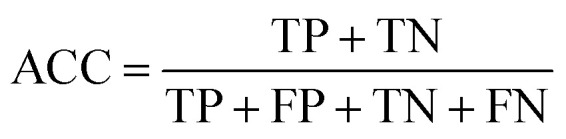 |
13 |
 |
14 |
The results of the jackknife test for dataset 1, dataset 2, and dataset 3 are listed in Tables 4, 5, and 6, respectively. Table 4 shows the results of our method and of microPred 52, iMcRNA 24, TripletSVM 53, and miPlantPre 14 methods applied to dataset 1. From the table, the ACC and MCC achieve 89.74% and 79.67% using our method, respectively, which are higher than others. Table 5 shows that the accuracy of our method is lower than the miPlantPre 14 method in dataset 2.
Comparison of prediction performance for different methods on the dataset 1 with a jackknife test.
Comparison of prediction performance for different methods on the dataset 2 with a jackknife test.
Comparison of prediction performance for different methods on the dataset 3 with a jackknife test.
| Datasets | iMcRNAa | microPredb | miPlantPrec | Our method |
|---|---|---|---|---|
| mtr_67 | 89.5 | 76.1 | 86.6 | 95.52 |
| osa_256 | 86.1 | 73.8 | 83.4 | 93.6 |
| ppt_184 | 76.9 | 68.8 | 84.5 | 96.5 |
| ath_153 | 86.2 | 67.6 | 85 | 96.1 |
| updated_aly_167 | 86.5 | 69.5 | 85 | 98.2 |
| ptc_133 | 78.6 | 72.2 | 82.7 | 91.4 |
| sbi_105 | 85.2 | 76.7 | 83.8 | 92.9 |
| updated_gma_105 | 88.1 | 82.4 | 83.8 | 92.4 |
| zma_74 | 85.8 | 74.3 | 85.1 | 96 |
| gma_69 | 88.4 | 71 | 85.5 | 92.8 |
In addition, our method did not use any machine learning classifiers, which can improve the accuracy by training and complicated computing. Thus, our method is easy to implement and requires a small amount of time. Table 6 shows the results of our method and of microPred 52, iMcRNA-PseSSC 24, and miPlantPre 14 methods applied to dataset 3. From the table, our method has the best ACC and MCC among the 10 plant pre-miRNA datasets (i.e., mtr, osa, ppt, ath, ptc, sbi, zma, gma, updated_aly, and updated_gma). This result indicates the effectiveness of our method.
In summary, our method obtains a good accuracy in identifying plant pre-miRNAs and has excellent stability based on the analysis of the aforementioned experiments. In comparison with existing machine learning algorithms, the proposed method is simple to operate and does not require training parameters.
Conclusions
Graphical representations based on sequences (e.g., DNA, RNA, and proteins) have been the focus of research.41,42,54–57 In this study, we proposed a 3D graphical representation of the secondary structure of the pre-miRNA in combination with the frequency and physicochemical properties of the base. We then subjected the pre-miRNA secondary structure to similarity analysis by calculating their Euclidean distance. The smaller the distance was, the higher the similarity between the two sequences would be and vice versa. Finally, the sequence similarity method proposed in this paper was used to identify plant pre-miRNA. The experimental results showed that the proposed method was reasonable and effective in the three common benchmark datasets.
In future work, we will develop an enhanced representation of the pre-miRNA secondary structure by merging additional information and designing a more complete graphical model and more efficient similarity analysis methods to improve the performance of pre-miRNA prediction. In addition, our method for predicting and classifying other noncoding RNAs, such as Piwi-interacting RNA and long-noncoding RNA, is a key issue that should be further investigated.
Conflicts of interest
There are no conflicts to declare.
Supplementary Material
Acknowledgments
This study is supported by the Program for New Century Excellent Talents in university (Grant No. NCET-10-0365), National Nature Science Foundation of China (Grant No. 11171369, 61272395, 61370171, 61300128, 61472127, 61572178 and 61672214).
References
- Lei J. Sun Y. Bioinformatics. 2014;30:2837–2839. doi: 10.1093/bioinformatics/btu380. [DOI] [PubMed] [Google Scholar]
- Zhang Y. Kim M. S. Jia B. Yan J. Zuniga-Hertz J. P. Han C. Cai D. Nature. 2017;548:52. doi: 10.1038/nature23282. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B. Pan X. Cobb G. P. Anderson T. A. Dev. Biol. 2006;289:3. doi: 10.1016/j.ydbio.2005.10.036. [DOI] [PubMed] [Google Scholar]
- Pritchard C. C. Cheng H. H. Tewari M. Nat. Rev. Genet. 2012;13:358. doi: 10.1038/nrg3198. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jr I. T. Bustamante C. J. Mol. Biol. 1999;293:271–281. doi: 10.1006/jmbi.1999.3001. [DOI] [PubMed] [Google Scholar]
- Xuan P. Guo M. Liu X. Huang Y. Li W. Huang Y. Bioinformatics. 2011;27:1368. doi: 10.1093/bioinformatics/btr153. [DOI] [PubMed] [Google Scholar]
- Berezikov E. Cuppen E. Plasterk R. H. Nat. Genet. 2006;38(suppl.):S2. doi: 10.1038/ng1794. [DOI] [PubMed] [Google Scholar]
- Khan A. Shah S. Wahid F. Khan F. G. Jabeen S. Mol. BioSyst. 2017;13:1640–1645. doi: 10.1039/C7MB00115K. [DOI] [PubMed] [Google Scholar]
- Paicu C. Mohorianu I. Stocks M. Xu P. Coince A. Billmeier M. Dalmay T. Moulton V. Moxon S. Bioinformatics. 2017;33:2446–2454. doi: 10.1093/bioinformatics/btx210. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Alptekin B. Akpinar B. A. Budak H. Front. Plant Sci. 2016;7:2058. doi: 10.3389/fpls.2016.02058. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yao Y. Ma C. Deng H. Liu Q. Zhang J. Yi M. Mol. BioSyst. 2016;12:3124. doi: 10.1039/C6MB00295A. [DOI] [PubMed] [Google Scholar]
- Evers M. Huttner M. Dueck A. Meister G. Engelmann J. C. BMC Bioinf. 2015;16:1–10. doi: 10.1186/s12859-015-0798-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- An J. Lai J. Sajjanhar A. Lehman M. L. Nelson C. C. BMC Bioinf. 2014;15:275. doi: 10.1186/1471-2105-15-275. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meng J. Liu D. Sun C. Luan Y. BMC Bioinf. 2014;15:423. doi: 10.1186/s12859-014-0423-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei L. Liao M. Yue G. Ji R. He Z. Quan Z. IEEE/ACM Trans. Comput. Biol. Bioinf. 2014;11:192–201. doi: 10.1109/TCBB.2013.146. [DOI] [PubMed] [Google Scholar]
- Helvik S. A. Jr S. O. Saetrom P. Bioinformatics. 2007;23:142–149. doi: 10.1093/bioinformatics/btl570. [DOI] [PubMed] [Google Scholar]
- Huang T. H. Fan B. Rothschild M. F. Hu Z. L. Li K. Zhao S. H. BMC Bioinf. 2007;8:341. doi: 10.1186/1471-2105-8-341. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xue C. Li F. He T. Liu G. P. Li Y. Zhang X. BMC Bioinf. 2005;6:310. doi: 10.1186/1471-2105-6-310. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Y. Chen X. Jiang W. Li L. Li W. Yang L. Liao M. Lian B. Lv Y. Wang S. Genomics. 2011;98:73–78. doi: 10.1016/j.ygeno.2011.04.011. [DOI] [PubMed] [Google Scholar]
- Wu Y. Wei B. Liu H. Li T. Simon R. BMC Bioinf. 2011;12:107. doi: 10.1186/1471-2105-12-107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nam J. W. Shin K. R. Han J. Lee Y. Kim V. N. Zhang B. T. Nucleic Acids Res. 2005;33:3570–3581. doi: 10.1093/nar/gki668. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei L. Liao M. Gao Y. Ji R. He Z. Zou Q. IEEE/ACM Trans. Comput. Biol. Bioinf. 2014;11:192–201. doi: 10.1109/TCBB.2013.146. [DOI] [PubMed] [Google Scholar]
- Lopes I. D. O. Schliep A. Carvalho A. C. D. L. D. BMC Bioinf. 2014;15:1–11. [Google Scholar]
- Liu B. Fang L. Liu F. Wang X. Chen J. Chou K. C. PLoS One. 2015;10:e0121501. doi: 10.1371/journal.pone.0121501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu B. Fang L. Wang S. Wang X. Li H. Chou K. C. J. Theor. Biol. 2015;385:153–159. doi: 10.1016/j.jtbi.2015.08.025. [DOI] [PubMed] [Google Scholar]
- Liu B. Fang L. Chen J. Liu F. Wang X. Mol. BioSyst. 2015;11:1194. doi: 10.1039/C5MB00050E. [DOI] [PubMed] [Google Scholar]
- Zhao T. Zhang N. Ying Z. Ren J. Xu P. Liu Z. Liang C. Yang H. J. Biomed. Semant. 2017;8:30. doi: 10.1186/s13326-017-0143-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiang L. Zhang J. Xuan P. Zou Q. BioMed Res. Int. 2016;2016:9565689. doi: 10.1155/2016/9565689. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stegmayer G. Yones C. Kamenetzky L. Milone D. H. IEEE/ACM Trans. Comput. Biol. Bioinf. 2016;14:1316–1326. doi: 10.1109/TCBB.2016.2576459. [DOI] [PubMed] [Google Scholar]
- Jiang P. Wu H. Wang W. Ma W. Sun X. Lu Z. Nucleic Acids Res. 2007;35:W339. doi: 10.1093/nar/gkm368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kandaswamy K. K. Chou K. C. Martinetz T. Möller S. Suganthan P. N. Sridharan S. Pugalenthi G. J. Theor. Biol. 2011;270:56–62. doi: 10.1016/j.jtbi.2010.10.037. [DOI] [PubMed] [Google Scholar]
- Lin W. Z. Fang J. A. Xiao X. Chou K. C. PLoS One. 2011;6:e24756. doi: 10.1371/journal.pone.0024756. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dezulian T. Remmert M. Palatnik J. F. Weigel D. Huson D. H. Bioinformatics. 2006;22:359–360. doi: 10.1093/bioinformatics/bti802. [DOI] [PubMed] [Google Scholar]
- Yao Y. H. Nan X. Y. Wang T. M. J. Comput. Chem. 2005;26:1339–1346. doi: 10.1002/jcc.20271. [DOI] [PubMed] [Google Scholar]
- Li C. Xing L. Wang X. Chem. Phys. Lett. 2008;458:249–252. doi: 10.1016/j.cplett.2008.04.112. [DOI] [Google Scholar]
- Jeffrey H. J. Nucleic Acids Res. 1990;18:2163. doi: 10.1093/nar/18.8.2163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu W. Liao B. Ding K. J. Mol. Struct.: THEOCHEM. 2005;757:193–198. doi: 10.1016/j.theochem.2005.04.042. [DOI] [Google Scholar]
- Liao B. Wang T. Ding K. Mol. Simul. 2005;22:455. doi: 10.1080/07391102.2005.10507016. [DOI] [PubMed] [Google Scholar]
- Liao B. Zhu W. Li P. J. Math. Chem. 2006;42:1015–1022. doi: 10.1007/s10910-006-9156-z. [DOI] [Google Scholar]
- Li Y. Duan M. Liang Y. BMC Bioinf. 2012;13:280. doi: 10.1186/1471-2105-13-280. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Y. Huang H. Dong X. Fang Y. Wang K. Zhu L. Wang K. Huang T. Yang J. PLoS One. 2016;11:e0152238. doi: 10.1371/journal.pone.0152238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Y. Shi X. Liang Y. Xie J. Zhang Y. Ma Q. BMC Bioinf. 2017;18:51. doi: 10.1186/s12859-017-1481-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li W. Godzik A. Bioinformatics. 2006;22:1658. doi: 10.1093/bioinformatics/btl158. [DOI] [PubMed] [Google Scholar]
- Hofacker I. L. Nucleic Acids Res. 2003;31:3429. doi: 10.1093/nar/gkg599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reusken C. B. Bol J. F. Nucleic Acids Res. 1996;24:2660. doi: 10.1093/nar/24.14.2660. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mathews D. H. Sabina J. Zuker M. Turner D. H. J. Mol. Biol. 1999;288:911. doi: 10.1006/jmbi.1999.2700. [DOI] [PubMed] [Google Scholar]
- Feng J. Wang T. M. Chem. Phys. Lett. 2008;454:355–361. doi: 10.1016/j.cplett.2008.01.041. [DOI] [Google Scholar]
- Xu D. Theresa L. Greenbaum N. L. Fenley M. O. Nucleic Acids Res. 2007;35:3836. doi: 10.1093/nar/gkm274. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen J. Wang X. Liu B. Sci. Rep. 2016;6:19062. doi: 10.1038/srep19062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kozomara A. Griffithsjones S. Nucleic Acids Res. 2011;39:D152–D157. doi: 10.1093/nar/gkq1027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kozomara A. Griffithsjones S. Nucleic Acids Res. 2014;42:68–73. doi: 10.1093/nar/gkt1181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Batuwita R. Palade V. Bioinformatics. 2009;25:989–995. doi: 10.1093/bioinformatics/btp107. [DOI] [PubMed] [Google Scholar]
- Liu G. P. He T. Li F. Xue C. Li Y. Zhang X. BMC Bioinf. 2005;6:310. doi: 10.1186/1471-2105-6-310. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yu H. J. Huang D. S. IEEE J. Biomed. Health Inform. 2013;17:503–511. doi: 10.1109/titb.2012.2227146. [DOI] [PubMed] [Google Scholar]
- Hu H. Li Z. Dong H. Zhou T. IEEE/ACM Trans. Comput. Biol. Bioinf. 2017;14:182. doi: 10.1109/TCBB.2015.2511731. [DOI] [PubMed] [Google Scholar]
- Watkins X. Garcia L. J. Pundir S. Martin M. J. U. Consortium Bioinformatics. 2017;33:2040–2041. doi: 10.1093/bioinformatics/btx120. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thieker D. F. Hadden J. A. Schulten K. Woods R. J. Glycobiology. 2016;26:786. doi: 10.1093/glycob/cww076. [DOI] [PMC free article] [PubMed] [Google Scholar]