

Abstract
The abnormal expression of miRNAs is directly related to the development of human diseases. Predicting the potential candidate miRNAs associated with diseases can contribute to the detection, diagnosis, treatment and prevention of human complex diseases. The effective inference of the calculation method of the relationship between miRNAs and diseases is an effective supplement to biological experiments. It is of great help in the prevention, treatment and prognosis of complex diseases. This paper proposes a novel information diffusion method based on network consistency (IDNC) for identifying disease related microRNAs. The model first synthesizes the miRNA family information and the miRNA function similarity to reconstruct the miRNA network, and reconstruct the disease network by using the known disease and miRNA-related information and the semantic score between diseases. Then the global similarity of the two networks is obtained by using the Laplacian score of graphs. The global similarity score is a measure of the similarity between diseases and miRNAs. The disease–miRNA relation network was reconstructed by integrating the global similarity relation. The network consistency diffusion seed is then obtained by combining the global similarity network with the reconstructed disease–miRNA association network. Thereafter, the stable diffusion spectrum is generated as the prediction score by using the restarted random walk algorithm. The AUC value obtained by performing the LOOCV in the gold benchmark dataset is 0.8814. The AUC value obtained by performing the LOOCV in the predictive dataset is 0.9512. Compared with other frontier methods, our method has higher accuracy, which is further illustrated by case studies of breast neoplasms and colon neoplasms to prove that IDNC is valuable.
The abnormal expression of miRNAs is directly related to the development of human diseases.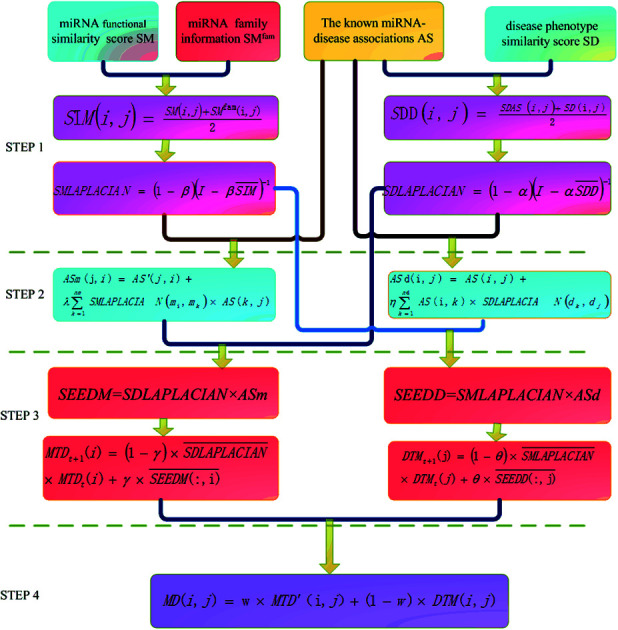
Introduction
RNA is the intermediate between DNA and encoded protein. It has a variety of important functions and is ubiquitous in organisms. The RNA that is not involved in the process of encoding protein is called non-coding RNA. About 98% of the human genome sequences are non-coding regions.1 miRNA means the single-strand endogenous non-coding RNA with a length of about 20–25 nucleotides and is evolutionarily conserved. miRNAs are widely distributed in eukaryotes. In human genes, the number of miRNAs can account for 1–4%2–5 of the total. The discovery of miRNA has been initially considered and has not received much attention. However, in recent years, there has been increasing evidence that shows the correlation between miRNAs and many life processes, such as cell growth,6,7 tissue differentiation,8 cell proliferation,9 embryonic development,10 apoptosis,11 metabolism12,13 and so on.
Recently, miRNAs have been found to be closely related to human tumors, especially the changes in the expression of miRNAs are involved in the occurrence, progression and metastasis of various types of human cancer.14 For example, hsa-mir-10b is unregulated in breast neoplasms compared with benign breast lesions;15 hsa-mir-126 and hsa-mir-145 can inhibit the growth of colonic tumor cells;16,17 hsa-mir-21 has higher expression level in colon cancer cells;18 Gao et al.19 found that the expression of hsa-mir-155 in serum of lung cancer patients was much higher than that of normal samples by PCR test; Johnson20 found that the down regulation of the let-7 family led to the development of lung cancer.
The identification of disease-related miRNAs is of great importance to human health. Identifying the interaction between miRNAs and diseases have become a key issue. Many researchers have worked hard to identify the interaction. The association between miRNAs and diseases can be accurately mined through sophisticated biological experiments but it is subject to high cost, long experimental period, and high requirements on equipment.21–24 In recent years, with the discovery of a large number of miRNAs, researchers have developed a variety of databases to store related information about miRNAs. With these data as the background, more and more bioinformatics calculation methods have been developed to predict their relationship.25–30 This kind of calculation method is the best supplement to biological experiments. The advantages include reducing the blindness of biologists' biological experiments, reducing the cost of biological experiments, and saving the human and material resources of biological experiments. At present, this method can be roughly divided into machine learning method and biological network method.31–33 The methods of predicting disease-associated miRNA are elaborated below from these two aspects.
In 2010, Jiang et al.34 extracted positive sample data from negative sample data by using support vector machine. The method extracted features from miRNA target data and phenotypic similarity data, which achieved good prediction results. In 2011, Xu et al.35 took prostate cancer as an example and proposed an MTDN calculation method to predict prostate cancer related miRNA by using miRNA target topology imbalance network. In 2016, Zeng et al.36 adopted two multipath methods to predict the association between miRNA and disease. All of these methods require the negative sample information of known disease-related miRNA, while negative miRNA–disease association is hard to obtain.
In 2014, Chen et al. proposed a regularized least squares semi supervised algorithm (RLSMDA)to predict potential miRNA–disease association.37 This method is built on semi supervised learning framework to predict potential disease–miRNA association and does not require related negative miRNA–disease information. In 2017, Chen et al.38 proposed LRSSLMDA model to predict miRNA–disease association with Laplacian Regularized Sparse Subspace Learning. In 2017, Peng et al.39 proposed a new information fusion strategy RLSSLP based on the regularization framework and the idea of Kronecker's regularized least squares based on multi-core learning. In 2017, Chen et al.40 established a MKRMDA model that can automatically optimize the combination of disease and miRNA multi-source data and efficiently use multi-core data to predict the potential association of miRNA–diseases. In 2017, Luo et al.41 used Kronecker regularized least squares to predict miRNA related diseases based on heterogeneous omics data.
Matrix factorization is designed to predict the association between disease and miRNA.42 In 2016, Lan et al.43 proposed a computational model kbmf-md to predict the association between miRNA and disease based on the improved microRNA and disease similarities. In 2016, Lan et al.44 used nuclear Bayesian matrix factorization to forecast potential miRNA–disease association. In 2018, Xiao et al.45 integrated the semantic information of diseases with the functional information of the miRNA to obtain the isomeric data, and then used the isomeric data to regularize the non-negative matrix factorization of the graph to predict the potential association between miRNA and the disease, which is called GRNMF. In 2018, Zhong et al.46 constructed a double layer network to express the complex relationship between miRNA, disease and miRNA–disease, and then sorted out the non-negative matrix factorization method to predict the potential disease miRNA. In 2018, Chen et al.47 developed a computational model of matrix decomposition and heterogeneous graph inference for miRNA–disease association prediction.
In addition, neural network and other algorithms are designed to predict the association between disease and miRNA. In 2017, Chen et al.48 proposed model EGBMMDA based on the relationship between Extreme Gradient Boosting Machine to predict association between miRNA and disease. In 2017, Chen et al.49 developed a miRNA–disease association prediction model DRMDA based on depth representation. After data extraction and depth representation, the unsupervised hierarchical layer-by-layer greedy pre-training and Support Vector Machine were used to predict the miRNA–disease association. In 2017, Fu et al.50 proposed a deep integration model, DeepMDA, which used an automatic encoder to extract advanced features from similar information, and then used a three layer neural network to predict the association between miRNAs and diseases. In 2015, Chen et al.51 used a Restricted Boltzmann Machine (RBM) to predict different types of miRNA–disease associations by applying RBMMMDA method. In 2017, Luo et al.52 developed a predictive method CPTL based on transduction learning.
However, previous studies are not adequate and have some disadvantages, such as the lack of miRNAs similarity data and the facts that known relationship between miRNAs and diseases is scarce and that there are few negative samples. In 2016, Zeng et al.53 proposed a method to predict miRNA–disease association by matrix completion algorithm based on miRNA–miRNA network and disease–disease network. In 2017, Li et al.54 propose MCMDA method to predict miRNA–disease association by using matrix completion algorithm. In 2017, Peng et al.55 used the improved low rank matrix recovery (ILRMR) algorithm to predict the correlation between miRNAs and diseases. In this method, it is possible to predict diseases which are not associated with any known miRNA. In 2018, Chen et al.56 presents a novel model of inductive matrix completion for miRNA–disease association prediction. Zhao et al.57 used symmetric nonnegative matrix factorization to reveal the relation of miRNA–disease pairs.
Bioinformatics researchers also utilized recommendation system.58 In 2014, Li et al.59 developed a computational system toxicology framework which used the recommendation system to predict the new association of environmental factors, miRNA and diseases by integrating the structural similarity of environmental factors and the phenotype similarity of diseases. In 2017, Gu et al.60 applies collaborative filtering recommendation algorithms to the miRNA–disease association prediction. In 2017, Peng et al.61 combined rating-based recommendation algorithm with negative-aware algorithm to predict miRNA–disease association. In 2017, Chen et al.62 proposed a new computational model HAMDA for miRNA–disease association by using hybrid graph-based recommendation algorithm. HAMDA not only considered the network structure and information dissemination, but also discussed the problem of node assignment. A satisfactory prediction result was achieved.
In 2015, inspired by social network analysis, Zou et al.63 proposed to using the methods based on social network analysis for the prediction of miRNA–disease association. They used two social network analysis methods, KATZ and CATAPULT, to analyze heterogeneous networks. CATAPULT is a deformation of supervised learning algorithm and can overcome the shortcoming that there are only positive samples and unmarked samples in miRNA–disease association. In 2018, Chen et al.64 proposed a computational model of Ensemble Learning and Link Prediction for miRNA–disease association prediction.
Based on the hypothesis, that functionally related miRNA tends to associate with phenotypically similar diseases, many calculation methods have been proposed to predict the potential association between miRNA and disease.25–27
In 2009, Jiang et al.65 first proposed a hypergeometric distribution model to predict miRNA–disease correlation. In 2010, Jiang et al.66 proposed a new method based on genomic data integration, integrating a variety of data resources with naive Bayes model and establishing a functional prediction model among genes. In 2011, Li et al. put forward a method of genes' functional consistency to predict carcinogenic miRNA.67 In 2013, Shi et al. further proposed a computational model that exploits the functional association between miRNAs and diseases.68 They integrated the disease–target association, the known disease–gene association, the protein inter-association to create a complex network. Then they made use of the random walk algorithm on the network and achieved a good prediction effect. In 2014, Xu et al.69 proposed a disease-associated miRNA prediction method which integrated the phenotypically similar miRNAs with mRNAs expression profiles. However, these methods depend on the prediction of miRNA–target association, and the false positive of the target gene is high. So they cannot obtain high predictive performance.
In 2011, Rossi et al.70 proposed a method called OMiR to predict the association of diseases in miRNA and OMIM. They calculated the degree of overlap between miRNA loci and disease loci in OMIM as the correlation between miRNA and disease. Xuan et al. proposed a prediction method based on weighted k most similar neighbors, which is called HDMP.71 However, HDMP cannot be applied to the prediction of isolated diseases. In 2017, Chen et al.72 designed a novel KNN-based disease-related sorting algorithm (RKNNMDA). In 2015, Le et al.73 used PageRank and k-step Markov algorithm, a classic algorithm for web page ranking in link analysis to predict the association between disease and miRNAs.
In 2012, Chen et al.74 proposed a RWRMDA computing model based on the similarity of global networks to predict the miRNA–disease association. They utilized the restarted random walk method to predict the pathogenetic miRNA. The results demonstrated that the global similarity network can improve the prediction accuracy more than the local similarity network. However, this method cannot predict new diseases without any known association. In 2013 and 2016, Shi68,75 integrated data such as protein–protein and gene ontology data to build heterogeneous networks where the random walk algorithm can also be employed to predict. In 2015, Xuan et al.76 designed a computing model named MIDP based on random walk algorithm. In 2015, Liao et al.77 designed a global similarity prediction model based on information diffusion, which is known as NDBM. In 2017, Luo et al.78 implemented the unbalanced bi-random walk algorithm (BRWH) on heterogeneous networks to search two-part graph sub-graphs to discover potential miRNA–disease associations. In 2017, Mugunga et al.79 combined the path-based features and the random walk algorithm to predict the association between miRNA and disease.
In 2013, Chen et al. proposed Net-CBI method to predict the relationship between miRNA and disease by using the consistency of disease network.80 In 2016, Gu et al.81 designed a network consistency method to predict miRNA–disease association (NCPMDA). In 2017, Li et al.82 proposed an integrated network similarity method (NSIM).
In 2015, Nalluri et al.83 designed two scientific methods from the perspective of graph theory: one is to choose the maximum weighted matching inference model of the dominant disease by solving an equation; the other is based on the model of motivation analysis. In 2016, Chen et al.84 constructed a heterogeneous graph method to predict miRNA–disease association method, which is called HGIMDA. In 2017, You et al.85 proposed A novel and effective path-based miRNA–disease association prediction method, PBMDA, which uses a unique depth-first search algorithm to search in the isomeric graph. In 2016, Sun et al.86 proposed a method to predict the association between them by using network topological similarity of miRNA–disease correlation network, which is called NTSMDA. In 2018, Chen et al.87 proposed a novel computational model of triple layer heterogeneous network based inference for miRNA–disease association prediction. Chen et al.88 proposed a method of graph regression to predict the miRNA–disease association.
In 2016, Chen et al.89 developed the model of within and between score to predict potential miRNAs associated with various complex diseases. In 2017, Chen et al.90 used the graphlet interaction of miRNAs (diseases) to represent the complex relationship between any two miRNAs (diseases), and established a GIMDA model for predicting the potential miRNA–diseases association by calculating the number of interactions of different types. In 2017, Chen et al.91 introduced the concepts of “super miRNA” and “super disease” to strengthen the similarity measurement of disease and miRNA. In 2018, Li et al.92 present a label propagation model with linear neighborhood similarity to predict unobserved miRNA–disease associations.
To sum up, due to the complexity of biological systems and the limitations of existing research methods, some problems and challenges exist in the field of disease–miRNA association prediction: firstly, the prediction accuracy is not high; secondly, many algorithms isolate disease and new miRNA prediction without known association; thirdly, the method of similarity construction is not reasonable in most of the current models; the fourth is the problem of model defects. At present, many machine-learning methods either need negative samples or have difficulties in model training. Some methods based on biological networks use local information instead of global information, which results in poor prediction accuracy. Many methods have data dependence problem. The generalization ability of some methods is not strong. Some methods have good prediction ability for a data set but not satisfactory for other data sets. It is urgent to develop simple, effective and universal models for disease-related miRNA prediction.
In view of the shortcomings of the algorithm described above, we designed an information diffusion disease association prediction method based on network consistency to reveal the potential relationship between miRNA and disease. On the basis of building disease and miRNA global similarity network, this method reconstructs two disease–miRNA association networks. By using the consistency of the network to capture the comprehensive information of the vector, the information diffusion method is used to forecast the correlation. The experimental results show that the proposed method has some advantages: no need for negative samples; the ability to predict isolated disease and new miRNA, the simple design of the algorithm and so on. In the comparison of methods, our method is superior to other methods on different data sets, and case studies show better prediction ability of the algorithm.
Materials and methods
Data preparation
We first downloaded 270 miRNA–disease pairs from the literature,27 removed 19 miRNAs that could not be found in the literature,27 and kept 99 miRNAs and 51 diseases including 242 disease–miRNA pairs, which we refer to as the gold standard dataset.
To verify that our method has better universality, we downloaded another disease–miRNA association data set from the literature,27 which contains 1616 experimentally verified human miRNA–disease associations. After merging different miRNA records and unifying the names of miRNA and disease, the data set eventually retained 1395 disease–miRNA associations, including 271 miRNA and 137 diseases. We refer to the data set as predictive dataset.
miRNA–miRNA functional similarity score is downloaded from the literature.27 The data set is successfully applied to multiple methods.80,93–95 We use matrix SM to represent the adjacency matrix of miRNA, and SM(i, j) is the score of functional similarity score between miRNA i and miRNA j.
Disease similarity data are downloaded from the literature.96 We use matrix SD to represent the adjacency matrix of disease, SD(i, j) representing the similarity score between di and disease dj. The family information of miRNA is obtained from miRBase database.97 The family information of miRNA is represented by matrix SMfam. If two miRNAs are in the same family, the corresponding set SMfam(i, j) is 1, otherwise it will set 0.
Algorithm flow
The basic work flow of disease-related miRNA prediction method based on network consistency has four steps (Fig. 1). Namely:
Fig. 1. The flow chart of information diffusion method based on network consistency is divided into four steps: (1) building a global similarity network. (2) Reconstruction of disease–miRNA association network. (3) Information diffusion based on network consistency. (4) Information fusion.

(1). Building a global similarity network
The global similarity network of disease is constructed by using the known disease and miRNA association information, the semantic score between the diseases and the Laplacian score of graphs. The global similarity network of the miRNA is constructed by utilizing the miRNA family information, the miRNA function similarity and the Laplacian score of graphs.
(2). Reconstruction of disease–miRNA association network
The disease and the miRNA association information and the global similarity between the miRNA nodes are utilized to construct the disease–miRNA association network ASm based on the global similarity information of the miRNA. The disease and miRNA association information and the global similarity between the disease nodes are used to construct the disease–miRNA association network ASd based on the global similarity information of the disease.
(3). Information diffusion based on network consistency
The miRNA consistency network diffusion seed is obtained by using the disease global similarity network and the disease–miRNA association network ASm based on the miRNA global similarity information. Then the stable diffusion spectrum is obtained by random walk in the global similarity network of the disease, which is used as the score of miRNA–disease association prediction based on miRNA network consistency information diffusion; the disease consistency network diffusion seed is obtained by using the miRNA global similarity network and the disease–miRNA association network ASd based on the disease global similarity information, then the stable diffusion spectrum is obtained by random walk in the global similarity network of miRNA as the disease–miRNA association prediction algorithm based on the disease network consistency information diffusion.
(4). Information fusion
The final score of miRNA–disease association prediction is calculated by the weighted calculation of the two predicted scores in the previous paragraph. The higher the score, the greater the probability that there is a correlation between the miRNA nodes mi and the disease nodes dj.
Step 1: similarity network construction
We integrate the known information of disease–miRNA association and the similarity of the disease semantic to obtain the similarity network of the disease. Then we use the Laplacian score of graphs to find the similarity of the disease to express the similarity between the diseases. We use the miRNA family information and the miRNA function similarity data to construct the miRNA similarity network. Laplacian score of graphs is used to find the global similarity of miRNA to represent the similarity between miRNA.
(1). The construction of disease global similarity network
The disease global similarity network is constructed in three steps. First, the disease similarity score in the known associated network structure is obtained through the association between the known disease and miRNA. Then this score and the semantic score between diseases are weighted. Thereafter, the global similarity network of disease is obtained by the Laplasse score of the weighted network.
Based on the hypothesis that the phenotype resemblance of disease tendency is associated with function related miRNA,27 we believe that the more common miRNA of two diseases are, the more similar the two diseases are. When the two diseases share the same amount of miRNA, if the miRNA of these two diseases is less, the two diseases are more similar. When there is no common miRNA between disease di and disease dj, the score of known association network structure is set to 0 directly. The formula is as follows:
 |
1 |
SDAS(i, j) indicates the similarity score between disease di and disease dj. comm(di, dj) indicates the number of miRNA shared by disease di and disease dj. deg(di) and deg(dj) were respectively the degrees of disease di and disease dj in disease–miRNA bipartite network (that is, the number of miRNA associated with disease di and disease dj).
Then we integrate the semantic correlation information of the disease and the score of the known association network structure to get the weighted score.
 |
2 |
SDAS(i, j) indicates the score of the known correlation network structure between disease di and disease dj. SD(i, j) is the semantic similarity score between disease di and disease dj.
Then we seek global similarity. Binary vector d = {d1, d2, …, dn} is used to represent the initial vector of disease di. The corresponding di values were set to 1 and the rest were 0. The global similarity between diseases is obtained by Laplacian score of graphs d̃. It can be solved by the optimization problem of formula (3).98
 |
3 |
In formula (3), the previous one is a smooth penalty item, 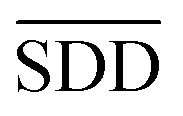 is the normalized matrix of the matrix SDD, which guarantees similar score for similar diseases. The second penalty items obtained the consistency between the disease and other diseases. α is a balance factor with a range of α ∈ (0,1). This factor is used to balance two penalty items' weight in formula (3). The approximate solution of formula (3) is as follows98:
is the normalized matrix of the matrix SDD, which guarantees similar score for similar diseases. The second penalty items obtained the consistency between the disease and other diseases. α is a balance factor with a range of α ∈ (0,1). This factor is used to balance two penalty items' weight in formula (3). The approximate solution of formula (3) is as follows98:
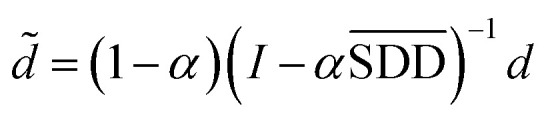 |
4 |
With the above method, we can get the global similarity score of all diseases in the disease network, which is represented by matrix SDLAPLACIAN.
(2). Construction of miRNA global similarity network
Construction of miRNA global similarity network is divided into two steps. First, miRNA similarity network is constructed by using miRNA similarity score and miRNA family information calculated by Wang et al.27 Then we use the Laplacian score of miRNA similarity network to get the global similarity score of miRNA.
Bandyopadhyay et al.26 found that the more the shared mRNA target targets were in the same family miRNA, the more similar their functions were. In order to make full use of family information of miRNA, we give higher weight to miRNA belonging to the same family when constructing miRNA network.
We use the following formula to calculate the similarity score of miRNA:
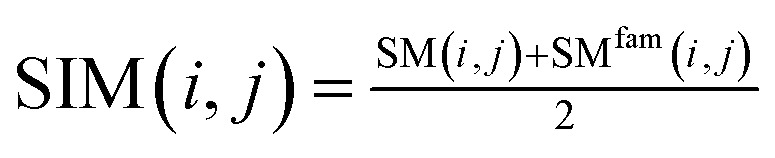 |
5 |
Among them, SIM(i, j) represents the similarity score between miRNA node mi and miRNA node mj after merging two kinds of information. SIM(i, j) is a functional similarity score between miRNA mi and miRNA mj calculated by Wang et al.27 SMfam is the miRNA family information matrix. When miRNA mi and miRNA mj are in the same family, SMfam(i, j) equals 1, which gives a higher score between two miRNA.
Then the global similarity weight matrix of miRNA is obtained by finding Laplacian score of graphs:
 |
6 |
SMLAPLACIAN represents miRNA global similarity network score matrix. I is a nm dimensional unit matrix, and nm is the total number of miRNA. 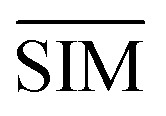 is the normalization matrix of miRNA similarity score SIM. β is a balance factor and β ∈ (0, 1).
is the normalization matrix of miRNA similarity score SIM. β is a balance factor and β ∈ (0, 1).
Step2: the reconstruction of disease–miRNA association network
From the previous analysis, we know that the known experimentally validated disease–miRNA association network is a Boolean bipartite network, which cannot fully characterize the tightness of the disease–miRNA association. We restructured the disease–miRNA association network by using the global similarity of the disease and the global similarity of the miRNA. Respectively, they are accounted as the disease–miRNA correlation network ASm based on the global similarity information of miRNA and the disease–miRNA correlation network ASd based on the global similarity information of the disease.
(1). Construction of disease–miRNA correlation network ASm based on miRNA global similarity information
Here we reconstruct the weight of the disease node dj and the miRNA node mi by introducing all the association information of the miRNA nodes mk and the disease nodes dj and the global similarity between the miRNA nodes. The calculation formula is as follows:
 |
7 |
Among them, ASm(j, i) is the weight of disease node dj to miRNA node mi in disease–miRNA bipartite network after reconstruction. AS(i, j) is the weight of miRNA nodes mi and disease nodes dj in the bipartite network before reconstruction. (In the experimentally verified disease–miRNA Boolean bipartite network, if the miRNA node mi is known to be associated with the disease node dj, the value is 1. Otherwise the value is 0.) AS′ is the transposed matrix of AS. SMLAPLACIAN(mi, mk) is the weight between the miRNA node mi and the miRNA node mk in the miRNA global similarity network. nm is the total number of miRNA, and λ is a balance parameter.
(2). Construction of disease–miRNA correlation network ASd based on disease global similarity information
We reconstruct the miRNA node mi and the weight of the disease node dj by introducing the association information of all the disease nodes dk and the miRNA node mi and the global similarity between the disease nodes. The calculation formula is as follows:
 |
8 |
Among them, ASd(i, j) is the weight of miRNA node mi and disease node dj in the reconstructed miRNA–disease bipartite network. AS(i, j) is used to reconstruct the weight of miRNA nodes mi and disease nodes dj in the miRNA–disease bipartite network before reconstruction. SDLAPLACIAN(dk, dj) is the weight of disease nodes dk and disease nodes dj in the global similarity network of diseases. nd is the total number of diseases. η is a balance parameter.
Step3: information diffusion based on network consistency
Based on the hypothesis that functionally similar miRNA is usually associated with phenotypically similar diseases, we designed an information diffusion method based on network consistency to reveal the potential association between miRNA and disease. We use network consistency to describe the relationship between two vectors in the same order and the same object. By using the similarity in the change rule of these two vectors, we can get comprehensive information of two heterogeneous networks. The projection of vectors can be used to express the degree of association between two vectors.
(1). Information diffusion based on miRNA network consistency(IDMNC)
First, we used the adjacency matrix of the disease global similarity network and the disease–miRNA association network ASm based on the miRNA global similarity information to do matrix multiplication, and got the miRNA consistency network diffusion seed. In the global similarity network, SDLAPLACIAN(j, :) represents the global similarity between disease dj and other disease nodes. ASm(:, i) represents the correlation between miRNA nodes mi and all other disease nodes. At this point, we use network consistency to describe SDLAPLACIAN(j, :) and ASm(:, i) as related disease nodes in the same order with the data relation of two different objects, the disease dj and the miRNA node mi, which are similar to the two vectors. The projection of SDLAPLACIAN(j, :) on ASm(:, i) represents the degree of association of the miRNA node mi with the disease node dj after integrating the information of the two heterogeneous networks, the miRNA–disease information association network and the disease global similarity network. Correlation degree of all miRNA nodes and disease nodes is calculated as follows:
| SEEDM = SDLAPLACIAN × ASm | 9 |
Next, in order to accurately describe the degree of association between miRNA nodes and disease nodes, we used random walk algorithm to walk in the global similarity network of disease, and captured the stable distribution of information called stable spread spectrum. Then the data of stable diffusion spectrum are utilized to represent the correlation between miRNA nodes and disease nodes. After the matrix normalization, each column is the seed sequence of associations between the miRNA node mi and all the disease nodes. The stable diffusion spectrum is obtained by SDLAPLACIAN random diffusion of these seed sequences in the adjacency matrix of the disease consistency network.
| 10 |
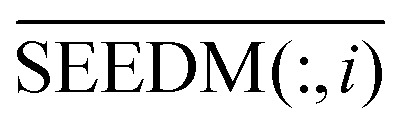 is the information of column I after the normalization of SEEDM matrix. The column vector is the seed sequence of the associations between miRNA node mi and all disease nodes.
is the information of column I after the normalization of SEEDM matrix. The column vector is the seed sequence of the associations between miRNA node mi and all disease nodes.  is the normalized matrix of the adjacency matrix SDLAPLACIAN of the disease consistency network. γ is the restart probability. MTDt(i) vector represents the information distribution after t iterations. After several iterations, the probability space can reach the steady state MTD∞(i) (|MTDt+1(i) − MTDt(i)| < 10−6) and stop the iteration. When the state is stable, the value of the vector is the correlation score between miRNA node mi and each disease. The correlation scores of all miRNA nodes and disease nodes are expressed by matrix MTD.
is the normalized matrix of the adjacency matrix SDLAPLACIAN of the disease consistency network. γ is the restart probability. MTDt(i) vector represents the information distribution after t iterations. After several iterations, the probability space can reach the steady state MTD∞(i) (|MTDt+1(i) − MTDt(i)| < 10−6) and stop the iteration. When the state is stable, the value of the vector is the correlation score between miRNA node mi and each disease. The correlation scores of all miRNA nodes and disease nodes are expressed by matrix MTD.
(2). Information diffusion based on disease network consistency(IDDNC)
Similar to the above, in the miRNA global similarity network, SMLAPLACIAN(i, :) represents the global similarity between the miRNA node mi and the remaining miRNA nodes. ASd(:, j) represents the correlation between disease nodes dj and all other miRNA nodes. At this point, we use network consistency to describe SMLAPLACIAN(i, :) and ASd(:, j) as related miRNA nodes in the same order with the data relation between two objects, the miRNA node mi and the disease node dj, which are similar to the two vectors. The projection of SMLAPLACIAN(i, :) on ASd(:, j) represents the degree of association of the miRNA node mi with the disease node dj after integrating the information of the two heterogeneous networks. We used the miRNA global similarity network adjacency matrix and the disease–miRNA association network ASd based on the disease global similarity information to do matrix multiplication, and got the disease consistency network diffusion seed. The formula is as follows:
| SEEDD = SMLAPLACIAN × ASd | 11 |
The seed matrix of the disease node dj is obtained through the above formula. After normalization of the matrix, each column is used as the seed sequence of the disease node dj and all miRNA. These seed sequences are SMLAPLACIAN randomly spread in the adjacency matrix of the miRNA consistency network in order to obtain stable diffusion spectra:
 |
12 |
 is the normalized matrix of the adjacency matrix SMLAPLACIAN of the miRNA consistency network. θ is the restart probability. DTMt(j) vector represents information distribution after t iterations. After several iterations, the probability space can reach a stable state DTM∞(j) (|DTMt+1(j) − DTMt(j)| < 10−6), and then the iteration can be stopped. Each value of the vector represents the correlation score of disease j and each miRNA. The correlation score of all diseases and each miRNA is expressed by matrix DTM.
is the normalized matrix of the adjacency matrix SMLAPLACIAN of the miRNA consistency network. θ is the restart probability. DTMt(j) vector represents information distribution after t iterations. After several iterations, the probability space can reach a stable state DTM∞(j) (|DTMt+1(j) − DTMt(j)| < 10−6), and then the iteration can be stopped. Each value of the vector represents the correlation score of disease j and each miRNA. The correlation score of all diseases and each miRNA is expressed by matrix DTM.
Step4: information fusion
Finally, we integrated the two prediction scores obtained in the third step to form the final prediction score.
| MD(i, j) = w × MTD′(i, j) + (1 − w) × DTM(i, j) | 13 |
MD(i, j) is the final prediction score of miRNA node mi and disease node dj. The greater the score, the greater the probability that miRNA node mi is associated with disease node dj.
Results
Parameter selection
The proposed method has four kinds of parameters: the information diffusion restart parameters γ and θ; the equilibrium factor α constructing the disease global similarity network, the equilibrium factor β constructing the miRNA global similarity network; equilibrium parameter λ based on global similarity network information for reconstructing the disease–miRNA association network ASm of miRNA, equilibrium parameter η based on disease global similarity network information for reconstructing the miRNA–disease association network ASd; the weight parameter w of information diffusion disease-related miRNA prediction score based on network consistency.
The selection and influence of these four kinds of parameters are discussed respectively. In the process of information diffusion, γ and θ indicate the probability of repetitive random walks that represent random callbacks to the source node. The greater γ and θ are, the greater the probability of returning the node for each step is. For the sake of simplicity, we set γ and θ to the same size. To verify the impact of γ and θ on the performance of the prediction algorithm, the other parameters are fixed (α = β = λ = η = w = 0.5) while the values of γ and θ are changed (0.1 for step length, from 0.1 to 0.9) to do cross-validation on the gold benchmark dataset and to calculate the AUC value. The experimental results are shown in Fig. 2. In the experiment, we found that when γ and θ increased from 0.1 to 0.9, the AUC value increased gradually from 0.7656 to 0.8460. The best prediction performance was obtained when the maximum value was obtained at 0.9.
Fig. 2. Influence of parameter variation on model prediction accuracy.

Then we set the balance factor α of the disease global similarity network and the balance factor β of the miRNA consistency network as the same. To verify the impact of such parameters on the predictive performance of the algorithm, other parameters are fixed on the basis of the previously obtained parameters (γ = θ = 0.9, λ = η = w = 0.5), and then the α and β values are changed (with 0.1 for step length, from 0.1 to 0.9). As you can see from Fig. 2 with the increase of α and β, the AUC value gradually decreases. When α = β = 0.1, the AUC value is the largest and the prediction performance is the best.
In order to measure the degree of disease–miRNA association more accurately, we used the global similarity of the disease and the global similarity of miRNA to reconstruct the disease–miRNA association network respectively. The balance parameters λ and η determine the contribution rate of other diseases and other miRNA to the disease–miRNA association network. To verify the impact of the two parameters on the predictive performance of the algorithm, other parameters are fixed on the basis of the previously obtained parameters (γ = θ = 0.9, α = β = 0.1, w = 0.5), and then the λ and η values are changed (from 0 to 0.9) for cross-validation. In the experiment, it was found that the AUC value was 0.8670 when the set value is 0.1 (0.8748 when the set value is 0.2; 0.8745 when the set value is 0.3; 0.8743 when the set value is 0.4). At this time, the AUC value was not very different. When the set value changes from 0.4, AUC decreased slowly. With the increase of λ and η, the AUC value became smaller and decreased to 0.8618 when the set value is 0.9.
In order to obtain the best prediction performance, we got the final correlation prediction score of the miRNA–disease association by weighting the miRNA–disease association prediction algorithm score (based on miRNA network consistency information diffusion) and the disease–miRNA association prediction algorithm score (based on disease network consistency information diffusion). The score weight parameter of miRNA–disease correlation prediction based on miRNA network consistency information diffusion is set as w (0 ≤ w ≤ 1), then 1 − w is the weight of disease–miRNA association prediction score based on disease network consistency information diffusion. When the w is larger, the weight of the miRNA–disease correlation prediction score based on miRNA network consistency information diffusion is greater, which means that the prediction results take more consideration of the miRNA–disease correlation prediction score based on miRNA network consistency information diffusion. When the w is smaller, the prediction results take more consideration of the disease–miRNA association prediction score based on disease network consistency information diffusion. Based on the previous discussion, we fixed the values of other parameters (γ = θ = 0.9, α = β = 0,1, λ = η = 0.3), and then changed the value of w (from 0 to 0.9). When w increases from 0.1 to 0.7, the AUC value increases gradually. When the w increases from 0.7 to 0.9, the AUC value gradually decreases. When w is 0.7, the prediction effect is the best, and AUC achieves the maximum value of 0.8814. When λ and η are set as 0.2 and 0.4, the experiment result is similar, that is, when w is 0.7, the prediction effect is the best.
Finally, we determine that the parameters are: γ = θ = 0.9, α = β = 0,1, λ = η = 0.3, w = 0.7.
Performance evaluation
In this paper, a disease-related miRNA prediction model based on network consistency information diffusion is proposed, which is the integration of the miRNA–disease correlation prediction score (based on miRNA network consistency information diffusion) and the disease–miRNA correlation prediction score (based on disease network consistency information diffusion). In the construction of the similarity network, we restructured the disease and miRNA in different ways, and used the global similarity score as the similarity score to measure the relationship between the nodes. When we tested the model, we considered the following nine cases falling into three categories: (1) information diffusion method based on miRNA network consistency without considering the miRNA network reconstruction (IDMNC without MNR); (2) information diffusion method based on disease network consistency without considering the disease network reconstruction (IDDNC without DNR); (3) information diffusion method based on network consistency without considering the network reconstruction (IDNC without NR); (4) information diffusion method based on miRNA network consistency by considering the miRNA network reconstruction with family information (IDMNC with FR); (5) information diffusion method based on disease network consistency by considering the miRNA network reconstruction with family information (IDDNC with FR); (6) information diffusion method based on network consistency by considering the miRNA network reconstruction with family information (IDNC with FR); (7) information diffusion method based on miRNA network consistency by considering the network reconstruction (IDMNC); (8) information diffusion method based on disease network consistency by considering the network reconstruction (IDDNC); (9) information diffusion method based on network consistency by considering the network reconstruction (IDNC). Based on the above conditions, parameters are selected on the gold standard dataset: γ = θ = 0.9, α = β = 0,1, λ = η = 0.3, w = 0.7. The calculated ROC curve and the AUC value are shown in Fig. 3.
Fig. 3. The ROC curve and AUC value for LOOCV in three classes of nine cases.

From Fig. 3, Information diffusion based on miRNA network consistency method, information diffusion based on disease network consistency method and information diffusion method based on network consistency method are gradually improved in the prediction accuracy.
The prediction accuracies of non network reconstruction, reconstruction of miRNA network with family information, reconstruction of both disease and miRNA network are gradually improved. When using all the information, the AUC value is 0.8814. When the method is information diffusion based on miRNA network consistency without network reconstruction, AUC value is only 0.7171. This fully demonstrated the effectiveness of our method of restructuring network and the feasibility of integrating the two scoring methods with the weighted method.
Comparison with other methods
We compared the algorithm proposed in this paper with three classical methods RLSMDA,37 NetCBI,99 GSTRW. In the LOOCV assessment, each known miRNA–disease association is considered as a test sample, while other known associations are considered as training samples. The miRNA–disease association without known evidence is considered to be a candidate sample. In the gold datum data set, the AUC value of NetCBI is 0.8001; the AUC value of RLSMDA is 0.8059; the AUC value of GSTRW is 0.8479; and the AUC value of the algorithm proposed in this paper is 0.8841, which is far superior to the other three methods. The ROC curves and AUC values of the four methods on the gold datum data set are shown in Fig. 4.
Fig. 4. The ROC curve and AUC value of our method compared with other methods on the gold benchmark dataset.

In order to avoid data dependence, we further verified the four methods on the forecast data set, and the AUC values of the four methods in the forecast dataset have been greatly improved. As shown in Fig. 5, the AUC value of NetCBI is 0.9053; the AUC value of RLSMDA is 0.9232; the AUC value of GSTRW is 0.9434; and the AUC value of the algorithm proposed in this paper is 0.9512. This is mainly due to the increase in the number of available disease–miRNA associations, and the higher accuracy of the constructed similarity network, which makes the prediction accuracy increase. Both in the gold datum data set, or in the forecast data set, the methods presented in this paper have shown strong predictive ability, especially in the case of less number of disease–miRNA associations. Because the method proposed in this paper takes advantage of global similarity and network consistency, the algorithm proposed in this paper has more advantages.
Fig. 5. The ROC curve and AUC value of our method compared with other methods in the predictive dataset.

The prediction of new miRNA and isolated disease
The new miRNA refers to the unknown miRNA associated with the disease. With the discovery of a large number of unknown miRNA, the new miRNA prediction becomes more important in the prediction of disease–miRNA association. This paper also used the LOOCV to predict the new miRNA. One by one, we removed the association information of verified miRNA with all other diseases and simulated them as new miRNA. In the gold benchmark dataset, the AUC value of our method is 0.8087. Its ROC curve and the AUC value are shown in Fig. 6, which is higher than the AUC value predicted by RLSMDA and NetCBI for the common disease. This shows that our method has a better prediction ability for the new miRNA.
Fig. 6. Results of our prediction method of new miRNA and isolated diseases in gold datum dataset.

Isolated diseases refer to diseases whose associations with miRNA are unknown. Prediction of isolated diseases is also a difficult problem to be solved in the prediction of disease–miRNA associations. Similarly, in order to test the predictive performance of this article on isolated diseases, we removed the associations between disease and miRNA. The ROC curve and AUC value obtained with LOOCV are listed in Fig. 6,It can be seen from the figure that the AUC predicted by this algorithm for isolated diseases is 0.7562. This shows that our method has certain predictive ability for isolated diseases, but the accuracy of prediction needs to be further improved.
Case studies
In 2017, 135 430 new cases of colon neoplasms were reported in the United States. Among them, 50 260 cases of colon neoplasms led to death.100 Colon neoplasms is associated with many miRNA, such as miR-126, which inhibits the growth of colon tumor cells;16 miR-21 has a high expression level in colon neoplasms cells.18 Using the calculation method to predict the association between colon neoplasms and miRNA can help us to diagnose the cancer patients in the early stage. This is of great importance to increase the survival rate of colon neoplasms patients. Therefore, it is urgent to develop a scientific method to forecast the miRNA which is related to colon neoplasms disease. In the forecast dataset, 37 miRNA related to colon tumors were experimentally verified. We used the method proposed in this article to experiment with colon tumors by using these 37 known associations and considering both disease similarity and miRNA similarity. Among the first 50 unknown disease–miRNA associations got in the experiment, 45 miRNA got supporting evidence in the updated HMDD, miR2Disease, and dbDEMC data sets (shown in Table 1). Only 5 miRNA have not been verified, which are hsa-mir-199a, hsa-mir-92b, hsa-mir-200a, hsa-mir-373 and hsa-mir-216b. However, in previous literatures, we have found supporting evidence, for example: Nonaka et al.101 found that miR-199a could be used as a biomarker for colorectal cancer; Mussnich et al.102 found that miR-199a and miR-375 affect the sensitivity of colon neoplasms cells to cetuximab by targeting PHLPP1. Niu et al.103 stated that hsa-miR-92b can be used as a reference gene for circulating microRNA in colorectal cancer. Pichler et al.104 found that miR-200a regulates the prognosis of patients with rectal cancer by regulating the expression of epithelial mesenchymal metastasis related genes. Tanaka et al.105 found that the apparent silencing of microRNA-373 played an important regulatory role in the proliferation of colon neoplasms cells. Previous studies also suggested that these miRNA are closely related to colon neoplasms, such as hsa-mir-199a and hsa-mir-200a, which are predicted to be associated with colon tumors in PBMDA,85 MCMDA,54 EGBMMDA.48 The two miRNA, hsa-mir-92b and hsa-mir-200a, were predicted to be associated with colon neoplasms in the case analysis of RLSMDA. These documents are published after the latest update date of the three databases, which fully demonstrates the strong predictive power of our method.
Prediction of the top 50 predicted miRNAs associated with colon neoplasms based on known associations in HMDD database.
| Rank | miRNA name | Evidences | Rank | miRNA name | Evidences |
|---|---|---|---|---|---|
| 1 | hsa-mir-196a | dbDEMC, miR2Disease | 26 | hsa-mir-421 | dbDEMC |
| 2 | hsa-mir-199a | Unconfirmed | 27 | hsa-mir-15b | dbDEMC, miR2Disease |
| 3 | hsa-mir-448 | dbDEMC | 28 | hsa-mir-30d | dbDEMC |
| 4 | hsa-mir-25 | dbDEMC | 29 | hsa-mir-29a | HMDD, dbDEMC, miR2Disease |
| 5 | hsa-mir-122 | dbDEMC | 30 | hsa-mir-451 | dbDEMC, miR2Disease |
| 6 | hsa-mir-181b | dbDEMC, miR2Disease | 31 | hsa-mir-203 | dbDEMC |
| 7 | hsa-mir-18b | dbDEMC | 32 | hsa-mir-212 | dbDEMC |
| 8 | hsa-mir-224 | dbDEMC | 33 | hsa-mir-30b | dbDEMC |
| 9 | hsa-mir-15a | HMDD, dbDEMC | 34 | hsa-mir-106b | HMDD, miR2Disease, dbDEMC |
| 10 | hsa-mir-92b | Unconfirmed | 35 | hsa-mir-214 | dbDEMC |
| 11 | hsa-mir-372 | dbDEMC, miR2Disease | 36 | hsa-mir-98 | dbDEMC |
| 12 | hsa-mir-34c | dbDEMC | 37 | hsa-mir-220 | dbDEMC |
| 13 | hsa-mir-200a | Unconfirmed | 38 | hsa-mir-137 | HMDD, dbDEMC, miR2Disease |
| 14 | hsa-mir-190 | dbDEMC | 39 | hsa-mir-33a | dbDEMC |
| 15 | hsa-mir-217 | dbDEMC | 40 | hsa-mir-216b | Unconfirmed |
| 16 | hsa-mir-222 | dbDEMC | 41 | hsa-mir-33b | dbDEMC |
| 17 | hsa-mir-205 | HMDD, dbDEMC | 42 | hsa-mir-216a | dbDEMC |
| 18 | hsa-mir-93 | dbDEMC | 43 | hsa-mir-199b | dbDEMC |
| 19 | hsa-mir-20b | dbDEMC | 44 | hsa-mir-429 | dbDEMC |
| 20 | hsa-mir-135b | HMDD, miR2Disease, dbDEMC | 45 | hsa-mir-376c | dbDEMC |
| 21 | hsa-mir-34b | dbDEMC | 46 | hsa-mir-16 | HMDD, dbDEMC |
| 22 | hsa-mir-29c | dbDEMC | 47 | hsa-mir-146b | dbDEMC |
| 23 | hsa-mir-373 | Unconfirmed | 48 | hsa-mir-302b | HMDD, dbDEMC |
| 24 | hsa-mir-125b | dbDEMC | 49 | hsa-mir-125a | dbDEMC, miR2Disease |
| 25 | hsa-mir-9 | dbDEMC | 50 | hsa-mir-95 | dbDEMC |
Breast neoplasms is one of the most important causes of cancer death in women every year. So many scientists have been studying the pathology of breast neoplasms. The study of the relationship between microRNA and breast neoplasms can help us understand the development of the disease at a molecular point of view. Of the first 50 unknown associations for breast neoplasms, only 3 were not verified: hsa-mir-518b, hsa-mir-612 and hsa-mir-657, which are shown in Table 2. hsa-miR-21 is significantly associated with many diseases, which can be proved by breast neoplasms related evidences in HMDD, miR2Disease and dbDEMC. Persson et al.106 stated that hsa-miR-4656 is associated with breast neoplasms. hsa-miR-21, hsa-miR-612 and hsa-miR-4656 share many common target genes.107 This indicates that these miRNA may have similar biological processes. So we highly believe that hsa-miR-612 is associated with breast neoplasms. In addition, we found that the three miRNA appeared in the breast neoplasms related miRNA collection in SDMMDA.91 Among them, hsa-mir-518b is located in the fifth position while hsa-mir-612 and hsa-mir-657 are located in the 22nd and 23rd positions respectively.
Prediction of the top 50 predicted miRNAs associated with breast neoplasms based on known associations in HMDD database.
| Rank | miRNA name | Evidences | Rank | miRNA name | Evidences |
|---|---|---|---|---|---|
| 1 | hsa-mir-518b | Unconfirmed | 26 | hsa-mir-658 | dbDEMC |
| 2 | hsa-mir-518c | dbDEMC | 27 | hsa-mir-575 | dbDEMC |
| 3 | hsa-mir-612 | Unconfirmed | 28 | hsa-mir-423 | HMDD, dbDEMC |
| 4 | hsa-mir-600 | dbDEMC | 29 | hsa-mir-500 | dbDEMC |
| 5 | hsa-mir-629 | HMDD, dbDEMC | 30 | hsa-mir-346 | HMDD, dbDEMC |
| 6 | hsa-mir-622 | dbDEMC | 31 | hsa-mir-99a | dbDEMC |
| 7 | hsa-mir-638 | HMDD, dbDEMC | 32 | hsa-mir-130b | dbDEMC |
| 8 | hsa-mir-486 | HMDD, dbDEMC | 33 | hsa-mir-208b | dbDEMC |
| 9 | hsa-mir-596 | dbDEMC | 34 | hsa-mir-134 | dbDEMC |
| 10 | hsa-mir-557 | dbDEMC | 35 | hsa-mir-433 | dbDEMC |
| 11 | hsa-mir-642 | dbDEMC | 36 | hsa-mir-484 | dbDEMC |
| 12 | hsa-mir-769 | dbDEMC | 37 | hsa-mir-663 | dbDEMC |
| 13 | hsa-mir-602 | dbDEMC | 38 | hsa-mir-365 | HMDD, dbDEMC |
| 14 | hsa-mir-611 | dbDEMC | 39 | hsa-let-7e | HMDD, dbDEMC |
| 15 | hsa-mir-185 | dbDEMC | 40 | hsa-mir-494 | dbDEMC |
| 16 | hsa-mir-583 | dbDEMC | 41 | hsa-let-7i | HMDD, miR2Disease, dbDEMC |
| 17 | hsa-mir-615 | dbDEMC | 42 | hsa-let-7b | HMDD, dbDEMC |
| 18 | hsa-mir-654 | dbDEMC | 43 | hsa-mir-198 | dbDEMC |
| 19 | hsa-mir-662 | dbDEMC | 44 | hsa-mir-373 | HMDD, miR2Disease, dbDEMC |
| 20 | hsa-mir-601 | dbDEMC | 45 | hsa-mir-203 | HMDD, miR2Disease, dbDEMC |
| 21 | hsa-mir-324 | HMDD, dbDEMC | 46 | hsa-mir-223 | HMDD, dbDEMC |
| 22 | hsa-mir-608 | HMDD | 47 | hsa-let-7g | HMDD, dbDEMC |
| 23 | hsa-mir-637 | dbDEMC | 48 | hsa-mir-101 | HMDD, dbDEMC |
| 24 | hsa-mir-657 | Unconfirmed | 49 | hsa-mir-92b | dbDEMC |
| 25 | hsa-mir-197 | HMDD, dbDEMC | 50 | hsa-let-7c | HMDD, dbDEMC |
The prediction of isolated disease and new miRNA
In order to verify our algorithm's ability to predict isolated diseases, we removed the known associations of miRNAs with the proven diseases, which ensures that we only use the similarity information of the confirmed disease and other diseases and the miRNAs information associated with other diseases. We used colon neoplasms and breast neoplasms as case studies. The results are shown in Tables 3 and 4 respectively.
The top 50 colon neoplasms-related miRNAs candidates predicted by IDNC with removed all known colon neoplasms–miRNAs associations and the confirmation of these associations.
| Rank | miRNA name | Evidences | Rank | miRNA name | Evidences |
|---|---|---|---|---|---|
| 1 | hsa-mir-21 | HMDD, miR2Disease, dbDEMC | 26 | hsa-mir-19b | HMDD, miR2Disease, dbDEMC |
| 2 | hsa-mir-15a | HMDD, dbDEMC | 27 | hsa-mir-92a | HMDD, dbDEMC |
| 3 | hsa-mir-451 | dbDEMC, miR2Disease | 28 | hsa-let-7a | HMDD, miR2Disease, dbDEMC |
| 4 | hsa-mir-373 | Unconfirmed | 29 | hsa-mir-10a | dbDEMC, miR2Disease |
| 5 | hsa-mir-16 | HMDD, dbDEMC | 30 | hsa-mir-205 | HMDD, dbDEMC |
| 6 | hsa-mir-155 | HMDD, miR2Disease, dbDEMC | 31 | hsa-mir-211 | Unconfirmed |
| 7 | hsa-mir-29c | dbDEMC | 32 | hsa-mir-200b | HMDD, dbDEMC |
| 8 | hsa-mir-34a | HMDD, miR2Disease, dbDEMC | 33 | hsa-mir-196a | dbDEMC, miR2Disease |
| 9 | hsa-mir-19a | HMDD, miR2Disease, dbDEMC | 34 | hsa-mir-181a | dbDEMC, miR2Disease |
| 10 | hsa-mir-17 | HMDD, dbDEMC | 35 | hsa-mir-141 | HMDD, miR2Disease, dbDEMC |
| 11 | hsa-mir-221 | HMDD, miR2Disease, dbDEMC | 36 | hsa-let-7e | HMDD, dbDEMC |
| 12 | hsa-mir-125b | dbDEMC | 37 | hsa-mir-145 | HMDD, miR2Disease, dbDEMC |
| 13 | hsa-mir-302b | HMDD, dbDEMC | 38 | hsa-mir-223 | HMDD, miR2Disease, dbDEMC |
| 14 | hsa-mir-372 | dbDEMC, miR2Disease | 39 | hsa-let-7d | HMDD, dbDEMC |
| 15 | hsa-mir-143 | HMDD, miR2Disease, dbDEMC | 40 | hsa-let-7b | HMDD, miR2Disease, dbDEMC |
| 16 | hsa-mir-20a | HMDD, miR2Disease, dbDEMC | 41 | hsa-mir-9 | dbDEMC |
| 17 | hsa-mir-184 | dbDEMC | 42 | hsa-let-7c | HMDD, dbDEMC |
| 18 | hsa-mir-181b | dbDEMC, miR2Disease | 43 | hsa-let-7i | HMDD, dbDEMC |
| 19 | hsa-mir-29a | HMDD, dbDEMC, miR2Disease | 44 | hsa-let-7f | HMDD, dbDEMC |
| 20 | hsa-mir-122 | dbDEMC | 45 | hsa-let-7g | HMDD, miR2Disease, dbDEMC |
| 21 | hsa-mir-18a | HMDD, miR2Disease, dbDEMC | 46 | hsa-mir-15b | dbDEMC, miR2Disease |
| 22 | hsa-mir-146a | HMDD, dbDEMC | 47 | hsa-mir-92b | Unconfirmed |
| 23 | hsa-mir-222 | dbDEMC | 48 | hsa-mir-30a | HMDD, dbDEMC |
| 24 | hsa-mir-212 | dbDEMC | 49 | hsa-mir-126 | HMDD, dbDEMC |
| 25 | hsa-mir-137 | HMDD, dbDEMC, miR2Disease | 50 | hsa-mir-19b | HMDD, miR2Disease, dbDEMC |
The top 50 breast neoplasms-related miRNAs candidates predicted by IDNC with removed all known breast neoplasms-miRNAs associations and the confirmation of these associations.
| Rank | miRNA name | Evidences | Rank | miRNA name | Evidences |
|---|---|---|---|---|---|
| 1 | hsa-mir-21 | HMDD, miR2Disease, dbDEMC | 26 | hsa-mir-10a | HMDD, miR2Disease, dbDEMC |
| 2 | hsa-mir-146a | HMDD, miR2Disease, dbDEMC | 27 | hsa-mir-211 | dbDEMC |
| 3 | hsa-mir-125b | HMDD, miR2Disease, dbDEMC | 28 | hsa-mir-137 | HMDD, dbDEMC |
| 4 | hsa-mir-373 | HMDD, miR2Disease, dbDEMC | 29 | hsa-mir-141 | HMDD, miR2Disease, dbDEMC |
| 5 | hsa-mir-155 | HMDD, miR2Disease, dbDEMC | 30 | hsa-mir-223 | HMDD, dbDEMC |
| 6 | hsa-mir-16 | HMDD, dbDEMC | 31 | hsa-let-7e | HMDD, dbDEMC |
| 7 | hsa-mir-451 | HMDD, miR2Disease | 32 | hsa-mir-200b | HMDD, miR2Disease, dbDEMC |
| 8 | hsa-mir-29c | HMDD, dbDEMC | 33 | hsa-mir-146b | HMDD, miR2Disease |
| 9 | hsa-mir-34a | HMDD, dbDEMC | 34 | hsa-let-7b | HMDD, dbDEMC |
| 10 | hsa-mir-19a | HMDD, dbDEMC | 35 | hsa-mir-181a | HMDD, miR2Disease, dbDEMC |
| 11 | hsa-mir-17 | HMDD, dbDEMC | 36 | hsa-let-7d | HMDD, miR2isease, dbDEMC |
| 12 | hsa-mir-184 | Unconfirmed | 37 | hsa-let-7c | HMDD, dbDEMC |
| 13 | hsa-mir-221 | HMDD, miR2Disease | 38 | hsa-let-7i | HMDD, miR2Disease, dbDEMC |
| 14 | hsa-mir-15a | HMDD, dbDEMC | 39 | hsa-mir-9 | HMDD, dbDEMC |
| 15 | hsa-mir-302b | HMDD, miR2Disease | 40 | hsa-let-7f | HMDD, miR2Disease, dbDEMC |
| 16 | hsa-mir-20a | HMDD, dbDEMC | 41 | hsa-let-7g | HMDD, dbDEMC |
| 17 | hsa-mir-29a | HMDD, dbDEMC | 42 | hsa-mir-143 | HMDD, miR2Disease, dbDEMC |
| 18 | hsa-mir-372 | HMDD, dbDEMC | 43 | hsa-mir-145 | HMDD, miR2Disease, dbDEMC |
| 19 | hsa-mir-18a | HMDD, dbDEMC | 44 | hsa-mir-92b | dbDEMC |
| 20 | hsa-mir-222 | HMDD, dbDEMC | 45 | hsa-mir-30a | HMDD, dbDEMC |
| 21 | hsa-mir-181b | HMDD, miR2Disease, dbDEMC | 46 | hsa-mir-150 | HMDD, dbDEMC |
| 22 | hsa-mir-19b | HMDD, dbDEMC | 47 | hsa-mir-15b | dbDEMC |
| 23 | hsa-mir-92a | HMDD, dbDEMC | 48 | hsa-mir-127 | HMDD, miR2Disease, dbDEMC |
| 24 | hsa-let-7a | HMDD, miR2Disease, dbDEMC | 49 | hsa-mir-203 | HMDD, miR2Disease, dbDEMC |
| 25 | hsa-mir-205 | HMDD, miR2Disease, dbDEMC | 50 | hsa-mir-126 | HMDD, miR2Disease, dbDEMC |
For colon neoplasms, 37 known associations of miRNAs with colon neoplasms were removed. Among the first 50 miRNAs predicted, 47 miRNAs were identified in the three databases while three miRNAs, hsa-mir-373, hsa-mir-211 and hsa-mir-92b, failed to find support in the three databases, which is shown in Table 3. However, Cai et al.108 found that hsa-miR-211 promoted the growth of colorectal cancer cells through targeting CHD5. The other two miRNAs were predicted in previous cases about colon tumor. As mentioned above, a number of references to the association of these miRNAs and colonic tumors are also introduced. Therefore, we think our algorithm performs well for the prediction of isolated diseases.
For breast neoplasms, we deleted 78 known associations of breast neoplasms with miRNAs. We used this method to predict a potential association between miRNAs and breast neoplasms. In the first 50 miRNAs projections, 49 were found in the HMDD, miR2Disease, and dbDEMC databases, and only hsa-mir-184 had not been found in the three databases. However, when Yang et al.109 studied the classification of breast tumor subtypes by immunohistochemical markers, it was found that there were differences in expression of hsa-miR-365, hsa-miR-1238 and hsa-miR-184.
Next, we studied the new miRNA association prediction. hsa-mir-21 plays a crucial role in carcinogenesis and can be used as a biomarker for detecting various cancers. In this section, we removed all the associations of hsa-mir-21 with diseases in the forecast data set. Among the first 50 projected diseases related to hsa-mir-21, 40 diseases are verified in the above three databases while 10 kinds of diseases that are not verified, which is shown in Table 5. But previous literature show that these diseases are associated with hsa-mir-21. For example, Han et al.110 discovered that hsa-mir-21 can slow down the apoptosis of cortical neurons by promoting PTEN-Akt signaling pathway in vitro after traumatic brain injury. Montalban et al.111 found that hsa-mir-21 could regulate the growth factor signal and regulate the degeneration of neurons in PC12 cells. Smigielska et al.112 found that hsa-mir-21 plays a role in supporting the survival of T cells in CD4+T cells. Zhang et al.113 found that hsa-mir-21 is associated with the development of liver fibrosis. Ding et al.114 found that hsa-miR-21 could be used as a new biomarker for diagnosing HBV related acute liver failure through real-time quantitative PCR technology. Liao et al.115 found that 80% of the patients with hepatocellular carcinoma have the background of chronic hepatitis B or type C hepatitis and cirrhosis, and hsa-miR-21 can be used for subdivision of hepatocellular carcinoma and chronic hepatitis. Yao et al.116 found that compared with patients with obstructive spermatozoa, miRNA in spermatocytes, such as hsa-miR-21, was decreased in patients with non obstructive spermatozoa. Gutsaeva et al.117 found that hsa-mir-21 is closely related to new vascularization in ischemic retina. Andrade et al.118 found differential expression of 11 kinds of miRNA (such as hsa-miR-424 and hsa-miR-21) in the muscles of the patients with amyotrophic lateral sclerosis (rapidly progressive neurodegenerative disease) by microarray. miR-21 plays a crucial role in carcinogenesis,119 which can be used as a diagnostic and prognostic marker for digestive cancers for Asians. These documents were published after the last update date of these three databases, which fully demonstrates the effectiveness of our method.
The top 50 hsa-mir-21-related diseases candidates predicted by IDNC and the confirmation of these associations.
| Rank | miRNA name | Evidences | Rank | miRNA name | Evidences |
|---|---|---|---|---|---|
| 1 | Heart failure | HDMM | 26 | Lymphoma, B-cell | HMDD, miR2Disease |
| 2 | Breast neoplasms | HMDD, miR2Disease, dbDEMC | 27 | Colorectal eoplasms | HMDD, miR2Disease, dbDEMC |
| 3 | Lung neoplasms | HMDD, miR2Disease, dbDEMC | 28 | Hodgkin disease | HMDD, miR2Disease |
| 4 | Ovarian neoplasms | HDMM | 29 | Carcinoma, renal cell | HMDD, miR2Disease, dbDEMC |
| 5 | Neoplasms | HDMM | 30 | Hepatitis, chronic | Unconfirmed |
| 6 | Melanoma | HMDD, dbDEMC | 31 | Lymphoma | HDMM |
| 7 | Adrenocortical carcinoma | dbDEMC | 32 | Azoospermia | Unconfirmed |
| 8 | Muscular disorders, atrophic | HDMM | 33 | Hepatitis C | Unconfirmed |
| 9 | Stomach neoplasms | HDMM | 34 | Lymphoma, primary effusion | dbDEMC |
| 10 | Pancreatic neoplasms | HMDD, dbDEMC | 35 | Sarcoma, kaposi | dbDEMC |
| 11 | Lupus vulgaris | HDMM | 36 | Cardiomyopathy, hypertrophic | HMDD, miR2Disease |
| 12 | Colonic neoplasms | HMDD, dbDEMC | 37 | Pituitary neoplasms | Unconfirmed |
| 13 | Autistic disorder | HDMM | 38 | Uterine cervical neoplasms | HMDD, dbDEMC |
| 14 | Prostatic neoplasms | HDMM | 39 | Waldenstrom macroglobulinemia | Unconfirmed |
| 15 | Head and neck neoplasms | HDMM | 40 | Polycythemia vera | HDMM |
| 16 | Carcinoma, hepatocellular | HMDD, miR2Disease, dbDEMC | 41 | Digestive system neoplasms | Unconfirmed |
| 17 | Salivary gland neoplasms | HDMM | 42 | Urinary bladder neoplasms | HDMM |
| 18 | Adenocarcinoma | HDMM | 43 | Leukemia, B-cell | dbDEMC |
| 19 | Schizophrenia | Unconfirmed | 44 | Leukemia, promyelocytic, acute | dbDEMC |
| 20 | Endometriosis | HDMM | 45 | Precursor B-cell lymphoblastic leukemia-lymphoma | miR2Disease |
| 21 | Leukemia, lymphocytic, chronic, B-cell | HMDD, miR2Disease, dbDEMC | 46 | Retinal neovascularization | Unconfirmed |
| 22 | Medulloblastoma | HDMM | 47 | ACTH-secreting pituitary adenoma | HDMM |
| 23 | Leukemia, myeloid, acute | miR2Disease, dbDEMC | 48 | Neurodegenerative diseases | Unconfirmed |
| 24 | Leukemia | HDMM | 49 | Multiple myeloma | HMDD, dbDEMC |
| 25 | Thyroid neoplasms | HMDD, dbDEMC | 50 | Hepatitis B | Unconfirmed |
Discussion and conclusions
miRNA has been found associated with the development of many complex diseases. miRNA imbalance can be regarded as a biomarker for complex disease diagnosis. Although biological experiments can be used to predict disease–related miRNA, it takes much time and lots of efforts to use biological experiments. The calculation method for predicting potential associations between miRNAs and diseases is an effective complement to biological experiments. A reasonable similarity relationship of diseases and miRNAs can improve the prediction accuracy of the calculation method. In order to build a reasonable similarity relationship, we first reconstructed the miRNA network by combining the miRNA family information and the miRNA function similarity, and reconstructed the disease network by using the semantic scores between the known disease and the association information of the miRNA and the disease. Then the global similarity of the two networks is obtained by Laplasse operator. The similarity between diseases and miRNA is measured by global similarity score. Thereafter, the disease–miRNA association network ASm based on the global similarity information of miRNA was constructed by using the global similarity of the miRNA nodes and the known diseases–miRNA relationship. The disease–miRNA correlation network ASd based on disease global similarity information was constructed by using the global similarity of disease nodes and the known disease–miRNA relationship. Then the consistency information between vectors is obtained by projection of vectors. By using this information to diffuse the disease and miRNA global network respectively, a stable diffusion spectrum was obtained as a corresponding prediction score. Finally, the weighted average of two prediction scores was used as the final score of disease–miRNA association miRNA prediction. This method does not need negative samples and can predict isolated disease and new miRNA. The design of the algorithm is simple. The AUC value of the LOOCV experiment in the gold datum dataset is up to 0.8814, and the AUC value in the forecast data set is up to 0.9512, which is superior to the methods of others. In the case study, we also chose breast tumor and colon tumor for experimental research. Among the top 50 and the corresponding disease related miRNAs predictions, the accuracy rate in the updated HDMM, miR2Disease and dbDEMC databases were 94% and 90% respectively. In the prediction of isolated disease cases, 98% and 94% of the top 50 were confirmed by the three databases mentioned above. Finally, we simulated hsa-mir-21 as a new miRNA for prediction. Of the top 50 diseases predicted, 40 were verified by the database. The rests have found supporting evidence in the latest literature, showing predictive capability of our method.
The algorithm presented in this paper shows strong predictive capability, mainly due to the following reasons. Firstly, we added family information to reconstruct the miRNA similarity network, and integrate the known miRNA related disease information and the disease phenotype similarity information to reconstruct the disease network; secondly, we used the Laplasse operator to obtain the global similarity of both miRNA network and disease network; thirdly, we reconstructed the disease–miRNA correlation network by adding the global similarity information of the network; the fourth is the use of network consistency to get data association between miRNA and disease. Although the disease-related miRNA prediction model based on IDNC has achieved a satisfactory prediction performance, there are still some defects. Firstly, there are too many parameters. It takes a lot of time to find the best parameter for different data sets; secondly, the construction of disease and miRNA similarity network needs more data to be integrated for accuracy; thirdly, the accuracy of prediction for isolated diseases and new miRNA needs to be improved.
Conflicts of interest
There are no conflicts to declare.
Supplementary Material
Acknowledgments
The research of this paper has been sponsored by National Nature Science Foundation of China (Grant No. 61772192, 61672214, 61672223), Nature Science Foundation of Hunan Province, China (Grant No. 2018JJ2085), Science-Technology of Hunan Province, China(Grant No. 2015GK3029), Science-Technology of Hengyang City, China (Grant No. 2016KJ17, 2012KS19), Major cultivation projects of Hunan Institute of Technology (Grant No. 2017HGPY001).
References
- Mattick J. S. Makunin I. V. Hum. Mol. Genet. 2006;15:R17–R29. doi: 10.1093/hmg/ddl046. [DOI] [PubMed] [Google Scholar]
- Meister G. Tuschi T. Nature. 2004;431:343. doi: 10.1038/nature02873. [DOI] [PubMed] [Google Scholar]
- Bartel D. P. Cell. 2004;116:281–297. doi: 10.1016/S0092-8674(04)00045-5. [DOI] [PubMed] [Google Scholar]
- Ambros V. Cell. 2001;107:823–826. doi: 10.1016/S0092-8674(01)00616-X. [DOI] [PubMed] [Google Scholar]
- Ambros V. Nature. 2004;431:350. doi: 10.1038/nature02871. [DOI] [PubMed] [Google Scholar]
- Zhu L. Zhao J. Wang J. Hu C. Peng J. Luo R. Zhou C. Liu J. Lin J. Jin Y. PLoS Pathog. 2016;12:e1005423. doi: 10.1371/journal.ppat.1005423. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fernando T. R. Rodriguez-Malave N. I. Rao D. S. J. Hematol. Oncol. 2012;5:7. doi: 10.1186/1756-8722-5-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miska E. A. Curr. Opin. Genet. Dev. 2005;15:563–568. doi: 10.1016/j.gde.2005.08.005. [DOI] [PubMed] [Google Scholar]
- Cheng A. M. Byrom M. W. Shelton J. Ford L. P. Nucleic Acids Res. 2005;33:1290–1297. doi: 10.1093/nar/gki200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ambros V. Cell. 2003;113:673–676. doi: 10.1016/S0092-8674(03)00428-8. [DOI] [PubMed] [Google Scholar]
- Xu P. Guo M. Hay B. A. Trends Genet. 2004;20:617–624. doi: 10.1016/j.tig.2004.09.010. [DOI] [PubMed] [Google Scholar]
- Alshalalfa M. Alhajj R. BMC Bioinf. 2013;14:S1. doi: 10.1186/1471-2105-14-S12-S1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bartel D. P. Cell. 2009;136:215–233. doi: 10.1016/j.cell.2009.01.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Volinia S. Galasso M. Costinean S. Tagliavini L. Gamberoni G. Drusco A. Marchesini J. Mascellani N. Sana M. E. Jarour R. A. Genome Res. 2010;20:589–599. doi: 10.1101/gr.098046.109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yong L. Jing Z. Zhang P. Y. Yu Z. Sun S. Y. Yu S. Y. Xi Q. S. Med. Sci. Monit. 2012;18:BR299. doi: 10.12659/MSM.883262. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guo C. Sah F. J. Beard L. Willson J. K. V. Markowitz S. D. Guda K. Genes, Chromosomes Cancer. 2008;47:939–946. doi: 10.1002/gcc.20596. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shi B. Sepp-Lorenzino L. Prisco M. Linsley P. Baserga R. J. Biol. Chem. 2007;282:32582–32590. doi: 10.1074/jbc.M702806200. [DOI] [PubMed] [Google Scholar]
- Schetter A. J. Leung S. Y. Sohn J. J. Zanetti K. A. Bowman E. D. Yanaihara N. Yuen S. T. Chan T. L. Kwong D. L. Au G. K. JAMA, J. Am. Med. Assoc. 2008;299:425–436. [Google Scholar]
- Gao F. Chang J. Wang H. Zhang G. Oncol. Rep. 2014;31:351–357. doi: 10.3892/or.2013.2830. [DOI] [PubMed] [Google Scholar]
- Johnson S. M. Grosshans H. Shingara J. Byrom M. Jarvis R. Cheng A. Labourier E. Reinert K. L. Brown D. Slack F. J. Cell. 2005;120:635–647. doi: 10.1016/j.cell.2005.01.014. [DOI] [PubMed] [Google Scholar]
- Pritchard C. C. Cheng H. H. Tewari M. Nat. Rev. Genet. 2012;13:358. doi: 10.1038/nrg3198. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dong H. Lei J. Ding L. Wen Y. Ju H. Zhang X. Chem. Rev. 2013;113:6207. doi: 10.1021/cr300362f. [DOI] [PubMed] [Google Scholar]
- Li X. Bioinformatics. 2017;33:2829–2836. doi: 10.1093/bioinformatics/btx339. [DOI] [PubMed] [Google Scholar]
- Li X. Curr. Bioinf. 2018;13:367–372. doi: 10.2174/1574893612666170619083537. [DOI] [Google Scholar]
- Lu M. Zhang Q. Deng M. Miao J. Guo Y. Gao W. Cui Q. PLoS One. 2008;3:e3420. doi: 10.1371/journal.pone.0003420. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bandyopadhyay S. Mitra R. Maulik U. Zhang M. Q. Silence. 2010;1:6. doi: 10.1186/1758-907X-1-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang D. Wang J. Lu M. Song F. Cui Q. Bioinformatics. 2010;26:1644–1650. doi: 10.1093/bioinformatics/btq241. [DOI] [PubMed] [Google Scholar]
- Chen X. Wang L. Y. Huang L. J. Cell. Mol. Med. 2018;22:2884–2895. doi: 10.1111/jcmm.13583. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peng L.-H. Sun C.-N. Guan N.-N. Li J.-Q. Chen X. Mol. Genet. Genomics. 2018:1–13. [Google Scholar]
- Li G. Luo J. Xiao Q. Liang C. Ding P. Cao B. IEEE Access. 2017;5:24032–24039. [Google Scholar]
- Zeng X. Zhang X. Zou Q. Briefings Bioinf. 2016;17:193–203. doi: 10.1093/bib/bbv033. [DOI] [PubMed] [Google Scholar]
- Zou Q. Li J. Song L. Zeng X. Wang G. Briefings Funct. Genomics. 2016;15:55–64. [Google Scholar]
- Chen X. Xie D. Zhao Q. You Z.-H. Briefings Bioinf. 2017;10:1–25. [Google Scholar]
- Jiang Q., Wang G., Zhang T. and Wang Y., Predicting human microRNA-disease associations based on support vector machine, in 2010 IEEE International Conference On Bioinformatics and Biomedicine (BIBM), 2010, pp. 467–472 [Google Scholar]
- Xu J. Li C.-X. Lv J.-Y. Li Y.-S. Xiao Y. Shao T.-T. Huo X. Li X. Zou Y. Han Q.-L. Mol. Cancer Ther. 2011;10:1857–1866. doi: 10.1158/1535-7163.MCT-11-0055. [DOI] [PubMed] [Google Scholar]
- Zeng X. Xuan Z. Liao Y. Pan L. Biochim. Biophys. Acta. 2016;1860:2735–2739. doi: 10.1016/j.bbagen.2016.03.016. [DOI] [PubMed] [Google Scholar]
- Chen X. Yan G.-Y. Sci. Rep. 2014;4:5501. doi: 10.1038/srep05501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Huang L. PLoS Comput. Biol. 2017;13:e1005912. doi: 10.1371/journal.pcbi.1005912. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peng L. Peng M. Liao B. Xiao Q. Liu W. Huang G. Li K. RSC Adv. 2017;7:44447–44455. doi: 10.1039/C7RA08894A. [DOI] [Google Scholar]
- Chen X. Niu Y. W. Wang G. H. Yan G. Y. J. Transl. Med. 2017;15:251. doi: 10.1186/s12967-017-1340-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo J. Xiao Q. Liang C. Ding P. IEEE Access. 2017;5:2503–2513. [Google Scholar]
- Li G. Luo J. Xiao Q. Liang C. Ding P. RSC Adv. 2018;8:4377–4385. doi: 10.1039/C7RA12491K. [DOI] [Google Scholar]
- Lan W. Wang J. Li M. Liu J. Wu F. X. Pan Y. IEEE/ACM Trans. Comput. Biol. Bioinf. 2016:1. [Google Scholar]
- Lan W., Wang J., Li M., Liu J. and Pan Y., Predicting microRNA-disease associations by integrating multiple biological information, in IEEE International Conference on Bioinformatics and Biomedicine, 2015, pp. 183–188 [Google Scholar]
- Xiao Q. Luo J. Liang C. Cai J. Ding P. Bioinformatics. 2018;34:239–248. doi: 10.1093/bioinformatics/btx545. [DOI] [PubMed] [Google Scholar]
- Zhong Y. Xuan P. Wang X. Zhang T. Li J. Liu Y. Zhang W. Bioinformatics. 2018;34:267–277. doi: 10.1093/bioinformatics/btx546. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Yin J. Qu J. Huang L. PLoS Comput. Biol. 2018;14:e1006418. doi: 10.1371/journal.pcbi.1006418. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Huang L. Xie D. Zhao Q. Cell Death Dis. 2018;9:3. doi: 10.1038/s41419-017-0003-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Gong Y. Zhang D. H. You Z. H. Li Z. W. J. Cell. Mol. Med. 2018;22:472–485. doi: 10.1111/jcmm.13336. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fu L. Peng Q. Sci. Rep. 2017;7:14482. doi: 10.1038/s41598-017-15235-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Yan C. C. Zhang X. Li Z. Deng L. Zhang Y. Dai Q. Sci. Rep. 2015;5:13877. doi: 10.1038/srep13877. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo J. Ding P. Cheng L. Cao B. Chen X. IEEE/ACM Trans. Comput. Biol. Bioinf. 2017;14:7. [Google Scholar]
- Zeng X. Ding N. Rodríguez-Patón A. Lin Z. Ju Y. Curr. Proteomics. 2016;13:151–157. doi: 10.2174/157016461302160514005711. [DOI] [Google Scholar]
- Li J. Q. Rong Z. H. Chen X. Yan G. Y. You Z. H. Oncotarget. 2017;8:21187–21199. doi: 10.18632/oncotarget.15061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peng L. Peng M. Liao B. Huang G. Liang W. Li K. Sci. Rep. 2017;7:6007. doi: 10.1038/s41598-017-06201-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Wang L. Qu J. Guan N.-N. Li J.-Q. Bioinformatics. 2018;2:503. [Google Scholar]
- Zhao Y. Chen X. Yin J. Front. Genet. 2018;9:324. doi: 10.3389/fgene.2018.00324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Xie D. Wang L. Zhao Q. You Z.-H. Liu H. Bioinformatics. 2018;1:9. [Google Scholar]
- Li J. Wu Z. Cheng F. Li W. Liu G. Tang Y. Sci. Rep. 2014;4:5576. doi: 10.1038/srep05576. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gu C. Liao B. Li X. Cai L. Chen H. Li K. Yang J. RSC Adv. 2017;7:44961–44971. doi: 10.1039/C7RA09229F. [DOI] [Google Scholar]
- Peng L. Chen Y. Ma N. Chen X. Mol. BioSyst. 2017:2650–2659. doi: 10.1039/C7MB00499K. [DOI] [PubMed] [Google Scholar]
- Chen X. Niu Y. W. Wang G. H. Yan G. Y. J. Biomed. Inf. 2017;76:50–58. doi: 10.1016/j.jbi.2017.10.014. [DOI] [PubMed] [Google Scholar]
- Zou Q. Li J. Hong Q. Lin Z. Wu Y. Shi H. Ju Y. BioMed Res. Int. 2015;2015:810514. doi: 10.1155/2015/810514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Zhou Z. Zh ao Y. RNA Biology. 2018:1–50. doi: 10.1080/15476286.2018.1460016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiang Q. Hao Y. Wang G. Juan L. Zhang T. Teng M. Liu Y. Wang Y. BMC Syst. Biol. 2010;4(suppl. 1):S2. doi: 10.1186/1752-0509-4-S1-S2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiang Q., Wang G. and Wang Y., An approach for prioritizing disease-related microRNAs based on genomic data integration, in International Conference on Biomedical Engineering and Informatics, 2010, pp. 2270–2274 [Google Scholar]
- Li X. Wang Q. Zheng Y. Lv S. Ning S. Sun J. Huang T. Zheng Q. Ren H. Xu J. Nucleic Acids Res. 2011;39:e153. doi: 10.1093/nar/gkr770. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shi H. Xu J. Zhang G. Xu L. Li C. Wang L. Zhao Z. Jiang W. Guo Z. Li X. BMC Syst. Biol. 2013;7:101. doi: 10.1186/1752-0509-7-101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu C. Ping Y. Li X. Zhao H. Wang L. Fan H. Xiao Y. Li X. Mol. BioSyst. 2014;10:2800–2809. doi: 10.1039/C4MB00353E. [DOI] [PubMed] [Google Scholar]
- Rossi S. Tsirigos A. Amoroso A. Mascellani N. Rigoutsos I. Calin G. A. Volinia S. Genomics. 2011;97:71–76. doi: 10.1016/j.ygeno.2010.10.004. [DOI] [PubMed] [Google Scholar]
- Xuan P. Han K. Guo M. Guo Y. Li J. Ding J. Liu Y. Dai Q. Li J. Teng Z. PLoS One. 2013;8:e70204. doi: 10.1371/journal.pone.0070204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Wu Q. F. Yan G. Y. RNA Biology. 2017:1. [Google Scholar]
- Le D. H. Comput. Biol. Chem. 2015;58:139–148. doi: 10.1016/j.compbiolchem.2015.07.003. [DOI] [PubMed] [Google Scholar]
- Chen X. Liu M.-X. Yan G.-Y. Mol. BioSyst. 2012;8:2792–2798. doi: 10.1039/C2MB25180A. [DOI] [PubMed] [Google Scholar]
- Shi H. Zhang G. Zhou M. Liang C. Yang H. Wang J. Sun J. Wang Z. PLoS One. 2016;11:e0148521. doi: 10.1371/journal.pone.0148521. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xuan P. Han K. Guo Y. Li J. Li X. Zhong Y. Zhang Z. Ding J. Bioinformatics. 2015;31:1805–1815. doi: 10.1093/bioinformatics/btv039. [DOI] [PubMed] [Google Scholar]
- Liao B. Ding S. Chen H. Li Z. Cai L. J. Bioinf. Comput. Biol. 2015;13:1550014. doi: 10.1142/S0219720015500146. [DOI] [PubMed] [Google Scholar]
- Luo J. Xiao Q. J. Biomed. Inf. 2017;66:194–203. doi: 10.1016/j.jbi.2017.01.008. [DOI] [PubMed] [Google Scholar]
- Mugunga I. Ju Y. Liu X. Huang X. Oncotarget. 2017;8:58526–58535. doi: 10.18632/oncotarget.17226. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen H. Zhang Z. BMC Med. Genomics. 2013;6:12. doi: 10.1186/1755-8794-6-12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gu C. Bo L. Li X. Li K. Sci. Rep. 2016;6:36054. doi: 10.1038/srep36054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li X. Lin Y. Gu C. RSC Adv. 2017;7:32216–32224. doi: 10.1039/C7RA05348G. [DOI] [Google Scholar]
- Nalluri J. J. Kamapantula B. K. Barh D. Jain N. Bhattacharya A. de Almeida S. S. Juca Ramos R. T. Silva A. Azevedo V. Ghosh P. BMC Genomics. 2015;16:S12. doi: 10.1186/1471-2164-16-S5-S12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Yan C. C. Xu Z. You Z. H. Yuan H. Yan G. Y. Oncotarget. 2016;7:65257–65269. doi: 10.18632/oncotarget.11251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- You Z. H. Huang Z. A. Zhu Z. Yan G. Y. Li Z. W. Wen Z. Chen X. PLoS Comput. Biol. 2017;13:e1005455. doi: 10.1371/journal.pcbi.1005455. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sun D. Li A. Feng H. Wang M. Mol. BioSyst. 2016;12:2224. doi: 10.1039/C6MB00049E. [DOI] [PubMed] [Google Scholar]
- Chen X. Qu J. Front. Genet. 2018;9:234. doi: 10.3389/fgene.2018.00234. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Yang J.-R. Guan N.-N. Li J.-Q. Frontiers in Physiology. 2018;9:92. doi: 10.3389/fphys.2018.00092. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Yan C. C. Zhang X. You Z. H. Deng L. Liu Y. Zhang Y. Dai Q. Sci. Rep. 2016;6:21106. doi: 10.1038/srep21106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Guan N. Li J. Yan G. J. Cell. Mol. Med. 2017:1548–1561. doi: 10.1111/jcmm.13429. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Jiang Z. C. Xie D. Huang D. S. Zhao Q. Yan G. Y. You Z. H. Mol. BioSyst. 2017;13:1202–1212. doi: 10.1039/C6MB00853D. [DOI] [PubMed] [Google Scholar]
- Li G. Luo J. Xiao Q. Liang C. Ding P. J. Biomed. Inf. 2018;82:169–177. doi: 10.1016/j.jbi.2018.05.005. [DOI] [PubMed] [Google Scholar]
- Chen X. Liu M. X. Yan G. Y. Mol. BioSyst. 2012;8:2792–2798. doi: 10.1039/C2MB25180A. [DOI] [PubMed] [Google Scholar]
- Gu C. Liao B. Li X. Li K. Sci. Rep. 2016;6:36054. doi: 10.1038/srep36054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen M. Lu X. Liao B. Li Z. Cai L. Gu C. PLoS One. 2016;11:e0166509. doi: 10.1371/journal.pone.0166509. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Driel M. A. Bruggeman J. Vriend G. Brunner H. G. Leunissen J. A. Eur. J. Hum. Genet. 2006;14:535. doi: 10.1038/sj.ejhg.5201585. [DOI] [PubMed] [Google Scholar]
- Kozomara A. Griffithsjones S. Nucleic Acids Res. 2011;39:D152–D157. doi: 10.1093/nar/gkq1027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou D., Bousquet O., Lal T. N., Weston J., and Schölkopf B., Learning with local and global consistency, in Advances in neural information processing systems, 2004, pp. 321–328 [Google Scholar]
- Chen H. Zhang Z. BMC Med. Genomics. 2013;6:12. doi: 10.1186/1755-8794-6-12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Siegel R. L. Miller K. D. Fedewa S. A. Ahnen D. J. Meester R. G. Barzi A. Jemal A. Ca-Cancer J. Clin. 2017;67:177. doi: 10.3322/caac.21395. [DOI] [PubMed] [Google Scholar]
- Nonaka R. Nishimura J. Kagawa Y. Osawa H. Hasegawa J. Murata K. Okamura S. Ota H. Uemura M. Hata T. Oncol. Rep. 2014;32:2354–2358. doi: 10.3892/or.2014.3515. [DOI] [PubMed] [Google Scholar]
- Mussnich P. Ros R. Bianco R. Fusco A. D'Angelo D. Expert Opin. Ther. Targets. 2015;19:1017–1026. doi: 10.1517/14728222.2015.1057569. [DOI] [PubMed] [Google Scholar]
- Niu Y. Wu Y. Huang J. Li Q. Kang K. Qu J. Li F. Gou D. Sci. Rep. 2016;6:35611. doi: 10.1038/srep35611. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pichler M. Ress A. L. Winter E. Stiegelbauer V. Karbiener M. Schwarzenbacher D. Scheideler M. Ivan C. Jahn S. W. Kiesslich T. Br. J. Cancer. 2014;110:1614–1621. doi: 10.1038/bjc.2014.51. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tanaka T. Arai M. Wu S. Kanda T. Miyauchi H. Imazeki F. Matsubara H. Yokosuka O. Oncol. Rep. 2011;26:1329. doi: 10.3892/or.2011.1401. [DOI] [PubMed] [Google Scholar]
- Persson H. Kvist A. Rego N. Staaf J. Vallon-Christersson J. Luts L. Loman N. Jonsson G. Naya H. Hoglund M. Cancer Res. 2011;71:78–86. doi: 10.1158/0008-5472.CAN-10-1869. [DOI] [PubMed] [Google Scholar]
- Shou J. Gu S. Gu W. Exp. Ther. Med. 2015;9:167–171. doi: 10.3892/etm.2014.2041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cai C. Ashktorab H. Pang X. Zhao Y. Sha W. Liu Y. Gu X. PLoS One. 2012;7:e29750. doi: 10.1371/journal.pone.0029750. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang L. Tang X. Q. Bai Z. Dai X. Sci. Rep. 2016;6:35773. doi: 10.1038/srep35773. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Han Z. Chen F. Ge X. Tan J. Lei P. Zhang J. Brain Res. 2014;1582:12. doi: 10.1016/j.brainres.2014.07.045. [DOI] [PubMed] [Google Scholar]
- Montalban E. Mattugini N. Ciarapica R. Provenzano C. Savino M. Scagnoli F. Prosperini G. Carissimi C. Fulci V. Matrone C. NeuroMol. Med. 2014;16:415–430. doi: 10.1007/s12017-014-8292-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smigielska-Czepiel K. Van d. B. A. Jellema P. Slezak-Prochazka I. Maat H. Van d. B. H. Rj V. D. L. Kluiver J. Brouwer E. Boots A. M. PLoS One. 2013;8:e76217. doi: 10.1371/journal.pone.0076217. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Z. Zha Y. Hu W. Huang Z. Gao Z. Zang Y. Chen J. Dong L. Zhang J. J. Biol. Chem. 2013;288:37082. doi: 10.1074/jbc.M113.517953. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ding W. Xin J. Jiang L. Zhou Q. Wu T. Shi D. Lin B. Li L. Li J. Sci. Rep. 2015;5:13098. doi: 10.1038/srep13098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liao Q. Han P. Huang Y. Wu Z. Chen Q. Li S. Ye J. Wu X. PLoS One. 2015;10:e0130677. doi: 10.1371/journal.pone.0130677. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yao C. Yuan Q. Niu M. Fu H. Zhou F. Zhang W. Wang H. Wen L. Wu L. Li Z. Mol. Ther.--Nucleic Acids. 2017;9:182–194. doi: 10.1016/j.omtn.2017.09.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gutsaeva D. R. Thounaojam M. Rajpurohit S. Powell F. L. Martin P. M. Goei S. Duncan M. Bartoli M. Oncotarget. 2017;8:103568–103580. doi: 10.18632/oncotarget.21592. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Andrade H. Albuquerque M. Peluzzo T. Dogni D. Nucci A. Lopes-Cendes I. Franca Jr M. Avansini S. Neurology. 2015:84. doi: 10.1186/s12883-015-0340-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yin C. Zhou X. Dang Y. Jin Y. Zhang G. Medicine. 2015;94:e2123. doi: 10.1097/MD.0000000000002123. [DOI] [PMC free article] [PubMed] [Google Scholar]