

Abstract
In an equivalence trial, researchers aim to show that a new intervention is more or less similar to an existing standard of care, i.e., the two are “equivalent”. In this article, we discuss some aspects of the design, analysis, interpretation and reporting of equivalence trials.
Keywords: Research design, Research Methodology, Randomized Controlled Trials as Topic
In this article in this series, we look at a different type of clinical trial – the “equivalence” trial. Here, the researcher aims to show that an intervention is not too different from the comparator (neither better nor worse by more than a predefined margin). Equivalence has been defined “as a difference in performance of two interventions for which the patient will not detect any change in effect when replacing one drug by the other.”[1]
EXAMPLES OF EQUIVALENCE TRIALS IN THE PUBLISHED LITERATURE
McCann hypothesized that neurodevelopment at 5 years of age would be equivalent in children who received either general anesthesia or regional anesthesia for surgical procedures during their infancy.[2] Equivalence was defined as a difference of no more than 5 points on an intelligence quotient score.
Marzocchi compared tirofiban with abciximab for facilitated angioplasty in patients with ST-elevation myocardial infarction.[3] The primary hypothesis was that tirofiban would be equivalent to abciximab in achieving complete ST-segment resolution. The margin of clinical equivalence between the two drugs was fixed at 10% in the proportion of patients achieving complete ST-segment resolution.
Cunningham evaluated the equivalence of starting oxygen therapy in infants with bronchiolitis when oxygen saturation had reached below 90% versus doing so when it had reached below 94%.[4] The primary outcome for equivalence was time to resolution of cough, with limits of equivalence defined as ± 2 days.
Equivalence trials are used to show that two interventions are not unacceptably different and that one can be substituted for another with nearly similar efficacy while offering other advantages, for example, lower cost, reduced toxicity, or greater ease of administration.
HYPOTHESIS TESTING AND STATISTICAL ERRORS IN EQUIVALENCE TRIALS
In equivalence trials, we start with the null hypothesis that the difference between the experimental arm and the comparator arm will be greater than the predefined margin of equivalence (d). We use a two-sided approach, which means that we allow for either of the arms to be superior (and the difference between experimental and comparator arms to be greater than +d or −d). The alternate hypothesis is that the difference between the arms will be less than d (difference ranging between +d and −d). Figure 1 illustrates the null and the alternate hypothesis in an equivalence trial.
Figure 1.

Null and alternate hypotheses in an equivalence trial
The type 1 error in an equivalence trial is the risk of falsely rejecting the null hypothesis; this means that we accept equivalence when the treatments are, in fact, not equivalent. This is usually set at 5%, which means that we need to be 95% confident that the difference between the treatments does not exceed d in either direction. The type 2 error in an equivalence trial is the risk of falsely rejecting the alternate hypothesis; this means that we fail to detect equivalence where it exists.
THE CONFIDENCE INTERVAL APPROACH
We use the confidence interval (CI) approach to express the results of an equivalence study. To prove equivalence, the CI for the difference between the interventions must lie within the boundaries of − d to + d. The determination of CI may be done in one of two ways:[5]
The two one-sided test (TOST) approach uses TOSTs with a 5% significance level each (corresponding to a two-sided 90% CI)
One could use a single two-sided test with a 5% significance level (corresponding to a two-sided 95% CI).
Figure 2 shows various possible results for an equivalence study.
Figure 2.

Interpretation of results of an equivalence trial
CHOOSING THE MARGIN OF EQUIVALENCE
The margin of equivalence “d” is set as the largest difference that would still allow the two interventions to be considered “nearly” equivalent. It is to be noted that “equivalence does not mean 100% absolute equivalence but that despite some small difference (<d), the two interventions are clinically indistinguishable.”[6] Superiority trials differ from equivalence trials in that they aim to prove that an intervention is substantially different from an existing standard. This is in contrast to an equivalence trial where the aim is to show that there is no substantial difference between interventions. The margin of difference in a superiority trial is, therefore, chosen based on the least difference that would be considered clinically meaningful and is, therefore, often larger than the margin that would be chosen in an equivalence trial.
DIFFERENCE BETWEEN NONINFERIORITY AND EQUIVALENCE TRIALS
Noninferiority (NI) trials set out with the hypothesis that the experimental arm is slightly inferior to the comparator (by no more than the predefined margin of inferiority) but with some ancillary benefits. These trials use a one-sided approach for testing and do not investigate whether the experimental arm may be actually superior to the comparator.
In contrast, equivalence trials have the objective of showing that the experimental arm is no different, i.e. only slightly different (superior or inferior) to the comparator (by no more than the predefined margin of equivalence). These studies use a two-sided approach for testing.
CHOICE OF CONTROL IN EQUIVALENCE TRIALS
For both NI and equivalence trials, the choice of control is a crucial aspect of the validity of the study. Superiority trials establish the superiority of a new intervention over the comparator; therefore, they may use a placebo as a control (if there is no active standard of care). By contrast, equivalence and NI trials aim to prove that the new intervention is equivalent or noninferior to a comparator and are undertaken only where there is a well-defined standard of care for a particular condition. For such comparisons, it is essential that the control that is chosen is already proven to be superior to placebo under similar conditions. If the comparator has not been validated in a placebo-controlled study, then the results of the NI or equivalence study are uninterpretable since equivalence means that the new intervention may be just as good as a placebo.
NEGATIVE RESULTS IN SUPERIORITY TRIALS DO NOT IMPLY EQUIVALENCE
Let us take the hypothetical example of a randomized trial to compare two antiemetics, A and B, for the primary outcome of the proportion of participants having postoperative vomiting. Figure 3 shows two possible results of this study. In scenario 1, the difference between treatments is 10% with 95% CIs of 5% to 15%. This suggests that we are 95% confident that treatment A is superior to treatment B, with the treatment benefit ranging from at least 5% to as much as 15%. In scenario 2, the difference between treatments is 10%, with 95% CIs ranging from −5 to 25%; this would be interpreted as the true treatment effect ranging anywhere from a 5% detriment to 25% benefit. This would not be a statistically significant result since the CIs for the difference include zero, suggesting that there may be no difference between the interventions, and in fact, the possibility of treatment A being worse than treatment B cannot be ruled out. It would be incorrect to conclude that since A is not superior to B, the two treatments are equivalent since A could be (a) worse than B by 5% or (b) better than B by 25%. We have not predefined the margin that we would consider equivalent and, therefore, cannot assume that absence of evidence of superiority is evidence of equivalence.
Figure 3.
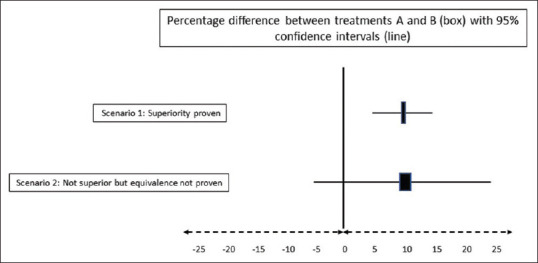
Negative results in superiority trials do not imply equivalence
SAMPLE SIZE FOR EQUIVALENCE TRIALS
Similar to comparative superiority trials, the sample size for an equivalence study depends on the margin of equivalence and the type 1 and 2 errors. Since the margin “d” is generally kept fairly small, the sample size for an equivalence study tends to be much larger than for a similar comparison in a superiority study.
ANALYSIS AND REPORTING OF RESULTS OF EQUIVALENCE STUDIES
Since intention-to-treat analysis tends to minimize differences between interventions (which could lead to an erroneous conclusion of equivalence), researchers should present the results of both the intention-to-treat and the per-protocol analysis of such trials.[7] The CONSORT statement for the reporting of clinical trials has an extension for the reporting of NI and equivalence trials.[8]
BIOEQUIVALENCE TRIALS
Bioequivalence studies are a special type of equivalence studies whose aim is to show that two drugs (often two formulations of the same drug) are comparable with respect to one or more pharmacokinetic properties, for example, peak or trough plasma levels, or plasma level at a specified time point. These parameters are important when one drug is to be substituted for another, as in the case of biosimilars. Bioequivalence studies, though similar in principle to equivalence studies, are usually carried out as cross-over studies and thus use statistical procedures for paired data.
Financial support and sponsorship
Nil.
Conflicts of interest
There are no conflicts of interest.
REFERENCES
- 1.Lesaffre E. Superiority, equivalence, and non-inferiority trials. Bull NYU Hosp Jt Dis. 2008;66:150–4. [PubMed] [Google Scholar]
- 2.McCann ME, de Graaff JC, Dorris L, Disma N, Withington D, Bell G, et al. Neurodevelopmental outcome at 5 years of age after general anaesthesia or awake-regional anaesthesia in infancy (GAS): An international, multicentre, randomised, controlled equivalence trial. Lancet. 2019;393:664–77. doi: 10.1016/S0140-6736(18)32485-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Marzocchi A, Manari A, Piovaccari G, Marrozzini C, Marra S, Magnavacchi P, et al. Randomized comparison between tirofiban and abciximab to promote complete ST-resolution in primary angioplasty: Results of the facilitated angioplasty with tirofiban or abciximab (FATA) in ST-elevation myocardial infarction trial. Eur Heart J. 2008;29:2972–80. doi: 10.1093/eurheartj/ehn467. [DOI] [PubMed] [Google Scholar]
- 4.Cunningham S, Rodriguez A, Adams T, Boyd KA, Butcher I, Enderby B, et al. Oxygen saturation targets in infants with bronchiolitis (BIDS): A double-blind, randomised, equivalence trial. Lancet. 2015;386:1041–8. doi: 10.1016/S0140-6736(15)00163-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Klasen M, Sopka S. Demonstrating equivalence and non-inferiority of medical education concepts. Med Educ. 2021;55:455–61. doi: 10.1111/medu.14420. [DOI] [PubMed] [Google Scholar]
- 6.Pater C. Equivalence and noninferiority trials – Are they viable alternatives for registration of new drugs.(III)? Curr Control Trials Cardiovasc Med. 2004;5:8. doi: 10.1186/1468-6708-5-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ranganathan P, Pramesh CS, Aggarwal R. Common pitfalls in statistical analysis: Intention-to-treat versus per-protocol analysis. Perspect Clin Res. 2016;7:144–6. doi: 10.4103/2229-3485.184823. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Piaggio G, Elbourne DR, Pocock SJ, Evans SJ, Altman DG CONSORT Group. Reporting of noninferiority and equivalence randomized trials: Extension of the CONSORT 2010 statement. JAMA. 2012;308:2594–604. doi: 10.1001/jama.2012.87802. [DOI] [PubMed] [Google Scholar]