

Abstract
Tuberculosis is a major global health challenge, with approximately 1.4 million deaths per year. There is still a need to develop novel treatments for patients infected with Mycobacterium tuberculosis (Mtb). There have been many large-scale phenotypic screens that have led to the identification of thousands of new compounds. Yet, there is very limited investment in TB drug discovery which points to the need for new methods to increase the efficiency of drug discovery against Mtb. We have used machine learning approaches to learn from the public Mtb data, resulting in many datasets and models with robust enrichment and hit rates leading to discovery of new active compounds. Recently we have curated predominantly small molecule Mtb data and developed new machine learning classification models with 18,886 molecules at different activity cut-offs. We now describe the further validation of these Bayesian models using a library of over 1000 molecules synthesized as part of the EU-funded New Medicines for TB and More Medicines for TB programs. We highlight molecular features which are enriched in these active compounds. In addition, we provide new regression and classification models which can be used for scoring compound libraries or used to design new molecules. We have also visualized these molecules in the context of known molecular targets and identified clusters in chemical property space which may aid in future target identification efforts. Finally, we are also making these datasets publicly available, representing a significant increase to the available Mtb inhibition data in the public domain.
Keywords: Assay Central, Deep Learning, Drug Discovery, Machine learning, Molecular features, Support Vector Machine, Tuberculosis
Graphical Abstract
INTRODUCTION
Tuberculosis (TB) represents a major world health challenge for which the search for new drug treatments continues. In 2019, the WHO annual TB report described ~1.4 million fatalities due to TB and 10.4 million new TB cases1. Drug-sensitive TB treatment has an 85% success rate; however, current TB treatments for multi-drug-resistant (MDR) Mycobacterium tuberculosis (Mtb) is a challenge as the available treatments suffer from lower efficacy, longer treatment duration, and debilitating side effects that range from liver toxicity, hearing loss, and psychosis2–4. Streptomycin was discovered in 1944 which is considered the ‘golden age’ of antibiotic drug discovery, which led to the TB drugs isoniazid and pyrazinamide (INH and PZA, 1952), ethambutol (EMB, 1961) and rifampicin (RIF, 1963), and remain the cornerstones of drug susceptible Mtb therapy today. There has been extensive research to develop molecules that overcome Mtb drug resistance while shortening the duration of TB therapy5–8. Relapse and treatment failure are observed with ca. 5% of drug susceptible cases9, 10 and in up to 50% of multidrug-resistant tuberculosis (MDR-TB) cases,11 despite prolonged treatment. Extended therapy and potentially limited access to therapy (requirement for daily injectable drugs and IV infusions) heightens the probability of partial non-compliance2, 4, which leads to both treatment failure and the emergence of new drug resistance12. Of major concern are reports of totally drug resistant (TDR) Mtb infections that are now resistant to all known drugs13, 14. Development of new treatments has been slow with only four new approved drugs in the last 40 years for TB (bedaquiline, delamanid, linezolid and pretomanid). However, these molecules are not widely used due to cost and concern regarding MDR-TB15, 16.
While the last 20 years have seen an increase in phenotypic and target-based screening for new drugs, these approaches have proven to be inefficient. Something must be done quickly to gain control of TB and provide any hope of achieving the WHO End TB goals of reducing TB deaths by 95% and cutting new cases by 90% between 2015 and 203517 especially as from 2015–2019 there was only a 9% reduction in TB incidence and 14% reduction in deaths1. Due to the global COVID-19 pandemic it is likely that the incidence of TB and associated deaths will increase18–20. To achieve these ambitious goals, shorter and simpler treatments are needed for both drug susceptible and resistant TB. There is therefore a dire need to develop and apply alternative approaches to Mtb drug discovery.
With a lack of funding for future research21 there is a need for enhancing the efficiency of TB drug discovery efforts. A faster path to new TB treatments may be to revisit and optimize preexisting drugs22. This could take the form of rescuing activity on drug resistant TB or improving activity or drug delivery/distribution to shorten treatment times, prevent reoccurrence and improve compliance to halt further drug resistance. Gopal and Dick23 proposed to go back to old TB drugs that are more like fragments (low molecular weight ~200–250 Da, e.g. INH (137.14 Da) and PZA (123.11 Da) or even smaller)23. There is increasing interest in drug repurposing, taking drugs that are already approved for another use and applying them for additional diseases24. This can be facilitated using high-throughput screening of libraries of approved drugs from the FDA or other regulatory agencies, computational or virtual screening using docking or pharmacophores, machine learning or combinations of methods, knowledge-based methods, gene-expression data or serendipity24–29. These various computational or experimental approaches are particularly important for addressing neglected and rare diseases where funding for drug discovery21 may be negligible or even non-existent or where an already approved drug would shorten the path to the clinic or shorten the treatment regimen.
There are 3 barriers to drug delivery including penetration of the granuloma, macrophage and Mtb cell wall30. For example, recent observations suggest that first line drugs may have much lower concentrations inside the granuloma than in the blood31–33. Ideally the most desirable TB drug properties include the inhibition of a druggable target, synergistic with other therapies, and a rapidly sterilizing action. A new TB drug should also ideally be cidal to clinical drug-sensitive as well as drug-resistant strains currently circulating. This may be achieved by potently inhibiting an essential gene product not modulated by currently approved TB therapies. To date the phenotypic screens providing whole-cell efficacy of molecules has been a primary driver in drug discovery efforts, but this does not provide information on primary target nor molecular interactions of the small molecule and the protein involved. Many years of drug development have uncovered several bacterial processes that contain excellent new targets for antibacterials34–37. These pathways include cell wall biosynthesis which may be important for Mtb. Drugs that can function by reducing the treatment duration for both drug susceptible and MDR-TB would also have high impact on the field. Antitubercular agents are therefore needed which demonstrate cidality in vitro and in vivo to reduce the bacterial infection. Drugs and combinations that are rapidly sterilizing in vivo would also be highly desirable and are more likely to lead to shortened therapy. Subsequently, the bacterial cell wall has been one of the most successful targets for Mtb drug discovery with molecules such as isoniazid (INH), ethambutol, and ethionamide. INH is a front-line TB therapy which is cidal in vitro and in vivo inhibiting the enoyl-acyl carrier protein reductase (inhA)36, 38 within the FAS-II system39. INH demonstrates biphasic kill kinetics in vitro, with resistance and persistence developing within a week of exposure which decreases cidality but this may be overcome by use of drugs that are synergistic with it. As mycolic acids are structural elements of the cell wall and essential for Mtb in vivo pathogenesis40–42 the type I fatty acid synthase (FAS-I) and FAS-II systems represent important targets42. Two different fatty acid biosynthetic steps have previously been described representing additional targets, namely Pks1343 and KasA44–46. Molecules that could potentiate the activity of INH as well as eradicate INH-induced persisters, may provide some substantial benefit for the treatment of TB patients.
For over a decade, we have focused our research on using machine learning models for in vitro Mtb datasets, initially using Bayesian approaches47, which we have also used widely for modeling ADME/Tox properties48, 49. We have modeled large Mtb high throughput screening (HTS) datasets that were made available by SRI/NIAID50, 51, as well as smaller datasets from Novartis52. Such Bayesian models were initially used to predict and rank molecules identified with pharmacophore methods before testing in vitro53, leading directly to subsequent prospective tests of models built with in vitro data. The first such study used Bayesian models to identify five active molecules out of just 7 tested54. A second study tested 550 molecules in vitro, identifying 124 actives55. A final study found 11 actives out of 48 compounds tested56. We also performed a retrospective validation with 1,924 molecules as a test and showed enrichments greater than ten-fold57. We also explored combining Mtb data sets followed by testing the machine learning models on data from other groups58, 59, which pointed to the need for multiple Mtb models as well as proposing important molecular features for actives59. These molecular features have in turn been utilized to create new β-lactam antibacterials60. Our use of machine learning for Mtb has also expanded to models for multiple targets61, 62 such as ThyX27 and Topoisomerase I63. We have also developed machine learning models using mouse models of Mtb infection64 where there is data built up over 70 years. This allowed us to collate nearly 800 molecules64 which we have also extended with additional data65. More recently we have described using multiple machine learning approaches with 18,886 molecules (with activity cut-offs of 10 μM, 1 μM and 100 nM)66. These models were both internally and externally validated. The Bayesian model at the 100 nM activity cut-off yielded promising metrics for 5-fold cross validation (Accuracy = 0.88, Precision = 0.22, Recall = 0.91, Specificity = 0.88, Kappa = 0.31, and MCC = 0.41) which resulted in comparable statistics for an external evaluation set (n = 153 compounds). We also compared these models with multiple machine learning algorithms demonstrating Bayesian models were equivalent to or outperformed other machine learning methods with external test sets. In recent years several diverse classes of antitubercular compounds have been identified with activity in vitro or in vivo as summarized by our recent analyses of over 100 active leads. We illustrated that researchers are repeatedly identifying compounds that are similar to molecules that have previously been described67. This led us to suggest that the field needs to dramatically increase the diversity of chemical libraries tested in order to explore beyond the historic Mtb property space. Machine learning approaches may represent one way to do this.
We have recently participated in the EU funded public-private consortia New Medicines for Tuberculosis (NM4TB) and More Medicines for Tuberculosis (MM4TB) which ran from 2005–201668, 69. In the process of this work > 1000 molecules were synthesized and tested and some of these molecules were described in earlier publications70–95. We have now curated this data and used it as a test set for our machine learning models as well as a unique training set for regression model building and for prediction of the potential targets for these compounds. In the course of this work, we are now making this data publicly available.
EXPERIMENTAL SECTION
Computing
All computing was done on three servers: (1) 2x Intel(R) Xeon(R) CPU E5–2620 v4, 64GB DDR4, 2x GeForce GTX 1080 Ti, (2) 2x Intel(R) Xeon(R) CPU E5–2630 v4, 128GB DDR4, 4x GeForce GTX 1080 Ti, (3) 2x Intel(R) Xeon(R) CPU E5–2630 v4, 128GB DDR4, 4x GeForce GTX 1080 Ti. Each server is running CentOS 7 with recent updates. Docker Engine Community v19.03.8 was installed on all three servers and was used to host all parts of the application. MongoDB 4.2.5 cluster is used to support all persistent operations. RabbitMQ 3.8.3 cluster is used to orchestrate asynchronous fail-safe long-running operations. Anaconda 4.8.3 with Python 3.7.6 was used to create the following environment: connexion, html2text, matplotlib, numpy, pandas, rdkit, scikit-learn, mongoengine, jinja2, pika, xgboost=1.3.3, docker-py, XlsxWriter, seaborn, gevent, epam.indigo, flask-cors, tf-nightly-gpu.
Data Curation
Our proprietary software “E-Clean” was used to “clean” and average activities for datasets prior to model building in Assay Central. “E-Clean” handles duplicate compounds by either averaging, removing, or keeping duplicates based on InChIKey. For these data, duplicate molecules with continuous activity data were first converted to -logM and then were averaged. “E-Clean” logs the SMILES strings of the duplicate compounds along with their activities and indices for inspection by the user. If needed, compounds are also subjected to charge neutralization, salt removal, and standardization via custom software using open-source RDkit functions.
The standardization within Assay Central was done as follows: A simple standardization workflow consisting of the following steps and using the Indigo Toolkit96 is applied: read molecule from the string representation (e.g. SMILES or MOL), generate InChI and InChIKey, use InChIKey to find and remove duplicates, dearomatize, remove enhanced stereo, remove unknown stereo, standardize and reposition, if necessary, stereo bonds (e.g., wedged bonds), standardize or flag erroneous charges, flag erroneous valences, remove isotopes, remove dative and hydrogen bonds, remove smaller component if multicomponent chemical, flag multicomponent chemicals, neutralize. All chemicals which are duplicates or flagged with errors (e.g. erroneous valences or charges) are then excluded from the result, but all erroneous or duplicate records are included into a Protocol associated with a given Dataset and available for review in the user interface.
The literature Mtb data was compiled from four distinct sources described previously66. A dataset that had not previously been used for machine learning, referred to as the “RCB” dataset, consisted of 1193 unique compounds. These compounds were synthesized during the last 12 years as part of the antituberculosis consortiums NM4TB and MM4TB. About 15 % of these compounds are related to Macozinone which was one of the main achievements of these two consortiums. Antituberculosis testing of these compounds with MIC99 determination was made under the same conditions by standard resazurin assay97 therefore they can be compared with each other. The synthesis and activity against Mtb for many of these compounds has been previously published70–95. The activity data were both in MIC and MIC99 values, which were defined as equivalent based on the criteria for Mtb activity from our previous published work. An additional step was used to quantify activity values that were ill defined (i.e. did not have an equal qualifier). Activity values that were reported as “<” were given a value of 0.5x the lowest non-ambiguous value and those that were “>” were assigned a value of 2x the highest defined value, but this was only used for classification models. For the continuous models all values that were “>” were removed from dataset for purposes of model building or when used as a test set for a regression model. In addition, there were 21 compounds from the RCB set that were in the previously published training set (classification). There were also 9 compounds that overlapped with the training set for the large regression Mtb model, which were removed from the test set to reduce bias.
Model Building with Assay Central (Legacy version)
We previously described how we generated Bayesian machine learning models with the literature Mtb data66. Three different TB Bayesian models of 18,886 molecules with cutoffs at 100 nM, 1 μM or 10 μM models were used from our Assay Central (AC) legacy software. Each model was previously internally validated by a five-fold cross-validation, where 20% of the dataset is left out and used as a test set five times and Receiver operator characteristic (ROC) plots were generated along with other model statistics66. These previously published models were used to score the RCB external test set for comparative purposes.
Model Building with Assay Central
Our updated proprietary Assay Central (AC) software uses multiple algorithms that are integrated in our web-based software to build classification models as described previously66 along with the addition of four new algorithms: linear regression, graph convolutional network (GCN), and end-to-end Convolutional Long-Short Term Memory Neural network (ConvLSTM-net), and XGboost. Furthermore, we have implemented multiple regression algorithms for model building of continuous data which include adaboost regression, Bayesian regression, elastic net regression, knn regression, random forest regression, support vector machine regression and XGboost regression. We removed 20% of the training set, in a stratified manner for the classification models, and these were used as external test sets for models trained on the remainder of the data. The same method was also used for the continuous data model validation.
Compounds and in vitro testing
The majority of compounds have been previously published70–95. The determination of minimum inhibitory concentration (MIC) against M. tuberculosis strain H37Rv and M. smegmatis was determined by the resazurin reduction assay methods which have been described previously97.
Model Validation (General)
Machine learning model validation was performed in several ways: a 20% leave out set, 5-fold cross validation and with external test sets. For the “20% leave out (LO)” classification model validation a random, stratified 20% is removed from the training set prior to model building. The model is then built with the remaining 80% of the training data and the hyperparameters (if applicable) are optimized using a grid search using five-fold dataset splits. Using the optimized hyperparameters a final model is built, which is then used to predict the activity of the LO set as an external test set. 5-fold cross validation is done using the Legacy software and since Bayesian does not use hyperparameters these cross-validation statistics are not biased. The validation statistics are generated for each of the 20% holdout sets and are then averaged together. These differences are visualized in Figure S1. External test sets are independent of the training data and are true external evaluations of the models. For regression model validation the data is split randomly and is chosen independent of actual activity.
Model Validation (Comparison)
For a direct comparison of our legacy and updated AC software we built Mtb inhibition models using the same training data as was previously published (18,886 molecules) at various thresholds (100nM, 1μm, 10μM). Due to a slightly different automated compound cleanup process our latest machine learning models built in the updated AC software included 18,738 compounds. Both the original test set (258 compounds)66 and RCB dataset (1196 compounds) were used as external test sets for these models.
Descriptors.
FCFP and ECFP fingerprints as generated by RDKit (http://www.rdkit.org/) are used with the options of specifying the radius of 2–4 (which corresponds to [EF]CFP4–8) and bits 512, 1024 and 2048. The particular type of the fingerprints is chosen before running the model training from the UI with an option to specify a combination of fingerprints. For the GCN, molecules were first translated into a graph G(V,E), with each atom comprising a node in V and each molecular bond comprising an edge in E. Each node was featurized with the default canonical features described in the DGL-LifeSci98, documentation, including Atom type, valence states, hybridization, chirality, whether the atom is in a ring, etc. For the ConvLSTM-net input, molecules are represented as tokenized SMILES strings. Briefly, each SMILES is tokenized, and each character is represented in a vocabulary (e.g. “c” [nH]”, “1”, =”). Each token in the vocabulary has a corresponding numerical representation (e.g., all “c” are represented by 1, all “=” are represented by the number 2, etc). SMILES are encoded by their integer vocabulary representation and padded to the longest sequence length with zeroes which were masked during training.
Machine learning.
The methods utilized have been previously published by our group in most cases66 and further details are described in the Supplemental Methods.
t-SNE visualization
t-SNE99 embeds data into a lower-dimensional space. 1024-bit ECFP6 fingerprints were generated for all compounds. The ECFP6 fingerprints were then embedded into a 2-dimensional vector using t-SNE. All t-SNE values were generated using the scikit-learn library in python with default hyperparameters (n_components = 2, perplexity = 30, early exaggeration = 12.0, learning rate = 200, n_iter = 1000).
Statistical analysis
In this study, several traditional measurements of model performance were used as described previously66 and further details are provided in the Supplemental Methods.
Rank Normalized Score and ΔRNS
External test set validation metrics between algorithms for 3 datasets (100 nM, 1 μM and 10 μM) were compared with a rank normalized score, which was also used in previous investigations100 101, 102 of various machine learning methods. Rank normalized scores can be evaluated in either a pairwise or independent fashion: the former is informative for a comparison of algorithms per training set, while the latter provides a more generalized comparison of algorithms overall. Additionally, a “difference from the top” (ΔRNS) metric, where the rank normalized score for each algorithm is subtracted from the highest corresponding score of a specific dataset102. This metric maintains the pairwise comparison results and enables a direct assessment of the performance of multiple machine learning algorithms. Statistical analyses were performed in Graphpad Prism 9.2.0.
Atomic Contribution to Model Prediction Similarity Maps
Coloring of atomic contributions to model predictions was performed using RDkit as previously described103. Briefly, model prediction scores were calculated for each molecule using ECFP6 fingerprints. We used a random forest model (described in methods above) to make model predictions. A weight is determined for each atom in the molecules by removing the circular fingerprint bits associated with the atom (each bit in an ECFP fingerprint has an associated set of atoms which can be determined in RDkit) followed by making a prediction on the molecule with the removed associated bits. The difference in prediction score probabilities between the original molecule fingerprint and the removed fingerprint bits is the atomic weight for each atom. The atomic weights are normalized by dividing all weights by the maximum absolute weight. Bivariate gaussian distributions are then fit over each atom, with the atomic weight corresponding to the peak of each atom gaussian (the variance remains the same among all atoms). This similarity map is then superimposed on an image of the molecule, with green indicating positive atomic contributions to prediction score (i.e., when bits containing the presence of the atom is removed, the prediction scores decrease) and red indicating negative atomic contributions to prediction scores. White or non-gaussians represent atoms which contribute little-to-none to the prediction of the models.
RESULTS
Analysis of RCB data
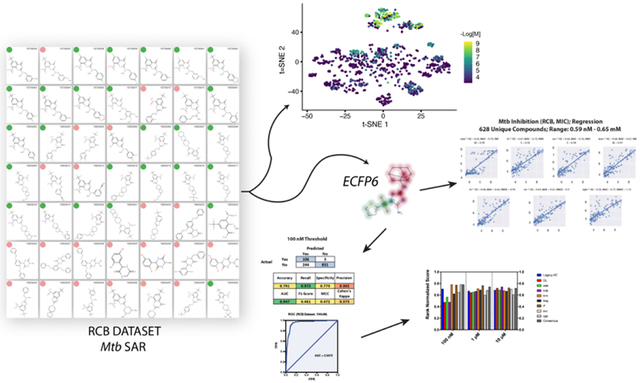
We calculated and analyzed the active (≤100nM) and inactive molecules from the RCB dataset as separate groups using simple molecular descriptors from Chemaxon software (Budapest, Hungary) to discern significant differences between these groups. The molecular descriptors used to describe each dataset were molecular weight, AlogP, molecular fraction polar surface area, logD (pH 7.4) as well as the number of aromatic rings, hydrogen bond acceptor and donor, rings and rotatable bonds. Normality tests were done for each group and all but the LogD active group failed the normality tests (Prism 9.2) therefore the median was used to represent these data and all follow-up comparison tests assumed non-parametric data distributions (Mann Whitney and Kolmogorov-Smirnov tests). Surprisingly, all characteristics examined except for the distribution of aromatic rings were statistically distinct between the active and inactive groups (Figure 1). The three most notable differences were in the molecular weight (Median active, 451.9; inactive, 319.3) and number of hydrogen bond acceptors (active, 6; inactive, 4) and donors (active, 0; inactive, 1). The distribution of the hydrogen bond donors was particularly different, where ~90% of the active (<100nM) compounds had none. The active compounds have a higher median AlogP and logD (pH 7.4) suggesting that on average these compounds are more hydrophobic, a trend that we had previously underscored66, 104, 105.
Figure 1.
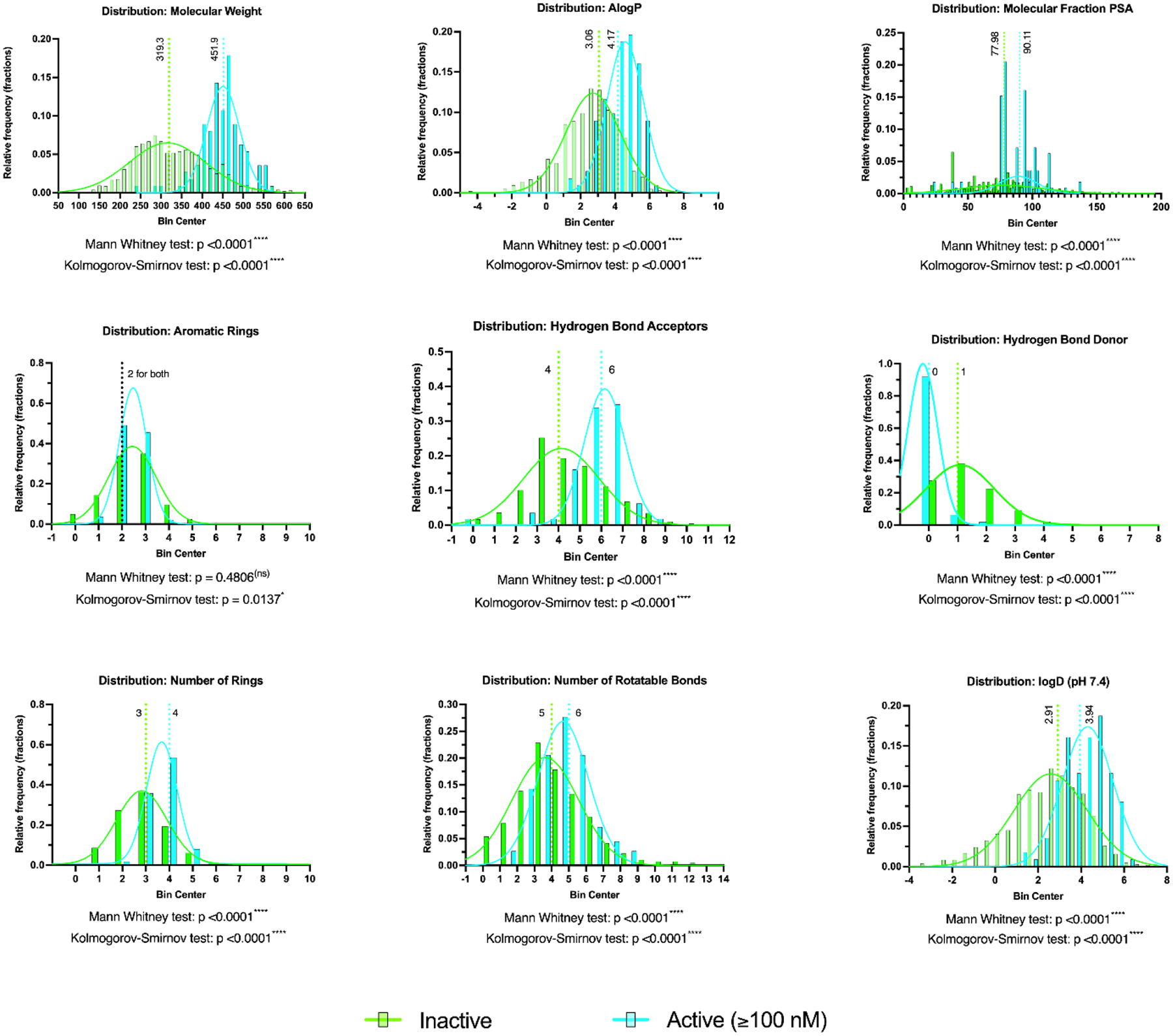
Comparison of the distribution of molecular properties for ~1200 unique compounds in the RCB dataset split into active (≤100nM; 112 compounds) and inactive (1081 compounds) groups. Median values are highlighted along with statistical analyses. Noted, is that gaussians are meant to visually highlight each group and are not meant to imply a normal distribution.
Internal Validation for the models built with RCB data
For comparison with our previously published work on Mtb66, the RCB dataset was binarized and analyzed using the same thresholds for the previously generated classification models (100nM, 1μM and 10μM). The total number of unique compounds for the RCB dataset is 1193 with the number of actives for the 100nM, 1μM and 10μM datasets of 112, 190 and 309, respectively (Figure S1). All the classification models had excellent validation statistics for the 20% leave-out set, with average cross validation ROC AUC values (across 8 algorithms) of 0.91–0.97 and an average F1 score range of 0.73–0.78 (Table 1).
Table 1.
Validation statistics of a 20% leave-out set for RCB Mtb models at various activity thresholds.
| AUC | F1-Score | Precision | Recall | Accuracy | Specificity | Cohen’s Kappa | MCC | |
|---|---|---|---|---|---|---|---|---|
| DL | 0.987 | 0.737 | 0.875 | 0.636 | 0.958 | 0.991 | 0.715 | 0.725 |
| ADA | 0.972 | 0.700 | 0.778 | 0.636 | 0.950 | 0.982 | 0.673 | 0.677 |
| BNB | 0.963 | 0.816 | 0.741 | 0.909 | 0.962 | 0.968 | 0.796 | 0.801 |
| KNN | 0.938 | 0.744 | 0.762 | 0.727 | 0.954 | 0.977 | 0.719 | 0.719 |
| LREG | 0.990 | 0.837 | 0.857 | 0.818 | 0.971 | 0.986 | 0.821 | 0.821 |
| RF | 0.977 | 0.792 | 0.677 | 0.955 | 0.954 | 0.954 | 0.767 | 0.782 |
| SVC | 0.990 | 0.809 | 0.760 | 0.864 | 0.962 | 0.972 | 0.788 | 0.790 |
| XGB | 0.980 | 0.791 | 0.810 | 0.773 | 0.962 | 0.982 | 0.770 | 0.770 |
| AUC | F1-Score | Precision | Recall | Accuracy | Specificity | Cohen’s Kappa | MCC | |
| DL | 0.966 | 0.769 | 0.750 | 0.789 | 0.925 | 0.950 | 0.724 | 0.725 |
| ADA | 0.958 | 0.746 | 0.862 | 0.658 | 0.929 | 0.980 | 0.706 | 0.714 |
| BNB | 0.949 | 0.750 | 0.714 | 0.789 | 0.916 | 0.940 | 0.700 | 0.701 |
| KNN | 0.954 | 0.762 | 0.696 | 0.842 | 0.916 | 0.930 | 0.712 | 0.716 |
| LREG | 0.963 | 0.775 | 0.738 | 0.816 | 0.925 | 0.945 | 0.730 | 0.731 |
| RF | 0.972 | 0.821 | 0.800 | 0.842 | 0.941 | 0.960 | 0.786 | 0.786 |
| SVC | 0.969 | 0.829 | 0.773 | 0.895 | 0.941 | 0.950 | 0.794 | 0.797 |
| XGB | 0.952 | 0.722 | 0.765 | 0.684 | 0.916 | 0.960 | 0.673 | 0.675 |
| AUC | F1-Score | Precision | Recall | Accuracy | Specificity | Cohen’s Kappa | MCC | |
| DL | 0.920 | 0.735 | 0.782 | 0.694 | 0.870 | 0.932 | 0.650 | 0.652 |
| ADA | 0.868 | 0.615 | 0.762 | 0.516 | 0.833 | 0.944 | 0.513 | 0.529 |
| BNB | 0.901 | 0.699 | 0.705 | 0.694 | 0.845 | 0.898 | 0.595 | 0.595 |
| KNN | 0.918 | 0.774 | 0.707 | 0.855 | 0.870 | 0.876 | 0.684 | 0.690 |
| LREG | 0.919 | 0.729 | 0.768 | 0.694 | 0.866 | 0.927 | 0.640 | 0.642 |
| RF | 0.928 | 0.762 | 0.750 | 0.774 | 0.874 | 0.910 | 0.677 | 0.677 |
| SVC | 0.925 | 0.758 | 0.758 | 0.758 | 0.874 | 0.915 | 0.673 | 0.673 |
| XGB | 0.920 | 0.740 | 0.723 | 0.758 | 0.862 | 0.898 | 0.646 | 0.647 |
RCB Test set analysis using existing classification models
Since we have added additional algorithms to our updated software, we have also rebuilt the classification models from our previous 2018 publication66 using the same previously manually curated datasets. One purpose of this was to analyze the predictive power of these models using both cross and external validation and to do a head-to-head comparison to our legacy AC software.
To compare between our legacy (Bayesian only) and updated software (8 classification algorithms and a consensus model for external testing only) we first compared the cross-validation statistics. It should be noted that the cross-validation comparison has a caveat, with the legacy software scores being averages from 5-fold cross validations and the updated software is assessing a single 20% leave-out set only to avoid bias due to data leakage with algorithms that use hyperparameters (Figure S2). The average validation scores for the 20% leave-out set were very good at each threshold with AUC of 0.77 – 0.92 and F1 scores having a range of 0.41 – 0.61 (Figure S3). The best individual machine learning algorithms for the leave-out set, based on their rank normalized scores100, were XGboost for 100 nM and svc for both the 1 μM and 10 μM thresholds (Figure 2A–B). This analysis is expanded for each algorithm by metric (Figure S4).
Figure 2.
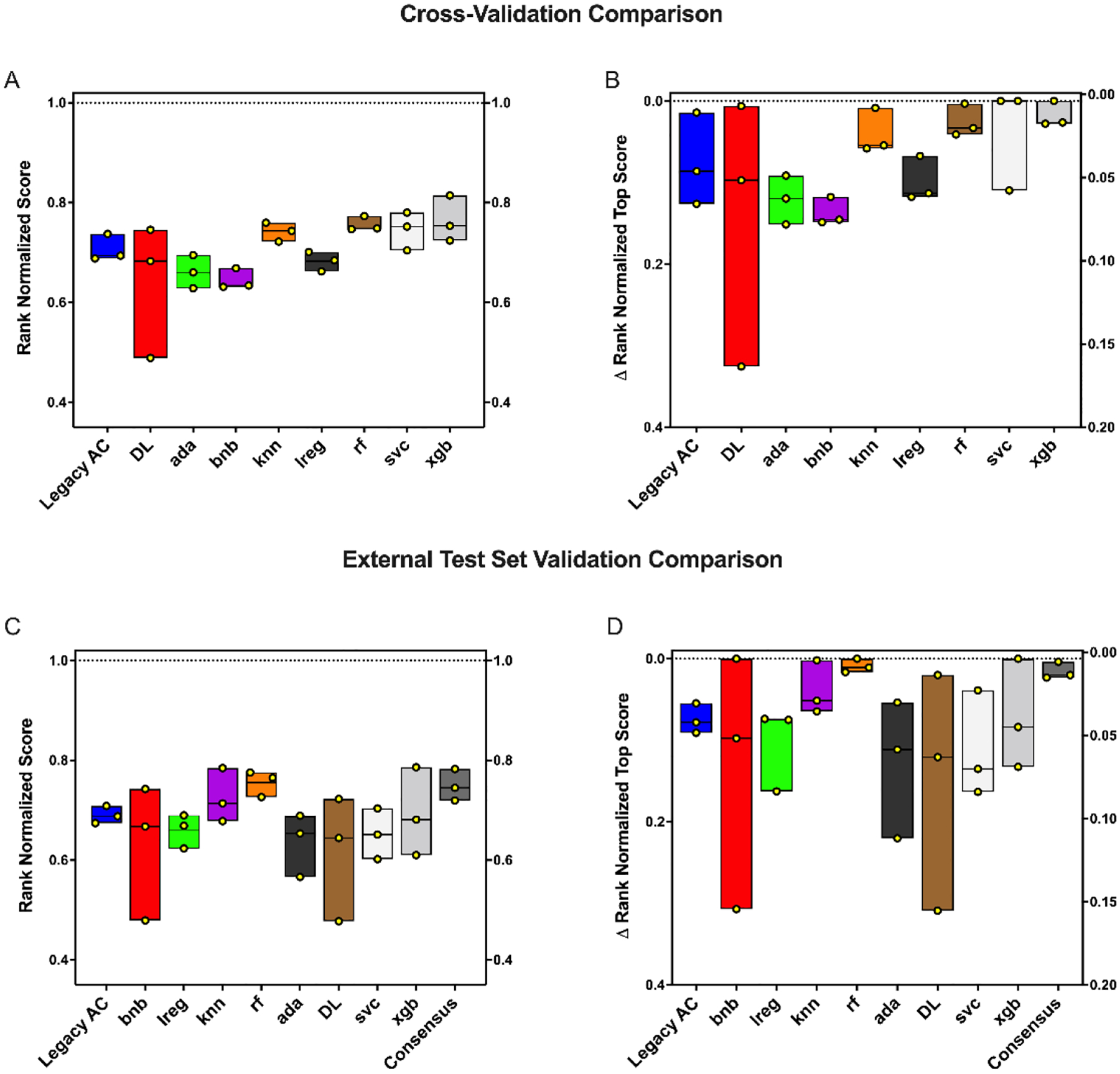
Mtb machine learning algorithm comparisons for an internal leave-out (A-B) and external test set (RCB) set (C-D) at three thresholds (100 nM, 1 μM and 10 μM) based on the rank normalized scores. Rank normalized score (A, C) and ΔRNS (B,D) distributions. Each floating bar represents the entire range of the scores and individual points are shown in yellow. The solid central line represents the median. Legacy AC = Legacy Assay Central (Bayesian), rf = Random Forest, knn = k-Nearest Neighbors, svc = Support Vector Classification, bnb = Naïve Bayesian, ada = AdaBoosted Decision Trees, DL = Deep Learning, xgb = xgboost, lreg = linear regression.
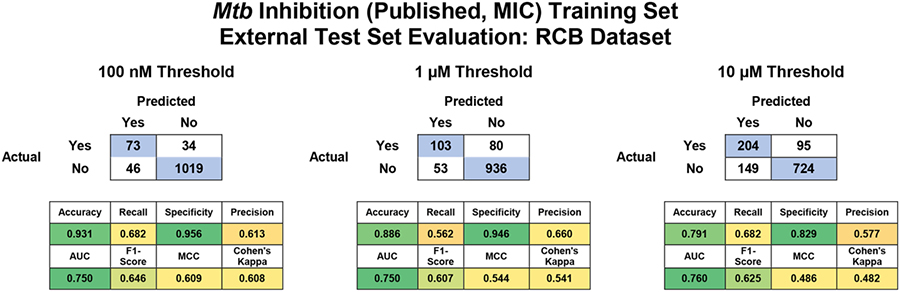
In addition to cross-validation analysis we also used the Bayesian models built with the published datasets66 to score the RCB dataset as an external test set. The external test set was very well predicted with a consensus AUC range of 0.75 – 0.76 and an average F1 score of 0.61 – 0.65 (Table 2). Accuracy was particularly high with the 100 nM and 1 μM thresholds where the average accuracy was 0.93 and 0.89, respectively (Table 2). The best individual ML algorithms for this external test set, based on their rank normalized scores100, were XGboost, random forest and naïve Bayesian for the 100 nM, 1 μM and 10 μM thresholds, respectively (Figure 2C–D). These differences were not statistically different from each other, but this is likely due to the small sample size. This analysis is expanded for each algorithm by metric in (Figure S5).
Table 2.
External test set statistics using the RCB dataset with Mtb Bayesian classification models built with a previously published dataset66 at various thresholds.
|
The validation statistics for the individual models are broken down further in Table 3C. For the updated software the scores for the consensus model are highlighted, but the individual statistics are also shown. Both models were able to predict these new data similarly, with a tendency to have a higher accuracy/specificity but a lower recall between the legacy and updated software, respectively (Table 3). Across all these models there was an increase to metrics developed to account for imbalanced dataset (F1 score, MCC and Cohen’s kappa) suggesting these have higher predictive power.
Table 3.
Head-to-head comparison of legacy and updated Assay Central using the RCB Mtb dataset as an external test set. (A) Validation statistics for Legacy Assay Central, (B) Assay Central consensus models and (C) full statistical breakdown by ML algorithm.

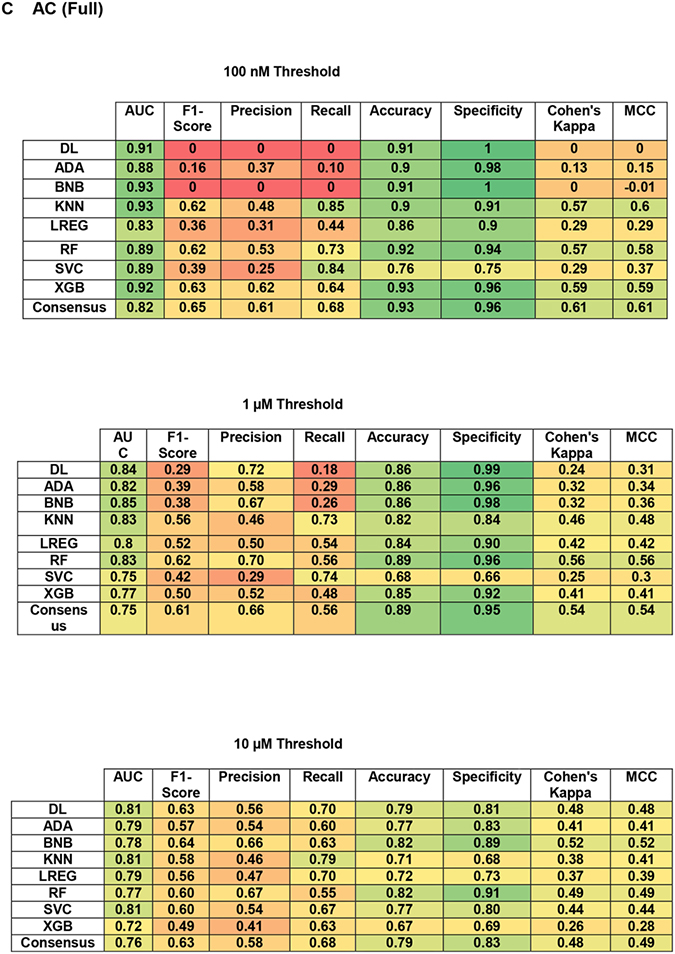
|
RCB Test set analysis using GCN and ConvLSTM net
In addition, we have also built a GCN model and a ConvLSTM neural network model to compare against the classical models described above. Our goal was to compare these newer algorithms to determine if they were significantly better or worse than the classical algorithms (Table S1). Our results suggest that the GCN is competitive with the classic machine learning algorithms at the 100nM cutoff and in the case of the 1 μM and 10 μM is one of the top-performing models. At the 1 μM threshold, the GCN displays the highest MCC and Cohen’s Kappa, while at the 10 μM threshold it maintains the highest AUC, albeit having a tied or slightly lower MCC and Cohen’s Kappa compared to the top classical models (BNB, RF, and DL).
ConvLSTM-net shows a significant improvement over DL at the 1 μM and 100nM threshold, showing a significant boost in the MCC, Cohen’s Kappa, and F1-scores, while lagging behind the DL model at the 10 μM threshold. This suggests that different architectures may excel under different scenarios, however ConvLSTM-net may serve as a better architecture over DL with ECFP6 fingerprints for investigating structure activity relationships, at least in the case of building models for Mtb inhibition with 2/3 threshold performing significantly better than DL. However, ConvLSTM-net did not improve significantly over most of the existing classical algorithms, which may be related to the challenge of hyperparameter optimization or end-to-end learning.
Regression models and test set
We have also built regression models for both the RCB data and for the previously published Mtb inhibition datasets66. We used a 20% leave out set to emulate an external test set for model internal validation for the Mtb inhibition models. In the case of the previously published Mtb dataset, we also used the RCB dataset as an external test set to access its predictive ability. Only compounds that had an actual MIC were used to train or test these model (i.e. we removed those with > a value).
The internal validation statistics for the RCB data continuous model were favorable, with svr (MAE, RMSE and R2 of 0.67, 0.90 and 0.69, respectively) and rfr (MAE, RMSE and R2 of 0.65, 0.92 and 0.68, respectively) performing the best for the 20% leave-out set, though all algorithms tested performed well except for adar (Table 4, Figure S6).
Table 4.
Cross validation statistics for the regression models built with the RCB Mtb inhibition data. Note that all compounds that did not have an exact MIC (i.e. > 100μg/ml) were removed from the regression training set. Regression model statistics are calculated with -logM units.
| Method | MAE | RMSE | R2 |
|---|---|---|---|
| adar | 0.79 | 0.99 | 0.62 |
| br | 0.73 | 0.92 | 0.67 |
| enr | 0.76 | 0.94 | 0.66 |
| knnr | 0.67 | 0.91 | 0.68 |
| rfr | 0.65 | 0.92 | 0.68 |
| svr | 0.67 | 0.9 | 0.69 |
| xgbr | 0.77 | 1.12 | 0.52 |
The regression model built with the previously published data (Table 5 and Figure S7) was chemically diverse and after all duplicates and ambiguous molecules were removed the training set included 15,618 unique molecules and had an activity span of 0.1 nM – 15.85 mM. The svr algorithm performed better with the 20% holdout set than the other tested algorithms with an MAE = 0.42 and RMSE = 0.56 (Table 5). Using an average prediction score, the model predicted the previously published test set well with and MAE and RMSE of 0.53 and 0.67, respectively (Figure 3A). The model performed similarly with the RCB dataset with R2, MAE and RMSE of 0.46, 1.00 and 1.21, respectively (Figure 3B). While svr performed better than average, it was a small variation, with MAE and RMSE of 0.98 and 1.20, respectively.
Table 5.
Regression model validation statistics for the previously published Mtb data. This was done by internal validation of a 20% leave-out set.
| Method | MAE | RMSE | R2 |
|---|---|---|---|
| adar | 0.61 | 0.78 | 0.11 |
| br | 0.53 | 0.68 | 0.3 |
| enr | 0.54 | 0.7 | 0.28 |
| knnr | 0.45 | 0.6 | 0.46 |
| rfr | 0.46 | 0.6 | 0.47 |
| svr | 0.42 | 0.56 | 0.54 |
| xgbr | 0.5 | 0.67 | 0.34 |
Figure 3.
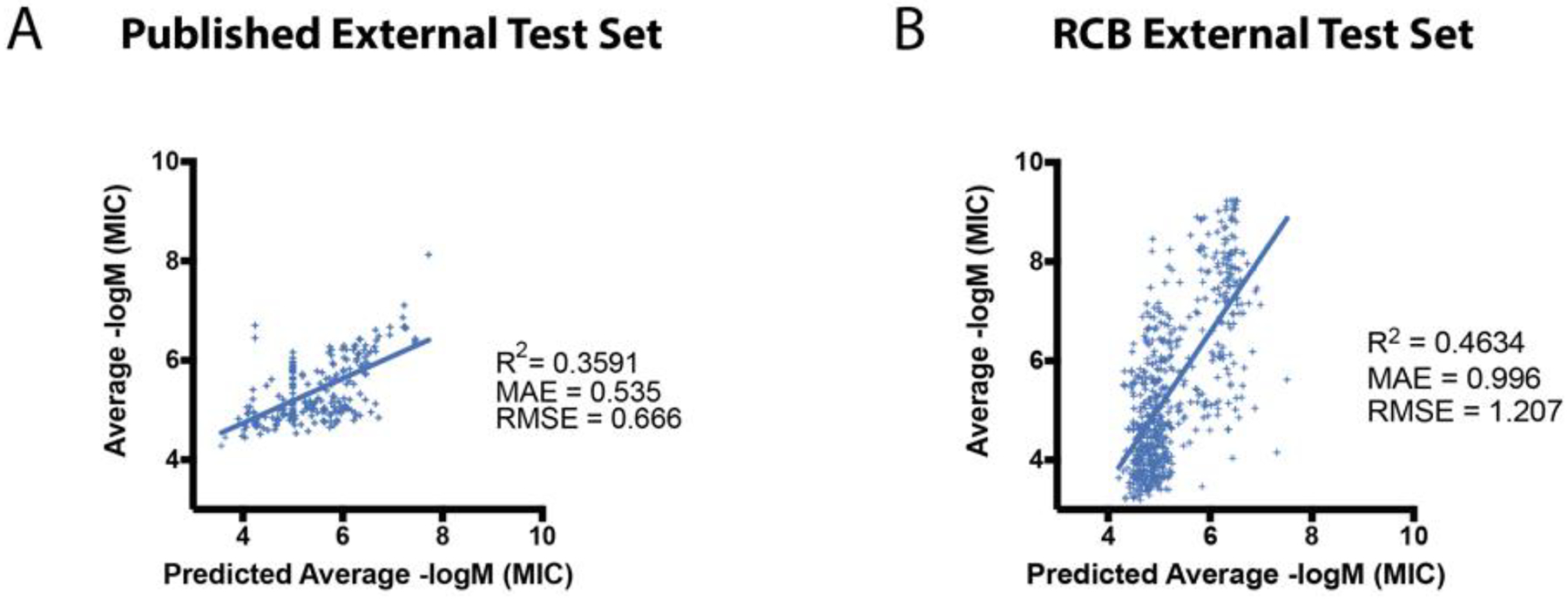
Regression model validation using the RCB Mtb dataset and published test set as external test sets for the 15,618 compound Mtb regression model.
t-SNE Plot for Model Property Space Analysis
t-SNE plots were used to visualize the difference in the chemical space explored between the RCB dataset and our previously published Mtb dataset66. As both datasets are large and have some overlap, we also took additional steps to help to differentiate these libraries based on their activity. We visualized only the active compounds at the same thresholds used for the classification models: 100 nM, 1 μM and 10 μM. The t-SNE plot coordinates were not recalculated for each activity threshold, but the inactive compounds were filtered visually. As the activity thresholds became more stringent the separation between the two libraries became more apparent (Figure 4). Two example groupings highlighted by the t-SNE plot at 1 μM are a series of novel likely DprE1 inhibitors (Figure 4C–D) and the likely cell-wall synthesis inhibitors (nitroimidazoles), showing the ability of these plots to partition compounds by classes. In addition, we also generated t-SNE plots for the RCB dataset alone to assess if compound class separation was also apparent using a smaller dataset. As shown in Figure S8, the DprE1 inhibitors are still distinct from the other compounds in this dataset.
Figure 4.
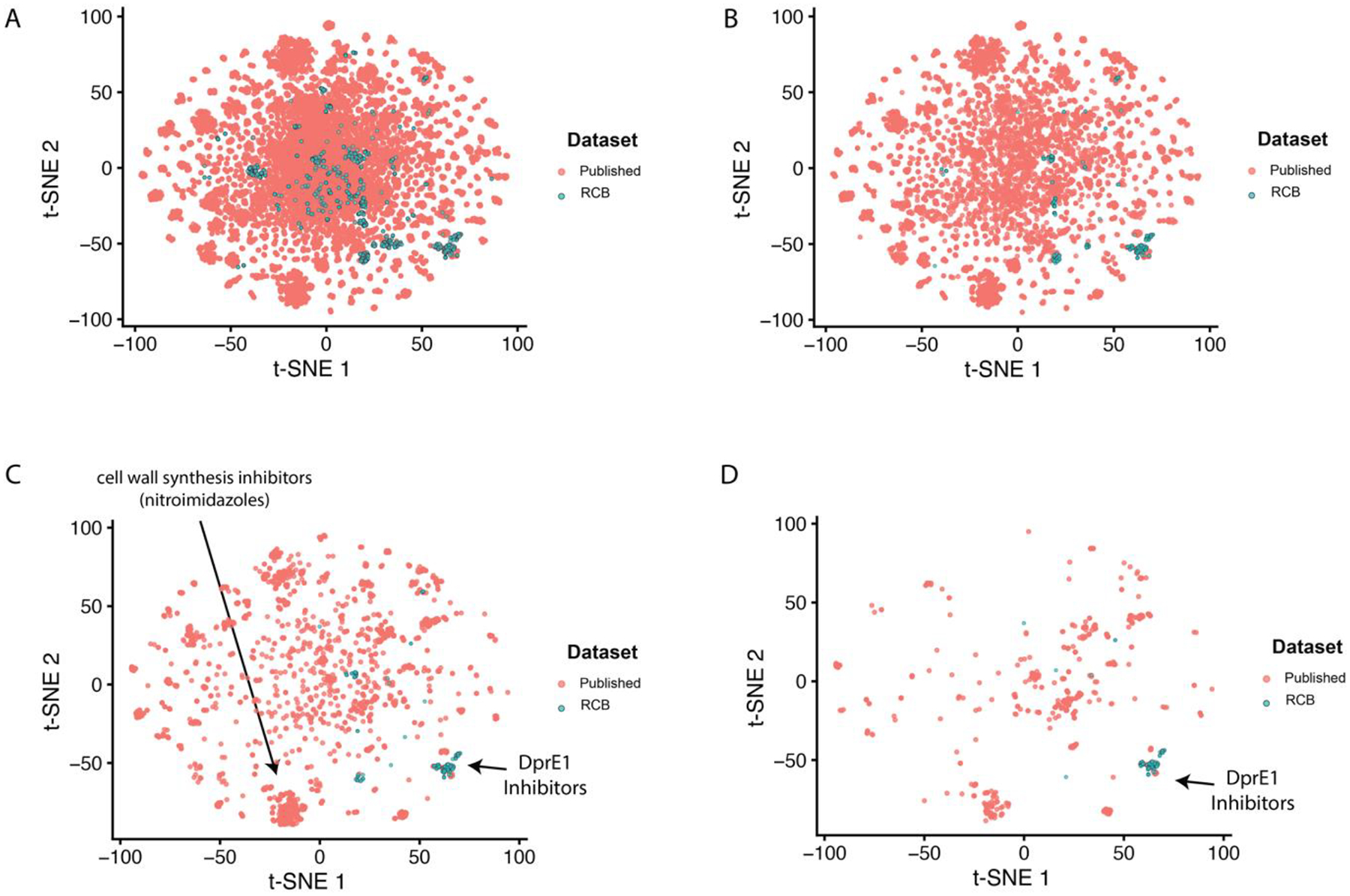
t-SNE plot data at different thresholds. (A) Full comparison of the RCB Mtb data and previously published Mtb dataset66. For clarity, an activity filter was also added for different thresholds (B,10μM; C,1μM; D,100nM) to highlight the difference in the active compounds visualized by the t-SNE plot.
Mtb Target Property Space
We have previously described the curation of molecules with both Mtb data and known targets as TB Mobile106, 107. We have now used this dataset along with the t-SNE approach to visualize the clustering of these molecules and predict potential targets for molecules in the RCB Mtb dataset as well as visualize molecules from a recent review67 (Figure 5).
Figure 5.
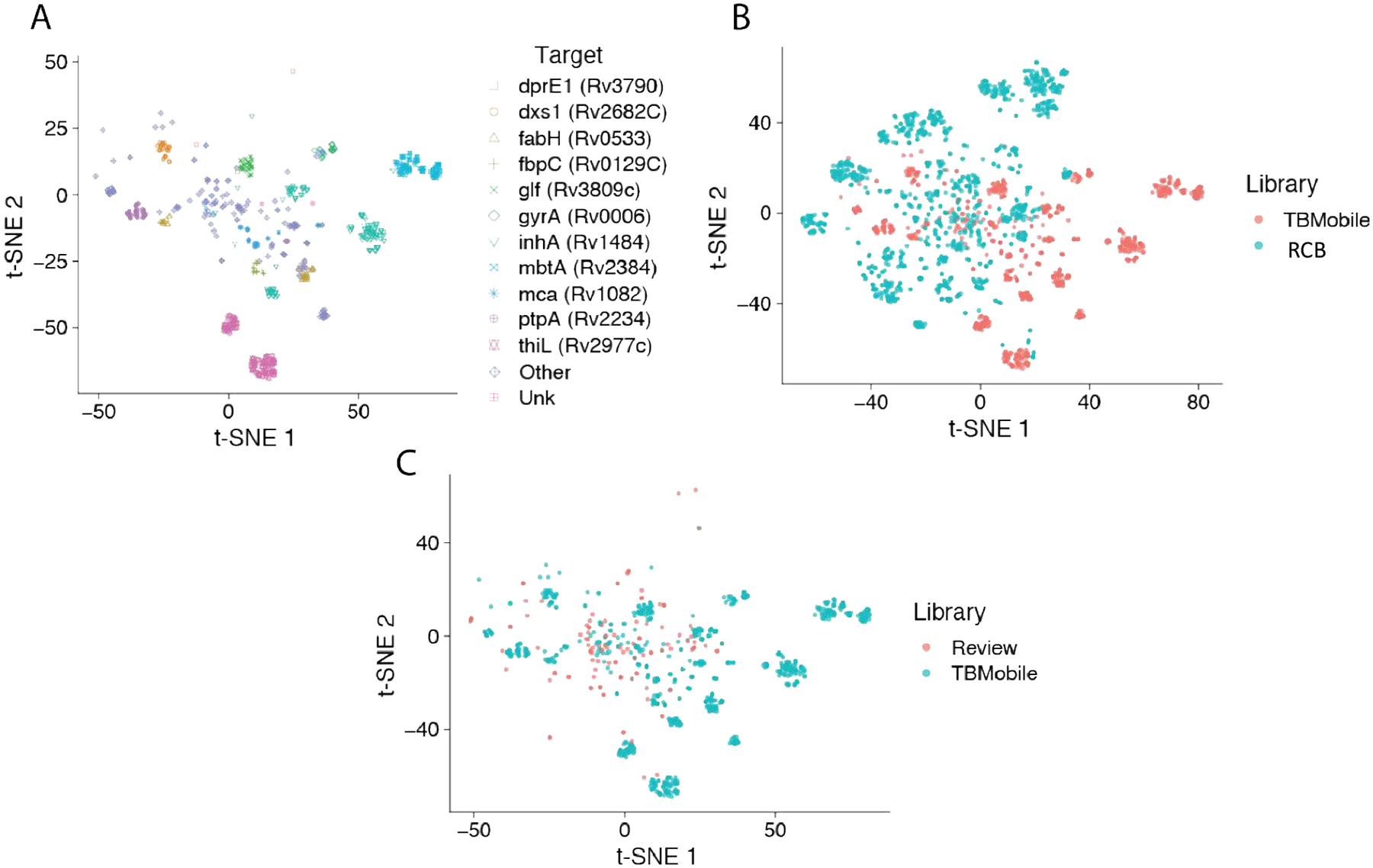
t-SNE plot of TB Mobile dataset106, 107 of Mtb inhibitors with annotated targets showing A. clustering of molecules with known Mtb targets B. overlap of RCB Mtb dataset C. overlap of over 100 recently reviewed Mtb inhibitors67.
DISCUSSION
Whole-cell HTS approaches have been widely used in both academia and industry to identify compounds with antitubercular activity, albeit with very low hit rates108–110. Machine learning has been used in many areas of biomedical and environmental research to assist in learning from patterns in the data111–116. We have advocated for the use of machine learning approaches which learn from earlier Mtb data from these screens as well as smaller scale studies in order to improve the efficiency of drug discovery which builds on our earlier work50–52, 54–59 that demonstrated an enhancement in hit rates. Having previously described the curation of a large (18,886 molecule), chemically diverse Mtb dataset using the primary literature, ChEMBL, and in vivo data66 followed by building and validation of machine learning models using extended connectivity fingerprints ECFP6 with Assay Central, we now provide further validation of these models using the RCB Mtb dataset of > 1000 molecules synthesized and tested by a single group.
The RCB Mtb dataset has a range of activities, with MICs that range from 0.59 nM – 0.65 mM as well as over 600 compounds showing no inhibition in the range tested. We have built a variety of classification models using these data, with 9.4, 15.9 and 25.9% actives for 100 nM, 1 μM and 10 μM thresholds, respectively. Analysis of molecular properties showed a significant difference between the highly active (≤ 100nM) and the low / inactive compounds in this library for the majority of descriptors generated (logD (pH=7.4), logP, MW, aromatic ring count, hydrogen-bond acceptor or donor count, ring count, rotatable bond count and polar surface area). One difference that was anticipated is that the logP (median active: 4.17; inactive: 3.06) and logD (active: 3.94; inactive: 2.91) have a higher median in the active compounds, which suggests that, on average, hydrophobicity is important for activity which is a trend that has previously been noted66, 104, 105. An interesting property difference was also in the number of hydrogen bond donors, as over 90% of the active compounds had zero, suggesting this may also be important for active compounds.
As we had previously built a series of classification models using a ~19,000 compound dataset we used these Bayesian models based on our legacy AC software to score the RCB Mtb data as an external test set. Overall, these models predicted the test set well (Figure 4), with high AUC (0.84 – 0.95) and recall (0.70 – 0.97) but with low precision (0.30 – 0.50). We now describe an expanded series of Mtb inhibition models, built with this previously compiled dataset66, including classification models with additional algorithms as well as a regression models and compared the predictive ability of these new models. We have extensively compared classification algorithms using our previously established methodology66, 100 using the RCB Mtb dataset as an external test set and found that there was a trend of the consensus and rf outperforming overall (based on rank normalized score and ΔRNS), but, possibly due to the small dataset (100 nM, 1 μM and 10 μM models), this was not statistically significant.
The GCN model is also a top-performing model, suggesting it is a promising algorithm to investigate for future QSAR model building. The ConvLSTM-net model outperformed DL and was comparable to the other classic models tested. One benefit of an end-to-end model such as ConvLSTM-net is the speed of preprocessing and predictions. As technologies such as DNA encoded libraries allow billions of molecules to be virtually screened, the computational cost of feature-generation and storage becomes a bottleneck in the screening process. ConvLSTM-net is comparable in performance to most of the classic models, while allowing datasets to be stored and entered into the model purely as SMILES. The slightly lower predictive capability compared to a top-performing model may be an acceptable tradeoff when considering the need to generate and store 1024 or more fingerprint bits for a billion molecules.
The Mtb regression model covered a large range of activities (MIC) and was of comparable size to the classification models. We validated this model by performing a leave-out test set approach as well as scoring two external test sets: one independently curated previously66 and the RCB dataset. A series of t-SNE plots were used to visualize the separation of these datasets, suggesting that these are distinct based on ECFP6 molecular fingerprints. These model validations suggest that this continuous model is able to perform well on novel compounds previously not seen by the models. We have also implemented the ability to identify the top enriched ECFP6 fingerprints in a dataset. As an example, we can observe the top 6 fingerprints at the 100nM in our large dataset as well as examples of molecules containing these fingerprints (Figure S9). Further we can assess the atomic contributions for the top molecules in the RCB dataset compared with those that are inactive (Figure 6). This illustrates the benzothiazinone molecules as the most active (DprE1 inhibitors).
Figure 6.
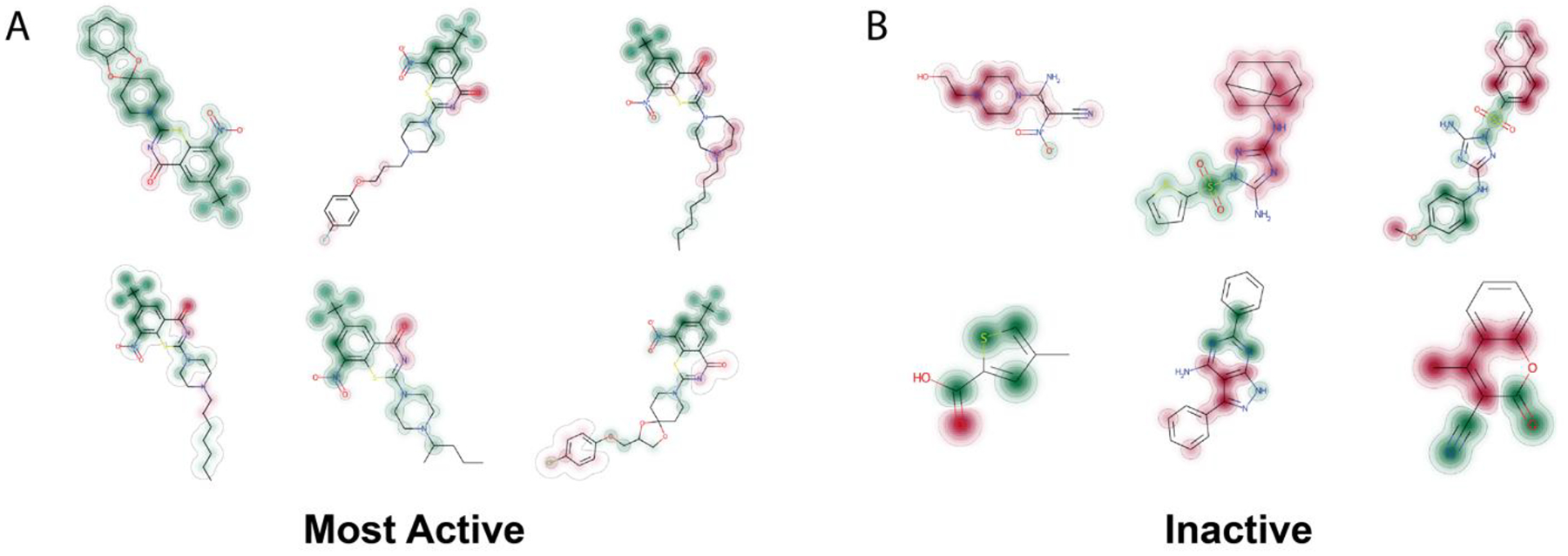
Atomic contributions for the top molecules in the RCB Mtb dataset A. Actives, dominated by benzothiazinones B. Inactives, of different compound classes. Green = contributes to predicting “active”, Red = contributes to predicting “inactive”, no color/close to nothing/white: no contribution to predictions.
Our t-SNE visualization of the distribution of Mtb data with known targets106, 107 illustrates how closely related molecules cluster in space and sometimes the same target may have multiple clusters (Figure 5A). This may have utility for predicting targets for molecules from phenotypic screens or as we have illustrated for the RCB Mtb dataset (Figure 5B). A recent review summarized over 100 molecules for which very few had targets identified67 and these molecules seem to be within the space covered by this annotated target dataset which may also allow us to propose potential targets (Figure 5C).
In conclusion, we previously proposed further prospective testing of our machine learning models66 and have now generated and tested numerous models for Mtb as suggested. There is continually new in vitro data that is generated by research groups and much of it is not published and therefore not accessible for machine learning modeling. We now describe how data generated in the course of a long-term project can be utilized to help in the design of new molecules in the future. We have also described how the initial three Mtb models can be used either together or in consensus as described for other models59. We can also utilize our t-SNE visualizations to predict potential targets for molecules derived from phenotypic testing by comparison to annotated datasets. With the RCB Mtb dataset we have illustrated that the DprE1 inhibitors are clustered in a specific region of chemical property space that appears distinct from the location of other Mtb targets. Clearly there are many other regions of this Mtb property / target space that need to be explored as we have previously suggested67 and these machine learning models may enable this in conjunction with methods such as generative approaches to design new molecules117–119.
Supplementary Material
ACKNOWLEDGMENTS
Ms. Kimberley Zorn and Dr. Alex Clark are acknowledged for assistance with Assay Central. Dr. Joel Freundlich is acknowledged for earlier collaborations and discussions on Mtb machine learning.
Grant information
We kindly acknowledge NIH funding: R44GM122196-02A1 from NIGMS, 3R43AT010585-01S1 from NCCAM, and 1R43ES031038-01 from NIEHS. “Research reported in this publication was supported by the National Institute of Environmental Health Sciences of the National Institutes of Health under Award Number R43ES031038. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. This work was supported by grants from the European Commission (LHSP-CT-2005-018923, 260872) and Russian Science Foundation under the grant 21-15-00042.
ABBREVIATIONS USED
- ABDT
AdaBoost
- ADME
absorption, distribution, metabolism, and excretion
- ANN
artificial neural networks
- AUC
area under the curve
- BNB
Bernoulli Naive Bayes
- ConvLSTM-net
Convolutional Long-Short Term Memory Neural Network
- DT
Decision Tree
- DNN
Deep Neural Networks
- ECFP6
extended connectivity fingerprints of maximum diameter 6
- GCN
Graph Convolutional Network
- HTS
high throughput screening
- kNN
k-Nearest Neighbors
- QSAR
quantitative structure activity relationships
- MIC
minimum inhibitory concentration
- Mtb
Mycobacterium tuberculosis
- NIAID
NIAID, National Institute of Allergy and Infectious Diseases
- QSAR
quantitative structure activity relationships
- RF
Random forest
- ROC
receiver operating characteristic
- RP
Recursive partitioning
- SI
selectivity index
- SVM
support vector machines
- TB
Tuberculosis
- XV ROC AUC
cross-validated receiver operator characteristic curve’s area under the curve
Footnotes
Competing interests:
S.E., is owner T.L., F.U., L.R. and J.R. are employees of Collaborations Pharmaceuticals, Inc. All others have no competing interests.
Supporting Information
The RCB Mtb dataset is available in sdf format. Supporting further details on the machine learning methods and models, are available. This material is available free of charge via the Internet at http://pubs.acs.org. Models generated with our software can also be made available to academic researchers upon written request.
REFERENCES
- 1.World Health Organisation. Global Tuberculosis Report 2020. https://www.who.int/publications/i/item/9789240013131 (accessed 2021-12-20).
- 2.Seung KJ; Keshavjee S; Rich ML Multidrug-Resistant Tuberculosis and Extensively Drug-Resistant Tuberculosis. Cold Spring Harb Perspect Med 2015, 5, a017863. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Arnold A; Cooke GS; Kon OM; Dedicoat M; Lipman M; Loyse A; Chis Ster I; Harrison TS Adverse Effects and Choice between the Injectable Agents Amikacin and Capreomycin in Multidrug-Resistant Tuberculosis. Antimicrob Agents Chemother 2017, 61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.TB Alliance. Inadequate Treatment. https://www.tballiance.org/why-new-tb-drugs/inadequate-treatment (accessed 2021-12-20).
- 5.Zignol M; Dean AS; Falzon D; van Gemert W; Wright A; van Deun A; Portaels F; Laszlo A; Espinal MA; Pablos-Méndez A; Bloom A; Aziz MA; Weyer K; Jaramillo E; Nunn P; Floyd K; Raviglione MC Twenty Years of Global Surveillance of Antituberculosis-Drug Resistance. N Engl J Med 2016, 375, 1081–1089. [DOI] [PubMed] [Google Scholar]
- 6.Zhang Y The Magic Bullets and Tuberculosis Drug Targets. Annu Rev Pharmacol Toxicol 2005, 45, 529–64. [DOI] [PubMed] [Google Scholar]
- 7.Ballel L; Field RA; Duncan K; Young RJ New Small-Molecule Synthetic Antimycobacterials. Antimicrob Agents Chemother 2005, 49, 2153–2163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Zumla AI; Gillespie SH; Hoelscher M; Philips PP; Cole ST; Abubakar I; McHugh TD; Schito M; Maeurer M; Nunn AJ New Antituberculosis Drugs, Regimens, and Adjunct Therapies: Needs, Advances, and Future Prospects. Lancet Infect Dis 2014, 14, 327–340. [DOI] [PubMed] [Google Scholar]
- 9.Datiko DG; Lindtjorn B Tuberculosis Recurrence in Smear-Positive Patients Cured under Dots in Southern Ethiopia: Retrospective Cohort Study. BMC Public Health 2009, 9, 348. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Sterling TR; Alwood K; Gachuhi R; Coggin W; Blazes D; Bishai WR; Chaisson RE Relapse Rates after Short-Course (6-Month) Treatment of Tuberculosis in Hiv-Infected and Uninfected Persons. AIDS 1999, 13, 1899–904. [DOI] [PubMed] [Google Scholar]
- 11.Who Global Tuberculosis Report 2015; 2015.
- 12.Menzies R; Rocher I; Vissandjee B Factors Associated with Compliance in Treatment of Tuberculosis. Tuber Lung Dis 1993, 74, 32–7. [DOI] [PubMed] [Google Scholar]
- 13.Jain A; Mondal R Extensively Drug-Resistant Tuberculosis: Current Challenges and Threats. FEMS Immunol Med Microbiol 2008, 53, 145–50. [DOI] [PubMed] [Google Scholar]
- 14.Velayati AA; Farnia P; Masjedi MR The Totally Drug Resistant Tuberculosis (Tdr-Tb). Int J Clin Exp Med 2013, 6, 307–9. [PMC free article] [PubMed] [Google Scholar]
- 15.Conradie F; Diacon AH; Ngubane N; Howell P; Everitt D; Crook AM; Mendel CM; Egizi E; Moreira J; Timm J; McHugh TD; Wills GH; Bateson A; Hunt R; Van Niekerk C; Li M; Olugbosi M; Spigelman M; Nix TBTT Treatment of Highly Drug-Resistant Pulmonary Tuberculosis. N Engl J Med 2020, 382, 893–902. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Thwaites G; Nahid P Triumph and Tragedy of 21st Century Tuberculosis Drug Development. N Engl J Med 2020, 382, 959–960. [DOI] [PubMed] [Google Scholar]
- 17.World Health Organisation. Global Tuberculosis Report 2016. http://www.who.int/tb/publications/global_report/en/ (accessed 2021-12-20).
- 18.Husain AA; Monaghan TM; Kashyap RS Impact of Covid-19 Pandemic on Tuberculosis Care in India. Clin Microbiol Infect 2021, 27, 293–294. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Kwak N; Hwang SS; Yim JJ Effect of Covid-19 on Tuberculosis Notification, South Korea. Emerg Infect Dis 2020, 26, 2506–2508. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.World Health Organisation. Impact of the COVID-19 Pandemic on TB Detection and Mortality in 2020. https://www.who.int/publications/m/item/impact-of-the-covid-19-pandemic-on-tb-detection-and-mortality-in-2020 (accessed 2021-12-20).
- 21.Riccardi G; Old IG; Ekins S Raising Awareness of the Importance of Funding for Tuberculosis Small-Molecule Research. Drug Discov Today 2016, 22, 487–491. [DOI] [PubMed] [Google Scholar]
- 22.Mikusova K; Ekins S Learning from the Past for Tb Drug Discovery in the Future. Drug Discov Today 2017, 22, 534–545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Gopal P; Dick T Reactive Dirty Fragments: Implications for Tuberculosis Drug Discovery. Curr Opin Microbiol 2014, 21, 7–12. [DOI] [PubMed] [Google Scholar]
- 24.Ekins S; Williams AJ; Krasowski MD; Freundlich JS In Silico Repositioning of Approved Drugs for Rare and Neglected Diseases. Drug Disc Today 2011, 16, 298–310. [DOI] [PubMed] [Google Scholar]
- 25.Ekins S; Williams AJ Finding Promiscuous Old Drugs for New Uses. Pharm Res 2011, 28, 1786–1791. [DOI] [PubMed] [Google Scholar]
- 26.Aliper A; Plis S; Artemov A; Ulloa A; Mamoshina P; Zhavoronkov A Deep Learning Applications for Predicting Pharmacological Properties of Drugs and Drug Repurposing Using Transcriptomic Data. Mol Pharm 2016, 13, 2524–30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Djaout K; Singh V; Boum Y; Katawera V; Becker HF; Bush NG; Hearnshaw SJ; Pritchard JE; Bourbon P; Madrid PB; Maxwell A; Mizrahi V; Myllyjallio H; Ekins S Predictive Modeling Targets Thymidylate Synthase Thyx in Mycobacterium Tuberculosis. Sci Rep 2016, 6, 27792. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Lamb J; Crawford ED; Peck D; Modell JW; Blat IC; Wrobel MJ; Lerner J; Brunet JP; Subramanian A; Ross KN; Reich M; Hieronymus H; Wei G; Armstrong SA; Haggarty SJ; Clemons PA; Wei R; Carr SA; Lander ES; Golub TR The Connectivity Map: Using Gene-Expression Signatures to Connect Small Molecules, Genes, and Disease. Science 2006, 313, 1929–35. [DOI] [PubMed] [Google Scholar]
- 29.Lamb J The Connectivity Map: A New Tool for Biomedical Research. Nat Rev Cancer 2007, 7, 54–60. [DOI] [PubMed] [Google Scholar]
- 30.Dartois V The Path of Anti-Tuberculosis Drugs: From Blood to Lesions to Mycobacterial Cells. Nat Rev Microbiol 2014, 12, 159–67. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Dartois V; Barry CE 3rd. A Medicinal Chemists’ Guide to the Unique Difficulties of Lead Optimization for Tuberculosis. Bioorg Med Chem Lett 2013, 23, 4741–50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Kjellsson MC; Via LE; Goh A; Weiner D; Low KM; Kern S; Pillai G; Barry CE 3rd; Dartois V Pharmacokinetic Evaluation of the Penetration of Antituberculosis Agents in Rabbit Pulmonary Lesions. Antimicrob Agents Chemother 2012, 56, 446–57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Prideaux B; Dartois V; Staab D; Weiner DM; Goh A; Via LE; Barry CE 3rd; Stoeckli M High-Sensitivity Maldi-Mrm-Ms Imaging of Moxifloxacin Distribution in Tuberculosis-Infected Rabbit Lungs and Granulomatous Lesions. Anal Chem 2011, 83, 2112–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Jovetic S; Zhu Y; Marcone GL; Marinelli F; Tramper J Beta-Lactam and Glycopeptide Antibiotics: First and Last Line of Defense? Trends Biotechnol 2010, 28, 596–604. [DOI] [PubMed] [Google Scholar]
- 35.Khoo KH; Douglas E; Azadi P; Inamine JM; Besra GS; Mikusova K; Brennan PJ; Chatterjee D Truncated Structural Variants of Lipoarabinomannan in Ethambutol Drug-Resistant Strains of Mycobacterium Smegmatis. Inhibition of Arabinan Biosynthesis by Ethambutol. J Biol Chem 1996, 271, 28682–90. [DOI] [PubMed] [Google Scholar]
- 36.Vilcheze C; Wang F; Arai M; Hazbon MH; Colangeli R; Kremer L; Weisbrod TR; Alland D; Sacchettini JC; Jacobs WR Jr. Transfer of a Point Mutation in Mycobacterium Tuberculosis Inha Resolves the Target of Isoniazid. Nat Med 2006, 12, 1027–9. [DOI] [PubMed] [Google Scholar]
- 37.Slayden RA; Lee RE; Armour JW; Cooper AM; Orme IM; Brennan PJ; Besra GS Antimycobacterial Action of Thiolactomycin: An Inhibitor of Fatty Acid and Mycolic Acid Synthesis. Antimicrob Agents Chemother 1996, 40, 2813–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Vilcheze C; Morbidoni HR; Weisbrod TR; Iwamoto H; Kuo M; Sacchettini JC; Jacobs WR Jr. Inactivation of the Inha-Encoded Fatty Acid Synthase Ii (Fasii) Enoyl-Acyl Carrier Protein Reductase Induces Accumulation of the Fasi End Products and Cell Lysis of Mycobacterium Smegmatis. J Bacteriol 2000, 182, 4059–67. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Heath RJ; Rock CO Fatty Acid Biosynthesis as a Target for Novel Antibacterials. Curr Opin Investig Drugs 2004, 5, 146–53. [PMC free article] [PubMed] [Google Scholar]
- 40.Glickman MS; Cox JS; Jacobs WR Jr. A Novel Mycolic Acid Cyclopropane Synthetase Is Required for Cording, Persistence, and Virulence of Mycobacterium Tuberculosis. Mol Cell 2000, 5, 717–27. [DOI] [PubMed] [Google Scholar]
- 41.Dubnau E; Chan J; Raynaud C; Mohan VP; Laneelle MA; Yu K; Quemard A; Smith I; Daffe M Oxygenated Mycolic Acids Are Necessary for Virulence of Mycobacterium Tuberculosis in Mice. Mol Microbiol 2000, 36, 630–7. [DOI] [PubMed] [Google Scholar]
- 42.Bhatt A; Molle V; Besra GS; Jacobs WR Jr.; Kremer L The Mycobacterium Tuberculosis Fas-Ii Condensing Enzymes: Their Role in Mycolic Acid Biosynthesis, Acid-Fastness, Pathogenesis and in Future Drug Development. Mol Microbiol 2007, 64, 1442–54. [DOI] [PubMed] [Google Scholar]
- 43.Wilson R; Kumar P; Parashar V; Vilchèze C; Veyron-Churlet R; Freundlich JS; Barnes SW; Walker JR; Szymonifka MJ; Marchiano E; Shenai S; Colangeli R; Jacobs WR; Neiditch MB; Kremer L; Alland D Antituberculosis Thiophenes Define a Requirement for Pks13 in Mycolic Acid Biosynthesis. Nat Chem Biol 2013, 9, 499–506. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Kumar P; Capodagli GC; Awasthi D; Shrestha R; Maharaja K; Sukheja P; Li SG; Inoyama D; Zimmerman M; Ho Liang HP; Sarathy J; Mina M; Rasic G; Russo R; Perryman AL; Richmann T; Gupta A; Singleton E; Verma S; Husain S; Soteropoulos P; Wang Z; Morris R; Porter G; Agnihotri G; Salgame P; Ekins S; Rhee KY; Connell N; Dartois V; Neiditch MB; Freundlich JS; Alland D Synergistic Lethality of a Binary Inhibitor of Mycobacterium Tuberculosis Kasa. MBio 2018, 9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Abrahams KA; Chung CW; Ghidelli-Disse S; Rullas J; Rebollo-Lopez MJ; Gurcha SS; Cox JA; Mendoza A; Jimenez-Navarro E; Martinez-Martinez MS; Neu M; Shillings A; Homes P; Argyrou A; Casanueva R; Loman NJ; Moynihan PJ; Lelievre J; Selenski C; Axtman M; Kremer L; Bantscheff M; Angulo-Barturen I; Izquierdo MC; Cammack NC; Drewes G; Ballell L; Barros D; Besra GS; Bates RH Identification of Kasa as the Cellular Target of an Anti-Tubercular Scaffold. Nat Commun 2016, 7, 12581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Puhl AC; Lane TR; Vignaux PA; Zorn KM; Capodagli GC; Neiditch MB; Freundlich JS; Ekins S Computational Approaches to Identify Molecules Binding to Mycobacterium Tuberculosis Kasa. ACS Omega 2020, 5, 26551–26561. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Prathipati P; Ma NL; Keller TH Global Bayesian Models for the Prioritization of Antitubercular Agents. J Chem Inf Model 2008, 48, 2362–70. [DOI] [PubMed] [Google Scholar]
- 48.Ekins S Progress in Computational Toxicology. J Pharmacol Toxicol Methods 2014, 69, 115–40. [DOI] [PubMed] [Google Scholar]
- 49.Zheng X; Ekins S; Raufman JP; Polli JE Computational Models for Drug Inhibition of the Human Apical Sodium-Dependent Bile Acid Transporter. Mol Pharm 2009, 6, 1591–603. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Ekins S; Bradford J; Dole K; Spektor A; Gregory K; Blondeau D; Hohman M; Bunin B A Collaborative Database and Computational Models for Tuberculosis Drug Discovery. Mol BioSystems 2010, 6, 840–851. [DOI] [PubMed] [Google Scholar]
- 51.Ekins S; Kaneko T; Lipinksi CA; Bradford J; Dole K; Spektor A; Gregory K; Blondeau D; Ernst S; Yang J; Goncharoff N; Hohman M; Bunin B Analysis and Hit Filtering of a Very Large Library of Compounds Screened against Mycobacterium Tuberculosis Mol BioSyst 2010, 6, 2316–2324. [DOI] [PubMed] [Google Scholar]
- 52.Ekins S; Freundlich JS Validating New Tuberculosis Computational Models with Public Whole Cell Screening Aerobic Activity Datasets Pharm Res 2011, 28, 1859–69. [DOI] [PubMed] [Google Scholar]
- 53.Sarker M; Talcott C; Madrid P; Chopra S; Bunin BA; Lamichhane G; Freundlich JS; Ekins S Combining Cheminformatics Methods and Pathway Analysis to Identify Molecules with Whole-Cell Activity against Mycobacterium Tuberculosis. Pharm Res 2012, 29, 2115–2127. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Ekins S; Reynolds R; Kim H; Koo M-S; Ekonomidis M; Talaue M; Paget SD; Woolhiser LK; Lenaerts AJ; Bunin BA; Connell N; Freundlich JS Bayesian Models Leveraging Bioactivity and Cytotoxicity Information for Drug Discovery. Chem Biol 2013, 20, 370–378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Ekins S; Reynolds RC; Franzblau SG; Wan B; Freundlich JS; Bunin BA Enhancing Hit Identification in Mycobacterium Tuberculosis Drug Discovery Using Validated Dual-Event Bayesian Models PLOSONE 2013, 8, e63240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Ekins S; Casey AC; Roberts D; Parish T; Bunin BA Bayesian Models for Screening and Tb Mobile for Target Inference with Mycobacterium Tuberculosis. Tuberculosis (Edinb) 2014, 94, 162–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Ekins S; Freundlich JS; Hobrath JV; Lucile White E; Reynolds RC Combining Computational Methods for Hit to Lead Optimization in Mycobacterium Tuberculosis Drug Discovery. Pharm Res 2014, 31, 414–35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Ekins S; Freundlich JS; Reynolds RC Fusing Dual-Event Datasets for Mycobacterium Tuberculosis Machine Learning Models and Their Evaluation. J Chem Inf Model 2013, 53, 3054–63. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Ekins S; Freundlich JS; Reynolds RC Are Bigger Data Sets Better for Machine Learning? Fusing Single-Point and Dual-Event Dose Response Data for Mycobacterium Tuberculosis. J Chem Inf Model 2014, 54, 2157–65. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Kumar P; Kaushik A; Lloyd EP; Li SG; Mattoo R; Ammerman NC; Bell DT; Perryman AL; Zandi TA; Ekins S; Ginell SL; Townsend CA; Freundlich JS; Lamichhane G Non-Classical Transpeptidases Yield Insight into New Antibacterials. Nat Chem Biol 2017, 13, 54–61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Ekins S; Clark AM; Sarker M Tb Mobile: A Mobile App for Anti-Tuberculosis Molecules with Known Targets. J Cheminform 2013, 5, 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Clark AM; Sarker M; Ekins S New Target Predictions and Visualization Tools Incorporating Open Source Molecular Fingerprints for Tb Mobile 2.0. J Cheminform 2014, 6, 38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Ekins S; Godbole AA; Keri G; Orfi L; Pato J; Bhat RS; Verma R; Bradley EK; Nagaraja V Machine Learning and Docking Models for Mycobacterium Tuberculosis Topoisomerase I. Tuberculosis (Edinb) 2017, 103, 52–60. [DOI] [PubMed] [Google Scholar]
- 64.Ekins S; Pottorf R; Reynolds RC; Williams AJ; Clark AM; Freundlich JS Looking Back to the Future: Predicting in Vivo Efficacy of Small Molecules Versus Mycobacterium Tuberculosis. J Chem Inf Model 2014, 54, 1070–82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Ekins S; Perryman AL; Clark AM; Reynolds RC; Freundlich JS Machine Learning Model Analysis and Data Visualization with Small Molecules Tested in a Mouse Model of Mycobacterium Tuberculosis Infection (2014–2015). J Chem Inf Model 2016, 56, 1332–1343. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Lane T; Russo DP; Zorn KM; Clark AM; Korotcov A; Tkachenko V; Reynolds RC; Perryman AL; Freundlich JS; Ekins S Comparing and Validating Machine Learning Models for Mycobacterium Tuberculosis Drug Discovery. Mol Pharm 2018, 15, 4346–4360. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Makarov V; Salina E; Reynolds RC; Kyaw Zin PP; Ekins S Molecule Property Analyses of Active Compounds for Mycobacterium Tuberculosis. J Med Chem 2020, 63, 8917–8955. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Cole ST Tuberculosis Drug Discovery Needs Public-Private Consortia. Drug Discov Today 2017, 22, 477–478. [DOI] [PubMed] [Google Scholar]
- 69.Ekins S A Summary of Some Eu Funded Tuberculosis Drug Discovery Collaborations. Drug Discov Today 2017, 22, 479–480. [DOI] [PubMed] [Google Scholar]
- 70.Ryabova OB; Evstratova MI; Makarov VA; Tafeenko VA; Granik VG New Method for the Synthesis of Thieno[2,3-D]Pyrimidines. Chemistry of Heterocyclic Compounds 2004, 40, 1352–1358. [Google Scholar]
- 71.Komarova ES; Makarov VA; Alekseeva LM; Avramenko GV; Granik VG 4,5-Diamino-1-Phenyl-1,7-Dihydro-6h-Pyrazolo[3,4-B]Pyridin-6-One in the Synthesis of Fused Tricyclic Systems. Russian Chemical Bulletin 2007, 56, 2337–2343. [Google Scholar]
- 72.Makarov V; Riabova OB; Yuschenko A; Urlyapova N; Daudova A; Zipfel PF; Mollmann U Synthesis and Antileprosy Activity of Some Dialkyldithiocarbamates. J Antimicrob Chemother 2006, 57, 1134–8. [DOI] [PubMed] [Google Scholar]
- 73.Sommer R; Neres J; Piton J; Dhar N; van der Sar A; Mukherjee R; Laroche T; Dyson PJ; McKinney JD; Bitter W; Makarov V; Cole ST Fluorescent Benzothiazinone Analogues Efficiently and Selectively Label Dpre1 in Mycobacteria and Actinobacteria. ACS Chem Biol 2018, 13, 3184–3192. [DOI] [PubMed] [Google Scholar]
- 74.Hogan AM; Scoffone VC; Makarov V; Gislason AS; Tesfu H; Stietz MS; Brassinga AKC; Domaratzki M; Li X; Azzalin A; Biggiogera M; Riabova O; Monakhova N; Chiarelli LR; Riccardi G; Buroni S; Cardona ST Competitive Fitness of Essential Gene Knockdowns Reveals a Broad-Spectrum Antibacterial Inhibitor of the Cell Division Protein Ftsz. Antimicrob Agents Chemother 2018, 62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Piton J; Vocat A; Lupien A; Foo CS; Riabova O; Makarov V; Cole ST Structure-Based Drug Design and Characterization of Sulfonyl-Piperazine Benzothiazinone Inhibitors of Dpre1 from Mycobacterium Tuberculosis. Antimicrob Agents Chemother 2018, 62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Salina EG; Huszar S; Zemanova J; Keruchenko J; Riabova O; Kazakova E; Grigorov A; Azhikina T; Kaprelyants A; Mikusova K; Makarov V Copper-Related Toxicity in Replicating and Dormant Mycobacterium Tuberculosis Caused by 1-Hydroxy-5-R-Pyridine-2(1h)-Thiones. Metallomics 2018, 10, 992–1002. [DOI] [PubMed] [Google Scholar]
- 77.Chiarelli LR; Mori G; Orena BS; Esposito M; Lane T; de Jesus Lopes Ribeiro AL; Degiacomi G; Zemanova J; Szadocka S; Huszar S; Palcekova Z; Manfredi M; Gosetti F; Lelievre J; Ballell L; Kazakova E; Makarov V; Marengo E; Mikusova K; Cole ST; Riccardi G; Ekins S; Pasca MR A Multitarget Approach to Drug Discovery Inhibiting Mycobacterium Tuberculosis Pyrg and Pank. Sci Rep 2018, 8, 3187. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Demina GR; Nikitushkin VD; Shleeva MO; Riabova OB; Lepioshkin AY; Makarov VA; Kaprelyants AS Benzoylphenyl Thiocyanates Are New, Effective Inhibitors of the Mycobacterial Resuscitation Promoting Factor B Protein. Ann Clin Microbiol Antimicrob 2017, 16, 69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Rosado LA; Wahni K; Degiacomi G; Pedre B; Young D; de la Rubia AG; Boldrin F; Martens E; Marcos-Pascual L; Sancho-Vaello E; Albesa-Jove D; Provvedi R; Martin C; Makarov V; Versees W; Verniest G; Guerin ME; Mateos LM; Manganelli R; Messens J The Antibacterial Prodrug Activator Rv2466c Is a Mycothiol-Dependent Reductase in the Oxidative Stress Response of Mycobacterium Tuberculosis. J Biol Chem 2017, 292, 13097–13110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Salina EG; Ryabova O; Vocat A; Nikonenko B; Cole ST; Makarov V New 1-Hydroxy-2-Thiopyridine Derivatives Active against Both Replicating and Dormant Mycobacterium Tuberculosis. J Infect Chemother 2017, 23, 794–797. [DOI] [PubMed] [Google Scholar]
- 81.Albesa-Jove D; Comino N; Tersa M; Mohorko E; Urresti S; Dainese E; Chiarelli LR; Pasca MR; Manganelli R; Makarov V; Riccardi G; Svergun DI; Glockshuber R; Guerin ME The Redox State Regulates the Conformation of Rv2466c to Activate the Antitubercular Prodrug Tp053. J Biol Chem 2015, 290, 31077–89. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Mori G; Chiarelli LR; Esposito M; Makarov V; Bellinzoni M; Hartkoorn RC; Degiacomi G; Boldrin F; Ekins S; de Jesus Lopes Ribeiro AL; Marino LB; Centarova I; Svetlikova Z; Blasko J; Kazakova E; Lepioshkin A; Barilone N; Zanoni G; Porta A; Fondi M; Fani R; Baulard AR; Mikusova K; Alzari PM; Manganelli R; de Carvalho LP; Riccardi G; Cole ST; Pasca MR Thiophenecarboxamide Derivatives Activated by Etha Kill Mycobacterium Tuberculosis by Inhibiting the Ctp Synthetase Pyrg. Chem Biol 2015, 22, 917–27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Makarov V; Neres J; Hartkoorn RC; Ryabova OB; Kazakova E; Sarkan M; Huszar S; Piton J; Kolly GS; Vocat A; Conroy TM; Mikusova K; Cole ST The 8-Pyrrole-Benzothiazinones Are Noncovalent Inhibitors of Dpre1 from Mycobacterium Tuberculosis. Antimicrob Agents Chemother 2015, 59, 4446–52. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Neres J; Hartkoorn RC; Chiarelli LR; Gadupudi R; Pasca MR; Mori G; Venturelli A; Savina S; Makarov V; Kolly GS; Molteni E; Binda C; Dhar N; Ferrari S; Brodin P; Delorme V; Landry V; de Jesus Lopes Ribeiro AL; Farina D; Saxena P; Pojer F; Carta A; Luciani R; Porta A; Zanoni G; De Rossi E; Costi MP; Riccardi G; Cole ST 2-Carboxyquinoxalines Kill Mycobacterium Tuberculosis through Noncovalent Inhibition of Dpre1. ACS Chem Biol 2015, 10, 705–14. [DOI] [PubMed] [Google Scholar]
- 85.Turapov O; Glenn S; Kana B; Makarov V; Andrew PW; Mukamolova GV The in Vivo Environment Accelerates Generation of Resuscitation-Promoting Factor-Dependent Mycobacteria. Am J Respir Crit Care Med 2014, 190, 1455–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Albesa-Jove D; Chiarelli LR; Makarov V; Pasca MR; Urresti S; Mori G; Salina E; Vocat A; Comino N; Mohorko E; Ryabova S; Pfieiffer B; Lopes Ribeiro AL; Rodrigo-Unzueta A; Tersa M; Zanoni G; Buroni S; Altmann KH; Hartkoorn RC; Glockshuber R; Cole ST; Riccardi G; Guerin ME Rv2466c Mediates the Activation of Tp053 to Kill Replicating and Non-Replicating Mycobacterium Tuberculosis. ACS Chem Biol 2014, 9, 1567–75. [DOI] [PubMed] [Google Scholar]
- 87.Makarov V; Lechartier B; Zhang M; Neres J; van der Sar AM; Raadsen SA; Hartkoorn RC; Ryabova OB; Vocat A; Decosterd LA; Widmer N; Buclin T; Bitter W; Andries K; Pojer F; Dyson PJ; Cole ST Towards a New Combination Therapy for Tuberculosis with Next Generation Benzothiazinones. EMBO Mol Med 2014, 6, 372–83. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Hartkoorn RC; Ryabova OB; Chiarelli LR; Riccardi G; Makarov V; Cole ST Mechanism of Action of 5-Nitrothiophenes against Mycobacterium Tuberculosis. Antimicrob Agents Chemother 2014, 58, 2944–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Salina E; Ryabova O; Kaprelyants A; Makarov V New 2-Thiopyridines as Potential Candidates for Killing Both Actively Growing and Dormant Mycobacterium Tuberculosis Cells. Antimicrob Agents Chemother 2014, 58, 55–60. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Mikusova K; Makarov V; Neres J Dpre1--from the Discovery to the Promising Tuberculosis Drug Target. Curr Pharm Des 2014, 20, 4379–403. [DOI] [PubMed] [Google Scholar]
- 91.Trefzer C; Skovierova H; Buroni S; Bobovska A; Nenci S; Molteni E; Pojer F; Pasca MR; Makarov V; Cole ST; Riccardi G; Mikusova K; Johnsson K Benzothiazinones Are Suicide Inhibitors of Mycobacterial Decaprenylphosphoryl-Beta-D-Ribofuranose 2’-Oxidase Dpre1. J Am Chem Soc 2012, 134, 912–5. [DOI] [PubMed] [Google Scholar]
- 92.Trefzer C; Rengifo-Gonzalez M; Hinner MJ; Schneider P; Makarov V; Cole ST; Johnsson K Benzothiazinones: Prodrugs That Covalently Modify the Decaprenylphosphoryl-Beta-D-Ribose 2’-Epimerase Dpre1 of Mycobacterium Tuberculosis. J Am Chem Soc 2010, 132, 13663–5. [DOI] [PubMed] [Google Scholar]
- 93.Demina GR; Makarov VA; Nikitushkin VD; Ryabova OB; Vostroknutova GN; Salina EG; Shleeva MO; Goncharenko AV; Kaprelyants AS Finding of the Low Molecular Weight Inhibitors of Resuscitation Promoting Factor Enzymatic and Resuscitation Activity. PLoS One 2009, 4, e8174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Makarov V; Manina G; Mikusova K; Mollmann U; Ryabova O; Saint-Joanis B; Dhar N; Pasca MR; Buroni S; Lucarelli AP; Milano A; De Rossi E; Belanova M; Bobovska A; Dianiskova P; Kordulakova J; Sala C; Fullam E; Schneider P; McKinney JD; Brodin P; Christophe T; Waddell S; Butcher P; Albrethsen J; Rosenkrands I; Brosch R; Nandi V; Bharath S; Gaonkar S; Shandil RK; Balasubramanian V; Balganesh T; Tyagi S; Grosset J; Riccardi G; Cole ST Benzothiazinones Kill Mycobacterium Tuberculosis by Blocking Arabinan Synthesis. Science 2009, 324, 801–4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Salina E; Egorova A; Chiarelli L; Pasca M; Makarov V Thienopyrimidines Kill Mycobacterium Tuberculosis by Production of Nitric Oxide. FEBS OPEN BIO 2018, 8, 239–240. [Google Scholar]
- 96.Pavlov D; Rybalkin M; Karulin B; Kozhevnikov M; Savelyev A; Churinov A Indigo: Universal Cheminformatics Api. Journal of Cheminformatics 2011, 3, P4. [Google Scholar]
- 97.Palomino JC; Martin A; Camacho M; Guerra H; Swings J; Portaels F Resazurin Microtiter Assay Plate: Simple and Inexpensive Method for Detection of Drug Resistance in Mycobacterium Tuberculosis. Antimicrob Agents Chemother 2002, 46, 2720–2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Li M; Zhou J; Hu J; Fan W; Zhang Y; Gu Y; Karypis G Dgl-Lifesci: An Open-Source Toolkit for Deep Learning on Graphs in Life Science. Submission date 2021-06-27, arXiv, 2106.14232v1. (accessed 2021-12-20). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.van der Maaten L; Hinton G Visualizing Data Using T-Sne. J Machine Learning Research 2008, 9, 2579–2605. [Google Scholar]
- 100.Zorn KM; Lane TR; Russo DP; Clark AM; Makarov V; Ekins S Multiple Machine Learning Comparisons of Hiv Cell-Based and Reverse Transcriptase Data Sets. Mol Pharm 2019, 16, 1620–1632. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 101.Caruana R; Niculescu-Mizil A, An Empirical Comparison of Supervised Learning Algorithms. In 23rd International Conference on Machine Learning, Pittsburgh, PA, 2006. [Google Scholar]
- 102.Korotcov A; Tkachenko V; Russo DP; Ekins S Comparison of Deep Learning with Multiple Machine Learning Methods and Metrics Using Diverse Drug Discovery Data Sets. Mol Pharm 2017, 14, 4462–4475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Riniker S; Landrum GA Similarity Maps - a Visualization Strategy for Molecular Fingerprints and Machine-Learning Methods. J Cheminform 2013, 5, 43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Ekins S; Kaneko T; Lipinski CA; Bradford J; Dole K; Spektor A; Gregory K; Blondeau D; Ernst S; Yang J; Goncharoff N; Hohman MM; Bunin BA Analysis and Hit Filtering of a Very Large Library of Compounds Screened against Mycobacterium Tuberculosis. Mol Biosyst 2010, 6, 2316–2324. [DOI] [PubMed] [Google Scholar]
- 105.Ekins S; Bradford J; Dole K; Spektor A; Gregory K; Blondeau D; Hohman M; Bunin BA A Collaborative Database and Computational Models for Tuberculosis Drug Discovery. Mol Biosyst 2010, 6, 840–51. [DOI] [PubMed] [Google Scholar]
- 106.Clark AM; Sarker M; Ekins S New Target Prediction and Visualization Tools Incorporating Open Source Molecular Fingerprints for Tb Mobile 2.0. J Cheminform 2014, 6, 38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107.Ekins S; Clark AM; Sarker M Tb Mobile: A Mobile App for Anti-Tuberculosis Molecules with Known Targets. J Cheminform 2013, 5, 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 108.Reynolds RC; Ananthan S; Faaleolea E; Hobrath JV; Kwong CD; Maddox C; Rasmussen L; Sosa MI; Thammasuvimol E; White EL; Zhang W; Secrist JA 3rd. High Throughput Screening of a Library Based on Kinase Inhibitor Scaffolds against Mycobacterium Tuberculosis H37rv. Tuberculosis (Edinb) 2012, 92, 72–83. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 109.Maddry JA; Ananthan S; Goldman RC; Hobrath JV; Kwong CD; Maddox C; Rasmussen L; Reynolds RC; Secrist JA 3rd; Sosa MI; White EL; Zhang W Antituberculosis Activity of the Molecular Libraries Screening Center Network Library. Tuberculosis (Edinb) 2009, 89, 354–363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 110.Ananthan S; Faaleolea ER; Goldman RC; Hobrath JV; Kwong CD; Laughon BE; Maddry JA; Mehta A; Rasmussen L; Reynolds RC; Secrist JA 3rd; Shindo N; Showe DN; Sosa MI; Suling WJ; White EL High-Throughput Screening for Inhibitors of Mycobacterium Tuberculosis H37rv. Tuberculosis (Edinb) 2009, 89, 334–353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 111.Zang Q; Mansouri K; Williams AJ; Judson RS; Allen DG; Casey WM; Kleinstreuer NC In Silico Prediction of Physicochemical Properties of Environmental Chemicals Using Molecular Fingerprints and Machine Learning. J Chem Inf Model 2017, 57, 36–49. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Wu Z; Ramsundar B; Feinberg EN; Gomes J; Geniesse C; Pappu AS; Leswing K; Pande V Moleculenet: A Benchmark for Molecular Machine Learning. Submission date 2018-10-26. arXiv, 1703.00564v3. (accessed 2021-12-20). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 113.Vock DM; Wolfson J; Bandyopadhyay S; Adomavicius G; Johnson PE; Vazquez-Benitez G; O’Connor PJ Adapting Machine Learning Techniques to Censored Time-to-Event Health Record Data: A General-Purpose Approach Using Inverse Probability of Censoring Weighting. J Biomed Inform 2016, 61, 119–31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 114.Libbrecht MW; Noble WS Machine Learning Applications in Genetics and Genomics. Nat Rev Genet 2015, 16, 321–32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 115.Mitchell JB Machine Learning Methods in Chemoinformatics. Wiley Interdiscip Rev Comput Mol Sci 2014, 4, 468–481. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 116.Stalring JC; Carlsson LA; Almeida P; Boyer S Azorange - High Performance Open Source Machine Learning for Qsar Modeling in a Graphical Programming Environment. J Cheminform 2011, 3, 28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 117.Urbina F; Lowden CT; Culberson JC; Ekins S Megasyn: Integrating Generative Molecule Design, Automated Analog Designer and Synthetic Viability Prediction. Submission date 2021-09-30, 10.33774/chemrxiv-2021-nlwvs. (accessed 2021-12-20). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 118.Blaschke T; Olivecrona M; Engkvist O; Bajorath J; Chen H Application of Generative Autoencoder in De Novo Molecular Design. Mol Inform 2018, 37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 119.Prykhodko O; Johansson SV; Kotsias PC; Arus-Pous J; Bjerrum EJ; Engkvist O; Chen H A De Novo Molecular Generation Method Using Latent Vector Based Generative Adversarial Network. J Cheminform 2019, 11, 74. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.