

ABSTRACT
Appropriate nomenclature for all pharmaceutical substances is important for clinical development, licensing, prescribing, pharmacovigilance, and identification of counterfeits. Nonproprietary names that are unique and globally recognized for all pharmaceutical substances are assigned by the International Nonproprietary Names (INN) Programme of the World Health Organization (WHO). In 1991, the INN Programme implemented the first nomenclature scheme for monoclonal antibodies. To accompany biotechnological development, this nomenclature scheme has evolved over the years; however, since the scheme was introduced, all pharmacological substances that contained an immunoglobulin variable domain were coined with the stem -mab. To date, there are 879 INN with the stem -mab. Owing to this high number of names ending in -mab, devising new and distinguishable INN has become a challenge. The WHO INN Expert Group therefore decided to revise the system to ease this situation. The revised system was approved and adopted by the WHO at the 73rd INN Consultation held in October 2021, and the radical decision was made to discontinue the use of the well-known stem -mab in naming new antibody-based drugs and going forward, to replace it with four new stems: -tug, -bart, -mig, and -ment.
KEYWORDS: International Nonproprietary Name (INN), nomenclature scheme, safety, pharmaceuticals, biologics, biological drugs, antibodies, therapeutic antibodies, antibody-based drugs, antibody-drug conjugates
Principles of INN classification
In 1953, the World Health Organization (WHO) established the International Nonproprietary Names (INN) Expert Group to assign nonproprietary names that are unique and globally recognized for pharmaceutical substances (chemical or biological). The existence of such an international nomenclature system is important for clear identification, safe prescription, communication and exchange of information for pharmaceutical products among healthcare professionals and scientists worldwide. These unique names, known as INN, must be distinctive in sound and spelling and easily pronounceable, but also distinctly different from names classified under class 5 of Nice Classification (NCL) and other common names.1,2
INN for pharmacologically and/or structurally related substances are grouped into classes by sharing the same common “stem”. This facilitates the recognition of similar pharmacological activity and/or structure. Stems are a string of letters that can be used as a prefix, infix, or suffix, though most INN stems are suffixes. The suffixes -ase for “enzyme” and -tide for “peptides and glycopeptides” are examples of biological stems used in INN. A fantasy (i.e., meaningless) prefix is added to the stem for identification of individual substances with different structures.3
Over the years, the INN nomenclature system has been continuously adapted and revised to encompass scientific developments in drug discovery and clinical practice. The majority of chemical substance classes are identified by a stem only, but there are some stems that also contain infixes, such as -ast for “anti-allergic or anti-inflammatory, not acting as anti-histaminics” (e.g., -lukast, – milast and -tegrast), -tinib for “tyrosine kinase inhibitors” (e.g., -brutinib, -citinib and -metinib) and vir for “antivirals” (e.g., -asvir, -ciclovir and -previr).3 With the advent of recombinant DNA biotechnology, many biological substances that are much larger and have greater complexity and diversity than chemicals have been produced. The stem alone was therefore not considered to be sufficiently descriptive for the INN for the majority of biological substances. Thus, the INN nomenclature for most biological substances is based on stems and infix(es) as well as the fantasy prefix.4
General INN policies have been formulated for several groups of biological substances. There are some biological groups that do not have an INN, such as natural blood products, skin substitutes, and traditional vaccines.5 Conversely, examples of biological groups with clear general policies for assigning an INN are monoclonal antibodies, fusion proteins with more than one pharmacologically active component and substances for cell and gene therapy.4
Monoclonal antibodies as active pharmaceutical substances
The feasibility and practicality of producing monoclonal antibodies with predefined specificity was first described by Köhler and Milstein in 1975.6 The huge clinical potential of these monoclonal antibodies was clearly apparent. However, problems with efficacy and safety of the early mouse and rat hybridoma-obtained products had to be overcome.
Following much research and development, a monoclonal antibody named Orthoclone OKT3 was approved by the United States Food and Drug Administration (US FDA) in 1986, making it the first monoclonal antibody to be approved anywhere for clinical use in humans.7 Soon after, the antibody was approved by many other regulatory agencies. Following this, several more hybridoma-derived monoclonal antibodies from a range of species were approved for therapeutic and in-vivo diagnostic clinical use. The problems of unwanted immunogenicity and low immunobiological function of non-human monoclonal antibodies when used in human recipients prompted the production of human monoclonal antibodies, but this proved technically difficult. As an alternative approach, recombinant DNA (rDNA) technology was initially used to prepare chimeric (e.g., immunoglobulin G (IgG) with mouse variable domains fused to a human constant region) followed by humanized monoclonal antibodies (e.g., human IgG with grafted mouse complementarity-determining regions (CDRs)). Later, entirely human sequence monoclonal antibodies were produced using a variety of technologies, ranging from natural or synthetic libraries of human antibodies (e.g., selected by phage display) to animal species carrying a human immunoglobulin locus (e.g., transgenic mice or rats). These antibodies are then typically expressed as recombinant proteins from eukaryotic cell culture. Many such monoclonal antibodies have been approved for use in humans and animals for a very broad range of clinical indications.8
More recently, a great variety of different antibody-based substances have been produced, ranging from small antibody fragments (e.g., single-chain fragment variable (scFv)), or antibody domains (e.g., variable domain of the heavy-chain-only camelid antibodies), to large immunoglobulin fusion constructs (e.g., IgG-2scFv). These constructs can be mono-, bi-, or multi-specific. An immunoglobulin can also be conjugated to a chemical payload to create an antibody-drug conjugate (ADC) or it can be fused to a protein with appropriate effector functions.
The first INN for a monoclonal antibody
Following the approval of Orthoclone OKT3, the INN Programme received an INN request for this substance in 1987 with the requested INN “muromonab-CD3”; this reflected the facts that the monoclonal antibody targets the CD3 complex and the name is an abbreviation of ‘murine monoclonal antibody’. At this time, the name muromonab-CD3 was already being widely used ‘unofficially’ in the medical and scientific literature prior to its submission to the INN program. Owing to this and despite the fact that numbers and hyphenated constructs are to be avoided according to the INN General principles for guidance in devising INN for pharmaceutical substances,9 the INN Expert Group confirmed muromonab-CD3 as the INN for this substance.10 However, it was made clear that this decision would not be considered a precedent for naming future monoclonal antibodies and no further products were named similarly. The reasoning in the INN General Principles for Guidance in devising INN for pharmaceutical substances for avoiding numbers, hyphens, and such is that when used in a medical prescription, or when spoken, they can be easily confused with the dose or frequency of use.9,11
The first official INN scheme for monoclonal antibodies
The clear importance of monoclonal antibodies as medicinal substances and the receipt of several requests for INN for new monoclonal antibodies indicated that a formal nomenclature system for monoclonal antibodies was urgently required. However, the creation of a comprehensive, appropriate INN system for monoclonal antibodies was challenging. The assignment of an INN is intended for a dual purpose: first to identify a substance in an unequivocal manner and second to convey information to healthcare professionals regarding the activity of the substance. For monoclonal antibodies, considering their considerable heterogeneity and diverse properties, the latter was particularly difficult. After in-depth discussion, the INN Expert Group agreed that the general stem for monoclonal antibodies would be -mab and this stem would refer to a class of substances that are grouped together based on a common biochemical structure, but it would not convey any pharmacological-activity information.
Since the information that the one-syllable stem -mab can convey is limited, it was considered necessary to add further information as infixes, as had been agreed for other groups of substances. It was decided to include two such infixes, one describing the disease context or target class, and a second that would refer to the source from which the antibody was derived, as had been the case for the first monoclonal antibody given an INN. The first eight INN using this new nomenclature scheme, which was approved at the 21st INN Consultation held in Geneva in April 1991, were biciromab, dorlimomab aritox, imciromab, maslimomab, nebacumab, sevirumab, telimomab aritox, and tuvirumab.12 Many more were to follow over subsequent years. The scheme was expanded and modified slightly over time as presented in Table 1. The most used infixes, -xi- and -zu- for ”chimeric” and ”humanized” monoclonal antibodies, respectively, were introduced during this time. For ADCs, the INN is made up of two words, the first for the antibody part following the established unconjugated monoclonal antibody scheme, and the second for the payload. For instance, for monoclonal antibodies conjugated to a toxin, the suffix -tox is used in the second word (e.g., dorlimomab aritox), and for monoclonal antibodies conjugated to a maytansinoid derivative, the stem -tansine is used in the second word (e.g., trastuzumab emtansine). If the monoclonal antibody is radiolabelled, the radioisotope is listed first in the INN (e.g., technetium (99mTc) nofetumomab merpentan). This scheme was used up to the 48th INN Consultation held in Geneva in March 2009.13
Table 1.
INN monoclonal antibody nomenclature scheme used up to 48th INN consultation held in Geneva during March 2009
| Prefix | Infix for disease or target class | Infix for source | Suffix |
|---|---|---|---|
| Random |
-ba(c)- for bacterial -ci(r)- for cardiovascular -fung- for fungal -ki(n)- for interleukin -le(s)- for inflammatory lesions -li(m)- for immunomodulator -os- for bone -vi(r)- for viral -co(l)- for colon tumor -go(t)- for testis tumor -go(v)- for ovary tumor (gonadal) -ma(r)- for breast tumor -me(l)- for melanoma -pr(o)- for prostate tumor -tu(m)- for miscellaneous tumors |
-a- for rat -axo- for rat-murine hybrid -e- for hamster -i- for primate -o- for mouse -u- for human -xi- for chimeric -zu- for humanized |
-mab |
The second scheme for INN for monoclonal antibodies
The field of monoclonal antibodies continued to evolve rapidly and the INN Programme received an increasing number of requests for monoclonal antibodies (Figures 1 and 2). The stem -mab, which had originally been intended for ‘conventional’ monoclonal antibodies, such as those produced by hybridoma technology, was now increasingly being used for more recently developed, rDNA-produced immunoglobulins with novel formats, as well as antibody fragments and variants with amino acid changes that often diverged from conventional antibodies. By 2009, it was clear that the definition of the stem -mab needed to be expanded so that it would include all substances that contained an immunoglobulin variable domain that binds to a defined target, whether it was a complete monoclonal antibody, a fragment, or another rDNA construct within this definition.
Figure 1.

‘The number of published INN through the years: totals, biologicals, and monoclonal antibodies.
Figure 2.
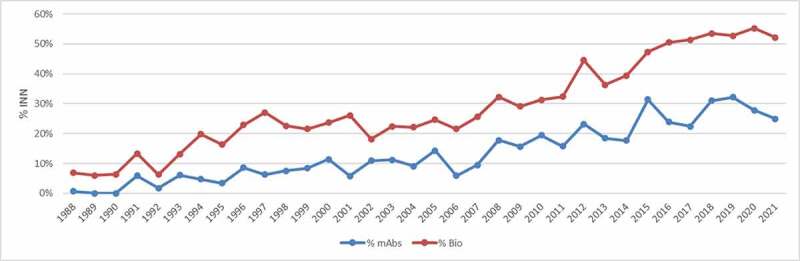
Percentage of published INN for biological requests and monoclonal antibodies through the years.
It was also noticed that some infixes were being used very frequently, like the source infixes -zu-, -o- and -u- for ”humanized”, ”mouse” and ”human”, respectively, and the target infixes -li(m)- and -tu(m)- for ”immunomodulator” and ”tumor”, respectively, creating popular suffixes such as -lizumab, -tumomab, -tumumab, and -tuzumab. However, other infixes were used infrequently or never, e.g., the source infixes -a-, -e- and -i-, for ”rat”, ”hamster”, and ”primate”, respectively, and the target infixes -go(t)- for ”tumor (testis)” and -ma(r)- for ”tumor (mammary)”.
This fact, and the issue of the ever-increasing number of applications for substances using the -mab stem was making the selection of “user friendly” (i.e., pronounceable) INN very difficult. It was therefore decided to modify the scheme officially to include the new definition of -mab and shorten some of the commonly used infixes. This latter modification was intended to help with shortening the INN for monoclonal antibodies and, where necessary, to allow for longer fantasy prefixes. Examples are -li(m)- became -l(i)- and -fung- was shortened to -f(u)-. The ‘source’ infix also needed redefining as ‘the species on which the immunoglobulin sequence of the monoclonal antibody is based’, rather than the source from which the antibody was derived, to take account of evolving changes in monoclonal antibody technology. Table 2 shows the revised INN nomenclature scheme for monoclonal antibodies implemented in November 2009 and is reflected in the INN for monoclonal antibodies published subsequently.
Table 2.
INN monoclonal antibody nomenclature scheme adopted at the 49th INN Consultation held in Geneva during November 2009, which includes names published from Proposed INN List 103 up to 117
| Prefix | Infix for the target class | Infix for the species | Suffix |
|---|---|---|---|
| Random | -am(i)- for serum amyloid protein (SAP) / amyloidosis -b(a)- for bacterial -c(i)- for cardiovascular -f(u)- for fungal -gr(o)- for skeletal muscle mass-related growth factors and receptors -k(i)- for interleukin -l(i)- for immunomodulator -n(e)- for neural -s(o)- for bone -t(u)- for tumor -tox(a)- for toxin -v(i)- for viral |
-a- for rat -axo- for rat-murine hybrid -e- for hamster -i- for primate -o- for mouse -u- for human -vet- for veterinary use -xi- for chimeric -xizu- for chimeric-humanized -zu- for humanized |
-mab |
Although most monoclonal antibodies are glycosylated, their INN does not include a terminal Greek letter as for other glycoproteins. It was decided that if an INN application was received for a monoclonal antibody with the same amino acid sequence as an existing INN, but with differences in the glycosylation pattern, a terminal Greek letter, starting from beta, would be added to the later INN, such as for adalimumab beta.14
The source infix is discontinued
From 2009 to 2015 the INN nomenclature scheme for monoclonal antibodies remained unchanged, but the definitions of ‘chimeric’ and ‘humanized’ were updated in 2011 and 2014 (Table 3). During this period, the INN Programme received criticisms regarding the designation of the source infix.15 While at its inception, the source infixes could be derived from how the antibody was constructed, progress in engineering technologies blurred molecular distinctions. Therefore, for a time, sequence identity to human was used to assign the infix. In parallel, the source infix was becoming clinically less relevant with no direct correlation between identity to human and safety profile.16,17 Nevertheless, differences had emerged in the perception of ”human” (-u-) versus ”humanized” (-zu-) versus ”chimeric” (-xi-) antibodies, leading some manufacturers to use the source infix as a marketing tool. It was claimed that some manufacturers were designing antibodies in a way that would guarantee the adoption of the perceived ‘better’ -zu- or -u- infix rather than the ‘undesirable’ -xi- or other infixes despite there being several very successful chimeric monoclonal antibody products, such as rituximab, infliximab, and cetuximab. As there is no scientific basis for considering any infix per se superior to any other, this practice was undesirable and not condoned by the WHO INN Secretariat or the INN Expert Group. For the reasons noted above and because it was still proving difficult to select clearly distinguishable INN owing to overcrowding of the -mab category, the source-infix was discontinued in 2016, although the “source” would continue to be specified in the definition paragraph of the INN. It was also recommended that the letters ‘u’, ‘o’ and the syllables ‘xi’ and ‘zu’ should be avoided in direct combination with the stem -mab, to avoid inconsistencies and conflicts with the previous nomenclature schemes, although these letters could still be used within the random prefix of the INN. Consequently, it was found necessary to alter certain target infixes; for example, the infix -t(u)- was discontinued and replaced by -ta-. Table 4 shows the nomenclature scheme for monoclonal antibodies that was recommended in 2016 and used until the 72nd INN Consultation in April 2021.
Table 3.
Definitions of chimeric and humanized antibody
| Year | Definition | |
|---|---|---|
| Chimeric | 2009 | A chimeric antibody is one that contains contiguous foreign-derived amino acids comprising the entire variable domain of both heavy and light chains linked to heavy and light constant regions of human origin. |
| 2011 | A chimeric antibody is one of which both chain types are chimeric as a result of antibody engineering. A chimeric chain is a chain that contains a foreign variable domain (V-D-J-REGION) (originating from one species other than human, or synthetic) linked to a constant region (C-REGION) of human origin. | |
| 2014 | A chimeric antibody is one for which both chain types are chimeric as a result of antibody engineering. A chimeric chain is a chain that contains a foreign variable domain (originating from one species other than human, or synthetic or engineered from any species including human) linked to a constant region of human origin. The variable domain of a chimeric chain has a V region amino acid sequence which, analyzed as a whole, is closer to non-human species than to human. | |
| Humanized | 2009 | A humanized antibody has segments of foreign-derived amino acids interspersed among variable domain segments of human-derived amino acid residues and the humanized variable heavy and variable light domains are linked to heavy and light constant regions of human origin. |
| 2011 | A humanized antibody is one of which both chain types are humanized as a result of antibody engineering. A humanized chain is a chain in which the complementarity determining regions (CDR) of the variable domains are foreign (originating from one species other than human, or synthetic) whereas the remaining chain is of human origin. By extension an antibody is described as humanized if more recent protocols were used for the humanization. | |
| 2014 | A humanized antibody is one for which both chain types are humanized as a result of antibody engineering. A humanized chain is typically a chain in which the complementarity determining regions (CDR) of the variable domains are foreign (originating from one species other than human, or synthetic) whereas the remainder of the chain is of human origin. Humanization assessment is based on the resulting amino acid sequence, and not on the methodology per se, which allows protocols other than grafting to be used. The variable domain of a humanized chain has a V region amino acid sequence which, analyzed as a whole, is closer to human than to other species. |
Table 4.
INN monoclonal antibody nomenclature scheme adopted at the 64th INN Consultation held in Geneva on 4–7 April 2017, which includes names published from Proposed INN List 118 up to 126
| Prefix | Infix for target class | Suffix | |
|---|---|---|---|
| Random | -ami- | Serum amyloid protein (SAP)/amyloidosis | -mab |
| -ba- | Bacterial | ||
| -ci- | Cardiovascular | ||
| -de- | Metabolic or endocrine pathways | ||
| -fung- | Fungal | ||
|
-gros- |
Skeletal muscle mass-related growth factors and receptors | ||
| -ki- | Interleukin | ||
| -li- | Immunomodulator | ||
| -ne- | Neural | ||
| -os- | Bone | ||
| -ta- | Tumor | ||
| -toxa- | Toxin | ||
| -vet- | Veterinary use | ||
| -vi- | Viral | ||
Discontinuing the stem “-mab” and its replacement with four new stems
By 2021, the very large number of INN requests for monoclonal antibodies, and thus an overcrowding of the name-space of INN with the stem -mab, as discussed above, led to adoption of very long names. Additionally, continued re-definition over its long period of use led to serious reservations concerning its current and future suitability. The meaning of -mab was no longer always clear for all stakeholders, as it was now being used for a great variety of different structures. These range from small immunoglobulin fragments to large molecules containing multiple antigen binding sites, but often with little similarity to conventional immunoglobulins. It is acknowledged that the stem -mab is very well known, easily recognized, and is ‘popular’. To date there are 879 INN ending in -mab, and this limits the number of sufficiently distinct future INN that can be created and names that cannot easily be distinguished increases the risk of medication errors.
It was therefore decided to discontinue the use of the stem -mab and to divide this group of substances into four different groups, with four new stems,18 to avoid any confusion between the monoclonal antibodies named according to the old nomenclature and those named according to the new nomenclature. The four new stems cover all the prior uses of stem -mab.
From a clinical point of view, for healthcare professionals, classification is useful if it can predict therapeutic activity and/or adverse event profiles. Within the group of monospecific monoclonal antibodies, various engineering techniques have been developed with the aim of increasing efficacy and reducing undesirable effects, such as immunogenicity. Furthermore, antibody fragments are being developed where the Fc part is neither needed nor desired, e.g., to achieve better diffusion and target access. Taken together, these developments have led to monospecific monoclonal antibodies being split into three distinct subgroups. Another new stem is applied to multispecific antibodies, including bispecifics that can bind to two different cells, e.g., cancer cells and immune cells, such as T lymphocytes. The antibody, by bringing these two types of cells together, thus facilitates the elimination of cancer cells by T lymphocytes. Blinatumomab was the first antibody in this class and was authorized in November 2015 for the treatment of acute lymphoblastic leukemia. Bispecific and multispecific antibodies can also bind to different epitopes on the same cell type or to different soluble factors (e.g., emicizumab, faricimab). The four new groups (three monospecific and one bi- and multispecific) described below, and illustrated by examples in Figure 3, are thus designed to map potential clinical correlates of these drug substances.
Figure 3.

Schematic figures of some possible formats that -tug, -bart, -ment and -mig stems can have. VH, variable heavy; CH1, constant heavy 1; CH2, constant heavy 2; CH3, constant heavy 3; VL, variable light; CL, constant light; VHH, camelid heavy chain-only; “red dot” and;*, modification; blue tones, single specificity; magenta tones, single specificity, but different than the one represented in blue tones.
-tug for “unmodified immunoglobulins”
The suffix -tug is used for monospecific full-length immunoglobulins with unmodified constant regions and identical sets of CDRs that recognize the same epitope. This includes monospecific full-length immunoglobulins of any species and of any class (IgG, IgA, IgM, IgD, and IgE), for which the amino acid sequence of the constant region of the heavy and light chains is encoded by a single naturally occurring allele. However, they may have engineered glycans and/or deleted C-terminal lysine codon (introduced for homogeneity since this is generally clipped in vivo and often during expression). Basically, this group includes all natural immunoglobulin molecules (which might occur as such in humoral responses of the immune system, including the Camelidae heavy-chain-only antibodies), as well as chimeric and humanized antibodies. It also includes immunoglobulins that use identical sets of CDRs to target multiple different epitopes or molecules.
-bart for “artificial immunoglobulins”
The suffix -bart is used for monospecific full-length immunoglobulins with engineered amino acid changes in the constant regions and identical sets of CDRs that recognize the same epitope. This includes monospecific full-length immunoglobulins of any species and of any class (IgG, IgA, IgM, IgD, IgE) that contain any amino acid change introduced by engineering for any reason anywhere in the constant regions, including hinge (e.g., IGHG4 hinge with Serine>Proline amino acid change), new glycan attachment site, mixed allelic variants that would not occur in nature, altered complement binding, altered neonatal Fc receptor (FcRn) binding, altered fragment crystallizable (Fc)-gamma receptor binding, and stabilized IgA. It also includes immunoglobulins with attachments of further variable domains with identical CDRs and that recognize the same epitope.
-ment for “immunoglobulin fragments”
The suffix -ment is used for monospecific fragments of any kind that do not fall under stem -tug or -bart, containing at least one immunoglobulin variable domain that contributes to binding, and feature a complete, partial, or absent constant region (e.g., monospecific immunoglobulin-derived constructs without an Fc domain, scFv-Fc constructs).
-mig for “multi-specific immunoglobulins”
The suffix -mig is used for bispecific and multispecific immunoglobulins, regardless of the format (conventional or engineered), type (full-length or fragments), or shape (extensions or not). This group includes immunoglobulins with a bi- or multi-specificity conferred by different variable domains with different sets of CDRs. It does not include monoclonal antibodies that have multiple specificities through a single set of CDRs (cross-reactivity, e.g., bimekizumab).
Further changes to infixes
Following the radical changes made to the stem(s) detailed above, the suitability and need for the current infixes was also evaluated. Should the precedent of discontinuing the source prefix mentioned above be also applied to the disease/target infix; or should more of the latter be introduced for greater clarity and diversity of INN? The conclusion from this discussion was that some infixes are useful, informative and should be retained, such as -ba-, -fung-, -toxa-, -vet- and -vi-, but others were less useful and poorly defined (e.g., -li- for “immunomodulating”). However, it would be confusing to continue using infixes for some INN, but not for others. It was also acknowledged that some infixes provide an indication of therapeutic utilization and side effects associated with particular types of monoclonal antibodies, and this is clinically useful.
It was subsequently decided to continue using infixes in the monoclonal antibody nomenclature scheme, but that they should be well defined, informative, and useful. The overused and nebulous infix -li- for “immunomodulatory” targets was discontinued and replaced by two new infixes that indicate the direction of the immunological action: -sto- for ”immunostimulatory” monoclonal antibodies and -pru- for ”immunosuppressive” monoclonal antibodies. The infix -ki-, which originally identified an ”interleukin” as the target for a monoclonal antibody was expanded to include all ”cytokines and cytokine receptors” (both membrane bound and soluble forms). The infix -gro- was slight modified and its definition was also expanded; previously it was -gros- to identify ”skeletal muscle mass-related growth factors and receptors”, while now it is -gro- to identify ”growth factors and growth factor receptors”.
Most infixes used in the new scheme are unchanged from those adopted for the 2016 modified system (Table 5). It is acknowledged that the mechanisms of action of monoclonal antibodies are complex, that it may be different for different indications, and that this might not be completely understood during the development phase. Therefore, the disease/target infix is assigned according to the applicant’s proposed known mode of action at the time of the INN request.
Table 5.
INN monoclonal antibody nomenclature scheme adopted at the 73rd INN Consultation held in Geneva during October 2021
| Prefix | Infix for target class | Suffix | |
|---|---|---|---|
| Random | -ami- | Serum amyloid protein (SAP)/amyloidosis |
-tug -bart -mig -ment |
| -ba- | Bacterial | ||
| -ci- | Cardiovascular | ||
| -de- | Metabolic or endocrine pathways | ||
| -eni- | Enzyme inhibition | ||
| -fung- | Fungal | ||
| -gro- | Growth factor and growth factor receptor | ||
| -ki- | Cytokine and cytokine receptor | ||
| -ler- | Allergen | ||
| -sto- | Immunostimulatory | ||
| -pru- | Immunosuppressive | ||
| -ne- | Neural | ||
| -os- | Bone | ||
| -ta- | Tumor | ||
| -toxa- | Toxin | ||
| -vet- | Veterinary use | ||
| -vi- | Viral | ||
Antibody-drug conjugates
The class of ADCs will remain and the definitions used in reforming the -mab scheme will be applied, with all new monoclonal antibody-drug applications being named based on the antibody part, using the four new stems, and with the conjugated drug name as the second word, as before.
Monoclonal antibodies as components of fusion proteins
The INN Programme defines a fusion protein as “a multifunctional protein derived from a single nucleotide sequence which may contain two or more genes or portions of genes with or without amino acid linker sequences. The genes should originally code for separate proteins, with at least two of them endowed with pharmacological action (e.g., action and targeting)”. Such substances can be made up of a great variety of different component structures and can be used for a large array of clinical indications. The suffix -fusp for fusion protein was adopted in 2017. A detailed description of the INN scheme for fusion proteins is beyond the remit of this publication. For further information, see ref. 19. Full-length monoclonal antibodies or antibody fragments/related substances often comprise parts of fusion proteins. Initially, these were given an INN using the -mab stem, but this was soon considered unsatisfactory and replaced by the -fusp stem when it was adopted. In the current scheme, fusion proteins containing a monoclonal antibody component as the targeting moiety are given an -a- infix (e.g., tebentafusp, bintrafusp alfa). Other infixes are used for other components of the fusion protein. Fusion proteins containing IgG Fc are commonly produced to enhance the half-life of the non-IgG component. These substances are given an INN with the ef- prefix to indicate the non-targeting Fc component (e.g., eftrenonacog alfa).
Monoclonal antibodies as components of substances for cell-based gene therapy
With the advent of new technologies, monoclonal antibody components can also be present in substances for cell-based gene therapy, as it is the case of chimeric antigen receptor (CAR) T-cell therapies. The CAR construct used in conventional CAR-T cells is composed of a scFv consisting of an antibody variable heavy (VH) and variable light (VL) domains. These substances do not follow the INN monoclonal antibody nomenclature scheme, instead they follow the INN nomenclature scheme for substances for cell-based gene therapy. A two-word name is given to these substances, in which the first word is identified with the suffix -gene and refers to the gene component, and the second word is identified with the suffix -cel and refers to the cell component. In the specific case of the CAR T-cell therapies named so far, the first word contains the gene infix -cabta- for “cell-expressed antibody and T-cell activation” (e.g., lisocabtagene maraleucel). A detailed description of the INN scheme for substances for cell-based gene therapy is beyond the remit of this publication. For further information, see refs. 4 and 20.
Engineered or synthetic scaffold proteins with non-immunoglobulin variable domain-derived binding domains
Recent advances in technology have allowed the production of engineered or synthetic scaffold proteins with non-immunoglobulin variable domain-derived binding domains. These engineered non-immunoglobulin variable domain scaffolds are not monoclonal antibodies, but they share the capacity to bind antigens. Although, they are sometimes described as ‘antibody mimetics’, they share little, if any, structural homology with monoclonal antibodies and their synthesis does not result from a V-D-J gene rearrangement, which is the hallmark of the variable domains of the antigen receptors (immunoglobulins or antibodies and T cell receptors). For these types of proteins, the suffix -bep has been adopted by the INN Expert Group.
Monoclonal antibodies: prescribers and patients
A major use of INN is for prescribing drugs. As of early 2022, 114 monoclonal antibodies with approved INN are actively marketed. This represents 13% of the total number of monoclonal antibodies with an INN. The clinical indications that are suitable for treatment with monoclonal antibodies are quite varied (Figure 4). The number of monoclonal antibodies within each clinical group also varies. Several modifications to the INN monoclonal antibody scheme have been driven at least in part by prescribing issues, e.g., division of -mab stem into four groups and subdivision of -li- infix.
Figure 4.

Caption: Marketed INN for monoclonal antibodies by target infix.
Conclusions, afterthoughts, and future challenges
INN for monoclonal antibodies have been assigned for many years with few significant unresolvable problems arising and with a broad acceptance in naming. However, the system has required several modifications and adaptations to take account of scientific and technological progress in monoclonal antibody production and the ever-increasing numbers of applications for such INN in order to remain useful and practicable. Although some monoclonal antibodies are very successful products, most monoclonal antibodies that receive an INN fail in clinical trials, including at the Phase 3 stage. Indeed, only 10–15% of those named have been approved in Europe or the United States. This indicates that many INN given for such monoclonal antibodies are effectively never used clinically, as the products they represent never reach the marketing stage. It would be impossible and dangerous to re-use such names, and so they remain assigned but in ‘limbo’, still being part of over-crowding of the name space, which increases the difficulties of formulating distinctive new INN for monoclonal antibodies.
It is hoped that the radical new changes to the monoclonal antibody INN system implemented recently and detailed above, will address this problem and update and improve the INN procedure, and that the present scheme will remain in use for some time. However, the adaptable and flexible approach adopted by the INN Expert group will allow any future necessary modifications to be made with relative ease. Modifications to INN schemes are not implemented retrospectively. To do so would be confusing and dangerous to drug (or medication) safety and existing INN will remain as they were originally assigned.19,20
Acknowledgments
We thank Dr Marjorie Shapiro, US FDA, Center for Drug Evaluation and Research, Dr David Lewis, US FDA, Center for Drug Evaluation and Research, Dr Gail Karet, USAN Program, and Dr Ursula Loizides, INN Unit, WHO, for their helpful comments and contribution to the discussions. We also would like to thank abYdraw and IMGT for their contribution in the monoclonal antibody analysis and representations.
The authors report that there are no competing interests to declare.
Funding Statement
The author(s) reported there is no funding associated with the work featured in this article.
List of abbreviations
ADC antibody-drug conjugate
CAR chimeric antigen receptor
CDR complementarity-determining region
Fc fragment crystallizable
FcRn neonatal Fc receptor
Ig Immunoglobulin
INN International Nonproprietary Names
NCL Nice Classification
rDNA recombinant DNA
scFv single-chain fragment variable
U.S. FDA United States Food and Drug Administration
VH variable heavy
VL variable light
WHO Programme of the World Health Organization
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- 1.World Intellectual Property Organization. About the nice classification. [accessed 2022 April 27]. https://www.wipo.int/classifications/nice/en/preface.html
- 2.World Intellectual Property Organization. Class 5 of nice classification. [accessed 2022 April 27]. https://www.wipo.int/classifications/nice/nclpub/en/fr/?class_number=5
- 3.The use of stems in the selection of International Nonproprietary Names (INN) for pharmaceutical substances. Geneva (Switzerland): World Health Organization; 2018. [accessed 2022 April 27]. https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/stembook-2018.pdf [Google Scholar]
- 4.International Nonproprietary Names (INN) for biological and biotechnological substances (a review). Geneva (Switzerland): World Health Organization; 2019. [accessed 2022 April 27]. https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/bioreview2019.pdf [Google Scholar]
- 5.Robertson JS, Loizides U, Adisa A, López de la Rica Manjavacas A, Rodilla V, Strnadova C, Weisser K, Balocco R.. International Nonproprietary Names (INN) for novel vaccine substances: a matter of safety. Vaccine. 2022;40(1):21–9. doi: 10.1016/j.vaccine.2021.11.054. PMID: 34844820 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Köhler G, Milstein C. Continuous cultures of fused cells secreting antibody of predefined specificity. Nature. 1975;256(5517):495–97. doi: 10.1038/256495a0. [DOI] [PubMed] [Google Scholar]
- 7.Ecker DM, Jones SD, Levine HL. The therapeutic monoclonal antibody market. MAbs. 2015;7(1):9–14. doi: 10.4161/19420862.2015.989042. PMID: 25529996 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.The Antibody Society. Therapeutic monoclonal antibodies approved or in review in the EU or US. [accessed 2022 April 27]. https://www.antibodysociety.org/resources/approved-antibodies/
- 9.International nonproprietary names: revised procedure. Geneva (Switzerland): World Health Organization; 2004. [accessed 2022 April 27]. https://apps.who.int/gb/archive/pdf_files/EB115/B115_11-en.pdf [Google Scholar]
- 10.WHO Drug Information. Vol. 2 (2), List 59 of proposed International Nonproprietary Names (INN) for pharmaceutical substances. Geneva (Switzerland): World Health Organization; 1988. [accessed 2022 April 27]. https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/pl59.pdf [Google Scholar]
- 11.Guidance on the use of international nonproprietary names (INNs) for pharmaceutical substances. Geneva (Switzerland): World Health Organization; 2017. [accessed 2022 April 27]. https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/who-pharm-s-nom-1570.pdf [Google Scholar]
- 12.WHO Drug Information. Vol. 5 (4), List 66 of proposed international nonproprietary names (INN) for pharmaceutical substances. Geneva (Switzerland): World Health Organization; 1991. [accessed 2022 April 27]. https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/pl66.pdf [Google Scholar]
- 13.WHO Drug Information. Vol. 23 (4), List 102 of proposed international nonproprietary names (INN) for pharmaceutical substances. Geneva (Switzerland): World Health Organization; 2009. [accessed 2022 April 27] https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/pl102.pdf [Google Scholar]
- 14.WHO Drug Information. Vol. 31 (4). List 118 of proposed International Nonproprietary Names (INN) for pharmaceutical substances. Geneva (Switzerland): World Health Organization; 2017. [accessed 2022 April 27]. https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/pl118.pdf [Google Scholar]
- 15.Jones TD, Carter PJ, Plückthun A, Vásquez M, Holgate RGE, Hötzel I, Popplewell AG, Parren PWHI, Enzelberger M, Rademaker HJ, et al. The INNs and outs of antibody nonproprietary names. MAbs. 2016;8(1):1–9. PMID: 26716992. doi: 10.1080/19420862.2015.1114320. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Baker MP, Reynolds HM, Lumicisi B, Bryson CJ. Immunogenicity of protein therapeutics: the key causes, consequences and challenges. Self Nonself. 2010;1(4):314–22. doi: 10.4161/self.1.4.13904. PMID: 21487506 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Schellekens H. The immunogenicity of therapeutic proteins. Discov Med. 2010;9(49):560–64. PMID: 20587346 [PubMed] [Google Scholar]
- 18.New INN monoclonal antibody (mAb) nomenclature scheme. Geneva (Switzerland): World Health Organization; [accessed 2022 May 11]. https://cdn.who.int/media/docs/default-source/international-nonproprietary-names-(inn)/new_mab_nomenclature-_2021rev.pdf [Google Scholar]
- 19.Robertson JS, Chui WK, Genazzani AA, Malan SF, López de la Rica Manjavacas A, Mignot G, Thorpe R, Balocco R, Rizzi M. The INN global nomenclature of biological medicines: a continuous challenge. Biologicals. 2019;60:15–23. PMID: 31130314. doi: 10.1016/j.biologicals.2019.05.006. [DOI] [PubMed] [Google Scholar]
- 20.Loizides U, Dominici M, Manderson T, Rizzi M, Robertson JS, de Sousa Guimarães Koch S, Timón M, Balocco R. The harmonization of World Health Organization International Nonproprietary Names definitions for cell and cell-based gene therapy substances: when a name is not enough. Cytotherapy. 2021;23(5):357–66. doi: 10.1016/j.jcyt.2021.02.114. PMID: 33820700 [DOI] [PMC free article] [PubMed] [Google Scholar]