

Abstract
One of the major problems in machine learning is data leakage, which can be directly related to adversarial type attacks, raising serious concerns about the validity and reliability of artificial intelligence. Data leakage occurs when the independent variables used to teach the machine learning algorithm include either the dependent variable itself or a variable that contains clear information that the model is trying to predict. This data leakage results in unreliable and poor predictive results after the development and use of the model. It prevents the model from generalizing, which is required in a machine learning problem and thus causes false assumptions about its performance. To have a solid and generalized forecasting model, which will be able to produce remarkable forecasting results, we must pay great attention to detecting and preventing data leakage. This study presents an innovative system of leakage prediction in machine learning models, which is based on Bayesian inference to produce a thorough approach to calculating the reverse probability of unseen variables in order to make statistical conclusions about the relevant correlated variables and to calculate accordingly a lower limit on the marginal likelihood of the observed variables being derived from some coupling method. The main notion is that a higher marginal probability for a set of variables suggests a better fit of the data and thus a greater likelihood of a data leak in the model. The methodology is evaluated in a specialized dataset derived from sports wearable sensors.
1. Introduction
Machine learning models typically receive input data and solve problems such as pattern recognition by applying a sequence of particular transformations. The majority of these transformations turn out to be extremely sensitive to modest changes in input. Under specific scenarios, using this sensitivity can result in a difference in the behavior of the learning algorithm [1, 2]. Adversarial attack is the design of an adequate input in a specific way that leads the learning algorithm to erroneous outputs while not easily noticed by human observers. It is a severe concern in the reliability and security of artificial intelligence technologies. The issue arises because learning techniques are intended for use in stable situations where training and test data are generated from the same, possibly unknown distribution [3]. A trained neural network, for example, represents a significant decision limit corresponding to a standard class. Of course, the restriction is not without flaws. A correctly designed and implemented attack, which corresponds to a modified input form a slightly differentiated dataset, can cause the algorithm to make an incorrect judgment (wrong class) [4–6].
Developing and selecting machine learning methodologies to solve complex, usually nonlinear, problems is inextricably linked to the area of application and the target problem it seeks to solve. This is one of the essential processes of preprocessing the area of interest and the dataset, as the choice of appropriate algorithms depends on not only the nature and dynamics of the problem but also the characteristics of the available data, such as volume, number, and type of variables in question. The preprocessing of the data concerns the tests and the preparation work that should be carried out in the examined dataset before the use and application of machine learning algorithms. This method is critical because if the quality of usage or training data is not ensured, the algorithms' performance will be subpar or the algorithms may produce false results [6, 7].
In general, data preparation/preprocessing entails dealing with scenarios when the original data have issues such as contradicting information, coding discrepancies, field terminology, and units of measurement. However, more critical issues such as the presence of lost values, noise, and extreme values and dealing with special requirements that necessitate data transformation, such as discretization, normalization, dimension reduction, or the selection of the most appropriate features, must be addressed [9–11]. It should be noted that several techniques can be used in preprocessing processes, with the choice of the best strategy arising from the nature of the field of knowledge, the problem to be addressed, the available data, and the machine learning algorithm used.
One of the most critical errors that occur during the preprocessing of data for use by machine learning algorithms is data leakage. The leak in question refers to cases where, inadvertently or even intentionally, the value that the model wishes to predict (dependent variable) is contained indirectly or directly in the features that are called to train the algorithm (independent variables). Any variable that provides transparent information about the value that the model is trying to predict is considered a data leak and leads to fictitious results. An obvious solution to this problem is to apply preprocessing only to the training set. Using preprocessing techniques to the whole dataset will make the model learn the training and the test sets, resulting in a data leak, and thus the model fails to generalize [2, 12, 13].
The major problem of data leakage occurs when there is a severe indirect interaction of features which is not easy to detect. It is, for example, a widespread phenomenon in machine learning experiments; the relationship between the dependent and the independent variable is complex (e.g., polynomial, trigonometric, and so on), so new features may be created that seem to help capture this relationship. Still, in practice, they create serious data leaks [14, 15].
Similarly, combinations may exist between independent and dependent variables through, for example, an arithmetic operation, a modification, or a conversion to make them more important in explaining the discrepancies in the data than if they remained separate. Creating a new opportunity through the interaction of existing features creates data leaks and significant bias in the final machine learning model [4, 7, 11].
For example, Lu et al. [15] developed a weighted context graph model (WCGM) for information leakage, with the critical goals of first increasing the contextual relevance of information, second classifying the tested data based on the commonality characteristics of its context graphs, and third preserving data proprietors' privacy. The weighted context network reduces complexity by using key sensitive phrases as nodes and contextual linkages as edges. The proposed maximum subgraph matching approach and deep learning algorithms are used to evaluate the similarity of the tested information and the pattern, as well as the responsiveness of the tested data to match the converted data better. The proposed model surpassed the competition regarding accuracy, recall, and run time, indicating its ability to detect real-time data leaks.
Using a variety of datasets, Salem et al. [14] provided research on the new and developing danger of membership inference attacks, demonstrating the efficacy of the suggested assaults across sectors. They offer two defensive strategies to alleviate the problem. The first, known as dropout, involves randomly deleting specific nodes in each fully linked neural system training step. In contrast, the second, known as model stacking, involves organizing numerous ML models in a ranked order [16]. Extensive testing has shown that our defensive strategies may significantly lower the performance of a membership inference attempt while retaining a high degree of usefulness, i.e., good target model prediction accuracy. They also suggest a defensive mechanism against a larger class of inclusion inference assaults while maintaining the ML model's high usefulness.
In this work, we proposed an innovative system of leakage prediction in machine learning models, which calculates a lower limit for the marginal probability of the observed variables coming from a coupling method, which shows that in an examined machine learning model, there is data leakage. The methodology is implemented based on the Bayesian inference methodology [17–19]. The model's goal is to generate an analytical approach to the reverse probability of unobserved variables [20, 21], to draw statistical inferences about the important correlated variables, and to compute a lower limit for the marginal likelihood of observable variables generated from a coupling method. The highest probability indicates that there is a data leak [22]. This is done to have a solid and generalized forecasting model, which will produce remarkable forecasting results without data leakages.
2. Proposed Approach
The proposed implementation is based on Bayesian inference [23–25], which is a method of approaching intractable problems that arise in highly fuzzy environments. More specifically, the methodology offers a secure solution for the observed variables and unknown parameters and latent states of variables, characterized by different types of relationships (interconnected, transformed, hidden, random, and so on). A prior distribution, a posterior distribution, and a likelihood function are used to illustrate Bayesian inference [26] in Figure 1.
Figure 1.
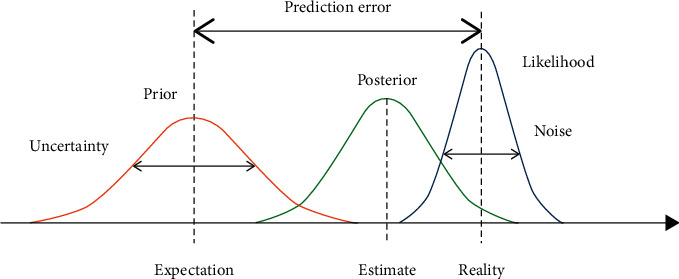
Bayesian inference.
The prediction error is defined as the difference between the previous expectation and the likelihood function's peak (i.e., reality). The variance of the prior is the source of uncertainty. The variance of the likelihood function is referred to as noise [27].
Parameters and latent variables are grouped as “unobserved variables.” So, with the proposed method, the purpose is as follows [28–31]:
In order to generate an analytical approach to the reverse probability of unobserved variables, develop statistical findings for the important correlated variables.
The marginal likelihood of the data presented in the model can be used to derive a lower limit for the marginal probability of the observed data, with the marginalization conducted on unobserved variables. The main notion is that a higher marginal probability for a set of variables suggests a better fit of the data and thus a greater likelihood of a data leak in the model.
An example of information gain vs prediction error is presented in Figure 2.
Figure 2.
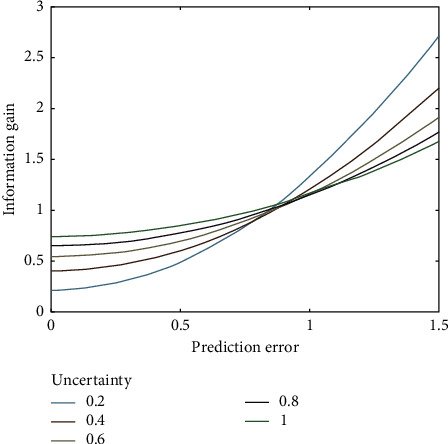
Information gain vs prediction error.
Information gain is calculated mathematically as a function of prediction errors for uncertainty levels ranging from 0.2 to 1.0. The external noise level is set to 0.1 [23, 27].
The method generally approaches a conditional latent variable density given the observed variables where we assume that a mixture is present. Mixing behavior occurs because the source of each observation is unknown, that is, the classification into a specific, exact domain of a variable [32]. Thus, each observation xi is predetermined to each of fi(·∣θi) with probability pi. Depending on the case, the purpose of the inference is to reconstruct the classification of observations into definition fields, construct estimators for the components' parameters, or even estimate the number of components themselves [15]. It is always feasible to map a mixture of k form distributions to a random variable Xi via a delimitation method [25, 33]:
| (1) |
The random variable Zi with {1, 2,…, k}, is as follows [34]:
| (2) |
Next, we assume that we have observed the extended data, which consist of independent pairs with distribution [35]:
| (3) |
In the particular case of the model:
| (4) |
where we consider the same normal a priori distribution in the media, μ1, μ2 ~ N(0,10), we will calculate the ex post weight ω(z) for a classification z, where in the first component are l observations [24, 36]:
| (5) |
So, we have [37]
| (6) |
The ex-weight ω(z) is obtained by completing the above function in RxR for μ1 and μ2, which is a double integral which is easily calculated. For the completion in terms of μ1, excluding the parts that do not contain it, it is enough to calculate [24, 33, 36, 38]
| (7) |
But
| (8) |
So, to calculate the integral, we have
| (9) |
because the last integral is crucial in the full support of the exponential distribution [39]:
| (10) |
For the completion in terms of μ2, excluding the parts that do not contain it, it is enough to calculate [23, 36, 38, 40]
| (11) |
Following the same methodology as before, we conclude that [41]
| (12) |
So, the ex post probability ω(z) is calculated as follows [21, 23, 42, 43]:
| (13) |
If we replace c1, c2, we take the relation:
| (14) |
Thus, from the above analysis, it appears that it is practically possible to arrive at detailed expressions of the maximum probability and Bayes estimators [44] for the ex ante distributions of the variables of interest and thus marginalize the set of variables for models where there is a data leak [28, 33].
3. Experiments and Results
A specialized scenario was implemented to model the proposed system that uses sports wearables data to record the movements of athletes playing beach volleyball. The dataset comprises three-dimensional acceleration data from joint actions of beach volleyball athletes, each of whom was fitted with an accelerometer worn on the wrist and sampled at 39 Hz. The signal was recorded at 14 bits per axis and then compressed to 16 g. The x, y, and z axes relate to the athletes' spatial arrangement, which is recorded in an independent coordinate system based on the sensor configuration, as there was no transfer to real-world coordinates [45, 46]. The 30 athletes recorded ranged in expertise from novice to professional volleyball players. The set's goal is to create an identification and classification system that extracts relevant portions from continuous input and classifies them [47]. The categorization includes ten various volleyball activities, such as homemade service, block, nail, and so on. For the evaluation of the system, 10 characteristics were selected, which were randomly combined into pairs to identify the observed variables, whether they come from a coupling method and whether there is a data leak.
We first describe some key features. Let g(·, ·|θ) be the joint density function of (X, Z) given by the parametric vector θ, f(·|θ) be the density function of X given θ, and k(·|x, θ) be the function density of the bounded distribution of Z given by observations x and θ. The algorithm is based on the use of incomplete data, i.e., we can write the distribution of sample x as follows [1, 2, 40]:
| (15) |
So, logarithm it:
| (16) |
We arrive at a complete (unobserved) logarithm of probability:
| (17) |
where L is the observed logarithm of the probability. The algorithm fills in the missing variables z based on k (z|x, θ) and then maximizes with θ the expected full logarithm probability [21, 25, 48].
So, the algorithm is configured as follows:
)Give some initial values to θ(0).
)For each t, t = 1, 2,…, n, calculate where .
)Maximize concerning θ the and set .
When performing the above algorithm, the result is that in each iteration, the (observed) L(θ|x) increases.
As an application of the above, we consider the particular case of the model of mixing two regular variables, where all parameters are known except θ = (μ1, μ2). For a simulated sample of 500 observations and actual values p=0.7 and (μ1, μ2) = (0, 2.5), the logarithm of probability has two peaks. Applying the algorithm to this model, we have that the total probability is [20, 49, 50]
| (18) |
where its logarithm is
| (19) |
For the first step, we need to calculate
| (20) |
where the mean value is taken for , and we have that Zi are independent of [51–54]
| (21) |
In step t, the expected rankings are equal to
| (22) |
Therefore:
| (23) |
which we maximize in the second step in terms of (μ1, μ2) and get
| (24) |
This example involved running the algorithm 20 times (each time with 100 repeats) while picking random numbers from a range of possibilities for the initial conditions. However, the proposed approach was only drawn to the highest and principal vertex of the logarithm probability eight times out of every 20 times in the experiments. It was drawn to the pseudo-vertex of the logarithm probability distribution for the remaining 12 times (although the likelihood is much lower). The original values were closer to the lower peak than the final values, indicating that the early values were more accurate. The algorithm converges to the pseudo-peak of likelihood, at which point we may make 84 percent correct predictions about the coupling between the variables in the dataset. Accordingly, we will have 93 percent of the variables accurately predicted to couple their coefficients if the algorithm converges to the dominant peak in probability.
4. Discussion and Conclusions
In this work, we proposed an innovative system of leakage prediction in machine learning models, which is based on Bayesian inference, to calculate a lower limit for the marginal probability of the observed variables coming from a coupling method, which shows that in an examined machine learning model, there is data leakage. The methodology is evaluated in a specialized dataset from sports wearable sensors, where the ability of the method to detect variable coupling is demonstrated, even when it is done randomly.
The proposed methodology is a Bayesian approach to statistical discoveries in complicated distributions that are difficult to evaluate directly or by sampling, and this is the methodology that has been offered. It is a method of selection that is different from Monte Carlo sampling methods. While Monte Carlo techniques use a sequence of samples to approximate a rear distribution numerically, the proposed algorithm provides a locally optimal, correct analytical solution, allowing even hidden variable coupling to be found. From the maximum ex post estimate of each variable's unique most probable value to the fully Bayesian estimation that calculates (approximately) the entire rear distribution of parameters and latent variables, the algorithm finds a set of optimal parameters of the interrelated variables, which can then be solved in detail using the information obtained from the data. Indeed, this is true even for conceptually comparable variables, such as a basic nonhierarchical model with only two parameters and no latent variables.
The extension of the methodology can focus on integrating countervailing machine learning techniques to be a complete defense system in case of attacks that attempt to deceive the models by providing misleading information. Determine strategies and procedures for running the model on specified sets of issues with training and test data generated from the same statistical distribution. Moreover, a future expansion of the proposed system will review the taxonomies of the characteristics of transfer learning, particularly whether and how this system can mitigate them. Finally, learning transfer approaches are investigated from known distribution attack methods seeking to exploit the dynamics of categorization decision-making limits.
Data Availability
The data used in this study are available from the corresponding author upon request.
Conflicts of Interest
The author declares that there are no conflicts of interest.
References
- 1.Alam K. M. R., Siddique N., Adeli H. A dynamic ensemble learning algorithm for neural networks. Neural Computing & Applications . 2020;32(12):8675–8690. doi: 10.1007/s00521-019-04359-7. [DOI] [Google Scholar]
- 2.Gawlikowski J. A Survey of Uncertainty in Deep Neural Networks. 2021. http://arxiv.org/abs/2107.03342 .
- 3.Demertzis K., Iliadis L., Kikiras P. A Lipschitz - Shapley Explainable Defense Methodology against Adversarial Attacks. Proceedings of the Artificial Intelligence Applications and Innovations. AIAI 2021 IFIP WG 12.5; June, 2021; Crete, Greece. pp. 211–227. [DOI] [Google Scholar]
- 4.Chauhan R., Shah Heydari S. Polymorphic Adversarial DDoS attack on IDS using GAN. Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC); July. 2020; Shenzhen, China. pp. 1–6. [DOI] [Google Scholar]
- 5.Liu Q., Guo J., Wen C.-K., Jin S. Adversarial attack on DL-based massive MIMO CSI feedback. Journal of Communications and Networks . 2020;22(3):230–235. doi: 10.1109/JCN.2020.000016. [DOI] [Google Scholar]
- 6.Yu P., Song K., Lu J. Generating adversarial examples with conditional generative adversarial net. Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR); August. 2018; Beijing, China. pp. 676–681. [DOI] [Google Scholar]
- 7.Zhu Z.-A., Lu Y.-Z., Chiang C.-K. Generating adversarial examples by makeup attacks on face recognition. Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP); September. 2019; Taipei, Taiwan. pp. 2516–2520. [DOI] [Google Scholar]
- 8.Yu J., Lee Y., Yow K. C., Jeon M., Pedrycz W. Abnormal event detection and localization via adversarial event prediction. IEEE Transactions on Neural Networks and Learning Systems . 2021;(–15):1–15. doi: 10.1109/TNNLS.2021.3053563. [DOI] [PubMed] [Google Scholar]
- 9.Shi Z., Ma Y., Yu X. An effective and efficient method for word-level textual adversarial attack. Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC); September. 2021; Athens, Greece. pp. 1–6. [DOI] [Google Scholar]
- 10.Tang P., Wang W., Lou J., Xiong L. Generating adversarial examples with distance constrained adversarial imitation networks. IEEE Transactions on Dependable and Secure Computing . 2021:p. 1. doi: 10.1109/TDSC.2021.3123586. [DOI] [Google Scholar]
- 11.Tarchoun B., Alouani I., Ben Khalifa A., Mahjoub M. A. Adversarial attacks in a multi-view setting: an empirical study of the adversarial patches inter-view transferability. Proceedings of the 2021 International Conference on Cyberworlds (CW); September. 2021; Caen, France. pp. 299–302. [DOI] [Google Scholar]
- 12.Gattineni P., Dharan G. S. Intrusion Detection Mechanisms: SVM, random forest, and extreme learning machine (ELM). Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA); September. 2021; Coimbatore, India. pp. 273–276. [DOI] [Google Scholar]
- 13.Rathore P., Basak A., Nistala S. H., Runkana V. Untargeted, targeted and universal adversarial attacks and defenses on time series. Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN); July. 2020; Glasgow, UK. pp. 1–8. [DOI] [Google Scholar]
- 14.Salem A., Zhang Y., Humbert M., et al. Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. 2018. http://arxiv.org/abs/1806.01246 .
- 15.Lu Y., Huang X., Ma Y., Ma M. A weighted context graph model for fast data leak detection. Proceedings of the 2018 IEEE International Conference on Communications (ICC); May, 2018; Kansas City, MO, USA. pp. 1–6. [DOI] [Google Scholar]
- 16.Miyatake M., Sawai H., Minami Y., Shikano K. Integrated training for spotting Japanese phonemes using large phonemic time-delay neural networks. International Conference on Acoustics, Speech, and Signal Processing . 1990;1:449–452. doi: 10.1109/ICASSP.1990.115746. [DOI] [Google Scholar]
- 17.Berger J. O. Statistical Decision Theory and Bayesian Analysis . New York, NY, USA: Springer; 1985. Bayesian analysis, Springer Series in Statistics; pp. 118–307. [DOI] [Google Scholar]
- 18.Berger J. O. Statistical Decision Theory and Bayesian Analysis . New York, NY, USA: Springer; 1985. Basic concepts; pp. 1–45. [DOI] [Google Scholar]
- 19.Kingma D. P., Welling M. Auto-Encoding Variational Bayes. 2014. http://arxiv.org/abs/1312.6114 .
- 20.Garrett A. J. M. Review: probability theory: the logic of science. Probability and Risk . 2004;3(3-4):243–246. doi: 10.1093/lawprj/3.3-4.243. [DOI] [Google Scholar]
- 21.Salasar L. E. B., Leite J. G., Louzada F. Likelihood-based inference for population size in a capture-recapture experiment with varying probabilities from occasion to occasion. Brazilian Journal of Probability and Statistics . 2016;30(1):47–69. doi: 10.1214/14-BJPS255. [DOI] [Google Scholar]
- 22.Lü J., Wang P. Modeling and Analysis of Bio-Molecular Networks . Singapore: Springer; 2020. Modeling and analysis of large-scale networks; pp. 249–292. [DOI] [Google Scholar]
- 23.Emma Wang Y., Zhu Y., Ko G. G., Reagen B., Wei G.-Y., Brooks D. Demystifying bayesian inference workloads. Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS); March, 2019; Madison, WI, USA. pp. 177–189. [DOI] [Google Scholar]
- 24.Jun S. Bayesian Inference and Learning for Neural Networks and Deep Learning. Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC); Octobar. 2020; Seoul, Korea. pp. 569–571. [DOI] [Google Scholar]
- 25.Rudong Z., Xianming S., Qian W., Xiaobo S., Xing S. Bayesian inference for ammunition demand based on Gompertz distribution. Journal of Systems Engineering and Electronics . 2020;31(3):567–577. doi: 10.23919/JSEE.2020.000035. [DOI] [Google Scholar]
- 26.Handbook of Statistics. Bayesian Thinking, Modeling and Computation - PDF Free Download. 2022. https://epdf.tips/handbook-of-statistics-volume-25-bayesian-thinking-modeling-and-computation.html .
- 27.Yanagisawa H., Kawamata O., Ueda K. Modeling emotions associated with novelty at variable uncertainty levels: a bayesian approach. 2019;13 doi: 10.3389/fncom.2019.00002. https://www.frontiersin.org/article/10.3389/fncom.2019.00002 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Zhang X.-d. An improved bayesian network inference algorithm. Proceedings of the 2010 Third International Conference on Intelligent Networks and Intelligent Systems; August. 2010; Shenyang, China. pp. 389–392. [DOI] [Google Scholar]
- 29.Yun-Jie J., Wen-Qi C., Ling H. Risk identification and simulation based on the bayesian inference. Proceedings of the 2018 4th Annual International Conference on Network and Information Systems for Computers (ICNISC); April. 2018; Wuhan, China. pp. 407–411. [DOI] [Google Scholar]
- 30.Hou D., Driessen T., Sun H. The Shapley value and the nucleolus of service cost savings games as an application of 1-convexity. IMA Journal of Applied Mathematics . 2015;80(6):1799–1807. doi: 10.1093/imamat/hxv017. [DOI] [Google Scholar]
- 31.Alessandrini G., Hoop M. V. D., Gaburro R., Sincich E. Lipschitz stability for a piecewise linear Schrödinger potential from local Cauchy data. Asymptot. Anal . 2018;108(3):115–149. doi: 10.3233/ASY-171457. [DOI] [Google Scholar]
- 32.Permutation principles for the change analysis of stochastic processes under strong invariance. 2022. https://dl.acm.org/doi/abs/10.5555/1124448.1716910 .
- 33.Barbier J. Overlap matrix concentration in optimal Bayesian inference. Information and Inference: A Journal of the IMA . 2020;10(2):597–623. doi: 10.1093/imaiai/iaaa008. [DOI] [Google Scholar]
- 34.Lee O. Probabilistic properties of a nonlinear ARMA process with markov switching. Communications in Statistics - Theory and Methods . 2005;34(1):193–204. doi: 10.1081/STA-200045822. [DOI] [Google Scholar]
- 35.Lu Y., Huang X., Li D., Zhang Y. Collaborative graph-based mechanism for distributed big data leakage prevention. Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM); September. 2018; Abu Dhabi, UAE. pp. 1–7. [DOI] [Google Scholar]
- 36.Koudahl M. T., de Vries B. Batman: bayesian target modelling for active inference. Proceedings of the 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); Febrauary. 2020; Barcelona, Spain. pp. 3852–3856. [DOI] [Google Scholar]
- 37.Dussmann D. K. Computational Systems Biology. 2022. https://www.kulturkaufhaus.de/en/detail/ISBN-2244012260139/Lecca-Paola/Computational-Systems-Biology .
- 38.Choi E.-H., Fujiwara T., Mizuno O. Weighting for combinatorial testing by bayesian inference. Proceedings of the 2017 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW); March, 2017; Tokyo, Japan. pp. 389–391. [DOI] [Google Scholar]
- 39.Fan S., Wang Y., Xiao L. Multidimensional BSDEs with uniformly continuous generators and general time intervals. Bulletin of the Korean Mathematical Society . 2015;52(2):483–504. doi: 10.4134/BKMS.2015.52.2.483. [DOI] [Google Scholar]
- 40.Fei Z., Liu K., Huang B., Zheng Y., Xiang X. Dirichlet process mixture model based nonparametric bayesian modeling and variational inference. Proceedings of the 2019 Chinese Automation Congress (CAC); August. 2019; Hangzhou, China. pp. 3048–3051. [DOI] [Google Scholar]
- 41.Hong X. Study of intergenerational mobility and urbanization based on OLS method and ordered probit mode. Proceedings of the 2020 Management Science Informatization and Economic Innovation Development Conference (MSIEID); September. 2020; Guangzhou, China. pp. 435–447. [DOI] [Google Scholar]
- 42.Chen H., Ren J. Structure-variable hybrid dynamic bayesian networks and its inference algorithm. Proceedings of the 2012 24th Chinese Control and Decision Conference (CCDC); Febrauary. 2012; Taiyuan, China. pp. 2815–2820. [DOI] [Google Scholar]
- 43.Guan H., Ni J.-C., Zhang Q., Sun L., Wang K. Saliency detection for $\mathbf{L}_{1/2}$ regularization-based SAR image feature enhancement via bayesian inference. Proceedings of the IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium; July. 2018; Valencia, Spain. pp. 4483–4486. [DOI] [Google Scholar]
- 44.Lijun Z., Guiqiu H., Qingsheng L., Guanhua D. An intuitionistic calculus to complex abnormal event recognition on data streams. Security and Communication Networks . 2021;2021:1–14. doi: 10.1155/2021/3573753. [DOI] [Google Scholar]
- 45.Kautz T., Groh B. H., Hannink J., Jensen U., Strubberg H., Eskofier B. M. Activity recognition in beach volleyball using a deep convolutional neural network. Data Mining and Knowledge Discovery . 2017;31(6):1678–1705. doi: 10.1007/s10618-017-0495-0. [DOI] [Google Scholar]
- 46.Link J., Perst T., Stoeve M., Eskofier B. M. Wearable sensors for activity recognition in ultimate frisbee using convolutional neural networks and transfer learning. Sensors . 2022;22(7):p. 2560. doi: 10.3390/s22072560. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Aira T., Salin K., Vasankari T., et al. Training volume and intensity of physical activity among young athletes: the health promoting sports club (HPSC) study. Advances in Physical Education . 2019;09(04):270–287. doi: 10.4236/ape.2019.94019. [DOI] [Google Scholar]
- 48.Worthington H., McCrea R. S., King R., Griffiths R. A. Estimation of population size when capture probability depends on individual states. Journal of Agricultural, Biological, and Environmental Statistics . 2019;24(1):154–172. doi: 10.1007/s13253-018-00347-x. [DOI] [Google Scholar]
- 49.Burgin M., Rocchi P. Ample probability in cognition. Proceedings of the 2019 IEEE 18th International Conference on Cognitive Informatics & Cognitive Computing (ICCI∗CC); July. 2019; Milan, Italy. pp. 62–65. [DOI] [Google Scholar]
- 50.Guopan S. The effect of probability on risk perception and risk preference in decision making. Proceedings of the 2010 International Conference on Education and Management Technology; November. 2010; Wasinghton, USA. pp. 690–693. [DOI] [Google Scholar]
- 51.Alves T. M. F., Soeiro R. O. J., Cartaxo A. V. T. Probability distribution of intercore crosstalk in weakly coupled MCFs with multiple interferers. Proceedings of the 2019 IEEE Photonics Conference (IPC); September. 2019; San Antonio, TX, USA. pp. 1–4. [DOI] [Google Scholar]
- 52.Gade B. H. H., Vooren C. N., Kloster M. Probability distribution for association of maneuvering vehicles. Proceedings of the 2019 22th International Conference on Information Fusion (FUSION); July. 2019; Ottawa, Canada. pp. 1–7. [Google Scholar]
- 53.Igarashi H., Watanabe K. Complex adjoint variable method for finite-element analysis of eddy current problems. IEEE Transactions on Magnetics . 2010;46(8):2739–2742. doi: 10.1109/TMAG.2010.2043936. [DOI] [Google Scholar]
- 54.Qian J., Lu J. P., Hui S. L., Ma Y. J., Li D. Y. Dynamic analysis and CFD numerical simulation on backpressure filling system. Mathematical Problems in Engineering . 2015;2015:8. doi: 10.1155/2015/160641.160641 [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data used in this study are available from the corresponding author upon request.