

Abstract
Medical images are naturally associated with rich semantics about the human anatomy, reflected in an abundance of recurring anatomical patterns, offering unique potential to foster deep semantic representation learning and yield semantically more powerful models for different medical applications. But how exactly such strong yet free semantics embedded in medical images can be harnessed for self-supervised learning remains largely unexplored. To this end, we train deep models to learn semantically enriched visual representation by self-discovery, self-classification, and self-restoration of the anatomy underneath medical images, resulting in a semantics-enriched, general-purpose, pre-trained 3D model, named Semantic Genesis. We examine our Semantic Genesis with all the publicly-available pre-trained models, by either self-supervision or fully supervision, on the six distinct target tasks, covering both classification and segmentation in various medical modalities (i.e., CT, MRI, and X-ray). Our extensive experiments demonstrate that Semantic Genesis significantly exceeds all of its 3D counterparts as well as the de facto ImageNet-based transfer learning in 2D. This performance is attributed to our novel self-supervised learning framework, encouraging deep models to learn compelling semantic representation from abundant anatomical patterns resulting from consistent anatomies embedded in medical images. Code and pre-trained Semantic Genesis are available at https://github.com/JLiangLab/SemanticGenesis.
Keywords: Self-supervised learning, Transfer learning, 3D model pre-training
1. Introduction
Self-supervised learning methods aim to learn general image representation from unlabeled data; naturally, a crucial question in self-supervised learning is how to “extract” proper supervision signals from the unlabeled data directly. In large part, self-supervised learning approaches involve predicting some hidden properties of the data, such as colorization [16,17], jigsaw [15,18], and rotation [11,13]. However, most of the prominent methods were derived in the context of natural images, without considering the unique properties of medical images.
In medical imaging, it is required to follow protocols for defined clinical purposes, therefore generating images of similar anatomies across patients and yielding recurrent anatomical patterns across images (see Fig. 1a). These recurring patterns are associated with rich semantic knowledge about the human body, thereby offering great potential to foster deep semantic representation learning and produce more powerful models for various medical applications. However, it remains an unanswered question: How to exploit the deep semantics associated with recurrent anatomical patterns embedded in medical images to enrich representation learning?
Fig. 1.
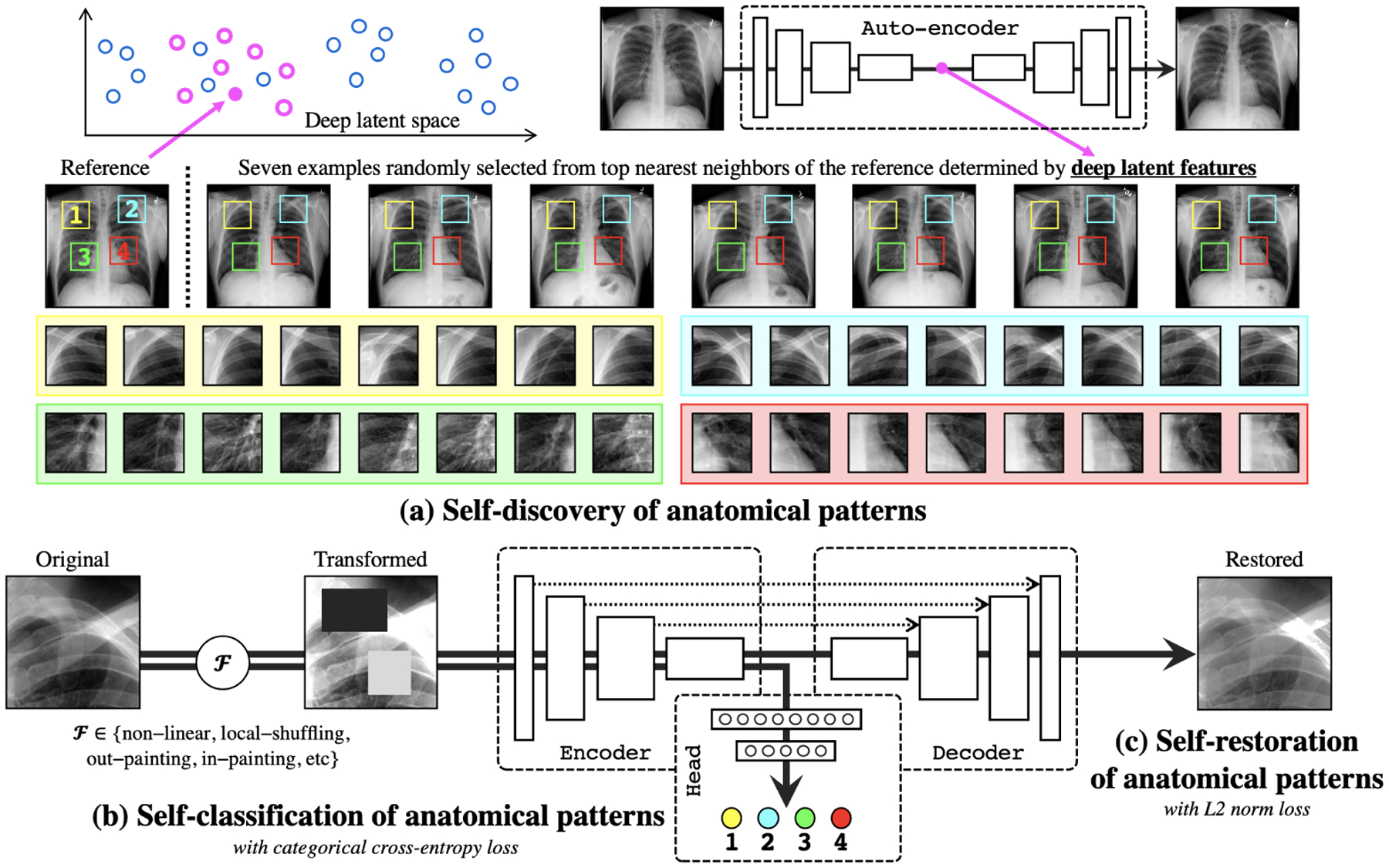
Our self-supervised learning framework consists of (a) self-discovery, (b) self-classification, and (c) self-restoration of anatomical patterns, resulting in semantics-enriched pre-trained models—Semantic Genesis—an encoder-decoder structure with skip connections in between and a classification head at the end of the encoder. Given a random reference patient, we find similar patients based on deep latent features, crop anatomical patterns from random yet fixed coordinates, and assign pseudo labels to the crops according to their coordinates. For simplicity and clarity, we illustrate our idea with four coordinates in X-ray images as an example. The input to the model is a transformed anatomical pattern crop, and the model is trained to classify the pseudo label and to recover the original crop. Thereby, the model aims to acquire semantics-enriched representation, producing more powerful application-specific target models.
To answer this question, we present a novel self-supervised learning framework, which enables the capture of semantics-enriched representation from unlabeled medical image data, resulting in a set of powerful pre-trained models. We call our pre-trained models Semantic Genesis, because they represent a significant advancement from Models Genesis [25] by introducing two novel components: self-discovery and self-classification of the anatomy underneath medical images (detailed in Sec. 2). Specifically, our unique self-classification branch, with a small computational overhead, compels the model to learn semantics from consistent and recurring anatomical patterns discovered during the self-discovery phase, while Models Genesis learns representation from random sub-volumes with no semantics as no semantics can be discovered from random sub-volumes. By explicitly employing the strong yet free semantic supervision signals, Semantic Genesis distinguishes itself from all other existing works, including colorization of colonoscopy images [20], context restoration [9], Rubik’s cube recovery [26], and predicting anatomical positions within MR images [4].
As evident in Sec. 4, our extensive experiments demonstrate that (1) learning semantics through our two innovations significantly enriches existing self-supervised learning approaches [9,19,25], boosting target tasks performance dramatically (see Fig. 2); (2) Semantic Genesis provides more generic and transferable feature representations in comparison to not only its self-supervised learning counterparts, but also (fully) supervised pre-trained 3D models (see Table 2); and Semantic Genesis significantly surpasses any 2D approaches (see Fig. 3).
Fig. 2.
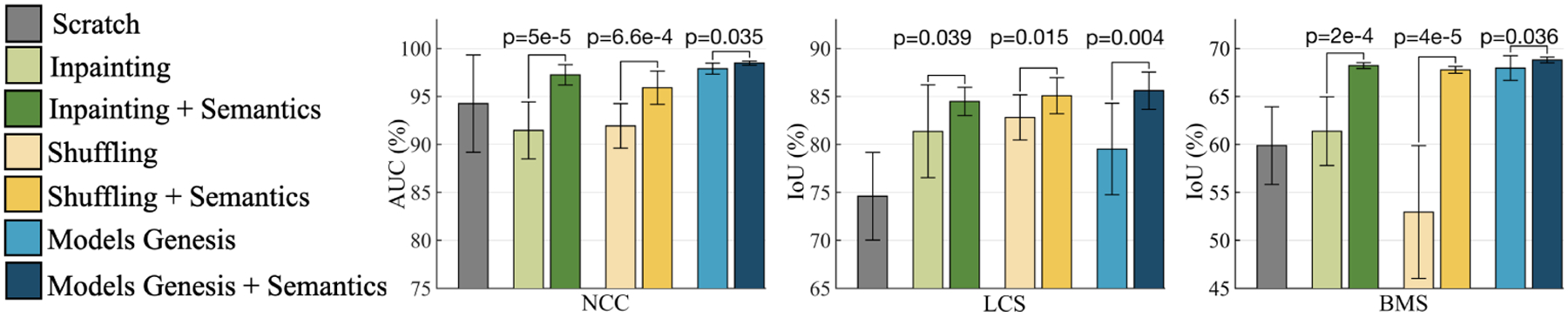
With and without semantics-enriched representation in the self-supervised learning approaches contrast a substantial (p < 0.05) performance difference on target classification and segmentation tasks. By introducing self-discovery and self-classification, we enhance semantics in three most recent self-supervised learning advances (i.e., image in-painting [19], patch-shuffling [9], and Models Genesis [25]).
Table 2.
Semantic Genesis outperforms learning 3D models from scratch, three competing publicly available (fully) supervised pre-trained 3D models, and four self-supervised learning approaches in four target tasks. For every target task, we report the mean and standard deviation (mean±s.d.) across ten trials and further perform independent two sample t-test between the best (bolded) vs. others and highlighted boxes in blue when they are not statistically significantly different at p = 0.05 level.
| Pre-training | Initialization | NCC (AUC%) | LCS (IoU%) | NCS (IoU%) | BMS‡ (IoU%) |
|---|---|---|---|---|---|
| Random | 94.25±5.07 | 74.60±4.57 | 74.05±1.97 | 59.87±4.04 | |
| Supervised | NiftyNet [12] | 94.14±4.57 | 83.23±1.05 | 52.98±2.05 | 60.78±1.60 |
| MedicalNet [10] | 95.80±0.51 | 83.32±0.85 | 75.68±0.32 | 66.09±1.35 | |
| Inflated 3D (I3D) [8] | 98.26±0.27 | 70.65±4.26 | 71.31±0.37 | 67.83±0.75 | |
| Self-supervised | Autoencoder | 88.43±10.25 | 78.16±2.07 | 75.10±0.91 | 56.36±5.32 |
| In-painting [19] | 91.46±2.97 | 81.36±4.83 | 75.86±0.26 | 61.38±3.84 | |
| Patch-shuffling [9] | 91.93±2.32 | 82.82±2.35 | 75.74±0.51 | 52.95±6.92 | |
| Rubik’s Cube [26] | 95.56± 1.57 | 76.07± 0.20 | 70.37±1.13 | 62.75±1.93 | |
| Self-restoration [25] | 98.07±0.59 | 78.78±3.11 | 77.41±0.40 | 67.96±1.29 | |
| Self-classification | 97.41±0.32 | 83.61±2.19 | 76.23±0.42 | 66.02±0.83 | |
| Semantic Genesis 3D | 98.47±0.22 | 85.60±1.94 | 77.24±0.68 | 68.80±0.30 |
Models Genesis used only synthetic images of BraTS-2013, however we examine real and only MR Flair images for segmenting brain tumors, so the results are not submitted to BraTS-2018.
Fig. 3.
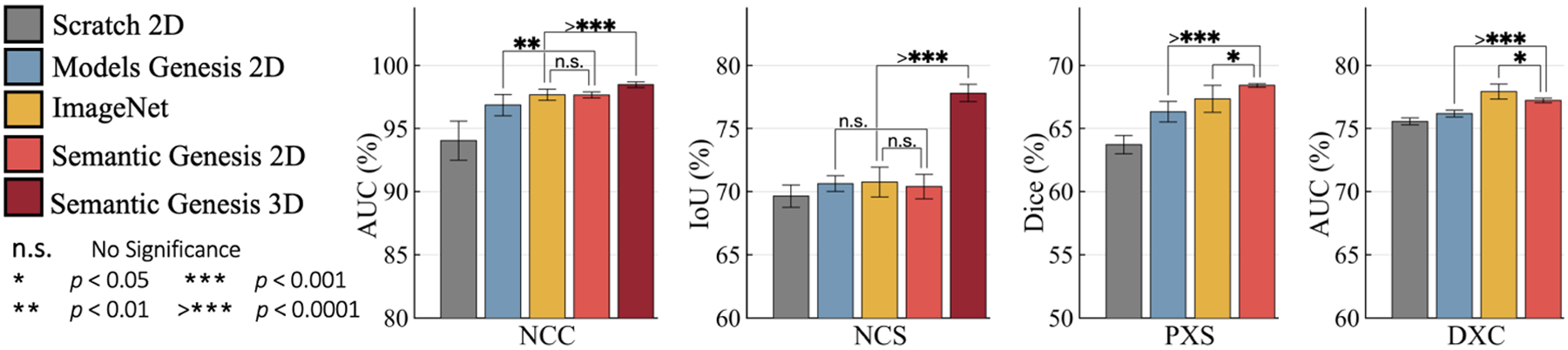
To solve target tasks in 3D medical modality (NCC and NCS), 3D approaches empowered by Semantic Genesis 3D, significantly outperforms any 2D slice-based approaches, including the state-of-the-art ImageNet models. For target tasks in 2D modality (PXS and DXC), Semantic Genesis 2D outperforms Models Genesis 2D and, noticeably, yields higher performance than ImageNet in PXS.
This performance is ascribed to the semantics derived from the consistent and recurrent anatomical patterns, that not only can be automatically discovered from medical images but can also serve as strong yet free supervision signals for deep models to learn more semantically enriched representation automatically via self-supervision.
2. Semantic Genesis
Fig. 1 presents our self-supervised learning framework, which enables training Semantic Genesis from scratch on unlabeled medical images. Semantic Genesis is conceptually simple: an encoder-decoder structure with skip connections in between and a classification head at the end of the encoder. The objective for the model is to learn different sets of semantics-enriched representation from multiple perspectives. In doing so, our proposed framework consists of three important components: 1) self-discovery of anatomical patterns from similar patients; 2) self-classification of the patterns; and 3) self-restoration of the transformed patterns. Specifically, once the self-discovered anatomical pattern set is built, we jointly train the classification and restoration branches together in the model.
1). Self-discovery of anatomical patterns:
We begin by building a set of anatomical patterns from medical images, as illustrated in Fig. 1a. To extract deep features of each (whole) patient scan, we first train an auto-encoder network with training data, which learns an identical mapping from scan to it-self. Once trained, the latent representation vector from the auto-encoder can be used as an indicator of each patient. We randomly anchor one patient as a reference and search for its nearest neighbors through the entire dataset by computing the L2 distance of the latent representation vectors, resulting in a set of semantically similar patients. As shown in Fig. 1a, due to the consistent and recurring anatomies across these patients, that is, each coordinate contains a unique anatomical pattern, it is feasible to extract similar anatomical patterns according to the coordinates. Hence, we crop patches/cubes (for 2D/3D images) from C number of random but fixed coordinates across this small set of discovered patients, which share similar semantics. Here we compute similarity in patient-level rather than pattern-level to ensure the balance between the diversity and consistency of anatomical patterns. Finally, we assign pseudo labels to these patches/cubes based on their coordinates, resulting in a new dataset, wherein each patch/cube is associated with one of the C classes. Since the coordinates are randomly selected in the reference patient, some of the anatomical patterns may not be very meaningful for radiologists, yet these patterns are still associated with rich local semantics of the human body. For example, in Fig. 1a, four pseudo labels are defined randomly in the reference patient (top-left most), but as seen, they carry local information of (1) anterior ribs 2–4, (2) anterior ribs 1–3, (3) right pulmonary artery, and (4) LV. Most importantly, by repeating the above self-discovery process, enormous anatomical patterns associated with their pseudo labels can be automatically generated for representation learning in the following stages (refer to Appendix Sec. A).
2). Self-classification of anatomical patterns:
After self-discovery of a set of anatomical patterns, we formulate the representation learning as a C-way multi-class classification task. The goal is to encourage models to learn from the recurrent anatomical patterns across patient images, fostering a deep semantically enriched representation. As illustrated in Fig. 1b, the classification branch encodes the input anatomical pattern into a latent space, followed by a sequence of fully-connected (fc) layers, and predicts the pseudo label associated with the pattern. To classify the anatomical patterns, we adopt categorical cross-entropy loss function: , where N denotes the batch size; C denotes the number of classes; and represent the ground truth (one-hot pseudo label vector) and the prediction, respectively.
3). Self-restoration of anatomical patterns:
The objective of self-restoration is for the model to learn different sets of visual representation by recovering original anatomical patterns from the transformed ones. We adopt the transformations proposed in Models Genesis [25], i.e., non-linear, local-shuffling, out-painting, and in-painting (refer to Appendix Sec. B). As shown in Fig. 1c, the restoration branch encodes the input transformed anatomical pattern into a latent space and decodes back to the original resolution, with an aim to recover the original anatomical pattern from the transformed one. To let Semantic Genesis restore the transformed anatomical patterns, we compute L2 distance between original pattern and reconstructed pattern as loss function: , where N, and denote the batch size, ground truth (original anatomical pattern) and reconstructed prediction, respectively.
Formally, during training, we define a multi-task loss function on each transformed anatomical pattern as , where λcls and λrec regulate the weights of classification and reconstruction losses, respectively. Our definition of allows the model to learn more semantically enriched representation. The definition of encourages the model to learn from multiple perspectives by restoring original images from varying image deformations. Once trained, the encoder alone can be fine-tuned for target classification tasks; while the encoder and decoder together can be fine-tuned for target segmentation tasks to fully utilize the advantages of the pre-trained models on the target tasks.
3. Experiments
Pre-training Semantic Genesis:
Our Semantic Genesis 3D and 2D are self-supervised pre-trained from 623 CT scans in LUNA-2016 [21] (same as the publicly released Models Genesis) and 75,708 X-ray images from ChestX-ray14 [23] datasets, respectively. Although Semantic Genesis is trained from only unlabeled images, we do not use all the images in those datasets to avoid test-image leaks between proxy and target tasks. In the self-discovery process, we select top K most similar cases with the reference patient, according to the deep features computed from the pre-trained auto-encoder. To strike a balance between diversity and consistency of the anatomical patterns, we empirically set K to 200/1000 for 3D/2D pre-training based on the dataset size. We set C to 44/100 for 3D/2D images so that the anatomical patterns can largely cover the entire image while avoiding too much overlap with each other. For each random coordinate, we extract multi-resolution cubes/patches, then resize them all to 64×64×32 and 224×224 for 3D and 2D, respectively; finally, we assign C pseudo labels to the cubes/patches based on their coordinates. For more details in implementation and meta-parameters, please refer to our publicly released code.
Baselines and implementation:
Table 1 summarizes the target tasks and datasets. Since most self-supervised learning methods are initially proposed in 2D, we have extended two most representative ones [9,19] into their 3D version for a fair comparison. Also, we compare Semantic Genesis with Rubik’s cube [26], the most recent multi-task self-supervised learning method for 3D medical imaging. In addition, we have examined publicly available pre-trained models for 3D transfer learning in medical imaging, including NiftyNet [12], MedicalNet [10], Models Genesis [25], and Inflated 3D (I3D) [8] that has been successfully transferred to 3D lung nodule detection [2], as well as ImageNet models, the most influential weights initialization in 2D target tasks. 3D U-Net3/U-Net4 architectures used in 3D/2D applications, have been modified by appending fully-connected layers to end of the encoders. In proxy tasks, we set λrec = 1 and λcls = 0.01. Adam with a learning rate of 0.001 is used for optimization. We first train classification branch for 20 epochs, then jointly train the entire model for both classification and restoration tasks. For CT target tasks, we investigate the capability of both 3D volume-based solutions and 2D slice-based solutions, where the 2D representation is obtained by extracting axial slices from volumetric datasets. For all applications, we run each method 10 times on the target task and report the average, standard deviation, and further present statistical analyses based on independent two-sample t-test.
Table 1.
We evaluate the learned representation by fine-tuning it for six publicly-available medical imaging applications including 3D and 2D image classification and segmentation tasks, across diseases, organs, datasets, and modalities.
| Codea | Object | Modality | Dataset | Application |
|---|---|---|---|---|
| NCC | Lung Nodule | CT | LUNA-2016 [21] | Nodule false positive reduction |
| NCS | Lung Nodule | CT | LIDC-IDRI [3] | Lung nodule segmentation |
| LCS | Liver | CT | LiTS-2017 [6] | Liver segmentation |
| BMS | Brain Tumor | MRI | BraTS2018 [5] | Brain Tumor Segmentation |
| DXC | Chest Diseases | X-ray | ChestX-Ray14 [23] | Fourteen chest diseases classification |
| PXS | Pneumothorax | X-ray | SIIM-ACR-2019 [1] | Pneumothorax Segmentation |
The first letter denotes the object of interest (“N” for lung nodule, “L” for liver, etc); the second letter denotes the modality (“C” for CT, “X” for X-ray, “M” for MRI); the last letter denotes the task (“C” for classification, “S” for segmentation).
4. Results
Learning semantics enriches existing self-supervised learning approaches:
Our proposed self-supervised learning scheme should be considered as an add-on, which can be added to and boost existing self-supervised learning methods. Our results in Fig. 2 indicate that by simply incorporating the anatomical patterns with representation learning, the semantics-enriched models consistently outperform each and every existing self-supervised learning method [19,9,25]. Specifically, the semantics-enriched representation learning achieves performance gains by 5%, 3%, and 1% in NCC, compared with the original in-painting, patch-shuffling, and Models Genesis, respectively; and the performance improved by 3%, 2%, and 6% in LCS and 6%, 14%, and 1% in BMS. We conclude that our proposed self-supervised learning scheme, by autonomously discovering and classifying anatomical patterns, learns a unique and complementary visual representation in comparison with that of an image restoration task. Thereby, due to this combination, the models are enforced to learn from multiple perspectives, especially from the consistent and recurring anatomical structure, resulting in more powerful image representation.
Semantic Genesis 3D provides more generic and transferable representations in comparison to publicly available pre-trained 3D models:
We have compared our Semantic Genesis 3D with the competitive publicly available pre-trained models, applied to four distinct 3D target medical applications. Our statistical analysis in Table 2 suggests three major results. Firstly, compared to learning 3D models from scratch, fine-tuning from Semantic Genesis offers performance gains by at least 3%, while also yielding more stable performances in all four applications. Secondly, fine-tuning models from Semantic Genesis achieves significantly higher performances than those fine-tuned from other self-supervised approaches, in all four distinct 3D medical applications, i.e., NCC, LCS, NCS, and BMS. In particular, Semantic Genesis surpasses Models Genesis, the state-of-the-art 3D pre-trained models created by image restoration based self-supervised learning, in three applications (i.e., NCC, LCS, and BMS), and offers equivalent performance in NCS. Finally, even though our Semantic Genesis learns representation without using any human annotation, we still have examined it with 3D models pre-trained from full supervision, i.e., MedicalNet, NiftyNet, and I3D. Without any bells and whistles, Semantic Genesis outperforms supervised pre-trained models in all four target tasks. Our results evidence that in contrast to other baselines, which show fluctuation in different applications, Semantic Genesis is consistently capable of generalizing well in all tasks even when the domain distance between source and target datasets is large (i.e., LCS and BMS tasks). Conversely, Semantic Genesis benefits explicitly from the deep semantic features enriched by self-discovering and self-classifying anatomical patterns embedded in medical images, and thus contrasts with any other existing 3D models pre-trained by either self-supervision or full supervision.
Semantic Genesis 3D significantly surpasses any 2D approaches:
To address the problem of limited annotation in volumetric medical imaging, one can reformulate and solve 3D imaging tasks in 2D [25]. However, this approach may lose rich 3D anatomical information and inevitably compromise the performance. Evidenced by Fig. 3 (NCC and NCS), Semantic Genesis 3D outperforms all 2D solutions, including ImageNet models as well as downgraded Semantic Genesis 2D and Models Genesis 2D, demonstrating that 3D problems in medical imaging demand 3D solutions. Moreover, as an ablation study, we examine our Semantic Genesis 2D with Models Genesis 2D (self-supervised) and ImageNet models (fully supervised) in four target tasks, covering classification and segmentation in CT and X-ray. Referring to Fig. 3, Semantic Genesis 2D: 1) significantly surpasses training from scratch and Models Genesis 2D in all four and three applications, respectively; 2) outperforms ImageNet model in PXS and achieves the performance equivalent to ImageNet in NCC and NCS, which is a significant achievement because to date, all self-supervised approaches lag behind fully supervised training [14,7,24].
Self-classification and self-restoration lead to complementary representation:
In theory, our Semantic Genesis benefits from two sources: pattern classification and pattern restoration, so we further conduct an ablation study to investigate the effect of each isolated training scheme. Referring to Table 2, the combined training scheme (Semantic Genesis 3D) consistently offers significantly higher and more stable performance compared to each of the isolated training schemes (self-restoration and self-classification) in NCS, LCS, and BMS. Moreover, self-restoration and self-classification reveal better performances in four target applications, alternatingly. We attribute their complementary results to the different visual representations that they have captured from each isolated pre-training scheme, leading to different behaviors in different target applications. These complementary representations, in turn, confirm the importance of the unification of self-classification and self-restoration in our Semantic Genesis and its significance for medical imaging.
5. Conclusion
A key contribution of ours is designing a self-supervised learning framework that not only allows deep models to learn common visual representation from image data directly, but also leverages semantics-enriched representation from the consistent and recurrent anatomical patterns, one of a broad set of unique properties that medical imaging has to offer. Our extensive results demonstrate that Semantic Genesis is superior to publicly available 3D models pre-trained by either self-supervision or even full supervision, as well as ImageNet-based transfer learning in 2D. We attribute this outstanding results to the compelling deep semantics learned from abundant anatomical patterns resulted from consistent anatomies naturally embedded in medical images.
Acknowledgments:
This research has been supported partially by ASU and Mayo Clinic through a Seed Grant and an Innovation Grant, and partially by the NIH under Award Number R01HL128785. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH. This work has utilized the GPUs provided partially by the ASU Research Computing and partially by the Extreme Science and Engineering Discovery Environment (XSEDE) funded by the National Science Foundation (NSF) under grant number ACI-1548562. We thank Zuwei Guo for implementing Rubik’s cube, and Jiaxuan Pang for evaluating I3D. The content of this paper is covered by patents pending.
Appendix
A. Visualizing the self-discovery process in Semantic Genesis
Fig. 4.
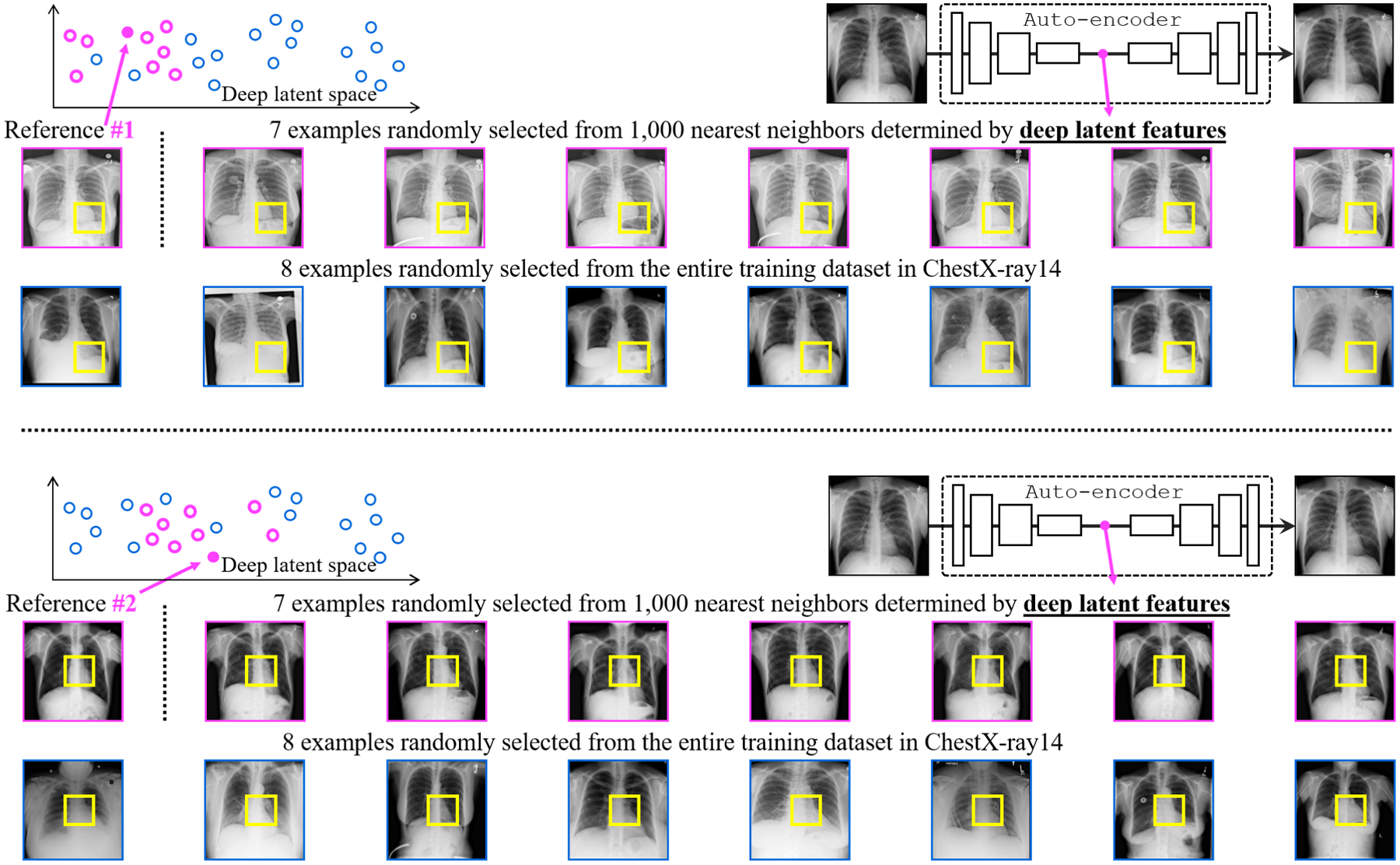
Our self-discovery process aims to automatically discover similar anatomical patterns across patients, as illustrated in the yellow boxes within the patients framed in pink. Patches extracted at the same coordinate across patients may be very different (the yellow boxes within the patients framed in blue). We overcome this issue by first computing similarity at the patient level using the deep latent features from an auto-encoder and then selecting the top nearest neighbors (framed in pink) of the reference patient. Extracting anatomical patterns from these similar patients strikes a balance between consistency and diversity in pattern appearance for each anatomical pattern.
B. Visualizing transformed anatomical patterns
Fig. 5.

In the self-restoration process, Semantic Genesis aims to learn general-purpose visual representation by recovering original anatomical patterns from their transformed ones. We have adopted four image transformations as suggested in [25]. To be self-contained, we provide three examples of anatomical patterns from CT slices and three from X-ray images. The original and transformed anatomical patterns are presented in Column 1 and Columns 2—7, respectively. Note that the original Models Genesis [25] involve no anatomical patterns but just random patches, while our Semantic Genesis benefits from the rich semantics associated with recurrent anatomical patterns embedded in medical images.
Footnotes
3D U-Net: github.com/ellisdg/3DUnetCNN
Segmentation Models: github.com/qubvel/segmentation_models
References
- 1.Siim-acr pneumothorax segmentation (2019), https://www.kaggle.com/c/siim-acr-pneumothorax-segmentation/
- 2.Ardila D, Kiraly AP, Bharadwaj S, Choi B, Reicher JJ, Peng L, Tse D, Etemadi M, Ye W, Corrado G, et al. : End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography. Nature medicine 25(6), 954–961 (2019) [DOI] [PubMed] [Google Scholar]
- 3.Armato III SG, McLennan G, Bidaut L, McNitt-Gray MF, Meyer CR, Reeves AP, Zhao B, Aberle DR, Henschke CI, Hoffman EA, et al. : The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical physics 38(2), 915–931 (2011) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Bai W, Chen C, Tarroni G, Duan J, Guitton F, Petersen SE, Guo Y, Matthews PM, Rueckert D: Self-supervised learning for cardiac mr image segmentation by anatomical position prediction. In: Shen D, Liu T, Peters TM, Staib LH, Essert C, Zhou S, Yap PT, Khan A (eds.) Medical Image Computing and Computer Assisted Intervention – MICCAI 2019. pp. 541–549. Springer International Publishing, Cham: (2019) [Google Scholar]
- 5.Bakas S, Reyes M, Jakab A, Bauer S, Rempfler M, Crimi A, Shinohara RT, Berger C, Ha SM, Rozycki M, et al. : Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the brats challenge. arXiv preprint arXiv:1811.02629 (2018) [Google Scholar]
- 6.Bilic P, Christ PF, Vorontsov E, Chlebus G, Chen H, Dou Q, Fu CW, Han X, Heng PA, Hesser J, et al. : The liver tumor segmentation benchmark (lits). arXiv preprint arXiv:1901.04056 (2019) [Google Scholar]
- 7.Caron M, Bojanowski P, Mairal J, Joulin A: Unsupervised pre-training of image features on non-curated data. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2959–2968 (2019) [Google Scholar]
- 8.Carreira J, Zisserman A: Quo vadis, action recognition? a new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017) [Google Scholar]
- 9.Chen L, Bentley P, Mori K, Misawa K, Fujiwara M, Rueckert D: Self-supervised learning for medical image analysis using image context restoration. Medical image analysis 58, 101539 (2019) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Chen S, Ma K, Zheng Y: Med3d: Transfer learning for 3d medical image analysis. arXiv preprint arXiv:1904.00625 (2019) [Google Scholar]
- 11.Feng Z, Xu C, Tao D: Self-supervised representation learning by rotation feature decoupling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 10364–10374 (2019) [Google Scholar]
- 12.Gibson E, Li W, Sudre C, Fidon L, Shakir DI, Wang G, Eaton-Rosen Z, Gray R, Doel T, Hu Y, et al. : Niftynet: a deep-learning platform for medical imaging. Computer methods and programs in biomedicine 158, 113–122 (2018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Gidaris S, Singh P, Komodakis N: Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728 (2018) [Google Scholar]
- 14.Hendrycks D, Mazeika M, Kadavath S, Song D: Using self-supervised learning can improve model robustness and uncertainty. In: Advances in Neural Information Processing Systems. pp. 15637–15648 (2019) [Google Scholar]
- 15.Kim D, Cho D, Yoo D, Kweon IS: Learning image representations by completing damaged jigsaw puzzles. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). pp. 793–802. IEEE; (2018) [Google Scholar]
- 16.Larsson G, Maire M, Shakhnarovich G: Learning representations for automatic colorization. In: European Conference on Computer Vision. pp. 577–593. Springer; (2016) [Google Scholar]
- 17.Larsson G, Maire M, Shakhnarovich G: Colorization as a proxy task for visual understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6874–6883 (2017) [Google Scholar]
- 18.Noroozi M, Favaro P: Unsupervised learning of visual representations by solving jigsaw puzzles. In: European Conference on Computer Vision. pp. 69–84. Springer; (2016) [Google Scholar]
- 19.Pathak D, Krahenbuhl P, Donahue J, Darrell T, Efros AA: Context encoders: Feature learning by inpainting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2536–2544 (2016) [Google Scholar]
- 20.Ross T, Zimmerer D, Vemuri A, Isensee F, Wiesenfarth M, Bodenstedt S, Both F, Kessler P, Wagner M, Müller B, et al. : Exploiting the potential of unlabeled endoscopic video data with self-supervised learning. International journal of computer assisted radiology and surgery 13(6), 925–933 (2018) [DOI] [PubMed] [Google Scholar]
- 21.Setio AAA, Traverso A, De Bel T, Berens MS, van den Bogaard C, Cerello P, Chen H, Dou Q, Fantacci ME, Geurts B, et al. : Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Medical image analysis 42, 1–13 (2017) [DOI] [PubMed] [Google Scholar]
- 22.Wang H, Zhou Z, Li Y, Chen Z, Lu P, Wang W, Liu W, Yu L: Comparison of machine learning methods for classifying mediastinal lymph node metastasis of non-small cell lung cancer from 18 f-fdg pet/ct images. EJNMMI research 7(1), 11 (2017) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Wang X, Peng Y, Lu L, Lu Z, Bagheri M, Summers RM: Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2097–2106 (2017) [Google Scholar]
- 24.Zhang L, Qi GJ, Wang L, Luo J: Aet vs. aed: Unsupervised representation learning by auto-encoding transformations rather than data. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2547–2555 (2019) [Google Scholar]
- 25.Zhou Z, Sodha V, Rahman Siddiquee MM, Feng R, Tajbakhsh N, Gotway MB, Liang J: Models genesis: Generic autodidactic models for 3d medical image analysis. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2019. pp. 384–393. Springer International Publishing, Cham: (2019), https://link.springer.com/chapter/10.1007/978-3-030-32251-9_42 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Zhuang X, Li Y, Hu Y, Ma K, Yang Y, Zheng Y: Self-supervised feature learning for 3d medical images by playing a rubik’s cube. In: Shen D, Liu T, Peters TM, Staib LH, Essert C, Zhou S, Yap PT, Khan A (eds.) Medical Image Computing and Computer Assisted Intervention – MICCAI 2019. pp. 420–428. Springer International Publishing, Cham: (2019) [Google Scholar]