

Abstract
The poor transferability of genetic risk scores (GRSs) derived from European ancestry data in diverse populations is a cause of concern. We set out to evaluate whether GRSs derived from data of African American individuals and multiancestry data perform better in sub-Saharan Africa (SSA) compared to European ancestry-derived scores. Using summary statistics from the Million Veteran Program (MVP), we showed that GRSs derived from data of African American individuals enhance polygenic prediction of lipid traits in SSA compared to European and multiancestry scores. However, our GRS prediction varied greatly within SSA between the South African Zulu (low-density lipoprotein cholesterol (LDL-C), R2 = 8.14%) and Ugandan cohorts (LDL-C, R2 = 0.026%). We postulate that differences in the genetic and environmental factors between these population groups might lead to the poor transferability of GRSs within SSA. More effort is required to optimize polygenic prediction in Africa.
Subject terms: Medical genetics, Genomics
A new study reveals that polygenic scores for lipid traits derived from data of African American individuals have high predictive value in a South African Zulu cohort but are poor predictors in a cohort from Uganda, further highlighting the need to improve polygenic predictions in populations of African ancestries.
Main
Genome-wide association studies (GWASs) have successfully identified and characterized genetic variants associated with lipid traits1–3. To date, roughly 700 single-nucleotide polymorphisms (SNPs) are associated with various lipid traits3–9. These discoveries are now beginning to unravel the biology of dyslipidemia and aid prediction for precision medicine. To date, polygenic risk across the genome can be aggregated by generating genome-wide weighted scores to predict the risk of a disease in an independent population10,11. However, most lipid trait discoveries have been made in European or Asian ancestries4–9. Genetic risk scores (GRSs) derived from European ancestry tend to perform poorly in genetically diverse populations, including Africans10, probably due to unique differences in linkage disequilibrium (LD) patterns, allele frequencies and environmental exposures12 between different populations. Lack of precise GRSs in Africans hinders risk stratification and targeted treatments essential for precision medicine and may exacerbate health disparities.
Recent studies have indicated that using multiancestry summary statistics enhance GRS performance in diverse populations13. Moreover, previous studies suggested that using summary statistics from African Americans may improve GRS performance in sub-Saharan Africans14. We, therefore, undertook a study to determine the best approach for lipid traits polygenic risk prediction, including low-density lipoprotein cholesterol (LDL-C), high-density lipoprotein cholesterol (HDL-C), triglycerides (TGs) and total cholesterol (TC) in sub-Saharan Africans using publicly available GWAS summary statistics. This study assessed the performance, portability and predictivity of GRSs derived from data of African Americans, Europeans and multiancestry (African American, European and Hispanic American) individuals in Ugandan and South African Zulu cohorts.
We computed GRSs using PRSice-2. Of the many GRSs computed at various P-value thresholds that ranged from 1 to 5 × 10−8, the GRS that explained the highest proportion of variance (R2) in any trait for the African, European and multiancestry populations (Methods) was selected as the best-performing one (Extended Data Table 1 and Extended Data Fig. 1). In the South African Zulu cohort, the best-performing GRSs for LDL-C was African American (R2 = 8.14%, P-value threshold (PT) < 5 × 10−8), followed by the multiancestry approach (derived from individuals of African ancestry, European ancestry and Hispanic American) (R2 = 6.32%, PT < 5 × 10−08), and the one from individuals of European ancestry (R2 = 1.61%, PT < 5 × 10−08, Fig. 1a and Extended Data Table 2). Although the African American-derived GRS predicted better in the South African Zulu cohort its prediction was lower in Ugandan cohort (Extended Data Table 3). Moreover, our African American-derived GRSs (coefficient ranging from 0.100 to 0.286) were better correlated with all serum lipid levels than the European GRSs (coefficients ranging from 0.091 to 0.123) in South African Zulu (Extended Data Fig. 2).
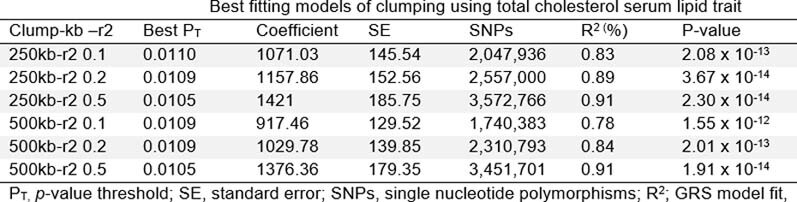
Extended Data Table 1.
Best-fitting models of clumping using the TC serum lipid trait
Extended Data Fig. 1. Proportion of variance of TC explained by GRS in the South African Zulu samples using GRS derived from GWAS.

(a) African American ancestry, (a) European ancestry and (a) multiethnic ancestry. The bars represent GRS calculated for subsets of markers at different p-value thresholds. The best GRS in red color was selected based on having the highest proportion of the variance (R2) for the trait in linear models adjusted for age, sex and principal components.
Fig. 1. Performance of GRSs for lipid traits in the South African Zulu cohort using the MVP GWAS summary statistic results of various ancestry populations, including individuals of African American, European and multiethnic ancestry populations.

a, Violin plots showing GRSs that explained the highest proportion of variance (R2) for lipids derived from African American (AFR), European (EUR) and multiancestry (MEA) populations. b, GRSs in deciles compared to the first decile. The y axis shows the mean, and the x axis is the GRSs in deciles. The points show mean, and error bars represent standard errors of the mean. All South African Zulu cohorts (n = 2,598) were used in this analysis.
Extended Data Table 2.
Best predictive polygenic risk scores of lipid traits in the South African Zulu cohort

Extended Data Table 3.
Best predictive polygenic risk scores of lipid traits in the Ugandan cohort
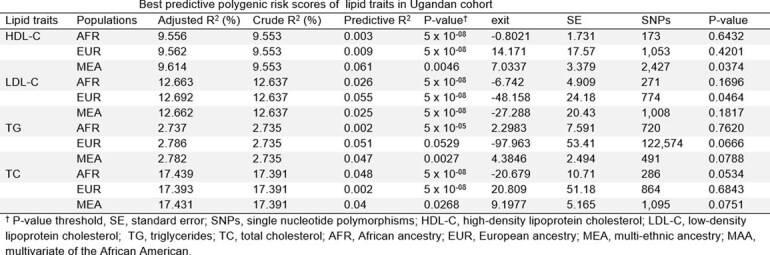
Extended Data Fig. 2. Correlation coefficients between GRS and serum lipid levels.
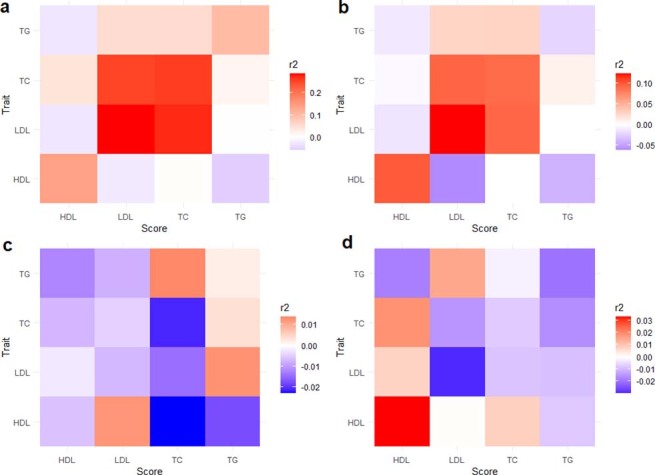
(a) African American derived GRS in the South African Zulu dataset. (b) European derived GRS in the South African Zulu. (c) African American derived GRS in the Ugandan cohort. (d) European derived GRS in the Ugandan cohort. The correlation coefficients r2 are given with colors corresponding to the direction and strength of r2. The r2 on the diagonal represents the strength of correlation of a GRS with its target lipid trait. The off-diagonal r2 represents the strength of correlation of a GRS with other lipid traits.
We proceeded to evaluate risk stratification based on the deciles of the GRSs for the lipid traits presented (Methods). We compared the effect sizes of serum lipid levels from the first GRS decile after correction for age, sex and ten principal components. In parallel, we observed that individuals in the top 10% of the GRSs had higher serum lipid levels than those in the first decile (Fig. 1b). Notably, multiancestry-derived GRS was the best-performing approach for HDL-C and TG (Fig. 1b). Individuals at the top 10% of the GRSs had a higher difference of 0.16 mmol liter−1 and 0.45 mmol liter−1 for HDL-C and TG levels, respectively, compared to individuals at the bottom 10% GRSs. For LDL-C and TC, the best-performing approach was the African American GRS, with a mean difference (first versus tenth decile) of 0.70 mmol liter−1 for LDL-C and 1.09 mmol liter−1 for TC (Fig. 1b) for those at the top 10% GRS decile.
We proceeded to evaluate the transferability of a GRS derived from an African American cohort in Ugandan and South African Zulu cohorts (Fig. 2a). Using TC as an example, we noted that the same African American GRS of 286 SNPs performed poorly in the Ugandan cohort (R2 = 0.045%) but much better in the South African Zulu cohort (6.345%) (Fig. 2b). The correlations of the GRS with lipid traits were lower among the Ugandan cohort compared to the South African Zulu cohort (Fig. 2c). Of all the lipid traits, predictability was lowest for TGs, possibly due to the nonfasting of participants before blood collection for lipid analysis. TGs, unlike TC and HDL, are sensitive to dietary intake, which might have affected their accurate estimation and consequently its prediction15.
Fig. 2. GRSs of individuals of African ancestry with dyslipidemia.

a, Map of Africa showing sample collection points in Kyamulibwa in Kalungu district, Uganda and Durban, Kwazulu-natal province, South Africa. b, Bar plot showing comparative performance of polygenic prediction of TC using the same GRS comprising 286 SNPs, which was developed in Ugandan cohort (n = 6,407) and then replicated in the South African Zulu cohort (n = 2,598). The y axis is the prediction accuracy (R2), and the x axis is the number of SNPs in the GRS for TC used. c, Correlation coefficients between African American-derived GRSs and serum lipid levels in the Ugandan cohort. d, Scatter plot for the correlation of the same minor allele frequencies (MAF) between the South African Zulu and Ugandan cohorts (R = Pearson correlation, one-sided test). PC, principal component. e, Scatter plot for the principal component analysis of the 1000 Genomes Project reference populations with the South African Zulu and Ugandan cohorts (GBR, British; MSL, Mende; UGR, Uganda genome resource; Zulu, South African Zulu; YRI, Yoruba).
We then sought to evaluate the contribution of minor allele frequencies to the poor transferability of the GRSs between the Ugandan and South African Zulu cohorts. We compared allele frequencies of the SNPs in the African American-derived GRSs in the Ugandan and South African Zulu cohorts (Fig. 2d). We noted that there were marked differences in age, body mass index and allele frequencies between these cohorts, which might have contributed to the poor transferability of the African American GRS (Extended Data Fig. 3 and Fig. 2e). The South African Zulu cohort recruited participants from an urbanized setting compared to the Ugandan cohort. Therefore the urban and rural environmental differences might also be playing a part in the poor transferability of the African American-derived GRSs between the Ugandan and South African Zulu cohorts. This finding suggests that both genetic and environmental factors might be responsible for the differences in the performance of GRSs in the Ugandan cohort.
Extended Data Fig. 3. Box plots showing the distribution of age, BMI and lipid traits among the Ugandan and South African Zulu cohorts.

The horizontal line is the median values, error bars are 25th and 75th percentiles. Extreme values are maximum and minimum for respective traits. Data analysis were performed in all Ugandan (n = 6,407) and South African Zulu (n = 2,598) cohorts.
Next, we then assessed the ability of the GRS to identify people with high lipid levels compared to conventional risk factors. We computed residuals of the linear model of TC adjusted for age and sex in the South African Zulu cohort. We then selected individuals at the top 10% of the residual density plot as ‘cases’ and the remaining 90% deciles as ‘controls’ (Extended Data Fig. 4a). For example, the average TC level in cases was 6.51 mmol liter−1 compared to 4.30 mmol liter−1 in controls, representing a difference of 2.21 mmol liter−1. Using logistic regression models, we evaluated the prediction of the African American GRSs trained from the Ugandan cohort in the South African Zulu cohort. The areas under the curve were 55.5% (95% confidence interval [CI], 53.4–57.6%) for clinical factors, including type 2 diabetes, body mass index, age, sex and five principal components, and 63.8% (95% CI, 61.8–65.9%) for GRSs only (Extended Data Fig. 4b). Moreover, the net reclassification index for the model of the clinical factors increased by 42% after adding the GRSs to this model, further supporting our results that the GRS was better at identifying individuals with high TC compared to conventional clinical factors. However, lipid profiles rather than conventional risk factors are used to assess for dyslipidemia in the clinical setting. Lipid profiles are easier to collect and interpret than GRSs, thereby limiting the clinical application of the GRS. Nonetheless, GRSs might find use in the risk stratification of children and young adults long before they start to exhibit elevated lipid levels15.
Extended Data Fig. 4. The discriminative power of our polygenic risk score or GRS to successfully identify the individuals of African ancestry with dyslipidaemia.
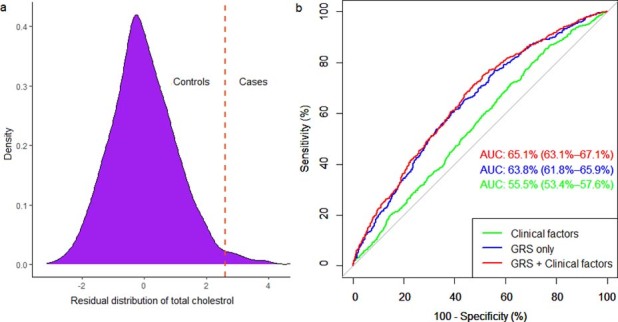
(a) Distribution of total cholesterol (TC) among South African Zulus. The top 10% deciles were named “cases,” and the lower deciles were designated as “controls.” (b) The area under the curve in South African Zulu.
Consistent with previous reports, GRSs derived from individuals of African ancestry performed significantly better in sub-Saharan Africans than GRSs derived from individuals of European ancestry10,16–18. The performance of GRS derived from data of African American individuals for LDL-C (R2 = 8.14%) was much higher than the performances reported by Johnson et al. (ranging from 1.99% to 4.48% in African American, Asian American, white and Hispanic individuals for LDL-C)18. This difference suggests that GRSs computed using African Ancestry discovery GWASs may lead to better polygenic predictions of lipids in individuals of African descent. However, continental Africans are characterized by high genetic diversity, which may affect the performance and transferability of GRSs within Africa12.
Moreover, our results suggest poor transferability of GRS between South African Zulu and Ugandan populations. This might be due to differences in environmental (Extended Data Fig. 3) and genetic factors (Fig. 2D) between the South African Zulu and Ugandan cohorts19,20. The poor performance of GRS within the same ancestry population hinders the implementation of GRS in preventative healthcare. It may lead to inaccurate results when applied to different ethnic groups within sub-Saharan Africa. This further suggests the need for more efforts to optimize polygenic prediction in Africa. A limitation of this study is the none inclusion of diet and regular physical activity for the prediction of dyslipidemia. Nevertheless, we included crucial clinical factors, including body mass index, which is strongly associated with diet and regular physical activity; hence, the overall performance of our GRSs were robust.
In conclusion, using GRSs derived from data of individuals of African ancestry performed better in predicting lipid traits in sub-Saharan African populations than GRSs derived from data of individuals of European ancestry. However, the GRS are likely to have variable performances across sub-Saharan African populations, as shown by the differences seen between South African Zulu and Ugandan populations.
Methods
Study population
The target data for GRS construction were taken from the South African Zulu cohort, a combination of the Durban Diabetes Study (DDS) and the Durban Case-Control Study (DCC) KwaZulu-Natal South Africa. DDS is a population-based cross-sectional study of individuals aged >18 years residing in the urban black communities in Durban, KwaZulu-Natal, South Africa. DCC is a case–control study of individuals aged >40 years with diabetes recruited from tertiary hospitals in Durban. Data collection was conducted from 2009 to 2013 for the DCC and from 2013 to 2014 for the DDS. The survey questionnaire included socioeconomic factors, health information, lifestyle factors, blood pressure, anthropometric measurements (including height, weight, and hip and waist circumferences), biomarkers for communicable and noncommunicable diseases and genetic data. Of the 2,804 individuals surveyed, 1,204 were from the DDS and 1,600 were from the DCC; more detailed information on the study design and quality controls has been published previously21,22. Informed consent was obtained from all DDS and DCC participants. The DDS was approved by the University of KwaZulu-Natal Biomedical Research Ethics Committee (BF030/12) and the UK National Research Ethics Service (14/WM/); the DCC was approved by the University of KwaZulu-Natal Biomedical Research Ethics Committee (BF078/08) and the UK National Research Ethics Service (11/H0305/6).
The comparative cohort was taken from the Uganda genome resource (UGR), which is the genomic and phenotypic resource generated from the Uganda General Population Cohort (GPC). The GPC is a population-based cohort study founded in the late 1980s, and it has over 22,000 participants from 25 neighboring villages in Kyamilibwa in rural Uganda. This open-cohort study was established to investigate the trends of HIV infection in Uganda. However, the cohort’s focus now is to examine the role of host genetic variants associated with communicable and noncommunicable diseases in rural Ugandans22. Informed consent was obtained from all participants, and the Uganda GPC was approved by Uganda Virus Research Institute Research and Ethics Committee (UVRI-REC HS 1978) and the Uganda National Council for Science and Technology (UNCST SS 4283).
Measurement of lipid traits
Nonfasting serum lipid levels were measured using the Cobas Integra 400 Plus Chemistry analyzer (Roche Diagnostics), an automated analyzer that uses four different technologies: absorption photometry, fluorescence polarization immunoassay, immune turbidimetry and potentiometry for accurate analysis. HDL-C and LDL-C were measured using the homogeneous enzymatic colorimetric assays23,24.
Polygenic risk score
GWAS meta-analysis summary statistics results from the MVP were used as the discovery data sets in GRS computation for the specific lipids. For instance, LDL-C summary statistics from the multiancestry, African American and European cohorts were used for the development of the LDL-C GRSs. The MVP summary statistics results comprised an average of 30 million SNPs from more than 800,000 individuals of diverse ancestry. Of these, 61,796 were African American, and 241,54 were European. The multiancestry summary statistics comprised 25,747 individuals from Hispanic American, European and African American populations. Methods used for genotyping and quality control of MVP data have been previously described25.
For GRS construction, SNPs from MVP serum lipid summary statistics were clumped based on their LD. We clumped SNPs at different R2 thresholds, and a 500-kb clumping window with R2 of 0.5 proved to be the best-fitting and best-performing model for all lipid traits. We also tested the best P-value threshold for selecting which clumped SNPs we would include in the final GRS for the range of 1 to 5 × 10−8. The P-value threshold, which accounted for the highest proportion of the variance of the trait R2, was selected as the best GRS for TC. The GRS was calculated by multiplying the weight of the SNPs with the number of risk alleles (0/1/2) carried by each individual using the algorithm implemented in the PRSice-2 software26. The GRS generated was incorporated into the generalized linear regression model to explain the serum lipids’ performance while adjusting for age, sex, type 2 diabetes and five principal components, which were calculated using unrelated individuals and on pruned genotyped data sets using PLINK. An incremental R2 was computed from each model by the PRSice algorithm and plotted against the PT. R2 is the difference between the R2 of the fully adjusted model (GRS, age, sex, five principal components and diabetes status) and the R2 of the null model (age, sex, five principal components and diabetes status); the best GRS achieved the highest proportion of R2 (Fig. 1a).
The best-performing GRS was then categorized into deciles. The bottom decile was used as a reference and compared to other deciles. The difference in the effect sizes of the lipid levels across different GRS deciles was tested using linear regression while adjusting for age, sex, five principal components and diabetes status. We then performed logistic regression with the top decile of the GRS as cases with the remaining 90% as controls. The output of the logistic regression was used to compute the receiver operating curves in R. Furthermore, we used a net reclassification index to assess the ability of the GRS to identify individuals with high TC in the South African Zulu cohort. This reclassification was done by comparing the improvement in reclassification of a null model that comprised the conventional risk factors with that of a null model plus the GRSs using the PredictAbel package in R. The performance of the GRS from each lipid trait was compared among individuals of African ancestry, European ancestry and multiethnic ancestry populations using the ggplot2 R statistical package27,28.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Online content
Any methods, additional references, Nature Research reporting summaries, source data, extended data, supplementary information, acknowledgements, peer review information; details of author contributions and competing interests; and statements of data and code availability are available at 10.1038/s41591-022-01835-x.
Supplementary information
Acknowledgements
A.B.K. is supported by the National Institutes of Health/National Human Genome Research Institute (CARDINAL grant 1U01HG011717) at The African Computational Genomics Research Group, Medical Research Council/Uganda Virus Research Institute (MRC/UVRI) and LSHTM (London School of Hygiene & Tropical Medicine Uganda Research Unit), Uganda and Malawi Epidemiology and Intervention Research Unit, Lilongwe/Karonga, Malawi; South African Medical Research Council (with funds received from the South African National Department of Health) and the UK Medical Research Council (with funds received from the UK Government’s Newton Fund) (MRC-RFA-SHIP01/2015) for the Evolving Risk Factors for Cancers in African populations study (ERICA-SA). S.F. is an Intermediate international fellow funded by the Wellcome Trust (grant 220740/Z/20/Z) at the MRC/UVRI and LSHTM. T.C. is an international training fellow supported by the Wellcome Trust (grant 214205/Z/18/Z). D.G. was supported by the British Heart Foundation Centre of Research Excellence (RE/18/4/34215) at Imperial College and a National Institute for Health Research Clinical Lectureship (CL-2020-1.0.6-001) at St. George’s, University of London. The DCC was funded by Servier South Africa, the South African Sugar Association and the Victor Daitz Foundation. We thank the Fogarty International Center of the National Institutes of Health of the United States for supporting Sounkou Mahamane Toure under grant U2RTW010673 of the West African Center of Excellence for Global Health Bioinformatics Research Training. We thank the MVP staff, researchers and volunteers who have contributed to MVP, especially participants who previously served their country in the military and generously agreed to enroll in the study (for more details, see https://www.research.va.gov/mvp/ or Gaziano, J. M. et al. Million Veteran Program: a mega-biobank to study genetic influences on health and disease. J. Clin. Epidemiol. 2016;70:214–223). This research is based on data from the MVP, Office of Research and Development, Veterans Health Administration, and was supported by the Veterans Administration Cooperative Studies Program (award G002)
Extended data
Author contributions
S.F. and T.C. conceptualized and designed the study. S.F., A.B.K. and T.C. performed the data analyses. S.M.T., M.V., T.M., O.S.S., C.K., F.P., E.Y., M.S.S., P.K., M.N. and A.M. conducted the study and/or collected data. S.F., T.C., A.B.K., M.C. and D.G. interpreted the data. A.B.K. wrote the first draft. S.F., T.C., M.C., D.G. and A.M. critically revised the article. All authors provided final approval of the version to be published. S.F. and T.C. supervised the project. All the authors read and provided final approval of the version to be published.
Peer review
Peer review information
Nature Medicine thanks Iftikhar Kullo, Mayowa Owolabi and Constantin Polychronakos for their contribution to the peer review of this work. Primary Handling editor: Anna Maria Ranzoni, in collaboration with the Nature Medicine team.
Data availability
Requests for resources and information should be directed to and will be fulfilled by the lead contact, S.F. (segun.fatumo@mrcuganda.org; segun.fatumo@lshtm.ac.uk). All individual-level data and phenotype, genotype and sequence data are available under managed access to researchers. Requests for access will be granted for all research consistent with the consent provided by participants. This would include any research in the context of health and disease that does not involve identifying the participants in any way. The array data have been deposited at the European Genome-phenome Archive (https://www.ebi.ac.uk/ega/, accession number EGAD00010000965). Requests for access to data may be directed to segun.fatumo@mrcuganda.org. Applications are reviewed by a data access committee, and access is granted if the request is consistent with the consent provided by participants. The data producers may be consulted by the data access committee to evaluate potential ethical conflicts. Requestors also sign an agreement that governs the terms on which access to data is granted. The genome-wide association summary statistics data are currently at https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs001672.v3.p1#:~:text=MVP%20is%20an%20ongoing%20prospective,health%20and%20disease%20among%20veterans.dbGaP Study Accession: phs001672.v3.p1. The data used to construct the PRS are available on the PGS catalog: https://www.pgscatalog.org/publication/PGP000313/ (PGS ID accession: PGP000313).
Code availability
We used publicly available software PRSice to compute PRS and its code is publicly available at https://www.prsice.info/. Other software programs used are listed and described in Methods.
Competing interests
D.G. is employed part-time by Novo Nordisk. At the time of writing, M.C. is associated with Cambridge Precision Medicine Limited, UK. All other authors have no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors contributed equally: Tinashe Chikowore, Segun Fatumo.
Contributor Information
Tinashe Chikowore, Email: tinashe.chikowore1@wits.ac.za.
Segun Fatumo, Email: segun.fatumo@lshtm.ac.uk.
Extended data
is available for this paper at 10.1038/s41591-022-01835-x.
Supplementary information
The online version contains supplementary material available at 10.1038/s41591-022-01835-x.
References
- 1.Sanna S, et al. Fine mapping of five loci associated with low-density lipoprotein cholesterol detects variants that double the explained heritability. PLOS Genet. 2011;7:e1002198. doi: 10.1371/journal.pgen.1002198. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Willer CJ, et al. Discovery and refinement of loci associated with lipid levels. Nat. Genet. 2013;45:1274–1283. doi: 10.1038/ng.2797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Asselbergs FW, et al. Large-scale gene-centric meta-analysis across 32 studies identifies multiple lipid loci. Am. J. Hum. Genet. 2012;91:823–838. doi: 10.1016/j.ajhg.2012.08.032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Willer CJ, et al. Newly identified loci that influence lipid concentrations and risk of coronary artery disease. Nat. Genet. 2008;40:161–169. doi: 10.1038/ng.76. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Chasman DI, et al. Forty-three loci associated with plasma lipoprotein size, concentration, and cholesterol content in genome-wide analysis. PLOS Genet. 2009;5:e1000730. doi: 10.1371/journal.pgen.1000730. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Kathiresan S, et al. Six new loci associated with blood low-density lipoprotein cholesterol, high-density lipoprotein cholesterol or triglycerides in humans. Nat. Genet. 2008;40:189–197. doi: 10.1038/ng.75. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Lu X, et al. Exome chip meta-analysis identifies novel loci and East Asian-specific coding variants that contribute to lipid levels and coronary artery disease. Nat. Genet. 2017;49:1722–1730. doi: 10.1038/ng.3978. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Liu DJ, et al. Exome-wide association study of plasma lipids in >300,000 individuals. Nat. Genet. 2017;49:1758–1766. doi: 10.1038/ng.3977. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Hoffmann TJ, et al. A large electronic-health-record-based genome-wide study of serum lipids. Nat. Genet. 2018;50:401–413. doi: 10.1038/s41588-018-0064-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Duncan L, et al. Analysis of polygenic risk score usage and performance in diverse human populations. Nat. Commun. 2019;10:1–9. doi: 10.1038/s41467-019-11112-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lewis CM, Vassos E. Polygenic risk scores: from research tools to clinical instruments. Genome Med. 2020;12:1–11. doi: 10.1186/s13073-020-00742-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Gomez F, Hirbo J, Tishkoff SA. Genetic variation and adaptation in Africa: implications for human evolution and disease. Cold Spring Harb. Perspect. Biol. 2014;6:a008524. doi: 10.1101/cshperspect.a008524. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Márquez-Luna, C., Loh, P.-R., South Asian Type 2 Diabetes (SAT2D) Consortium, SIGMA Type 2 Diabetes Consortium & Price, A. L. Multiethnic polygenic risk scores improve risk prediction in diverse populations. Genet. Epidemiol. 41, 811–823 (2017). [DOI] [PMC free article] [PubMed]
- 14.Bentley AR, Callier SL, Rotimi CN. Evaluating the promise of inclusion of African ancestry populations in genomics. NPJ Genom. Med. 2020;5:1–9. doi: 10.1038/s41525-019-0111-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Bloetzer C, et al. Screening for cardiovascular disease risk factors beginning in childhood. Public Health Rev. 2015;36:1–9. doi: 10.1186/s40985-015-0011-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Cavazos TB, Witte JS. Inclusion of variants discovered from diverse populations improves polygenic risk score transferability. Hum. Genet. Genomics Adv. 2021;2:100017. doi: 10.1016/j.xhgg.2020.100017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Martin AR, et al. Clinical use of current polygenic risk scores may exacerbate health disparities. Nat. Genet. 2019;51:584–591. doi: 10.1038/s41588-019-0379-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Johnson L, Zhu J, Scott ER, Wineinger NE. An examination of the relationship between lipid levels and associated genetic markers across racial/ethnic populations in the multi-ethnic study of atherosclerosis. PLOS One. 2015;10:e0126361. doi: 10.1371/journal.pone.0126361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Lucchese B. Implications of African genetic diversity. Nat. Rev. Nephrol. 2009;5:663–663. doi: 10.1038/nrneph.2009.202. [DOI] [PubMed] [Google Scholar]
- 20.Yu N, et al. Larger genetic differences within Africans than between Africans and Eurasians. Genetics. 2002;161:269–274. doi: 10.1093/genetics/161.1.269. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Hird TR, et al. Study profile: the Durban Diabetes Study (DDS): a platform for chronic disease research. Glob. Health Epidemiol. Genom. 2016;1:e2. doi: 10.1017/gheg.2015.3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Gurdasani D, et al. Uganda Genome Resource enables insights into population history and genomic discovery in Africa. Cell. 2019;179:984–1002. doi: 10.1016/j.cell.2019.10.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Sugiuchi H, et al. Direct measurement of high-density lipoprotein cholesterol in serum with polyethylene glycol-modified enzymes and sulfated alpha-cyclodextrin. Clin. Chem. 1995;41:717–723. doi: 10.1093/clinchem/41.5.717. [DOI] [PubMed] [Google Scholar]
- 24.Sugiuchi H, et al. Homogeneous assay for measuring low-density lipoprotein cholesterol in serum with triblock copolymer and α-cyclodextrin sulfate. Clin. Chem. 1998;44:522–531. doi: 10.1093/clinchem/44.3.522. [DOI] [PubMed] [Google Scholar]
- 25.Klarin D, et al. Genetics of blood lipids among ~300,000 multi-ethnic participants of the Million Veteran Program. Nat. Genet. 2018;50:1514–1523. doi: 10.1038/s41588-018-0222-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Choi SW, O’Reilly PF. PRSice-2: polygenic risk score software for biobank-scale data. Gigascience. 2019;8:giz082. doi: 10.1093/gigascience/giz082. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.R Core Team. R: a language and environment for statistical computing https://www.R-project.org/ (R Foundation for Statistical Computing, 2019).
- 28.Wickham, H. ggplot2: Elegant Graphics for Data Analysis (Springer-Verlag, 2009). 10.1007/978-0-387-98141-3
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Requests for resources and information should be directed to and will be fulfilled by the lead contact, S.F. (segun.fatumo@mrcuganda.org; segun.fatumo@lshtm.ac.uk). All individual-level data and phenotype, genotype and sequence data are available under managed access to researchers. Requests for access will be granted for all research consistent with the consent provided by participants. This would include any research in the context of health and disease that does not involve identifying the participants in any way. The array data have been deposited at the European Genome-phenome Archive (https://www.ebi.ac.uk/ega/, accession number EGAD00010000965). Requests for access to data may be directed to segun.fatumo@mrcuganda.org. Applications are reviewed by a data access committee, and access is granted if the request is consistent with the consent provided by participants. The data producers may be consulted by the data access committee to evaluate potential ethical conflicts. Requestors also sign an agreement that governs the terms on which access to data is granted. The genome-wide association summary statistics data are currently at https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs001672.v3.p1#:~:text=MVP%20is%20an%20ongoing%20prospective,health%20and%20disease%20among%20veterans.dbGaP Study Accession: phs001672.v3.p1. The data used to construct the PRS are available on the PGS catalog: https://www.pgscatalog.org/publication/PGP000313/ (PGS ID accession: PGP000313).
We used publicly available software PRSice to compute PRS and its code is publicly available at https://www.prsice.info/. Other software programs used are listed and described in Methods.