

Abstract
This paper introduces a closed-form expression for the Kullback–Leibler divergence (KLD) between two central multivariate Cauchy distributions (MCDs) which have been recently used in different signal and image processing applications where non-Gaussian models are needed. In this overview, the MCDs are surveyed and some new results and properties are derived and discussed for the KLD. In addition, the KLD for MCDs is showed to be written as a function of Lauricella D-hypergeometric series . Finally, a comparison is made between the Monte Carlo sampling method to approximate the KLD and the numerical value of the closed-form expression of the latter. The approximation of the KLD by Monte Carlo sampling method are shown to converge to its theoretical value when the number of samples goes to the infinity.
Keywords: Multivariate Cauchy distribution (MCD), Kullback–Leibler divergence (KLD), multiple power series, Lauricella D-hypergeometric series
1. Introduction
Multivariate Cauchy distribution (MCD) belongs to the elliptical symmetric distributions [1] and is a special case of the multivariate t-distribution [2] and the multivariate stable distribution [3]. MCD has been recently used in several signal and image processing applications for which non-Gaussian models are needed. To name a few of them, in speckle denoizing, color image denoizing, watermarking, speech enhancement, among others. Sahu et al. in [4] presented a denoizing method for speckle noise removal applied to a retinal optical coherence tomography (OCT) image. The method was based on the wavelet transform where the sub-bands coefficients were modeled using a Cauchy distribution. In [5], a dual tree complex wavelet transform (DTCWT)-based despeckling algorithm was proposed for synthetic aperture radar (SAR) images, where the DTCWT coefficients in each subband were modeled with a multivariate Cauchy distribution. In [6], a new color image denoizing method in the contourlet domain was suggested for reducing noise in images corrupted by Gaussian noise where the contourlet subband coefficients were described by the heavy-tailed MCD. Sadreazami et al. in [7] put forward a novel multiplicative watermarking scheme in the contourlet domain where the watermark detector was based on the bivariate Cauchy distribution and designed to capture the across scale dependencies of the contourlet coefficients. Fontaine et al. in [8] proposed a semi-supervised multichannel speech enhancement system where both speech and noise follow the heavy-tailed multi-variate complex Cauchy distribution.
Kullback–Leibler divergence (KLD), also called relative entropy, is one of the most fundamental and important measures in information theory and statistics [9,10]. KLD was first introduced and studied by Kullback and Leibler [11] and Kullback [12] to measure the divergence between two probability mass functions in the case of discrete random variables and between two univariate or multivariate probability density functions in the case of continuous random variables. In the literature, numerous entropy and divergence measures have been suggested for measuring the similarity between probability distributions, such as Rényi [13] divergence, Sharma and Mittal [14] divergence, Bhattacharyya [15,16] divergence and Hellinger divergence measures [17]. Other general divergence families have been also introduced and studied like the -divergence family of divergence measures defined simultaneously by Csiszár [18] and Ali and Silvey [19] where the KLD measure is a special case, the Bregman family divergence [20], the R-divergences introduced by Burbea and Rao [21,22,23], the statistical f-divergences [24,25] and recently the new family of a generalized divergence called the -divergence measures introduced and studied in Menéndez et al. [26]. Readers are referred to [10] for details about these divergence family measures.
KLD has a specific interpretation in coding theory [27] and is therefore the most popular and widely used as well. Since information theoretic divergence and KLD in particular are ubiquitous in information sciences [28,29], it is therefore important to establish closed-form expressions of such divergence [30]. An analytical expression of the KLD between two univariate Cauchy distributions was presented in [31,32]. To date, the KLD of MCDs has no known explicit form, and it is in practice either estimated using expensive Monte Carlo stochastic integration or approximated. Monte Carlo sampling can efficiently estimate the KLD provided that a large number of independent and identically distributed samples is provided. Nevertheless, Monte Carlo integration is a too slow process to be useful in many applications. The main contribution of this paper is to derive a closed-form expression for the KLD between two central MCDs in a general case to benchmark future approaches while avoiding approximation using expensive Monte Carlo (MC) estimation techniques. The paper is organized as follows. Section 2 introduces the MCD and the KLD. Section 3 gives some definitions and propositions related to a multiple power series used to compute the closed-form expression of the KLD between two central MCDs. In Section 4 and Section 5, expressions of some expectations related to the KLD are developed by exploiting the propositions presented in the previous section. Section 6 demonstrates some final results on the KLD computed for the central MCD. Section 7 presents some particular results such as the KLD for the univariate and the bivariate Cauchy distribution. Section 8 presents the implementation procedure of the KLD and a comparison with Monte Carlo sampling method. A summary and some conclusions are provided in the final section.
2. Multivariate Cauchy Distribution and Kullback–Leibler Divergence
Let be a random vector of which follows the MCD, characterized by the following probability density function (pdf) given as follows [2]
| (1) |
This is for any , where p is the dimensionality of the sample space, is the location vector, is a symmetric, positive definite scale matrix and is the Gamma function. Let and be two random vectors that follow central MCDs with pdfs and given by (1). KLD provides an asymmetric measure of the similarity of the two pdfs. Indeed, the KLD between the two central MCDs is given by
| (2) |
| (3) |
Since the KLD is the relative entropy defined as the difference between the cross-entropy and the entropy, we have the following relation:
| (4) |
where denotes the cross-entropy and the entropy. Therefore, the determination of KLD requires the expression of the entropy and the cross-entropy. It should be noted that the smaller , the more similar are and . The symmetric KL similarity measure between and is . In order to compute the KLD, we have to derive the analytical expressions of and which depend, respectively, on and . Consequently, the closed-form expression of the KLD between two zero-mean MCDs is given by
| (5) |
To provide the expression of these two expectations, some tools based on the multiple power series are required. The next section presents some definitions and propositions used for this goal.
3. Definitions and Propositions
This section presents some definitions and exposes some propositions related to the multiple power series used to derive the closed-form expression of the expectation and , and as a consequence the KLD between two central MCDs.
Definition 1.
The Humbert series of n variables, denoted , is defined for all , by the following multiple power series (Section 1.4 in [33])
(6)
The Pochhammer symbol indicates the i-th rising factorial of q, i.e., for an integer
| (7) |
3.1. Integral Representation for
Proposition 1.
The following integral representation is true for and where denotes the real part of the complex coefficients
(8) where and the multivariate beta function B is the extension of beta function to more than two arguments (called also Dirichlet function) defined as (Section 1.6.1 in [34])
(9)
Proof.
The power series of exponential function is given by
(10) By substituting the expression of the exponential into the multiple integrals we have
(11) where the multivariate integral , which is a generalization of a beta integral, is the type-1 Dirichlet integral (Section 1.6.1 in [34]) given by
(12) Knowing that , the expression of can be written otherwise
(13) Finally, plugging (13) back into (11) leads to the final result
(14) □
Given Proposition 1, we consider the particular cases one by one as follows:
Case
| (15) |
where is the confluent hypergeometric function of the first kind (Section 9.21 in [35]).
Case
| (16) |
where the double series is one of the components of the Humbert series of two variables [36] that generalize Kummer’s confluent hypergeometric series of one variable. The double series converges absolutely at any , .
3.2. Multiple Power Series
Definition 2.
We define a new multiple power series, denoted by and given by
(17) The multiple power series (17) is absolutely convergent on the region in .
The multiple power series can also be transformed into two other expressions as follows
| (18) |
| (19) |
By Horn’s rule for the determination of the convergence region (see [37], Section 5.7.2), the multiple power series (18) and (19) are absolutely convergent on region in .
Equation (18) can then be deduced from (17) by using the following development where the function can be written as
| (20) |
and is used here to alleviate writing equations. Using the definition of Gauss’ hypergeometric series [34] and the Pfaff transformation [38], we can write
| (21) |
| (22) |
| (23) |
By substituting (23) into (20), and using the following two relations:
| (24) |
| (25) |
we can get (18).
The second transformation is given as follows
| (26) |
| (27) |
By substituting (27) into (20), we get (19).
Lemma 1.
The multiple power series is equal to the Lauricella D-hypergeometric function (see Appendix A) [39] when and is given as follows
(28)
(29)
Proof.
By using Equation (18) of the multiple power series and after having simplified to the numerator and to the denominator, we can get the result. □
3.3. Integral Representation for
Proposition 2.
The following integral representation is true for
(30) where is the confluent hypergeometric function of the second kind (Section 9.21 in [35]) defined for , by the following integral representation
(31) and is defined by Equation (6).
Proof.
The multiple power series and the confluent hypergeometric function are absolutely convergent on . Using these functions in the above integral and changing the order of integration and summation, which is easily justified by absolute convergence, we get
(32) where integral is defined as follows
(33) Substituting the integral expression of in the previous equation and replacing to alleviate writing equations, we have
(34) Knowing that [35]
(35) and
(36) the new expression of is then given by
(37) Using the fact that and , and developing the same method to , the final complete expression of the integral is then given by
(38) □
4. Expression of
Proposition 3.
Let be a random vector that follows a central MCD with pdf given by . Expectation is given as follows
(39) where is the digamma function defined as the logarithmic derivative of the Gamma function (Section 8.36 in [35]).
Proof.
Expectation is developed as follows
(40) where . Utilizing the following property , as a consequence the expectation is given as follows
(41) Consider the transformation where . The Jacobian determinant is given by (Theorem 1.12 in [40]). The new expression of the expectation is given by
(42) Let be a transformation where the Jacobian determinant is given by (Lemma 13.3.1 in [41])
(43) The new expectation is as follows
(44) Using the definition of beta function, we can write that
(45) The derivative of the last integral w.r.t a is given by
(46) Finally, the expression of is given by
(47) □
5. Expression of
Proposition 4.
Let and be two random vectors that follow central MCDs with pdfs given, respectively, by and . Expectation is given as follows
(48) where ,…, are the eigenvalues of the real matrix , and represents the Lauricella D-hypergeometric function defined for p variables.
Proof.
To prove Proposition 4, different steps are necessary. They are described in the following:
5.1. First Step: Eigenvalue Expression
Expectation is computed as follows
| (49) |
where . Consider transformation where . The Jacobian determinant is given by (Theorem 1.12 in [40]) and matrix is a real symmetric matrix since and are real symmetric matrixes. Then, the expectation is evaluated as follows
| (50) |
Matrix can be diagonalized by an orthogonal matrix with and where is a diagonal matrix composed of the eigenvalues of . Considering that , the expectation can be written as
| (51) |
Let with be a transformation where the Jacobian determinant is given by . Using the fact that and , then the previous expectation (51) is given as follows
| (52) |
| (53) |
where ,…, are the eigenvalues of .
5.2. Second Step: Polar Decomposition
Let the independent real variables be transformed to the general polar coordinates r, as follows, where , , , [40],
| (54) |
| (55) |
| (56) |
| (57) |
The Jacobian determinant according to theorem (1.24) in [40] is
| (58) |
It is clear that with the last transformations, we get and the multiple integral in (53) is then given as follows
| (59) |
By replacing the expression of by , for , we have the following expression
| (60) |
Let be a transformation to use where . Then the expectation given by the multiple integral over all , is as follows
| (61) |
where , and . In the following, we use the notation instead of to alleviate writing equations.
Let be transformation to use. Then, one can write
| (62) |
In order to solve the integral in (62), we consider the following property given by and the following equation given as follows
| (63) |
Making use of the above equation, we obtain a new expression of (62) given as follows
| (64) |
| (65) |
where is defined as
| (66) |
5.3. Third Step: Expression for H(t,y) by Humbert and Beta Functions
Let , be transformations to use. Then
| (67) |
| (68) |
| (69) |
| (70) |
Adding equations from (67) to (70), we can state that the new expression of the function becomes
| (71) |
Then, the multiple integral given by (66) can be written otherwise
| (72) |
Let the real variables be transformed to the real variables as follows
| (73) |
| (74) |
| (75) |
| (76) |
The Jacobian determinant is given by
| (77) |
Accordingly, the new expression of becomes
| (78) |
As a consequence, the new domain of the multiple integral (72) is , and the expression of is given as follows
| (79) |
| (80) |
| (81) |
| (82) |
Using Proposition 1, we subsequently find that
| (83) |
where is the Humbert series of variables and is the multivariate beta function. Applying the following successive two transformations () and (), the new expression of the expectation given by (65) is written as follows
| (84) |
5.4. Final Step
The last integral is related to the confluent hypergeometric function of the second kind as follows
| (85) |
As a consequence, the new expression is
| (86) |
Using the transformation and the Proposition 2, and taking into account the expression of A, the new expression becomes
| (87) |
Knowing that
| (88) |
| (89) |
the new expression of becomes
| (90) |
Applying the expression given by (18) of Definition 2 and relying on Lemma 1, the final result corresponds to the D-hypergeometric function of Lauricella given by
| (91) |
| (92) |
The final development of the previous expression is as follows
| (93) |
□
In this section, we presented the exact expression of . In addition, the multiple power series which appears to be a special case of provides many properties and numerous transformations (see Appendix A) that make easier the convergence of the multiple power series. In the next section, we establish the KLD closed-form expression based on the expression of the latter expectation.
6. KLD between Two Central MCDs
Plugging (39) and (93) into (5) yields the closed-form expression of the KLD between two central MCDs with pdfs and . This result is presented in the following theorem.
Theorem 1.
Let and be two random vectors that follow central MCDs with pdfs given, respectively, by and . The Kullback–Leibler divergence between central MCDs is
(94) where ,…, are the eigenvalues of the real matrix , and represents the Lauricella D-hypergeometric function defined for p variables.
Lauricella [39] gave several transformation formulas (see Appendix A), whose relations (A5)–(A7), and (A9) are applied to in (94). The results of transformation are as follows
| (95) |
| (96) |
| (97) |
| (98) |
Considering the above equations, it is easy to provide different expressions of shown in Table 1. The derivative of the Lauricella D-hypergeometric series with respect to a goes through the derivation of the following expression
| (99) |
| (100) |
Table 1.
KLD and KL distance computed when and are two random vectors following central MCDs with pdfs and .
|
| |
|
| |
|
|
The derivative with respect to a of the Lauricella D-hypergeometric series and its transformations goes through the following expressions (see Appendix B for demonstration)
| (101) |
| (102) |
| (103) |
| (104) |
To derive the closed-form expression of we have to evaluate the expression of . The latter can be easily deduced from as follows
| (105) |
Proceeding in the same way by using Lauricella transformations, different expressions of are provided in Table 1. Finally, given the above results, it is straightforward to compute the symmetric KL similarity measure between and . Technically, any combination of the and expressions is possible to compute . However, we choose the same convergence region for the two divergences for the calculation of the distance. Some expressions of are given in Table 1.
7. Particular Cases: Univariate and Bivariate Cauchy Distribution
7.1. Case of
This case corresponds to the univariate Cauchy distribution. The KLD is given by
| (119) |
where is the Gauss’s hypergeometric function. The expression of the derivative of is given as follows (see Appendix C.1 for details of computation)
| (120) |
Accordingly, the KLD is then expressed as
| (121) |
| (122) |
We conclude that KLD between Cauchy densities is always symmetric. Interestingly, this is consistent with the result presented in [31].
7.2. Case of
This case corresponds to the Bivariate Cauchy distribution. The KLD is then given by
| (123) |
where is the Appell’s hypergeometric function (see Appendix A). The expression of the derivative of can be further developed
| (124) |
In addition, when the eigenvalue for takes some particular values, the expression of the KLD becomes very simple. In the following, we show some cases:
or
For this particular case, we have
| (125) |
| (126) |
The demonstration of the derivation is shown in Appendix C.2. Then, KLD becomes equal to
| (127) |
For this particular case, we have
| (128) |
| (129) |
For more details about the demonstration see Appendix C.3. The KLD becomes equal to
| (130) |
It is easy to deduce that
| (131) |
This result can be demonstrated using the same process as . It is worth to notice that which leads us to conclude that the property of symmetry observed for the univariate case is no longer valid in the multivariate case. Nielsen et al. in [32] gave the same conclusion.
8. Implementation and Comparison with Monte Carlo Technique
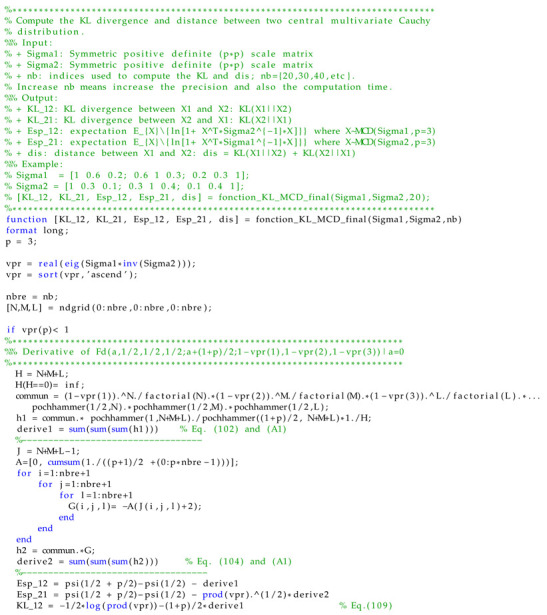
In this section, we show how we practically compute the numerical values of the KLD, especially when we have several equivalent expressions which differ in the region of convergence. To reach this goal, the eigenvalues of are rearranged in a descending order . This operation is justified by Equation (53) where it can be seen that the permutation of the eigenvalues does not affect the expectation result. Three cases can be identified from the expressions of KLD.
8.1. Case
The expression of is given by Equation (109) and is given by (115).
8.2. Case
is given by the Equation (110) and is given by (114).
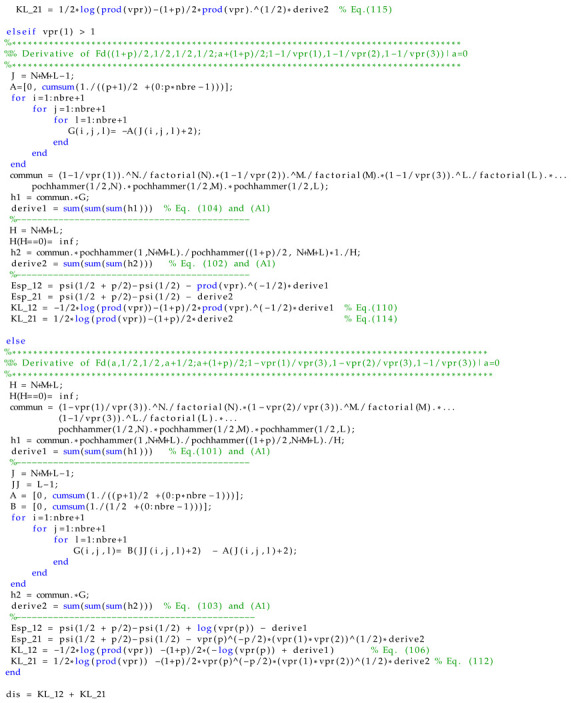
8.3. Case and
This case guarantees that , and . The expression of the is given by Equation (106) and is given by (112) or (113). To perform an evaluation of the quality of the numerical approximation of the derivative of the Lauricella series, we consider a case where an exact and simple expression of is possible. The following case where allows the Lauricella series to be equivalent to the Gauss hypergeometric function given as follows
| (132) |
This relation allows us to compare the computational accuracy of the approximation of the Lauricella series with respect to the Gauss function. In addition, to compute the numerical value the indices of the series will evolve from 0 to N instead of infinity. The latter is chosen to ensure a good approximation of the Lauricella series. Table 2 shows the computation of the derivative of and , along with the absolute value of error , where . The exact expression of when is given by Equation (129). We can deduce the following conclusions. First, the error is reasonably low and decreases as the value of N increases. Second, the error increases for values of close to 1 as expected, which corresponds to the convergence region limit.
Table 2.
Computation of and when and .
| 0.1 | 0.0694 | 0.0694 | 9.1309 | 0.0694 | 9.1309 | 0.0694 | 9.1309 |
| 0.3 | 0.2291 | 0.2291 | 3.7747 | 0.2291 | 1.1102 | 0.2291 | 1.1102 |
| 0.5 | 0.4292 | 0.4292 | 2.6707 | 0.4292 | 1.2458 | 0.4292 | 6.6613 |
| 0.7 | 0.7022 | 0.7022 | 5.9260 | 0.7022 | 8.2678 | 0.7022 | 1.3911 |
| 0.9 | 1.1673 | 1.1634 | 0.0038 | 1.1665 | 7.2760 | 1.1671 | 1.6081 |
| 0.99 | 1.7043 | 1.5801 | 0.1241 | 1.6267 | 0.0776 | 1.6514 | 0.0529 |
In the following section, we compare the Monte Carlo sampling method to approximate the KLD value with the numerical value of the closed-form expression of the latter. The Monte Carlo method involves sampling a large number of samples and using them to calculate the sum rather than the integral. Here, for each sample size, the experiment is repeated 2000 times. The elements of and are given in Table 3. Figure 1 depicts the absolute value of bias, mean square error (MSE) and box plot of the difference between the symmetric KL approximated value and its theoretical one, given versus the sample sizes. As the sample size increases, the bias and the MSE decrease. Accordingly, the approximated value will be very close to the theoretical KLD when the number of samples is very large. The computation time of the proposed approximation and the classical Monte Carlo sampling method are recorded using Matlab on a 1.6 GHz processor with 16 GB of memory. For the proposed numerical approximation, the computation time is evaluated to 1.56 s with . The value of N can be increased to further improve the accuracy, but it will increase the computation time. For the Monte Carlo sampling method, the mean time values at sample sizes of {65,536; 131,072; 262,144} are seconds, respectively.
Table 3.
Parameters and used to compute KLD for central MCD.
| , , , , , | |
| 1, 1, 1, 0.6, 0.2, 0.3 | |
| 1, 1, 1, 0.3, 0.1, 0.4 |
Figure 1.

Top row: Bias (left) and MSE (right) of the difference between the approximated and theoretical symmetric KL for MCD. Bottom row: Box plot of the error. The mean error is the bias. Outliers are larger than or smaller than , where , , and are the 25th, 75th percentiles, and the interquartile range, respectively.
To further encourage the dissemination of these results, we provide a code available as attached file to this paper. This is given in Matlab with a specific case of . This can be easily extended to any value of p, thanks to the general closed-form expression established in this paper.
9. Conclusions
Since the MCDs have various applications in signal and image processing, the KLD between central MCDs tackles an important problem for future work on statistics, machine learning and other related fields in computer science. In this paper, we derived a closed-form expression of the KLD and distance between two central MCDs. The similarity measure can be expressed as function of the Lauricella D-hypergeometric series . We have also proposed a simple scheme to compute easily the Lauricella series and to bypass the convergence constraints of this series. Codes and examples for numerical calculations are presented and explained in detail. Finally, a comparison is made to show how the Monte Carlo sampling method gives approximations close to the KLD theoretical value. As a final note, it is also possible to extend these results on the KLD to the case of the multivariate t-distribution since the MCD is a particular case of this multivariate distribution.
Acknowledgments
Authors gratefully acknowledge the PHENOTIC platform node of the french national infrastructure on plant phenotyping ANR PHENOME 11-INBS-0012. The authors would like also to thank the anonymous reviewers for their helpful comments valuable comments and suggestions.
Appendix A. Lauricella Function
In 1893, G. Lauricella [39] investigated the properties of four series of n variables. When , these functions coincide with Appell’s , respectively. When , they all coincide with Gauss’ . We present here only the Lauricella series given as follows
| (A1) |
where . The Pochhammer symbol indicates the i-th rising factorial of q, i.e.,
| (A2) |
If , . Function can be expressed in terms of multiple integrals as follows [42]
| (A3) |
where , Real for and Real . Lauricella’s can be written as a one-dimensional Euler-type integral for any number n of variables. The integral form of is given as follows when Real and Real
| (A4) |
Lauricella has given several transformation formulas, from which we use the two following relationships. More details can be found in Exton’s book [43] on hypergeometric equations.
| (A5) |
| (A6) |
| (A7) |
| (A8) |
| (A9) |
Appendix B. Demonstration of Derivative
Appendix B.1. Demonstration
We use the following notation to alleviate the writing of equations. Knowing that , and we can state that
| (A10) |
Using the fact that
| (A11) |
we can state that
| (A12) |
Appendix B.2. Demonstration
| (A13) |
| (A14) |
By developing the previous expression we can state that
| (A15) |
Appendix B.3. Demonstration
| (A16) |
As a consequence,
| (A17) |
Appendix B.4. Demonstration
| (A18) |
| (A19) |
Finally,
| (A20) |
Appendix C. Computations of Some Equations
Appendix C.1. Computation
Let f be a function of defined as follows:
| (A21) |
The multiplication of the derivative of f with respect to by is given as follows
| (A22) |
As a consequence,
| (A23) |
Finally,
| (A24) |
Appendix C.2. Computation
| (A25) |
where f is a function of . The multiplication of the derivative of f with respect to by is given as follows
| (A26) |
| (A27) |
Knowing that
| (A28) |
| (A29) |
we can deduce an expression of
| (A30) |
Accordingly,
| (A31) |
| (A32) |
Appendix C.3. Computation
| (A33) |
where f is a function of . The multiplication of the derivative of f with respect to by is given as follows
| (A34) |
| (A35) |
Knowing that
| (A36) |
we can state that
| (A37) |
As a consequence,
| (A38) |
| (A39) |
Author Contributions
Conceptualization, N.B.; methodology, N.B.; software, N.B.; writing original draft preparation, N.B.; writing review and editing, N.B. and D.R.; supervision, D.R. All authors have read and agreed to the published version of the manuscript.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Funding Statement
This research received no external funding.
Footnotes
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Ollila E., Tyler D.E., Koivunen V., Poor H.V. Complex Elliptically Symmetric Distributions: Survey, New Results and Applications. IEEE Trans. Signal Process. 2012;60:5597–5625. doi: 10.1109/TSP.2012.2212433. [DOI] [Google Scholar]
- 2.Kotz S., Nadarajah S. Multivariate T-Distributions and Their Applications. Cambridge University Press; Cambridge, UK: 2004. [DOI] [Google Scholar]
- 3.Press S. Multivariate stable distributions. J. Multivar. Anal. 1972;2:444–462. doi: 10.1016/0047-259X(72)90038-3. [DOI] [Google Scholar]
- 4.Sahu S., Singh H.V., Kumar B., Singh A.K. Statistical modeling and Gaussianization procedure based de-speckling algorithm for retinal OCT images. J. Ambient. Intell. Humaniz. Comput. 2018:1–14. doi: 10.1007/s12652-018-0823-2. [DOI] [Google Scholar]
- 5.Ranjani J.J., Thiruvengadam S.J. Generalized SAR Despeckling Based on DTCWT Exploiting Interscale and Intrascale Dependences. IEEE Geosci. Remote Sens. Lett. 2011;8:552–556. doi: 10.1109/LGRS.2010.2089780. [DOI] [Google Scholar]
- 6.Sadreazami H., Ahmad M.O., Swamy M.N.S. Color image denoising using multivariate cauchy PDF in the contourlet domain; Proceedings of the 2016 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE); Vancouver, BC, Canada. 15–18 May 2016; pp. 1–4. [DOI] [Google Scholar]
- 7.Sadreazami H., Ahmad M.O., Swamy M.N.S. A Study of Multiplicative Watermark Detection in the Contourlet Domain Using Alpha-Stable Distributions. IEEE Trans. Image Process. 2014;23:4348–4360. doi: 10.1109/TIP.2014.2339633. [DOI] [PubMed] [Google Scholar]
- 8.Fontaine M., Nugraha A.A., Badeau R., Yoshii K., Liutkus A. Cauchy Multichannel Speech Enhancement with a Deep Speech Prior; Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO); A Coruna, Spain. 2–6 September 2019; pp. 1–5. [Google Scholar]
- 9.Cover T.M., Thomas J.A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing) Wiley-Interscience; Hoboken, NJ, USA: 2006. [DOI] [Google Scholar]
- 10.Pardo L. Statistical Inference Based on Divergence Measures. CRC Press; Abingdon, UK: 2005. [Google Scholar]
- 11.Kullback S., Leibler R.A. On Information and Sufficiency. Ann. Math. Stat. 1951;22:79–86. doi: 10.1214/aoms/1177729694. [DOI] [Google Scholar]
- 12.Kullback S. Information Theory and Statistics. Wiley; New York, NY, USA: 1959. [Google Scholar]
- 13.Rényi A. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability. Volume 1. University of California Press; Berkeley, CA, USA: 1961. On Measures of Entropy and Information; pp. 547–561. [Google Scholar]
- 14.Sharma B.D., Mittal D.P. New non-additive measures of relative information. J. Comb. Inf. Syst. Sci. 1977;2:122–132. [Google Scholar]
- 15.Bhattacharyya A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943;35:99–109. [Google Scholar]
- 16.Kailath T. The Divergence and Bhattacharyya Distance Measures in Signal Selection. IEEE Trans. Commun. Technol. 1967;15:52–60. doi: 10.1109/TCOM.1967.1089532. [DOI] [Google Scholar]
- 17.Giet L., Lubrano M. A minimum Hellinger distance estimator for stochastic differential equations: An application to statistical inference for continuous time interest rate models. Comput. Stat. Data Anal. 2008;52:2945–2965. doi: 10.1016/j.csda.2007.10.004. [DOI] [Google Scholar]
- 18.Csiszár I. Eine informationstheoretische Ungleichung und ihre Anwendung auf den Beweis der Ergodizität von Markoffschen Ketten. Publ. Math. Inst. Hung. Acad. Sci. Ser. A. 1963;8:85–108. [Google Scholar]
- 19.Ali S.M., Silvey S.D. A General Class of Coefficients of Divergence of One Distribution from Another. J. R. Stat. Soc. Ser. B (Methodol.) 1966;28:131–142. doi: 10.1111/j.2517-6161.1966.tb00626.x. [DOI] [Google Scholar]
- 20.Bregman L. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967;7:200–217. doi: 10.1016/0041-5553(67)90040-7. [DOI] [Google Scholar]
- 21.Burbea J., Rao C. On the convexity of some divergence measures based on entropy functions. IEEE Trans. Inf. Theory. 1982;28:489–495. doi: 10.1109/TIT.1982.1056497. [DOI] [Google Scholar]
- 22.Burbea J., Rao C. On the convexity of higher order Jensen differences based on entropy functions (Corresp.) IEEE Trans. Inf. Theory. 1982;28:961–963. doi: 10.1109/TIT.1982.1056573. [DOI] [Google Scholar]
- 23.Burbea J., Rao C. Entropy differential metric, distance and divergence measures in probability spaces: A unified approach. J. Multivar. Anal. 1982;12:575–596. doi: 10.1016/0047-259X(82)90065-3. [DOI] [Google Scholar]
- 24.Csiszar I. Information-type measures of difference of probability distributions and indirect observation. Stud. Sci. Math. Hung. 1967;2:229–318. [Google Scholar]
- 25.Nielsen F., Nock R. On the chi square and higher-order chi distances for approximating f-divergences. IEEE Signal Process. Lett. 2014;21:10–13. doi: 10.1109/LSP.2013.2288355. [DOI] [Google Scholar]
- 26.Menéndez M.L., Morales D., Pardo L., Salicrú M. Asymptotic behaviour and statistical applications of divergence measures in multinomial populations: A unified study. Stat. Pap. 1995;36:1–29. doi: 10.1007/BF02926015. [DOI] [Google Scholar]
- 27.Cover T.M., Thomas J.A. Information theory and statistics. Elem. Inf. Theory. 1991;1:279–335. [Google Scholar]
- 28.MacKay D.J.C. Information Theory, Inference and Learning Algorithms. Cambridge University Press; Cambridge, UK: 2003. [Google Scholar]
- 29.Ruiz F.E., Pérez P.S., Bonev B.I. Information Theory in Computer Vision and Pattern Recognition. Springer Science & Business Media; Berlin/Heidelberg, Germany: 2009. [Google Scholar]
- 30.Nielsen F. Statistical Divergences between Densities of Truncated Exponential Families with Nested Supports: Duo Bregman and Duo Jensen Divergences. Entropy. 2022;24:421. doi: 10.3390/e24030421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Chyzak F., Nielsen F. A closed-form formula for the Kullback–Leibler divergence between Cauchy distributions. arXiv. 20191905.10965 [Google Scholar]
- 32.Nielsen F., Okamura K. On f-divergences between Cauchy distributions. arXiv. 20212101.12459 [Google Scholar]
- 33.Srivastava H., Karlsson P.W. Multiple Gaussian Hypergeometric Series. Horwood Halsted Press; Chichester, UK: West Sussex, UK: New York, NY, USA: 1985. (Ellis Horwood Series in Mathematics and Its Applications Statistics and Operational Research, E). [Google Scholar]
- 34.Mathai A.M., Haubold H.J. Special Functions for Applied Scientists. Springer Science+Business Media; New York, NY, USA: 2008. [Google Scholar]
- 35.Gradshteyn I., Ryzhik I. Table of Integrals, Series, and Products. 7th ed. Academic Press is an Imprint of Elsevier; Cambridge, MA, USA: 2007. [Google Scholar]
- 36.Humbert P. The Confluent Hypergeometric Functions of Two Variables. Proc. R. Soc. Edinb. 1922;41:73–96. doi: 10.1017/S0370164600009810. [DOI] [Google Scholar]
- 37.Erdélyi A. Higher Transcendental Functions. Volume I McGraw-Hill; New York, NY, USA: 1953. [Google Scholar]
- 38.Koepf W. Hypergeometric Summation an Algorithmic Approach to Summation and Special Function Identities. 2nd ed. Universitext, Springer; London, UK: 2014. [Google Scholar]
- 39.Lauricella G. Sulle funzioni ipergeometriche a piu variabili. Rend. Del Circ. Mat. Palermo. 1893;7:111–158. doi: 10.1007/BF03012437. [DOI] [Google Scholar]
- 40.Mathai A.M. Jacobians of Matrix Transformations and Functions of Matrix Argument. World Scientific; Singapore: 1997. [Google Scholar]
- 41.Anderson T.W. An Introduction to Multivariate Statistical Analysis. John Wiley & Sons; Hoboken, NJ, USA: 2003. [Google Scholar]
- 42.Hattori A., Kimura T. On the Euler integral representations of hypergeometric functions in several variables. J. Math. Soc. Jpn. 1974;26:1–16. doi: 10.2969/jmsj/02610001. [DOI] [Google Scholar]
- 43.Exton H. Multiple Hypergeometric Functions and Applications. Wiley; New York, NY, USA: 1976. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Not applicable.