

Abstract
We propose a lag functional linear model to predict a response using multiple functional predictors observed at discrete grids with noise. Two procedures are proposed to estimate the regression parameter functions: (1) an approach that ensures smoothness for each value of time using generalized cross-validation; and (2) a global smoothing approach using a restricted maximum likelihood framework. Numerical studies are presented to analyze predictive accuracy in many realistic scenarios. The methods are employed to estimate a magnetic resonance imaging (MRI)-based measure of tissue damage (the magnetization transfer ratio, or MTR) in multiple sclerosis (MS) lesions, a disease that causes damage to the myelin sheaths around axons in the central nervous system. Our method of estimation of MTR within lesions is useful retrospectively in research applications where MTR was not acquired, as well as in clinical practice settings where acquiring MTR is not currently part of the standard of care. The model facilitates the use of commonly acquired imaging modalities to estimate MTR within lesions, and outperforms cross-sectional models that do not account for temporal patterns of lesion development and repair.
Keywords: Functional data analysis, functional linear model, magnetization transfer ratio, image analysis
1. Introduction.
Multiple sclerosis (MS) is an inflammatory disease of the central nervous system in which the myelin sheaths around the axons of the neurons in the brain and spinal cord are damaged. Focal areas of tissue damage in the brain and spinal cord are known as “lesions.” These lesions appear in various locations in the brain at different time points. Magnetic resonance imaging (MRI) is sensitive to these lesions and is the most important tool used by clinicians to diagnose and monitor the disease. One benchmark diagnostic criterion that is observed via MRI is the number of white matter lesions [McDonald et al. (2001), Polman et al. (2005)]. Conventional MRI modalities that are used in routine clinical practice to observe lesions are T1-weighted (T1w), T2-weighted (T2w) and T2-weighted fluid attenuated inversion recovery (FLAIR) images. However, it has been argued that rudimentary measures of lesion burden, including the number and volume of lesions, only moderately correlate with disability [Barkhof (2002), Brex et al. (2002), Hawkins et al. (1990), Schmierer et al. (2004)]. Therefore, much research in the field has centered on investigating the use of images that quantify tissue damage (e.g., white matter) and are believed to correlate with disability, such as magnetization transfer ratio (MTR) maps, which are sensitive to the degree of demyelination as well as lesion remyelination. Axons of the neurons in the white matter of the brain are insulated with a myelin sheath, which increases the speed at which impulses propagate along the axon. Demyelinating diseases, such as MS, destroy this layer of myelin, in a process called demyelination. Remyelination is the process of creating new myelin sheaths along these axons.
Here, we estimate MTR within lesions after lesion incidence using only the T1w and FLAIR images. MTR is not typically acquired in clinical settings, yet it would be a valuable addition to the typically acquired images and is believed to contain information about the disease process in MS [Chen et al. (2007, 2008)]. While MTR is not typically collected in clinical practice, the FLAIR and T1w volumes are routinely collected. Prediction of MTR in lesions will be useful in research applications where MTR was not acquired, as well as in clinical practice settings where acquiring MTR is not currently part of the standard of care. In practice, MTR is also an imaging sequence known to contain much noise [Reich et al. (2015)]. Predicting MTR within lesions with the longitudinal information in the FLAIR and T1w volume could therefore potentially provide a less noisy measurement of the MTR.
We propose a voxel-level model that uses sparsely sampled functional measurements of the T1w and FLAIR images over a fixed window of time to predict MTR within lesions. The model yields improvement over cross-sectional models that do not account for temporal patterns of early lesion evolution. This will ultimately allow researchers to study the effect of treatments on tissue damage in patients with MS.
We analyze data that were obtained from a group of 53 MS patients at the National Institute of Neurological Disorders and Stroke (NINDS). Each patient was scanned between 9 and 38 times over a period of 5.5 years. In this longitudinal study, the number of visits varies for each patient; MTR maps, T1w, and FLAIR images were acquired at each of the visits. For our analysis, the voxels in all of the images are temporally registered to obtain voxel-level intensity trajectories over time. The images are also segmented to obtain the set of voxel trajectories that correspond to areas of white matter containing MS lesions. Our objective is to relate current MTR intensity in a given voxel (within a lesion) to the T1w and FLAIR intensities in the same voxel observed over time. The observed voxel-level trajectories are discrete observations arising from a continuous process over time. Therefore, to predict MTR, we employ a function-on-function regression framework.
We propose a model for prediction of the functional response (MTR) beginning 6 months after lesion incidence, using the prior six months of the observed intralesional functional predictors (T1w and FLAIR) at the voxel level. As documented by Van Den Elskamp et al. (2008), MTR values may decrease subtly in areas of future lesion formation within a six-month period. Current methods in the functional data analysis literature do not model the relationship between a functional response and more than one functional predictor when it is assumed that only the recent past of the predictors affect the current value of the response. We develop a model that is able to use only the intensity of the T1w and FLAIR images observed in the previous six months of historical data to predict MTR at the current time point.
Functional data analysis has been a very active research area due to a surge of applications; see Besse and Ramsay (1986), Ferraty, Vieu and Viguier-Pla (2007), Horváth and Kokoszka (2012), Ramsay and Silverman (2005), Rice and Silverman (1991), to name a few. In particular, function-on-function regression has attracted increasing interest, starting with the functional linear model introduced in Ramsay and Silverman (2005) for which Scheipl and Greven (2015) address identifiability issues. Meyer et al. (2015) proposes a multilevel, wavelet-based, Bayesian function-on-function regression framework. Additionally, Scheipl, Staicu and Greven (2015) proposed a framework that incorporates additive regression models in penalized function-on-function regression. Recently, Ivanescu et al. (2015) developed a penalized regression method for association models between functional responses and multiple functional predictors, where the current response is allowed to depend on the entire trajectory of the predictor. Until recently, the work related to function-on-function regression has been able to account for only one functional predictor; see He et al. (2010), Ramsay and Dalzell (1991), Ramsay and Silverman (2005), Wu, Fan and Müller (2010), Yao, Müller and Wang (2005b). For a complete review of the current literature in this area, see Morris (2015).
Motivated by the medical application, we focus on the scientific problem of estimating the functional response at a specific time point using only a fixed window of history of the functional predictors. To address this problem when there is only one covariate, Malfait and Ramsay (2003) introduced the Historical Functional Linear Model (HFLM). In their model, they represent the coefficient function using a triangular basis function that is estimated using information from the predictor, and estimate a coefficient function at each observation point. Harezlak et al. (2007) present a penalized approach that allows for varying lags for the HFLM. Kim, Şentürk and Li (2011) propose a least-squares approach to fitting this model by estimating the coefficient function at each timepoint known as the Recent HFLM. However, their methods do not account for more than one predictor.
In this paper we study function-on-function regression where the response and predictors are functions defined on the same domain, multiple functional predictors are considered, and the response depends solely on a fixed window of the functional predictors. To estimate the regression parameter functions, we propose two methods: (1) a semi-local smoothing approach; and (2) a global smoothing approach.
We introduce the modeling framework in Section 2. Two estimation procedures are presented in Sections 2.1 and 2.2. Medically relevant extensions to sparse and noisy predictors are discussed in Section 2.3. We evaluate the proposed methods in a simulation experiment in Section 3. In Section 4, the proposed estimation approaches are then applied for predicting MTR trajectories using the recent past of T1w and FLAIR voxel-level intensities.
2. Methodology.
Suppose we observe data, [Yij, tij : i ∈ {1, …, n} and j ∈ {1, …, m0i}], [X1ij, r1ij : i ∈ {1, …, n} and j ∈ {1, …, m1i}] and [X2ij, r2ij : i ∈ {1, …, n} and j ∈ {1, …, m2i}], where tij, r1ij, , a bounded and closed interval. For example, Yij corresponds to the MTR measurement at voxel i at time tij. In our data, there are n voxels under consideration and m0i observations for voxel i. The variables X1ij and X2ij correspond to the smooth T1w and FLAIR intensities for voxel i at times r1ij and r2ij, respectively. Our data analysis relies on the working assumption that the measurements are independent across voxels. Additionally, we assume the voxels in the scans of patients are properly registered over time. Throughout the rest of this section we consider r1ij = tij and r2ij = tij, and make use of r1ij and r2ij again in Section 3 where we present simulations.
Let X1ij = X1i(tij) and X2ij = X2i(tij), and assume that X1i(·) and X2i(·) are independent and square-integrable random smooth functions over . Without loss of generality, let us assume E[X1i(t)] = E[X2i(t)] = 0. Assume that the predictor functions are observed on a dense grid of points and without noise, and the response is observed on a dense and equidistant grid of points tij = tj; more realistic sampling designs and scenarios will be considered in Section 2.3. We assume the fixed-lag HFLM with multiple covariates for the response Yij,
| (2.1) |
where i ∈ {1, …, n}, j ∈ {1, …, mi}, and β1, are continuous functions, and εi(·) is an independent (across i) measurement error with zero-mean and covariance . εi(·)is also assumed to be independent of X1i(·) and X2i(·).
This model (2.1) is used throughout the paper. For intuition, notice that . The model assumes that, given the entire predictor trajectories, the response is affected by the predictor values over only recent time windows of length Δ1 and Δ2, respectively; these lag parameters are chosen based on scientific knowledge. For simplicity of illustration, we let Δ = Δ1 = Δ2. The time-varying coefficient functions, β1(·, ·) and β2(·, ·), weigh the predictor values over the Δ lag-window, and quantify the effect of the predictors on the current response. While historical functional linear models have been presented in the current literature [Kim, Şentürk and Li (2011), Malfait and Ramsay (2003)] they have not accounted for multiple covariates as model (2.1) does.
We discuss two approaches for estimating the model parameters β0(·), β1(·, ·) and β2(·, ·). The first approach considers a pointwise (PW) estimation procedure for each observed time point tij. The second approach considers a basis function expansion using prespecified bases for each model parameter and conceptually controls the smoothness over globally (GB). The two approaches are detailed in the next two sections.
2.1. PW model representation.
Model assumption.
As is common in the nonparametric regression literature, we assume that smooth coefficient functions can be represented using a basis function expansion. Specifically, let {Bs1,k(s)}k and {Bs2,k(s)}k be two prespecified functional bases on [0, Δ]. Then β1(s, t) is assumed to be represented as a tensor product of the form , where K1 is large enough to capture the flexibility of the model and the α1k(t)’s are unknown time-varying coefficient functions defined on . We use a similar basis expansion for , where α2k(t)’s are unknown functions defined on .
Without loss of generality, we assume that K1 = K2 = K. Although many choices for basis functions are possible, we use B-spline functions of degree 4 with 6 equally spaced interior knots over [0, Δ], which correspond to K = 10, as the sets {Bs1,k(s)}k and {Bs2,k(s) k}. B-splines are determined by the degree of the polynomial, and the number and location of the knots. The degree usually does not have a strong effect on the model performance [Wood (2006)]. Typically the knots are placed at equally spaced locations or equally spaced quantile locations. Furthermore, it is common practice to use a large number of basis functions and use a smoothness parameter to determine the smoothness of the fit [Ruppert, Wand and Carroll (2003)]. The value of K in our application was selected empirically. Substituting the expressions for the coefficient functions into equation (2.1) yields
| (2.2) |
Furthermore, by denoting and similarly, equation (2.2) reduces to
| (2.3) |
Fitting.
This representation captures the dependence between the precomputed covariates ( and ) and the response using a varying-coefficient model. Nevertheless, when the functional predictors are observed at sparse sampling points for each i and possibly contaminated with error, these derived quantities may not be directly computable. In this section, we develop an estimation procedure of the HFLM model that depends on the continuous second moments of the additive predictors. It does not require direct computation of and accounts for the correlation between the functional predictors. A working independence assumption over time for the error process εi(·) is assumed for fitting. This representation of the function-on-function regression model will allow us to obtain smooth pointwise estimates for the coefficient functions. A similar approach was considered by Kim, Şentürk and Li (2011) for the recent history functional linear model with one functional predictor. Here we present estimation of the coefficient functions and prediction of the response for the dense case; and extensions to more realistic settings are considered in Section 2.3.
Fix tj, and define α1kj = α1k(tj) and α2kj = α2k(tj). Notice that β0(tj) = E[Yij], and thus β0(·) can be estimated by smoothing Yij ’s and using a working independence assumption. By an abuse of notation, in the rest of the subsection, let Yij denote , where is a smooth estimator of β0(·). We estimate α1kj ’s and α2kj ’s by minimizing the following penalized criterion:
| (2.4) |
where λ1 > 0 and λ2 > 0 are the regularization parameters. Let αpj = [αp1j ⋯ αpKj]⊤ for p = 1, 2. Then the minimizer is
| (2.5) |
where IK is the K × K identity matrix, Yj is the vector of all observations at time tj, μY (t) = E[Y (t)], and
| (2.6) |
For fixed tj, the analytic solution (2.5) is the solution in a ridge regression framework for fixed values of the tuning parameters λ1 and λ2. In our case, α1kj ’s and α2kj ’s represent the evaluations of smooth functions α1k(t) and α2k(t) at times t = tj. However, selecting optimal values of λ1 and λ2 for each t could lead to high variability of the tuning parameters over t. One approach to accommodate this situation is to assume that the tuning parameters are constant across t.
The parameter functions α1k(t) and α2k(t) can be estimated using the probability limits of the standardized block submatrices, and , that are included in expression (2.5). Specifically, for arbitrary t,
| (2.7) |
where is a vector, is an estimator of , is a K × K matrix, and is an estimator of for p, q ∈ {1, 2}. Although the model framework and estimation are discussed for two functional predictors, it is straightforward to extend it to accommodate three or more functional predictors.
To obtain the necessary quantities, observe that
| (2.8) |
where is the covariance between Xpi(s1) and Xqi(s2). Similarly, we also have that , where is the covariance between Xpi(s1) and Yi(s2).
To use expression (2.7), we first need to obtain estimates of G11(t), G12(t), G21(t), G22(t), G1Y (t) and G2Y (t). Once estimates of α1(t) and α2(t) are available, estimates for the coefficient functions are given by and similarly for . We note that this estimation is restricted to the class of regression parameter functions that can be expanded using Bs1,k(s) and Bs2,k(s) for k ∈ {1, …, K}. It follows that the response for the ith voxel can be predicted at any time point t by
| (2.9) |
Selection of the smoothing parameters λ1 and λ2 is very important. To ensure that the regularization parameters are the same for all tj, these parameters can be selected using cross-validation (CV) to minimize an error-based criterion that we call the Normalized Prediction Error,
| (2.10) |
a similar criterion is used in Kim, Şentürk and Li (2011). The algorithm for fitting of the model using the PW approach is included in the Supplementary Material [Pomann et al. (2016)].
2.2. GB model representation.
Model assumption.
In this section, we propose the BG method, which takes a global smoothing approach to estimate the regression coefficient functions of the HFLM. This method estimates all the parameter functions β0(·), β1(·,·) and β2(·,·) simultaneously. To do this, we assume an expansion of the coefficient functions of the form , , and , where M0, M1 and M2 are large enough constants to capture the variability of the coefficient functions. The discussion on the choice of K in the PW approach is applicable for M0, M1 and M2. {Bt0,l(·)}, {B1,l(·, ·)} and {B2,l(·, ·)} are preselected basis functions; and b0l, b1l and b2l are unknown basis coefficients. For this study, the bivariate thin plate regression splines (TPRS) are selected as the sets {Bp,l(·, ·)} with M1 = M2 = 30, and one-dimensional TPRS are chosen as the set {Bt0,l(·)} with M0 = 10. These basis functions are commonly used in the literature, and they are the default choices for the package mgcv [Wood (2006, 2011)] in R that is used in our study. As in the PW approach, other choices of basis functions could also be used with this framework.
Similar to Section 2.1, the conditional mean, fi(tj), can be represented as
| (2.11) |
where and is defined analogously. This representation is inspired by Ivanescu et al. (2015), which presents a penalized function-on-function regression framework that uses the entire range for the predictor functions. Equation (2.11) looks similar to equation (2.3); the main difference is that the unknown coefficients, b0k, b1k and b2k are not time varying. This modeling approach ensures smoothness of the regression parameter functions β1(s, t) and β2(s, t) over both s and t.
Fitting.
The coefficient vectors, , and , are estimated by minimizing the following penalized criterion:
| (2.12) |
where λ0, λ1 and λ2 are smoothing parameters and P0, P1 and P2 are the penalty terms [Ivanescu et al. (2015), Wood (2011)]. In particular, the integral of the square of the second derivative is a common measure for smoothness, in which case and , where S0 and Sp are penalty matrices specified by the choice of basis functions for p = 0, 1, 2 [Wood (2006)]. A working independence assumption over time for the error process εi(·) is assumed for fitting.
Selection of the optimal regularization parameters can be done via generalized cross-validation (GCV). However, empirical evidence suggests that GCV leads to undersmoothing [Reiss and Ogden (2009), Wood (2011)]. Instead, the problem can be posed as a mixed model of the form Xf bf + Zbr, where bf contains the fixed effect parameters and br is a random effect vector [Wood (2006, 2011)]. In this context, λ0, λ1 and λ2 represent variance components of the random effect covariance structure. This framework allows us to use a restricted maximum likelihood (REML) to estimate λ0, λ1 and λ2 [Reiss and Ogden (2009), Wood (2006, 2011)]. This approach is also more robust to nonindependent error assumptions [Ivanescu et al. (2015), Krivobokova and Kauermann (2007)]. The algorithm for fitting of the model using the GB approach is included in the Supplementary Material [Pomann et al. (2016)].
Predictions of the functional response can be obtained using the same methodology presented for the PW method. In particular, given that and with a similar expression for , then .
2.3. Noisy and sparsely observed data.
The estimation approach presented above is applicable to smooth predictors observed on a fine grid of time points. However, the response MTR and both covariates T1w and FLAIR are observed at few time points for each voxel. Additionally, the measurements are contaminated with noise. To accommodate this situation, let Wpi(t) Xpi(t) εpi(t) for p = 1, 2, where εpi(·) is a zero mean white noise process with variance . Assuming the same sampling design for the functional covariates, we distinguish 4 different scenarios according to whether the response is sparse or dense, and whether the functional predictors are sparse or dense. Namely, the scenarios are as follows: sparse/sparse, dense/sparse, sparse/dense and dense/dense. In the following we discuss in detail the case sparse/sparse which is the most relevant for our application; the remaining cases are detailed in the Supplementary Material [Pomann et al. (2016)].
PW method.
This approach requires smooth estimators of , , , and , which can be obtained using functional principal component analysis (FPCA). Mercer’s theorem yields the spectral decomposition of the covariance in terms of non-negative eigenvalues ωp1 ≥ ωp2 ≥ ⋯ ≥ 0 and orthogonal eigenfunctions ψpl(t) with , where 1(l = l′) is the indicator function which equals 1 when l = l′ and 0=otherwise [Bosq (2000)]. Given that E [Xpi(t)] = 0, the above decomposition of the covariance implies that Xpi (t) can be represented via the Karhunen–Loève (KL) expansion as , where are commonly called the functional principal component (FPC) scores and are uncorrelated random variables with zero mean and variance equal to ωpl. For practical and theoretical reasons, the KL expansion is often truncated [Di et al. (2009), Hall, Müller and Wang (2006), Yao, Müller and Wang (2005a)]; let and be the truncated KL expansions of X1(t) and X2(t), respectively, for finite L1 and L2. The spectral decomposition of the smooth estimates of and yields the pairs of estimated eigenfunctions and eigenvalues and , respectively. Then one can obtain consistent estimators of the scores and [Hall, Müller and Wang (2006), Zhang and Chen (2007)].
Since the response is observed on a sparse grid of points, bivariate kernel smoothing [Yao, Müller and Wang (2005a)] or spline-based smoothing [Wood (2006)] can be used to estimate the covariance functions. In our implementation, we make use of B-spline-based smoothing techniques [Crainiceanu, Staicu and Di (2009), Di et al. (2009)]. To account for the measurement error, the diagonal elements are left out when smoothing is carried out. The resulting covariance estimator is adjusted to be symmetric and positive semidefinite. Then the variance of the noise, and , can be estimated based on the difference between the empirical pointwise variance of the corresponding observed predictors and the estimated pointwise variance , , [Staniswalis and Lee (1998)]. In this setting, the conditional expectation formula should be employed to estimating the scores, [Yao, Müller and Wang (2005a)]. Here W1i is a vector of length m1i containing the observed values of the first predictor function, is a vector of length m1i with the jth entry equal to , is a m1i × m1i-dimensional matrix with the (j, j′)th entry equal to and is the m1i × m1i identity matrix. can be estimated similarly. Yao, Müller and Wang (2005a) showed that, under the assumption that the predictors and their errors are jointly Gaussian, this equation yields the empirical best linear unbiased predictor of the scores.
In this case, there is an alternative approach to predict the response trajectory. Specifically, let be the KL expansion for the covariate functions. Then by substituting this into equation (2.2) we obtain
| (2.13) |
where and are the estimators of α1k(t) and α2k(t), respectively, and is defined similarly.
GB method.
Densely sampled covariate functions are needed for the GB method; hence, smooth estimators for the covariates can be obtained using the predicted scores, eigenfunctions and KL expansion; that is, . The methodology can be applied by using the predicted functional covariates in place of the true smooth functions.
3. Simulation studies.
This section presents results from an extensive simulation study used to evaluate the predictive performance of the two proposed methods, PW and GB. We consider two settings for data generated as in model (2.1): (I) the response and functional predictors are observed densely so that m0i, m1i and m2i are large and the predictors are observed without measurement error; and (II) the functional predictors and response are observed on a sparse grid of points so that m0i, m1i and m2i are small and the predictors are observed with measurement error.
We first generate the response and predictor functions on a dense and equally spaced grid of points, . In setting (I), we generate observed data, {tij, Yij, W1ij, W2ij}j, where Yij is the response function and W1ij = X1i(tij) and W2ij = X2i (tij) are the predictor functions measured without error. We define the predictors, and for uik1, uik2 and . We use regression parameter functions , β1(s, t) = cos(2πt) cos(πs) and β2(s, t) = cos(πt) cos(πs). We take Δ = 0.4 so that β1, β2 : [0, 0.4] × [0, 1] → [0, 1] and β0 [0, 1] → [0, 1]. Illustrations of the simulated data and predictions are included in the Supplementary Material [Pomann et al. (2016)].
The response for voxel i ∈ 1, …, n is generated from model (2.1) via numerical integration for each . The measurement error in model (2.1) is taken to be εi(t) = εa,i(t) + εg,i(t), where εg,i(t) is a zero-mean i.i.d. normal random variable with variance , and εa,i(t) is a zero-mean AR(1) process with covariance structure given by with ρ = 0.5. It follows that . Note that an AR(1) process is considered in the simulation study to analyze the effect of nonindependent (over time) noise structure in the fitting process. We simulate data under a framework similar to Ivanescu et al. (2015) and McLean et al. (2014) by using a version of the empirical signal to noise ratio (eSNRε), which we define as . The value of is chosen by specifying the eSNRε for each Monte Carlo (MC) replication. In this section, we present results for eSNRε = 5. It was observed that the predictive error decreases (increases) as eSNRε is increased (decreased). Results for eSNRε = 1 as well as for responses generated with a white noise error process are included in the Supplementary Material [Pomann et al. (2016)].
In setting (II) the response and predictors are first generated as in setting (I). Then, to generate the sparse data, we evaluate the functions at points for a randomly sampled subset of size mi. To determine the number of observations for each voxel, we take on {10, 11, …, 15}. This level of sparsity is consistent with the 13.6 average number of samples observed per curves in the real data (see the Data Analysis Details section in the Supplementary Material [Pomann et al. (2016)]). To generate the predictors that are observed with error, we take W1ik = X1i(rij) + ε1ik and W2ik = X2i(rij) + ε2ik, where ε1ik ~ N(0, 0.1) and ε2ik ~ N(0, 0.05). The latter error variances were selected to correspond to a signal-to-noise ratio of 5.
The main simulation factors of interest are the number of observations and the lag parameter used for fitting the model. We present results for n ∈ {20, 50, 100}. To understand how the model performs when the lag parameter is misspecified, we let ΔF be the lag parameter used for fitting the model and present results for ΔF ∈ {0.4, 0.6}. As expected, when ΔF < Δ, both estimation methods have poor predictive accuracy and results in increased bias. Intuitively, this case corresponds to fitting a misspecified model, as it enforces the two regression parameters to be null on domains where they are not. Namely, β1(s, t) = 0 and β2(s, t) = 0 are enforced for s ∈ [ΔF, Δ].
To fit the model, the predictors are first standardized to have a zero mean function and pointwise variance equal to 1. For the model using the PW method, we consider the bases sets {Bs1,k} and {Bs2,k} to be the set of K = 10 B-spline basis functions o degree 4 with 6 interior knots over [0, ΔF]. This value of K was selected empirically. We use one tuning parameter λ that is selected using a grid search over Iλ = [0.0001, 0.01] and cross-validation. The range was determined empirically. Using a larger range and two tuning parameters produced similar results. To obtain the smooth covariance and cross-covariance functions, , , , and , we use bivariate smoothing, via tensor products of 20 univariate cubic regression splines with 15 equally spaced interior knots. The positive semidefiniteness of the covariance functions is ensured by truncating the eigenvalues to be positive.
For the GB method, the functions Bp,k(s, t) are chosen to be 30 thin plate spline basis functions with 30 knots equally spaced. The penalty for equation (2.12) is taken to be , where Sl is chosen to be the thin plate spline penalty [Wood (2006)]. In setting (II), the reconstructed trajectories are estimated using FPCA with 20 basis functions to smooth the covariance and cross-covariance functions; the percent variance explained is set to 99%. The smooth predictor trajectories are sampled over a grid of 100 equally spaced observation points on [0, 1]. To obtain the necessary smooth estimates, we use fpca.sc function of the package refund [Di et al. (2009), Goldsmith, Greven and Crainiceanu (2012), Staniswalis and Lee (1998), Yao, Müller and Wang (2005b)]. To obtain predictions, we use the gam function of the mgcv package [Wood (2006, 2011)].
The computational cost and empirical performance of the PW method depends directly on the range of values Iλ used to search for the optimal regularization parameter. Since the estimation of regression parameters for the PW method uses only the smooth covariance and cross-covariance estimates at each time tij, it is more computationally efficient than the GB method which uses large matrices that grow linearly with ; see the Supplementary Material [Pomann et al. (2016)] for algorithms that outline the implementation details.
3.1. Simulation results.
To evaluate model performance, we present the relative mean square error (reMSE) for Y (t) as . Since our main objective is prediction, we report the mean and standard error of the reMSE(Y) values over 500 Monte Carlo (MC) replications. We compare the resulting prediction errors by evaluating improvement of quantity “A” over “B,” defined to be [(B − A)/B] 100%. The discussion in this section focuses on the comparison of the reMSE(Y) values found in the last column of the tables provided.
First we describe and compare the results for the two estimation methods under the dense setting. Table 1 reports the simulation results for the PW and the GB methods under setting (I). On average, the GB method yields an improvement of 92% over the PW method in reMSE of prediction for this setting. For both the PW and GB methods, the case ΔF = Δ has smaller prediction errors than the case when ΔF ≥ Δ. As expected, the prediction error decreases in both cases as the sample size increases. For the PW method, n = 50 yields an average improvement of 47% over the case of n = 20, and for n = 100 we observe an improvement over the case when n = 50. Using the GB method with n = 50 yields an average improvement of 56% over the case when n = 20, and a clear improvement as the sample size increases.
Table 1.
Prediction Error—Setting (I), Average Error Variance = 0.012
| n | Δ | ΔF | reMSE(Y) (SE)—PW Method | reMSE(Y) (SE)—GB Method |
|---|---|---|---|---|
| 20 | 0.4 | 0.4 | 5.1e–3 (5.9e–3) | 5.2e–4 (1.6e–4) |
| 20 | 0.4 | 0.6 | 6.5e–3 (1.1e–2) | 6.5e–4 (2.3e–4) |
| 50 | 0.4 | 0.4 | 2.9e–3 (4.6e–3) | 2.3e–4 (6.4e–5) |
| 50 | 0.4 | 0.6 | 3.2e–3 (2.8e–3) | 2.9e–4 (8.4e–5) |
| 100 | 0.4 | 0.4 | 1.8e–3 (1.4e–3) | 1.2e–4 (3.2e–5) |
| 100 | 0.4 | 0.6 | 2.1e–3 (2.0e–3) | 1.5e–4 (4.3e–5) |
Next, we compare performance under the dense and sparse settings for each of the estimation methods. As expected, the performance of both approaches is affected by the sparse sampling design of the functional covariates and response. For the PW method, prediction errors in setting (I) are on average 70% smaller than in setting (II). Similarly, for the GB method the prediction errors in setting (I) are on average 95% smaller than in setting (II).
Last, we describe and compare the results for the two estimation methods under the sparse setting (II) (see Table 2). On average, in these datasets, the GB method yields an improvement of 55% over the PW method. For PW, we observe that the case when ΔF = Δ has smaller prediction errors than the case when ΔF ≥ Δ. For GB, on average, having ΔF = Δ yields a slight improvement over having ΔF ≥ Δ. As expected, the prediction error decreases in both cases as the sample size increases.
Table 2.
Prediction Error–Setting (II), Average Error Variance = 0.012
| n | Δ | ΔF | reMSE(Y) (SE)—PW Method | reMSE(Y) (SE)—GB Method |
|---|---|---|---|---|
| 20 | 0.4 | 0.4 | 1.6e–2 (2.4e–2) | 7.1e–3 (1.9e–2) |
| 20 | 0.4 | 0.6 | 2.2e–2 (7.7e–2) | 9.0e–3 (6.1e–2) |
| 50 | 0.4 | 0.4 | 9.6e–3 (4.3e–3) | 4.2e–3 (3.2e–3) |
| 50 | 0.4 | 0.6 | 1.0e–2 (4.6e–3) | 4.0e–3 (2.4e–3) |
| 100 | 0.4 | 0.4 | 6.7e–3 (4.3e–3) | 3.6e–3 (5.7e–3) |
| 100 | 0.4 | 0.6 | 7.1e–3 (3.1e–3) | 3.2e–3 (3.9e–3) |
4. Prediction of Magnetization Transfer Ratio within lesions of MS patients.
Recall that the data consist of MTR maps and T1w and FLAIR images obtained for 53 MS patients who were imaged as part of a natural history study at the National Institute of Neurological Disorders and Stroke. Time to each observed scan is measured from the first scan after lesion incidence. With this definition of observation times, each patient had between 9 and 38 observed scans with the maximum time ranging from 20 weeks to 5.5 years. Our objective is to predict MTR at voxels within lesions using the T1w and FLAIR measurements acquired within the previous six months. This is important as MTR is not typically acquired in clinical settings, yet it would be a valuable addition to the typically acquired images and is believed to contain information about the disease process in MS [Chen et al. (2007, 2008)]. Predicting the MTR in MS lesions from the T1w and FLAIR information will provide information within lesions, without needing to acquire the MTR volume. This information will be of use in research for retrospective analysis where the MTR is not available as well as in clinical practice in settings where the MTR is not acquired. For this model, the window is chosen to be six months because it has been reported that MTR values may decrease subtly in areas of future lesion formation within a six-month period [Van Den Elskamp et al. (2008)]. Previously, Mejia et al. (2016) proposed a cross-sectional model to predict quantitative T1 maps, which estimate T1 relaxation times as a function of T1-weighted, T2-weighted, PD-weighted and FLAIR images; and Suttner et al. (2015) applied this method to predict DTI measures. To the best of our knowledge, this is the only other work in the literature that has been presented to estimate images of quantitative MR values. Jog et al. (2013a) do attempt to estimate average quantitative tissue properties, but not the quantitative images themselves. In addition, work has been done to predict standard nonquantitative clinical images using cross-sectional models [Jog et al. (2013b); Roy, Carass and Prince (2011, 2013)].
It is common practice to use cross-sectional linear models to make other voxel-level predictions [Pomann et al. (2015), Sweeney et al. (2013a, 2013b)]. Therefore, we evaluate the performance of the proposed approaches against two cross-sectional models that do not take temporal dependence of the data into account. Section 4.1 discusses the preprocessing of the data, and Section 4.2 presents implementation details and results for this analysis.
4.1. Data processing.
Details about the data acquisition, preprocessing, image registration and normalization are provided in Sweeney et al. (2015). After image preprocessing, we temporally align the voxel trajectories by aligning the voxels to the time point when it first is identified as belonging to a new or enlarging lesion. We identify this time of incidence for each voxel using the Subtraction-Based Logistic Inference for Modeling and Estimation (SuBLIME) procedure [Sweeney et al. (2013a)]. For each voxel, we obtain the time marker that corresponds to the time when the voxel is first identified as being part of a lesion (“time zero”). We then measure all following time points as the time difference in weeks from this marker. The alignment is appropriate because our goal is to predict MTR in the time window after the lesion develops; see the Supplementary Material [Pomann et al. (2016)] for more details.
4.2. Model implementation and results.
After normalization and spatiotemporal registration, we measure time in weeks, and let Yij be the MTR at voxel i in the brain of a subject at week tij ∈ [0, 190]. Similarly, we let the predictors W1ij and W2ij be the normalized T1w and FLAIR intensities, respectively, of voxel i at time tij, which are assumed to be observed with noise. We consider these two predictors as they are commonly acquired images as part of clinical MRI studies. We omit times after 190 weeks, as there are too few observations beyond this point. After ΔF = 26 weeks (approximately six months), lesion evolution is approximately stable [Meier, Weiner and Guttmann (2007)], which justifies our choice for lag window.
Figure 1 presents images for a lesion for one of the patients with MS in our study. From top to bottom, the FLAIR, T1w and MTR images are displayed for this patient obtained over time in weeks from left to right (indicated below in white text). Time zero corresponds to lesion incidence for each voxel. The lesion is the hypointense region in the center of the image on the T1w and MTR images and the hyperintense on the FLAIR. Figure 2(a), (b) and (a) present the corresponding T1w, FLAIR and MTR voxel-level trajectories for this image.
Fig. 1.
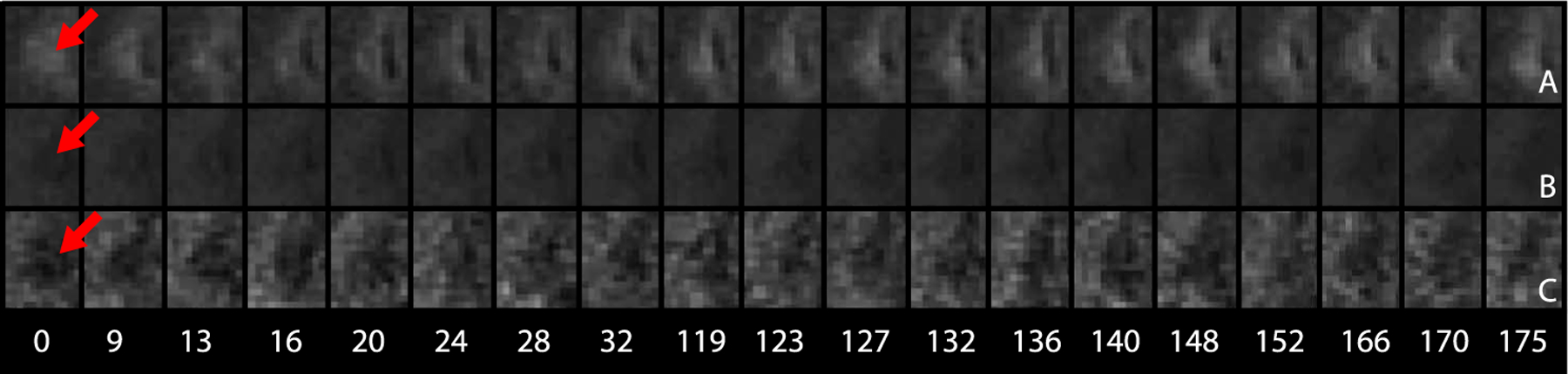
From top to bottom, axial slices of an MS lesion in the FLAIR (A), T1w (B) and MTR (C) sequences. This MS patient is imaged over time in weeks from left to right. Time zero corresponds to lesion incidence, and the lesion on each sequence is denoted at time zero with a red arrow. On the MTR and T1w images the lesion is the hypointense region; on the FLAIR the lesion is hyperintense.
Fig. 2.
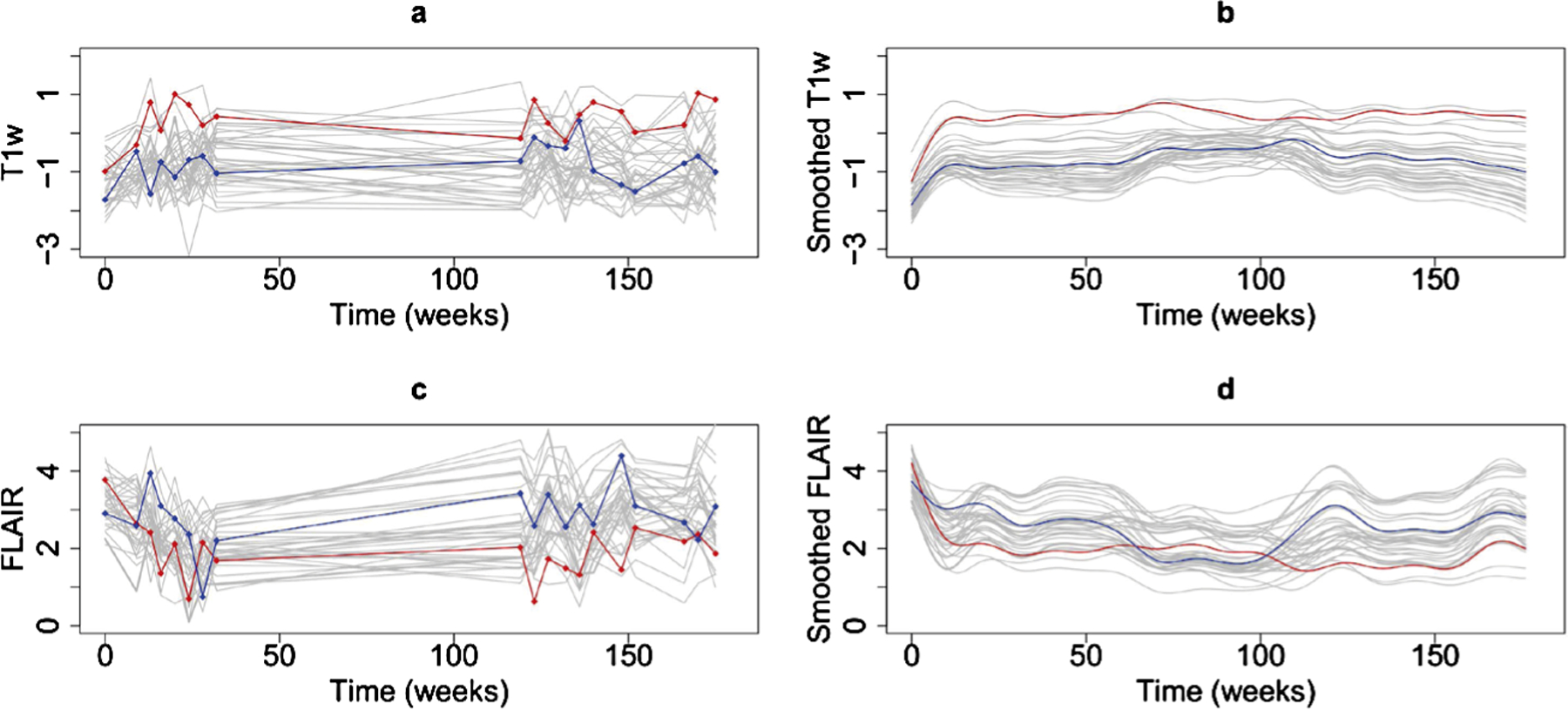
(a) Normalized T1w voxel intensities for a subset of the lesion voxels in the same patient as in Figure 1; (b) corresponding smoothed T1w voxel intensities using 20 basis functions to smooth all of the data; (c) corresponding FLAIR voxel intensities; (d) corresponding smoothed FLAIR voxel intensities using 20 basis functions to smooth all of the data. The red and blue curves are two particular curves.
In order to determine the benefit of the HFLM model for predicting MTR, we compare its performance against a cross-sectional model (CS),
| (4.1) |
Additionally, we compare the performance against a cross-sectional nonlinear model (CSNL),
| (4.2) |
where g1(·) and g2(·) are unknown nonlinear functions. These models do not account for any temporal dependencies that may be present in the data. To fit the cross-sectional models, the predictors are standardized to have a mean zero and standard deviation of one. Predictions for the CSNL model are obtained using the gam function of the mgcv package in R with 10 thin plate basis functions with 10 equally spaced knots.
To fit the HFLM models, the predictors are first standardized to have a zero mean function and pointwise variance equal to 1. Prediction is performed only for voxels in lesions at times after the corresponding lesion incidence. The analysis is performed on the logit transform of the MTR trajectories since the response values lie in the range [0, 1]. The same analysis is also conducted on the raw data which yields comparable results (see the Supplementary Material [Pomann et al. (2016)]). There are some zero values in the response but no values of 1, and most of the MTR values are concentrated between 0.2 and 0.5. Hence, in order to avoid division by zero, we shift the data by 0.01 when performing the logit transformation; that is, for our analysis we define and . When using the logit option in the implementation, the response data is transformed before fitting the model. Then predictions are transformed back to the probabilities using the logit−1 function. All analysis is conducted using R version 2.15.1.
For the PW method, the basis set and are taken to be the set of K = 10 B-spline basis functions of degree 4 with 6 interior knots over [0, 26]. The value of K was selected empirically. Similar results were observed for K = 20. We use one tuning parameter, λ, that is selected using GCV over [0.1,100]. To obtain the smooth covariance and cross-covariance functions, , , , , and , we use bivariate smoothing, via tensor products of univariate bases. The positive semidefiniteness of the covariance and cross-covariance functions is ensured by truncating the eigenvalues to be positive. The results are based on using the tensor product of 20 univariate cubic regression splines with 15 equally spaced interior knots.
For the GB method, the functions Bp,k(s, t) are chosen to be 30 thin plate spline basis functions with 30 knots equally spaced. The penalty for equation (2.12) is taken to be , where Sl is obtained by using the thin plate spline penalty [Wood (2006)]. The reconstructed trajectories are estimated for tij ∈ [0, 190] using FPCA with 20 basis functions to smooth the covariance and cross-covariance functions and the percent variance explained set to 99%. To obtain the necessary smooth estimates, we use the fpca.sc function of the package refund. To obtain predictions, we use the bam function of the mgcv package [Wood (2006, 2011)].
Using this smoothing procedure, we are able to capture the natural variation in the predictor functions. To see this, we display a subset of voxels in the brain of a patient in this study; Figure 2(a) and (c) display the observed voxel-level predictor trajectories of the T1w and FLAIR images, respectively, and Figure 2(b) and (d) show the respective smoothed trajectories. The voxel-level trajectories in these figures correspond to the voxels in the lesion displayed on the observed images in Figure 1.
Since the true underlying MTR functions are unknown, we perform a 10-fold cross-validation of the data based on subject ID. The subject IDs are first randomly sorted, and then the corresponding voxel observations are split into groups. The first three groups consist of six subjects, and the other seven groups consist of five subjects. The validation was designed in this manner in order to produce a more realistic scenario in which imaging information is observed from entire subjects and prediction is also done for all voxels in the scan of a subject. Histograms of the number of voxels and observations per subject are included in the Supplementary Material [Pomann et al. (2016)].
We evaluate prediction by comparing the integrated mean squared error (MSE) of the models. We also compare this prediction error with the empirical measurement error of the MTR voxel-level trajectories. To do this, for each cross-validation step, we compute such that , where mi is the number of time samples per curve, and n is the total number of observed voxels, and are the smoothed response trajectories without noise. A ratio of 1 indicates that the prediction is as good as smoothing the observed data. The smooth trajectories are obtained by using the fpca.sc function in the refund package in R with 20 basis functions to smooth the covariance and 99% variance explained to obtain the number of eigenfunctions used to reconstruct the data.
Figure 3(a) and (b) display the observed and smoothed MTR voxel-level trajectories, respectively, for the voxels in the lesion of Figure 1. For these same voxel-level trajectories, Figure 3(c) and (d) present the predicted response trajectories from using the PW and GB methods. Due to the lag window being fixed at six months, the estimation is restricted to t > 26 weeks. We see that the predictions obtained using our model are similar to the smoothed MTR trajectories.
Fig. 3.
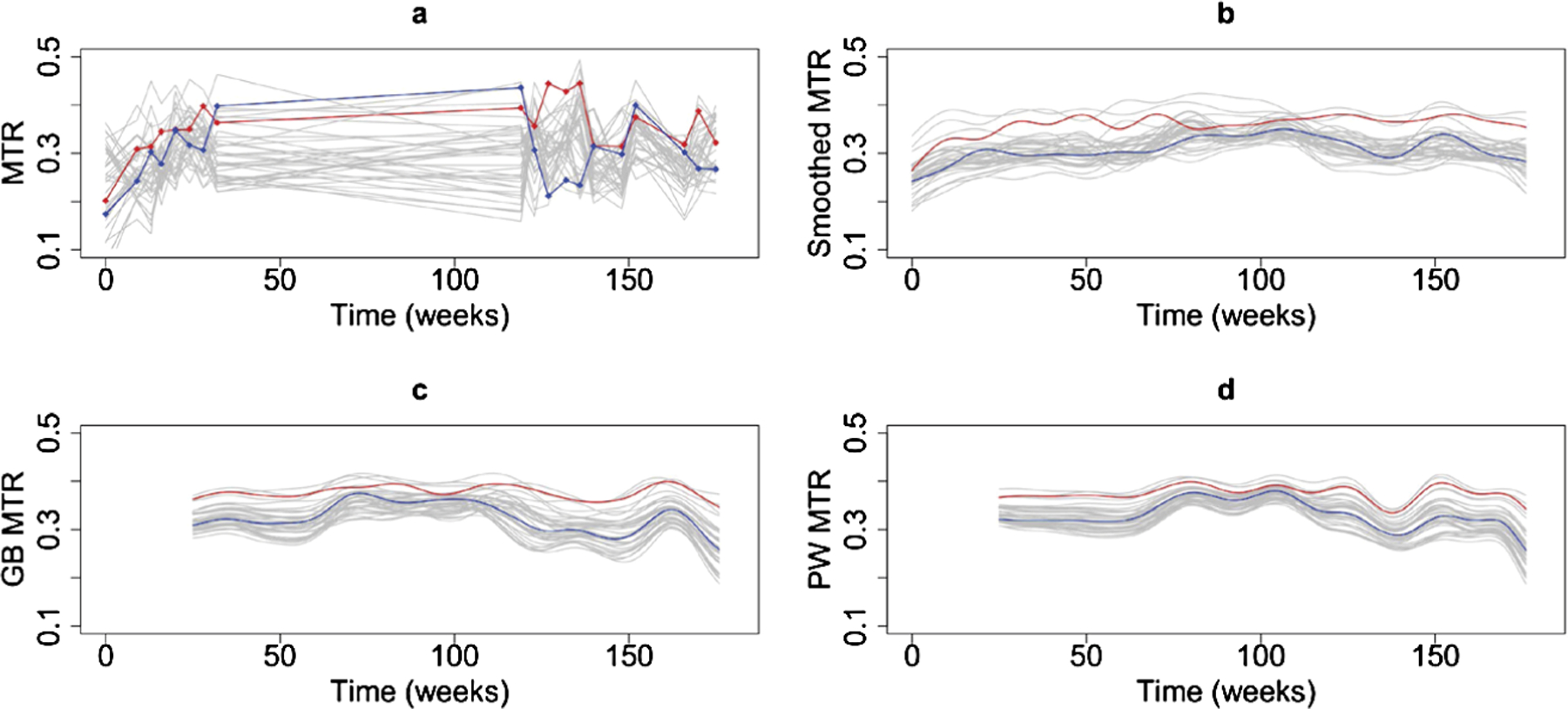
(a) MTR voxel intensities for a subset of the lesion voxels in the same patient as in Figure 1; (b) smoothed MTR voxel intensities using 20 basis functions to smooth all of the data; (c) predicted MTR voxel intensities using the GB method; (d) predicted MTR voxel intensities using the PW method. The values for the predicted MTR are not available for the first 26 weeks since this is the window used for prediction. The red and blue curves are two particular curves.
Table 3 displays the prediction error results for the different approaches. The HFLM model consistently has higher predictive accuracy than the corresponding cross-sectional models. Both estimation approaches for the HFLM model perform comparably. This model yields a 61% improvement over the CS model and a 48% improvement over the CSNL model. These improvements indicate the importance of accounting for temporal dependence over the previous six months when predicting MTR. Similar results were observed for the average in-sample error.
Table 3.
Prediction error from 10-fold cross-validation on MTR data with T1w and FLAIR predictors. Integrated mean squared error (MSE) along with the average , where is the estimated measurement error in the observed MTR voxel trajectories for all models and estimation approaches. The last two columns show the improvement for each approach over the CS and CSNL models
| Model | MSE[SE] · (103) | Imp. over CS | Imp. over CSNL | |
|---|---|---|---|---|
| CS | 12.7 [3.4] | 4.1 | 0% | −32% |
| CSNL | 9.6 [2.7] | 3.1 | 31% | 0% |
| HFLM (GB) | 5.0 [2.1] | 1.6 | 61% | 48% |
| HFLM (PW) | 4.9 [2.1] | 1.6 | 61% | 49% |
This analysis was repeated for a lag window of 3 and 9 months, and it was observed that the error between the different window sizes was the same up to the third significant digit for both methods. It may be of future interest to explore the model with interactions as well as other commonly acquired predictors such as proton density volumes or T2w images. This analysis can provide further insight regarding which commonly acquired images can be used to predict MTR and analyze tissue damage. Observe that using both predictors in the HFLM model yields a 9% improvement over the model with only one predictor (see the Supplementary Material [Pomann et al. (2016)]). However, when using the cross-sectional models, this relationship is not maintained; each of the two-predictor models does not perform as well as the corresponding model with only the T1w intensities used as a predictor. The models with only FLAIR intensities used as a predictor consistently do worse than all of the corresponding cross-sectional two-predictor models. These results confirm the qualitative assessment that the T1w image on its own contains detailed information about tissue damage. Furthermore, adding the FLAIR intensities to any of the cross-sectional models does not improve predictive power.
5. Conclusion.
We propose using the HFLM to estimate the current value of MTR in lesions using only the previous six months of both the T1w and FLAIR voxel intensities. We provide two methods to estimate the regression parameter functions: the PW method, a pointwise least squares approach; and the GB method, a global penalized functional regression approach. The PW method directly accounts for the covariance of the predictor functions by using a pointwise least squares approach to estimate the regression parameters. Additionally, in the case of sparse data, this method does not require the estimation of smooth trajectories as the GB method does. However, the GB method has a few advantages over the PW method. First, the performance of the PW method depends on the choice of the range of λ values for cross-validation. It was observed experimentally that if this range were not properly selected, then high out-of-sample prediction errors would be observed. Second, the PW method does not guarantee smoothness across time since estimated coefficients and predictions are performed at each time value. Finally, the PW method assumes that the β functions can be modeled as a sum of tensor products of basis functions, whereas the GB method makes use of general bivariate basis functions.
Our findings from the study suggest that the MRI signal within lesions depends on the local recent history of the signal at that location. Thus, the proposed model can facilitate the study of tissue damage in lesions of patients with MS. Furthermore, estimation of MTR using the HFLM model with the recent six months of both the T1w and FLAIR voxel trajectories outperforms cross-sectional models that do not take temporal dependence of the voxel-level trajectories into account. Future work will explore the use of this HFLM model to predict other quantitative imaging modalities and its application to other tissue classes. Estimability should be investigated further when making inference about the β coefficients is of interest.
The estimation of MTR in lesions using the traditional clinical FLAIR and T1w sequences has implications for both research and clinical practice. Estimating MTR within lesions with these sequences will provide additional information about lesions without needing to acquire MTR. As MTR has not been a traditional imaging modality, most retrospective data will not have MTR measured. Estimating the MTR in lesions may allow us to answer important research questions in large historical databases of MRI images. The proposed methods facilitate the estimation of MTR within lesions, providing additional information to clinicians to make treatment decisions in patients with MS.
Supplementary Material
Acknowledgments.
We would like to acknowledge the conscientious efforts of the hard-working Associate Editor, whose clear guidance led to this publication. The study was supported in part by the Intramural Research Program of NINDS. Its contents are solely the responsibility of the authors and do not necessarily represent the official view of the granting organizations.
Gina-Maria Pomann Supported in part by Grant Number UL1TR001117 from the National Center for Advancing Translational Sciences (NCATS), a component of the National Institutes of Health (NIH), and NIH Roadmap for Medical Research. Also supported in part by the NSF Grant No. DGE-0946818.
Ana-Maria Staicu Supported in part by NSF Grant DMS-14-54942 and NIH/NIMH RO1 MH 086633.
Gina-Maria Pomann, Ana-Maria Staicu, Amanda F. Mejia, Elizabeth M. Sweeney, Russell T. Shinohara Supported in part by NIH Grant RO1 NS085211.
Elizabeth M. Sweeney Supported in part by NIH/NIA T32AG021334 and NIH/NINDS R01 NS060910.
Amanda F. Mejia Supported in part by NIH Grant R01 EB016061 and the NSF Graduate Research Fellowship Program under grant DGE-1232825.
Russell T. Shinohara Supported in part by NIH/NINDS R21 NS093349.
Footnotes
SUPPLEMENTARY MATERIAL
Algorithms and additional results (DOI: 10.1214/16-AOAS981SUPP; .zip). In this file, we include a sample sourcecode for estimation of the HFLM model, implementation details of the PW and GB approaches, figures for the simulated dense and sparse data, and additional results.
Contributor Information
Gina-Maria Pomann, Department of Biostatistics and Bioinformatics, Duke University, Durham, North Carolina 27710, USA.
Ana-Maria Staicu, Department of Statistics, North Carolina State University, Raleigh, North Carolina 27695, USA.
Edgar J. Lobaton, Department of Electrical and Computer Engineering, North Carolina State University, Raleigh, North Carolina 27695, USA
Amanda F. Mejia, Department of Statistics, Indiana University Bloomington, Bloomington, Indiana 47405, USA
Blake E. DEWEY, National Institute of Neurological Disorders and Stroke NIH, Bethesda, Maryland 20892, USA
Daniel S. Reich, National Institute of Neurological Disorders and Stroke NIH, Bethesda, Maryland 20892, USA
Elizabeth M. Sweeney, Statistics Department, Rice University, Houston, Texas 77005, USA
Russell T. Shinohara, Department of Biostatistics and Epidemiology, Center for Clinical Epidemiology and Biostatisti Perelman School of Medicine, University of Pennsylvania, Philadelphia, Pennsylvania 19104, USA
REFERENCES
- Barkhof F (2002). The clinico-radiological paradox in multiple sclerosis revisited. Curr. Opin. Neurol 15 239–245. [DOI] [PubMed] [Google Scholar]
- Besse P and Ramsay JO (1986). Principal components analysis of sampled functions. Psychometrika 51 285–311. [Google Scholar]
- Bosq D (2000). Linear Processes in Function Spaces: Theory and Applications. Lecture Notes in Statistics 149. Springer, New York. [Google Scholar]
- Brex PA, Ciccarelli O, O’Riordan JI, Sailer M, Thompson AJ and Miller DH (2002). A longitudinal study of abnormalities on MRI and disability from multiple sclerosis. N. Engl. J. Med 346 158–164. [DOI] [PubMed] [Google Scholar]
- Chen JT, Kuhlmann T, Jansen GH, Collins DL, Atkins HL, Freedman MS, O’Connor PW, Arnold DL, Group CMS et al. (2007). Voxel-based analysis of the evolution of magnetization transfer ratio to quantify remyelination and demyelination with histopathological validation in a multiple sclerosis lesion. NeuroImage 36 1152–1158. [DOI] [PubMed] [Google Scholar]
- Chen JT, Collins DL, Atkins HL, Freedman MS and Arnold DL (2008). Magnetization transfer ratio evolution with demyelination and remyelination in multiple sclerosis lesions. Ann. Neurol 63 254–262. [DOI] [PubMed] [Google Scholar]
- Crainiceanu CM, Staicu A-M and Di C-Z (2009). Generalized multilevel functional regression. J. Amer. Statist. Assoc 104 1550–1561. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Di C-Z, Crainiceanu CM, Caffo BS and Punjabi NM (2009). Multilevel functional principal component analysis. Ann. Appl. Stat 3 458–488. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferraty F, Vieu P and Viguier-Pla S (2007). Factor-based comparison of groups of curves. Comput. Statist. Data Anal 51 4903–4910. [Google Scholar]
- Goldsmith J, Greven S and Crainiceanu, C. I. P. R. I. A. N. (2012). Corrected confidence bands for functional data using principal components. Biometrics [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hall P, Müller H-G and Wang J-L (2006). Properties of principal component methods for functional and longitudinal data analysis. Ann. Statist 34 1493–1517. [Google Scholar]
- Harezlak J, Coull BA, Laird NM, Magari SR and Christiani DC (2007). Penalized solutions to functional regression problems. Comput. Statist. Data Anal 51 4911–4925. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hawkins CP, Munro PMG, Mackenzie F, Kesselring J, Tofts PS, Du Boulay EPGH, Landon DN and McDonald WI (1990). Duration and selectivity of blood-brain barrier breakdown in chronic relapsing experimental allergic encephalomyelitis studied by gadolinium-DTPA and protein markers. Brain 113 365–378. [DOI] [PubMed] [Google Scholar]
- He G, Müller H-G, Wang J-L and Yang W (2010). Functional linear regression via canonical analysis. Bernoulli 16 705–729. [Google Scholar]
- Horváth L and Kokoszka P (2012). Inference for Functional Data with Applications Springer, New York. [Google Scholar]
- Ivanescu AE, Staicu A-M, Scheipl F and Greven S (2015). Penalized function-on-function regression. Comput. Statist 30 539–568. [Google Scholar]
- Jog A, Roy S, Carass A and Prince JL (2013a). Pulse sequence based multi-acquisition MR intensity normalization. In SPIE Medical Imaging 86692H–86692H. International Society for Optics and Photonics [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jog A, Roy S, Carass A and Prince JL (2013b). Magnetic resonance image synthesis through patch regression. In IEEE 10th International Symposium on Biomedical Imaging (ISBI) 350–353. IEEE, New York. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim K, Şentürk D and Li R (2011). Recent history functional linear models for sparse longitudinal data. J. Statist. Plann. Inference 141 1554–1566. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krivobokova T and Kauermann G (2007). A note on penalized spline smoothing with correlated errors. J. Amer. Statist. Assoc 102 1328–1337. [Google Scholar]
- Malfait N and Ramsay JO (2003). The historical functional linear model. Canad. J. Statist 31 115–128. [Google Scholar]
- McDonald WI, Compston A, Edan G, Goodkin D, Hartung H-P, Lublin FD, Mcfarland HF, Paty DW, Polman CH, Reingold SC et al. (2001). Recommended diagnostic criteria for multiple sclerosis: Guidelines from the international panel on the diagnosis of multiple sclerosis. Ann. Neurol 50 121–127. [DOI] [PubMed] [Google Scholar]
- Mclean MW, Hooker G, Staicu A-M, Scheipl F and Ruppert D (2014). Functional generalized additive models. J. Comput. Graph. Statist 23 249–269. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meier DS, Weiner HL and Guttmann CRG (2007). Time-series modeling of multiple sclerosis disease activity: A promising window on disease progression and repair potential? Neurotherapeutics 4 485–498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mejia A, Sweeney EM, Dewey B, Nair G, Sati P, Shea C, Reich DS and Shinohara RT (2016). Statistical estimation of T1 relaxation times using conventional magnetic resonance imaging. NeuroImage 133 176–188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meyer MJ, Coull BA, Versace F, Cinciripini P and Morris JS (2015). Bayesian function-on-function regression for multilevel functional data. Biometrics 71 563–574. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morris JS (2015). Functional regression. Annual Reviews of Statistics and Its Applications 2 321–359. [Google Scholar]
- Polman CH, Reingold SC, Edan G, Filippi M, Hartung H-P, Kappos L, Lublin FD, Metz LM, Mcfarland HF, O’Connor PW et al. (2005). Diagnostic criteria for multiple sclerosis: 2005 revisions to the “McDonald criteria”. Ann. Neurol 58 840–846. [DOI] [PubMed] [Google Scholar]
- Pomann G-M, Sweeney EM, Reich DS, Staicu A-M and Shinohara RT (2015). Scan-stratified case-control sampling for modeling blood-brain barrier integrity in multiple sclerosis. Stat. Med 34 2872–2880. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pomann G-M, Staicu A, Lobaton EJ, Mejia AF, Dewey BE, Reich DS, Sweeney EMEM and Shinohara RTRT (2016). Supplement to “A lag functional linear model for prediction of magnetization transfer ratio in multiple sclerosis lesions.” DOI: 10.1214/16-AOAS981SUPP. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramsay JO and Dalzell CJ (1991). Some tools for functional data analysis. J. R. Stat. Soc. Ser. B. Stat. Methodol 53 539–572. [Google Scholar]
- Ramsay JO and Silverman BW (2005). Functional Data Analysis, 2nd ed. Springer, New York. [Google Scholar]
- Reich DS, White R, Cortese IC, Vuolo O, Shea CD, Collins TL and Petkau J (2015). Sample-size calculations for short-term proof-of-concept studies of tissue protection and repair in multiple sclerosis lesions via conventional clinical imaging. Mult. Scler 21 1693–1704. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reiss PT and Ogden RT (2009). Smoothing parameter selection for a class of semiparametric linear models. J. R. Stat. Soc. Ser. B. Stat. Methodol 71 505–523. [Google Scholar]
- RICE JA and Silverman BW (1991). Estimating the mean and covariance structure nonparametrically when the data are curves. J. R. Stat. Soc. Ser. B. Stat. Methodol 53 233–243. [Google Scholar]
- Roy S, Carass A and Prince J (2011). A compressed sensing approach for MR tissue contrast synthesis. In Information Processing in Medical Imaging 371–383. Springer, Berlin. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roy S, Carass A and Prince JL (2013). Magnetic resonance image example-based contrast synthesis. IEEE Trans. Med. Imag 32 2348–2363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ruppert D, Wand MP and Carroll RJ (2003). Semiparametric Regression. Cambridge Series in Statistical and Probabilistic Mathematics 12. Cambridge Univ. Press, Cambridge. [Google Scholar]
- Scheipl F and Greven S (2015). Identifiability in penalized function-on-function regression models Technical report, Univ. of Munich. [Google Scholar]
- Scheipl F, Staicu A-M and Greven S (2015). Functional additive mixed models. J. Comput. Graph. Statist 24 477–501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schmierer K, Scaravilli F, Altmann DR, Barker GJ and Miller DH (2004). Magnetization transfer ratio and myelin in postmortem multiple sclerosis brain. Ann. Neurol 56 407–415. [DOI] [PubMed] [Google Scholar]
- Staniswalis JG and Lee JJ (1998). Nonparametric regression analysis of longitudinal data. J. Amer. Statist. Assoc 93 1403–1418. [Google Scholar]
- Suttner L, Mejia A, Dewey B, Sati P, Reich DS and Shinohara RT (2015). Statistical estimation of white matter microstructure from conventional MRI. UPenn Biostatistics Working Papers. Working Paper 44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sweeney EM, Shinohara RT, Shea CD, Reich DS and Crainiceanu CM (2013a). Automatic lesion incidence estimation and detection in multiple sclerosis using multisequence longitudinal MRI. Am. J. Neuroradiol 34 68–73. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sweeney EM, Shinohara RT, Shiee N, Mateen FJ, Chudgar AA, Cuzzocreo JL, Calabresi PA, Pham DL, Reich DS and Crainiceanu CM (2013b). OASIS is automated statistical inference for segmentation, with applications to multiple sclerosis lesion segmentation in MRI. NeuroImage: Clinical 2 402–413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sweeney EM, Shinohara RT, Dewey BE, Schindler MK, Muschelli J, Reich DS, Crainiceanu CM and Eloyan A (2015). Relating multi-sequence longitudinal intensity profiles and clinical covariates in new multiple sclerosis lesions. Preprint. Available at arXiv:1509.08359 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Den Elskamp IJ, Lembcke J, Dattola V, Beckmann K, Pohl C, Hong W, Sandbrink R, Wagner K, Knol DL, Uitdehaag B et al. (2008). Persistent T1 hypointensity as an MRI marker for treatment efficacy in multiple sclerosis. Mult. Scler 14 764–769. [DOI] [PubMed] [Google Scholar]
- Wood SN (2006). Generalized Additive Models: An Introduction with R Chapman & Hall, Boca Raton, FL. [Google Scholar]
- Wood SN (2011). Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. Ser. B. Stat. Methodol 73 3–36. [Google Scholar]
- Wu Y, Fan J and Müller H-G (2010). Varying-coefficient functional linear regression. Bernoulli 16 730–758. [Google Scholar]
- Yao F, Müller H-G and Wang J-L (2005a). Functional data analysis for sparse longitudinal data. J. Amer. Statist. Assoc 100 577–590. [Google Scholar]
- Yao F, Müller H-G and Wang J-L (2005b). Functional linear regression analysis for longitudinal data. Ann. Statist 33 2873–2903. [Google Scholar]
- Zhang J-T and Chen J (2007). Statistical inferences for functional data. Ann. Statist 35 1052–1079. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.