

Abstract
Wearable data is a rich source of information that can provide a deeper understanding of links between human behaviors and human health. Existing modelling approaches use wearable data summarized at subject level via scalar summaries in regression, temporal (time-of-day) curves in functional data analysis (FDA), and distributions in distributional data analysis (DDA). We propose to capture temporally local distributional information in wearable data using subject-specific time-by-distribution (TD) data objects. Specifically, we develop scalar on time-by-distribution regression (SOTDR) to model associations between scalar response of interest such as health outcomes or disease status and TD predictors. Additionally, we show that TD data objects can be parsimoniously represented via a collection of time-varying L-moments that capture distributional changes over the time-of-day. The proposed method is applied to the accelerometry study of mild Alzheimer’s disease (AD). We found that mild AD is significantly associated with reduced upper quantile levels of physical activity, particularly during morning hours. In-sample cross validation demonstrated that TD predictors attain much stronger associations with clinical cognitive scales of attention, verbal memory, and executive function when compared to predictors summarized via scalar total activity counts, temporal functional curves, and quantile functions. Taken together, the present results suggest that SOTDR analysis provides novel insights into cognitive function and AD.
Subject terms: Statistical methods, Statistics, Translational research
Introduction
Wearables are electronic sensors which can be worn as accessories and provide almost real-time continuous streams of user-specific physiological data such as minute-level step counts, heart rate (beats per minute via PPG) and heart rhythm (via ECG), brainwave (EEG), and many others. This rich source of information can be analyzed for a deeper understanding of human behaviours and their influence on human health and disease. For example, wearable physical activity (PA) monitors provide continuous and objective measurements of PA of individuals in their free-living environment1,2. The diverse applications of wearable data in biosciences include studies of aging3,4, circadian rhythms5, estimation of gait parameters and their application in clinical trials6,7, comparing patterns and intensity of physical activity between different clinical groups8,9 among many others.
In many epidemiological and clinical studies, wearable data is summarized via scalar summaries such as total log activity count (TLAC)3, minutes of moderate-to-vigorous-intensity physical activity (MVPA)3,10, active-to-sedentary transition probability (ASTP)11,12 and others. Scalar summaries, although useful for a particular problem of interest, can often ignore temporal and/or distributional information in continuous streams of data. Temporal or time-of-day information in wearable data can be accounted for using functional data analysis (FDA) approaches that treat wearable data streams as functional observations recorded over 24 hours5,13–15. Temporal effects of scalar predictors on physical activity can be captured via function-on-scalar regression and generalized multilevel function-on-scalar regression16. Scalar outcomes of interest, e.g., health or disease status can be modelled via scalar-on-function regression models17,18 using diurnal physical activity curves as functional predictors typically averaged across the days of observation.
Distributional information in wearable data can be accounted for using distributional data analysis (DDA). Distributions can be encoded via subject-specific histograms19, subject-specific quantile functions20–22 or subject-specific densities23–27. The quantile-function based representation of information in wearable data allows us to model not just mean, but all other quantile-based distributional aspects of wearable data such as variability, skewness, and others. Ghosal et al.21 developed a scalar-on-quantile function regression framework (SOQFR) for modelling scalar outcomes of interest based on subject specific quantile functions of wearable data. Matabuena and Petersen22 used quantile-function representation for NHANES (2003-2006) accelerometer data to predict health outcomes using survey weighted nonparametric regression models. Talská et al.28 developed a compositional scalar-on-function regression method using a centred log ratio transformation29 of subject-specific densities. In this article, we propose to use time-by-distribution data objects that capture temporally local distributional information in the user-specific wearable data. In previous work, Horváth et al.30 proposed a statistical testing framework for detecting a change in a sequence of distributions, but the distributions were coming from the same unit (monthly financial returns of the same stock). Sharma and Greig31 considered distributions over space by time domain and modelled the change over time as linear with respect to the Wasserstein distance. Our approach is different in modelling subject-specific time-by-distribution objects that may have non-linear effects on the outcome with respect to time. Note that two different subjects could have markedly different diurnal patterns of activity but similar distributions. The proposed time-by-distribution data object captures both temporal and distributional aspects of subject-specific PA patterns. Treated as bivariate functional summaries of PA, TD objects can be further used in penalized scalar-on-function regression (SOFR)32 for modelling scalar outcomes of interest. We use a penalized bivariate SOFR approach, which simultaneously identifies time of the day and quantile levels of subject-specific PA distribution associated with outcomes of interest. In addition, we employ decompositions of quantile functions via Legendere polynomials and corresponding L-moments33 that connect quantile and moment based representations of distributions. This connection enables a decomposition of TD objects via novel diurnal time-varying L-moments.
We are motivated by the application of wearable data in the study of Alzheimer’s Disease (AD) and cognitive performance among older adults. AD is one of the most rapidly growing neurodegenerative diseases in the world. The high prevalence of AD and AD-related death in developed countries can be partially attributed to low levels of physical activity (PA) and sedentary lifestyles34. In the absence of any currently existing cure for AD, there is growing interest in identifying cost-effective biomarkers for early identification of risk for AD. Non-invasive, cost-efficient biomarkers are essential for improving early diagnosis of AD35. “Digital” biomarkers from sensor and mobile/wearable devices36 offer an alternative to existing fluid and imaging markers and there is a growing body of evidence which suggests PA changes might precede clinical manifestation of the disease itself. Physical activities, including activities of everyday living (ADLs), are dependent on mobility and cognitive functioning. Several prospective longitudinal studies have identified physical inactivity as a risk factor for dementia37–40. Older adults generally spend most of their waking time in sedentary activities41 and individuals with Alzheimer’s disease (AD) have been found to be even less active in previous studies42.
In our motivating study by Varma and Watts8, physical activity was monitored continuously for seven days using body-worn accelerometers in older adults with mild AD and cognitively normal controls (CNC). Mild AD was found to be associated with reduced moderate-intensity physical activity, reduced peak activity but not with increased sedentary activity or reduced low-intensity physical activity. Although prior research has focused on exploring effects of mild AD on diurnal patterns of PA8 and on average or IIV (intra-individual variability) of PA across days9, we are interested in whether temporally local distributional information in PA profiles can be used to differentiate between CNC and mild AD and explain cognitive performance.
The article is organized as follows. In “Motivating study” section, we present the background of our motivating study. In “Modelling framework” section, we present our modelling framework and illustrate some existing approaches for modelling scalar outcomes via scalar, temporal and distributional summaries of wearable PA data. In “Scalar on time-by-distribution regression” section, we introduce time-by-distribution PA data objects and describe the proposed estimation approach using penalized bivariate scalar-on-function regression. In addition, an alternative representation of TD objects via diurnal time-varying L-moments is introduced. In “Application of SOTDR to modelling cognitive status and function in Alzheimer’s disease” section, we demonstrate applications of the proposed method in an Alzheimer’s disease (AD) study and provide comparisons with existing approaches. “Discussion” section concludes with a discussion of the findings, limitations and some possible extensions of the approach.
Motivating study
Study participants
Mild AD and cognitively normal control (CNC) participants were recruited by the University of Kansas Alzheimer’s Disease Center Registry (KU-ADC). The study protocol was approved by the KU Medical Center Institutional Review Board. All methods were performed following the relevant guidelines and regulations. Informed consent was obtained from all subjects. A detailed description of recruitment and evaluation of participants in the KU-ADC have been previously reported in Graves et al.43 All participants received annual cognitive and clinical examinations, and experienced clinicians trained in dementia assessment provided consensus diagnoses (see “Cognitive status and psychometric test battery” section below for more details). The study sample consisted of individuals with mild AD, defined as a clinical dementia rating (CDR;44) scale scores of 0.5 (very mild) or 1 (mild), and control participants, defined as a CDR score of 0. A total of 100 community-dwelling older adults with and without mild AD were recruited. Out of them, N=92 had valid actigraphy data (n = 39 mild AD; n = 53 controls). Descriptive summaries of participant demographics are displayed in Table 1. Age, sex, and years of formal education were reported by either the participant or study partner. The details about other measures are provided in Graves et al.43.
Table 1.
Summary statistics for the complete, AD and CNC samples.
| Characteristic | Complete sample | AD | CNC | P value | |||
|---|---|---|---|---|---|---|---|
| Mean/Freq | SD | Mean/Freq | SD | Mean/Freq | SD | ||
| Age | 73.36 | 7.11 | 73.59 | 7.92 | 73.19 | 6.53 | 0.797 |
| % Female | 52.17 | N/A | 28.20 | N/A | 69.81 | N/A | < 0.001 |
| Years of edu | 16.56 | 3.24 | 15.53 | 2.77 | 17.32 | 3.38 | 0.0064 |
| BMI | 26.78 | 4.52 | 27.28 | 5.04 | 26.42 | 4.11 | 0.3892 |
| VO2 max | 21.99 | 5.34 | 21.61 | 5.24 | 22.24 | 5.43 | 0.592 |
No statistical difference between the AD and CNC groups are observed across age, BMI, or V02 max. However, AD group had a smaller percentage of females (28.2 vs 69.8 for CNC) and lower education (15.5 years vs 17.3 years for CNC).
Physical activity
Activity counts were produced by a GT3x+ tri-axial accelerometer. A detailed description of accelerometry measurement can be found in8. Briefly, the GT3x+ (Pensacola FL; Actigraph, 2012; 30 Hz sampling rate) is a triaxial accelerometer validated across a range of community dwelling older adults. The accelerometer was placed on the dominant hip of the participants via an elastic belt and the participants were instructed to wear the device 24 hours a day for seven days. Activity counts, collected every second from medio-lateral (ML; front-to-back), antero-posterior (AP; side-to-side), and vertical (VT; rotational) axes were quantified into a single tri-axial composite metric known as vector magnitude45, calculated as . Average vector magnitude was then computed by aggregating VM (averaging) for each second into minute level activity.
Cognitive status and psychometric test battery
Cognitive status of the participants were determined through consensus diagnosis by trained clinicians using comprehensive clinical research evaluations and a review of medical records following NINCS-ADRDA criteria46. Cognitive tests were administered by a trained psychometrician. The cognitive test battery included tests of verbal memory (Wechsler Memory Scale (WMS)–Revised Logical Memory I and II, Free and Cued Selective Reminding Task), attention (Digits Forward and Backward, Wechsler Adult Intelligence Scale (WAIS) subscale Letter– Number Sequencing) and executive function (Digit Symbol Substitution Test, and Stroop Color–Word Test (interference score), Trail Making Test Part B, and Category Fluency). Composite scores for each domain (verbal memory (VM), attention (ATTN), and executive function (EF)) were derived using confirmatory factor analysis (CFA), a flexible approach for summarizing multiple cognitive scores into empirically and theoretically justified components. Scores were standardized to the mean performance of CNC participants. Additional information on the CFA derived factor scores can be found in Varma et al.7.
Modelling frameworks
Suppose, we have minute-level wearable observations such as activity counts or the number of steps per minute denoted by for subject , on j-th day, , at time t, . We denote by a scalar outcome of interest such as a cognitive status or a score on a psychometric test that can be continuous or discrete and we assume it comes from an exponential family. We also denote by a vector of covariates. In this section, we review three existing modelling approaches that relates and including a simple Generalized Linear Model (GLM) regression using scalar summaries of wearable observations, functional data regression of temporal (time-of-day) curves, and distributional data regression using subject-specific quantile functions.
GLM regression using subject-specific scalar summaries
In this approach, the scalar response variable is modelled via a subject-specific scalar summary of wearable observations aggregated across all times and days. Examples include a total mean as a measure of tendency, a standard deviation as a measure of variability, minutes spent in activities of certain intensity such as light or moderate-to-vigorous, and others. For example, subject-specific average activity count . The top left panel of Fig. 1 displays the distribution of subject-specific averages for CNC (blue) and AD (red) groups in our study.
Figure 1.

Top left: violin plot of subject-specific averages for CNC and AD participants. top right: smoothed diurnal activity profiles averaged across CNC (blue) and AD (red) participants. Bottom left: average quantile functions of physical activity for AD and CNC participants.
We observe that participants with AD on average, have a lower mean physical activity level compared to CNC. There is also significant overlap between the two distributions and they are not clearly separable using this PA metric. To formally model this, a generalized linear model (GLM) can be used
| 1 |
where a scalar regression coefficient represents the effect of average PA on the mean of the response of interest adjusted for covariates and is a known link function (e.g., logit or identity).
Functional data analysis of subject-specific temporal curves
Functional data analysis (FDA) allows us to model temporal aspects in wearable observations . To derive subject-specific diurnal minute-level curves, one may average wearable observations across all days at each time-point as . The top right panel of Fig. 1 displays average smoothed diurnal activity profiles for CNC (blue) and AD (red) groups. It can be noticed that the curve for mild-AD group have a unimodal diurnal shape, compared to a bimodal shape for CNC, and the largest difference between the two groups appears to be in the morning and in the afternoon (during the second peak for CNC). Similar observations were also made by Varma and Watts8 during their analysis of this data. To formally model the association with functional predictors, scalar-on-function regression (SOFR)17 can be used as follows
| 2 |
where the functional regression coefficient captures the time-varying effect of the diurnal curve on the response and is the daily 24 hour window. Note that, the average subject-specific PA can be estimated back from the diurnal profile as , therefore for a constant functional regression coefficient , one gets back the generalized linear model (1) for scalar predictors from model (2).
Distributional data analysis using subject-specific quantile functions
Distributional data analysis can capture and model distributional aspect of wearable observations via subject-specific probability density functions (pdf), cumulative distribution functions (CDF), or quantile functions21. If we ignore the temporal information by suppressing the time index t, we can denote by , , all wearable observations for subject i. We assume follow the same subject-specific distribution defined by subject-specific cumulative distribution function , where . Then, we can define the subject-specific quantile function . The subject-specific quantile function characterizes the distribution of wearable observations for a specific subject. The subject-specific cdf can be estimated via its empirical counterpart and subject-specific quantile function can be estimated as . In this paper, we use the following estimator of quantile functions via a linear interpolation of the order statistics47:
where are the corresponding order statistics from a sample and w is a weight satisfying . Note that the subject-specific average of wearable observations can be also estimated from the subject-specific quantile function as .
The bottom left panel of Fig. 1 displays the average quantile functions of physical activity for the CNC and AD groups. A reduced capacity of physical activity can be observed for the AD samples compared to CNC across upper quantile levels such as . Following the approach of Ghosal et al.21, the subject-specific quantile functions of PA can be used for modelling using scalar-on-function regression (SOFR) (3) adjusted for . SOFR model is as follows
| 3 |
where the functional regression coefficient captures the distributional effect of the PA quantile function on the response of interest . In the case , a constant, one again get back the generalized linear model (1) from model (3), since .
Ghosal et al.21 re-represented SOFR model for quantile function predictors via L-moments33. L-moments are defined as the expectation of a linear combination of order statistics. In particular, the r-th order L-moment of a random variable X is defined as
where denote the order statistics of a random sample of size n drawn from the distribution of X. The first order L-moment, , equals the traditional mean. The second order L-moment, , represents a robust measure of scale, and equals exactly a half of Gini-coefficient or mean absolute difference. The third and fourth order L-moments, and , capture higher-order distributional properties and normalized by can be interpreted similarly to traditional higher-order moments such as skewness and kurtosis. The main advantages of L-moments is the existence of all moments, if first moment exist, their uniqueness and robustness. For SOQFR Ghosal et al.21 adapted an alternative representation of L-moments as projections of quantile functions on Legendre polynomial basis, given by
Here is the shifted Legendre polynomial (LP) of degree r defined as
The shifted Legendre polynomials form an orthogonal basis of . Using the LP decomposition for subject-specific quantile functions and , SOFR model can be reduced to a GLM as . This representation of SOFR via L-moments provides both the functional interpretation of significance of via and the distributional interpretation in terms of the significance of specific L-moments via .
Scalar on time-by-distribution regression
In this section, we propose to capture temporally local distributional information in wearable observations using subject-specific time-by-distribution data objects and use bivariate scalar-on-function regression to relate these to a scalar response of interest. We refer to this as scalar on time-by-distribution regression (SOTDR) and also show how two-way TD data objects can be parsimoniously represented via a collection of time-varying L-moments that capture distributional changes over the time-of-day.
SOTDR via time-by-distribution data objects
We develop quantile-based time-by-distribution data objects that capture the temporally local distributional aspects of wearable observations. The quantile-based time-by-distribution data object is then defined as
Here 2h is the window length around time t. Note that is a bivariate functional summary of subject-specific observational data. For each fixed t (time of the day), it provides distributional encoding as a function of quantile-level p, e.g., is a quantile function for each t. For each fixed p, captures the diurnal pattern of the p-th quantile level of wearable observations as a function of time t. Note that the subject-specific average PA can be again be estimated back aggregating the bivariate time-by-distribution data objects as . For the analysis presented in this paper, we fix total window length minutes (i.e., ), but any other window lengths can be used as well. Since the sample considered in this study is highly sedentary9, a window length of 10 minutes still retains the diurnal patterns of PA without any significant loss of information.
Figure 2 displays the heatmaps of average time-by-distribution surfaces for CNC (top left) and AD (top right), the difference between them (bottom left). One can see that the largest differences between the two groups exist during the morning (8 a.m.–11 a.m.) and in afternoon (3 p.m.–5 p.m.) across the upper quantile levels (). At the bottom right panel of Fig. 2 we plot the heatmap of difference in time-by-distribution surfaces between the participants with high (above -percentile) and low (below -percentile) cognitive scores of attention (ATTN) in a combined sample including subjects from both AD and CNC groups. Overall, TD encoding of physical activity is clearly more informative than just temporal or just distributional information from Fig. 1.
Figure 2.

The average bivariate time-by-distribution PA surface for CNC (top left) and AD (top right) groups. The difference between CNC and AD (bottom left) and the difference between subjects with high (above percentile) and low (below -percentile) of cognitive attention (ATTN) scores (bottom right).
To formally model the association of TD data objects with a scalar response, we propose to use them as predictors in two-way scalar-on-function regression (SOFR) as follows:
| 4 |
Here represents the bivariate functional regression coefficient that captures both the temporal and distributional effect of on the response of interest . As before, with the constant regression , the bivariate SOFR model (4) reduces to the generalized linear model (1) for scalar predictors. The estimation approach of this model is discussed below.
Estimation of the time-by-distribution regression coefficient
We follow a two-step estimation approach for the bivariate SOFR model (4) in the paper. In step 1, we model the bivariate regression functional coefficient using a tensor product of univariate cubic B-spline basis functions of both temporal and quantile level arguments, t and p. Suppose, and are the set of known basis functions over t and p, respectively. Then, is modelled as . Using this expansion model (4) is reformulated as
| 5 |
where we denote by the -dimensional stacked vectors of and is the corresponding -dimensional vector of unknown basis coefficients ’s. Thus, the model (5) can be seen as a GLM with subject specific predictors . We use a penalized negative log-likelihood criterion with LASSO48 penalty on the coefficients, which selects only those which influences the response of interest . This effectively helps to reduce the number of parameters in the model (especially important because of a relatively small sample size ) and allows a sparse representation of the functional regression coefficient . The penalized negative log likelihood criterion is given by
| 6 |
In step 2, the selected predictors (with non-zero coefficients) are used in the GLM (5) without any penalization (this also overcomes penalization bias of LASSO) for inference. The estimated regression coefficient function is then given by (note that if is not selected in the first step).
SOTDR-L: SOTDR via time-varying L-moments
Following Ghosal et al.21 who adapted L-moments to SOFR with quantile function predictors, we adapt L-moments to SOTDR by introducing subject-specific time-varying L-moments that depend on the time of the day t. Specifically, we define the diurnal time-varying r-th order L-moment for subject i as
Here we again consider a window of total length 2h centered at time t. The diurnal time-varying curves capture the temporal change of the subject-specific distribution. For example, the first order time-varying L-moment simply represents the diurnal mean curve aggregated into 10 minutes epoch (for ). The second order time-varying L-moment captures a temporal change in variability and is similar to the diurnal standard deviation curve of physical activity considered by8.
Figure 3 displays the first four time-varying L-moments of physical activity, averaged within CNC (blue) and AD (red) groups. Note that the first time-varying L-moments exactly equal to the temporal diurnal curves from the top right panel of Fig. 1. Subject-specific r-th order time-varying L-moment is related to the time-by-distribution PA data object through its projection on Legendre polynomial basis as follows
One can notice that mild AD has lower , , , and moments compared to the CNC, particularly in the morning and somewhat in the afternoon.
Figure 3.

The first four time-varying L-moments of daily physical activity averaged within CNC (blue) and AD (red) groups.
We propose to use the time-varying subject-specific L-moments for modelling using an additive SOFR model. If the shifted Legendre polynomials are used as the basis in p for modelling the bivariate functional effect , the additive SOFR model (7) in terms of time-varying L-moments of PA provides an alternative representation of the bivariate SOFR model (4) that is additionally interpretable from distributional point of view. We will refer to this approach as SOTDR-L. In particular, we have,
| 7 |
Here the functional regression coefficient capture the diurnal time-varying effect of the r-th order time-varying L-moment on the response at time t. Thus, we get an additive SOFR with time-varying L-moments. It is important to note that if we get exactly the SOFR model (2) that uses subject-specific temporal curves as predictors. Thus, SODTR-L model (7) strictly includes model (2).
Application of SOTDR to modelling cognitive status and function in Alzheimer’s disease
In this section, we apply SOTDR to model cognitive status and function in the Alzheimer’s disease (AD) study and compare it to the three existing approaches including a GLM regression with scalar total activity count summary, SOFR with temporal diurnal curves and SOFR with quantile functions.We use penalized spline regression49 to estimate the unknown coefficient functions and in SOFR. For both diurnal and distribution modelling, 12 B-Spline basis functions with a second order difference penalty are used. The refund package50 in R51 is used for implementation of SOFR. First, we will model cognitive status (CNC vs AD) and the three cognitive scores of attention (ATTN), visual memory (VM), and executive function (EF) using the bivariate time-by-distribution data objects as illustrated in the “SOTDR via time-by-distribution data objects” section. Second, we alternatively use an additive SOFR with time-varying L-moments.
SOTDR modelling of cognitive status
We model cognitive status (CNC vs AD) using the SODTR model (4) with an additive adjustment for age, sex and years of education. For comparison with existing approaches, we fit models (1), (2) and (3) using as predictors subject-specific average PA, diurnal PA curves, quantile PA functions, respectively. Ten-minute diurnal PA curves have been calculated by aggregating minute-level data into 10 minutes epochs, resulting in subject-specific diurnal PA curves of length 144. As mentioned earlier, since the participants of the study were highly sedentary9 such 10-minute aggregation serves as pre-smoothing and retains the key temporal patterns of PA. When we report predictive performance summaries such as the area under the curve (AUC) of the receiver operating characteristic, we perform repeated five-fold cross-validation and report the average cross-validated AUC (cvAUC). In Model (4), cross-validated AUC involves only cross-validation of part 2 of the estimation process, that is the same components of selected in Step 1 are used in each iteration of the cross validation. It is important to note that for a large dataset this step will not be necessary as could directly be used as a bivariate functional predictor. The results of the analyses are presented in Table 2.
Table 2.
The results of modelling cognitive status (CNC vs AD) and physical activity using Model 1–4 with an adjustment for age, sex, and education.
| Dependent variable: cognitive status (CNC vs AD) | ||||
|---|---|---|---|---|
| Model 1 | Model 2 | Model 3 | Model 4 | |
| Intercept | 7.608** | 6.549* | 10.588** | 12.368*** |
| (3.567) | (3.615) | (4.139) | (4.591) | |
| Age | −0.051 | −0.040 | − 0.072* | − 0.089* |
| (0.038) | (0.039) | (0.043) | (0.047) | |
| Sex | 2.134*** | 2.111*** | 2.527*** | 2.637*** |
| (0.554) | (0.553) | (0.624) | (0.676) | |
| Education | − 0.224** | − 0.213** | − 0.167* | − 0.174* |
| (0.091) | (0.091) | (0.092) | (0.095) | |
| − 0.005*** | NA | NA | NA | |
| (0.002) | ||||
| NA | NA | NA | ||
| NA | NA | NA | ||
| NA | NA | NA | ||
| Observations | 92 | 92 | 92 | 92 |
| cvAUC | 0.781 | 0.773 | 0.792 | 0.811 |
The standard deviation of the estimated coefficients for the scalar predictors are indicated in the parenthesis. Predictors: model 1-scalar average PA, model 2–diurnal PA curves, model 3-quantile functions, model 4-SOTDR with time-by-distribution data objects.
*; **; ***.
The p values for and in SOFR correspond to the p values from global test of these coefficients and are as reported by the pfr function for scalar-on-function regression within the refund package50 in R51. These are based on a test statistic motivated by an extension of Nychka’s analysis52 of the frequentist properties of Bayesian confidence intervals for smooths53. The p values for are based on a likelihood ratio test (LRT) (of inclusion) in the second stage of the estimation process with the selected components of coming from the first stage.
Model (1) shows that higher subject-specific average PA is significantly associated () with a lower odds of AD. The cvAUC value of 0.781 illustrates a satisfactory discriminatory power of the model and is set as a benchmark for comparison with the other three models. The estimated functional regression coefficient for Model (2) illustrating a diurnal effect of PA profile on log-odds of AD is displayed in the top left panel of Fig. 4. Model (2) finds that higher PA during morning hours ( 10 a.m.–3 p.m.) is significantly associated () with a lower odds of AD49. The average cvAUC of 0.773 suggests that, although, the diurnal patterns of average PA offer additional temporal insights, they do not necessarily offer more discrimination between CNC and AD groups compared to the use of simple average PA (Model 1, cvAUC = 0.781). Model (3) finds the significance of subject-specific quantile functions of PA.
Figure 4.

The estimated regression coefficients for Models 2–4. Estimated temporal effect (top left. t denoting time of the day). Estimated distributional effect (top right, ). Estimated bivariate effect of time-by-distribution PA surface (bottom left).
The estimated functional regression coefficient for Model (3) illustrating a distributional effect of PA on log-odds of AD is displayed ( not significant for ) in the top right panel of Fig. 4 and shows that higher upper quantile levels () of PA are significantly associated with lower odds of AD49. Increased cvAUC of 0.792 indicates higher discriminatory power of distributional encoding of PA (in particular, maximal PA) between CNC and AD compared to the average PA.
The estimated bivariate functional effect for Model (4) is shown in the bottom left panel of Fig. 4. We used cubic B-spline basis functions for modelling . Increased maximal capacity of PA during the morning ( 7 a.m.–10 a.m.) and in the afternoon ( 3 p.m.–5 p.m.) is found to be associated with lower odds of AD. An increased cvAUC of 0.811 (around 3.8% gain) illustrates additional discriminatory power of the time-by-distribution PA data objects, while simultaneously capturing temporally local distributional effects of the PA on log-odds of AD.
SOTDR-L modelling of cognitive status
Next, we illustrate an application of SOTDR-L that uses diurnal time-varying L-moments for modelling cognitive status (CNC vs AD) outcome. For interpretability, we use the first four diurnal L-moments profile () as functional predictors and adjust for age, sex and years of education. Since we have a relatively small sample size (), we follow a penalized SOFR approach to select the L-moments -s, which are most informative.
In particular, we re-express the SOFR model (7) in terms of functional principal component scores of following a functional principal component regression approach54,55,
| 8 |
Here is the projection of the diurnal L-moment on the eigenbasis and is modelled as . We use the group exponential Lasso (GEL) penalty56 on the basis coefficients to perform variable selection in order to identify informative time-varying L-moments . GEL is a bi-level selection penalty and enjoys the added flexibility of forcing some of the coefficients within a particular group to be zero, thus effectively reducing the number of parameters, which is especially useful in our scenario due to the very low sample size. The proposed variable selection approach selects the 3rd order time-varying L-moments to be most informative i.e, most discriminating between the two groups (CNC and AD) while adjusting for age, sex and years of education. The grpreg package57 in R is used for implementing the variable selection method using GEL. The estimated diurnal effect of is shown in Fig. 5. We observe that an increase in the value of third order L-moment of physical activity, during the window (8 a.m.–6 p.m.) is associated with a lower odds of AD. The third order L-moment is related to L-skewness of the PA and its significance is therefore very interesting from a clinical perspective. We also perform repeated cross-validation using as predictor in a SOFR model while adjusting for age, sex, and years of education. An increased cvAUC of 0.802 (around 2.7% gain) illustrates satisfactory discriminatory power of the proposed metric offering both distributional and temporal encoding of physical activity. Likely, because of restricting the number of L-moments and the use of GEL, the temporal findings of SOTDR-L differ from temporal findings of SOTDR. While SOTDR highlights activity in the upper quantile levels during 6–10 a.m. and 2–6 p.m. time periods, SOTDR-L highlights the third order L-moment of activity during mid-day hours that are similar to those from SOFR on temporal diurnal curves. Chosen third order time-varying L-moments in SOTDR-L also seems to result in an increase in cvAUC compared to SOFR that uses temporal diurnal curves (that are equivalent to the first order time-varying L-moments).
Figure 5.
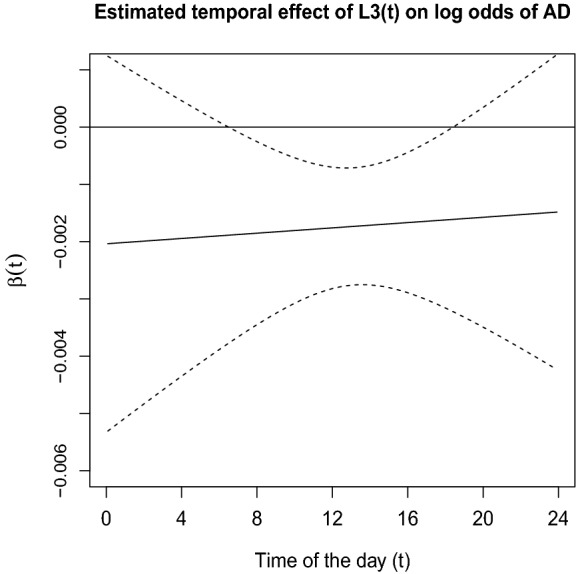
Estimated diurnal effect of of PA on log odds of AD.
Modelling attention
In this section, we apply SOTDR to model the cognitive score of attention (ATTN) of all the subjects and the results are compared with those from regression with subject-specific average PA, FDA using diurnal PA curves, DDA using quantile functions. Adjusted R-squared, defined as the adjusted proportion of variance explained, where original variance and residual variance are both estimated using unbiased estimators58, is used in Models 2-4 for the evaluation of in-sample predictive performance. Cross-Validated R-squared (from repeated 5 fold cross-validation) is reported to compare out-of-sample prediction performance of the different models.
Table 3 presents the result of the analyses from these four modelling approaches. The association between average PA and attention is not found to be significant at level. Adjusted R-squared of the model is reported to be 0.161 and is set as the benchmark for comparison with the other approaches. Although the diurnal curves of PA were not found to be significant ( level), the estimated quantile-function effect is significant. The estimated regression coefficient is shown in Fig. 6 (top right panel). It shows that creates a contrast between a higher quantile levels () and lower quantile levels (). Specifically, an increase in higher quantile of PA is found to be associated with higher performance on attention. Although one needs to be cautious in interpreting the results as subject- specific quantiles of PA are mostly zero below the quantile level as illustrated in Fig. 1. A increase in the adjusted R-squared is observed using DDA with subject-specific quantile functions of PA compared to the benchmark model.
Table 3.
The results of modelling attention score and physical activity using Model 1–4 with an adjustment for age, sex, and education.
| Dependent variable : ATTN score | ||||
|---|---|---|---|---|
| Model 1 | Model 2 | Model 3 | Model 4 | |
| Intercept | − 1.423 | − 1.157 | − 2.045** | − 3.696*** |
| (0.929) | (0.960) | (0.927) | (0.988) | |
| Age | 0.002 | − 0.001 | 0.006 | 0.021* |
| (0.011) | (0.011) | (0.010) | (0.011) | |
| Sex | − 0.354** | − 0.349** | − 0.443*** | − 0.476*** |
| (0.150) | (0.150) | (0.150) | (0.134) | |
| Education | 0.083*** | 0.080*** | 0.072*** | 0.069*** |
| (0.023) | (0.023) | (0.023) | (0.021) | |
| 0.0005 | NA | NA | NA | |
| (0.0005) | ||||
| NA | NA | NA | ||
| NA | NA | NA | ||
| NA | NA | NA | ||
| Observations | 92 | 92 | 92 | 92 |
| Adjusted | 0.161 | 0.163 | 0.218 | 0.378 |
| cv | 0.167 | 0.189 | 0.240 | 0.333 |
The standard deviation of the estimated coefficients for the scalar predictors are indicated in the parenthesis. Predictors: model 1-scalar average PA, model 2-diurnal PA curves, model 3-quantile functions, model 4-SOTDR with time-by-distribution data objects. All models are adjusted for age, sex, years of education.
*; **; ***.
Figure 6.

The estimated effects of the different PA metrics (Model 2-4) on ATTN score. Estimated temporal effect (solid line) (top left). Estimated distributional effect (top right). Estimated bivariate effect of time-by-distribution PA surface (bottom left). The same plot (zoomed-in) with p restricted to the distributional domain (0.5, 1) (bottom right).
The estimated bivariate coefficient , capturing the TD effect on attention is displayed in Fig. 6 (bottom left panel). Increased maximal capacity of PA during the morning ( 7 a.m.–10 a.m.) and in the evening ( 8 p.m.–10 p.m.) is found to be associated with higher attention score after adjusting for age, sex and years of education. Importantly, when quantile levels are constrained to be above 0.5 (re-estimated is shown in the bottom right), there are two contrasts between upper quantile levels () and lower quantile levels () which are not time-aligned and actually capture quantile contrast between adjacent time periods. The morning TD effect can be interpreted as lower level quantile activity centered around 4–6 a.m. are negatively associated and higher level quantile activity centered around 7–9 a.m. are positively associated with attention.
The evening TD effect can be interpreted higher level quantile activity centered around 8–10 p.m. are positively associated and lower level quantile activity centered around 10 p.m.–12 a.m. are negatively associated with with attention. Adjusted R-squared of SOTDR model using the time-by-distribution PA surface is reported to be 0.378, giving a gain from the benchmark model using average physical activity, demonstrating very strong time-by-distribution effect, compared to the non-significant average and diurnal effect and significant distributional effect. In terms of cross-validated R-squared also, we see a increase using the SOTDR approach compared to the benchmark model.
The results from the similar SOTDR analysis of verbal memory (VM) and executive function (EF) are presented in the Supplementary Tables 1, 2 and Supplementary Figures 1, 2 of the Supplementary Material. For both outcomes, we observed significant improvements in adjusted R-squared and CV R-squared.
SOTDR-based scalar biomarkers
Estimates from SOTDR can be used to create simpler to use and interpretable scalar biomarkers. For example, based on the previously fitted models for an outcome of interest, one can calculate SOTDR biomarkers defined as and compare them with the biomarkers based on the average PA, diurnal curves of PA, and quantile functions of PA: , , . Figure 7 displays the scatterplot matrix for all four types of biomarkers to discriminate either cognitive status (left) or attention score (right). Although, they are mostly positively correlated, the large amount of spread indicates that they likely capture somewhat different aspects of PA.
Figure 7.

Scatterplots of the estimated weighted scores corresponding to the predictors average PA, diurnal PA curve, PA quantile function and time-by-distribution PA metric respectively for cognitive status (left) and ATTN (right). Note: corresponds to average daily total count, corresponds to temporal curves of PA, corresponds to distribution representation (via quantile functions) of PA and corresponds to time-by-distribution representation of PA.
Discussion
In this paper, we have proposed to use subject-specific time-by-distribution data objects to capture and model temporally local distributional information in wearable data. We then developed a scalar on time-by-distribution regression that handles TD objects as predictors. We have also provided an alternative and parsimonious representation of the time-by-distribution objects in terms of time-varying L-moments, robust rank-based analogs of traditional moments. This representation allowed us to illustrate that SOTDR generalizes SOFR.
Our approach revealed novel insights into the associations between distributional and diurnal aspects of physical activity and various domains of cognitive function and Alzheimer’s disease status. The time-by-distribution representation provided better discrimination between the CNC and AD participants. Our results revealed strong associations between temporally local distributional aspects of PA across the day and clinical cognitive scales impacted in early AD, especially, attention. These results highlight the potential value of designing and testing physical activity interventions targeting a specific time of the day, in the early stages of AD. As there may be times of the day when cognitively impaired individuals are most alert59,60, it might be specifically suited for individual specific PA interventions. Note that, although, we have not established a causal direction here, it could also be that people with AD have poorer sleep, so are less active in the morning compared to cognitively normal controls. The maximal capacity of physical activity represents the reserve of an individual and our study has revealed strong and significant associations between cognitive performance and maximal PA levels, indicating changes in the reserve of a person might be sensitive to specific disease pathology and cognitive decline.
In this paper, we have proposed a two stage estimation approach of 1) using a LASSO penalty to identify the components of the stacked vectors that are associated with the outcome 2) re-estimating the GLM model using components selected in Step 1. Step 2 does depend on components selected in Step 1, and our approach does not account for variability involved in selecting the components. This is not a limitation of the SOTDR model but of the current estimation approach that needs to address the smaller size of the application dataset. Note that for a larger dataset, this regularization in the estimation step will not be necessary. Also, methods for doing post-selection inference for LASSO (Lee et al. 2016; Taylor and Tibshirani 2018) may be extended to our framework in future work. A related concern is the penalization bias of LASSO which is known to shrink smaller coefficients to zero. An alternative would be to use adaptive LASSO61 or non-convex penalties such as SCAD62 or MCP63 which are known to overcome the penalization bias by adaptively relaxing the rate of penalization when the magnitude of the coefficient gets larger.
This paper opens interesting research questions on how to efficiently capture information with TD data objects. In our approach, we encoded distributional information via quantile functions, the use of other distributional representation such as CDF or hazard function could be explored in future work. In our application, the window length h for calculating and was chosen to be consistent with the window size for diurnal curves. However, in other applications, an adaptive procedure of the choice of optimal window size h may be developed. Time registration or time-warping is often a desirable pre-processing step to make sure the amplitude and phase variations in functional data are properly separated64–66. This is especially important for wearable data which is often driven by subject-specific schedules and time preferences. Thus, pre-registration of TD objects is another exciting area of future research. We have focused on a linear effect of the TD data objects in this paper due to its simplicity, interpretability and connection with summary level modelling approaches. Accounting for the circular nature of the data may be another interesting direction. Future applications might benefit from considering nonlinear effects of the TD objects and this could be done via nonlinear extensions scalar-on-function regression models17. Another interesting area of research would be to extend and apply the proposed method for modelling longitudinal or multilevel data that at each visit generate distribution. To address day-to-day specific variation and account for weekly social structures, a possible approach could be to extend multilevel methods16,67 to TD objects or to employ a three dimensional day-by-time-by-distribution object , with . This approach, of course, would require more wearable data at subject level. Shared parameter model68 can also be useful for accommodating possible systematic differences across days of the week or times of the wday due to exogenous factors. The bivariate time-by-distribution object in the SOTDR framework could be modelled using a semi-parametric model and then linked to the scalar outcome via one or more shared latent parameters. These modifications that can be done in future work could help us to better understand associations between human health and temporal and distributional aspects of daily physical activity.
Supplementary Information
Author contributions
R.G. led methods development, implementation, manuscript conceptualization and preparation. V.V., D.V., J.U., J.H. were involved in study conceptualization and manuscript preparation. A.W. led the data collection and was involved in results interpretation. V.Z. was involved with methods development, conceptualization, and manuscript preparation. All authors interpreted findings and reviewed the manuscript.
Data availability
Illustration of the proposed framework via R51, along with the dataset analyzed, is available online with this article and on Github at https://github.com/rahulfrodo/SOTDR.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-022-15528-5.
References
- 1.Karas M, et al. Accelerometry data in health research: Challenges and opportunities. Stat. Biosci. 2019;11:210–237. doi: 10.1007/s12561-018-9227-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Warmerdam E, et al. Long-term unsupervised mobility assessment in movement disorders. Lancet Neurol. 2020;19:462–470. doi: 10.1016/S1474-4422(19)30397-7. [DOI] [PubMed] [Google Scholar]
- 3.Varma VR, et al. Re-evaluating the effect of age on physical activity over the lifespan. Prev. Med. 2017;101:102–108. doi: 10.1016/j.ypmed.2017.05.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Schrack JA, et al. Assessing the “physical cliff: detailed quantification of age-related differences in daily patterns of physical activity. J. Gerontol. Ser. A Biomed. Sci. Med. Sci. 2014;69:973–979. doi: 10.1093/gerona/glt199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Xiao L, et al. Quantifying the lifetime circadian rhythm of physical activity: A covariate-dependent functional approach. Biostatistics. 2015;16:352–367. doi: 10.1093/biostatistics/kxu045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Urbanek JK, et al. Validation of gait characteristics extracted from raw accelerometry during walking against measures of physical function, mobility, fatigability, and fitness. J. Gerontol. Ser. A. 2018;73:676–681. doi: 10.1093/gerona/glx174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Varma, V. R. et al. Continuous gait monitoring discriminates community dwelling mild ad from cognitively normal controls. in Alzheimer’s and Dementia, Translational Research and Clinical Interventions (2020), In press. [DOI] [PMC free article] [PubMed]
- 8.Varma VR, Watts A. Daily physical activity patterns during the early stage of Alzheimers disease. J. Alzheimers Dis. 2017;55:659–667. doi: 10.3233/JAD-160582. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Watts A, Walters RW, Hoffman L, Templin J. Intra-individual variability of physical activity in older adults with and without mild Alzheimers disease. PLoS ONE. 2016;11:e0153898. doi: 10.1371/journal.pone.0153898. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Bakrania K, et al. Associations of moderate-to-vigorous-intensity physical activity and body mass index with glycated haemoglobin within the general population: A cross-sectional analysis of the 2008 health survey for England. BMJ Open. 2017;7:e014456. doi: 10.1136/bmjopen-2016-014456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Di, J. et al. Patterns of sedentary and active time accumulation are associated with mortality in US adults: The NHANES study. bioRxiv 182337. 10.1101/182337 (2017).
- 12.Schrack JA, et al. Active-to-sedentary behavior transitions, fatigability, and physical functioning in older adults. J. Gerontol. Ser. A. 2019;74:560–567. doi: 10.1093/gerona/gly243. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Morris JS, et al. Using wavelet-based functional mixed models to characterize population heterogeneity in accelerometer profiles: A case study. J. Am. Stat. Assoc. 2006;101:1352–1364. doi: 10.1198/016214506000000465. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Goldsmith J, Liu X, Jacobson J, Rundle A. New insights into activity patterns in children, found using functional data analyses. Med. Sci. Sports Exerc. 2016;48:1723. doi: 10.1249/MSS.0000000000000968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Cui E, Crainiceanu CM, Leroux A. Additive functional Cox model. J. Comput. Graph. Stat. 2020;30:780–793. doi: 10.1080/10618600.2020.1853550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Goldsmith J, Zipunnikov V, Schrack J. Generalized multilevel function-on-scalar regression and principal component analysis. Biometrics. 2015;71:344–353. doi: 10.1111/biom.12278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Reiss PT, Goldsmith J, Shang HL, Ogden RT. Methods for scalar-on-function regression. Int. Stat. Rev. 2017;85:228–249. doi: 10.1111/insr.12163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Leroux A, et al. Organizing and analyzing the activity data in NHANES. Stat. Biosci. 2019;11:262–287. doi: 10.1007/s12561-018-09229-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Augustin NH, Mattocks C, Faraway JJ, Greven S, Ness AR. Modelling a response as a function of high-frequency count data: The association between physical activity and fat mass. Stat. Methods Med. Res. 2017;26:2210–2226. doi: 10.1177/0962280215595832. [DOI] [PubMed] [Google Scholar]
- 20.Yang H, Baladandayuthapani V, Rao AU, Morris JS. Quantile function on scalar regression analysis for distributional data. J. Am. Stat. Assoc. 2020;115:90–106. doi: 10.1080/01621459.2019.1609969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Ghosal, R. et al. Distributional data analysis via quantile functions and its application to modelling digital biomarkers of gait in Alzheimer’s disease. Biostatistics. https://academic.oup.com/biostatistics/advance-article-abstract/doi/10.1093/biostatistics/kxab041/6431736 (2021). [DOI] [PMC free article] [PubMed]
- 22.Matabuena, M. & Petersen, A. Distributional data analysis with accelerometer data in a NHANES database with nonparametric survey regression models. arXiv (2021).
- 23.Petersen A, Müller H-G. Functional data analysis for density functions by transformation to a Hilbert space. Ann. Stat. 2016;44:183–218. doi: 10.1214/15-AOS1363. [DOI] [Google Scholar]
- 24.Hron K, Menafoglio A, Templ M, Hruzova K, Filzmoser P. Simplicial principal component analysis for density functions in Bayes spaces. Comput. Stat. Data Anal. 2016;94:330–350. doi: 10.1016/j.csda.2015.07.007. [DOI] [Google Scholar]
- 25.Kokoszka P, Miao H, Petersen A, Shang HL. Forecasting of density functions with an application to cross-sectional and intraday returns. Int. J. Forecast. 2019;35:1304–1317. doi: 10.1016/j.ijforecast.2019.05.007. [DOI] [Google Scholar]
- 26.Tang, B. et al. Differences in functional connectivity distribution after transcranial direct-current stimulation: A connectivity density point of view. bioRxiv. 10.1101/2020.11.23.395160 (2020). [DOI] [PMC free article] [PubMed]
- 27.Matabuena, M., Petersen, A., Vidal, J. C. & Gude, F. Glucodensities: A new representation of glucose profiles using distributional data analysis. Stat. Methods Med. Res.30(6), 1445–1464 (2021). [DOI] [PMC free article] [PubMed]
- 28.Talská, R., Hron, K. & Grygar, T. M. Compositional scalar-on-function regression with application to sediment particle size distributions. Math. Geosci.53, 1667–1695 (2021).
- 29.Aitchison J. The statistical analysis of compositional data. J. R. Stat. Soc. Ser. B (Methodol.) 1982;44:139–160. [Google Scholar]
- 30.Horváth, L., Kokoszka, P. & Wang, S. Monitoring for a change point in a sequence of distributions. Ann. Stat.49(4), 2271–2291 (2020).
- 31.Sharma, A. & Gerig, G. Trajectories from distribution-valued functional curves: A unified Wasserstein framework. in International Conference on Medical Image Computing and Computer-Assisted Intervention 343–353 (Springer, 2020). [DOI] [PMC free article] [PubMed]
- 32.Marx BD, Eilers PH. Multidimensional penalized signal regression. Technometrics. 2005;47:13–22. doi: 10.1198/004017004000000626. [DOI] [Google Scholar]
- 33.Hosking JR. L-moments: Analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B (Methodol.) 1990;52:105–124. [Google Scholar]
- 34.Gronek P, et al. Physical activity and Alzheimers disease: A narrative review. Aging Dis. 2019;10:1282. doi: 10.14336/AD.2019.0226. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Zvěřová M. Alzheimers disease and blood-based biomarkers-potential contexts of use. Neuropsychiatr. Dis. Treat. 2018;14:1877. doi: 10.2147/NDT.S172285. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Kourtis LC, Regele OB, Wright JM, Jones GB. Digital biomarkers for Alzheimers disease: The mobile/wearable devices opportunity. NPJ Digit. Med. 2019;2:1–9. doi: 10.1038/s41746-019-0084-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Larson EB, et al. Exercise is associated with reduced risk for incident dementia among persons 65 years of age and older. Ann. Intern. Med. 2006;144:73–81. doi: 10.7326/0003-4819-144-2-200601170-00004. [DOI] [PubMed] [Google Scholar]
- 38.Andel R, et al. Physical exercise at midlife and risk of dementia three decades later: A population-based study of Swedish twins. J. Gerontol. A Biol. Sci. Med. Sci. 2008;63:62–66. doi: 10.1093/gerona/63.1.62. [DOI] [PubMed] [Google Scholar]
- 39.Geda YE, et al. Physical exercise, aging, and mild cognitive impairment: A population-based study. Arch. Neurol. 2010;67:80–86. doi: 10.1001/archneurol.2009.297. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Buchman A, et al. Total daily physical activity and the risk of ad and cognitive decline in older adults. Neurology. 2012;78:1323–1329. doi: 10.1212/WNL.0b013e3182535d35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Harvey JA, Chastin SF, Skelton DA. Prevalence of sedentary behavior in older adults: A systematic review. Int. J. Environ. Res. Public Health. 2013;10:6645–6661. doi: 10.3390/ijerph10126645. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Watts AS, Loskutova N, Burns JM, Johnson DK. Metabolic syndrome and cognitive decline in early Alzheimers disease and healthy older adults. J. Alzheimers Dis. 2013;35:253–265. doi: 10.3233/JAD-121168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Graves RS, et al. Open-source, rapid reporting of dementia evaluations. J. Registry Manag. 2015;42:111. [PMC free article] [PubMed] [Google Scholar]
- 44.Morris JC. The clinical dementia rating (CDR): Current version and scoring rules. Neurology. 1993;43:2412. doi: 10.1212/WNL.43.1_Part_1.241-a. [DOI] [PubMed] [Google Scholar]
- 45.Actigraph L. Actilife 6 Users Manual. Pensacola, FL, USA: ActiGraph, LLC; 2012. [Google Scholar]
- 46.McKhann G, et al. Clinical diagnosis of Alzheimers disease: Report of the Nincds-Adrda work group* under the auspices of department of health and human services task force on Alzheimers disease. Neurology. 1984;34:939–939. doi: 10.1212/WNL.34.7.939. [DOI] [PubMed] [Google Scholar]
- 47.Parzen E, et al. Quantile probability and statistical data modeling. Stat. Sci. 2004;19:652–662. doi: 10.1214/088342304000000387. [DOI] [Google Scholar]
- 48.Tibshirani R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996;58:267–288. [Google Scholar]
- 49.Goldsmith J, Bobb J, Crainiceanu CM, Caffo B, Reich D. Penalized functional regression. J. Comput. Graph. Stat. 2011;20:830–851. doi: 10.1198/jcgs.2010.10007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Goldsmith, J. et al. refund: Regression with functional data. R package version 0.1-17 (2018).
- 51.R Core Team. R: A Language and Environment for Statistical Computing (2018).
- 52.Nychka D. Bayesian confidence intervals for smoothing splines. J. Am. Stat. Assoc. 1988;83:1134–1143. doi: 10.1080/01621459.1988.10478711. [DOI] [Google Scholar]
- 53.Marra G, Wood SN. Coverage properties of confidence intervals for generalized additive model components. Scand. J. Stat. 2012;39:53–74. doi: 10.1111/j.1467-9469.2011.00760.x. [DOI] [Google Scholar]
- 54.Reiss PT, Ogden RT. Functional principal component regression and functional partial least squares. J. Am. Stat. Assoc. 2007;102:984–996. doi: 10.1198/016214507000000527. [DOI] [Google Scholar]
- 55.Kong D, Staicu A-M, Maity A. Classical testing in functional linear models. J. Nonparametr. Stat. 2016;28:813–838. doi: 10.1080/10485252.2016.1231806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Breheny P. The group exponential lasso for bi-level variable selection. Biometrics. 2015;71:731–740. doi: 10.1111/biom.12300. [DOI] [PubMed] [Google Scholar]
- 57.Breheny P, Huang J. Group descent algorithms for nonconvex penalized linear and logistic regression models with grouped predictors. Stat. Comput. 2015;25:173–187. doi: 10.1007/s11222-013-9424-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Wood SN. Generalized Additive Models: An Introduction with R. Cham: CRC Press; 2017. [Google Scholar]
- 59.Musiek ES, Xiong DD, Holtzman DM. Sleep, circadian rhythms, and the pathogenesis of Alzheimer disease. Exp. Mol. Med. 2015;47:e148–e148. doi: 10.1038/emm.2014.121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Volicer L, Harper DG, Manning BC, Goldstein R, Satlin A. Sundowning and circadian rhythms in Alzheimers disease. Am. J. Psychiatry. 2001;158:704–711. doi: 10.1176/appi.ajp.158.5.704. [DOI] [PubMed] [Google Scholar]
- 61.Zou H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006;101:1418–1429. doi: 10.1198/016214506000000735. [DOI] [Google Scholar]
- 62.Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001;96:1348–1360. doi: 10.1198/016214501753382273. [DOI] [Google Scholar]
- 63.Zhang C-H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010;38:894–942. doi: 10.1214/09-AOS729. [DOI] [Google Scholar]
- 64.Dryden IL, Mardia KV. Statistical Shape Analysis: With Applications in R. Cham: Wiley; 2016. [Google Scholar]
- 65.Wrobel J, Zipunnikov V, Schrack J, Goldsmith J. Registration for exponential family functional data. Biometrics. 2019;75:48–57. doi: 10.1111/biom.12963. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Marron, J. S., Ramsay, J. O., Sangalli, L. M. & Srivastava, A. Functional data analysis of amplitude and phase variation. Stat. Sci.30(4), 468–484 (2015).
- 67.Di C-Z, Crainiceanu CM, Caffo BS, Punjabi NM. Multilevel functional principal component analysis. Ann. Appl. Stat. 2009;3:458. doi: 10.1214/08-AOAS206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Lin X, Mermelstein R, Hedeker D. A shared parameter location scale mixed effect model for EMA data subject to informative missing. Health Serv. Outcomes Res. Methodol. 2018;18:227–243. doi: 10.1007/s10742-018-0184-5. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Illustration of the proposed framework via R51, along with the dataset analyzed, is available online with this article and on Github at https://github.com/rahulfrodo/SOTDR.