

Abstract
We propose a construction of simultaneous confidence bands (SCBs) for functional parameters over arbitrary dimensional compact domains using the Gaussian Kinematic formula of t-processes (tGKF). Although the tGKF relies on Gaussianity, we show that a central limit theorem (CLT) for the parameter of interest is enough to obtain asymptotically precise covering even if the observations are non-Gaussian processes. As a proof of concept we study the functional signal-plus-noise model and derive a CLT for an estimator of the Lipshitz–Killing curvatures, the only data-dependent quantities in the tGKF. We further discuss extensions to discrete sampling with additive observation noise using scale space ideas from regression analysis. Our theoretical work is accompanied by a simulation study comparing different methods to construct SCBs for the population mean. We show that the tGKF outperforms state-of-the-art methods with precise covering for small sample sizes, and only a Rademacher multiplier-t bootstrap performs similarly well. A further benefit is that our SCBs are computational fast even for domains of dimension greater than one. Applications of SCBs to diffusion tensor imaging (DTI) fibers (1D) and spatio-temporal temperature data (2D) are discussed.
Keywords: Simultaneous inference, Confidence bands, Random fields, Functional data, Climate
1. Introduction
In the past three decades functional data analysis has received increasing interest due to the possibility of recording and storing data collected with high frequency and/or high resolution in time and space. Many methods have been developed to study these complex data objects; for overviews of some recent developments in this fast growing field we refer the reader to the review articles Cuevas (2014) and Wang et al. (2016) and books among others Ferraty and Vieu (2006) and Ramsay and Silverman (2007).
Despite the success of functional data analysis, only recently quantification of uncertainty with simultaneous confidence bands has received increasing attention. The existing methods for construction of simultaneous confidence bands (SCBs) split into three groups. The first group is based on functional central limit theorems (fCLTs) in the Banach space of continuous functions endowed with the maximum metric and evaluation of the maximum of the limiting Gaussian field often using Monte-Carlo simulations with an estimate of the limiting covariance structure, cf. Bunea et al. (2011), Degras (2011, 2017), Cao et al. (2012) and Cao et al. (2014). The second group is based on the bootstrap, among others (Cuevas et al., 2006; Chang et al., 2017; Wang et al., 2019) and Belloni et al. (2018). Thirdly, recently the use of a generalized Kac Rice formula for fast construction of SCBs for one dimensional functional data has been proposed in Liebl and Reimherr (2019), which is similar to our proposal, but limited to one dimensional domains.
Except for Liebl and Reimherr (2019) the mentioned methods are computationally expensive, since they either simulate from an estimated limiting field or require to draw many bootstrap samples. This hinders their use for domains of dimension greater than one. Moreover, they often perform poorly on small samples.
In order to construct precise and efficiently computable SCBs for functional parameters over arbitrarily dimensional domains, we propose to use random field theory (RFT). RFT was studied extensively in Adler (1981) and Adler and Taylor (2009), and has been successfully used in the neuroimaging community to control the FWER of statistical 3D images, among others (Worsley et al., 1996, 2004). More precisely we use the so called Gaussian kinematic formula (GKF) for pointwise t-distributed random fields (Taylor, 2006; Taylor and Worsley, 2007).
In a nutshell GKFs express the expected Euler characteristic (EEC) of the excursion set of a Gaussian related random field F(Z1, … , ZN), in terms of a finite linear combination of D known functions, called Euler characteristic (EC) densities. Here Z1, … , ZN ~ Z are i.i.d. zero-mean, unit-variance Gaussian fields with twice differentiable sample paths over a nice compact subset of . The linear coefficients in this formula are called Lipshitz–Killing curvatures (LKCs) and depend solely on the domain and the covariance structure of the derivative of Z. Remarkably, the only difference between GKFs for different Gaussian related fields is that the EC densities change, see Adler and Taylor (2009, p.315, (12.4.2)). Takemura and Kuriki (2002) have shown that the GKF for Gaussian fields is closely related to the Volume of Tubes formula dating all the way back to Working and Hotelling (1929). The latter has been applied for SCBs in nonlinear regression analysis, e.g., Johansen and Johnstone (1990), Krivobokova et al. (2010) and Lu and Kuriki (2017). In this sense the GKFs of Taylor (2006) can be interpreted as a generalization of the volume of tube formula for repeated observations of functional data.
Our main contributions are the following. In Theorem 2 we show based on the main result in Taylor et al. (2005) that, asymptotically, the error in the covering rate of SCBs for a function-valued population parameter based on the tGKF can be bounded and is small, if the targeted covering probability of the SCB is sufficiently high. This requires neither Gaussianity nor stationarity of the observed fields. It only requires that the estimator of the targeted function-valued parameter fulfills an fCLT in the Banach space of continuous functions with a sufficiently regular Gaussian limit field. Moreover, it requires consistent estimators for the LKCs. The latter have been studied in Taylor and Worsley (2007) and Telschow et al. (2020). We illustrate the general approach for the special case of SCBs of the population mean curve and the difference of population means for functional signal-plus-noise models, where we allow the error fields to be non-Gaussian. Especially we derive for such models defined over sufficiently regular domains , D = 1, 2, consistent estimators for the LKCs and derive CLTs for them. In order to deal with observation noise we discuss SCBs for scale spaces. In Theorem 8 we give sufficient conditions to have weak convergence of a scale space field to a Gaussian limit extending the results from Chaudhuri and Marron (2000) from regression analysis to repeated observations of functional data. Additionally, we prove that the LKCs of this limit field can be consistently estimated and therefore Theorem 2 can be used to bound the error in the covering rate for SCBs of the population mean of a scale space field.
Scale spaces are not the only way to deal with the observation noise and discrete sampling. For example local polynomial estimators can be used to estimate the population mean (Zhang et al., 2007; Degras, 2011; Zhang et al., 2016). Our proposed construction of SCBs is applicable in these cases provided that the LKCs can be consistently estimated and a bias correction is introduced. Note that in the ultra dense sampling case (Zhang et al., 2016) our developed theory for the SCBs of signal-plus-noise models can be directly used, since the bias introduced by the smoother is negligible. For less dense sampling schemes a bias correction and consistent estimates of the LKCs need to be derived, yet Theorem 2 can then still be applied.
The theory is accompanied by a simulation study using the Rpackage SIRF (Spatial Inference for Random Fields), which can be found on https://github.com/ftelschow/SIRF, and demonstrate the use of SCBs on two different data applications. In the simulation study we compare the performance of the tGKF approach to SCBs for different error fields mainly with bootstrap approaches and conclude that the tGKF approach does not only often give better coverings for small sample sizes, but outperforms bootstrap approaches computationally. Moreover, the average width of the tGKF confidence bands is lower for large sample sizes. As a first application we demonstrate the use of SCBs for scale spaces on a diffusion tensor imaging (DTI) experiment to detect differences in population means between healthy subjects and patients. The second application constructs simultaneous confidence bands for the expected increase in mean summer and winter temperatures over North America obtained from NARCAP simulations (Mearns et al., 2013).
Organization of the article.
Section 2.1 introduces necessary notations and definitions. In Section 2.2 and Section 2.3 we describe the general idea of construction of SCBs for functional parameters using the tGKF. In Section 2.4 we prove a theorem establishing that the SCBs from the tGKF give accurate covering rates. Applications to the functional signal-plus-noise model are given in Section 3. Especially, we provide consistent estimators of the LKCs and prove consistency and a CLT for them in Section 3.2. SCBs for scale space models are discussed in Section 3. In Section 4 we compare the tGKF approach in different simulations to competing state of the art methods to construct SCBs for functional signal-plus-noise models. Section 5 applies these ideas to real data.
2. Simultaneous confidence bands
2.1. Preliminary definitions and notations
Definition 1.
A random field G is a random function from a parameter space S to . The function , where ω ∈ Ω is an element of the underlying probability space, is called a sample path. Moreover, G is called Gaussian random field, if for all (s1, … , sM) ∈ SM, , the random vector (G(s1), … , G(sM)) has a multivariate Gaussian distribution.
A detailed treatment of random fields can be found in Adler and Taylor (2009). Another important quantity, which we need is the Euler characteristic (EC) of a set A ⊆ S denoted by χ(A). The EC of a topological space is an invariant that can be rigorously defined using homology groups of a topological space (Bredon, 2013) or it can be defined using triangulations (Flegg, 2001). Intuitively, the EC of is the number of connected components for D = 1, the number of connected components minus the number of holes for D = 2 and the number of connected components minus the number of holes plus the number of hollows (for example the hole in the 2-sphere) for D = 3.
Classical results on functional central limit theorems (fCLTs), which we will use later, make use of semi-metrics (Jain and Marcus, 1975). Hence we recall the definition:
Definition 2.
A semi-metric on a topological space S is a map such that (1.) δ(s, s′) ≥ 0, (2.) δ(s, s′) = 0 if and only if s = s′, (3.) δ(s, s′) = δ(s′, s). This implies that each metric is a semi-metric. A semi-metric is called continuous with respect to the topology of S, if it is a continuous function in the product topology of S × S.
To improve readability we abbreviate higher order partial derivatives using the following notation
where K = |I| denotes the number of elements in the multi-index I = (d1, … , dK). We denote with the space of continuous functions from S to and with “⇒” weak convergence in endowed with the maximum norm ‖f‖∞ = maxs∈S|f(s)|. Moreover, a letter in Fraktur font, for example , will always denote the covariance function of a random field.
2.2. SCBs for functional parameters
We describe a general well-known scheme for construction of simultaneous confidence bands (SCBs) for a functional parameter s ↦ θ(s), s ∈ S, where is compact. Hereafter, we assume that all functions of s ∈ S belong to .
Let and be estimators of functional parameters θ, ς respectively, fulfilling
| (E1) |
| (E2) |
Here G is a zero-mean Gaussian field with covariance function satisfying for all s ∈ S, τN → ∞ is a sequence of positive numbers. Under (E1) and (E2) Slutzky’s Lemma implies
| (1) |
Thus, it is easy to verify that the collection of intervals
| (2) |
form (1 − α)-simultaneous confidence bands of θ, i.e.
provided that
| (3) |
The quantiles qα,N are in general unknown and need to be estimated.
To the best of our knowledge there are two approaches for this. Limit approximations try to estimate qα,N by estimation of the asymptotic covariance function and simulations of sample paths from the corresponding Gaussian field (Degras, 2011, 2017). Better performances for small samples can be achieved by bootstrap approaches such as the parametric bootstrap proposed in Degras (2011) or the multiplier bootstrap (Chang et al., 2017). Compare also Appendix A.
2.3. Estimation of the quantile using the tGKF
In this section we propose to use the Gaussian kinematic formula for t-fields (tGKF) as proven in Taylor (2006) to approximate the quantiles qα,N.
2.3.1. The Gaussian Kinematic Formula for t-fields
Let be zero-mean, unit-variance Gaussian fields. The field T satisfying
is called a tN−1-field. We pose the following assumptions on G:
-
(G1)
G has almost surely -sample paths.
-
(G2)
The joint distribution of the derivative fields (G(d)(s), G(d,l)(s)) is nondegenerate for all s ∈ S and d, l = 1, … , D.
-
(G3)There is an ϵ > 0 such that
for all d, l = 1, … , D and for all |s − s′| < ϵ. Here K > 0 and γ > 0 are finite constants. -
(G4)
if and only if s = s′.
Remark 1.
Assumptions (G1)-(G3) imply (cf., Adler and Taylor (2009, Thm 11.3.3)) that the paths of G are almost surely Morse functions. This is necessary since the proof of the GKF is based on the classical Morse theorem for Whitney-stratified manifolds (Goresky and MacPherson, 1988). Thus, (G2) is necessary to ensure that almost surely all critical points are nondegenerate. Assumption (G3) is satisfied for any field G having almost surely -sample paths and all third derivatives have a finite second -moment, see Definition 3. In particular, this holds true for any Gaussian field with -sample paths. For completeness the argument is carried out in more detail in Appendix B.1. Condition (G4) excludes, for example, periodic fields.
Under these assumptions the tGKF is an exact, analytical formula of the expectation of the Euler characteristic χ of the excursion sets A(T, u) = {s ∈ S | T(s) > u} of T. This formula as proven in Taylor (2006) or Adler and Taylor (2009) is
| (4) |
where , d = 0, … , D, is the d-th Euler characteristic density of a tN−1-field (Taylor and Worsley, 2007), usually known, and Ld denotes the d-th Lipshitz–Killing curvature, which only depends on G and the parameter space S. Note that L0(S, G) = χ(S) and hence is usually known.
Eq. (4) is useful, since by the expected Euler characteristic heuristic (EECH) (Taylor et al., 2005), we expect
| (5) |
to be a good approximation for large thresholds u. In the case that this approximation is always from above. This is due to the fact that the Euler characteristic of one-dimensional sets is always non-negative and hence using the Markov-inequality we obtain
The same argument is heuristically valid for high enough thresholds in any dimension, since the excursion set will with high probability consist mostly of simply-connected sets. This heuristic has been rigorously proven in Taylor et al. (2005) for T being a Gaussian field.
2.3.2. The tGKF-estimator of qα,N
Let be consistent estimators of the LKCs Ld(S, G) for d = 1, … , D, then combining the tGKF (4) and the EEC heuristic Eq. (5) yields the natural plug-in estimator of the quantile qα,N defined in Eq. (3) as the largest solution u of
| (6) |
The following result is important for the proof of the accuracy of the SCBs derived using the tGKF estimator of qα,N.
Theorem 1.
Assume that is a consistent estimator of Ld(S, G). Then given by (6) converges almost surely for N tending to infinity to the largest solution of
| (7) |
where ρd are the Euler characteristic densities of a Gaussian field, which can be found in Adler and Taylor (2009, p.315, (12.4.2)).
Remark 2.
Estimation of LKCs is not widely studied yet. For stationary random fields this has been done in Kiebel et al. (1999). For non-stationary random fields over domains in arbitrary dimensions, consistent estimators based on residuals have been introduced in Taylor and Worsley (2007) and Telschow et al. (2020). The former uses a warping to stationary transform, while the latter uses projections onto Hermite polynomials. For signal-plus-noise models and D ≤ 2 we take a more direct approach based on normalized residuals in Section 3.2.
2.4. Asymptotic covering rates
This section discusses the accuracy of the SCBs obtained using the tGKF. Since the expected Euler characteristic of the excursion sets is only an approximation of the excursion probabilities, there is no hope to prove that the covering of these confidence bands is exact. Especially, if α is large the approximation fails badly and usually will lead to confidence bands that are too wide. However, for values of α < 0.1 typically used for confidence bands, the EEC approximation works astonishingly well. Theoretically, this has been made precise for Gaussian fields in Theorem 4.3 of Taylor et al. (2005), which is the main ingredient in the proof of the next result. Additionally, it relies on the fCLT (1) and the consistency of for proved in Theorem 1.
Theorem 2.
Assume (E1–E2) and assume that the limiting Gaussian field G satisfies (G1–G3). Moreover, let be a sequence of consistent estimators of Ld for d = 1, … , D. Then there exists an α′ ∈ (0, 1) such that for all α ≤ α′ we have that the SCBs defined in Eq. (2) fulfill
where is the critical variance of an associated field of G, is the quantile estimated using Eq. (6) and is defined in Theorem 1.
Typically, in our simulations we have that, for α = 0.05, the quantile is about 3 leading to an upper bound of ≈ 0.011, if we use the weaker bound without the critical variance.
3. Application to the functional signal-plus-noise model
As it is an important example, we discuss in depth SCBs for the population mean in the functional signal-plus-noise model given by
| (8) |
Here μ, σ are continuously differentiable functions on a compact domain and Z is a stochastic process with zero mean and covariance function for s, s′ ∈ S satisfying if and only if s = s′. Additionally, we will need regularity conditions based on Definition 3 to guarantee that an i.i.d. sample of (8) fulfills a functional central limit theorem.
Definition 3.
- We say a random field Z with domain S is -Lipshitz, if there exists a (semi)-metric δ on S, continuous in the standard topology of , and a random variable A satisfying such that
and , where H(S, δ, ϵ) denotes the metric entropy function of the (semi)-metric space (S, δ), e.g., Adler and Taylor (2009, Def. 1.3.1.).(9) We say a random field Z has finite pth -moment, if .
Proposition 1.
Any -Lipshitz field over a compact set S has finite pth -moment if for some s ∈ S.
Remark 3.
Any -Lipshitz field Z has necessarily almost surely continuous sample paths. Moreover, this property is the main ingredient in the version of a CLT in proven in Jain and Marcus (1975) or Ledoux and Talagrand (2013, Section 10.1).
Since any continuous Gaussian field satisfies the finite pth -moment condition, cf. Landau and Shepp (1970), it is possible to prove a reverse of Proposition 1 for continuously differentiable Gaussian fields. Moreover, finite pth -moment conditions are often assumed, when uniform consistency of estimates of the covariance function are required, e.g., Hall et al. (2006) and Li et al. (2010).
3.1. Asymptotic SCBs for the one and two sample case
As an application of Theorem 2 we derive SCBs for the population mean and the difference of population means in one and two sample scenarios of the signal-plus-noise model. We base our assumptions on the -Lipshitz property.
Theorem 3 (Asymptotic SCBs for the Signal-plus-noise Model).
Let be a sample of model (8) and assume Z is an -Lipshitz field. Define Y(s) = (Y1(s), … , YN(s)).
- Then the estimators
fulfill the conditions (E1–2) with , θ = μ, ς = σ and . - Let be consistent estimators of the LKCs of G. Additionally, assume that the -Lipshitz field Z has almost surely -sample paths, that all partial derivatives up to order 3 of Z are -Lipshitz and that G fulfills the non-degeneracy condition (G2). Then the accuracy result of Theorem 2 holds true for the SCBs
with given in Theorem 1.
Remark 4.
Under the assumptions on Z and G in (ii), the warping estimator (Taylor and Worsley, 2007), the Hermite Projection estimator (Telschow et al., 2020) and the estimators discussed in Section 3.2 are all consistent estimators of the LKCs of G. Hence the first assumption in (ii) is not restrictive.
A simple condition on Z to ensure that G fulfills the non-degeneracy condition (G2) is that for all d, l ∈ {1, … , D} we have that cov [(Z(l)(s), Z(d,l)(s))] has full rank for all s ∈ S. A proof is provided in Lemma 13 in the Appendix.
Theorem 4 (Asymptotic SCBs for Difference of Means of Two Signal-plus-noise Models).
Let and be independent samples, where
with ZY, ZX both -Lipshitz fields and assume that c = limN,M→∞ N/M. Then
3.2. Estimation of LKCs
For D ≤ 2, we can obtain consistent estimators of the LKCs by directly implementing their definitions. These estimators are conceptually easier to understand than existing estimators (Taylor and Worsley, 2007; Telschow et al., 2020). Additionally, they allow for simple proofs of their consistency and fulfill a CLT.
For a zero-mean, unit-variance Gaussian field G, the LKCs Ld(S, G) are intrinsic volumes of S with respect to the pseudo-Riemannian metric Λ given in standard coordinates of as
| (10) |
Using this notation the general expression of the LKCs (Adler and Taylor, 2009, Definition 10.7.2) for D = 1 yields
| (11) |
In the case of with piecewise -boundary ∂S parametrized by a piecewise -function the LKCs are given by
| (12) |
An application of the chain rule shows that L1 is independent of the parametrization γ of S.
These formulas allow to estimate the unknown LKCs from a sample Y1, … , YN ~ Y of model (8). The estimators are built on the normalized residuals
| (13) |
To abbreviate the following formulas we define R(s) = (R1(s), … , RN(s)). In view of Eq. (11) a natural estimator of L1 for D = 1 is given by
| (14) |
and Eqs. (12) suggest the estimators
| (15) |
for D = 2. Here is the empirical covariance matrix of the sample ∇R1, … , ∇RN consisting of the gradients of the normed residuals. In order to prove consistency of the LKC estimates, we establish that converges uniformly almost surely to Λ.
Theorem 5.
If Z and Z(d) for d = 1, … , D are -Lipshitz fields, then
If Z and Z(d) for d = 1, … , D are even -Lipshitz, we obtain
with mapping
and the matrix valued covariance function is given componentwise by
| (16) |
for all s, s′ ∈ S and d, l = 1, … , D.
This theorem is the backbone in the proof of consistency and the CLT for the estimators (14) and (15).
Theorem 6 (Consistency of LKCs).
Under the setting of Theorem 3(ii) it follows for d = 1, 2 that
Remark 5.
Our proposed sample estimator of Λ through residuals is only one viable possibility. In general consistent estimation of the LKCs can be achieved by any estimator of Λ, which converges uniformly almost surely to Λ. Especially, this means that it is not necessary to observe complete fields as our residual approach suggests.
Theorem 7 (CLT for LKCs).
Assume Z and Z(d) for d = 1, 2 are -Lipshitz fields. Then, if ,
and, if , we obtain
where G(s) is a Gaussian field with zero-mean and covariance function as in Theorem 5 and γ is a parametrization of the boundary ∂S.
Corollary 1.
Assume additionally to the Assumptions of Theorem 7 that Z is Gaussian with covariance function and . Then, we have the simplified representation
where
Estimation of LKCs in the scenario of two independent samples can be achieved along the same lines as in the one sample case. Here the independence of the samples implies that the covariance matrix Λ of the partial derivatives of the limiting field in Theorem 4(i) splits into a sum of covariance matrices depending on GX and GY, i.e.,
Under the assumptions of Theorem 4(ii) these summands can be separately consistently estimated using the respective normalized residuals
and the sum of these estimators is a uniformly almost surely consistent estimator of Λ(G). Thus it yields a consistent estimator of the LKCs in the two sample scenario.
3.3. Discrete sampling and additive noise: A scale space approach
In applications data of a signal-plus-noise model is usually observed on a discrete grid with possible additive measurement noise yielding the model
| (17) |
where is a random (or deterministic) sampling of the domain S, ε is a random field on S with finite second -moment representing the observation noise and covariance function and ε, Z and S are mutually independent.
A generic way to estimate μ and perform inference on it is via local polynomial smoothers. Degras (2011) discussed construction of SCBs for these estimators. Since he proved that local linear smoothers under certain conditions similar to ours satisfy a fCLT, it is easy to extend our previous results of the signal plus noise model to his setup. However, there is no satisfactory solution to the question of choosing a data-driven bandwidth for finite sample sizes. Therefore, we consider scale spaces and their SCBs for inference on the population mean μ instead. This concept was originally introduced for regression in Chaudhuri and Marron (1999, 2000). Our goal is to construct SCBs for the smoothed population mean simultaneously across different bandwidths. For simplicity we restrict ourselves to the Priestley–Rao smoothing estimator. Extensions to local polynomial or other appropriate linear smoothers are possible.
Definition 4 (Scale Space Field).
We define the Scale Space field with respect to a continuous kernel function with and 0 < h0 < h1 < ∞ corresponding to Model (17) as
with mean
In order to apply the previously presented theory we have to obtain first a functional CLT. The version we present is similar to Theorem 3.2 of Chaudhuri and Marron (2000) with the difference that we consider the limit with respect to the number of observed curves and include the case of possibly having the (random) measurement points depend on the number of samples, too. The regression version in Chaudhuri and Marron (2000) treats the limit of observed measurement points going to infinity for one noisy observed function.
Theorem 8.
Let be a sample from Model (17), where P is allowed to depend on N and assume that Z has finite second -moment. Further assume maxs∈S σ(s) ≤ B < ∞ and
| (18) |
exists for all (s, h), , where the expectation is w.r.t. the sampling distribution of S = (s1, … , sP). Finally, assume that the smoothing kernel (s, h) ↦ K(s, h) is α-Hölder continuous. Then in
Remark 6.
Suppose S ⊂ [0, 1] is non-random. If P independent of N and sp = (p − 0.5)/P for p = 1, … , P for all n = 1, … , N and , then Assumption (18) is trivially satisfied. If instead P → ∞ as N → ∞ it is sufficient that the following integral exists and is finite for all (s, h),
in order to have Assumption (18) satisfied. For example, this is the case if and are continuous.
In order to use Theorem 2 it remains to show that the LKCs can be consistently estimated and the assumptions of the GKF from Section 2.3 are satisfied.
Proposition 2.
Under the setting of Theorem 8 assume additionally that the kernel . Define
and assume that has continuous partial derivatives up to order 3 and the covariance matrices of
have rank 2. Then and satisfy Assumptions (L), (E2) and (G3). Thus, all assumptions of Theorem 2 are satisfied.
Remark 7.
Assume the situation of Remark 6. Then the assumption that has continuous partial derivatives up to order 3 follows directly from the assumption .
4. Simulations
All simulations are based on 5000 Monte Carlo simulations in order to estimate the covering rate of the SCBs. We compare SCBs constructed using the tGKF, the non-parametric bootstrap-t (Boots-t) and the multiplier-t with Gaussian (gMult-t) or Rademacher (rMult-t) multipliers. For the Gaussian simulations we include the fast and fair bands (ffscb) from Liebl and Reimherr (2019). Bootstrap methods are based on 5000 bootstrap replicates.
4.1. Coverage: Smooth Gaussian case
This first set of simulations deals with the most favorable case for the tGKF method. We simulate samples from the following smooth signal-plus-noise models (8)
with , and . The vector KA(s) has entries , the (i, 6)-th Bernstein polynomial for i = 0, … , 6, KB(s) has entries with xi = i/21, hi = 0.04 for i < 10, h11 = 0.2 and hi = 0.08 for i > 10 and KC(s) is the vector of all entries from the 6 × 6-matrix with xij = (i, j)/6 with h = 0.06. Examples of sample paths of the signal-plus-noise models and the error fields, are shown in the top two rows of Fig. 1.
Fig. 1.
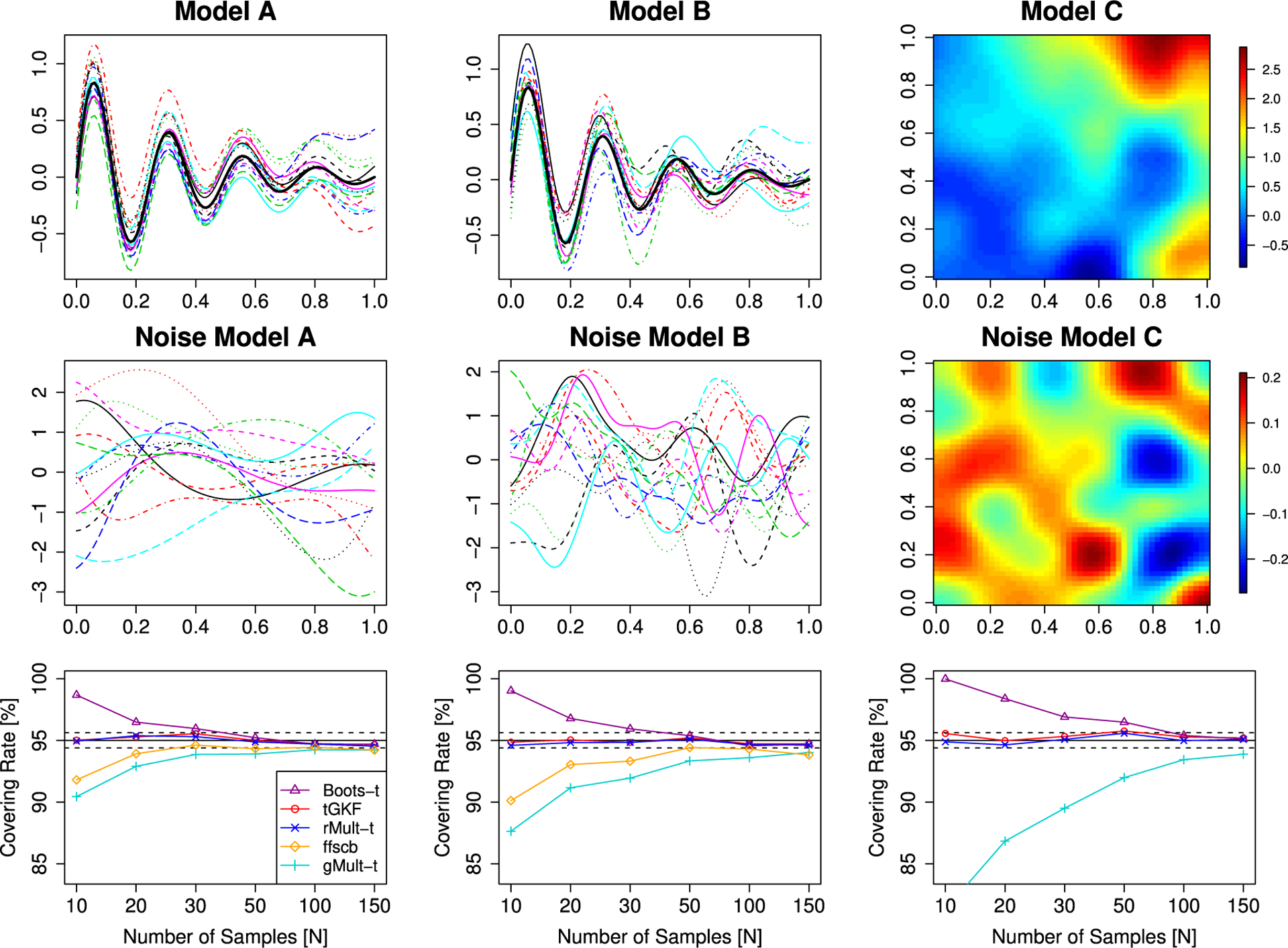
Simulation results for smooth Gaussian fields. Top row: samples from the signal-plus-noise models. Middle row: samples from the error fields. Bottom row: simulated covering rates. The solid black line is the targeted level of the SCBs and the dashed black line is twice the standard error for a Bernoulli random variable with p = 0.95.
We simulated samples from Model A and B on an equidistant grid of 200 points of [0, 1]. Model C was simulated on an equidistant grid with 50 points in each dimension.
According to the results of this simulation, shown in the bottom row of Fig. 1, the tGKF and the rMult-t method perform best since they are close to nominal level for all considered sample sizes; ffscb converges to the nominal level, too. Table 1 summarizes the computation times of the compared methods. It shows that the tGKF SCBs do not only provide the correct covering rates, it is also approximatively 20 times faster than its competitors. That ffscb has similar computation times as bootstrap methods is surprising. Personal communication with the authors suggests that their R-code needs to be optimized.
Table 1.
Comparison of the runtime for different methods to construct SCBs. The reported runtime is the average over 1000 calls to construct a SCB for a sample of size N = 50 from Model A in 1D and Model C in 2D.
| tGKF | ffscb | Boots-t | gMult-t | rMult-t | |
|---|---|---|---|---|---|
| Model A (1D) | 4.2 s | 115.2 s | 88.4 s | 86.6 s | 83.9 s |
| Model C (2D) | 92.8 s | - | 2039.6 s | 1858.4 s | 1864.9 s |
4.2. Coverage: Smooth non-Gaussian case
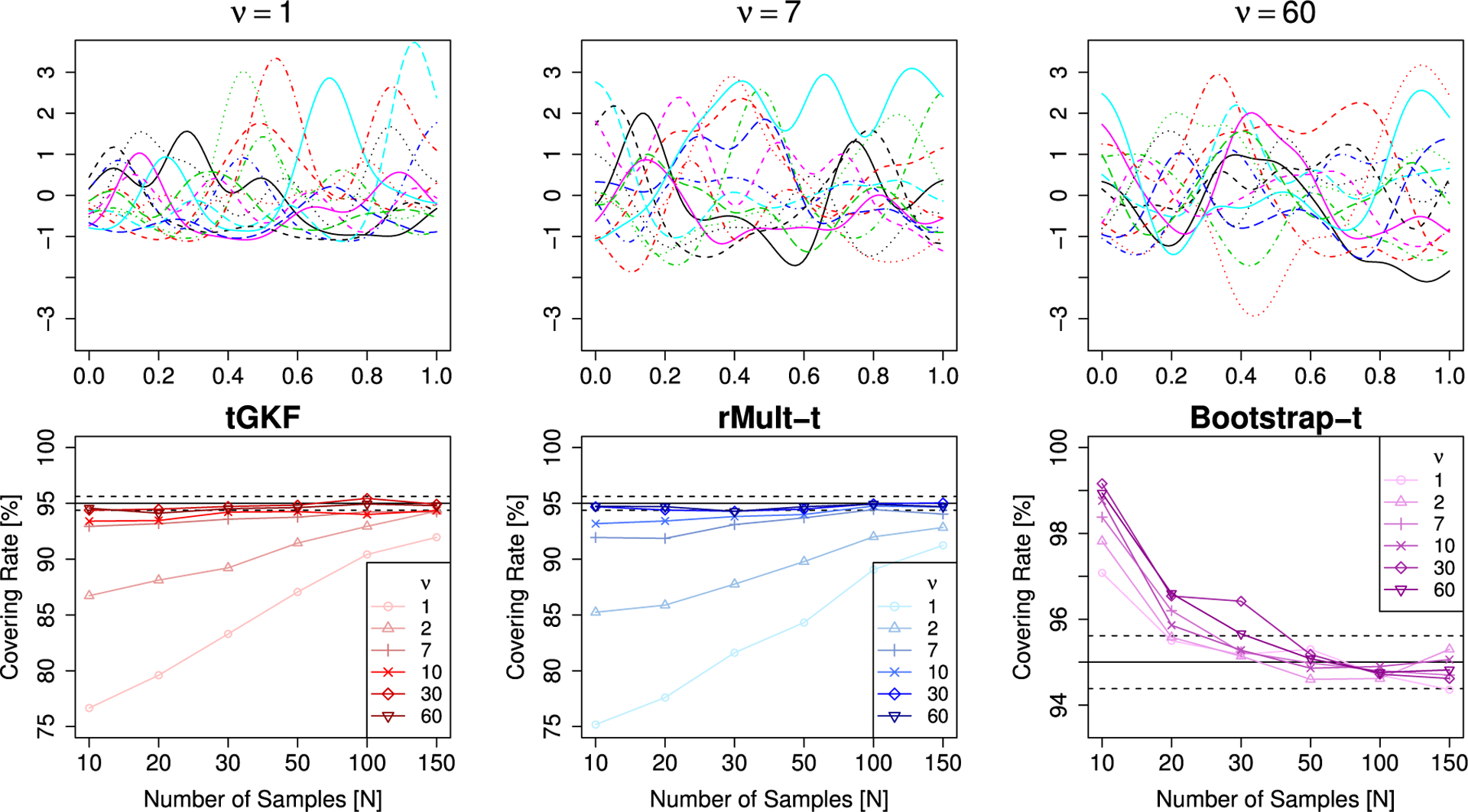
The tGKF method is based on a formula valid for Gaussian fields only. However, we have seen in Section 2.4 that under appropriate conditions the covering is expected to be good asymptotically even if this condition is not fulfilled. For the simulations here we use Model A with the only change that a has i.i.d. entries of a Student’s random variable, which is non-Gaussian, but still symmetric. A second simulation study tackles asymmetry of the noise distribution and increasing similarity to Gaussianity. Here we use Model B where b has i.i.d. entries of random variables for different parameters of ν. These random variables are non-symmetric, but for ν → ∞ they converge to a standard normal.
Fig. 2 shows that in the symmetric distribution case of Model A the tGKF has some over coverage for small sample sizes, but eventually it is in the targeted region for 95% coverage. For the particular process used in this simulation, ffscb seems to converge faster to nominal than tGKF SCBs. A possible explanation might be that the slight undercovering, which was present in the Gaussian case, is compensated due to the non-Gaussianity. A careful comparison of these cases will be part of future research. For this symmetric non-Gaussian distribution the rMult-t still works well. This is probably because it preserves all moments up to the fourth. The case of non-symmetric distributions produces usually undercovering for the tGKF. However, as predicted by Theorem 3 eventually for large N it gets close to the targeted covering. In this case, the bootstrap-t converges faster to the correct covering rate because it does not require symmetry (see Fig. 3).
Fig. 2.
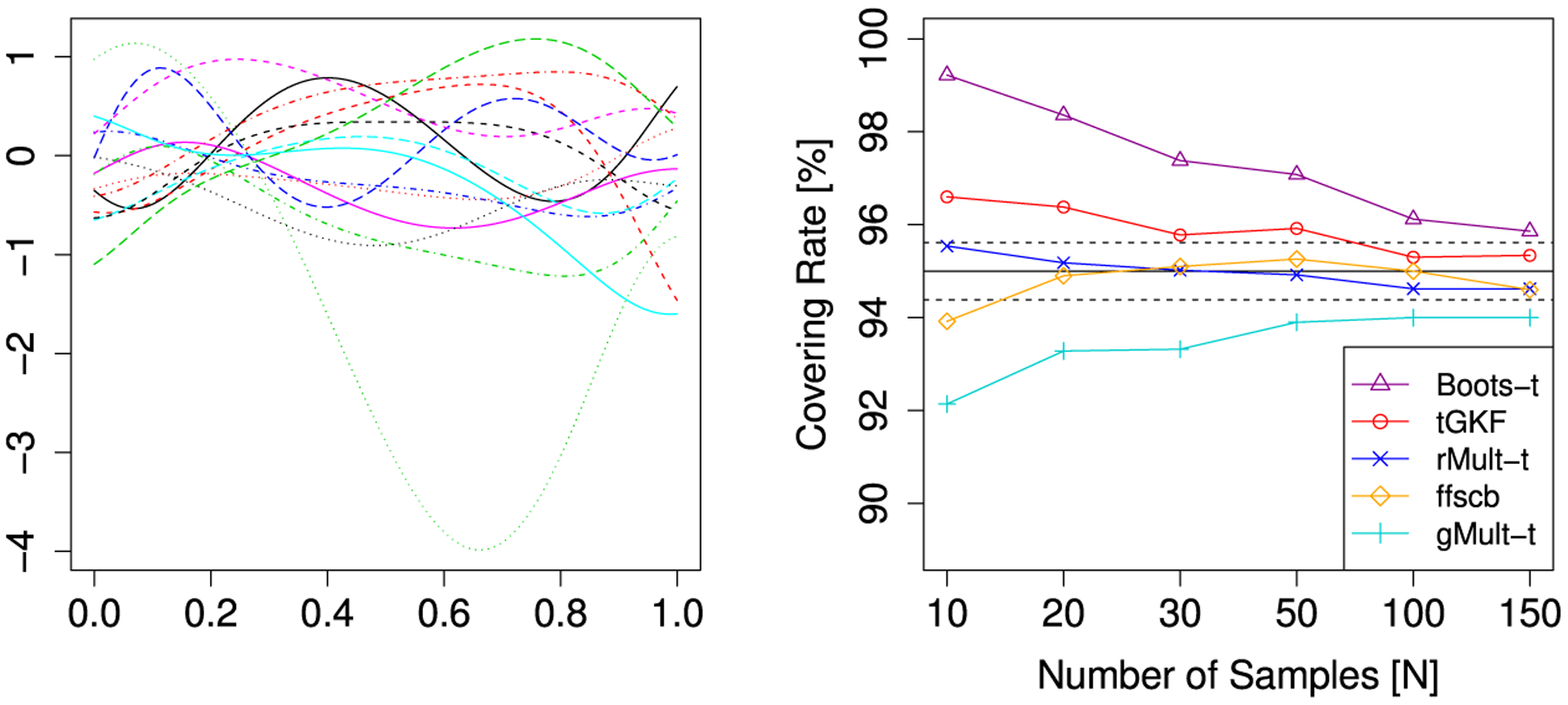
Simulation results for smooth non Gaussian fields (Model A). Left: samples from the error fields. Right: simulated covering rates. The solid black line is the targeted level of the SCBs and the dashed black line is twice the standard error for a Bernoulli random variable with p = 0.95.
Fig. 3.
Simulation results for smooth non Gaussian fields (Model B). Left: samples from the error fields. Right: simulated covering rates. The solid black line is the targeted level of the SCBs and the dashed black line is twice the standard error for a Bernoulli random variable with p = 0.95.
4.3. Average width and variance of different SCBs
An important feature of confidence bands is its pointwise width averaged over the domain and the variance of this average width over repeated experiments. It is preferable to have the smallest possible width that still has the correct coverage. Moreover, the width of a SCB should remain stable, meaning that its variance should be small.
Here we focus on the estimation of the quantile , which for all methods except for ffscb is closely related to the width of the confidence band averaged over the domain. We decided to present this estimate, since it can be compared to its theoretical value and is easier to interpret. We simulate estimates of the quantile obtained from different methods for the Gaussian Model B and the non-Gaussian Model B with ν = 7. The optimal quantile qα is simulated using a Monte-Carlo simulation with 50,000 replications. Since the ffscb method from the R-package ffscb is not based on the quantile qα we instead compute for this method
and report its average value over S. This quantity is comparable to the quantile from the other methods and closely related to the average width of the ffscb.
We compare ffscb from the R-package ffscb, Degras’ asymptotic method from the R-package SCBmeanfd, SCBs based on the GKF and the tGKF, the non-parametric bootstrap-t, multiplier-t, non parametric bootstrap and a simple multiplier bootstrap. Here the latter two methods use the variance of the original sample instead of its bootstrapped version, compare Appendix A.
Tables 2 and 3 show the simulation results. We can draw two main conclusions from these tables. First, the tGKF method has the smallest standard deviation among the compared methods in the quantile while still having good coverage (at least asymptotically in the non-Gaussian case). Second, the main competitor – the bootstrap-t – has a much higher standard error in the width, but its coverage converges faster in the highly non-Gaussian and asymmetric case. This shows that the tGKF method is the most stable among the compared methods.
Table 2.
Bias of average estimate of and twice its standard error for different methods of SCBs and the Gaussian Model B. The simulations are based on 1000 Monte Carlo simulations.
| N | 10 | 20 | 30 | 50 | 100 | 150 |
|---|---|---|---|---|---|---|
| true | 4.118 | 3.382 | 3.211 | 3.081 | 2.993 | 2.960 |
| tGKF | −0.140 ± 0.033 | −0.016 ± 0.011 | −0.008 ± 0.007 | +0.003 ± 0.004 | +0.007 ± 0.002 | +0.013 ± 0.001 |
| GKF | −1.190 ± 0.016 | −0.459 ± 0.008 | −0.289 ± 0.005 | −0.159 ± 0.003 | −0.072 ± 0.002 | −0.039 ± 0.001 |
| Degras | −1.252 ± 0.021 | −0.500 ± 0.011 | −0.324 ± 0.007 | −0.191 ± 0.005 | −0.100 ± 0.003 | −0.063 ± 0.003 |
| Boots | −1.427 ± 0.023 | −0.569 ± 0.012 | −0.360 ± 0.010 | −0.202 ± 0.007 | −0.096 ± 0.005 | −0.058 ± 0.004 |
| Boots-t | + 1.701 ± 0.604 | +0.226 ± 0.050 | +0.083 ± 0.019 | +0.027 ± 0.009 | +0.006 ± 0.005 | +0.010 ± 0.004 |
| gMult | −1.121 ± 0.159 | −0.460 ± 0.031 | −0.297 ± 0.016 | −0.168 ± 0.009 | −0.080 ± 0.005 | −0.048 ± 0.004 |
| gMult-t | −0.688 ± 0.046 | −0.292 ± 0.017 | −0.200 ± 0.011 | −0.121 ± 0.007 | −0.060 ± 0.005 | −0.035 ± 0.004 |
| rMult | −1.428 ± 0.179 | −0.616 ± 0.032 | −0.403 ± 0.015 | −0.232 ± 0.009 | −0.111 ± 0.005 | −0.067 ± 0.004 |
| rMult-t | −0.018 ± 0.122 | −0.000 ± 0.023 | −0.009 ± 0.013 | −0.003 ± 0.008 | +0.001 ± 0.005 | +0.005 ± 0.004 |
| ffscb | −0.530 ± 0.055 | −0.181 ± 0.027 | −0.111 ± 0.018 | −0.057 ± 0.013 | −0.022 ± 0.009 | −0.048 ± 0.007 |
Table 3.
Bias of average estimate of and twice its standard error for different methods of SCBs and the non-Gaussian Model B with ν = 7. The simulations are based on 1000 Monte Carlo simulations.
| N | 10 | 20 | 30 | 50 | 100 | 150 |
|---|---|---|---|---|---|---|
| true | 4.532 | 3.628 | 3.373 | 3.190 | 3.048 | 3.004 |
| tGKF | −0.558 ± 0.040 | −0.262 ± 0.014 | −0.170 ± 0.008 | −0.106 ± 0.004 | −0.048 ± 0.002 | −0.031 ± 0.001 |
| GKF | −1.606 ± 0.019 | −0.705 ± 0.010 | −0.451 ± 0.006 | −0.268 ± 0.004 | −0.127 ± 0.002 | −0.083 ± 0.001 |
| Degras | −1.666 ± 0.022 | −0.749 ± 0.011 | −0.488 ± 0.008 | −0.301 ± 0.005 | −0.156 ± 0.003 | −0.108 ± 0.003 |
| Boots | −1.835 ± 0.025 | −0.809 ± 0.013 | −0.516 ± 0.010 | −0.307 ± 0.007 | −0.147 ± 0.005 | −0.099 ± 0.004 |
| Boots-t | + 1.618 ± 0.699 | +0.218 ± 0.098 | +0.080 ± 0.042 | +0.023 ± 0.016 | +0.006 ± 0.006 | +0.001 ± 0.004 |
| gMult | −1.471 ± 0.205 | −0.703 ± 0.036 | −0.457 ± 0.018 | −0.278 ± 0.009 | −0.135 ± 0.005 | −0.091 ± 0.004 |
| gMult-t | −1.104 ± 0.047 | −0.544 ± 0.018 | −0.371 ± 0.012 | −0.240 ± 0.008 | −0.128 ± 0.005 | −0.090 ± 0.004 |
| rMult | −1.763 ± 0.234 | −0.870 ± 0.039 | −0.574 ± 0.018 | −0.352 ± 0.009 | −0.175 ± 0.005 | −0.116 ± 0.004 |
| rMult-t | −0.422 ± 0.133 | −0.278 ± 0.027 | −0.194 ± 0.015 | −0.130 ± 0.009 | −0.064 ± 0.005 | −0.044 ± 0.004 |
| ffscb | −0.947 ± 0.053 | −0.427 ± 0.026 | −0.274 ± 0.018 | −0.166 ± 0.013 | −0.077 ± 0.008 | −0.092 ± 0.006 |
4.4. The influence of observation noise
In order to study the influence of observation noise, we evaluate the dependence of the covering rate of the smoothed mean of a signal-plus-noise model with added i.i.d. Gaussian observation noise on the bandwidth used in a local linear smoother (Degras, 2011) and the standard deviation of the observation noise. For the simulations we generate samples from the Gaussian Model A and Model B on an equidistant grid of [0, 1] with 100 points and add -distributed independent observation noise with σ ∈ {0.02, 0.1, 0.2}. Afterwards we smooth the samples with a Gaussian kernel with bandwidths h ∈ {0.02, 0.03, 0.05, 0.1}. The smoothed curves are evaluated on an equidistant grid with 400 points. The results of these simulations are shown in Figs. 4 and 5. In most cases the nominal covering is achieved independent of N. Only for small smoothing bandwidths and large standard deviation of the observation errors a slight overcoverage is present. This might be a problem with the estimation of LKCs, since they depend on numerical derivatives of the sample paths, which are in these particular scenarios highly variable.
Fig. 4.
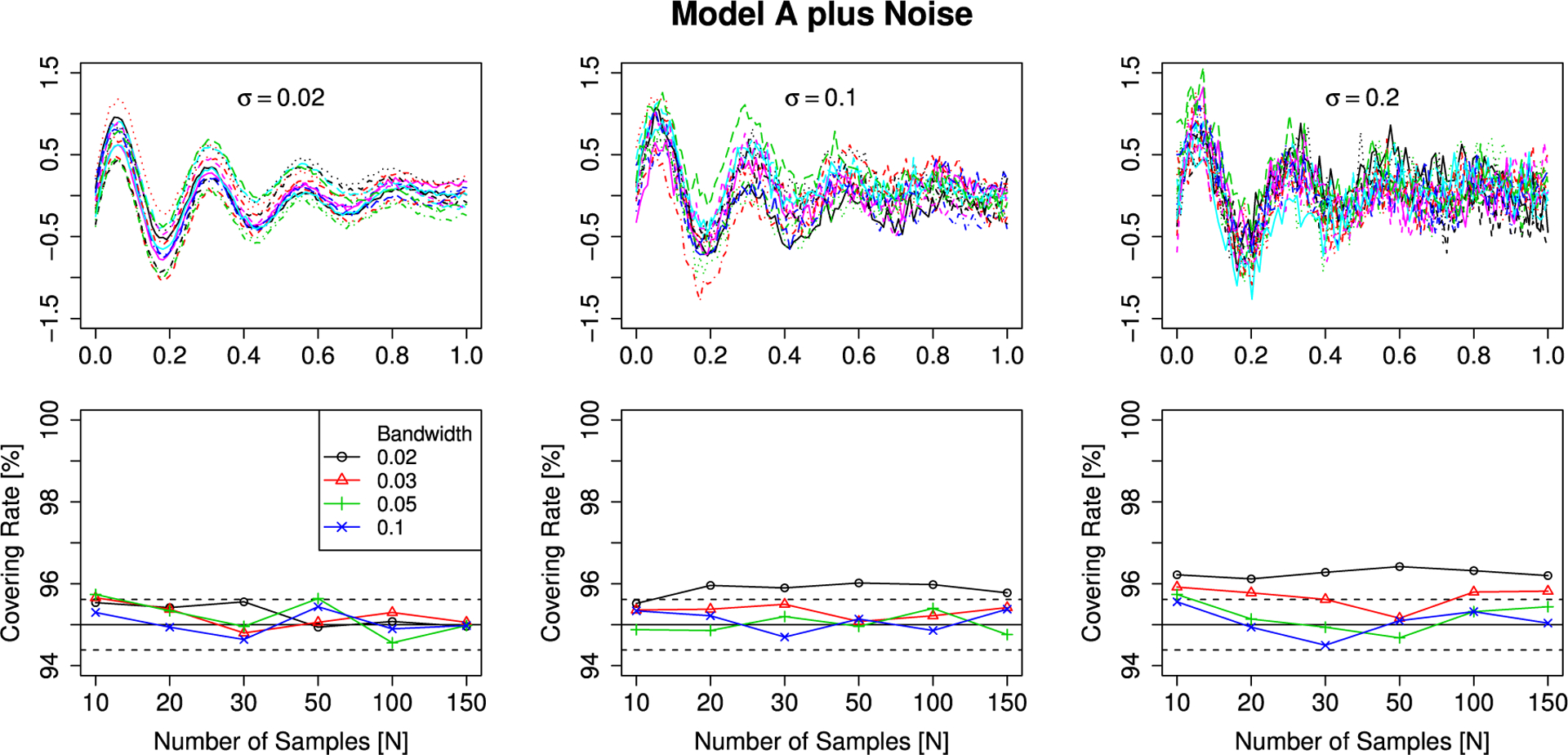
Simulation results for Gaussian fields (Model A) with observation noise. Top row: samples from the error fields. Bottom row: simulated covering rates. The solid black line is the targeted level of the SCBs and the dashed black line is twice the standard error for a Bernoulli random variable with p = 0.95.
Fig. 5.
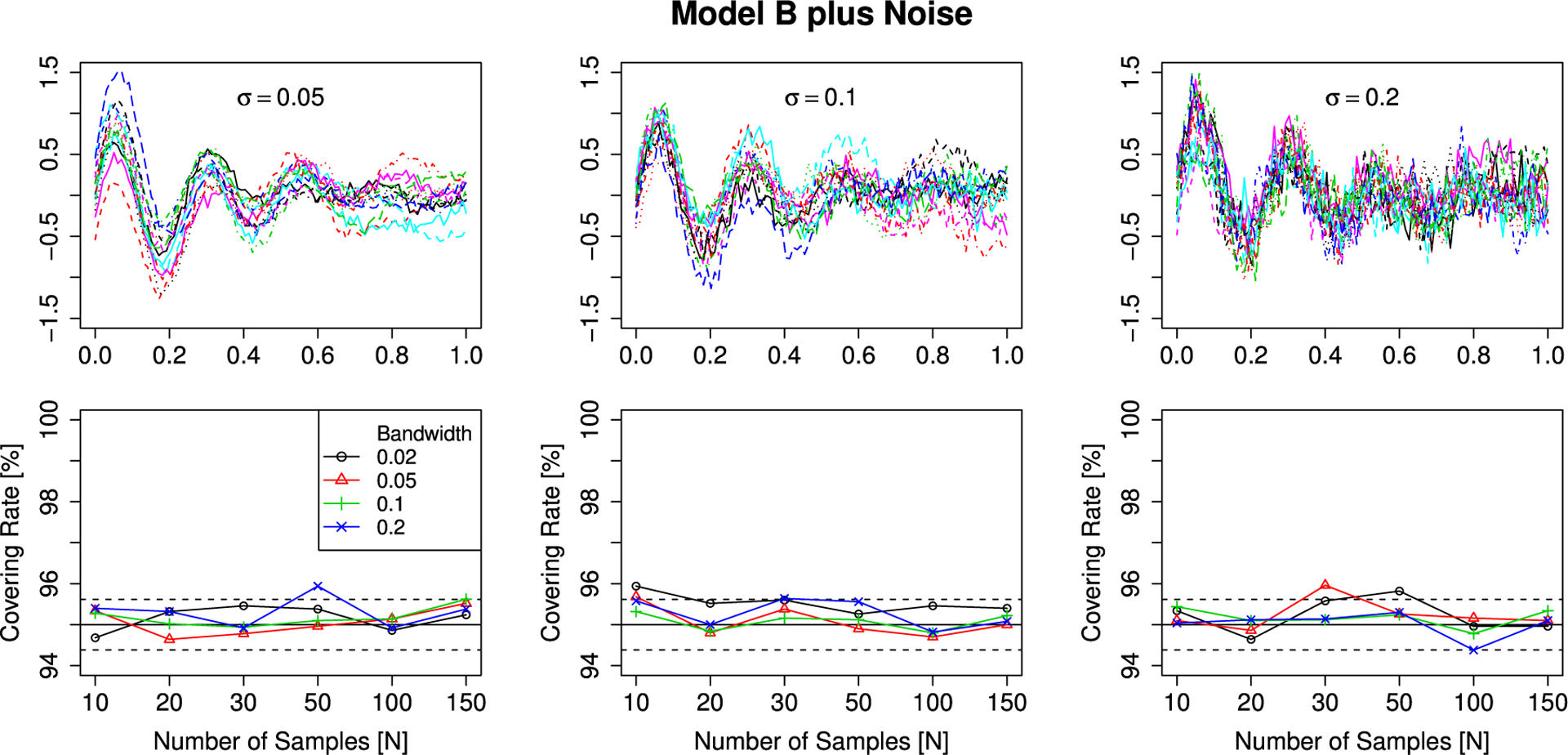
Simulation results for Gaussian fields (Model B) with observation noise. Top row: samples from the error fields. Bottom row: simulated covering rates. The solid black line is the targeted level of the SCBs and the dashed black line is twice the standard error for a Bernoulli random variable with p = 0.95.
We also study the covering rate of the population mean of the scale space field of Model B. The generation of the samples is the same as for the previous simulations. The only difference is that instead of smoothing with one bandwidth we construct the scale space field. Here we use a equidistant grid of 100 points of the interval [0.02, 0.1]. The results can be found in Fig. 6 and show that the covering rate of the tGKF SCB is close to nominal.
Fig. 6.
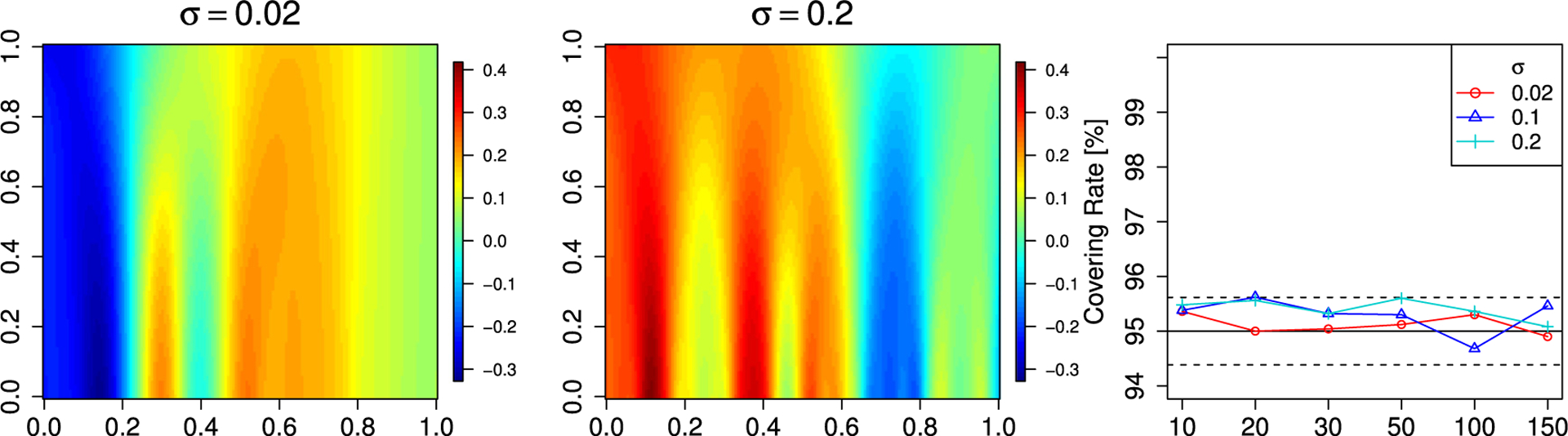
Simulation results for the scale space field from the Gaussian fields of Model B with added observation noise. Left two panels: samples from the error fields. Right panel: simulated covering rates. The solid black line is the targeted level of the SCBs and the dashed black line is twice the standard error for a Bernoulli random variable with p = 0.95.
4.5. SCBs for the difference of population means of two independent samples
Since the single sample scenario was studied in great detail, we only present the case of one dimensional smooth Gaussian noise fields in the two sample scenario. Moreover, we only report the results for the tGKF approach. The previous observations regarding the other methods carry over to this scenario.
The simulations are designed as follows. We generate two samples of sizes N and M such that N/M = c ∈ {1, 2, 4}. We are interested in four different scenarios. The first scenario is the most favorable having the same correlation structure and the same variance function. Here we use for both samples the Gaussian Model A from Section 4.1. In all remaining scenarios one of the samples will always be this error field. In order to check the effect of the two samples having different correlation structures, we use Gaussian Model B as the second sample from Section 4.1. For dependence on the variance, while the correlation structure is the same, we change the variance function in the Gaussian Model A to σ2(s) = 0.04 for the second sample. As an example field where both the correlation and the variance are different we use Gaussian Model B with the modification that the error field has pointwise variance σ2(s) = 0.04. The results of these simulations are shown in Fig. 7 and show that, except for very unbalanced sample sizes between the two groups, the covering rate of the tGKF SCB is close to nominal.
Fig. 7.
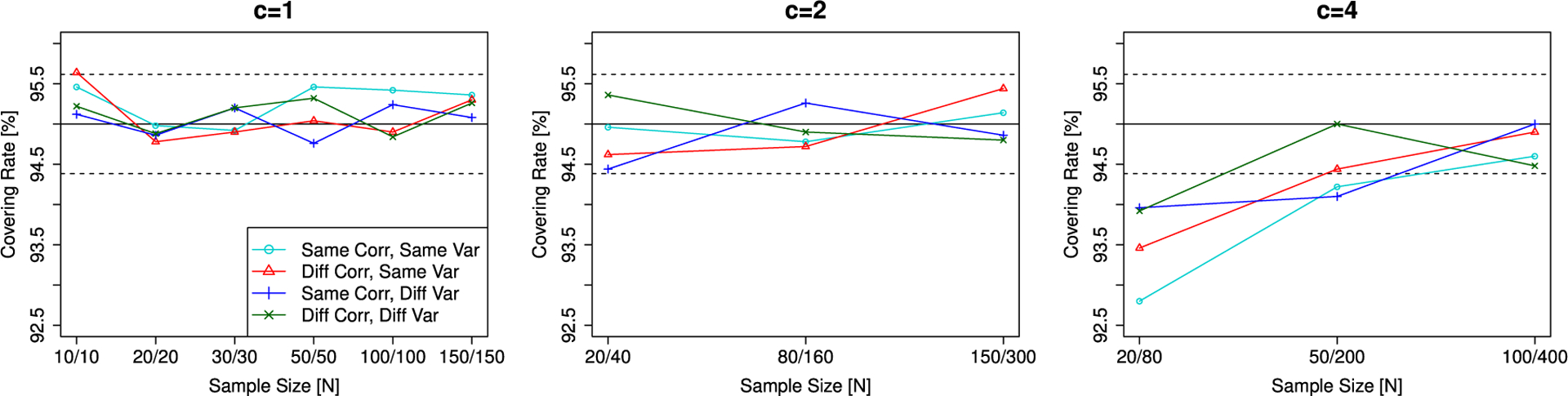
Simulation results for the SCBs of the difference between mean curves of two samples of smooth Gaussian fields for varying c = M/N. The solid black line is the targeted level of the SCBs and the dashed black line is twice the standard error for a Bernoulli random variable with p = 0.95.
5. Applications
5.1. DTI fibers
Our first data example (1D) concerns the impact of the eating disorder anorexia nervosa on white-matter tissue properties during adolescence in young females. The experimental setup and a different methodology to statistically analyze the data using pointwise testing and permutation tests can be found in the original article (Travis et al., 2015). The data set consists of a control group of 15 healthy subjects and 15 patients. For each subject 27 different neural fibers were extracted. The data for each fiber consists of fractional anisotropy values sampled on an equidistant grid of length 100.
In order to locate differences in the DTI fibers between the two groups, we computed for each fiber defined on the domain S = [0, 100] the two-sample 95%-SCBs for the difference of the population mean of the control group and the patients as explained in Section 3. Robustness of detected differences across scales is tested by computing the SCBs for the corresponding scale space fields, see Section 3. For the latter we used a Gaussian smoothing kernel and the considered bandwidth range was sampled at 200 equidistant bandwidths.
The results for the three fibers for which we find significant differences are shown in Fig. 8. Our results are mostly consistent with the results from Travis et al. (2015) in the sense that both approaches find significant differences at similar locations in the right thalamic radiation and the left superior longitudinal fasciculus (SLF). Additionally, SCBs detect significant differences in the right cingulum hippocampus. Travis et al. (2015) claim further significant findings. However, these belong to criteria, which do not take simultaneous testing along the fibers into account. Therefore SCBs might not be able to detect them, since they correct for multiplicity along the fiber.
Fig. 8.
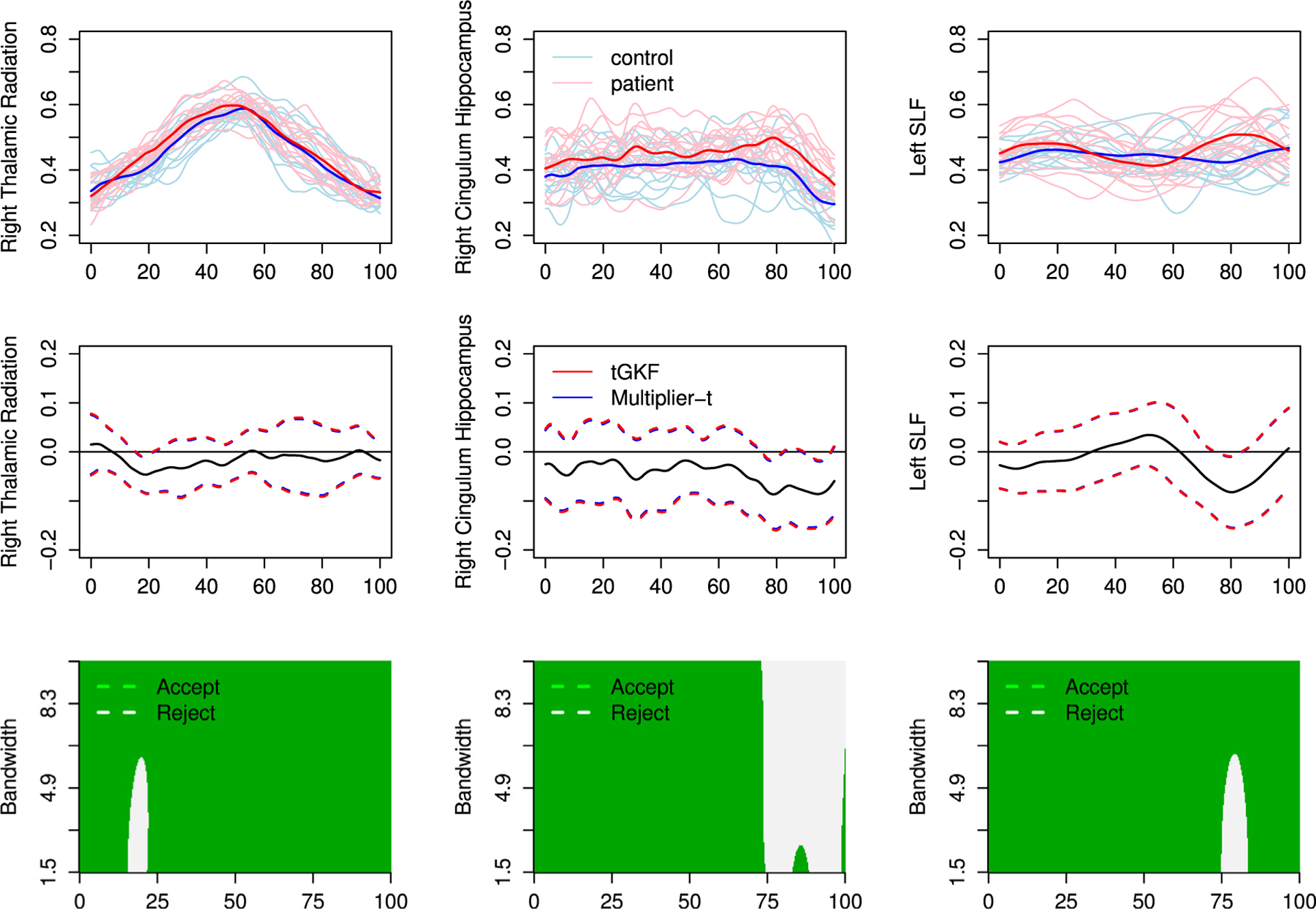
DTI fibers with significant differences in the mean function. Top row: data and sample means. Middle row: estimated difference of the mean function and 95%-SCBs constructed using the tGKF and the Multiplier-t. Bottom row: areas where the confidence bands for the difference in the mean function for the scale field do not include 0.
5.2. Climate data
Our second data example (2D) concerns the change in temperature over North America within the next century. The data was obtained from the North American Regional Climate Change Assessment Program (NARCCAP) project (Mearns et al., 2013). It consist of two sets of 29 spatially registered arrays of mean seasonal temperatures for summer (June–August) and winter (December–February) evaluated at a fine grid of fixed locations 0.5 degrees apart in geographic longitude and latitude over the time periods 1971–1999 and 2041–2069. Sommerfeld et al. (2018) analyzed this data set with the aim to detect regions at risk of exceeding a 2 °C temperature increase. To complement their analysis, we use their model and data processing and provide 90% SCBs for the estimated difference of mean temperatures between the two time periods assuming that the two samples have the same covariance structure.
Our results are shown in Fig. 9. From the 2 °C contour lines (yellow) of the lower bound for the SCBs we conclude that there is likely an increase of at least 2 °C in the time period 2041–2069 compared to 1971–1999 during the summer months in the region of the Rocky Mountains and the Sierra Madre Occidental mountains of Mexico, since in this region the lower bound of the SCBs is here larger than 2 °C. Similarly we obtain that for mean winter temperatures, small regions around the Hudson Bay and in the Canadian Shield are at risk of having an increase of more than 2 °C. The area enclosed by the 2 °C contour lines for the upper bound of the SCBs show that during summer large areas in Canada and Alaska as well as smaller patches at the Hudson Bay and the Gulf of Mexico are not at risk experiencing an temperature increases of more than 2 °C. For winter mean temperature there are only small regions for which we are certain that the temperature does not rise above 2 °C.
Fig. 9.
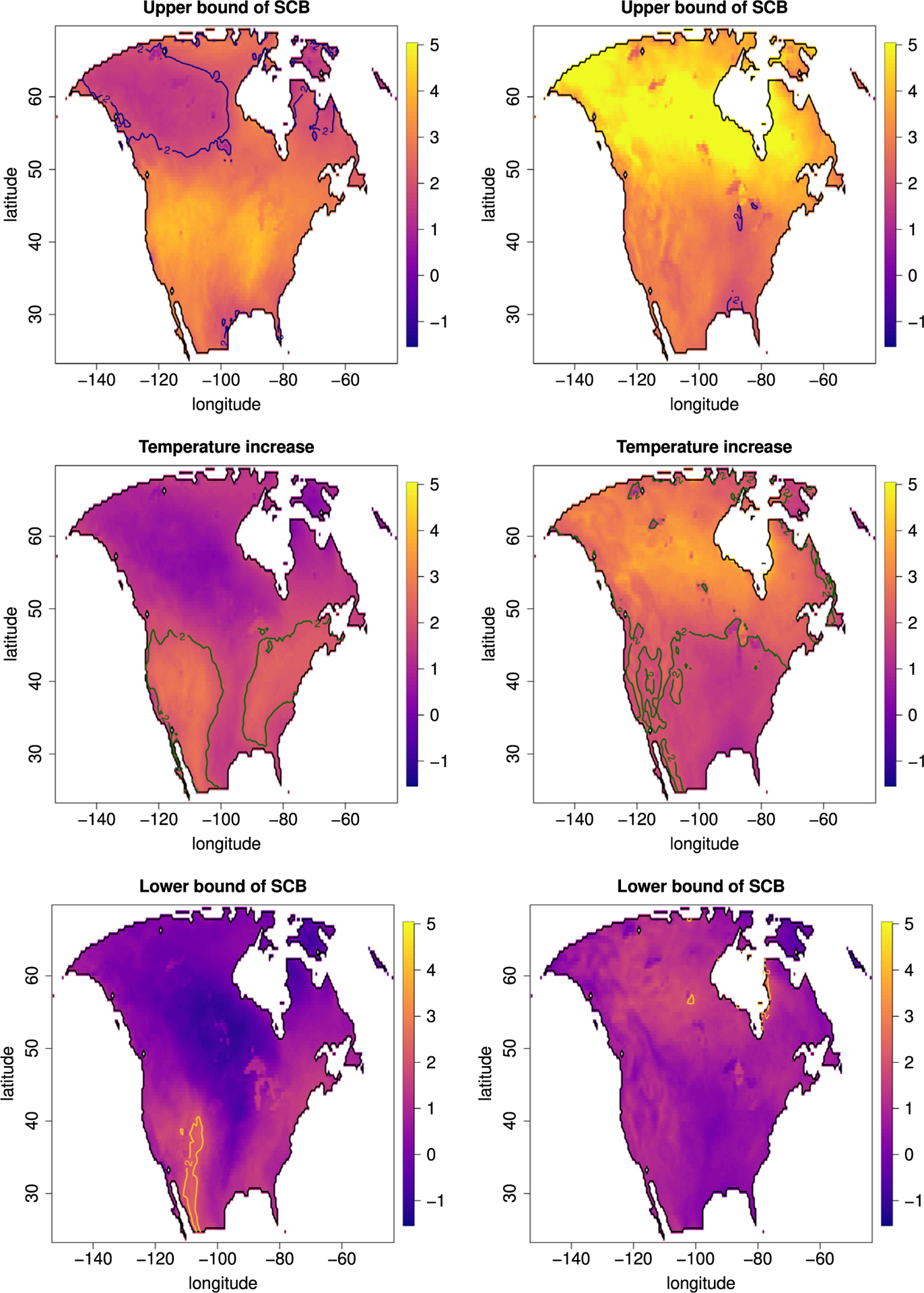
Visualization of the difference of mean temperatures in summer (left) and winter (right) of the time periods 2041–2069 and 1971–1999. To visualize regions at risk to experience an increase of more than 2 °C we report in each figure the 2 °C contour line. Top row: upper bound of the SCBs. Middle row: point estimate. Bottom row: lower bound of SCBs.
The aforementioned areas within the contour lines of the lower and upper bounds of the SCBs are similar to the COverage Probability Excursion (CoPE) sets introduced in Sommerfeld et al. (2018). CoPE sets are a pair of data driven random sets, for which completely contains with a preset probability the true excursion set, while the set is completely contained in the true excursion set.
The interior of the yellow contour lines, i.e., thresholding of the lower bound of the SCB yields a set similar to , while thresholding the upper bound can be compared to . In fact, we believe thresholding SCBs can be interpreted as conservative CoPE sets, explaining why our analysis is comparable to the results in Sommerfeld et al. (2018). Exploring this connection between CoPE sets and SCBs will be future research.
Acknowledgments
F.T. and A.S. were partially supported by NIH grant R01EB026859. F.T. thanks the WIAS Berlin for its hospitality where parts of the research for this article was performed. We also thank Samuel Davenport for proofreading the manuscript and spotting an error in the proof of Theorem 2.
This work was partially funded by National Institute of Health, USA grant R01EB026859.
Appendix A. Bootstrap methods
Parametric bootstrap-t for qα,N (Degras, 2011).
Assume that the estimators and are obtained from a sample of random functions, then the parametric bootstrap-t estimator of qα,N is obtained as follows:
Resample from Y1, … , YN with replacement to produce a bootstrap sample .
Compute and using the sample .
Compute .
Repeat steps 1 to 3 many times to approximate the conditional law and take the (1 − α) · 100% quantile of to estimate qα,N.
Remark 8.
Note that the variance in the denominator is also bootstrapped, which corresponds to the standard bootstrap-t approach for confidence intervals, cf. DiCiccio and Efron (1996). This is done in order to mimic the l.h.s. in (1) and improves the small sample coverage.
According to our simulations in Section 4 this estimator works well only for large enough sample sizes, although Degras (2011) introduced it especially for small sample sizes. Moreover, it is well known that confidence intervals for finite dimensional parameters based on the bootstrap-t have highly variable end points for small sample sizes, cf., Good (2005, Section 3.3.3). Evidence that this remains the case in the functional world is provided in Tables 2 and 3.
Multiplier-t bootstrap for qα,N.
The second bootstrap method builds on residuals and a version of the multiplier (or wild) bootstrap as introduced in Chang et al. (2017). Here we assume that we can construct residuals for n = 1, … , N satisfying and as N → ∞ uniformly almost surely. For example for the signal-plus-noise model the residuals do satisfy these conditions, if the error field Z is -Lipshitz and has finite second -moment. Here as before and denote the pointwise sample mean and the pointwise sample standard deviation. Algorithmically, the multiplier bootstrap estimates qα,N are as follows:
Compute residuals and multipliers with and var[g] = 1
Compute , i.e. the sample standard deviation of .
Compute .
Repeat steps 1 to 3 many times to approximate the conditional law and take the (1 − α) · 100% quantile of to estimate qα,N.
In our simulations we use Gaussian and Rademacher multipliers. The latter perform much better for small sample sizes than Gaussian multipliers. This is the reason why they probably have been used in Chang et al. (2017).
Appendix B. Proofs
B.1. Proof of Claim in Remark 1
Using the multivariate mean value theorem and the Cauchy–Schwarz inequality yields
Applying the expectation to both sides and then taking the maximum of the resulting sums we obtain
The proof follows now from the following two observations. Firstly, by Remark 3 each of the expectations we take the maximum of is finite (Landau and Shepp, 1970, Thm 5), since all components of the gradient of ∇G(d,l) are Gaussian fields with almost surely continuous sample paths. Secondly, |log‖x‖|−2 ≥ x2 for all 0 < x < 1.
B.2. Proof of Theorem 1
Lemma 9.
Let the function and its first derivative be uniformly consistent estimators of the function f(u) and its first derivative f′(u), respectively, where both are uniformly continuous over . Assume there exists an open interval I = (a, b) such that f is strictly monotone on I and there exists a unique solution u0 ∈ I to the equation f(u) = 0. Define . Then is a consistent estimator of u0.
Proof.
Assume w.l.o.g. that f is strictly decreasing on I. Thus, for any ε > 0 we have f(u0 − ε) > 0 > f(u0 + ε) by f(u0) = 0. The assumption that is a consistent estimator of f(u) yields
which implies that with probability tending to 1, there is a root of in I0,ε = (u0 − ε, u0 + ε). On the other hand the monotonicity of f guarantees the existence of an δ > 0 such that inf{|f(u)| : u ∈ I \ I0,ε } > δ. Moreover, by the uniform consistency of , we have that
Therefore, using the inequality
we can conclude that
which implies that with probability tending to 1, there is no root of outside I0,ε. Hence from the definition of , it is clear that is the only root of in I with probability tending to 1. As an immediate consequence we have that
which finishes the proof that is a consistent estimator of u0.
Lemma 10.
Let be a consistent estimator of Ld and EECG(u) given in Eq. (7).
almost surely.
almost surely.
Proof.
Part 1.:
This is a direct consequence of the consistency of the LKC estimates and the observation that the EC densities ρtν of a tν-field with ν = N − 1 degrees of freedom converges uniformly to the EC densities of a Gaussian field ρG as N tends to infinity, i.e.
The latter follows from Worsley (1994, Theorem 5.4), which implies that the uniform convergence of EC densities is implied by the uniform convergence of
To see this, note that the distance
fulfills limu→ ± ∞ hν(u) = 0. Thus, there is a by continuity of hν. Moreover, note that hν(u) ≥ hν+1(u) for ν ≥ 1, all and limν→∞ hν(u) = 0. Hence, Cν converges to zero for ν → ∞.
Part 2.:
This follows similar by the same arguments as above applied to the derivatives of the EC densities.
Proof of Theorem 1.
In order to prove the almost sure convergence , note that for u large enough u ↦ EECG(u) is strictly monotonically decreasing and therefore combining Lemmas 9 and 10 yields the claim.
B.3. Proof of Theorem 2
By Taylor et al. (2005, Theorem 4.3) we have for a zero-mean Gaussian field over a parameter set that
where is a variance depending on an associated field to . This implies that there is a such that for all we have that
| (19) |
Equipped with this result using the definition M = maxs∈S G(s) and |M| = maxs∈S|G(s)| we compute
Here II converges to zero for N tending to infinity by the fCLT for and the consistent estimation of from (E1–2). Therefore it remains to treat I.
To deal with this summand, note that
where the Gaussian random field over , where S0 = {1, −1}, is defined by .
Using the above equality, , i.e. the definition of our estimator from Eq. (6) and Lemma 10 we have that
Thus, using the fact that and (19) and the observation that is monotonically increasing in α for α small enough, we can bound I by
for all α smaller than some α′, which finishes the proof.
Remark 9.
The specific definition of σc associated with the Gaussian field can be found in Taylor et al. (2005).
B.4. Proof of Proposition 1
Assume that Z is -Lipshitz, then using convexity of |·|p we compute
Hence Z has also a finite pth -moment.
B.5. Proofs of Theorems 3 and 4
The following Lemma provides almost sure uniform convergence results and will be used often in the following proofs.
Lemma 11.
Assume that and are -Lipshitz, Then uniformly almost surely. If X and Y are -Lipshitz, then uniformly almost surely.
Proof.
First claim:
Using the generic uniform convergence result in Davidson (1994, Theorem 21.8), we only need to establish strong stochastical equicontinuity (SSE) of the random function , since pointwise convergence is obvious by the SLLNs. SSE, however, can be easily established using Davidson (1994, Theorem 21.10 (ii)), since
for all s, s′ ∈ S. Here denote the random variables from the -Lipshitz property of the Xn’s and X and hence the random variable CN converges almost surely to the constant by the SLLNs.
Second claim:
Adapting the same strategy as above and assuming w.l.o.g. , we compute
where and denote the random variables from the -Lipshitz property of the Yn’s and Y. Again by the SLLNs the random Lipshitz constant converges almost surely and is finite, since X and Y have finite second -moments and are -Lipshitz.
Lemma 12.
Let be a covariance function. Then
- If is continuous and has continuous partial derivatives up to order K, then the zero-mean Gaussian field with covariance has -sample paths with almost surely uniform and absolutely convergent expansions
where λi, φi are the eigenvalues and eigenfunctions of the covariance operator of Z and are i.i.d. . If Z and all its partial derivatives ZI with |I| = K′ ≤ K, , are -Lipshitz fields with finite -variances, then is continuous and all partial derivatives for |I|, |I′| ≤ K exist and are continuous for all s, s′ ∈ S.
Proof.
- Since is continuous the field G is mean-square continuous. Hence there is a Karhunen–Loéve expansion of the form
with λi, φi are the eigenvalues and eigenfunctions of the covariance operator associated with and are i.i.d. . From Ferreira and Menegatto (2012, Theorem 5.1) we have that . Moreover, it is easy to deduce from their equation (4.3) that
is almost surely absolutely and uniformly convergent. - The continuity is a simple consequence of the -Lipshitz property and the finite -variances. Let X be a field with these properties, then using the Cauchy–Schwarz inequality
for some C < ∞ and therefore and the covariances of ZI are continuous. We only show that exists and is continuous. The argument is similar for the higher partial derivatives. From the definition we obtain for all s, s′
where ed denotes the dth element of the standard basis of . Thus, we only have to prove that we can interchange limits and integration. The latter is an immediate consequence of Lebesgue’s dominated convergence theorem, where we obtain the majorant from the -Lipshitz property as AZ(s′), where .
Proof of Theorem 3.
Since Z is -Lipshitz the main result in Jain and Marcus (1975) immediately implies (E1) with and . Condition (E2) is obtained from the second part of Lemma 11, since σ(s)Z(s) is -Lipshitz and has finite second -moment.
We only need to show that the Gaussian limit field with the covariance fulfills (G1) and (G3). Note that condition (G3) is a consequence of (G1) and the -sample paths by Remark 1. But (G1) is already a consequence of Lemma 12.
Lemma 13.
Let Z fulfill the assumptions of Theorem 3(ii) except for (G2) and for all d, l ∈ {1, … , D} suppose that cov [(Z(d)(s), Z(d,l)(s))] has full rank for all s. Then fulfills (G2).
Proof.
Using the series expansions from Lemma 12 we have that for multi-indices I1, … , IK, and all it follows that
is convergent for all s (even uniformly). Note that we used here that the expansions are absolutely convergent such that we can change orders in the infinite sums. Thus, it is easy to deduce that (GIk, … , GIk) is a Gaussian field.
Therefore (G(d)(s), G(d,l)(s)) is a multivariate Gaussian random variable for all s ∈ S, which is non-degenerate if and only if its covariance matrix is non-singular. But this is the case by the assumption, since it is identical to the covariance matrix cov [(Z(d)(s), Z(d,l)(s))].
Proof of Theorem 4.
The proof is almost identical to the proof of Theorem 3 and therefore omitted.
B.6. Proof of Theorem 5
First note that using the definition of Rn from Eq. (13) we obtain
Thus, the entries of the sample covariance matrix are given by
| (20) |
Now, the second part of Lemma 11 applied to Z, Z(d) and Z(l) and the fact that by
| (21) |
| (22) |
the terms involving σ’s convergence uniformly almost surely to one and zero by Lemma 11 implies
uniformly almost surely. Thus, uniformly almost surely.
Now let X, Y be -Lipshitz, then
with A, B the random variables in the -Lipshitz property of Y, X. Note that
by (a + b)2 ≤ 2a2 + 2b2 for all a, and the Cauchy–Schwarz inequality. Thus, a sample fulfills the assumptions for the CLT in given in Jain and Marcus (1975). Therefore, the following sums converge to a Gaussian field in :
Thus, using the latter together with Eq. (20) and the uniform almost sure convergence from (21) and (22), we obtain
with . This combined with the standard multivariate CLT yields the claim.
B.7. Proof of Theorem 7
By Theorem 5 the claim follows from the functional delta method (Kosorok, 2008, Theorem 2.8), if we prove that the corresponding functions are Hadamard differentiable and can compute this derivative.
Case 1D:
We have to prove that the function
is Hadamard differentiable. Therefore, note that the integral is a bounded linear operator and hence it is Fréchet differentiable with derivative being the integral itself. Moreover, is Hadamard differentiable by Kosorok (2008, Lemma 12.2) with Hadamard derivative tangential even to the Skorohod space D(S). Combining this, we obtain the limit distribution from the fCLT for given in Theorem 5 to be distributed as
where G(s) is the asymptotic Gaussian field given in Theorem 5.
Case 2D:
The strategy of the proof is the same as in 1D, i.e. we need to calculate the Hadamard (Fréchet) derivative of
The arguments are the same as before. Thus, using the chain rule and derivatives of matrices with respect to their components the Hadamard derivative evaluated at the field G is given by
B.8. Proof of Corollary 1
Note that it is well-known that the covariance function of the derivative of a differentiable field with covariance function is given by . Moreover, using the moment formula for multivariate Gaussian fields we have that
Combining this with the observation that the variance of the zero mean Gaussian random variable is given by
yields the claim.
B.9. Proof of Theorem 8
We want to apply Pollard (1990, Theorem 10.6). Therefore, except for the indices we adapt the notations of that theorem and define the necessary variables. Recall that maxs∈S σ(s) ≤ B < ∞. We obtain
We have to establish the assumptions (i), (iii) and (iv) as (v) is trivially satisfied in our case and (ii) is Assumption (18). As discussed in Degras (2011, p.1759) the manageability (i) follows from the inequality
if ‖(s, h) − (s′, h′)‖ < ϵ1/α. Assumption (iii) follows since we can compute
and (iv) is due to
for all ϵ > 0, which follows from the convergence theorem for integrals with monotonically increasing integrands and the fact that by Markov’s inequality
| (23) |
for fixed ϵ > 0.
The weak convergence to a Gaussian field now follows from Pollard (1990, Theorem 10.6).
B.10. Proof of Proposition 2
The first step is to establish that for each N the field with -sample paths
has finite second -moment. Moreover, the constant is uniformly bounded over all N. Additionally, we require that the field itself and its first derivatives are -Lipshitz again uniformly over all N, since then the same arguments as in Lemma 11 will yield the consistency of the estimators of the LKCs from Theorem 6. Therefore, note that
This yields using (a + b)2 ≤ 2(a2 + b2) that
where the bound is independent of N. Basically, the same argument yields the -Lipshitz property for and all of its partial derivatives up to order 3 with a bounding random variable independent of N. The differentiability of the sample paths of the limiting Gaussian field follows again from Lemma 12(i).
Footnotes
CRediT authorship contribution statement
Fabian J.E. Telschow: Conceptualization, Methodology, Software.
References
- Adler RJ, 1981. The Geometry of Random Fields, Vol. 62. Siam. [Google Scholar]
- Adler RJ, Taylor JE, 2009. Random Fields and Geometry. Springer Science & Business Media. [Google Scholar]
- Belloni A, Chernozhukov V, Chetverikov D, Wei Y, 2018. Uniformly valid post-regularization confidence regions for many functional parameters in z-estimation framework. Ann. Statist 46 (6B), 3643. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bredon GE, 2013. Topology and Geometry, Vol. 139. Springer Science & Business Media. [Google Scholar]
- Bunea F, Ivanescu AE, Wegkamp MH, 2011. Adaptive inference for the mean of a Gaussian process in functional data. J. R. Stat. Soc. Ser. B Stat. Methodol 73 (4), 531–558. [Google Scholar]
- Cao G, Yang L, Todem D, 2012. Simultaneous inference for the mean function based on dense functional data. J. Nonparametr. Stat 24 (2), 359–377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cao G, et al. , 2014. Simultaneous confidence bands for derivatives of dependent functional data. Electron. J. Stat 8 (2), 2639–2663. [Google Scholar]
- Chang C, Lin X, Ogden RT, 2017. Simultaneous confidence bands for functional regression models. J. Statist. Plann. Inference 188, 67–81. [Google Scholar]
- Chaudhuri P, Marron JS, 1999. Sizer for exploration of structures in curves. J. Amer. Statist. Assoc 94 (447), 807–823. [Google Scholar]
- Chaudhuri P, Marron JS, 2000. Scale space view of curve estimation. Ann. Statist 408–428. [Google Scholar]
- Cuevas A, 2014. A partial overview of the theory of statistics with functional data. J. Statist. Plann. Inference 147, 1–23. [Google Scholar]
- Cuevas A, Febrero M, Fraiman R, 2006. On the use of the bootstrap for estimating functions with functional data. Comput. Statist. Data Anal 51 (2), 1063–1074. [Google Scholar]
- Davidson J, 1994. Stochastic Limit Theory: An Introduction for Econometricians. OUP Oxford. [Google Scholar]
- Degras DA, 2011. Simultaneous confidence bands for nonparametric regression with functional data. Statist. Sinica 21 (4), 1735–1765. [Google Scholar]
- Degras D, 2017. Simultaneous confidence bands for the mean of functional data. Wiley Interdiscip. Rev. Comput. Stat 9 (3). [Google Scholar]
- DiCiccio TJ, Efron B, 1996. Bootstrap confidence intervals. Statist. Sci 189–212. [Google Scholar]
- Ferraty F, Vieu P, 2006. Nonparametric Functional Data Analysis: Theory and Practice. Springer Science & Business Media. [Google Scholar]
- Ferreira JC, Menegatto VA, 2012. Reproducing properties of differentiable Mercer-like kernels. Math. Nachr 285 (8–9), 959–973. [Google Scholar]
- Flegg G, 2001. From Geometry to Topology. Courier Corporation. [Google Scholar]
- Good PI, 2005. Permutation, Parametric and Bootstrap Tests of Hypotheses: A Practical Guide to Resampling Methods for Testing Hypotheses. Springer Science & Business Media. [Google Scholar]
- Goresky M, MacPherson R, 1988. Stratified morse theory. In: Stratified Morse Theory. Springer, pp. 3–22. [Google Scholar]
- Hall P, Müller H-G, Wang J-L, 2006. Properties of principal component methods for functional and longitudinal data analysis. Ann. Statist 1493–1517. [Google Scholar]
- Jain NC, Marcus MB, 1975. Central limit theorems for C (S)-valued random variables. J. Funct. Anal 19 (3), 216–231. [Google Scholar]
- Johansen S, Johnstone IM, 1990. Hotelling’s theorem on the volume of tubes: some illustrations in simultaneous inference and data analysis. Ann. Statist 18 (2), 652–684. [Google Scholar]
- Kiebel SJ, Poline J-B, Friston KJ, Holmes AP, Worsley KJ, 1999. Robust smoothness estimation in statistical parametric maps using standardized residuals from the general linear model. Neuroimage 10 (6), 756–766. [DOI] [PubMed] [Google Scholar]
- Kosorok MR, 2008. Introduction to Empirical Processes and Semiparametric Inference. Springer. [Google Scholar]
- Krivobokova T, Kneib T, Claeskens G, 2010. Simultaneous confidence bands for penalized spline estimators. J. Amer. Statist. Assoc 105 (490), 852–863. [Google Scholar]
- Landau H, Shepp LA, 1970. On the supremum of a Gaussian process. Sankhyā 369–378. [Google Scholar]
- Ledoux M, Talagrand M, 2013. Probability in Banach Spaces: Isoperimetry and Processes. Springer Science & Business Media. [Google Scholar]
- Li Y, Hsing T, et al. , 2010. Uniform convergence rates for nonparametric regression and principal component analysis in functional/longitudinal data. Ann. Statist 38 (6), 3321–3351. [Google Scholar]
- Liebl D, Reimherr M, 2019. Fast and fair simultaneous confidence bands for functional parameters. arxiv preprint arXiv:1910.00131. [Google Scholar]
- Lu X, Kuriki S, 2017. Simultaneous confidence bands for contrasts between several nonlinear regression curves. J. Multivariate Anal 155, 83–104. [Google Scholar]
- Mearns L, Sain S, Leung L, Bukovsky M, McGinnis S, Biner S, Caya D, Arritt R, Gutowski W, Takle E, et al. , 2013. Climate change projections of the North American regional climate change assessment program (NARCCAP). Clim. Change 120 (4), 965–975. [Google Scholar]
- Pollard D, 1990. Empirical processes: theory and applications. In: NSF-CBMS Regional Conference Series in Probability and Statistics. JSTOR, pp. i–86. [Google Scholar]
- Ramsay JO, Silverman BW, 2007. Applied Functional Data Analysis: Methods and Case Studies. Springer. [Google Scholar]
- Sommerfeld M, Sain S, Schwartzman A, 2018. Confidence regions for spatial excursion sets from repeated random field observations, with an application to climate. J. Amer. Statist. Assoc 113 (523), 1327–1340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Takemura A, Kuriki S, 2002. On the equivalence of the tube and Euler characteristic methods for the distribution of the maximum of Gaussian fields over piecewise smooth domains. Ann. Appl. Probab 768–796. [Google Scholar]
- Taylor JE, 2006. A Gaussian kinematic formula. Ann. Probab 34 (1), 122–158. [Google Scholar]
- Taylor J, Takemura A, Adler RJ, 2005. Validity of the expected Euler characteristic heuristic. Ann. Probab 1362–1396. [Google Scholar]
- Taylor JE, Worsley KJ, 2007. Detecting sparse signals in random fields, with an application to brain mapping. J. Amer. Statist. Assoc 102 (479), 913–928. [Google Scholar]
- Telschow F, Schwartzman A, Cheng D, Pranav P, 2020. Estimation of expected Euler characteristic curves of nonstationary smooth Gaussian random fields. arxiv preprint arXiv:1908.02493. [Google Scholar]
- Travis KE, Golden NH, Feldman HM, Solomon M, Nguyen J, Mezer A, Yeatman JD, Dougherty RF, 2015. Abnormal white matter properties in adolescent girls with anorexia nervosa. NeuroImage: Clin 9, 648–659. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang J-L, Chiou J-M, Müller H-G, 2016. Functional data analysis. Annu. Rev. Stat. Appl 3, 257–295. [Google Scholar]
- Wang Y, Wang G, Wang L, Ogden RT, 2019. Simultaneous confidence corridors for mean functions in functional data analysis of imaging data. Biometrics. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Working H, Hotelling H, 1929. Applications of the theory of error to the interpretation of trends. J. Amer. Statist. Assoc 24 (165A), 73–85. [Google Scholar]
- Worsley KJ, 1994. Local maxima and the expected Euler characteristic of excursion sets of χ 2, F and t fields. Adv. Appl. Probab 26 (1), 13–42. [Google Scholar]
- Worsley KJ, Marrett S, Neelin P, Vandal AC, Friston KJ, Evans AC, et al. , 1996. A unified statistical approach for determining significant signals in images of cerebral activation. Hum. Brain Mapp 4 (1), 58–73. [DOI] [PubMed] [Google Scholar]
- Worsley KJ, Taylor JE, Tomaiuolo F, Lerch J, 2004. Unified univariate and multivariate random field theory. Neuroimage 23, S189–S195. [DOI] [PubMed] [Google Scholar]
- Zhang J-T, Chen J, et al. , 2007. Statistical inferences for functional data. Ann. Statist 35 (3), 1052–1079. [Google Scholar]
- Zhang X, Wang J-L, et al. , 2016. From sparse to dense functional data and beyond. Ann. Statist 44 (5), 2281–2321. [Google Scholar]