

Abstract
In long-term follow-up studies, data are often collected on repeated measures of multivariate response variables as well as on time to the occurrence of a certain event. To jointly analyze such longitudinal data and survival time, we propose a general class of semiparametric latent-class models that accommodates a heterogeneous study population with flexible dependence structures between the longitudinal and survival outcomes. We combine nonparametric maximum likelihood estimation with sieve estimation and devise an efficient EM algorithm to implement the proposed approach. We establish the asymptotic properties of the proposed estimators through novel use of modern empirical process theory, sieve estimation theory, and semiparametric efficiency theory. Finally, we demonstrate the advantages of the proposed methods through extensive simulation studies and provide an application to the Atherosclerosis Risk in Communities study.
MSC 2010 subject classifications: Primary 62N02; secondary 62G05, 62H30
Keywords and phrases: Censored data, Joint analysis, Mixture models, Nonparametric estimation, Sieve estimation
1. Introduction.
Many clinical and epidemiological studies generate data on repeated measures of response variables at multiple time points as well as on time to the occurrence of a clinical event. In cardiovascular cohort studies, for example, data are often recorded for both repeated measures of risk factors (e.g., blood pressures, cholesterol levels) and time to a cardiovascular event (e.g., stroke, heart attack) or death [5]. Shared random-effect models and joint latent-class models have been proposed to investigate the dynamic relationships among such longitudinal and survival data.
In shared random-effect models, a linear mixed model with a set of unobserved random effects is assumed for the longitudinal outcomes, and a proportional hazards model or transformation model with the same random effects as covariates is assumed for the survival time [4, 23, 18, 24, 8]. The shared random effects account for the dependence between the longitudinal and survival outcomes. These models typically assume that, conditional on the random effects, the distribution of the survival time and the effects of covariates on the longitudinal and survival outcomes are the same across subjects.
Joint latent-class models assume that the population consists of subgroups and within each subgroup, subjects have the same distributions of longitudinal and survival outcomes [14, 7]. These models allow the baseline risk of event and the association pattern between the longitudinal and survival outcomes to vary flexibly across subgroups. However, the existing work is mostly confined to fully parametric models. Lin et al. [6] proposed a semiparametric latent-class model with a nonparametric baseline hazard function for the survival time in each latent class but did not investigate the theoretical properties of the proposed nonparametric maximum likelihood estimators (NPMLE). In fact, such NPMLEs are inconsistent [12, 20]; see Section S1 of the supplementary materials [21].
We propose a general model for the joint analysis of multivariate longitudinal data and survival time. We assume that the population consists of a mixture of latent subgroups such that within each subgroup, the joint distribution of the longitudinal and survival outcomes is described by a separate random-effect model, in which the survival time is characterized by a separate nonparametric baseline hazard function. This model naturally extends those of Henderson, Diggle and Dobson [4] and Tsiatis and Davidian [18] by allowing the existence of latent subgroups. The model can be used to address important scientific questions:
Identification of latent subgroups within a heterogeneous study population;
Estimation of the effects of baseline covariates, such as treatment, on longitudinal and survival outcomes within each subgroup;
Evaluation of the event risk given baseline covariates and trajectories of longitudinal outcomes; and
Estimation of the association between the trajectories of longitudinal outcomes and covariates with proper adjustment of informative dropout due to the occurrence of the event.
The proposed modeling framework also extends existing work by accommodating multivariate longitudinal outcomes measured at multiple time points. This framework is particularly useful in cardiovascular studies, where multiple risk factors, such as blood pressures and cholesterol levels, are repeatedly measured. Including multivariate longitudinal outcomes not only provides a comprehensive depiction of the dynamic relationships among the event of interest and relevant risk factors but also helps identify the latent subgroup structure.
Due to the presence of multiple nonparametric components in the model and the lack of a closed-form expression for the likelihood function, model estimation is highly challenging both theoretically and computationally. To overcome the non-identifiability of the fully nonparametric likelihood approach, we propose to combine nonparametric likelihood estimation with sieve estimation, such that the cumulative hazard function of a reference latent class is estimated by a step function with jumps at the observed event times, and the ratios of the baseline hazard functions across latent classes are estimated by spline functions. We develop a stable and efficient (accelerated) EM algorithm [3] to compute the proposed estimators.
We prove that the proposed estimators are consistent and the parametric components of the estimators are asymptotically efficient. The derivations involve novel applications of empirical process theory, sieve estimation theory, and semiparametric efficiency theory. One major challenge in our theoretical development is to show that the proposed model is identifiable with an invertible information operator. Due to the presence of latent classes, techniques for establishing model identifiability or invertibility of the information operator for semiparametric shared random-effect models are not directly applicable to the current setting. In addition, existing methods for latent-class models are not readily applicable to semiparametric models. To establish model identifiability and the invertibility of the information operator, we note that the likelihood and the score function are the sums of the terms arising from the likelihood of semiparametric shared random-effect models and show that the terms in the summation can be separated by properly varying the observed data values.
The rest of this article is structured as follows. In Section 2, we formulate the model and describe the proposed estimation approach. In Section 3, we discuss the computation of the proposed estimators, and in Section 4, we present the theoretical results. In Section 5, we report the results from our simulation studies. In Section 6, we provide an application to the Atherosclerosis Risk in Communities (ARIC) study [5]. In Section 7, we make some concluding remarks. We relegate technical proofs to the Appendix.
2. Model, likelihood, and sieve estimation.
Suppose that there are G latent classes. Let C denote the latent class membership, with C = g if a subject belongs to the gth latent class (g = 1,…,G). We relate C to a set of time-independent covariates W, which generally includes the constant 1, through a multinomial logistic regression model:
| (1) |
where αg is the vector of class-specific regression parameters. For model identifiability, we set αG = 0. Each latent class is characterized by class-specific trajectories of multivariate longitudinal outcomes and a class-specific risk of the event of interest. The longitudinal outcomes and the event time are assumed to be conditionally independent given the latent class membership and a multivariate random effect.
Suppose that there are J types of longitudinal outcomes and the jth type is measured at Nj time points. For j = 1,…,J and k = 1,…,Nj, let Yjk denote the kth measurement of the jth longitudinal outcome and Xjk and denote corresponding covariates, which include the constant 1. The covariates Xjk, and W may partially or completely overlap. We relate Yjk to Xjk and through the multivariate linear mixed model:
| (2) |
for g = 1,…,G, where βg is a vector of class-specific regression parameters, b is a vector of random effects assumed to follow the multivariate normal distribution with mean 0 and variance , are independent zero-mean normal random variables with variance , and Σ(ξg) is a covariance matrix indexed by a vector of class-specific variance parameters ξg.
Let T denote the event time of interest. We relate T to a set of potentially time-dependent covariates Z(·) through the proportional hazards model:
| (3) |
where λg(·) is an arbitrary class-specific baseline hazard function, and γg and ηg are class-specific regression parameters. In the presence of censoring, we observe and ∆ = I(T ≤ U), where U is the censoring time, and I(·) is the indicator function. Let Y = (Y11,…,Y1N1,…,YJ1,…,YJNJ)T, , and . The data consist of n independent observations , for i = 1, …, n, where is the end of study time.
Let denote the set of all Euclidean parameters and for . Under the assumption of noninformative censoring and longitudinal measurement times, rigorously formulated in Section S2 of the supplementary materials [21], the likelihood function concerning (θ,Λ1,…,ΛG) is proportional to
| (4) |
We reparametrize the model by setting Λ = Λ1 and ψg = log(λg/λ1); we then estimate Λ nonparametrically and approximate ψg using a sieve of B-spline functions for g = 2,…, G. In particular, we treat Λ as a step function that jumps at the observed event times and replace in the likelihood by , where Λ{t} is the jump size of Λ at t. Let be B-spline functions on a grid over , where the number of spline functions mn increases with the sample size. For g = 2,…, G, we approximate by , where is a set of regression parameters. Ideally, NPMLE would be adopted for every nonparametric function because it does not require tuning and is more flexible than splines. However, because the NPMLE for (Λ1, …, ΛG) is inconsistent, we estimate the cumulative baseline hazard function of a reference group using NPMLE and estimate the remaining nonparametric functions using splines, so as to achieve as much model flexibility as possible while ensuring estimation consistency.
Let be the maximizer of
and let , where is the corresponding element of . Let . The sieve NPMLE of is , where .
3. Computation of the sieve NPMLE.
In this section, we use Z(·) to denote the combination of the original set of time-dependent covariates and the B-spline functions (B1, …, Bm), with γg being the corresponding vector of regression parameters for the gth latent class. We compute the sieve NPMLE using an accelerated version of the EM algorithm, with C and b treated as missing data. The proposed algorithm iteratively performs the EM steps. Unlike the standard EM algorithm, an E-step may not be performed under the current parameter estimates but under some function of the estimates at the previous steps.
We first introduce the standard EM algorithm. The complete-data log-likelihood function is
In the E-step, we compute the expectation of functions of (b,C) involved in the M-step. The conditional density of bi given Ci = g and the observed data is proportional to
and the conditional probability of Ci = g given the observed data is proportional to
The conditional expectation of any function h of (bi,Ci) given the observed data is
where . The integrations in the above equation can be approximated with the adaptive Gauss–Hermite quadrature [9].
In the M-step, we update the parameters by maximizing the expected complete-data log-likelihood function given the observed data. In particular, we update αg (g = 1,…,G − 1) by maximizing the weighted multinomial log-likelihood
via the Newton-Raphson algorithm. Then, we update βg and by maximizing
and update ξg (g = 1,…,G) by maximizing
where denotes the conditional expectation with respect to bi given Ci = g and the observed data. If closed-form solutions for the maximization problems are not available, then we employ the Newton-Raphson algorithm. In addition, we update (γg,ηg) (g = 1,…,G) by maximizing the (weighted) partial likelihood
via the Newton-Raphson algorithm. Finally, we update the cumulative baseline hazard function Λ by
for i = 1,…,n, where (, ) are the current estimates of the parameters.
The standard EM algorithm, which iteratively performs the E-step and M-step until convergence, may be slow, especially when the number of parameters is large. To accelerate the convergence, we adopt a modification of the EM algorithm proposed by Varadhan and Roland [19]. Let ϑ denote the set of all parameters and s(ϑ) be the set of updated parameters after a single EM step if the initial parameter value is ϑ. With ϑ(k) being the set of current estimates, a step of the accelerated EM algorithm consists of
Calculate ϑ1 = s(ϑ(k)).
Calculate ϑ2 = s(ϑ1).
Calculate r = ϑ1 −ϑ(k), v = ϑ2 −ϑ1 −r, and a = −||r||2/||v||2.
Update the parameter estimates by ϑ(k+1) = s(ϑ(k) −2ar +a2v).
To improve stability, we update the parameters using the standard EM steps at early steps of the algorithm. Once the difference between consecutive parameter estimates becomes smaller than a certain threshold, we perform the accelerated EM steps until convergence. When the assumed number of latent classes is larger than the actual number, the model is nonidentifiable, and the parameter estimates may not converge; therefore, we terminate the algorithm when the difference between the log-likelihood values of consecutive iterations is smaller than a certain threshold.
The algorithm may converge to a local maximum of the log-likelihood. To improve the chance of obtaining the global maximum, we can run the algorithm with different initial values and set the estimates to the converged values that yield the largest log-likelihood. One strategy for setting the initial values is to classify subjects into G classes by some clustering method and set the parameter values for each class to be the estimates obtained from subjects assigned to the class.
Upon convergence, we use Louis’s formula [11] to compute the observed information matrix, essentially treating the model as parametric, with parameters θ, and . The submatrix of the inverse of the observed information matrix corresponding to θ can be used to estimate the standard errors of . This submatrix is essentially an estimate of the inverse of the efficient information matrix defined in the proof of Theorem 4.2, where the least-favorable directions are estimated by solving the empirical counterparts of the integral equations they satisfy. The consistency of this standard error estimator is established in Theorem 4.3.
We propose to use the Bayesian information criterion (BIC) [16] to select the number of latent classes G. Specifically, for each G, we estimate the model using the sieve NPMLE and compute
where Ln is the likelihood function, and s is the number of free parameters in the model, including the regression parameters for the B-spline functions. We select the G that yields the smallest BIC value.
4. Asymptotic properties of the sieve NPMLE.
Assume that the degree of the B-spline functions is fixed at some p ≥ 1 and that the distance between adjacent knots is within for some large constant K. Let d be the dimension of the Euclidean parameters and Θ be a known, compact parameter space of θ. Let denote the true parameter values, where . Let and Λ0g be its true value (g = 1,…,G).
We impose the following conditions.
(C1) The parameter θ0 lies in the interior of Θ, and the function Λ0g is continuously differentiable up to the third order on for g = 1, …, G.
(C2) With probability one, for some fixed δ0 > 0.
(C3) With probability one, Z(·) has left-continuous sample paths on with right derivatives. In addition, there exists a large constant K such that
where Z′ is the (componentwise) left derivative of Z.
(C4) The number of knots mn satisfies mn = O(nq) for some 1/12 < q < 1/8.
The next condition is more technical and ensures model identifiability and invertibility of the information operator. Essentially, it requires that the covariates take enough distinct values such that the class-specific distributions of the longitudinal outcomes can be distinguished and the effect of each covariate on each class-specific distribution can be identified. Let , , and , where 1k is a k-vector of ones, Ψ0g is an orthogonal matrix such that , and and ξ0g are the true values of the corresponding parameters. Note that Σ0Y g is the covariance matrix of Y given C = g and (N1,…,NJ).
(C5) There exist some positive integers (n1,…,nJ) such that P(N1 = n1; …; NJ = nJ) > 0 and that the following holds. Let X be the set of possible values of given (N1 = n1,…,NJ = nJ) such that is invertible and
whenever g ≠ l. For k= 1, …, nj and j = 1, …, J, if , , and Z(t)ThZ = 0 almost surely for all and , then hW = 0, hXjk = 0, , , and hZ = 0, where hW, , , and hZ are fixed vectors of appropriate dimensions.
The final condition ensures that the least-favorable direction for the Euclidean parameters is sufficiently smooth.
(C6) The conditional density of the censoring variable U given the observed covariates is continuously differentiable on the support of U with respect to some dominating measure up to the third order.
Remark 1. Conditions (C1)–(C3) are common assumptions in the analysis of right-censored data under semiparametric survival models. Condition (C4) pertains to the rate at which the number of B-spline functions increases to infinity. Condition (C5) pertains to the class-specific distributions of the longitudinal outcomes and event time. Instead of directly assuming the identifiability and invertibility of the information operator of the proposed model, we derive these properties under assumptions on individual class-specific distributions. Condition (C5) requires that after removing specific covariate values that yield equality of certain quantities of the class-specific distributions of the observed variables, the set of possible covariate values are linearly independent. For latent-class models in general, linear independence of the covariates and distinctness of parameter values across latent classes are not sufficient for the invertibility of the information operator. To see this, consider a simple model with two latent classes, a known mixture probability of 0.5 for each class, a single binary covariate X, and a single outcome variable Y with Y | (X,C = g) ∼ N(αg + βgX,1) for g = 1,2, where C denotes the latent class membership. The score statistic along the direction α1 = α01 + ϵ, α2 = α02 ‒ ϵ, β1 = β01 ‒ ϵ, and β2 = β02 + ϵ, and is zero when α01 = α02, even if β01 ≠ β02, where (α01,α02,β01,β02) are the true parameter values. This model does not satisfy (a simplified version of) condition (C5) because the two latent classes are different only at X ≠ 0, but given X ≠ 0, (1,X) is no longer linearly independent. A simple sufficient condition for condition (C5) is that all covariates are linearly independent and the class-specific variances of Y are distinct almost surely.
Let || · ||∞ be the supremum norm over . We have the following results.
Theorem 4.1. Under conditions (C1)–(C5), there exists a local maximum of the nonparametric likelihood in the sieve space, denoted by , such that
This theorem provides a preliminary, combined rate of convergence for the estimators of the Euclidean and infinite-dimensional parameters. Based on this convergence rate, the following theorem establishes that the Euclidean parameter estimators converge at the optimal n1/2 rate and attain the semiparametric efficiency bound [1].
Theorem 4.2. Under conditions (C1)–(C6), converges weakly to the normal distribution with zero mean, and its asymptotic variance attains the semiparametric efficiency bound.
Let In be the negative Hessian matrix of the log-likelihood evaluated at the estimated parameters, with the jump sizes of and the coefficients of the spline functions in treated as Euclidean parameters. Let be the submatrix of (n−1In)−1 that corresponds to θ.
Theorem 4.3. Under conditions (C1)–(C6), , where is the efficient information matrix of θ defined in the proof of Theorem 4.2.
The proofs of Theorems 4.1 and 4.2 are given in Appendix A, whereas the proof of Theorem 4.3 is given in Section S3 of the supplementary materials [21].
5. Simulation studies.
We considered a longitudinal study where data were collected on repeated measures of longitudinal outcomes as well as on the time to the occurrence of an event of interest. Each subject was examined periodically until the event of interest occurred or the subject was lost to follow-up. At the initial examination, a set of baseline covariates, which may represent sex, age, and other information, were measured, and at each examination, two types of longitudinal outcomes were measured. The latent class for each subject was generated from model (1) with G = 3 and W = (1,X1,X2)T, where X1 and X2 are independent Bernoulli(0,5) and N(0,1), respectively. We set the examination times at sk = 0,15(k−1) for k = 1,…,10. For j = 1,2 and k = 1,…,10, we generated
| (5) |
where , Xk = (1,sk,X1,X2)T, , and (b1,b2,b3) are independent of each other and of (X1,X2). Note that the random effects b1 and b2 account for the dependence among repeated measures of a single type of longitudinal outcome, whereas b3 accounts for the dependence between the two types of longitudinal outcomes. The event time T was generated from model (3) with a single random effect term b3 and Z(t) = (X1,X2)T for all t, and the censoring variable U was generated from Uniform with . Note that the number of longitudinal outcome measurements is max{k : k ≤ 10,sk ≤ T ∧U}.
The true values of the Euclidean parameters are given in Table S1 of the supplementary materials [21]. The class-specific baseline hazard functions are λ1(t) = 0,5, λ2(t) = exp(0,25t), and λ3(t) = 1. The proportions of subjects belonging to latent classes 1, 2, and 3 are approximately 35%, 35%, and 30%, respectively. The average number of longitudinal outcome measurements per subject is about 5.4. The censoring proportion is about 25%.
We set the degree of the B-spline functions to be 1 and the number of interior knots to be 2; in our experience, the results are largely insensitive to the choice of the number of knots. The locations of the knots were set data-adaptively to be the 33% and 66% empirical quantiles of the observed event times. We considered G = 2, 3, and 4 latent classes and used BIC to select G. To set the initial values, we use k-mean clustering based on the event (or censoring) time, the censoring indicator, and the baseline longitudinal outcome values to classify subjects into subgroups with k = G. Then, we fit the generalized linear models and survival models (without random effects) on each subgroup and set the initial parameter values to be the corresponding estimated values. The initial values for the coefficients of the B-splines and the regression parameters of the random effects are set to 0, the initial values of Var(bj)+Var(ϵjk) are set to be the estimated variances in the corresponding fitted linear models with Var(bj) = Var(ϵjk) (j = 1,2; k = 1; …, 10), and the variance of b3 is set to be 0.1. The initial cumulative baseline hazard function is set to be the Breslow estimator. We constrained all Euclidean parameter estimates (including the regression parameters for the B-spline functions and the logarithm of the variance parameters) to be smaller than or equal to 10 in absolute value. This constraint is imposed because in the early iterations of the EM algorithm, the unconstrained estimates may sometimes become too extreme and cause numerical problems. We set the sample size to be n = 1000 or 2000 and considered 1000 simulation replicates for each setting.
Under G = 3, in no replicates do any parameter estimates (in absolute value) equal the boundary value of 10. Some parameter estimates are equal to the boundary value in about 60% of the replicates for G = 4 and in less than 5% of the replicates for G = 2. The convergence to the boundary under G = 4 is expected, because the model is nonidentifiable. In all but ten replicates under n = 1000, BIC selected the correct number of latent classes, and thus we only present the estimation results under G = 3. Because the labels of the latent classes are arbitrary, after convergence of the EM algorithm, we redefined the latent classes such that the orders of the estimated values of certain parameters across latent classes match the orders of the corresponding true parameter values. The estimation results for n = 1000 and n = 2000 are summarized in Tables S1 and S2 in the supplementary materials [21], respectively. The estimators of all parameters, including the class-specific cumulative baseline hazard functions at particular time points, are virtually unbiased. The standard errors are estimated accurately, and the coverage probabilities of the confidence intervals are close to the nominal level, especially for n = 2000. Thus, the proposed estimation method effectively uncovers the latent structure of the population, produces consistent estimators, and yields valid statistical inference.
6. A real study.
The ARIC study is a prospective epidemiological cohort study conducted in the United States. In the study, a total of about 15,000 subjects received a baseline examination in 1987–1989 and potentially six subsequent examinations in 1990–1992, 1993–1995, 1996–1998, 2011–2013, 2016–2017, and 2018–2019. At each examination, medical data, such as body mass index (BMI), blood pressure, and cholesterol levels, were collected. The subjects were also followed through reviews of hospital records, and potentially right-censored observations on time to myocardial infarction (MI), stroke, and death were also obtained.
We aimed to study the risk of cardiovascular diseases or death among African American subjects and to detect the presence of latent subgroups. The event of interest is MI, stroke, or death. The African American subjects were recruited from two centers of study in Forsyth County, NC and Jackson, MS. We set study location, sex, and BMI, glucose level, smoking status, and age at the first examination as covariates; these are referred to as the baseline covariates in the sequel. We considered systolic blood pressure and total cholesterol level, which were measured at each examination, as longitudinal outcomes. After removing 347 subjects with prior (or unknown status of) stroke or coronary heart disease at baseline and 178 subjects with missing data, the sample size is 3284, and the censoring proportion is 49.2%.
We fit models (1)–(3), where T is the time from the first examination to MI, stroke, or death, whichever occurred first, (Y1k,Y2k) are respectively the systolic blood pressure and total cholesterol level at the kth examination, and Nj is the total number of examinations (k = 1,…,Nj;j = 1,2). The set of covariates W consists of the baseline covariates (and the constant 1 for the intercept). For the jth longitudinal outcome at the kth examination, we assumed model (5) with the set of covariates Xk consisting of the baseline covariates and the time of the kth examination. In the survival model, the set of covariates Z(t) is time-independent and consists of the baseline covariates, and the set of random effects consists of a single term b3. We set the degree of the B-spline functions to be 1 and considered 2–4 interior knots. The locations of the knots were chosen to be empirical quantiles of the observed event times. We ranged the number of latent classes G from 1 to 6.
For any numbers of knots for the B-spline functions, the BIC picked G = 4 latent classes. The BIC values at G = 1,…,6 under 2 interior knots are plotted in Figure S1 of the supplementary materials [21]. Since the estimation results across different numbers of knots are similar, we reported the results under 2 interior knots. The point estimates, standard errors, and p-values of all Euclidean parameters in the survival model are given in Table 1, and the estimated class-specific cumulative hazard functions are plotted in Figure 1; the estimation results for the remaining Euclidean parameters are given in Tables S3 and S4 of the supplementary materials [21]. The estimated trajectories of the mean longitudinal outcomes for a typical subject from each latent class are plotted in Figure S2 of the supplementary materials [21]. We classified a subject to a latent class if the (estimated) posterior probability of the class is larger than 0.7; a subject is unclassified if none of the posterior probabilities is larger than 0.7. The Kaplan–Meier curves for the (predicted) latent classes are plotted in Figure S3 of the supplementary materials [21].
TABLE 1.
Estimation results for the Euclidean parameters in the survival model for the ARIC data
| Parameter | Estimate | SE | p-value | Parameter | Estimate | SE | p-value |
|---|---|---|---|---|---|---|---|
| γ 1,Center | 0.2431 | 0.3041 | 4.24E–01 | γ 3,Glucose | 0.2304 | 0.0450 | 3.15E–07 |
| γ 1,BMI | −0.0775 | 0.0949 | 4.14E–01 | γ 3,Smoke | 0.8147 | 0.1487 | 4.26E–08 |
| γ 1,Glucose | 0.4086 | 0.1325 | 2.04E–03 | γ 3,Sex | 0.3840 | 0.1355 | 4.61E–03 |
| γ 1,Smoke | 0.7848 | 0.1505 | 1.84E–07 | γ 3,Age | 0.5433 | 0.0673 | 7.13E–16 |
| γ 1,Sex | 0.5965 | 0.1617 | 2.25E–04 | γ 4,Center | 0.0770 | 0.3369 | 8.19E–01 |
| γ 1,Age | 0.6440 | 0.1303 | 7.75E–07 | γ 4,BMI | −0.1136 | 0.1082 | 2.94E–01 |
| γ 2,Center | 0.1269 | 0.1887 | 5.01E–01 | γ 4,Glucose | 0.2954 | 0.0411 | 7.05E–13 |
| γ 2,BMI | 0.1052 | 0.0552 | 5.65E–02 | γ 4,Smoke | 0.5983 | 0.2039 | 3.34E–03 |
| γ 2,Glucose | 0.0634 | 0.0403 | 1.16E–01 | γ 4,Sex | 0.4959 | 0.1986 | 1.25E–02 |
| γ 2,Smoke | 0.6472 | 0.1378 | 2.65E–06 | γ 4,Age | 0.2654 | 0.0980 | 6.78E–03 |
| γ 2,Sex | 0.3533 | 0.1298 | 6.49E–03 | η 1 | 1.8929 | 2.5689 | 4.61E–01 |
| γ 2,Age | 0.3426 | 0.0721 | 2.00E–06 | η 2 | 1.5561 | 0.6952 | 2.52E–02 |
| γ 3,Center | −0.0954 | 0.1920 | 6.19E–01 | η 3 | 0.9861 | 2.3893 | 6.80E–01 |
| γ 3,BMI | 0.1853 | 0.0641 | 3.86E–03 | η 4 | 1.3614 | 1.0065 | 1.76E–01 |
NOTE: For the parameters labeled γ, the first subscript represents the latent class, and the second subscript represents the covariate that corresponds to the parameter. “Center” is the indicator for the Jackson center; “Sex” is the indicator for male; “Smoke” is the indicator for smoker; “Glucose” represents glucose level. All continuous covariates are standardized. The parameter ηg is the regression parameter of b3 for the gth latent class.
FIG 1.
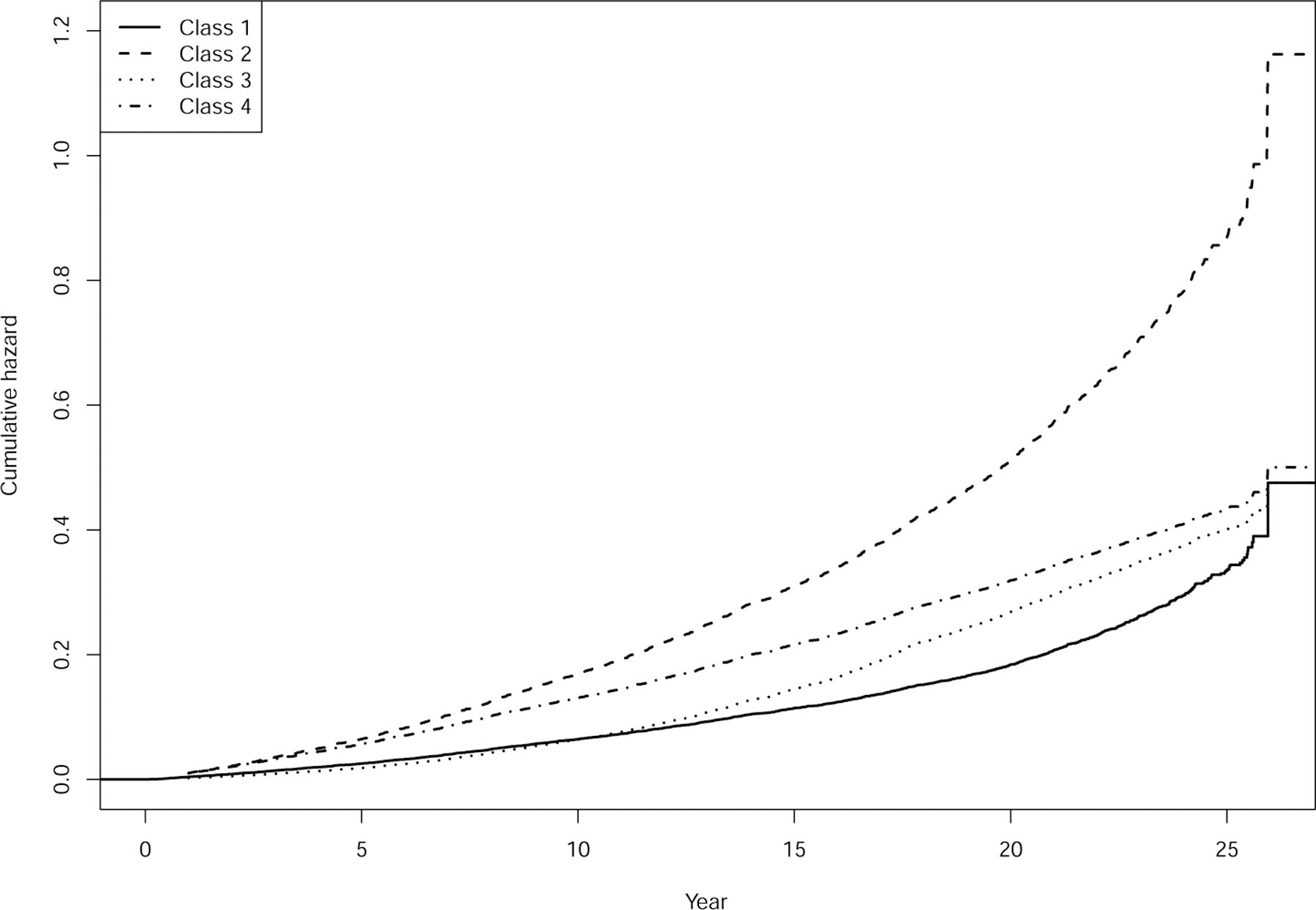
Estimated class-specific baseline hazard functions for the ARIC data.
Older subjects, males, and smokers have higher risk of MI, stroke, or death across all latent classes. Subjects with higher BMI tend to have higher risk of disease or death in the third latent class, but BMI has no significant association with the risk in other latent classes. Glucose level has highly significant positive effect on the risk of disease or death in all but the second latent class. The random effect b3, which captures the dependence of the systolic blood pressure and the total cholesterol level, is significantly associated with the risk of disease or death only in the second latent class. This suggests that systolic blood pressure and total cholesterol level are associated with the risk of disease or death even conditional on the latent class membership. The estimated class-specific cumulative hazard of the second latent class is substantially higher than those of the other classes, and the empirical survival probabilities of the second latent class are smaller. The mean systolic blood pressure of subjects in the second latent class tends to be higher than those of the other classes. The results suggest that the second latent class is characterized by elevated risk of disease or death. The other groups also exhibit differences in the risk of disease or death, distributions of the longitudinal outcomes, and effects of covariates on the longitudinal and survival outcomes. In the latent-class membership model, the regression parameters for glucose level are significantly negative for the first three latent classes, suggesting that the fourth latent class is characterized by high glucose level. In addition, the second latent class is characterized by older subjects, and the third latent class is characterized by males and subjects with higher BMI.
Suppose that we are interested in the conditional survival function for a subject at risk at time s given the trajectories of the longitudinal outcome measurements up to s. For a subject with time-independent covariates in the survival model, this probability function can be estimated by h(t)/h(s) for t ≥ s, where
Kj is the number of observations on the jth longitudinal outcome by time s, and the parameters are evaluated at the sieve NPMLE. Figure S4 in the supplementary materials [21] shows the estimated curves for two hypothetical subjects at s = 10.
We use cross-validation to evaluate the robustness of the latent-class structure. We split the data into 20 pairs of training and validation datasets with a ratio of sample sizes of 3 : 2. On each training dataset, we fit the latent-class model with G = 4 and 2 interior knots for the B-spline functions, and for each subject in the corresponding validation dataset, we used the estimated model to compute the posterior probabilities of class membership given the subject’s covariates and longitudinal outcomes (but not the event time). A subject is predicted to belong to a latent class if the posterior probability of the class is larger than 0.7; a subject is unclassified if none of the posterior probabilities is larger than 0.7. Note that the prediction of latent class does not directly involve the event time of the subjects in the validation dataset.
To evaluate the explanatory power of the (predicted) latent classes, in each validation dataset, we fit the Cox model with covariates, including the baseline systolic blood pressure, the baseline total cholesterol level, and the predicted latent classes; unclassified subjects were discarded. We tested the significance of the latent classes in the model using the likelihood-ratio test. The combined p-value across data splits is 0.0248, where the combined p-value is defined as , ps is the p-value for the sth split, and Φ is the standard normal distribution function. In addition, we fit a stratified Cox model, stratifying on the latent classes, with covariates including the baseline covariates, the baseline systolic blood pressure, the baseline total cholesterol level, and the interaction between the latent classes and the other covariates. The combined p-value for the likelihood-ratio tests for the interaction terms is 0.0250. These results suggest the existence of heterogeneity in the population that is not captured by the observed covariates. Subjects from different latent classes have not only different baseline hazards but also different association patterns between the covariates and the risk of disease or death.
7. Discussion.
In this article, we consider a semiparametric latent-class model for the joint analysis of longitudinal outcomes and a potentially right-censored event time. We develop a novel estimation approach that combines NPMLE and sieve estimation. We prove that the nonparametric components of the proposed estimators are consistent at a rate of o(n1/4). Although sieve estimators generally converge at a rate slower than n1/2, the Euclidean components of the estimators are nevertheless n1/2-consistent and asymptotically normal.
Under the proposed model, covariates may be associated with the event time through the latent class membership or directly through the class-specific survival models. The regression parameters in the survival models are best interpreted conditional on the latent variables b and C, so that for a subject in a specific latent class, each covariate in the survival model contributes multiplicatively to the baseline hazard. To obtain an “overall” effect of the covariates, we may adopt a Monte-Carlo approach: repeatedly generate data from the estimated model and the observed covariates, and fit the Cox model on the generated event times and covariates. The estimated regression parameters could be interpreted as the overall effects of the covariates, combining the effects on the latent class membership and the class-specific event-time distributions.
We proposed to estimate the standard error of the estimators by the inverse of the observed information matrix. This approach yields satisfactory performance in our extensive numerical studies, but it may be numerically unstable in very large samples or models. If one is interested only in the inference of the Euclidean parameters, then alternative methods based on the profile likelihood can be adopted [22].
The constraints on the number of B-spline functions given by condition (C4) guarantee that converges to the true value at a rate faster than n1/4, so that the Euclidean parameters can attain the efficiency bound. Because ψ0g’s are continuously differentiable up to the third order, the approximation error of the spline functions is of rate O(n−3q), and q > 1/12 is necessary for ; this bound can be relaxed under stronger assumptions on the smoothness of Λ0g’s. The upper limit q < 1/8 arises from the shrinking-neighborhood-based argument for consistency. In the proof, we show that a local maximum of the log-likelihood exists in an o(n−1/4)-neighborhood of the true parameter values. The upper limit q < 1/8 is to guarantee that the second-order term in the linear expansion of the log-likelihood dominates other terms in the expansion.
An intuitively appealing nonparametric estimation approach is to set each class-specific cumulative baseline hazard function to be a step function that jumps at the observed event times. This approach, however, yields inconsistent estimators even in the simple settings considered by Ma and Wang [12] and Wang, Garcia and Ma [20] because the parameter space is overly complex. Each (uncensored) observation belongs to a specific latent class and should only contribute to the jump of the corresponding cumulative baseline hazard function at the observed event time. However, the latent class membership is unknown, and this nonparametric approach incorrectly allows all cumulative baseline hazard functions to jump at the event time. To overcome this difficulty, we only estimate the cumulative baseline hazard function of a reference class nonparametrically and approximate the relative magnitudes of the baseline hazard functions between the reference class and other classes using spline functions. With a properly-chosen number of grid points for the spline functions, the complexity of the parameter space is controlled to yield consistent estimators.
During the preparation of this article, independent work of Liu et al. [10] was brought to our attention. Our model is more general than that of Liu et al. [10], which allows only a single type of longitudinal outcome with a random intercept in the longitudinal outcome model, and Liu et al. [10] adopted spline approximation for all nonparametric functions. In addition, we establish the asymptotic properties of the proposed estimators under specific assumptions on the proposed models and the observed data, whereas the assumptions in Liu et al. [10] are expressed in very general terms and are difficult to verify for given models. To demonstrate the extra flexibility of the proposed model over that of Liu et al. [10], we conducted a simulation study, which showed that misspecification of the latent variable structure may yield substantial estimation bias; see Section S4 of the supplementary materials [21].
Our work can be extended in several directions. First, one may be interested in the joint analysis of multiple event times, such as the times to the occurrence of different diseases. The proposed modeling framework can be readily extended to allow for multivariate event times by assuming a separate regression model for each event time with a set of shared random effects b. The sieve NPMLE can be easily extended to the multivariate setting, and its theoretical properties can be established along the lines of the proofs of Theorems 4.1 and 4.2.
Second, one may consider interval-censored event time(s). In ARIC, the onset of asymptomatic diseases, such as diabetes and hypertension, was not directly observed but was known to fall within certain time intervals. To accommodate interval censoring, we can extend the proposed methods and use the NPMLE [28] to estimate the cumulative baseline hazard function of the reference class. However, interval censoring results in a different likelihood function, which poses great challenges to the derivation of the asymptotic properties of the sieve NPMLE.
Finally, it would be of interest to consider high-dimensional longitudinal outcomes or covariates. In current biomedical studies, different types of molecular data, such as DNA alteration and gene expression, are collected along with clinical data. Such molecular data are often high-dimensional, with the number of variables much larger than the sample size. These data contain rich genetic information that can be used to classify subjects into biologically distinct disease subtypes [17]. We can set variables for the molecular data as longitudinal outcomes or covariates in models (1)–(3) and adopt a penalized (sieve) likelihood approach for estimation.
Supplementary Material
Acknowledgements.
This work was supported by a research grant from the Hong Kong Polytechnic University (P0030124), the Hong Kong Research Grants Council grant PolyU 253042/18P, and the National Institutes of Health awards R01-HL149683 and R01-HG009974. The Atherosclerosis Risk in Communities study has been funded in whole or in part with Federal funds from the National Heart, Lung, and Blood Institute, National Institutes of Health, Department of Health and Human Services, under Contract nos. (HHSN268201700001I, HHSN268201700002I, HHSN268201700003I, HHSN268201700005I, HHSN268201700004I). The authors thank the staff and participants of the ARIC study for their important contributions.
APPENDIX A: PROOFS OF THEOREMS
In this appendix, we prove Theorems 4.1 and 4.2. The proofs make use of the lemmas given in Appendix B. To facilitate the presentation, we introduce the following notation. Let is monotone nondecreasing, }. For some large enough positive constant K, let be the parameter space of (θ,Λ,ψ2,…,ψG), where , and || · ||V is the total variation over , such that
The subscript K for the parameter spaces may be suppressed in the sequel. Let denote
so that the likelihood for a generic subject is proportional to . Let denote the derivative of with respect to θ, denote the derivative of with respect to Λ along the direction H, and denote the derivative of with respect to ψg along the direction h.
In the sequel, we use || · || to denote the Euclidean norm for vectors and the L2-norm with respect to the Lebesgue measure for functions over . For a set of functions , let . Let and denote the true and empirical measures, respectively.
Proof of Theorem 4.1. Following Schumaker [15], under condition (C1), there exist functions such that for g = 2,…,G, where for some regression parameters . Let
where ϵn is a positive sequence such that . For ,
Therefore, each function ψng of has bounded total variation and converges uniformly to ψ0g.
The outline of the proof is as follows. For any sequence of , we define
First, we show that uniformly over . Then, we derive the rate of convergence of in terms of ϵn. Finally, we show that the maximum of the profile log-likelihood over lies in the interior of for some and for large enough n. For simplicity of presentation, we suppress the argument in and in the sequel.
Step 1. We prove the existence of the NPMLE, i.e., . Let and fg(Y,b) denote the joint density of (Y, b) for the gth latent class (given N1, …, NJ ); we suppress the parameter or covariate values in the expressions for simplicity of presentation. Note that
for some constant κ > 1, where ≲ denotes “smaller than up to a scaling factor.” Therefore, if , then the right-hand side of the above inequality is zero. We conclude that , so that the NPMLE exists.
Step 2. We show that the NPMLE is uniformly bounded. Note that
Let . We have
where the second term on the right-hand side is asymptotically bounded uniformly over . Thus,
Using a partitioning argument similar to that of Murphy [13], we can show that the right-hand side of the above inequality tends to ‒∞ if . By the definition of , the left-hand side of the inequality is nonnegative, so that .
Step 3. We show that is consistent. Because belongs to a function space with bounded total variation, by Helly’s selection theorem, for every subsequence of {n}n=1,2,…, there exists a further subsequence such that and for some (θ*,Λ*). We show that θ∗ = θ0 and Λ∗ = Λ0 for any subsequence. With an abuse of notation, let {n}n=1,2,… be the subsequence. Let
Note that , where
By the definition of the NPMLE, , so
| (6) |
Note that
where the first term on the right-hand side goes to zero almost surely because the class of is Gilvenko–Cantelli by Lemma B.1, and the second term is o(1) by the dominated convergence theorem; note that both terms converge uniformly over . By a similar argument on , the second term on the left-hand side of (6) is
where the op(1) term tends to 0 almost surely.
Consider the first term on the left-hand side of (6). Note that
| (7) |
where . By Lemma B.1, is Glivenko-Cantelli, so
By the dominated convergence theorem, converges to for each t. In addition, it is easy to see that the derivative of with respect to t is uniformly bounded, so that is equicontinuous with respect to t. Thus, by the Arzela-Ascoli theorem, uniformly in . Furthermore, we can follow the argument in Zeng, Lin and Lin [26, p. 374] to show by contradiction that . Taking limit on both sides of (7) yields
We conclude that Λ∗ is absolutely continuous with respect to Λ0 and thus is differentiable. Let λ∗ be the derivative of Λ∗. Combining the above results with (6), we have
By the nonnegativity of the Kullback-Leibler divergence and Lemma B.2, the left-hand side of the above inequality is nonpositive and is equal to zero if and only if (θ*,Λ∗) = (θ*,Λ∗). Therefore, is consistent.
Step 4. We derive a bound on in terms of . For any and , let
Clearly, and for any (hθ,hΛ). Suppressing the arguments (hθ,hΛ), we have
By Lemma B.1, the class is Donsker, so that the first term on the right-hand side above is Op(n−1/2) uniformly over . By repeated applications of the mean-value theorem, we can show that the second term is and the third term is . To evaluate the left-hand side of the above display, note that is the score statistic of a survival model with a single nonparametric component; the model falls under the framework of, for example, Zeng and Lin [25]. Using arguments analogous to the proof of Theorem 3.2 of Zeng and Cai [24] and the proof of Theorem 2 of Zeng and Lin [27], we can show that the map is Frechet-differentiable with a derivative that takes the form of a Fredholm operator. By Lemma B.4, (evaluated at the true parameter values) is one-to-one, so it is continuously invertible. Therefore, there exists some positive constant c1 such that , where the norm on the left-hand side of the inequality is the supremum norm over . By the consistency of and the differentiability of ,
Combining the above results, we conclude that
where An is some random variable that may depend on and satisfies .
Step 5. We show that a local maximum of with respect to exists in the interior of for large enough n. It suffices to show that with probability going to 1 as n → ∞, where . Let
| (8) |
By Lemma B.1, the first term on the right-hand side of (8) can be written as Cnn−1/2 for some variable Cn such that . To evaluate the second term on the right-hand side above, let
where is a step function that jumps at the observed event times, with points. The second term of the right-hand side of (8) is equal to for some ϵ ∈[0, 1]. Note that ξʹ(0;Λen) is equal to
where for . The last equality above follows from the mean-value theorem and that the score statistic is mean zero. By standard arguments for the NPMLE, . Also, and , so the right-hand side of the above equation is op(n−1/2). To evaluate , we write
Using the mean-value theorem, we can show that the first term on the right-hand side of the above equation is . Following the arguments for the evaluation of , we can show that the second term is op(n−1/2). Note that the third term is the negative information of the one-dimensional submodel θ = θ0 + ϵhθ, dΛ = (1 + ϵhΛ)dΛ0, and , where , , and . Let . For any , the score statistic of the submodel along direction h is
where , is the derivative of fg(Y, b) with respect to , , are the directions that correspond to the parameters for , , and . For h(1), , we can write
where G1(h) is some linear function of h, and G2g(t;h) is equal to
where fT (· | Y) is the conditional density of the survival time T given Y, SU(· | Y) is the conditional survival function of the censoring time U given Y, and a is a d-dimensional vector. Define an inner product 〈.,.〉 on such that
and let be the adjoint operator of . By the definition of , , such that
On the space , we define a seminorm . By Lemma B.4, ||h||I = 0 implies that h = 0, such that || · ||I is a norm in . Clearly, ||h||I ≤ c2〈h,h〉1/2 for some constant c2. By the bounded inverse theorem in Banach spaces, we have 〈h,h〉1/2 ≤ c3||h||I for some constant c3. We conclude that
By Donsker properties of the class of and the mean-value theorem,
In addition, a linear expansion argument shows that the third term of (8) is of order up to . Combining the above results, we have
for some sequences of positive variables Dn and En such that and and some positive constant c4. The second inequality holds because by Theorem 5.2 of de Boor [2],
Suppose that . By the same theorem of de Boor [2], for some g and c5 > 0. Therefore, by choosing ϵn such that and
we have P(Bn < 0) → 1; the existence of such an ϵn with is guaranteed under condition (C4). We conclude that there exists a local maximum of with respect to in the interior of ; let be the maximizer. Note that by Theorem 5.2 of de Boor [2], for all . We have
□
Proof of Theorem 4.2. Let be the score statistic for θ, be the score statistic for Λ along the submodel , and be the score statistic for ψg along the submodel ψg + ϵhψg (g = 2,…,G). For a set of functions h ≡ (h1,…,hd), let and . Let and be the least favorable directions for the nonparametric functions, such that , where the integration in the second term in the norm is carried out componentwise. The existence of and follows from the invertibility of the information operator, established in Step 5 of the proof of Theorem 4.1. In addition, from the expressions of given in Step 5 of the proof of Theorem 4.1 and condition (C6), each component of is continuously differentiable up to the third order. Let be the (componentwise) projection of onto the sieve space, such that . By the definition of the sieve NPMLE, , , and . Note that
The first two terms of the right-hand side above are zero. By Lemma B.1, the class of is Donsker, so that the third term is op(n−1/2). By the mean-value theorem, Theorem 4.1, and condition (C4), the fourth term is op(n−1/2). Obviously, , , and . We have
| (9) |
By Lemma B.1, the class
is Donsker. Therefore, the left-hand side of (9) is equal to
which converges in distribution to , where
is the efficient information matrix for θ. By the Taylor series expansion, Theorem 4.1, and the definition of and , the right-hand side of (9) is
where , are the derivatives of , , and with respect to θ, respectively. As established in Step 5 in the proof of Theorem 4.1, the information operator is invertible, so the efficient information matrix is invertible. We conclude that . Because is an asymptotically linear estimator with the influence function lying in the space spanned by the score functions, is asymptotically efficient [1]. □
APPENDIX B: USEFUL LEMMAS
In this appendix, we present four lemmas that are useful for the proofs of Theorems 4.1 and 4.2. The proofs of the lemmas are given in Section S3 of the supplementary materials [21].
Lemma B.1. For any finite K, the classes of functions
are Donsker.
Lemma B.2. Under conditions (C1)–(C3) and (C5), the latent-class model given by (1)–(3) is locally identifiable.
Lemma B.3. Consider the following normal mixture model. Let W be a set of covariates and C be a latent class indicator with distribution specified by (1). For g = 1,…,G, let Yg ∼ N(µg, Ωg), where (µ1, …,µG) are vectors of mean parameters, and (Ω1,…,ΩG) are covariance matrices. The observed outcome variable is . Let (µ0g,Ω0g) be the true values of (µg,Ωg). If (µ01,Ω01),…,(µ0G,Ω0G) are distinct and the components of W are linearly independent, then the score statistic along any submodel is nonzero.
Lemma B.4. Under conditions (C1)–(C3) and (C5), the score statistic along any one-dimensional submodel for the latent-class model given by (1)–(3) is nonzero.
Footnotes
SUPPLEMENTARY MATERIAL
Supplement to “Semiparametric latent-class models for multivariate longitudinal and survival data”. We present additional regularity conditions, the proofs of Theorem 4.3 and Lemmas B.1–B.4, additional simulation results, and additional real data analysis results.
REFERENCES
- [1].BICKEL PJ, KLAASSEN CA, RITOV Y and WELLNER JA (1993). Efficient and Adaptive Estimation for Semiparametric Models Johns Hopkins University Press, Baltimore. [Google Scholar]
- [2].DE BOOR C (1976). Splines as linear combinations of B-splines. A survey. In Approximation Theory II (Lorentz GG, Chui CK and Schumaker LL, eds.) 1–47. Academic Press, New York. [Google Scholar]
- [3].DEMPSTER AP, LAIRD NM and RUBIN DB (1977). Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B. Stat. Methodol 39 1–22. 10.1111/j.2517-6161.1977.tb01600.x [DOI] [Google Scholar]
- [4].HENDERSON R, DIGGLE P and DOBSON A (2000). Joint modelling of longitudinal measurements and event time data. Biostatistics 1 465–480. 10.1093/biostatistics/1.4.465 [DOI] [PubMed] [Google Scholar]
- [5].THE ARIC INVESTIGATORS (1989). The atherosclerosis risk in communities (ARIC) study: Design and objectives. American Journal of Epidemiology 129 687–702. 10.1093/oxfordjournals.aje.a115184 [DOI] [PubMed] [Google Scholar]
- [6].LIN H, TURNBULL BW, MCCULLOCH CE and SLATE EH (2002). Latent class models for joint analysis of longitudinal biomarker and event process data: application to longitudinal prostate-specific antigen readings and prostate cancer. J. Amer. Statist. Assoc 97 53–65. 10.1198/016214502753479220 [DOI] [Google Scholar]
- [7].LIU Y, LIU L and ZHOU J (2015). Joint latent class model of survival and longitudinal data: an application to CPCRA study. Comput. Statist. Data Anal 91 40–50. 10.1016/j.csda.2015.05.007 [DOI] [Google Scholar]
- [8].LIU L, MA JZ and O’QUIGLEY J (2008). Joint analysis of multi-level repeated measures data and survival: an application to the end stage renal disease (ESRD) data. Stat. Med 27 5679–5691. 10.1002/sim.3392 [DOI] [PubMed] [Google Scholar]
- [9].LIU Q and PIERCE DA (1994). A note on Gauss-Hermite quadrature. Biometrika 81 624–629. 10.2307/2337136 [DOI] [Google Scholar]
- [10].LIU Y, LIN Y, ZHOU J and LIU L (2020). A semi-parametric joint latent class model with longitudinal and survival data. Stat. Interface 13 411–422. 10.4310/SII.2020.v13.n3.a10 [DOI] [Google Scholar]
- [11].LOUIS TA (1982). Finding the observed information matrix when using the EM algorithm. J. R. Stat. Soc. Ser. B. Stat. Methodol 44 226–233. 10.1111/j.2517-6161.1982.tb01203.x [DOI] [Google Scholar]
- [12].MA Y and WANG Y (2012). Efficient distribution estimation for data with unobserved sub-population identifiers. Electron. J. Stat 6 710–737. 10.1214/12-EJS690 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].MURPHY SA (1994). Consistency in a proportional hazards model incorporating a random effect. Ann. Statist 22 712–731. 10.1214/aos/1176325492 [DOI] [Google Scholar]
- [14].PROUST-LIMA C, SÉNE M, TAYLOR JM and JACQMIN-GADDA H (2014). Joint latent class models for longitudinal and time-to-event data: a review. Stat. Methods Med. Res 23 74–90. 10.1177/0962280212445839 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].SCHUMAKER LL (2007). Spline Functions: Basic Theory (3rd ed.). Wiley. [Google Scholar]
- [16].SCHWARZ G (1978). Estimating the dimension of a model. Ann. Statist 6 461–464. 10.1214/aos/1176344136 [DOI] [Google Scholar]
- [17].SHEN R, OLSHEN AB and LADANYI M (2009). Integrative clustering of multiple genomic data types using a joint latent variable model with application to breast and lung cancer subtype analysis. Bioinformatics 25 2906–2912. 10.1093/bioinformatics/btp543 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].TSIATIS AA and DAVIDIAN M (2004). Joint modeling of longitudinal and time-to-event data: an overview. Statist. Sinica 14 809–834. [Google Scholar]
- [19].VARADHAN R and ROLAND C (2008). Simple and globally convergent methods for accelerating the convergence of any EM algorithm. Scand. J. Statist 35 335–353. 10.1111/j.1467-9469.2007.00585.x [DOI] [Google Scholar]
- [20].WANG Y, GARCIA TP and MA Y (2012). Nonparametric estimation for censored mixture data with application to the Cooperative Huntington’s Observational Research Trial. J. Amer. Statist. Assoc 107 1324–1338. 10.1080/01621459.2012.699353 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].WONG KY, ZENG D and LIN DY (2021). Supplement to “Semiparametric latent-class models for multivariate longitudinal and survival data” [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].XU C, BAINES PD and WANG J-L (2014). Standard error estimation using the EM algorithm for the joint modeling of survival and longitudinal data. Biostatistics 15 731–744. 10.1093/biostatistics/kxu015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].XU J and ZEGER SL (2001). Joint analysis of longitudinal data comprising repeated measures and times to events. J. R. Stat. Soc. Ser. C. Appl. Stat 50 375–387. 10.1111/1467-9876.00241 [DOI] [Google Scholar]
- [24].ZENG D and CAI J (2005). Asymptotic results for maximum likelihood estimators in joint analysis of repeated measurements and survival time. Ann. Statist 33 2132–2163. 10.1214/009053605000000480 [DOI] [Google Scholar]
- [25].ZENG D and LIN DY (2007). Maximum likelihood estimation in semiparametric regression models with censored data. J. R. Stat. Soc. Ser. B. Stat. Methodol 69 507–564. 10.1111/j.1369-7412.2007.00606.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].ZENG D, LIN DY and LIN X (2008). Semiparametric transformation models with random effects for clustered failure time data. Statist. Sinica 18 355–377. [PMC free article] [PubMed] [Google Scholar]
- [27].ZENG D and LIN DY (2010). A general asymptotic theory for maximum likelihood estimation in semiparametric regression models with censored data. Statist. Sinica 20 871–910. [PMC free article] [PubMed] [Google Scholar]
- [28].ZENG D, MAO L and LIN DY (2016). Maximum likelihood estimation for semiparametric transformation models with interval-censored data. Biometrika 103 253–271. 10.1093/biomet/asw013 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.