

Abstract
We study a natural variant of scheduling that we call partial scheduling: in this variant an instance of a scheduling problem along with an integer k is given and one seeks an optimal schedule where not all, but only k jobs, have to be processed. Specifically, we aim to determine the fine-grained parameterized complexity of partial scheduling problems parameterized by k for all variants of scheduling problems that minimize the makespan and involve unit/arbitrary processing times, identical/unrelated parallel machines, release/due dates, and precedence constraints. That is, we investigate whether algorithms with runtimes of the type or exist for a function f that is as small as possible. Our contribution is two-fold: First, we categorize each variant to be either in , -complete and fixed-parameter tractable by k, or -hard parameterized by k. Second, for many interesting cases we further investigate the runtime on a finer scale and obtain run times that are (almost) optimal assuming the Exponential Time Hypothesis. As one of our main technical contributions, we give an time algorithm to solve instances of partial scheduling problems minimizing the makespan with unit length jobs, precedence constraints and release dates, where is the graph with precedence constraints.
Keywords: Fixed-parameter tractability, Scheduling, Precedence constraints
Introduction
Scheduling is one of the most central application domains of combinatorial optimization. In the last decades, huge combined effort of many researchers led to major progress on understanding the worst-case computational complexity of almost all natural variants of scheduling: By now, for most of these variants it is known whether they are -complete or not. Scheduling problems provide the context of some of the most classic approximation algorithms. For example, in the standard textbook by Shmoys and Williamson on approximation algorithms [29] a wide variety of techniques are illustrated by applications to scheduling problems. See also the standard textbook on scheduling by Pinedo [24] for more background.
Instead of studying approximation algorithms, another natural way to deal with -completeness is Parameterized Complexity (PC).
While the application of general PC theory to the area of scheduling has still received considerably less attention than the approximation point of view, recently its study has seen explosive growth, as witnessed by a plethora of publications (e.g. [2, 13, 18, 22, 27, 28]). Additionally, many recent results and open problems can be found in a survey by Mnich and van Bevern [21], and even an entire workshop on the subject was recently held [20].
In this paper we advance this vibrant research direction with a complete mapping of how several standard scheduling parameters influence the parameterized complexity of minimizing the makespan in a natural variant of scheduling problems that we call partial scheduling. Next to studying the classical question of whether parameterized problems are in , in parameterized by k, or -hard parameterized by k, we also follow the well-established modern perspective of ‘fine-grained’ PC and aim at run times of the type or for the smallest function f of parameter k.
Partial Scheduling In many scheduling problems arising in practice, the set of jobs to be scheduled is not predetermined. We refer to this as partial scheduling. Partial scheduling is well-motivated from practice, as it arises naturally for example in the following scenarios:
Due to uncertainties a close-horizon approach may be employed and only few jobs out of a big set of jobs will be scheduled in a short but fixed time-window,
In freelance markets typically a large database of jobs is available and a freelancer is interested in selecting only a few of the jobs to work on,
The selection of the jobs to process may resemble other choices the scheduler should make, such as to outsource non-processed jobs to various external parties.
Partial scheduling has been previously studied in the equivalent forms of maximum throughput scheduling [25] (motivated by the first example setting above), job rejection [26], scheduling with outliers [12], job selection [8, 16, 30] and its special case interval selection [5].
In this paper, we conduct a rigorous study of the parameterized complexity of partial scheduling, parameterized by the number of jobs to be scheduled. We denote this number by k. While several isolated results concerning the parameterized complexity of partial scheduling do exist, this parameterization has (somewhat surprisingly) not been rigorously studied yet.1 We address this and study the parameterized complexity of the (arguably) most natural variants of the problem. We fix as objective to minimize the makespan while scheduling at least k jobs, for a given integer k and study all variants with the following characteristics:
1 machine, identical parallel machines or unrelated parallel machines,
release/due dates, unit/arbitrary processing times, and precedence constraints.
Note that a priori this amounts to variants.
Our Results
We give a classification of the parameterized complexity of these 48 variants. Additionally, for each variant that is not in , we give algorithms solving them and lower bounds under ETH. To easily refer to a variant of the scheduling problem, we use the standard three-field notation by Graham et al. [11]. See Sect. 2 for an explanation of this notation. To accommodate our study of partial scheduling, we extend the notation as follows:
Definition 1
We let k-sched in the -field indicate that we only schedule k out of n jobs.
We study the fine-grained parameterized complexity of all problems , where , the options for are all combinations for , , , , and is fixed to . Our results are explicitly enumerated in Table 1.
Table 1.
The fine-grained parameterized complexity of partial scheduling, where denotes k-sched, and S.I. abbreviates Subgraph Isomorphism (Color table online)

Since implies that the machines are identical, the mentioned number of 48 combinations reduces to 40 different scheduling problems. The notation omits factors polynomial in the input size. The highlighted table entries are new results from this paper
The rows of Table 1 are lexicographically sorted on (i) precedence relations/no precedence relations, (ii) a single machine, identical machines or unrelated machines (iii) release dates and/or deadlines. Because their presence has a major influence on the character of the problem we stress the distinction between variants with and without precedence constraints.2 On a high abstraction level, our contribution is two-fold:
We present a classification of the complexity of all aforementioned variants of partial scheduling with the objective of minimizing the makespan. Specifically, we classify all variants to be either solvable in polynomial time, to be fixed-parameter tractable in k and -hard, or to be -hard.
For most of the studied variants we present both an algorithm and a lower bound that shows that our algorithm cannot be significantly improved unless the Exponential Time Hypothesis (ETH) fails.
Thus, while we completely answer a classical type of question in the field of Parameterized Complexity, we pursue in our second contribution a more modern and fine-grained understanding of the best possible runtime with respect to the parameter k. For several of the studied variants, the lower bounds and algorithms listed in Table 1 follow relatively quickly. However, for many other cases we need substantial new insights to obtain (almost) matching upper and lower bounds on the runtime of the algorithms solving them. We have grouped the rows in result types [A]–[G] depending on our methods for determining their complexity.
Our New Methods
We now describe some of our most significant technical contributions for obtaining the various types (listed as [A]–[G] in Table 1) of results. Note that we skip some less interesting cases in this introduction; for a complete argumentation of all results from Table 1 we refer to Sect. 6. The main building blocks and logical implications to obtain the results from Table 1 are depicted in Fig. 1. We now discuss these building blocks of Fig. 1 in detail.
Fig. 1.

An illustration of the various result types as indicated in Table 1. Arrows indicate how a problem is generalized by another problem
Precedence Constraints
Our main technical contribution concerns result type [C]. The simplest of the two cases, , cannot be solved in time assuming the Exponential Time Hypothesis and not in unless sub-exponential time algorithms for the Biclique problem exist, due to reductions by Jansen et al. [14]. Our contribution lies in the following theorem that gives an upper bound for the more general of the two problems that matches the latter lower bound:
Theorem 1
can be solved in time,3 where is the precedence graph given as input.
Theorem 1 will be proved in Sect. 3. The first idea behind the proof is based on a natural4 dynamic programming algorithm indexed by anti-chains of the partial order naturally associated with the precedence constraints. However, evaluating this dynamic program naïvely would lead to an time algorithm, where n is the number of jobs.
Our key idea is to only compute a subset of the table entries of this dynamic programming algorithm, guided by a new parameter of an antichain called the depth. Intuitively, the depth of an antichain A indicates the number of jobs that can be scheduled after A in a feasible schedule without violating the precedence constraints.
We prove Theorem 1 by showing we may restrict attention in the dynamic programming algorithm to antichains of depth at most k, and by bounding the number of antichains of depth at most k indirectly by bounding the number of maximal antichains of depth at most k. We believe this methodology should have more applications for scheduling problems with precedence constraints.
Surprisingly, the positive result of Theorem 1 is in stark contrast with the seemingly symmetric case where only deadlines are present: Our next result, indicated as [B] in Fig. 1 shows it is much harder:
Theorem 2
The problem is -hard, and it cannot be solved in time assuming the ETH.
Theorem 2 is a consequence of a reduction outlined in Sect. 4. Note the -hardness follows from a natural reduction from the k-Clique problem (presented originally by Fellows and McCartin [9]), but this reduction increases the parameter k to and would only exclude time algorithms assuming the ETH. To obtain the tighter bound from Theorem 2, we instead provide a non-trivial reduction from the 3-Coloring problem based on a new selection gadget.
For result type [D], we give a lower bound by a (relatively simple) reduction from Partitioned Subgraph Isomorphism in Theorem 6 and Corollary 4. Since it is conjectured that Partitioned Subgraph Isomorphism cannot be solved in time assuming the ETH, our reduction is a strong indication that the simple time algorithm (see Sect. 6) cannot be improved significantly in this case.
No Precedence Constraints
The second half of our classification concerns scheduling problems without precedence constraints, and is easier to obtain than the first half. Results [E], [F] are consequences of a greedy algorithm and Moore’s algorithm [23] that solves the problem in time. Notice that this also solves the problem , by reversing the schedule and viewing the release dates as the deadlines. For result type [G] we show that a standard technique in parameterized complexity, the color coding method, can be used to get a time algorithm for the most general problem of the class, being . All lower bounds on the runtime of algorithms for problems of type [G] are by a reduction from Subset Sum, but for this reduction is slightly different.
Related Work
The interest in parameterized complexity of scheduling problems recently witnessed an explosive growth, resulting in e.g. a workshop [20] and a survey by Mnich and van Bevern [21] with a wide variety of open problems.
The parameterized complexity of partial scheduling parameterized by the number of processed jobs, or equivalently, the number of jobs ‘on time’ was studied before: Fellows et al. [9] studied a problem called k-Tasks On Time that is equivalent to and showed that it is -hard when parameterized by k,5 and in parameterized by k and the width of the partially ordered set induced by the precedence constraints. Van Bevern et al. [27] showed that the Job Interval Selection problem, where each job is given a set of possible intervals to be processed on, is in parameterized by k. Bessy et al. [2] consider partial scheduling with a restriction on the jobs called ‘Coupled-Task’, and also remarked the current parameterization is relatively understudied.
Another related parameter is the number of jobs that are not scheduled, that also has been studied in several previous works [4, 9, 22]. For example, Mnich and Wiese [22] studied the parameterized complexity of scheduling problems with respect to the number of rejected jobs in combination with other variables as parameter. If n denotes the number of given jobs, this parameter equals . The two parameters are somewhat incomparable in terms of applications: In some settings only few jobs out of many alternatives need to be scheduled, but in other settings rejecting a job is very costly and thus will happen rarely. However, a strong advantage of using k as parameter is in terms of its computational complexity: If the version of the problem with all jobs mandatory is -complete it is trivially -complete for , but it may still be in parameterized by k.
Organization of this Paper
This paper is organized as follows: We start with some preliminaries in Sect. 2. In Sect. 3 we present the proof of Theorem 1, and in Sect. 4 we describe the reductions for result types [B] and [D]. In Sect. 5 we give the algorithm for result type [G] and in Sect. 6 we motivate all cases from Table 1. Finally, in Sect. 7 we present a conclusion.
Preliminaries
The Three-Field Notation by Graham Et al
Throughout this paper we denote scheduling problems using the three-field notation by Graham et al. [11]. Problems are classified by parameters . The describes the machine environment. We use , indicating whether there are one (1), identical (P) or unrelated (R) parallel machines available. Here identical refers to the fact that every job takes a fixed amount of time process independent of the machine, and unrelated means a job could take different time to process per machine. The field describes the job characteristics, which in this paper can be a combination of the following values: (precedence constraints), (release dates), (deadlines) and (all processing times are 1). We assume without loss of generality that all release dates and deadlines are integers.
The field concerns the optimization criteria. A given schedule determines , the completion time of job j, and , the unit penalty which is 1 if , and 0 if . In this paper we use the following optimization criteria
: minimize the makespan (i.e. the maximum completion time of any job),
: minimize the number of jobs that finish after their deadline,
: maximize the number of processed jobs; in particular, process at least k jobs.
A schedule is said to be feasible if no constraints (deadlines, release dates, precedence constraints) are violated.
Notation for Posets
Any precedence graph G is a directed acyclic graph and therefore induces a partial order on V(G). Indeed, if there is a path from x to y, we let . An antichain is a set of mutually incomparable elements. We say that A is maximal if there is no antichain with , where ‘’ denotes strict inclusion. The set of predecessors of A is , and the the set of comparables of A is . Note if and only if A is maximal.
An element is a minimal element if for all . An element is a maximal element if for all . Furthermore, and .
Notice that is exactly the antichain A such that . We denote the subgraph of G induced by S with G[S]. We may assume that if since job will be processed later than in any schedule. To handle release dates we use the following:
Definition 2
Let G be a precedence graph. Then is the precedence graph restricted to all jobs that can be scheduled on or before time t, i.e. all jobs with release date at most t.
We assume , since all jobs with release date greater than can be ignored.
Parameterized Complexity
We say a problem is Fixed-Parameter Tractable (and in the complexity class ) parameterized by parameter k, if there exists an algorithm with runtime , where n denotes the size of the instance, f is a computable function and c some constant. There also exist problems for which inclusion in for some parameter is unlikely, such as k -Clique. This is because k -Clique is complete for the complexity class and it is conjectured that . One could view as the parameterized version of and of the parameterized version of . To prove a problem to be -hard, one can use a parameterized reduction from another problem that is -hard, where the reduction is a polynomial-time reduction with the following two additional restrictions: (1) the parameter of is bounded by g(k) for some function computable g and k the parameter of , (2) the runtime of the reduction is bounded by for f some computable function, n the size of the instance of and c a constant.
We exclude fixed-parameter tractable algorithms for problems that are -hard. To exclude runtimes in a more fine-grained manner, we use the Exponential Time Hypothesis (ETH). Roughly speaking, the ETH conjectures that no algorithm for 3-SAT exists, where n is the number of variables of the instance. As a consequence we can, for example, exclude algorithms with runtime for Subset Sum where n is the number of input integers, and algorithms with runtime for k -Clique where n is the number of vertices of the input graph and k the size of the clique that we are after. The function g(k) bounding the size of in the parameterized reductions plays an important role in these types of proofs, as for example a reduction with g(k) from k -Clique yields a lower bound under ETH of .
Result Type C: Precedence Constraints, Release Dates and Unit Processing Times
In this section we provide a fast algorithm for partial scheduling with release dates and unit processing times parameterized by the number k of scheduled jobs (Theorem 1). There exists a simple, but slow, algorithm with runtime that already proves that this problem is in parameterized by k: This algorithm branches k times on jobs that can be processed next. If more than k jobs are available at a step, then processing these jobs greedily is optimal. Otherwise, we can recursively try to schedule all non-empty subsets of jobs to schedule next, and a time algorithm is obtained via a standard (bounded search-tree) analysis. To improve on this algorithm, we present a dynamic programming algorithm based on table entries indexed by antichains in the precedence graph G describing the precedence relations. Such an antichain describes the maximal jobs already scheduled in a partial schedule. Our key idea is that, to find an optimal solution, it is sufficient to restrict our attention to a subset of all antichains. This subset will be defined in terms of the depth of an antichain. With this algorithm we improve the runtime to .
By binary search, we can restrict attention to a variant of the problem that asks whether there is a feasible schedule with makespan at most , for a fixed universal deadline .
The Algorithm
We start by introducing our dynamic programming algorithm for . Let m be the number of machines available. We start with defining the table entries. For a given antichain and integer t we define
Computing the values of S(A, t) can be done by trying all combinations of scheduling at most m jobs of A at time t and then checking whether all remaining jobs of can be scheduled in makespan . To do so, we also verify that all the jobs in A actually have a release date at or before t. Formally, we have the following recurrence for S(A, t):
Lemma 1
Proof
If , then there is a job with . And thus .
For any , X is a set of maximal elements with respect to , and consists of pair-wise incomparable jobs, since A is an antichain. So, we can schedule all jobs from X at time t without violating any precedence constraints. Define as the unique antichain such that . If and , we can extend the schedule of by scheduling all X at time t. In this way we get a feasible schedule processing all jobs of before or at time t. So if we find such an X with and , we must have .
For the other direction, if for all with , , then no matter which set we try to schedule at time t, the remaining jobs cannot be scheduled before t. Note that only jobs from A can be scheduled at time t, since those are the maximal jobs. Hence, there is no feasible schedule and .
The above recurrence cannot be directly evaluated, since the number of different antichains of a graph can be big: there can be as many as different antichains with , for example in the extreme case of an independent set. Even when we restrict our precedence graph to have out degree k, there could be different antichains, for example in k-ary trees. To circumvent this issue, we restrict our dynamic programming algorithm only to a specific subset of antichains. To do this, we use the following new notion of the depth of an antichain.
Definition 3
Let A be an antichain. Define the depth (with respect to t) of A as
We also denote .
The intuition behind this definition is that it quantifies the number of jobs that can be scheduled before (and including) A without violating precedence constraints. See Fig. 2 for an example of an antichain and its depth. We restrict the dynamic programming algorithm to only compute S(A, t) for A satisfying . This ensures that we do not go ‘too deep’ into the precedence graph unnecessarily at the cost of a slow runtime.
Fig. 2.
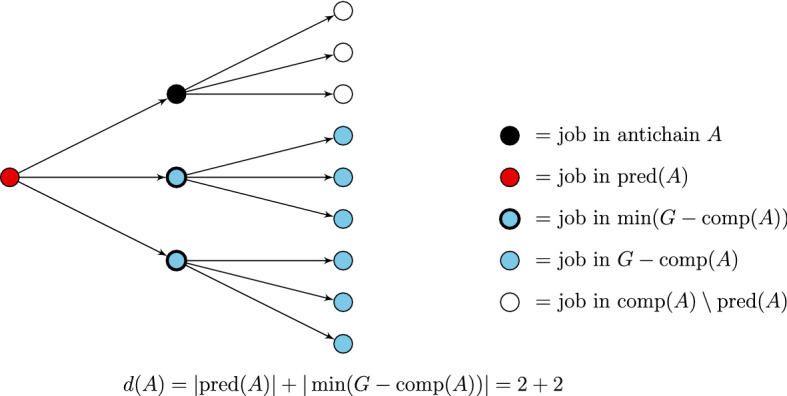
Example of an antichain and its depth in a perfect 3-ary tree. We see that , but . If , the dynamic programming algorithm will not compute S(A, t) since . The only antichains with depth are the empty set and the root node r on its own as a set. Indeed, . Note that for instances with , a feasible schedule may exist. If so, we will find that , which will be defined later. In this way, we can still find the antichain A as a solution
Because of this restriction in the depth, it could happen that we check no antichains with k or more predecessors, while there are corresponding feasible schedules. It is therefore possible that for some antichains A with , there is a feasible schedule for all jobs in before time , but the value will not be computed. To make sure we still find an optimal schedule, we also compute the following condition R(A, t) for all and antichains A with :
By definition of R(A, t), if for any A and , then we find a feasible schedule that processes k jobs on time.6 We show that there is an algorithm, namely , that quickly computes R(A, t). The algorithm does the following: first it checks if and if so, greedily schedules jobs from after t in order of smallest release date. If jobs can be scheduled before , it returns ‘true’ (). Otherwise, it returns ‘false’ ().
Lemma 2
There is an time algorithm that, given an antichain A, integer t, and value S(A, t), computes R(A, t).
Proof
We show that , defined above, fulfills all requirements. First we prove that if returns ‘true’, it follows that . Since , all jobs from can be finished at time t. Take that feasible schedule and process jobs from between t and . This is possible because is true. All predecessors of jobs in are in and therefore processed before t. Hence, no precedence constraints are violated and we find a feasible schedule with the requirements, i.e. .
For the other direction, assume that , i.e. we find a feasible schedule where exactly the jobs from are processed on or before t and only jobs from are processed after t. Thus . Define M as the set of jobs processed after t in . If M equals the set of jobs with the smallest release dates of , we can also process the jobs of M in order of increasing release dates. Then will be ‘true’, since M has size at least . However, if M is not that set, we can replace a job which does not have one of the smallest release dates, by one which has and was not in M yet. This new set can then still be processed between and because smaller release dates impose weaker constraints. We keep replacing until we end up with M being exactly the set of jobs with smallest release dates, which is then proved to be schedulable between t and . Hence, will return ‘true’.
Computing the set can be done in time. Sorting them on release date can be done in time, as there are at most k different release dates. Finally, greedily scheduling the jobs while checking feasibility can be done in time. Hence this algorithm runs in time .
Combining all steps gives us the algorithm as described in Algorithm 1. It remains to bound its runtime and argue its correctness.
Runtime
To analyze the runtime of the dynamic programming algorithm, we need to bound the number of checked antichains. Recall that we only check antichains A with for each time . We first analyze the number of antichains A with in any graph and use this to upper bound the number of antichains checked at time t.
To analyze the number of antichains A with , we give an upper bound on this number via an upper bound on the number of maximal antichains. Recall from the notations for posets, that for a maximal antichain A we have , and therefore . The following lemma connects the number of antichains and maximal antichains of bounded depth:
Lemma 3
For any antichain A, there exists a maximal antichain such that and .
Proof
Let . By definition, all elements in are incomparable to each other and incomparable to any element of A. Hence is an antichain. Since , is a maximal antichain. Moreover,
since the elements in are minimal elements and all their predecessors are in besides themselves.
For any (maximal) antichain A with , we derive that and so each maximal antichain of depth at most k has at most subsets. By Lemma 3, we see that each antichain is a subset of a maximal antichain with the same depth.
Corollary 1
This corollary allows us to restrict attention to only upper bounding the number of maximal antichains of bounded depth.
Lemma 4
There are at most maximal antichains A with in any precedence graph , and they can be enumerated in time.
Proof
Let be the set of maximal antichains in G with depth at most k. We prove that for any graph G by induction on k. Clearly, for any graph G, since the only antichain with is if .
Let and assume for for any graph G. If we have a precedence graph G with minimal elements , we partition into different sets . For , the set is defined as the set of maximal antichains A of depth at most k in which , but (and no restrictions on elements in the set ). If , then since A is maximal, so any such maximal antichain has a successor of in A. If we define as the set of all successors of (including ), we see that . Indeed, if , then . Hence we can remove those elements and its successors from the graph, as they are comparable to any such antichain. Moreover, we can also remove (but not its successors) from the graph, since it is in . Thus is then exactly the set of maximal antichains with depth i less in the remaining graph. The set is defined as all antichains not in some , which is all maximal antichains of A of depth at most k for which . Note that . We get the following recurrence relation:
| 1 |
since . Notice that we may assume that , because otherwise the depth of the antichain will be greater than k. Then if we use the induction hypothesis that for for any graph G, we see by (1) that:
The lemma follows since the above procedure can easily be modified in a recursive algorithm to enumerate the antichains, and by using a Breadth-First Search we can compute in time. Thus, each recursion step takes time.
Returning to (non-maximal) antichains, we see that we can enumerate all maximal antichains of depth at most k with Lemma 4 and by Corollary 1 we can find all antichains of depth at most k by taking all subsets of the found maximal antichains.
Corollary 2
There are at most antichains A with in any precedence graph , and they can be enumerated within time.
Notice that the runtime is indeed correct, as it dominates both the time needed for the construction of the set and the time needed for taking the subsets of (which is ).
We now restrict the number of antichains A in with . Take to be the graph in Corollary 2 and notice that for any antichain A in . By Corollary 2 we obtain Lemma 5.
Lemma 5
For any t, there are at most antichains A with in any precedence graph , and they can be enumerated within time.
To compute each S(A, t), we look at a maximum of different sets X. Computing the antichain such that takes time. After this computation, R(A, t) is directly computed in time. For each time , there are at most different antichains A for which we compute S(A, t) and R(A, t). Since , we therefore have total runtime of . Hence, Algorithm 1 runs in time .
Correctness of Algorithm
To show that the algorithm described in Algorithm 1 indeed returns the correct answer, the following lemma is clearly sufficient:
Lemma 6
A feasible schedule for k jobs with makespan at most exists if and only if for some and antichain A with .
Before we are able to prove Lemma 6, we need one more definition.
Definition 4
Let be a feasible schedule. Then is the antichain such that is exactly the set of jobs that was scheduled in .
Equivalently, if X is the set of jobs processed by , then .
Proof (Lemma 6)
Clearly, if for some and antichain A with , we have a feasible schedule with k jobs by definition of R(A, t). Hence, it remains to prove that if a feasible schedule for k jobs exists, then for some and antichain B with . Let
so is the set of all possible solutions. Define
i.e. is a schedule for which has minimal depth (with respect to ). We now define t and B such that .
Let job not in was scheduled at time , so from and on, only maximal jobs (with respect to ) are scheduled.
Let job x was scheduled at or later in .
Let , so is exactly the set of jobs scheduled on or before time t in .
See Fig. 3a for an illustration of these concepts. There are two cases to distinguish:
Fig. 3.

Visualization of the definitions of M and B and the schedule in the proof of Lemma 6 is shown in a. b Depicts the schedule as chosen in the subcase . The grey boxes indicate which jobs are processed in the schedules. We will prove that
. In this case we prove that . The feasible schedule we are looking for in the definition of R(B, t) is exactly . Indeed, all jobs from were finished at time t. Furthermore, all jobs in M are maximal, so all their predecessors are in . Hence, . So, by definition .
. In this case we prove that there is a schedule such that , i.e. we find a contradiction to the fact that was minimal. This can be found as follows: take schedule only up until time t. Let C be a subset of such that . This C can be found since . Process the jobs in C after time t in . These can all be processed without precedence constraint or release date violations, since their predecessors were already scheduled and . So, we find a feasible schedule that processes k jobs, called . The choice of is depicted in Fig. 3. Note that and not all jobs of are necessarily processed in .
It remains to prove that . Define for any antichain A. So D(A) is the set of jobs that contribute to d(A) and so . We will prove that . This will be done in two steps, first we show that
In the last step we prove , which gives us .
Notice that since , hence . Since it follows that . Next we prove that Clearly, if then . It remains to show that implies that . If , then either or . If , then so . If , then since x was a minimal element in . Since , and thus , we observe that . We then conclude that .
We are left to show that . Remember that t was chosen such that there is a job processed at time t that was not in . In other words, there was a job in at time t with such that . Note that , since , so y is not in and y is clearly comparable to x. However, , so we find that . Hence, we found a schedule with smaller , which leads to a contradiction.
Result Types B and D: One Machine and Precedence Constraints
In this section we show that Algorithm 1 cannot be even slightly generalized further: if we allow job-dependent deadlines or non-unit processing times, the problem becomes -hard parameterized by k and cannot be solved in time unless the ETH fails. In the following reductions we reduce to a variant of the scheduling problems that asks whether there is a feasible schedule with makespan at most , where is given as input. If for a given instance such a schedule exists, we call the instance a yes instance, and a no instance otherwise. We may restrict ourselves to this variant because of binary search.
Job-Dependent Deadlines
The fact that combining precedence constraints with job-dependent deadlines makes the problem -hard, is a direct consequence from the fact that is -hard, parameterized by where n is the number of jobs [9]. It is important to notice that the notation of these problems implies that each job can have its own deadline. Hence, we conclude from this that is -hard parameterized by k. This is a reduction from k-Clique that yields a quadratic blow-up on the parameter, giving a lower bound on algorithms for the problem of . Based on the Exponential Time Hypothesis, we now sharpen this lower bound with a reduction from 3-Coloring:
Theorem 3
is -hard parameterized by k. Furthermore, there is no algorithm solving in time where n is the number of jobs, assuming ETH.
Proof
The proof will be a reduction from 3-Coloring, for which no algorithm exists under the Exponential Time Hypothesis [7, pages 471–473]. Let the graph be the instance of 3-Coloring with and . We label the vertices and the edges . We then create the following instance for .
- For each vertex , create 6 jobs:
- , and with deadline ,
- , and with deadline ,
- For each edge , create 12 jobs:
- , , , , and with deadline ,
- , , , , and with deadline ,
For each with and with , add the precedence constraints and .
Set .
We now prove that the created instance is a yes instance if and only if the original 3-Coloring instance is a yes instance. Assume that there is a 3-coloring of the graph . Then there is also a feasible schedule: For each vertex with color a, process the jobs and at their respective deadlines. For each edge with u colored a and v colored b, process the jobs and exactly at their respective deadlines. Notice that because it is a 3-coloring, each edge has endpoints of different colors, so these jobs exist. Also note that no two jobs were processed at the same time. Exactly jobs were processed before time . Furthermore, no precedence constraints were violated.
For the other direction, assume that we have a feasible schedule in our created instance of . Let , for all , and let and for all . We show by induction on i that out of each of the sets , , and , exactly one job was scheduled at its deadline.
Since we have a feasible schedule, at time one of the jobs of must be scheduled, since they are the only jobs with a deadline greater than . If was scheduled at time , then the job must be processed at time 1 because of precedence constraints and since its deadline is 1. No other jobs from and can be processed, due to their deadlines and precedence constraints.
Now assume that all sets have exactly one job scheduled at their respective deadline, and no more can be processed. Since we have a feasible schedule, one job should be scheduled at time . However, since no more jobs from can be scheduled, the only possible jobs are from since they are the only other jobs with a deadline greater than . However, if was scheduled at time , then the job must be processed at time i because of precedence constraints, its deadline at i and because at times other jobs had to be processed. Also, no other job from can be processed in the schedule, since they all have deadline i. As a consequence, no other jobs from can be processed, as they are restricted to precedence constraints. So the statement holds for all sets and . In the exact same way, one can conclude the same about all sets and .
Because of this, we see that each job and each vertex have received a color from the schedule. They must form a 3-coloring, because a job from could only be processed if the two endpoints got two different colors. Hence, the 3-Coloring instance is a yes instance.
As we therefore conclude there is no algorithm under the ETH.
Note that this bound significantly improves the old lower bound of implied by the the reduction from k-Clique reduction. Since and is an increasing function, Theorem 3 implies that
Corollary 3
Assuming ETH, there is no algorithm solving in where n is the number of jobs.
Non-unit Processing Times
We show that having non-unit processing times combined with precedence constraints make the problem -hard even on one machine. The proof of Theorem 4 heavily builds on the reduction from k-Clique to k-Tasks On Time by Fellows and McCartin [9].
Theorem 4
is -hard, parameterized by k, even when for all jobs j.
Proof
The proof is a reduction from k-Clique. We start with , an instance of k-Clique. For each vertex , create a job with processing time . For each edge , create a job with processing time . Now for each edge (u, v), add the following two precedence relations: and , so before one can process a job associated with an edge, both jobs associated with the endpoints of that edge need to be finished. Now let and . We will now prove that is a yes instance if and only if the k-Clique instance is a yes instance.
Assume that the k-Clique instance is a yes instance, then process first the k jobs associated with the vertices of the k-clique. Next process the jobs associated with the edges of the k-clique. In total, jobs are now processed with a makespan of . Hence, the instance of is a yes instance.
For the other direction, assume to be a yes instance, so there exists a feasible schedule. For any feasible schedule, if one schedules jobs associated with vertices, then at most jobs associated with edges can be processed, because of the precedence constraints. However, because jobs were done in the feasible schedule before , at most k jobs associated with vertices can be processed, because they have processing time of size 2. Hence, we can conclude that exactly k vertex-jobs and edge-jobs were processed. Hence, there were k vertices connected through edges, which is a k-clique.
The proofs of Theorem 6 and Corollary 4 are reductions from Partitioned Subgraph Isomorphism. Let be a ‘pattern’ graph, be a ‘target’ graph, and a ‘coloring’ of the vertices of G with elements from P. A -colorful P-subgraph of G is a mapping such that (1) for each it holds that and (2) for each it holds that . If and G are clear from the context they may be omitted in this definition.
Definition 5
(Partitioned Subgraph Isomorphism) Given graphs and , , determine whether there is a -colorful P-subgraph of G.
Theorem 5
(Marx [19]) Partitioned Subgraph Isomorphism cannot be solved in time assuming the Exponential Time Hypothesis (ETH), where n is the size of the input.
We will now reduce Partitioned Subgraph Isomorphism to .
Theorem 6
cannot be solved in time assuming the Exponential Time Hypothesis (ETH).
Proof
Let , and . We will write . Define for the following important time stamps:
Construct the following jobs for the instance of the problem:
- For :
- For each vertex such that , create a job with processing time and release date .
For each such that , create a job with and release date . Add precedence constraints and .
Then ask whether there exists a solution to the scheduling problem for with makespan .
Let the Partitioned Subgraph Isomorphism instance be a yes-instance and let be a colorful P-subgraph. We claim the following schedule is feasible:
- For :
- Process at its release date .
Process for each the job somewhere in the interval .
Notice that all jobs are indeed processed after their release date and that in total there are jobs processed before . Furthermore, all precedence constraints are respected as any edge job is processed after both its predecessors. Also, the edge jobs must exist, as is a properly colored P-subgraph. Therefore, we can conclude that indeed this schedule is feasible.
For the other direction, assume that there is a solution to the created instance of . Define . We will first prove that at most one job from each set can be processed in a feasible schedule. To do this, we first prove that at most one job from each set can be processed before . Any job in has release date . Therefore, there is only time left to process the jobs from before time . However, the processing time of any job in is , and since , at most one job from can be processed before . Since all jobs not in some have their release date at , at most s jobs are processed at time . Thus, at time , there are time units left to process jobs, because of the choice of k and makespan. Hence, the only way to get a feasible schedule is to process exactly one job from each set at its respective release date and process exactly edge jobs after .
Let be the vertex, such that was processed in the feasible schedule with color i. We will show that , defined as , is a properly colored P-subgraph of G. Hence, we are left to prove that for each , the edge , i.e. that for each , the job was processed. Because only the vertex jobs were processed, the precedence constraints only allow for edge jobs to be processed. We created edge job if and only if and , hence the edge jobs have to be exactly the edge jobs for . Therefore, we proved indeed that is a colorful P-subgraph of G.
Notice that as we may assume the number of vertices in P is at most . The given bound follows.
Corollary 4
cannot be solved in time assuming the Exponential Time Hypothesis (ETH).
Proof
We can use the same idea for the reduction from Partitioned Subgraph Isomorphism as in the proof of Theorem 6, except for the release dates, as they are not allowed in this type of scheduling problem. To simulate the release dates, we use the second machine as a release date machine, meaning that we will create a job for each upcoming release date and will require these new jobs to be processed. More formally: For , create a job with processing time and precedence constraints for any job J that had release date in the original reduction. Furthermore, let . Then we add jobs with processing time 1 and with precedence relations . We then ask whether there exists a feasible schedule with and with makespan . All newly added jobs are required in any feasible schedule and therefore, all other arguments from the previous reduction also hold. Finally, note that k is again linear in .
Result Type G: k-scheduling without Precedence Constraints
The problem cannot be solved in time assuming the ETH, since there is a reduction to Subset Sum for which algorithms were excluded by Jansen et al. [15].
We show that the problem is fixed-parameter tractable with a matching runtime in k, even in the case of unrelated machines, release dates and deadlines, denoted by .
Theorem 7
is fixed-parameter tractable in k and can be solved in time.
Proof
We give an algorithm that solves any instance of within time. The algorithm is a randomized algorithm that uses the color coding method; it can can be derandomized as described by Alon et al. [1]. The algorithm first (randomly) picks a coloring , so each job is given one of the k available colors. We then compute whether there is a feasible colorful schedule, i.e. a feasible schedule that processes exactly one job of each color. If this colorful schedule can be found, then it is possible to schedule at least k jobs before .
Given a coloring c, we compute whether there exists a colorful schedule in the following way. Define for and :
Clearly , and all values can be computed in time using the following:
Lemma 7
Let . Then
Proof
In a schedule on one machine with |X| jobs using all colors from X, one job should be scheduled as last, defining the makespan. So for all possible jobs j, we compute what the minimal end time would be if j was scheduled at the end of the schedule. This j cannot start before its release date or before all other colors are scheduled.
Next, define for and , to be 1 if , and to be 0 otherwise. So if and only if |X| jobs, each from a different color of X, can be scheduled on machine i before . A colorful feasible schedule exists if and only if there is some partition of such that . The subset convolution of two functions is defined as . Then there is some partition of such that if and only if . The value of can be computed in time using fast subset convolution [3].
An overview of the randomized algorithm is given in Algorithm 2. If the k jobs that are processed in an optimal solution are all in different colors, the algorithm outputs true. By standard analysis, k jobs are all assigned different colors with probability at least , and thus independent trials to boost the error probability of the algorithm to at most 1/2.
By using the standard methods by Alon et al. [1], Algorithm 2 can be derandomized.
Argumentation of the Results in Table 1
For completeness and the readers convenience, we explain in this section for each row of Table 1 how the upper and lower bounds are obtained.
First notice that the most general variant can be solved in time as follows: Guess for each machine the set of jobs that are scheduled on it, and guess how they are ordered in an optimal solution, to get sequences with a joint length equal to k. For each such , run the following simple greedy algorithm to determine whether the minimum makespan achieved by a feasible schedule that schedules for each machine i the jobs as described in : Iterate and schedule the job at machine i as early as possible without violating release dates/deadline and precedence constraints (if this is not possible, return NO). Since each optimal schedule can be assumed to be normalized in the sense that no single job can be executed earlier, it is easy to see that this algorithm always returns an optimal schedule for some choice of . Since there are only different sequences of combined length k, the runtime follows.
- Cases 1–2
The polynomial time algorithms behind result [A] are obtained by a straightforward greedy algorithm: For , build the schedule from beginning to end, and schedule an arbitrary job if any is available; otherwise wait until one becomes available.
- Cases 3–4, 7–8
The given lower bound is by Corollary 3.
- Cases 5–6
The upper bound is by the algorithm of Theorem 1. The lower bound is due to reduction by Jansen et al. [14]. In particular, if no subexponential time algorithm for the Biclique problem exists, there exist no algorithms in time for these problems.
- Case 9
The lower bound is by Theorem 4, which is a reduction from k -Clique and heavily builds on the reduction from k -Clique to k-Tasks On Time by Fellows and McCartin [9]. This reduction increases the parameter k to , hence the lower bound of .
- Cases 10–20
The given lower bound is by Theorem 6, which is a reduction from Partitioned Subgraph Isomorphism. It is conjectured that there exist no algorithms solving Partitioned Subgraph Isomorphism in time assuming ETH, which would imply that the algorithm for these problems cannot be improved significantly.
- Cases 21–28
Result [E] is established by a simple greedy algorithm that always schedules an available job with the earliest deadline.
- Cases 29–31
Result [F] is a consequence of Moore’s algorithm [23] that solves the problem in time. The algorithm creates a sequence of all jobs in earliest due date order. It then repeats the following steps: It tries to process the sequence (in the given order) on one machine. Let be the first job in the sequence that is late. Then a job from with maximal processing time is removed from the sequence. If all jobs are on time, it returns the sequence followed by the jobs that have been removed from the sequence. Notice that this also solves the problem , by reversing the schedule and viewing the release dates as the deadlines.
- Cases 32
The lower bound for this problem is a direct consequence of the reduction from Knapsack to by Lenstra et al. [17], which is a linear reduction. Jansen et al. [15] showed that Subset Sum (and thus also Knapsack) cannot be solved in time assuming ETH.
- Cases 33–40
Since is equivalent to Subset Sum and can therefore not be solved in time assuming ETH, as shown by Jansen et al. [15]. Therefore, its generalizations, in particular those mentioned in cases 33–40, have the same lower bound on run times assuming ETH. The upper bound is by the algorithm of Theorem 7.
Concluding Remarks
We classify all studied variants of partial scheduling parameterized by the number of jobs to be scheduled to be either in , -complete and fixed-parameter tractable by k, or -hard parameterized by k. Our main technical contribution is an time algorithm for .
In a fine-grained sense, the cases we left open are cases 3–20 from Table 1. We believe in fact algorithms in rows 5–6 and 10–20 are optimal: An time algorithm for any case from result type or would imply either a time algorithm for Biclique or an time algorithm for Partitioned Subgraph Isomorphism, which both would be surprising. It would be interesting to see whether for any of the remaining cases with precedence constraints and unit processing times a ‘subexponential’ time algorithm exists.
A related case is (where P3 denotes three machines). It is a famously hard open question (see e.g. [10]) whether this can be solved in polynomial time, but maybe it is doable to try to solve this question in subexponential time, e.g. ?
Acknowledgements
The authors would like to thank the anonymous referees for useful comments.
Footnotes
We compare the previous works and other relevant studied parameterization in the end of this section.
A precedence constraint a b enforces that job a needs to be finished before job b can start.
We assume basic arithmetic operations with the release dates take constant time.
A similar dynamic programming approach was also present in, for example, [6].
Our results and build on and improve this result.
The reverse direction is more difficult and postponed to Lemma 6.
J. Nederlof ERC project No. 617951. and No. 853234. and NWO project No. 024.002.003. C.M.F. Swennenhuis NWO project No. 613.009.031b, ERC project No. 617951.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Jesper Nederlof, Email: j.nederlof@uu.nl.
Céline M. F. Swennenhuis, Email: c.m.f.swennenhuis@tue.nl
References
- 1.Alon N, Yuster R, Zwick U. Color-coding. J. ACM. 1995;42(4):844–856. doi: 10.1145/210332.210337. [DOI] [Google Scholar]
- 2.Bessy S, Giroudeau R. Parameterized complexity of a coupled-task scheduling problem. J. Sched. 2019;22(3):305–313. doi: 10.1007/s10951-018-0581-1. [DOI] [Google Scholar]
- 3.Björklund, A., Husfeldt, T., Kaski, P., Koivisto, M.: Fourier meets Möbius: fast subset convolution. In: Proceedings of the Thirty-Ninth Annual ACM Symposium on Theory of Computing, pp. 67–74. ACM (2007)
- 4.Bodlaender HL, Fellows MR. W[2]-hardness of precedence constrained -processor scheduling. Oper. Res. Lett. 1995;18(2):93–97. doi: 10.1016/0167-6377(95)00031-9. [DOI] [Google Scholar]
- 5.Chuzhoy J, Ostrovsky R, Rabani Y. Approximation algorithms for the job interval selection problem and related scheduling problems. Math. Oper. Res. 2006;31(4):730–738. doi: 10.1287/moor.1060.0218. [DOI] [Google Scholar]
- 6.Cygan M, Pilipczuk M, Pilipczuk M, Wojtaszczyk JO. Scheduling partially ordered jobs faster than . Algorithmica. 2014;68(3):692–714. doi: 10.1007/s00453-012-9694-7. [DOI] [Google Scholar]
- 7.Cygan M, Fomin FV, Kowalik Ł, Lokshtanov D, Marx D, Pilipczuk M, Pilipczuk M, Saurabh S. Parameterized Algorithms. Berlin: Springer; 2015. [Google Scholar]
- 8.Eun J, Sung CS, Kim ES. Maximizing total job value on a single machine with job selection. J. Oper. Res. Soc. 2017;68(9):998–1005. doi: 10.1057/s41274-017-0238-z. [DOI] [Google Scholar]
- 9.Fellows MR, McCartin C. On the parametric complexity of schedules to minimize tardy tasks. Theoret. Comput. Sci. 2003;298(2):317–324. doi: 10.1016/S0304-3975(02)00811-3. [DOI] [Google Scholar]
- 10.Garey MR, Johnson DS. Computers and Intractability: A Guide to the Theory of NP-Completeness. New York: W. H. Freeman; 1979. [Google Scholar]
- 11.Graham RL, Lawler EL, Lenstra JK, Rinnooy Kan AHG. Optimization and approximation in deterministic sequencing and scheduling: a survey. Ann. Discret. Math. 1979;5(2):287–326. doi: 10.1016/S0167-5060(08)70356-X. [DOI] [Google Scholar]
- 12.Gupta, A., Krishnaswamy, R., Kumar, A., Segev, D.: Scheduling with outliers. In: Dinur, I., Jansen, K., Naor, J., Rolim, J.D.P. (eds.) Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques, 12th International Workshop, APPROX 2009, and 13th International Workshop, RANDOM 2009, Berkeley, CA, USA, August 21–23, 2009. Proceedings, Lecture Notes in Computer Science, vol. 5687, pp. 149–162. Springer, Berlin (2009). 10.1007/978-3-642-03685-9_12
- 13.Hermelin, D., Mnich, M., Omlor, S.: Single machine batch scheduling to minimize the weighted number of tardy jobs. CoRR (2019)
- 14.Jansen, K., Land, F., Kaluza, M.: Precedence scheduling with unit execution time is equivalent to parametrized biclique. In: International Conference on Current Trends in Theory and Practice of Informatics, pp. 329–343. Springer, Berlin (2016)
- 15.Jansen K, Land F, Land K. Bounding the running time of algorithms for scheduling and packing problems. SIAM J. Discret. Math. 2016;30(1):343–366. doi: 10.1137/140952636. [DOI] [Google Scholar]
- 16.Koulamas C, Panwalkar SS. A note on combined job selection and sequencing problems. Nav. Res. Logist. 2013;60(6):449–453. doi: 10.1002/nav.21543. [DOI] [Google Scholar]
- 17.Lenstra JK, Rinnooy Kan AHG, Brucker P. Complexity of machine scheduling problems. Ann. Discret. Math. 1977;1:343–362. doi: 10.1016/S0167-5060(08)70743-X. [DOI] [Google Scholar]
- 18.Lenté, C., Liedloff, M., Soukhal, A., T’Kindt, V.: Exponential algorithms for scheduling problems. Tech. rep. (2014). https://hal.archives-ouvertes.fr/hal-00944382
- 19.Marx D. Can you beat treewidth? Theory Comput. 2010;6:85–112. doi: 10.4086/toc.2010.v006a005. [DOI] [Google Scholar]
- 20.Megow, N., Mnich, M., Woeginger, G.: Lorentz Workshop ‘Scheduling Meets Fixed-Parameter Tractability’ (2019)
- 21.Mnich, M., van Bevern, R.: Parameterized complexity of machine scheduling: 15 open problems. Comput. Oper. Res. (2018)
- 22.Mnich M, Wiese A. Scheduling and fixed-parameter tractability. Math. Program. 2015;154(1–2):533–562. doi: 10.1007/s10107-014-0830-9. [DOI] [Google Scholar]
- 23.Moore JM. An job, one machine sequencing algorithm for minimizing the number of late jobs. Manag. Sci. 1968;15(1):102–109. doi: 10.1287/mnsc.15.1.102. [DOI] [Google Scholar]
- 24.Pinedo, M.L.: Scheduling: Theory, Algorithms, and Systems, 3rd edn. Springer Publishing Company, Incorporated (2008)
- 25.Sgall, J.: Open problems in throughput scheduling. In: Epstein, L., Ferragina, P. (eds.) Algorithms—ESA 2012—20th Annual European Symposium, Ljubljana, Slovenia, September 10–12, 2012. Proceedings, Lecture Notes in Computer Science, vol. 7501, pp. 2–11. Springer, Berlin (2012). 10.1007/978-3-642-33090-2_2
- 26.Shabtay D, Gaspar N, Kaspi M. A survey on offline scheduling with rejection. J. Sched. 2013;16(1):3–28. doi: 10.1007/s10951-012-0303-z. [DOI] [Google Scholar]
- 27.van Bevern R, Mnich M, Niedermeier R, Weller M. Interval scheduling and colorful independent sets. J. Sched. 2015;18(5):449–469. doi: 10.1007/s10951-014-0398-5. [DOI] [Google Scholar]
- 28.van Bevern, R., Bredereck, R., Bulteau, L., Komusiewicz, C., Talmon, N., Woeginger, G.J.: Precedence-constrained scheduling problems parameterized by partial order width. In: Discrete Optimization and Operations Research—9th International Conference, DOOR 2016, Vladivostok, Russia, September 19–23, 2016, Proceedings, pp. 105–120 (2016)
- 29.Williamson DP, Shmoys DB. The Design of Approximation Algorithms. Cambridge: Cambridge University Press; 2011. [Google Scholar]
- 30.Yang B, Geunes J. A single resource scheduling problem with job-selection flexibility, tardiness costs and controllable processing times. Comput. Ind. Eng. 2007;53(3):420–432. doi: 10.1016/j.cie.2007.02.005. [DOI] [Google Scholar]