

Abstract
High resolution geospatial data are challenging because standard geostatistical models based on Gaussian processes are known to not scale to large data sizes. While progress has been made towards methods that can be computed more efficiently, considerably less attention has been devoted to methods for large scale data that allow the description of complex relationships between several outcomes recorded at high resolutions by different sensors. Our Bayesian multivariate regression models based on spatial multivariate trees (SpamTrees) achieve scalability via conditional independence assumptions on latent random effects following a treed directed acyclic graph. Information-theoretic arguments and considerations on computational efficiency guide the construction of the tree and the related efficient sampling algorithms in imbalanced multivariate settings. In addition to simulated data examples, we illustrate SpamTrees using a large climate data set which combines satellite data with land-based station data. Software and source code are available on CRAN at https://CRAN.R-project.org/package=spamtree.
Keywords: Directed acyclic graph, Gaussian process, Geostatistics, Multivariate regression, Markov chain Monte Carlo, Multiscale/multiresolution
1. Introduction
It is increasingly common in the natural and social sciences to amass large quantities of geo-referenced data. Researchers seek to use these data to understand phenomena and make predictions via interpretable models that quantify uncertainty taking into account the spatial and temporal dimensions. Gaussian processes (GP) are flexible tools that can be used to characterize spatial and temporal variability and quantify uncertainty, and considerable attention has been devoted to developing GP-based methods that overcome their notoriously poor scalability to large data. The literature on scaling GPs to large scale is now extensive. We mention low-rank methods (Quiñonero-Candela and Rasmussen, 2005; Snelson and Ghahramani, 2007; Banerjee et al., 2008; Cressie and Johannesson, 2008); their extensions (Low et al., 2015; Ambikasaran et al., 2016; Huang and Sun, 2018; Geoga et al., 2020); methods that exploit special structure or simplify the representation of multidimensional inputs—for instance, a Toeplitz structure of the covariance matrix scales GPs to big time series data, and tensor products of scalable univariate kernels can be used for multidimensional inputs (Gilboa et al., 2015; Moran and Wheeler, 2020; Loper et al., 2020; Wu et al., 2021). These methods may be unavailable or perform poorly in geostatistical settings, which focus on small-dimensional inputs, i.e. the spatial coordinates plus time. In these scenarios, low-rank methods oversmooth the spatial surface (Banerjee et al., 2010), Toeplitz-like structures are typically absent, and so-called separable covariance functions obtained via tensor products poorly characterize spatial and temporal dependence. To overcome these hurdles, one can use covariance tapering and domain partitioning (Furrer et al., 2006; Kaufman et al., 2008; Sang and Huang, 2012; Stein, 2014; Katzfuss, 2017) or composite likelihood methods and sparse precison matrix approximations (Vecchia, 1988; Rue and Held, 2005; Eidsvik et al., 2014); refer to Sun et al. (2011), Banerjee (2017), Heaton et al. (2019) for reviews of scalable geostatistical methods.
Additional difficulties arise in multivariate (or multi-output) regression settings. Multivariate geostatistical data are commonly misaligned, i.e. observed at non-overlapping spatial locations (Gelfand et al., 2010). Figure 1 shows several variables measured at non-overlapping locations, with one measurement grid considerably sparser than the others. In these settings, replacing a multi-output regression with separate single-output models is a valid option for predicting outcomes at new locations. While single-output models may some-times perform equally well or even outperform multi-output models, they fail to characterize and estimate cross-dependences across outputs; testing the existence of such dependences may be scientifically more impactful than making predictions. This issue can be solved by modeling the outputs via latent spatial random effects thought of as a realization of an underlying multivariate GP and embedded in a larger hierarchical model.
Figure 1:
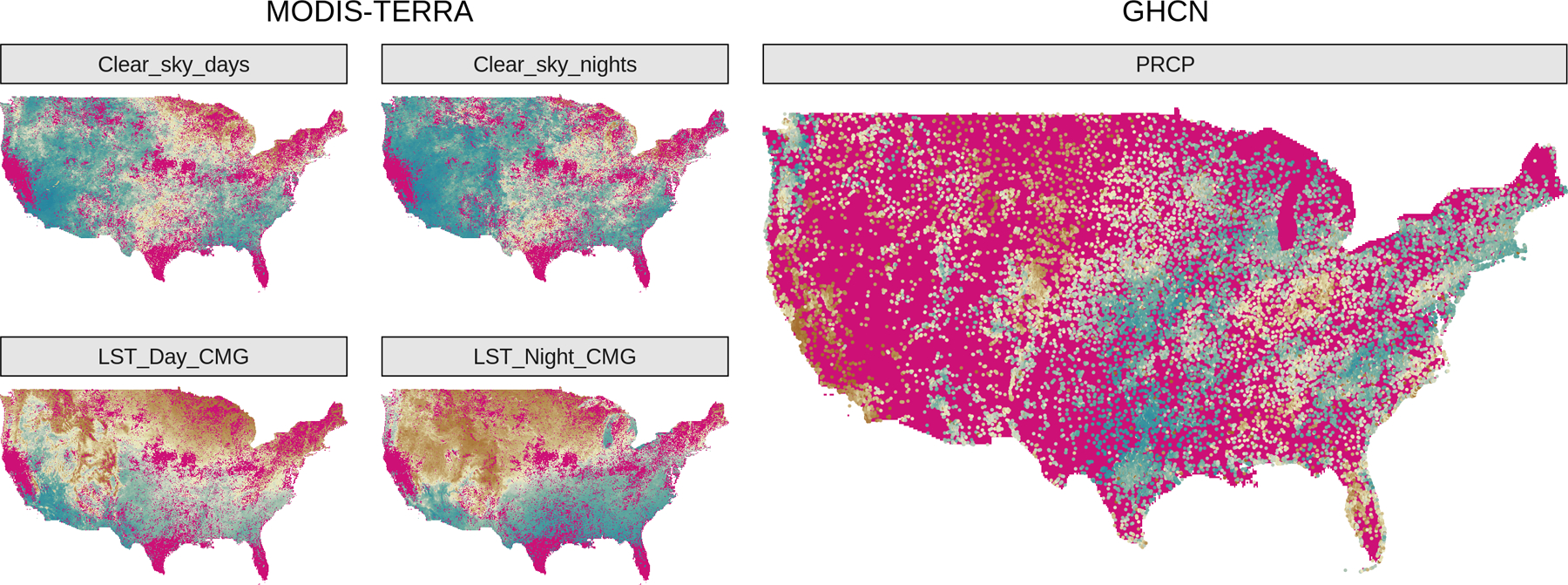
Observed data of Section 4.2. Missing outcomes are in magenta. GHCN data are much more sparsely observed compared to satellite imaging from MODIS.
Unfortunately, GP approximations that do not correspond to a valid stochastic process may inaccurately characterize uncertainty, as the models used for estimation and interpolation may not coincide. Rather than seeking approximations to the full GP, one can develop valid standalone spatial processes by introducing conditional independence across spatial locations as prescribed by a sparse directed acyclic graph (DAG). These models are advantageous because they lead to scalability by construction; in other words, posterior computing algorithms for these methods can be interpreted not only as approximate algorithms for the full GP, but also as exact algorithms for the standalone process.
This family of methods includes nearest-neighbor Gaussian processes, which limit dependence to a small number of neighboring locations (NNGP; Datta et al. 2016a,b), and block-NNGPs (Quiroz et al., 2019). There is a close relation between DAG structure and computational performance of NNGPs: some orderings may be associated to improved approximations (Guinness, 2018), and graph coloring algorithms (Molloy and Reed, 2002; Lewis, 2016) can be used for parallel Gibbs sampling. Inferring ordering or coloring can be problematic when data are in the millions, but these issues can be circumvented by forcing DAGs with known properties onto the data; in meshed GPs (MGPs; Peruzzi et al., 2020), patterned DAGs associated to domain tiling are associated to more efficient sampling of the latent effects. Alternative so-called multiscale or multiresolution methods correspond to DAGs with hierarchical node structures (trees), which are typically coupled with recursive domain partitioning; in this case, too, efficiencies follow from the properties of the chosen DAG. There is a rich literature on Gaussian processes and recursive partitioning, see e.g Ferreira and Lee (2007); Gramacy and Lee (2008); Fox and Dunson (2012); in geospatial contexts, in addition to the GMRF-based method of Nychka et al. (2015), multi-resolution approximations (MRA; Katzfuss, 2017) replace an orthogonal basis decomposition with approximations based on tapering or domain partitioning and also have a DAG interpretation (Katzfuss and Guinness, 2021).
Considerably less attention has been devoted to process-based methods that ensure scalability in multivariate contexts, with the goal of modeling the spatial and/or temporal variability of several variables jointly via flexible cross-covariance functions (Genton and Kleiber, 2015). When scalability of GP methods is achieved via reductions in the conditioning sets, including more distant locations is thought to aid in the estimation of unknown covariance parameters (Stein et al., 2004). However, the size of such sets may need to be reduced excessively when outcomes are not of very small dimension. One could restrict spatial coverage of the conditioning sets, but this works best when data are not misaligned, in which case all conditioning sets will include outcomes from all margins; this cannot be achieved for misaligned data, leading to pathological behavior. Alternatively, one can model the multivariate outcomes themselves as a DAG; however this may only work on a case-by-case basis. Similarly, recursive domain partitioning strategies work best for data that are measured uniformly in space as this guarantees similarly sized conditioning sets; on the contrary, recursive partitioning struggles in predicting the outcomes at large unobserved areas as they tend to be associated to the small conditioning sets making up the coarser scales or resolutions.
In this article, we solve these issues by introducing a Bayesian regression model that encodes spatial dependence as a latent spatial multivariate tree (SpamTree); conditional independence relations at the reference locations are governed by the branches in a treed DAG, whereas a map is used to assign all non-reference locations to leaf nodes of the same DAG. This assignment map controls the nature and the size of the conditioning sets at all locations; when severe restrictions on the reference set of locations become necessary due to data size, this map is used to improve estimation and predictions and overcome common issues in standard nearest-neighbor and recursive partition methods while maintaining the desirable recursive properties of treed DAGs. Unlike methods based on defining conditioning sets based solely on spatial proximity, SpamTrees scale to large data sets without excessive reduction of the conditioning sets. Furthermore, SpamTrees are less restrictive than methods based on recursive partitioning and can be built to guarantee similarly-sized conditioning sets at all locations.
The present work adds to the growing literature on spatial processes defined on DAGs by developing a method that targets efficient computations of Bayesian multivariate spatial regression models. SpamTrees share similarities with MRAs (Katzfuss, 2017); however, while MRAs are defined as a basis function expansion, they can be represented by a treed graph of a SpamTree with full “depth” as defined later (the DAG on the right of Figure 2), in univariate settings, and “response” models. All these restrictions are relaxed in this article. In considering spatial proximity to add “leaves” to our treed graph, our methodology also borrows from nearest-neighbor methods (Datta et al., 2016a). However, while we use spatial neighbors to populate the conditioning sets for non-reference locations, the same cannot be said about reference locations for which the treed graph is used instead. Our construction of the SpamTree process also borrows from MGPs on tessellated domains (Peruzzi et al., 2020); however, the treed DAG we consider here induces markedly different properties on the resulting spatial process owing to its recursive nature. Finally, a contribution of this article is in developing self-contained sampling algorithms which, based on the graphical model representation of the model, will not require any external libraries.
Figure 2:
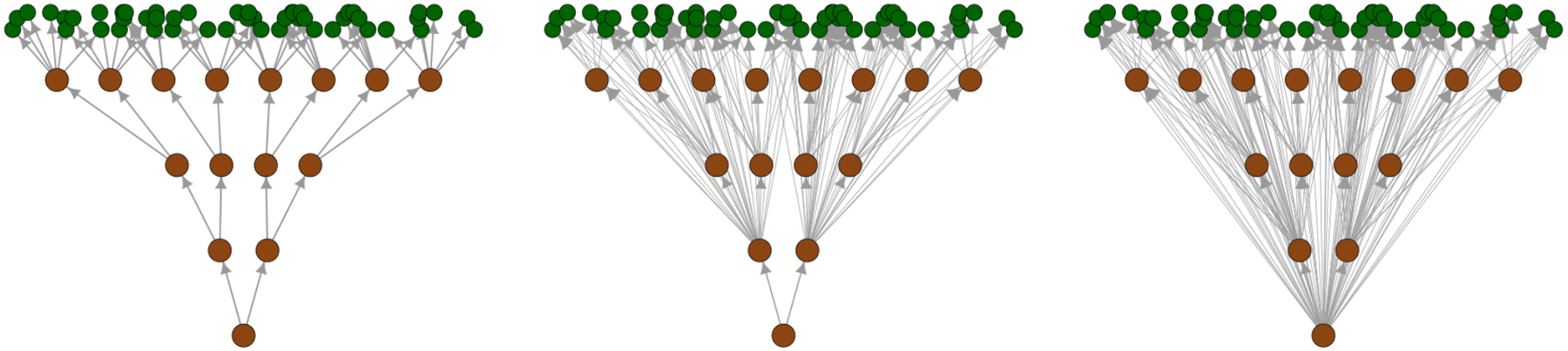
Three SpamTrees on M = 4 levels with depths δ = 1 (left), δ = 3 (center), and δ = 4 (right). Nodes are represented by circles, with branches colored in brown and leaves in green.
The article builds SpamTrees as a standalone process based on a DAG representation in Section 2. A Gaussian base process is considered in Section 3 and the resulting properties outlined, along with sampling algorithms. Simulated data and real-world applications are in Section 4; we conclude with a discussion in Section 5. The Appendix provides more in-depth treatment of several topics and additional algorithms.
2. Spatial Multivariate Trees
Consider a spatial or spatiotemporal domain . With the temporal dimension, we have , otherwise . A q-variate spatial process is defined as an uncountable set of random variables , where is a q × 1 random vector with elements for i = 1, 2,…, q, paired with a probability law P defining the joint distribution of any finite sample from that set. Let be of size . The random vector has joint density . After choosing an arbitrary order of the locations, , where the conditioning set for each can be interpreted as the set of nodes that have a directed edge towards in a DAG. Some scalable spatial processes result from reductions in size of the conditioning sets, following one of several proposed strategies (Vecchia, 1988; Stein et al., 2004; Gramacy and Apley, 2015; Datta et al., 2016a; Katzfuss and Guinness, 2021; Peruzzi et al., 2020). Accordingly,
| (1) |
where Pa[ℓi] is the set of spatial locations that correspond to directed edges pointing to ℓi in the DAG. If Pa[ℓi] is of size J or less for all , then is of size Jq. Methods that rely on reducing the size of parent sets are thus negatively impacted by the dimension q of the multivariate outcome; if q is not very small, reducing the number of parent locations J may be insufficient for scalable computations. As an example, an NNGP model has Pa[ℓi] = N (ℓi), where N (·) maps a location in the spatial domain to its neighbor set. It is customary in practice to consider Jq = m ≤ 20 for accurate and scalable estimation and predictions in univariate settings, but this may be restrictive in some multivariate settings as one must reduce J to maintain similar computing times, possibly harming estimation and prediction accuracy.
We represent the ith component of the q × 1 vector as , where for some k and Ξ serves as the k-dimensional latent spatial domain of variables. The q-variate process is thus recast as , with representing the latent location in the domain of variables. We can then write (1) as
| (2) |
where , , and w(·) is a univariate process on the expanded domain . This representation is useful as it provides a clearer accounting of the assumed conditional independence structure of the process in a multivariate context.
2.1. Constructing Spatial Multivariate DAGs
We now introduce the necessary terminology and notation, which are the basis for later detailing of estimation and prediction algorithms involving SpamTrees. The specifics for building treed DAGs with user-specified depth are in Section 2.1.1, whereas Section 2.1.2 gives details on cherry picking and its use when outcomes are imbalanced and misaligned.
The three key components to build a SpamTree are (i) a treed DAG with branches and leaves on M levels and with depth δ ≤ M; (ii) a reference set of locations ; (iii) a cherry picking map. The graph is where the nodes are , . We separate the nodes into reference A and non-reference B nodes, as this will aid in showing that SpamTrees lead to standalone spatial processes in Section 2.2. The reference or branch nodes are , where for all i = 0,…, M − 1 and with if . The non-reference or leaf nodes are , . We also denote Vr = Ar for r = 0,…, M – 1 and VM = B. The edges are and similarly . The reference set is partitioned in M levels starting from zero, and each level is itself partitioned into reference subsets:, where if or and its complement set of non-reference or other locations . The cherry picking map is and assigns a node (and therefore all the edges directed to it in ) to any location in the domain, following a user-specified criterion.
2.1.1. Branches and Leaves
For a given M and a depth δ ≤ M , we impose a treed structure on by assuming that if and then there exists a sequence of nodes such that for and . If then with . A0 is the tree root and is such that for all . The depth δ determines the number of levels of (from the top) across which the parent sets are nested. Choosing δ = 1 implies that all nodes have a single parent; choosing δ = M implies fully nested parent sets (i.e. if then for all . The mi elements of are the branches at level i of and they have i – Mδ parents if the current level i is above the depth level Mδ and 1 parent otherwise. We refer to terminal branches as nodes such that . For all choices of δ, , and implies i < j; this guarantees acyclicity.
As for the leaves, for all we assume for some integer sequence and with . We allow the existence of multiple leaves with the same parent set, i.e. there can be k and such that for all i2,…, ik,. Acyclicity of is maintained as leaves are assumed to have no children. Figure 2 represents the graph associated to SpamTrees with different depths.
2.1.2. Cherry Picking Via η(·)
The link between , and is established via the map which associates a node in to any location in the expanded domain :
| (3) |
This is a many-to-one map; note however that all locations in Sij are mapped to aij: by calling then for any i = 0,…, M – 1 and any j = 1,…, mi we have . SpamTrees introduce flexibility by cherry picking the leaves, i.e. using , the restriction of η to . Since each leaf node bj determines a unique path in ending in bj, we use ηB to assign a convenient parent set to w(u), , following some criterion.
For example, suppose that meaning that is the realization of the s-th variable at the spatial location ℓ, and we wish to ensure that Pa[w(u)] includes realizations of the same variable. Denote as the set of terminal branches of . Then we find where d(·,·) is the Euclidean distance. Since for some i, j we have . We then set ηB(u) = bk where Pa[bk] = {aij}. In a sense aij is the terminal node nearest to u; having defined ηB in such a way forces the parent set of any location to include at least one realization of the process from the same variable. There is no penalty in using as we can write , which also implies that the size of the parent set may depend on the variable index. Assumptions of conditional independence across variables can be encoded similarly. Also note that any specific choice of ηB induces a partition on ; let , then clearly with if . This partition does not necessarily correspond to the partitioning scheme used on . may by designed to ignore part of the tree and result in . However, we can just drop the unused leaves from and set for terminal nodes whose leaf is inactive, resulting in . We will thus henceforth assume that without loss of generality.
2.2. SpamTrees as a Standalone Spatial Process
We define a valid joint density for any finite set of locations in satisfying the Kolmogorov consistency conditions in order to define a valid process. We approach this problem analogously to Datta et al. (2016a) and Peruzzi et al. (2020). Enumerate each of the reference subsets as where , and each of the non-reference subsets as where . Then introduce where and for , for . Then take as the random vector with elements of for each . Denote . Then
| (4) |
which is a proper multivariate joint density since is acyclic (Lauritzen, 1996). All locations inside Uj always share the same parent set, but a parent set is not necessarily unique to a single Uj. This includes as a special case a scenario in which one can assume
| (5) |
in this case each location corresponds to a leaf node. To conclude the construction, for any finite subset of spatial locations we can let and obtain
leading to a well-defined process satisfying the Kolmogorov conditions (see Appendix A).
2.2.1. Positioning of Spatial Locations in Conditioning Sets
In spatial models based on sparse DAGs, larger conditioning sets yield processes that are closer to the base process p in terms of Kullback-Leibler divergence (Banerjee, 2020; Peruzzi et al., 2020), denoted as . The same results cannot be applied directly to SpamTrees given the treed structure of the DAG. For a given , we consider the distinct but related issues of placing individual locations into reference subsets (1) at different levels of the treed hierarchy; (2) within the same level of the hierarchy.
Proposition 1 Suppose where and ,. Take . Consider the graph ; denote as p0 the density of a SpamTree using , and , whereas let p1 be the density of a SpamTree with , and . Then .
The proof proceeds by an “information never hurts” argument (Cover and Thomas, 1991). Denote , , and . Then
therefore ; then by Jensen’s inequality
| (6) |
Intuitively, this shows that there is a penalty associated to positioning reference locations at higher levels of the treed hierarchy. Increasing the size of the reference set at the root augments the conditioning sets at all its children; since this is not true when the increase is at a branch level, the KL divergence of p0 from p is smaller than the divergence of p1 from the same density. In other words there is a cost of branching in which must be justified by arguments related to computational efficiency. The above proposition also suggests populating near-root branches with locations of sparsely-observed outcomes. Not doing so in highly imbalanced settings may result in possibly too restrictive spatial conditional independence assumptions.
Proposition 2 Consider the same setup as Proposition 1 and let p2 be the density of a SpamTree such that . Let Hp be the conditional entropy of base process p. Then implies .
The density of the new model is
Then, noting that , we get and
While we do not target the estimation of these quantities, this result is helpful in designing SpamTrees as it suggests placing a new reference location s∗ in the reference subset least uncertain about the realization of the process at s∗. We interpret this as justifying recursive domain partitioning on in spatial contexts in which local spatial clusters of locations are likely less uncertain about process realization in the same spatial region. In the remainder of this article, we will consider a given reference set which typically will be based on a subset of observed locations; the combinatorial problem of selecting an optimal (in some sense) is beyond the scope of this article. If is not partitioned, it can be considered as a set of knots or “sensors” and one can refer to a large literature on experimental design and optimal sensor placement (see e.g. Krause et al., 2008, and references therein). It might be possible to extend previous work on adaptive knot placement (Guhaniyogi et al., 2011), but this will come at a steep cost in terms of computational performance.
3. Bayesian Spatial Regressions Using SpamTrees
Suppose we observe an l-variate outcome at spatial locations which we wish to model using a spatially-varying regression model:
| (7) |
where is the j-th point-referenced outcome at ℓ, is a pj × 1 vector of spatially referenced predictors linked to constant coefficients βj, is the measurement error for outcome j, and is the k-th (of q) covariates for the j-th outcome modeled with spatially-varying coefficient , ,. This coefficient corresponds to the k-th margin of a q-variate Gaussian process denoted as with cross-covariance Cθ indexed by unknown parameters θ which we omit in notation for simplicity. A valid cross-covariance function is defined as , where is a subset of the space of all q × q real matrices . It must satisfy for any two locations ℓ, and for any integer n and finite collection of points and for all .
We replace the full GP with a Gaussian SpamTree for scalable computation considering the q-variate multivariate Gaussian process w(·) as the base process. Since the (i, j)-th entry of is , i.e. the covariance between the i-th and j-th elements of at and , we can obtain a covariance function on the augmented domain as where and are the locations in Ξ of variables i and j, respectively. Apanasovich and Genton (2010) use a similar representation to build valid cross-covariances based on existing univariate covariance functions; their approach amounts to considering or as a parameter to be estimated. Our approach can be based on any valid cross-covariance as we may just set Ξ = 1,…, q . Refer to e.g. Genton and Kleiber (2015) for an extensive review of cross-covariance functions for multivariate processes. Moving forward, we will not distinguish between C∗ and C. The linear multivariate spatially-varying regression model (7) allows the l outcomes to be observed at different locations; we later consider the case l = q and resulting in a multivariate space-varying intercept model.
3.1. Gaussian SpamTrees
Enumerate the set of nodes as , and denote , Cij as the ni × nj covariance matrix between wi and wj, Ci,[i] the ni × Ji covariance matrix between wi and w[i], Ci the ni × ni covariance matrix between wi and itself, and C[i] the Ji × Ji covariance matrix between w[i] and itself. A base Gaussian process induces , where
| (8) |
implying that the joint density is multivariate normal with covariance and precision matrix . At we have , where Hj and Rj are as in (8). All quantities can be computed using the base cross-covariance function. Given that the densities are Gaussian, so will be the finite dimensional distributions.
The treed graph leads to properties which we analyze in more detail in Appendix B and summarize here. For two nodes vi, denote the common descendants as . If denote Hi→j and as the matrix obtained by subsetting Hj to columns corresponding to vi, or to , respectively. Similarly define and . As a special case, if the tree depth is δ = 1 and {vj} = Pa[vi] then cd(vi, vj) = {vi}, Hi→j = Hj, and w[i→j] = w[j]. Define as the matrix whose (i, j) block is if , and otherwise .
3.1.1. Precision Matrix
The (i, j) block of the precision matrix at both reference and non-reference locations is denoted by , with i, j = 1,…, mV corresponding to nodes vi, for some i, j; it is nonzero if , otherwise:
| (9) |
where Iij is the (i, j) block of an identity matrix with nS + nU rows and is nonzero if and only if i = j. We thus obtain that the number of nonzero elements of is
| (10) |
where , , and by symmetry .
If δ > 1, the size of C[i] is larger for nodes vi at levels of the treed hierarchy farther from . However suppose vi, vj are such that . Then computing proceeds more cheaply by recursively applying the following:
| (11) |
3.1.2. Induced Covariance
Define a path from vk to vj as where , , and . The longest path is such that if and then . The shortest path is the path from vk to vj with minimum number of steps. We denote the longest path from the root to vj as ; this corresponds to the full set of ancestors of vj, and . For two nodes vi and vj we have . We define the concestor between vi and vj as i.e. the last common ancestor of the two nodes.
Take the path in from a node at leading to vj. After defining the cross-covariance function and denoting we can write
| (12) |
where for the es are independent zero-mean GPs with covariance and we set and . Take two locations ℓ, ℓꞌ such that , and let ; if then the above leads to
| (13) |
where . If take the shortest paths and ; setting we get
| (14) |
In particular if δ = M then for all i, j and only (13) is used, whereas if δ = 1 then the only scenario in which (13) holds is in which case the two are equivalent. In univariate settings, the special case in which δ = M , and hence Mδ = 0, leads to an interpretation of (12) as a basis function decomposition; considering all leaf paths for , this leads to an MRA (Katzfuss, 2017; Katzfuss and Gong, 2019). On the other hand, keeping other parameters constant, δ < M and in particular δ = 1 may be associated to savings in computing cost, leading to a trade-off between graph complexity and size of reference subsets; see Appendix B.5.
3.1.3. Block-Sparse Cholesky Decompositions
In recent work Jurek and Katzfuss (2020) consider sparse Cholesky decompositions of co-variance and precision matrices for treed graphs corresponding to the case δ = M above in the context of space-time filtering; their methods involve sparse Cholesky routines on reverse orderings of at the level of individual locations. In doing so, the relationship between Cholesky decompositions and , and the block structure in remains somewhat hidden, and sparse Cholesky libraries are typically associated to bottlenecks in MCMC algorithms. However we note that a consequence of (9) is that it leads to a direct algorithm, for any δ, for the block-decomposition of any symmetric positive-definite matrix conforming to , i.e. with the same block-sparse structure as . This allows us to write where I is the identity matrix, L is block lower triangular with the same block-sparsity pattern as above, and D is block diagonal symmetric positive-definite. In Appendix B.2.3 we outline Algorithm 4 which (i) makes direct use of the structure of , (ii) computes the decomposition at blocks of reference and non-reference locations, and (iii) requires no external sparse matrix library, in particular no sparse Cholesky solvers. Along with Algorithm 5 for the block-computation of (I – L)−1, it can be used to compute where is a block-diagonal matrix; it is thus useful in computing the Gaussian integrated likelihood.
3.2. Estimation and Prediction
We introduce notation to aid in obtaining the full conditional distributions. Write (7) as
| (15) |
where , , , , . The l × q matrix with acts a design matrix for spatial location ℓ. Collecting all locations along the j-th margin, we build and . We then call and similarly, , and . The full observed data are y, X, Z. Denoting the number of observations as , Z is thus a n × qn block-diagonal matrix, and similarly w is a qn × 1 vector. We introduce the diagonal matrix Dn such that .
By construction we may have and such that and where , and similarly for non-reference subsets. Suppose is a generic reference or non-reference subset. We denote as the set of all combinations of spatial locations of and variables i.e. where is the set of unique spatial locations in and are the unique latent variable coordinates. By subtraction we find as the set of locations whose spatial location is in but whose variable is not. Let ,; values corresponding to unobserved locations will be dealt with by defining as the diagonal matrix obtained from Dn by replacing unobserved outcomes with zeros. Denote and similarly. If includes L unique spatial locations then is a L l × l vector and is a matrix. In particular, is a L l × Lql matrix; the subset of its columns with locations in is denoted as whereas at other locations we get . We can then separate the contribution of to from the contribution of by writing , using which we let .
With customary prior distributions and along with a Gaussian SpamTree prior on w, we obtain the posterior distribution as
| (16) |
We compute the full conditional distributions of unknowns in the model, save for θ; iterating sampling from each of these distributions corresponds to a Gibbs sampler which ultimately leads to samples from the posterior distribution above.
3.2.1. Full Conditional Distributions
The full conditional distribution for β is Gaussian with covariance and mean . For , where and with .
Take a node . If then η−1(vi) = Si and for denote . The full conditional distribution of wi is , where
| (17) |
If instead and . Sampling of w at nodes at the same level r proceeds in parallel given the assumed conditional independence structure in . It is thus essential to minimize the computational burden at levels with a small number of nodes to avoid bottlenecks. In particular computing and can become expensive at the root when the number of children is very large. In Algorithm 3 we show that one can efficiently sample at a near-root node vi by updating and via message-passing from the children of vi.
3.2.2. Update of θ
The full conditional distribution of θ—which may include for j = 1,…, q or equivalently if the chosen cross-covariance function is defined on a latent domain of variables—is not available in closed form and sampling a posteriori can proceed
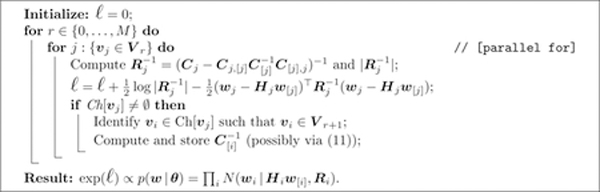
Algorithm 1: Computing p(w|θ).
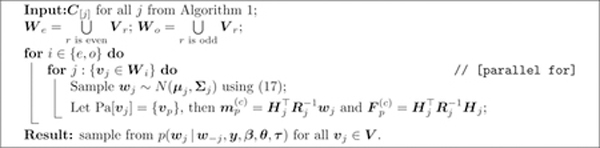
Algorithm 2: Sampling from the full conditional distribution of wi when δ = 1.

Algorithm 3: Sampling from the full conditional distribution of wj when δ = M.
via Metropolis-Hastings steps which involve accept/reject steps with acceptance probability . In our implementation, we adaptively tune the standard deviation of the proposal distribution via the robust adaptive Metropolis algorithm (RAM; Vihola, 2012). In these settings, unlike similar models based on DAG representations such as NNGPs and MGPs, direct computation via is inefficient as it requires computing whose size grows along the hierarchy in . We thus outline Algorithm 1 for computing via (11). As an alternative we can perform the update using ratios of using Algorithms 4 and 5 outlined in Appendix B.2.3 which require no sparse matrix library.
3.2.3. Graph Coloring for Parallel Sampling
An advantage of the treed structure of is that it leads to fixed graph coloring associated to parallel Gibbs sampling; no graph coloring algorithms are necessary (see e.g. Molloy and Reed, 2002; Lewis, 2016). Specifically, if δ = M (full depth) then there is a one to one correspondence between the M + 1 levels of and graph colors, as evidenced by the parallel blocks in Algorithms 1 and 3. In the case δ = 1, is associated to only two colors alternating the odd levels with the even ones. This is possible because the Markov blanket of each node at level r, with r even, only includes nodes at odd levels, and vice-versa.
3.2.4. Prediction of the Outcome at New Locations
The Gibbs sampling algorithm will iterate across the above steps and, upon convergence, will produce samples from . We obtain posterior predictive inference at arbitrary by evaluating . If , then we draw one sample of for each draw of the parameters from . Otherwise, considering that for some j, with parent nodes , we sample from the full conditional , where and , then draw .
3.2.5. Computing and Storage Cost
The update of and β can be performed at a minimal cost as typically is small; almost all the computation budget must be dedicated to computing and sampling . Assume that reference locations are all observed and that all reference subsets have the same size i.e. for all i. We show in Appendix B.5 that the cost of computing SpamTrees is . As a result, SpamTrees compare favorably to other models specifically in not scaling with the cube of the number of samples. δ does not impact the computational order, however, compared to δ = M , choosing δ = 1 lowers the cost by a factor of M or more. For a fixed reference set partition and corresponding nodes, choosing larger δ will result in stronger dependence between leaf nodes and nodes closer to the root—this typically corresponds to leaf nodes being assigned conditioning sets that span larger distances in space. The computational speedup corresponding to choosing δ = 1 can effectively be traded for a coarser partitioning of , resulting in large conditioning sets that are more local to the leaves.
4. Applications
We consider Gaussian SpamTrees for the multivariate regression model (15). Consider the spatial locations ℓ, and the locations of variables i and j in the latent domain of variables , , then denote , , and
For j = 1,…, q we also introduce . A non-separable cross-covariance function for a multivariate process can be defined as
| (18) |
which is derived from eq. (7) of Apanasovich and Genton (2010); locations of variables in the latent domain are unknown, therefore for a total of 3q + q(q − 1)/2 + 3 unknown parameters.
4.1. Synthetic Data
In this section we focus on bivariate outcomes (q = 2). We simulate data from model (15), setting β = 0, Z = Iq and take the measurement locations on a regular grid of size 70 × 70 for a total of 4,900 spatial locations. We simulate the bivariate spatial field by sampling from the full GP using (18) as cross-covariance function; the nuggets for the two outcomes are set to and . For j = 1, 2 we fix σj2 = 1, α = 1, β = 1 and independently sample , ϕj1 ~ U(−0.1, 3), , , , generating a total of 500 bivariate data sets. This setup leads to empirical spatial correlations between the two outcomes smaller than 0.25, between 0.25 and 0.75, and larger than 0.75 in absolute value in 107, 330, and 63 of the 500 data sets, respectively. We introduce misalignment and make the outcomes imbalanced by replacing the first outcome with missing values at ≈50% of the spatial locations chosen uniformly at random, and then repeating this procedure for the second outcome keeping only ≈ 10% of the total locations. We also introduce almost-empty regions of the spatial domain, independently for each outcome, by replacing observations with missing values at ≈ 99% of spatial locations inside small circular areas whose center is chosen uniformly at random in [0, 1]2. As a result of these setup choices, each simulated data set reproduces some features of the real-world unbalanced misaligned data we consider in Section 4.2 at a smaller scale and in a controlled experiment. Figure 3 shows one of the resulting 500 data sets.
Figure 3:
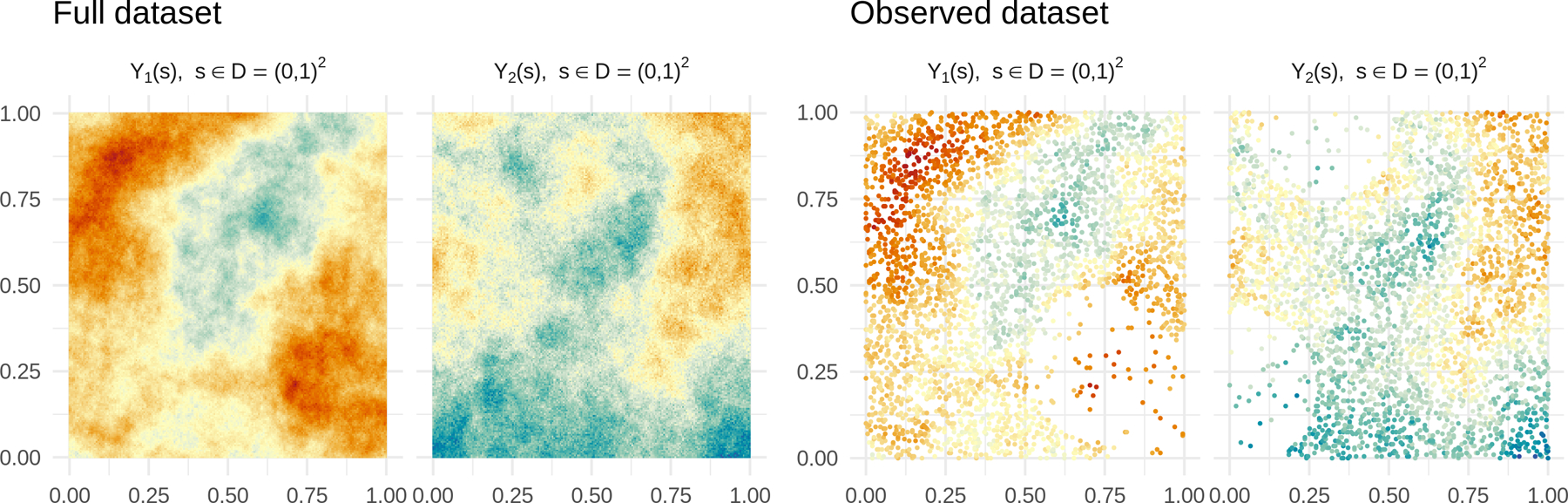
Left half: Full data set – a bivariate outcome is generated on 4,900 spatial locations. Right half: Observed data set – the training sample is built via independent subsampling of each outcome.
We consider SpamTrees with δ = 1 and implement multiple variants of SpamTrees with δ = M in order to assess their sensitivity to design parameters. Table 1 reports implementation setups and the corresponding results in all cases; if the design variable “All outcomes at ℓ” is set to “No” then a SpamTree is built on the domain. If it is set to “Yes” the DAG will be built using only – in other words, the q margins of the latent process are never separated by the DAG if they are measured at the same spatial location. “Cherry pick same outcome” indicates whether the map η(·) should search for neighbors by first filtering for matching outcomes – refer to our discussion at Section 2.1.2. We mention here if the DAG is built using only, then the nearest neighbor found via cherry picking will always include a realization of the same margin of . Finally, if SpamTree is implemented with “Root bias” then the reference set and the DAG are built with locations of the more sparsely observed outcome closer to root nodes of the tree as suggested by Proposition 1.
Table 1:
Prediction and estimation performance on multivariate synthetic data. The four columns on the right refer to root mean square error (RMDE) and mean absolute error (MAE) in out-of-sample predictions, average coverage of empirical 95% prediction intervals, and RMDE in the estimation of θ.
| All outcomes at ℓ | Cherry pick same outcome | Root bias | RMDE(y) | MAE(y) | COVG(y) | RMSE(θ) | |
|---|---|---|---|---|---|---|---|
| SpamTrees δ = M | No | No | No | 1.078 | 0.795 | 0.955 | 4.168 |
| No | No | Yes | 1.065 | 0.786 | 0.955 | 4.138 | |
| No | Yes | No | 1.083 | 0.799 | 0.954 | 4.168 | |
| No | Yes | Yes | 1.085 | 0.799 | 0.954 | 4.138 | |
| Yes | Yes | No | 1.081 | 0.797 | 0.954 | 4.080 | |
| Yes | Yes | Yes | 1.087 | 0.801 | 0.954 | 4.188 | |
|
| |||||||
| SpamTrees δ = 1 | Yes | Yes | No | 1.198 | 0.880 | 0.956 | 4.221 |
|
| |||||||
| Q-MGP | Yes | – | – | 1.125 | 0.819 | 0.951 | 4.389 |
|
| |||||||
| IND-PART | Yes | – | – | 1.624 | 1.229 | 0.948 | 8.064 |
|
| |||||||
| LOWRANK | Yes | – | – | 1.552 | 1.173 | 0.952 | 5.647 |
|
| |||||||
| SPDE-INLA | Yes | – | – | 1.152 | 0.862 | 0.913 | |
|
| |||||||
| SpamTrees Univariate | – | – | – | 1.147 | 0.846 | 0.953 | |
|
| |||||||
| NNGP Univariate | – | – | – | 1.129 | 0.832 | 0.952 | |
|
| |||||||
| BART | – | – | – | 1.375 | 1.036 | 0.488 | |
SpamTrees are compared with multivariate cubic meshed GPs (Q-MGPs; Peruzzi et al., 2020), a method based on stochastic partial differential equations (Lindgren et al., 2011) estimated via integrated nested Laplace approximations (Rue et al., 2009) implemented via R-INLA using a 15 × 15 grid and labeled SPDE-INLA, a low-rank multivariate GP method (labeled LOWRANK) on 25 knots obtained via SpamTrees by setting M = 1 with no domain partitioning, and an independent partitioning GP method (labeled IND-PART) implemented by setting M = 1 and partitioning the domain into 25 regions. Refer e.g. to Heaton et al. (2019) for an overview of low-rank and independent partitioning methods. All multivariate SpamTree variants, Q-MGPs, LOWRANK and IND-PART use (18) as the cross-covariance function in order to evaluate their relative performance in estimating θ in terms of root mean square error (RMDE) as reported in Table 1. We also include results from a non-spatial regression using Bayesian additive regression trees (BART; Chipman et al., 2010) which uses the domain coordinates as covariates in addition to a binary fixed effect corresponding to the outcome index. All methods were setup to target a compute time of approximately 15 seconds for each data set. We focused on comparing the different methods under computational constraints because (a) without constraints it would not be feasible to implement the methods for many large simulated spatial datasets; and (b) the different methods are mostly focused on providing a faster approximation to full GPs; if constraints were removed one would just be comparing the same full GP method.
Table 1 reports average performance across all data sets. All Bayesian methods based on latent GPs exhibit very good coverage; in these simulated scenarios, SpamTrees exhibit comparatively lower out-of-sample prediction errors. All SpamTrees perform similarly, with the best out-of-sample predictive performance achieved by the SpamTrees cherry picking based solely on spatial distance (i.e. disregarding whether or not the nearest-neighbor belongs to the same margin). Additional implementation details can be found in Appendix C.2.1. Finally, we show in Figure 4 that the relative gains of SpamTrees compared to independent univariate NNGP model of the outcomes are increasing with the magnitude of the correlations between the two outcomes, which are only available due to the simulated nature of the data sets.
Figure 4:
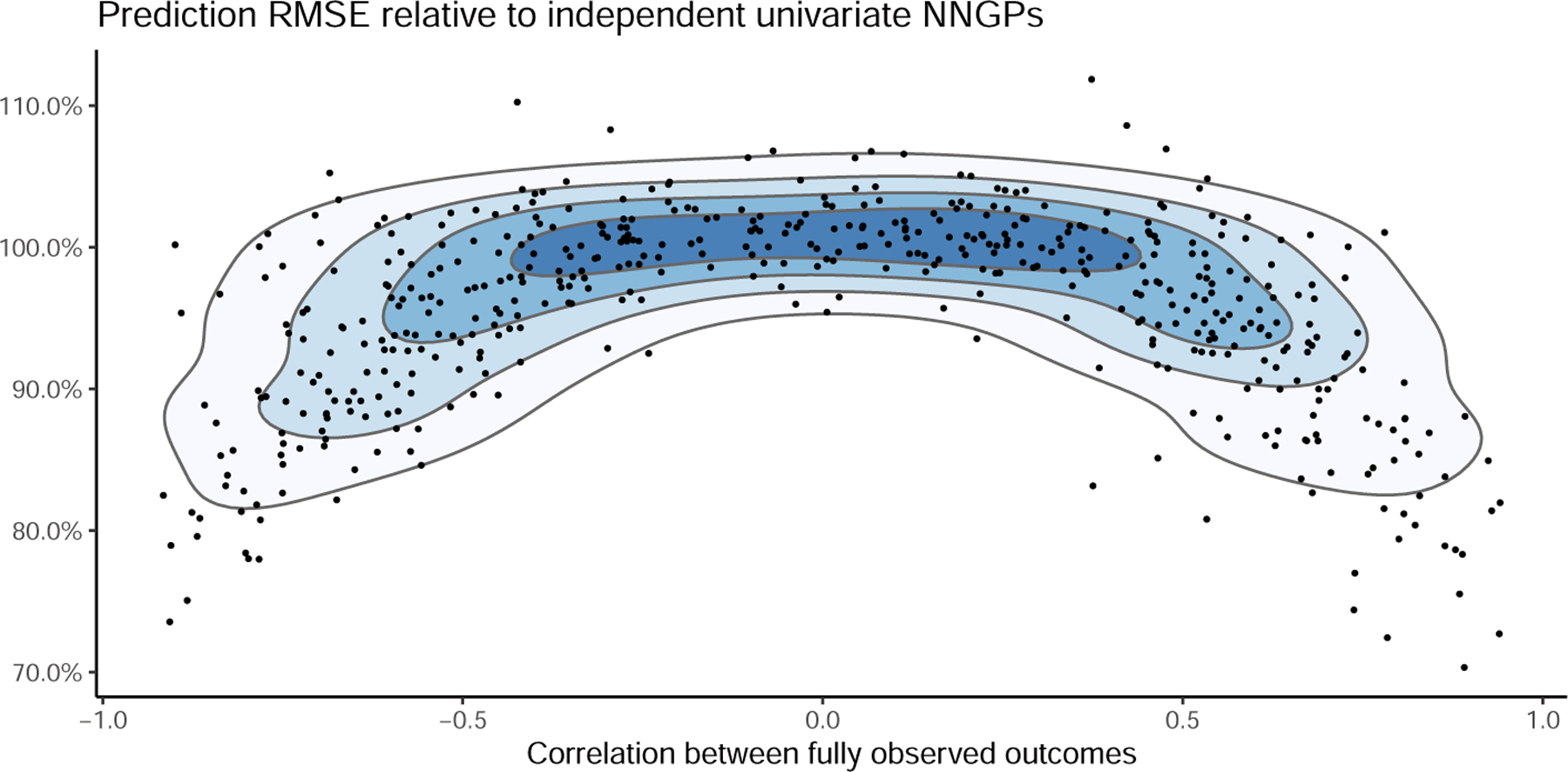
Predictive RMSE of the best-performing SpamTree of Table 1 relative to independent univariate NNGP models of the two outcomes, for different empirical correlations between the two outcomes in the full data. Lower values indicate smaller errors of SpamTrees in predictions.
4.2. Climate Data: MODIS-TERRA and GHCN
Climate data are collected from multiple sources in large quantities; when originating from satellites and remote sensing, they are typically collected at high spatial and relatively low temporal resolution. Atmospheric and land-surface products are obtained via post-processing of satellite imaging, and their quality is negatively impacted by cloud cover and other atmospheric disturbances. On the other hand, data from a relatively small number of land-based stations is of low spatial but high temporal resolution. An advantage of land-based stations is that they measure phenomena related to atmospheric conditions which cannot be easily measured from satellites (e.g. precipitation data, depth of snow cover).
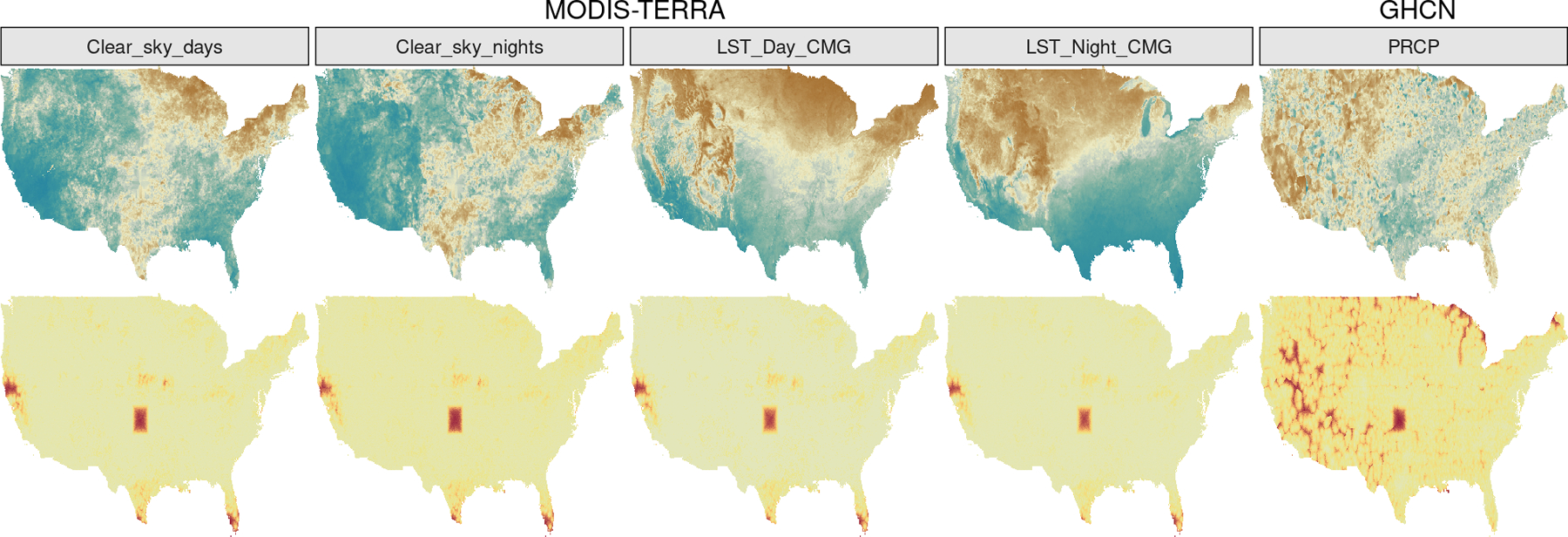
We consider the joint analysis of five spatial outcomes collected from two sources. First, we consider Moderate Resolution Imaging Spectroradiometer (MODIS) data from the Terra satellite which is part of the NASA’s Earth Observing System. Specifically, data product MOD11C3 v. 6 provides monthly Land Surface Temperature (LST) values in a 0.05 degree latitude/longitude grid (the Climate Modeling Grid or CMG). The monthly data sets cover the whole globe from 2000–02-01 and consist of daytime and nighttime LSTs, quality control assessments, in addition to emissivities and clear-sky observations. The second source of data is the Global Historical Climatology Network (GHCN) database which includes climate summaries from land surface stations across the globe subjected to common quality assurance reviews. Data are published by the National Centers of Environmental Information (NCEI) of the National Oceanic and Atmospheric Administration (NOAA) at several different temporal resolutions; daily products report five core elements (precipitation, snowfall, snow depth, maximum and minimum temperature) in addition to several other measurements.
We build our data set for analysis by focusing on the continental United States in October, 2018. The MODIS data correspond to 359,822 spatial locations. Of these, 250,874 are collected at the maximum reported quality; we consider all remaining 108,948 spatial locations as missing, and extract (1) daytime LST (LST_Day_CMG), (2) nighttime LST (LST_Night_CMG), (3) number of days with clear skies (Clear_sky_days), (4) number of nights with clear skies (Clear_sky_nights). From the GHCN database we use daily data to obtain monthly averages for precipitation (PRCP), which is available at 24,066 spatial locations corresponding to U.S. weather stations; we log-transform PRCP. The two data sources do not share measurement locations as there is no overlap between measurement locations in MODIS and GHCN, with the latter data being collected more sparsely—this is a scenario of complete spatial misalignment. From the resulting data set of size n =1,027,562 we remove all observations in a large 3 × 3 degree area in the central U.S. (from -100W to -97W and from 35N to 38N, i.e. the red area of Figure 5) to build a test set on which we calculate coverage and RMDE of the predictions.
Figure 5:
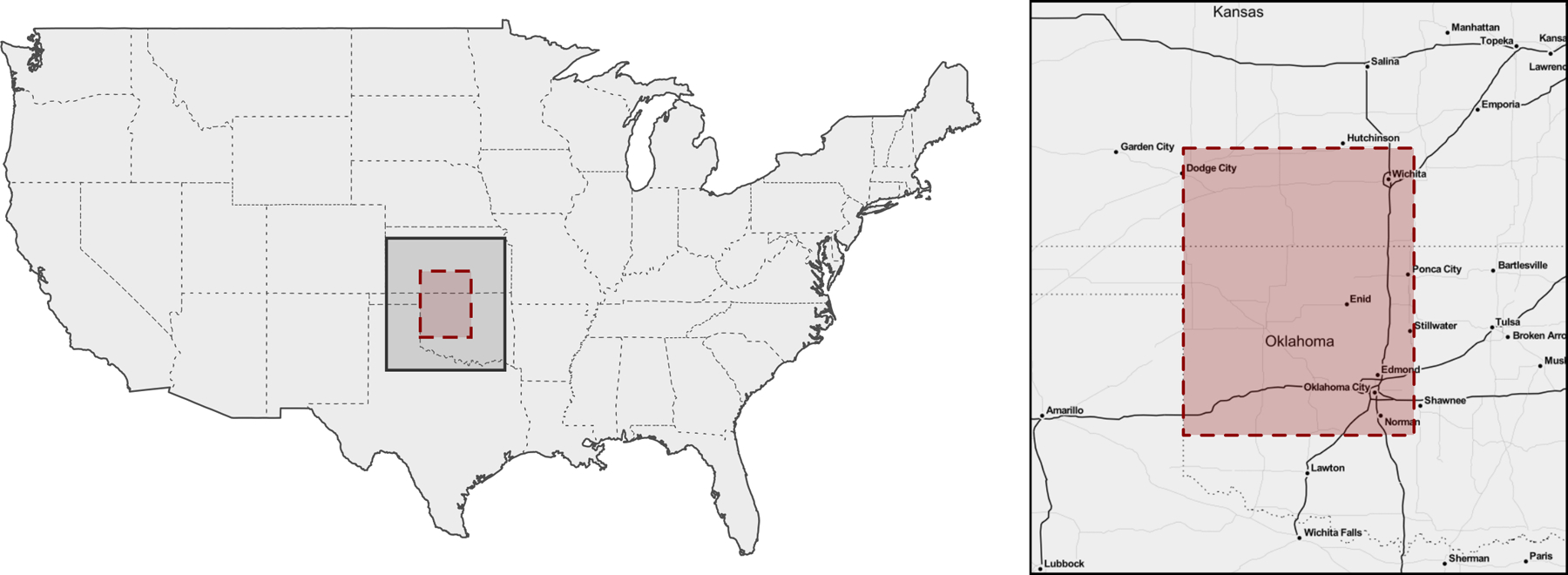
Prediction area
We implement SpamTrees using the cross-covariance function (18). Considering that PRCP is more sparsely measured and following Proposition 1, we build SpamTrees favoring placement of GHCN locations at root nodes. We compare SpamTrees with a Q-MGP model built on the same cross-covariance function, and two univariate models that make predictions independently for each outcome. Comparisons with other multivariate methods are difficult due to the lack of scalable software for this data size which also deals with misalignment and imbalances across outcomes. Compute times per MCMC iteration ranged from 2.4s/iteration of the multivariate Q-MGP model, to 1.5s/iteration of the univariate NNGP model. The length of the MCMC chains (30,000 for SpamTrees and 20,000 for Q-MGP) was such that the total compute time was about the same for both models at less than 16 hours. Univariate models cannot estimate cross-covariances of multivariate outcomes and are thus associated to faster compute times; we set the length of their MCMC chains to 15,000 for a total compute time of less than 7 hours for both models. We provide additional details about the models we implemented at Appendix C.
Table 2 reports predictive performance of all models, and Figure 6 maps the predictions at all locations from SpamTrees and the corresponding posterior uncertainties. Multivariate models appear advantageous in predicting some, but not all outcomes in this real world illustration; nevertheless, SpamTrees outperformed a Q-MGP model using the same cross-covariance function. Univariate models perform well and remain valid for predictions, but cannot estimate multivariate relationships. We report posterior summaries of θ in Appendix C.2.2. Opposite signs of σi1 and σj1 for pairs of variables imply a negative relationship; however, the degree of spatial decay of these correlations is different for each pair as prescribed by the latent distances in the domain of variables δij. Figure 7 depicts the resulting cross-covariance function for three pairs of variables.
Table 2:
Prediction results over the 3 × 3 degree area shown in Figure 5
| MODIS/GHCN variables | Multivariate | Univariate | |||
|---|---|---|---|---|---|
| SpamTree | Q-MGP | SpamTree | NNGP | ||
| Clear_sky_days | RMDE | 1.611 | 1.928 | 1.466 | 1.825 |
| COVG | 0.980 | 0.866 | 0.984 | 0.986 | |
|
| |||||
| Clear_sky_nights | RMDE | 1.621 | 1.766 | 2.002 | 2.216 |
| COVG | 0.989 | 0.943 | 0.992 | 0.992 | |
|
| |||||
| LST_Day_CMG | RMDE | 1.255 | 1.699 | 1.645 | 1.666 |
| COVG | 1.000 | 1.000 | 1.000 | 1.000 | |
|
| |||||
| LST_Night_CMG | RMDE | 1.076 | 1.402 | 0.795 | 1.352 |
| COVG | 0.999 | 0.999 | 1.000 | 1.000 | |
|
| |||||
| PRCP | RMDE | 0.517 | 0.632 | 0.490 | 0.497 |
| COVG | 0.972 | 1.000 | 0.969 | 0.958 | |
Figure 6:
Predicted values of the outcomes at all locations (top row) and associated 95% uncertainty (bottom row), with darker spots corresponding to wider credible intervals.
Figure 7:
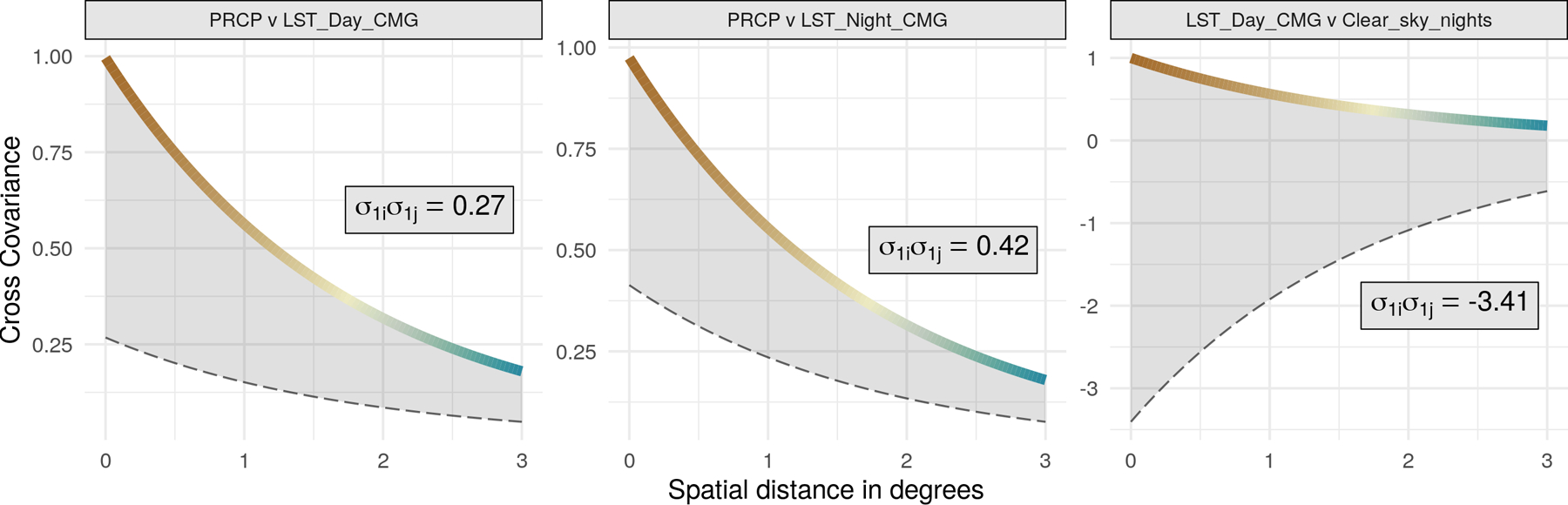
Given the latent dimensions δij, the color-coded lines represent whereas is shown as a dashed grey line.
5. Discussion
In this article, we introduced SpamTrees for Bayesian spatial multivariate regression modeling and provided algorithms for scalable estimation and prediction. SpamTrees add significantly to the class of methods for regression in spatially-dependent data settings. We have demonstrated that SpamTrees maintain accurate characterization of spatial dependence and scalability even in challenging settings involving multivariate data that are spatially misaligned. Such complexities create problems for competing approaches, including recent DAG-based approaches ranging from NNGPs to MGPs.
One potential concern is the need for users to choose a tree, and in particular specify the number of locations associated to each node and the multivariate composition of locations in each node. Although one can potentially estimate the tree structure based on the data, this would eliminate much of the computational speedup. We have provided theoretical guidance based on KL divergence from the full GP and computational cost associated to different tree structures. This and our computational experiments lead to practical guidelines that can be used routinely in tree building. Choosing a tree provides a useful degree of user-input to refine and improve upon an approach.
We have focused on sampling algorithms for the latent effects because they provide a general blueprint which may be used for posterior computations in non-Gaussian outcome models; efficient algorithms for non-Gaussian big geostatistical data sets are currently lacking and are the focus of ongoing research. SpamTrees can be built on larger dimensional inputs for general applications in regression and/or classifications; such a case requires special considerations regarding domain partitioning and the construction of the tree. In particular, when time is available as a third dimension it may be challenging to build a sparse DAG with reasonable assumptions on temporal dependence. For these reasons, future research may be devoted to building sparse DAG methods combining the advantages of treed structures with e.g. Markov-type assumptions of conditional independence, and applying SpamTrees to data with larger dimensional inputs.
Figure 8:
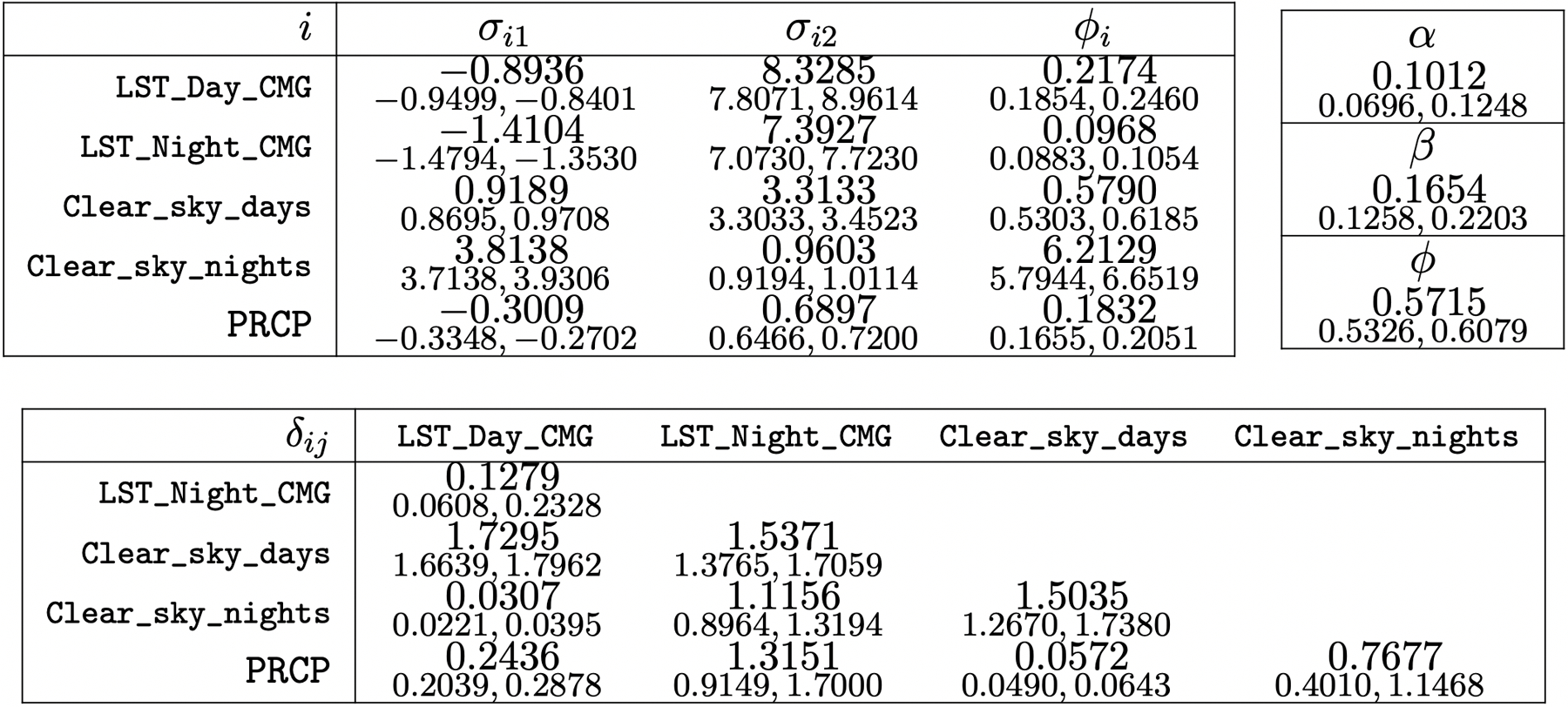
Posterior means and 95% credible intervals for components of θ for SpamTrees.
Acknowledgments
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 856506). This project was also partially funded by grant R01ES028804 of the United States National Institutes of Health (NIH).
Appendix A. Kolmogorov consistency conditions for SpamTrees
We adapt results from Datta et al. (2016a) and Peruzzi et al. (2020). Let be the univariate representation in the augmented domain of the multivariate base process . Fix the reference set and let and . Then
hence is a proper joint density. To verify the Kolmogorov consistency conditions, take the permutation and call . Clearly and similarly so that
Implying
Next, take a new location location . Call . We want to show that .If then and hence
If we have
Appendix B. Properties of Gaussian SpamTrees
Consider the treed graph of a SpamTree. In this section, we make no distinction between reference and non-reference nodes, and instead label Vi = Ai for i = 0,…, M −1 and V M = B so that V = {A, B} = {V 0,…, V M−1, V M } and the V M are the leaf nodes. Each wi is ni × 1 and corresponds to vi ∈ V r for some r = 0,…, M so that for some sequence {j1,…, jr}, and . Denote the h-th parent of vi as Pa[vi](h).
B.1. Building the precision matrix
We can represent each conditional density as a linear regression on wi:
| (19) |
where each hij is an ni × nj coefficient matrix representing the regression of wi given for i = 0, 1,…, M , and each Ri is an ni × ni residual covariance matrix. We set hii = O and hij = O, where O is the matrix of zeros, whenever . Using this representation, we have which is an ni × Ji block matrix formed by stacking hi,jk side by side for k = 1,…, r. Since we obtain . We also obtain , hence all Hi’s, hij’s, and Ri’s can be computed from the base covariance function.
In order to continue building the precision matrix, define the block matrix .
We can write
| (20) |
where refers to the h-th block column. More compactly using the indicator function we have . If we stack all the hik horizontally for k = 0,…, MS − 1, we obtain the ni × n matrix , which is i-th block row of . Intuitively, is a sparse matrix with the coefficients linking the full w to wi, with zero blocks at locations whose corresponding node is vj ∈/ Pa[vi]. The ith block-row of is of size ni × n but only has r non-empty sub-blocks, with sizes ni × nj for j ∈ {j1,…, jr}, respectively. Instead, Hi is a dense matrix obtained by dropping all the zero-blocks from , and stores the coefficients linking w[i] to wi. The two are linked as .
Since , where R = b.diag{Ri} and is block lower-triangular with unit diagonal, hence non-singular. We find the precision matrix as .
B.2. Properties of
When not ambiguous, we use the notation Xij to denote the (i, j) block of X. An exception to this is the (i, j) block of which we denote as . In SpamTrees, is nonzero if i = j or if the corresponding nodes vi and vj are connected in the moral graph , which is an undirected graph based on in which an edge connects all nodes that share a child. This means that either (1) vi ∈ Pa[vj] or vice-versa, or (2) there exists a∗ such that {vi, vj} ⊂ Pa[a∗]. In SpamTrees,. In fact, suppose there is a node a∗ ∈ vr∗ such that a∗ ∈ Ch[vj] ∩ Ch[vk], where . By definition of there exists a sequence {i1,…, ir∗ } such that , and furthermore for h ≤ r∗. This implies that if j = k then vj = vk, whereas if j > k then vk ∈ Pa[vj], meaning that no additional edge is necessary to build .
B.2.1. Explicit Derivation of
Denote , and define the “common descendants” as cd(vi, vj) = ({vi} ∪ Ch[vi]) ∩ ({vj} ∪ Ch[vj]). Then consider ai ∈ A, vj ∈ V such that ai ∈ Pa[vj] and denote as Hi→j the matrix obtained by subsetting Hj to columns corresponding to ai and note that . The (i, j) block of U is then
Then and, as in (9), each block of the precision matrix is:
| (21) |
where implies and Iij a zero matrix unless i = j as it is the (i, j) block of an identity matrix of dimension n × n.
B.2.2. Computation of Large Matrix Inverses
One important aspect in building is that it requires the computation of the inverse of dimension Ji × Ji for all nodes with parents, i.e. at r > 0. Unlike models which achieve scalable computations by limiting the size of the parent set (e.g. NNGPs and their blocked variant, or tessellated MGPs), this inverse is increasingly costlier when δ > 1 for nodes at a higher-level of the tree as those nodes have more parents and hence larger sets of parent locations (the same conclusion holds for non-reference nodes). However, the treed structure in allows one to avoid computing the inverse in . In fact, suppose we have a symmetric, positive-definite block-matrix A and we wish to compute its inverse. We write
where is the Schur complement of D in A. If C−1 was available, the only necessary inversion is that of S. In SpamTrees with δ > 1, suppose vi, vj are two nodes such that – this arises for nodes . Regardless of whether vj is a reference node or not, η−1(Pa[vj]) = {Si, S[i]} and
where the Schur complement of is . Noting that we write
| (22) |
B.2.3. Computing and its determinant without sparse Cholesky
Bayesian estimation of regression models requiring the computation of and its determinant use the Sherman-Morrison-Woodbury matrix identity to find , where . A sparse Cholesky factorization of can be used as typically Σ is diagonal or block-diagonal, thus maintaining the sparsity structure of . Sparse Cholesky libraries (e.g. Cholmod, Chen et al., 2008), which are embedded in software or high-level languages such as MATLAB™ or the Matrix package for R, scale to large sparse matrices but are either too flexible or too restrictive in our use cases: (1) we know and its properties in advance; (2) SpamTrees take advantage of block structures and grouped data. In fact, sparse matrix libraries typically are agnostic of and heuristically attempt to infer a sparse given its moralized counterpart. While this operation is typically performed once, a priori knowledge of implies that reliance on such libraries is in principle unnecessary.
We thus take advantage of the known structure in to derive direct algorithms for computing and its determinant. In the discussion below we consider δ = M , noting here that choosing δ = 1 simplifies the treatment as cd(vi, vj) = vi if vi = vj, and it is empty otherwise. We now show how (21) leads to Algorithm 4 for the decomposition of any precision matrix Λ which conforms to – i.e. it has the same block-sparse structure as a precision matrix built as in Section B.1. Suppose from Λ we seek a block lower-triangular matrix L and a block diagonal D such that
Start with vi, vj taken from the leaf nodes, i.e. . Then and we set . If i = j then cd(vi, vi) = {vi} and
we then set Lii = O and get the i-th block of Di simply setting Di = Λii. Proceeding downwards along , if we have and thus set . We then note that cd(vj, vj) = {vj, vi} and obtain where Lij and Di have been fixed at the previous step; this results in .
Then, the s-th (of M ) step takes and , implying . Nothing that has been fixed at previous steps since each vk is at level M−s + 2, we split the sum in (21) and get
where Di has been fixed at step s−1, obtaining ; Dj can be found using the same logic. Proceeding until M − s = 0 from the leaves of to the root, we ultimately fill each non-empty block in L and D resulting in . Algorithm 4 unifies these steps to obtain the block decomposition of any sparse precision matrix Λ conforming to resulting in , where L is block lower triangular and D is block diagonal. This is akin to a block-LDL decomposition of Λ indexed on nodes of . Algorithm 5 complements this decomposition by providing a -specific block version of forward substitution for computing (I−L)−1 with L as above.
In practice, a block matrix with K2 blocks can be represented as a K2 array with rows and columns indexed by nodes in and matrix elements which may be zero-dimensional whenever corresponding to blocks of zeros. The specification of all algorithms in block notation allows us to never deal with large (sparse) matrices in practice but only with small block matrices indexed by nodes in , bypassing the need for external sparse matrix libraries. Specifically we use the above algorithms to compute and its determinant: and . We have not distinguished non-reference and reference nodes in this discussion. In cases in which the non-reference set is large, we note that the conditional independence of all non-reference locations, given their parents, results in being diagonal for all (i.e. η(ℓ) = vi ∈ B). This portion of the precision matrix can just be stored as a column vector.
B.2.4. Sparsity of
We calculate the sparsity in the precision matrix; considering an enumeration of nodes by level in , denote , , and , and noting that by symmetry , the number of nonzero elements of is
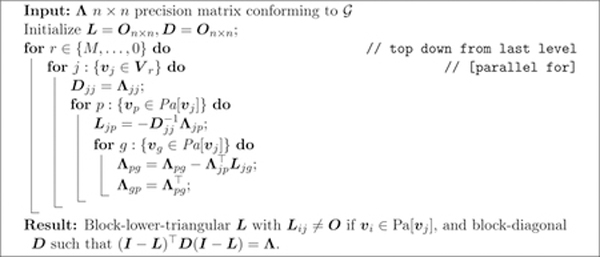
Algorithm 4: Precision matrix decomposition given treed graph with M levels.

Algorithm 5: Calculating the inverse of I − L with L output from Algorithm 4.
where nij1 {j = M} refers to the diagonal elements of the precision matrix at non-reference locations.
B.3. Properties of SpamTrees with δ = M
We outline recursive properties of induced by when δ = M . In the case 1 < δ < M , these properties hold for nodes at or above level Mδ, using as root. We focus on paths in . These can be represented as sequences of nodes such that for 1 < j < k < r. Take two successive elements of such a sequence, i.e. vi, vj such that vi → vj in . Consider and . By (22) we can write
Now define the covariance function ; recalling that the reference set is we use a shorthand notation for these subsets: Ki(Sh, Sk) = Ki(h, k). Also denote for all i. The above expression becomes
we can use this recursively on where and and get
where the expectations on the r.h.s. are taken with respect to the distributions of es which are Gaussian with mean zero and var{eh} = Kh(h, h) – this is a compact expression of the conditionals governing the process as prescribed by . We can also write the above as ;using , for h < k we find
The above results also imply and suggest an additive representation via orthogonal basis functions:
| (23) |
Finally, considering the same sequence of nodes, recursively introduce the covariance functions F 0(r, s) = Cr,s and for .
We get
which can be iterated forward and results in an additional recursive way to compute co-variances in SpamTrees. Notice that while Kj is formulated using the inverse of Jj × Jj matrix C[j], the F j’s require inversion of smaller nj × nj matrices F j−1(j-1, j-1).
B.4. Properties of
B.4.1. δ = 1
Choosing depth δ = 1 results in each node having exactly 1 parent. In this case the path from vk to vj, where and , is unique, and there is thus no distinction between shortest and longest paths:. Then denote . Let vz be the concestor between vi and vj i.e. and the associated paths and where and . Then we can write where and proceed expanding to get ; continuing downwardly along the tree we eventually find where is independent of wz. After proceeding analogously with wj , take ℓi, ℓj such that η(ℓi) = vi and η(ℓj) = vj. Then
| (24) |
where and similarly for .
B.4.2. 1 < δ < M
Take two nodes vi,. If then we apply the same logic as in B.4.3 using vz = con(vi, vj) as root. If Pa[vi] ∩ Pa[vj] = ∅ and both nodes are at levels below Mδ then we use B.4.1. The remaining scenario is thus one in which vi ∈ Ar, r > Mδ and . We take , for simplicity in exposition and without loss of generality. By (23)
| (25) |
where is the parent node of vi at level Mδ. The final result of (14) is then achieved by noting that the relevant subgraph linking vx and vj has depth δx = 1 and thus Cov(wx, wj) can be found via B.4.1, then . Notice that Fi directly uses the directed edge in ; for this reason the path between wi and is the actually the shortest path and we have .
B.4.3. δ = M
Take vi, and the full paths from the root and , respectively. Then using (23) we have
| (26) |
where . Then since es are independent and we find
| (27) |
We conclude by noting that δ = M implies ; considering two locations ℓi, such that and we obtain
B.5. Computational cost
We make some assumptions here to simplify the calculation of overall cost: first, we assume that reference locations are all observed , and consequently . Second, we assume that all reference subsets have the same size i.e. for all i. Third, we assume all nodes have the same number of children at the next level in , i.e. if with , then , whereas if r = M − 1 then . Fourth, we assume that all non-reference subsets are singletons i.e. if then |Ui|= 1. The latter two assumptions imply (5). We also fix . As a result, the number of nodes at level is Cr, therefore . Then the sample size is hence . Starting with , the parent set sizes Ji for a node grow with r as and if then . The cost of computing p(w θ) is driven by the calculation of , which is for reference nodes at level r, for a total of . Since for common choices of C and M we have then the cost for reference sets is . Analogously for non reference nodes we get which leads to a cost of . The cost of sampling w is mainly driven by the computation of the Cholesky factor of a Ns × Ns matrix at each of reference nodes, which amounts to . For the non-reference nodes the main cost is in computing which is MNs for overall cost which is smaller than . Obtaining at the root of is associated to a cost which is but constitutes a bottleneck if such operation is performed simultaneously to sampling; however this bottleneck is eliminated in Algorithm 3.
If δ = 1 then the parent set sizes Ji for all nodes are constant ; since the nodes at levels 0 to have C children, the asymptotic cost of computing is . However there are savings of approximately a factor of M associated to δ = 1 in fixed samples since . Fixing C and M one can thus choose larger Ns and smaller δ, or vice-versa.
The storage requirements are driven by the covariance at parent locations for nodes with i.e. all reference nodes at level and non-reference nodes. Taking δ = M , suppose is the last parent of , meaning . Then . If then these matrices are of size ; each of these is thus in terms of storage. Considering all such matrices brings the overall storage requirement to which is O(nNs using analogous arguments as above. For δ = 1 we apply similar calculations as above. The same number of Hj and Rj must be stored but these are smaller in size and therefore do not affect the overall storage requirements. The design matrix Z is stored in blocks and never as a large (sparse) matrix implying a storage requirement of O(nq).
Appendix C. Implementation details
Building a SpamTree DAG proceeds by first constructing a base-tree at depth δ = 1 and then adding edges to achieve the desired depth level. The base tree is built from the root by branching each node v into children where d is the dimension of the spatial domain and c is a small integer. The spatial domain is partitioned recursively; after setting , each recursive step proceeds by partitioning each coordinate axis of into c intervals. As a consequence and if . This recursive partitioning scheme is used to partition the reference set which we consider as a subset of the observed locations. Suppose we wish to associate node v to approximately nS locations where nS = kd for some k. Start from the root i.e.. Then take and partition it via parallel partitioning of each coordinate axis into k intervals. Collect 1 location from each subregion to build S0. Then set and . Then, take such that . We find via axis-parallel partitioning of into kd regions and selecting one location from each partition, as above, and setting . All other reference subsets are found by sequentially removing locations from the reference set, and proceeding analogously as above. This stepwise procedure is stopped when either the tree reaches a predetermined height M , or when there is an insufficient number of remaining locations to build reference subsets of size nS. The remaining locations are assigned to the leaf nodes via ηB as defined in Section 2.1 in order to include at least one neighboring realization of the process from the same variable.
One specific issue arises when multivariate data are imbalanced, i.e. one of the margins is observed at a much sparser grid, e.g. in Section 4.2 PRCP is collected at a ratio of 1:10 locations compared to other variables. In these cases, if locations were chosen uniformly at random to build the reference subsets then the root nodes would be associated via η to reference subsets which likely do not contain such sparsely observed variables. This scenario goes against the intuition of 1 suggesting that a naïve approach would result in poor performance at the sparsely-observed margins. To avoid such a scenario, we bias the sampling of locations to favor those at which the sparsely-observed variables are recorded. As a result, in Section 4.2 near-root nodes are associated to reference subsets in which all variables are balanced; the imbalances of the data are reflected by imbalanced leaf nodes instead.
The source code for SpamTrees is available at https://CRAN.R-project.org/package=SpamTree and can be installed as an R package. The SpamTree package is written in C++ using the Armadillo library for linear algebra (Sanderson and Curtin, 2016) interfaced to R via RcppArmadillo (Eddelbuettel and Sanderson, 2014). All matrix operations are performed efficiently by linkage to the LAPACK and BLAS libraries (Blackford et al., 2002; Anderson et al., 1999) as implemented in OpenBLAS 0.3.10 (Zhang, 2020) or the Intel Math Kernel Library. Multithreaded operations proceed via OpenMP (Dagum and Menon, 1998).
C.1. On the dependencies on sparse Cholesky libraries
SpamTrees do not require the use of external Cholesky libraries because Cholesky-like algorithms can be written explicitly by referring to the treed DAG and its edges. This is unusual for DAG-based models commonly used in geostatistical settings. For example, an NNGP model uses neighbors to build a DAG. The DAG can be used to fill the L and D matrices leading to , where C−1 is the sparse precision matrix of the latent process. When one then adds measurement error in a regression setting and marginalizes out the latent process, the goal is to find the Cholesky decomposition of C−1 + τ2 In . The original NNGP DAG used for L and D is not useful for this purpose – hence the need for NNGP to use sparse Cholesky libraries in collapsed samplers (Finley et al., 2019). On the other hand, with SpamTrees we can still look at the original DAG to “update” Land D by using Algorithm 4. We included it in the Appendix as our software package implements the Gibbs sampler in the main article, which does not involve Cholesky decompositions of large sparse precision matrices.
Furthermore, one of the initial steps in Cholesky algorithms for sparse symmetric positive-definite matrices involves finding “good” reordering rows and columns. These reorderings simplify the (undirected) graphical model that corresponds to the sparsity structure in the matrix. Once a simple-enough graphical model is found heuristically, it is used for the decomposition. On the other hand, the sparse Cholesky algorithm for SpamTrees can be written explicitly using the underlying DAG, without any intermediate step, because it is fixed and with a convenient treed structure. It might be possible to write software that out-performs excellent libraries such as CHOLMOD (Chen et al., 2008) at decomposing the matrices needed in collapsed sampling algorithms for SpamTrees.
Regarding a more general perspective about dependencies on well established software libraries, we should clarify that the software for SpamTree does take advantage of highly efficient libraries such as BLAS/LAPACK provided in Intel MKL 2019.5, OpenMP (Dagum and Menon, 1998) for parallelizing the algorithms as described in the main article. These libraries are optional and our code does not strictly depend on them. For example, noting that it is considerably more difficult to compile OpenMP code on Macs, one can just disable OpenMP and let the Accelerate BLAS (rather than OpenBLAS or Intel MKL) deal with all matrix algebra for Apple computers, at the cost of some performance in big data settings. Our code also has R package dependencies for data pre-processing, but these are peripheral to the proposed methods and algorithms. Any improvement in the upstream libraries we used for coding SpamTree will positively impact the performance of our software.
C.2. Applications
C.2.1. Simulated Datasets
SpamTrees with full depth are implemented by targeting reference subsets of size nS = 25 and tress with c = 4 additional children for each branch. The tree is built starting from a 2 × 2 partition of the domain, hence there are 4 root nodes with no parents in the DAG. The cherry-pickying function η is set as in Section 2.1; with these settings the tree height is M = 3. For SpamTrees with depth δ = 1 we build the tree with reference subsets of size nS = 80 and c = 4. Multivariate Q-MGPs are implemented via axis-parallel partitioning using 57 intervals along each axis. The multivariate SPDE-INLA method was implemented following the examples in Krainski et al. (2019), Chapter 3, setting the grid size to 15 × 15 to limit the compute time to 15 seconds when using 10 CPU threads. BART was implemented on each dataset via the wbart function in the R package BART; the set of covariates for BART was built using the spatial coordinates in addition to a binary variable representing the output variable index (i.e. taking value 1 whenever yi is of the first outcome variable, 0 otherwise).
C.2.2. MODIS-TERRA and GHCN
The implemented SpamTrees are built with 36 root nodes and c = 6 additional children for each level of the tree, 25 reference locations for each tree node, and for up to M = 5 levels of the tree and δ = 5 (i.e. full depth). The non-reference observed locations are linked to leaves via cherry-pickying as in Section 2.1. Multivariate models were run on an AMD Epyc 7452-based virtual machine with 256GB of memory in the Microsoft Azure cloud; the SpamTree R package was set to run on 20 CPU threads, on R version 4.0.3 linked to the Intel Math Kernel Library (MKL) version 2019.5–075. The univariate models were run on an AMD Ryzen 5950X-based dedicated server with 128GB of memory, on 16 threads, R version 4.1.1 linked to Intel MKL 2019.5–075. The univariate NNGP model was implemented using R package spNNGP (Finley et al., 2020) using 20 neighbors for all outcomes and a “latent” algorithm. The univariate SpamTree was implemented on each outcome with full depth, c = 16 additional chidren for each level of the tree, and 25 reference locations for each node.
The MGP model was implemented via the development package at github.com/mkln/meshgp targeting a block size with 4 spatial locations, resulting in an effective average block dimension of 20. Caching was unavailable due to the irregularly spaced PRCP values. Fewer MCMC iterations were run compared to SpamTrees to limit total runtime to less than 16h.
References
- Ambikasaran S, Foreman-Mackey D, Greengard L, Hogg DW, and O’Neil M. Fast direct methods for Gaussian processes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(2):252–265, 2016. doi: 10.1109/TPAMI.2015.2448083. [DOI] [PubMed] [Google Scholar]
- Anderson E, Bai Z, Bischof C, Blackford S, Demmel J, Dongarra J, Du Croz J, Greenbaum A, Hammarling S, McKenney A, and Sorensen D. LAPACK Users’ Guide Society for Industrial and Applied Mathematics, Philadelphia, PA, third edition, 1999. [Google Scholar]
- Apanasovich TV and Genton MG. Cross-covariance functions for multivariate random fields based on latent dimensions. Biometrika, 97:15–30, 2010. doi: 10.1093/biomet/asp078. [DOI] [Google Scholar]
- Banerjee S. High-dimensional Bayesian geostatistics. Bayesian Analysis, 12(2):583–614, 2017. doi: 10.1214/17-BA1056R. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Banerjee S. Modeling Massive Spatial Datasets Using a Conjugate Bayesian Linear Modeling Frame-work. Spatial Statistics, in press, 2020. doi: 10.1016/j.spasta.2020.100417. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Banerjee S, Gelfand AE, Finley AO, and Sang H. Gaussian predictive process models for large spatial data sets. Journal of the Royal Statistical Society, Series B, 70:825–848, 2008. doi: 10.1111/j.1467-9868.2008.00663.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Banerjee S, Finley AO, Waldmann P, and Ericsson T. Hierarchical spatial process models for multiple traits in large genetic trials. Journal of American Statistical Association, 105(490): 506–521, 2010. doi: 10.1198/jasa.2009.ap09068. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blackford LS, Petitet A, Pozo R, Remington K, Whaley RC, Demmel J, Dongarra J, Duff I, Hammarling S, Henry G, et al. An updated set of basic linear algebra subprograms (BLAS). ACM Transactions on Mathematical Software, 28(2):135–151, 2002. [Google Scholar]
- Chen Y, Davis TA, Hager WW, and Rajamanickam S. Algorithm 887: CHOLMOD, Supernodal Sparse Cholesky Factorization and Update/Downdate. ACM Trans. Math. Softw, 35(3), 2008. doi: 10.1145/1391989.1391995. [DOI] [Google Scholar]
- Chipman HA, George EI, and McCulloch RE. BART: Bayesian additive regression trees. Annals of Applied Statistics, 4(1):266–298, 2010. doi: 10.1214/09-AOAS285. [DOI] [Google Scholar]
- Cover TM and Thomas JA. Elements of information theory. Wiley Series in Telecommunications and Signal Processing Wiley Interscience, 1991. [Google Scholar]
- Cressie N and Johannesson G. Fixed Rank Kriging for Very Large Spatial Data Sets. Journal of the Royal Statistical Society, Series B, 70:209–226, 2008. doi: 10.1111/j.1467-9868.2007.00633.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dagum L and Menon R. OpenMP: an industry standard api for shared-memory programming. Computational Science & Engineering, IEEE, 5(1):46–55, 1998. [Google Scholar]
- Datta A, Banerjee S, Finley AO, and Gelfand AE. Hierarchical nearest-neighbor Gaussian process models for large geostatistical datasets. Journal of the American Statistical Association, 111:800–812, 2016a. doi: 10.1080/01621459.2015.1044091. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Datta A, Banerjee S, Finley AO, Hamm NAS, and Schaap M. Nonseparable dynamic nearest neighbor gaussian process models for large spatio-temporal data with an application to particulate matter analysis. The Annals of Applied Statistics, 10:1286–1316, 2016b. doi: 10.1214/16-AOAS931. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eddelbuettel D and Sanderson C. RcppArmadillo: Accelerating R with high-performance C++ linear algebra. Computational Statistics and Data Analysis, 71:1054–1063, March 2014. doi: 10.1016/j.csda.2013.02.005. [DOI] [Google Scholar]
- Eidsvik J, Shaby BA, Reich BJ, Wheeler M, and Niemi J. Estimation and prediction in spatial models with block composite likelihoods. Journal of Computational and Graphical Statistics, 23: 295–315, 2014. doi: 10.1080/10618600.2012.760460. [DOI] [Google Scholar]
- Ferreira MA and Lee HK. Multiscale Modeling: A Bayesian Perspective Springer Publishing Company, Incorporated, 1st edition, 2007. ISBN 0387708979, 9780387708973. [Google Scholar]
- Finley AO, Datta A, Cook BD, Morton DC, Andersen HE, and Banerjee S. Efficient Algorithms for Bayesian Nearest Neighbor Gaussian Processes. Journal of Computational and Graphical Statistics, 28:401–414, 2019. doi: 10.1080/10618600.2018.1537924. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Finley AO, Datta A, and Banerjee S. R package for Nearest Neighbor Gaussian Process models. 2020. arXiv:2001.09111 [Google Scholar]
- Fox EB and Dunson DB. Multiresolution Gaussian processes In Proceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1, NIPS’12, page 737–745, Red Hook, NY, USA, 2012. Curran Associates Inc. 10.5555/2999134.2999217. [DOI] [Google Scholar]
- Furrer R, Genton MG, and Nychka D. Covariance Tapering for Interpolation of Large Spatial Datasets. Journal of Computational and Graphical Statistics, 15:502–523, 2006. doi: 10.1198/106186006X132178. [DOI] [Google Scholar]
- Gelfand A, Diggle P, Fuentes M, , and Guttorp P. Handbook of Spatial Statistics CRC Press, Boca Raton, FL, 2010. [Google Scholar]
- Genton MG and Kleiber W. Cross-Covariance Functions for Multivariate Geostatistics. Statistical Science, 30:147–163, 2015. doi: 10.1214/14-STS487. [DOI] [Google Scholar]
- Geoga CJ, Anitescu M, and Stein ML. Scalable Gaussian process computations using hierarchical matrices. Journal of Computational and Graphical Statistics, 29:227–237, 2020. doi: 10.1080/10618600.2019.1652616. [DOI] [Google Scholar]
- Gilboa E, Saatçi Y, and Cunningham JP. Scaling multidimensional inference for structured gaussian processes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(2): 424–436, 2015. doi: 10.1109/TPAMI.2013.192. [DOI] [PubMed] [Google Scholar]
- Gramacy RB and Apley DW. Local Gaussian Process Approximation for Large Computer Experiments. Journal of Computational and Graphical Statistics, 24:561–578, 2015. doi: 10.1080/10618600.2018.1537924. [DOI] [Google Scholar]
- Gramacy RB and Lee HKH. Bayesian Treed Gaussian Process Models With an Application to Computer Modeling. Journal of the American Statistical Association, 103:1119–1130, 2008. doi: 10.1198/016214508000000689. [DOI] [Google Scholar]
- Guhaniyogi R, Finley AO, Banerjee S, and Gelfand AE. Adaptive Gaussian predictive process models for large spatial datasets. Environmetrics, 22:997–1007, 2011. doi: 10.1002/env.1131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guinness J. Permutation and grouping methods for sharpening gaussian process approximations. Technometrics, 60(4):415–429, 2018. doi: 10.1080/00401706.2018.1437476. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heaton MJ, Datta A, Finley AO, Furrer R, Guinness J, Guhaniyogi R, Gerber F, Gramacy RB, Hammerling D, Katzfuss M, Lindgren F, Nychka DW, Sun F, and Zammit-Mangion A. A case study competition among methods for analyzing large spatial data. Journal of Agricultural, Biological and Environmental Statistics, 24(3):398–425, Sep 2019. doi: 10.1007/s13253-018-00348-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang H and Sun Y. Hierarchical low rank approximation of likelihoods for large spatial datasets. Journal of Computational and Graphical Statistics, 27(1):110–118, 2018. doi: 10.1080/10618600.2017.1356324. [DOI] [Google Scholar]
- Jurek M and Katzfuss M. Hierarchical sparse cholesky decomposition with applications to high-dimensional spatio-temporal filtering, 2020. arXiv:2006.16901 [Google Scholar]
- Katzfuss M. A multi-resolution approximation for massive spatial datasets. Journal of the American Statistical Association, 112:201–214, 2017. doi: 10.1080/01621459.2015.1123632. [DOI] [Google Scholar]
- Katzfuss M and Gong W. A class of multi-resolution approximations for large spatial datasets. Statistica Sinica, 30:2203–2226, 2019. doi: 10.5705/ss.202018.0285. [DOI] [Google Scholar]
- Katzfuss M and Guinness J. A general framework for Vecchia approximations of Gaussian processes. Statistical Science, 36(1):124–141, 2021. doi: 10.1214/19-STS755. [DOI] [Google Scholar]
- Kaufman CG, Schervish MJ, and Nychka DW. Covariance Tapering for Likelihood-Based Estimation in Large Spatial Data Sets. Journal of the American Statistical Association, 103: 1545–1555, 2008. doi: 10.1198/016214508000000959. [DOI] [Google Scholar]
- Krainski ET, Gómez-Rubio V, Bakka H, Lenzi A, Castro-Camilo D, Simpson D, Lindgren F, and Rue H. Advanced Spatial Modeling with Stochastic Partial Differential Equations Using R and INLA CRC Press/Taylor and Francis Group, 2019. [Google Scholar]
- Krause A, Singh A, and Guestrin C. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies. Journal of Machine Learning Research, 8: 235–284, 2008. http://www.jmlr.org/papers/v9/krause08a.html. [Google Scholar]
- Lauritzen L, S. Graphical Models Clarendon Press, Oxford, UK, 1996. [Google Scholar]
- Lewis R. A guide to graph colouring Springer International Publishing, 2016. doi: 10.1007/978-3-319-25730-3. [DOI] [Google Scholar]
- Lindgren F, Rue H, and Lindström J. An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. Journal of the Royal Statistical Society: Series B, 73:423–498, 2011. doi: 10.1111/j.1467-9868.2011.00777.x. [DOI] [Google Scholar]
- Loper J, Blei D, Cunningham JP, and Paninski L. General linear-time inference for Gaussian processes on one dimension, 2020. arXiv:2003.05554 [Google Scholar]
- Low KH, Yu J, Chen J, and Jaillet P. Parallel Gaussian process regression for big data: Low-rank representation meets Markov approximation In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, page 2821–2827, 2015. http://hdl.handle.net/1721.1/116273. [Google Scholar]
- Molloy M and Reed B. Graph colouring and the probabilistic method Springer-Verlag Berlin Heidelberg, 2002. doi: 10.1007/978-3-642-04016-0. [DOI] [Google Scholar]
- Moran KR and Wheeler MW. Fast increased fidelity approximate Gibbs samplers for Bayesian Gaussian process regression, 2020. arXiv:2006.06537 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nychka D, Bandyopadhyay S, Hammerling D, Lindgren F, and Sain S. A multiresolution gaussian process model for the analysis of large spatial datasets. Journal of Computational and Graphical Statistics, 24:579–599, 2015. doi: 10.1080/10618600.2014.914946. [DOI] [Google Scholar]
- Peruzzi M, Banerjee S, and Finley AO. Highly scalable Bayesian geostatistical modeling via meshed Gaussian processes on partitioned domains. Journal of the American Statistical Association, 2020. in press. doi: 10.1080/01621459.2020.1833889. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Quiroz ZC, Prates MO, and Dey DK. Block Nearest Neighboor Gaussian processes for large datasets, 2019. arXiv:1604.08403 [Google Scholar]
- Quiñonero-Candela J and Rasmussen CE. A unifying view of sparse approximate Gaussian process regression. Journal of Machine Learning Research, 6:1939–1959, 2005. https://www.jmlr.org/papers/volume6/quinonero-candela05a/quinonero-candela05a.pdf. [Google Scholar]
- Rue H and Held L. Gaussian Markov Random Fields: Theory and Applications Chapman & Hall/CRC, 2005. doi: 10.1007/978-3-642-20192-9. [DOI] [Google Scholar]
- Rue H, Martino S, and Chopin N. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. Journal of the Royal Statistical Society: Series B, 71:319–392, 2009. doi: 10.1111/j.1467-9868.2008.00700.x. [DOI] [Google Scholar]
- Sanderson C and Curtin R. Armadillo: a template-based C++ library for linear algebra. Journal of Open Source Software, 1:26, 2016. [Google Scholar]
- Sang H and Huang JZ. A full scale approximation of covariance functions for large spatial data sets. Journal of the Royal Statistical Society, Series B, 74:111–132, 2012. doi: 10.1111/j.1467-9868.2011.01007.x. [DOI] [Google Scholar]
- Snelson E and Ghahramani Z. Local and global sparse Gaussian process approximations In Proceedings of the Eleventh International Conference on Artificial Intelligence and Statistics, volume 2 of Proceedings of Machine Learning Research, pages 524–531, 2007. http://proceedings.mlr.press/v2/snelson07a.html. [Google Scholar]
- Stein ML. Limitations on low rank approximations for covariance matrices of spatial data. Spatial Statistics, 8:1–19, 2014. doi:doi: 10.1016/j.spasta.2013.06.003. [DOI] [Google Scholar]
- Stein ML, Chi Z, and Welty LJ. Approximating likelihoods for large spatial data sets. Journal of the Royal Statistical Society, Series B, 66:275–296, 2004. doi: 10.1046/j.1369-7412.2003.05512.x. [DOI] [Google Scholar]
- Sun Y, Li B, and Genton M. Geostatistics for large datasets. In Montero J, Porcu E, and Schlather M, editors, Advances and Challenges in Space-time Modelling of Natural Events, pages 55–77. Springer-Verlag, Berlin Heidelberg, 2011. doi: 10.1007/978-3-642-17086-7. [DOI] [Google Scholar]
- Vecchia AV. Estimation and model identification for continuous spatial processes. Journal of the Royal Statistical Society, Series B, 50:297–312, 1988. doi: 10.1111/j.2517-6161.1988.tb01729.x. [DOI] [Google Scholar]
- Vihola M. Robust adaptive Metropolis algorithm with coerced acceptance rate. Statistics and Computing, 22:997–1008, 2012. doi: 10.1007/s11222-011-9269-5. [DOI] [Google Scholar]
- Wu L, Miller A, Anderson L, Pleiss G, Blei D, and Cunningham J. Hierarchical inducing point Gaussian process for inter-domain observations In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS), 2021. arXiv:2103.00393. [Google Scholar]
- Zhang X. An Optimized BLAS Library Based on GotoBLAS2, 2020. URL https://github.com/xianyi/OpenBLAS/.