

Abstract
To improve the performance in multiclass classification for small datasets, a new approach for schizophrenic classification is proposed in the present study. Firstly, the Xgboost classifier is introduced to discriminate the two subtypes of schizophrenia from health controls by analyzing the functional magnetic resonance imaging (fMRI) data, while the gray matter volume (GMV) and amplitude of low-frequency fluctuations (ALFF) are extracted as the features of classifiers. Then, the D-S combination rule of evidence is used to achieve fusion to determine the basic probability assignment based on the output of different classifiers. Finally, the algorithm is applied to classify 38 healthy controls, 16 deficit schizophrenic patients, and 31 nondeficit schizophrenic patients. 10-folds cross-validation method is used to assess classification performance. The results show the proposed algorithm with a sensitivity of 73.89%, which is higher than other classification algorithms, such as supported vector machine (SVM), logistic regression (LR), K-nearest neighbor (KNN) algorithm, random forest (RF), BP neural network (NN), classification and regression tree (CART), naive Bayes classifier (NB), extreme gradient boosting (Xgboost), and deep neural network (DNN). The accuracy of the fusion algorithm is higher than that of classifier based on the GMV or ALFF in the small datasets. The accuracy rate of the improved multiclassification method based on Xgboost and fusion algorithm is higher than that of other machine learning methods, which can further assist the diagnosis of clinical schizophrenia.
1. Introduction
Schizophrenia (SZ) is a serious mental illness that interferes with a person's ability to think clearly, manage emotions, make decisions, and relate to others [1]. The positive symptoms, such as hallucinations and delusions, can lead to suicidal or aggressive behavior, while negative symptoms and cognitive impairment lead to a decline in quality of life and social function; all these symptoms will cause tremendous human suffering and economic burden [2]. However, SZ is diagnosed on the basis of clinical evaluation of symptoms and functional, no objective diagnostic biomarker set. In addition, there are two main types of schizophrenia, which are called deficit schizophrenia (DS) and nondeficit schizophrenia (NDS) [3]. Deficit syndrome of schizophrenia, also called negative symptoms of schizophrenia, includes social withdrawal, loss of motivation, poverty of speech, and blunting of affect. Compared with NDS, DS has greater cognitive impairment, worse long-term prognosis, and lower recovery rates, which persist or are found even during psychotic remissions [4, 5]. Therefore, it is quite important to diagnose SZ accurately and discriminate the two subtypes of SZ from healthy control (HC), particularly the discrimination between the DS and NDS.
Classification is a machine learning algorithm where we get the labeled data as input and we need to predict the output into a class [6]. If there are two classes, then it is called binary classification [7]. If there are more than two classes, then it is called multiclass classification. Nowadays, classification algorithm is widely used in the medical diagnosis, especially in the field of mental disorders. Early published research applied support vector machines with radial basis function kernel method to classify 15 schizophrenic patients and 15 HCs based on the structural image of the hippocampal complex only with 63% classification accuracy [8]. With the rapid development of computational psychiatry, a growing body of classification approaches are applied to discriminate SZ in recent years, such as logistic regression (LR), support vector machine (SVM), neural network (NN), random forest (RF), extreme gradient boosting (XGBoost), and deep learning [9]. In the early studies, many researchers focused on the binary classification problem in SZ. Greenstein et al. proposed the logistic regress classifier to discriminate 99 SZ patients from 99 HCs with 73.7% accuracy [10]. Nieuwenhuis et al. proposed the SVM classifier to discriminate 128 SZ patients from 111 HCs and achieved an accuracy of 71.4% [11]. Thereby, in the past years, feature reduction approaches were discussed and applied to improve the performance of classification. Ershad and Hashemi proposed the dispelling reduction approaches [12], Juneja and his colleagues obtained the discriminative features by using SVD model and a novel multivariate feature selection algorithm [13]. However, the accuracy was not high enough based on the classical classification algorithms, which was usually less than 75%. Then, many new classifiers and feature selection approaches are proposed to improve the classification performance. Up to 2018, Wang et al. developed the SVM model to discriminate SZ from HCs and achieved an accuracy of 92.4% [14]. In 2020, Kim et al. proposed the feature reduction method when there are redundant or correlated features based on the FDR value and achieved an accuracy of 96.2% [15]. Patel et al. proposed a classification algorithm to discriminate SZ versus HCs by busing deep learning in fMRI, and the accuracy was 92% [16]. Nowadays, the binary classification is not a hard work in the field of mental disorders. However, there is not only one type of SZ, such as DS and NDS, which is more difficult to discriminate each other or from HCs. In order to solve this problem, multiple classification methods for schizophrenic subtypes are necessary.
Few previous literatures have reported multiclass classifications for different types of psychiatric patients, and most of these classifications used traditional machine learning methods such as SVM and LR. For examples, Zhu et al. proposed the SVM model to classify first-episode, drug-naive SZ, ultrahigh risk for psychosis and HC with the global balanced accuracy only 73.37% and the sensitivity only 68.42%, using the fivefold cross-validation method [17]. Soon afterwards, multiple classification methods have been explored, such as three SVM models to classify the SZ, bipolar disorder, and HC [18] and classify depression, bipolar disorder, and HC [19]; an SVM combined with recursive feature elimination was used to classify first-episode SZ, chronic SZ, and HC [20]. Unfortunately, almost all the accuracy rate of the multiclass classification is less than 70%. In addition, because of the poor coordination in psychiatric patients, the amount of imaging data is generally small, which leads to an accuracy far below 70%.
In recent years, deep learning is widely used in the pattern recognition. Zeng et al. proposed a deep discriminant autoencoder network to learn imaging site-shared functional connectivity features to discriminate SZ from normal subjects. In their work, the accuracy of 85% is achieved [21]. Oh et al. collected 873 structural MRI datasets and discriminate the SZ from normal subjects by using a deep convolutional neural network [22]. Srinivasagopalan et al. proposed a deep learning algorithm for diagnosing SZ [23]. These deep learning algorithms are based on the original image data, such as CNN and DNN. However, the original image data is usually quite difficult to obtain. Many deep learning algorithms on small dataset is usually overfitting. Therefore, the machine learning algorithms are more suitable to improve the performance of the classical classifiers.
To the best of our knowledge, there is no study to implement the multiclass classification of DS, NDS, and HC based on multimodal imaging data of schizophrenia. Therefore, in order to achieve multiclass classification of schizophrenia and obtain higher classification results in small data, a new classification algorithm is proposed in this paper. In this algorithm, GMV and ALFF are selected as the features to construct multiclassifier based on Xgboost, respectively. Then, the fused model is built to improve the accuracy for the small datasets. The D-S fusion model is used to combine the output from different classifiers to determine the probability assignment for different subtypes and HC. The rest of this paper is structured as follows. In Section 2, the Xgboost classifier is proposed to discriminate DS and NDS from HC and the fusion model is introduced to combine information of output. The results obtained by applying our model are shown in Section 3. In Section 4, the main contribution of this paper is summarized.
2. The Fused Classification Algorithm Based on Xgboost for Three-Class Classification
In this section, a fused classification algorithm is proposed to improve the accuracy for the small datasets. This algorithm is applied to discriminate the subtypes of SZ from HC. There are three labels (DS, NDS, and HC) that should be assigned to each collected subject. To solve this problem, an improved multiclassification algorithm is introduced. Firstly, Xgboost algorithm is applied to classify them, which is one of the most widely used machine learning algorithms in classification problems [24]. The classifiers are constructed based on the features of GMV or ALFF, which is extracted from fMRI data. Then, the fusion model is used to combine the output information of the different classifier to determine the probability assignment of each class. Finally, the test subject will be classified into the class with the maximum probability. The flow chart of the proposed algorithm is shown in Figure 1.
Figure 1.
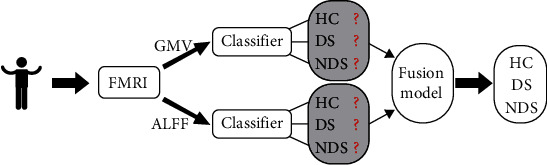
Flow chat of improved multiclassification algorithm.
2.1. Classifier Based on the Xgboost Algorithm
The Xgboost algorithm is composed of many weak classification and regression trees (CARTs). Taking the ith dataset (xi,yi) as an example, xi is the input variable with several attributes of fMRI data and yi is the real value of the given subject. For example, yi = (1, 0, 0) means the ith subject is HC, yi = (0, 1, 0) means the ith subject is DS, and yi = (0, 0, 1) means the ith subject is NDS.
Then, an Xgboost model can be mathematically expressed in the following form [25]:
| (1) |
where K is the number of the CARTs, fk is the predicted value of each independent CART, and is the predicted value with respect to input xi.
The additive training model of Xgboost can be expressed as
| (2) |
where is the predicted value of the kth CART.
The objective function of Xgboost includes a loss function and regularization term, which is expressed as
| (3) |
where can be used to measure the error between predicted value and real value, n is the number of the subjects, and Ω is the regularization item to avoid overfitting.
The specific form of Ω(fk) of the kth CART is given as
| (4) |
where γ and λ present the penalty coefficients, T is the number of leaf nodes, and w is the weight of the leaf nodes.
Then, the objective function of the tth step obj(t) can be calculated by Equation (5) based on the previous step obj(t − 1) based on the Equations (2) and (3).
| (5) |
By applying the second-order Taylor expansion to above equation, the objective function can be transformed into
| (6) |
In the above expression, Const is a constant term at the step t; the parameters pair gi and hi can be calculated as
| (7) |
Becauseis the constant item, the objective function can be rewritten as
| (8) |
where const′ is a new constant item at step t.
According to the definition of fk, fk can be written in the following form as
| (9) |
Then, Equation (8) can be rewritten in the following form as
| (10) |
denoted by∑i∈Ijgi = Gjand∑i∈Ijhi = Hj; then, the objective function is expressed as
| (11) |
The leaf nodes of the tth CART are each independent; Gj and Hj are the determined items. Then, minimizing the function equation (11), the optimal parameter wj can be calculated as
| (12) |
Therefore, the final objective function is shown in the following form as
| (13) |
The splitting algorithm [26] based on the above function is used to find the best split in Xgboost by
| (14) |
The gain function has four terms: the first two terms are the profits of left and right parts of a node, where GL and GR are the left and right parts of Gj and HL and HR are the left and right parts of Hj; and the third item is the total profit of that node. The last item is the regularization item for preventing overfitting. The greedy algorithm determines whether a node obtains the maximum gain. Thus far, the optimal tree structure that maximizes the gain can be generated.
The above description leads to the split finding algorithm for Xgboost presented as Algorithm 1.
Algorithm 1.

Greedy algorithm for split finding.
2.2. The Fusion Model Based on the D-S Evidence Theory
Analyses of the amplitude of low-frequency fluctuations (ALFF) and gray matter volume (GMV) are two important methods used in fMRI studies. Selecting GMV as the feature to construct the classifier based on the Xgboost algorithm, the predicted value of the ith subject can be obtained and denoted as , while the other predicted value can be calculated by selecting ALFF as the feature,usually. Taking the ith subject as an example, the output information of the classifiers is and . According to the output of classifier based on the feature of GMV, this subject should be classified into NDS, while the classifier based on the feature of ALFF will classify this subject into HC.
To overcome the conflict of different classifiers, the D-S evidence model is used to fuse the information of and [27]. The softmax function [28] is used in many machine learning applications for multiclass classifications to assign probability for each subject. The softmax function is expressed in the following form as Equation (15), which is used to calculate the probability assignment of each class.
| (15) |
where is the element in the set and j = 1, 2, 3 represents HC, DS, and NDS, respectively. For example,is the probability that theith subject is HC according to the GMV feature, andis the probability that theith subject is HC according to the ALFF feature.
Though softmax function, the probability assignment of the ith subject can be obtained as
| (16) |
Then, the combined strategy based on the D-S evidence is expressed as
| (17) |
The probability of subject into each group , where K reflects the conflict level of evidences and can be represented as
| (18) |
The result of the above example is by Equation (17). According to the output of the fusion information, this subject will be classified into the class of NDS.
3. Experiments and Results
To evaluate performance of the proposed classification method, we scan 246 brain regions of 85 subjects by fMRI to extract the features of GMV and ALFF, including 16 DS, 31 NDS, and 38 HC. Obviously, it is a hard task to classify them in these small datasets. We apply the proposed algorithm to classify all the subjects.
The present study classifies all subjects into three classes by applying linear regression (LR), supported vector classifier (SVC), K-nearest Neighbor (KNN), neural network (NN), naive Bayes (NB), classification and regression tree (CART), random forest (RF), extreme gradient boosting (Xgboost), deep neural network (DNN), and the proposed fusion algorithm. The flow of 10-fold cross-validation is shown in Figure 2. The results of 10-fold cross-validation of different classifiers are shown as below.
Figure 2.

Flow chat of 10-fold cross-validation.
The receiver operating characteristic (ROC) curve is considered to evaluate the performance of classifiers. For different classification thresholds, the true-positive rate (TPR) (Equation (19)) is plotted against the false-positive rate (FPR) (Equation (20)). The area under the ROC curve (AUC) indicates the classifier's ability to distinguish between classes. The value of the AUC is in the range [0,1]. AUC is 1 for a perfect classifier. In this work, the ROC curve is plotted for each class, as this is a multiclass problem. The microaverage and macroaverage are also computed by summing the individual values for true positive (TP), true negative (TN), false positive (FP), and false negative (FN). Then, the accuracy (Equation (21)), recall (Equation (22)), precision (Equation (23)), and F1-score (Equation (24)) are selected as the important metrics to evaluate the performance of different classifiers [29].
| (19) |
| (20) |
| (21) |
| (22) |
| (23) |
| (24) |
The ROC of the above classifiers are shown in Figures 3–8. In these figures, DS is the class 0, HC is the class 1, and NDS is the class 2. The key classification metrics are extracted from the results listed in Table 1.
Figure 3.

Results of logistic classifier (GMV).
Figure 4.

Results of logistic classifier (ALFF).
Figure 5.

Results of SVM with kernel of RBF (GMV).
Figure 6.

Results of SVM with kernel of RBF (ALFF).
Figure 7.

Results of Xgboost (GMV).
Figure 8.
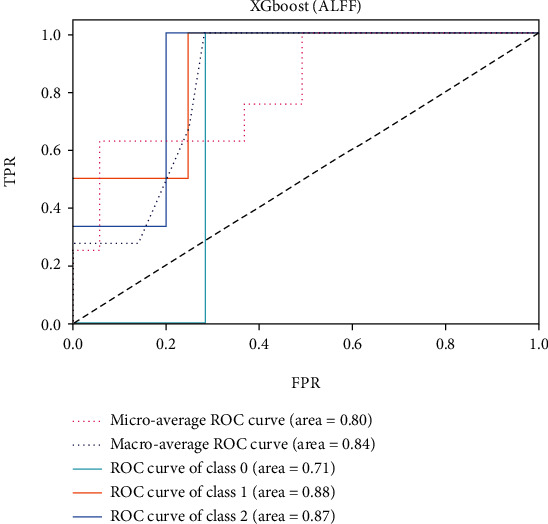
Results of Xgboost (ALFF).
Table 1.
Classification metrics of different methods.
| Methods | Accuracy | Precision | Recall | F1-scores | AUC |
|---|---|---|---|---|---|
| LR (GMV) | 64.8611% | 65.0509% | 64.8611% | 0.6237 | 0.8160 |
| LR (ALFF) | 65.9722% | 65.5394% | 65.9722% | 0.6388 | 0.7743 |
| SVC (GMV) | 61.5278% | 51.5602% | 61.5277% | 0.5508 | 0.7403 |
| SVC (ALFF) | 67.0833% | 59.4147% | 67.0833% | 0.6114 | 0.6114 |
| KNN (GMV) | 63.4722% | 61.4259% | 63.4722% | 0.5899 | 0.7174 |
| KNN (ALFF) | 58.6111% | 67.3175% | 58.6111% | 0.5601 | 0.6731 |
| NN (GMV) | 55.4167% | 56.4749% | 47.2222% | 0.5425 | 0.8066 |
| NN (ALFF) | 64.4444% | 67.0764% | 60.8333% | 0.6266 | 0.7618 |
| NB (GMV) | 53.8889% | 55.8657% | 53.8889% | 0.5216 | 0.7389 |
| NB (ALFF) | 68.8889% | 74.0139% | 68.8889% | 0.6781 | 0.8308 |
| CART (GMV) | 45.8333% | 47.7870% | 51.9444% | 0.4721 | 0.6375 |
| CART (ALFF) | 60% | 57.6075% | 56.6667% | 0.5667 | 0.6542 |
| RF (GMV) | 62.6389% | 60.0883% | 62.6389% | 0.5874 | 0.7722 |
| RF (ALFF) | 65.6944% | 57.1042% | 65.6944% | 0.5943 | 0.7969 |
| Xgboost (GMV) | 62.6389% | 60.4445% | 62.6389% | 0.5888 | 0.7958 |
| Xgboost (ALFF) | 68.0556% | 62.9610% | 68.0556% | 0.6364 | 0.8351 |
| DNN | 62.7083% | 40.3380% | 62.7083% | 0.5152 | 0.6723 |
| Our classifier (fusion) | 73.8889% | 65.4242% | 73.8889% | 0.6746 | 0.8524 |
Due to the limited number of the DS, the AUC of class 0 is lower than other classes in the above figures. Therefore, it is hard to discriminate DS from NDS and HC. Taking Figure 5 as an example, the macroaverage AUC score is 0.81 and the microaverage AUC score is 0.85 based on the feature of GMV by using the SVM classifier, which are better than the performance based on the feature of ALFF. The AUC score of HC is 0.85 based on the feature of GMV, which is better than the AUC scores of DS and NDS. The Xgboost classifier showed better performance than the SVM and logistic classifier. The microaverage AUC score is 0.90 and 0.80, respectively, on the feature of GMV and ALFF. The macroaverage AUC score is 0.90 and 0.84, respectively, on the feature of GMV and ALFF. The ROC of the fusion algorithm is shown in Figure 9. In this figure, we find the AUC score of the class 0 is 1, which means it is a perfect classifier. This classifier combines the advantages of the classifier based on feature of GMV and ALFF. Therefore, the performance of this fusion classifier is much better than others.
Figure 9.

Results of Xgboost (fusion).
From Table 1, 10-fold cross-validation showed our algorithm with an accuracy of 73.89%, which is higher than other classifiers. Many metrics of the proposed classifier are better than other classifiers. In many present studies, the accuracy of the present classifier is usually less than 70% when the datasets are small. In this paper, the proposed fusion classifier will improve the performance effectively for the small datasets by combining the advantages of each feature. The accuracy of different classifiers is shown in Figure 10.
Figure 10.

Accuracy of different classifiers.
4. Conclusion
In this paper, a new multiple classifier method was proposed for the small datasets and applied to discriminate the two subtypes of schizophrenia and health controls based on the fMRI data. Due to the limitation data and indexes, this study constructed the Xgboost algorithm based on the different features. To improve the accuracy, the fusion model was used to combine the information from different classifiers. Finally, the subject would be classified into the class with the maximum probability. This method was applied to classify 38 healthy controls, 16 deficit schizophrenic patients, and 31 nondeficit schizophrenic patients. 10-fold cross-validation showed our algorithm with a sensitivity of 73.89%, which was much higher than other classification algorithms when the datasets were small. In addition, the proposed algorithm can be used to discriminate different classes for the large datasets. The performance of the proposed algorithm would be effective than other algorithms when the datasets are small. It will bring the better performance in diagnosing subtypes of schizophrenia. Although the findings in our study are rigorous, there are some limitations: (1) relatively small sample size; (2) interference caused by antipsychotic drugs during experiment; and (3) limitations of the algorithm itself. In the future work, more subjects will be collected in the project, including different subtypes and HC. The original image data should be obtained in the processing of experiments, and more deep learning approaches will be proposed to solve this multiclass classification problem.
Acknowledgments
This work is supported by the National Natural Science Key Foundation of China (81830040 to ZJZ), the National Key Research and Development Plan of China (No. 2016YFC1306700; ZJZ), the Youth Innovative Talent Support Program Fund of Department of Health of Zhejiang Province (2022493976), and Program of Excellent Talents in Medical Science of Jiangsu Province (JCRCA2016006 to ZJZ).
Data Availability
No data were used to support this study.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Authors' Contributions
Wenjing Zhu was responsible for the conceptualization, investigation, methodology, and writing of original draft and undertook the data analysis. Shoufeng Shen was responsible for the software, conceptualization, and methodology. Zhijun Zhang supervised the data analysis, provided infrastructure, and was responsible for writing, reviewing, and editing. All authors contributed to and have approved the final manuscript.
References
- 1.Kusudo K., Ochi R., Nakajima S., et al. Decision tree classification of cognitive functions with D2 receptor occupancy and illness severity in late-life schizophrenia. Schizophrenia Research . 2022;241:p. 113. doi: 10.1016/j.schres.2022.01.044. [DOI] [PubMed] [Google Scholar]
- 2.Antonucci L. A., Pergola G., Pigoni A., et al. A pattern of cognitive deficits stratified for genetic and environmental risk reliably classifies patients with schizophrenia from healthy control subjects. Biological Psychiatry . 2020;87(8):697–707. doi: 10.1016/j.biopsych.2019.11.007. [DOI] [PubMed] [Google Scholar]
- 3.Fan L., Yu M., Pinkham A., et al. Aberrant large-scale brain modules in deficit and non-deficit schizophrenia. Progress in Neuro-Psychopharmacology & Biological Psychiatry . 2022;113, article 110461 doi: 10.1016/j.pnpbp.2021.110461. [DOI] [PubMed] [Google Scholar]
- 4.Strauss G. P., Harrow M., Grossman L. S., Rosen C. Periods of recovery in deficit syndrome schizophrenia: a 20-year multi-follow-up longitudinal study. Schizophrenia Bulletin . 2010;36(4):788–799. doi: 10.1093/schbul/sbn167. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Kirkpatrick B., Gurbuz Oflezer O., Delice Arslan M., Hack G., Fernandez-Egea E. An early developmental marker of deficit versus nondeficit schizophrenia. Schizophrenia Bulletin . 2019;45(6):1331–1335. doi: 10.1093/schbul/sbz024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Khare S. K., Bajaj V. A self-learned decomposition and classification model for schizophrenia diagnosis. Computer Methods and Programs in Biomedicine . 2021;211, article 106450 doi: 10.1016/j.cmpb.2021.106450. [DOI] [PubMed] [Google Scholar]
- 7.Dadi K., Rahim M., Abraham A., et al. Benchmarking functional connectome-based predictive models for resting-state fMRI. NeuroImage . 2019;192:115–134. doi: 10.1016/j.neuroimage.2019.02.062. [DOI] [PubMed] [Google Scholar]
- 8.Golland P., Grimson W. E. L., Shenton M. E., Kikinis R. Small sample size learning for shape analysis of anatomical structures. Medical Image Computing and Computer-Assisted Intervention–MICCAI . 2000;1935:72–82. doi: 10.1007/978-3-540-40899-4_8. [DOI] [Google Scholar]
- 9.Lai J. W., Ang C. K. E., Acharya U. R., Cheong K. H. Schizophrenia: a survey of artificial intelligence techniques applied to detection and classification. International Journal of Environmental Research and Public Health . 2021;18(11):p. 6099. doi: 10.3390/ijerph18116099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Greenstein D., Malley J. D., Weisinger B., Clasen L., Gogtay N. Using multivariate machine learning methods and structural MRI to classify childhood onset schizophrenia and healthy controls. Frontiers in Psychiatry . 2012;3:p. 53. doi: 10.3389/fpsyt.2012.00053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Nieuwenhuis M., van Haren N. E. M., Hulshoff Pol H. E., Cahn W., Kahn R. S., Schnack H. G. Classification of schizophrenia patients and healthy controls from structural MRI scans in two large independent samples. NeuroImage . 2012;61(3):606–612. doi: 10.1016/j.neuroimage.2012.03.079. [DOI] [PubMed] [Google Scholar]
- 12.Ershad S. F., Hashemi S. To increase quality of feature reduction approaches based on processing input datasets. 2011 IEEE 3rd International Conference on Communication Software and Networks; 2011; Xi'an, China. pp. 367–371. [DOI] [Google Scholar]
- 13.Juneja A., Rana B., Agrawal R. K. A combination of singular value decomposition and multivariate feature selection method for diagnosis of schizophrenia using fMRI. Biomedical Signal Processing and Control . 2016;27:122–133. doi: 10.1016/j.bspc.2016.02.009. [DOI] [Google Scholar]
- 14.Wang S., Zhang Y., Lv L., et al. Abnormal regional homogeneity as a potential imaging biomarker for adolescent-onset schizophrenia: a resting-state fMRI study and support vector machine analysis. Schizophrenia Research . 2018;192:179–184. doi: 10.1016/j.schres.2017.05.038. [DOI] [PubMed] [Google Scholar]
- 15.Kim J., Kim M. Y., Kwon H., et al. Feature optimization method for machine learning-based diagnosis of schizophrenia using magnetoencephalography. Journal of Neuroscience Methods . 2020;338, article 108688 doi: 10.1016/j.jneumeth.2020.108688. [DOI] [PubMed] [Google Scholar]
- 16.Patel P., Aggarwal P., Gupta A. Classification of schizophrenia versus normal subjects using deep learning. Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing; 2016; Guwahati, Assam, India. pp. 1–6. [DOI] [Google Scholar]
- 17.Zhu F., Liu Y., Liu F., et al. Functional asymmetry of thalamocortical networks in subjects at ultra-high risk for psychosis and first-episode schizophrenia. European Neuropsychopharmacology . 2019;29(4):519–528. doi: 10.1016/j.euroneuro.2019.02.006. [DOI] [PubMed] [Google Scholar]
- 18.Schnack H. G., Nieuwenhuis M., van Haren N. E. M., et al. Can structural MRI aid in clinical classification? A machine learning study in two independent samples of patients with schizophrenia, bipolar disorder and healthy subjects. NeuroImage . 2014;84:299–306. doi: 10.1016/j.neuroimage.2013.08.053. [DOI] [PubMed] [Google Scholar]
- 19.Ranlund S., Rosa M. J., de Jong S., et al. Associations between polygenic risk scores for four psychiatric illnesses and brain structure using multivariate pattern recognition. NeuroImage: Clinical . 2018;20:1026–1036. doi: 10.1016/j.nicl.2018.10.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Liu J., Wang X., Zhang X., Pan Y., Wang X., Wang J. MMM: classification of schizophrenia using multi-modality multi-atlas feature representation and multi-kernel learning. Multimedia Tools and Applications . 2018;77(22):29651–29667. doi: 10.1007/s11042-017-5470-7. [DOI] [Google Scholar]
- 21.Zeng L. L., Wang H., Hu P., et al. Multi-site diagnostic classification of schizophrenia using discriminant deep learning with functional connectivity MRI. eBioMedicine . 2018;30:74–85. doi: 10.1016/j.ebiom.2018.03.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Oh J., Oh B. L., Lee K. U., Chae J. H., Yun K. Identifying schizophrenia using structural MRI with a deep learning algorithm. Frontiers in Psychiatry . 2020;11(11):p. 16. doi: 10.3389/fpsyt.2020.00016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Srinivasagopalan S., Barry J., Gurupur V., Thankachan S. A deep learning approach for diagnosing schizophrenic patients. Journal of Experimental & Theoretical Artificial Intelligence . 2019;31(6):803–816. doi: 10.1080/0952813X.2018.1563636. [DOI] [Google Scholar]
- 24.Wang F., Yu J., Liu Z., Kong M., Wu Y. Study on offshore seabed sediment classification based on particle size parameters using XGBoost algorithm. Computers & Geosciences . 2021;149, article 104713 doi: 10.1016/j.cageo.2021.104713. [DOI] [Google Scholar]
- 25.Ullah B., Kamran M., Rui Y. Predictive modeling of short-term rockburst for the stability of subsurface structures using machine learning approaches: t-SNE, K-means clustering and XGBoost. Mathematics . 2022;10(3):p. 449. doi: 10.3390/math10030449. [DOI] [Google Scholar]
- 26.Ching P. M. L., Zou X., Wu D., So R. H. Y., Chen G. H. Development of a wide-range soft sensor for predicting wastewater BOD5 using an eXtreme gradient boosting (XGBoost) machine. Environmental Research . 2022;210, article 112953 doi: 10.1016/j.envres.2022.112953. [DOI] [PubMed] [Google Scholar]
- 27.Dan Y., Hongbing J., Yongchan G. A robust D–S fusion algorithm for multi-target multi-sensor with higher reliability. Information Fusion . 2019;47:32–44. doi: 10.1016/j.inffus.2018.06.009. [DOI] [Google Scholar]
- 28.Gao F., Li B., Chen L., Shang Z., Wei X., He C. A softmax classifier for high-precision classification of ultrasonic similar signals. Ultrasonics . 2021;112, article 106344 doi: 10.1016/j.ultras.2020.106344. [DOI] [PubMed] [Google Scholar]
- 29.Prabha A., Yadav J., Rani A., Singh V. Design of intelligent diabetes mellitus detection system using hybrid feature selection based XGBoost classifier. Computers in Biology and Medicine . 2021;136, article 104664 doi: 10.1016/j.compbiomed.2021.104664. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
No data were used to support this study.