

Abstract
Experimental design applications for discriminating between models have been hampered by the assumption to know beforehand which model is the true one, which is counter to the very aim of the experiment. Previous approaches to alleviate this requirement were either symmetrizations of asymmetric techniques, or Bayesian, minimax, and sequential approaches. Here we present a genuinely symmetric criterion based on a linearized distance between mean‐value surfaces and the newly introduced tool of flexible nominal sets. We demonstrate the computational efficiency of the approach using the proposed criterion and provide a Monte‐Carlo evaluation of its discrimination performance on the basis of the likelihood ratio. An application for a pair of competing models in enzyme kinetics is given.
Keywords: discrimination experiments, exact designs, flexible nominal sets, nonlinear regression
1. INTRODUCTION
Besides optimization and parameter estimation, discrimination between rival models has always been an important objective of an experiment, and, therefore, of the optimization of experimental design. The crucial problem is that one typically cannot construct an optimal model‐discrimination design without already knowing which model is the true one, and what are the true values of its parameters. In this respect, the situation is analogous to the problem of optimal experimental design for parameter estimation in nonlinear statistical models (e.g., Pronzato & Pazman, 2014), and many standard techniques can be used to tackle the dependence on the unknown characteristics: local, Bayesian, minimax, and sequential approaches, as well as their various combinations.
A big leap from initial ad hoc methods for model discrimination (see Hill, 1978, for a review) was Atkinson and Fedorov (1975) who introduced T‐optimality, derived from the likelihood‐ratio test under the assumption that one model is true and its parameters are fixed at nominal values chosen by the experimenter. There, maximization of the noncentrality parameter is equivalent to maximizing the power of the likelihood‐ratio test for the least favorable parameter of the model assumed to be wrong. Thus, T‐optimality can be considered a combination of a localization and a minimax approach.
When the models are nested and (partly) linear, T‐optimality can be shown to be equivalent to ‐optimality for a single parameter that embodies the deviations from the smaller model (see, e.g., Dette & Titoff, 2009; Stigler, 1971). For this setting the optimal design questions are essentially solved and everything hinges on the asymmetric nature of the NP‐lemma with respect to the null‐ and alternative hypotheses. However, for a nonnested case the design problem itself is often inherently symmetric with respect to the exchangeability of the compared models and it is the purpose of the experiment to decide which of those two different models is true.
The aim of this paper is to solve the discrimination design problem in a symmetric way focusing on nonnested models. Thus, standard methods that are inherently asymmetric like T‐optimality, albeit being feasible, are not a natural choice. We further suppose that we do not use the full prior distribution of the unknown parameters of the models, which rules out Bayesian approaches such as Felsenstein (1992) and Tommasi and López‐Fidalgo (2010). Nevertheless, as we will make more precise in the next section, we will utilize what can be perceived as a specific kind of prior knowledge about the unknown parameters, extending the approach of local optimality. Our goal is to provide a lean, computationally efficient and scalable method as opposed to the heavy machinery recently employed in the computational statistics literature, for example, Hainy, Price, Restif, and Drovandi (2018). Furthermore, we strive for practical simplicity, which at first prohibits sequential (see Buzzi‐Ferraris & Forzatti, 1983; Müller & Ponce De Leon, 1996; Schwaab et al., 2006) or sequentially generated (see Vajjah & Duffull, 2012) designs.
A standard solution to the symmetric discrimination design problem is to employ symmetrizations of asymmetric criteria such as compound T‐optimality, which usually depend on some weighting chosen by the experimenter. Also the minimax strategy recently presented in Tommasi, Martín‐Martín, and López‐Fidalgo (2016) is essentially a symmetrization. Moreover, the usual minimax approaches lead to designs that completely depend on the possibly unrealistic extreme values of the parameter space and their calculation again demands enormous computational effort.
As the closest in spirit to our approach could be considered a proposal for linear models in section 4.4 of Atkinson and Fedorov (1975) and its extension in Fedorov and Khabarov (1986) which, however, was not taken up by the literature. The probable reason is that it involves some rather arbitrary restrictions on the parameters as well as taking an artificial lower bound to convert it into a computationally feasible optimization problem.
For expositional purposes we will now restrict ourselves to a rather specific design task but will discuss possible extensions at the end of the paper.
Let be a finite design space and let be a design on , that is, a vector of design points , where n is the chosen size of the experiment. Hence, in the terminology of the theory of optimal experimental design, we will work with exact designs. We will consider discrimination between a pair of nonlinear regression models
where are observations, , are the mean‐value functions, , are parameter spaces with nonempty interiors int(Θ0), int(Θ1), and are unobservable random errors. For both and any , we will assume that the functions are differentiable on ; the gradient of in will be denoted by . Our principal assumption is that one of the models is true but we do not know which, that is, for or for there exists such that .
Let the random errors be i.i.d. , where . The assumption of the same variances of the errors for both models is plausible if, for instance, the errors are due to the measurement device and hence do not significantly depend on the value being measured. The situation with different error variances requires a more elaborate approach, compared with Fedorov and Pázman (1968).
Eventually we are aiming not just at achieving some high design efficiencies with respect to our newly proposed criterion, but also want to test its usefulness in concrete discrimination experiments, that is, the probability that using our design we arrive at the correct decision about which model is the true one. So, to justify our approach numerically, we require a model‐discrimination rule that will be used after all observations based on the design are collected for evaluational purposes.
The choice of the best discrimination rule based on the observations is generally a nontrivial problem. However, it is natural to compute the maximum likelihood estimates and of the parameters under the assumption of the first and the second model, respectively, and then base the decision on whether
| (1) |
that is, the likelihood ratio being smaller or greater than 1, or perhaps more simply whether . Under the normality, homoskedasticity, and independence assumptions, this decision is equivalent to a decision based on the proximity of the vector of observations to the vectors of estimated mean values and .
For the case to counterbalance favoring models with greater number of parameters, Cox (2013) recommends instead the use of , which corresponds to the Bayesian information criterion; see Schwarz (1978). Here corresponds to the number of observations in a real or fictitious prior experiment. For the sake of simplicity however, we will now restrict ourselves to the case of . Note that for the evaluational purposes we are taking a purely model selection based standpoint. More sophisticated testing procedures for instance allowing both models to be rejected based on the pioneering work of Cox (1961) are reviewed and outlined in Pesaran and Weeks (2007).
Let and let be the design used for the collection of data prior to the decision, and assume that model η0 is true, with the corresponding parameter value . Note that this comes without loss of generality and symmetry as we can equivalently assume model η1 to be true. Then, the probability of the correct decision based on the likelihood ratio is equal to
| (2) |
where follows the normal distribution with mean and covariance .
Clearly, probability (2) depends on the true model, the unknown true parameter, and also on the unknown variance of errors. Even if these parameters were known, the probability of the correct classification would be very difficult to compute for a given design because this requires a combination of high‐dimensional integration and multivariate nonconvex optimization. Therefore, it is practically impossible to directly optimize the design based on formula (2). However, we can simplify the problem by constructing a lower bound on (2) which does not depend on unknown parameters and is relatively much simpler to maximize with respect to the choice of the design. The bound based on the distance , where is the set of all possible mean values of the observations under the model j, , and d(., .) denotes the infimum distance between all pairs of elements of two sets, is developed as follows.
Consider a fixed experimental design , and denote , for . Note that we can express (2) as . Now, let , where , be the norm of the vector of errors. Assuming we obtain
which implies and consequently
Thus, the event implies the event , that is, (2) can be bounded from below by
| (3) |
To make (2) as high as possible, it makes sense to maximize (3), that is, maximize , which depends on the underlying experimental design. Although this maximization is much simpler than maximizing (2) directly, it still generally requires nonconvex multidimensional optimization at each iteration of the maximization procedure, which is impractical for computing exact optimal designs. A realistic approach must be numerically feasible and address the problem of the dependence of the design on unknown true model parameters, which we will achieve by rapidly computable approximation of through linearization, as will be explained in the following section.
1.1. Example 1: A motivating example
Let and . Furthermore, for the moment we assume just two observations at fixed design points and , respectively. In this case evidently and is the solution of , which for is the log root of the polynomial . Figure 1 displays the log‐likelihood‐ratio contours for the original and linearized models and it is obvious that the former are nonconvex and complex while the latter are much simpler, convex, and do approximate fairly well for a wide range of responses. Note that while this example is for a fixed design it motivates why the linearizations can serve as the cornerstones of our design method as will become clearer in the following sections.
Figure 1.
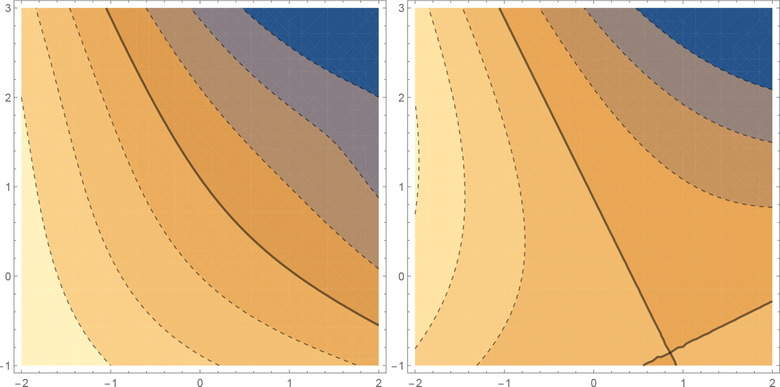
Left panel: contour plot of for Example 1, solid line corresponds to 0, horizontal y 1, vertical y 2; right panel: corresponding contour plot for the model η1 linearized at
2. THE LINEARIZED DISTANCE CRITERION
We suggest an extension of the idea of local optimality used for nonlinear experimental design. Let and be nominal parameter values, which satisfy the basic discriminability condition for some . Let us introduce regions and containing and ; we will consequently call and flexible nominal sets. It is evident that optimal designs depend on the parameter spaces in the same way as on our flexible nominal sets (cf. Dette, Melas, & Shpilev, 2013), but the latter will not be considered fixed like the parameter spaces Θ0 and Θ1. A novelty of our procedure is that we use these sets as a tuning device.
Let be a design. Let us perform the following particular linearization of Model in :
where is the matrix given by
is the n‐dimensional vector
and is a vector of independent errors.
Note that for the proposed method the vector plays an important role and, although it is known, we cannot subtract it from the vector of observations, as is usual when we linearize a single nonlinear regression model. However, if corresponds to the standard linear model then for any .
2.1. Definition of the δ criterion
Consider the design criterion
| (4) |
| (5) |
for . The criterion δ can be viewed as an approximation of the nearest distance d of the mean‐value surfaces of the models, in the neighborhoods of the vectors and ; see the illustrative Figure 2.
Figure 2.
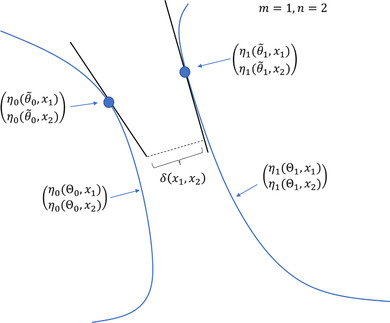
Illustrative graph for the definition of for two one‐parameter models () and a design of size two (). The line segments correspond to the sets and for some flexible nominal sets and
We will now express the δ‐criterion as a function of the design represented by the counting measure ξ on defined as
where means the size of a set. Let . For all let
For any , and we have
| (6) |
Therefore
| (7) |
where
| (8) |
| (9) |
| (10) |
The matrix in Equations (7) and (8) can be recognized as the information matrix for the parameter θ in the linear regression model
| (11) |
where is the ith row of the matrix , with parameter θ and independent, homoskedastic errors with mean 0; we will call (11) a response difference model.
2.2. Computation of the δ criterion value for a fixed design
For a fixed design , expression (5) shows that is a quadratic function of . Moreover, both and are convex because they are compositions of an affine function of θ and convex functions and , respectively. Clearly, if the flexible nominal sets are compact, convex, and polyhedral, optimization (4) can be efficiently performed by specialized solvers for linearly constrained quadratic programming.
Alternatively, we can view the computation of as follows. As
the minimization in (4) is equivalent to computing the minimum sum of squares for a least squares estimate of θ restricted to in the response difference model with artificial observations
Thus, if , the infimum in (4) is attained, and it can be computed using the standard formulas of linear regression in the response difference model. If the flexible nominal sets are compact cuboids, (4) can be evaluated by the very rapid and stable method for bounded variable least squares implemented in the R package bvls; see Stark and Parker (1995) and Mullen (2013).
The following simple proposition collects the analytic properties of a natural analogue of δ defined on the linear vector space Ξ of all finite signed measures on .
Proposition 2.1
For , and a finite signed measure ξ on let be defined via formula (6). Then, is linear on Ξ. Moreover, let
Then, is positive homogeneous and concave on Ξ.
Positive homogeneity of implies that an s‐fold replication of an exact design leads to an s‐fold increase of its δ2 value. Consequently, a natural and statistically interpretable definition of relative δ‐efficiency of two designs and is given by , provided that .
Let be the set of all n‐point designs. A design will be called δ‐optimal, if
Note that the basic discriminability condition implies that if and , then is strictly positive. However, for larger flexible nominal sets it can happen that .
As the evaluation of the δ‐criterion is generally very rapid, the calculation of a δ‐optimal, or nearly δ‐optimal design is similar to that for standard design criteria. For instance, in small problems we can use complete‐enumeration and in larger problems we can employ an exchange heuristic, such as the KL exchange algorithm (see, e.g., Atkinson, Donev, & Tobias, 2007).
Note that the δ‐optimal designs depend not only on η0, η1, , n, , and , but also on and .
2.3. Parametrization of flexible nominal sets
For simplicity, we will focus on cuboid flexible nominal sets centered at the nominal parameter values. This choice can be justified by the results of Sidak (1967), in particular if we already have confidence intervals for individual parameters; see further discussion in Section 4. Specifically, we will employ the homogeneous dilations
| (12) |
, , such that r can be considered a tuning (set) parameter governing the size of the flexible nominal sets. In (12), and are “unit” nondegenerate compact cuboids centered on respective nominal parameters. For any design and , we define
| (13) |
Note that for our choice of flexible nominal sets the infimum in (13) is attained. The ‐optimal values of the problem will be denoted by
Proposition 2.2
(a) Let be a design. Functions , , , are nonincreasing and convex in r on the entire interval [0, ∞]. (b) There exists , such that for all : (i) ; (ii) Any ‐optimal design is also a ‐optimal design.
(a) Let be an n‐point design and let .
Inequality follows from definitions (12) and (13), and inequality follows from the fact that a maximum of nonincreasing functions is a nonincreasing function. Monotonicity of and in r can be shown analogously.
To prove the convexity of in r, let and let . For all , let denote a minimizer of on . Convexity of in θ and a simple fact yield
which proves that is convex in r. The convexity of in r can be shown analogously. The functions o 2 and o, as pointwise maxima of a system of convex functions, are also convex.
(b) For any design of size n, the function is nonnegative and quadratic on , therefore its minimum is attained in some . There is only a finite number of exact designs of size n, and , which means that there exists such that for all designs of size n. Let . We have
proving (i). Let be any ‐optimal n‐trial design. The equality (i) and the fact that and are nonincreasing with respect to r gives
which proves (ii).
The second part of Proposition 2.2 implies the existence of a finite interval of relevant set parameters; increasing the set parameter beyond leaves the optimal designs as well as the optimal value of the δ‐criterion unchanged. We will call any such a set upper bound.
Algorithm 1 provides a simple iterative method of computing . Our experience shows that it usually requires only a small number of recomputations of the ‐optimal design, even if is small and q is close to 1, resulting in a good set upper bound (see the metacode of Algorithm 1 for details). Due to the high speed and stability of the computation of the values of for candidate designs, it is possible to use an adaptation of the standard KL exchange heuristic to compute the input value , as well as to obtain ‐optimal designs in steps 2 and 9 of the algorithm itself.
Algorithm 1. A simple algorithm for computing a set upper bound.

|
2.4. Example 1 continued
Consider the models from the motivating example. Let , , and . Note that these nominal values satisfy . Moreover, let us set and , and let the required size of the experiment be . First, we computed the value . Next, we used Algorithm 1 with and , which returned a set upper bound after as few as seven computations of ‐optimal designs. Informed by , we computed ‐optimal designs for . The resulting ‐optimal designs are displayed in Figure 3. Note that if s are very narrow, the ‐optimal design is concentrated in the design point , effectively maximizing the difference between and . For larger values of r, the ‐optimal design has a 2‐point and ultimately a 3‐point support.
Figure 3.
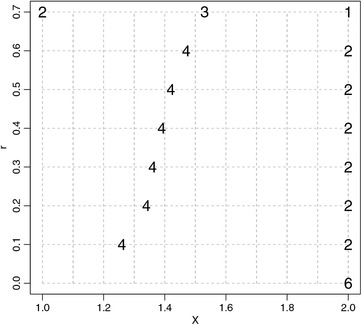
‐Optimal designs of size for different rs; see the second part of the motivating example. The horizontal axis corresponds to the design space, and the vertical axis corresponds to different spans r of the flexible nominal sets. For each r, the figure displays the number of repeated observations at different design points, corresponding to the ‐optimal design
For some pairs of competing models there exists a set upper bound , beyond which the values of are constantly 0 for all designs. These cases can be identified by solving a linear programming (LP) problem, as we show next.
Proposition 2.3
Let be the design that performs exactly one trial in each point of . Consider the following LP problem with variables , , :
(14) Assume that (14) has some solution, and denote one solution of (14) by . Then, is a finite set upper bound. Moreover, for all .
From the expression (7) we see that for any design and its nonreplication version we have implies . Moreover, if in the sense that is an augmentation of then implies . Now let be a solution of (14), let and let be any design. Definition of and the form of (14) imply . From we see that then , hence . The proposition follows.
Note that obtained using Proposition 2.3 does not depend on n, that is, it is a set upper bound simultaneously valid for all design sizes. The basic discriminability condition implies that .
If the competing models are linear, vectors and are zero. Therefore, (2.3) has a feasible solution for any such that both and cover . That is, for the case of linear models, there is a finite set upper bound beyond which the ‐values of all designs vanish. However, the same holds for specific nonlinear models, including the ones from Section 3.
Proposition 2.4
Assume that both competing regression models are linear provided that we consider a proper subset of their parameters as known constants. Then (2.3) has a finite feasible solution, that is, there exists a finite set upper bound such that for all .
Without loss of generality, assume that fixing the first components of θ0 converts Model 0 to a linear model. More precisely, let denote the components of θ0 and assume that
for some functions , . Choose such that for , and for . Make an analogous assumption for Model 1 and also define analogously. It is then straightforward to verify that for the design from Proposition 2.3 we have , where , for both . Therefore, any such that and is a solution of (14) in Proposition 2.3.
In the following, we numerically demonstrate that the δ design criterion leads to designs which yield a high probability of correct discrimination.
3. AN APPLICATION IN ENZYME KINETICS
This real applied example is taken from Bogacka, Patan, Johnson, Youdim, and Atkinson (2011) and was already used in Atkinson (2012) to illustrate model‐discrimination designs. There two types of enzyme kinetic reactions are considered, where the reactions velocity y is alternatively modeled as
| (15) |
and
| (16) |
which represent competitive and noncompetitive inhibition, respectively. Here x 1 denotes the concentration of the substrate and x 2 the concentration of an inhibitor. The data used in Bogacka et al. (2011) from an initial experiment of 120 observations are on Dextrometorphan–Sertraline and yields the estimates displayed in Table 1, where Gaussian errors were assumed. Assumed parameter spaces were not explicitly given there, but can be inferred from their figures as , , and , respectively. Designs for parameter estimation in these models were recently given in Schorning, Dette, Kettelhake, and Möller (2017).
Table 1.
| Estimate |
SE
|
Estimate |
SE
|
|||||
|---|---|---|---|---|---|---|---|---|
| θ01 | 7.298 | 0.114 | θ11 | 8.696 | 0.222 | |||
| θ02 | 4.386 | 0.233 | θ12 | 8.066 | 0.488 | |||
| θ03 | 2.582 | 0.145 | θ13 | 12.057 | 0.671 |
In Atkinson (2012), the two models are combined into an encompassing model:
| (17) |
where corresponds to (15) and to (16), respectively. Following the ideas of Atkinson (1972) as used, for example, in Atkinson (2008) or Perrone, Rappold, and Müller (2017) one can then proceed to find so‐called ‐optimal (i.e., D‐optimal for only a subset of parameters) designs for λ and employ them for model discrimination. Note that also this method is not fully symmetric as it requires a nominal value for λ for linearization of (17), which induces some kind of weighting.
The nominal values used in Atkinson (2012) obviously motivated by the estimates of (15) were , , , , and . However, note that particularly for model (16) the estimates in Table 1 give considerably different values and also nonlinear least squares directly on (17) yields the deviating estimates given in Table 2. The design region used was rectangular .
Table 2.
Parameter estimates and corresponding standard errors for the encompassing model (17)
| Estimate |
SE
|
||
|---|---|---|---|
| θ21 | 7.425 | 0.130 | |
| θ22 | 4.681 | 0.272 | |
| θ23 | 3.058 | 0.281 | |
| λ | 0.964 | 0.019 |
In Table 2 of Atkinson (2012) four approximate optimal designs (we will denote them as A1–A4) were presented: the optimal designs assuming (A1) and (A4), a compound T‐optimal design (A3), and a ‐optimum (A2) for the encompassing model (for the latter note that Atkinson assumed , whereas the estimate suggest a much higher value). We will compare our δ‐optimal designs against exact versions of these designs, properly rounded by the method of Pukelsheim and Rieder (1992).
3.1. Confirmatory experiment , normal errors
Let us first assume we want to complement the knowledge from our initial experiment by another experiment for which, however, we were given only limited resources, for example, for the sample sizes of only observations. Note that the aim is not to augment the previous 120 observations but to make a confirmatory decision just using the new observations. That is we are using the data from the initial experiment just to provide us with nominal values for parameter estimates and noise variances for the simulation, respectively. This is a realistic scenario if for instance for legal reasons the original data had to be deleted and only summary information was available.
As we are assuming equal variances for the two models we are using the estimate for the error standard deviation from the encompassing model as a base value for the simulation error standard deviation. However, using was not very revealing for the discriminatory performance was consistently high for all designs. Thus, to accentuate the differences the actual standard deviation used was instead (unfortunately an even higher inflation is not feasible as it would result in frequent negative observations leading to faulty ML‐estimates). We then simulated the data‐generating process under each model for times and calculated the total percentages of correct discrimination (hit rates) when using the likelihood ratio as decision rule.
We are comparing the designs A1–A4 to three specific δ designs , and δ3, which represent a range of different nominal intervals. Specifically we chose , where we chose and for and . The tuning parameter r was set to three levels: (which is close to the lower bound of still providing a regular design), and (which is sufficiently close to the theoretical upper bound to yield a stable design), respectively. To make the latter more precise: the models in considerations are such that if we fix the last two out of the three parameters, then they become one‐parameter linear models. Therefore, using Proposition 2.4 we know that there exists a finite set upper bound . Solving (14) provides the numerical value . Note that the same bound is valid for all design sizes n. Designs A1–A4 and δ1 all contain four support points, while δ2 has six and δ3 has five, respectively. A graphical depiction of the designs is given in Figure 4.
Figure 4.
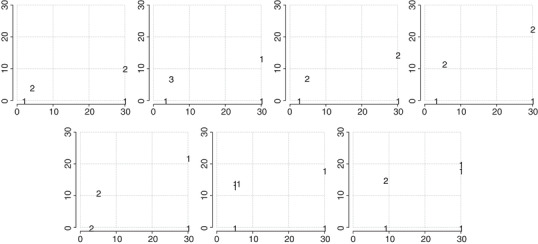
Compared designs: first row A1–A4, second row δ1–δ3
Robustness study: As we would like to avoid comparing designs only when the data are generated from the nominal values (although this favors all designs equally), we perturbed the data‐generating process by drawing parameters from uniform distributions drawn at , where c then acts as a perturbation parameter. Under these settings all these designs fare pretty well as can be seen from Table 3. However, and δ2 seem to outperform the other competing designs by usually narrow margins except perhaps for , which is consistently doing worst. Note that in a real situation the true competitors of δ‐optimal designs are just and as it is unknown beforehand which model is true.
Table 3.
Total hit rates for under each model, maximal values in boldface
| c | 0 | 1 | 5 | |||
|---|---|---|---|---|---|---|
| True model | η0 | η1 | η0 | η1 | η0 | η1 |
| A1 | 91.11 | 94.45 | 91.35 | 93.95 | 90.44 | 93.24 |
| A2 | 97.11 | 96.75 | 97.47 | 96.64 | 96.74 | 96.27 |
| A3 | 96.60 | 96.51 | 96.47 | 96.40 | 95.69 | 96.06 |
| A4 | 97.94 | 96.57 | 97.73 | 96.29 | 97.62 | 96.07 |
| δ1 | 97.59 | 95.11 | 97.43 | 94.90 | 97.71 | 94.56 |
| δ2 | 97.93 | 97.03 | 97.77 | 96.67 | 97.20 | 96.54 |
| δ3 | 96.50 | 95.29 | 96.42 | 95.36 | 96.19 | 95.64 |
3.2. A second large‐scale experiment , log‐normal errors
As the discriminatory power of all the designs for is nearly perfect, we are required to inflate the error variance. However, using additive normal errors in the data‐generating process and inflating the variance by a large enough factor, would generate a large number of negative observations, which renders likelihood estimation invalid. So, the data‐generating process was adapted to use multiplicative log‐normal errors. The observations were then rescaled to match the means from the original process. This way we are at liberty to inflate the error variance by any factor without producing faulty observations. Note that now the data‐generating process does not fully match the assumptions under which the designs were generated, but this can just be considered an extended robustness study as it holds for all compared designs equally. We could of course also have calculated the designs under the same data‐generating process, but as the fit of the model to the original data is not greatly improved and models (15) and (16) seem firmly established in the pharmacological literature, we refrained from doing this.
Perturbation of the parameters here did not exhibit a discernible effect, while the error inflation still does. For brevity, we here report only again the results for using (and ). The respective designs δ1–3 were qualitatively similar to those given in Figure 4 albeit with more diverse weights. In this simulation we generated 100 instances of observations from these designs a thousand times.
The corresponding boxplots of the correct classification rates are given in Figure 5. In this setting A4 seems a bit superior even under η1 (remember it being the T‐optimum design assuming η0 true), while δ1 and δ2 come close (and beat the true competitors A2 and A3) with A1 again being clearly the worst.
Figure 5.
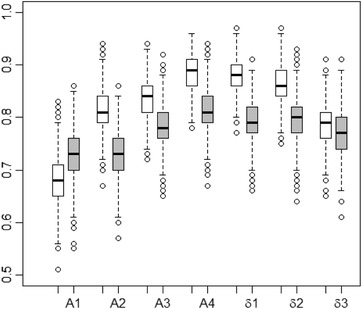
Boxplot for the total correct classification rates for all designs using nominal values and error standard deviations of ; white under η0, grey under η1
4. CONCLUSIONS AND DIRECTIONS FOR FURTHER RESEARCH
We have presented a novel design criterion for symmetric model discrimination. Its main advantage is that design computations, unlike for T‐optimality, can be undertaken with efficient routines of quadratic optimization that in general enhance the speed of computations by an order of magnitude. An optimal exact design problem is a problem of discrete optimization, and the efficiency of its solution critically depends on the speed of evaluation of the design criterion. By a series of approximations, we substituted the theoretically ideal but numerically infeasible computation of the probability of correct discrimination with a simple convex optimization, which can be solved rapidly and reliably. Combined with the proposed methodology of flexible nominal sets, we can construct an entire sequence of exact experimental designs efficient for discrimination between models. Also it was shown in an example that resulting designs are competitive in their actual discriminatory abilities.
The notion of flexible nominal sets may have independent merit. Note again the distinction between parametric spaces and flexible nominal sets (and thus the principal distinction to “rigid” minimax approaches). Parametric spaces usually encompass all theoretically possible values of the parameters, while flexible nominal sets can contain the unknown parameters with very high likelihood, and still be significantly smaller than the original parameter spaces. In this paper, we do not completely specify the process of constructing the flexible nominal sets, but if we perform a two stage experiment, with a second, discriminatory phase, the potential specification through confidence intervals is an important problem.
As the approach suggested offers a fundamentally new way of constructing discriminatory designs, many properties are yet unexplored. A nonexhaustive list of questions follows.
Sequential procedure. The proposed method lends itself naturally to a two‐stage procedure, where parameter estimates and confidence intervals are employed as nominal values in the second stage. Even sequential generation of design points can be straightforwardly implemented.
Approximate designs. Proposition 2.1 is a possible gateway for the development of the standard approximate design theory for δ‐optimality because the criterion is concave on the set of all approximate designs. Therefore, it is possible to work out a minimax‐type equivalence theorem for δ‐optimal approximate designs, and use specific convex optimization methods to find a δ‐optimal approximate designs numerically. For instance, it would be possible to employ methods analogous to Burclová and Pázman (2016) or Yue, Vandenberghe, and Wong (2018).
Utilization of the δ‐optimal designs for related criteria. For a design , a natural criterion closely related to ‐optimality can be defined as
The criterion requires a multivariate nonconvex optimization for the evaluation in each design , which entails possible numerical difficulties and a long time to compute an optimal design. However, the ‐optimal design, which can be computed rapidly and reliably, can serve as efficient initial design for the optimization of . Note that if is a singleton containing only the nominal parameter value for Model 0, the ‐optimal designs could potentially be used as efficient initial designs for computing the exact version of the criterion of T‐optimality.
Selection of the best design from a finite set of possible candidates. As most proposals for the construction of optimal experimental designs, the method depends on the choice of some tuning parameters or even on entire prior distributions (in the Bayesian approach), which always results in a set of possible designs. It would be interesting to develop a comprehensive Monte‐Carlo methodology for the choice of the best design out of this pre‐selected small set of candidate designs. A useful generalization of the rule would take into account possibly unequal losses for the wrong classification.
Noncuboid sets. The methodology could certainly be extended to other types of flexible nominal sets, particularly when we are interested in functional relations among the parameters. However, then the particularly efficient box constrained quadratic programming algorithm could not be utilized.
Higher order approximations. As a referee remarked it is possible to employ tighter approximations of the sets of mean values of responses than the one that we suggest. For instance, it would be possible to use the local curvature of the mean‐value function. However, this may also lead to the loss of numerical efficiency of the method.
More than two rival models. Another referee remark leads us to point out the natural extension to investigate a weighted sum or the minimum δ over all paired comparisons. The implications of these suggestions, however, requires deeper investigations.
Different error variances. Yet another referee requested a clarification for how to proceed in case of unequal error variances for the two models. In case the functional form of these variances are known simple standardizations of the models will suffice. All other cases, including dependencies of the errors, will require more elaborate strategies.
Combination with other criteria. The proposed method can produce poor or even singular designs for estimating model parameters. Because of this problem, already mentioned in Atkinson and Fedorov (1975), Atkinson (2008) used a compound criterion called ‐optimality. The same approach is possible for δ‐optimality. However, our numerical experience suggests that for a large enough size of the flexible nominal set, the δ‐optimal designs tend to be supported on a set that is large enough for estimability of the parameters, without any combination with an auxiliary criterion. A detailed analysis goes beyond the scope of this paper.
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest.
Open Research Badges
This article has earned an Open Data badge for making publicly available the digitally‐shareable data necessary to reproduce the reported results. The data is available in the Supporting Information section.
This article has earned an open data badge “Reproducible Research” for making publicly available the code necessary to reproduce the reported results. The results reported in this article could fully be reproduced.
Supporting information
SUPPORTING INFORMATION
ACKNOWLEDGMENTS
We are very grateful to Stefanie Biedermann from the University of Southampton for intensive discussions on earlier versions of the paper. We also thank Stephen Duffull from the University of Otago for sharing his code and Barbara Bogacka for sharing the data. We also thank various participants of the design workshop in Banff, August 2017, and to Valerii Fedorov for many helpful comments. Sincerest gratitude to the associate editor and the referees of the paper, whose remarks led to considerable improvements. The work of RH was supported by the VEGA 1/0341/19 grant from the Slovak Scientific Grant Agency, W.M.'s research was partially supported by project grants LIT‐2017‐4‐SEE‐001 funded by the Upper Austrian Government, and Austrian Science Fund (FWF): I 3903‐N32.
Harman R, Müller WG. A design criterion for symmetric model discrimination based on flexible nominal sets. Biometrical Journal. 2020;62:1090–1104. 10.1002/bimj.201900074
REFERENCES
- Atkinson, A. C. (1972). Planning experiments to detect inadequate regression models. Biometrika, 59(2), 275–293. [Google Scholar]
- Atkinson, A. C. (2008). DT‐optimum designs for model discrimination and parameter estimation. Journal of Statistical Planning and Inference, 138(1), 56–64. [Google Scholar]
- Atkinson, A. C. (2012). Optimum experimental designs for choosing between competitive and non competitive models of enzyme inhibition. Communications in Statistics—Theory and Methods, 41(13–14), 2283–2296. [Google Scholar]
- Atkinson, A. C. , Donev, A. , & Tobias, R. (2007). Oxford Statistical Science Series. Optimum experimental designs, with SAS. Oxford: Oxford University Press. [Google Scholar]
- Atkinson, A. C. , & Fedorov, V. V. (1975). The design of experiments for discriminating between two rival models. Biometrika, 62(1), 57–70. [Google Scholar]
- Bogacka, B. , Patan, M. , Johnson, P. J. , Youdim, K. , & Atkinson, A. C. (2011). Optimum design of experiments for enzyme inhibition kinetic models. Journal of Biopharmaceutical Statistics, 21(3), 555–572. [DOI] [PubMed] [Google Scholar]
- Burclová, K. , & Pázman, A. (2016). Optimal design of experiments via linear programming. Statistical Papers, 57(4), 893–910. [Google Scholar]
- Buzzi‐Ferraris, G. , & Forzatti, P. (1983). A new sequential experimental design procedure for discriminating among rival models. Chemical Engineering Science, 38(2), 225–232. [Google Scholar]
- Cox, D. R. (1961). Tests of separate families of hypotheses. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability: Contributions to the theory of statistics (Volume 1, pp. 105–123). Berkeley, CA: University of California Press. [Google Scholar]
- Cox, D. R. (2013). A return to an old paper: “Tests of separate families of hypotheses.” Journal of the Royal Statistical Society, Series B, 75(2), 207–215. [Google Scholar]
- Dette, H. , Melas, V. B. , & Shpilev, P. (2013). Robust T‐optimal discriminating designs. Annals of Statistics, 41(4), 1693–1715. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dette, H. , & Titoff, S. (2009). Optimal discrimination designs. Annals of Statistics, 37(4), 2056–2082. [Google Scholar]
- Fedorov, V. V. , & Khabarov, V. (1986). Duality of optimal designs for model discrimination and parameter estimation. Biometrika, 73(1), 183–190. [Google Scholar]
- Fedorov, V. V. , & Pázman, A . (1968). Design of physical experiments (statistical methods). Fortschritte der Physik, 16, 325–355. [Google Scholar]
- Felsenstein, K. (1992). Optimal Bayesian design for discrimination among rival models. Computational Statistics & Data Analysis, 14(4), 427–436. [Google Scholar]
- Hainy, M. , Price, D. J. , Restif, O. , & Drovandi, C. (2018). Optimal Bayesian design for model discrimination via classification. Retrieved from arXiv:1809.05301 [DOI] [PMC free article] [PubMed]
- Hill, P. D. H. (1978). A review of experimental design procedures for regression model discrimination. Technometrics, 20(1), 15–21. [Google Scholar]
- Mullen, K. M. (2013). R‐package BVLS: The Stark‐Parker algorithm for bounded‐variable least squares. CRAN. [Google Scholar]
- Müller, W. G. , & Ponce De Leon, A. C. M. (1996). Discrimination between two binary data models: Sequentially designed experiments. Journal of Statistical Computation and Simulation, 55(1–2), 87–100. [Google Scholar]
- Perrone, E. , Rappold, A. , & Müller, W. G. (2017). ‐optimality in copula models. Statistical Methods & Applications, 26(3), 403–418. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pesaran, M. H. , & Weeks, M. (2007). Nonnested hypothesis testing: An overview. In Baltagi B. H. (Ed.), A companion to theoretical econometrics (pp. 279–309). Hoboken, NJ: Wiley. [Google Scholar]
- Pronzato, L. , & Pázman, A. (2014). Design of experiments in nonlinear models: Asymptotic normality, optimality criteria and small‐sample properties. Lecture Notes in Statistics. Berlin: Springer. [Google Scholar]
- Pukelsheim, F. , & Rieder, S. (1992). Efficient rounding of approximate designs. Biometrika, 79(4), 763–770. [Google Scholar]
- Schorning, K. , Dette, H. , Kettelhake, K. , & Möller, T. (2017). Optimal designs for enzyme inhibition kinetic models. Statistics: A Journal of Theoretical and Applied Statistics, 52(12), 1–20. [Google Scholar]
- Schwaab, M. , Silva, F. M. , Queipo, C. A. , Barreto, A. G. , Nele, M. , & Pinto, J. C. (2006). A new approach for sequential experimental design for model discrimination. Chemical Engineering Science, 61(17), 5791–5806. [Google Scholar]
- Schwarz, G. (1978). Estimating the dimension of a model. Annals of Statistics, 6(2), 461–464. [Google Scholar]
- Sidak, Z. (1967). Rectangular confidence regions for the means of multivariate normal distributions. Journal of the American Statistical Association, 62(318), 626–633. [Google Scholar]
- Stark, P. B. , & Parker, R. L. (1995). Bounded‐variable least‐squares: An algorithm and applications. Computational Statistics, 10(2), 129–141. [Google Scholar]
- Stigler, S. M. (1971). Optimal experimental design for polynomial regression. Journal of the American Statistical Association, 66(334), 311–318. [Google Scholar]
- Tommasi, C. , & López‐Fidalgo, J. (2010). Bayesian optimum designs for discriminating between models with any distribution. Computational Statistics & Data Analysis, 54(1), 143–150. [Google Scholar]
- Tommasi, C. , Martín‐Martín, R. , & López‐Fidalgo, J. (2016). Max‐min optimal discriminating designs for several statistical models. Statistics and Computing, 26(6), 1163–1172. [Google Scholar]
- Vajjah, P. , & Duffull, S. B. (2012). A generalisation of T‐optimality for discriminating between competing models with an application to pharmacokinetic studies. Pharmaceutical Statistics, 11(6), 503–510. [DOI] [PubMed] [Google Scholar]
- Yue, Y. , Vandenberghe, L. , & Wong, W. K. (2018). T‐optimal designs for multi‐factor polynomial regression models via a semidefinite relaxation method. Statistics and Computing, 29(4), 725–738. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
SUPPORTING INFORMATION