

Abstract
We integrate an epidemiological model, augmented with contact and mobility analyses, with a two‐sector macroeconomic model, to assess the economic costs of labor supply disruptions in a pandemic. The model is designed to capture key characteristics of the U.S. input–output tables with a core sector that produces intermediate inputs not easily replaceable by the other sectors, possibly subject to minimum‐scale requirements. Using epidemiological and mobility data to inform our exercises, we show that the reduction in labor services due to the observed social distancing (spontaneous and mandatory) could explain up to 6–8 percentage points of the roughly 12% U.S. GDP contraction in the second quarter of 2020. We show that public measures designed to protect workers in core industries and occupations with tasks that cannot be performed from home, can flatten the epidemiological curve at reduced economic costs—and contain vulnerabilities to supply disruptions, namely a new surge of infections. Using state‐level data for the United States, we provide econometric evidence that spontaneous social distancing was no less costly than mandated social distancing.
Keywords: Infectious disease , pandemic , recession , COVID‐19
Keywords: E1 , E3 , I1
1. Introduction
By the end of March 2020, nearly 4 months after the first detection of significant coronavirus infections in China, most advanced economies adopted measures restricting people's movements and activity on their territory, introduced tough controls at their borders, and mandated norms implementing social distancing. If only with some delay, governments converged on the idea that restrictions were required to reduce the human cost of the disease. The decision to adopt mandated restrictions was strongly influenced by early scenario analyses stressing that an uncontrolled and rapid spread of the disease would have overwhelmed national health systems and caused a sharp rise in mortality rates. 1 At the same time, mobility fell precipitously, although not uniformly across locations, as individuals took precautions. During the subsequent months, contagion and death rates, while high, turned out to be much lower than indicated by these early scenario analyses, as social distancing, whether mandated or spontaneous, became widespread practice. At the end of 2020, a new surge associated with more infectious variants of the virus motivated once again the widespread adoption of strict lockdown policies.
Our analysis contributes to the literature on the policy trade‐offs raised by a pandemic, with an assessment of the extent to which a large upfront reduction in the supply of labor services caused by the disease and social distancing can weigh on economic activity. Specifically, working in real time in the early months of 2020, we were concerned that labor shortages could have hit industries and parts of the economy that, directly and indirectly, provide essential inputs to production and/or are essential for the economy to run. While it may be difficult to identify precisely which specific industries and activities produce essential inputs and services, and hence should be included in the core sector, there are some reasonable choices: distribution services, transportation, sanitation, energy supply, health care services, and food. 2 Labor shortages that hobble industries in this “core sector” can amplify the impact economic contraction of a pandemic. First, the services and goods produced by the core sector are not easily substitutable, and second, the production processes in many industries in this sector may be subject to a minimum‐scale requirement for labor, that is, they require a sufficient number of specialized and not easily substitutable employees to show up for work. This amplification mechanisms may not be apparent during normal business cycle fluctuations, but can be expected to become relevant with the scale and timing of a pandemic shock.
We develop a stylized “integrated assessment model for infectious diseases,” which combines a deterministic multigroup epidemiological model with a two‐sector economic growth model. 3 Using this framework, we can map both the incapacitating effects of the disease on workers and the intensity of social distancing, proxied by mobility data, into the spread of the disease and the number of people able to work as well as the associated contraction in economic activity.
Our main contributions are as follows. First, prior to our quantitative exercises, we motivate our use of mobility data in the model calibration by providing econometric evidence on the epidemiological and economic effects of social distancing. Based on U.S. state‐level data for 2020, we find that the reduction in mobility lowered the reproduction rate (defined below) with an elasticity from 3 to 5, and raised initial jobless claims with an elasticity around 0.15. We derive our regression tests from the standard epidemiological SIRD model, proxying contacts using Google mobility data, and instrumenting mobility with either the stay‐at‐home orders issued by individual U.S. states, or political leanings by state. Strikingly, even though most of the decrease in mobility at the onset of the pandemic was driven by spontaneous social distancing, it was no less costly than stay‐at‐home orders.
Second, using epidemiological, mobility, and occupational data, we show that the reduction in labor services due to the observed social distancing (spontaneous or mandatory) can explain up to 8 percentage points of the 12% output collapse experienced by the United States in 2020. 4
To be clear, we are not claiming that supply disruptions were the only mechanism by which the pandemic translated into a sudden large drop in activity in 2020—if anything, our exercise led us to conclude that these disruptions were not as biting as we initially feared. The precipitous fall in demand in early 2020 stemmed from a combination of factors, including: the sudden stop in the consumption of services exposing people to contagion risk (from hospitality to travel and entertainment), the spike in precautionary saving/drop in investment due to the large uncertainty on the medium and long‐run effects of the pandemic, and lockdowns and precautionary suspensions of services such as nonemergency health care. 5 To put it simply, in the context of a low demand and mandatory restrictions, possible problems in the supply of, say, public transportation or health services may have not emerged in the open. Yet, we believe it would be wrong to conclude that supply disruptions played no role at the outset of the COVID‐19 shock, or that a pandemic would at no time raise issues on the supply side.
A benefit of our focus on the supply side is transparent guidance in the design of social distancing measures. Specifically, our model underscores the benefits of public measures aiming to protect workers in core industries and occupations with tasks that cannot be performed from home. We show that, in a spike of contagion, such measures can flatten the epidemiological curve at reduced economic costs. We argue that, looking at the future, this strategy could contain vulnerabilities to supply disruptions, namely a new surge of infections—as well as in structuring health measures to accompany the administration of a vaccine. 6
For the purpose of our analysis, the epidemiological block of our framework includes an extension of the standard susceptible‐infective‐removed‐death (SIRD) model with a homogeneous population to a setting with multiple groups, accounting for the heterogeneous roles that individuals play in the economic production process and accounting for different age groups. 7 This setup gives us the flexibility to differentiate lockdowns across groups by sector and occupational task. The economic block of our framework, in turn, assumes a low degree of substitutability between core and noncore inputs in producing final output goods, as well as a realistically low degree of worker mobility across sectors (i.e., we set intersectoral mobility to zero). The minimum‐scale requirement in the core sector captures the idea that technology in the industries in this sector is such that workers need to operate as members of a team, reflecting the difficulty of replacing team members with specialized skills. By way of example, surgery operations cannot be performed without a complete team of doctors, nurses, and technicians; the subway system cannot run if not enough train operators show up for work. A reduction in the number of workers could lead to inefficient work arrangements and/or outright shut‐downs of production facilities—so that labor supply and productivity fall in tandem. In addition, we allow for endogenous capacity utilization, investment adjustment costs, and put a lower bound on disinvestment, implying that accumulated capital cannot be consumed.
The two blocks of the model are tied together by the dynamic of the infection (and death) rates, which influence the labor supply. In general, this dynamic is driven by complex interactions of possibly time‐varying features of the virus (e.g., mutations) and environmental conditions (e.g., seasonality), with social distancing (spontaneous or mandatory) reducing contacts among people and also influencing the labor supply, and the adoption of precautions conditional on contacts (e.g., masks and hand washing). Because of these complex interactions, the fluctuations in the infection and death rates throughout 2020—with the spread of the pandemic more limited than foreshadowed by early pessimistic scenarios—are a challenge to integrated epidemiological and economic models. We address this challenge by bringing our model to bear on the dynamic of the (estimated) reproduction rates, calibrating it with mobility data as evidence on contact rates, and estimates of workers who can supply their labor services from home. 8
The rest of the paper is organized as follows. Section 2 reviews key data for the United States and provides empirical evidence on the effects of social distancing. Section 3 introduces the integrated model, specifying both the epidemiological and the economic elements as well as the structure of social distancing. Section 4 discusses our calibration and solution methods. Section 5 discusses our results on the effects of varying the type and intensity of social distancing measures. Section 6 concludes. Further details on the model and sensitivity analysis are presented in the Appendix of the Online Supplementary Material (Bodenstein, Giancarlo, and Guerrieri (2022)).
2. Setting the stage: A review of epidemiological models and evidence for the United States in 2020
In this section, we set the stage for our analysis by providing and discussing evidence on the dynamic of the COVID‐19 pandemic in the United States in the first three quarters of 2020, and the effects of social distancing on the spread of the disease and unemployment across U.S. states. Throughout our analysis, we will make extensive use of mobility data to approximate social distancing and trace its effect on the economy. The evidence in this section is an important preliminary step motivating our theoretical exercises below.
Section 2.1 describes a one‐group SIRD model—capturing how a disease spreads by direct person‐to‐person contact in a population. At this stage, we let individuals differ only with regard to their health status—our baseline model in which individuals differ also with regard to their socioeconomic characteristics will be introduced later. Section 2.2 reviews stylized facts on the diffusion of the disease over time and across states in the United States, including data on mobility and health measures adopted at state level. Drawing on the SIRD model, Section 2.3 specifies a simple econometric framework and provides evidence on the effects of social distancing on the dynamic of the pandemic and employment.
2.1. A baseline one‐group SIRD model
The one‐group SIRD model in this section follows Fernández‐Villaverde and Jones (2020), as we later use their estimates in the validation of our integrated model. 9 Time is discrete and measured in days. At every instant in time, the total population N is divided into the classes of:
-
1.
susceptible consisting of individuals who can incur the disease but are not yet infected;
-
2.
infective consisting of individuals who are infected and can transmit the disease;
-
3.
resolving consisting of sick individuals who are no longer infective;
-
4.
recovered (or, equivalently, cured) consisting of individuals who have recovered from the disease;
-
5.
deceased consisting of individuals who died from the disease.
This model differs from the standard SIRD model by distinguishing between the infective and the resolving class. Fernández‐Villaverde and Jones (2020) found this distinction necessary to obtain a good model fit in their empirical application to U.S. data.
An important assumption of standard SIRD models is that the “law of mass action” applies: The rate at which infective and susceptible individuals meet is proportional to their spatial density . The effective contact rate per period is the average number of adequate contacts per infective period. An adequate contact of an infective individual is an interaction that results in infection of the other individual if that person is susceptible. Thus, can be expressed as the product of the average of all contacts and the probability of infection (transmission risk) given contact between an infective and a susceptible individual, .
It is important to note that the effective contact rate is not constant but can vary over time for a number of reasons. First, an individual's number of contacts, , can drop in a pandemic because of mandated social restrictions (e.g., school closures, closures of shops and restaurants, stay‐at‐home orders) or voluntary adjustments of behavior (e.g., online shopping instead of in‐person shopping, refraining from attending larger gatherings). As both mandated and spontaneous contact restrictions may take place simultaneously, it may be challenging to disentangle their effects on . Nonetheless, restrictions have an impact on the economy regardless of whether they are mandated or spontaneous in nature. Second, the probability of infection given contact between an infectious and a susceptible individual can vary over time. In the case of COVID‐19, this probability is influenced both by human behavior (e.g., masks, keeping sufficient physical distance) and by the characteristics of the virus (e.g., transmission in closed versus open spaces, sensitivity to temperature and seasonality, aggressiveness of the virus strains).
In detail, we write the discrete time SIRD model as
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
| (6) |
with the initial conditions and . In addition, , , and . Total new infections at time t are given by . Infections resolve at the Poisson rate γ. A person in the resolving class () either recovers () with probability or dies () with probability ϖ. The recovery rate is denoted by ϑ. In principle, the recovery rate and the death rate could also be time‐varying to reflect advancements in medical treatment as the pandemic progresses.
2.2. The dynamic of the COVID‐19 spread in the United States
Conditional on a constant contact rate β, with an empirically relevant reproduction rate equal to 2, a mainstream estimate for the onset of the pandemic, almost the entire population is infected in a matter of months. According to leading scenarios debated in March 2020, for instance, it could not be ruled out that between 15 and 20% of the U.S. population could have simultaneously developed symptoms, and that, over a short time frame, 20% of these symptomatic individuals would have required hospitalization. 10 These developments would have put devastating pressure on the health care system of any country.
Scenarios conditional on a constant β played a crucial role in motivating stark health measures in many countries—for this reason, we will study this type of scenario as a benchmark reference below. Remarkably, however, these grim developments did not come to pass. Figure 1 superimposes data for the spread of COVID‐19 in the United States, death rates and confirmed cases, and data on the timing of stay‐at‐home orders and changes in residential mobility—culled from cell phones, as captured in Google's mobility reports, and reflecting both trips toward residential addresses and time spent at those addresses. 11
Figure 1.
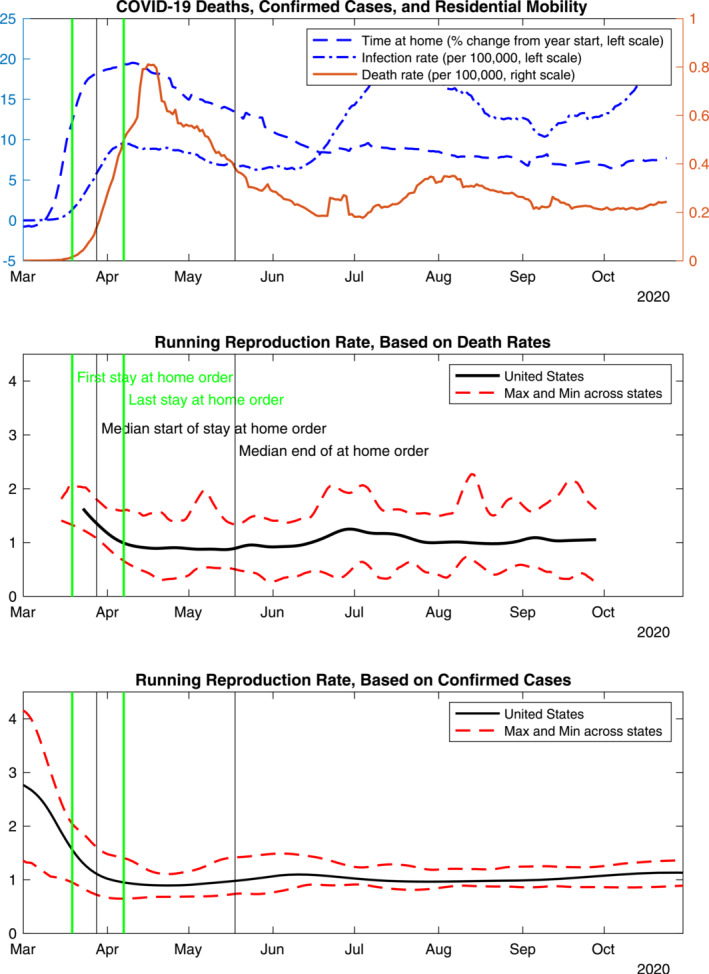
Stay‐at‐home orders, mobility, COVID‐19 death and infection rates—7‐day moving average. Note: The vertical lines denoting key dates are repeated in each panel. Sources: The data for death rates and confirmed cases are from JHU (2020). The data on stay‐at‐home orders are from Raifman et al. (2020). The residential mobility data are from Google (2020). The estimates of the reproduction rate based on deaths are from Fernández‐Villaverde and Jones (2020). The estimates of the reproduction rate based on confirmed cases are from Systrom, Vladek, and Krieger (2020).
Tracking the spread of COVID‐19 is no easy feat. Even the best available data are subject to important drawbacks. As Figure 1 shows, confirmed new cases surged in March 2020, reached a first peak in early April, a second peak in mid‐July and climbed back up through the fall. Using confirmed new cases to measure the intensity of the pandemic is challenging since severe rationing of testing at the beginning of the pandemic kept the data artificially low. Data on death rates do not suffer from that problem and confirm at least three cycles for the spread of the disease. However, the relationship between the spread of the disease and death rates can also vary as new treatment protocols are developed or the age composition of infected individuals evolve, given that older individuals experience greater mortality rates. The middle panel of the figure shows the reproduction rate for the model in equations (1)–(6) estimated by Fernández‐Villaverde and Jones (2020) based on data on death rates. The solid line shows the overall estimate for the United States. Two cycles are clearly visible in the estimates of the reproduction rate. The state‐level estimates show much greater variation, as indicated by the pointwise maximum and minimum dashed lines for these estimates.
Figure 1 also shows that stay‐at‐home orders were put in place at different points in time across states, roughly within a 3‐week window from mid‐March to early April. 12 These orders had a median duration of 6 weeks, but the duration also varied considerably by state. Twelve states did not impose stay‐at‐home orders. In the states that did, the shortest orders lasted 3 weeks and the longest, for California, was still standing in parts of the state at the time of writing.
The figure suggests that social distancing contributed significantly to slowing down the spread of the disease. It also shows that mobility measures capturing time spent at home ramped up even before the imposition of stay‐at‐home orders at the regional level. We will take advantage of the timing of these events to gain some insight on the relative role of spontaneous vs. mandated social distancing in driving the evolution of the disease.
2.3. The effects of social distancing
In this section, we provide evidence that social distancing, be it spontaneous or mandatory, has comparable epidemiological and economic effects. Specifically, based on the epidemiological model, we derive and apply two empirical tests of the hypothesis that contacts, as proxied by mobility data, have an effect on the reproduction rate and the initial jobless claims. First, we will focus on changes in mobility in response to stay‐at‐home orders, using a difference‐in‐difference approach. Then we will investigate the dynamic evolution of contagion in the 2‐week period in March that preceded any mandatory measure, based on cross‐sectional evidence.
Several other papers have sized empirically the economic effects of mandated social distancing, including Allcott et al. (2020) and Coibion, Gorodnichenko, and Weber (2020). Our approach is closest to Gupta et al. (2020), who also use a difference in difference approach to size the effects on the labor market. Our specific approach helps us distinguish between the direct effects of the social‐distancing policies through reduction in mobility and outcomes related to spontaneous social distances predating the policies. 13 Goolsbee and Syverson (2021) also rely on a difference in difference estimation method but use more capillary data at the local level. Nonetheless, their results on the economic effects of mandated social distancing are broadly in line with ours.
For both tests below, we derive our regression framework from the SIRD model described in Section 2.1. In the SIRD framework, the status of the pandemic is summarized by the reproduction rate
where the effective contact rate is the product of contacts , normalized to 1, and the probability of transmission, . We can therefore express the reproduction rate as
| (7) |
where the term represents policy restrictions that can reduce the level of contacts. We will use equation (7) to derive a panel regression and a cross‐sectional test. 14 Atkeson, Kopecky, and Zha (2021) provide framework consistent with ours to decompose the reproduction rate but allow for a feedback mechanism between the reproduction and infection rates.
2.3.1. Mandated social distancing: A panel regression approach
The relationship between the reproduction rate and contacts in equation (7) can be mapped into the following panel regression equation:
| (8) |
where the subscript s denotes the geographical region and the term is the regional counterpart to the aggregate in equation (7). The dependent variable in our baseline, consistent with the model in Section 2.1, is the reproduction rate estimated by Fernández‐Villaverde and Jones (2020). We average the daily estimates by these authors to the weekly frequency and use readings for the 48 U.S. states in their data set and the District of Columbia. 15 We use monthly fixed effects, , to capture the time‐varying probability of transmission , which might depend on taking precautions such as frequent handwashing and mask‐wearing that have become more prevalent with the spread of the virus. 16 We proxy contacts at the regional level with the term , the Google index for residential mobility in percent deviation from its value at the beginning of 2020, also averaged to the weekly frequency. The term denotes regional‐level fixed effects, which allow for regional characteristics to influence the relationship between contacts and mobility. Finally, is a stochastic term in the relationship between contacts and mobility. Our main interest is the regression coefficient b. An important restriction imposed by our regression framework is that this coefficient does not vary across regions.
We estimate equation (8) by two‐stage least squares, using a dummy for the stay‐at‐home orders as an instrument for residential mobility. To lessen endogeneity concerns we lag the dummy for the stay‐at‐home orders by one week. At the first stage, we also allow for monthly and regional fixed effects. The estimation sample has starting points that vary by region, in line with regional variation in the spread of the disease. The earliest estimates of the reproduction rate are for the state of Washington, starting on March 12, 2020. By contrast, estimates of the reproduction rate for Hawaii only start on August 7, 2020. The end point for the estimation sample across all regions is September 28, 2020. Overall, the sample includes 1204 observations.
Our estimates of equation (8), first and second stage, are shown in Table 1. In the table, Column 1 indicates that, on average, stay‐at‐home orders push up the mobility index 1.85%. Returning to the table, Column 2 shows that a 1% increase in residential mobility reduces the reproduction rate by about 3.5%, all else equal. Putting the two estimates in columns 1 and 2 together, on average, the stay‐at‐home orders led to a decline in the reproduction rate of about . In other words, starting from a basic reproduction rate of 2, the stay‐a‐home order would reduce it to about 1.9. One may note that, at its peak, the index of residential mobility increased by about 20% (reflecting an increase in time spent at home). Even if all states had enacted stay‐at‐home orders, our estimates would attribute only 1.85 percentage points of this increase to those orders. Accordingly, the great majority of the 20% p increase was linked to spontaneous social distancing.
Table 1.
The effects of stay‐at‐home orders.
|
(1) |
(2) |
(3) |
|
|---|---|---|---|
|
Res. Mobility |
Reproduction Rate |
Init. Unemp Claims |
|
|
2sls 1st step |
2sls 2nd step |
2sls 2nd step |
|
|
Stay‐at‐home orders |
1.850 |
||
|
(0.000) |
|||
|
Residential mobility index |
−3.502 |
0.153 |
|
|
(0.010) |
(0.000) |
||
|
r2 |
0.918 |
0.153 |
0.610 |
|
N |
1204 |
1204 |
1204 |
Note: p‐values are reported in parentheses. All the regressions are run with data at the weekly frequency and include state and month fixed effects. A state‐by‐state dummy that takes a value of 1 if a stay‐at‐home order is in force and zero otherwise is the instrument for the Google residential mobility index in the 2‐stage‐least‐squares regressions in columns (2) and (3). The results in column (2) are based on the reproduction rate from the data set of Fernández‐Villaverde and Jones (2020).
To gauge the effects of the stay‐at‐home orders on initial unemployment claims, we use a regression framework analogous to that of equation (8). We consider
| (9) |
where the term represents initial jobless claims as a share of the working age population in region s at time t. For the sake of comparison, we select an estimation sample with exactly the same span of the sample for the regression of the reproduction rate. We also estimate equation (9) by two‐stage least squares, using a dummy for the stay‐at‐home orders as an instrument for residential mobility. Once again, using standard Durbin and Wu‐Hausman tests, we fail to reject the null hypothesis that the instrument is exogenous. This time, probability values for the tests are of 0.13 and 0.14, respectively. Connecting the estimates in columns (1) and (3) of Table 1, the regression results point to an increase in the unemployment rate of roughly 0.3 () percentage point for every week that the stay‐at‐home orders were in force. With a median duration of 6 weeks and the orders applying to much of the country, they could have accounted for an increase in the unemployment rate of about 2 percentage points.
2.3.2. Spontaneous social distancing: A cross‐sectional approach
To study the effect of spontaneous social distancing, we consider a 2‐week period before the imposition of any stay‐at‐home order—the 14‐day period through March 17, which is 2 days before the first stay‐at‐home order went into effect in California. The evidence reviewed above suggests that much of the reduction in mobility had already occurred by the time mandatory rules started to be imposed. Yet, this initial mobility reduction was far from homogeneous across states.
A useful observation for our purpose is by Gollwitzer et al. (2020), who note that individual political leanings influence social distancing practices, and through these practices also influence health outcomes. We design a second test of our hypothesis building on this observation. Namely, we instrument mobility with political leanings by U.S. state, as captured in the share of the vote for the Republican candidate in the 2016 presidential election. Given our focus on the first part of March, before the introduction of mandatory measures, we collapse the time dimension of our initial panel regression and rely only on the cross‐sectional variation at the state level.
Starting from the regression framework in equation (8), we now difference the specification between two points in time on the same month. Focusing on the regression for reproduction rate, this differencing yields
| (10) |
(We proceed analogously for initial jobless claims using equation (9) as a starting point.)
We again estimate the elasticity coefficient b by two‐stage least squares. In the first stage, we use political leanings to instrument the change in mobility between two points in time. In the second stage, we regress our dependent variable—either the reproduction rate or the initial claims—on the fitted change in residential mobility. In this exercise, we cannot use the estimates of the reproduction rate in Fernández‐Villaverde and Jones (2020), since these start in the second‐half of March for most regions. We rely instead on the estimates from Systrom, Vladek, and Krieger (2020), which start earlier and are based on an adaptation of the estimation method of Bettencourt and Ribeiro (2008). The middle and bottom panels of Figure 1 offer a comparison of these alternative estimates of the reproduction rate when aggregated at the national level.
The estimates of the reproduction rate from Systrom, Vladek, and Krieger (2020) cover all 50 U.S. states and the District of Columbia. The starting date for these estimates varies by state, in line with the differential spread of the disease. The earliest estimates are for February 19, 2020, for the state of Washington, whereas, at the other end of the spectrum, estimates for Alaska, Idaho, and West Virginia only start on March 8, 2020. 17
The message from our new exercise is loud and clear. As shown in Table 2, Column 1, there is a strong correlation between political leanings and the change in mobility. In columns 2 and 3, the null hypothesis that the coefficient on the instrumented mobility is 0 can be rejected at standard significance levels, despite the fact that we only have 51 observations. The elasticity of initial jobless claims with respect to mobility in column 3 of this table, at about 0.17, is remarkably close to the analogous elasticity in column 3 of Table 1, which is approximately 0.15. This finding indicates that the economic costs of changes in mobility are comparable, regardless of whether the changes are driven by mandated or spontaneous measures. However, it could still be the case that for comparable costs, the spontaneous measures could have induced a bigger decline in the reproduction rate. Moving back to Table 1 for the panel regression instrumented with stay‐at‐home orders, Column 2 shows an elasticity of the reproduction rate with respect to mobility of about −3.5. By contrast the analogous estimate in Column 2 of Table 2 is about −2.3, which implies a lower effectiveness of spontaneous measures in reducing the reproduction rate relative to mandated measures. 18
Table 2.
The effects of spontaneous social distancing.
|
(1) |
(2) |
(3) |
|
|---|---|---|---|
|
% Change Res. Mobility |
% Change R |
PPt. Change Init. Claims |
|
|
2sls 1st step |
2sls 2nd step |
2sls 2nd step |
|
|
% Republican votes in 2016 |
−0.189 |
||
|
(0.000) |
|||
|
PPt. Change res. mobility |
−2.268 |
0.168 |
|
|
(0.099) |
(0.003) |
||
|
r2 |
0.607 |
0.0439 |
0.140 |
|
N |
51 |
51 |
51 |
Note: p‐values are reported in parentheses. Political leanings, as measured by the share of votes for the Republican presidential candidate in the 2016 election are the instrument for the Google residential mobility index in the 2‐stage‐least‐squares regressions in columns (2) and (3). The results in column (2) are based are based on the reproduction rate from the Rt.Live data set of Systrom, Vladek, and Krieger (2020). These regressions focus on the 2‐week period prior to the enactment of any state‐level stay‐at‐home orders.
In sum, we have produced evidence that, despite the fact that spontaneous measures at the onset of the pandemic drove the bulk of the reduction in mobility, they were no less costly than mandated measures, even when controlling for their impact on the reproduction rate. This result is an original contribution of our analysis. While subsets of our results have also been documented by related analyses, the value added from our study consists of comparing the effects of mandated social distancing with the effects of spontaneous distancing, on both epidemiological and economic indicators.
3. A four‐group, two‐sector integrated model
In this section, we motivate and present our integrated assessment model for infectious diseases. This model combines a deterministic compartmental SIRD model of epidemiology with four population groups, and a two‐sector economic growth model.
As we have seen above, epidemiological models attempt to map the complex transmission interactions of infectious diseases in a population into a formal mathematical structure that can describe the large scale dynamics. To integrate epidemiological and economic models, we have to make assumptions about the interaction of the spread of the disease with economic activity. In our framework, we allow for three channels. First, if at least some of the individuals who have fallen ill from the disease cannot work, the aggregate labor supply shrinks temporarily and reduces economic activity. Second, social distancing to control the spread of the infectious disease either prevents individuals from conducting their work altogether or limits their productivity (e.g., by imposing inefficient home‐office arrangements). Again, the reduction in effective labor causes economic activity to fall and, if the social distancing is implemented over a long time period, a decline in investment activity may cushion the near‐term fall in consumption but add persistence to the economic repercussions. Third, in our two‐sector economic growth model, it matters greatly for economic activity how the health measures affect labor supply across across sectors.
We should stress from the start a key difference between our approach and leading contributions, pioneered by Eichenbaum, Rebelo, and Trabandt (2020), that redefine preferences to capture how agents reduce consumption or labor supply in view of contagion risk when engaging in these activities. Instead of modifying preferences to account for the unobservable spontaneous precautionary behavior in social interactions, we calibrate our integrated model with evidence on differential contact rates implied by engaging in different activities, to gain insight on how the observed reduction in contacts, proxied by mobility, can affect economic activity via supply disruptions. By no means is this choice meant to downplay the importance of modeling and investigating theoretically the roots of behavior driving the precautionary reduction in consumption and labor. On the contrary, we see the two modeling strategies as complementary lines of research.
In our approach, we treat variations in mobility from the data equally regardless of whether they are driven by spontaneous decision or mandated measures. The evidence in the previous section, showing that both types of changes in mobility had comparable effects on the reproduction rate and unemployment, lends empirical support to our choice.
Our approach nonetheless places demands on the epidemiological model. In particular, relative to the model presented in the previous section, we need to track different population groups depending on their roles in the economy. This multi‐group model is described in the next section.
3.1. The epidemiological block of the integrated model: A four‐group SIRD model
As a key bridge between epidemiology and economics, we expand the SIRD model presented in Section 2.1 by splitting the population N in four groups. The size of group is denoted by with . The members of each group are homogeneous and share specific socioeconomic characteristics. The members of groups 1 and 2 are in the labor force and are employed in sectors 1 and 2, respectively. The members of the third group, the young, attend school and do not work. Similarly, the members of the last group, the old, do not work either.
Relative to the one‐group model, another important innovation in our four‐group model is the possibility that at time a highly effective vaccine becomes available. For each of the four group of the population, we now have susceptible, infective, resolving, recovered (cured), deceased, as well as a subgroup of vaccinated, denoted, respectively, , , , , , with . Notably, both the average number of contacts per person and the probability of transmission can differ across groups, so that the effective contact rate transmission can be group‐dependent. 19 We refer to as the matrix of effective contacts in the multigroup SIRD model. The elements of are the group‐dependent contact rates which measure the probability that a susceptible person in group j meets an infective person from group k and becomes infective.
As far as there is no vaccine, susceptible individuals remain susceptible until they become infected. Once a vaccine becomes available at time —assuming that the vaccines is fully effective—the subpopulation of susceptibles shrinks as individuals are vaccinated. We denote by the vaccination rate for group j at time t. Note that it is for for all j.
The system of equations for the four‐group SIRD model is given by
with . We discuss the parameterization of the effective contact rates in detail below.
3.2. The macroeconomic block of the integrated model: A two‐sector model
Individuals live in identical households that pool consumption risk across the different household members, that is, the composition of each household reflects the relative group sizes in the population. However, we do not allow labor to be substitutable across sectors. Absent social distancing, all susceptible and recovered individuals work. Infective individuals may or may not be symptomatic: we assume that symptomatic individuals do not work. We describe the connection between the economic and the epidemiological model in the next section.
Our model comprises two intermediate sectors, Sector 1 and Sector 2. Individuals in Group 1 provide labor services inelastically to firms in Sector 1. Individuals in Group 2 provide labor services inelastically to firms in Sector 2. Individuals in groups 3 and 4, the young and the old, are not in the labor force. Final goods are produced with inputs from the two intermediate sectors with a constant elasticity of substitution function. These inputs are imperfect substitutes for each other. 20 The two sectors differ by their production structure. In Sector 1, labor inputs are subject to a minimum scale requirement. This scale requirement is a simple way to capture the specialized skills of different workers, all of which are necessary to produce a certain product. Larger labor shortfalls make it more likely that production will be impaired by the absence of essential members of a team. We abstract from modeling the interaction of capital with the labor input in Sector 1. We have in mind production structures in which capital cannot easily compensate for shortfalls in the labor input. For example, if doctors and nurses do not show up for work, it seems unlikely that adjustments could be made to compensate for their absence. By contrast, with Sector 2, we are attempting to capture production processes in which the utilization of capital services can be more easily adapted, and in which labor inputs are more readily substitutable for capital services.
Households maximize consumption and supply two types of labor, and inelastically. Households also rent capital services to firms in Sector 2, where captures variable capacity utilization that can also be adjusted for those services. The utility function of households is
Households choose streams of consumption, investment, capital, and utilization to maximize utility subject to the budget constraint
where the term captures costs from adjusting capital utilization. The parameter allows us to normalize utilization to 1 in the steady state, whereas the parameter ν determines how costly it is to change utilization. The term captures costs of adjusting investment, with these costs governed by the parameter ζ. Households' utility maximization is also subject to the law of motion for capital, given by
and to a threshold level of investment,
| (11) |
where ϕi denotes a fraction of steady‐state investment. Notice that when , equation (11) implies the irreversibility of capital.
Moving to the description of the production sector, firms in Sector 1 use labor to produce the good and charge the price . The production function is given by
| (12) |
Firms in Sector 2 use capital and labor to produce good ,
The final output good is a composite of the goods 1 and 2:
| (13) |
3.3. Integrating the epidemiological and the macroeconomic model
The dynamics of the epidemiological and the macroeconomic models are interwoven. On the one hand, the virus and mitigation measures—both spontaneous and mandated—directly reduce economic activity: Symptomatic sick individuals may not work. The labor supply may also decline if healthy individuals decide not to work either because of workplace closures or because of their own choosing to reduce their exposure to the virus. Similar considerations can also precipitate a contraction in consumption. On the other hand, individuals' ability and willingness to engage in economic activity has direct implications for the spread of the virus. People who, for whichever reason, work from home or not at all have fewer relevant contacts that could result in an infection. The lower risk of infection is reflected in the decline in the effective contact rate .
3.3.1. Dynamics of the effective contact rate
Similar to other recent contributions on the macroeconomics of epidemics, in our setting is sensitive to economic conditions and choices. 21 However, rather than positing a direct functional relationship between economic variables and the effective contact rate , our functional form for is consistent with the key feature of the “law of mass action” assumed in the SIRD and other popular epidemiological models. Under this law, the rate at which infective and susceptible individuals meet is proportional to their spatial density. We specify a mapping from spatial density to economic variables, which accounts for the fact that not all reductions in spatial density translate necessarily into a reduction of economic activity.
Recall that is defined as the product of the matrix of average contacts and the transmission risk . Epidemiologists have carefully studied people's social contact patterns to understand the spread of infectious diseases. Importantly, contacts differ by location and age. The POLYMOD study, one influential study of social contacts, allows to derive matrices for the contacts between the members of different age groups in four location settings: home (h), school (s), work (w), and other (o). 22 The time‐invariant matrix with informs about the number of contacts that a typical member of each demographic group has with the members of each demographic group. Absent contact restrictions, the average contact matrix aggregated over locations satisfies
Spontaneous and mandatory restrictions reduce social contacts through lowering spatial density. Consistent with the law of mass action, we assume the quadratic form
| (14) |
where the row vector denotes the reduction in the spatial marginal density of each demographic group. Time‐variation in induces time‐variation in the average contact matrix aggregated over locations even if the underlying contact matrices are constant. Equation (14) foreshadows our calibration assumption that contacts at home between family members cannot be reduced by mitigation measures. Of course, the economic costs can differ across types of restrictions.
While data on contact rates and contact restrictions are available, little is known about the factors influencing the transmission risk of the coronavirus. Viruses mutate and they can become more or less contagious. Appropriate hygiene, masks, and keeping proper physical distance seem to lower the transmission risk according to the Center for Disease Control and Prevention. The transmission also appears to be higher indoors than outdoors; increased outside activity during the warmer months of the year may thus lower temporarily the transmission risk. Absent direct quantitative evidence how these factors affect the transmission risk, we shy away from specifying a functional form that describes the evolution of the transmission risk over time. Instead, we treat as an exogenous variable.
3.3.2. Disease spread, disease management and the labor supply
A pandemic may cause economic costs and disruptions through different channels. Our focus is on how infections and contact restrictions impair the labor supply—a key driver of economic activity. Specifically, we link the evolution of the labor supply explicitly to infections and contact restrictions using data on mobility and the ability to work from home. Our modeling choice does not mean that we view other channels, such as a drop in “social consumption” (restaurants and hospitality) as unimportant. Rather, it reflects the difficulty to establish a data‐oriented link between these channel and the pandemic. 23 We should nonetheless note that our approach also accounts for a reduction in consumption triggered by changes in the labor supply, wage income, and investment.
Without the disease, the labor supply in each sector is
for for all t. As the disease starts spreading, we assume that sick and symptomatic individuals that are in the resolving state, , do not work. In addition, the labor force of each sector is reduced by deaths. Hence, denoting with ι the share of resolving individuals who are asymptomatic, the labor supply in sector j satisfies
for .
We have already shown how spontaneous and mandatory restrictions reduce contacts; see equation (14). Consistent with our focus on potential supply disruptions from the disease, we posit that contact restrictions directly relate to economic activity only by affecting the supply of labor services. As defined earlier, denotes the share of individuals in group j, that stop going to the workplace per effects of contact restrictions. Now, not all work restrictions imply a fall in labor services, since some jobs can be carried out from home. Assuming that contact restrictions apply to all individuals in a group regardless of their health status, then the labor supply in sector j is given by
| (15) |
In equation (15), the contraction in the supply of labor services (in addition to deaths) is accounted for by three terms. A first term, , nets out the services provided by individuals in group j with contact restrictions, where is the share of individuals in group j who can continue working from home. The second and third terms net out individuals who are sick and symptomatic. The term is the number of sick and symptomatic individuals in group j who are under restrictions and are working from home. The term is the number of individuals in group j who get sick and are symptomatic but are not under restrictions.
3.3.3. The special case of a one‐sector macroeconomic model
We conclude noting how our four‐group/two‐sector model can be simplified and made comparable with other models in the literature. Trivially, the four‐group SIRD model readily collapses to a three‐group model when we impose that all the shares pertaining to Group 1 are zero, that is, . For comparability with the literature, it is also useful to keep the nonworking‐age population (Groups 3 and 4), separate from the others. By the same token, our two‐sector model collapses to a prototypical one‐sector real business cycle model when we impose that the quasi‐share parameter ω in equation (13) is one.
4. Calibration and solution
In this section, we present our calibration, summarized in Table 3, distinguishing parameters relevant for the SIRD model and for the two‐sector economic model. We then discuss our solution method.
Table 3.
Parameters for the integrated assessment model.
|
Parameter |
Used to Determine |
Parameter |
Used to Determine |
||
|---|---|---|---|---|---|
|
μ 0 = 0.023 |
Initial transmission probability (daily) |
γ = 0.2 |
Resolution rate (daily) |
||
|
ϑ = 0.1 |
Recovery rate |
ϖ = 0.01 |
Death rate (daily) |
||
|
ι = 0.40 |
Share of symptomatic infectives |
ψ = 0 |
Vaccination rate |
||
|
N 1 = 0.23 |
Size Group 1 |
N 2 = 0.37 |
Size Group 2 |
||
|
N 3 = 0.25 |
Size Group 3 |
N 4 = 0.15 |
Size Group 4 |
||
|
υ 1 = 0.15 |
Share working from home Sector/Group 1 |
υ 2 = 0.40 |
Share working from home Sector/Group 2 |
||
|
|
Discount factor (monthly) |
|
Capital depreciation rate (monthly) |
||
|
κ = 0.6 |
Habit persistence |
ν = 0.001 |
Elasticity capacity utilization |
||
|
ϕ = 0 |
Degree of capital reversibility |
1 − ω = 0.27 |
Quasi‐share value added Sector 1 |
||
|
|
Scaling parameter Sector 1 |
|
Minimum scale Sector 1 |
||
|
|
Substitution elasticity Sectors 1 and 2 |
α = 0.3 |
Share capital in production Sector 2 |
||
|
ζ = 10 |
Investment adjustment cost |
Note: This table summarizes the parameterization of the baseline integrated assessment model.
4.1. The parameters of the SIRD model
We take many of the parameters to calibrate the epidemiological model from the work by Fernández‐Villaverde and Jones (2020), the study on which we built our econometric work in Section 2.2. Infectiousness resolves at the Poisson rate in all four groups, that is, within 5 days. Individuals move into the recovering class at the rate from which they either recover with probability or die with probability . Hence, after 10 about days, an individual either is cured or deceased. Again, we assume the probability of death to be identical across groups.
To parameterize the effective contact rate, we first use data derived from the POLYMOD study to build contact matrices by age‐group and location. We then combine the information on contact matrices with estimates for the reproduction number to obtain estimates for the transmission rate. The POLYMOD study, funded by the European Union, aims to strengthen public health decision making in Europe through the development, standardization, and application of mathematical, risk assessment, and economic models of infectious diseases. Mossong et al. (2008) offer a detailed discussion. In particular, the POLYMOD study offers data on contacts by age‐group and location for a number of European countries.
Prem, Cook, and Jit (2017) and Prem et al. (2020) project the data from the POLYMOD study to a large set of countries including the United States. We aggregate the contact data by location and age provided in Prem, Cook, and Jit (2017) into three age groups (young, middle‐aged, and old). The matrices are displayed in Table 4. The young and the middle‐aged have considerably more total contacts than the old and most of their contacts are with members of their own age group. For the young, more than half of the contacts occur at school and for the middle‐aged about half of the contacts occur at work. Contacts in locations other than school, work, and home include contacts during commuting, shopping, and leisure activities. Other contacts account for an important fraction of total contacts only for the old. We assume the same contact patterns for middle‐aged individuals regardless of their sector of employment. 24
Table 4.
Contacts by age and location.
|
Contacts at home (young, middle‐aged, old): |
|
q h = |
|
Contacts at work (young, middle‐aged, old): |
|
q w = |
|
Contacts at school (young, middle‐aged, old): |
|
q s = |
|
Other contacts (young, middle‐aged, old): |
|
q o = |
|
Total contacts (without reductions): |
|
q h + q w + q s + q o = |
Note: Contacts by age—ordered as young (0–19), middle‐aged (20–64), and old (65+)—were obtained by aggregation over more detailed data provided in Prem, Cook, and Jit (2017) and Prem et al. (2020). We present the contacts for middle‐aged working individuals not disaggregated by sectors.
To obtain an estimate of the transmission risk we use the contact matrices and estimates of the basic reproduction number. Note that in the multigroup SIRD model the reproduction rate is given by the spectral radius of the matrix where is the sum over the contact matrices by location. We set to match the empirical value of the reproduction number given the contact patterns and the infection rate γ. Initially, the transmission probability equals 0.023, which is consistent with an initial value of 2 of the reproduction number absent restrictions on mobility.
It is worth reiterating that the calibration of our SIRD model is daily. In order to link the results from the epidemiological model to the macroeconomic models, we average the results of the epidemiological model across thirty‐day intervals.
4.2. The parameters of the economic model
The relative sizes of the four groups are informed by the employment to population ratio, the age distribution of the U.S. population, and the employment share in the core sector. We set the combined size of Group 1 and Group 2, , at about 0.6 (or 60% of the total population), in line with data from the U.S. Bureau of Labor Statistics (BLS) for the employment‐to‐population ratio. Group 3 (the young) accounts for about 25% of the population and Group 4 (the old) accounts for about 15% of the population.
The individual group sizes and reflect the employment share of the group of industries in the economy that we deem essential and that are reported in Table 5. The data on value added come from the tables on GDP by Industry of the Bureau of Economic Analysis (BEA). The employment shares reflect hours worked by industry in the productivity release of the BLS. The shares reported in the table are for 2018, the latest year for which data are available at the time of writing. The total share of employment for the industries listed in the table is about 38%. Identifying the individuals working in the essential industries as the Group 1 individuals in the SIRD model we set . Hence, Group 2 is of size .
Table 5.
The core sector: Share of GDP and of employment.
|
Line |
Sector |
Value Added,$ bn. |
Percent of GDP |
Percent of Employment |
|---|---|---|---|---|
|
3 |
Agriculture, forestry, fishing, and hunting |
166.5 |
0.81 |
2.65 |
|
10 |
Utilities |
325.9 |
1.58 |
0.52 |
|
26 |
Food and beverage and tobacco products |
268.9 |
1.31 |
1.86 |
|
31 |
Petroleum and coal products |
172.2 |
0.84 |
0.12 |
|
37 |
Food and beverage stores |
156.4 |
0.76 |
2.2 |
|
40 |
Transportation and warehousing |
658.1 |
3.2 |
5.27 |
|
76 |
Health care and social assistance |
1536.9 |
7.47 |
8.66 |
|
91 |
Federal government, general services |
729.0 |
3.54 |
0.88 |
|
96 |
State government, general services |
1600.5 |
7.78 |
15.38 |
|
Total |
5614.4 |
27.29 |
37.56 |
Note: Source: Authors' calculations based on Bureau of Economic Analysis, GDP by Industry, and Bureau of Labor Statistics, Productivity Release.
The total share of GDP for the industries listed in the table is about 27%. We fix the quasi‐share parameter ω so that the value added of Sector 1 in the steady state is the same percent of total output in the model, that is, denoting steady‐state variables by omitting the time subscript, .
The unit of time for the economic model is set to 1 month. We set the discount factor θ to , implying an annualized interest rate of 4% in the steady state. The depreciation rate δ is set to , implying an annual depreciation rate of 10%. The parameters governing consumption habits κ is set to 0.6, in line with estimates for medium‐scale macromodels such as Smets and Wouters (2007). We set the parameter α governing the share of capital in the production function of Sector 2 to 0.3. The elasticity of substitution between factor inputs is , implying a choice of as derived in the Appendix. We set the parameter ν governing the elasticity of capacity utilization to 0.01, as in Christiano, Eichenbaum, and Evans (2005). The parameter ϕ is equal to 0, implying that investment, once installed as capital, is irreversible. In line with the broad range in Altig et al. (2011) and the literature, we set to 10 the parameter ζ, which governs the costs of adjustment for investment.
We set χ, the minimum scale parameter for the production function of Sector 1, to times , implying that of the steady state labor input for sector 1 is essential for production. The scaling parameter η is set to , offsetting the reduction in productivity implied by our choice of the minimum‐scale parameter in the steady state. This choice for η leaves the steady state production level unchanged relative to a case without a minimum scale (i.e., when χ is 0). The Appendix discusses how our calibration of the scale parameters allows the model to match the observed collapse in economic activity when we feed into the model a series of labor supply shocks that replicates the reduction in labor inputs implied by the increase in unemployment from March through October 2020, relative to the unemployment level in February 2020.
4.3. Cross‐model parameters
In our model, the macroeconomic cost of inaction is driven by the reduction in the labor supply caused by the inability of symptomatic infective individuals to work until recovered. To calculate the reduction in labor supply, we need to rely on an estimate of the asymptomatic infected individuals. A study of the passengers of the Diamond Princess cruise ship provides useful guidance. As reported in Russell et al. (2020), about half of the passengers that tested positive for the virus were asymptomatic. The asymptomatic share was also found to be different by age group. We use a 40% estimate that applies to passengers of working age, that is, . Given that labor supply is exogenous in our economic model, the fall in labor supply becomes more acute as the infective share increases.
When we study the effects of social distancing measures, we need to allow for the possibility that a fraction of the individuals subject to lockdown measures may still be able to work from home. To estimate the fraction of individuals who can do so, we use the American Time Use Survey of the BLS. According to survey data for 2018, the latest available at the time of writing, about 30% of American workers can work from home. The survey also provides differential rates by industry. Mapping the coarser industry categories onto our industry choices for Sector 1 as listed in Table 5, we extrapolate that 15% of individuals in Group 1 can work from home, compared to 40% of individuals in Group 2. Thus, we set and .
4.4. Solution method
The solution method has three important characteristics: First, it allows for a solution of the SIRD model that is exact up to numerical precision; second, it conveys the expected path of the labor supply in each group to the economic model as a set of predetermined conditions, following the numerical approach detailed in the Appendix of Bodenstein, Guerrieri, and Gust (2013); and third, it resolves the complication of the occasionally binding constraints, implied by capital irreversibility, with a regime switching approach following Guerrieri and OccBin (2015). The modular solution approach has the advantage of allowing us to consider extensions of either module without complicating the solution of the other.
5. Simulation results
We are now ready to use our model. We carry out two main exercises. In a first exercise (the next subsection), we show that labor supply disruption can go a long way to explain a contraction in output similar to the one experienced by the United States at the beginning of the pandemic. To this end, we calibrate our model using mobility data and estimates of the share of workers that can work from home.
In our second exercise, we repeat the analysis replacing the estimates of mobility with a lockdown, which we design drawing on the main lessons from our integrated model. From our supply‐side perspective, health measures can reduce economic disruptions to the extent that they are successful in protecting workers in the core sector from the infection externality when other workers and people circulate without restrictions. For comparison, we also build a scenario with “inaction,” under which, counterfactually, there is no social distancing at all. This is meant to highlight the potentially large economic consequences of the disease when its spread is unmitigated by any, spontaneous or mandatory, social distancing.
We emphasize from the start that our main goal is assessing the economic consequences of potential supply disruptions from labor market shortages. Important economic costs may stem from shifts in demand patterns, associated with large re‐allocation costs, in the presence of nominal, financial and other frictions. However, a shock of the size and nature of a pandemic raises a unique set of questions concerning how the supply structure of an economy can continue to work when confronting an abrupt reduction in the scale of production. This reduction is what our model is designed to capture.
5.1. Labor supply and output disruptions
In this first set of simulations, our model tracks data on the observed reduction in mobility from the beginning of March through the end of October 2020, together with labor market and occupational data. Our goal is to bring our integrated model to bear on the estimated path of the reproduction rate over the same period.
Figure 2 shows an abrupt decline in the workplace mobility measure from Google (2020) at the onset of the pandemic. Over the second‐half of March, workplace mobility was cut in half. Thereafter, over April and May, workplace mobility partially bounced back but remained 30% below prepandemic levels through the end of October. The figure also shows that the decline in workplace mobility was mirrored by an increase in the residential mobility measure from Google (2020)—basically proxying for the time spent at home.
Figure 2.
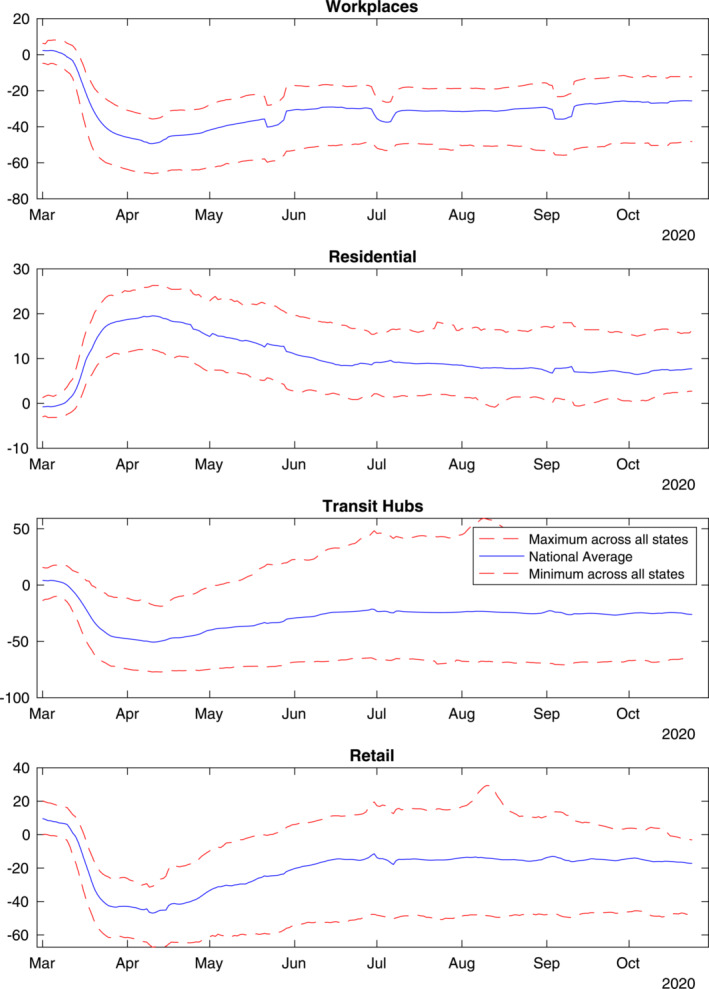
Workplace and residential mobility—7‐day moving average. Note: The dips in workplace mobility at the end of May, beginning of July and end of September correspond to national holidays. Their effects are prolonged by the moving average. Source: Google (2020).
For our analysis, we need to map the decline in mobility into a reduction in contacts through the workplace and a reduction in labor inputs. Accordingly, we need to take a stand on the share of workers who continued to work from home. As discussed in the calibration section, estimates based on the BLS American Time Use Survey point to about 30% of the work force being able to continue working from home. As a baseline, we can treat any reduction in mobility in excess of this 30% mark as a reduction in labor inputs. For instance, at the peak of 50% reduction in workplace contacts, we will assume that the fall in labor input amounts to percentage points. This approach is backed by estimates of office occupancy rates based on entry card swipes, which also show a precipitous decline in the second‐half of March 2020 to de minimis levels, followed by only a modest rebound in occupancy rates through the end of October 2020. Overall, the evidence suggests that a large share of the workers who had the ability to work from home stayed at home. 25
In our simulations, we impose that the path of the reproduction rate implied by our simulations is close to realistic estimates of this rate. 26 The top panel of Figure 3 shows again the estimate of the reproduction rate from Fernández‐Villaverde and Jones (2020), the solid line, matched by construction in our simulation. This panel also shows the reproduction rate implied by our epidemiological model, incorporating the changes in mobility discussed above but without overriding the probability of transmission needed to match the estimates of Fernández‐Villaverde and Jones (2020). The panel clarifies that the mobility changes go a long way in capturing the empirically relevant reproduction rate.
Figure 3.
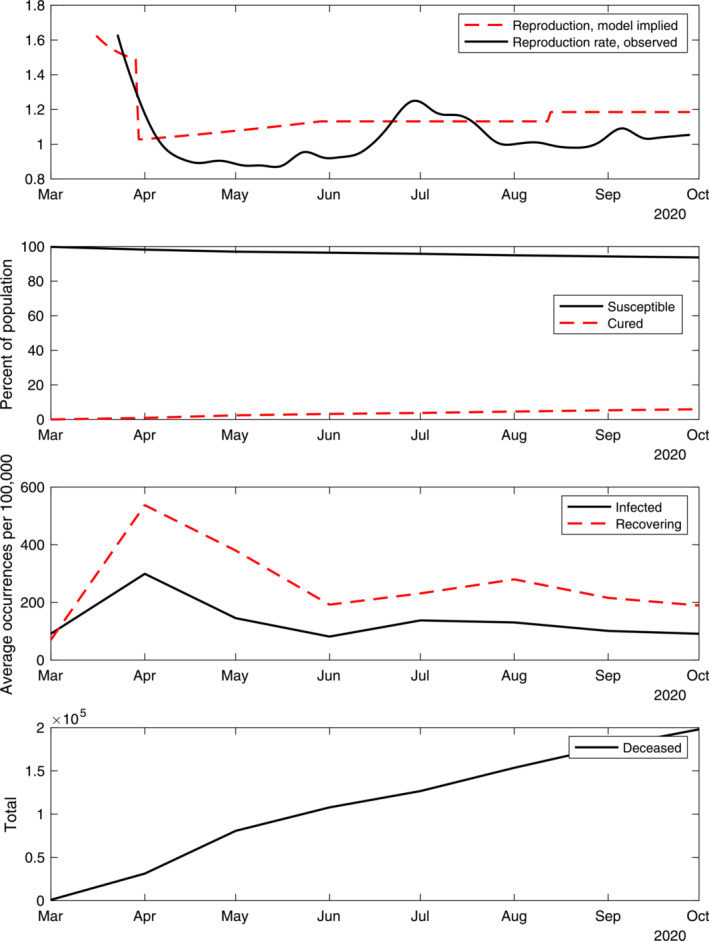
Dynamics in the SIRD model. Note: The paths shown are aggregates for the total population. The observed reproduction rate is used in the model simulations and to back out the paths in the bottom three panels. The model‐implied paths are generated varying the number of contacts in line with the residential mobility measure from Google (2020) and school closures but keeping the probability of contagion given contacts unchanged from its baseline value. The paths in the top panel are daily. All other panels show monthly averages of daily series.
We stress that our model‐implied path for the reproduction rate includes not only the reduction in workplace contacts, but also a reduction in nonwork activities/contacts for all population groups (whether or not in the work force), which we assume to be of the same magnitude as the reduction in work contacts. This assumption is buttressed by the reduction in nonwork mobility measures indicative of social distancing across different population groups. Looking back to Figure 2, note that the reduction of mobility towards retail outlets and transit hubs is strikingly close to the reduction in mobility toward workplaces. Moreover, in our simulations, we set school contacts to 0 from the beginning of April to the beginning of August, in line with the widespread school closures in the United States during this period. After August, we allow for an increase in school contacts, but only by half the pre‐COVID‐19 levels, to account for a partial reopening of schools across the country.
The paths for the reproduction rate that our model generates based on this stylized set of assumptions is remarkably close to estimates based on deaths from COVID‐19. The estimated path does dip below the model‐implied path for most of the period (apart from a window in July and August). It is worth reiterating here that mobility and contacts, however important, are not the only factors affecting the spread of the disease. The rate of disease transmission may fall if people wear masks (a precaution that has become more prevalent over time), and/or in response to seasonal factors. With good weather, people may spend more time outside, except when very high temperatures push them back inside, in air‐conditioned spaces.
The top two panels of Figure 4 show the model‐implied progression of the infection at the quarterly frequency. The number of infected individuals reaches a peak in the second quarter. Even at this peak, however, the reduction in labor supply attributable to the inability to work of symptomatic infected individuals was too small to have a significant effect on the overall labor supply. 27
Figure 4.
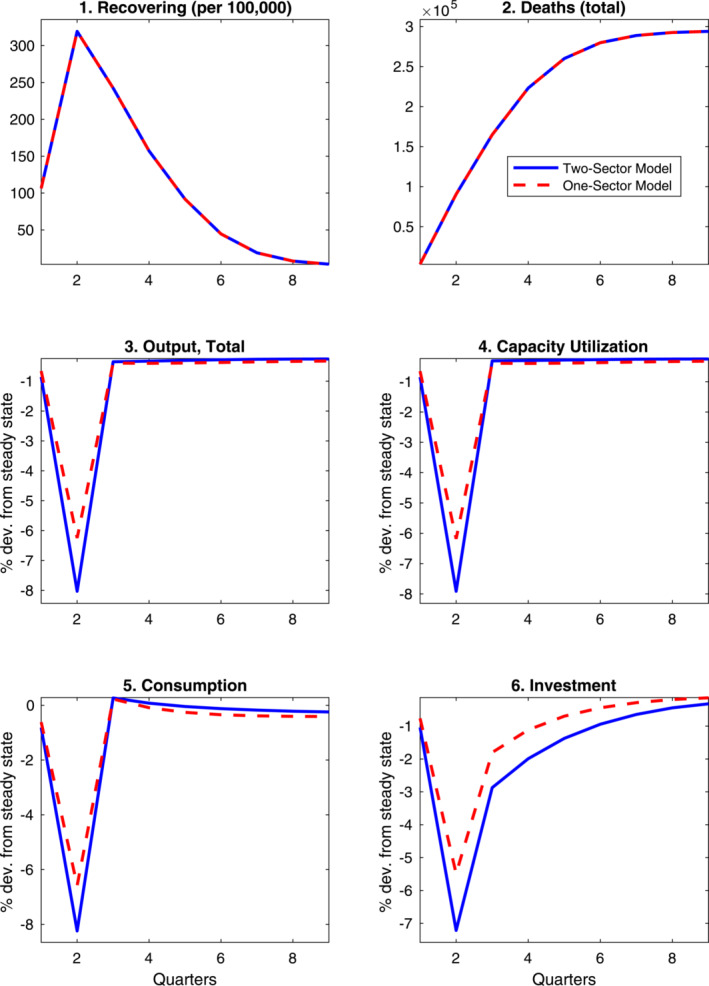
Aggregate economic consequences of COVID‐19: Comparing one‐sector and two‐sector models.
The economic scenarios generated by our model are shown in the bottom four panels of Figure 4, contrasting the predictions of our one‐ and the two‐sector version of the model. While both models have qualitatively similar implications for the course of economic activity, there is a marked quantitative difference. In the one‐sector model, the output collapse in the second quarter is about 6%. In our two‐ sector model, the collapse is one‐fourth larger, 8%. Both models predict large contractions—a significant share of the observed decline in GDP in the United States in the second quarter of 2020 (which clearly reflects a number of other forces). The difference between the one‐ and the two‐sector models is also apparent in the paths of utilization, consumption, and investment.
What explains these differences is the fact that, in our two‐sector version of the model, the consequences of a fall in the labor inputs in the essential sector are amplified by the nonmonotonic feature of the production function—the minimum scale assumption implies a significant fall in overall labor productivity. Because of this specific feature of the model, the distribution of labor supply cuts across sectors is of first‐order importance. In our simulations, we take the conservative approach of adjusting the sectoral labor cuts so to keep the reduction in value added in the second quarter of 2020 balanced across sectors, as shown in Figure 5. The rationale for this assumption is that the share of work from home is different across the two sectors. If we applied the mobility data homogeneously across sectors, the reduction in labor inputs would be heavily skewed toward the essential sector. By keeping the reduction in value added balanced across the two sectors, our distribution of labor cuts actually minimizes the drop in aggregate output—as a way to reduce the risk of overstating the incidence of supply shortages in disrupting economic activity.
Figure 5.
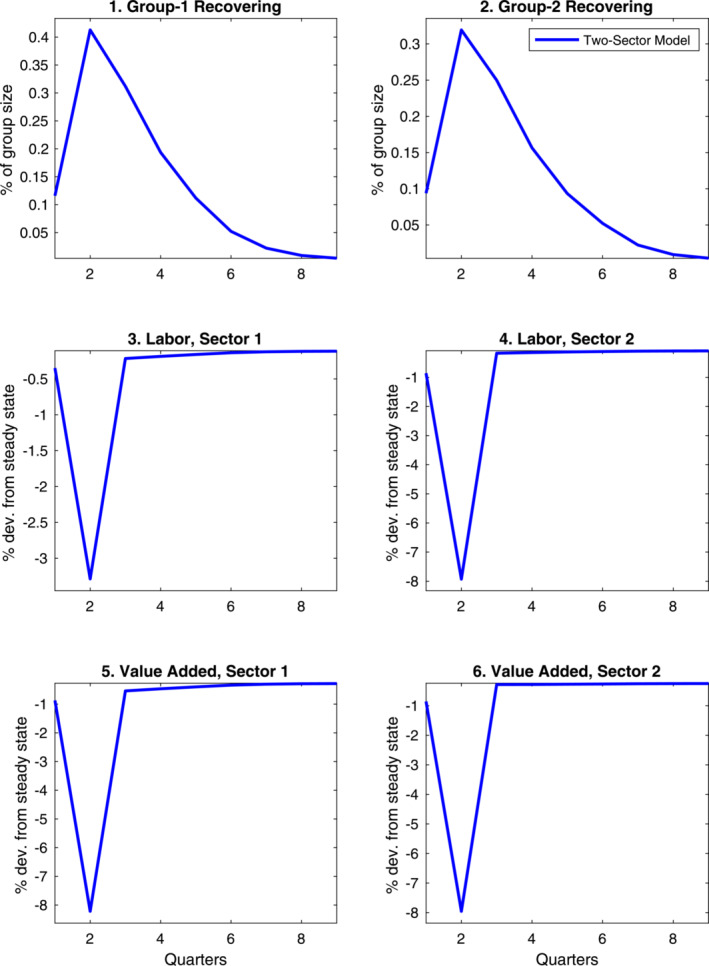
Economic consequences of COVID‐19: Sectoral detail for the two‐sector model. Note: This figure provides additional sectoral details for the two‐sector model, complementing the paths for aggregate variables shown in Figure 4.
The main takeaway is that supply disruptions in the wake of a pandemic could play a nonnegligible role in the collapse in GDP—even if these are not amplified by a drop in the productivity of the core‐sector (as shown by our one‐sector model); and even when the spread of the disease remains contained (possibly because of social distancing) and the economic costs of social distancing are mitigated by a widespread switch to working from home. Larger supply disruptions may of course result from a recrudescence of the disease motivating widespread and stricter lockdowns—which would also increase the distance between the one‐ and the two‐sector model. 28
5.2. The effects of mandated social distancing
In this section, we discuss how the tradeoffs between health and economic outcomes can be improved by adopting mandated social distancing measures that recognize the need to protect the core sector of the economy. In simulations that follow, changes in the reproduction rate (from the initial level of 2) come about exclusively from the reduction in contacts implied by mandated social distancing measures. For comparison, we also bring forward a scenario under a constant reproduction rate, that is, conditional on no social distancing. This scenario will be labeled “inaction.” We note that the inaction scenario arguably weighed on policymakers' perception of the disease in March 2020 (see Ferguson et al. (2020)). Indeed, in the absence of a clear understanding of the factors that could influence the transmission of the disease, early debates were sometimes conducted under the assumption that, absent policy intervention, the reproduction rate would stay constant at its initial level.
It is worth stressing that we intentionally steer away from “optimal policy” analysis, as it would require a richer model as well as taking a stand on such parameters as the value of human lives. However, our analysis draws on key principles that are also building blocks in optimal policy exercises. Specifically, we consider policy measures that are meant to internalize the infection externality from individual interactions, not efficiently accounted for by optimizing individuals on their own (see, e.g., Eichenbaum, Rebelo, and Trabandt (2020)).
5.2.1. A baseline social‐distancing configuration
To minimize the supply disruption of a lockdown, the health measures we consider in our experiment target first and foremost workers who are able to continue supplying their labor services from home. In line with the American Time Use Survey, conducted by the Bureau of Labor Statistics, the share of the labor force that can work from home is 15% of workers in Group 1 (the group that supplies labor to the core sector), and 40% of workers in Group 2 (the group that supplies labor to the other sector). Accounting for the sizes of Group 1 and Group 2, combined, this boils down to subject about 30% of the labor force to a complete lockdown. A second set of restrictive measures are then targeted to reduce contacts between core‐sector workers who cannot provide their services from home, and the general population. Consistently, we extend our health measures to individuals not in the labor force, those in Group 3 and Group 4, up to restricting 30% p of group members, the same proportion used for the working population. With a lockdown imposed on 1/3 of the total population, keeping the reproduction rate unchanged for the population not subject to these measures, lifting the restrictions after 12 months would lead to a resurgence of the pandemic, but one that, due to the building up of herd immunity at a controlled pace, would spread more slowly.
The health consequences of the lockdown policy just described are illustrated by the top two panels of Figure 6. The policy successfully flattens the infection curve: the peak of the infection share of recovering individuals drops from about 8% to about 3%—admittedly still high relative to the capacity constraint of healthcare systems, even when taking account of the fact that not all infected individuals experience symptoms. A notable result is that the health outcomes of individuals are similar in Groups 1 and 2, despite the fact that workers in the Group 1 continue working “on the road” in higher proportion than workers in Group 2. The near‐equalization of infection rates results from the way our lockdown measures internalize the infection externality—the higher degree of social distancing in Group 2 and a high share of population under a lockdown helps shield individuals in Group 1.
Figure 6.
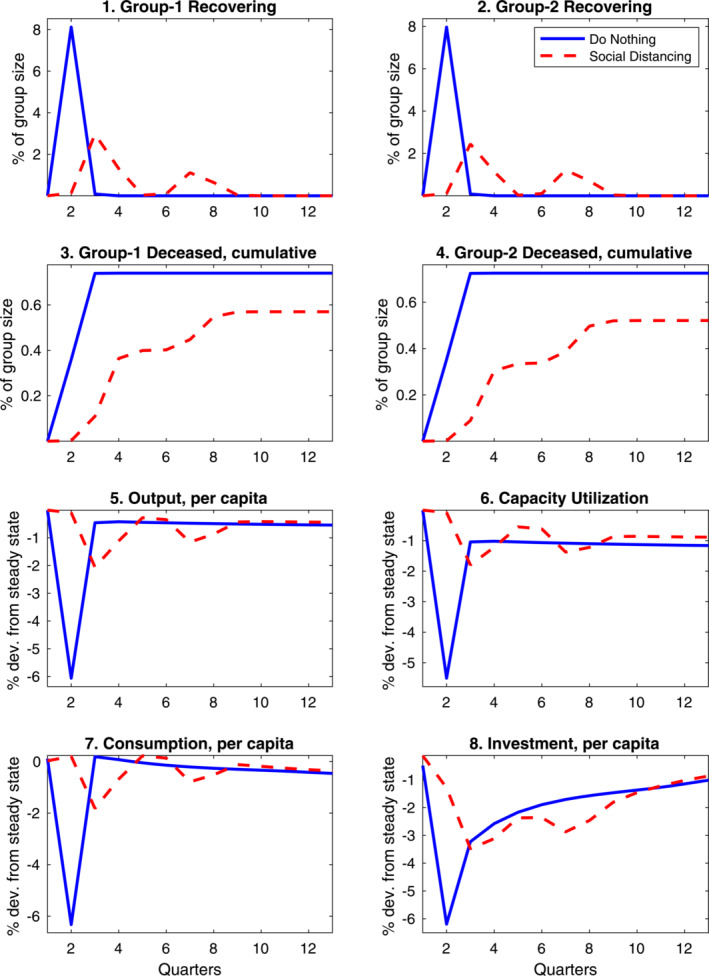
Comparing the aggregate economic consequences of COVID‐19 with and without social distancing: A two‐sector approach.
Panels 5 through 8 of the figure contrast the economic consequences of mandated social distancing with a counterfactual scenario of “inaction.” The reason to call attention to this counterfactual scenario is that it allows to highlight the potentially high upfront economic costs of the rapid peak in the disease due to labor supply disruptions from (i) the inability of the symptomatic ill to continue working (in the aggregate this may become relevant when the disease spreads at high rates); and (ii) the reduction in labor supply due to deaths of individuals in the labor force. In our work, we further stress the indirect, potentially significant costs from supply constraints on the economy that follows a large contraction of the core sector.
Comparing these scenarios, the importance of smoothing out the peak of the infection curve is apparent. Under our mandated social distancing baseline, the peak contraction in output is less than one‐half relative to the case of inaction. Key to this result is that, while the social distancing policy compresses the trough for value added similarly in both sectors, Sector 1 remains more active relative to the scenario without intervention.
Another notable result in the figure is that, independently of mandated social distancing measures, the pandemic has persistent economic consequences. These consequences reflect both the death toll on the size of labor force, and the fact that a smaller labor force leads to a persistent reduction in the productivity of the essential sector, weighing on final output, consumption, and investment—not only in the aggregate but also in per capita terms.
In sum, the key takeaway from our exercise is that lockdowns can be structured to reduce the risks of large supply disruption in the economy. In particular, lockdown policies should be stricter on workers in the noncore sector and nonactive population, and targeted specifically at workers who could reasonably keep performing their occupational tasks from home. Such combination of measures is successful to the extent that they address the infection externality where it has more economic bite, that is, they keep the infection rate among the workers in core industries low.
5.3. Waiting for a vaccine
The rest of this section uses the model to address the costs of a long lockdown put in place in view of the availability of a vaccine, including some sensitivity analysis motivated by the considerable uncertainty surrounding the parameters of the model.
The prospects of a vaccine in the nondistant future from the eruption of the pandemic raise the benefits of investing in social distancing, keeping contagion rates to a level that can be effectively dealt with by the national health system until the immunization programs can be rolled out. The lockdown measures studied in the previous sections do not fully qualify: they smooth out the infection curve considerably, but do not go insofar as preventing persistent hikes in the share of infected/recovering individuals—which in all likelihood remains well above the response capacity of the health care system. We thus turn our attention to mandated measures extended and modified to keep the share of infected individuals low enough to avoid overtaxing the health care system.
Specifically, we target our lockdown to keep the share of recovering individuals in the population below 1% until a vaccine becomes available, set to 9 months after the onset of the pandemic. 29 At that point, the immunization campaign starts. We assume that the vaccine is perfectly protective and that 10% of the population is inoculated each month.
In the logic of our model, the cost of containing the share of the infected population can be significantly reduced by extending the lockdown on nonworking population (groups 3 and 4) and by imposing measures that reduce nonwork contacts more aggressively. Relative to our baseline example discussed in Section 5.2.1, we increase the share of the population under lockdown in groups 3 and 4 from 30% to 40%—and posit that nonwork contacts can be reduced in this greater proportion for all groups. Results are shown in Figure 7, whereas the lockdown measures are relaxed after 12 months, as immunity is then built with immunization. Provided that all the measures remain effective over this long time span, the results in the figure suggest that well‐structured health interventions are in principle able to reduce both the spread of the disease and the economic consequences.
Figure 7.
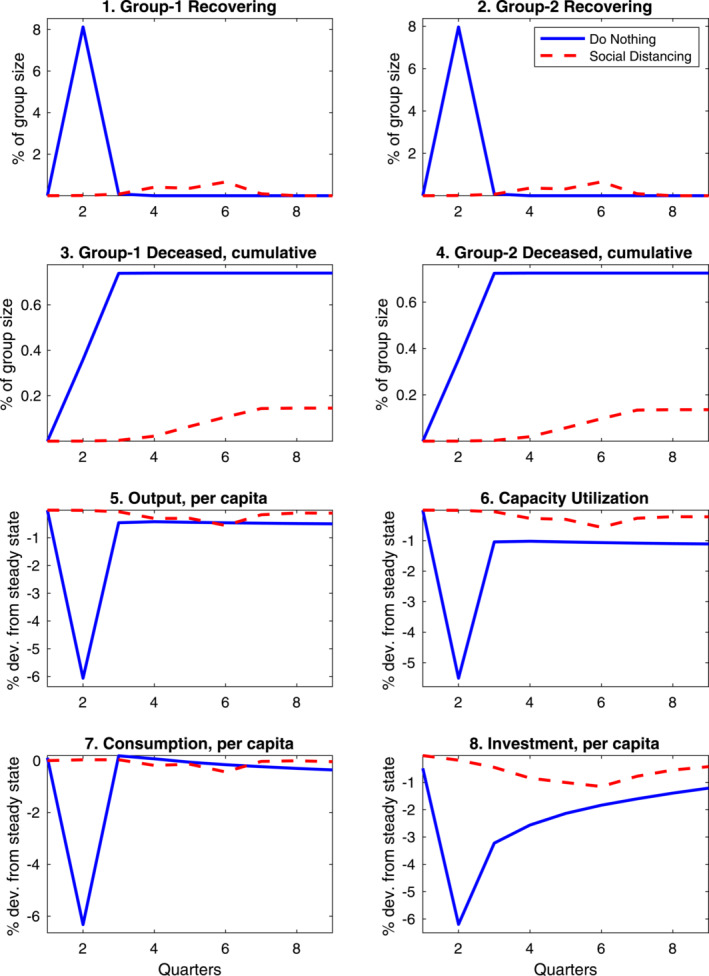
Waiting for a vaccine.
In our baseline, the assessment of the economic costs of a strict lockdown waiting for a vaccine is arguably overly optimistic. Our model abstracts from many factors that can amplify the crisis via demand and income disruptions. But even keeping focus exclusively on labor supply disruptions, the assessment crucially depends on both the degree of effectiveness of (and compliance in) a lockdown, and the characteristics of the COVID‐19 virus. We investigate robustness in these two dimensions running two exercises below. In each of these two exercises, we maintain the basic design features of our baseline simulation in Figure 7. Namely, we still target a population share of recovering individuals below 1% until the arrival of the vaccine 9 months after the onset of the pandemic, and assume the same monthly rate of vaccination of 10%.
So far, we have assumed that the social distancing measures can bring the contact rates to 0. As robustness, we follow Alvarez, Argente, and Lippi (2020), who consider a lower effectiveness of social distancing, only reducing contacts by 80%. Under this assumption, with our lockdown measures in place, the peak of the population share of recovering individuals would rise from just under 1% to about 2%. A target below 1% would then require a tighter lockdown. For instance, the target could be met by raising the share of individuals in groups 1 and 2 under lockdown, to about 20 and 50%, respectively—while also extending the lockdown to 40% of the nonworking population for 12 months. 30 With these stricter measures in place, however, the economy would experience a drop in output of about 8% for the duration of the wait for a vaccine. 31
The cost of waiting for a vaccine would also be higher with an increase in the probability of transmission due to a virus mutation. The new variant of the COVID‐19 virus identified in the United Kingdom at the end of 2020 is estimated to be up to 70% more transmissible. Mapping this estimate into a change in the probability of transmission given contacts, would imply a rise in the reproduction rate from 2 to 3.3. With our baseline lockdown in place, the higher reproduction rate would be sufficient to raise the share of recovering individuals to about 8%, nearly as high as in a scenario of inaction. The goal of keeping this share below 1% in this case would require more drastic measures. For instance, the goal could be achieved by placing under lockdown 40 and 90% of individuals in Group 1 and Group 2, respectively, and about 80% of individuals outside the labor force. Furthermore, the lockdown would have to be extended for a longer period, 15 months, since a greater share of the population would have to be vaccinated to achieve herd immunity. The economic consequences would be dire. According to our model, the reduction in output would be as large as 50% before herd immunity is reached and the lockdown is lifted. The contraction in investment would be so large to cause the capital irreversibility constraint to bind—in turn amplifying the contraction in consumption. 32
6. Conclusion
A precipitous decline in employment brought about by the spread of an infectious disease can have outsize economic costs if it ends up compromising linkages in the production structure that are critical for the working of the economy as a whole. We study the aggregate effects of supply disruptions potentially brought about by a disease, specifying a two‐sector model featuring a set of industries that produce core inputs used by all the other industries. Core inputs are both poorly substitutable with other inputs, and produced subject to a minimum scale of production.
Our integrated assessment framework suggests that the way an unchecked spread of a pandemic can damage the economy is through labor drawdowns in core industries that could undermine efficient production in other sectors, and thus, aggregate economic activity. This is an economic argument for social distancing, distinct from the argument stressing the need to reduce the loss of human life resulting from congestion overwhelming hospitals and health care systems. Simulations of our integrated assessment model suggest that even moderate mandated social distancing may actually improve economic outcomes.
In our framework, the direct economic cost of the disease stems from the inability of symptomatic infected individuals to continue working and the drop in labor services due to spontaneous or mandated social distancing. Additional indirect costs come from the constraint that malfunctioning core industries may place on other industries via input–output linkages. Social distancing measures modulated to shield essential economic linkages can buffet the fall in aggregate economic activity effectively and without compromising the primary goal of flattening the infection curve. The experiments we consider in this paper consist of applying social distancing measures proportionally more to the nonworking‐age population, and workers in noncore industries and to occupations that involve tasks that can be performed from home. These measures work through a key epidemiological externality that ends up protecting workers in the core industries.
Calibrated with mobility data and estimates of the incidence of work‐from‐home, our model comes close to matching the dynamic evolution of COVID‐19 in the United States through the summer of 2020. The spread of the disease, while pervasive, was substantially less dramatic than suggested by some early epidemiological studies, which underestimated the mitigating effects of the widespread adoption of both spontaneous and mandated social distancing on the reproduction rate. We investigate empirically the epidemiological benefits and economic costs of social distancing at the onset of the pandemic. We derive our empirical framework from the standard model, proxying contacts using Google mobility data, and instrumenting mobility with either the stay‐at‐home orders issued by individual U.S. states, or political leanings by state. Our results suggest that, at the margin, changes in mobility through the first quarters of 2020 in the United States had significant effects on both reproduction rates and initial jobless claims. Strikingly, spontaneous social distancing was no less costly than stay‐at‐home orders.
This paper was first drafted at the very beginning of the COVID‐19 pandemic, conditional on early epidemiological scenarios of a rapid spread of the disease. Ex post, the rate of contagion, while high, was not as dramatic and initially feared. Supply disruptions did not emerge as a systemic binding constraint. By no means does this observation downplay the need to model carefully the resilience of production network and analyze its vulnerabilities. While supply chains remained remarkably resilient in 2020, the sharp and sudden drop in demand and the temporary suspension in the supply of services (e.g., in the healthcare sector) may have hidden the potential difficulties in producing core services when there are not enough workers to meet the minimum scale of production.
Supporting information
Online Appendix
Data and Programs
The views expressed in this paper are solely the responsibility of the authors and should not be interpreted as reflecting the views of the Board of Governors of the Federal Reserve System or of any other person associated with the Federal Reserve System. We thank Jason Brown and Zeina Hasna for useful suggestions. Giancarlo Corsetti gratefully acknowledges support from Cambridge‐INET.
Footnotes
Among the leading papers that formalized this view early on, see Eichenbaum, Rebelo, and Trabandt (2020), Callum Jones, Philippon, and Venkateswaran (2020), and Alvarez, Argente, and Lippi (2020). The literature on the economic effects of the COVID‐19 pandemic has grown very fast; see Atkeson (2020), Alfaro et al. (2020), Baker et al. (2020), Guerrieri et al. (2020), and Koren and Petó (2020) among many others.
For an analysis of production structures and core sectors, see Carvalho (2014) and Carvalho and Tahbaz‐Salehi (2018). Barrot, Grassi, and Sauvagnat (2020) offers a sectoral analysis of the effect of the COVID‐19 pandemic.
We borrow the term “integrated assessment model” from the literature on climate change to emphasize the importance of linking economics to phenomena that are relevant for the well‐being of humankind but that are outside the traditional focus of the economics profession. As in the case of climate change policies, public health policies may have consequences for economic activity that can influence the choices of policymakers.
We calculated this decline relative to the consensus level of GDP in the Blue Chip forecasts published in January 2020, before private forecasters entertained the possibility of a pandemic.
Jordà, Singh, and Taylor (2020) provide estimates on how pandemics are different from other destructive episodes, such as wars, based on a dataset stretching back to the 14th century. For pandemics, they point to changes in consumption that they attribute to heightened precautionary behavior.
See, for example, Correia, Luck, and Verner (2020) for empirical evidence and an account of the beneficial effects of health policies for the case of the 1918 influenza epidemic.
The origins of the SIRD model and other closely related models of mathematical epidemiology trace back to the seminal contributions of Kermack and McKendrick (1927). Brauer, Driessche, and Wu (2008) offer an introduction to state‐of‐the‐art mathematical epidemiology with numerous models that are more detailed about the dynamics of infectious diseases. However, most of these models feature the SIRD model (or its close cousin the SIS model) at their core.
An alternative strategy would be to modify consumer preferences to model spontaneous social distancing following the lead of, for example, Eichenbaum, Rebelo, and Trabandt (2020). Our choice is not meant to downplay the importance of investigating theoretically the roots of behavior driving the precautionary reduction in consumption and labor. On the contrary, we see our analysis as strictly complementary to theirs.
Broader introductions to epidemiological modeling are given in Hethcote (1989), Allen (1994), and Brauer, Driessche, and Wu (2008).
For instance, see Ferguson et al. (2020).
The data for death rates and confirmed cases are from JHU (2020), also see Dong, Du, and Gardner (2020). The data on stay‐at‐home orders are from Raifman et al. (2020). The mobility data are from Google (2020).
The earliest stay‐at‐home order started in California on March 19.
See Atkeson, Kopecky, and Zha (2021) for an extension of the canonical SIR model that incorporates spontaneous feedback from disease prevalence to disease transmission.
Alternative approaches to estimating the effects of mandated social distancing measures are offered by Chernozhukov, Kasahara, and Schrimpf (2021) and Huang (2020). They focus on epidemiological effects, whereas we are also interested in a comparison of the epidemiological benefits and of the economic consequences of mandated and spontaneous social distancing.
The data set of Fernández‐Villaverde and Jones (2020) excludes Wyoming and Montana.
The framework of Atkeson, Kopecky, and Zha (2021) captures these effects as a time‐varying wedge.
Given the later start of estimates for the reproduction rate, for Alaska, Idaho, and West Virginia, we use a shorter window of 9 days when computing the changes in equation (10).
For our comparison, we used estimates based on different datasets for the mandated and spontaneous measures, the data sets of Fernández‐Villaverde and Jones (2020) and of Systrom, Vladek, and Krieger (2020), respectively. We can also estimate the elasticity of the reproduction rate with respect to mobility for mandated measures using the data set of Systrom, Vladek, and Krieger (2020) and find an even more sizable elasticity of about −5.1.
A straightforward example of two groups with different transmission coefficients are hospital patients and medical personnel.
Krueger, Uhlig, and Xie (2020) also bridge an epidemiological model and a two‐sector economic model, building on the setup of Eichenbaum, Rebelo, and Trabandt (2020). In the model of Krueger, Uhlig, and Xie (2020), different contact rates distinguish each sector. Furthermore, labor is the only input into production and labor mobility across sectors helps blunt the economic impact of the pandemic.
See, for example, Alvarez, Argente, and Lippi (2020), Eichenbaum, Rebelo, and Trabandt (2020), and Kaplan, Moll, and Violante (2020).
The POLYMOD study, discussed in Mossong et al. (2008), reports contact patterns for several European countries.
In the case of consumption, note that social contact studies provide little detail on consumption‐related contacts. Even if we classify all “other contacts” as consumption‐related, neither theory nor data provide clear guidance for how reductions in consumption‐related contacts map into reductions in consumption, and thus economic activity. For example, a wider use of technology (online transactions, delivery, and pickup services) or product substitution (food at home vs. food away from home) may imply little change in consumption expenses even as consumers manage to reduce consumption‐related contacts. The closing of providers of consumption services to reduce consumption‐related contacts mechanically implies a reduction in the consumption of services. But such a decline in consumption could also be viewed as supply‐driven and linked to a reduction in labor.
The contact patterns for the United States are qualitatively similar to those reported for other advanced economies. The average of total contacts per individual for the United States is similar to the average for Italy and somewhat above the average for Korea and the UK. The POLYMOD study implies significantly lower contacts for Germany reflecting much lower contacts at schools and the workplace.
For instance, see coverage of office occupancy rates based on Kastle card swipes in the Wall Street Journal “Companies Tiptoeing Back to the Office Encounter Legal Minefield” published on November 16, 2020.
As explained in the calibration section, we set the probability of transmission given contact, , to match the empirical value of the reproduction number given the contact patterns and the infection rate, γ. This is important: if the model missed in this dimension, an excessively high reproduction rate would lead to a significant share of infected symptomatic workers, that would counterfactually amplify the drop in the labor input.
As shown in the figure, the number of deaths plateaus at 300,000 after 6 quarters from the start of the sample period. This is because in our simulations the reproduction rate becomes constant at the level estimated for the end of October, which was close to 1.
The main focus of our exercise is on labor supply disruptions and its effects on overall productivity. As the model misses in other dimensions of the current crisis, such as omitting shifts in the composition of demand, in our simulation economic activity tends to rebound more quickly than observed.
We use the 1% share for illustrative purposes. Alternatively, one could target the peak incidence of the disease explicitly to the capacity of the health care sector as in Moghadas et al. (2020).
We still constrain the share of individuals under lockdown in Group 3 to match the share for groups 1 and 2 combined.
See Figure A.3 in the Appendix.
See Figure A.4 in the Appendix.
Contributor Information
Martin Bodenstein, Email: martin.r.bodenstein@frb.gov.
Giancarlo Corsetti, Email: gc422@cam.ac.uk.
Luca Guerrieri, Email: luca.guerrieri@frb.gov.
References
- Alfaro, Laura , Chari Anusha, Greenland Andrew N., and Schott Peter K. (2020), Aggregate and Firm‐Level Stock Returns During Pandemics, in Real Time. Technical report, NBER Working Paper No. 26950.
- Allcott, Hunt , Boxell Levi, Conway Jacob C., Ferguson Billy A., Gentzkow Matthew, and Goldman Benny (2020), “What explains temporal and geographic variation in the early US coronavirus pandemic?” NBER Working Papers 27965, National Bureau of Economic Research, Inc.
- Allen, Linda J. S. (1994), “Some discrete‐time SI, SIR, and SIS epidemic models.” Mathematical Bioscience, 124 (1), 83–105. [DOI] [PubMed] [Google Scholar]
- Altig, David , Christiano Lawrence, Eichenbaum Martin, and Linde Jesper (2011), “Firm‐specific capital, nominal rigidities and the business cycle.” Review of Economic Dynamics, 14 (2), 225–247. [Google Scholar]
- Alvarez, Fernando , Argente David, and Lippi Francesco (2020), A Simple Planning Problem for COVID‐19 Lockdown. Technical report, NBER working paper 26981.
- Atkeson, Andrew (2020), What Will Be the Economic Impact of COVID‐19 in the US? Rough Estimates of Disease Scenarios. Staff Report 595. Federal Reserve Bank of Minneapolis.
- Atkeson, Andrew , Kopecky Karen A., and Zha Tao (2021), Behavior and the Transmission of COVID‐19. Staff. Report 618. Federal Reserve Bank of Minneapolis.
- Baker, Scott R. , Bloom Nicholas, Davis Steven J., Kost Kyle J., Sammon Marco C., and Viratyosin Tasaneeya (2020), The Unprecedente Stock Market Impact of Covid‐19. Technical report, NBER Working Paper No. 26945.
- Barrot, Jean‐Noel , Grassi Basile, and Sauvagnat Julien (2020), “Sectoral effects of social distancing.” Covid Economics, 1 (3), 85–102. [Google Scholar]
- Bettencourt, Luis M. A. and Ribeiro Rui M. (2008), “Real time Bayesian estimation of the epidemic potential of emerging infectious diseases.” PLoS ONE. [DOI] [PMC free article] [PubMed]
- Bodenstein, Martin , Giancarlo Corsetti, and Guerrieri Luca (2022), “Supplement to ‘Social distancing and supply disruptions in a pandemic’.” Quantitative Economics Supplemental Material, 13, 10.3982/QE1618. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bodenstein, Martin , Guerrieri Luca, and Gust Christopher J. (2013), “Oil shocks and the zero bound on nominal interest rates.” Journal of International Money and Finance, 32 (C), 941–967. [Google Scholar]
- Brauer, Fred , van den Driessche Pauline, and Wu Jianhong (2008), Mathematical Epidemiology. Number 1945 in Lecture Notes in Mathematics. Springer, Berlin, Heidelberg. [Google Scholar]
- Callum, Jones , Philippon Thomas, and Venkateswaran Venky (2020), Optimal Mitigation Policies in a Pandemic: Social Distancing and Working From Home. Technical report, NBER working paper 26984.
- Carvalho, Vasco M. (2014), “From micro to macro via production networks.” Journal of Economic Perspectives, 28 (4), 23–48. [Google Scholar]
- Carvalho, Vasco M. and Tahbaz‐Salehi Alireza (2018), “Production networks: A primer.” Cambridge Working Papers in Economics 1856, Faculty of Economics, University of Cambridge.
- Chernozhukov, Victor , Kasahara Hiroyuki, and Schrimpf Paul (2021), “Causal impact of masks, policies, behavior on early Covid‐19 pandemic in the u.s.” Journal of Econometrics, 220 (1), 23–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Christiano, Lawrence J. , Eichenbaum Martin, and Evans Charles L. (2005), “Nominal rigidities and the dynamic effects of a shock to monetary policy.” Journal of Political Economy, 113 (1), 1–45. [Google Scholar]
- Coibion, Olivier , Gorodnichenko Yuriy, and Weber Michael (2020), “The cost of the Covid‐19 crisis: Lockdowns, macroeconomic expectations, and consumer spending.” NBER Working Papers 27141, National Bureau of Economic Research, Inc.
- Correia, Sergio , Luck Stephan, and Verner Emil (2020), Pandemics Depress the Economy, Public Health Interventions Do not: Evidence From the 1918 Flu. Technical report. Available at SSRN.
- Dong, Ensheng , Du Hongru, and Gardner Lauren (2020), “An interactive web‐based dashboard to track Covid‐19 in real time.” The Lancet Infectious Diseases, 20 (5), 533–534. ISSN 1473‐3099. 10.1016/S1473-3099(20)30120-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eichenbaum, Martin S. , Rebelo Sergio, and Trabandt Mathias (2020), “The macroeconomics of epidemics.” NBER Working Papers 26882, National Bureau of Economic Research, Inc.
- Ferguson, Neil M. , Laydon Daniel, Nedjati‐Gilani Gemma, Imai Natsuko, Ainslie Kylie, Baguelin Marc, Bhatia Sangeeta, Boonyasiri Adhiratha, Cucunubá Zulma, Cuomo‐Dannenburg Gina, Dighe Amy, Dorigatti Ilaria, Fu Han, Gaythorpe Katy, Green Will, Hamlet Arran, Hinsley Wes, Okell Lucy C., van Elsland Sabine, Thompson Hayley, Verity Robert, Volz Erik, Wang Haowei, Wang Yuanrong, Walker Patrick G. T., Walters Caroline, Winskill Peter, Whittaker Charles, Donnelly Christl A., Riley Steven, and Ghani Azra C. (2020), Impact of Non‐Pharmaceutical Interventions (Npis) to Reduce Covid‐19 Mortality and Healthcare Demand. Report 9. Imperial College, COVID‐19 Response Team.
- Fernández‐Villaverde, Jesús and Jones Charles I. (2020), “Macroeconomic outcomes and Covid‐19: A progress report.” NBER Working Papers 28004, National Bureau of Economic Research, Inc.
- Gollwitzer, Anton , Martel Cameron, Brady William J., Pärnamets Philip, Freedman Isaac G., Knowles Eric D., and Van Bavel Jay J. (2020), “Partisan differences in physical distancing are linked to health outcomes during the Covid‐19 pandemic.” Nature Human Behaviour, 4 (11), 1186–1197. [DOI] [PubMed] [Google Scholar]
- Google, L. L. C. (2020), “Google Covid‐19 community mobility reports.” https://www.google.com/covid19/mobility/, accessed on October 29.
- Goolsbee, Austan and Syverson Chad (2021), “Fear, lockdown, and diversion: Comparing drivers of pandemic economic decline 2020.” Journal of Public Economics, 193, 104311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guerrieri, Luca and OccBin Matteo Iacoviello (2015), “A toolkit for solving dynamic models with occasionally binding constraints easily.” Journal of Monetary Economics, 70 (C), 22–38. [Google Scholar]
- Guerrieri, Veronica , Lorenzoni Guido, Straub Ludwig, and Werning Iván (2020), Macroeconomic Implications of Covid‐19: Can Negative Supply Shocks Cause Demand Shortages? Technical report, NBER Working Paper No. 26918.
- Gupta, Sumedha , Montenovo Laura, Nguyen Thuy D., Rojas Felipe Lozano, Schmutte Ian M., Simon Kosali I., Weinberg Bruce A., and Wing Coady (2020), “Effects of social distancing policy on labor market outcomes.” NBER Working Papers 27280, National Bureau of Economic Research, Inc. [DOI] [PMC free article] [PubMed]
- Hethcote, Herbert (1989), “Three basic epidemiological models.” In Applied Mathematical Ecology. Biomathematics (Levin S. A., Hallam T. G., and Gross L. J., eds.). Springer, Berlin, Heidelberg. [Google Scholar]
- Huang, Difang (2020), “How effective is social distancing?” Covid Economics, Vetted and Real‐Time Papers, 59, 118–148. [Google Scholar]
- JHU CSSE (2020), “Covid‐19 data.” https://github.com/CSSEGISandData/COVID-19 accessed on October 29.
- Jordà, Òscar , Singh Sanjay R., and Taylor Alan M. (2020), Longer‐Run Economic Consequences of Pandemics. Technical report, NBER Working Paper No. 26934.
- Kaplan, Greg , Moll Benjamin, and Violante Giovanni L. (2020), “The great lockdown and the big stimulus: Tracing the pandemic possibility frontier for the U.S.” CEPR Discussion Papers 15256, C.E.P.R. Discussion Papers.
- Kermack, William Ogilvy and McKendrick Anderson G. (1927), “A contribution to the mathematical theory of epidemics.” Proceedings of the Royal Society, A, 115, 700–721. [Google Scholar]
- Koren, Miklós and Petó Rita (2020), Business Disruptions From Social Distancing. Technical report. arXiv:2003.13983. [DOI] [PMC free article] [PubMed]
- Krueger, Dirk , Uhlig Harald, and Xie Taojun (2020), Macroeconomic Dynamics and Reallocation in an Epidemic. Technical report, National Bureau of Economic Research No. 27047.
- Moghadas, Seyed M. , Shoukat Affan, Fitzpatrick Meagan C., Wells Chad R., Sah Pratha, Pandey Abhishek, Sachs Jeffrey D., Wang Zheng, Meyers Lauren A., Singer Burton H., and Galvani Alison P. (2020), “Projecting hospital utilization during the Covid‐19 outbreaks in the United States.” Technical report. Proceedings of the National Academy of Sciences of the United States of America. [DOI] [PMC free article] [PubMed]
- Mossong, Joel , Hens Niel, Jit Mark, Beutels Philippe, Auranen Kari, Mikolajczyk Rafael, Massari Marco, Salmaso Stefania, Scalia Tomba Gianpaolo, Wallinga Jacco, Heijne Janneke, Sadkowska‐Todys Malgorzata, Rosinska Magdalena, and Edmunds W. John (2008), “Social contacts and mixing patterns relevant to the spread of infectious diseases.” PLoS Medicine, 5 (3), 381–391. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Prem, Kiesha , Cook Alex, and Jit Mark (2017), “Projecting social contact matrices in 152 countries using contact surveys and demographic data.” PLoS Computational Biology, 13 (9), 1–21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Prem, Kiesha , van Zandvoort Kevin, Klepac Petra, Eggo Rosalind M., Davies Nicholas G., Cook Alex R., and Jit Mark (2020), “Projecting contact matrices in 177 geographical regions: An update and comparison with empirical data for the Covid‐19 era.” medRxiv doi: 10.1101/2020.07.22.20159772. [DOI] [PMC free article] [PubMed]
- Raifman, Julia , Nocka Kristen, Jones David K., Bor Jacob, Lipson Sarah K., Jay Jonathan, and Chan Philip (2020), “Covid‐19 US state policy database.” accessed on October 29, https://github.com/USCOVIDpolicy/COVID-19-US-State-Policy-Database.
- Russell, Timothy W. , Hellewell Joel, Jarvis Christopher I., Van Zandvoort Kevin, Abbott Sam, Ratnayake Ruwan, Flasche Stefan, Eggo Rosalind M., Edmunds William John, and Kucharski Adam J. (2020), Estimating the Infection and Case Fatality Ratio for Covid‐19 Using Age‐Adjusted Data From the Outbreak on the Diamond Princess Cruise Ship. Technical report, MedRxiv. [DOI] [PMC free article] [PubMed]
- Smets, Frank and Wouters Rafael (2007), “Shocks and frictions in US business cycles: A Bayesian DSGE approach.” American Economic Review, 97 (3), 586–606. [Google Scholar]
- Systrom, Kevin , Vladek Thomas, and Krieger Mike (2020). Covid‐19. https://github.com/rtcovidlive/covid-model.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Online Appendix
Data and Programs