

Abstract
Objective:
To develop an objective and easy-to-use glaucoma staging system based on visual fields (VFs).
Subjects and Participants:
A total of 13,231 VFs from 8077 subjects were used to develop models and 8024 VFs from 4445 subjects were used to validate models.
Methods:
We developed an unsupervised machine learning model to identify clusters with similar VF values. We annotated the clusters based on their respective mean deviation (MD). We computed optimal MD thresholds that discriminate clusters with highest accuracy based on Bayes minimum error principle. We evaluated the accuracy of the staging system and validated findings based on an independent validation dataset.
Results:
The unsupervised k-means algorithm discovered four clusters with 6784, 4034, 1541, and 872 VFs and average MDs of 0.0 dB (±1.4: Standard Deviation), −4.8 dB (±1.9), −12.2 dB (±2.9), and −23.0 dB (±3.8), respectively. The supervised Bayes minimum error classifier identified optimal MD thresholds of −2.2 dB, −8.0 dB, and −17.3 dB for discriminating normal eyes and eyes at the early, moderate, and advanced stages of glaucoma. The accuracy of the glaucoma staging system was 94%, based on identified MD thresholds with respect to the initial k-means clusters.
Conclusions:
We discovered that four severity levels based on MD thresholds of −2.2 dB, −8.0 dB, and −17.3 dB, provides the optimal number of severity stages based on unsupervised and supervised machine learning. This glaucoma staging system is unbiased, objective, easy-to-use, and consistent, which makes it highly suitable for use in glaucoma research and for day-to-day clinical practice.
Keywords: Glaucoma staging, glaucomatous visual field loss, artificial intelligence, unsupervised machine learning, clustering
Introduction
Glaucoma is an optic neuropathy accompanied by characteristic structural and functional changes.1 Due to its slowly progressing nature, patients are required to be monitored over a long period of time. Diagnosis of glaucoma typically includes evaluation of characteristic optic disc damage through retinal examination and imaging tools, as well as assessment of functional defects through VF testing. In the assessment of both VF loss and optic nerve damage it is essential to properly identify disease severity.
Classification of glaucomatous VF defects is important not only to diagnose the disease but also to adjust therapy based on the severity stage and type of defect. For instance, eyes with severe VF loss typically require lower targeted intraocular pressure (IOP) and likely more aggressive treatments. Accurate classification of VF could also aid in determining prognosis and corresponding plans to maintain the quality of the life of patients.2 Additionally, it could provide a common ground for both glaucoma research and clinical practice.2
Manual staging of glaucoma (e.g., level of structural/functional loss) requires significant clinical training, is highly subjective with limited reader agreement (even among glaucoma specialists) and is labor intensive.3,4 Several approaches have been proposed for glaucoma staging and disease characterization based on VF tests.5–11 Among these, the approach proposed by Hodapp, Parrish, and Anderson (HPA) has gained considerable acceptance for staging glaucoma to three severity levels.5 The HPA system includes assessment of global VF severity in terms of mean deviation (MD), local VF damage, and the extent of damage to the para-central vision.
There are several requirements for a staging and classification system to become clinically useful and gain acceptance. The ideal staging system must be unbiased, objective, reproducible, transparent, clinically relevant, and easy-to-use.2 While the HPA model and some of the other proposed approaches for staging VF severity exhibit a number of useful attributes (being objective and reproducible), significant limitations remain, in particular the need for a staging system that is transparent, clinician-friendly and easy-to-use2.
For example, in current models there is lack of transparency in the method used to select a given number of severity levels (e.g., three-stage system5 or five-stage system6) or corresponding MD thresholds and there is no evidence supporting the choice of pre-specified VF test points and their threshold values in different retinal regions and hemifields5,6,8,11,12. Additionally, staging systems that include assessment of VF test locations5,6,12 are typically time-intensive thus more appropriate for clinical trials and glaucoma research and not easily accommodated in day-to-day clinical practice.
With recent advances in artificial intelligence models and significant growth in data availability, these methods have shown promise for providing unbiased and objective systems to assess VF data.13–20 However, most of those models have been employed to identify spatial patterns of VF loss and none have explored staging glaucoma to different severity levels. We developed unsupervised machine learning to identify different severity levels of glaucoma based on VFs. Unlike some machine-learning models that require clinically annotated training datasets and human expert intervention imposing predefined assumptions and rules, our unsupervised learning models requires no data annotation nor human expertise thus could generate unbiased and transparent objective outcomes.
Methods
Subjects and Data (Discovery dataset and independent validation dataset)
We used two independent datasets in this study. The VFs in the first dataset were obtained from the clinical practice of Massachusetts Eye and Ear (MEE). The study was conducted according to the tenets of the declaration of Helsinki. A total of 31,591 VFs from 8,077 subjects (visited MEE glaucoma clinic between October 2006 and April 2012) were collected using the Humphrey Field Analyzers (HFA, Carl Zeiss Meditec, Dublin, CA). To avoid bias due to VFs from multiple visits, we included 13,231 VFs from the most recent visit of patients. We will refer to this dataset as the discovery dataset.
The second dataset was an independent dataset with 8024 VFs collected from 4445 subjects using HFA instruments in our center. We only used the most recent visit of subjects to avoid bias. We will refer to this dataset as independent validation dataset.
We included only reliable VFs in both datasets in which the reliability criteria was based on false-negative rate, false positive rates, and fixation loss rate less than 33%.21
Overview of the Data Processing Pipeline
Figure 1 shows the diagram of the data processing we used to develop the VF staging system. We first developed an unsupervised clustering approach based on k-means to find clusters with similar VFs based on all 52 VF test locations (Fig. 3). We then investigated the optimal number of clusters objectively. To assure the clustering step was stable, and the clusters are reproducible, we repeated the clustering several times, each time we selected a subset of VFs randomly (without replacement) and assessed cluster memberships. We then performed post-hoc analyses to annotate statistical clusters and generate clinical clusters based on average MD values of each cluster. As the VFs have labels now (belonging to one of the statistical clusters), we performed a supervised analysis based on Bayes minimum error classification (maximum area under the receiver operating characteristic curve) to find MD thresholds that separated clusters with highest accuracy (minimum classification error) and generated clinical clusters (Fig. 4, left panel). We verified the reproducibility of the MD thresholds based on selecting subsets of the dataset randomly (without replacement) and repeating the process. We then established an objective VF severity staging system based on the discovered clinical clusters and identified MD thresholds (Fig. 4, right panel). We validated the entire pipeline using VFs in another independent validation dataset.
Figure 1.

Diagram of the pipeline. All 52 visual fields (VFs) test locations are input to the unsupervised clustering algorithm to identify statistical clusters. Clinical labels are assigned to clusters based on average mean deviation (MD) of eyes in each cluster. Bayes’ minimum error classifier is used to identify optimal MD thresholds that distinguishes clinical clusters with the highest accuracy. This glaucoma staging system is unbiased and generates consistent outcomes objectively.
Figure 3.
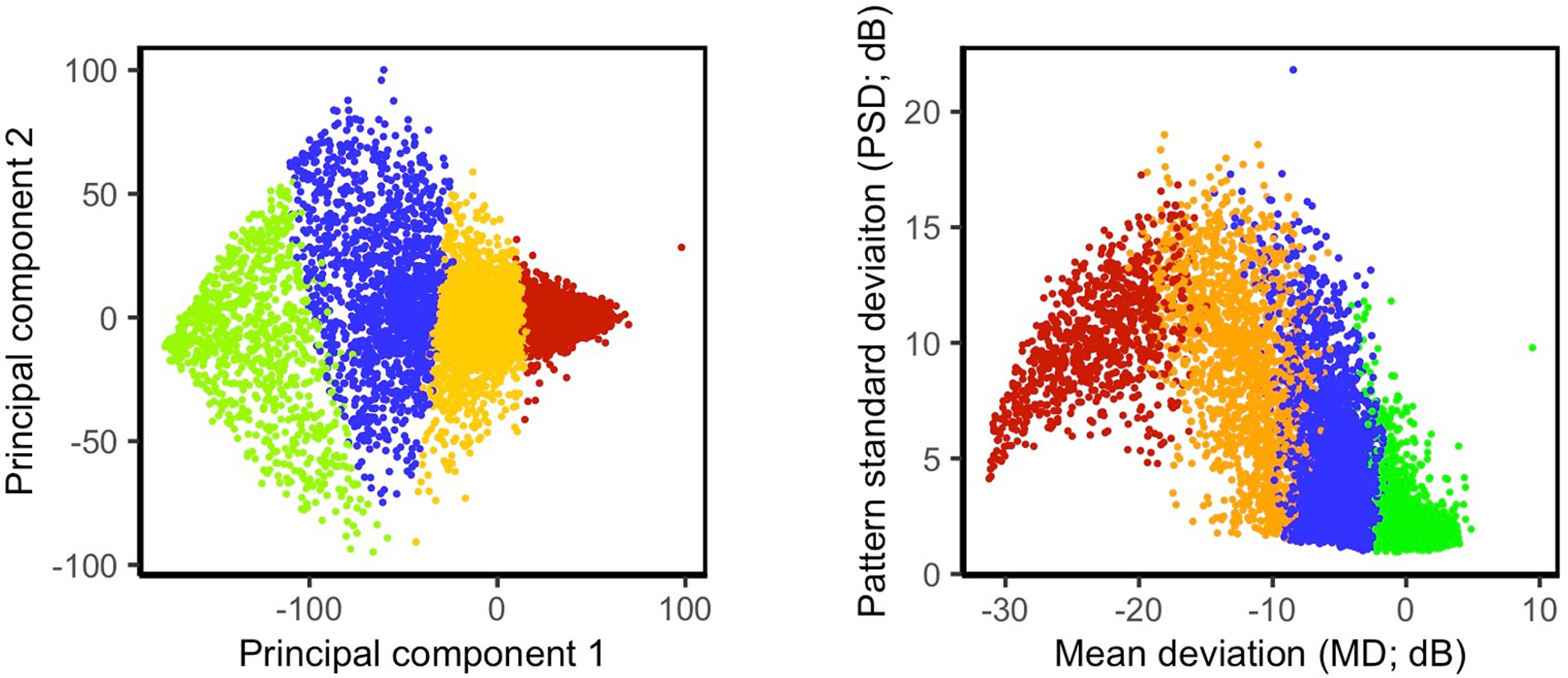
Scatter plot of the statistical clusters. Left: Principal component analysis (PCA) was used to reduce the dimensionality of visual fields (VFs) from the initial 52 dimensions to two dimensions to visualize statistical clusters. Right: Statistical clusters are visualized based on mean deviation (MD) and pattern standard deviation (PSD). Green, blue, orange, and red colors represent eyes in the Normal, Early, Moderate, and Advanced statistical clusters.
Figure 4.
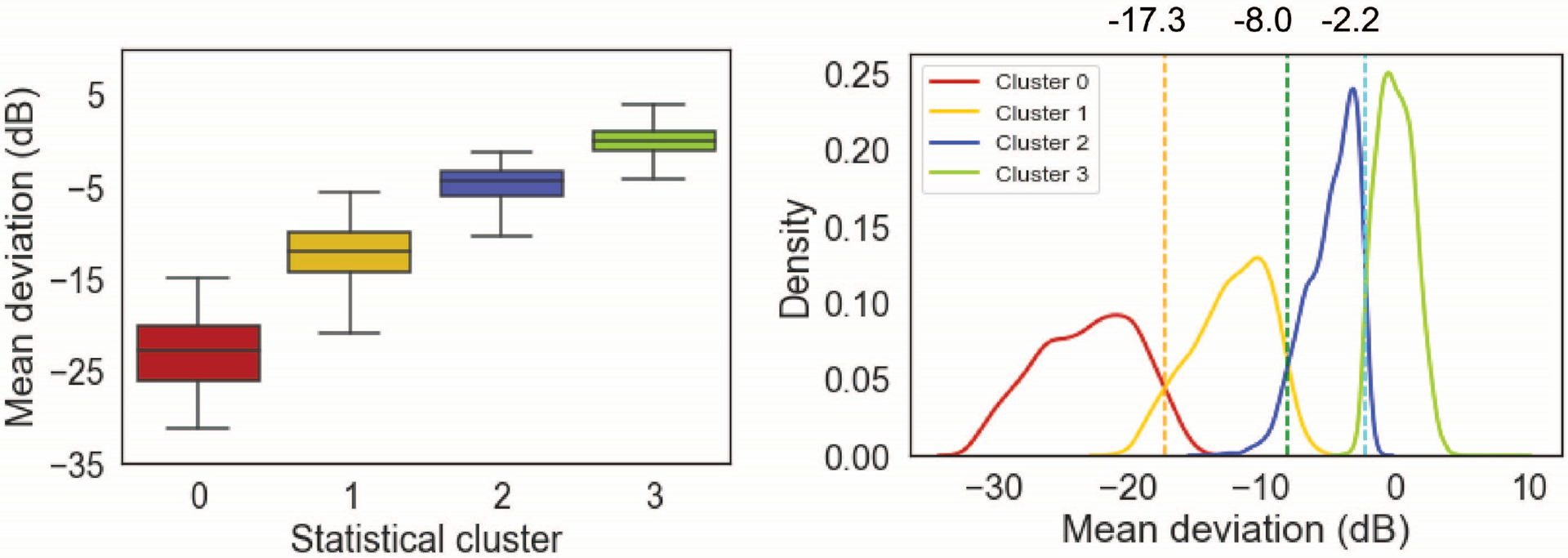
Mean deviation (MD) of VFs in statistical clusters. Left: Distribution of MD based on the discovery dataset. Right: The optimum thresholds are identified based on the Bayes’ minimum error classifier to identify clinical clusters and to establish the objective staging system.
Unsupervised Machine Learning to Identify Statistical Clusters
We developed an unsupervised k-means clustering22 to partition VFs to k clusters. Essentially, k-means clustering finds groups of clusters that are compact and highly separated from each other. In fact, k-means algorithm minimizes the distances within VFs in each group (to identify VFs within a group that are closer to each other) while maximizing the distance among groups (to find groups that are as far as possible from each other), which is an intuitive notion of an optimal clustering algorithm.23 This way, based on k-means, those with early VF loss will be grouped together and those with severe VF loss will be grouped together too. To identify the optimal number of clusters, we computed the mean distances of VFs in clusters (within-class distance) and the mean distance between clusters (between-class distance). The intuition is that VFs in a cluster should be compact while clusters of VFs should be as distant as feasible. This process is typically performed by computing related metrics such as Silhouette or knee-plot to objectively identify the optimal number of clusters reflecting compactness and spread of the clusters.24 After finding the optimal number of clusters, we investigated the stability of clustering and whether the clusters are reproducible. We therefore selected subsets of VFs in the discovery dataset randomly and repeated the clustering step based on the optimal number of clusters several times and cross-checked the membership each time (proportion of VFs that fall in same clusters each time). We then computed the membership agreement based on the percentage of the VFs that were consistently assigned to same cluster.
Annotating Clusters
We performed post-hoc analyses to annotate statistical clusters and assign attributes to the identified statistical clusters. Specifically, we computed the average MD of the eyes in each cluster to identify VF severity levels. We then labeled the clusters as Normal (cluster with highest average MD), Early, Moderate, and Advanced (cluster with lowest average MD) stages of glaucoma based on their average MD values. We expected to discover clusters at both ends of the glaucoma spectrum as our datasets were large and spanned the entire spectrum of glaucoma VF severity levels (Fig. 2). We assessed this subjectively by visualizing MD versus pattern standard deviation (PSD) and distribution of MDs of the eyes in two datasets. As visualizing about 8,000 VFs in 52-dimensional space is not feasible, we visualized the statistical clusters on 2-dimentional plots based on principal component analysis (PCA). Specifically, we applied PCA to 52 VF test points and selected two largest principal components of VFs for visualization only (Fig. 3-left). Essentially, PCA linearly transforms VFs and retains most of the variability of VFs in the top principal components thus an appropriate means for visualization of high-dimensional data. It is worth mentioning that the outcome of PCA was not used in the clustering or any other steps of the pipeline and was only utilized to visualize clusters. We also visualized clusters based on MD and pattern standard deviation (PSD) values of VFs (Fig. 3-right).
Figure 2.

Mean Deviation (MD) distribution and scatter plot of MD versus pattern standard deviation (PSD) of cross-sectional visual fields (VFs) in two datasets. Left: Distribution of VFs in the discovery dataset, Right: Distribution of VFs in the independent validation dataset.
Supervised Machine Learning and Clinical Clusters
As the clusters were annotated in the previous step, each VF has a label that indicates its corresponding cluster. We thus developed a supervised Bayes minimum error classifier to identify optimal MD thresholds that discriminate VFs (based on statistical cluster labels) with highest area under the receiver operating characteristic curve (minimum error).25,26 We called the identified new clusters based on MD thresholds as clinical clusters. These clinical clusters will be used to develop the proposed staging system.
Glaucoma Severity Staging System
To avoid utilizing a relatively complex unsupervised learning model as the glaucoma severity staging system, we performed the supervised learning and computed MD thresholds that could discriminate eyes in statistical clusters. As there was no expert intervention in cluster discovery and MD threshold establishment, in contrast to several other VF staging systems like HPA, the proposed staging system is unbiased and objective. Using MD alone for assigning patients to different glaucoma severity levels provides a simple, easy-to-use, and clinician-friendly staging system. However, it may undermine the severity of patients with local VF defects in central vision. To investigate the effect of central VF loss on our system, we assessed the number of eyes with central VF defects in clinical clusters. We also assessed the number of eyes with depressed central VF test locations in both superior and inferior hemifields. We also compared MD thresholds of the proposed stating system against some of the previously developed VF staging systems.5–11
Validation of the Pipeline
We applied the entire pipeline (unsupervised clustering, supervised learning and clinical clusters, and staging system) to another independent dataset of VFs to assure generalizability and robustness of the system. We used an independent dataset with 8024 cross-sectional VFs (most recent visit of subjects) to validate all steps of our pipeline. We first investigated whether we could discover (reproduce) statistical clusters with similar properties we identified based on the discovery dataset. We thus applied the k-means clustering (using same parameters) on the validation dataset and identified statistical clusters. We then evaluated the optimal number of clusters using the Silhouette metric as was used for the discovery dataset. We then labeled clusters based on the average MD of eyes in clusters and compared corresponding clusters based on the discovery and validation datasets. We then computed the MD thresholds that generate highest accuracy in discriminating clinical clusters based on the validation dataset and compared against MD thresholds that we had identified based on the discovery dataset. Validation based on independent datasets is critical to verify robustness and generalizability of the proposed VF staging system.
Statistical Analyses
We used a generalized estimating equation (GEE) approach27 to compare different parameters of subjects in the discovery and validation datasets such as age as we included both eyes of some of the subjects in datasets. Essentially, GEE utilizes generalized regression models to adjusts for the inter-eye correlation of subjects. Machine learning and statistical analyses were performed in Python 3.8 and R (v.4.0.3) platforms.
Results
The demographic characteristics of the subjects are included in Table 1. Briefly, the discovery dataset included 13,231 VFs from 13,231 eyes with the mean age of 60.6 years (±17.9: Standard Deviation; SD) and MD of −4.4 dB (±6.6). The independent dataset included 8024 VFs from 8,024 eyes with the mean age of 62.4 years (±15.9) and average MD of −4.6 dB (±7.2). Figure 2 shows MD versus PSD of eyes in the discovery and independent datasets. Eyes in the validation dataset had worse MD compared to eyes in the discovery dataset (p < 0.01; GEE model).
Table 1.
Characteristics of VFs used in this study. Numbers in parentheses show standard deviation (SD).
| Discovery dataset | Validation dataset | |
|---|---|---|
| Number of VFs | 13231 | 8024 |
| Mean deviation (MD) | −4.4 dB (±6.6) | −4.6 dB (±7.2) |
| Pattern standard deviation (PSD) | 3.9 dB (±3.5) | 3.9 dB (±3.6) |
| Age | 60.6 years (±17.9) | 62.4 years (±15.9) |
Statistical Clusters Based on the Discovery Dataset
Based on the discovery dataset, the Silhouette and knee-plot measures suggested that the optimal number of statistical clusters is four (which reflects the optimal number of severity levels). Figure 3 (left) shows the scatter plot of the first and second principal components of the VFs in four statistical clusters. Figure 3 (right) presents the scatter plot of MD versus PSD of the VFs in four statistical clusters. On average, 99% of the VFs were assigned to the same cluster (membership reproducibility) based on repeated k-means clustering applied 10 times; each time selecting 90% of the discovery dataset (without replacement) randomly. Table 2 shows the details of the membership accuracies (mean accuracy and range) based on 10 times repeated clustering applied on different randomly selected subsets of the discovery dataset.
Table 2.
Membership accuracy of the clustering based on 10 times repeating k-means on randomly selected (without replacement) subsets of the discovery dataset.
| Percentage of discovery dataset (%) | Mean accuracy (%) | Range of accuracy (%) |
|---|---|---|
| 100 | 0.999 | [0.996, 1.000] |
| 90 | 0.992 | [0.967, 0.999] |
| 80 | 0.984 | [0.956. 0.999] |
| 70 | 0.987 | [0.953, 0.999] |
| 60 | 0.987 | [0.963, 0.995] |
We annotated statistical clusters by assigning Normal, Early, Moderate, and Advanced labels to clusters based on their respective VF severity levels in terms of MD (Fig. 4, Left). The average MD of eyes in Normal, Early, Moderate, and Advanced clusters were 0.0 dB (±1.4), −4.8 dB (±1.9), −12.2 dB (±2.9), and −23.0 dB (±3.8), respectively (Fig. 4, Left).
The number of VFs in these four statistical clusters were 6784, 4034, 1541, and 872, respectively. Based on the statistical clusters, the proportion of eyes with VF loss in at least one of the four para-central VF test locations (within 5 degrees) in the Normal, Early, Moderate, and Advanced clusters were 0.5% (38 eyes), 7% (276 eyes), 45% (700 eyes), and 85% (739 eyes), respectively.
Clinical Clusters and Glaucoma Staging System Based on the Discovery Dataset
Bayes minimum error classifier suggested −2.2 dB, − 8.0 dB, and −17.3 dB, as optimal MD thresholds for discriminating normal eyes and eyes in early, moderate, and advanced stages of glaucoma (Fig. 4, Right). Table 3 shows the range of MD thresholds based on repeated identification of MD thresholds ten times each time selecting a subset of the discovery dataset randomly. Tight intervals reflect the reproducibility of the model.
Table 3.
Identified mean deviation (MD) thresholds based on Bayes minimum error classifier. Numbers in parentheses show the range.
| Mean Deviation (MD) threshold | Discovery dataset | Validation dataset |
|---|---|---|
| MD threshold (early) | −2.18 dB (−2.19, −2.18) | −2.45 dB (−2.46, −2.45) |
| MD threshold (moderate) | −8.01 dB (−8.02, −8.00) | −8.75 dB (−8.75, −8.74) |
| MD threshold (advanced) | −17.25 dB (−17.27, −17.23) | −18.71 dB (−18.71, −18.70) |
The number of VFs in four clinical clusters (based on the identified MD thresholds) were 6621, 3996, 1683, and 931, respectively. The (weighted) mean accuracy of clinical clusters to discriminate normal eyes and eyes at the early, moderate, and advanced stages of glaucoma was approximately 94%. Figure 5 shows the confusion matrix (agreement between statistical clusters based on unsupervised k-means algorithm and clinical clusters based on Bayes minimum error classifier) of the glaucoma staging system (clinical clusters) based on the identified MD thresholds.
Figure 5.

The agreement between statistical clusters based on unsupervised k-means algorithm and clinical clusters based on Bayes minimum error classifier.
Based on the proposed glaucoma staging system, the proportion of normal eyes and eyes in the early, moderate, and advanced stages of glaucoma with VF loss in at least one of the four para-central VF test locations were 0.2% (17 eyes), 6% (224 eyes), 42% (696 eyes), and 88% (816 eyes), respectively. The proportion of normal eyes and eyes in the early stage of glaucoma with VF loss in at least one of the four para-central VF test locations was 2.3% (241 out of 10,617 eyes).
Validating Statistical Clusters Based on the Validation Dataset
Based on the validation dataset, we observed four clusters were optimum according to Silhouette and knee-plot. We then annotated the statistical clusters by assigning Normal, Early, Moderate, and Advanced labels to clusters based on their MD. The average MD of eyes in Normal, Early, Moderate, and Advanced clinical clusters were −0.4 dB (±1.3), −5.6 dB (±2.6), −14.0 dB (±3.3), and −24.3 dB (±4.9), respectively.
The number of VFs in Normal, Early, Moderate, and Advanced clusters were 4712, 2074, 629, and 609, respectively. The proportion of eyes with VF loss in at least one of the four para-central VF test locations in the Normal, Early, Moderate, and Advanced clusters were 0.8% (38 eyes), 16% (322 eyes), 64% (401 eyes), and 85% (517 eyes), respectively.
Validating Clinical Clusters and Glaucoma Staging System Based on the Validation Dataset
The Bayes minimum error classifier suggested −2.4 dB, − 8.7 dB, and −18.7 dB, as optimal MD thresholds for identifying normal eyes and eyes in early, moderate, and advanced stages of glaucoma (Table 3). In Table 3, we have also demonstrated the range of MD thresholds based on repeated identification of thresholds ten times each time selecting 80% of the validation dataset randomly.
The number of VFs in four clinical clusters (based on the identified MD thresholds) were 4508, 2035, 907, and 574, respectively. The (weighted) mean accuracy of clinical clusters to discriminate normal eyes and eyes at the early, moderate, and advanced stages of glaucoma was approximately 90%.
Based on the proposed staging system, the proportion of normal eyes and eyes in the early, moderate, and advanced stages of glaucoma with VF loss in at least one of the four para-central VF test locations were 0.3% (15 eyes), 12% (245 eyes), 53% (479 eyes), and 91% (521 eyes), respectively. The proportion of normal eyes and eyes in the early stage of glaucoma with VF loss in at least one of the four para-central VF test locations was 3.9% (260 out of 6,543 eyes).
Based on the validation dataset (in which we had access to GHT and PSD information), the percentage of eyes with GHT labeled as “Outside Normal Limits” or PSD < 2% were 15%, 80%, 100%, and 100% for normal eyes and eyes in the early, moderate, and advanced stages of glaucoma, respectively.
Discussion
We developed a pipeline with unsupervised and supervised machine learning models to stage glaucoma severity based on VFs. We applied an unsupervised clustering model to VF data and discovered four clusters of eyes with similar VF characteristics (statistical clusters). We then labeled clusters as normal, early, moderate, and advanced based on average MD of eyes in clusters and generated clinical clusters. Rather than using the complex unsupervised machine learning model as the severity staging system, we investigated if a simple criterion based on the readily available MD could separate these four clusters with reasonable accuracy. To achieve this goal, we developed a supervised Bayes minimum error classifier to identify MD thresholds that discriminate these clusters with highest accuracy. This statistical approach identifies thresholds that lead to minimum classification error among four clusters. We found that MD thresholds of −2.2 dB, − 8.0 dB, and −17.3 dB could stage VFs into four severity levels with an accuracy of 94% compared to the initial complex statistical clusters identified based on unsupervised learning. To our knowledge, this is the first fully unsupervised and unbiased criterion for glaucoma staging based on VFs.
There is no definite metric to evaluate the performance of the unsupervised clustering models and the optimal number of clusters. We used a large dataset with over 13,000 cross-sectional VFs collected from patients visited MEE glaucoma services to develop unsupervised models and assessed different objective metrics to identify the optimal number of clusters. Widely used Silhouette metric and knee plot suggested that four clusters were optimum.24 We then investigated if the model is reproducible in cluster membership assignment by repeating the clustering based on randomly selected subsets of the initial dataset and observed approximately 99% of eyes fall in same cluster if we repeat clustering 10 times, reflecting the fact that the unsupervised machine learning step is stable and reproducible.
Glaucoma staging systems based on VFs typically rely on number and depth of defective points5,8, patterns of VF loss28, VF summary parameters7,9, box plots10,29, or cumulative defect curve11. These VF staging systems have been derived based on fully or partially subjective criteria. For instance, the widely used HPA VF staging system suggests MD thresholds of −6 dB, −12 dB, and −18 dB along with assessment of VF test points including those within central 5 degrees to discriminate early, moderate, and advanced stages of glaucoma.5 However, these MD threshold values were derived subjectively. We, on the other hand, employed an unbiased unsupervised machine learning along with objective Bayes statistical analysis to identify MD thresholds that stage glaucoma. We found that MD thresholds of −2.2 dB, − 8.0 dB, and −17.3 dB are optimum for staging VFs into four severity levels based on a large dataset of VFs. We observed that this novel staging system based on the MD thresholds provides a 94% accuracy compared to the initial statistical clusters derived based on k-means and analysis of all individual VF test points (Fig. 5). The misclassification rate was higher in the moderate and advanced clusters compared to other clusters (Fig. 5) which may be justified by more variability of VFs in more severe cases. By slightly compromising the accuracy, the severity staging system is based on clinical clusters that require MD thresholds only compared to statistical clusters that require access to 52 VF test locations and preforming complex unsupervised learning.
Brusini el al.7 suggested MD thresholds of −3 dB, −5 dB, −8 dB, −12 dB, and −20 dB for identifying six stages of VF damage. Mills et al.8 suggested an enhanced HPA system with MD thresholds of 0 dB, −6 dB, −12 dB, −18 dB, and −20 dB along with PSD assessment and sensitivity of several VF test locations for identifying six stages of VF severity levels. While most other systems have not proposed any threshold to identify normal range of VFs (e.g., HPA), these two systems have suggested MD threshold of 0 dB and −3 dB as to discriminate eyes with normal VFs. Interestingly, our identified MD threshold of −2.2 dB is in the range of these two models. Additionally, our identified MD threshold of – 8.0 dB is similar to the threshold of −8.0 dB suggested by Brusini e al.7.
Unlike HPA5, Brusini el al.7, Mills et al.8, and several other VF staging systems9–11,29, we suggest MD as the only parameter in our VF staging system. We have several reasons for using MD as the only parameter in the final system. First, we intended to provide an easy-to-use approach that could be ultimately used in clinical practice and glaucoma research. Second, MD is a widely used metric that is readily available to clinicians while hemifield analysis is not readily available and assessment of VF test point sensitivity, probability assessments, and other criteria used by other staging systems are labor intensive and complicated thus hampering their clinical utility. Additionally, it has been shown that MD is also appropriate for glaucoma progression detection.30
Although our staging system is ultimately based on the MD parameter alone, MD thresholds were derived based on an unbiased and objective approaches that maximized staging accuracy. In fact, the accuracy of the staging system based on the identified MD thresholds was only 6% less accurate than the initial k-means clustering that utilized all VF test locations in identifying statistical clusters (Fig. 5). Given this modest difference, we did not suggest the initial k-means model as the VF staging system because the likelihood of such a complex model gaining widespread popularity and being widely used by clinicians, is minimal. Instead, we have turned a quite complex k-means into a simple and easy-to-use glaucoma staging system while maintaining the accuracy at 94%. Another interesting observation was that only eyes from one neighboring severity level may be confused, i.e., a small percentage of eyes in the early stage were either confused with normal or moderate and no eye at the early stage was confused with advanced stage of glaucoma. This was consistently valid for all stages of glaucoma; (see Fig. 5). This is in agreement with the Occam’s razor theory that suggests that using a simpler model may be a superior choice compared to a more complex model if the accuracy is not compromised substantially.31
One may argue that although the HPA system is more complex, but it considers the central VF loss in staging as well, which is critical in managing glaucoma patients. While there is no supporting evidence, many clinicians probably use a simplified version of HPA based on MD cutoffs only to stage glaucoma in pressing day-to-day clinical practice for patient management and for billing purposes. Therefore, having a glaucoma system based on MD only supports our system. Moreover, our MD thresholds are relatively closed to those that are used based on HPA thus we indirectly verify what the community was using for a long time. To see the impact of not assessing central VF loss in our staging system, we applied the same HPA criterion to identify the number of eyes with VF damage in four VF central test locations. We observed that, based on our glaucoma staging system, only a small percentage of normal eyes and eyes in the early stage of glaucoma (0.2% and 6%, respectively) had at least one depressed central VF test location (sensitivity < 15 dB based on HPA criteria). On the other hand, large percentages of eyes in the moderate and advanced stages of glaucoma (42% and 88%, respectively) had at least one depressed central VF test location. An interesting observation was that the number of eyes with central VF loss based on our staging system was even lower than the number of eyes with central VF loss based on the initial k-means (with 0.5% and 7% of eyes with central VF loss in Normal and Early statistical clusters, respectively).
Additionally, we analyzed the hemifield location of central VF test points. Based on the proposed glaucoma staging system, we observed that 0%, 0.2%, 6.7%, and 44.6% of normal eyes and eyes in the early, moderate, and advanced stages of glaucoma had depressed central VF test locations in both hemifields (sensitivity < 15 dB). As such, just a few eyes in the early stage of glaucoma had central VF damage in both hemifields. We observed that 0.1%, 0.4%, 4.6%, and 12.1% of normal eyes and eyes in the early, moderate, and advanced stages of glaucoma had at least one severely damaged central VF test location (sensitivity of 0 dB). Therefore, based on our staging system, only a few normal eyes and eyes in the early stage of glaucoma had severe central VF loss (sensitivity of 0 dB). We also observed that only 15% of eyes in normal group had GHT labeled as “Outside Normal Limits” or PSD < 2% while abnormal GHT or PSD were present in 80%, 100%, and 100% of eyes in the early, moderate, and advanced stages of glaucoma, respectively. These are critical as we have not employed any VF test location assessment in our final glaucoma staging system but k-means clustering, and Bayes minimum error classifier together have identified optimal MD thresholds that lead to a reasonable agreement with HPA regarding central VF loss criteria.
Only recently several studies, including ours, have proposed unsupervised and objective approaches for VF data analysis including glaucoma progression detection.32–34 In this study, however, we employed both unsupervised and supervised models for glaucoma staging. Although we investigated the reproducibility of the clustering membership and identified MD thresholds based on the discovery dataset, we validated the entire pipeline based on another independent VF dataset. We repeated the clustering based on the independent validation dataset and observed that the optimal number of clusters based on Silhouette metric and knee plot is four. The Bayes minimum error classifier suggested MD thresholds of −2.4 dB, − 8.7 dB, and −18.7 dB based on the independent validation dataset. While the first two thresholds identified based on the discovery and independent validation datasets were relatively close, the threshold for discriminating advanced stages of glaucoma was relatively different. The discrepancy may be justified based on several facts. First, the eyes in the independent dataset had worse MDs compared to the eyes in the development dataset (p < 0.01; GEE) thus it is expected that all thresholds move a bit towards the more severe end of the glaucoma spectrum. Second, this issue is somewhat universal to many studies and not specific to our study only as even the summary statistics of the VFs in normative datasets of different instruments could be different. However, a possible solution to address this issue is to select the MD thresholds based on the average of corresponding thresholds of the two datasets. It is also feasible to combine discovery and validation datasets and recompute the MD thresholds based on the merged data which is expected to fall in the same range.
Most VF classification methods have limited clinical utility because of two major reasons. First, some of those models may be simple and easy-to-use but are developed based on subjective criteria thus not standardized. Second, some models may be more accurate and quite standardized but too complicated and time-consuming to utilize.2 We however propose a VF staging system that is simple, easy-to-use, clinician-friendly, quick, yet precise enough to be used in glaucoma research and clinical practice.
While we used large VF datasets and established the staging system without expert intervention, our study has some limitations. First, both datasets were retrospective and cross-sectional, thus providing limited information on true advancement of eyes to VF severity levels. Second, the datasets were collected from glaucoma clinics with no information regarding possible comorbidities such as cataracts or surgical history which may impact findings. However, we only included the last VF from each eye and likely patients have received care for other major co-morbidities (particularly cataract). As such, a small percentage of non-glaucomatous types of VF loss from cataract, AMD, or other retinal disease may be admixed in this dataset. Using visual field index (VFI) rather than MD may address this issue partially, but we had no access to VFI in this study. Anyhow, our dataset may better represent glaucoma patients who often have co-existing non-glaucomatous diseases as well. Third, while our model provides information on normal eyes and eyes at three different severity levels of glaucoma, it is not geared towards glaucoma diagnosis. Follow up studies are desirable to develop models for distinguishing normal eyes from eyes with glaucoma (two classes only) based on visual fields. Finally, future studies may incorporate longitudinal datasets to identify not only the severity stage of glaucoma, but also assess glaucomatous progression based on VFs.
Conclusion
We developed a pipeline of unsupervised and supervised machine learning models to develop an unbiased and objective glaucoma staging system based on VFs in two independent large datasets. We discovered four clusters of VFs with similar characteristics without expert intervention. We evaluated the quality of learning based on several objective metrics and assured clusters are reproducible. We then employed objective supervised learning through Bayes’ minimum error criteria to identify MD thresholds to discriminate different severity levels of glaucoma. Our VF staging system suggested MD thresholds of −2.2 dB, −8.0 dB, and −17.3 dB to distinguish normal eyes and eyes in the early, moderate, and advanced stages of glaucoma. Unlike other VF staging models, our system is simple, easy-to-use, evidence-based, and clinician-friendly. Our system supports HPA as MD thresholds we identified are relatively close to those proposed by initial HPA.
Acknowledgment
This work was supported by NIH Grants EY033005, EY030142 and EY031725 and a Challenge Grant from Research to Prevent Blindness (RPB), New York. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Foster PJ, Buhrmann R, Quigley HA, Johnson GJ. The definition and classification of glaucoma in prevalence surveys. Br J Ophthalmol. 2002;86(2):238–242. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Brusini P, Johnson CA. Staging functional damage in glaucoma: review of different classification methods. Surv Ophthalmol. 2007;52(2):156–179. [DOI] [PubMed] [Google Scholar]
- 3.Spaeth GL, Henderer J, Liu C, et al. The disc damage likelihood scale: reproducibility of a new method of estimating the amount of optic nerve damage caused by glaucoma. Trans Am Ophthalmol Soc. 2002;100:181–185; discussion 185–186. [PMC free article] [PubMed] [Google Scholar]
- 4.Jampel HD, Friedman D, Quigley H, et al. Agreement among glaucoma specialists in assessing progressive disc changes from photographs in open-angle glaucoma patients. Am J Ophthalmol. 2009;147(1):39–44 e31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Hodapp E, Parrish RK, Anderson DR. Clinical decisions in glaucoma. St Louis: The CV Mosby Co. 1993:52–61. [Google Scholar]
- 6.Advanced Glaucoma Intervention Study. 2. Visual field test scoring and reliability. Ophthalmology. 1994;101(8):1445–1455. [PubMed] [Google Scholar]
- 7.Brusini P Clinical use of a new method for visual field damage classification in glaucoma. Eur J Ophthalmol. 1996;6(4):402–407. [DOI] [PubMed] [Google Scholar]
- 8.Mills RP, Budenz DL, Lee PP, et al. Categorizing the stage of glaucoma from pre-diagnosis to end-stage disease. Am J Ophthalmol. 2006;141(1):24–30. [DOI] [PubMed] [Google Scholar]
- 9.Flammer J The concept of visual field indices. Graefe’s archive for clinical and experimental ophthalmology = Albrecht von Graefes Archiv fur klinische und experimentelle Ophthalmologie. 1986;224(5):389–392. [DOI] [PubMed] [Google Scholar]
- 10.Heijl A, Lindgren G, Olsson J. A package for the statistical analysis of visual fields. In: Greve EL, Heijl A, eds. Seventh International Visual Field Symposium, Amsterdam, September 1986. Dordrecht: Springer Netherlands; 1987:153–168. [Google Scholar]
- 11.Bebie H, Flammer J, Bebie T. The cumulative defect curve: separation of local and diffuse components of visual field damage. Graefe’s archive for clinical and experimental ophthalmology = Albrecht von Graefes Archiv fur klinische und experimentelle Ophthalmologie. 1989;227(1):9–12. [DOI] [PubMed] [Google Scholar]
- 12.Gillespie BW, Musch DC, Guire KE, et al. The collaborative initial glaucoma treatment study: baseline visual field and test-retest variability. Invest Ophthalmol Vis Sci. 2003;44(6):2613–2620. [DOI] [PubMed] [Google Scholar]
- 13.Bowd C, Weinreb RN, Balasubramanian M, et al. Glaucomatous patterns in Frequency Doubling Technology (FDT) perimetry data identified by unsupervised machine learning classifiers. PLoS One. 2014;9(1):e85941. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Yousefi S, Goldbaum MH, Balasubramanian M, et al. Learning from data: recognizing glaucomatous defect patterns and detecting progression from visual field measurements. IEEE Trans Biomed Eng. 2014;61(7):2112–2124. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Yousefi S, Goldbaum MH, Zangwill LM, Medeiros FA, Bowd C. Recognizing patterns of visual field loss using unsupervised machine learning. Proc SPIE Int Soc Opt Eng. 2014;2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Yousefi S, Balasubramanian M, Goldbaum MH, et al. Unsupervised Gaussian Mixture-Model With Expectation Maximization for Detecting Glaucomatous Progression in Standard Automated Perimetry Visual Fields. Transl Vis Sci Technol. 2016;5(3):2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Elze T, Pasquale LR, Shen LQ, Chen TC, Wiggs JL, Bex PJ. Patterns of functional vision loss in glaucoma determined with archetypal analysis. J R Soc Interface. 2015;12(103). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Wang M, Shen LQ, Pasquale LR, et al. Artificial Intelligence Classification of Central Visual Field Patterns in Glaucoma. Ophthalmology. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Yousefi S, Elze T, Pasquale LR, et al. Monitoring Glaucomatous Functional Loss Using an Artificial Intelligence-Enabled Dashboard. Ophthalmology. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Thakur A, Goldbaum M, Yousefi S. Convex Representations Using Deep Archetypal Analysis for Predicting Glaucoma. IEEE J Transl Eng Health Med. 2020;8:3800107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Bickler-Bluth M, Trick GL, Kolker AE, Cooper DG. Assessing the utility of reliability indices for automated visual fields. Testing ocular hypertensives. Ophthalmology. 1989;96(5):616–619. [DOI] [PubMed] [Google Scholar]
- 22.Hartigan JA. Clustering Algorithms. John Wiley & Sons, Inc.; 1975. [Google Scholar]
- 23.Telgarsky M, Vattani A. Hartigan’s Method: k-means Clustering without Voronoi. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics; 2010; Proceedings of Machine Learning Research. [Google Scholar]
- 24.Rousseeuw PJ. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics. 1987;20:53–65. [Google Scholar]
- 25.Huang K, Yang H, King I, Lyu MR, Chan L. The Minimum Error Minimax Probability Machine. J Mach Learn Res. 2004;5:1253–1286. [Google Scholar]
- 26.Duda ROHPESDG. Pattern Classification. 2012.
- 27.Zeger SL, Liang KY, Albert PS. Models for longitudinal data: a generalized estimating equation approach. Biometrics. 1988;44(4):1049–1060. [PubMed] [Google Scholar]
- 28.Keltner JL, Johnson CA, Cello KE, et al. Classification of visual field abnormalities in the ocular hypertension treatment study. Arch Ophthalmol. 2003;121(5):643–650. [DOI] [PubMed] [Google Scholar]
- 29.Shin Y, Suzumura H, Furuno F. Classification of glaucomatous visual field defects using the Humphrey Field Analyzer box plots. Mills RP, Heijl A (eds): Perimetry Update 1990/91 Amsterdam, New York, Kugler Publications. 1991; :235 - —243. [Google Scholar]
- 30.Gardiner SK, Demirel S. Detecting Change Using Standard Global Perimetric Indices in Glaucoma. Am J Ophthalmol. 2017;176:148–156. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Schaffer J What Not to Multiply Without Necessity. Australasian Journal of Philosophy. 2015;93(4):644–664. [Google Scholar]
- 32.Yousefi S, Kiwaki T, Zheng Y, et al. Detection of Longitudinal Visual Field Progression in Glaucoma Using Machine Learning. Am J Ophthalmol. 2018;193:71–79. [DOI] [PubMed] [Google Scholar]
- 33.Gardiner SK, Mansberger SL, Demirel S. Detection of Functional Change Using Cluster Trend Analysis in Glaucoma. Invest Ophthalmol Vis Sci. 2017;58(6):BIO180-BIO190. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Wang M, Shen LQ, Pasquale LR, et al. An Artificial Intelligence Approach to Detect Visual Field Progression in Glaucoma Based on Spatial Pattern Analysis. Invest Ophthalmol Vis Sci. 2019;60(1):365–375. [DOI] [PMC free article] [PubMed] [Google Scholar]