

Abstract
Recommendation systems play an important role in today’s digital world. They have found applications in various areas such as music platforms, e.g., Spotify, and movie streaming services, e.g., Netflix. Less research effort has been devoted to physical exercise recommendation systems. Sedentary lifestyles have become the major driver of several diseases as well as healthcare costs. In this paper, we develop a recommendation system to recommend daily exercise activities to users based on their history, profiles and similar users. The developed recommendation system uses a deep recurrent neural network with user-profile attention and temporal attention mechanisms. Moreover, exercise recommendation systems are significantly different from streaming recommendation systems in that we are not able to collect click feedback from the participants in exercise recommendation systems. Thus, we propose a real-time, expert-in-the-loop active learning procedure. The active learner calculates the uncertainty of the recommendation system at each time step for each user and asks an expert for recommendation when the certainty is low. In this paper, we derive the probability distribution function of marginal distance, and use it to determine when to ask experts for feedback. Our experimental results on a mHealth and MovieLens datasets show improved accuracy after incorporating the real-time active learner with the recommendation system.
Keywords: Active learning, attention networks, deep learning, marginal distance, recommendation system
I. Introduction
A MAJOR driver of healthcare costs in different countries are unhealthy behaviors such as physical inactivity, increased food intake, and unhealthy food choice [1], [2]. Behavioral and environmental health factors account for more deaths than genetics [1]. Pervasive computational, sensing, and communication technology can be leveraged to support individuals in their everyday lives to develop healthier lifestyles. For instance, the pervasive use of smartphones is a potential platform for the delivery of behavior-change methods at great economies of scale. Commercial systems such as noom [3] aim to provide psychological support via mobile health (mHealth) systems. Research platforms, such as the Fittle+ system [4], have demonstrated the efficacy of translating known behavior-change techniques [5] into personal mHealth applications. However, most work in the mHealth domain are limited to the development of smartphone applications and connecting subjects and expert knowledge.
On the other hand, recommendation systems are becoming popular in various applications. E-commerce websites have been using recommendation systems to suggest new products and items to existing and new users to entice them into purchasing new items [6], [7]. With the advent of streaming movies and music services, e.g., Netflix, Spotify, service providers need to keep their users interested or lose their customers and profits. Thus, these streaming service providers deploy recommendation systems to suggest new movies and musics to their existing and new users based on their history of watching movies and listening to musics [8], [9]. However, not many research studies have been devoted to developing recommendation systems for exercise activities [10].
In this paper, we develop an attention-based recommendation system for exercise activities to new users using a mHealth application. The proposed recommendation system is based on a deep recurrent neural network that takes advantage of users’ profiles and exercise characteristics as features and temporal attention mechanisms. However, one major difference between exercise activities and other domains is that the recommendation system is not able to collect users’ feedback. In movie, e-commerce, and music applications, recommendation systems constantly receive feedback from users’ clicks data. When a recommendation system suggests a new music (or a movie) to a user, the user may click on the suggested music (or movie) and listen to (or watch) it completely. The click and duration of playback is used as a feedback to fine-tune the recommendation system. Although users are able to provide ratings in these systems, they may choose not to do so. As a result, the systems will use the click data, duration of playback, etc. to assess whether the recommended music (or movie) was a good recommendation or not.
However, when a recommendation system suggests an exercise activity to the user, the application is not able to collect the click data because the application cannot observe the user, and the only way to collect the feedback is if the user chooses to rate the exercise. In other words, the recommendation system doesn’t know whether the user completed the exercise, i.e. if it was a good recommendation. In some mHealth apps [11], users were asked to provide that information manually, but the missing data is tremendous as most users were ignorant of that feedback. The problem is more challenging when the recommendation system faces a new user without any history. To address this issue, in this paper, we take advantage of a real time expert-in-the-loop mechanism. Individuals trust expert personal trainers to provide them with exercises plans based on the experts’ knowledge and experience. Our proposed system will leverage this trust to use experts’ knowledge when the system is uncertain. As a result, more individuals will have access to exercises plans with expert personal trainers in the loop. Our proposed network will calculate the certainty of a new recommendation using the probability distribution of the marginal distance, the difference between the highest probability and the second highest probability of exercise classes in the output of the recommendation system. To quantify the certainty, we derive the probability distribution of the marginal distance from the probability distribution of the last layer of the recommender. Even though the marginal distance has been used in active learning, this is the first work to provide its probability distribution for statistical hypothesis testing.
The other challenge with most recommendation systems is the initialization of the recommendation system for new users. Much work has been devoted to address this issue, including metal-learning approaches [12]. In this paper, we leverage the questionnaire filled by users and their demographic information to find the existing users with similar interests and demographic information. Then, the global recommendation model is fined tuned with the history of the similar users. Comparing to other existing methods, this approach has less complexity. Fig. 1 shows the overall architecture of the recommendation system.
Fig. 1.
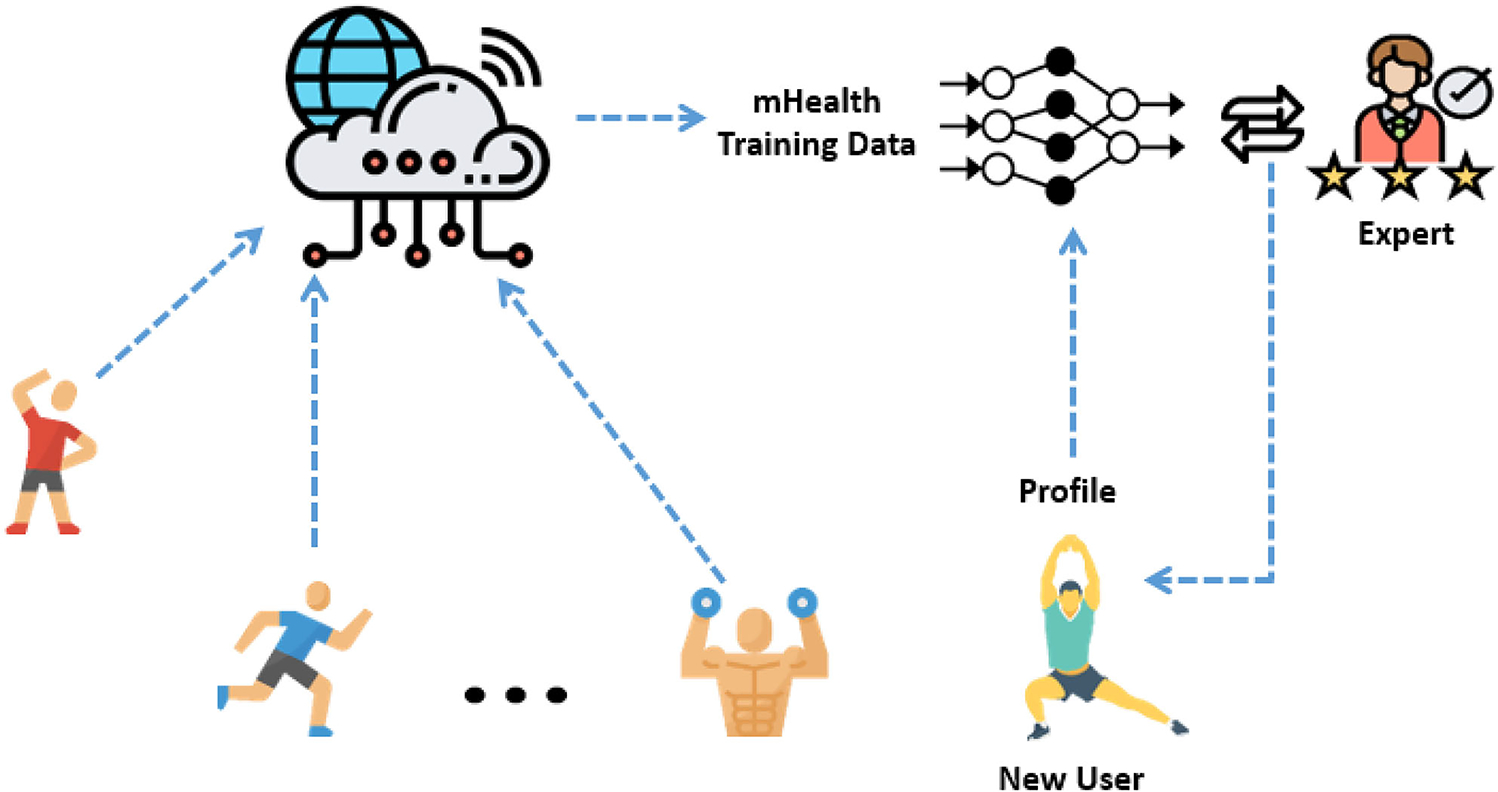
The overall architecture of the proposed recommendation system with expert-in-the-loop. The exercise activities are recommended through a smartphone app, and their completion is collected from smartphones. The deep recommendation system is trained on the collected history data and its augmentation. The new recommender system is initialized for each new participant from the global trained model, and fine-tuned with similar users based on their profiles. At each time step, a new exercise is recommended to users. If the recommendation system is uncertain about the new recommendation, i.e. whether the user will complete the exercises or not, the recommendation system will ask the expert for correction.
The rest of this paper is organized as follows: Section II describes the mHealth data used in this study. The architecture of the proposed recommendation system is explained in Section III-A. Section III-B explains how we take advantage of the user profiles to initialize a recommendation system for new users. Section IV describes the proposed active learning procedure based on the distribution of the marginal distance. Section V is devoted to the experimental results and discussion.
A. Related Work
More recently, mHealth systems have found applications in different healthcare domains since the advent of smart phones. Dunsmuir et al. [13] developed mHealth for diagnosis and management of pregnant women with pre-eclampsia. In [14], the inter-pulse-interval security keys was used to authenticate entities for various mHealth applications. Schiza et al. [15] proposed a unified framework for an eHealth national healthcare system for European Union. In another work [16], WE-CARE, a mobile 7-lead ECG device, was developed to provide 24/7 cardiovascular monitoring system. In [17], an mHealth system was designed and developed to provide exercise advice to participants based on their Body Mass Index, Basal Metabolic Rate, and the energy used in each activity or sport, e.g. aerobic dancing, cycling, jogging working and swimming. However, this work does not use machine learning algorithms.
On the other hand, recommendation systems have been used in e-commerce and online shopping for several years [18]–[21]. The goal of recommendation systems is to recommend products that suit the consumers’ tastes. Traditional recommendation systems have used collaborative filters to suggest products similar to those the consumers have purchased. With the advancements in deep learning algorithms [22], several studies have proposed deep learning-based recommendation systems [23]. In [23], a multi-stack recurrent neural network (RNN) architecture is used to develop a recommendation system to suggest businesses in Yelp based on their reviews. Wu et al. [24] used an RNN with long-short term memories (LSTM) to predict future behavioral trajectories. A few studies have proposed exercise recommendation systems [25]. Sami et al. [25] used several independent variables to recommend various sports such as swimming using collaborative approaches. Ni et al. [26] developed an LSTM-based model called FitRec for estimating a user’s heart rate profile over candidate activities and then predicting activities on that basis. The model was tested against 250 thousand workout records with associated sensor measurements including heart rate.
In the health care domain, Yoon et al. [27] developed a recommendation system for a personalized clinical decision making. The system used electronic health records of different patients and their clinical decisions to recommend clinical decisions for new patients. In a recent work [28], support vector machines (SVMs), random forest, and logistic regression were used to recommend skin-health products based on genetic phenotypes of consumers. In a similar study [29], user contextual features and daily trajectories of steps over time were used to develop a recommendation system for planning an hour-by-hour activity. The model classifies users to subgroups and recommend activities based on the history of similar users. The proposed method doesn’t use any time series modeling, e.g., recurrent neural networks, to learn patterns, thus lacking the ability to generalize to more users.
In a related field, several works have been devoted to the cold-start problem in recommendation systems [30], [31]. The cold-start problem refers to the new users whose historical data is not available to the recommendation system. Thus, the recommendation system is not able to accurately recommend items, e.g., music, movies, etc., to the new users. Meta-learning approaches try to learn a global model from all users to initialize the recommendation systems for new users [30]. The shortcoming of these approaches is that they are not personalized in the beginning. The second approach is zero-shot, one-shot, or transfer learning methods [31], [32]. These approaches transfer a global model learned from other users’ historic data to new users. These approaches have great performance in classifiers, but they still have shortcomings as recommendation systems dealing with sequences of data. The proposed approach leverage experts (human personal trainers) to actively learn personalized exercise programs for new users. While many people use trainers to get recommendation for their daily exercise activities, the proposed approach leverages the expert knowledge to reach a broader group of users at a lower cost because the expert does not need to be continuously involved in recommending new exercises, just in the beginning when the system is uncertain about new users.
II. Mhealth Data
The data we use comes from the Konrad et al. [11] mHealth experiment with DStress. It was developed to provide coaching on exercise and meditation goals for adults seeking to reduce stress. The purpose of the experiment was to test the efficacy of an adaptive daily exercise recommender (DStress-adaptive) against two alternative exercises programs in which the daily exercises changed according to fixed schedules (Easy-fixed and Difficult-fixed). The DStress-adpative recommender was a hand engineered finite state machine. The transition rules are described in more detail in Konrad et al. [11], but they implement a policy whereby, if a person successfully completes all three exercises assigned for a day, they advance to the next higher level of exercise difficulty. If they do not succeed at exercises or meditation activities, then they are regressed to exercises or meditation activities at an easier level of difficulty. The 44 exercises used in DStree and their difficulty ratings were obtained from three certified personal trainers (e.g., Wall Pushups, Standing Knee Lifts, Squats, and Burpees, etc.). The experiment took place over a 28-day period. In a given week, users encountered three kinds of days: Exercise Days (occurring on Mondays, Wednesdays, Fridays), Meditation Days (Tuesdays, Thursdays, Saturdays), and Rest Days (Sundays).
72 adult participants (19–59 yr) were randomly assigned to three conditions with different 28-day goal progressions: (1) a DStress-adaptive condition using the adaptive coaching system in which goal difficulties adjusted to the user based on past performance, (2) an Easy-fixed condition in which the difficulty of daily goals increased at the same slow rate for all participants assigned to that condition, and (3) a Difficult-fixed condition in which the goal difficulties increased at a greater rate. Konrad et al. [11] found that the adaptive DStress-adaptive condition produced significant reductions in self-reported stress levels compared to the Easy-fixed and Difficult-fixed goal schedules. The DStress-adaptive condition also produced superior rates of performing assigned daily exercise goals.
User Profile:
A variety of pretest survey data were collected in the Konrad et al. [11] study that provides our user data. These included the (1) Perceived Stress Scale (PSS), which is a 10-item psychometric scale assessing perceived stress over the past month, (2) Depression, Anxiety, Stress Scale (DASS), a 21 item assessment of depression, anxiety, and stress, (3) the Cohen-Hoberman Inventory of Physical Symptoms (CHIPS): a 33-item scale measuring concerning physical symptoms over the past 2 week, (4) BMI, the Body Mass Index, and (5) Goldin Leisure-Time Exercise Questionnaire (GLTEQ), a 4-item scale measuring frequency of physical activity during leisure time, and (6) the Exercise Self-Efficacy Scale (EXSE), and 8-item assessment of self-efficacy about exercising in next 1–8 weeks.
The Perceived Stress Scale (PSS) is the most widely used instrument for measuring the perception of street [33], [34]. The Depression Anxiety Stress Scale [35] is a valid, reliable instrument measuring depression, anxiety, and stress [36]. The Cophen-Hoberman Inventory of Phsyical Symptoms (CHIPS) measures concerns about physical symptoms over the past 2 weeks was included because stress is often manifested in such symptoms [37]. The Godin Leisure-Time Exercise Questionnaire (GLTEQ; 4 item test) was included to assess pre-experimental activity levels [38]. The Exercise Self-efficacy Scale (EXSE) is an 8-item test assessing individuals’ beliefs in the ability to exercise [39].
Exercise Profile:
The original Konrad et al. study [11] obtained difficulty ratings of the exercises from three subject matter experts (SMEs; personal trainers) that were predictive of the probability of performing the exercises [40]. We augmented these data with exercise classification, attributes, and relations obtained from a 60 minute structured interview with an SME (fitness coach) that was followed up with specific clarification questions. The structured interview consisted of a card-sorting task and an exercise program planning task.
For the card-sorting task, exercise names and descriptions were placed on 3×5 cards. The cards were shuffled and the SME was asked to go through the cards to familiarize herself with the exercises. The SME was asked to sort the exercises into piles by whatever criteria “seemed natural.” The SME was asked to label those piles. These original piles were grouped into super-categories and labeled. Then the original piles were sorted into subcategories and labeled recursively until no further subgroups made sense to the SME. The SME was then asked if there was a possible “alternative grouping” of the exercises. The SME was also asked to rate the difficulty of each exercise. This card sorting produced an initial hierarchical classification of the exercises into a top level of resistance exercises and metabolic conditioning exercises. Within those supercategories there were subcategories for push, pull, squats, lunges, single leg stance, and core exercises. Further subcategories consisted of back, chest, legs. legs/glutes, core/abs, and abs/glute exercises. The alternative grouping consisted of full body, compound, and power categories.
III. Proposed Recommendation System
The goal of this paper is to recommend the next exercise for a given participants based on the history of exercises the participant completed. Let Xi(0), Xi(1), . . ., Xi(T) represent the exercise history for the ith participant, where is the one-hot encoding of the exercise and N is the total number of exercises (N = 44 in mHealth dataset). Let and represent the ith participant’s profile and the jth exercise’s profile, respectively. The recommender gets Xi(t − ω + 1), . . ., Xi(t − 1) as the input in addition to the ith user’s profile and the exercises’ profiles and predicts Xi(t) to recommend to the user. The length of the window, ω, is determined by the developer. In this paper, we use autocorrelation function (ACF) of X to determine the appropriate window length, similar to the statistical time series analysis methods [41].
A. Network Architecture
The proposed network consists of five modules: encoder, decoder, recurrent neural network (RNN), user attention, exercise temporal attention. The hyper-parameters of this architecture are selected empirically. Fig. 2 shows the architecture and modules of the proposed deep recurrent neural network.
Fig. 2.
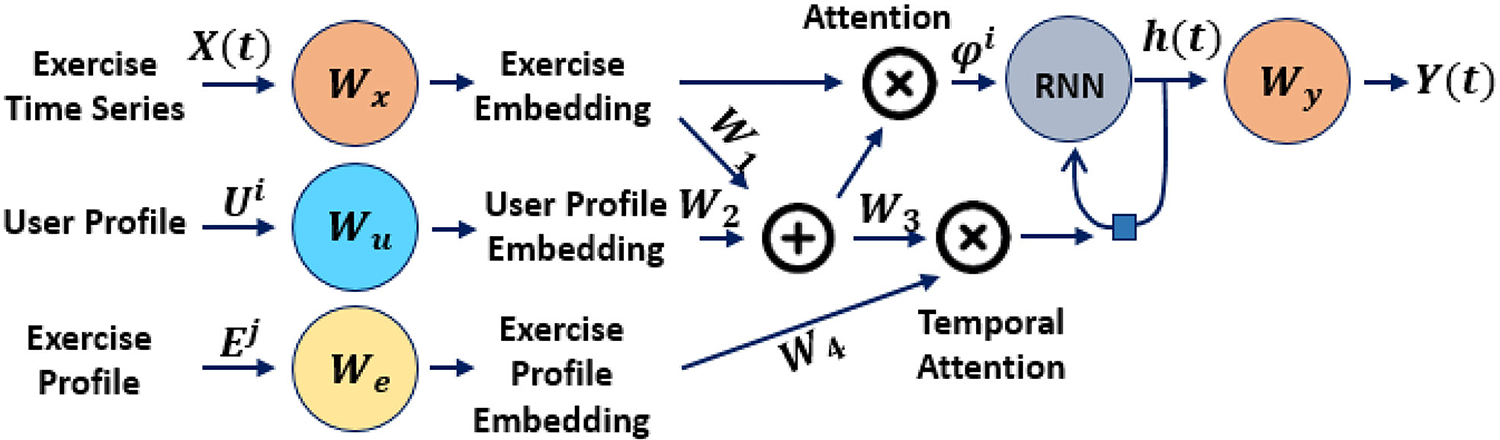
The architecture and modules of the proposed deep recurrent neural network. The recommendation system uses users and exercise profiles as attention mechanism. The attention mechanism will highlight the most relevant characters tics of the exercises to each user.
Exercise input:
The encoder is a fully connected (FC) linear layer that embeds the N-dimensional exercise names onto a KX-dimensional vector space:
| (1) |
where is the exercise name’s embedding at time t for the ith participant, is a trainable weight matrix learned from the training data, and ReLU is the activation function.
User Profile input:
The profile of the ith user is provided as a Nu-dimensional vector. The user profile is embedded onto a Ku-dimensional vector space:
| (2) |
where is the embedding of the ith user’s profile, and .
Users’ profiles, e.g., demographic information, provide valuable information about paying attention to specific aspects and features of exercises. For example, age and gender are two important variables that can significantly affect the types of exercises users will likely to perform. The attention mechanism will highlights the features of the exercise (extracted by neural network) that are more relevant to the current user based on their demographic information. Thus, we combine the exercise name embedding and the user profile embedding using:
| (3) |
where and are trainable mapping matrices, is the combination vector of the exercise and the user profiles which provides the attention probability for each entity of the input exercise. The final vector is the element-wise multiplication of the exercise name embedding and the attention probability: . The exercise name embedding is a vector in a Kx-dimensional space, and multiplying it with the attention probability pu(t) rotates this vector in the Kx-dimensional space.
Exercise Profile input and temporal attention mechanism:
Similarly, the profile of the jth exercises is provided with a Ne-dimensional vector and embedded using a linear layer:
| (4) |
where is the embedding of the jth exercise, and is the trainable matrix. Note that we use (t) in front of the exercise profile similar to the exercise names X(t) to represent the time information.
At each time step, the user performs an exercise that has a huge impact on the future exercises the user has desire to complete. For example, an user who is doing exercises focused on upper body may want to continue upper-body exercises for a day and then focus on the lower-body exercises on another day. In another example, the difficulty of the current exercise affects the difficulty level of the short-term future exercises. To incorporate this information into the recommendation system, we use the exercise profiles as an attention mechanism to give weights to different exercises at different time steps. The temporal attention mechanism assigns probability values to different time steps within the ω-length window. The exercise embeddings are combined with ψi(t):
| (5) |
where and are trainable mapping matrices, is the combination vector of the user-attention exercise and exercise profiles giving the attention probability for each time step. The final time series of vectors with length ω used as the input to the RNN module is: ϕi(t − k) = pe(k) × ψi(t − k) for k = {1, 2, . . ., ω}.
RNN:
The RNN module is responsible for learning the sequential pattern of the exercise history. Although there are different variants of RNN modules with long short-term memory (LSTM) and gated recurrent units (GRU), we will use regular RNN modules. The reason is that LSTMs and GRUs have built-in units to learn the dependencies of time series over time and accentuate or de-emphasize relevant information at different time steps. In this paper, we will use temporal attention mechanism that will take into account the importance of different time steps. Moreover, our auto-correlation function (ACF) analysis of this dataset shows a short-term dependencies for exercise recommendation. However, in developing recommendation systems for datasets with long-term dependencies, we will replace regular RNNs with RNNs with LSTM or GRU units. The RNN module consists of one hidden layer with ReLU activation function:
| (6) |
where Wϕ and Wh are trainable weights and h(t) is the hiddent state at time t.
Exercise name prediction:
The decoder converts the predicted hidden state at time t into exercise names:
| (7) |
where Wy is a trainable matrix and is the multinomial distribution over N exercises.
Training:
The whole network is trained end-to-end with the cross entropy loss function:
| (8) |
All modules are analytically differential. Thus, the gradient can back-propagate through decoder, recurrent layers through time, and user and temporal attention modules. Adam optimizer is used for training the network [42].
B. New User Initialization
The recommendation system is trained with a set of training data collected from different users. The system is general and not personalized for new users. To personalized the recommender, we fine tune our network with the training dataset of the users whose profiles are very similar to the new user. To achieve this goal, we calculate the similarity between Ui and the existing users by Euclidean distance, for i ≠ j, to find the most similar users. Then, users are sorted from the most similar to the least similar, and the k most similar users are selected. Afterwards, the recommender system is fine-tuned with the training data of the selected users, small learning rate, and one epoch.
IV. Active Learning
Active learning is used to ask experts for providing annotation for unlabeled samples [43], [44]. However, it is impossible to ask experts for annotating a large set of unlabeled samples. The active learner is usually presented with a limited budget to ask experts for annotation. The active learner selects the most informative samples based on the uncertainty that a trained classifier has about these samples. Two most common methods of measuring the uncertainty are entropy and marginal distance [45]–[47].
In this paper, we use active learning to personalize the recommender for each user. The recommender is trained on a set of training data from different people. Thus, the recommender is not tailored for new users. The profile of the users will provide the attention mechanism in the feature space, but not enough to personalize the recommender. When we get a new user, the recommender will be used. However, when the recommender is uncertain about the next recommended exercise, the recommender will ask the expert to intervene and provide the next recommendation. We will use the marginal distance and entropy of the series of recommendation as criteria to decide when to ask the expert. However, the existing work has set an arbitrary threshold on the marginal distance. In this paper, we derive the probability distribution function of the marginal distance.
A. Marginal Distance Random Variable
The output of the classifier (the last layer of the recommender) is a vector of N random variables, Y = [y1, y2, . . ., yN]T, with a Multinomial distribution. Ideally, one of the yis is one and the rest are zeros. However, N random variables represent the probability of the input sample belonging to each of these classes. Let p = [p1, p2, . . ., N ]T represent the probability values. pi has a Beta distribution and the vector p is drawn from a Dirichlet distribution [48]. Thus, these N random variables are sorted in ascending order y(1) ≤ y(2) ≤ … ≤ y(N) and the marginal distance is defined as Z = y(N) − y(N−1). The distribution of the marginal distance is (see Appendix A for proof):
| (9) |
The Monte Carlo method will be used to approximate this distribution.
B. Active Learning Procedure
The key component in active learning is to determine when to ask the expert for feedback. The recommender system needs to ask for the expert opinion when the input sample is out of the distribution of the training dataset. Let represents the distribution of the training dataset. We use to derive the probability distribution function as the marginal distance as defined in § IV-A. Let represent this distribution, and zi(t) represent the marginal distance for the ith user at time t. Then, our hypothesis is:
The α-level hypothesis testing determines whether the recommended exercise should be given to the user or ask the expert for the right exercise recommendation (feedback or label).Then, the trained recommender is fine-tuned with the feedback from the expert for personalization.
V. Experimental Results
In this section, the proposed approach with different components are evaluated on the offline mHealth dataset. The proposed architecture is also evaluated on the MovieLens100 K dataset [49].
A. mHealth
This section is devoted to the evaluation of the proposed exercises recommendation system on an exercises activity dataset. The dataset was described comprehensively in Section II.
1). Data Augmentation:
The challenge with recommendation systems is not having enough training data. One way to increase the amount of training data is to use data augmentation [50], [51]. While data augmentation in computer vision is straightforward and can be achieved by adding noise or cropping images randomly, it requires careful attention for sequential and symbolic data, e.g., language [50]. The random creation of sequential data has negative effect as it introduces noise to the data that does not follow the sequential pattern in the real data.
For exercise activities, there are two ways to augment the sequential data: asking the human expert or using association mining on the training data. In the first approach, an exercise expert was asked to categorize different exercises available for participants. Then, the augmentation algorithm goes over the sequence of exercises for each participant in the training data, chooses 10% of exercises and replace them with similar exercises in the same category.
In the second approach, we propose to use association rule mining [52] to extract rules from frequent itemsets. Then, the augmentation algorithms go over the sequence of exercises of each participant, choose 10% of exercises and replace them with their similar exercises based on these rules.
2). Experiment Setup and Discussion:
In order to find the appropriate length of window for the RNN model, we looked at the autocorrelation function of the exercise sequence. The autocorrelation function shows the degree of the dependencies of time series data and is often used to select the order of the time series analysis methods. Our ACF analysis shows that the length of the sequence for the RNN model should be w = 3. Processing the data with w = 3 results in 2343 sequence of training samples. The architecture of the proposed recommendation system is selected empirically as follows: KX = 20, Ku = 15, Ke = 3, and K = 10.
Baseline:
We use the proposed RNN model with the user profile attention mechanism and the exercise profile temporal attention mechanism (described in § III-A) as our baseline method. The model is trained with Cross-entropy loss function and Adam optimizer [42] for 30 epochs. We use k-fold approach for evaluating the performance of the recommender. In our k-fold setup, we kept one participant out of the training dataset and used the remaining 71 participants data for the training. Then, the left-out participant is treated as a new participant and the trained recommender is used to recommend exercises to the new participant. The actual data from the left-out participant is used as the groundtruth to calculate the accuracy of the recommendation system. We calculate the top-1, top-5, and top-10 accuracy for evaluating the recommendation system. The experiment is repeated 5 times and the average of the top-k accuracy are reported in Table I. In the first experiment, we only use the demographic information of users in the attention mechanism of the proposed recommendation system. Table I row 1 shows the accuracy. In the second, experiment, we used all information extracted from questionnaires in addition to their demographic information for the attention mechanism, and observed a slight decline in the accuracy (Table I row 2). We hypothesize that most people don’t have an accurate evaluation of their own ability. Thus, the answers to the questionnaires may not accurately represent their profiles, leading to a conflict to what exercises they performed and what they answered. For example, two persons may give exact similar answers to the questions (possibly not accurate answers), but have different ability and interest to perform exercises. In the rest of this paper, we only use demographic information to represent the user’s profile.
TABLE I.
Accuracy of the Recommendation System
| Method | top-1 Accuracy | top-5 Accuracy | top-10 Accuracy |
|---|---|---|---|
| 1. Baseline (Demographic) | 63.78% | 92.19% | 97.33% |
| 2. Baseline (Full Profile) | 61.16% | 90.76% | 96.98% |
| 3. Baseline + Data Augmentation (Expert) | 72.53% | 95.53% | 98.56% |
| 4. Baseline + Data Augmentation (Rule based) | 69.74% | 95.28% | 98.68% |
| 5. Baseline (Demographic) + Active Learning | 74.45% | 95.29% | 98.48% |
| 6. Baseline (Demographic) + New user Init | 65.91% | 93.14% | 97.65% |
| 7. Baseline + Data Augmentation (Expert) + Active Learning | 80.12% | 97.23% | 99.26% |
| 8. Baseline + Data Augmentation (Expert) + New user Init | 71.90% | 95.27% | 98.42% |
| 9. Baseline + Data Augmentation (Expert) + New user Init + Active Learning | 80.08% | 97.00% | 99.11% |
We compared the baseline model with user demographic information with a slightly different network architecture to study the affect of the architecture. In the new architecture, we reduced the dimension of the RNN module to half, and also we reduce the dimension of the output module. The top-1, top-5, and top-10 accuracy are 60.87%, 90.55%, and 94.71%. Compared to the row 1 of Table I, the alternative architecture has a worse performance. The original structure proposed in Section III-A has the best performance for the mHealth data and is selected empirically.
Baseline with Data Augmentation:
The training dataset was augmented with two approaches described in § V-A1. The training and augmented data were used to train the baseline model and evaluated as described in the baseline section. Table I row 3 shows the accuracy results of the baseline model trained with the training data and the expert augmented data. The data augmentation generalizes the model and improves the accuracy compared to the baseline (Table I row 1).
On the other hand, we see a decline in the accuracy of the baseline model when it is trained on the training dataset and the augmented data by association rule mining algorithms (Table I row 4). This observation points to the importance of having the expert in the loop for exercise recommendation systems. Because in this experiment the augmented dataset with expert knowledge gives higher accuracy, we use this method for other experiments in this paper.
Baseline with Active Learning:
The training data was used to estimate the parameters of the Dirichlet distributions: . The marginal distribution is calculated numerically, and the α = 0.01-level hypothesis testing results in:
where P(zi(t) ≥ 0.18) > 1 − α. During the test, if zi(t) falls bellow 0.18, then the recommender asks the expert for the feedback and fine-tunes the network with the feedback. Because we are evaluating the proposed model on a dataset collected in the past, we cannot ask for the expert for feedback in our evaluation. Therefore, whenever zi(t) falls bellow 0.18, we take the actual exercise the test participant performed at that time step and provide it as the feedback by an expert to our active learning algorithm (Table I row 5). Comparing the results with our baseline model, the top-1 accuracy is increased by 10%. The increased in accuracy is the results of fine-tuning the recommender system with the feedback received from the expert, which makes the recommendation system personalized.
Baseline with New User Initialization:
We calculated the pairwise similarity across all participants. For each new participant, we fine-tuned the recommendation system with the training data of the three most similar participants based on their profiles. The recommendation system is initialized for the new user by the fine-tuned network. We didn’t use data augmentation and active learning in this experiment just to examine the effect of new user initialization. We see a minor improvement in top-1 accuracy (Table I row 6). However, we believe that when it comes to more diverse participants, e.g., different age groups, race, ethnicity, the proposed initialization strategy improve the accuracy significantly.
Baseline with Data Augmentation and Active Learning:
In this experiment, we combined the data augmentation and active learning as we hypothesise that the accuracy will improve. Table I row 7 shows the results. As we expected, the accuracy has improved with respect to only active learning (Table I row 5) and only augmentation (Table I row 3).
Baseline with Data Augmentation, New User Initialization, and Active Learning:
In the last experiment, we combined all modules. Table I row 9 represents the results indicating a very minor decline in accuracy by adding the new user initialization procedure (compared to Table I row 7). More study with different questionnaires, medical records, etc. may lead to increase in the accuracy of the new user initialization method.
Comparison with the state-of-the-art:
The proposed model is evaluated against some of the well-known sequential recommendation systems [53]–[56] 1. Because the sequential models, including the proposed method, use the history of items for each users to propose the next item, they cannot be compared directly with matrix factorization approaches, e.g. SVD. The factorization approaches estimate the rating of different items without explicitly recommending the next item. However, the sequential models take into account the order of items in the history and recommend the next item without estimating the user’s rating.
To have a fair comparison, the baseline model with user demographic is used in this experiment. Table II shows the Top-k accuracy for different models. The proposed baseline model outperforms the existing state-of-the-art in top-1, top-5, top-10 accuracy. The best performance after the proposed baseline method in Table II belongs to the CNN method [55]. However, the performance of the CNN method is not as good as the proposed method. The superior performance of the proposed baseline model extends to the other variations of the proposed model, e.g. the baseline with active learning.
TABLE II.
Comparison of the Accuracy Across Different Recommendation Systems for the mHealth Data
| Method | top-1 Accuracy | top-5 Accuracy | top-10 Accuracy |
|---|---|---|---|
| GRU4REC | 7.89% | 22.74% | 40.04% |
| Pooling | 8.83% | 41.16% | 50.38% |
| CNN | 12.97% | 33.83% | 53.00% |
| Mixture | 5.45% | 20.48% | 40.41% |
| Baseline (Demographic) | 63.78% | 92.19% | 97.33% |
B. Movielens
In the second experiment, the proposed method is applied to the MovieLens100 K dataset [49] and compared with the state of the art sequential recommendation systems [53]–[56]. The dataset contains 100,000 user IDs, movie IDs, the user ratings of movies, and timestamps. We group the dataset by the user IDs and sorted them with their timestamps.
1). Experiment Setup and Discussion:
Our proposed recommendation system was developed specifically for recommending exercises, when the number of exercises is limited (unlike the number of movies). However, the proposed method is evaluated on the MovieLens dataset to show its strength in scaling to other applications. To this end, we pre-processed the dataset and limited the number of movies in this dataset to the 100 most watched movies in Movielens100 K. Thus, the new subset of MovieLens100 K is more comparable to the exercises activity dataset when the number of items are limited.
Similar to the mHealth dataset, we selected the window length of w = 3 resulted in 29931 sequence samples, and are split to 80% training and 20% test samples. The architecture of the proposed recommendation system is selected empirically as follows: KX = Ku = 1000, Ke = 3, and K = 300. Table III shows top-1, top-5, and top-10 accuracy of different recommendation systems. In recommending new movies in the subset of MovieLens100 K, the proposed method surpasses the accuracy of the state of the art methods. After the proposed method, the pooling method [54] comes second with accuracy less than the proposed baseline method.
TABLE III.
Comparison of the Accuracy Across Different Recommendation Systems for a Subset of MovieLens100 K
| Method | top-1 Accuracy | top-5 Accuracy | top-10 Accuracy |
|---|---|---|---|
| GRU4REC | 2.5% | 12.27% | 21.55% |
| Pooling | 3.93% | 18.91% | 39.66% |
| CNN | 2.26% | 10.91% | 20.23% |
| Mixture | 2.47% | 11.37% | 21.34% |
| Baseline (Demographic) | 5.90% | 26.38% | 46.32% |
VI. Conclusion
In this paper, a physical exercise recommendation system was developed. The main challenge in developing recommendation systems is to make them personalized, especially for new users when the training dataset does not exist. Analyzing the outcomes of the experimental results indicates the importance of user and exercise profiles as attention mechanisms.Thus, the developed system took advantage of the health and demographic questionnaires filled out by users before joining the program to use as attention mechanism.
In spite of all fine tuning and the attention mechanism, the experimental results show that the perfect personalization cannot be achieved. While constant feedback from the user interaction can be collected in e-commerce, music and movie recommendation systems, having an expert in the loop is inevitable in exercise recommendation systems because we don’t know whether the user performed the exercise or not (while in e-commerce the user either buys the product or listen completely to a music on a music platform). The expert knowledge provides information when the recommender is uncertain and fails to make accurate predictions, which is why a real time active learning mechanism in conjunction with our developed recommendation systems showed a significant increase in the accuracy of the system.
Acknowledgment
The authors would like to thank Dr. Choh Man Teng for assisting with the expert studies.
This work was supported by the National Institute on Aging of the National Institutes of Health under Grant R01AG053163.
Appendix A. Probability Distribution of The Marginal Distance
In marginal distance, the output variables are sorted in ascending order as y(1) ≤ y(2) ≤ … ≤ y(N). The marginal distance is defined as M = y(N) − y(N−1). When the value of the marginal distance falls below a given threshold θm, the recommender asks the human expert for labeling. While in prior works the threshold was determined by users, we define the probability distribution of the marginal distance. The output variable is drawn from a Dirichlet probability distribution function, . In the Dirichlet distribution, the amount of the variables sum up to one: . In the marginal distance, we are only interested in y(N) and y(N−1). To simplify the calculation, we define a new random variable . Note that the marginal distribution of y(ks are Beta distribution and the summation of several Beta distribution, y, is a Beta distribution. The joint distribution of Y = [y(N), y(N−1), y]T is a Dirichlet distribution, :
| (10) |
where 0 ≤ y(N),y(N−1),y < 1, and y(N) + y(N−1) + y = 1. The parameters α1, α2 and α3 are estimated from the training dataset using Maximum Likelihood approach [58], [59].
The probability distribution of the marginal distance is derived from transforming y(N) and y(N−1) based on Z = y(N) − y(N−1). Because the support of y(N),y(N−1),y is restricted to the hyper-plane defined by y(N) + y(N−1) + y = 1, the third argument, y, is known given y(N) and y(N−1). Fig. 3(a) shows the y(N) + y(N−1) + y = 1 hyper-plane. Because the support of y(N), y(N−1), y is restricted and the value of y depends on y(N) and y(N−1), we can just visualize the projection of the hyperplane on the y(N) − y(N−1) plane. This makes defining the boundaries of the integrals easier. Fig. 3(b) shows this projection with y(N) > y(N−1) and Z = y(N) − y(N−1) lines. In the first step, we derive the cumulative probability distribution F(z) = P(Z ≤ z), as in (11), shown at the top of next page. Then, to get the probability distribution function, we take the derivatives from both sides with respect to z to obtain (12), shown at the top of next page. Thus, we get the probability distribution function the marginal distance as in (13), shown at the top of next page. We calculate f(z) numerically by approximating the integral with a summation for different value of z, even though calculation of the closed form is not impossible.
| (11) |
| (12) |
| (13) |
Fig. 3.
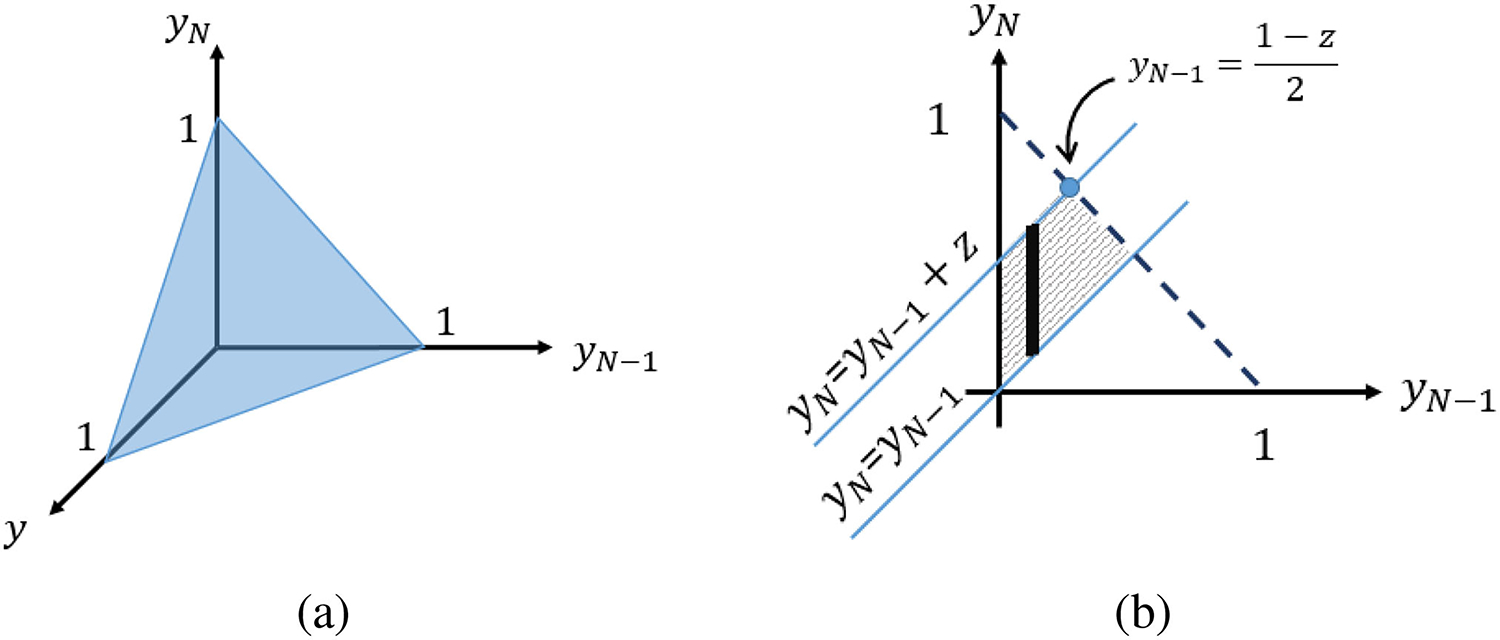
(a) The valid surface of y(N),y(N−1), y variables with the Dirichlet distribution. (b) The integral area projected on y(N) − y(N−1) plane.
Appendix B. Computational Cost
In this section, the computational cost of different modules are calculated. The computational cost of the exercise input module is because N > Kx. The computational cost of the User Profile input module is , and that of the Exercise Profile input is . The computational cost of the RNN module is . K is smaller than N but not a lot smaller. So the overall computational cost is dominated by the RNN module. Thus, the overal computational cost is .
Footnotes
The code repository: https://github.com/arashmahyari/ExerRecomActiveLearn
Implemented in [57].
Contributor Information
Arash Mahyari, Research Scientist, Florida Institute for Human and Machine Cognition (IHMC), Pensacola, FL 32502 USA.
Peter Pirolli, Research Scientist, Florida Institute for Human and Machine Cognition (IHMC), Pensacola, FL 32502 USA.
Jacqueline A. LeBlanc, Certified Health and Fitness Coach and Independent Consultant, USA
References
- [1].Riley WT, Nilsen WJ, Manolio TA, Masys DR, and Lauer M, “News from the NIH: Potential contributions of the behavioral and social sciences to the precision medicine initiative,” Transl. Behav. Med, vol. 5, no. 3, pp. 243–246, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Thorpe KE, “The future costs of obesity: National and state estimates of the impact of obesity on direct health care expenses,” A collaborative report from United Health Foundation, the American Public Health Association and Partnership for Prevention, 2009. [Google Scholar]
- [3].“Noom,” 2021. [Online]. Available: www.noom.com
- [4].Pirolli P, Youngblood GM, Du H, Konrad A, Nelson L, and Springer A, “Scaffolding the mastery of healthy behaviors with fittle systems: Evidence-based interventions and theory,” Hum.- Comput. Interact, vol. 36, no. 2, pp. 73–106, 2018. [Google Scholar]
- [5].Michie S, West R, Campbell R, Brown J, and Gainforth H, “ABC of behavior change theories: An essential resource for researchers,” in Policy Makers and Practitioners. vol. 402. Sutton, U.K.: Silverback Publishing, 2014. [Google Scholar]
- [6].Linden G, Smith B, and York J, “Amazon.com recommendations: Item-to-item collaborative filtering,” IEEE Internet Comput, vol. 7, no. 1, pp. 76–80, Jan./Feb. 2003. [Google Scholar]
- [7].Bodapati AV, “Recommendation systems with purchase data,” J. Marketing Res, vol. 45, no. 1, pp. 77–93, 2008. [Google Scholar]
- [8].Bennett J et al. , “The Netflix prize,” in Proc. KDD Cup Workshop, New York, NY, USA, vol. 2007, 2007, Art. no. 35. [Google Scholar]
- [9].Song Y, Dixon S, and Pearce M, “A survey of music recommendation systems and future perspectives,” in Proc. 9th Int. Symp. Comput. Music Model. Retrieval, vol. 4, 2012, pp. 395–410. [Google Scholar]
- [10].Mahyari A and Peter P “Physical exercise recommendation and success prediction using interconnected recurrent neural networks,” in Proc. IEEE Int. Conf. Digit. Health (ICDH), 2021, pp. 148–153. [Google Scholar]
- [11].Konrad A et al. , “Finding the adaptive sweet spot: Balancing compliance and achievement in automated stress reduction,” in Proc. 33rd Annu. ACM Conf. Hum. Factors Comput. Syst., 2015, pp. 3829–3838. [Google Scholar]
- [12].Bharadhwaj H, “Meta-learning for user cold-start recommendation,” in Proc. Int. Joint Conf. Neural Netw., 2019, pp. 1–8. [Google Scholar]
- [13].Dunsmuir DT et al. , “Development of mHealth applications for pre-eclampsia triage,” IEEE J. Biomed. Health Informat, vol. 18, no. 6, pp. 1857–1864, Nov. 2014. [DOI] [PubMed] [Google Scholar]
- [14].Seepers RM, Strydis C, Sourdis I, and De Zeeuw CI, “Enhancing heart-beat-based security for mHealth applications,” IEEE J. Biomed. Health Informat, vol. 21, no. 1, pp. 254–262, Jan. 2017. [DOI] [PubMed] [Google Scholar]
- [15].Schiza EC, Kyprianou TC, Petkov N, and Schizas CN, “Proposal for an eHealth based ecosystem serving national healthcare,” IEEE J. Biomed. Health Informat, vol. 23, no. 3, pp. 1346–1357, May 2019. [DOI] [PubMed] [Google Scholar]
- [16].Huang A et al. , “WE-CARE: An intelligent mobile telecardiology system to enable mHealth applications,” IEEE J. Biomed. Health Informat, vol. 18, no. 2, pp. 693–702, Mar. 2014. [DOI] [PubMed] [Google Scholar]
- [17].Wuttidittachotti P, Robmeechai S, and Daengsi T, “mHealth: A design of an exercise recommendation system for the android operating system,” Walailak J. Sci. Technol, vol. 12, no. 1, pp. 63–82, 2015. [Google Scholar]
- [18].Reddy S, Nalluri S, Kunisetti S, Ashok S, and Venkatesh B, “Content-based movie recommendation system using genre correlation,” in Smart Intelligent Computing and Applications. Berlin, Germany: Springer, 2019, pp. 391–397. [Google Scholar]
- [19].Khoali M, Tali A, and Laaziz Y, “Advanced recommendation systems through deep learning,” in Proc. 3rd Int. Conf. Netw., Inf. Syst. Secur., 2020, pp. 1–8. [Google Scholar]
- [20].Panagiotakis C, Papadakis H, Papagrigoriou A, and Fragopoulou P, “Improving recommender systems via a dual training error based correction approach,” Expert Syst. Appl, vol. 183, 2021, Art. no. 115386. [Google Scholar]
- [21].Fessahaye F et al. , “T-RECSYS: A novel music recommendation system using deep learning,” in Proc. IEEE Int. Conf. Consum. Electron., 2019, pp. 1–6. [Google Scholar]
- [22].Ravì D et al. , “Deep learning for health informatics,” IEEE J. Biomed. Health Informat, vol. 21, no. 1, pp. 4–21, Jan. 2017. [DOI] [PubMed] [Google Scholar]
- [23].Liu DZ and Singh G, “A recurrent neural network based recommendation system,” Tech. Rep., Stanford Univ., Stanford, CA, USA, 2016. [Online]. Available: https://cs224d.stanford.edu/reports/LiuSingh.pdf [Google Scholar]
- [24].Wu C-Y, Ahmed A, Beutel A, Smola AJ, and Jing H, “Recurrent recommender networks,” in Proc. 10th ACM Int. Conf. Web Search Data Mining, 2017, pp. 495–503. [Google Scholar]
- [25].Sami A, Nagatomi R, Terabe M, and Hashimoto K, “Design of physical activity recommendation system,” in Proc. Eur. Conf. Data Mining, 2008, pp. 148–152. [Google Scholar]
- [26].Ni J, Muhlstein L, and McAuley J, “Modeling heart rate and activity data for personalized fitness recommendation,” in Proc. World Wide Web Conf., 2019, pp. 1343–1353. [Google Scholar]
- [27].Yoon J, Davtyan C, and van der Schaar M, “Discovery and clinical decision support for personalized healthcare,” IEEE J. Biomed. Health Informat, vol. 21, no. 4, pp. 1133–1145, Jul. 2017. [DOI] [PubMed] [Google Scholar]
- [28].Liu X, Chen C-H, Karvela M, and Toumazou C, “A DNA-based intelligent expert system for personalised skin-health recommendations,” IEEE J. Biomed. Health Informat, vol. 24, no. 11, pp. 3276–3284, Nov. 2020. [DOI] [PubMed] [Google Scholar]
- [29].Li Z et al. , “An adaptive, data-driven personalized advisor for increasing physical activity,” IEEE J. Biomed. Health Informat, vol. 23, no. 3, pp. 999–1010, May 2019. [DOI] [PubMed] [Google Scholar]
- [30].Lee H, Im J, Jang S, Cho H, and Chung S, “MELU: Meta-learned user preference estimator for cold-start recommendation,” in Proc. 25th ACM SIGKDD Int. Conf. Knowl. Discov. Data Mining, 2019, pp. 1073–1082. [Google Scholar]
- [31].Li J, Jing M, Lu K, Zhu L, Yang Y, and Huang Z, “From zero-shot learning to cold-start recommendation,” in Proc. AAAI Conf. Artif. Intell, 2019, vol. 33, pp. 4189–4196. [Google Scholar]
- [32].Mahyari A and Locker T, “Robust predictive maintenance for robotics via unsupervised transfer learning,” in Proc. Int. FLAIRS Conf. Proc., 2021, vol. 34. [Online]. Available: 10.32473/flairs.v34i1.128451 [DOI] [Google Scholar]
- [33].Cohen S, Kamarck T, and Mermelstein R, “A global measure of perceived stress,” J. Health Social Behav, vol. 24, no. 4, pp. 385–396, 1983. [PubMed] [Google Scholar]
- [34].Cohen S and Williamson GM, “Perceived stress in a probability sample of the United States,” in The Social Psychology of Health, Spacapan S and Oskamp S Eds., Newbury Park, CA, USA: Sage Publications, 1988, pp. 31–67. [Online]. Available: https://psycnet.apa.org/record/1988-98838-002 [Google Scholar]
- [35].Coker A, Coker O, and Sanni D, “Psychometric properties of the 21-item depression anxiety stress scale (DASS-21),” Afr. Res. Rev, vol. 12, no. 2, pp. 135–142, 2018. [Google Scholar]
- [36].Antony MM, Bieling PJ, Cox BJ, Enns MW, and Swinson RP, “Psychometric properties of the 42-item and 21-item versions of the depression anxiety stress scales in clinical groups and a community sample,” Psychol. Assessment, vol. 10, no. 2, 1998, Art. no. 176. [Google Scholar]
- [37].McFarlane AC, Atchison M, Rafalowicz E, and Papay P, “Physical symptoms in post-traumatic stress disorder,” J. Psychosomatic Res, vol. 38, no. 7, pp. 715–726, 1994. [DOI] [PubMed] [Google Scholar]
- [38].Godin G, “The Godin-Shephard leisure-time physical activity questionnaire,” Health Fitness J. Canada, vol. 4, no. 1, pp. 18–22, 2011. [Google Scholar]
- [39].McAuley E, “Self-efficacy and the maintenance of exercise participation in older adults,” J. Behav. Med, vol. 16, no. 1, pp. 103–113, 1993. [DOI] [PubMed] [Google Scholar]
- [40].Pirolli P, “A computational cognitive model of self-efficacy and daily adherence in mHealth,” Transl. Behav. Med, vol. 6, no. 4, pp. 496–508, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Hamilton JD, Time Series Analysis. Princeton, NJ, USA: Princeton Univ. Press, 2020. [Google Scholar]
- [42].Kingma DP and Ba J, “Adam: A method for stochastic optimization,” 3rd Int. Conf. Learn. Representations ICLR, San Diego, CA, USA: May 2015, arXiv:1412.6980. [Google Scholar]
- [43].Aghdam HH, Gonzalez-Garcia A, Weijer J. V. d., and López AM, “Active learning for deep detection neural networks,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 3672–3680. [Google Scholar]
- [44].Zhang B, Li L, Yang S, Wang S, Zha Z-J, and Huang Q, “State-relabeling adversarial active learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 8756–8765. [Google Scholar]
- [45].Wang K, Zhang D, Li Y, Zhang R, and Lin L, “Cost-effective active learning for deep image classification,” IEEE Trans. Circuits Syst. Video Technol, vol. 27, no. 12, pp. 2591–2600, Dec. 2017. [Google Scholar]
- [46].Joshi AJ, Porikli F, and Papanikolopoulos N, “Multi-class active learning for image classification,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2009, pp. 2372–2379. [Google Scholar]
- [47].Gu S, Jiao Y, Tao H, and Hou C, “Recursive maximum margin active learning,” IEEE Access, vol. 7, pp. 59933–59943, 2019. [Google Scholar]
- [48].Forbes C, Evans M, Hastings N, and Peacock B, Statistical Distributions. vol. 4. Hoboken, NJ, USA: Wiley, 2011. [Google Scholar]
- [49].Harper FM and Konstan JA, “The movielens datasets: History and context,” ACM Trans. Interactive Intell. Syst, vol. 5, no. 4, pp. 1–19, 2015. [Google Scholar]
- [50].Yu S, Yang J, Liu D, Li R, Zhang Y, and Zhao S, “Hierarchical data augmentation and the application in text classification,” IEEE Access, vol. 7, pp. 185476–185485, 2019. [Google Scholar]
- [51].Kafle K, Yousefhussien M, and Kanan C, “Data augmentation for visual question answering,” in Proc. 10th Int. Conf. Natural Lang. Gener., 2017, pp. 198–202. [Google Scholar]
- [52].Tan P-N, Steinbach M, and Kumar V, Introduction to Data Mining. Noida, India: Pearson Education India, 2016. [Google Scholar]
- [53].Hidasi B, Karatzoglou A, Baltrunas L, and Tikk D, “Session-based recommendations with recurrent neural networks,” Proc. 27th ACM Int. Conf. Inf. Knowl. Manage., pp. 843–852, 2018. [Google Scholar]
- [54].Covington P, Adams J, and Sargin E, “Deep neural networks for youtube recommendations,” in Proc. 10th ACM Conf. Recommender Syst., 2016, pp. 191–198. [Google Scholar]
- [55].Kalchbrenner N, Espeholt L, Simonyan K, Oord A. v. d., Graves A, and Kavukcuoglu K, “Neural machine translation in linear time,” 2016, arXiv:1610.10099. [Google Scholar]
- [56].Kula M, “Mixture-of-tastes models for representing users with diverse interests,” 2017, arXiv:1711.08379. [Google Scholar]
- [57].Kula M, “Spotlight,” 2017. [Online]. Available: https://github.com/maciejkula/spotlight
- [58].Minka T, “Estimating a Dirichlet distribution,” Massachusetts Institute of Technology, 2000. [Google Scholar]
- [59].Suh E, “Dirichlet python package,” 2021. [Online]. Available: https://github.com/ericsuh/dirichlet