

Abstract
Introduction:
Falls are a leading cause of unintentional injury in the elderly. Electronic health records (EHRs) offer the unique opportunity to develop models that can identify fall events. However, identifying fall events in clinical notes requires advanced natural language processing (NLP) to simultaneously address multiple issues because the word “fall” is a typical homonym.
Methods:
We implemented a context-aware language model, Bidirectional Encoder Representations from Transformers (BERT) to identify falls from the EHR text and further fused the BERT model into a hybrid architecture coupled with post-hoc heuristic rules to enhance the performance. The models were evaluated on real world EHR data and were compared to conventional rule-based and deep learning models (CNN and Bi-LSTM). To better understand the ability of each approach to identify falls, we further categorize fall-related concepts (i.e., risk of fall, prevention of fall, homonym) and performed detailed error analysis.
Results:
The hybrid model achieved the highest f1-score on sentence (0.971), document (0.985), and patient (0.954) level. At the sentence level (basic data unit in the model), the hybrid model had 0.954, 1.000, 0.988, and 0.999 in sensitivity, specificity, positive predictive value, and negative predictive value, respectively. The error analysis showed that that machine learning-based approaches demonstrated higher performance than a rule-based approach in challenging cases that required contextual understanding. The context-aware language model (BERT) slightly outperformed the word embedding approach trained on Bi-LSTM. No single model yielded the best performance for all fall-related semantic categories.
Conclusion:
A context-aware language model (BERT) was able to identify challenging fall events that requires context understanding in EHR free text. The hybrid model combined with post-hoc rules allowed a custom fix on the BERT outcomes and further improved the performance of fall detection.
Keywords: NLP, BERT, Fall, EHR
INTRODUCTION
Falls are a leading cause of unintentional injury, especially among older adults (1–3). Studies have estimated that between 30–40% of patients over the age of 65 will fall at least once, (4, 5) and that over 40–60% of falls lead to injuries, which include body injuries, fractures, and brain trauma (6). The estimated direct medical costs were $616.5 million and $30.3 billion for fatal and non-fatal fall injuries in 2012 (7). Identifying individuals at high risk for future falls can provide the opportunity to implement multifactorial interventions to reduce the risk of future falls (8). The rich data available in electronic health records (EHRs) offer the unique opportunity to develop models that can identify fall events and persons at risk of falling. However, the use of billing codes may underestimate true fall events. A study of patients treated by the Veteran’s Administration found that fall-related codes were assigned to about 74% of patients with falls documented in the medical record (9). Tremblay and colleagues have noted that the failure to identify falls with only billing codes may occur because billing codes are designed for reimbursement purposes, and may be applied inconsistently across clinical practices (10). In particular, billing codes may underestimate the frequency of less severe falls that do not require immediate medical attention, but that may be documented by health care providers during the course of other health care visits. To fully leverage the EHR data to accurately, clinical free text, such as clinical notes, are required identify fall events.
Identifying fall events in clinical notes requires natural language processing (NLP) to simultaneously address multiple issues because the word “fall” is a typical homonym. Word sense disambiguation is needed to identify the correct semantic meaning of a word given a particular context (11, 12). Specifically, there are various fall related synonyms and semantic variations in clinical notes. Based on the definition proposed by the American Nurses Association (ANA), a true fall in the context of EHRs is “an unplanned descent to the floor with or without injury”(13). Traditional symbolic approaches that use keywords (e.g., “falls”) and description patterns (e.g., regular expressions) can be overwhelmed by the variation of the context. For example, common expressions found in patient clinical notes include the following: 1) True fall: “patient fell yesterday at about 1 p.m.”; 2) False fall (did not happen): “almost falling at the end”; 3) Not a fall event (fall risk): “patient remains at fall risk due to right hemiplegia, right hip pain”; or 4) False fall (homonym): “TSH (thyroid-stimulating hormone) normal this fall”; “Skin falls apart”; “lives in Cannon Falls”; “symptoms worse in fall and winter”.
Recently, researchers have developed text mining methods to extract falls information from clinical free text in EHRs (10, 14, 15). Tremblay et al. used term frequency-based representation on a k-mean algorithm for cluster analysis and a logistic regression model for fall classification (10). Similarly, McCart leveraged a term frequency–inverse document frequency (tf-idf) based statistical machine learning approach to identify falls in ambulatory care settings (16). Toyabe combines statistical testing methods (chi-square or Fisher’s exact) with syntactic category rules to classify fall related incidental reports (17). However, these models lack the ability to understand context to discern the true meaning of falls. More recently, Santos et al attempted to compare classic machine learning methods with deep learning (i.e., word embedding and recurrent neural networks [RNN]) to detect fall in EHR documents (18). They reported deep learning models (best model: f1-score 0.90 in a document level) outperformed classical machine learning models. This work, however, has potentials to be enhanced by using context-aware language models that are necessary to fully leverage context to identify complex fall events in the EHR free text.
To address these gaps, we explored the ability of a contextual pre-trained language model, Bidirectional Encoder Representations from Transformers (BERT) to identify falls from the EHR text. BERT leveraged the bidirectional training of transformers from the large unlabeled corpus, resulting in a strong ability to capture complex dependencies and context (19). To further improve the performance, we fused the BERT model into a hybrid architecture coupled with post-hoc heuristic rules built under an open-source UIMA–based(20) information extraction framework (21). The models were evaluated on real world EHR data and were compared to conventional rule-based and deep learning models. To better understand the ability of each approach to identify falls, we further categorize fall-related concepts (i.e., risk of fall, prevention of fall, homonym) and performed detailed error analysis.
MATERIALS AND METHODS
Study Cohort
Our study population consisted of persons who were participants in the Mayo Clinic Biobank (22, 23), and who were ≥65 years at the time of consent to enroll (n=22,772). Among these participants, we randomly selected 302 persons for manual chart review to annotate fall events: 152 persons who had an ICD-9 or ICD-10 code for “accidental fall” after the enrollment in the Mayo Clinic Biobank and 150 persons without any of these codes. ICD-9 codes used for fall identification were as follows: E804, E833-E835, E843, E880-E888, E917.5-E917.8, E929.3, and E987. ICD-10 codes were: W00.0XXA-W18.49XS.
Annotation and Data Set
There were two phases involved in the annotation process: 1) training and annotation guideline development phase to become familiar with the annotation process and to refine annotation guidelines, and 2) production phase to create the gold standard for NLP algorithm development and evaluation (24).
During the training and guideline development phase, the annotation guidelines were developed by a geriatrician (ZX) and a palliative care physician (BT). We used the all-inclusive definition of falls proposed by the ANA National database for nursing quality indicators (13):“An unplanned descent to the floor (or extension of the floor, e.g., trash can or other equipment) with or without injury. All types of falls are included, whether they result from physiological reasons or environmental reasons.” Two subject matter experts (ZX and BT) manually reviewed an age-stratified sample of 30 persons with an ICD-9 or ICD-10 code for “fall” and determined the point of interests for annotation (Table 1). A true fall event should satisfy the following attributes: confirmed certainty, present status or follow-up visit, experiencer (patient), and exclusion (no).
Table 1.
Summary of fall concepts for annotation
| Concept | Examples | Attribute |
|---|---|---|
| Mention | fall/fell, tripped, slipped, slid | Certainty (negated, possible, hypothetical, confirmed) Status (present, follow-up visit, history) Experiencer (patient, other) Exclusion (yes, no) (e.g., fall asleep - exclusion: yes) |
| Indication | seizure, syncope/fainting, narcolepsy |
The full annotation task was performed by two trained abstractors (DMI, CMP). The matched cases were determined by comparing the bipartite set alignment for two annotated sentences using the Kuhn-Munkres algorithm (25). The final corpus yield a concept-level IAA of 0.72 in f1-score. A consensus meeting was organized to resolve disagreements and annotation issues. The gold standard dataset includes 302 patients (5,447 documents, 308,967 sentences). In our study, we randomly selected 242 patients (148 positives, 94 negatives) as a training set (4,357 documents [862 positives, 3495 negatives], 243,582 sentences [4,256 positives, 239,326 negatives]) and 60 patients (32 positives, 28 negatives) as a test set (1,090 documents [263 positives, 827 negatives], 65,385 sentences [1,073 positives, 64,312 negatives]).
Modeling
We examined multiple approaches (26) for fall detection: a rule-based, word embedding (i.e., fit embedding features to machine learning models), pre-trained language (BERT), and hybrid (heuristic rules and BERT) approach. These approaches use different architecture designs and training processes (Figure 1). A comprehensive evaluation and error analysis were conducted for each approach. We evaluated the results in a different level of granularity: a concept (sentence), document, and patient level of falls. Each model first identifies sentences that contain fall events and aggregates them to determine a document level and patient level fall event status based on presence or absence of sentence-level fall events. The details of each model are described in Figure 1.
Figure 1.
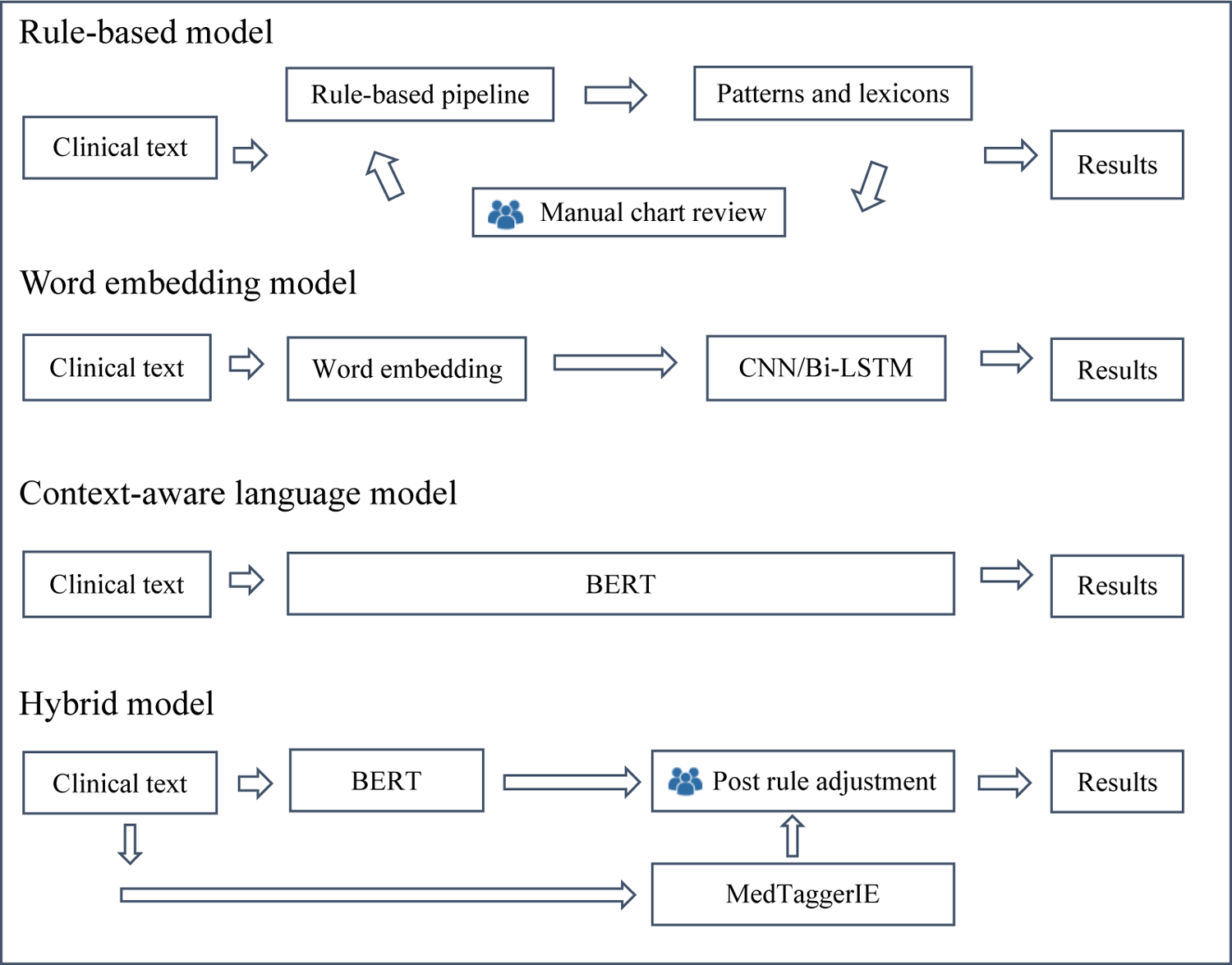
Approaches to detect falls using EHR text
Rule-based Model
A rule-based model uses a comprehensive set of rules and keyword-based features to identify pre-defined patterns in text. This method was adopted because of its advantage of simplicity, transparency and tractability. We used the open-source clinical NLP pipeline MedTaggerIE to handle clinical context and apply lexicon search. MedTaggerIE is a resource-driven open-source information extraction (IE) framework based on the Apache Unstructured Information Management Architecture (21), where the knowledge sources (i.e., keywords, rules) are separated from the generic NLP processes in order to increase algorithm portability and customizability. Three steps were involved in developing the rule-based model. First, we compiled the initial keywords and regex search patterns based on existing studies (14) and domain experts (ZX, BT). Second, the initial model was iteratively evaluated using the training data. False positive and negative cases were manually reviewed for rule refinement. This process was repeated on the training set after acceptable performance was reached (f1-score > 0.95). Lastly, the final algorithm was evaluated on the independent test set. The fall-related keywords were provided in Supplementary Appendix.
Word Embedding Model
A deep learning model paired with embedding representation is a common approach for extracting clinical concepts (27). We defined the task as a sequential sentence classification, and explored two well-established deep learning models: Convolutional neural network (CNN) and Bi-directional long short-term memory networks (Bi-LSTM). Both models used word vectors as input representation, where each word from the input sentence is represented as the k-dimensional word vector. The embedding model is based on the Global Vectors for Word Representation, an unsupervised learning algorithm proposed by Pennington et al (28). The pretrained data were based on Wikipedia and Gigaword. LSTM is a variant of recurrent neural network (RNN) with the ability to learn long-term dependencies. An LSTM cell contains a forget gate, an update date and an output gate. We used sigmoid functions to calculate the gate value and tanh function to calculate candidate value. To enhance the ability of capturing additional contextual information, we applied bi-directional forward and backward passing components to LSTM cells. Lastly, we used a fully connected linear layer for outputting a prediction.
Context-aware Language Model
A pretrained language representation model (BERT) was used because of its capability of context understanding and recent impact in various areas of research and state-of-the-art results (29). Each sentence is represented as a consecutive array of tokens. The first word of the sequence is labeled as the [CLS] token. The last layer of the [CLS] token is connected with a fully connected layer and a SoftMax layer for computing the sentence level classification. Minimal processing methods were applied including sentence segmentation and converting all text to lowercase. For computational efficiency, we used BERTbase, a pre-trained model with pre-trained sentences on 11,038 unpublished books and Wikipedia. The model contains 768 hidden layers and 12 self-attention heads. For the model fine-tuning, we set 218 as the maximum sequence length with a batch size of 32. We applied the early stopping technique to prevent overfitting. We also explored ClinicalBERT and other transformer variants such as XLNet, XLMs and Albert. These models, however, did not outperform BERT in this study.
Hybrid Model
A hybrid model leverages both a rule- and machine learning-based approach into one system and potentially offers some learning advantages and yields better performance. We adopted a post-hoc hybrid design that leverages rules to correct false BERT fall detection sentences. The hybrid model consists of a rule-based (MedTaggerIE), BERT and post rule adjustment module. As illustrated in Figure 1, the input sentence is processed independently by the BERT model and the rule-based model. Results of the models are reconciled by a summarization engine, where BERT results are overwritten by heuristic rules (Figure 1). These post-hoc rules are different from the rules in the pure rule-based model, which uses complex and comprehensive rules, but the rules in the hybrid model are rather complimentary focused on fixing the errors of the BERT model. For example, any generic fall expressions follow by the predefined positive trigger patterns such as “chief complaint”, “cause of wound”, or “landed on” reconcile the case as a true fall. Similarly, negative trigger patterns such as “risk” or “educated” will determine the case as negative event regardless of BERT’s output. These trigger patterns were determined based on the error cases in the training data. The implementation details for all models can be found in supplementary appendix.
Evaluation
All fall detection models were evaluated on a same independent test set at three levels (sentence, document, and patient level). Performance was assessed through sensitivity (recall), specificity, positive predictive value (PPV, precision), negative predictive value (NPV), and f1-score [2(precision × recall)/(precision + recall)] (30). The error analysis was performed by the same annotation team through manually reviewing incorrect cases from EHRs.
We also conducted comprehensive analyses of incorrect fall detection to understand each model’s behavior. The Oxford dictionary (31) was used to categorize different types of fall detection errors (Table 2). The cases with the highest number of misclassifications from all models were qualitatively analyzed.
Table 2.
Semantic categories of incorrect fall events
| Category of fall detection errors | Example |
|---|---|
| Negation (Neg) | Denies a fall event. |
| Historical fall (Hx) | Patient was injured after falling in the last year. |
| Fall prevention (Prv) | Patient required handhold assist to prevent falling. |
| Fall risk (Rsk) | Risk of falls with injuries. |
| Lack of context (L) | Fall. |
| Homonyms (Hmn) | |
| Pass into physical or mental condition (Cond) | Falls back to sleep easily. |
| Pass at a certain time (T) | Until the fall of 2010. |
| Become of a lower level (Low) | With falling blood pressure and mental status changes. |
| To come by chance (Chc) | Fall into the following categories. |
| To come by chance into a particular position (Pos) | To fall among. |
| To have its proper place (Plc) | It falls on the last syllable. |
RESULTS
Concordance between Fall Detection Models and Gold Standard
As shown in Table 3, the models produced f1-score of 0.877 to 0.971 at the sentence level (basic data unit in the models) in detecting fall events from clinical notes. Machine learning-based methods had the higher performance than a rule-based method except CNN. The hybrid model achieved the highest f1-score at all levels; sentence (0.971), document (0.985), and patient (0.981). Specifically, the highest performance among all models at the sentence level was a sensitivity=0.954, specificity=1.000, PPV=0.988, and NPV=0.999, which matches with the performance of the hybrid model. All models performed high in f1-score at a patient level (≥0.9).
Table 3.
Model performance on three levels of evaluation
| Level | Model | Sensitivity | Specificity | PPV | NPV | f1-score |
|---|---|---|---|---|---|---|
| Sentence P: 1073, n: 64312) | Hybrid | 0.9543 | 0.9998 | 0.9884 | 0.9992 | 0.9711 (0.96, 0.98) |
| BERT | 0.9534 | 0.9995 | 0.9724 | 0.9992 | 0.9628 (0.95, 0.97) | |
| ClinicalBERT | 0.9422 | 0.9992 | 0.9520 | 0.9990 | 0.9471 (0.94, 0.96) | |
| Rule | 0.8509 | 0.9985 | 0.9040 | 0.9975 | 0.8766 (0.86, 0.89) | |
| CNN | 0.9422 | 0.9965 | 0.8220 | 0.9990 | 0.8780 (0.86, 0.89) | |
| Bi-LSTM | 0.8779 | 0.9993 | 0.9554 | 0.9979 | 0.9150 (0.9, 0.93) | |
| 0.9696 | 0.9927 | 0.977 | 0.9903 | 0.9733 | ||
| Document (p: 263, n: 827) | Hybrid | 0.9924 | 0.9927 | 0.9775 | 0.9976 | 0.9849 0.97, 0.99) |
| BERT | 0.9696 | 0.9927 | 0.977 | 0.9903 | 0.9733 (0.96, 0.99) | |
| ClinicalBERT | 0.9544 | 0.9867 | 0.958 | 0.9855 | 0.9562 (0.94, 0.97) | |
| Rule | 0.9468 | 0.9637 | 0.8925 | 0.9827 | 0.9188 (0.9, 0.94) | |
| CNN | 0.9734 | 0.9166 | 0.7877 | 0.9908 | 0.8707 (0.83, 0.89) | |
| Bi-LSTM | 0.9202 | 0.994 | 0.9798 | 0.9751 | 0.949 (0.93, 0.97) | |
| Patient (p: 32, n: 28) | Hybrid | 0.9688 | 0.9286 | 0.9394 | 0.9630 | 0.9538 (0.91, 1.0) |
| BERT | 0.9688 | 0.8929 | 0.9118 | 0.9615 | 0.9394 (0.87, 0.99) | |
| ClinicalBERT | 0.9688 | 0.8929 | 0.9118 | 0.9615 | 0.9394 (0.87, 0.99) | |
| Rule | 0.9375 | 0.8571 | 0.8824 | 0.9231 | 0.9091 (0.82, 0.98) | |
| CNN | 0.9688 | 0.7500 | 0.8158 | 0.9545 | 0.8857 (0.8, 0.96) | |
| Bi-LSTM | 0.9375 | 0.9643 | 0.9677 | 0.9310 | 0.9524 (0.9, 1.0) | |
| Level | Model | Sensitivity | Specificity | PPV | NPV | f1-score(95% CI‡) |
| Sentence (p=1073, n=64312†) | Hybrid | 0.9543 | 0.9998 | 0.9884 | 0.9992 | 0.9711 (0.96, 0.98) |
| BERT | 0.9534 | 0.9995 | 0.9724 | 0.9992 | 0.9628 (0.95, 0.97) | |
| Rule | 0.8509 | 0.9985 | 0.9040 | 0.9975 | 0.8766 (0.86, 0.89) | |
| CNN | 0.9422 | 0.9965 | 0.8220 | 0.9990 | 0.8780 (0.86, 0.89) | |
| Bi-LSTM | 0.8779 | 0.9993 | 0.9554 | 0.9979 | 0.9150 (0.9, 0.93) | |
| Document (p=263, n=827†) | Hybrid | 0.9924 | 0.9927 | 0.9775 | 0.9976 | 0.9849 0.97, 0.99) |
| BERT | 0.9696 | 0.9927 | 0.9770 | 0.9903 | 0.9733 (0.96, 0.99) | |
| Rule | 0.9468 | 0.9637 | 0.8925 | 0.9827 | 0.9188 (0.9, 0.94) | |
| CNN | 0.9734 | 0.9166 | 0.7877 | 0.9908 | 0.8707 (0.83, 0.89) | |
| Bi-LSTM | 0.9202 | 0.994 | 0.9798 | 0.9751 | 0.949 (0.93, 0.97) | |
| Patient (p=32, n=28†) | Hybrid | 0.9688 | 0.9286 | 0.9394 | 0.9630 | 0.9538 (0.91, 1.0) |
| BERT | 0.9688 | 0.8929 | 0.9118 | 0.9615 | 0.9394 (0.87, 0.99) | |
| Rule | 0.9375 | 0.8571 | 0.8824 | 0.9231 | 0.9091 (0.82, 0.98) | |
| CNN | 0.9688 | 0.7500 | 0.8158 | 0.9545 | 0.8857 (0.8, 0.96) | |
| Bi-LSTM | 0.9375 | 0.9643 | 0.9677 | 0.9310 | 0.9524 (0.9, 1.0), |
p: positive fall event, n: negative fall event;
bootstrap confidence interval
Analysis of Semantic Categories of Incorrect Fall Detection
We analyzed fall detection errors at the sentence level based on the contextual and semantic categories shown in Table 2. Figure 2 shows errors in different categories for each model. In general, machine learning-based approaches could correctly identify challenging fall events that required context understanding better than a rule-based approach. A rule-based model relatively had more error in negation but less in fall risk than the BERT. A hybrid model (BERT + post-hoc rules) was able to take advantage from both approaches – e.g., low error both in fall risk and negation. However, no single model yielded the best performance for all semantic categories. For example, a hybrid model performed better than Bi-LSTM in Rsk (fall risk) and Low (become a lower) but opposite in T (Time) and Pos (Position).
Figure 2.
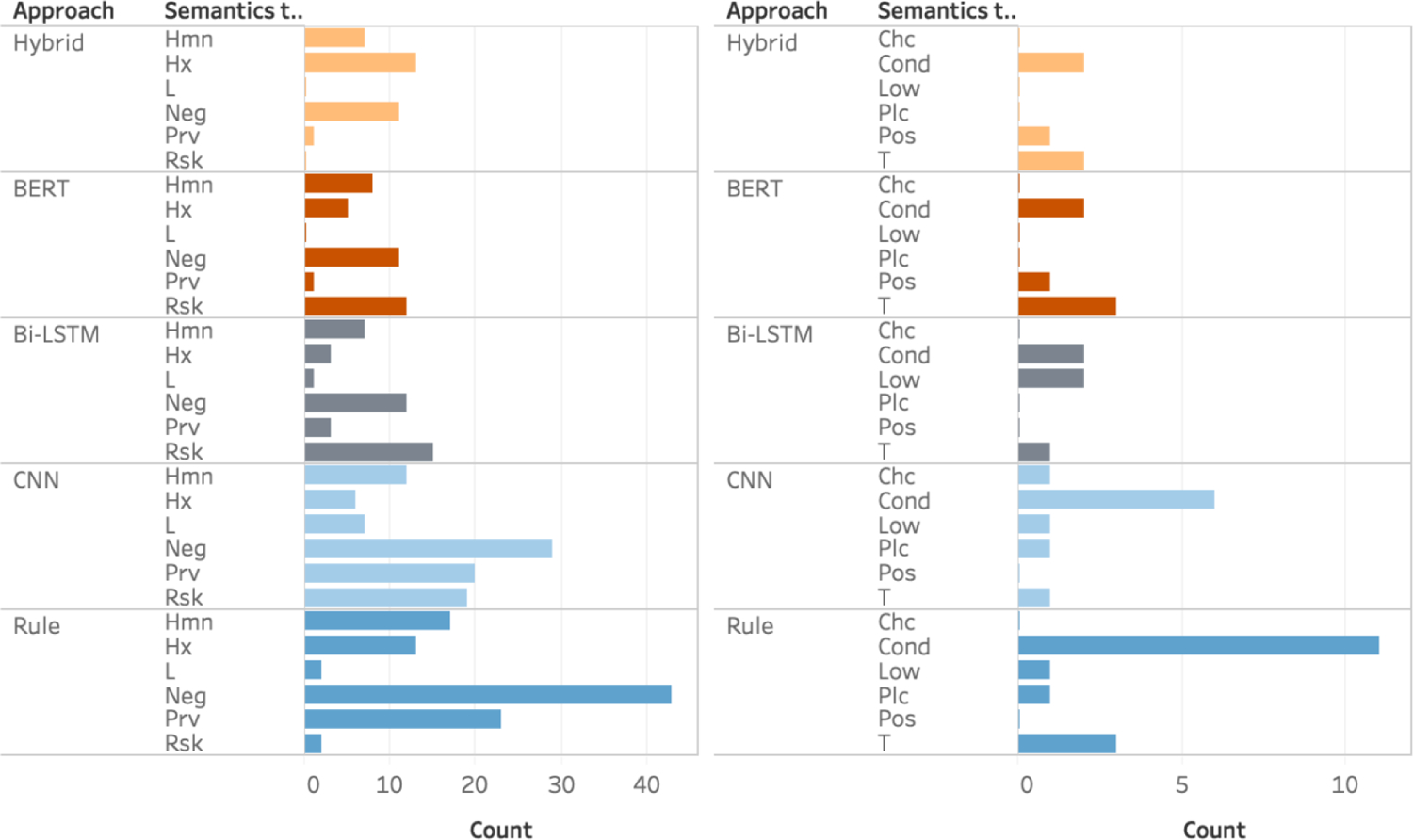
Errors of fall detection in different semantic categories. Count: the number of false positive cases. Neg: Negation, Hx: Historical fall, Prv: Fall prevention, Rsk: Fall risk, L: Lack of context, Hmn: Homonyms, Cond: Pass into physical or mental condition, T: Pass at a certain time, Low: Become a lower level, Chc: To come by chance, Pos: To come by chance into a particular position, Plc: To have its proper place
Sentence Level Error Analysis
We analyzed challenging fall detection cases that were difficult to identify correctly. Table 4 lists common false negative (FN) and false positive (FP) examples. These cases either presented a complex syntactic sentence structure (e.g., #3, 10), expressions that may be caused by spelling or typographical errors (e.g., #4), or rare semantics patterns (e.g., #2, 8). A hybrid model was able to correctly detect true falls missed by BERT (#1) and rules (#2–5) and exclude incorrect fall cases miss-identified by BERT (#6, 8–10) and rules (#6–8). The false positive events (#6, 8, 9, 10) suggest some misclassification of the fall risk related expressions by the BERT model. The true positive rate for BERT model among the fall risk-related expressions was 0.74, indicating that the BERT model was able to distinguish more than half of the cases related to fall risk. We believe that a lack of relevant training data results in incorrect identification. However, 26% of the cases failed to be classified by the model, which provided the rationale for using a hybrid approach.
Table 4.
Challenging fall event cases (H: Hybrid, B: BERT, R: Rules, C: CNN, L: Bi-LSTM, TP: true positive, FN, false negative, FP: false positive).
| True fall events prone to be missed | H | B | R | C | L |
| 1. #2 fall from ladder on 12/3/2016 transfer from la crosse 12/5/16 | TP | FN | TP | FN | FN |
| 2. When he went down, his hands were behind him | FN | FN | FN | FN | FN |
| 3. Continue cervical collar for now, however, given that it was ground level fall with negative c-spine CT will discuss with dr about removal of cervical collar. | TP | TP | FN | FN | FN |
| 4. Fallin in parking lot of bowling lanes | TP | TP | FN | FN | FN |
| 5. Denies any dizziness or light-headedness at any point, including preceding the two recent falls. | TP | TP | FN | FN | FN |
| False fall events prone to be considered as falls | H | B | R | C | L |
| 6. Patient presents for evaluation of fall, while walking or running, landing on hard surface, landing on left side. | TN | FP | FP | FP | FP |
| 7. These will likely fall off a few weeks after application | TN | TN | FP | FP | FP |
| 8. Patient remains at fall risk due to right hemiplegia, right hip pain, and weight bearing as tolerated restrictions | TN | FP | TN | TN | FP |
| 9. He was also somewhat impulsive, quickly getting up out of his wheelchair, and he tried to step over the edge with his right foot, which put him at high risk of falling. | TN | FP | TN | TN | TN |
| True fall events prone to miss | H | B | R | C | L |
| 10. #2 fall from ladder on 12/3/2016 transfer from la crosse 12/5/16 | TP | FN | TP | FN | FN |
| 11. When he went down, his hands were behind him | FN | FN | FN | FN | FN |
| 12. Continue cervical collar for now, however, given that it was ground level fall with negative c-spine CT will discuss with dr about removal of cervical collar. | TP | TP | FN | FN | FN |
| 13. Fallin in parking lot of bowling lanes | TP | TP | FN | FN | FN |
| 14. Denies any dizziness or light-headedness at any point, including preceding the two recent falls. | TP | TP | FN | FN | FN |
| False fall events prone to be considered as falls | H | B | R | C | L |
| 15. Patient presents for evaluation of fall, while walking or running, landing on hard surface, landing on left side. | TN | FP | FP | FP | FP |
| 16. These will likely fall off a few weeks after application | TN | TN | FP | FP | FP |
| 17. Patient presents for evaluation of fall, while walking or running, landing on hard surface, landing on left side. | TN | FP | FP | FP | FP |
| 18. patient remains at fall risk due to right hemiplegia, right hip pain, and weight bearing as tolerated restrictions | TN | FP | TN | TN | FP |
| 19. he was also somewhat impulsive, quickly getting up out of his wheelchair, and he tried to step over the edge with his right foot, which put him at high risk of falling. | TN | FP | TN | TN | TN |
To illustrate the ability to handle complex syntactic and semantic expressions from real-world EHRs data, we summarized the challenging cases correctly identified by the hybrid model) in Table 5. Based on our results, machine learning models are able identify fall events without a word ‘fall’ if there were enough relevant training data. However, events without keyword ‘fall’ are rare and thus more likely to be missed but the ML models.
Table 5.
Examples of challenging cases that are correctly identified by the hybrid model
| Category | False Fall Events |
|---|---|
| Homonym / Fall risk and prevention |
|
| Ambiguous Context |
|
| True Fall Events | |
| Rare Expression |
|
| Complex Sentence Structure |
|
| Negation |
|
DISCUSSION
In this study, we developed a hybrid model to identify fall events from the EHR free text. The evaluation of the hybrid approach against other approaches demonstrated excellent performance in identifying fall occurrences that are typically described in patient clinical notes. The ability to accurately detect true fall events from EHRs is largely dependent on the context understanding of clinical narratives. Leveraging the advantage of context-aware language models and domain knowledge represented by heuristic rules demonstrated the ability to handle complex syntactic and semantic fall expressions from real-world EHR data compared with other methods. Our hybrid model was able to identify indirect fall expressions and negated concepts reasonably well as in Table 5. For example, “waking up on the ground” has no direct fall indicative keywords; “denies any falls” indicate a false fall. However, the hybrid model correctly identified both expressions. The BERT model incorrectly identified some explicit fall events, and this might be due to lack of appropriate training data. The hybrid model using post-hoc heuristic rules combined with the BERT model was able to fix those misclassified cases, showing the potential to further improve the performance. We applied the ClinicalBERT(32) (0.9471 for sentence, 0.9562 for document, and 0.9394 for patient level) to evaluate the effect of pretraining on clinical notes; however, we did not observe any performance improvement over the BERT. This may be due to the different nature of clinical notes, especially fall event description, in our institution.
There are noticeable variations in fall events as shown in Table 2 and 5. We found that no single model outperformed all other models in all fall event categories. The hybrid model demonstrated similar learning patterns with the two other statistical machine learning models with a better ability to handle complex sentence structure and negation patterns. Although the rule-based approach yielded lower performance (sentence level f1-score) than the others, its consistency and customizability to handle explicit fall events cannot be ignored. Despite the overall promising performance of BERT, we found a handful of misclassified explicit fall events that could be fixed by rules. For example, a very common documentation pattern by Mayo Clinic clinicians is the use of “#” to document important diagnostic findings or problem lists (e.g., “# falls in 30 seconds”). Another example is the section information (e.g., section name + documentation structure patterns + fall expressions). The hybrid model was able to fix these issues and further improve the performance over the BERT model. In addition, we believe that the hybrid model can help customize fall detection in EHR data when the model is used in different institutions.
Despite the high performance in fall detection, our study has several limitations. The model may behave differently on the EHR data in other institutions due to heterogeneity of clinical documentation. Our study cohort consists of older, less racially or ethnically diverse, and more affluent than the general population of the United States. Other populations may have different care-seeking behaviors and health care providers may document falls differently. In the future, we plan to refine and deploy our model on EHR data from other institutions to evaluate the model portability.. A word embedding pretrained on a given institution may has a potential to improve the performance of fall detection. Transfer learning techniques may be considered to augment the learning process in different EHR data, but nonetheless needs to be paired with rigorous evaluation to ensure site-specific heterogeneity, and population variation.
CONCLUSION
In this study, we demonstrated that a context-aware language model (BERT) can be used to accurately detect challenging fall events from EHR free text that are difficult to be captured by simple methods. In addition, the hybrid model coupling with post-hoc rules allowed customizability to overcome the weakness of the BERT model and further enhance the performance, rectifying incorrect fall detection determined by the BERT model.
Supplementary Material
Summary Table.
| Known on the topic | Newly added to our knowledge |
|---|---|
|
|
Acknowledgments
The authors would like to gratefully acknowledge Donna M. Ihrke and Christine M. Prissel for case validation.
Funding
This work was supported by National Institute on Aging R21 AG58738, National Institute on Aging R01 AG34676, and National Institute on Aging R01AG068007.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Conflict of Interest
The authors declare that there is no conflict of interest regarding the publication of this article.
Citation
- 1.Zecevic AA, Salmoni AW, Speechley M, Vandervoort AA. Defining a fall and reasons for falling: comparisons among the views of seniors, health care providers, and the research literature. The Gerontologist. 2006;46(3):367–76. [DOI] [PubMed] [Google Scholar]
- 2.Close J, Ellis M, Hooper R, Glucksman E, Jackson S, Swift C. Prevention of falls in the elderly trial (PROFET): a randomised controlled trial. Lancet. 1999;353(9147):93–7. [DOI] [PubMed] [Google Scholar]
- 3.Davies AJ, Kenny RA. Falls presenting to the accident and emergency department: types of presentation and risk factor profile. Age Ageing. 1996;25(5):362–6. [DOI] [PubMed] [Google Scholar]
- 4.Hausdorff JM, Rios DA, Edelberg HK. Gait variability and fall risk in community-living older adults: a 1-year prospective study. Arch Phys Med Rehabil. 2001;82(8):1050–6. [DOI] [PubMed] [Google Scholar]
- 5.Yoshida-Intern S. A global report on falls prevention epidemiology of falls. Geneva: WHO. 2007. [Google Scholar]
- 6.Masud T, Morris RO. Epidemiology of falls. Age Ageing. 2001;30 Suppl 4(suppl_4):3–7. [DOI] [PubMed] [Google Scholar]
- 7.Burns ER, Stevens JA, Lee R. The direct costs of fatal and non-fatal falls among older adults—United States. Journal of safety research. 2016;58:99–103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Campbell AJ, Robertson MC. Implementation of multifactorial interventions for fall and fracture prevention. Age Ageing. 2006;35 Suppl 2(suppl_2):ii60–ii4. [DOI] [PubMed] [Google Scholar]
- 9.Luther SL, McCart JA, Berndt DJ, Hahm B, Finch D, Jarman J, et al. Improving identification of fall-related injuries in ambulatory care using statistical text mining. American journal of public health. 2015;105(6):1168–73. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Tremblay MC, Berndt DJ, Luther SL, Foulis PR, French DD. Identifying fall-related injuries: Text mining the electronic medical record. Information Technology and Management. 2009;10(4):253. [Google Scholar]
- 11.Navigli R. Word sense disambiguation: A survey. ACM computing surveys (CSUR). 2009;41(2):1–69. [Google Scholar]
- 12.Sanderson M, editor Word sense disambiguation and information retrieval. SIGIR’94; 1994: Springer. [Google Scholar]
- 13.Association AN. Nursing-sensitive quality indicators for acute care settings and ANA’s safety & quality initiative. Nursing Facts from the ANA. 1999. [Google Scholar]
- 14.Zhu VJ, Walker TD, Warren RW, Jenny PB, Meystre S, Lenert LA, editors. Identifying falls risk screenings not documented with administrative codes using natural language processing. AMIA annual symposium proceedings; 2017: American Medical Informatics Association. [PMC free article] [PubMed] [Google Scholar]
- 15.Patterson BW, Jacobsohn GC, Shah MN, Song Y, Maru A, Venkatesh AK, et al. Development and validation of a pragmatic natural language processing approach to identifying falls in older adults in the emergency department. BMC Med Inform Decis Mak. 2019;19(1):138. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.McCart JA, Berndt DJ, Jarman J, Finch DK, Luther SL. Finding falls in ambulatory care clinical documents using statistical text mining. Journal of the American Medical Informatics Association. 2013;20(5):906–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Toyabe S. Detecting inpatient falls by using natural language processing of electronic medical records. BMC Health Serv Res. 2012;12(448):448. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.dos Santos HDP, Silva AP, Maciel MCO, Burin HMV, Urbanetto JS, Vieira R, editors. Fall detection in ehr using word embeddings and deep learning. 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE); 2019: IEEE. [Google Scholar]
- 19.Devlin J, Chang M-W, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:181004805. 2018. [Google Scholar]
- 20.Ferrucci D, Lally A. UIMA: an architectural approach to unstructured information processing in the corporate research environment. Natural Language Engineering. 2004;10(3–4):327–48. [Google Scholar]
- 21.Ferrucci D, Lally A. UIMA: an architectural approach to unstructured information processing in the corporate research environment. Nat Lang Eng. 2004:1–26. [Google Scholar]
- 22.Olson JE, Ryu E, Johnson KJ, Koenig BA, Maschke KJ, Morrisette JA, et al. , editors. The Mayo Clinic Biobank: a building block for individualized medicine. Mayo Clinic Proceedings; 2013: Elsevier. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Olson JE, Ryu E, Hathcock MA, Gupta R, Bublitz JT, Takahashi PY, et al. Characteristics and utilisation of the Mayo Clinic Biobank, a clinic-based prospective collection in the USA: cohort profile. BMJ Open. 2019;9(11):e032707. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Fu SY, Leung LY, Raulli AO, Kallmes DF, Kinsman KA, Nelson KB, et al. Assessment of the impact of EHR heterogeneity for clinical research through a case study of silent brain infarction. BMC Med Informatics Decis Mak. 2020;20(1):1–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Kuhn HW. The Hungarian method for the assignment problem. Naval research logistics quarterly. 1955;2(1–2):83–97. [Google Scholar]
- 26.Fu SY, Chen D, He H, Liu SJ, Moon S, Peterson KJ, et al. Clinical concept extraction: A methodology review. Journal of Biomedical Informatics. 2020;109:103526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Wu S, Roberts K, Datta S, Du J, Ji Z, Si Y, et al. Deep learning in clinical natural language processing: a methodical review. 2019. [DOI] [PMC free article] [PubMed]
- 28.Pennington J, Socher R, Manning CD, editors. Glove: Global vectors for word representation. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP); 2014. [Google Scholar]
- 29.Fu S, Chen D, He H, Liu S, Moon S, Peterson KJ, et al. Clinical concept extraction: a methodology review. Journal of Biomedical Informatics. 2020:103526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Nadkarni PM, Ohno-Machado L, Chapman WW. Natural language processing: an introduction. J Am Med Inform Assoc. 2011;18(5):544–51. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Blackburn S. The Oxford dictionary of philosophy: OUP Oxford; 2005.
- 32.Alsentzer E, Murphy JR, Boag W, Weng W-H, Jin D, Naumann T, et al. Publicly available clinical BERT embeddings. arXiv preprint arXiv:190403323. 2019. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.