

Abstract
This manuscript provides information on datasets pertaining to Project KIDS. Datasets include behavioral and achievement data for over 4,000 students between five and twelve years old participating in nine randomized control trials of reading instruction and intervention between 2005–2011, and information on home environments of a subset of 442 students collected via parent survey in 2013. All data is currently stored on an online data repository and freely available. Data might be of interest to researchers interested in individual differences in reading development and response to instruction and intervention, as well as to instructors of data analytic methods such as hierarchical linear modeling and psychometrics.
Keywords: Reading intervention, response to intervention, academic achievement, home literacy environment, individual differences
In this paper, we introduce Project KIDS. Project KIDS, funded through the Eunice Kennedy Shriver National Institute of Child Health and Development, gathered data from several RCTs of comprehensive approaches to reading instruction with the intent to investigate individual differences in response to reading instruction and intervention. These comprehensive approaches included professional development, classroom instruction focused on both code and meaning, and flexible grouping. From previous reading research, it is known that not all children benefit from reading instruction and intervention to the same extent, but the cognitive and behavioral mechanisms underlying differential responses are not yet well understood (e.g., Al Otaiba & Fuchs, 2002; Ritchey et al., 2012; Vadasy et al., 2008). Project KIDS was designed to capitalize on extant randomized control trial data that included cognitive, behavioral, and achievement measures and provide a richer dataset by collecting additional information on the home environment, familial history, and parent perception of students’ behavior.
Project KIDS had two distinct phases. In Phase I, raw item level data across nine independent intervention projects was gathered, entered, and combined. Each original project was large, both in participant size but also in measures collected. As the end goal of Phase I was to have a combined dataset, the focus of this phase was to gather and enter raw data of measures that were collected across at least two projects (see Table 1). Therefore, measures that were unique to a single project were not brought into Phase I of Project KIDS. Phase II of Project KIDS was to locate families of the original intervention projects participants and recruit them as participants for this additional phase. Families choosing to participate completed a survey packet that was mailed to them. The survey packet contained questions on family history, the home and neighborhood environment, parenting practices, parent and child behavior, and others.
Table 1.
Overlapping Assessments Provided in Each Project
| Project | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Assessment | Subtest | 1 | 2 | 3 | 5 | 6 | 7 | 8 | 9 |
|
| |||||||||
| CTOPP | X | X | X | X | |||||
| CTRS | X | X | |||||||
| KBIT | X | X | X | ||||||
| SSRS | X | X | X | X | X | X | X | X | |
| SWAN | X | X | X | X | X | ||||
| TOLD | X | X | X | ||||||
| TOPEL | Print Knowledge | X | X | ||||||
| TOSREC | X | X | X | ||||||
| WJ_III | Academic Knowledge | X | X | X | X | X | |||
| Applied Problems | X | ||||||||
| Letter-word ID | X | X | X | X | X | X | X | X | |
| Math fluency | X | ||||||||
| Passage Comprehension | X | X | X | X | X | X | X | X | |
| Picture Vocabulary | X | X | X | X | X | X | X | X | |
| Quantitative Concepts | X | ||||||||
| Sound awareness | X | X | X | ||||||
| Spelling | X | X | X | X | X | ||||
| Word Attack | X | X | X | X | X | X | X | X | |
| Writing Fluency | X | X | X | X | |||||
Note: CTOPP = Comprehensive Test of Phonological Processing. CTRS = Conners Teacher Rating Scale. KBIT = Kaufmann Brief Intelligence Test. SSRS = Social Skills Rating Scale. SWAN = The Strengths and Weaknesses of ADHD Symptoms and Normal Behavior Scale. TOLD = Test of Language Development. TOPEL = Test of Preschool Early Literacy. TOSREC = Test of Silent Reading Efficiency and Comprehension. WJ-III = Woodcock Johnson Test of Achievement, third edition.
Specific Aims
Project KIDS had two overarching goals. The first was to create an integrated data sample by pooling item level achievement and behavior data from nine independent data sets. The second goal was to use this integrated dataset to conduct analyses of individual differences in how children respond to reading instruction and intervention to explore three specific aims as listed in the grant application: (1) child trait characteristics (i.e., cognitive and psychosocial outcomes); (2) the family environment, such as home literacy practices and parental beliefs; and (3) the familial risk status of various learning disabilities and difficulties in response to intervention and instruction.
Data Sample
The students in the total Project KIDS sample were a heterogenous group between five and twelve years old attending elementary school in North Florida, US, between 2005 and 2011. About 50% (n = 2,033) of students were female. Most students were either Black (41%) or White (42%), and the sample further included Native American (2%), Asian (< 1%), Hawaiian/Pacific Islander (< 1%), and multi-racial (3%) students. About 4% of the students identified as Hispanic. A third of the students (36%) qualified for free or reduced lunch, and 1% were considered limited English proficient. Information on ESE status was only available for 9% of the students in the sample. Similarly, in Phase II of the project about 49% (n = 216) of students were female. Most students were White (54%) or Black (34%), and non-Hispanic (94%), which was representative of demographics in that region during that timeframe. About a third of the participants qualified for Free or Reduced Lunch (n = 134). As with the Phase I sample, very few students were classified as limited proficient in English (< 1%) or received special education services (< 1 %). Table 2 provides demographics separated by original project and both phases of Project KIDS.
Table 2.
Select Student Demographics
| Variable | Project | 1 | 2 | 3 | 5 | 6 | 7 | 8 | 9 | Total Phase I | Phase II |
|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||
| Gender | Female | 338 | 281 | 183 | 354 | 219 | 242 | 175 | 241 | 2033 | 216 |
| Male | 301 | 233 | 148 | 363 | 175 | 238 | 184 | 271 | 1913 | 223 | |
| Missing | 2 | - | - | 87 | 1 | - | - | - | 90 | 3 | |
| Race | American Indian/ Alaskan Native | - | 3 | 2 | - | 1 | - | 1 | 1 | 8 | 1 |
| Asian | 12 | 7 | 11 | 12 | 18 | 22 | 12 | 9 | 103 | 9 | |
| Black | 340 | 298 | 149 | 334 | 154 | 183 | 182 | 25 | 1665 | 150 | |
| Hawaiian/ Pacific Islander | 4 | 18 | - | - | - | 1 | - | 3 | 23 | 1 | |
| White | 222 | 150 | 151 | 245 | 182 | 233 | 113 | 419 | 1715 | 238 | |
| Multiracial | 6 | 23 | 13 | 6 | 12 | 21 | 17 | 31 | 129 | 16 | |
| Other | 3 | 10 | 2 | 24 | 5 | 20 | 32 | 19 | 115 | 14 | |
| Missing | 54 | 5 | 3 | 183 | 23 | - | 2 | 5 | 275 | 13 | |
| Ethnicity | Hispanic | 28 | 39 | 18 | 17 | 7 | 17 | 14 | 33 | 173 | 16 |
| Non-Hispanic | 534 | 472 | 292 | 621 | 370 | 463 | 344 | 474 | 3570 | 415 | |
| Missing | 79 | 3 | 21 | 166 | 18 | - | 1 | 5 | 293 | 11 | |
| FARL | Eligible | 316 | 260 | 86 | 391 | 146 | 126 | 146 | - | 1471 | 134 |
| Not eligible | 302 | 235 | 146 | 264 | 218 | 125 | 100 | - | 1390 | 159 | |
| Missing | 23 | 19 | 99 | 149 | 31 | 229 | 113 | 512 | 1175 | 149 | |
| LEP | Yes | 15 | 9 | 4 | 18 | 4 | - | - | - | 50 | 3 |
| No | 623 | 496 | 317 | 744 | 391 | 251 | 246 | - | 3068 | 311 | |
| Missing | 3 | 9 | 10 | 42 | - | 229 | 113 | 512 | 918 | 128 | |
| ESE | Receiving | 1 | - | - | - | - | - | - | 11 | 12 | 4 |
| Not receiving | 29 | 2 | - | 129 | 76 | 52 | 39 | 14 | 341 | 39 | |
| Missing | 611 | 512 | 331 | 675 | 319 | 428 | 320 | 487 | 3683 | 399 | |
Note: Due to its non-RCT status, Project 4 is not included.
FARL = Eligibility for Free or Reduced Lunch. LEP = considered limited proficient in English. ESE = Exceptional student education.
Procedures
The original data for Phase I were collected as part of eight randomized control trials and one follow-up intervention study provided to the waitlist control condition of one randomized control trial. Each of the original intervention studies were conducted as part of a comprehensive, multitiered systems of support approach to early reading in the early elementary grades (K-3). This approach was based on the premise that the effect of instruction and intervention depends on each student’s language and literacy skills and included three dimensions: flexible grouping, code-based and meaning-focused instruction, and teacher led or independent work (see Al Otaiba et al., 2011 for more details). The content dimension (code based and meaning-focused instruction) aligned with the Simple View or Reading (Gough & Tunmer, 1986; Hoover & Gough, 1990). Each study spanned one complete academic year between 2005–2013. Students typically start Kindergarten at age 5 and the age of students ranges between 5 and 12 years old. Each individual study obtained approval from the university Internal Review Board (IRB). Consent was first obtained from the classroom teachers who then recruited the students in their class. Caregivers then provided consent for their children to participate. Because some of the studies were conducted in the same schools, we ensured that for Project KIDS, data for students who participated in more than one project, or in longitudinal studies, were represented only once in the final combined dataset. As we just described, the additional data on the families and students were collected as part of Phase II by a parent survey sent out to all families who had participated in the earlier interventions. The university IRB provided additional approval for combining data in Phase I and collecting the additional data in Phase II. By returning the mail-in survey, parents provided consent for their data to be included in Phase II. Figure 1 provides an overview of Project KIDS. We will describe the research designs of each original intervention project in more details below.
Figure 1. Overview of Project KIDS.
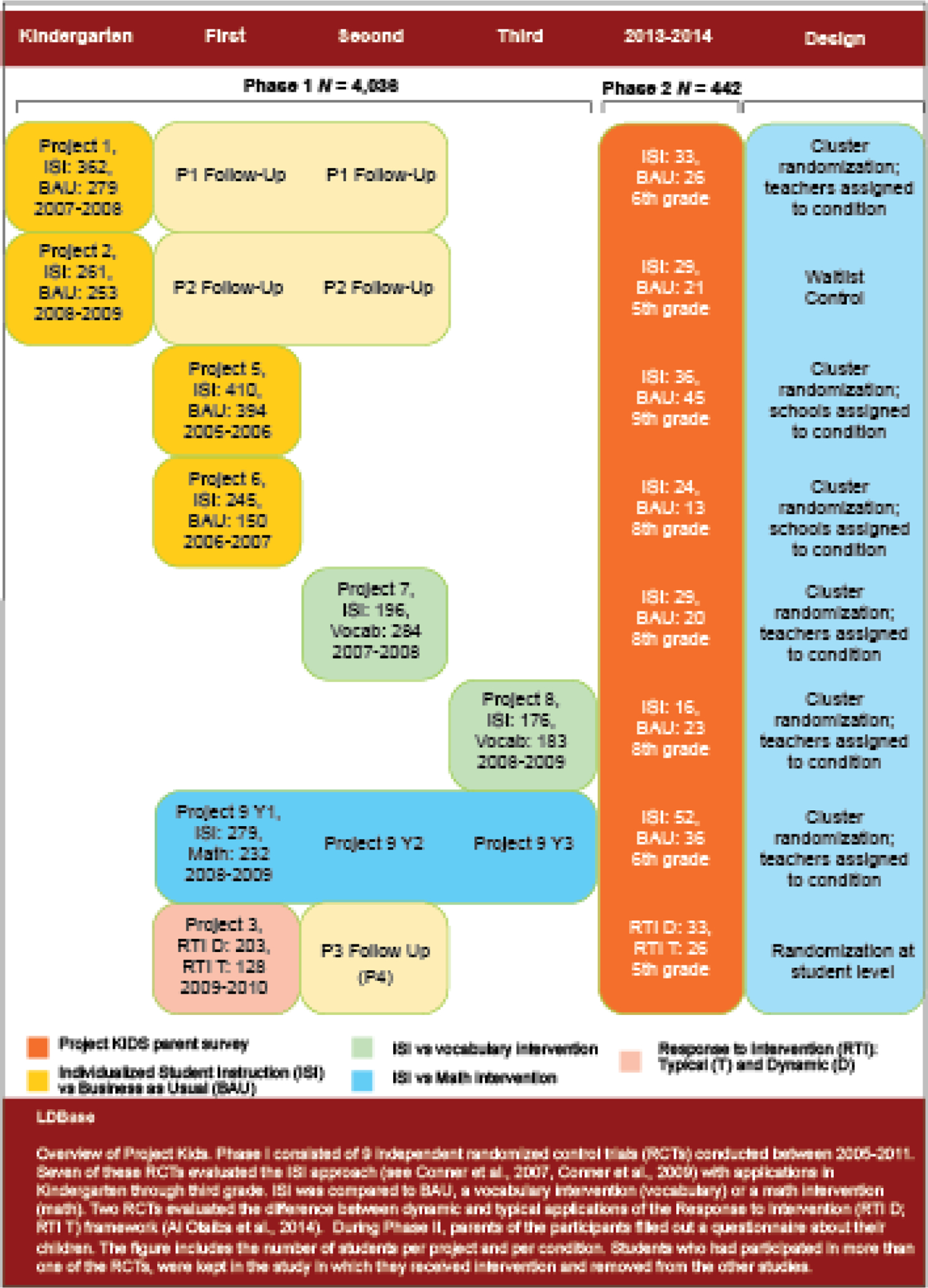
Note. Figure by van Dijk and colleagues (2021), available at https://doi.org/10.6084/m9.figshare.16989652.v1 under a CC BY 4.0 license
Project KIDS Phase I
Project 1
Project 1 was an iteration of the individualizing student instruction (ISI; Conner et al., 2007, Conner et al., 2009) intervention. In this iteration, ISI was applied with kindergarten students and their teachers (Al Otaiba et al., 2011). The intervention was randomized at the school level, with teachers assigned to condition. The sample consists of 641 students in 44 classrooms, 362 students were in the treatment condition and received the ISI intervention and the 279 students in the control condition received typical classroom instruction (BAU). Data were collected in the fall, winter, and spring of the 2007–2008 academic year, as well as in the spring of 2009 and 2010 as follow-up measures.
Project 2
Project 2 also evaluated ISI in kindergarten, and this was the project that provided treatment to teachers who had been in either the treatment or wait-list control conditions (Al Otaiba et al., 2016). This sample consists of 514 students in 34 classrooms, 261 in the treatment condition (ISI) and 253 in the control condition (BAU). Data were collected in the fall, winter, and spring of the 2008–2009 academic year, as well as in the spring of 2010 and 2011 as follow-up measures.
Project 3
Project 3 was a study in which two types of response to intervention (RTI) models were compared (Al Otaiba et al., 2014). In the dynamic model, students were immediately placed into intervention, if pretest scores indicated at-risk status. In the traditional model, regardless of pretest scores, students completed one 8-week cycle of classroom instruction prior to determining their eligibility for supplemental intervention. Tier 1 and Tier 2 instruction was ISI based, with Tier 2 and Tier 3 intervention provided by the research team above and beyond Tier 1 instruction. In this study, 522 students in 34 first grade classrooms participated (191 students had also participated in an earlier cohort and were removed from the project KIDS project 3 dataset). Two hundred and three students were in the treatment condition (dynamic RTI) and 128 students were in the control condition (typical RTI condition). RTI status was assigned at the student level. Data were collected in the fall, winter, and spring of the 2009–2010 academic year.
Project 4
Data for project 4 came from the follow-up of project 3. During this year, students’ data were assessed in grade two, but no additional treatment was provided. Data were collected in the fall, winter, and spring of the 2010–2011 academic year.
Project 5
In project 5, ISI was evaluated in first grade. Details about this study are described in Connor and colleagues (2007). The project consisted of 804 first grade students from 53 classrooms of which 410 were in the treatment condition (ISI) and 394 in the control condition (BAU). Randomization occurred at the school level. Data were collected in the fall, winter, and spring of the 2005–2006 academic year.
Project 6
Project 6 was also an iteration of ISI conducted in first grade (see for details Connor, Morrison, Schatschneider, et al., 2011), and included 395 first grade participants from 26 teachers, 245 students were in the treatment condition (ISI) and 150 in the control condition (BAU). The intervention was randomized at the school level. Data were collected in the fall, winter, and spring of the 2006–2007 academic year.
Project 7
Project 7 was an ISI intervention study in second grade where this intervention was compared to a vocabulary intervention condition. This study included 480 second grade participants from 40 classrooms; 196 students were in the intervention condition (ISI) and 284 students were in the control condition where they received the vocabulary instruction. Randomization occurred at the teacher level blocked at the school level. Data from this study have not been used for peer-reviewed journal articles previously. Data were collected in the fall, winter, and spring of the 2006–2007 academic year.
Project 8
Project 8 evaluated the ISI intervention against a vocabulary intervention conducted in third grade (see Connor, Morrison, Fishman, et al., 2011 for details). Data from this project included 359 third grade students in 31 classrooms; 176 students were in the treatment condition (ISI) and 183 students were in the control condition where they received the vocabulary intervention. Randomization occurred at the teacher level blocked at the school level. Data were collected in the fall, winter, and spring of the 2008–2009 academic year.
Project 9
Project 9 was a three-year longitudinal study of the ISI intervention. Students in this sample were followed in first through third grade, and each year received either the ISI intervention or a math intervention (see Connor et al., 2013 for details). For the current study, we only used data from first grade. This included data on 512 first grade students, 279 of which were in the treatment condition (ISI) and 232 were in the control condition where they received the math intervention. Randomization occurred at the teacher level blocked at the school level. Data were collected in the fall, winter, and spring of the 2008–2009 academic year.
The Treatments Conditions
All projects included ISI, sometimes compared to a business-as-usual control, and sometimes to a treated control. Below are descriptions of each of the interventions, ISI, vocabulary, and Math.
ISI
The ISI reading intervention had three main features, (a) a software program through which recommended amounts of instruction for each student was calculated based on student data, (b) extensive professional development for teachers, and (c) coaching for literacy instruction in the classroom (Al Otaiba et al., 2011; Connor et al., 2013).
The A2i software used student reading scores on letter word reading and comprehension or vocabulary to calculate the optimal, daily, amounts of code-focused and meaning-focused reading instruction. The program also recommended teacher-small group versus child-centered instructional groupings. Optimal amounts of daily instruction changed at every assessment wave, depending on current skills and progress of the students.
The professional development followed a coaching model where teachers attended half day workshops at the beginning of the school year. During professional development, teachers learned how about response to intervention, why it was important to individualize amounts and times of instruction to student need, to use the software program, and to adapt instruction accordingly. Project personnel provided classroom-based observations and support every other week. In some studies conducted by Connor et al., teachers also met once a month with other teachers in a community of practice.
Classroom instruction under ISI involved providing the students with the appropriate amount of code-based and meaning-based instruction in either teacher-directed small group settings or independent student centers. Activities and instruction followed core reading curricula that were adapted to meet the needs of the students, and were supplemented with other sources, such as activities from the Florida Center for Reading Research.
Vocabulary Intervention
The vocabulary intervention was used as a treated-control condition in Projects 7 and 8 (i.e., Connor, Morrison, Fishman, et al., 2011). Similar to the ISI intervention, the vocabulary intervention condition consisted of (a) professional development and (b) implementation in the classroom. Classroom implementation was modeled after the approach by Beck, McKeown, and Kucan (2002) Bringing Words to Life. During the professional development component, teachers came together once a month to discuss a chapter of the book, design vocabulary lesson collaboratively, and discuss student work to adapt lessons. The monthly sessions were led by a member of the research team. Like the ISI intervention, there were general ramifications for the interventions based on the book, but each teacher could implement the vocabulary intervention in their own way (i.e., choose the words to focus on, the example, etc.) (see Connor, Morrison, Fishman, et al., 2011 for more details).
Math Intervention
The math intervention also consisted of a professional development component and an implementation component. This professional development was equal to that of ISI: half-day workshops at the beginning of the year, monthly community of practice meetings, and classroom observations and support from research personnel every other week. The intervention used each district’s math curriculum and supplemented instruction with Math Pals (Fuchs et al., 1997). In second and third grade, researchers developed specific math activities for students based on their skills (see Connor et al., 2013 for more details).
Measures
In all projects, students completed a battery of cognitive and achievement tests administered by research staff consisting of graduate students in special education and school psychology. Staff received training on test administration and scoring and needed to be 98% accurate on training sessions before being able to assess the students. Staff were not blinded to condition, because they also provided classroom support to teachers. Additionally, teachers provided information on students’ behavior. The assessment battery was completed in the fall, winter, and spring of each intervention year, and some projects provided yearly follow up assessments up to two years after completion of the intervention. Across projects, there was partial overlap of specific assessments, and Table 1 provides an overview of this.
Data Sets
Data for Phase I of Project KIDS are freely available in two datasets which can be accessed through the Project KIDS project page on LDbase.org (Hart et al., 2021). Data in these datasets have not been harmonized. That is, while all data are contained in one dataset, the scores have not been processed to be on the same, unbiased scale, except for a factor score on Social Skills Rating Scale. All Woodcock-Johnson scores are the raw scores.
Project KIDS Item Level Data
One dataset, Project KIDS Item Level Data, contains all item level raw data for each of the standardized achievement and behavioral assessments (doi: 10.33009/ldbase.1620837890.bcf8). This dataset has been available since August 1, 2021 under an ODC-BY license. Items are either on a binary scale (0 = incorrect, and 1 = correct) or numerical representation of Likert-type scales. Missing data is indicated by NA, and variables can be missing because the measure was not administered in a particular project (see Table 1) at a certain wave, or for other, unknown, reasons particular to each participant. The dataset is available in a delimited format as PK_ItemLevelData.csv and no additional software is required to access these data. Additional metadata related to and a codebook pertaining the dataset is available on the LDbase page where the data are stored. Data from this dataset can be linked to other Project KIDS datasets by the child ID variable (PKID).
Project KIDS Total Scores Data
The second dataset, Project KIDS Total Scores Data, includes processed data such as total scores, subscale scores, and standard scores of the standardized measures, and raw data at the item level of a parent survey and participant and teacher demographic variables (doi: 10.33009/ldbase.1620844399.85a0). This dataset has been available since August 1, 2021 under an ODC-BY license. All data are numerical representation with the codebook containing the items and labels in American English. The dataset is available in a delimited format as PK_FullData.csv. Similar to the item level dataset, missing data is indicated by NA, with variables either missing because the measure was not administered in a particular project (see Table 1) at a certain wave, or for other, unknown, reasons particular to each participant. The dataset is available in a delimited format as PK_FullData.csv and no additional software is required to access these data. Additional metadata related to and a codebook pertaining the dataset is available on the LDbase page where the data are stored. Data from this dataset can be linked to other Project KIDS datasets by the child ID variable (PKID).
Several steps were taken to ensure data from the archival files were reliable and valid. First, the physical data files were located and reviewed to ensure each of the original projects’ participants had a physical folder with administered assessments. Secondly, before data entry began, a quality check of the assessment administration was performed for a random selection of 10% of participants from each project. These quality checks included establishing if administration of an assessment has started at the correct item and if basal and ceiling rules had been applied correctly. Assessments with these types of discrepancies were considered invalid and discarded. Finally, item-level data was double-entered by trained Project KIDS personnel in a database software (i.e., FileMaker).
Project KIDS Phase II
In Phase II, a survey packet was sent to the last known address of participants of the original eight randomized control trial projects. If the survey packet was returned to sender, efforts were made to locate the new address of the family using online look up services. Surveys were sent out in the fall of 2013 and returned during the fall and winter of the 2013–2014 academic year. Primary caregivers were offered $40 USD to complete the survey, and were given an alternative option to complete the survey using an electronic version through Qualtrics. Of the original 4,036 participants, 442 survey packets were returned. The survey was 36 pages long and included 24 sections. These sections included topics such as basic demographics of the child’s primary caregivers and extended family, family medical history (including learning difficulties) and child health information, diet and nutrition, sleep habits, home literacy environment, academic achievement and learning, home and neighborhood environment, and child behavior. Items on the survey were either open ended or on Likert scales. A full sample survey can be found on the Project KIDS project page on ldbase.org (Hart et al., 2021). All data were double entered into a database program, and discrepancies were checked against the original survey. The lab had a set protocol to deal with entry questions. Before publication of the data, all identifying information were removed (i.e., names, birthdays, etc.) and additional checks were done to reduce possible reidentification by following recommendations set forth in Schatschneider et al. (2021) using crosstabs. Additionally, we performed a final quality check of the data by checking for out-of-range or implausible values for each variable and re-checking these against the original survey entries.
Data Set
Project KIDS FHQ Data contains all data from the survey. This is primary data including item level data of all sections and processed data such as total scores and subscale scores of several of the standardized measures of child behavior (doi: 10.33009/ldbase.1632933602.9c08). This data set has been available since October 20, 2021 under an ODC-BY license. All data are numerical representations with the codebook containing the items and labels in American English. The dataset is available in a delimited format as PK_FHQ.csv and no additional software is required to access these data. Missing data is indicated by NA. Additional metadata related to and a codebook pertaining the dataset is available on the LDbase page where the data are stored. Data from this dataset can be linked to other Project KIDS datasets by the child ID variable (PKID).
Project Outcomes
Data from Project KIDS have, to date, led to two peer-reviewed articles and two preprints. In the first Project KIDS paper, Daucourt and colleagues (2018) used both Phase I and II data to investigate if executive function is related to reading disability status in a hybrid classification model (low word reading achievement, unexpected low word reading achievement, poorer reading comprehension compared to listening comprehension, and dual-discrepancy response-to-intervention). This hybrid model states an individual can have any, or a combination of, four possible indicators of reading disability. The outcomes of the analyses show that inhibition, shifting, and updating working memory (all components of executive function) predicted reading disability. That is, lower performance on executive function increased the likelihood of being classified as having a reading disability. In the second paper, van Dijk and colleagues (2021b) used the Project KIDS data to demonstrate a novel approach to combine data from multiple projects. The authors combined measurement invariance modeling with the good enough principle (MacCallum et al., 2006) and generating random normal deviates (Widaman et al., 2013) to account for the excess of power in large sample sizes and the fact that not all data sets have the same measures. Their paper demonstrated this combination of existing methodologies as a useful alternative approach for researchers who have access to total scores of measures across several datasets.
Related to the second goal of Project KIDS, two preprints investigate the underlying factors that influence how children respond to reading intervention and instruction. Norris and colleagues (2020) examined whether socioeconomic status (measured as eligibility for free or reduced lunch) influenced response to intervention. Using a quantile regression approach, the authors found higher socioeconomic status was associated with higher residualized gain scores in decoding and expressive vocabulary skills for students receiving the ISI intervention. Van Dijk et al. (2021a) explored whether teacher ratings of student problem behavior influenced their response to reading instruction and intervention. Using multi-level moderation analysis, the outcomes from this investigation indicate that students who are rated (by their teachers) as above or below average on the Social Skills Rating System (SSRS; Gresham & Elliott, 1990) did not significantly increase their overall reading skills even though they were receiving ISI. The results from these preprints suggest that both child trait characteristics and the familial environment can be of influence on how students respond to intervention and instruction.
In addition to these published and preprinted manuscripts, three projects are currently in progress. The first project aims to shed light on the shared cognitive mechanism underlying mathematics and reading by examining the influence of early reading intervention on math fact fluency. The second project will examine if students respond differently to reading instruction and intervention based on their post-intervention reading ability, and if this different response is dependent on their pre-intervention ability. The third project, currently available as an unpublished dissertation (Haughbrook, 2020), used the Phase I Project KIDS data to compare levels of standardized testing bias versus teacher assessment bias by race.
Reuse Potential
These four papers highlight the benefits of capitalizing on extant data and using an integrative approach to generate large datasets that can be expanded upon by adding new data. Additionally, they show the wide variety of research questions that have been explored with the Project KIDS data sample that were not part of the original intervention studies’ aims. Beyond the need to replicate findings from original interventions and moving beyond their aims, the richness of Project KIDS data suggest many more diverse questions might be answered in the future. One largely unexplored area is the influence of the home environment on students’ reading achievement and response to instruction and intervention. Another area of potential interest is the relation between teacher ratings of behavior during the intervention year, and parent assessment of the same behaviors during phase II of Project KIDS. While our main approach has been to highlight additional research questions that might be answered with these data, the data can also be used in meta-analyses evaluating the overall effect of reading approaches.
Data can also be used in data analysis courses, for example in hierarchical linear modeling (HLM) and structural equation modeling (SEM) courses. These data might be of interest to HLM instructors since the project included the same intervention but different control groups and randomization methods. Using these data can help to show differences in estimation of intervention effects with various randomization methods. Furthermore, the dataset is large enough to provide well powered examples for multi-level mediation and moderation models. With regard to SEM courses, the datasets can be used in many basic and advanced SEM models, such as path models, latent growth models, growth mixture models, and panel models. In addition to HLM courses, the data can be used in psychometric courses as all data is available at the item level. Data is suitable to demonstrate classical test theory, IRT modeling, and factor analytic models. Finally, the data can be used to demonstrate data harmonization methods, such as integrative data analysis using moderated non-linear factor analysis (Curran et al., 2014; Hussong et al., 2013) or adapted measurement invariance models (van Dijk, Schatschneider, et al., 2021b).
Acknowledgements:
We thank the original project participants, research staff, and funding agencies. We also honor the late Dr. Carol Connor for her tremendous contributions to the science of reading interventions and child by instruction interaction literature. Dr. Connor was an original Co-Investigator of Project KIDS.
Funding:
This work is supported by Eunice Kennedy Shriver National Institute of Child Health & Human Development Grants R21HD072286, P50HD052120, and R01HD095193. Cynthia Norris is supported by the McKnight Fellowship at the Florida State University and the Institute of Education Sciences FIREFLIES Doctoral Training Fellowship (H325D190037). Views expressed herein are those of the authors and have neither been reviewed nor approved by the granting agencies.
References
- Al Otaiba S, Connor CM, Folsom JS, Wanzek J, Greulich L, Schatschneider C, & Wagner RK (2014). To wait in Tier 1 or intervene immediately: A randomized experiment examining first-grade response to intervention in reading. Exceptional Children, 81(1), 11–27. 10.1177/0014402914532234 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Al Otaiba S, Folsom JS, Wanzek J, Greulich L, Waesche J, Schatschneider C, & Connor CM (2016). Professional development to differentiate kindergarten Tier 1 instruction: Can already effective teachers improve student outcomes by differentiating Tier 1 instruction? Reading & Writing Quarterly, 32(5), 454–476. 10.1080/10573569.2015.1021060 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Al Otaiba S, & Fuchs D (2002). Characteristics of children who are unresponsive to early literacy intervention: A review of the literature. Remedial and Special Education, 23(5), 300–316. 10.1177/07419325020230050501 [DOI] [Google Scholar]
- AlOtaiba S, Connor CM, Folsom JS, Greulich L, Meadows J, & Li Z (2011). Assessment data–informed guidance to individualize kindergarten reading instruction: Findings from a cluster-randomized control field trial. The Elementary School Journal, 111(4), 535–560. 10.1086/659031 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Connor CM, Morrison FJ, Fishman B, Crowe EC, Al Otaiba S, & Schatschneider C (2013). A longitudinal cluster-randomized controlled study on the accumulating effects of individualized literacy instruction on students’ reading from first through third grade. Psychological Science, 24(8), 1408–1419. 10.1177/0956797612472204 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Connor CM, Morrison FJ, Fishman B, Giuliani S, Luck M, Underwood PS, Bayraktar A, Crowe EC, & Schatschneider C (2011). Testing the impact of child characteristics × instruction interactions on third graders’ reading comprehension by differentiating literacy instruction. Reading Research Quarterly, 46(3), 189–221. 10.1598/RRQ.46.3.1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Connor CM, Morrison FJ, Fishman BJ, Schatschneider C, & Underwood P (2007). Algorithm-guided individualized reading instruction. Science, 315(5811), 464–465. 10.1126/science.1134513 [DOI] [PubMed] [Google Scholar]
- Connor CM, Morrison FJ, Schatschneider C, Toste J, Lundblom E, Crowe EC, & Fishman B (2011). Effective classroom instruction: Implications of child characteristics by reading instruction interactions on first graders’ word reading achievement. Journal of Research on Educational Effectiveness, 4(3), 173–207. 10.1080/19345747.2010.510179 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Curran PJ, McGinley JS, Bauer DJ, Hussong AM, Burns A, Chassin L, Sher K, & Zucker R (2014). A moderated nonlinear factor model for the development of commensurate measures in Integrative Data Analysis. Multivariate Behavioral Research, 49(3), 214–231. 10.1080/00273171.2014.889594 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Daucourt MC, Schatschneider C, Connor CM, Al Otaiba S, & Hart SA (2018). Inhibition, updating working memory, and shifting predict reading disability symptoms in a hybrid model: Project KIDS. Frontiers in Psychology, 9. 10.3389/fpsyg.2018.00238 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gough PB, & Tunmer WE (1986). Decoding, Reading, and Reading Disability. Remedial and Special Education, 7(1), 6–10. 10.1177/074193258600700104 [DOI] [Google Scholar]
- Gresham FM, & Elliott SN (1990). Social skills rating system (SSRS). American Guidance Service. [Google Scholar]
- Hart SA, Schatschneider C, Al Otaiba S, & Connor CM (2021). Project KIDS [Data set]. 10.33009/ldbase.1619716971.79ee [DOI]
- Haughbrook R (2020). Exploring Racial Bias in Standardized Assessments and Teacher-Reports of Student Achievement with Differential Item and Test Functioning Analyses [Doctoral dissertation]. Florida State University. [Google Scholar]
- Hoover WA, & Gough PB (1990). The simple view of reading. Reading and Writing, 2(2), 127–160. [Google Scholar]
- Hussong AM, Curran PJ, & Bauer DJ (2013). Integrative Data Analysis in clinical psychology research. Annual Review of Clinical Psychology, 9(1), 61–89. 10.1146/annurev-clinpsy-050212-185522 [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacCallum RC, Browne MW, & Cai L (2006). Testing differences between nested covariance structure models: Power analysis and null hypotheses. Psychological Methods, 11(1), 19–35. 10.1037/1082-989X.11.1.19 [DOI] [PubMed] [Google Scholar]
- Norris CU, Shero JSA, Haughbrook R, Holden LR, van Dijk W, Al Otaiba S, Schatschneider C, & Hart SA (2020). Socioeconomic status and response to a reading intervention: A quantile regression approach [Preprint]. PsyArXiv. 10.31234/osf.io/xqbc5 [DOI] [Google Scholar]
- Ritchey KD, Silverman RD, Montanaro EA, Speece DL, & Schatschneider C (2012). Effects of a Tier 2 supplemental reading intervention for at-risk fourth-grade students. Exceptional Children, 78(3), 318–334. 10.1177/001440291207800304 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schatschneider C, Edwards Ashley, & Shero Jeffrey. (2021). De-Identification Guide 24104 Bytes. 10.6084/M9.FIGSHARE.13228664.V2 [DOI] [Google Scholar]
- Vadasy PF, Sanders EA, & Abbott RD (2008). Effects of supplemental early reading intervention at 2-year follow up: Reading skill growth patterns and predictors. Scientific Studies of Reading, 12(1), 51–89. 10.1080/10888430701746906 [DOI] [Google Scholar]
- van Dijk W, Canarte D, Al Otaiba S, & Hart SA (2021). Intervention_projects.png (p. 65276 Bytes). figshare. 10.6084/M9.FIGSHARE.16989652.V1 [DOI]
- van Dijk W, Schatschneider C, Al Otaiba S, & Hart SA (2021a). Do Student Behavior Ratings Predict Response to Comprehensive Reading Approaches? [Preprint]. EdArXiv. 10.35542/osf.io/jfxz5 [DOI] [Google Scholar]
- van Dijk W, Schatschneider C, Al Otaiba S, & Hart SA (2021b). Assessing measurement invariance across multiple groups: When is fit good enough? Educational and Psychological Measurement, 1–24. 10.1177/00131644211023567 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Widaman KF, Grimm KJ, Early DR, Robins RW, & Conger RD (2013). Investigating factorial invariance of latent variables across populations when manifest variables are missing completely. Structural Equation Modeling: A Multidisciplinary Journal, 20(3), 384–408. 10.1080/10705511.2013.797819 [DOI] [PMC free article] [PubMed] [Google Scholar]