

Abstract
Background
Trust in science and scientists has received renewed attention because of the “infodemic” occurring alongside COVID-19. A robust evidence basis shows that such trust is associated with belief in misinformation and willingness to engage in public and personal health behaviors. At the same time, trust and the associated construct of credibility are complex meta-cognitive concepts that often are oversimplified in quantitative research. The discussion of research often includes both normative language (what one ought to do based on a study’s findings) and cognitive language (what a study found), but these types of claims are very different, since normative claims make assumptions about people’s interests. Thus, this paper presents a protocol for a large randomized controlled trial to experimentally test whether some of the variability in trust in science and scientists and perceived message credibility is attributable to the use of normative language when sharing study findings in contrast to the use of cognitive language alone.
Objective
The objective of this trial will be to examine if reading normative and cognitive claims about a scientific study, compared to cognitive claims alone, results in lower trust in science and scientists as well as lower perceived credibility of the scientist who conducted the study, perceived credibility of the research, trust in the scientific information on the post, and trust in scientific information coming from the author of the post.
Methods
We will conduct a randomized controlled trial consisting of 2 parallel groups and a 1:1 allocation ratio. A sample of 1500 adults aged ≥18 years who represent the overall US population distribution by gender, race/ethnicity, and age will randomly be assigned to either an “intervention” arm (normative and cognitive claims) or a control arm (cognitive claims alone). In each arm, participants will view and verify their understanding of an ecologically valid claim or set of claims (ie, from a highly cited, published research study) designed to look like a social media post. Outcomes will be trust in science and scientists, the perceived credibility of the scientist who conducted the study, the perceived credibility of the research, trust in the scientific information on the post, and trust in scientific information coming from the author of the post. Analyses will incorporate 9 covariates.
Results
This study will be conducted without using any external funding mechanisms.
Conclusions
If there is a measurable effect attributable to the inclusion of normative language when writing about scientific findings, it should generate discussion about how such findings are presented and disseminated.
Trial Registration
Open Science Framework n7yfc; https://osf.io/n7yfc
International Registered Report Identifier (IRRID)
PRR1-10.2196/41747
Keywords: trust, trust in science, scientific communication, meta-science, RCT, randomized controlled trial, infodemic, COVID-19, misinformation, normative language, meta-cognitive, cognitive, scientific information, credible, credibility
Introduction
Trust in Science and Scientists
The “infodemic” [1] accompanying the COVID-19 pandemic [2,3] has reinforced the importance of studying how people perceive information about and from scientific studies. When people are presented with a high volume of information of varying accuracy, we propose that there exists a broad social interest in people making decisions based on the best available evidence. Our team’s epistemological framework is that the scientific method is an excellent means of producing evidence. However, the suitability of the scientific method for producing knowledge, in general, does not necessarily mean that all purported scientific findings are of equal weight or that all scientists’ findings or statements are trustworthy [4,5]. Indeed, alongside truly remarkable scientific discoveries during the pandemic, Retraction Watch recently documented its 250th COVID-19 paper retraction, and many of the papers on their list are associated with commonly shared misinformation about the pandemic (eg, the supposed role of 5G networks in spreading COVID-19) [6]. Thus, although we will shortly argue that trust in science and scientists is valuable to understand, it is important not to conflate such trust with a more simplified aphorism such as “trust the science” [7], which (in our view, inappropriately) implies a singular “science” that is inherently worthy of trust.
At the same time, even though trust is defined and measured in a variety of different ways, studies conducted across multiple different populations have identified associations between trust in science and intention to get vaccinated or boosted for COVID-19 [8-12], as well as adherence to other measures to mitigate harm from the pandemic (eg, nonpharmaceutical interventions) [13-17]. Thus, even if the exact nature of the relationship is unclear, it is reasonable to speculate that trust in science and scientists is associated with people’s behaviors during a public health emergency such as COVID-19. We also note that trust in science and scientists is associated with belief in misinformation. Our research team has been studying trust in science and scientists as a complex and multifaceted variable using a conceptualization from Nadelson et al [18]. They validated a 21-item measure that includes multiple conceptual domains related to trust, computed using responses to items such as “We cannot trust scientists to consider ideas that contradict their own,” and “When scientists form a hypothesis they are just guessing” [18]. Using their 21-item measure to compute an aggregated value for trust, we found evidence of strong associations between low trust in science and belief in scientifically unsupported statements (eg, “misinformation”) about COVID-19 [19,20] and opioid overdose and naloxone [21].
We used those findings to develop a digital intervention, very deliberately rejecting approaches focused on the manipulation of trust in favor of creating truthful informational infographics to explain common misperceptions about science (ie, why it is appropriate for scientists to change their minds in response to new evidence) [22]. In a large preregistered, randomized controlled trial, we found evidence that 60 seconds of exposure to one such infographic, which featured an example of changing recommendations around butter and margarine, slightly and significantly increased trust in science and scientists and slightly reduced the likelihood that participants whose trust was thereby increased would endorse COVID-19 misinformation (ie, a mediational, but not direct, intervention effect) [20]. However, we observed no effects on behavioral intentions whatsoever, even though exploratory analyses showed that the trust variable remained associated with behavioral intentions [20].
This difference between the intervention’s effects on beliefs and behavioral intentions may raise questions about the ways in which scientific claims, as well as misinformation, may contain both cognitive and normative elements (which we unpack subsequently) and whether such elements are associated with trust in science and scientists. Furthermore, recent papers have reemphasized the importance of attending to both universals (eg, “trust in science and scientists”) and particulars (eg, “credibility of a specific scientist or claim”) in this area of study [4,5]. Thus, the remainder of this introduction makes the case for rigorously examining a seemingly small—but potentially important—distinction between cognitive and normative claims and the impact of such a difference on universal and particularized trust and describes our plan to do so.
Cognitive and Normative Scientific Claims
In this study, we will scrutinize the differences between “cognitive” (ie, epistemic) claims of scientific findings and “normative” claims (ie, recommendations). For many scientific endeavors (such as experiments or evaluative studies), a key outcome of the research is 1 or more cognitive claims. A basic example of a cognitive claim is “the current is really strong out by the pier,” which is an assertion about the strength of the current. Importantly, a cognitive claim does not include a recommendation about what we ought to do if the claim is true. Such “ought” statements are instead normative claims, which pertain to what a person should do (eg, if it is the case that the current is really strong out by the pier, “...you should not swim there”) [23].
In a consequentialist account of rationality, cognitive claims can be separated from normative or practical claims [23]. We often use others’ cognitive claims to understand the world around us (eg, “we know by trusting what others tell us”) [24]. This trust is necessary because no person has the ability to generate empirical knowledge about everything (given constraints such as capacity, resources, interest, and time). Thus, people frequently make decisions about which and whose cognitive claims to trust [25].
In contrast, normative claims presume a framework of interests (eg, not wanting to swim in dangerous places), but such framing may not always apply to all persons (eg, someone who is at the pier to test a device built to measure current strength). Even if we trust a cognitive claim, we may not trust an associated recommendation [26]. A helpful real-life anecdote can be found in a headline from July 2021 titled “People are dressing in disguise for COVID-19 vaccines, Missouri doctor says” [27]. For the people in that story, the recommendation to get vaccinated was complicated, not because of any explicit disbelief in scientific cognitive claims about the vaccine, but because it did not account for a strong competing interest in not being “ridiculed” by friends, family, or coworkers. Similarly, when physical conflicts—including some resulting in death—erupted across the United States in 2021 over face masks, media coverage suggests the primary concern was not the science behind face masks, per se, but rather whether people should or should not be wearing them in a particular public space and time [28-31].
We hypothesize that some meaningful percentage of variability in trust in science and scientists, both generally and at the level of specific claims and persons, is attributable to the linguistic entanglement of cognitive and normative claims (eg, in press releases, popular summaries, and social media). In particular, we expect that some portion of mistrust is unrelated to scientific epistemic claims and may instead be explained by perceptions of discordant interests between laypersons and scientists. If that is the case, then we would expect to see reduced levels of trust and perceived credibility in study participants exposed to both a cognitive and normative claim about a study compared to those exposed only to a cognitive claim (ie, “I believe your finding, but I don’t agree with your recommendation”). If we are correct, it may have important ramifications for the way in which scientific findings are reported at multiple levels (eg, abstract, press release, news coverage, and social media).
Study Objectives and Hypotheses
Our study will draw conclusions by randomizing a large, nationally representative sample of US adults to view a sample social media post that either (1) shares a cognitive claim from a 2020 study on face masks (control group), or (2) shares the same cognitive claim but also includes a normative claim about what people should do, given the cognitive claim, which is also from that study (intervention group; see Methods). We hypothesize the following (see Table 1):
Table 1.
Design table.
| Question | Hypothesis (if applicable) | Sampling plan (eg, power analysis) | Analysis plan | Interpretation given to different outcomes |
| What is the effect of intervention arm assignment on overall trust in science and scientists (21-item scale)? | Overall trust in science and scientists (21-item scale) will be significantly lower in the intervention arm than the control arm. | With 80% power (2-tailed test), this sample will allow us to detect small effects at α=.05 (Cohen d=0.14) and at corrected α=.01 (Cohen d=0.18) for differences between groups. | ANCOVAa, incorporating all 9 listed covariates | A significant effect will be interpreted as evidence that the inclusion of normative language caused the change (if the change exists), regardless of direction. |
| What is the effect of intervention arm assignment on the credibility of the research, credibility of the scientist who conducted the study, trust in scientific information from the author of the post, and trust in the scientific information on the post? | For hypotheses 2 through 5, each dependent variable will be significantly lower in the intervention arm than the control arm. | With 80% power (2-tailed test), this sample will allow us to detect very small effects at α=.05 (Cohen d=0.14) and at corrected α=.01 (Cohen d=0.18) for differences between groups. | ANCOVA, incorporating all 9 listed covariates | A significant effect will be interpreted as evidence that the inclusion of normative language caused the change (if the change exists), regardless of direction. |
| Are there any significant interactions between intervention arm assignment and political orientation on any of the prespecified dependent variables? | N/Ab | N/A | Linear regression including the interaction between intervention arm and political orientation; the model will include the remaining 8 covariates | A significant interaction will be interpreted as possible evidence that political orientation may mediate or moderate the effect of including normative language in some way, regardless of direction, but that further research is needed. |
aANCOVA: analysis of covariance.
bN/A: not applicable.
Hypothesis 1: Overall trust in science and scientists (21-item scale) [18] will be significantly lower in the intervention arm (cognitive and normative claims) than the control arm (cognitive claim only).
Hypotheses 2-5: The credibility of the scientist who conducted the study, credibility of the research, trust in the scientific information on the post, and trust in scientific information coming from the author of the post [32] will each be significantly lower in the intervention arm (cognitive and normative claims) than the control arm (cognitive claim only).
Preregistered analyses (without hypotheses): We will study the interaction between the study arm and political orientation for each of the 5 preregistered hypotheses.
Methods
Ethics Approval and Consent to Participate
This study will comply with relevant ethical regulations as outlined and approved by the Indiana University Institutional Review Board (16141) on August 2, 2022. Informed consent will be obtained from participants using electronic agreement to a study information sheet embedded at the beginning of the experiment. Participants will be paid US $1.50 on the successful completion of the study and submission for compensation (see Sampling Plan).
Design
Trial Design
We will conduct a randomized controlled trial consisting of 2 parallel groups and a 1:1 allocation ratio. Our planned study workflow is provided in Figure 1. Allocation will be automated by the Randomizer feature in the QualtricsXM platform [33] and thus, by definition, will be concealed from researchers until after each case has been assigned. However, we note that based on our prior experience, the use of data quality checks and the 2-step survey completion procedures in the Prolific platform can result in unbalanced allocation for a very small portion of the sample as recruitment approaches the planned limit (eg, if the number of usable surveys exceeds the number of surveys solicited, the excess surveys may not be allocated 1:1 but will still be included following sensitivity analysis) [20].
Figure 1.
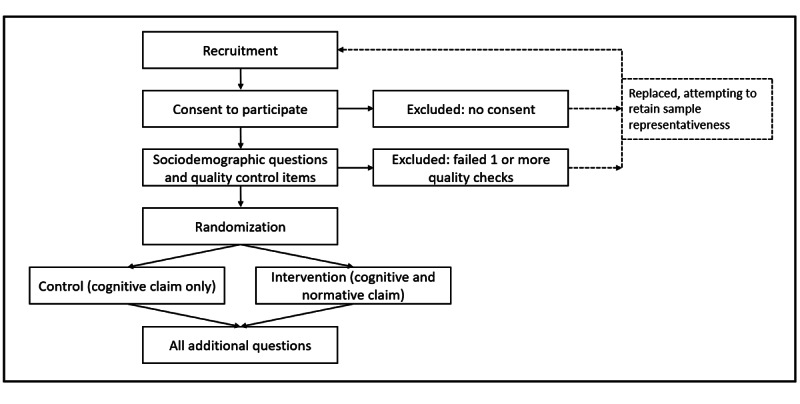
Study design and workflow.
This study will be, in principle, a double-blind study; participants will be unaware that they are being randomized to a condition, and allocation will be done exclusively by software. However, analysts will not be blinded to the meaning of the group assignment variable.
Participants and Procedures
This study will solicit participants (n=1500) from the Prolific crowdsourced US representative participant pool, which provides a cross-section of age, sex, and race/ethnicity that mirrors the national US population [34]. This sampling frame also provides the de facto eligibility criteria of being aged ≥18 years and residing in the United States. Studies have found the Prolific platform to produce high-quality research data in general and relative to competing services (eg, Qualtrics and Dynata panels, Amazon MTurk, and CloudResearch) [35,36].
When individuals indicate interest in participating in the study, they will be provided with a link to the experiment, which will be hosted on the QualtricsXM platform. Participants who agree to participate in the study (study information sheet) will complete the first block of questions, which will include sociodemographic items intermixed with screening questions to identify the risk of low-quality data (ie, virtual private network or bot use, inattention, and dishonesty) [37]. Individuals who fail 1 or more checks will be considered ineligible for the study and asked to return the study to the Prolific platform for reselection.
As noted in Figure 1, randomization will occur after all determinations of eligibility to preserve sample composition and allocation. The study will be fully insular (eg, all components occur within the QualtricsXM platform and within 1 “sitting”). To mitigate the potential impact of missing data, participants will not be permitted to advance the survey if they have not answered all questions on a given page. All data will be exported directly from the QualtricsXM platform to a local data file once the study closes, and the code used for data cleaning (see Sampling Plan) will be shared alongside the raw data.
Intervention and Control Description
To isolate the specific effects of normative language in describing scientific findings, we will show participants 1 of 2 fake social media posts depending on the study arm to which they are randomized. The posts will be identical except for the inclusion of normative language in the intervention post. To improve ecological validity [38], both posts will be designed using the formatting parameters for modern Facebook timeline posts as displayed in a web browser using “night” mode (see Figures 2 and 3). The posts will appear as posts “Suggested for you” from a generic science page, which is the primary subheading that Facebook uses when inserting content that is not explicitly followed on a person’s timeline. The lead-in text will read, “Today’s post highlights a study published back in April 2020, right after the COVID-19 pandemic arrived in the United States. This was from a peer-reviewed paper in Infectious Disease Modeling.” Both posts will be accompanied by the same generic image of a surgical face mask and a bottle of hand sanitizer.
Figure 2.
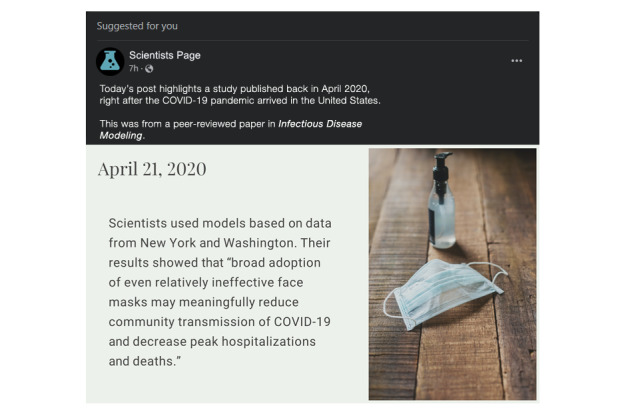
Control image.
Figure 3.
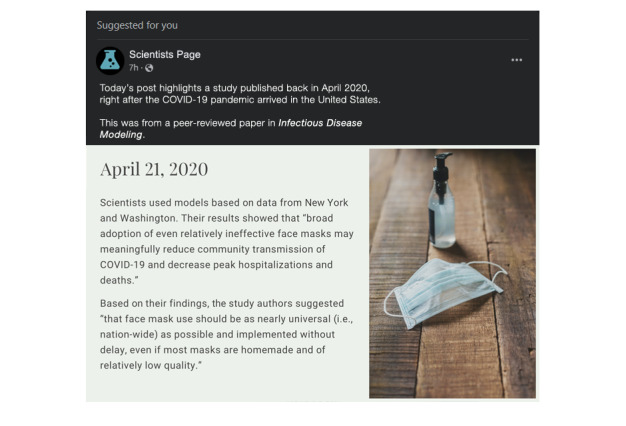
Intervention image.
Additionally, in service of ecological validity, the written content of the graphics will be drawn directly from a highly cited April 2020 paper on face masks for the prospective prevention of COVID-19 [39]. The control post (Figure 2) will feature only a cognitive claim: “Scientists used models based on data from New York and Washington. Their results showed that ‘broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths.’”
The intervention post (Figure 3) will include the same cognitive language but also add a normative statement derived from the same source paper. It will add “Based on their findings, the study authors suggested ‘that face mask use should be as nearly universal (i.e., nation-wide) as possible and implemented without delay, even if most masks are homemade and of relatively low quality.’”
Once the image is displayed, participants will not be able to advance the survey for at least 30 seconds (the button to continue the survey will be linked to a timer). A message indicating this delay will be provided on the screen. After participants advance, they will transition to a screen featuring a smaller copy of the image appropriate for their study arm, along with 1 (control) or 2 (intervention) comprehension questions.
Both arms: (True/False) “In the social media post you read about a scientific study from April 2020, the study authors found that face masks could reduce the spread of COVID-19 as well as lowering hospitalizations and deaths.”
Intervention arm only: (True/False) “In the social media post you read about a scientific study from April 2020, the study authors recommended that everyone in the US should start wearing masks immediately.”
Any response other than “True” for either question will display a message asking the participant to read the post carefully again, and then participants will be returned to the social media post (no 30-second delay on subsequent viewings), from which they can proceed forward to the comprehension questions again.
Sampling Plan
Sample Size Determination and Power Analysis
As previously described, we will recruit 1500 individuals from the Prolific platform, with equal allocation to study arms. This sample size is currently the largest number of people for which the Prolific platform can assure national representativeness. We made the decision to recruit a large number of participants because we were unable to locate any baseline studies with which to estimate effect size, so we wanted to be conservative. In addition, although the issue of face masks continues to be a point of public contention, the prevalence of public health mandates related to face masks is lower than those in 2020-2021, which we suspect may serve to suppress the effect size relative to what it would be in the midst of more active social discord focused on that topic. With 80% power (2-tailed test), this sample will allow us to detect small effects at α=.05 (Cohen d=0.14) and at corrected α=.01 (Cohen d=0.18) for differences of trust in science between treatment and control. In keeping with modern inferential statistical recommendations, we will report all P values precisely rather than by threshold [40] and provide a balanced interpretation, especially where .01<P<.05.
Technical Exclusion and Inclusion Procedures
With participant recruitment through a web-based pool, the number of usable responses is specified first (ie, the sample size)—in this case, 1500. When participants complete the survey, they will submit evidence of completion to the researchers, who will then approve payment via the Prolific platform. When an individual is rejected for payment (either at the time of submission for payment or at any other time), they will be resampled and replaced by a new member of the pool who matches their sociodemographic characteristics (eg, age, sex, and race/ethnicity). As a result, the number of participants who accept the survey initially will generally be different than the final sample size. This difference can occur for the following reasons (we provide rough estimates of prevalence based on a prior large study with the Prolific platform) [20]:
Excluded: refusal to participate by declining consent (approximately 0.19%)
Excluded: failing a quality control check and “returning” the survey (approximately 2.14%)
Excluded: exiting the Qualtrics platform immediately after consenting to participate (approximately 0.37%)
Excluded: exiting the Qualtrics platform prior to accessing the intervention, typically, but not always, after being informed of failing a quality control check (approximately 2.88%)
Included: completing the full study correctly but failing to submit a request for payment (approximately 1.58%)
The overall estimated impact is that is roughly 5.57% of individuals who initially access the survey from the study pool will end up being rejected and resampled in the process of reaching the targeted sample size of 1500. Subsequently, a small number of individuals (roughly 1.58%) may fail to submit for payment but otherwise provide good data; these individuals will be analyzed in the arms to which they were assigned (but as noted earlier, will not be allocated 1:1).
Analysis Plan
Primary Outcomes
The primary outcomes are as follows.
-
Hypothesis 1
Overall trust in science and scientists will be measured by the 21-item scale developed and validated by Nadelson et al [18]. An example item from the scale measures agreement with the statement, “When scientists change their mind about a scientific idea it diminishes my trust in their work.” This scale has demonstrated excellent internal reliability in our previous studies with crowdsourced samples (α>.900) [19-22,41].
-
Hypotheses 2 through 5
Single-item measures of credibility and trust that are specific to the hypothetical social media post and the scientist who conducted the study, from Song et al [32]
“How credible is the scientist who conducted the study described in the post?” (1=not credible at all to 7=extremely credible); note that this language is slightly different than the original item to avoid ambiguity arising from the potential that a scientist authored the social media post
“How credible is this research?” (1=not credible at all to 7=extremely credible)
“I would trust scientific information if I knew it came from this author.” (1=strongly disagree to 7=strongly agree)
“I trust this scientific information.” (1=strongly disagree to 7=strongly agree)
Covariates
The covariates are as follows.
Familiarity with science will be measured by 1 item asking, “How often do you read science papers or science in the news?” (1=never to 5=always) [32]; this item was suggested in Song et al [32] as being potentially important to consider
Level of religious commitment (0=low to 10=high), as used in our previous studies [19,20,41]
Political orientation (0=liberal to 10=conservative), as used in our previous studies [19,20,41]
Political party (Republican, Democrat, or other), given recent research suggesting divergence between political orientation and party orientation pertaining to face masks [42]
Race, ethnicity, gender, age (“About how old are you (in years)?”), and education level (“What is the highest grade or level of school you have completed, or the highest degree you have received?”) [43]
Statistical Analyses
Descriptive statistics of demographics and outcomes will be calculated. We will explore distributions of trust in science (Hypothesis 1) and each of the single-item measures (Hypotheses 2-5).
Data will be analyzed using analysis of covariance (ANCOVA), with the assignment of the study arm (intervention vs control) used as the independent variable and the specified outcomes (depending on the hypothesis) set as the dependent variable. All specified covariates will be included in each model, and assumptions for the analyses will be evaluated (eg, the normality of residuals and linear relationships between covariates and the dependent variable). If assumptions are not met, the research team will explore different transformations or nonparametric models as recommended by statistical experts.
Missingness is not anticipated owing to the study design, but if it occurs at a meaningful level (>5%), we will perform sensitivity analysis using Multiple Imputation by Chained Equations to explore how missingness affects the results, and in the case that the results differ, we will report Multiple Imputation by Chained Equations as the primary analysis.
Data and Code Availability
Raw data will be included as a digital supplement in each format needed to execute the included code (eg, .csv and .sav) alongside the full paper when published. All code needed to replicate the specific data cleaning and analysis steps in this paper will be included as a digital supplement alongside the full paper when published.
Results
This protocol was prepared in full and submitted for review prior to any data collection or subject recruitment. The study will be conducted without using any external funding mechanisms. Results are expected to be published in late 2022 or early 2023.
Discussion
Expected Findings
This study is designed to determine whether the use of normative language in addition to cognitive language has an effect on a variety of measures related to general and specific trust in science and scientists as well as the credibility of the claims and their author(s). As indicated previously, we expect to see lower levels of general and localized trust in science and as well as reduced perceptions of credibility of both the post and the scientist(s) conducting the study among study participants who are exposed to both a cognitive and normative claim about a study than those exposed only to a cognitive claim.
Next Steps
If 1 or more of our hypotheses are correct, then we hope to use these findings to initiate discussions about research dissemination and communication and the ways in which communication about research findings might more closely attend to and explicitly draw distinctions between cognitive and normative claims. This discussion may include conversations around changing the ways in which scientists communicate generally and addressing the complexity of separating normative and cognitive claims when communicating outside of the field (eg, with the media or policy makers).
We plan to disseminate the results of this study regardless of the findings through peer-reviewed publications as well as other avenues, as appropriate.
Limitations
We anticipate that this study design may result in several limitations to its interpretation. First, we cannot control the conditions in which people participate; thus, although we will incorporate comprehension checks for the intervention, we cannot be assured that all participants will sufficiently engage with the intervention content. Second, since this is a web-based study through the Prolific platform, even though the results have a degree of national US generalizability, they still reflect the unique characteristics of those who have signed up for the Prolific platform as well as, by extension, those who actively use the internet. In a recent protocol for our COVID-19 intervention study, we outline why we believe these concerns are somewhat attenuated for this type of experiment [44]. Other limitations may be identified during the study itself or by reviewers at each stage of the project and will be noted after their identification.
Acknowledgments
We would like to thank Dr Judith Greenberg for her insightful suggestions and edits to the first draft of this manuscript. The authors did not receive any funding to complete this work.
Data Availability
Data sharing is not applicable to this article as no data sets were generated or analyzed in the preparation of this protocol.
Footnotes
Authors' Contributions: JA contributed to conceptualization, project administration, resources, visualization, and writing the original draft. YX and LGA contributed to formal analysis. JA, YX, and LGA contributed to the methodology. All authors contributed to investigation, validation, and writing—review and editing.
Conflicts of Interest: None declared.
References
- 1.Eysenbach G. Infodemiology: The epidemiology of (mis)information. Am J Med. 2002 Dec 15;113(9):763–5. doi: 10.1016/s0002-9343(02)01473-0.S0002934302014730 [DOI] [PubMed] [Google Scholar]
- 2.Zarocostas J. How to fight an infodemic. Lancet. 2020 Feb 29;395(10225):676. doi: 10.1016/S0140-6736(20)30461-X. https://europepmc.org/abstract/MED/32113495 .S0140-6736(20)30461-X [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Tangcharoensathien V, Calleja N, Nguyen T, Purnat T, D'Agostino M, Garcia-Saiso S, Landry Mark, Rashidian Arash, Hamilton Clayton, AbdAllah Abdelhalim, Ghiga Ioana, Hill Alexandra, Hougendobler Daniel, van Andel Judith, Nunn Mark, Brooks Ian, Sacco Pier Luigi, De Domenico Manlio, Mai Philip, Gruzd Anatoliy, Alaphilippe Alexandre, Briand Sylvie. Framework for managing the COVID-19 infodemic: methods and results of an online, crowdsourced WHO technical consultation. J Med Internet Res. 2020 Jun 26;22(6):e19659. doi: 10.2196/19659. https://www.jmir.org/2020/6/e19659/ v22i6e19659 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Contessa G. It takes a village to trust science: towards a (thoroughly) social approach to public trust in science. Erkenntnis. 2022 Feb 17;:1–26. doi: 10.1007/s10670-021-00485-8. https://europepmc.org/abstract/MED/35194273 .485 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.O'Doherty K. Trust, trustworthiness, and relationships: ontological reflections on public trust in science. J Responsible Innov. 2022 Jul 11;:1–22. doi: 10.1080/23299460.2022.2091311. doi: 10.1080/23299460.2022.2091311. [DOI] [Google Scholar]
- 6.Retracted coronavirus (COVID-19) papers. Retraction Watch. 2022. [2022-07-25]. https://retractionwatch.com/retracted-coronavirus-covid-19-papers/
- 7.Krause NM, Scheufele DA, Freiling I, Brossard D. The trust fallacy: scientists' search for public pathologies is unhealthy, unhelpful, and ultimately unscientific. Am Sci. 2021 Jul;109(4):226–31. doi: 10.1511/2021.109.4.226. [DOI] [Google Scholar]
- 8.Agley J, Xiao Y, Thompson EE, Golzarri-Arroyo L. Factors associated with reported likelihood to get vaccinated for COVID-19 in a nationally representative US survey. Public Health. 2021 Jul;196:91–94. doi: 10.1016/j.puhe.2021.05.009. https://linkinghub.elsevier.com/retrieve/pii/S0033-3506(21)00189-X .S0033-3506(21)00189-X [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Osuji VC, Galante EM, Mischoulon D, Slaven JE, Maupome G. COVID-19 vaccine: a 2021 analysis of perceptions on vaccine safety and promise in a U.S. sample. PLoS One. 2022 May 19;17(5):e0268784. doi: 10.1371/journal.pone.0268784. https://dx.plos.org/10.1371/journal.pone.0268784 .PONE-D-21-24238 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Seddig D, Maskileyson D, Davidov E, Ajzen I, Schmidt P. Correlates of COVID-19 vaccination intentions: attitudes, institutional trust, fear, conspiracy beliefs, and vaccine skepticism. Soc Sci Med. 2022 Jun;302:114981. doi: 10.1016/j.socscimed.2022.114981. https://linkinghub.elsevier.com/retrieve/pii/S0277-9536(22)00287-8 .S0277-9536(22)00287-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lee RC, Hu H, Kawaguchi ES, Kim AE, Soto DW, Shanker K, Klausner Jeffrey D, van Orman Sarah, Unger Jennifer B. COVID-19 booster vaccine attitudes and behaviors among university students and staff in the United States: the USC Trojan pandemic research Initiative. Prev Med Rep. 2022 Aug;28:101866. doi: 10.1016/j.pmedr.2022.101866. https://linkinghub.elsevier.com/retrieve/pii/S2211-3355(22)00173-5 .S2211-3355(22)00173-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Barattucci M, Pagliaro S, Ballone C, Teresi Manuel, Consoli C, Garofalo A, De Giorgio Andrea, Ramaci Tiziana. Trust in science as a possible mediator between different antecedents and COVID-19 booster vaccination intention: an integration of health belief model (HBM) and theory of planned behavior (TPB) Vaccines (Basel) 2022 Jul 08;10(7):1099. doi: 10.3390/vaccines10071099. https://www.mdpi.com/resolver?pii=vaccines10071099 .vaccines10071099 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Dohle S, Wingen T, Schreiber M. Acceptance and adoption of protective measures during the COVID-19 pandemic: the role of trust in politics and trust in science. Soc Psychol Bull. 2020 Dec 23;15(4):1–23. doi: 10.32872/spb.4315. [DOI] [Google Scholar]
- 14.Hromatko I, Tonković Mirjana, Vranic A. Trust in science, perceived vulnerability to disease, and adherence to pharmacological and non-pharmacological COVID-19 recommendations. Front Psychol. 2021 Apr 30;12:664554. doi: 10.3389/fpsyg.2021.664554. doi: 10.3389/fpsyg.2021.664554. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Plohl N, Musil B. Modeling compliance with COVID-19 prevention guidelines: the critical role of trust in science. Psychol Health Med. 2021 Jan 01;26(1):1–12. doi: 10.1080/13548506.2020.1772988. [DOI] [PubMed] [Google Scholar]
- 16.Han H. Trust in the scientific research community predicts intent to comply with COVID-19 prevention measures: an analysis of a large-scale international survey dataset. Epidemiol Infect. 2022 Feb 08;150:e36. doi: 10.1017/S0950268822000255. https://europepmc.org/abstract/MED/35131001 .S0950268822000255 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Ochel P, Eitze S, Siegers R, Betsch C, Seufert A. Determinants of adoption and rejection of protective measures during the SARS-CoV-2 pandemic: a longitudinal study in Germany’s second wave. Soc Psychol Bull. 2022 Jul 04;17:1–17. doi: 10.32872/spb.7515. [DOI] [Google Scholar]
- 18.Nadelson L, Jorcyk C, Yang D, Jarratt Smith M, Matson S, Cornell K, Husting V. I just don't trust them: the development and validation of an assessment instrument to measure trust in science and scientists. Sch Sci Math. 2014 Jan 19;114(2):76–86. doi: 10.1111/ssm.12051. [DOI] [Google Scholar]
- 19.Agley J, Xiao Y. Misinformation about COVID-19: evidence for differential latent profiles and a strong association with trust in science. BMC Public Health. 2021 Jan 07;21(1):89. doi: 10.1186/s12889-020-10103-x. https://bmcpublichealth.biomedcentral.com/articles/10.1186/s12889-020-10103-x .10.1186/s12889-020-10103-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Agley J, Xiao Y, Thompson E, Chen X, Golzarri-Arroyo L. Intervening on trust in science to reduce belief in COVID-19 misinformation and increase COVID-19 preventive behavioral intentions: randomized controlled trial. J Med Internet Res. 2021 Oct 14;23(10):e32425. doi: 10.2196/32425. https://www.jmir.org/2021/10/e32425/ v23i10e32425 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Agley J, Xiao Y, Eldridge L, Meyerson B, Golzarri-Arroyo L. Beliefs and misperceptions about naloxone and overdose among U.S. laypersons: a cross-sectional study. BMC Public Health. 2022 May 10;22(1):924. doi: 10.1186/s12889-022-13298-3. https://bmcpublichealth.biomedcentral.com/articles/10.1186/s12889-022-13298-3 .10.1186/s12889-022-13298-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Agley J, Xiao Y, Thompson E, Golzarri-Arroyo L. Using infographics to improve trust in science: a randomized pilot test. BMC Res Notes. 2021 May 29;14(1):210. doi: 10.1186/s13104-021-05626-4. https://bmcresnotes.biomedcentral.com/articles/10.1186/s13104-021-05626-4 .10.1186/s13104-021-05626-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Schurz G, Hertwig R. Cognitive success: a consequentialist account of rationality in cognition. Top Cogn Sci. 2019 Jan;11(1):7–36. doi: 10.1111/tops.12410. doi: 10.1111/tops.12410. [DOI] [PubMed] [Google Scholar]
- 24.Faulkner P, Simpson T, editors. Simpson. Oxford, United Kingdom: Oxford University Press; 2017. May 02, [Google Scholar]
- 25.Hardwig J. The role of trust in knowledge. J Philos. 1991 Dec;88(12):693–708. doi: 10.2307/2027007. [DOI] [Google Scholar]
- 26.Bennett M. Should I do as I'm told? trust, experts, and COVID-19. Kennedy Inst Ethics J. 2020 Jun 17;(Special Issue on Ethics, Pandemics, and COVID-19) https://kiej.georgetown.edu/trust-experts-and-covid-19-special-issue/ [Google Scholar]
- 27.Miranda G. People are dressing in disguise for COVID-19 vaccines, Missouri doctor says. USA Today. 2021. Jul 29, [2022-07-25]. https://www.usatoday.com/story/news/health/2021/07/29/missouri-doctor-says-people-disguise-coming-covid-vaccine/5413341001/
- 28.Lim CJ. The other victims of the pandemic: workers killed in fights over masks. Buzzfeed News. 2021. Jul 15, [2022-07-25]. https://www.buzzfeednews.com/article/clarissajanlim/workers-killed-fights-masks .
- 29.Sweeney D. Security guard stabs grocery shopper in fight over face masks, California police say. The Sacramento Bee. 2021. Nov 09, [2022-07-25]. https://www.sacbee.com/news/coronavirus/article255668351.html .
- 30.Lemon J. Delta Air Lines passengers fight over wearing mask on Christmas Eve flight. Newsweek. 2021. Dec 25, [2022-07-25]. https://www.newsweek.com/delta-air-lines-passengers-fight-over-wearing-mask-christmas-eve-flight-1663126 .
- 31.Kauffman C. Iowa man in face-mask fight sentenced to 10 years in prison. Iowa Capital Dispatch. 2021. Jun 10, [2022-07-25]. https://iowacapitaldispatch.com/2021/06/10/iowa-man-in-face-mask-fight-sentenced-to-10-years-in-prison/
- 32.Song H, Markowitz DM, Taylor SH. Trusting on the shoulders of open giants? open science increases trust in science for the public and academics. J Commun. 2022 Jun 30;72(4):497–510. doi: 10.1093/joc/jqac017. doi: 10.1093/joc/jqac017. [DOI] [Google Scholar]
- 33.Randomizer. QualtricsXM. 2020. [2020-09-04]. https://www.qualtrics.com/support/survey-platform/survey-module/survey-flow/standard-elements/randomizer/
- 34.Representative samples. Prolific. 2020. [2020-07-16]. https://researcher-help.prolific.co/hc/en-gb/articles/360019236753-Representative-Samples-on-Prolific-limited-release-
- 35.Peer E, Brandimarte L, Samat S, Acquisti A. Beyond the Turk: alternative platforms for crowdsourcing behavioral research. J Exp Soc Psychol. 2017 May;70:153–163. doi: 10.1016/j.jesp.2017.01.006. [DOI] [Google Scholar]
- 36.Peer E, Rothschild D, Gordon A, Evernden Z, Damer E. Data quality of platforms and panels for online behavioral research. Behav Res Methods. 2022 Aug 29;54(4):1643–1662. doi: 10.3758/s13428-021-01694-3. https://europepmc.org/abstract/MED/34590289 .10.3758/s13428-021-01694-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Agley J, Xiao Y, Nolan R, Golzarri-Arroyo L. Quality control questions on Amazon's Mechanical Turk (MTurk): a randomized trial of impact on the USAUDIT, PHQ-9, and GAD-7. Behav Res Methods. 2022 Apr;54(2):885–897. doi: 10.3758/s13428-021-01665-8. https://europepmc.org/abstract/MED/34357539 .10.3758/s13428-021-01665-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Lewkowicz DJ. The concept of ecological validity: what are its limitations and is it bad to be invalid? Infancy. 2001 Oct;2(4):437–450. doi: 10.1207/S15327078IN0204_03. [DOI] [PubMed] [Google Scholar]
- 39.Eikenberry SE, Mancuso M, Iboi E, Phan T, Eikenberry K, Kuang Y, Kostelich Eric, Gumel Abba B. To mask or not to mask: modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic. Infect Dis Model. 2020 Apr 21;5:293–308. doi: 10.1016/j.idm.2020.04.001. https://linkinghub.elsevier.com/retrieve/pii/S2468-0427(20)30011-7 .S2468-0427(20)30011-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Wasserstein RL, Lazar NA. The ASA statement on p-Values: context, process, and purpose. Am Stat. 2016 Jun 09;70(2):129–133. doi: 10.1080/00031305.2016.1154108. [DOI] [Google Scholar]
- 41.Agley J. Assessing changes in US public trust in science amid the COVID-19 pandemic. Public Health. 2020 Jun;183:122–125. doi: 10.1016/j.puhe.2020.05.004. https://europepmc.org/abstract/MED/32405095 .S0033-3506(20)30157-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Howard M. Are face masks a partisan issue during the COVID-19 pandemic? differentiating political ideology and political party affiliation. Int J Psychol. 2022 Feb;57(1):153–160. doi: 10.1002/ijop.12809. https://europepmc.org/abstract/MED/34545946 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Hamilton CM, Strader LC, Pratt JG, Maiese D, Hendershot T, Kwok RK, Hammond JA, Huggins W, Jackman D, Pan H, Nettles DS, Beaty TH, Farrer LA, Kraft P, Marazita ML, Ordovas JM, Pato CN, Spitz MR, Wagener D, Williams M, Junkins HA, Harlan WR, Ramos EM, Haines J. The PhenX toolkit: get the most from your measures. Am J Epidemiol. 2011 Aug 01;174(3):253–60. doi: 10.1093/aje/kwr193. https://europepmc.org/abstract/MED/21749974 .kwr193 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Agley J, Xiao Y, Thompson EE, Golzarri-Arroyo L. COVID-19 misinformation prophylaxis: protocol for a randomized trial of a brief informational intervention. JMIR Res Protoc. 2020 Dec 07;9(12):e24383. doi: 10.2196/24383. https://www.researchprotocols.org/2020/12/e24383/ v9i12e24383 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Raw data will be included as a digital supplement in each format needed to execute the included code (eg, .csv and .sav) alongside the full paper when published. All code needed to replicate the specific data cleaning and analysis steps in this paper will be included as a digital supplement alongside the full paper when published.
Data sharing is not applicable to this article as no data sets were generated or analyzed in the preparation of this protocol.