

Abstract
Prokaryotic viruses, which infect bacteria and archaea, are key players in microbial communities. Predicting the hosts of prokaryotic viruses helps decipher the dynamic relationship between microbes. Experimental methods for host prediction cannot keep pace with the fast accumulation of sequenced phages. Thus, there is a need for computational host prediction. Despite some promising results, computational host prediction remains a challenge because of the limited known interactions and the sheer amount of sequenced phages by high-throughput sequencing technologies. The state-of-the-art methods can only achieve 43% accuracy at the species level. In this work, we formulate host prediction as link prediction in a knowledge graph that integrates multiple protein and DNA-based sequence features. Our implementation named CHERRY can be applied to predict hosts for newly discovered viruses and to identify viruses infecting targeted bacteria. We demonstrated the utility of CHERRY for both applications and compared its performance with 11 popular host prediction methods. To our best knowledge, CHERRY has the highest accuracy in identifying virus–prokaryote interactions. It outperforms all the existing methods at the species level with an accuracy increase of 37%. In addition, CHERRY’s performance on short contigs is more stable than other tools.
Keywords: phage host prediction, link prediction, graph convolutional network, deep learning
1 Introduction
Prokaryotic viruses (shortened as viruses hereafter), including bacteriophages and archaeal viruses, are highly ubiquitous and abundant. They are key players in a wide range of microbial communities. By infecting their hosts, they can regulate both the composition and function of the microbiome. Thus, identifying the hosts of novel viruses play an essential role in characterizing the interactions of the organisms inhabiting the same niche.
Despite the importance of understanding the virus–host interactions, the characterized interactions between viruses and prokaryotes is just the tip of the iceberg. Experimental methods for host identification cannot keep pace with the rapid accumulation of sequenced phages. In addition, many experimental methods require cultivation of the prokaryotes [13], limiting their large-scale applications. As reported in [14, 15], no more than 1% of microbial hosts can be cultivated successfully in laboratories. With advancements of high-throughput sequencing, a large number of new phages can be sequenced from host-associated or environmental samples. As a result, host identification for newly sequenced phages lagged behind the fast accumulation of the sequencing data. Thus, computational approaches for host prediction are in great demand.
There are two major challenges for computational host prediction. The first one is the lack of known virus–host interactions. For example, the number of known interactions dated up to 2020 only accounted for ˜40% (1940) of the prokaryotic viruses at the NCBI RefSeq at that time. Meanwhile, among the 60 105 prokaryotic genomes at the NCBI RefSeq, only 223 of them have annotated interactions with the 1940 viruses. The limited known interactions require carefully designed models or algorithms for host prediction. Second, although sequence similarity between viruses and hosts is an insightful feature for host prediction, not all viruses share common regions with their host genomes. For example, in the RefSeq database, ˜24% viruses do not have significant alignments with their hosts. Therefore, the alignment-based methods cannot identify hosts for some phages.
1.1 Related work
Multiple attempts have been made to predict hosts for viruses [1, 12, 16–18]. According to the design, these methods can be roughly divided into two groups: alignment-based and learning-based. Alignment-based methods utilize the similarities between viruses or the similarities between viruses and prokaryotic genomes for host identification. For example, VPF-Class [4] utilizes Viral Protein Families (VPFs) downloaded from the IMG/VR system to estimate the similarity between query viruses and viruses with known hosts. According to the alignment results with VPFs, VPF-class can return predictions for each query contig. PHIST [7] utilizes sequence matches between viral and prokaryotic genomes for host prediction. By identifying the common 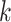 -mers shared by viral and prokaryotic genomes, PHIST estimates the probability of a virus–prokaryote pair forming a real interaction.
-mers shared by viral and prokaryotic genomes, PHIST estimates the probability of a virus–prokaryote pair forming a real interaction.
Alignment-based tools also use CRISPR for host prediction. Some prokaryotes keep a record of virus infection via CRISPR [17] to prevent recurring infections [19]. Thus, local alignment programs such as BLAST [20] can be employed to predict hosts by searching for short matches between prokaryotes and viruses. However, it is estimated that only 2~0% of sequenced prokaryotes contain CRISPRs [21, 22]. Although CRISPR is an informative host prediction signal, many viruses do not have alignment results with the annotated or predicted CRISPRs of prokaryotes and thus cannot use this signal for host prediction.
Learning-based methods are more flexible. Most of these methods learn sequence-based features for host prediction. For example, WIsH [1] trains a homogeneous Markov model for potential host genomes. The model then calculates the likelihood of a prokaryote genome as the host for a query virus and assigns the host with the highest likelihood. vHULK [10] formulates host prediction as a multi-class classification problem where the inputs are viruses and the labels are the prokaryotes. The features used in their deep learning model is the protein profile alignment results against pVOGs database of phage protein families [23]. Rather than using the public database, RaFAH [5] uses MMseqs2 [24] to generate protein clusters and constructs profile hidden Markov models (HMMs). Then, they use features output by the HMM alignments and train a multi-class random forest model. HoPhage [3], another multi-class classification model-based host prediction tool, uses deep learning and Markov chain algorithm. They use the CDS of each candidate host genome to construct a Markov chain model and then calculate the likelihood of query phage fragments infecting the candidate host genomes. They also use a deep learning model and finally integrate the results of deep learning model with the Markov model for host prediction. On the other hand, PHP [2] utilizes the 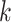 -mer frequency, which can reflect the codon usage patterns shared by the viruses and the hosts [25, 26]. DeepHost [11] and PHIAF [9] also utilize
-mer frequency, which can reflect the codon usage patterns shared by the viruses and the hosts [25, 26]. DeepHost [11] and PHIAF [9] also utilize 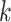 -mer-based features to train a convolutional neural network for host prediction. Boeckaerts et al. build learning models using features extracted from receptor-binding proteins (RBPs) for host prediction [27]. However, it is not trivial to annotate RBPs in all viruses. The authors only collected RBPs related to nine hosts and thus this tool can only predict very limited host species. HostG [6] utilizes the shared protein clusters between viruses and prokaryotes to create a knowledge graph and trains a graph convolutional network for prediction. Although it has high accuracy of prediction, it can only predict the host at the genus level. The best host prediction performance at the species level is reported by VHM-Net [12], which incorporates multiple features between viruses and prokaryotes such as CRISPRs, the output score of WIsH, BLASTN alignments, etc. By combining these features, VHM-net utilizes the Markov random field framework for predicting whether a virus infects a target prokaryote. Nevertheless, the accuracy at the species level is only 43%.
-mer-based features to train a convolutional neural network for host prediction. Boeckaerts et al. build learning models using features extracted from receptor-binding proteins (RBPs) for host prediction [27]. However, it is not trivial to annotate RBPs in all viruses. The authors only collected RBPs related to nine hosts and thus this tool can only predict very limited host species. HostG [6] utilizes the shared protein clusters between viruses and prokaryotes to create a knowledge graph and trains a graph convolutional network for prediction. Although it has high accuracy of prediction, it can only predict the host at the genus level. The best host prediction performance at the species level is reported by VHM-Net [12], which incorporates multiple features between viruses and prokaryotes such as CRISPRs, the output score of WIsH, BLASTN alignments, etc. By combining these features, VHM-net utilizes the Markov random field framework for predicting whether a virus infects a target prokaryote. Nevertheless, the accuracy at the species level is only 43%.
1.2 Overview
In this work, we develop a new method, CHERRY, which can predict the hosts’ taxa (phylum to species) for newly identified viruses. First, we construct a multimodal graph that incorporates multiple types of interactions, including protein organization information between viruses, the sequence similarity between viruses and prokaryotes and the CRISPR signals (Figure 1 A). In addition, we use 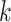 -mer frequency as the node features to enhance the learning ability. Second, rather than directly using these features for prediction, we design an encoder–decoder structure to learn the best embedding for input sequences and predict the interactions between viruses and prokaryotes. The graph convolutional encoder (Figure 1 B) utilizes the topological structure of the multimodal graph and thus, features from both training and testing sequences can be incorporated to embed new node features. Then a link prediction decoder (Figure 1 C) is adopted to estimate how likely a given virus–prokaryote pair forms a real infection. Unlike many existing tools, CHERRY can be flexibly used in two scenarios. It can take either query viruses or prokaryotes as input. For viruses, it can predict their hosts. For input prokaryotes, it can predict the viruses infecting them. Another feature behind the high accuracy of CHERRY is the construction of the negative training set. The dataset for training is highly imbalanced, with the real host as the positive data and all other prokaryotes as negative data. We carefully addressed this issue using negative sampling [28]. Instead of using a random subset of the negative set for training the model, we apply end-to-end optimization and negative sampling to automatically learn the hard cases during training. To demonstrate the reliability of our method, we rigorously tested CHERRY on multiple datasets including the RefSeq dataset, simulated short contigs, metagenomic datasets. We compared CHERRY with WIsH, PHP, HoPhage, VPF-Class, RaFAH, HostG, vHULK, PHIST, DeepHost, PHIAF and VHM-net, whose brief descriptions can be found in Table 1. The results show that CHERRY competes favorably against the state-of-the-art tools and yields 37% improvements at the species level.
-mer frequency as the node features to enhance the learning ability. Second, rather than directly using these features for prediction, we design an encoder–decoder structure to learn the best embedding for input sequences and predict the interactions between viruses and prokaryotes. The graph convolutional encoder (Figure 1 B) utilizes the topological structure of the multimodal graph and thus, features from both training and testing sequences can be incorporated to embed new node features. Then a link prediction decoder (Figure 1 C) is adopted to estimate how likely a given virus–prokaryote pair forms a real infection. Unlike many existing tools, CHERRY can be flexibly used in two scenarios. It can take either query viruses or prokaryotes as input. For viruses, it can predict their hosts. For input prokaryotes, it can predict the viruses infecting them. Another feature behind the high accuracy of CHERRY is the construction of the negative training set. The dataset for training is highly imbalanced, with the real host as the positive data and all other prokaryotes as negative data. We carefully addressed this issue using negative sampling [28]. Instead of using a random subset of the negative set for training the model, we apply end-to-end optimization and negative sampling to automatically learn the hard cases during training. To demonstrate the reliability of our method, we rigorously tested CHERRY on multiple datasets including the RefSeq dataset, simulated short contigs, metagenomic datasets. We compared CHERRY with WIsH, PHP, HoPhage, VPF-Class, RaFAH, HostG, vHULK, PHIST, DeepHost, PHIAF and VHM-net, whose brief descriptions can be found in Table 1. The results show that CHERRY competes favorably against the state-of-the-art tools and yields 37% improvements at the species level.
Figure 1.

The key components of CHERRY. (A) The multimodal knowledge graph. The triangle represents the prokaryotic node and circle represents virus nodes. Different colors represent different taxonomic labels of the prokaryotes. I–III illustrate graph convolution using neighbors of increasing orders. (B) The graph convolutional encoder of CHERRY. (C) The decoder of CHERRY.
Table 1.
A comparison of models/methods employed for host prediction of prokaryotic viruses
| Name | Model | Description | Prediction level |
|---|---|---|---|
| WIsH [1] | Markov model | Trained a homogeneous Markov model for potential host genomes and calculated the likelihood of a prokaryote genome as the host for a query virus. | Genus |
| PHP [2] | Gaussian mixture model | Utilized the k-mer frequency, which can reflect the codon usage patterns shared by the viruses and the hosts, to train a Gaussian mixture model. | Genus |
| HoPhage [3] | Deep learning model and Markov chain algorithm | Used the CDS of each candidate host genome to construct a Markov chain model and then calculated the likelihood of query phage fragments infecting the candidate host genomes. They also use a deep learning model and finally integrated the results of deep learning model with the Markov model for host prediction. | Genus |
| VPF-Class [4] | Sequence match-based model | Utilized Viral Protein Families (VPFs) downloaded from the IMG/VR system to estimate the similarity between query viruses and viruses with known hosts. | Genus |
| RaFAH [5] | Random forest model | Used MMseqs2 to generate protein clusters and constructed profile hidden Markov models (HMMs). Then, they used features output by the HMM alignments and trained a multi-class random forest model. | Genus |
| HostG [6] | Graph convolutional network (GCN) | Utilized the shared protein clusters between viruses and prokaryotes to create a knowledge graph and trained a GCN for prediction. | Genus |
| PHIST [7] | Alignment-based model | Predicted prokaryotic hosts of viruses based on exact matches between viral and host genomes. | Species |
| PredPHI [8] | Convolutional neural network (CNN) | Utilized chemical component information, such as abundance of the amino acids, from protein sequences to train a CNN for host prediction. | Species |
| PHIAF [9] | Generative adversarial network (GAN) and convolutional neural network (CNN) | Used the features originated from DNA and protein sequences, such as k-mer frequency and molecular weight, to train a CNN for host prediction. They also applied GAN to generate pseudo virus–host pairs from known virus–host interactions to enlarge the dataset. | Species |
| vHULK [10] | Multi-layer perceptron models (MLP) | Formulated host prediction as a multi-class classification problem where the inputs are viruses and the labels are the prokaryotes. The features used in their model are the protein profile alignment results against pVOGs database of phage protein families. | Species |
| DeepHost [11] | Convolutional neural network (CNN) | Designed a genome encoding method to encode genomes of various lengths into 3D matrices using k-mer features and trained a CNN model for host prediction. | Species |
| VHM-net [12] | Markov random field | Utilized the Markov random field framework for predicting whether a virus infects a target prokaryote by combining multiple features between viruses and prokaryotes such as CRISPRs, the output score of WIsH, BLASTN alignments, etc. | Species |
| CHERRY | Graph convolutional encoder and decoder for link prediction | Formulated the host prediction problem as a link prediction problem in a multimodal graph and designed an encoder-decoder structure for host prediction. The multimodal graph integrates of different types of features, including protein organization, CRISPR, sequence similarity, and k-mer frequency, into the nodes and edges. The edges connect viruses and prokaryotes from labeled (training) and unlabeled (test) data. | Species |
2 Method
We formulate host prediction as a link prediction problem [29] on a multimodal graph, which encodes virus–virus and virus–prokaryote relationships. To be specific, these relationships can be represented by a knowledge graph 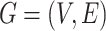 with node
with node 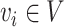 , where
, where 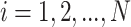 . An edge between
. An edge between 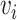 and
and 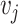 is denoted as a tuple
is denoted as a tuple 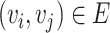 . There are two kinds of nodes in the graph: viral nodes
. There are two kinds of nodes in the graph: viral nodes 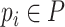 and prokaryotic nodes
and prokaryotic nodes 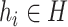 (
(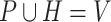 ). Then the link prediction task can be defined as: given a viral node
). Then the link prediction task can be defined as: given a viral node 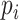 and a prokaryotic node
and a prokaryotic node 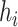 , what is the probability of
, what is the probability of 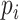 and
and 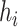 having a link (infection). In the following section, first, we will describe how we construct the multimodal graph. Then, we will introduce the encoder–decode structure of CHERRY.
having a link (infection). In the following section, first, we will describe how we construct the multimodal graph. Then, we will introduce the encoder–decode structure of CHERRY.
2.1 Construction of the knowledge graph 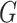
To utilize the features from both training and testing samples, we construct a multimodal graph 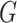 by connecting viruses and prokaryotes in both the reference database and the test set. This multimodal graph is composed of protein organizations, sequence similarity and CRISPR-based similarity. The node in the graph encodes
by connecting viruses and prokaryotes in both the reference database and the test set. This multimodal graph is composed of protein organizations, sequence similarity and CRISPR-based similarity. The node in the graph encodes 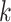 -mer frequency feature from the DNA sequences. According to the type of the connections, the edges in the knowledge graph can be divided into virus–virus connections and virus–prokaryote connections.
-mer frequency feature from the DNA sequences. According to the type of the connections, the edges in the knowledge graph can be divided into virus–virus connections and virus–prokaryote connections.
Virus–virus connections:
we utilize the protein organizations to measure the similarity of biological functions between viruses. Intuitively, if two viruses share similar protein organizations, they are more likely to infect the same host. First, we construct protein clusters using the Markov clustering algorithm (MCL) on all viral proteins. For reference viral genomes, the proteins are downloaded from NCBI RefSeq. For query contigs, we use Prodigal [30] to conduct gene finding and protein translation. Then, we employ MCL to cluster proteins with  based on the DIAMOND BLASTP [31] comparisons (E-value <1e-5). Second, we followed [32, 33] and use Eq. 1 to estimate the probability of two viruses
based on the DIAMOND BLASTP [31] comparisons (E-value <1e-5). Second, we followed [32, 33] and use Eq. 1 to estimate the probability of two viruses 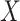 and
and 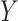 sharing at least
sharing at least 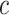 common protein clusters by assuming that each protein cluster has the same chance to be chosen.
common protein clusters by assuming that each protein cluster has the same chance to be chosen. 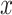 and
and 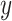 are the numbers of proteins in
are the numbers of proteins in 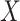 and
and 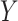 , respectively. Because Eq. 1 computes the background probability under the hypothesis that virus
, respectively. Because Eq. 1 computes the background probability under the hypothesis that virus 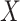 and
and 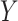 do not share common host, we will reject this hypothesis when P is smaller than a cutoff. Finally, only pairs with P(
do not share common host, we will reject this hypothesis when P is smaller than a cutoff. Finally, only pairs with P( 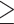 c) smaller than
c) smaller than 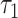 will form virus–virus connections (Eq. 2).
will form virus–virus connections (Eq. 2).
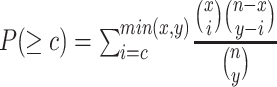 |
(1) |
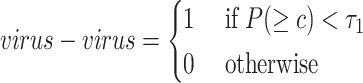 |
(2) |
virus–prokaryote connections: we apply the sequence similarity between viral and prokaryotic sequences to define the virus–prokaryote connections. There are two kinds of sequence similarity that can be employed: CRISPR-based and general local similarity. Some prokaryotes will integrate some viral DNA fragments into their own genomes to form spacers [34, 35] in CRISPR. Therefore, many existing tools have used CRISPR as a main feature for host prediction [17, 36]. In our method, CRISPR Recognition Tool [37] is applied to capture potential CRISPRs from prokaryotes. If a viral sequence shares a similar region with the CRISPR, we will connect this viral node to the prokaryotic node.
However, only a limited number of CRISPRs can be found. We thus also use BLASTN to measure the sequence similarity between the sequences. Viruses can mobilize host genetic material and incorporate it into their own genomes. Occasionally, these genes can bring an evolutionary advantage and the viruses will preserve them [17]. For all viruses  and prokaryotes
and prokaryotes  , we will run BLASTN for each pair
, we will run BLASTN for each pair 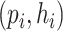 . Only pairs with BLASTN E-value smaller than
. Only pairs with BLASTN E-value smaller than 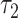 will form virus–prokaryote connections. In addition, because we have known virus–prokaryote connections from the public dataset, we connect the viruses with their known hosts regardless of their alignment E-values. Finally, the edges
will form virus–prokaryote connections. In addition, because we have known virus–prokaryote connections from the public dataset, we connect the viruses with their known hosts regardless of their alignment E-values. Finally, the edges 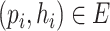 can be formulated as Eq. 3. If there is an overlap between CRISPR-based and BLASTN-based edge, we will only create one edge between the virus and prokaryote.
can be formulated as Eq. 3. If there is an overlap between CRISPR-based and BLASTN-based edge, we will only create one edge between the virus and prokaryote.
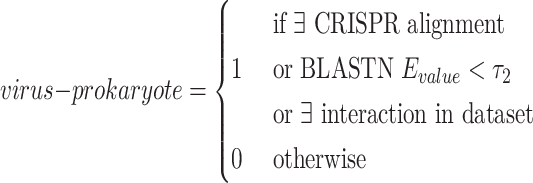 |
(3) |
Both 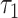 and
and 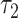 are the default parameters given in [33] and [38].
are the default parameters given in [33] and [38].
Nodes construction:
The nodes in the multimodal graph represent the features from both viral and host genomes. In our work, we utilize the 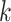 -mer frequency as our node feature. Because the dimension of the feature vector increases exponentially with
-mer frequency as our node feature. Because the dimension of the feature vector increases exponentially with 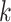 , we choose
, we choose 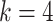 and obtain a 256-dimensional vector for each viral or host genome.
and obtain a 256-dimensional vector for each viral or host genome.
2.2 The encoder-decoder framework in CHERRY
After constructing the multimodal graph 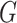 , we will feed it to our model for training and prediction. Given a virus–prokaryote pair
, we will feed it to our model for training and prediction. Given a virus–prokaryote pair 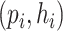 , our aim is to determine how likely there is a link (infection) between virus
, our aim is to determine how likely there is a link (infection) between virus 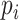 and prokaryote
and prokaryote 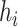 . Toward this goal, we develop a nonlinear, multilayer decoder–encoder network CHERRY that operates on the multimodal graph
. Toward this goal, we develop a nonlinear, multilayer decoder–encoder network CHERRY that operates on the multimodal graph 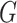 . CHERRY has two main components:
. CHERRY has two main components:
Graph convolutional encoder: a graph convolutional network operating on
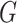 and embedded node features in
and embedded node features in 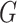 (Figure 1 B)
(Figure 1 B)Query pairs decoder: a two-layer neural network classifier that can output a probability score for each virus–prokaryote pair (Figure 1 C)
Detailed information about the two components and the end-to-end training method will be discussed in the following sections.
2.2.1 Graph convolutional encoder
The input of the encoder is the multimodal graph 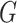 . Because we have both labeled (viruses with known hosts) and unlabeled (viruses without known hosts) nodes in the graph, the main idea of the encoder is to utilize the topological structure to propagate information from labeled nodes to unlabeled nodes. The output of the encoder will be
. Because we have both labeled (viruses with known hosts) and unlabeled (viruses without known hosts) nodes in the graph, the main idea of the encoder is to utilize the topological structure to propagate information from labeled nodes to unlabeled nodes. The output of the encoder will be 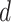 -dimensional embedded vectors that integrate virus–virus similarity and virus–prokaryote similarity gained from the multimodal graph
-dimensional embedded vectors that integrate virus–virus similarity and virus–prokaryote similarity gained from the multimodal graph 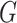 .
.
We will use graph convolutional neural network (GCN) to conduct feature embedding of the nodes. GCN is one well-studied model for graph data. Recently, it has some successful applications in biological data [33, 39]. In our encoder, we will take advantage of the feature embedding of GCN to encode the feature vectors for viruses and prokaryotes. Specifically, for a given node (Figure 1 AI), our encoder performs convolution on its neighbors’ node vectors and itself. In each convolution operation, the encoder considers the one-step neighborhood of the nodes (Figure 1 AII) and applies the same transformation to all nodes in the graph. Then the successive convolution will be applied in the 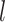 layers, and finally, each node will effectively convolve the information from its
layers, and finally, each node will effectively convolve the information from its 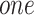 -step neighborhood (Figure 1 AIII).
-step neighborhood (Figure 1 AIII). 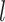 is the number of the graph convolutional layers in the encoder. A single graph convolutional layer can be represented as Eq. 4.
is the number of the graph convolutional layers in the encoder. A single graph convolutional layer can be represented as Eq. 4.
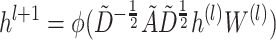 |
(4) |
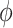 is the activation function in the graph convolutional layer.
is the activation function in the graph convolutional layer. 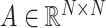 is the adjacency matrix, where
is the adjacency matrix, where 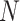 is the number of nodes in the multimodal graph.
is the number of nodes in the multimodal graph. 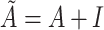 , where
, where 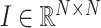 is the identity matrix.
is the identity matrix. 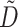 is the diagonal matrix calculated by
is the diagonal matrix calculated by 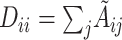 .
. 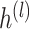 is the hidden feature in the
is the hidden feature in the 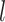 th layer and
th layer and 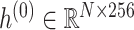 is the 4-mer frequency vector of each node.
is the 4-mer frequency vector of each node. 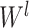 is a matrix of the trainable filter parameters in the
is a matrix of the trainable filter parameters in the 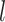 -layer. Finally, the encoder will output a
-layer. Finally, the encoder will output a 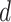 -dimensional embedded vector, which encoded prior knowledge from
-dimensional embedded vector, which encoded prior knowledge from 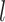 -step neighborhood for each node in the graph.
-step neighborhood for each node in the graph. 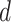 is the dimension of
is the dimension of 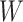 in the output layer. Because the convolutional layer will be conducted on all nodes in
in the output layer. Because the convolutional layer will be conducted on all nodes in 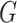 , features from both training and testing samples can be used in the encoder to enhance the learning ability.
, features from both training and testing samples can be used in the encoder to enhance the learning ability.
2.2.2 Decoder for link prediction
After encoding the feature vectors for viral and host genomes, we apply a two-layer neural network classifier to decode the embedded vectors outputted from the encoder. This decoder aims to judge how likely these query pairs form actual infections. Thus, the input of the decoder is a query set 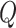 , and the output of the decoder is a probability score. Each element in
, and the output of the decoder is a probability score. Each element in 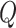 is called a query vector
is called a query vector 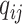 and is calculated by Eq. 5.
and is calculated by Eq. 5.
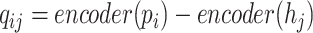 |
(5) |
First, we generate all-against-all virus–prokaryote pairs and calculate all query vectors 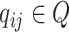 .
. 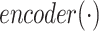 represents the output of graph convolutional encoder.
represents the output of graph convolutional encoder. 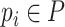 represents the virus node, and
represents the virus node, and 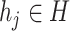 represents the prokaryotic node. Then we employ a two-layer neural network to decode the feature vector for each input
represents the prokaryotic node. Then we employ a two-layer neural network to decode the feature vector for each input 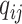 as shown in Eq. 6.
as shown in Eq. 6.
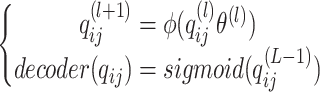 |
(6) |
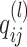 is the hidden feature in the
is the hidden feature in the 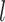 th layer.
th layer. 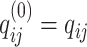 and
and 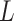 is the maximum number of the layers in the network.
is the maximum number of the layers in the network. 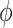 is the activation function.
is the activation function. 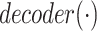 represents the output of the link prediction decoder. Because the activation function of the output layer is the
represents the output of the link prediction decoder. Because the activation function of the output layer is the 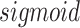 function,
function, 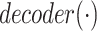 can be used as the probability score for each pair.
can be used as the probability score for each pair.
2.2.3 Model training
Recent results show that the modeling of topological structure data can be greatly improved through end-to-end learning [40, 41]. Thus, we optimize overall trainable parameters for CHERRY and backpropagate loss on the multimodal graph. The trainable parameters of CHERRY are: (i) convolutional filters’ weight matrices 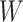 in the encoder and (ii) query parameter matrices
in the encoder and (ii) query parameter matrices 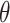 in the decoder.
in the decoder.
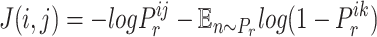 |
(7) |
There are two kinds of query pairs that will be generated by Eq. 5: positive pairs and negative pairs. Positive pairs represent known virus–prokaryote interactions given by the dataset. Negative pairs represent the pairs with no evidence for interaction. Then, during the training process, we optimize the model using the cross-entropy loss as shown in Eq. 7. This equation encourages the model to assign higher probabilities to positive pairs 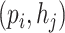 than the randomly created negative pair
than the randomly created negative pair 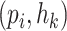 .
.
Because we form all-against-all query pairs from all viruses and hosts, the number of negative query pairs will be much larger than the positive query pairs. To solve this problem, rather than sampling a subset of the negative pairs, we optimize the model through negative sampling, a method introduced in recent publications [28, 42]. Negative sampling allows us to train the model using hard cases. When calculating the negative sampling loss in training, we replace the prokaryotic node 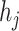 in a positive pair
in a positive pair 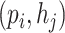 with another prokaryotic node
with another prokaryotic node 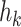 (thus forming a negative sample) according to a sampling distribution
(thus forming a negative sample) according to a sampling distribution 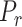 defined in [28]. Intuitively, if a negative sample has a higher loss, it will have a higher probability to be selected for training. Thus, the negative sampling method helps enhance the learning ability of the model compared with subsampling because the latter cannot represent the real distribution of the sample space, especially when the number of negative samples is much larger than the number of positive samples. With negative sampling, CHERRY can automatically learn a more accurate boundary using the hard cases.
defined in [28]. Intuitively, if a negative sample has a higher loss, it will have a higher probability to be selected for training. Thus, the negative sampling method helps enhance the learning ability of the model compared with subsampling because the latter cannot represent the real distribution of the sample space, especially when the number of negative samples is much larger than the number of positive samples. With negative sampling, CHERRY can automatically learn a more accurate boundary using the hard cases.
To ensure that the optimization process can learn as many query pairs as possible during the negative sampling process, we train it for a maximum of 250 epochs using the Adam optimizer [43] with a 0.01 learning rate to update the parameters. Before evaluating our model, we fixed the random seed in the program to ensure that we had the same initial parameters. To guarantee the model’s reliability, we also save the parameters so that users can directly load the parameters when applying CHERRY on their own dataset. Users can also use the parameters as a pre-trained model and add more interactions for training, which will help the model converge faster.
2.3 Experimental setup
This section will introduce how we evaluate our model and compare it with the state-of-the-art tools.
2.3.1 Metrics
According to the usage of link prediction, CHERRY can be employed in two different scenarios: (1) predicting host for newly identified viruses; and (2) identifying viruses that infect targeted prokaryotes. Thus, we apply two different evaluation methods, respectively.
Scenario 1: predicting hosts for newly identified viruses
We use the same experimental setup and metrics as the previous works to ensure consistency and a fair comparison. Following the previous work, one virus is assumed to infect only one species, which is not always true but is a commonly used assumption for evaluation. Thus, in the experiments, for each test virus 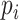 , we will compute the score between
, we will compute the score between 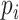 and all prokaryotes in set
and all prokaryotes in set 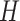 and output the prokaryote with the highest decoder score (Eq. 8).
and output the prokaryote with the highest decoder score (Eq. 8).
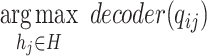 |
(8) |
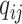 is defined in Eq. 5. We predict hosts for all viruses in the test set and evaluate the performance by checking whether the predicted prokaryotes are from the same taxon (such as same species) as the known interactions. The ratio of correct prediction is the accuracy, which has the same definition as previous works. In addition, because the graph contains all the potential hosts (prokaryotes) and the number of predictions is equal to the number of test viruses, the recall and precision are the same as the accuracy.
is defined in Eq. 5. We predict hosts for all viruses in the test set and evaluate the performance by checking whether the predicted prokaryotes are from the same taxon (such as same species) as the known interactions. The ratio of correct prediction is the accuracy, which has the same definition as previous works. In addition, because the graph contains all the potential hosts (prokaryotes) and the number of predictions is equal to the number of test viruses, the recall and precision are the same as the accuracy.
Scenario 2: identifying viruses that infect targeted prokaryotes
The goal is to identify which viruses can infect a specified prokaryote. Because one prokaryote can be infected by multiple viruses, we set a threshold 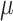 to output a set of candidate viruses.
to output a set of candidate viruses.
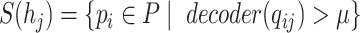 |
(9) |
As shown in Eq. 9, for each specified prokaryote, we will predict a set of viruses whose interaction probabilities (calculated by the decoder) are larger than 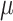 . Unlike the host prediction task, this equation might return viruses infecting different prokaryotes as long as the probability is larger than the threshold. Then, for each prokaryote
. Unlike the host prediction task, this equation might return viruses infecting different prokaryotes as long as the probability is larger than the threshold. Then, for each prokaryote 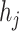 , the precision represents how many viruses in
, the precision represents how many viruses in 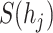 truly infect
truly infect 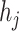 based on the ground truth. The recall represents how many viruses infecting
based on the ground truth. The recall represents how many viruses infecting 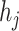 are included in
are included in 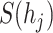 .
.
2.3.2 Dataset
We followed [2] and used the same virus–host relationship benchmark dataset for training (the VHM dataset) and testing (the TEST dataset). This benchmark dataset contains viruses and prokaryotic genomes that were deposited to NCBI RefSeq in or before 2020. The detailed information is shown in Figure 2 (A). Following [2], we download all 1940 viruses from the NCBI RefSeq database and separate the training set and test set according to their submission time (before and after 2015). Thus, we have 1306 positive pairs for training and 634 positive pairs for testing, respectively. Although every virus is unique, some of them infect the same host. The training and test set share 59 host species. To show the overall similarity between the training and test set, we use Dashing [44] to estimate the sequence similarity between viruses. We record the largest value for each test virus against all training viruses and report the overall similarity in Figure 2 (B). The result reveals that only a few test viruses are similar to the training viruses, with the mean similarity being 0.1. Along with 233 host species, we also have 60 105 prokaryotic genomes obtained from the NCBI genome database.
Figure 2.
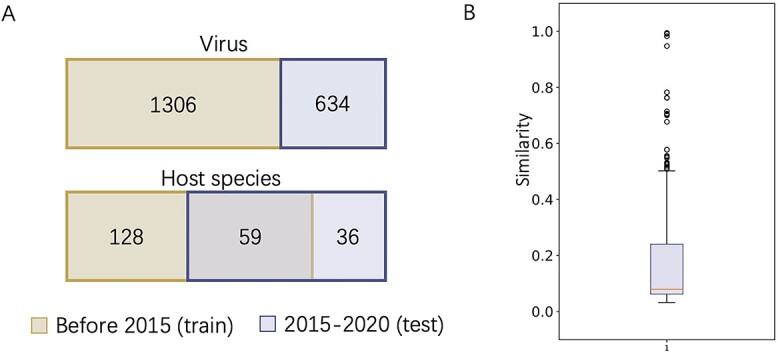
The benchmark dataset for virus–host interactions. (A) The viruses and their hosts in the training and test set, respectively. (B) Similarity between viruses in the training and test sets.
To further assess the utility of CHERRY on predicting hosts for newly discovered viruses, we applied it to viruses from three recently published metagenomic datasets. The information of the datasets are summarized as below:
MetaHiC data from healthy human gut: 6545 host–phage interactions were identified from human gut metagenomic samples using a proximity ligation-based approach named MetaHiC [45]. The dataset is available at: https://github.com/mmarbout/HGP-Hi-C.
Glacier metagenomic dataset: a newly published metagenomic dataset sampled from the ice core on the Tibetan Plateau [46]. The authors present 33 new phage contigs and four dominant bacteria genus isolated from the sample. The dataset is available at: https://datacommons.cyverse.org/browse/iplant/home/shared/iVirus/Tibet_Glacier_viromes_2017.
Gut metagenomic dataset: 3738 previously unknown phages discovered from human gut metagenomic data [47]. These phage genomes represent 451 putative genera whose hosts remain unknown. The dataset is available at: ftp://ftp.ncbi.nih.gov/pub/yutinn/benler_2020/gut_phages/.
3 Result
In this section, we will show our experimental results on multiple datasets and compare CHERRY against 11 host prediction tools: WIsH [1], PHP [2], Hophage [3], VPF-Class [4], HostG [6], RaFAH [5], PHIST [7], PHIAF [9], vHULK [10], DeepHost [11] and VHM-Net [12]. We also recorded the host prediction performance using either BLASTN or CRISPRs, which are two frequently used features for identifying the interactions. The experimental results consist of two parts.
Usage 1: predicting hosts for viruses First, we will report the host prediction performance across different taxonomic levels (from species to phylum) on the benchmark dataset. We will analyze how the knowledge graph and the encoder–decoder structure impact the host prediction accuracy. In addition, we will investigate why the alignment-based method fails to perform well in the host prediction task. Second, because many metagenomic assemblies contain short contigs, we will evaluate the performance of CHERRY with short contigs as input. Third, we will visualize the results of host prediction on different viral families and analyze data-related challenges for species-level host prediction. Then, we present how CHERRY can be used to narrow the search scope of the potential hosts for newly identified viruses. Finally, we will show the application of CHERRY on predicting hosts for newly discovered phage genomes/contigs from three metagenomic datasets. Usage 2: predicting viruses that infect prokaryotes In this part, we will present the performance of CHERRY on identifying viruses that can infect given prokaryotes.
3.1 Visualization of the knowledge graph
We use Gephi [48] to visualize the topological structure of the knowledge graph in Figure 3. The GCN encoder utilizes the local topology of the graph to embed the node features. If the edges only connect nodes with the same label, a simple label propagation method based on graph connectivity can achieve accurate predictions. However, although there are some clusters containing nodes with consistent labels (e.g. region A and region B in Figure 3), some subgraphs are mixed with multiple labels. For example, region C contains more than six labels. In addition, we also found that prokaryotic nodes usually connect to the virus nodes with different labels. For example, node A1 represents Cutibacterium acnes, but it has many edges (alignments) with phages that infect Mycobacterium smegmatis. In this case, simple alignment-based or label propagation methods will fail to make the correct host prediction. But the GCN-based encoder can integrate both the sequence similarity,  -mer composition, and the topological information for making correct predictions using this graph.
-mer composition, and the topological information for making correct predictions using this graph.
Figure 3.

Visualization of the multimodal graph. The colors of the nodes represent their labels. For prokaryotic nodes, the labels represent their species. For virus nodes, the labels represent their hosts’ species. Because there are a large number of labels, this graph only colors the top eight labels with the largest number of nodes. All others are gray.
3.2 Predicting hosts for prokaryotic viruses
In this experiment, we used the benchmark dataset associated with Figure 2 for training and evaluation. For each test virus, our predicted host is the one with the highest prediction score out of the 60 105 prokaryotes. Then we calculate the accuracy according to the known hosts in the benchmark dataset.
3.2.1 Cross-validation results and ablation study
To train a reliable model and evaluate the overall learning ability of CHERRY, we applied 10-fold cross-validation on the training set. First, we randomly split the training set into 10 subsets. Then, we trained the model on nine subsets, validated it on the 10th iteratively, and recorded the prediction performance. As shown in Figure 4(A), we reported the highest, lowest and average performance of the 10-fold cross-validation from the species to phylum level. We also reported the BLAST results of the host prediction. Specifically, we used 60 105 prokaryotes as reference genomes and then conducted alignments between test viruses and the reference set. Then we predict the host using k nearest neighbor (KNN) with 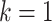 (the best alignment) or
(the best alignment) or 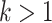 (majority vote). Here, we only report the results based on the best alignment because it has higher accuracy. Figure 4(A) shows that CHERRY largely improves the performance at the species level. Also, it is worth noting that BLASTN and CRISPRs can only return results for ˜65.5% and ˜24.6% viruses, respectively. However, CHERRY can predict hosts for all viruses.
(majority vote). Here, we only report the results based on the best alignment because it has higher accuracy. Figure 4(A) shows that CHERRY largely improves the performance at the species level. Also, it is worth noting that BLASTN and CRISPRs can only return results for ˜65.5% and ˜24.6% viruses, respectively. However, CHERRY can predict hosts for all viruses.
Figure 4.

Host prediction performance on the benchmark dataset. Y-axis: accuracy. (A) 10-fold cross-validation on the training set. X-axis represents different types of graphs and BLAST-based host prediction. without graph: training with only decoder. Virus–virus: the knowledge graph only contains virus–virus edges. virus–prokaryote: the knowledge graph only contains virus–prokaryote edges. random sampling: the model is trained on the complete graph with a randomly sampled negative set. complete graph: the model is trained on the complete graph with negative sampling. Error bar represents the highest, lowest and average accuracy of the 10-fold cross-validation. (B) Comparison of host prediction accuracy on the test set from species to phylum. Tools that can output predictions at the species level (PHIST, PHIAF, vHULK, DeepHost, VHM-net and CHERRY) are grouped together and ordered based on their species-level performance.
Ablation study In addition, we investigated how different components in the knowledge graph affect the prediction accuracy. Our knowledge graph contains two types of edges: virus–virus and virus–prokaryote. We tested CHERRY by removing the graph, only keeping one type of edge in the graph, and using the complete graph. The comparison is shown in Figure 4(A).
without graph: We trained the model without graph (without encoder). The decoder only uses the
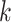 -mer frequency vectors as inputs.
-mer frequency vectors as inputs.virus–virus: We trained the model with a graph that only contains virus–virus edges.
virus–prokaryote: We trained the model with a graph that only contains virus–prokaryote edges.
complete graph: We trained the model with the complete multimodal graph.
The results show that both virus–virus similarity and virus–prokaryote similarity can enhance the learning ability and improve the performance. The complete knowledge graph that contains two types of edges achieves the best performance. We also show the comparison between training with random sampling and negative sampling in Figure 4(A). The prediction results show that negative sampling can largely improve the host prediction accuracy.
3.2.2 Evaluation on the test set
We fixed the model parameters based on the highest validation accuracy and applied the trained model to host prediction for test viruses. To conduct a fair comparison, we also retrained the learning-based models on the same training set and applied them on the same test set. Because VPF Class is an alignment-based method, we used their database for host prediction. As shown in Figure 4 (B), CHERRY achieved the best accuracy of 78% in predicting the hosts’ species, which is 35% higher than the next best tool VHM-net. To prove that the convolutional graph encoder can enhance the learning ability of CHERRY, we reused the model without graph in Figure 4(A) for host prediction. The final result on the test set decreases to 56%, and thus, the convolutional graph encoder helps host prediction.
3.2.3 Impact of training vs test similarity on the prediction performance
In the Dataset section, we used Dashing to measure the similarity between the test set and training set. To show how the similarity affects the host prediction performance, we divided the test set according to the dashing similarity. We recorded the accuracy at the genus level in Figure 5. X-axis stands for the maximum similarity between genomes in the training set and test set. For example, X-axis value 0.8 indicates that all the genomes in the test set have similarity 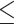 0.8 against the genomes in the training set. Figure 5 also shows how the similarity influences other tools.
0.8 against the genomes in the training set. Figure 5 also shows how the similarity influences other tools.
Figure 5.
The impact of training-vs-test sequence similarity on host prediction at the genus level. X-axis: maximum dashing similarity. Left Y-axis: accuracy (line segments). Right Y-axis: number of test viruses under each similarity cutoff (gray bars).
As expected, with the increase of the similarity, more test genomes with high similarities are included, and the accuracy of all methods increases. The gap between CHERRY and all other methods clearly shows that our model outperforms the state-of-the-art tools on a wide range of similarities.
3.2.4 Sequence similarity between viruses and prokaryotes
Then, we further investigated the performance of these tools on predicting hosts for viruses that lack significant similarities with prokaryotic genomes. All the test viruses that do not have BLASTN alignments with the reference prokaryotes are used for evaluation. As shown in Figure 6, the accuracy of most methods decreases. Nevertheless, CHERRY still renders the best performance. vHULK, RaFAH, VPF-Class and HostG have better accuracy than VHM-net, PHIST, WIsH and PHIAF probably because they mainly rely on the viral protein similarity for host prediction. The experimental results shown in Figure 5 and Figure 6 reveal that integrating the virus–virus and virus–prokaryote relationships in the multimodal graph enhances host prediction.
Figure 6.
Host prediction accuracy for viruses that lack significant alignments against the prokaryotes. X-axis: taxonomic rankings. Y-axis: accuracy.
A case study As described in Section Visualization of the knowledge graph, we can have heterogeneous labels in subgraphs. An example is given in Figure 7. Test viruses (white nodes) connect with multiple nodes in different colors. Applying majority vote based on neighbors’ labels will assign Bacillus subtilis as the host for virsues ‘Test_120’, ‘Test_64’ and ‘Test_178’. However, according to the given labels in the database, only ‘Test_178’ is a Bacillus subtilis virus. ‘Test_120’ and ‘Test_64’ are Bacillus thuringiensis viruses.
Figure 7.
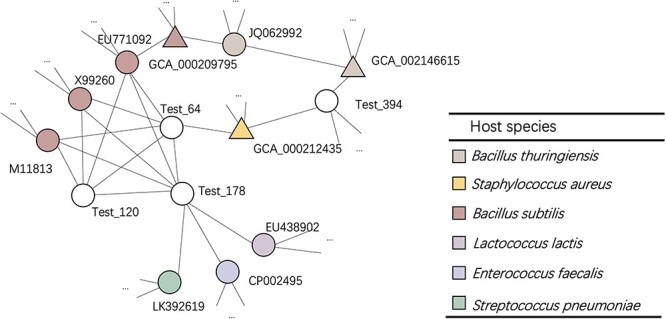
A case study for a sub-graph with heterogeneous labels. Triangles: prokaryotic nodes. Circles: virus nodes. White nodes: test viruses. Nodes with other colors: training samples. Different colors represent different species/labels. The open-end edges adjacent to the nodes indicate that these nodes have more connections.
The GCN-based encoder in CHERRY was not limited by the heterogeneous connections and predicted the hosts correctly. We recorded the prediction score of CHERRY in Table 2. We also reported the results of vHULK, VHM-net, PHIST, PHIAF and DeepHost because they can predict hosts at the species level.
Table 2.
Host predictions for two hard cases (Test_120 and Test_64 in Figure 7) using six methods that can predict the host at the species level. ‘-’: no prediction. The correct prediction is in bold font
| Method | Virus | Prediction |
|---|---|---|
| CHERRY | Test_64 | Bacillus thuringiensis |
| Test_120 | Bacillus thuringiensis | |
| vHULK | Test_64 | Bacillus subtilis |
| Test_120 | Bacillus thuringiensis | |
| VHM-net | Test_64 | Bacillus subtilis |
| Test_120 | Staphylococcus aureus | |
| PHIST | Test_64 | Bacillus anthracis |
| Test_120 | − | |
| PHIAF | Test_64 | Bacillus anthracis |
| Test_120 | Staphylococcus aureus | |
| DeepHost | Test_64 | Lactococcus lactis |
| Test_120 | Lactococcus lactis |
The results show that CHERRY can predict both viruses correctly and vHULK can assign host to one of the viruses correctly. Other methods failed to provide correct predictions. A plausible explanation is CHERRY not only considers alignment similarity/connections in the multimodal graph but also considers the 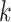 -mer frequency of the genomes when training the link prediction decoder. In summary, 73.7% of viruses have multiple alignments/connections with different labeled nodes (viruses or prokaryotes) in our knowledge graph. While using only the graph topology might return ambiguous/wrong predictions, CHERRY can provide more accurate host identification for these viruses.
-mer frequency of the genomes when training the link prediction decoder. In summary, 73.7% of viruses have multiple alignments/connections with different labeled nodes (viruses or prokaryotes) in our knowledge graph. While using only the graph topology might return ambiguous/wrong predictions, CHERRY can provide more accurate host identification for these viruses.
3.3 Performance on short contigs
Because the assembly programs may not generate complete virus genomes from viral metagenomic data, virus host prediction programs should be able to predict hosts on assembled contigs. To evaluate the robustness of CHERRY on short contigs, we generated DNA segments with different length ranges.
First, we generated contigs by cutting the test viruses’ genomes with five different lengths: 1, 5, 10, 15 and 20kbp. We pick a random starting position in the genome and cut a substring of the given length. We repeated this process multiple times until we have sufficient contigs. Finally, we generated 6340 contigs for each length. We used these contigs to evaluate PHIST, PHIAF, vHULK, DeepHost, VHM-net and CHERRY, which can predict hosts at the species level, and reported the average accuracy in Figure 8. As the figure shows, although the performance of all methods decreases with the decrease of the contigs’ length, CHERRY still achieves the best performance under all different lengths.
Figure 8.
Host prediction performance on contigs. X-axis: length of the input contigs. Y-axis: accuracy.
3.4 Performance on different viral families
Although CHERRY has the best performance in host prediction, its accuracy at the species level is slightly lower than 0.8. In order to identify the reasons, we conducted a closer examination of CHERRY’s performance for different viral families. Caudovirales, which contains phages with tails, is the order with the largest number of sequenced prokaryotic viruses in the RefSeq database. The test set is dominated by three families under Caudovirales: Siphoviridae, Myoviridae and Podoviridae. Thus, we group the phages by their family taxonomy and record the host prediction results accordingly.
As shown in Figure 9, the accuracy of viruses that do not belong to Caudovirales is always the best. The performance of phages in Mydoviridae is worse than other groups at species and genus level but increases largely at the family level. One possible reason is that, as discussed in [49, 50], some phages in Myoviridae have the potential to infect multiple hosts from different species and even genera. But our data only contain one host species for each virus. Thus, for the viruses in Myoviridae, some of the false predictions might indicate that the viruses of interest infect multiple hosts.
Figure 9.
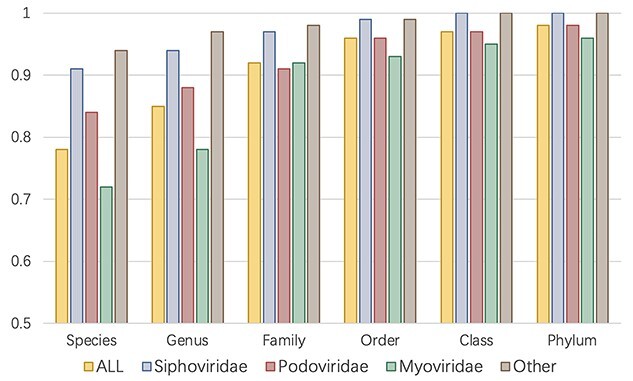
Host prediction results for different groups of viruses. X-axis: taxonomic rank. Y-axis: accuracy. ALL: the accuracy on the whole dataset, which is the same as Figure 4 (B). Other: accuracy for viruses that do not belong to Caudovirales.
3.5 Top 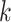 prediction scores
prediction scores
Given the possibility of multiple hosts for some viruses, we also provide an alternative evaluation metric based on top 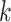 predictions. Instead of only reporting the prokaryote with the highest prediction score, CHERRY also allows users to output multiple hosts based on ranked scores. In this section, we will first show the tendency of the prediction score. Because there are 60 105 candidate prokaryotic genomes for each testing virus, the decoder will score each virus–prokaryote pair, leading to 60 105 sorted scores for each test virus. We will calculate the average of the highest score for all test viruses, the second highest score, etc. Because there are 60 105 values, we only show the highest 30 scores in Figure 10(A). The results show that the average score drops precipitously after the first 10 values, suggesting that CHERRY has a strong selection preference for a few possible hosts.
predictions. Instead of only reporting the prokaryote with the highest prediction score, CHERRY also allows users to output multiple hosts based on ranked scores. In this section, we will first show the tendency of the prediction score. Because there are 60 105 candidate prokaryotic genomes for each testing virus, the decoder will score each virus–prokaryote pair, leading to 60 105 sorted scores for each test virus. We will calculate the average of the highest score for all test viruses, the second highest score, etc. Because there are 60 105 values, we only show the highest 30 scores in Figure 10(A). The results show that the average score drops precipitously after the first 10 values, suggesting that CHERRY has a strong selection preference for a few possible hosts.
Figure 10.

The experimental results of top-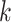 prediction. (A): Tendency of the prediction score. X-axis: the sorted index by
prediction. (A): Tendency of the prediction score. X-axis: the sorted index by 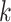 . Y-axis: average score of the top-
. Y-axis: average score of the top-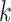 prediction. (B): The accuracy using top-
prediction. (B): The accuracy using top-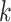 prediction.
prediction.
In Figure 10(B), we present the top-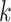 host prediction accuracy using the 60 105-dimensional score vector. Specifically, if the real host label of a test virus exists in the highest
host prediction accuracy using the 60 105-dimensional score vector. Specifically, if the real host label of a test virus exists in the highest 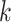 predictions (scores), we will consider this as a correct prediction for the top-
predictions (scores), we will consider this as a correct prediction for the top-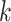 accuracy. As shown in Figure 9(B), the top-2 accuracy increases largely from top-1, and the growth trend becomes slower after that. We also found that even if the scores of some real virus–host interactions are not the top-1 score, their scores are usually larger than 0.9, indicating that they are predicted with high confidence. Thus, CHERRY can support a method for further improving the host prediction results: using score threshold (0.9) and outputting top k predictions above the threshold. Although this method might predict more than one virus–prokaryote interaction for a given virus, it can largely narrow the search scope of the potential host.
accuracy. As shown in Figure 9(B), the top-2 accuracy increases largely from top-1, and the growth trend becomes slower after that. We also found that even if the scores of some real virus–host interactions are not the top-1 score, their scores are usually larger than 0.9, indicating that they are predicted with high confidence. Thus, CHERRY can support a method for further improving the host prediction results: using score threshold (0.9) and outputting top k predictions above the threshold. Although this method might predict more than one virus–prokaryote interaction for a given virus, it can largely narrow the search scope of the potential host.
3.6 Host prediction on metagenomic data
In this section, we will validate CHERRY on host prediction for possibly novel viruses from metagenomic data. Because metagenomic data usually contain many different species or components, such as eukaryotic viruses or plasmids, users should run prokaryotic virus identification tools to screen viral contigs from metagenomic data before using CHERRY for host prediction. For example, Metaviral spades [51], Seeker [52] and VirSorter [53] are widely used for virus identification. We first evaluate CHERRY on a Hi-C sequencing dataset that provides annotated phage–host interactions [45]. Then, we choose two newly published metagenomic datasets containing viruses in two habitats: glacier [46] and human gut [45, 47]. The authors used assembly tools and virus identification tools, such as VirSorter [53], to obtain virus-originating contigs from the samples. Then, we applied CHERRY to predict hosts for these virus contigs.
3.6.1 Case study one: phage–host interactions derived using MetaHiC
Recently, a metagenomic Hi-C approach named MetaHiC was applied to human gut samples to identify interactions between phages and assembled bacterial genomes [45]. Based on the design of MetaHiC, this approach can capture DNA–DNA collisions during phages’ replication inside bacterial cells, thus providing a quality test set for computational host prediction. In this experiment, we use the phage–bacteria interactions provided by the this study [45] as the ground truth to evaluate the performance of the state-of-the-art methods.
We downloaded the supplementary data from the paper’s GitHub repository. The authors provided the taxonomic annotations for contigs and bins in these data files, enabling us to extract the phage contigs from each bin and label the phage contigs’ hosts using the bin’s taxon. Finally, we have 995 bins and 6545 phage contigs. We then removed the phage contigs from the bins, and thus, all these phage contigs can be used as the test set. The length of these phage contigs ranges from 1 to 10kbp. Because each bacterial bin is assigned to a taxon that ranges from kingdom to species, we used the lowest rank as the host label for each phage contig. For example, if the lowest rank of a bin’s annotation is a family, the host label of the phage contig is the name of this family. The distribution of phage contigs with different ranks of host labels is summarized in Figure 11 (A). If a tool can predict the same label as the given one (the lowest rank) by MetaHiC, the prediction will be counted as correct. Out of the 12 tools we tested in this work, only PHIST, PHIAF, vHULK, DeepHost, VHM-net and CHERRY can predict hosts at the species level; thus we compared their accuracy in Figure 11 (B). CHERRY still has the highest accuracy. PHIST also shows good performance for predicting new interactions. vHULK and DeepHost have lower accuracy, showing that they are not optimized for predicting new interactions.
Figure 11.

The experimental results on the MetaHiC dataset. For each bin, we use the lowest rank of the assigned taxon as the host label for the phage contigs in the bin. Phage contigs from the same bins have the same label. (A): The number of phage contigs with host labels at different taxonomic ranks. (B): The host prediction accuracy (Y-axis) on the 6545 phage contigs. The comparison includes six tools that can predict hosts at species level.
3.6.2 Case study two: newly identified viruses in glacier metagenomic data
This data set was sequenced from the core of the glacier [46]. Due to global warming, the melting glacier might release those ancient viruses to the environment in the future. Metagenomic sequencing provides a powerful means to study the virus composition. The authors reported 33 virus contigs identified by VirSorter [53] with high confidence. The length of the contigs range from 12 041 to 93 811. According to the authors’ analysis, these metagenomic data contain four dominant bacterial genera including Methylobacterium, Sphingomonas, Janthinobacterium and Herminiimonas and three putative laboratory contaminants including Synechococcus phages, Cellulophaga phages and Pseudoalteromonas phages. Thus, we use the bacteria under these genera with all prokaryotes in our database as candidate hosts and run CHERRY.
Because the authors already reported the host prediction results using BLASTN and CRISPR, we reused their predictions and compared them with our method. To report a more precise prediction, we only keep the predictions of prokaryotes with a score larger than 0.9. Thus, some viruses do not have predicted hosts. The Venn diagram of the three methods is shown in Figure 12. CHERRY can predict hosts for more viruses (about 80% of 33 contigs) on this dataset. This is expected because our previous analysis and experiments have shown that BLASTN and CRISPR can only predict hosts for a very limited number of viruses. For the viruses with predictions from either BLASTN or CRISPR, the prediction of CHERRY is largely consistent with them. Specifically, among the 14 BLASTN-predicted viruses and two CRISPR-predicted viruses, CHERRY has 11 identical predictions as BLASTN and one identical prediction as CRISPR.
Figure 12.
Host prediction on the glacier metagenomic data. The numbers without parentheses represent the number of viruses. The numbers with parentheses represent the number of viruses with the same predicted hosts. For example, 12 viruses have predictions by both CHERRY and BLASTN and 11 of them have the same predicted hosts.
3.6.3 Case study three: newly identified viruses in gut metagenomic data
In a newly published human gut metagenomic study [47], the authors identified 3738 complete viruses genomes that represent 451 putative genera using both ViralVerify [51] and Seeker [52]. Investigating the hosts of these viruses will shed lights on both the composition and functional analysis of the underlying metagenomic data.
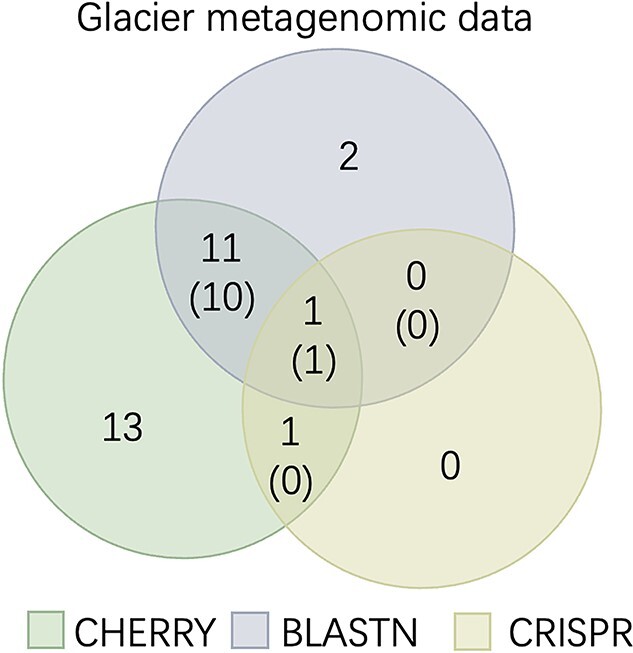
We reused the reported results of CRISPR from [47] and ran BLASTN and CHERRY. Because there is no prior information of the prokaryotes in the this metagenomic data, we use all prokaryotes in our database to construct a graph. The result is shown in Figure 13. CHERRY significantly improves the number of predicted viruses compared with BLASTN and CRISPR. About 89% (3321/3738) of viruses were assigned hosts by CHERRY with a score threshold of 0.9. What’s more, the predictions of CHERRY are highly consistent with CRISPR. Only two virus contigs predicted by CRISPR have no predictions by CHERRY because their scores are less than the threshold. All other CRISPR-predicted contigs (460+63) have the same labels (275+248) as CHERRY. We also found that although BLASTN output hosts for 2131 (57%) viruses, many have multiple alignments. Only 59% (275/460) of the BLAST predictions are consistent with CRISPR. Considering that CRISPR is a reliable signal for host prediction, CHERRY’s output is consistent with our previous experiments, demonstrating both high accuracy.
Figure 13.
Host prediction on the gut metagenomic data. The numbers without parentheses represent the number of viruses. The numbers with parentheses represent the number of viruses with the same predicted hosts.
3.7 Predicting viruses that infect prokaryotes
CHERRY can estimate how likely there is a link (infection) between a virus  and a prokaryote
and a prokaryote 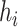 . Thus, CHERRY can also be used to output viruses that infect a prokaryote of interest. We use Eq. 9 to predict the viruses that infect given prokaryotic genomes. CHERRY will take prokaryotic genomes as input and output viruses with prediction scores above a given threshold. This function can help users identify candidate viruses that can infect targeted prokaryotes. We use recall and precision introduced in the Experimental setup Section to evaluate the performance.
. Thus, CHERRY can also be used to output viruses that infect a prokaryote of interest. We use Eq. 9 to predict the viruses that infect given prokaryotic genomes. CHERRY will take prokaryotic genomes as input and output viruses with prediction scores above a given threshold. This function can help users identify candidate viruses that can infect targeted prokaryotes. We use recall and precision introduced in the Experimental setup Section to evaluate the performance.
As shown in Figure 14, we draw the precision-recall curve by recording the precision and recall under different thresholds. When using a more lenient threshold, the recall increases with a sacrifice of the precision. Users can choose the thresholds according to their needs. In order to achieve high precision, we use 0.9 as the default threshold in our program.
Figure 14.
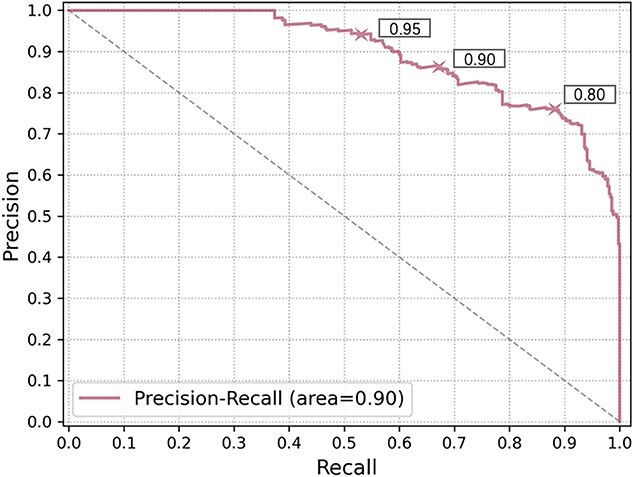
The precision-recall curve of predicting viruses infecting targeted prokaryotes. X-axis: recall, Y-axis: precision. The performance for three thresholds 0.95, 0.9 and 0.8 are marked with the the cross sign on the curve.
4 Discussion
In this work, we describe a new virus host prediction tool, which formulates the host prediction problem as link prediction in a multimodal graph. This multimodal graph integrates different types of prior knowledge, including protein organization, CRISPR, sequence similarity and 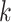 -mer frequency, from both labeled (training) and unlabeled (test) data. Then we apply a graph convolutional encoder to embed feature vectors on the graph and use a two-layer neural network decoder to calculate the probability of a query (virus–prokaryote) pair forms an interaction. We apply the end-to-end training process and the negative sampling method to optimize the loss. This semi-supervised learning scheme helps the model learn features from both the training set and test set and thus leads to high prediction accuracy. The large-scale experiments on 1940 viruses and 60 105 prokaryotic genomes show that we improve the host prediction accuracy from 43% to 8~0% at the species level. We also use two case studies to validate the reliability and practicality of our model in real-world applications.
-mer frequency, from both labeled (training) and unlabeled (test) data. Then we apply a graph convolutional encoder to embed feature vectors on the graph and use a two-layer neural network decoder to calculate the probability of a query (virus–prokaryote) pair forms an interaction. We apply the end-to-end training process and the negative sampling method to optimize the loss. This semi-supervised learning scheme helps the model learn features from both the training set and test set and thus leads to high prediction accuracy. The large-scale experiments on 1940 viruses and 60 105 prokaryotic genomes show that we improve the host prediction accuracy from 43% to 8~0% at the species level. We also use two case studies to validate the reliability and practicality of our model in real-world applications.
Although CHERRY has greatly improved the performance of host prediction, we will further optimize or extend CHERRY in our future work. First, CHERRY currently only uses sequence-based features such as sequence similarity and 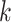 -mer frequency. Because the binding between RBPs and the host cells’ receptors is essential for the virus to gain entry into the host cells, one possible extension is to include protein–protein interactions (PPI) between RBPs and receptors in the edge construction. However, because only a few PPIs about prokaryotic viruses are reported, more experiments or computational structure and interaction predictions are needed to augment the graph. Second, other sequence-based features can be added to the node features if those features can help host prediction. We will support users to add their customized features to enhance the learning ability. Third, CHERRY is trained for species-level host prediction and is not optimized for strain-level host prediction. The high similarity between strains can lead to ambiguous predictions. In addition, another challenge is the fewer training samples at the strain level. We will explore whether CHERRY can be extended for strain-level host prediction in our future work. Finally, our method can benefit from using more characterized virus–host interactions. In order to investigate whether CHERRY can be generalized to new viruses, the current version of CHERRY was trained using viruses submitted before 2015. If we use viruses submitted before 2014 as the training set, the decreased number of labeled nodes (from 1306 to 968) reduces the species-level accuracy from 78% to 73% on the test set. Thus, with increased availability of characterized interactions, the accuracy of CHERRY will increase too.
-mer frequency. Because the binding between RBPs and the host cells’ receptors is essential for the virus to gain entry into the host cells, one possible extension is to include protein–protein interactions (PPI) between RBPs and receptors in the edge construction. However, because only a few PPIs about prokaryotic viruses are reported, more experiments or computational structure and interaction predictions are needed to augment the graph. Second, other sequence-based features can be added to the node features if those features can help host prediction. We will support users to add their customized features to enhance the learning ability. Third, CHERRY is trained for species-level host prediction and is not optimized for strain-level host prediction. The high similarity between strains can lead to ambiguous predictions. In addition, another challenge is the fewer training samples at the strain level. We will explore whether CHERRY can be extended for strain-level host prediction in our future work. Finally, our method can benefit from using more characterized virus–host interactions. In order to investigate whether CHERRY can be generalized to new viruses, the current version of CHERRY was trained using viruses submitted before 2015. If we use viruses submitted before 2014 as the training set, the decreased number of labeled nodes (from 1306 to 968) reduces the species-level accuracy from 78% to 73% on the test set. Thus, with increased availability of characterized interactions, the accuracy of CHERRY will increase too.
Key Points
In this work, we present CHERRY, a new virus–prokaryote interaction prediction tool. Our large-scale experiment on finding the interactions for 1940 viruses and 60 105 prokaryotic genomes shows that CHERRY improves the host prediction accuracy from 43% to ˜80% at the species level.
Our rigorous test of CHEERY on other datasets and the benchmark experiments against 11 recently published tools show that CHERRY is the most accurate host prediction tool.
Unlike many existing tools, CHERRY can be flexibly used in two scenarios. It can take either query viruses or prokaryotes as inputs. For input viruses, it can predict their hosts. For input prokaryotes, it can predict the viruses infecting them.
Jiayu Shang received his bachelor’s degree from Sun Yat-sen University. He is now pursuing his Ph.D. degree at the City University of Hong Kong. His research interest is bioinformatics, with a focus on algorithm design for analyzing microbial sequencing data.
Yanni Sun is currently an associate professor in the Department of Electrical Engineering at the City University of Hong Kong. She got her Ph.D. in Computer Science and Engineering from Washington University in Saint Louis, USA. Her research interests are sequence analysis and metagenomics.
Data availability
All data and codes used for this study are available online or upon request to the authors. The source code of CHERRY is available via: https://github.com/KennthShang/CHERRY. The accessions of training set and test set are available via: https://github.com/KennthShang/CHERRY/Interactiondata. The training set is listed in VHM_PAIR_TAX.xls. The test set is listed in TEST_PAIR_TAX.xls.
Funding
This work was supported by City University of Hong Kong (Project 9678241), Hong Kong Institute of Data Science (9360163), and the Hong Kong Innovation and Technology Commission (InnoHK Project CIMDA).
References
- 1. Galiez C, Siebert M, Enault F, et al. . WIsH: who is the host? Predicting prokaryotic hosts from metagenomic phage contigs. Bioinformatics 2017;33(19):3113–4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Congyu L, Zhang Z, Cai Z, et al. . Prokaryotic virus host predictor: a Gaussian model for host prediction of prokaryotic viruses in metagenomics. BMC Biol 2021;19(1):1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Tan J, Fang Z, Shufang W, et al. . HoPhage: an ab initio tool for identifying hosts of phage fragments from metaviromes. Bioinformatics 2021;543–5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Pons JC, Paez-Espino D, Riera G, et al. . VPF-Class: taxonomic assignment and host prediction of uncultivated viruses based on viral protein families. Bioinformatics 2021;1805–13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Coutinho FH, Zaragoza-Solas A, López-Pérez M, et al. . RaFAH: Host prediction for viruses of Bacteria and Archaea based on protein content. Patterns 2021;2:100274. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Shang J, Sun Y. Detecting the hosts of bacteriophages using GCN-based semi-supervised learning. BMC Biol 2021;19(250):1–15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Zielezinski A, Deorowicz S, Gudyś A. PHIST: fast and accurate prediction of prokaryotic hosts from metagenomic viral sequences. Bioinformatics 2021;38(5):1447–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Li M, Wang Y, Li F, et al. . A deep learning-based method for identification of bacteriophage-host interaction. IEEE/ACM Trans Comput Biol Bioinform 2020;1801–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Li M, Zhang W. PHIAF: prediction of phage-host interactions with GAN-based data augmentation and sequence-based feature fusion. Brief Bioinform 2021;23(1):09. [DOI] [PubMed] [Google Scholar]
- 10. Amgarten D, Iha BKV, Piroupo CM, et al. . vHULK, a new tool for bacteriophage host prediction based on annotated genomic features and deep neural networks. bioRxiv. Cold Spring Harbor Laboratory, 2020;1:1–16. [Google Scholar]
- 11. Ruohan W, Xianglilan Z, Jianping W, et al. . DeepHost: phage host prediction with convolutional neural network. Brief Bioinform 2021;23(1):09. [DOI] [PubMed] [Google Scholar]
- 12. Wang W, Ren J, Tang K, et al. . A network-based integrated framework for predicting virus–prokaryote interactions. NAR genomics and bioinformatics 2020;2(2):lqaa044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Džunková M, Low SJ, Daly JN, et al. . Defining the human gut host–phage network through single-cell viral tagging. Nat Microbiol 2019;4(12):2192–203. [DOI] [PubMed] [Google Scholar]
- 14. Edwards RA, Rohwer F. Viral metagenomics. Nat Rev Microbiol 2005;3(6):504–10. [DOI] [PubMed] [Google Scholar]
- 15. Wawrzynczak E. A global marine viral metagenome. Nat Rev Microbiol 2007;5(1):6–6. [Google Scholar]
- 16. Coclet C, Roux S. Global overview and major challenges of host prediction methods for uncultivated phages. Curr Opin Virol 2021;49:117–26. [DOI] [PubMed] [Google Scholar]
- 17. Edwards RA, McNair K, Faust K, et al. . Computational approaches to predict bacteriophage–host relationships. FEMS Microbiol Rev 2016;40(2):258–72. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Ahlgren NA, Ren J, Yang Young L, et al. . Alignment-free oligonucleotide frequency dissimilarity measure improves prediction of hosts from metagenomically-derived viral sequences. Nucleic Acids Res 2017;45(1):39–53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Achigar R, Magadán AH, Tremblay DM, et al. . Phage-host interactions in Streptococcus thermophilus: Genome analysis of phages isolated in Uruguay and ectopic spacer acquisition in CRISPR array. Sci Rep 2017;7(1):1–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Johnson M, Zaretskaya I, Raytselis Y, et al. . NCBI BLAST: a better web interface. Nucleic Acids Res 2008;36(suppl_2):W5–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Burstein D, Sun CL, Brown CT, et al. . Major bacterial lineages are essentially devoid of CRISPR-Cas viral defence systems. Nat Commun 2016;7:10613. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Grissa I, Vergnaud G, Pourcel C. The CRISPRdb database and tools to display CRISPRs and to generate dictionaries of spacers and repeats. BMC bioinformatics 2007;8(1):1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Grazziotin AL, Koonin EV, Kristensen DM. Prokaryotic Virus Orthologous Groups (pVOGs): a resource for comparative genomics and protein family annotation. Nucleic Acids Res 2016;gkw975:D491–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Steinegger M, Söding J. MMseqs2 enables sensitive protein sequence searching for the analysis of massive data sets. Nat Biotechnol 2017;35(11):1026–8. [DOI] [PubMed] [Google Scholar]
- 25. Gouy M, Gautier C. Codon usage in bacteria: correlation with gene expressivity. Nucleic Acids Res 1982;10(22):7055–74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Carbone A. Codon bias is a major factor explaining phage evolution in translationally biased hosts. J Mol Evol 2008;66(3):210–23. [DOI] [PubMed] [Google Scholar]
- 27. Boeckaerts D, Stock M, Criel B, et al. . Predicting bacteriophage hosts based on sequences of annotated receptor-binding proteins. Sci Rep 2021;11(1):1–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Mikolov T, Sutskever I, Chen K, et al. . Distributed representations of words and phrases and their compositionality. In: Burges CJ, Bottou L, Welling M, Ghahramani Z, Weinberger KQ (eds). Advances in neural information processing systems. Harrahs and Harveys, Lake Tahoe: Curran Associates, Inc., 2013, 3111–9.
- 29. Al Hasan M, Chaoji V, Salem S, et al. . Link prediction using supervised learning. In: Ghosh J (ed). SDM06: workshop on link analysis, counter-terrorism and security. Bethesda, Maryland: Society for Industrial and Applied Mathematics, Vol. 30, 2006, 798–805. [Google Scholar]
- 30. Hyatt D, Chen G-L, LoCascio PF, et al. . Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC bioinformatics 2010;11(1):1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Buchfink B, Xie C, Huson DH. Fast and sensitive protein alignment using DIAMOND. Nat Methods 2015;12(1):59–60. [DOI] [PubMed] [Google Scholar]
- 32. Bolduc B, Jang HB, Doulcier G, et al. . vConTACT: an iVirus tool to classify double-stranded DNA viruses that infect Archaea and Bacteria. PeerJ 2017;5:e3243. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Shang J, Jiang J, Sun Y. Bacteriophage classification for assembled contigs using graph convolutional network. Bioinformatics 2021;37(Supplement_1):i25, 07–33. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Dutilh BE, Cassman N, McNair K, et al. . A highly abundant bacteriophage discovered in the unknown sequences of human faecal metagenomes. Nat Commun 2014;5:4498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Roux S, Brum JR, Dutilh BE, et al. . Ecogenomics and potential biogeochemical impacts of globally abundant ocean viruses. Nature 2016;537(7622):689–93. [DOI] [PubMed] [Google Scholar]
- 36. Wang W, Ren J, Tang K, et al.. A network-based integrated framework for predicting virus-prokaryote interactions. NAR Genomics and Bioinformatics 2020; 2(2). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Bland C, Ramsey TL, Sabree F, et al. . CRISPR recognition tool (CRT): a tool for automatic detection of clustered regularly interspaced palindromic repeats. BMC bioinformatics 2007;8(1):1–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Camacho C, Coulouris G, Avagyan V, et al. . BLAST+: architecture and applications. BMC bioinformatics 2009;10(1):1–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Cramer P. AlphaFold2 and the future of structural biology. Nat Struct Mol Biol 2021;1–2. [DOI] [PubMed] [Google Scholar]
- 40. Defferrard M, Bresson X, Vandergheynst P. Convolutional neural networks on graphs with fast localized spectral filtering. Advances in neural information processing systems 2016;29:3844–52. [Google Scholar]
- 41. Gilmer J, Schoenholz SS, Riley PF, et al. . Neural message passing for quantum chemistry. In: International conference on machine learning. PMLR, 2017, 1263–72. [Google Scholar]
- 42. Trouillon T, Welbl J, Riedel S, et al. . Complex embeddings for simple link prediction. In: International conference on machine learning. PMLR, 2071, 2016–80. [Google Scholar]
- 43. Kingma DP, Ba J. Adam: A method for stochastic optimization arXiv preprint arXiv:1412.6980, 2014.
- 44. Baker DN, Langmead B. Dashing: fast and accurate genomic distances with HyperLogLog. Genome Biol 2019;20(1):1–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Marbouty M, Thierry A, Millot GA, et al. . MetaHiC phage-bacteria infection network reveals active cycling phages of the healthy human gut. Elife 2021;10:e60608. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Zhong Z-P, Tian F, Roux S, et al. . Glacier ice archives nearly 15,000-year-old microbes and phages. Microbiome 2021;9(1):1–23. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Benler S, Yutin N, Antipov D, et al. . Thousands of previously unknown phages discovered in whole-community human gut metagenomes. Microbiome 2021;9(1):1–17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Bastian M, Heymann S, Jacomy M. Gephi: an open source software for exploring and manipulating networks. In: Third international AAAI conference on weblogs and social media, 2009.
- 49. Chibani-Chennoufi S, Bruttin A, Dillmann M-L, et al. . Phage-host interaction: an ecological perspective. J Bacteriol 2004;186(12):3677–86. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Hamdi S, Rousseau GM, Labrie SJ, et al. . Characterization of two polyvalent phages infecting Enterobacteriaceae. Sci Rep 2017;7(1):1–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Antipov D, Raiko M, Lapidus A, et al. . Metaviral SPAdes: assembly of viruses from metagenomic data. Bioinformatics 2020;36(14):4126–9. [DOI] [PubMed] [Google Scholar]
- 52. Auslander N, Gussow AB, Benler S, et al. . Seeker: alignment-free identification of bacteriophage genomes by deep learning. Nucleic Acids Res 2020;48(21):e121–1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. Roux S, Enault F, Hurwitz BL, et al. . VirSorter: mining viral signal from microbial genomic data. PeerJ 2015;3:e985. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All data and codes used for this study are available online or upon request to the authors. The source code of CHERRY is available via: https://github.com/KennthShang/CHERRY. The accessions of training set and test set are available via: https://github.com/KennthShang/CHERRY/Interactiondata. The training set is listed in VHM_PAIR_TAX.xls. The test set is listed in TEST_PAIR_TAX.xls.