

Abstract
In precision medicine, especially in the pharmacodynamic area, the lack of an adequate long-term drug effect monitoring model leads to a quite low robustness to the instant drug treatment. Modelling the effect of drug based on the monitoring variables is essential to measure the drug benefit and its side effect preciously. In order to model the complex drug behavior in the context of time series, a sin function is selected to describe the basic trend of heart rate variable that is medically monitored. A Hawkes self-exciting point process model is chosen to describe the effect caused by multiple and sequential drug usage at different time points. The model considers the time lag between the drug given time and the drug effect during the whole drug emission period. A cumulative Gamma distribution is employed to describe the time lag effect. Simulation results demonstrate the established model effectively when describing the baseline trend and the drug effect with low noise levels, where the maximal overlap discrete wavelet transformation is utilized for the information decomposition in the frequency zone. The real data of the variables heart rate and drug liquemin from a medical database is analyzed. Instead of the original time series, scale variable s4 is selected according to the Granger cointegration test. The results show that the model accurately characterizes the cumulative drug effect with the Pearson correlation test value as 0.22, which is more significant for the value under 0.1. In the future, the model can be extended to more complicated scenarios through taking into account multiple monitoring variables and different kinds of drugs.
1. Introduction
Pharmacokinetics (PK) and pharmacodynamics (PD) are aimed at building mathematical models to extract scientific basis of modern pharmacotherapy. Specifically, pharmacokinetics describes the drug concentration-time courses in body fluids resulting from the intake of a certain dose of drug, and pharmacodynamics describes the observed effect arising from a certain drug concentration [1]. Between PK and PD, PD is more important for describing the variation of body conditions after drug treatment. Following a drug treatment, the original organ function can be enhanced or suppressed. Thus, determining the accurate dosage of the drug is rather essential in the drug prescription. During the treatment process with a given drug dosage, the body condition may be improved but may also suffer some untoward reaction or adverse reaction, including side effect, toxic reaction, allergy reaction, secondary reaction, residual effect, and teratogenesis. Therefore, drug treatment can be helpful to the patient but might be harmful as well, and monitoring the drug effect by observing the clinically monitored variables plays an important role in understanding the mechanism.
The major objective of PD is to explore how the drug influences the monitored variables including heart rate, cardiac output, and mean arterial pressure. Modelling the drug effect can help improve medical precision by applying more suitable treatment for the patient under a target criteria of the monitored variable. Drug effect modelling is critical to realize the online forecasting of the dynamic status of patient's disease. On the other hand, this can reduce the expenditure of medical resources including human resources like physicians and caregivers, drug usage, and economic cost.
Due to the special property of drug effect, the influence of the drug on patient is complex. The instant usage of drug has a long-term and dynamic effect on the patient. For example, there may exist a time delay for some drug to show the medical effects, which may be half an hour in some special circumstances. The time length taken by the drug effect is different not only among different drugs but also for different intake methods. For epinephrine, the effect of intramuscular injection is approximately maintained between 10 and 30 minutes, while the effect of subcutaneous injection can take as long as around 1 hour. Drug effect may increase rapidly and then decrease slowly afterwards before finally vanishes. Before the drug effect vanishes, more drug dosage may be required to be applied to the patient. Besides, multiple drug usages can cause multiple cumulative effects. Determining the correct drug dosage becomes quite challenging as the monitored variables vary with an unpredictable trend. To give a precise dose under a target value of the monitored variable, the whole past drug usage that is still effective should be taken into consideration, as their influence on the patient's future health condition still affects the current required dosage.
In this work, the influence of drug usage on the monitored variables is specifically analyzed, particularly in terms of the cumulative effect from the past drug usage. The rest of the paper is organized as follows: Section 2 gives the research review of drug effect modelling including the state of the art and our contributions, Section 3 presents the method proposed in this research, Sections 4 and 5 show the analysis and the simulation using the real medical data, and Section 6 presents a conclusion of the results and the viewpoints on the further research. All computations are implemented using the software R [2] of the version 4.0.2, and “waveslim” [3] was used for the wavelet decompositions. The hardware platform is iMac Pro (2017) configured with the processor 3.2 GHz 8-Core Intel Xeon W, the memory 32 GB 2666 MHz DDR4, and the Graphics Radeon Pro VEga 56 8 GB.
2. Literature Review
The approaches to establishing the models for characterizing the effect of drug on electrocardiogram (ECG) signals like heart rate can be generally divided into three main groups. The pros and cons of the available approaches are compared in detail in the following. The first group includes the typical statistical methods like linear regression, logit regression, analysis of variance (ANOVA) and basic statistical description methods like box plot. In order to study how the choice of anesthetic agent can greatly influence CSF tracer influx, Hablitz et al. [4] used the linear regression analysis. Linear regression with extensions like Lasso, Ridge, and Elastic-net such penalized linear regression methods are good at explanation of the real application background and are simple to understand. Capel et al. [5] used 1- or 2-way ANOVA to investigate the propensity of hydroxychloroquine to cause bradycardia. ANOVA is effective to compare the drug efficiency difference among two or more comparison experiments. In the research of Sun et al. [6], pairwise network meta-analyze was performed using DerSimonian–Laird random effects model to analysis the impact of GLP-1 receptor agonists on blood pressure, heart rate, and hypertension among patients with type 2 diabetes. Gilbert and Krum [7] analyzed the effects of antihyperglycemic drug therapy on heart failure in diabetes by using the meta analysis as well. The pros and cons of this type of methods include that these methods are rather efficient when the data has simple format including cross section data, and the research purpose is more focused on producing the medical experiment results instead of the method improvement. When the data structure is complicated or the objective is lied on the methodology, more interests are concentrated on the subsequent second or third group of methods.
The second type of drug effect models mainly includes machine learning and deep learning methods such as ensemble decision tree methods (AdaBoost or XGBoost), neural networks (convolutional neural network and long-short term neural network), support vector machine, and Bayesian classifiers [8, 9]. For example, Sherman et al. [10] used machine learning methods to identify drug-cancer cell interaction based on some large in vitro databases. Bresso et al. [11] applied the methods decision trees and inductive logic programming to characterizing each drug's side-effect profiles in terms of drug and target properties. Costabal et al. [12] characterized the effect of 30 drugs on the QT interval using Gaussian process regression, sensitivity analysis, and uncertainty quantification. In the research of Juhola et al. [13], several machine learning methods are compared in the analysis of drug effects on iPSC cardiomyocytes, including decision trees, K-nearest neighbor nearest searching, multinomial logistic regression, and least squares support vector machines. Results show that random forests classifier and least-squares support vector machines have better performance than the other methods. Ekins et al. [14] compared the performance of different machine learning methods for end-to-end drug discovery and development including Naïve Bayesian, support vector machines, and more recently concerned deep neural networks. Madhukar et al. [15] proposed a Bayesian approach to the drug target identification using diverse data types. Soft computing techniques [16, 17], which although have not been directly applied to the drug effect modelling, can still be the promising solutions to the problem. The pros and cons of this type of methods include the following aspects. It is pretty impressive that the machine learning methods have high prediction accuracy and many of them have reliable generalization. However, most of the machine learning methods are based on quite complex parametric systems and lack of interpretability of parameter meanings, such that may not be the ideal tools for achieving both high accuracy and good explanation.
The third type of drug effect models mainly includes mathematical models such as Cox hazard model based on ordinary differential equations and partial differential equations. Chatterjee and Ahmad [18] applied the fractional-order differential equation model to analyzing the COVID-19 infection of epithelial cells. Huang et al. [19] gave the hierarchical Bayesian inference for HIV dynamic differential equation models which incorporated multiple treatment factors. Thirumalai et al. [20] proposed the fractional differential equations based method to analyze the combined drug therapy for HIV infection. Leander et al. [21] used the stochastic differential equations to analyze the mixed effects involved in pharmacokinetic data of nicotinic acid. Fuentes-Gari et al. [22] have compared the performance of different differential equations in the leukemia treatment, from which it can be found that stochastic differential mixed effects models are useful tools for identifying incomplete or inaccurate model dynamics. In general, those mathematical models have sound performance in both prediction accuracy and explanation.
The motivation of this research is that although the existing results have achieved good performance in PD, especially on drug effect modelling, they still have some shortcomings unsolved due to the complex background of pharmacodynamic, that is, the instant usage of drug can have long and complicated effect on the patient that is shown with the monitored variables. To illustrate this complicated effect, a stochastic modelling approach called Hawkes point process model is introduced to describe stochastic point process. In this work, a Hawkes point process model [23], namely, the self-exciting point process [24] is proposed to characterize the complex drug effect. The essential property of self-exciting point process is the occurrence of any event increased the probability of further events occurring which is consistent with the behavior of drug on patient. This model origins from the area of earthquake behavior analysis [25] and is recently extended to the fields of finance [26], disease prediction [27], and social media [28], where the model has shown satisfactory performance, but it has not been used for drug effect modelling yet.
The acquired data sets of the input variables in this work are time series that have clearly nonstationary property. They are also stochastic time series involved with random noise. Instead of using the original data in the model, the maximum overlap discrete wavelet transform (MODWT) is applied for the feather extraction [29]. MODWT is a method of decomposing the original time series into scaling and wavelet coefficients on different resolution levels, which can be seen as its smooth information and detail information [30]. In this research, these coefficients are used as the deep information involved in the original information. The method Fourier transform [31] can also decompose similar information but it is not suitable for non-stationary time series [32].
The innovation and contribution points in this research mainly have three aspects. The first one and also the main one is that self-exciting point process is proposed to describe the complex behavior of drug on patient. The second one is that MODWT is applied as the feather extraction method to find deep information involved in the original time series. The third one is that the drug effect model developed in this research can describe the effect of a sequence of drug usage on the monitored variables instead of only one usage. The results can be further developed for assisting precision medicine.
3. Method
The data contain two variables, the drug usage variable di and the monitored variable xt. di denotes the ith drug dosage at time ti, and xt gives the value of the monitored variable at time t. The goal is to describe xt by using di, that is
| (1) |
where g represents the other information included in the prediction of xt. In this paper, we mainly analyze the monitored variable heart rate as it is a typical variable that has similar properties to the other monitored variables. Variable xt such as the changes of the heart rate mainly contains three components: the original waveform change involved in the heart beat change itself, the trend change resulting from the disease, and the trend change arising from the drug usage. In order to keep track of the trend caused by the drug and disease, the wavelet transform method MODWT is applied before implementing the self-exciting point process.
Since the wavelet basis Haar wavelet is simple to understand and has good modelling performance, it is chosen as the basis for the MODWT. The Haar scaling function is defined as
| (2) |
Using dilation and translation, the scaling function at resolution level j and location k is
| (3) |
For more details, see Graps [33]. Then, the scale variables sj,k can be given by
| (4) |
The Haar mother wavelet function ψ(t) is defined as
| (5) |
And the wavelet function at resolution level j and location k is ψj,k(t) = 2j/2ψ(2jt − k). The wavelet coefficients dj,k are defined as dj,k = <x(t), ψj,k>. The scale variables vector sj = (sj,0, sj,1, ⋯, sj,t) and wavelet coefficient vector dj = (dj,0, dj,1, ⋯, dj,t) become new variables which can be used for classification and regression [34, 35]. We name them as scale variables (or scale information) and detail variables (or detail information) in the following sections. For convenience, sj,t is rewritten as st,j. By applying the Haar wavelet to the data xt, the new data Wt is given by
| (6) |
So far, the step of feature extraction has been finished by using MODWT with the input variables extracted as W. Instead of regarding all the variables in W as the target variables, Granger cointegration test is performed to verify how the drug influence the variables. The variable with the highest significance is chosen as the final target variable. In the Granger test, we set
| (7) |
where εt is the random noise that follows the Gaussian distribution. Granger test is based on the F test, and the hypothesis is defined as
| (8) |
and the corresponding F statistic is
| (9) |
where SSRr is the residual sum of squares being restricted, and SSRur is that unrestricted. If F > Fα(m, n − k), then, the hypothesis H0 that dt is not the Granger reason of xt is rejected.
By applying the Granger cointegration test to all the variables in W, the most significant variable can be selected as the final target variable, and we can regard the variable as the original xt without the rest information g. In that case, the trend caused by the drug instead of x itself or the trend incurred by the disease can be discarded to some extent. For convenience, we still use the symbol x to represent the final target variable.
After getting the final target variable x, it can be applied to the Hawkes point process involved with the drug information. In the self-exciting point process, the target variable is a number that can be counted, and in this work, we extend it to a continuous context. As a result, the conditional intensity of xt during the time interval (tj, tj+1) is given by
| (10) |
where gt includes the information available up to time t. After that, a fairly general self-exciting process can be defined in terms of an intensity of the form
| (11) |
where ti is the time when the ith drug usage occurs. μt > 0 provides a base level for the process, and we set it as a sin function for simplicity,
| (12) |
The function γ(t − ti, di) ≥ 0 is defined as the exciting kernel of the process, which can be a Gamma distribution. The kernel provides the contribution to the intensity at time t that is made by all the previous drug usage events that occur at previous time ti < t, with the associated drug dosage di. The meaning of the intensity function is that each event increases the intensity and then decays according to the function γ until the next drug usage occurs to push it up again. The chosen kernel function is a sigmoid function and a Gamma distribution function with the form as
| (13) |
where a1, a2, b1, b2, m1, κ1, and κ2 are all parameters to be determined using the real data. In this kernel function, the sigmoid function is proposed to describe the instant drug effect, which we assume the appropriate drug dosage can bring about the corresponding correct effect while using an extra dosage can make little effect when the drug has been already too much or rare. In that case, the sigmoid function is chosen to make it consistent with the assumptions. The Gamma function can be used to describe the trend of the drug effect from the increasing stage to the decreasing stage slowly. It can also describe the decaying process of the drug effect with the time. In the function of λt, the cumulative of the γ(t − ti, di) describes all the previous drug effect until the current time. In order to calculate the parameters θ = {a0, b0, α0, β0, a1, a2, b1, b2, m1, κ1, κ2}, the ordinary least squares method (OLS) is used to estimate these parameters. The target function to be minimized can be expressed as
| (14) |
Since is not easy to be obtained, is used for the replacement of it. Thus, the target function L can be given by
| (15) |
Replacing with λt in L gives
| (16) |
It follows that
| (17) |
Taking the derivative of each parameter in θ, for parameter a1, we have
| (18) |
Similar results can be obtained for the other parameters in θ. It is clear that we cannot get a closed form solution from the derivation as the estimated parameters are mutually dependent with each other. Hence, an optimization method of Broyden–Fletcher–Goldfarb–Shanno (BFGS) is proposed to minimize L, which is a quasi-Newton method, also known as the variable scale method. This algorithm improves the weakness of Newton's method from the aspects that BFGS will not be easily affected by the initial value without the cost of computing the exact hessian matrix and its inverse in the process of each step of optimization. The NFGS, namely, the Newton improved BFGS, has the characteristic of fast searching of Newton's method and has an improvement in efficient searching for the global optimal solution.
The measurement of the goodness of fit has the metric using R2, which ranges from 0 to 1, with 1 as the best fit. R2 has the form as
| (19) |
where SST is the total sum of squares, and SSE is the residual (error) sum of squares,
| (20) |
| (21) |
In addition to the R2, the Pearson correlation test value is also selected for comparison, which is formulated as
| (22) |
Some other evaluation criteria to assess the performance of the models include mean absolute error and mean percentage error. They all give the measurement of the model fitness, and R2 and the correlation test can have similar or better effect in measuring the results as their values are constrained in 0 to 1 or -1 to 1, such that the performance can be compared with the significant level. In conclusion, we develop a method to analysis the influence of drug usage on the monitored variable by using self-exciting point process with the kernel function of Gamma distribution.
4. Simulation
In this section, we analyze the performance of the method under different noise levels. Since the drug effect can produce the cumulative effect, as shown in Figure 1, we will also analyze how the drug effect influences the model performance. In this Figure 1, the black line represents the cumulative effect ∑ti−tγ(t − ti, di), and the dashed lines represent the separate drug effect γ(t − ti, di) for each i.
Figure 1.
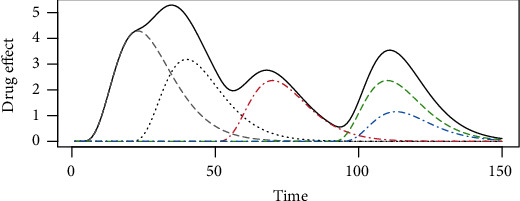
The drug effect of each drug entry. The black solid line represents the cumulative effect, and the dashed lines represent each drug entry.
In order to explore how the parameters influence the model performance, the simulation is performed using different parameter settings. The true parameter and the simulated parameters are shown in Table 1. With the parameter given in Table 1, the R2 results are shown in Figure 2. It can be seen that some parameters have few influence on the R2, including b1, a1, a2, b0, a0. The parameters that have the apparent influence on the R2 include b2, κ2, κ1, m1, b0, α0, β0. From Figure 2, it can be seen that when the values of b2 and κ2 keep in a fixed ratio around 10, the R2 keeps in its good performance. When κ1 increases from 0 to around its best value 0.3, the R2 increases, but deceases afterwards when κ1 continues to grow. For the parameter m1, R2 has the similar trend. The model performance is not good when m1 is below its best value but performs relatively well when m1 is above its best value. For b0, α0 and β0, as they are in the sin function, R2 shows some kind of routinely performance.
Table 1.
Parameter setting under different value.
| Parameter | True parameter value | Parameter value range |
|---|---|---|
| a 0 | 70 | [1, 100] |
| b 0 | 5 | [0.1 10] |
| α 0 | 1 | [0.1 10] |
| β 0 | 2 | [0.1 10] |
| a 1 | 1 | [0.1, 50] |
| b 1 | 1 | [0.01, 10] |
| κ 1 | 0.3 | [0.01, 1] |
| m 1 | -20 | [-100, 98] |
| a 2 | 3 | [0.01, 10] |
| κ 2 | 5 | [2.1, 22] |
| b 2 | 0.4 | [0.01, 2] |
Figure 2.
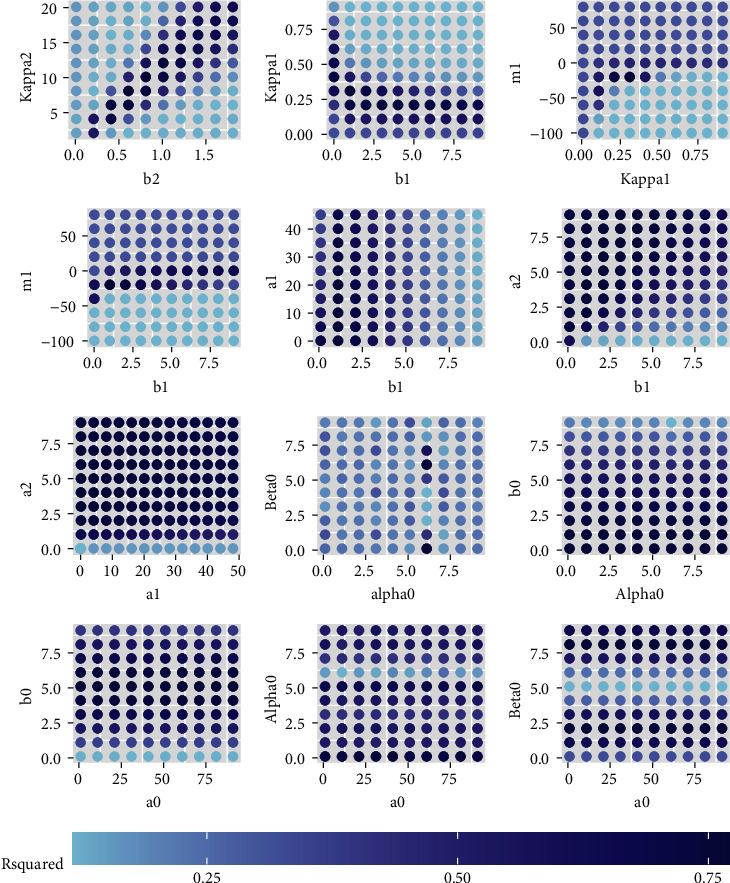
The R2 under different parameter settings. The true values are shown in Table 1.
The level of noise also influences the best fitting ability. That is why MODWT is applied before the model training. For example, as shown in Figure 3, by adding the noise which follows the Gaussian distribution, the monitored variable with noise becomes far away from the one without noise. This gap causes the R2 to be smaller than it should be. By setting the noise level as 0.1 to 10, we can get the best possible R2 value by choosing the best parameters, and the results are shown in Figure 4. The R2 decreases as the noise level increases. When the variance of the noise level is bigger than 4, the R2 decreases below 0.9. When the noise level is 5, the R2 decreases below 0.8. This result also shows the best possible R2 under different noise levels.
Figure 3.
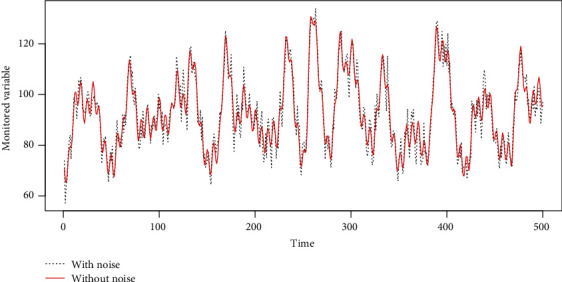
The simulated monitored variable with noise and the one without noise.
Figure 4.
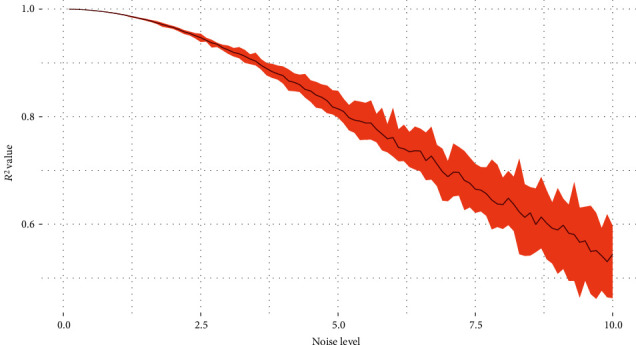
The best possible R2 under different noise levels.
5. Real Data Analysis
The real data we use in this work is the circulatory failure data Hyland et al. [36]. The original source of the data comes from the Medical Information Mart for Intensive Care- (MIMIC-) III database [37], which provides the critical care data of over 40,000 patients admitted to intensive care units at the Beth Israel Deaconess Medical Center. Importantly, MIMIC-III was deidentified, and patient identifiers were removed according to the Health Insurance Portability and Accountability Act Safe Harbor provision. MIMIC-III has been integral in driving large amounts of research in clinical informatics, epidemiology, and machine learning. The data we use contain 812 observations, with 1-minute gap per observation as the resolution level. There are totally 18 variables in the data including heart rate, MAP, cardiac output, and SpO2.
Instead of using all the variables, the variable heart rate is selected as the monitored variable as it has quite few missing values. The minimum and maximum of the heart rate are 61 and 117, respectively. The average and standard deviation are 77 and 9.17, respectively. The drug data in use is the amount of dosage of drug liquemin with unit 5000 U/ml for per dosage. The dosage in use in this real data is 25. The number of usage is 63 times. Liquemin is used to decrease the clotting ability of the blood and help prevent harmful clots from forming in blood vessels. This medicine is sometimes called a blood thinner, although it does not actually thin the blood. Specifically, it is also used in the treatment of heart attacks and unstable angina. Two time-series phases are selected for the real data analysis which contain only liquemin. The flowchart of the proposed method is shown in Figure 5. As shown in Figure 6, the original heart rate variable is transformed by using MODWT to leave out the noise, and the scaling information is selected by using the Granger cointegration test. After that, the scaling information and the drug information are put into the Hawkes point process model with the R2 or correlation test as the results. In this case, scale variable s4 on resolution level is selected as the target variable x according to the Granger cointegration test, and the results are shown in Figure 7. The computed parameters are θ = (75, 1.21, 0.13, 1.39, 0.30, 2.08, 0.80, 0.47, 0.0022, 2.77, 0.12). The R2 is not big as there are other trend inside the original data, but the correlation is obvious with a Pearson test value as 0.22.
Figure 5.
The flowchart of the proposed method.
Figure 6.
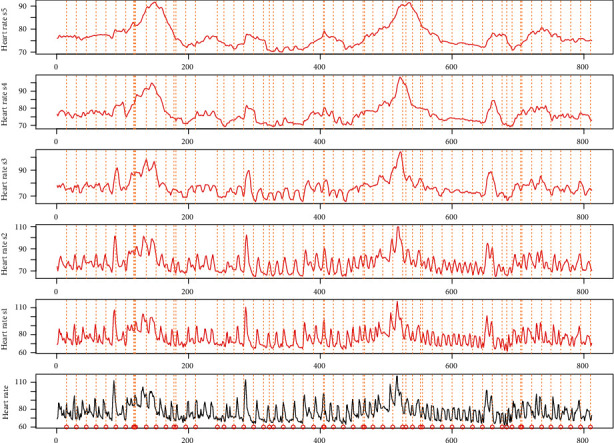
The scale variables of the original heart rate time series with drug labelled as the vehicle lines.
Figure 7.
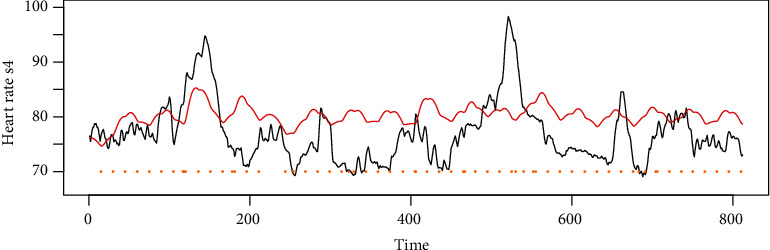
The scale variables of the original heart rate time series with drug labelled as the vehicle lines.
Instead of comparing to the time series of the original data, the scale variables on level 4 is compared with the model output since it leaves out most of the noise and with only the trend left for comparison. From Figure 7, we can see that most of the increases and drops are caught by the red line, which means the proposed Hawkes model can effectively measure the drug effect. The Pearson test result is 0.22 that is significantly below the level of 0.1. The obtained model is given by
| (23) |
To sum up, due to the complex development of the monitored variables, there are still some trends caused by the disease that cannot be fully described by our model. We propose a model that gives a different and efficient method for the drug effect measurement in pharmacodynamic.
6. Conclusion
In this research, we develop a Hawkes model by using self-exciting point process and sin function to describe the development of medical monitored variable heart rate. Self-exciting point process can describe the effect of the drug and the dosage of the drug. The sin function can describe the basic trend of heart rate. By combining these two functions together, some of the heart rate trend can be described. The model can be used for drug effect prediction and solve the problem of drug precision suggestion. It can also be used for the medical assistant by giving more precise drug dosage description. Specifically, the results show that the model can have a correlation Pearson test to be significant under the significant level of 0.1. The increases and decreases of the trained drug effect can fit the trend of the real drug effect.
The limitations of this research are summarized as the following. In our research, only one kind of drug is modelled, but if many kinds of drug are considered in the model, the model can also be complex. Specifically, in the further research, more complex model can be developed to describe the details of the monitored variable trend including the trend caused by the disease, in addition to the basic trend and drug effect trend. The trend caused by the disease is quite complex to be described but still can be modelled. The analysis of multiple drugs is not simply based on the adding of single drugs, in that case, using many self-exciting point process cannot meet the demand of multiple drug effect analysis. Mutual-exciting point process Hawkes model can be considered to describe the effect of multiple kinds of drug and cumulative drug effect dosage. If multiple drug effect can be modelled, then the further analysis can be concentrated on the inverse problem of drug dosage decision under a predefined monitored variable value.
The proposed modelling solution can be further extended to some other areas in addition to the medical area. For example, in the financial area, the model can be used to monitor the effect of economic events or political events to predict the stock price and security price trend after the event occurs. In the environmental area, the model can be used to monitor the effect of air pollution by decomposing the original time series into three aspects, namely, the basic routine trend, the trend arising from events, and that caused by solar circles. In conclusion, the model developed in this research is an efficient and generalized model for time series data which contains multiple kinds of trends either embraced by the time series itself or caused by the external events.
Acknowledgments
Xin Zhao and Xiaokai Nie gratefully acknowledge the support from the Fundamental Research Funds for the Central Universities (2242020R40073, 2242022k30038, MCCSE2021B02, and 2242020R10053), Southeast University Zhishan Youth Scholar Foundation, Natural Science Foundation of Jiangsu Province (BK20200347 and BK20210218), Nanjing Scientific and Technological Innovation Foundation for Selected Returned Overseas Chinese Scholars (1108000241), Jiangsu Foundation for Innovative and Entrepreneurial Doctor (1107010306 and 1108000245), Guangdong Basic and Applied Basic Research Foundation (2020A1515110129), and National Natural Science Foundation of China (62103105, 12201108, and 12171085).
Abbreviations
- MODWT:
Maximal overlap discrete wavelet transform
- PK:
Pharmacokinetic
- PD:
Pharmacodynamic
- ECG:
Electrocardiogram
- ANOVA:
Analysis of variance
- BFGS:
Broyden–Fletcher–Goldfarb–Shanno
- MIMIC:
Medical Information Mart for Intensive Care.
Data Availability
The source code in the method are available from the corresponding author upon request. The real data in application can be requested from Hyland et al. [36].
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- 1.Meibohm B., Derendorf H. Basic concepts of pharmacokinetic/pharmacodynamic (pk/pd) modelling. International Journal of Clinical Pharmacology and Therapeutics . 1997;35(10):401–413. [PubMed] [Google Scholar]
- 2.R Core Team. R: A Language and Environment for Statistical Computing . Vienna, Austria: R Foundation for Statistical Computing; 2018. [Google Scholar]
- 3.Whitcher B. Waveslim: Basic Wavelet Routines for One-, Two-and Three-Dimensional Signal Processing. R Package Version 1.7.5.1 . CRAN; 2019. [Google Scholar]
- 4.Hablitz L. M., Vinitsky H. S., Sun Q., et al. Increased glymphatic influx is correlated with high eeg delta power and low heart rate in mice under anesthesia. Science Advances . 2019;5(2):p. eaav5447. doi: 10.1126/sciadv.aav5447. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Capel R. A., Herring N., Kalla M., et al. Hydroxychloroquine reduces heart rate by modulating the hyperpolarization- activated current If: novel electrophysiological insights and therapeutic potential. Heart Rhythm . 2015;12(10):2186–2194. doi: 10.1016/j.hrthm.2015.05.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Sun F., Wu S., Guo S., et al. Impact of glp-1 receptor agonists on blood pressure, heart rate and hypertension among patients with type 2 diabetes: a systematic review and network meta-analysis. Diabetes Research and Clinical Practice . 2015;110(1):26–37. doi: 10.1016/j.diabres.2015.07.015. [DOI] [PubMed] [Google Scholar]
- 7.Gilbert R. E., Krum H. Heart failure in diabetes: effects of anti-hyperglycaemic drug therapy. The Lancet . 2015;385(9982):2107–2117. doi: 10.1016/S0140-6736(14)61402-1. [DOI] [PubMed] [Google Scholar]
- 8.Ding H., Takigawa I., Mamitsuka H., Zhu S. Similarity-based machine learning methods for predicting drug–target interactions: a brief review. Briefings in Bioinformatics . 2014;15(5):734–747. doi: 10.1093/bib/bbt056. [DOI] [PubMed] [Google Scholar]
- 9.Stephenson N., Shane E., Chase J., et al. Survey of machine learning techniques in drug discovery. Current Drug Metabolism . 2019;20(3):185–193. doi: 10.2174/1389200219666180820112457. [DOI] [PubMed] [Google Scholar]
- 10.Sherman J., Verstandig G., Rowe J. W., Brumer Y. Application of machine learning to large in vitro databases to identify drug-cancer cell interactions: azithromycin and KLK6 mutation status. Oncogene . 2021;40(21):3766–3770. doi: 10.1038/s41388-021-01807-4. [DOI] [PubMed] [Google Scholar]
- 11.Bresso E., Grisoni R., Marchetti G., et al. Integrative relational machine-learning for understanding drug side-effect profiles. BMC Bioinformatics . 2013;14(1):1–11. doi: 10.1186/1471-2105-14-207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Costabal F. S., Matsuno K., Yao J., Perdikaris P., Kuhl E. Machine learning in drug development: characterizing the effect of 30 drugs on the qt interval using gaussian process regression, sensitivity analysis, and uncertainty quantification. Computer Methods in Applied Mechanics and Engineering . 2019;348:313–333. doi: 10.1016/j.cma.2019.01.033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Juhola M., Penttinen K., Joutsijoki H., Aalto-Setälä K. Analysis of drug effects on ipsc cardiomyocytes with machine learning. Annals of Biomedical Engineering . 2021;49(1):129–138. doi: 10.1007/s10439-020-02521-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Ekins S., Puhl A. C., Zorn K. M., et al. Exploiting machine learning for end-to-end drug discovery and development. Nature Materials . 2019;18(5):435–441. doi: 10.1038/s41563-019-0338-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Madhukar N. S., Khade P. K., Huang L., et al. A bayesian machine learning approach for drug target identification using diverse data types. Nature Communications . 2019;10(1):1–14. doi: 10.1038/s41467-019-12928-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Hempel T., Al-Hamadi A. An online semantic mapping system for extending and enhancing visual slam. Engineering Applications of Artificial Intelligence . 2022;111:p. 104830. doi: 10.1016/j.engappai.2022.104830. [DOI] [Google Scholar]
- 17.Ma J., Xia D., Guo H., et al. Metaheuristic based support vector regression for landslide displacement prediction: a comparative study. Landslides . 2022;19(10):2489–2511. doi: 10.1007/s10346-022-01923-6. [DOI] [Google Scholar]
- 18.Chatterjee A. N., Ahmad B. A fractional-order differential equation model of COVID-19 infection of epithelial cells. Solitons & Fractals . 2021;147:p. 110952. doi: 10.1016/j.chaos.2021.110952. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Huang Y., Wu H., Acosta E. P. Hierarchical Bayesian inference for hiv dynamic differential equation models incorporating multiple treatment factors. Biometrical Journal . 2010;52(4):470–486. doi: 10.1002/bimj.200900173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Thirumalai S., Seshadri R., Yuzbasi S. Spectral solutions of fractional differential equations modelling combined drug therapy for HIV infection. Solitons & Fractals . 2021;151:p. 111234. doi: 10.1016/j.chaos.2021.111234. [DOI] [Google Scholar]
- 21.Leander J., Almquist J., Ahlström C., Gabrielsson J., Jirstrand M. Mixed effects modeling using stochastic differential equations: illustrated by pharmacokinetic data of nicotinic acid in obese Zucker rats. The AAPS Journal . 2015;17(3):586–596. doi: 10.1208/s12248-015-9718-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Fuentes-Gari M., Misener R., Georgiadis M. C., et al. Selecting a differential equation cell cycle model for simulating leukemia treatment. Industrial & Engineering Chemistry Research . 2015;54(36):8847–8859. doi: 10.1021/acs.iecr.5b01150. [DOI] [Google Scholar]
- 23.Hawkes A. G. Hawkes jump-diffusions and finance: a brief history and review. The European Journal of Finance . 2020;28(7):627–641. [Google Scholar]
- 24.Derek Tucker J., Shand L., Lewis J. R. Handling missing data in self-exciting point process models. Spatial Statistics . 2019;29:160–176. doi: 10.1016/j.spasta.2018.12.004. [DOI] [Google Scholar]
- 25.Fox E. W., Schoenberg F. P., Gordon J. S. Spatially inhomogeneous background rate estimators and uncertainty quantification for nonparametric Hawkes point process models of earthquake occurrences. The Annals of Applied Statistics . 2016;10(3):1725–1756. doi: 10.1214/16-AOAS957. [DOI] [Google Scholar]
- 26.Lesage L., Deaconu M., Lejay A., Meira J. A., Nichil G., State R. Hawkes processes framework with a gamma density as excitation function: application to natural disasters for insurance. Methodology and Computing in Applied Probability . 2022;24:1–29. doi: 10.1007/s11009-022-09938-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Sun Z., Dong W., Shi J., Huang Z. Towards predictive analysis on disease progression: a variational Hawkes process model. IEEE Journal of Biomedical and Health Informatics, Biomedical and Health Informatics . 2021;25(11):4195–4206. doi: 10.1109/JBHI.2021.3101113. [DOI] [PubMed] [Google Scholar]
- 28.Abouzeid A., Granmo O.-C., Webersik C., Goodwin M. Learning automata-based misinformation mitigation via Hawkes processes. Information Systems Frontiers: A Journal of Research and Innovation . 2021;23(5):1169–1188. doi: 10.1007/s10796-020-10102-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Avina-Corral V., De Jesus Rangel-Magdaleno J., Peregrina-Barreto H., Ramirez-Cortes J. Bearing fault detection in asd-powered induction machine using modwt and image edge detection. IEEE Access . 2022;10:24181–24193. doi: 10.1109/ACCESS.2022.3154410. [DOI] [Google Scholar]
- 30.Dai B., Li J., Zhou J., et al. Application of a modified empirical wavelet transform method in vlf/lf lightning electric field signals. Remote Sensing . 2022;14(6):p. 1308. doi: 10.3390/rs14061308. [DOI] [Google Scholar]
- 31.Ge Y., Li L., Zhang G. A Fourier transform method for solving backward stochastic differential equations. Methodology and Computing in Applied Probability . 2022;24(1):385–412. doi: 10.1007/s11009-021-09860-y. [DOI] [Google Scholar]
- 32.Revathi T., Rajalaxmi T., Sundara Rajan R., Freire W. P. Deep quaternion Fourier transform for salient object detection. Journal of Intelligent Fuzzy Systems . 2021;40(6):11331–11340. doi: 10.3233/JIFS-202502. [DOI] [Google Scholar]
- 33.Graps A. An introduction to wavelets. IEEE Computational Science and Engineering . 1995;2(2):50–61. doi: 10.1109/99.388960. [DOI] [Google Scholar]
- 34.Zhao X., Barber S., Taylor C. C., Milan Z. Classification tree methods for panel data using wavelet-transformed time series. Computational Statistics and Data Analysis . 2018;127(11):204–216. doi: 10.1016/j.csda.2018.05.019. [DOI] [Google Scholar]
- 35.Zhao X., Barber S., Taylor C. C., Milan Z. Interval forecasts based on regression trees for streaming data. Advances in Data Analysis and Classification . 2021;15(1):5–36. doi: 10.1007/s11634-019-00382-7. [DOI] [Google Scholar]
- 36.Hyland S. L., Faltys M., Hüser M., et al. Early prediction of circulatory failure in the intensive care unit using machine learning. Nature Medicine . 2020;26(3):364–373. doi: 10.1038/s41591-020-0789-4. [DOI] [PubMed] [Google Scholar]
- 37.Johnson A. E., Pollard T. J., Shen L., et al. Mimic-iii, a freely accessible critical care database. Scientific Data . 2016;3(1):p. 160035. doi: 10.1038/sdata.2016.35. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The source code in the method are available from the corresponding author upon request. The real data in application can be requested from Hyland et al. [36].