

Abstract
Background
In today's industrialized world, coronary artery disease (CAD) is one of the leading causes of death, and early detection and timely intervention can prevent many of its complications and eliminate or reduce the resulting mortality. Machine learning (ML) methods as one of the cutting-edge technologies can be used as a suitable solution in diagnosing this disease.
Methods
In this study, different ML algorithms' performances were compared for their effectiveness in developing a model for early CAD diagnosis based on clinical examination features. This applied descriptive study was conducted on 303 records and overall 26 features, of which 26 were selected as the target features with the advice of several clinical experts. In order to provide a diagnostic model for CAD, we ran most of the most critical classification algorithms, including Multilayer Perceptron (MLP), Support Vector Machine (SVM), Logistic Regression (LR), J48, Random Forest (RF), K-Nearest Neighborhood (KNN), and Naive Bayes (NB). Seven different classification algorithms with 26 predictive features were tested to cover all feature space and reduce model error, and the most efficient algorithms were identified by comparison of the results.
Results
Based on the compared performance metrics, SVM (AUC = 0.88, F-measure = 0.88, ROC = 0.85), and RF (AUC = 0.87, F-measure = 0.87, ROC = 0.91) were the most effective ML algorithms. Among the algorithms, the KNN algorithm had the lowest efficiency (AUC = 0.81, F-measure = 0.81, ROC = 0.77). In the diagnosis of coronary artery disease, machine learning algorithms have played an important role. Proposed ML models can provide practical, cost-effective, and valuable support to doctors in making decisions according to a good prediction. Discussion. It can become the basis for developing clinical decision support systems. SVM and RF algorithms had the highest efficiency and could diagnose CAD based on patient examination data. It is suggested that further studies be performed using these algorithms to diagnose coronary artery disease to obtain more accurate results.
1. Introduction
According to the World Health Organization (WHO), in 2020, cardiovascular disease, as one of the noncommunicable diseases, was the most important cause of death globally. Among cardiovascular diseases, coronary artery disease (CAD) is one of the most common diseases and the leading cause of death in developed countries. This disease is caused by the accumulation of platelets in the arteries or atherosclerosis, which blocks blood flow and increases the risk of heart attack and stroke. After the collection of fatty plaques and calcification, the blood vessels, which are initially soft and elastic, become narrow and hard, causing myocardial infarction in addition to narrowing the arteries [1–3].
Early CAD disease and early interventions to treat the disease and prevent its complications are vital strategies to combat and reduce mortality effectively. That is why healthcare providers use strategies to diagnose the disease early and start the treatment or intervention process early. In recent decades, numerous methods have been proposed for the early diagnosis of coronary artery disease. Many researchers across a wide range of scientific disciplines have argued that one of the most successful solutions for the early diagnosis of diseases, which has become increasingly common in recent years, is artificial intelligence (AI), which can improve diagnostic accuracy [3–6]. AI uses human intelligence to explore data relationships and mimic human problem-solving patterns. An essential category of AI is machine learning techniques that have played a pivotal role in diagnosing diseases. Machine learning (ML), as a common category of AI, has many applications in diagnosing and predicting different diseases. ML techniques have been used in various health research fields, and good results have been obtained. ML algorithms are a standard tool in knowledge exploration, which isused to create prediction and diagnosis models with high accuracy [7–9]. ML classification algorithms learn to analyze data by monitoring and discovering relationships between data. Monitoring by learning from labelled data allows us to identify data output that has never been seen before. This method is a general ML technique that gives a system a list of input-output pairs, and the system tries to find a function from input to output. This method is known as supervised learning since it requires some input data. However, there are specific issues for which supervised learning systems cannot generate the required output [10–15]. Previous studies on CAD datasets have included data from various care and diagnostic methods, including demographic information, lifestyle indicators, multiple examinations, patient laboratory test results, and cardiac tests such as ECG, exercise testing, etc. They had used the information. However, in the present study, only clinical examination data of patients and their demographic data were used to reach an early diagnosis. Therefore, the present study aimed to evaluate and compare different ML classification algorithms to determine an efficient algorithm for diagnosing coronary artery disease based on examination data of patients with coronary artery disease based on a clean dataset.
2. Related Work
With the increasing prevalence of CAD and the limitations of diagnostic tests, many studies have used several machine learning techniques to improve the accuracy of the adopted diagnostic methods. Table 1 lists some relevant studies.
Table 1.
Studies evaluating machine learning algorithms used for CAD detection.
| Authors, year, country | Aim of study | Data and features | Sample size | ML method and algorithms | Performance | Validation technique | Detail | ||
|---|---|---|---|---|---|---|---|---|---|
| Abdar et al. 2019, Poland [16] | Accurate diagnosis | Alizadeh dataset: demographic; symptom, examination, ECG, laboratory, echo | 303 | C-SVC, NU SVC, linear SVM | F1score = 91.51 Acc = 93.08 | 10-fold | One hot encoding, genetic algorithm, genetic optimizer | ||
|
| |||||||||
| Gupta et al. 2019, Canada [17] | Estimating the risk of CAD | Z-Alizadeh Sani (demographic, health history, medical procedure features) | 303 | BN (Bayesian network) | AUC = (0.93 + 0.04) | 10-fold | LR, SVM, ANN graphical reasoning introduces | ||
|
| |||||||||
| Joloudari et al. 2020, Iran [18] | CAD diagnosis | Z-Alizadeh Sani dataset | 303 | DT (Decision tree) | AUC = 91.47 | 10-fold | RTS (Random tree), SVM, DT | ||
|
| |||||||||
| Tama et al. 2020, S. Korea [19] | Detection CHD | 5 dataset (Z-Alizadeh Sani, statlog, cleveland, Hungarian) | 303 | Two-tier ensemble (GBM, GXboost, RF) | Proposed AUC > other ensemble and individual models | 10-fold | Random forest (RF), gradient boosting. Correlation-based feature | ||
|
| |||||||||
| Iong et al. 2021, Taiwan. [20] | Early prediction of CAD | 7 feature (demographic and medical history) | NM | SVM with pooling layer | SVM | NM | SVN NB | ||
|
| |||||||||
| Chen et al. 2020, China [21] | Detection of CAD | 1163 variables (morphological) | Polynomial SVM with grid search optimization | Acc = 100% | 10-fold | LR, DT, LDA, KNN, ANN.SVM | |||
|
| |||||||||
| Zhang et al. 2020, China [22] | Detection of CAD | Holter monitoring, echocardiography (ECHO), and biomarker levels (BIO) | 62 | Holter model | Sen = 96.67% Spe = 96.67% Acc = 96.64% | 5-fold | Random forest, and SVM. Bioexamination reach the best result. | ||
|
| |||||||||
| Ricciardi et al. 2020, Italy [23] | Prediction of CAD | 22 features (laboratory and medical history) | 10,265 | LDA and PCA | Acc = 84.5 and 86.0 Spe > 97% Sen > 66% | 10-fold | PCA and LDA for feature extraction PostgreSQL, a DBMS | ||
|
| |||||||||
| Pattarabanjird et al., 2020, USA [24] | Prediction of CAD severity | Demographics and laboratory | 481 | NN (ID3 rs11574) | AUC = 72% to 84% | NM | Crf, ID3 | ||
The studies were limited by the lack of clinical methods for selecting features. For these studies, two approaches were used to select features: either all features were used without data reduction techniques, or they were selected based on mathematical algorithms without considering their clinical relevance.
3. Methods
The present study aimed to design a model based on cheap clinical data for the first time in CAD diagnosis. In 2022, this study was carried out as a cross-sectional analysis of ML algorithms. To achieve the best performance in CAD data pattern recognition, different ML algorithms were used to analyze the data and compare their efficiency.
3.1. Dataset Description and Feature Selection
The used dataset is the Z-Alizadeh Sani dataset, which includes 303 data points from people suspected of having CAD, including 215 individuals who had CAD and 88 patients with normal which was their exact status confirmed using catheterization. This dataset contains 54 attributes (features) for every case in the dataset that can be utilized as CAD markers for patients (the features are arranged in four groups: demographics, symptoms and examination, ECG, and laboratory and echo features) This dataset is one of the most widely used datasets for automatic CAD detection in ML. A patient is diagnosed with CAD when one or more of his or her coronary arteries are stenosed. If the diameter of a coronary artery narrows by 50%, it is called stenosis [25].
In the present study, the development of a reliable selection model for diagnosing CAD disease was entirely based on clinical characteristics. These features were selected after consideration of the recommendations of three clinical cardiologists. A checklist was made to help determine the features. Following the registration of each feature using the checklist, the cost of measuring and registering each feature was calculated based on its accessibility. Finally, after this checklist was analyzed by the researchers, these clinical specialists checked and completed the checklists, and 26 features out of a total of 54 elements were chosen based on their clinical value and accessibility. By selecting these features from the original dataset, a dataset that was clinically useful and had features that had the most effects on the diagnosis of CAD was obtained. The models given in this research can be utilized to diagnose CAD using native data because access to the database with these features is more straightforward and less expensive (Table 2).
Table 2.
Specifications of the dataset features used in the study.
| Feature name | Type of feature | Missing | |
|---|---|---|---|
| Age | Numeric | 0 | M = 59 ± 10 |
| Weight | Numeric | 0 | 73.83 ± 12 |
| Length | Numeric | 0 | 165 ± 9.33 |
| Sex | Nominal | 0 | Male = 176, female = 127 |
| BMI (body mass index) | Numeric | 0 | 27.25 ± 4.01 |
| Diabetes mellitus (DM) | Nominal | 0 | Yes, no |
| Hypertension (HTN) | Nominal | 0 | Yes, no |
| Current smoker | Nominal | 0 | Yes, no |
| Exsmoker | Nominal | 0 | Yes, no |
| Family history (FH) | Nominal | 0 | Yes, no |
| Obesity | Nominal | 0 | Yes = 211, no = 92 |
| Chronic renal failure (CRF) | Nominal | 0 | Yes = 6, no = 297 |
| Cardiovascular diseases (CVA) | Nominal | 0 | Yes = 5, no = 298 |
| Airway diseases | Nominal | 0 | Yes = 11, no = 292 |
| Thyroid diseases | Nominal | 0 | Yes = 7, no = 296 |
| Congestive heart failure (CHF) | Nominal | 0 | Yes = 1, no = 302 |
| Dyslipidemia (DLP) | Nominal | 0 | Yes = 112, no = 191 |
| Edema | Nominal | 0 | Yes, no |
| Weak peripheral pulse | Nominal | 0 | Yes = 5, no = 298 |
| Systolic murmur | Nominal | 0 | Yes = 41, no = 262 |
| Diastolic murmur | Nominal | 0 | Yes = 9, no = 294 |
| Typical chest pain | Nominal | 0 | Yes, no |
| Dyspnea | Nominal | 0 | Yes = 134, no = 169 |
| Atypical | Nominal | 0 | Yes = 93, no = 210 |
| Nonanginal | Nominal | 0 | Yes = 16, no = 287 |
| Catheterization (cath) | Nominal | 0 | CAD = 216, normal = 87 |
In the used dataset, the selected features were nominal (binary), and only age, weight, length, and BMI were numeric features. One of the strengths of the study is the use of cleaned data without any missing data. Utilization of this data has prevented the data preprocessing steps in the data mining process from being performed, and instead the data analysis process was performed directly using ML algorithms.
Data categorization is a crucial first step in using learning-based research models based on ML [15]. With no normalization and a ratio of 64 : 20 : 16, the dataset was divided into training, testing, and validation sets in the current study. Of the present research dataset, 80% was used for training (learning and validation), and 20% for testing. Table 3 provides a detailed presentation of this classification. Additionally, to prevent the network from seeing data from a particular class during training, the training data were shuffled several times, each category comprising data with distinct labels.
Table 3.
The ratio of dividing the original dataset into sets for training, testing, and validation.
| Training set | Testing set | Validation set | Total | |
|---|---|---|---|---|
| Percentage (%) | 80% | 16% | 4% | 100% |
| No. of paired samples | 242 | 48 | 13 | 303 |
In the present study, because the dataset is a standard public dataset and was collected under the supervision of a cardiologist, no preprocessing techniques including data cleansing and feature engineering were performed in this study.
3.2. Selective ML Algorithms
In light of the strengths of each ML algorithm and its capability to extract patterns from the datasets, several algorithms were used to find the most efficient algorithm for designing the diagnosis model of CAD. The algorithms selected include the multilayer perceptron (MLP), the support vector machine (SVM), the logistic regression (LR), the J48, the random forest (RF), the K-Nearest neighborhood (KNN), and the naive bayes (NB).
One of the most widely used ML algorithms is a neural network (NN), and the most prevalent algorithm on NN architectures is MLP which belongs to the class of supervised neural networks. An MLP network typically consists of three or more layers of nodes: an input layer that receives external inputs, one or more hidden layers, and an output layer that produces classification results. Errors are reduced using the gradient descent algorithm in this model [13, 26, 27].
SVM is one of the main supervised learning algorithms presented by Vladimir Vapnik within the area of statistical learning theory and structural risk minimization, which has been successfully applied to several classification and forecasting problems. The SVM has been applied to various problems related to pattern recognition and regression estimation, as well as medical diagnosis for disease classification. SVM is a powerful method for building classifiers. It allows the prediction of labels from one or more feature vectors by creating a decision boundary between two classes. Known as the hyperplane, this boundary is oriented to be as far away as possible from the closest data points from each class. The closest points are called support vectors [28].
| (1) |
where yi is the class label (positive or negative) of a training compound I and xi is a feature vector representation. Thus, the optimal hyperplane is given by equations (1)–(3):
| (2) |
For all components of the training set, the w and b would meet the following inequalities:
| (3) |
Vectors xi for which | yi | WxiT+b=1 will be termed support vectors (Figure 1).
Figure 1.
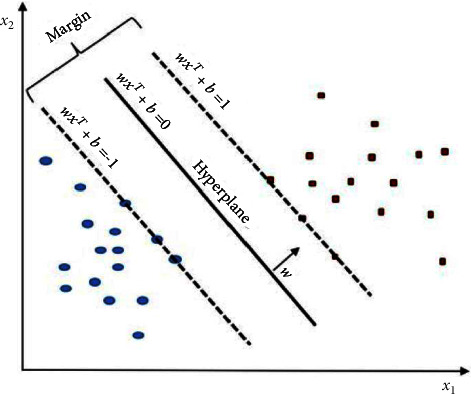
Linear SVM model (present a hyperplane to classify two classes).
LR is a type of nonlinear regression that takes categorical data as input. COX introduced the idea of LR in 1958, based on the principle of estimating a binary response based on a set of independent features. LR uses the logistic function to predict the probability of occurrence using the input feature set [29].
J48 is an upgraded version of the ID3 classification ML algorithm choice tree, which is based on a calculation called ID3 (Iterative Dichotomiser variant 3), developed by the WEKA undertaking group. The J48 calculation has a clear decision tree for the C4.5 gathering. There is a double tree in the situation. It is also known as a decision tree prediction algorithm for its steadiness in grouping issues. This way, simple, easy-to-understand rules can be constructed using this algorithm [30].
RF was introduced in 2001. The random space approach and bagging decision trees (DT) are the two methods that make up RF. The RF classifier comprises numerous DTs that have been trained using the bagging approach. After receiving the results of all DTs and voting on the results of all DTs, the final classification result is determined. Several classification and regression trees (CART) will be created by RF, each trained on a bootstrap sample of the original training data, and each searching a randomly chosen subset of input variables to find the split. By continually dividing the data in a node into child nodes, starting with the root node that holds the entire learning sample, binary decision trees known as CARTs are created. Each tree in the RF will vote for one or more inputs, and the majority vote of the trees will determine the classifier's output. High-dimensional data may be handled by RF, and the ensemble uses several trees. RF is a highly recommended classifier for dealing with situations like overfitting and underfitting. Noise and outliers can also be handled with RF. RF is a well-known classification technique that has been successfully applied to the categorization of a variety of medical datasets [31]. Some key characteristics of RF include:
It has a good method for guessing data that are absent.
Weighted random forest (WRF) is a technique for balancing inaccuracy in unbalanced data.
It calculates the significance of the classification's variables.
The simplest of all classifiers is KNN which belongs to the lazy learning algorithms family. Because KNN is a classifier-based instance, it may simply be constructed in parallel. In feature space, KNN utilizes majority voting among the labels for the K nearest data points, where K is an integer number. For continuous variables, Euclidean distance is used as a distance measure, while for discrete variables, hamming distance is used [15, 32] as a distance measure. The KNN classifier, also known as case-based reasoning, has been employed in a wide range of applications, including recognition and estimation. It is preferred over other classifiers due to its simplicity and high convergence speed [33, 34]. NB is a probabilistic statistical classifier with the advantages of accurate classification and excellent processing efficiency. When the input data have high dimensionality, NB is chosen. The label that optimizes the posterior probability is returned as an output in NB-based classification [35].
3.3. Metrics Evaluation
In this study, the performance of the selective classifier algorithms is evaluated via clinically meaningful statistical measures like precision, recall, F-measure, MCC (Matthews correlation coefficient), PRC (precision-recall curve) specificity, and F1 Score. To calculate these evaluation metrics, the following variables are required: TP (true positive), FP (false positive), which is how to calculate the indicators with the calculation formula.
The number of incorrect predictions of negative cases by the method. However, accuracy is not always a proper metric to evaluate model performance, especially in the case of an asymmetrical dataset. However, in this research, the accuracy metrics were to select the most efficient model through the selected pretrained networks. Equations (4)–(8) are used to briefly describe these measurements.
Accuracy: This parameter measures the ratio of accurately predicted cases to the total number of cases to assess a method's performance [15]. Mathematically, it is expressed as:
| (4) |
Recall, the ratio of observations in the actual classes that were correctly predicted as positive to all other observations [15, 32].
| (5) |
Precision, the ratio of observations in the actual classes that were correctly predicted as positive to all other observations [15, 32]. This metric shows how often different illness types are correctly classified.
| (6) |
F1 score, is one of the measures used frequently to assess a classifier's effectiveness. It is the harmonic mean of precision and recall [15]. The F-1 score is a relevant measurement for classification issues on unbalanced datasets, since it is more sensitive to data distribution.
| (7) |
MCC (Matthews correlation coefficient), the most important metric that has been selected as the elective metric in the USFDA-led initiative MAQCII which aims at developing and validating predictive models for personalized medicine. The MCC is calculated as (5).
| (8) |
4. Result
In this research to reach high performance in the diagnosis of CAD using a clinical dataset, we selected seven different well-known classifiers for the diagnosis of coronary artery disease, based on the most frequently used ML algorithms in the field of diagnosis and classification of diseases. We assessed the efficacy of selective algorithms concerning patient data suspected of having CAD. The values for the performance metrics of the ML algorithms are shown in Table 3. In this table, eight proprietary metrics are used to assess the performance of ML algorithms. Based on the TP, PT, recall, F-measure, and MCC metrics for all algorithms implemented, it can be concluded that the highest amount of these metrics is attributed to the SVM algorithm, and the highest amount of ROC and PRC are related to the RF algorithm. Also, the lowest FP was related to the SVM algorithm. As a general rule, cross-validation epochs involve partitioning data into two complementary subsets. One of these sets will be used for training and fitting, and the other will be used for validation and testing. The results are averaged after numerous iterations of the validation using various subsets. The data are divided into K subsets for K-fold cross-validation, one of which is utilized for validation and the other K-1 for training. In this approach, each data fold is utilized exactly once for training and once for validation. As a result, we decide to base our final estimate on the averages of these K validation periods. Therefore, in this study, the 10-fold validation method was used, and the mean of the final results are presented. The obtained values of these metrics after testing ten times on the test dataset and averaging these ten values are shown in Table 4.
Table 4.
Performance comparison of seven ML algorithms for diagnosis CAD using different evaluation metrics.
| Algorithms | TP | FP | Precision | Recall | F-measure | MCC | ROC | PRC |
|---|---|---|---|---|---|---|---|---|
| MLP | 0.83 | 0.25 | 0.83 | 0.83 | 0.83 | 0.59 | 0.88 | 0.88 |
| SVM | 0.88 | 0.17 | 0.88 | 0.88 | 0.88 | 0.70 | 0.85 | 0.83 |
| LR | 0.86 | 0.21 | 0.86 | 0.86 | 0.86 | 0.65 | 0.87 | 0.86 |
| J48 | 0.80 | 0.28 | 0.81 | 0.81 | 0.81 | 0.52 | 0.74 | 0.74 |
| RF | 0.87 | 0.22 | 0.87 | 0.87 | 0.87 | 0.67 | 0.91 | 0.91 |
| KNN | 0.81 | 0.28 | 0.81 | 0.81 | 0.81 | 0.54 | 0.77 | 0.77 |
| NB | 0.85 | 0.18 | 0.86 | 0.85 | 0.85 | 0.65 | 0.89 | 0.88 |
To provide a better comparison of the performance indicators of selected ML algorithms, such as precision, recall, F-measure, and ROC, a confusion matrix was used. After calculating the confusion matrix we concluded RF and SVM are the most effective approaches for the classification of CAD data. Figure 2 depicts the ROC and other metrics for selected ML algorithms.
Figure 2.
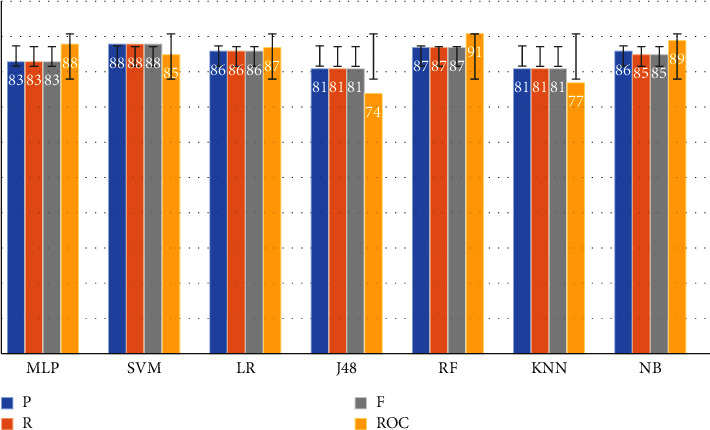
Comparison of the algorithm's metrics (P: Precision, R: Recall, F: F-measure, and ROC).
In order to accurately evaluate chosen ML algorithms, it is better to use more accurate metrics. Therefore, correctly classified instances (CCI) and incorrectly classified instances (ICI) were used in this study. Therefore, Figure 3 generally shows the amount of correctly detected and incorrectly detected samples based on different algorithms.
Figure 3.
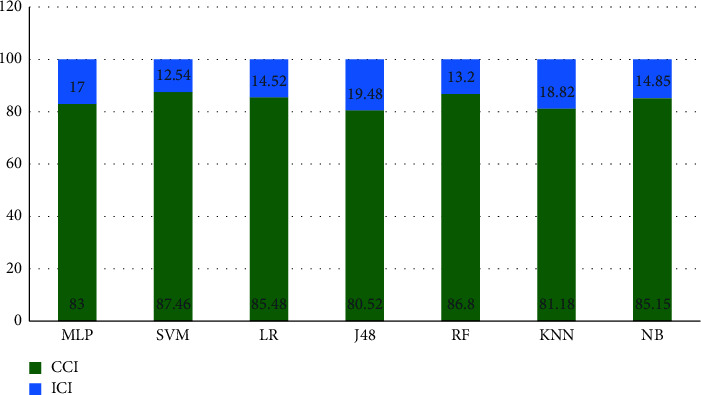
Correctly classified instances (CCI) and incorrectly classified instances (ICI) in the algorithms.
Two of the factors used to compare different ML algorithms are correctly classified instances (CCI) and incorrectly classified instances (ICI). In many studies, these metrics determine the performance of ML algorithms [36]. Based on the two indicators, CCI and ICI, SVM and RF algorithms had the highest efficiency among the run algorithms (Figure 2). Selected ML models employ the confusion matrix as a performance evaluation metric. The confusion matrix of the model evaluation on the test data is shown in Figure 4, which offers a clearer insight of the outcomes.
Figure 4.
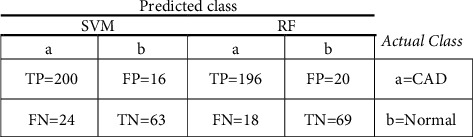
The confusion matrix of SVM and RF algorithms.
ROC is an important index that includes a range of values for receiver operating characteristics (ROC). This term is used in signal detection to describe the tradeoff between hit rate and false alarm rate when the channel is noisy. ROC curves illustrate the performance of a classifier without regard to class distribution or error costs. They plot the true positive rate against the true negative rate. In Figure 5, we show the ROC diagram for both RF and SVM algorithms. Based on this diagram, it appears that these two algorithms have produced extraordinary results.
Figure 5.
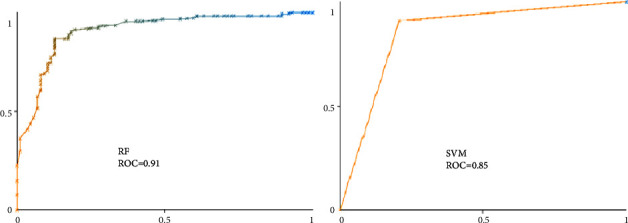
The ROC of the most efficient algorithms (SVM, RF).
Each algorithm has specific parameters and settings. In this study, algorithms have been recorded to maintain the validity and reliability of the parameters and settings. In Table 5 the parameter value is presented. The selected algorithms were manually tuned with different parameters in order to improve their efficiency and minimize their errors. By varying these values, the speed of convergence, the learning steps, and the categories of feeding data to the models changed, resulting in the models reaching the most optimal state and the least error.
Table 5.
The specifications and settings of algorithms including parameters.
| Algorithm | Setting |
|---|---|
| MLP | Batch size = 100, learning rate = 0.3, momentum = 0.2, number of decimal places = 2 |
| SVM | Batch size = 100, the polynomial kernel: K (x, y) = <x, y>^p or K (x, y) = (<x, y >+ 1) ^p, random seed = 1, tolerance parameter = 0.001 number of decimal places = 2 |
| LR | Batch size = 100, max lets = −1, ridge = 1.0E−8, number of decimal places = 4 |
| J48 | Batch size = 100, confidence factor = 0.25, min num obj = 2, num folds = 3, seed = 1, number of decimal places = 2 |
| RF | Batch size = 100, number of iterations = 100, seed = 1, number of decimal places = 2 |
| KNN | Batch size = 100, number of decimal places = 2 |
| NB | Batch size = 100, number of decimal places = 2 |
The algorithms were implemented and run using Weka v 3.5.9 software (The University of Waikato, Hamilton, New Zealand) and the results were presented to select the optimal algorithm (s) from the analysis in the form of graphs and comparison tables. In order to increase the efficiency of the selected algorithm (s), the properties of the algorithms, which are shown in Table 5, were manually adjusted and changed.
5. Discussion and Conclusion
Many studies have been conducted on CAD using ML algorithms, and significant results have been obtained in recent years. Many of these studies used paraclinical data to analyze CAD, some of which also used heart tissue imaging data. Using clinical examination criteria to design a CAD diagnosis model drastically reduces the cost and time of the diagnosis process. According to the findings of this study, when the CAD diagnostic model is used in a specific instance, the chance of its correctness is close to 90%. Therefore, the cardiologist can employ the ML models as an additional diagnostic tool to get a definitive determination.
ML algorithms have played a pivotal role in diagnosing coronary artery disease. It can become the basis for developing clinical decision support systems. SVM and RF algorithms had the highest efficiency and could diagnose CAD based on patient examination data. It is suggested that further studies be performed using these algorithms to diagnose coronary artery disease to obtain more accurate results. More precise disease prediction tools will be required to avoid coronary artery disease. Imaging methods, such as echo and esophageal echo, can play a decisive role in diagnosing CAD disease. Therefore, a combination of clinical data and cardiac imaging data and the use of newer artificial intelligence methods such as deep learning as a powerful tool can play an important role in predicting the occurrence of CAD.
Such ML models could be used with more extensive data, such as ECG features and other data, and examination data can help specialists detect coronary artery disease more correctly. Demographic data play a significant role in implementing ML-based models for disease prediction and diagnosis. According to the results, it can be claimed that variables such as age, sex, patient weight, BMI, and FH are effective in the initial diagnosis of CAD. So, it is suggested that these predictor variables for the diagnosis of coronary artery disease and patients' clinical examination variables should be used in studies based on ML. In other words, these variables, along with the variables of patients' clinical examinations, are somewhat indicative of the disease status and can help the physician make an accurate diagnosis. It seems that using a more comprehensive data set can increase the accuracy of patient prediction and diagnosis models. Because additional data can lead to greater pattern extraction and, consequently, a better understanding of the data's complexity in learning-based models; therefore, one of the limits of researching the limited amount of the dataset was employed because using big volume data will be one of the influential variables in achieving models with better accuracy and precision. Future research should take advantage of a more comprehensive data collection. Another drawback of the study was that the factors were limited to clinical examination and patient identifying information. Tests and ECGs are instrumental in detecting CAD; nonetheless, the variables were chosen based on the study's aims.
ML algorithms have played a pivotal role in diagnosing coronary artery disease. It can become the basis for developing clinical decision support systems. SVM and RF algorithms had the highest efficiency and could diagnose CAD based on patient examination data. It is suggested that further studies be performed using these algorithms to diagnose coronary artery disease to obtain more accurate results. More precise disease prediction tools will be required to avoid coronary artery disease. Imaging methods such as echo and esophageal echo can play a decisive role in diagnosing CAD disease. Therefore, a combination of clinical and cardiac imaging data and the use of newer artificial intelligence methods such as deep learning as a powerful tool can play an important role in predicting the occurrence of CAD.
Data Availability
The data used to support the findings of this study are available publicly at https://archive.ics.uci.edu/ml/datasets/Z-Alizadeh+Sani.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- 1.Nielsen R. E., Banner J., Jensen S. E. Cardiovascular disease in patients with severe mental illness. Nature Reviews Cardiology . 2021;18(2):136–145. doi: 10.1038/s41569-020-00463-7. [DOI] [PubMed] [Google Scholar]
- 2.Virani S. S., Alonso A., Aparicio H. J., et al. American Heart Association Council on Epidemiology and Prevention Statistics Committee and Stroke Statistics Subcommittee. Heart disease and stroke statistics—2021 update: a report from the American Heart Association Circulation . 2021;143(8):e254–e743. doi: 10.1161/CIR.0000000000000950. [DOI] [PubMed] [Google Scholar]
- 3.Finegold J. A., Asaria P., Francis D. P. Mortality from ischaemic heart disease by country, region, and age: statistics from World Health Organisation and United Nations. International Journal of Cardiology . 2013;168(2):934–945. doi: 10.1016/j.ijcard.2012.10.046. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Cassar A., Holmes D. R., Rihal C. S., Gersh B. J. Chronic coronary artery disease: diagnosis and management. Mayo Clinic Proceedings . 2009;84(12):1130–1146. doi: 10.4065/mcp.2009.0391. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Mirbabaie M., Stieglitz S., Frick N. R. J. Artificial intelligence in disease diagnostics: a critical review and classification on the current state of research guiding future direction. Health Technology . 2021;11(4):693–731. doi: 10.1007/s12553-021-00555-5. [DOI] [Google Scholar]
- 6.Mastoi Q. u a, Wah T. Y., Gopal Raj R., Iqbal U. Automated diagnosis of coronary artery disease: a review and workflow. Cardiology Research and Practice . 2018;2018:9. doi: 10.1155/2018/2016282. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Hamet P., Tremblay J. Artificial intelligence in medicine. Metabolism . 2017;69:S36–S40. doi: 10.1016/j.metabol.2017.01.011. [DOI] [PubMed] [Google Scholar]
- 8.Kononenko I. Machine learning for medical diagnosis: history, state of the art and perspective. Artificial Intelligence in Medicine . 2001;23(1):89–109. doi: 10.1016/s0933-3657(01)00077-x. [DOI] [PubMed] [Google Scholar]
- 9.Kumar Y., Koul A., Sisodia P. S., Shafi J., Kavita V., Gheisari M. Heart failure detection using quantum-enhanced machine learning and traditional machine learning techniques for internet of artificially intelligent medical things. Wireless Communications and Mobile Computing . 2021;2021:9. [Google Scholar]
- 10.Ghaderzadeh M., Aria M., Asadi F. X-ray equipped with artificial intelligence: changing the COVID-19 diagnostic paradigm during the pandemic. In: Fancellu A., editor. Biomed Res Int [Internet . Vol. 2021. 9942873; 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Teng X., Gong Y. IOP Conference Series: Materials Science and Engineering . IOP Publishing; 2018. Research on application of machine learning in data mining.62202 [Google Scholar]
- 12.Alpaydin E. Introduction to Machine Learning . Cambridge, Massachusetts: MIT press; 2020. [Google Scholar]
- 13.Ghaderzadeh M., Sadoughi F., Ketabat A. Designing a Clinical Decision Support System Based on Artificial Neural Network for Early Detection of Prostate Cancer and Differentiation from Benign Prostatic Hyperplasia. Stud Health Technol Inform . 2012;2013:192–928. [PubMed] [Google Scholar]
- 14.Ghaderzadeh M., Eshraghi M. A., Asadi F., Hosseini A., Jafari R., Bashash D. Efficient Framework for Detection of COVID-19 Omicron and Delta Variants Based on Two Intelligent Phases of CNN Models. Comput Math Methods Med . 2022;2022 doi: 10.1155/2022/4838009.4838009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Ghaderzadeh M., Aria M., Hosseini A., Asadi F., Bashash D., Abolghasemi H. A fast and efficient CNN model for B‐ALL diagnosis and its subtypes classification using peripheral blood smear images. International Journal of Intelligent Systems . 2021 [Google Scholar]
- 16.Abdar M., Książek W., Acharya U. R., Tan R. S., Makarenkov V., Pławiak P. A new machine learning technique for an accurate diagnosis of coronary artery disease. Computer Methods and Programs in Biomedicine . 2019;179 doi: 10.1016/j.cmpb.2019.104992.104992 [DOI] [PubMed] [Google Scholar]
- 17.Gupta A., Slater J. J., Boyne D., et al. Probabilistic graphical modeling for estimating risk of coronary artery disease: applications of a flexible machine-learning method. Medical Decision Making . 2019;39(8):1032–1044. doi: 10.1177/0272989x19879095. [DOI] [PubMed] [Google Scholar]
- 18.Joloudari J. H., Hassannataj Joloudari E., Saadatfar H., et al. Coronary artery disease diagnosis; ranking the significant features using a random trees model. International Journal of Environmental Research and Public Health . 2020;17(3):p. 731. doi: 10.3390/ijerph17030731. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Tama B. A., Im S., Lee S. Improving an intelligent detection system for coronary heart disease using a two-tier classifier ensemble. BioMed Research International . 2020;2020 doi: 10.1155/2020/9816142.9816142 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Iong J., Chen Z. Early prediction of coronary artery disease (CAD) by machine learning method - a comparative study. BMC Public Health . 2021;19(1) [Google Scholar]
- 21.Chen X., Fu Y., Lin J., Ji Y., Fang Y. applied sciences Coronary Artery Disease Detection by Machine Learning with Coronary Bifurcation Features . 2020. [Google Scholar]
- 22.Zhang H., Wang X., Liu C., et al. Detection of coronary artery disease using multi-modal feature fusion and hybrid feature selection. Physiological Measurement . 2020;41(11):115007–115015. doi: 10.1088/1361-6579/abc323. [DOI] [PubMed] [Google Scholar]
- 23.Ricciardi C., Cuocolo R., Megna R., Cesarelli M., Petretta M. Machine learning analysis: general features, requirements and cardiovascular applications. Minerva Cardiology and Angiology . 2022;70(1):67–74. doi: 10.23736/S2724-5683.21.05637-4. [DOI] [PubMed] [Google Scholar]
- 24.Pattarabanjird T., Cress C., Nguyen A., Taylor A., Bekiranov S., McNamara C. A machine learning model utilizing a novel SNP shows enhanced prediction of coronary artery disease severity. Genes (Basel) . 2020;11(12):p. 1446. doi: 10.3390/genes11121446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Alizadehsani R., Roshanzamir M., Abdar M., et al. A database for using machine learning and data mining techniques for coronary artery disease diagnosis. Scientific Data . 2019;6(1):1–13. doi: 10.1038/s41597-019-0206-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Ramchoun H., Ghanou Y., Ettaouil M., Janati Idrissi M. A. Multilayer Perceptron: Architecture Optimization and Training. International Journal of Interactive Multimedia and Artificial Intelligence . 2016;4(1):26–30. [Google Scholar]
- 27.Ghaderzadeh M. Clinical decision support system for early detection of prostate cancer from benign hyperplasia of prostate. Studies in Health Technology and Informatics . 2013;192:p. 928. [PubMed] [Google Scholar]
- 28.Christmann A., Steinwart I. Support Vector Machines . 2008. [Google Scholar]
- 29.LaValley M. P. Logistic regression. Circulation . 2008;117(18):2395–2399. doi: 10.1161/circulationaha.106.682658. [DOI] [PubMed] [Google Scholar]
- 30.Arora R., Suman S. Comparative analysis of classification algorithms on different datasets using WEKA. International Journal of Computer Application . 2012;54(13):21–25. doi: 10.5120/8626-2492. [DOI] [Google Scholar]
- 31.Belgiu M., Drăguţ L. Random forest in remote sensing: a review of applications and future directions. ISPRS Journal of Photogrammetry and Remote Sensing . 2016;114:24–31. doi: 10.1016/j.isprsjprs.2016.01.011. [DOI] [Google Scholar]
- 32.Ghaderzadeh M., Asadi F., Jafari R., Bashash D., Abolghasemi H., Aria M. Deep convolutional neural network–based computer-aided detection system for COVID-19 using multiple lung scans: design and implementation study. Journal of Medical Internet Research . 2021;23(4) doi: 10.2196/27468.e27468 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Peterson L. E. K-nearest neighbor. Scholarpedia . 2009;4(2):p. 1883. doi: 10.4249/scholarpedia.1883. [DOI] [Google Scholar]
- 34.Zhang M. L., Zhou Z. H. A k-nearest neighbor based algorithm for multi-label classification. Proceedings of the 2005 IEEE International Conference on Granular Computing; 2005; Manhattan, New York. IEEE; pp. 718–721. [Google Scholar]
- 35.Murphy K. P. Naive bayes classifiers. Univ Br Columbia . 2006;18(60):1–8. [Google Scholar]
- 36.Comendador B. E. V., Rabago L. W., Tanguilig B. T. An educational model based on Knowledge Discovery in Databases (KDD) to predict learner’s behavior using classification techniques. Proceedings of the 2016 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC); 2016; Manhattan, New York. IEEE; pp. 1–6. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data used to support the findings of this study are available publicly at https://archive.ics.uci.edu/ml/datasets/Z-Alizadeh+Sani.