

Abstract
Elliptic boundary value problems which are posed on a random domain can be mapped to a fixed, nominal domain. The randomness is thus transferred to the diffusion matrix and the loading. While this domain mapping method is quite efficient for theory and practice, since only a single domain discretisation is needed, it also requires the knowledge of the domain mapping. However, in certain applications, the random domain is only described by its random boundary, while the quantity of interest is defined on a fixed, deterministic subdomain. In this setting, it thus becomes necessary to compute a random domain mapping on the whole domain, such that the domain mapping is the identity on the fixed subdomain and maps the boundary of the chosen fixed, nominal domain on to the random boundary. To overcome the necessity of computing such a mapping, we therefore couple the finite element method on the fixed subdomain with the boundary element method on the random boundary. We verify on one hand the regularity of the solution with respect to the random domain mapping required for many multilevel quadrature methods, such as the multilevel quasi-Monte Carlo quadrature using Halton points, the multilevel sparse anisotropic Gauss–Legendre and Clenshaw–Curtis quadratures and multilevel interlaced polynomial lattice rules. On the other hand, we derive the coupling formulation and show by numerical results that the approach is feasible.
Keywords: Uncertainty quantification, Random domain, Regularity, Multilevel method, FEM-BEM coupling
Introduction
Many practical problems in science and engineering lead to elliptic boundary value problems for an unknown function. Their numerical treatment by e.g. finite difference or finite element methods is in general well understood provided that the input parameters are given exactly. This, however, is often not the case in practical applications.
If a statistical description of the input data is available, one can mathematically describe data and solutions as random fields and aim at the computation of corresponding deterministic statistics of the unknown random solution. The present article is dedicated to the treatment of uncertainties in the description of the computational domain. Applications are, besides traditional engineering, for example uncertain domains which are derived from inverse methods such as tomography. In recent years, this situation has become of growing interest: In [44] the so-called domain mapping method was introduced as an approach to describe and solve boundary value problems on random domains; this was extended in [42], where the same authors used the domain mapping method to consider an advection-diffusion equation on a random tube shaped domain. Recently, the domain mapping method has also been considered for partial differential equations on random bulk and surface domains in [6]. The domain mapping method was rigorously analysed for elliptic partial differential equations on random domains in [5, 28] and for acoustic scattering problems in [35], where analytic dependency of the solution on the random domain mapping with regard to the energy norm has been verified. Moreover, the use of Multilevel Monte Carlo quadrature together with the domain mapping approach has been considered in [40].
Apart from the domain mapping method, other methods of describing and solving boundary value problems on random domains have also been considered; by the necessity of being domain mapping free, they can only be directly posed and solved on realisations of the random domain or its boundary. In [4] for example, a fictious domain formulation is used, enabling the prescription of boundary data for the Poisson problem at a random boundary inside the domain of computation yielding a random domain. An approach based on describing a random domain as a random mesh with deterministic connectivity was considered in [39]. While in [38] a random domain is described by randomly perturbing the boundary, which suffices since a surface integral equation formulation is used. More recently, a kind of boundary mapping method based on Jordan curves for a boundary integral equation formulation of the Laplacian on simply connected random domains in was considered in [33], where it is shown that the solution of the boundary integral equation depends analytically on the boundary mapping.
A further alternative approach based on shape calculus is considered in [29, 31] for elliptic boundary value problems. Describing the random domain by a random perturbation of a fixed domains boundary one arrives at a shape Taylor expansion, with which approximations of the expectation and correlation of the solution are computed requiring the solving of tensor produt boundary value problems.
In this article, we are going to focus on the domain mapping method. Given enough spatial regularity of the random domain mapping, we first prove that the solution is analytically dependent on the random domain mapping also in the -norm for . The key idea of the domain mapping method is to map the boundary value problem
| 1 |
which is posed on a random domain
defined by the random domain mapping , on a fixed, nominal reference domain , back onto that fixed reference domain D. Thus, the randomness is transferred to the diffusion matrix and the loading of the boundary value problem
| 2 |
Herein, it holds
| 3 |
where denotes the Jacobian of the field
| 4 |
and is connected to by .1 As one arrives at a formulation of a boundary value problem with random data for the diffusion matrix and the loading, the result that the solution in the -norm is analytically dependent on the random data for the diffusion matrix and the loading follows essentially from [30]. Therefore, we have to verify that the diffusion matrix and the loading depend analytically on the domain mapping with respect to appropriate norms. This analytical dependence is then sufficient to justify using multilevel versions of many quadrature methods to evaluate quantity of interest expressions of the form
where is a smooth, possibly non-linear, operator into some Banach space , with ,2 and the integral is over the probability space with sample space and measure , cf. [27].
Indeed, when the random domain mapping is given in a parametric form
where is a sequence of independent and identically uniformly distributed random variables with its pushforward measure denoted by , the quantity of interest expression may be written as an infinite-dimensional integral,
Then, bounds on the partial derivative of of the form
where is a sequence relating to the decay of the importance of the sequence of parameters with respect to the domain mapping , imply similar estimates for the integrand .
Given that these estimates hold for all finitely supported multi-indices with a sufficiently fast decaying , this justifies approximating a truncation of the infinite-dimensional integral with the quasi-Monte Carlo quadrature with Halton points, see e.g. [22, 28, 43] and the sparse anisotropic Gauss–Legendre and Clenshaw–Curtis quadratures, see e.g. [18, 21], yielding provable error rates. Similarly, if these estimates only hold for all finitely supported multi-indices for some with a sufficiently fast decaying , one may instead consider higher-order quasi-Monte Carlo quadratures, such as interlaced polynomial lattice rules, see e.g. [10, 11]. In general, these types of bounds on the partial derivative of will require an analytic dependence of the solution in the -norm on the domain mapping, as they all include bounds for mixed derivatives of in the integration variables.
When one wants to consider the multilevel versions of the previously mentioned quadratures, one is considering a sparse grid combination technique of the quadrature methods and the spatial discretisation. This requires mixed smoothness between the smoothness in the integration variables and the spatial smoothness, see e.g. [18, 19, 27], which means bounds of the form
This type of mixed smoothness follows, when the solution in the -norm is analytically dependent on the domain mapping.
However, while the random domain mapping approach is mathematically natural, it is not necessarily the setting that is directly encountered in practical applications. This mainly stems from the fact that the random domain mapping does not only describe the random domains themselves but also includes a specific point correspondence between the domain realisations. In applications often only a description of the random boundary might be known, however in such cases the quantity of interest
| 5 |
is generally sought on a deterministic subdomain, B, which almost surely is a subset of the domain realisations, where is a smooth, possibly non-linear, operator into some Banach space .3 Therefore, it is then necessary to be able to transform the description of the random domains given by a description of the random boundary and the specification of the subdomain into the form of a random domain mapping. To be able to justify the use of the multilevel versions of the above mentioned quadrature methods, we therefore require that the method for transforming the description of the random boundary into a random domain mapping is an analytic map from boundary descriptions to domain mappings. This then implies that the solution in the -norm is also analytically dependent on the description of the random boundary. In [44], the authors consider using the vector-valued Laplace equation to compute such a random domain mapping. If more structure is given, for example when the random domains are described by star-shaped boundaries or more generally when they are directly given by a boundary mapping from a nominal boundary, one may also consider other approaches, such as transfinite interpolation techniques, see e.g. [14–16], to extend the mapping onto the whole reference domain.
To overcome the necessity of computing such a random domain mapping in this setting, we propose to compute the quantity of interest by performing the calculations on the realisations of the random domains. However, in our setting, care then must be taken that the discretisation chosen is regular enough to ensure that the spatially discretised problems inherit sufficient regularity with respect to their dependence on the boundary description, such that the multilevel quadrature method stays viable. Therefore, we choose to sidestep the generation of a mesh on the random part of the domain completely by coupling the finite element method with the boundary element method for the spatial approximation as follows: we apply finite elements on the subdomain B and treat the rest of the domain by a boundary element method. This is also advantageous, since large domain deformations on coarse discretisations can be handled more easily, as we do not need to mesh the random part of the domain but only its boundary. Moreover, such an approach may also be useful when computing on an unbounded domain.
The contribution of this article is thus twofold:
First, we extend results regarding the regularity of the domain mapping method for elliptic partial differential equations on random domains from [5, 28] to allow for higher spatial smoothness, which justifies many multilevel quadrature methods.
Second, we propose and discuss using a coupling of the finite element method and the boundary element method as the spatial discretisation in a multilevel quadrature method. This yields an efficient method that only requires a domain mapping to exist, but does neither need to know it nor need to compute it. Thus, it is very applicable to practical problems, where only knowledge of a random boundary description is available, for example, from nondestructive measurements.
The rest of this article is organised as follows. Section 2 is dedicated to the mathematical formulation of the problem under consideration. The problem’s regularity is studied in Sect. 3. Here, we provide estimates in stronger spatial norms which are needed for many multilevel accelerated quadrature methods. The coupling of finite elements and boundary elements is the topic of Sect. 4. The multilevel quadrature method for the approximation of quantities of interest of the solution of the boundary value problem on random domains is then discussed in Sect. 5. Numerical experiments are carried out in Sect. 6. Finally, we state concluding remarks in Sect. 7.
Notation and model problem
Before we complete the mathematical setting of our model problem, we will introduce the notations used throughout the rest of the article. Especially, for the regularity considerations in Sect. 3 some of the notation—and the choice of a certain weighting in the Sobolev–Bochner norms—helps keep formulas somewhat more concise and compact.
Notation and precursory remarks
We use to denote the natural numbers including 0 and when excluding 0. For a sequence of natural numbers, , we define the support of the sequence as
and say that is finitely supported, if is of finite cardinality. Then, denotes the set of finitely supported sequences of natural numbers and we refer to its elements as multi–indices. Furthermore, for all we will identify the elements with their extension by zero into , that is . Thus, by this identification, all notations defined for elements of also carry over to the elements of and we also refer to elements of as multi–indices.
For multi-indices and a sequence of real numbers , we use the following common notations:
Furthermore, we say that holds, when holds for all , and , when and hold.
Subsequently, we will always equip with the norm induced by the canonical inner product and with the induced norm . Moreover, when considering itself or an open domain as a measure space we always equip it with the Lebesgue measure. Similarly, we always equip and with the counting measure, when considering them as measure spaces.
Let , and be Banach spaces, then we denote the Banach space of bounded, linear maps from to as ; furthermore, we recursively define
For and we use the shorthand notation
For a given Banach space and a complete measure space with measure the space for denotes the Bochner space, see [34], which contains all equivalence classes of strongly measurable functions with finite norm
A function is strongly measurable if there exists a sequence of countably–valued measurable functions , such that for almost every we have . Note that, for finite measures , we also have the usual inclusion for .
For a given Banach space and an open domain , with , the space for and denotes the Sobolev–Bochner space, which contains all equivalence classes of strongly measurable functions , such that the function itself and all weak derivatives up to total order are in with the norm
Moreover, denotes the closure of the linear subspace of smooth functions with compact support, , in and we also define and . As usual, we use to denote the real analytic functions4 from to and to denote the Hölder spaces. For a bi-Lipschitz function we denote its bi-Lipschitz constants by
In the notation for the Bochner, Sobolev–Bochner and Hölder spaces, we may omit specifying the Banach space when . Especially, denotes the topological dual space of . Moreover, if the we are considering is itself a Bochner or Sobolev–Bochner space, then we replace the in the subscript of the norm with the subscripts of its norm, for example
Further, for computational complexity estimates we will make use of the Big Theta notation, that is means that and . Lastly, to avoid the use of generic but unspecified constants in certain formulas, we use to mean that c can be bounded by a multiple of d, independently of parameters which c and d may depend on. Obviously, is defined as and we write if and .
Model problem
Let and ; denote the reference domain with boundary that is of class —when then we also consider the case where D is a bounded and convex domain with Lipschitz continuous boundary—and be a separable, complete probability space with -field and probability measure . Furthermore, let
be the random domain mapping. Moreover, we require that, for -almost any , is bi-Lipschitz and fulfils the uniformity condition
for independent of . Finally, we require that the we have a hold-all domain that satisfies for -almost any , a deterministic subdomain B that satisfies for -almost any with a and consider .
While, by definition, we know that is a -diffeomorphism from for -almost any , we also have the following stronger result.
Proposition 1
For -almost any , is a -diffeomorphism from D to .
Proof
The fact that is a -diffeomorphism follows directly from the inverse funtion theorem. Then, with the explicit formula for the -th derivative of from the inverse funtion theorem, one can bound independently of .
Now, since for -almost any we have a -diffeomorphism from we can use the one-to-one correspondence to pull back the model problem onto the reference domain D instead of considering it on the actual domain realisations . According to the chain rule, we then have for that and
Now, with (3) this leads us to the following formulation of our model problem (2) on the reference domain, cf. [28]:
| 6 |
Note, especially, that by the uniformity condition we have that
| 7 |
Without loss of generality, we assume .
From here on, we assume that the spatial variable and the stochastic parameter of the random field have been separated by the Karhunen–Loève expansion of coming from the mean field and the covariance yielding a parametrised expansion
| 8 |
where is a sequence of uncorrelated random variables, see e.g. [28]. We now impose some common assumptions, which make the Karhunen–Loève expansion computationally feasible.
Assumption 1
The random variables are independent and identically distributed. Moreover, they are uniformly distributed on .
- We assume that the are elements of and that the sequence , given by
is at least in , where we have defined and . Furthermore, we define
Therefore, we now can restrict to be in and introduce the pushforward measure of onto as . We then view all randomness as being parametrised by , i.e. from the next section onwards , and are considered to have been replaced by , and .
Remark 1
Note that while we restrict ourselves to the stated model problem here to simplify the analysis, the regularity result can be extended. For example, it is not necessary that has an affine dependence on as in (8), as long as a weakend version of Lemma 2 with bounds of the form stays true. Moreover, it is also possible to consider the partial differential equation
instead of the one in (1) for an with fulfilling an ellipticity condition, that is to prescribe a deterministic diffusion coefficient in Eulerian coordinates; or to consider
for an and with fulfilling an ellipticity condition almost surely almost everywhere, that is to prescribe a stochastic diffusion coefficient and loading in Lagrangian coordinates.
Regularity
Our aim is to consider quantities of interest that are of the form
where is a smooth operator into a Banach space , that is is analytic for . However, since we will require our domain mapping to fulfil5, we will be able to use the fact that . Therefore, we now discuss the regularity of the mapping , as that then directly implies the regularity of the mapping . Showing that the mapping is analytic justifies considering many discretisations for the computation of the integral. However, having that smoothness with regard to the space instead of only justifies the use of their respective multilevel version, see for example [27].
To prove the analyticity of the mapping , we first investigate the analyticity of the mappings and . Based on that analyticity we then can essentially leverage results from [30] to arrive at the analyticity for . Indeed, the whole section relies heavily on the regularity results from [30] and uses the same notations: Note especially, that the weighting in the Sobolev–Bochner norms makes them submultiplicative and that to make the notation less cumbersome, since we are considering the norm of spaces of the form , we use the shorthand notation
As we mainly make use it for spaces of the form , this then becomes .
A combinatorial lemma
In the following subsection we will derive the bounds on the derivatives of the diffusion coefficient and the loading piece by piece by using addition, multiplication and composition of functions with bounds of the form
and using [30, Lemma 2, 3 and 4]. To be able to combine bounds on the derivatives of functions combined by composition with the bounds of the inner function being of the form
we will use [30, Lemma 8] together with the following combinatorial lemma.
Lemma 1
Let be a multi–index with and with . Then, we have
where is the set of all compositions of the multi-index into r non-vanishing multi-indices ,
Proof
For convenience, we introduce the following notation for this proof: For a multi-index with we say that is a serialisation of if for any there exist exactly different such that .
Now, as the expression
is just a compact notation for the multinomial, it is equal to the cardinality of the set containing all serialisations of . Therefore, for any ,
is the cardinality of the set
Thus, the expression
gives the cardinality of the set
which may also be seen as the set giving all the ways to cut all the serialisations of into r non-empty blocks. The cardinality is thus also given by the expression
as the first factor counts the serialisations of and the second the ways to cut a sequence of length into r non-empty blocks, which yields the desired assertion
Remark 2
We will use this combinatorial lemma to give the following bound
| 9 |
We note that this bound can be improved by using the identity
with denoting the Stirling numbers of the second kind and bounding this, as is done, for example, in [30], which will yield smaller constants in Theorems 1 and 2. However, using this identity is more restrictive as it requires Lemma 2 to hold as stated, whereas, by the bound (9), we actually only require a weakend version of Lemma 2, as noted in Remark 1.
Parametric regularity of the diffusion coefficient and the loading
To provide regularity estimates for the diffusion coefficient and the right hand side , that are based on the decay of the expansion of as per Assumption 1, we first note that we can write6
| 10 |
with
| 11 |
| 12 |
where . Therefore, we first discuss the regularity of the combined mapping
for which we have the following result.7
Lemma 2
We have for all that
where . Here, denotes the constant coming from the embedding .
Proof
By definition we have that and so it follows that
From this we can derive that first order derivatives are given by
for and all higher derivatives vanish. Clearly, this affine dependence on implies the bounds.
Next, we supply bounds on the derivatives of the mappings and s.
Lemma 3
The mapping is infinitely Fréchet differentiable with
for all and with and .
Proof
We start with the mappings
which are infinitely Fréchet differentiable with
for all , and , . Then, using [30, Lemma 3], we see that the mapping
is infinitely Fréchet differentiable with
for all , and , .
Next, we consider the mapping
Clearly, the r-th Fréchet derivative of at the point in the directions of is given by
where is the set of all bijections on the set . Thus, we have
for all with . Therefore, we can use [30, Lemma 4] to see that the mapping
is infinitely Fréchet differentiable with
for all , and , .
Finally, we consider the mapping
which has the r-th Fréchet derivative of given by8
where denotes the matrix whose -th column is replaced by the -th column of the matrix for all k from 1 to r. Now, since we can bound the determinant of a matrix by the product of the norms of its columns, i.e.
and since we know that
it follows that,
with and . As before, we can use [30, Lemma 4] to see that the mapping
is infinitely Fréchet differentiable with
for all , and , .
Finally, the use of [30, Lemma 3] yields the assertion, as .
Lemma 4
The mapping s is infinitely Fréchet differentiable with
for all with and , where , are constants such that holds for all .
Proof
We start with the mapping
which is infinitely Fréchet differentiable with
for all , and , . Then, using [30, Lemma 4], we see that the mapping
is infinitely Fréchet differentiable with
for all , and , .
Moreover, as shown in the previous proof we also have that
is infinitely Fréchet differentiable with
for all , and , . Lastly, the use of [30, Lemma 3] yields the assertion, as .
Now, these results enable us to show the following regularity estimates for the diffusion coefficient and the right hand side .
Theorem 1
We know for all that
where
Proof
Because , we can employ [30, Lemma 8] to arrive at
as well as, for ,
where we make use of the combinatorial identity shown in Lemma 1 yielding the bound (9).
This proves the assertion for , while the assertion for follows analogously after remarking that
Parametric regularity of the solution
It follows from [20, Propositions 3.2.1.2 and 3.1.3.1], when and D is convex and bounded, or from [13, Theorem 8.13], when D is of class , that for almost any we have with
where only depends on D, , , and . This obviously directly implies the following result.
Lemma 5
The unique solution of (6) indeed also fulfils , with
Moreover, this higher spatial regularity also carries over to the derivates .9
Theorem 2
The derivatives of the solution of (6) satisfy
where .
The coupling of FEM and BEM
While the results in the previous subsections are valid for general random domain mappings, we will now restrict them according to the remarks made in the introduction. That is, we assume for the rest of the article that we are given a random boundary description, , and the fixed, deterministic subdomain B, which describe our random domain, compare Fig. 1 when .
Fig. 1.
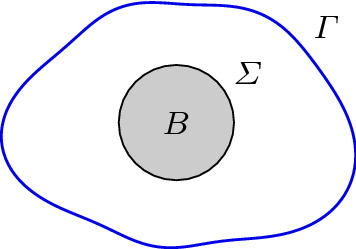
The domain D, the subdomain B, and the boundaries and
We will assume that there is a random domain mapping which fulfils the Assumption 1 as well as fulfilling and for almost any . Then, we know from the previous section that is analytic which also implies that is analytic.
So, to be able to use multilevel quadrature to compute the quantity of interest efficiently, we consider a formulation here, that enables us to compute the Galerkin solution with a mesh on B but without needing a mesh on or needing the knowledge of the random domain mapping. Similiar to the approach in [12], one arrives at such a formulation by reformulating the boundary value problem as two coupled problems involving only boundary integral equations on the random boundary , see for example [8, 23], and then discretising the variational formulation of that formulation with a Galerkin approach, along the lines of [25].
Newton potential
For sake of simplicity in representation, we shall restrict ourselves in this and the following subsections to the deterministic boundary value problem
| 13 |
i.e., the domain D is assumed to be fixed. Of course, when applying a sampling method for (1), the underlying domains are always different. In order to resolve the inhomogeneity in (13), we introduce a Newton potential which satisfies
| 14 |
Here, is a sufficiently large domain containing almost surely.
The Newton potential is supposed to be explicitly known like in our numerical example (see Sect. 6) or computed with sufficiently high accuracy. Especially, since the domain can be chosen fairly simple, one can apply finite elements based on tensor products of higher order spline functions (in ) or dual reciprocity methods. Notice that the Newton potential has to be computed only once in advance.
By making the ansatz
| 15 |
and setting , we arrive at the problem of seeking a harmonic function which solves the following Dirichlet problem for the Laplacian
| 16 |
Now, we are able to apply the coupling of finite elements and boundary elements.
Reformulation as a coupled problem
For the subdomain , we set , see Fig. 1 for an illustration. The normal vectors at and are assumed to point into . We shall split (16) in two coupled boundary value problems in accordance with
 |
17 |
In order to derive suitable boundary integral equations for the problem in , we define the single layer operator , the double layer operator and its adjoint , and the hypersingular operator with respect to the boundaries by
Here, denotes the fundamental solution of the Laplacian which is given by
By introducing the variables and , the coupled system (17) yields the following nonlocal boundary value problem: Find such that
This system is the so-called two integral formulation, which is equivalent to our original model problem (16), see for example [8, 23].
Variational formulation
We next introduce the product space , equipped by the product norm
Further, let , be the bilinear form defined by
where . For sake of simplicity in representation, we omitted the trace operator in expressions like etc.
Introducing the linear functional ,
the variational formulation is given by: Seek such that
| 18 |
for all . In accordance with [12, Theorem 4.1], the variational formulation (18) admits a unique solution for all , provided that D has a conformal radius which is smaller than one if .
Galerkin discretisation
Since the variational formulation is stable without further restrictions, the discretisation is along the lines of [25]. We first introduce a uniform triangulation of B which in turn induces a uniform triangulation of . Moreover, we introduce a uniform triangulation of the boundary . Note, that the precise approach used to mesh in applications will depend on which description of the random boundary is given. However, as some form of description of the random boundary must be available, it generally will be easier to mesh it, as opposed to meshing the whole domain, cf. for example [24]. Indeed, if the random boundary is given as a star-shaped parametrisation or if it is given by a random boundary mapping, a mesh on the d-sphere or reference boundary may be used to construct triangulations on all sampled boundaries. On the other hand, if the random boundary is described by some (parametric or geometric) surface mesh, coming for example from some computer assisted design system, which is perturbed by moving control points or mesh vertices, then this immeadiately supplies triangulations on all sampled boundaries.
We define the maximum diameter of all elements of the triangulation of B and of the surface triangulation of by h. For the FEM part, we consider continuous, piecewise linear ansatz functions with respect to the given domain mesh. For the BEM part, we employ piecewise constant ansatz functions on the respective triangulations of the boundaries .
For sake of simplicity in representation, we set for all . Note that most of these functions vanish except for those with nonzero trace which coincide with continuous, piecewise linear ansatz functions on . Finally, we shall introduce the set of continuous, piecewise linear ansatz functions on the triangulation of , which we denote by , where we have .
Then, introducing the system matrices
where again , and the data vector
we obtain the following linear system of equations
| 19 |
We mention that corresponds to the -orthogonal projection of the given Dirichlet data onto the space of the continuous, piecewise linear ansatz functions on . That way, we can also apply fast boundary element techniques to the boundary integral operators on the right hand side of the system (19) of linear equations.
By applying standard error estimates for the Galerkin scheme and possibly also the Aubin–Nitsche trick, see for example [12, Proposition 4.1], the present discretisation now yields the following error estimate.10
Proposition 2
We denote the solution of (18) by and the Galerkin solution by , respectively. Then, we have the error estimates
and
uniformly in h.
Multigrid based solver for the coupling formulation
To arrive at an efficient solver for the linear system (19) of equations some issues need to be addressed. As we will require a hierarchy of discretisations for the use of the multilevel quadrature method, we introduce a hierarchy of uniform triangulations of B and of uniform triangulations of the boundary yielded by uniformly refining a given coarse triangulation of B and a given coarse triangulation of the boundary and enumerated by the level of refinement . With this at hand, we consider how to solve the linear system (19) of equations for the -th triangulations of B and in that hierarchy of triangulations.
The complexity is governed by the BEM part since the boundary element matrices are densely populated. Following [25, 26], we apply wavelet matrix compression to reduce this complexity such that the over-all complexity is governed by the FEM part. On the other hand, according to [26, 32], the Bramble–Pasciak–CG (see [2]) provides an efficient and robust iterative solver for the above saddle point system. Combining a nested iteration with the BPX preconditioner (see [3]) for the FEM part and a wavelet preconditioning (see [9, 41]) for the BEM part, we derive an asymptotical optimal solver for the above system, see [26] for the details. We refer the reader to [26] for the details of the implementation of a similar coupling formulation.
Multilevel quadrature method
The crucial idea of the multilevel quadrature to compute the quantity of interest (5) is to combine an appropriate sequence of quadrature rules for the stochastic variable with a sequence of multilevel discretisations in the spatial variable, for a detailed treaty we refer to [27].
For the spatial approximation, we shall use the hierarchy of triangulations introduced in Subsect. 4.5 to compute the Galerkin solution on the level triangulations as described there. The Galerkin solution on these triangulations, which by uniform refining have a mesh size , thus yield the approximate decomposition
Next, we consider a general sequence of quadrature formulas of the form
with nodes and weights for the approximation of the integration over the stochastic variable in its parametrised form . We will assume that the number of points of the quadrature formula is chosen such that the corresponding accuracy11 is
| 20 |
Consequently, since we can state the quantity of interest as
based on the expansion (8), we may approximate it by the multilevel quadrature
| 21 |
as opposed to considering the single-level quadrature
| 22 |
Since the multilevel quadrature can be interpreted as a sparse grid approximation, cf. [27], it is known that mixed regularity results of the integrand have to be provided as derived in Section 3, compare [10, 18, 27, 37] for example. Since the mapping is analytic, we can especially apply the quasi-Monte Carlo method, the Gaussian quadrature, or the sparse grid quadrature, see e.g. [18, 21, 36, 43]. Especially, in case of -regularity () and , i.e., , we then obtain the error estimate, see [27],
| 23 |
As the spatial discretisations employ the hierarchy of triangulations introduced in Subsect. 4.5, which are yielded by uniform refining, the number of degrees of freedom in the linear system (19) for the level triangulations are . Thus, the linear complexity solver also has complexity for one level system to solve, compare [26]. The quadrature formula obviously has a complexity of . Now, in view of Theorem 2, we can consider some examples of quadrature methods and explicitly state how may be choosen to satisfy the accuracy required in (20).
- Similarily, if we assume that there is a such that holds and we consider the anisotropic sparse grid Gauss–Legendre quadrature, then, we use [21, Theorem 5.7] to see that we may choose
for any .
As these quadrature method examples use for some , we will assume this algebraic computational complexity from here on. Thus, the standard single-level quadrature method (22) shows a computational complexity of
while the computational complexity of the multilevel quadrature (21) as a sparse grid combination is given by
see e.g. [17]. That is, the computational complexity of the multilevel quadrature (21) is considerably reduced compared to the standard single-level quadrature method (22), which has the same accuracy, see also [1, 7, 27] for example. This is also visible in the numerical example shown in Fig. 3.
Fig. 3.

Cost of methods in total number of degrees of freedom (vertical axis) versus maximum level L (horizontal axis), when using the number of quadrature points (27) (left) and (28) (right) with .  shows the cost of the quadrature,
shows the cost of the quadrature,  the cost of the FEM-BEM discretisation,
the cost of the FEM-BEM discretisation,  the resulting cost of the single-level and
the resulting cost of the single-level and  of the multilevel methods
of the multilevel methods
Remark 3
By choosing the accuracy of the quadrature in accordance with for instead of (20), the application of the Aubin–Nitsche trick in Proposition 2 implies the -error estimate
| 25 |
when using the same hierarchy of uniform refined triangulations with mesh size . To achieve this increased accuracy, (24) must be replaced by
| 26 |
for any , and, where applicable, subsequent equations also be modified accordingly. Lastly, we note that the computational complexity of the deterministic solver is not affected when accounting for the -error instead of the -error.
Numerical results
In our numerical example, we consider the reference domain D to be the ellipse with semi-axis 0.7 and 0.5. We represent its boundary by in polar coordinates and perturb this parametrisation in accordance with
where for all are independent and identically uniformly distributed random variables and . The weights are chosen as for all and for all . Hence, we have the decay for the choice , which is sufficient for applying the quasi-Monte Carlo method based on the Halton sequence, see Sect. 5 and the references [28, 43]. In practice, we set all to zero if which corresponds to a dimension truncation after 129 dimensions. The random parametrisation induces the random domain . The fixed subset is given as the ball of radius 0.2, centered in the origin. For an illustration of six draws, see Fig. 2. We choose , for which a suitable Newton potential is then analytically given by , and consider the -tracking type functional
as quantity of interest.
Fig. 2.

Six samples of the random domain with finite element triangulation of B on refinement level 2
The coarse triangulation of B, based on Zlámal’s curved finite elements [45], consists of 14 curved triangles on the coarse grid, which are then uniformly refined to get the triangulation on the finer grids. The 14 triangles correspond to eight piecewise linear and constant boundary elements each on the boundary . At the boundary , we likewise consider eight piecewise linear and constant boundary elements each on level 0. We then apply successive uniform refinement on the triangulation of B and the boundary elements yielding the discretisations of level 1 to 10, with mesh size . In order to compute the quantity of interest, we will employ the quasi-Monte Carlo method based on the Halton sequence, see [22] for example, as the quadrature method. For this, essentially12 following (24) and (26), we set
| 27 |
and
| 28 |
respectively, with . Thus, is the number of samples the multilevel quadrature uses on the fine grid L. Since the exact solution is unknown, we use the quantity of interest computed on level with and as a reference solution.
The computational costs of these choices are shown in Fig. 3, where the cost is quantified in terms of the total number of degrees of freedom. The FEM-BEM spatial discretisation shows a cost of , while the quadrature discretisation obviously shows costs of and , respectively. In both settings the multilevel combination, given by (21), seems to show up as having a cost of ; however when using the number of quadrature points (28) there is an additional logarithmic factor in the cost, i.e. the cost is . For comparison purposes the cost of the single-level approach, as given by (22), is also shown, demonstrating the expected costs of and , respectively.
As it is seen in Fig. 4, we observe the essentially quadratic convergence rate, when using the number of quadrature points (27). This is in accordance with (25). The situation, when using the number of quadrature points (27), is less clear. The convergence rate is first seemingly quadratic and only then flattens out to be essentially linear, which is what is in accordance with (23). This faster convergence in the preasymptotic regime may be caused by having a spatial discretisation error, which is significantly larger on the coarse triangulations than the error of the coarse quadratures of the quadrature discretisation.
Fig. 4.

Absolute error of the output functional (vertical axis) versus cost in degrees of freedom (horizontal axis), when using the number of quadrature points (27) (left) and (28) (right).  shows the situation with ,
shows the situation with ,  with and
with and  with .
with .  and
and  show the asymptotic rates and
show the asymptotic rates and
Conclusion
We provided regularity estimates of the solution to elliptic problems on random domains which allow for the application of many multilevel quadrature methods. In order to avoid the need to compute either a random domain mapping or to generate meshes for every domain sample, we couple finite elements with boundary elements. It has been shown by numerical experiments that this approach is indeed able to exploit the additional regularity we have in the underlying problem without causing numerical problems on too coarse grids.
Funding
Open Access funding provided by Universität Basel (Universitätsbibliothek Basel). The work of the authors was supported by the Swiss National Science Foundation (SNSF) through the project “Multilevel Methods and Uncertainty Quantification in Cardiac Electrophysiology" (Grant 205321_169599).
Data availability
The results presented in this article can be replicated solely using the information contained in this article and its references.
Footnotes
We use the function composition ‘’ as usual. Moreover, we will only use it for composition in the spatial variable. For example, , expands to .
The upper bound on accounts for the energy space of .
We denote the usual restriction operator, continuously extended by density arguments to the Sobolev spaces, by .
Care should be taken to not confuse the in , which should be considered pure notation, with a sample of the probability space .
The results of this section themselves howeever do not require that the domain mapping fulfils .
It is obviously possible to define such that it does not depend on . Nevertheless, we include it here so that we can compose both and s directly with . Moreover, in general, such when working with an analytic determinstic diffusion coeffcient, cf. Remark 1, it may be necessary to include it.
The bound we give here could be reduced to 0 when , which possibly can be used to derive smaller bounds in some of the subsequent results, see Remark 2. However, we choose to use it as is, as any tightening of the bound makes it loose this structure, which is also found for more general models of , cf. Remark 1.
The formula follows directly from the fact that the determinant function is a polynomial over the entries of the matrix given by the Leibniz formula. Especially, the formula yields an empty sum (of value 0) for .
We omit the proof, as it is essentially identical to the proof of [30, Theorem 3], apart from the fact that one has to also account for the depenence of on , which poses no problems.
While the orders chosen for the elements are well-suited when , higher order elements should be chosen for to reach higher algebraic convergence rates for this error estimate.
This choice of accuracy rate is based on the -error estimate from the FEM-BEM discretisation, with .
We ignore the fact that should fulfil and just use .
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Helmut Harbrecht, Email: helmut.harbrecht@unibas.ch.
Marc Schmidlin, Email: marc.schmidlin@unibas.ch.
References
- 1.Barth A, Schwab C, Zollinger N. Multi-level Monte Carlo finite element method for elliptic PDEs with stochastic coefficients. Numer. Math. 2011;119(1):123–161. [Google Scholar]
- 2.Bramble J, Pasciak JE. Preconditioner technique for indefinite systems resulting from mixed approximation of elliptic problems. Math. Comput. 1988;50:1–17. [Google Scholar]
- 3.Bramble J, Pasciak JE, Xu J. Parallel multilevel preconditioners. Math. Comput. 1990;55:1–22. [Google Scholar]
- 4.Canuto C, Kozubek T. A fictitious domain approach to the numerical solution of PDEs in stochastic domains. Numer. Math. 2007;107(2):257–293. [Google Scholar]
- 5.Castrillon-Candas JE, Nobile F, Tempone R. Analytic regularity and collocation approximation for PDEs with random domain deformations. Comput. Math. Appl. 2016;71(6):1173–1197. [Google Scholar]
- 6.Church L, Djurdjevac A, Elliott CM. A domain mapping approach for elliptic equations posed on random bulk and surface domains. Numer. Math. 2020;146(1):1–49. [Google Scholar]
- 7.Cliffe KA, Giles MB, Scheichl R, Teckentrup AL. Multilevel Monte Carlo methods and applications to elliptic PDEs with random coefficients. Comput. Vis. Sci. 2011;14(1):3–15. [Google Scholar]
- 8.Costabel M, Stephan EP. Coupling of finite element and boundary element methods for an elasto-plastic interface problem. SIAM J. Numer. Anal. 1988;27:1212–1226. [Google Scholar]
- 9.Dahmen W, Kunoth A. Multilevel preconditioning. Numer. Math. 1992;63(3):315–344. [Google Scholar]
- 10.Dick J, Kuo FY, Le Gia QT, Nuyens D, Schwab C. Higher order QMC Petrov–Galerkin discretization for affine parametric operator equations with random field inputs. SIAM J. Numer. Anal. 2014;52(6):2676–2702. [Google Scholar]
- 11.Dick J, Kuo FY, Le Gia QT, Schwab C. Multilevel higher order QMC Petrov-Galerkin discretization for affine parametric operator equations. SIAM J. Numer. Anal. 2016;54(4):2541–2568. [Google Scholar]
- 12.Eppler K, Harbrecht H. Coupling of FEM and BEM in shape optimization. Numer. Math. 2006;104(1):47–68. [Google Scholar]
- 13.Gilbarg D, Trudinger NS. Elliptic Partial Differential Equations of Second Order. Berlin: Springer; 2001. [Google Scholar]
- 14.Gordon WJ. Blending-function methods of bivariate and multivariate interpolation and approximation. SIAM J. Numer. Anal. 1971;8(1):158–177. [Google Scholar]
- 15.Gordon WJ, Hall CA. Construction of curvilinear co-ordinate systems and applications to mesh generation. Int. J. Numer. Meth. Eng. 1973;7(4):461–477. [Google Scholar]
- 16.Gordon WJ, Thiel LC. Transfinite mappings and their application to grid generation. Appl. Math. Comput. 1982;10–11:171–233. [Google Scholar]
- 17.Griebel M, Harbrecht H. On the construction of sparse tensor product spaces. Math. Comput. 2013;82(282):975–994. [Google Scholar]
- 18.Griebel M, Harbrecht H, Multerer M. Multilevel quadrature for elliptic parametric partial differential equations in case of polygonal approximations of curved domains. SIAM J. Numer. Anal. 2020;58(1):684–705. [Google Scholar]
- 19.Griebel M, Schneider M, Zenger C. A combination technique for the solution of sparse grid problems. In: de Groen P, Beauwens R, editors. Iterative Methods in Linear Algebra. Elsevier, North Holland: IMACS; 1992. pp. 263–281. [Google Scholar]
- 20.Grisvard, P.: Elliptic Problems in Nonsmooth Domains. Classics in Applied Mathematics. Society for Industrial and Applied Mathematics (2011)
- 21.Haji-Ali AL, Harbrecht H, Peters MD, Siebenmorgen M. Novel results for the anisotropic sparse grid quadrature. J. Complexity. 2018;47:62–85. [Google Scholar]
- 22.Halton JH. On the efficiency of certain quasi-random sequences of points in evaluating multi-dimensional integrals. Numer. Math. 1960;2(1):84–90. [Google Scholar]
- 23.Han H. A new class of variational formulation for the coupling of finite and boundary element methods. J. Comput. Math. 1990;8(3):223–232. [Google Scholar]
- 24.Harbrecht H. Analytical and numerical methods in shape optimization. Math. Methods Appl. Sci. 2008;31(18):2095–2114. [Google Scholar]
- 25.Harbrecht H, Paiva F, Pérez C, Schneider R. Biorthogonal wavelet approximation for the coupling of FEM-BEM. Numer. Math. 2002;92:325–356. [Google Scholar]
- 26.Harbrecht H, Paiva F, Pérez C, Schneider R. Wavelet preconditioning for the coupling of FEM-BEM. Numer. Linear Algebra Appl. 2003;3:197–222. [Google Scholar]
- 27.Harbrecht H, Peters M, Siebenmorgen M. On multilevel quadrature for elliptic stochastic partial differential equations. Sparse Grids Appl. 2013;88:161–179. [Google Scholar]
- 28.Harbrecht H, Peters M, Siebenmorgen M. Analysis of the domain mapping method for elliptic diffusion problems on random domains. Numer. Math. 2016;134(4):823–856. [Google Scholar]
- 29.Harbrecht H, Peters MD. The second order perturbation approach for elliptic partial differential equations on random domains. Appl. Numer. Math. 2018;125:159–171. [Google Scholar]
- 30.Harbrecht H, Schmidlin M. Multilevel methods for uncertainty quantification of elliptic PDEs with random anisotropic diffusion. Stoch. Partial Differ. Equ. Anal. Comput. 2020;8:54–81. [Google Scholar]
- 31.Harbrecht H, Schneider R, Schwab C. Sparse second moment analysis for elliptic problems in stochastic domains. Numer. Math. 2008;109(3):385–414. [Google Scholar]
- 32.Heise B, Kuhn M. Parallel solvers for linear and nonlinear exterior magnetic field problems based upon coupled FE/BE formulations. Computing. 1996;56:237–258. [Google Scholar]
- 33.Henriquez, F., Schwab, C.: Shape holomorphy of the Calderón projector for the Laplacean in R2. Tech. Rep. 2019-43, Seminar for Applied Mathematics, ETH Zürich, Switzerland (2019)
- 34.Hille, E., Phillips, R.S.: Functional Analysis and Semi-Groups, Am. Math. Soc. Collog. Publ., vol. 31. American Mathematical Society, Providence (1957)
- 35.Hiptmair R, Scarabosio L, Schillings C, Schwab C. Large deformation shape uncertainty quantification in acoustic scattering. Adv. Comput. Math. 2018;44:1475–1518. [Google Scholar]
- 36.Kuo FY, Schwab C, Sloan IH. Quasi-Monte Carlo finite element methods for a class of elliptic partial differential equations with random coefficient. SIAM J. Numer. Anal. 2012;50(6):3351–3374. [Google Scholar]
- 37.Kuo FY, Schwab C, Sloan IH. Multi-level quasi-Monte Carlo finite element methods for a class of elliptic PDEs with random coefficients. Found. Comput. Math. 2015;15(2):411–449. [Google Scholar]
- 38.Litvinenko A, Yucel AC, Bagci H, Oppelstrup J, Michielssen E, Tempone R. Computation of electromagnetic fields scattered from objects with uncertain shapes using multilevel Monte Carlo method. IEEE J. Multiscale Multiphys. Comput. Tech. 2019;4:37–50. [Google Scholar]
- 39.Mohan PS, Nair PB, Keane AJ. Stochastic projection schemes for deterministic linear elliptic partial differential equations on random domains. Int. J. Numer. Meth. Eng. 2011;85(7):874–895. [Google Scholar]
- 40.Scarabosio L. Multilevel Monte Carlo on a high-dimensional parameter space for transmission problems with geometric uncertainties. Int. J. Uncertain. Quantif. 2019;9(6):515–541. [Google Scholar]
- 41.Schneider R. Multiskalen- und Wavelet-Matrixkompression: Analysisbasierte Methoden zur Lösung großer vollbesetzter Gleichungssyteme. Stuttgart: B. G. Teubner; 1998. [Google Scholar]
- 42.Tartakovsky DM, Xiu D. Stochastic analysis of transport in tubes with rough walls. J. Comput. Phys. 2006;217(1):248–259. [Google Scholar]
- 43.Wang X. A constructive approach to strong tractability using quasi-Monte Carlo algorithms. J. Complexity. 2002;18:683–701. [Google Scholar]
- 44.Xiu D, Tartakovsky DM. Numerical methods for differential equations in random domains. SIAM J. Sci. Comput. 2006;28(3):1167–1185. [Google Scholar]
- 45.Zenisek A. Nonlinear Elliptic and Evolution Problems and Their Finite Element Approximation. London: Academic Press; 1990. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The results presented in this article can be replicated solely using the information contained in this article and its references.