

Abstract
An approach for integrating the wealth of heterogeneous brain data—from gene expression and neurotransmitter receptor density to structure and function—allows neuroscientists to easily place their data within the broader neuroscientific context.
Imagine we conduct a human neuroimaging experiment that shows that neural activity in Brodmann area 46 scales with the demands of the task the participants performed, and that the activity is statistically higher in older, compared to younger, adults. What do we do with this information? An expert might guess that this was a working memory or attention task, based on their familiarity with the relevant neuroimaging literature. But that expert, like myself, may know relatively little about neurogenetics, neurochemistry, or cortical evolution and, because of their (and my) own knowledge gaps, will be unable to see how those results fit into the broader neuroscientific context. If we are to develop anything close to resembling a set of theories for how the brain gives rise to behavior, cognition, and disease, we need a way for placing human neuroimaging data within that greater context. The open-source Python package, neuromaps, introduced by Markello and Hansen and colleagues in this issue of Nature Methods1, provides an invaluable tool for doing just that.
Given the incredible wealth of information published in neuroscience, it’s simply impossible for a research group—let alone a single scientist—to understand how age-related changes in neurogenetics, receptor densities, cell types, structural connectivity, and so on might all contribute to the neural activity differences observed in our above hypothetical experiment. Thus, our inability to integrate these many different facets of the brain is understandable and, hopefully, even excusable. However, this separation of data from knowledge has often led to neuroscience being described as data rich, but theory poor, where every research group is collecting more and more data, unable to fit all these different pieces together as a unified whole.
To accomplish this feat of contextualization, Markello and Hansen et al. solved several technical problems that allow for easy data integration. First, neuromaps offers functions for easily transforming between four standard human brain template atlases: fsaverage, fsLR, CIVET, and MNI-152. Armed with this ability to transform between different coordinate systems, Markello and Hansen et al. then sought out numerous heterogeneous datasets, placing them into the same coordinate system. We can group the included datasets into four broad categories: Architecture, Cellular, Dynamics, and Function (Fig. 1):
Architecture: cortical thickness; T1w/T2w ratio; functional connectivity; intersubject variability
Cellular: gene expression from the Allen Human Brain Atlas; neurotransmitter receptor positron emission tomography tracer images
Dynamics: canonical MEG frequency bands; intrinsic neuronal timescale; glucose and oxygen metabolism; cerebral blood flow and volume
Function: evolutionary expansion; developmental expansion; Neurosynth-derived functional maps
Figure 1|.
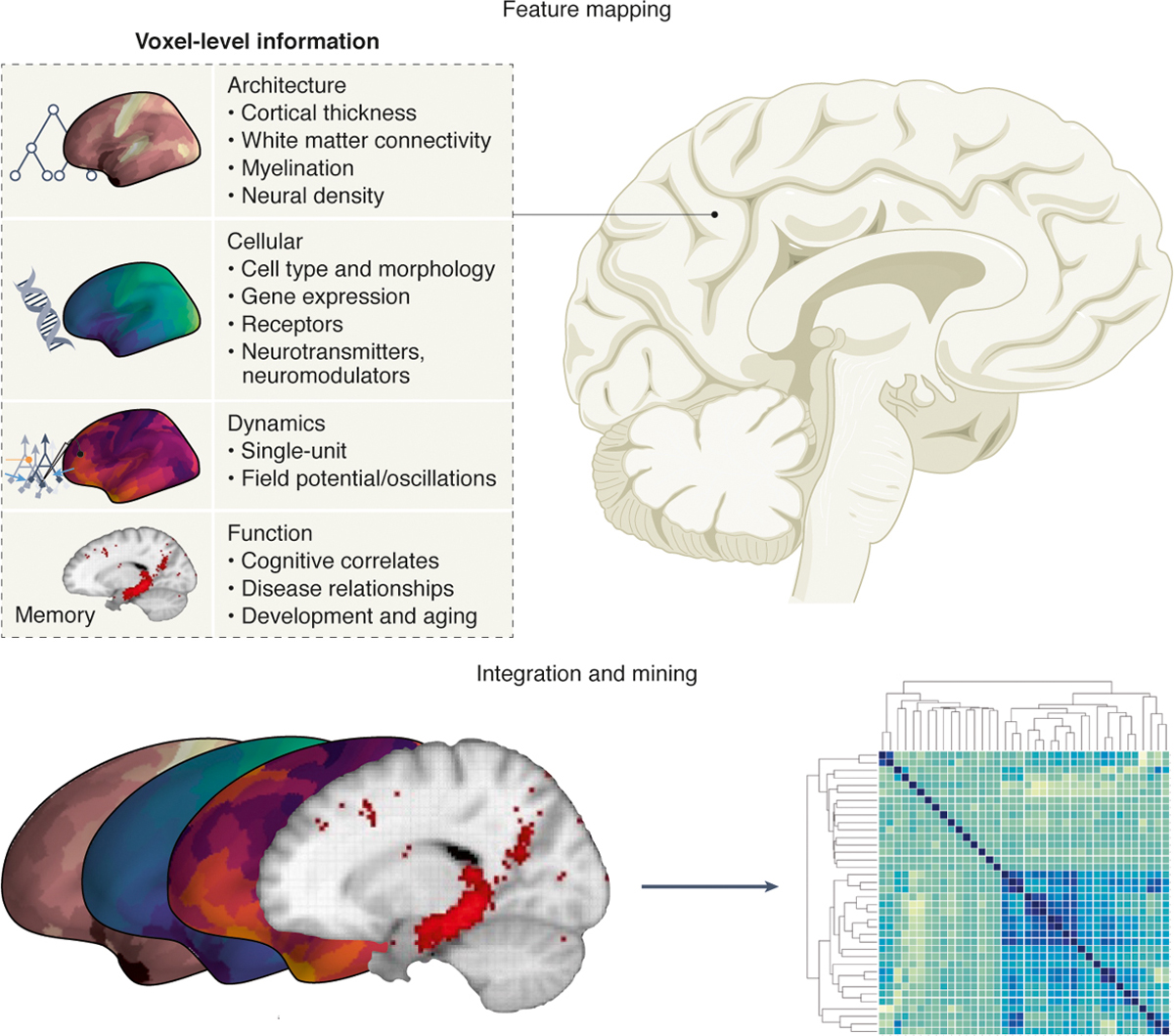
For any arbitrary region of the human brain there exists a wealth of knowledge about its various features: architecture, cellular composition and genetics, neural dynamics, and functions (top). The neuromaps package collates and aligns these features to facilitate comparisons across domains, opening new avenues for data mining across features, potentially allowing for novel forms of data-driven, semi-automated hypothesis generation (bottom).
Placing all these different datasets in the same spatial framework then allows researchers to statistically compare their spatial profiles to ask novel research questions. Importantly, however, these spatial maps can’t be compared using simple correlations, because the topography of neural data is spatially autocorrelated. That is, features that are closer together in space are inherently likely to look more similar than features that are farther apart. The fact that nearly all neural data are spatially autocorrelated practically guarantees that correlations will be found between neural data maps, just like maps of human population density are strongly correlated with maps of economic activity—technically correct but not mechanistically insightful. To address this, Markello and Hansen et al. include several approaches for performing spatial permutations for significance testing in neuromaps, to help minimize the inflated p-values that result from spatial autocorrelations.
To test the potential for heterogeneous data integration, Markello and Hansen et al. then leveraged multiple open datasets to run several comparisons. For example, using an open dataset of cortical thinning in patients with chronic schizophrenia, they showed that the spatial topography of cortical thinning is greatest in regions that show the greatest neurodevelopmental expansion, as quantified from an entirely different set of independent data. Using other datasets, they also showed that the brain regions that have the greatest evolutionary expansion also have the greatest inter-individual variability in regional functional connectivity.
Markello and Hansen et al. take a pure data science approach to neuroscience with neuromaps, integrating multiple heterogeneous datatypes and bringing them together into a unified framework. These data types include categorical gene expression data, time-series oscillation and timescale data, functional data derived from text-mining of the neuroscience literature, and functional and structural connectivity graphs. A common refrain in what limits the development of a systems-level mechanistic understanding of behavior and cognition is the difficulty in bridging between scales, between genetics and structure2 or dynamics and function3. If we could better bridge these scales, it is argued, we could better reveal key neuroscientific insights. It’s exciting that neuromaps allows us to place results from one domain—such as the functional neuroimaging example from above—into the greater context of neural architecture, cellular composition, dynamics, and function.
So, what does neuromaps portend for the future of neuroscience? Are more data and better data integration enough? Algorithmically churning through massive amounts of data is no guarantee to mechanistic understanding4, but is it possible to derive a systems-level mechanistic understanding without massive amounts of data5? Will more neural data be as “unreasonably effective” for uncovering mechanistic insights, similar to how more data has been shown to improve the performance of deep learning and artificial intelligence6?
Markello and Hansen et al. emphasize that the current state of neuromaps is a beginning, not an end. One criticism of these data-driven approaches is that the data reflect the historical biases of researchers and research trends, just as has been demonstrated using data-driven clustering of functional domains in human neuroimaging7. However, in theory, as more data are collected, from more data types and from more people, the fidelity of these maps should only improve, allowing for more fine-scaled links across domains. In addition, the future of neuromaps can be expanded to include even more maps, such as single-neuron electrophysiological properties, laminar profiles for neuron and glial cell types, dendritic geometry, and more, further improving our ability to place results into the broader context.
To demonstrate its future potential, let’s revisit the opening neuroimaging scenario, but from the neuromaps perspective. Here, we begin from a desire to understand the possible neurogenetic underpinnings of Alzheimer’s disease. We can take the maps for the brain regions associated with Alzheimer’s disease, as algorithmically extracted using text-mining via the Neurosynth platform8. We can then compare the spatial topography of these maps against maps of gene expression in the human brain to find genes that are statistically over- or under-expressed in these putative Alzheimer’s disease brain regions, to see if there are any potential genes that have been historically overlooked. Or we can look to see whether these putative Alzheimer’s disease brain regions have a greater density of specific neuronal or glial cell types compared to other brain regions not associated with Alzheimer’s disease, to see if there’s an overlooked cellular driver of Alzheimer’s disease.
This hypothetical scenario demonstrates the powerful potential for data-driven semi-automated hypothesis generation9. From this perspective, neuromaps isn’t something that is just used to answer new questions, it can be used to form entirely new hypotheses (Fig. 1). This approach complements experimental research, where we’re no longer living in a fractured, data rich and theory poor world; rather we find ourselves within a data-rich neuroscience ecosystem that may lead to a theory-rich neuroscientific environment10.
Acknowledgements
B.V. is supported by the National Institute of General Medical Sciences Grant R01GM134363.
Footnotes
Competing Interests Statement
The author declares no competing financial interests.
References
- 1.Markello RD et al. Neuromaps: structural and functional interpretation of brain maps. Nature Methods (this issue). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Fornito A, Arnatkevičiūtė A & Fulcher BD Bridging the Gap between Connectome and Transcriptome. Trends in Cognitive Sciences 23, 34–50 (2019). [DOI] [PubMed] [Google Scholar]
- 3.Kopell NJ, Gritton HJ, Whittington MA & Kramer MA Beyond the Connectome: The Dynome. Neuron 83, 1319–1328 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Jonas E & Kording K Could a neuroscientist understand a microprocessor? PLOS Computational Biology (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Churchland PS & Sejnowski TJ Blending computational and experimental neuroscience. Nature Reviews Neuroscience 17, 667–668 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Halevy A, Norvig P & Pereira F The Unreasonable Effectiveness of Data. IEEE Intelligent Systems 24, 8–12 (2009). [Google Scholar]
- 7.Beam E, Potts C, Poldrack RA & Etkin A A data-driven framework for mapping domains of human neurobiology. Nat Neurosci (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Yarkoni T, Poldrack RA, Nichols TE, Van Essen DC & Wager TD Large-scale automated synthesis of human functional neuroimaging data. Nature Methods 8, 665–670 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Voytek JB & Voytek B Automated cognome construction and semi-automated hypothesis generation. Journal of Neuroscience Methods 208, 92–100 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Voytek B The Virtuous Cycle of a Data Ecosystem. PLOS Computational Biology 12, e1005037 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]