

Abstract
Mendelian randomization (MR) is a statistical method exploiting genetic variants as instrumental variables to estimate the causal effect of modifiable risk factors on an outcome of interest. Despite wide uses of various popular two‐sample MR methods based on genome‐wide association study summary level data, however, those methods could suffer from potential power loss or/and biased inference when the chosen genetic variants are in linkage disequilibrium (LD), and also have relatively large direct effects on the outcome whose distribution might be heavy‐tailed which is commonly referred to as the idiosyncratic pleiotropy phenomenon. To resolve those two issues, we propose a novel Robust Bayesian Mendelian Randomization (RBMR) model that uses the more robust multivariate generalized ‐distribution to model such direct effects in a probabilistic model framework which can also incorporate the LD structure explicitly. The generalized ‐distribution can be represented as a Gaussian scaled mixture so that our model parameters can be estimated by the expectation maximization (EM)‐type algorithms. We compute the standard errors by calibrating the evidence lower bound using the likelihood ratio test. Through extensive simulation studies, we show that our RBMR has robust performance compared with other competing methods. We further apply our RBMR method to two benchmark data sets and find that RBMR has smaller bias and standard errors. Using our proposed RBMR method, we find that coronary artery disease is associated with increased risk of critically ill coronavirus disease 2019. We also develop a user‐friendly R package RBMR (https://github.com/AnqiWang2021/RBMR) for public use.
Keywords: COVID‐19 outcomes, EM‐type algorithm, idiosyncratic pleiotropy, linkage disequilibrium, Mendelian randomization, multivariate generalized t‐distribution
1. INTRODUCTION
Mendelian randomization (MR) is a useful statistical method that leverages genetic variants as instrumental variables (IVs) for assessing the causal effect of a modifiable risk factor on a health outcome of interest even in the presence of unmeasured confounding factors (Ebrahim & Smith, 2008; Evans & Davey Smith, 2015; Lawlor et al., 2008). Because of the inborn nature of genetic variants, the associations between genetic variants and phenotypes after adjusting for possible population stratification will not be confounded by the environmental factors, socioeconomic status and life styles after birth. Genome‐wide association studies (GWAS) have identified tens of thousands of common genetic variants associated with thousands of complex traits and diseases (MacArthur et al., 2017). Those GWAS summary level data contain rich information about genotype–phenotype associations (https://www.ebi.ac.uk/gwas/), and thus provide us valuable resources for MR studies. Therefore, we have seen a boost of two‐sample MR method developments and applications based on GWAS summary statistics recently due to the increasing availability of candidate genetic variant IVs for thousands of phenotypes. (Bowden et al., 2015; Burgess et al., 2013; Pickrell et al., 2016). In particular, a genetic variant serving as a valid IV must satisfy the following three core assumptions (Lawlor et al., 2008; Martens et al., 2006):
-
1.
Relevance: The genetic variant must be associated (not necessarily causally) with the exposure;
-
2.
Effective Random Assignment: The genetic variant must be independent of any (measured or unmeasured) confounders of the exposure‐outcome relationship;
-
3.
Exclusion Restriction: The genetic variant must affect the outcome only through the exposure, that is, the genetic variant must have no direct effect on the outcome not mediated by the exposure.
When these three core IV assumptions hold, the inverse variance weighted (IVW) (Ehret et al., 2011) method can be simply used to obtain unbiased causal effect estimate of the exposure on the outcome. However, among those three core assumptions, only the IV relevance assumption can be empirically tested, for example, by checking the empirical association strength between the candidate IV and the exposure using the GWAS catalog (https://www.ebi.ac.uk/gwas/). The association between the IV and the exposure must be strong enough (the IV explains a large amount of the variation of the exposure variable) to ensure unbiased causal effect estimate. The problem of weak IVs has been studied previously in the econometric literature (Bound et al., 1995; Hansen et al., 2008). In MR settings, the method that uses genetic score by combining multiple weak IVs together to increase the IV‐exposure association strength to reduce weak IV bias has also been proposed (Evans et al., 2013). Unfortunately, the other two IV core assumptions cannot be empirically tested and might be violated in practice. Violation of the exclusion restriction assumption can occur when the genetic variant indeed has a non‐null direct effect on the outcome not mediated by the exposure, referred to as systematic pleiotropy (Solovieff et al., 2013; Verbanck et al., 2018; Q. Zhao, Wang, et al., 2020). However, very often, genetic variants might have relatively large direct effects whose distribution exhibits a heavy‐tailed pattern, a phenomenon referred to as the idiosyncratic pleiotropy in this paper. For example, there exists idiosyncratic pleiotropy when estimating the causal effect of low‐density lipoprotein (LDL) cholesterol on the risk of Alzheimer's disease. In Section 4, we will describe more details about this real data example.
To address those possible violations of the IV core assumptions and potential risk, many efforts have been made recently. The MR‐Egger regression method introduced an intercept term to capture the presence of unbalanced systematic pleiotropy under the Instrument Strength Independent of Direct Effect (InSIDE) assumption (Bowden et al., 2015). However, MR‐Egger would be biased when there exists idiosyncratic pleiotropy. Z. Zhu et al. (2018) proposed the GSMR method that removes suspected genetic variants with relatively large direct effects and also takes the LD structure into account by using the generalized least squares approach. However, removal of a large number of relatively large direct effects might lead to efficiency loss. Q. Zhao, Wang, et al. (2020) proposed MR‐RAPS to improve statistical power for causal inference and limit the influence of relatively large direct effects by using the adjusted profile likelihood and robust loss functions assuming that those single‐nucleotide polymorphism (SNP) IVs are independent. However, this independent IV assumption might not hold in practice because SNPs within proximity tend to be correlated. Cheng et al. (2020) proposed a two‐sample MR method named MR‐LDP that built a Bayesian probabilistic model accounting for systematic pleiotropy and LD structures among SNP IVs. One drawback of the MR‐LDP method is that it cannot handle relatively large direct effects well.
To overcome the limitations of those aforementioned methods, we propose a more robust method named “Robust Bayesian Mendelian Randomization (RBMR)” accounting for LD, systematic and idiosyncratic pleiotropy simultaneously in a unified framework. Specifically, to account for LD, we first estimate the LD correlation matrix of SNP IVs and then explicitly include it in the model likelihood. To account for idiosyncratic pleiotropy, we propose to model the direct effects using the more robust multivariate generalized ‐distribution (Arellano‐Valle & Bolfarine, 1995; Frahm, 2004) which will be shown to have improved performance than using the Gaussian distribution when the idiosyncratic pleiotropy is present. Moreover, this more robust distribution can be represented as a Gaussian scaled mixture to facilitate model parameter estimation using the parameter expanded variational Bayesian expectation maximization algorithm (PX‐VBEM) (Yang et al., 2020) which combines the VB‐EM (Beal, 2003) and the PX‐EM (Liu et al., 1998) together. We further calculate the standard error by calibrating the evidence lower bound (ELBO) according to a nice property of the likelihood ratio test (LRT). Both extensive simulation studies in Section 3 and analysis of two real benchmark data sets in Section 4 show that our proposed RBMR method outperforms competitors. The real data analysis results show that coronary artery disease (CAD) is associated with increased risk of critically ill coronavirus disease 2019 (COVID‐19) outcomes.
2. METHODS
2.1. The linear structural model
Suppose that we have possibly correlated genetic variants (e.g., SNPs) , the exposure variable , the outcome variable of interest and unknown confounding factors . Let and denote the effects of confounders on exposure and outcome respectively. The coefficients denote the SNP‐exposure true effects. Suppose that all the IVs are valid, then the exposure can be represented as a linear structural function of the SNPs, confounders and an independent random noise term . The outcome can be represented as a linear structural function of the exposure, confounders and the independent random noise term . The true effect size of the exposure on the outcome is denoted as . Then, we have the following linear structural equation models (Bowden et al., 2015):
| (1) |
Let be the true effects of SNPs on the outcome. With valid IVs, we have
| (2) |
To accommodate possible violations of the exclusion restriction assumption, we now consider the following modified linear structural functions (Bowden et al., 2015):
| (3) |
where the coefficients represent the direct effects of the SNPs on the outcome. Then we have
| (4) |
So far, many existing MR methods assign the Gaussian distribution on each direct effect , that is (Cheng et al., 2020; J. Zhao, Ming, et al., 2020; Q. Zhao, Wang, et al., 2020), where is a ‐dimensional vector of direct effects. However, real genetic data might contain some relatively large direct effects whose distribution can be heavy‐tailed, and thus the Gaussian distribution might not be a good fit. Therefore, we propose to assign the multivariate generalized ‐distribution on (Arellano‐Valle & Bolfarine, 1995; Kotz & Nadarajah, 2004), which is a robust alternative to the Gaussian distribution (Frahm, 2004).
2.2. The robust Bayesian MR model
Let and be the GWAS summary statistics for the exposure and the outcome respectively, where are the corresponding estimated standard errors. Many existing MR methods assume that IVs are independent from each other (Bowden et al., 2015; Ehret et al., 2011; Q. Zhao, Wang, et al., 2020), and the uncorrelated SNPs can be chosen by using a tool called LD clumping (Hemani et al., 2016; Purcell et al., 2007), which might remove many SNP IVs and thus cause efficiency loss. To include more SNP IVs even if they are in LD, we need to account for the LD structure explicitly. To achieve this goal, we use a reference panel sample to assist with reconstructing LD matrix, such as the 1000 Genome Project Phase 1 ( = 379) (The 1000 Genomes Project Consortium, 2012). We first apply the LDetect method to partition the whole genome into blocks (Berisa & Pickrell, 2016) and then estimate the LD matrix using the estimator first proposed by Rothman (2012). Then, the distributions of and are given by
| (5) |
| (6) |
where and are both diagonal matrices (X. Zhu & Stephens, 2017).
To account for the presence of idiosyncratic pleiotropy, we propose to model the direct effects using the more robust multivariate generalized ‐distribution (Ala‐Luhtala and Piché, 2016; Arellano‐Valle & Bolfarine, 1995; Kotz & Nadarajah, 2004) whose density function is given by
| (7) |
where denotes the ‐dimensional Gaussian distribution with mean and covariance , is a diagonal matrix, and is the Gamma distribution of a univariate positive variable referred to as a weight variable
| (8) |
where denotes the Gamma function. When in equation (8), the distribution in Equation (7) reduces to a multivariate ‐distribution, where is the degree of freedom. Gaussian scaled mixture representation enables the use of EM‐type algorithms for statistical inference, such as the PX‐VBEM (Yang et al., 2020) described in Section 2.3.
Then we denote the distribution of the latent variable as
| (9) |
where is a diagonal matrix. By assuming that , and are latent variables, the complete data likelihood can be written as
| (10) |
2.3. Estimation and inference
The standard expectation‐maximization (EM) algorithm (Dempster et al., 1977) is a popular choice for finding the maximum likelihood estimate in the presence of missing (latent) variables. However, one difficulty for implementing the EM algorithm is to calculate the marginal likelihood function which might involve difficult integration with respect to the distributions of the latent variables. In addition, the original EM algorithm might be slow (Liu et al., 1998). To address these numerical issues, we utilize a parameter expanded variational Bayesian expectation‐maximization algorithm, namely, PX‐VBEM (Yang et al., 2020), by replacing the EM algorithm in VB‐EM (Beal, 2003) with PX‐EM algorithm (Liu et al., 1998) to accelerate the speed of convergence. To start with, for the purpose of applying the PX‐EM algorithm, the distribution of in equation (5) can be rewritten as follows:
| (11) |
We also rewrite the complete data likelihood in equation (10) as:
| (12) |
where the expanded model parameters for RBMR are . Let be a variational posterior distribution. The logarithm of the marginal likelihood can be decomposed into two parts,
| (13) |
where
| (14) |
Given that the is an evidence lower bound (ELBO) of the marginal log‐likelihood, the non‐negative Kullback‐Leibler (KL) divergence is equal to zero if and only if the variational posterior distribution is equal to the true posterior distribution. Minimizing the KL divergence is equivalent to maximizing ELBO. Before calculating the maximization of ELBO, due to the fact that latent variables are independent of each other, the decomposition form of the posterior distribution is obtained using the mean field assumption (Blei et al., 2017),
| (15) |
In the PX‐VB‐E step, the optimal variational posterior distributions for , and can be written as
| (16) |
The updating equations for the parameters are given by
| (17) |
where , and .
In the PX‐VB‐M step, by setting the derivate of the ELBO to be zero, the model parameters can be obtained as:
| (18) |
where , , and . Finally, we use the updated model parameters to construct the evidence lower bound to check the convergence. Since we adopt PX‐EM algorithm, the reduction step should be used to process the obtained parameters. More technical details can be found in the Supporting Information.
After obtaining an estimate of the causal effect, we further calculate the standard error according to the property of likelihood ratio test (LRT) statistics which asymptotically follows the under the null hypothesis (Van der Vaart, 2000). We first formulate the statistical tests to examine the association between the risk factor and the outcome.
| (19) |
the likelihood ratio test (LRT) statistics for the causal effect is given by
| (20) |
where and are collections of parameter estimates obtained by maximizing the marginal likelihood under the null hypothesis and under the alternative hypothesis . We utilize PX‐VBEM algorithm to maximize the ELBO to get the and instead of maximizing the marginal likelihood to overcome the computational intractability. Although PX‐VBEM produces accurate posterior mean estimates (Blei et al., 2017; Dai et al., 2017; Yang et al., 2018), it would underestimate the marginal variance because we use the estimated posterior distribution from the ELBO to approximate the marginal likelihood in equation (20) (Wang & Titterington, 2005). Thus, we calibrate ELBO by plugging our estimates ( and ) from PX‐VBEM into the equation (20) to construct the test statistics (Yang et al., 2020):
| (21) |
Then, we can get the well‐calibrated standard error as .
3. SIMULATION STUDIES
Although our proposed method is based on GWAS summary level data, we still simulate the individual‐level data to better mimic real genetic data sets. Specifically, the data sets are generated according to the following models:
| (22) |
where is the exposure vector, is the outcome vector, and are the genotype data sets for the exposure and the outcome , and are matrices for confounding variables, and are the corresponding sample sizes of exposure and outcome , is the number of genotyped SNPs. The error terms and are independent noises generated from and , where the values of and are around 0.8 and 0.4 on average, respectively. In model (22), is the true causal effect and represents the direct effect of the SNPs on the outcome not mediated by the exposure variable, where , . To simulate the idiosyncratic pleiotropy, we randomly select 5 of IVs so that their direct effect s have mean 0 and standard deviation , where .
An external reference panel is chosen for estimating the LD matrix among SNPs, where is the sample size of the chosen reference panel. We used the R package MR.LDP to generate the genotype matrices , and by mimicking the LD structure in the CAD‐CAD data set as in Section 4. We fix . The number of blocks is set to be 10 and the number of SNPs within each block is 50. Thus, the total number of SNPs is . The confounders are generated as follows:
| (23) |
Each row of and is sampled from and , where , respectively. We sample each column of and from a standard normal distribution, while each row of the corresponding coefficients and of the confounders is sampled from a multivariate normal distribution where the diagonal elements of are 1 and the off‐diagonal elements are 0.85. The signal magnitude for is controlled by the heritability due to systematic pleiotropy, . The signal magnitude for is chosen such that the heritability . Then we control the heritability for at 0.1. The true causal effect is set to be 1.
We first run single‐variant genetic association analysis for the exposure and the outcome respectively, and then we obtain the summary‐level statistics with their corresponding standard errors . Then we use the summary‐level data to conduct MR analyses using the proposed RBMR, MR‐LDP, MR‐Egger, RAPS, GSMR and IVW methods. As the prerequisite for MR‐Egger, RAPS and IVW methods is that the IVs are independent of each other, we perform LD pruning by controlling the LD at the threshold 0.05 (Z. Zhu et al., 2018). We repeat the simulations for 500 times.
We evaluate the type‐I error rates under the null that and evaluate the estimation accuracy of point estimates under the alternative that . Figures 1 and 2 display the point estimates and type‐I error rates for all the methods. As shown in Figure 2, the proposed RBMR and MR‐LDP methods control the type‐I errors at the nominal level 0.05. Although after LD pruning, genetic variants are independent, however, the competing methods, GSMR, RAPS, MR‐Egger and IVW still fail to control the type‐I error because of the presence of idiosyncratic pleiotropy. We found that our method RBMR and MR‐LDP are more stable than the other four methods as shown in Figure 1a. But we found that our method RBMR is more accurate than MR‐LDP in terms of relative bias, root mean square error (RMSE%) and coverage probabilities as shown in Figure 1b and Table 1. We conducted more simulation studies and obtain essentially the same conclusion. Detailed results are provided in the Supporting Information.
Figure 1.
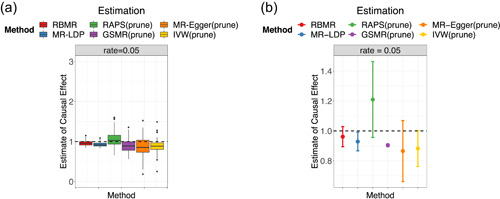
Comparisons of MR methods affected by the LD and pleiotropy. (a) Boxplot and (b) point estimates and 95% confidence intervals. LD, linkage disequilibrium; MR, Mendelian randomization
Figure 2.
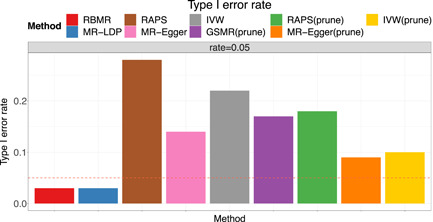
Comparisons of the type I error rates for MR methods affected by the LD and pleiotropy. LD, linkage disequilibrium; MR, Mendelian randomization
Table 1.
Comparisons of the point estimates in the terms of bias%, RMSE%, and the coverage probabilities
| Method |
|
Bias% | RMSE% | Cover% | |
|---|---|---|---|---|---|
| RBMR | 0.962 | −3.837 | 7.583 | 94.000 | |
| MR‐LDP | 0.929 | −7.107 | 8.834 | 86.000 | |
| GSMR (prune) | 0.905 | −9.549 | 18.728 | 5.000 | |
| RAPS (prune) | 1.210 | 20.981 | 155.223 | 87.000 | |
| MR‐Egger (prune) | 0.865 | −13.484 | 27.689 | 86.000 | |
| IVW (prune) | 0.882 | −11.768 | 19.996 | 73.000 |
Abbreviation: RMSE, root mean square error.
4. REAL DATA ANALYSIS
In this section, we analyzed four real data sets to demonstrate the performance of our proposed method. The 1000 Genome Project Phase 1 (1KGP) is used as the reference panel to compute the LD matrix (The 1000 Genomes Project Consortium, 2012). We first analyze two benchmark data sets commonly used for method comparison purpose, then we will estimate the causal effect of coronary artery disease (CAD) on the risk of critically ill COVID‐19 outcomes defined as those who end up on respiratory support or die from COVID‐19. We also estimate the causal effect of low‐density lipoprotein (LDL) cholesterol on the risk of Alzheimer's disease.
The first benchmark data analysis is based on the summary‐level data sets from two nonoverlapping GWAS studies for the coronary artery disease (CAD), usually referred to as the CAD‐CAD data. The true causal effect should be exactly one. The selection data set is from the Myocardial Infarction Genetics in the UK Biobank, the exposure data is from the Coronary Artery Disease (C4D) Genetics Consortium (Coronary Artery Disease (C4D) Genetics Consortium, 2011), and the outcome data is from the transatlantic Coronary Artery Disease Genome Wide Replication and Meta‐analysis (CARDIoGRAM) (Schunkert et al., 2011). We first filter the genetic variants using the selection data under different association ‐value thresholds (‐value ). Then we applied our proposed RBMR method and the MR‐LDP to all the selected and possibly correlated SNPs by accounting for the LD structure explicitly. We applied the GSMR, IVW, MR‐Egger and MR‐RAPS methods using the independent SNPs after LD pruning at the LD threshold 0.05. We obtain causal effect point estimates and the corresponding 95% confidence intervals (CI) as shown in Figure 3a. We found that our proposed RBMR method outperforms other methods because it has the smallest bias and shortest confidence intervals for a range of ‐value thresholds. Our proposed method RBMR used all selected SNPs (without LD pruning) in the selection data set and thus we might obtain more accurate causal effect estimate. However, other methods might be biased due to the pruning process, because the pruning process might filter out the “good” IVs and keep the “bad” IVs.
Figure 3.
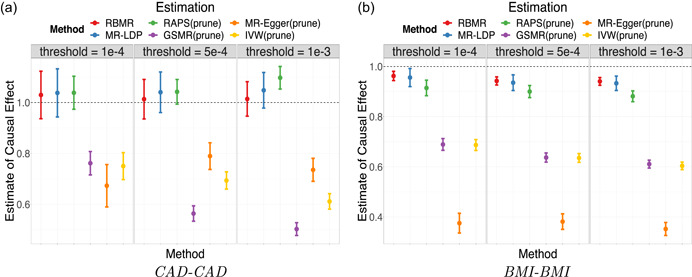
The results of CAD‐CAD and BMI‐BMI using 1KGP as the reference panel with shrinkage parameter . The SNPs are selected at the three thresholds (‐value ). (a) point estimates and 95% confidence intervals of CAD‐CAD, (b) point estimates and 95% confidence intervals of BMI‐BMI. BMI, body mass index; CAD, coronary artery disease; SNP, single‐nucleotide polymorphism
To further investigate the performance of our proposed RBMR method, we consider the case that both the exposure and outcome are body mass index (BMI). We select SNPs based on previous research (Locke et al., 2015). The exposure is the BMI for physically active men and the outcome is the BMI for physically active women, both are of European ancestry (https://portals.broadinstitute.org/collaboration/giant/index.php/GIANT_consortium_data_files#2018_GIANT_and_UK_BioBank_Meta_Analysis_for_Public_Release). The point estimates and the corresponding 95% confidence intervals are shown in Figure 3b. We found that our proposed RBMR method has smaller bias than other competing methods. More numerical results are provided in the Supplementary Materials.
We apply our proposed RBMR method together with other competing methods to estimate the causal effect of CAD on the risk of critically ill coronavirus disease 2019 (COVID‐19) defined as those who end up on respiratory support or die from COVID‐19. Specifically, the selection data set is the Myocardial Infraction Genetics in the UK Biobank and the exposure data set is from Coronary Artery Disease (C4D) Genetics Consortium (2011). The outcome is obtained from Freeze 5 (January 2021) of the COVID‐19 Host Genetics Initiative (COVID‐19 HGI) Genome‐Wide Association Study (COVID‐19 Host Genetics Initiative, 2020) (https://www.covid19hg.org/results/). The data combines the genetic data of 49562 patients and two million controls from 46 studies across 19 countries (COVID‐19 Host Genetics Initiative, 2021). We mainly consider the GWAS data on the 6179 cases with critical illness due to COVID‐19 and 1483780 controls from the general populations in our analysis. We use the selection data with ‐value threshold to select genetic variants as IVs. As shown in Figure 4, we found a significant effect of CAD on the risk of critically ill COVID‐19 using our RBMR method ( , ‐value = 0.008, 95 CI = [0.067, 0.454]), MR‐LDP (, ‐value = 0.009, 95 CI = [0.065, 0.452]), GSMR (, ‐value = 0.045, 95 CI = [0.004, 0.398]), MR‐Egger (, ‐value = 0.036, 95% CI = [0.020, 0.605]) and IVW (, ‐value = 0.045, 95% CI = [0.005, 0.397]). However, the result of GSMR (, ‐value = 0.073, 95 CI = [−0.025, 0.561]) is not significant (‐value 0.05). Our RBMR is more accurate as its confidence interval is slightly shorter and its ‐value is more significant.
Figure 4.
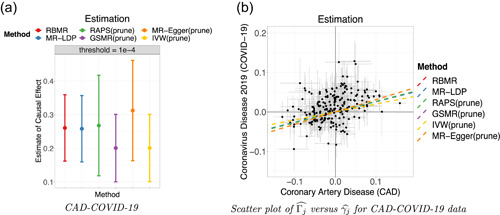
The results of CAD‐COVID‐19 using 1KGP as the reference panel with shrinkage parameter . The 220 SNPs are selected at the threshold (‐value ). Each point of the scatter plot is augmented by the standard errors of on the vertical and horizontal sides respectively. Dashed lines are the slopes fitted by the six methods. (a) point estimates and 95% confidence intervals, (b) scatter plot. CAD, coronary artery disease; SNP, single‐nucleotide polymorphism
We further apply our proposed RBMR and other competing methods to estimate the causal effect of LDL cholesterol on the risk of Alzheimer's disease. The selection data set is from Teslovich et al. (2010) with 95454 individuals, and the exposure data set is from Willer et al. (2013) with 188577 individuals. The outcome data set is obtained from the stage 1 meta‐analysis of four GWAS samples (n = 54,612) of the International Genomics of Alzheimer's Project (Lambert et al., 2013). We select the SNPs at the ‐value threshold . The results are summarized in Figure 5. We find that the causal effect of RBMR is (‐value = , 95 CI = [0.048, 0.196]), the estimate of MR‐LDP is (‐value = , 95 CI = [0.091, 0.374]) and the estimate of RAPS is (‐value = , 95 CI = [0.093, 0.212]). The estimates of IVW (, ‐value = , 95 CI = [0.520, 1.196]) and the MR‐Egger (, ‐value = , 95 CI = [0.871 2.072]) are much larger than the estimates of RBMR, MR‐LDP and RAPS. And the estimate of GSMR (, ‐value = 0.393, 95 CI = [−0.043 0.109]) is much smaller than the estimates of RBMR, MR‐LDP, and RAPS. Since there exists obvious idiosyncratic pleiotropy in this data set, hence the estimates of IVW, MR‐Egger and GSMR are likely to be biased. Both RAPS and MR‐LDP use the normal distribution to model the direct effects which might be violated in the presence of the idiosyncratic pleiotropy as in this data set, therefore the estimates of RAPS and MR‐LDP might have upward bias.
Figure 5.
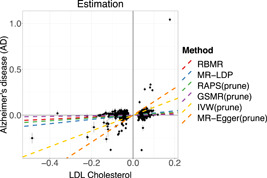
The results of LDL cholesterol on Alzheimer's disease using 1KGP as the reference panel with shrinkage parameter . The 292 SNPs are selected at the threshold (p‐value ). Each point of the scatter plot is augmented by the standard errors of and on the vertical and horizontal sides respectively. Dashed lines are the slopes fitted by the six methods. LDL, low‐density lipoprotein; SNP, single‐nucleotide polymorphism
5. DISCUSSION
In this paper, we propose a novel two‐sample robust MR method RBMR by accounting for the LD structure, systematic pleiotropy, and idiosyncratic pleiotropy simultaneously in a unified framework. Specifically, we propose to use the more robust multivariate generalized ‐distribution rather the less robust Gaussian distribution to model the direct effects of the IV on the outcome not mediated by the exposure. Moreover, the multivariate generalized ‐distribution can be reformulated as Gaussian scaled mixtures to facilitate the estimation of the model parameters using the parameter expanded variational Bayesian expectation‐maximum algorithm (PX‐VBEM). Through extensive simulations and analysis of two real benchmark data sets, we found that our method outperforms the other competing methods. We find that CAD might increase the risk of critically ill COVID‐19, and higher level of LDL cholesterol might increase the risk of Alzheimer's disease.
We make the following two major contributions. First, our method can account for the LD structure explicitly and thus can include more possibly correlated SNPs to reduce bias and increase estimation efficiency. Second, our RBMR method is more robust to the presence of idiosyncratic pleiotropy. This enhanced robustness can be very helpful in practice as shown by our simulation studies and real data analysis. One limitation of our proposed method is that it cannot handle correlated pleiotropy where the direct effect of the IV on the outcome might be correlated with the IV strength. We leave it as our future work.
Supporting information
Supplementary Information
ACKNOWLEDGMENTS
The authors also thank the editors and reviewers for their constructive comments. Dr. Zhonghua Liu's research is supported by the Start‐up research fund (000250348) of the University of Hong Kong, Guangdong Natural Science Fund (2021A1515010268), and Hong Kong Research Grants Council Early Career Scheme (27307920).
Wang, A. , Liu, W. , & Liu, Z. (2022). A two‐sample robust Bayesian Mendelian Randomization method accounting for linkage disequilibrium and idiosyncratic pleiotropy with applications to the COVID‐19 outcomes. Genetic Epidemiology, 46, 159–169. 10.1002/gepi.22445
REFERENCES
- Ala‐Luhtala, J. , & Piché, R. (2016). Gaussian scale mixture models for robust linear multivariate regression with missing data. Communications in Statistics‐Simulation and Computation, 45(3), 791–813. [Google Scholar]
- Arellano‐Valle, R. B. , & Bolfarine, H. (1995). On some characterizations of the t‐distribution. Statistics & Probability Letters, 25(1), 79–85. [Google Scholar]
- Beal, M. J. (2003). Variational algorithms for approximate Bayesian inference. University of London.
- Berisa, T. , & Pickrell, J. K. (2016). Approximately independent linkage disequilibrium blocks in human populations. Bioinformatics, 32(2), 283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blei, D. M. , Kucukelbir, A. , & McAuliffe, J. D. (2017). Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(528), 859–877. [Google Scholar]
- Bound, J. , Jaeger, D. A. , & Baker, R. M. (1995). Problems with instrumental variables estimation when the correlation between the instruments and the endogenous explanatory variable is weak. Journal of the American Statistical Association, 90(430), 443–450. [Google Scholar]
- Bowden, J. , Davey Smith, G. , & Burgess, S. (2015). Mendelian randomization with invalid instruments: Effect estimation and bias detection through Egger regression. International Journal of Epidemiology, 44(2), 512–525. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burgess, S. , Butterworth, A. , & Thompson, S. G. (2013). Mendelian randomization analysis with multiple genetic variants using summarized data. Genetic Epidemiology, 37(7), 658–665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng, Q. , Yang, Y. , Shi, X. , Yeung, K.‐F. , Yang, C. , Peng, H. , & Liu, J. (2020). MR‐LDP: A two‐sample Mendelian randomization for GWAS summary statistics accounting for linkage disequilibrium and horizontal pleiotropy. NAR Genomics and Bioinformatics, 2(2), lqaa028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Coronary Artery Disease (C4D) Genetics Consortium . (2011). A genome‐wide association study in Europeans and South Asians identifies five new loci for coronary artery disease. Nature Genetics, 43(4), 339. [DOI] [PubMed] [Google Scholar]
- COVID‐19 Host Genetics Initiative . (2020). The covid‐19 host genetics initiative, a global initiative to elucidate the role of host genetic factors in susceptibility and severity of the SARS‐COV‐2 virus pandemic. European Journal of Human Genetics, 28(6), 715. [DOI] [PMC free article] [PubMed] [Google Scholar]
- COVID‐19 Host Genetics Initiative . (2021). Mapping the human genetic architecture of covid‐19 by worldwide meta‐analysis. MedRxiv.
- Dai, M. , Ming, J. , Cai, M. , Liu, J. , Yang, C. , Wan, X. , & Xu, Z. (2017). IGESS: A statistical approach to integrating individual‐level genotype data and summary statistics in genome‐wide association studies. Bioinformatics, 33(18), 2882–2889. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dempster, A. P. , Laird, N. M. , & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1), 1–22. [Google Scholar]
- Ebrahim, S. , & Smith, G. D. (2008). Mendelian randomization: Can genetic epidemiology help redress the failures of observational epidemiology? Human Genetics, 123(1), 15–33. [DOI] [PubMed] [Google Scholar]
- Ehret, G. B. , Munroe, P. B. , Rice, K. M. , Bochud, M. , Johnson, A. D. , Chasman, D. I. , Smith, A. V. , Tobin, M. D. , Verwoert, G. C. , Hwang, S. J. , Pihur, V. , Vollenweider, P. , O'Reilly, P. F. , Amin, N. , Bragg‐Gresham, J. L. , Teumer, A. , Glazer, N. , Launer, J. , Zhao, J. H. , … Johnson, T (2011). Genetic variants in novel pathways influence blood pressure and cardiovascular disease risk. Nature, 478(7367), 103–109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Evans, D. M. , Brion, M. J. A. , Paternoster, L. , Kemp, J. P. , McMahon, G. , Munafò, M. , Whitfield, J. B. , Medland, S. E. , Montgomery, G. W. , Timpson, N. J. , St. Pourcain, B. , Lawlor, D. A. , Martin, N. G. , Dehghan, A. , Hirschhorn, J. , & Smith, G. D. (2013). Mining the human phenome using allelic scores that index biological intermediates. PLoS Genetics, 9(10):e1003919. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Evans, D. M. , & DaveySmith, G. (2015). Mendelian randomization: New applications in the coming age of hypothesis‐free causality. Annual Review of Genomics and Human Genetics, 16, 327–350. [DOI] [PubMed] [Google Scholar]
- Frahm, G. (2004). Generalized elliptical distributions: Theory and applications (PhD thesis). Universitätsbibliothek.
- Hansen, C. , Hausman, J. , & Newey, W. (2008). Estimation with many instrumental variables. Journal of Business & Economic Statistics, 26(4), 398–422. [Google Scholar]
- Hemani, G. , Zheng, J. , Wade, K. H. , Laurin, C. , Elsworth, B. , Burgess, S. , Bowden, J. , Langdon, R. , Tan, V. , Yarmolinsky, J. , Shihab, H. A. , Timpson, N. J. , Evans, D. M. , Relton, C. , Martin, R. M. , Smith, G. D. , Gaunt, T. R. , & Haycock, P. C. (2016). MR‐Base: A platform for systematic causal inference across the phenome using billions of genetic associations. BioRxiv, 078972. [Google Scholar]
- Kotz, S. , & Nadarajah, S. (2004). Multivariate T‐distributions and their applications. Cambridge University Press. [Google Scholar]
- Lambert, J. C. , Ibrahim‐Verbaas, C. A. , Harold, D. , Naj, A. C. , Sims, R. , Bellenguez, C. , DeStafano, A. L. , Bis, J. C. , Beecham, G. W. , Grenier‐oley, B. , Russo, G. , Thorton‐Wells, T. A. , Jones, N. , Smith, A. V. , Chouraki, V. , Thomas, C. , Ikram, M. A. , Zelenika, D. , Vardarajan, B. N. , … Amouyel, P. (2013). Meta‐analysis of 74,046 individuals identifies 11 new susceptibility loci for Alzheimer's disease. Nature Genetics, 45(12), 1452–1458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lawlor, D. A. , Harbord, R. M. , Sterne, J. A. , Timpson, N. , & DaveySmith, G. (2008). Mendelian randomization: Using genes as instruments for making causal inferences in epidemiology. Statistics in Medicine, 27(8), 1133–1163. [DOI] [PubMed] [Google Scholar]
- Liu, C. , Rubin, D. B. , & Wu, Y. N. (1998). Parameter expansion to accelerate EM: The PX‐EM algorithm. Biometrika, 85(4), 755–770. [Google Scholar]
- Locke, A. E. , Kahali, B. , Berndt, S. I. , Justice, A. E. , Pers, T. H. , Day, F. R. , Powell, C. , Vedantam, S. , Buchkovich, M. L. , Yang, J. , Croteau‐Chonka, D. C. , Esko, T. , Fall, T. , Ferreira, T. , Gustafsson, S. , Kutalik, Z. , Luan, J. , Mägi, R. , Randall, J. C. … Speliotes, E. K. (2015). Genetic studies of body mass index yield new insights for obesity biology. Nature, 518(7538), 197–206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacArthur, J. , Bowler, E. , Cerezo, M. , Gil, L. , Hall, P. , Hastings, E. , Junkins, H. , McMahon, A. , Milano, A. , Morales, J. , Pendlington, Z. M. , Welter, D. , Burdett, T. , Hindorff, L. , Flicek, P. , Cunningham, F. , & Parkinson, H. (2017). The new NHGRI‐EBI Catalog of published genome‐wide association studies (GWAS catalog). Nucleic Acids Research, 45(D1), D896–D901. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martens, E. P. , Pestman, W. R. , de Boer, A. , Belitser, S. V. , & Klungel, O. H. (2006). Instrumental variables: Application and limitations. Epidemiology, 17, 260–267. [DOI] [PubMed] [Google Scholar]
- Pickrell, J. K. , Berisa, T. , Liu, J. Z. , Ségurel, L. , Tung, J. Y. , & Hinds, D. A. (2016). Detection and interpretation of shared genetic influences on 42 human traits. Nature Genetics, 48(7), 709. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Purcell, S. , Neale, B. , Todd‐Brown, K. , Thomas, L. , Ferreira, M. A. , Bender, D. , Maller, J. , Sklar, P. , De Bakker, P. I. , Daly, M. J. , & Sham, P. C. (2007). PLINK: A tool set for whole‐genome association and population‐based linkage analyses. The American Journal of Human Genetics, 81(3), 559–575. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rothman, A. J. (2012). Positive definite estimators of large covariance matrices. Biometrika, 99(3), 733–740. [Google Scholar]
- Schunkert, H. , König, I. R. , Kathiresan, S. , Reilly, M. P. , Assimes, T. L. , Holm, H. , Preuss, M. , Stewart, A. F. , Barbalic, M. , Gieger, C. , Absher, D. , Aherrahrou, Z. , Allayee, H. , Altshuler, D. , Anand, S. S. , Andersen, K. , Anderson, J. L. , Ardissino, D. , Ball, S. G. , … Samani, N. J. (2011). Large‐scale association analysis identifies 13 new susceptibility loci for coronary artery disease. Nature Genetics, 43(4), 333–338. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Solovieff, N. , Cotsapas, C. , Lee, P. H. , Purcell, S. M. , & Smoller, J. W. (2013). Pleiotropy in complex traits: Challenges and strategies. Nature Reviews Genetics, 14(7), 483–495. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Teslovich, T. M. , Musunuru, K. , Smith, A. V. , Edmondson, A. C. , Stylianou, I. M. , Koseki, M. , Pirruccello, J. P. , Ripatti, S. , Chasman, D. I. , Willer, C. J. , Johansen, C. T. , Fouchier, S. W. , Isaacs, A. , Peloso, G. M. , Barbalic, M. , Ricketts, S. L. , Bis, J. C. , Aulchenko, Y. S. , Thorleifsson, G. , … Kathiresan, S. (2010). Biological, clinical and population relevance of 95 loci for blood lipids. Nature, 466(7307), 707–713. [DOI] [PMC free article] [PubMed] [Google Scholar]
- The 1000 Genomes Project Consortium . (2012). An integrated map of genetic variation from 1,092 human genomes. Nature, 491(7422), 56. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van der Vaart, A. W. (2000). Asymptotic statistics (Vol. 3). Cambridge University Press. [Google Scholar]
- Verbanck, M. , Chen, C.‐Y. , Neale, B. , & Do, R. (2018). Detection of widespread horizontal pleiotropy in causal relationships inferred from Mendelian randomization between complex traits and diseases. Nature Genetics, 50(5), 693–698. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang, B. , & Titterington, D. (2005). Inadequacy of interval estimates corresponding to variational Bayesian approximations. In AISTATS. Citeseer.
- Willer, C. J. , Schmidt, E. M. , Sengupta, S. , Peloso, G. M. , Gustafsson, S. , Kanoni, S. , Ganna, A. , Chen, J. , Buchkovich, M. L. , Mora, S. , Beckmann, J. S. , Bragg‐Gresham, J. L. , Chang, H. Y. , Demirkan, A. , Den Hertog, H. M. , Do, R. , Donnelly, L. A. , Ehret, G. B. , Esko, T. , … Abecasis, G. R (2013). Discovery and refinement of loci associated with lipid levels. Nature Genetics, 45(11), 1274–1283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang, Y. , Dai, M. , Huang, J. , Lin, X. , Yang, C. , Chen, M. , & Liu, J. (2018). LPG: A four‐group probabilistic approach to leveraging pleiotropy in genome‐wide association studies. BMC Genomics, 19(1), 503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang, Y. , Shi, X. , Jiao, Y. , Huang, J. , Chen, M. , Zhou, X. , Sun, L. , Lin, X. , Yang, C. , & Liu, J. (2020). CoMM‐S2: A collaborative mixed model using summary statistics in transcriptome‐wide association studies. Bioinformatics, 36(7), 2009–2016. [DOI] [PubMed] [Google Scholar]
- Zhao, J. , Ming, J. , Hu, X. , Chen, G. , Liu, J. , & Yang, C. (2020). Bayesian weighted Mendelian randomization for causal inference based on summary statistics. Bioinformatics, 36(5), 1501–1508. [DOI] [PubMed] [Google Scholar]
- Zhao, Q. , Wang, J. , Hemani, G. , Bowden, J. , & Small, D. S. (2020). Statistical inference in two‐sample summary‐data Mendelian randomization using robust adjusted profile score. Annals of Statistics, 48(3), 1742–1769. [Google Scholar]
- Zhu, X. , & Stephens, M. (2017). Bayesian large‐scale multiple regression with summary statistics from genome‐wide association studies. The Annals of Applied Statistics, 11(3), 1561. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu, Z. , Zheng, Z. , Zhang, F. , Wu, Y. , Trzaskowski, M. , Maier, R. , Robinson, M. R. , McGrath, J. J. , Visscher, P. M. , Wray, N. R , & Yang, J. (2018). Causal associations between risk factors and common diseases inferred from GWAS summary data. Nature Communications, 9(1), 224. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Information