

Abstract
The applications of Normal distribution in literature are verse, the new modified univariate normal power distribution is a new distribution which is adequate for modelling bimodal data. There are many data that would have been modelled by normal distribution, but because of their bimodality, they are not, since normal distribution is unimodal. In this paper, a new extension of the normal linear model called the normal-Power generalized linear model, derived from the T-PowerLogistic framework is presented. The statistical properties of the distribution and the proposed model were derived such as quantiles, median, mode, robust skewness, robust kurtosis and moment. The maximum likelihood estimation method was considered to obtain the unknown model parameters. Three real data sets were analyzed to demonstrate the flexibility and usefulness of the proposed model. The new model would be very useful as alternative in cases where skewed or bimodal response variables, which are not well fitted with normal linear model.
Keywords: Bimodal, Exponential family, Generalized linear model, Normal-powerlogistic, Quantile function
Introduction
In probability and statistics, the power function and normal distributions are very useful in their individual applications. Not many authors have thought it to combine these two distributions. The normal distribution does not have a shape parameter, but power function has; while power function does not have a location parameter but normal has. Both are flexible, so combining them will produce a more flexible distribution. The power function distribution is the inverse of Pareto distribution (Dallas 1976). The power function distribution is a special model that can be formed or related to the uniform, Weibull, Kumaraswamy distributions. The power function distribution is considered one of the simplest and handy lifetime distributions.
Meniconi and Barry (1996) proposed the two-parameter power function distribution as a simple alternative to the exponential distribution when it comes to modelling failure data related to mortality rate and component failures. It is a special case of the beta distribution and one may sight the importance of the distribution in statistical tests such as the likelihood ratio test. The normal distribution on the other hand has been combined with other distribution to form a more flexible distribution, such as exponentiated-Normal (Gupta et al. 1998), Beta-Normal distribution (Eugene and Lee 2002), Gamma-Normal (GN) distribution (Zografos and Balakrishnan 2009), Kumaraswamy-Normal distribution (Cordeiro and de Castro 2011). Estimation of the power function parameters has been done by various authors, such as Zaka and Akhter (2013) .
Many classical distributions have been extensively used for modelling real data in many areas. However, in many situations; there is a clear need for extended forms of these distributions to improve the flexibility and goodness of fit of these distributions. For that reason, families of continuous distributions are developed by introducing one or more additional shape parameter(s) to the baseline distribution or by combining two or more distributions to produce new ones. Akarawak et al. (2013) described such new distributions as convoluted distributions. Some authors in recent years have developed frameworks used in combining these distributions to form new ones. A good example is the T-RY framework (Aljarrah et al. 2014). Since then, a lot of authors have been using it to develop flexible life time distributions that are hazard weighted functions of the baseline distributions. Weibull-Normal distribution (Alzaatreh et al. 2014) was one of the first normal distribution combined with other distribution using the T-RY framework. The Weibull power function distribution (Tahir et al. 2016) has a combination of power function and weibull distribution, using weibull distribution as a baseline distribution.
Among the authors that used the T-RY framework in 2016 includes (Alzaatreh et al. 2016) and Almagambetova et al. (2016). Okorie et al. (2017) proposed the modified power function distribution. Famoye et al. (2018) developed the Weibull-Normallog-logistics distribution with the normal distribution as the baseline. Zubair et al. (2018) also used the framework to develop a new convoluted distribution. Other convoluted distributions developed using the framework include the reduced beta skewed laplace distribution (Arowolo et al. 2019); Odd Lomax-exponentiallog-logistic distribution (Ogunsanya et al. 2019); exponentiated-exponential-DagumLomax distribution (Ekum et al. 2020a); Lomax-Cauchyuniform (Amalare et al. 2020); and Rayleigh-Cauchyuniform (Ogunsanya et al. 2021).
The simplicity and usefulness of the power function distribution compelled the researchers to explore its further extensions, generalizations, and applications in different areas of science (Arshad et al. 2020; Ekum et al. 2020b). Recently, Gamma-Powerlog-logistic distribution was proposed by Ekum et al. (2021) and demonstrated its usefulness in modelling skewed data. None of these study have combined normal and power function distribution, especially making power function distribution a baseline, except the normal-powerlogistic distribution (NPLD) proposed in the work of Ekum et al. (2021). More so, many properties of the NPLD has not been defined and studied, and it has not been developed into a generalized linear model for predicting relationship in regression applications.
Predicting oil spillage is of a major interest to researchers in the field of Geo-science and geological statistics. In Nigeria, oil spillage is a major problem that have devastated the ecosystem and biodiversity of the Niger Delta region in Nigeria. The quantity of oil spilled may be estimated using the estimated spilled volume. The estimated spill volume of crude oil may be determined by the duration of clean-up (Whanda et al. 2016; Deinkuro et al. 2021). Also, researchers may want to know if they can predict their researchgate score using their citations and research items. These are emerging issues of interest to researchers, especially the ones in academics (Jordan (2015); O’Brien (2019)). More so, the COVID-19 mortality rate per population and the linear effect on the economic wellbeing of Nigerians is also worth to study. This is because, the GDP per capita can be affected by COVID-19 mortality. The COVID-19 factor is also an extra burden to the wellbeing of the people (Pak et al. (2020); Iluno et al. (2021)).
In literature, there are some modifications of the normal distribution, which produced multimodality (Kundu 2017), which has multiple modes with less number of parameters. The modification of the normal distribution developed by Kundu (2017) is a bivariate family of distributions, why the one developed here is a univariate family. More so, Kundu (2017) did not extend their distribution to generalized linear model. The motivation of this work is based on the modelling of independent variables in regression modelling that have bimodal features. Other authors such as Famoye et al. (2018), Kundu (2017), etc, had developed distributions that are bimodal but none has extended it to regression modelling. More so, real life problems like the crude oil spill volume, number of citations in research gate, GDP per Capita, etc are real variables which maximum values can be estimated, so they are bounded below by zero (non negative) and above by a real value, rather than infinity. Thus, a distribution with bounded support is necessary [0, ], where is a real upper bound (Ekum et al. 2020b).
Thus, in this study, the aim is to adopt a novel univariate continuous probability distribution called the normal-power-logistics distribution NPLD, which was derived from the T-Powerlogistic family proposed and studied by Ekum et al. (2021) and extends it into generalized linear model in order to solve real regression problems, where the dependent variables are bimodal and skewed with a known maximum value. The model has four parameters, two from the normal distribution and the other two from the power function distribution, which one of it is a shape parameter and the other is an upper bound parameter to control the extremes of the distribution. The scope covers different characterizations, properties, regression model, and parameter estimation of the NPLD model. The method of Maximum Likelihood Estimation (MLE) was used to estimate the model parameters. The importance of the new model was proved empirically using three real-life datasets. The proposed model would be very useful in engineering, medicine, and all fileds of life, where the dependent variable of interest to be predicted has bimodal features. It is expected to perform well when normal distribution fails to fit the data of interest.
Materials and Methods
In this section, the theory and application of the proposed scheme are considered.
The Method of Generating the T-RY Family of Distributions
The method of generating T-RY family of distributions is considered. The T-RY is a general approach for defining the W[F(x)] (a non-decreasing differentiable function) using the quantile function of a random variable Y in the T-X framework. Let T, R and Y be three random variables with cdf , and respectively, with corresponding pdf, , and . Also, , and are their corresponding quantile functions. It is assumed that T is supported on the interval (a, b) and Y is supported on the interval (c, d) such that and are real numbers.
Important Operational Definition of Terms
The following definitions will be very useful in characterising the proposed model.
Definition 1
The cdf of T-logistic family of distributions proposed by Ekum et al. (2021) is given by
| 1 |
Definition 2
: The pdf of the T-logistic family is derived by taking the first derivative of with respect to x and it is given by
| 2 |
Definition 3
: The survival function of the distribution from T-logistic family is given by
| 3 |
Definition 4
: The hazard function of the distribution from T-logistic family is given by
| 4 |
Definition 5
: The cumulative hazard function of the distribution from T-logistic family is given by
| 5 |
Definition 6
: The reverse hazard function of the distribution from T-logistic family is given by
| 6 |
Definition 7
: The quantile function of T-logistic family is the inverse function of its cdf and it is given by
| 7 |
where . The quantile function is used in Monte Carlo method to simulate random variates of a distribution, and it is used to determine measures of partition. Several ways of quantile approximation when it is not in closed form are available in literature, of which quantile mechanics is one of such approach (Akagbue et al. 2017).
Definition 8
: The T-logistic family of distributions is derived from T-RY family proposed by Aljarrah et al. (2014) and Alzaatreh et al. (2014). The relationship among T, R, and Y are given thus: (i) in distribution, (ii) , (iii) if in distribution, then in distribution, and (iv) if in distribution, then in distribution.
Definition 9
: Let R be a non-negative random variable with pdf , and let denote the moment of R, then
where is the moment of the random variable, X; [] is the survival function of the random variable Y, and T is the quantile values random variable T with respect to .
Normal-Power function logistic Model
The proposed model is a generalized linear model that takes the form
where is the link function, and the right hand side is the linear predictor. Six goodness-of-fit criteria are used to compare the flexibility of the proposed model with other known models. The goodness-of-fit criteria are log-likelihood (LogL), Akaike Information Criterion (AIC), Kolmogorov-Smirnov statistic (D), Anderson-Darling statistic (A), Cramer-von Mises statistic () and Chi-square statistic (). See (Chen and Balakrishnan 1995) for detailed information on A and . The lower the value of the criteria, the better the performance of the model. Also, to show the relationship between the observed dependent variable y and the predicted dependent variable , the coefficient of correlation is used. This shows the model that performs well if the correlation coefficient is high. It is assumed that the dependent variable y has a normal-power distribution.
Cumulative Distribution and Probability Density Functions of NPLD
Recall the cdf of T- defined by Ekum et al. (2021) given in Definition (1) as
where is the cdf random variable T. So, T can follow any known distribution.
If T follows a normal distribution with parameters and , then the pdf of T is given by
and the cdf of T is given by
Therefore
So, put the value of t into to have
So, put the value of t into to have
| 8 |
where error function, erf(.) is given by
Equation (8) is the cdf of Normal-Power function logistic distribution (NPLD)
The corresponding pdf of NPLD is given by taking the first derivative of with respect to x and it is given by
| 9 |
where is a location parameter, k is a shape parameter, is a scale parameter, and doubles as a scale and upper bound parameter. A random variable X follows a NPLD if it can be defined as .
Figure 1 is the pdf plot of NPLD, which shows that NPLD can be bimodal for some parameters values, skewed and kurtosis .
Fig. 1.
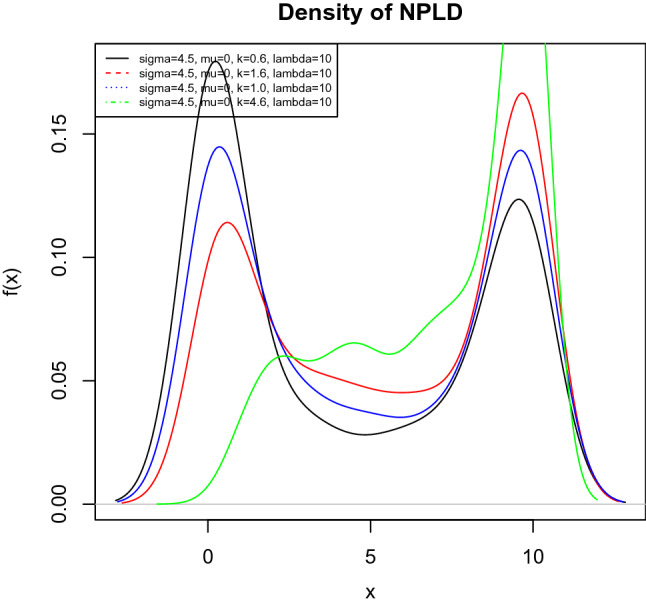
Probability Density Function with different parameters values showing bimodal features
Useful Transformation
Lemma 2.1
If , a random variable follows a normal distribution with parameters and , then the pdf of W is given by
Proof
Recall the pdf of NPLD in (9)
We want to show that random variable W follows a normal distribution with parameters and .
| 10 |
By change of variable, let
| 11 |
Differentiating w with respect to x, and making dx the subject of the equation gives
| 12 |
Now, changing the support from x to that of w, we have
| 13 |
It follows from inverse transformation and we have
| 14 |
is the pdf of normal distribution with parameters and . Equation (14) completes the proof.
From Lemma 2.1, it shows that the pdf of NPLD with parameters is a proper pdf. No further proof is needed.
Survival and Related Functions of NPLD
The survival function of NPLD is given by
| 15 |
The hazard function of NPLD is given by
| 16 |
The cumulative hazard function of NPLD is given by
| 17 |
The reverse hazard function of NPLD is given by
| 18 |
Quantile Function and Measures of Partition of NPLD
Quantile Function
Theorem 2.2
Let X be a random variable that follows NPLD with cdf , then the inverse function of the cdf, which is the quantile function exist, and it is given by
Proof
Recall the cdf of NPLD given by
Since is a probability value, letting gives
| 19 |
Solving for x gives
| 20 |
Equation (20) is the inverse function of the cdf of X, and it can be written as
| 21 |
where is the quantile function of NPLD; is the inverse function of the cdf of standard normal distribution, and p is a probability value uniformly generated, that is, . Thus, Equation (21) completes the proof.
Measures of Partition
The quantile function can be used to derive all the measures of partition, such as, median, quartile, octile, decile and percentile.
The median of NPLD is
| 22 |
But , so that
| 23 |
The 1st quartile of NPLD, which is the same as the 25th percentile is given by
| 24 |
But , so that
| 25 |
The 3rd quartile of NPLD, which is the same as the 75th percentile is given by
| 26 |
But , so that
| 27 |
Skewness and Kurtosis of NPLD
Robust Measure of Skewness
By definition, the robust coefficient of skewness based on quantiles proposed by Bowley (1920) is given by
| 28 |
where is the ith quartile.
Theorem 2.3
Let X be a random variable that follows NPLD with quantile function , then the skewness is robust, because it is a resistance measure, which is not affected by extreme value, .
Proof
Recall the median, 1st quartiles () and 3rd quartile () of NPLD given by
and
respectively.
Substituting the values of , and into (28) gives
| 29 |
Factorising out gives
| 30 |
Equation (30) completes the proof, showing that it is free of .
Robust Measure of Kurtosis
Be definition, the robust coefficient of kurtosis based on quantiles proposed by Moors (1988) is given by
| 31 |
where is the ith octile.
Theorem 2.4
Let X be a random variable that follows NPLD with quantile function , then the kurtosis is robust, because it is a resistance measure, which is not affected by extreme value, .
Proof
Recall the quantile function of NPLD given by
The 1st octile () is derived thus
| 32 |
The 2nd octile () is derived thus
| 33 |
The 3rd octile () is derived thus
| 34 |
The 5th octile () is derived thus
| 35 |
The 6th octile () is derived thus
| 36 |
The 7th octile () is derived thus
| 37 |
Substituting the values of , , , , and into (31) gives
| 38 |
where ; ; ;
Factorising out gives
| 39 |
Equation (39) completes the proof, showing that it is free of .
Mode of NPLD
Theorem 2.5
Let X be a random variable that follows NPLD with pdf , a differentiable function, then the mode is not unique and possibly bimodal for some parameter values.
Proof
Recall the pdf of NPLD given by
The mode can be derived by differentiating the pdf, equate to zero, and solve for x.
Using product rule
| 40 |
Let
| 41 |
and
| 42 |
Differentiating u with respect to x gives
| 43 |
Differentiating v with respect to x gives
| 44 |
Inserting (41), (42), (43) and (44) into (40) and equating to zero gives
| 45 |
The solution to (45) is the mode of NPLD.
Now, assume that and , (45) becomes
| 46 |
It is obvious from (46) that the mode of NPLD is not unique and it is possibly bimodal. The value of the shape parameter determines if it is bimodal or multi-modal. If k = 1, it is bimodal, if k = 2, it will have 3 peaks, if k = 3, it will have 4 peaks. However, some of these peaks might not be visible or obvious graphically because there can be repeated roots of the polynomial equation. The resulting equation for the mode is a polynomial of order k+1 as shown in equation (45).
Series Expansion of NPLD
Theorem 2.6
Let X be a random variable that follows NPLD with parameters , the pdf of X, , is a weighted pdf of power function distribution with parameters k and , that is,
| 47 |
where is the pdf of power function distribution, and is the weight.
Proof
Recall the pdf of NPLD given in (9). Given the following series expansions
| 48 |
| 49 |
| 50 |
| 51 |
| 52 |
| 53 |
| 54 |
| 55 |
| 56 |
Inserting (48–56) into the pdf of NPLD in (9) gives
| 57 |
Equation (57) is the series expansion form of NPLD pdf.
Now, let
| 58 |
If , then
| 59 |
where is the pdf of power function distribution. Hence, Equation (59) completes the proof.
Moment of NPLD
Let X be a continuous random variable with pdf , the rth moment is given by
| 60 |
Recall the series expansion form of NPLD pdf given as
Inserting into Equation (60) gives
| 61 |
Note that
| 62 |
So that
| 63 |
Let
| 64 |
So that
| 65 |
Equation (65) is the rth moment of GPLD.
Mean of NPLD
If , then (65) becomes
| 66 |
Note that if , then Equation (66) becomes
| 67 |
Maximum Likelihood Estimation (MLE) of NPLD
The likelihood function of NPLD is given by
Taking the log gives
| 68 |
The maximum likelihood estimation parameters of the NPLD are given by differentiating partially with respect to , and k and equating the results to zero and solve for each parameter.
| 69 |
| 70 |
| 71 |
Equating (69) to zero gives
| 72 |
Equating (70) to zero gives
| 73 |
Equating (71) to zero gives
| 74 |
The equations obtained by setting the partial derivatives with respect to k to zero is not in closed form and the values of the parameter k is found using Newton’s numerical procedure provided by R package (R Development Core Team 2009). The parameter cannot be estimated using the MLE method because it depends on X, thus, is estimated from from data using
| 75 |
where is a very small positive number less than 1 chosen by the user.
It should be noted that the maximum likelihood estimators of the parameters and are in close form and will always exist provided the values of parameters k and are known. The value of parameter cannot be determined by the maximum likelihood estimation method because it is an upper bound, so it can be estimated by equation (75) from the data. Parameter k is not in closed form and a numerical optimization method is used to estimate it. We find the initial value of k used in the numerical optimization by first assuming that the random sample is from power function distribution. We estimate the initial value of k from power function distribution. The moment estimate of parameter k is given by , where is the sample mean (Ekum et al. 2020b), estimated from data.
Numerical Optimization of Parameter k
In a case where the parameter estimated using Newton approximation is not optimal, a new relationship is derived by EM algorithm.
Let
| 76 |
where is the parameter space of NPLD, so that we have
| 77 |
Recall the pdfs of normal distribution and NPLD as
and
respectively.
Substituting the pdfs of normal distribution and NPLD into Equation (77) gives
| 78 |
where , and are known, such that, , , and , where and S are the sample mean and sample standard deviation of . Note that . Note is the initial value of k assumed as suggested, that is, . So that is the new estimate of k and it is optimal.
Now that optimal value of k is known, then we can estimate the values of and using equations (72) and (73) respectively.
Error Bound and Confidence Interval for NPLD
The error bound for estimating a generic parameter of NPLD is given by
| 79 |
where is the level of significance, is the parameter to be estimated, is the standard quantile function of NPLD with , and is the standard error of , that is, the square root of the variance of .
The standard quantile function of NPLD is derived when and from the quantile function of NPLD and it is given by
| 80 |
where is the standard quantile function of NPLD, is the inverse function of the cdf of standard normal distribution known as the quantile function, and p is a probability value uniformly generated. Note that is a regulator parameter in this case. Its value is adjusted to determine how large the error bound should be. In this research, is taken as 2 to accommodate the population parameter. So, the level of significance, and are always chosen. The values of can be 1, 2 or 3 depending on how large you want the error bound to be.
Thus, the confidence interval for parameter is given by
| 81 |
where is the point estimate of .
Simulation Study of NPLD
The simulation study is presented to show the performances of the maximum likelihood estimators and their consistency. The procedure used to perform the simulation studies involves, generating uniform distribution of n quantiles, p. The quantile function defined in equation (21) for NPLD was used to generate NPLD random variates for the sample sizes n = 50, 100, 200 and 300 replicated 1000 times. The parameters values are set as , , and and for a fixed . The actual values, mean estimates, standard errors, and 95% confidence interval are presented in Tables 1, 2 and 3. Tables 1, 2 and 3 show that the standard error decreases as the sample size increases, which implies that the MLEs are consistent.
Table 1.
Simulation Study showing Mean estimates, standard error, and confidence interval of the MLE for
| n | Parameters | Actual values | Mean | Standard error | Confidence interval |
|---|---|---|---|---|---|
| 50 | k | 0.5 | 0.5503 | 0.0503 | (0.4660, 0.6346) |
| 0.5 | 0.5005 | 0.1005 | (0.3320, 0.6690) | ||
| 0.5 | 0.5488 | 0.1488 | (0.2994, 0.7982) | ||
| 100 | k | 0.5 | 0.5323 | 0.0203 | (0.4983, 0.5663) |
| 0.5 | 0.5004 | 0.1001 | (0.3326, 0.6682) | ||
| 0.5 | 0.5286 | 0.1178 | (0.3311, 0.7261) | ||
| 200 | k | 0.5 | 0.5104 | 0.0102 | (0.4933, 0.5275) |
| 0.5 | 0.5002 | 0.0055 | (0.491, 0.5094) | ||
| 0.5 | 0.5078 | 0.0468 | (0.4293, 0.5863) | ||
| 300 | k | 0.5 | 0.5003 | 0.0100 | (0.4835, 0.5171) |
| 0.5 | 0.4998 | 0.0014 | (0.4975, 0.5021) | ||
| 0.5 | 0.5008 | 0.0088 | (0.486, 0.5156) |
Table 2.
Simulation Study showing Mean estimates, standard error, and confidence interval of the MLE for
| n | Parameters | Actual values | Mean | Standard error | Confidence interval |
|---|---|---|---|---|---|
| 50 | k | 1 | 1.0046 | 0.0158 | (0.9781, 1.0311) |
| 1 | 1.0019 | 0.0981 | (0.8374, 1.1664) | ||
| 1 | 1.4142 | 0.3144 | (0.8871, 1.9413) | ||
| 100 | k | 1 | 1.0053 | 0.0141 | (0.9817, 1.0289) |
| 1 | 1.0014 | 0.0942 | (0.8435, 1.1593) | ||
| 1 | 1.4018 | 0.2980 | (0.9022, 1.9014) | ||
| 200 | k | 1 | 1.0030 | 0.0032 | (0.9976, 1.0084) |
| 1 | 1.0012 | 0.0902 | (0.8500, 1.1524) | ||
| 1 | 1.3154 | 0.2100 | (0.9634, 1.6674) | ||
| 300 | k | 1 | 1.0028 | 0.0028 | (0.9981, 1.0075) |
| 1 | 1.0011 | 0.0682 | (0.8868 1.1154) | ||
| 1 | 1.4158 | 0.1158 | (1.2217, 1.6099) |
Table 3.
Simulation Study showing Mean estimates, standard error, and confidence interval of the MLE for
| n | Parameters | Actual values | Mean | Standard error | Confidence interval |
|---|---|---|---|---|---|
| 50 | k | 2 | 1.9986 | 0.1017 | (1.8281, 2.1691) |
| 2 | 2.0035 | 0.2965 | (1.5065, 2.5005) | ||
| 2 | 2.1415 | 0.4451 | (1.3953, 2.8877) | ||
| 100 | k | 2 | 1.9987 | 0.0325 | (1.9442, 2.0532) |
| 2 | 2.0031 | 0.0964 | (1.8415, 2.1647) | ||
| 2 | 2.0544 | 0.3547 | (1.4598, 2.6490) | ||
| 200 | k | 2 | 1.9992 | 0.0064 | 1.9885, 2.0099) |
| 2 | 2.0026 | 0.0163 | (1.9753, 2.0299) | ||
| 2 | 2.0066 | 0.0178 | (1.9768, 2.0364) | ||
| 300 | k | 2 | 2.0001 | 0.0060 | (1.9900, 2.0102) |
| 2 | 2.0011 | 0.0112 | (1.9823, 2.0199) | ||
| 2 | 2.0018 | 0.0129 | (1.9802, 2.0234) |
Generalized Linear Regression Model for NPLD (NPGLM)
Let assume that the dependent random variable Y of interest in our linear model follows a NPLD given independent variable(s) X. The linear regression model is called NPLD Generalized Linear Model (NPGLM).
Given the linear model in matrix form
| 82 |
where Y is a n-dimensional vector called the dependent vector for all observations n; X is the set of k independent variables packed into a () matrix called the design matrix; B is a ()-dimensional vector called the slope vector; e is the error term packed into a n-dimensional vector called the error vector.
Conditions for NPGLM
The conditions to use the GPGLM to fit the model are given thus:
Y must be continuous random variable
Y must be positive real number strictly greater than zero but strictly less than (upper bound for Y)
Y must follow NPLD
NPLD must be a member of the exponential family
Exponential Class of NPLD
An exponential family or class is a parametric set of probability distributions that has a certain form. This special form is chosen for mathematical convenience, based on some useful algebraic properties, as well as for generality (Akarawak et al. 2017). It is assumed that each component of Y follows a distribution in the exponential family of the form
| 83 |
where is a function of a known parameter only, is a function of a canonical parameter and is a function of y and only, and T(y) is a function of y, known as the sufficient statistics for Y.
Let assume that Y is a random variable that follows NPLD. Recall the pdf of the NPLD with parameters given by
where parameter is an upper bound. The pdf f(y) is not free from parameter (), and hence, might be difficult to express as a member of the exponential family.
However, a simple transformation can be done with the data that follows a NPLD to a normal distribution as proved in Lemma (2.1).
Recall the transformed pdf
| 84 |
Taking the log of (84) gives
| 85 |
Taking the exponential of (85) gives
| 86 |
Comparing (86) with (83) gives
, , , , , and ,
where w is a function of given by
Since (86) can be written in exponential class, we can directly derive the joint sufficient statistics from it. So, the joint sufficient statistics for and are w and respectively. Thus, w and can give all information concerning parameters and respectively.
Maximum Likelihood Estimation of the Parameters of NPLD Regression Model
The log-likelihood of the pdf of NPLD is
| 87 |
The link function is given by
| 88 |
So that
| 89 |
where , and . Note that p is the number of independent variables, and , k and are known parameters.
Then
| 90 |
The MLE parameter estimate for is in closed form and it is given by
| 91 |
where , is a matrix, so that is a matrix, W is an matrix, so that is a matrix. Thus, is a () matrix. Note that , where the value of lambda can be approximated from the data using nth order statistic or simply i, where is the standard error of y computed from the data. An approximation for k can also be derived from data using , where is the sample mean, derived from Ekum et al. (2020b).
Results
Application
In this section, applications to three real data sets were provided to illustrate the uses and importance of the NPLD. Three competing models are used to fit the two data of interest, they are NPLD, Normal are Gamma GLMs.
Application 1: Estimated Spill Volume (ESV) of Crude Oil in Nigeria
The data on the estimated spilled volume (ESV) is collected from 7th January 2011 to 27th December 2019, at Shell Nigeria webisite (www.shell.com.ng/sustainability/environment/oil-spills.html).
Figure 2 shows that the oil spill data is bimodal with positive skewness (1.1302) and kurtosis (3.3977).
Fig. 2.
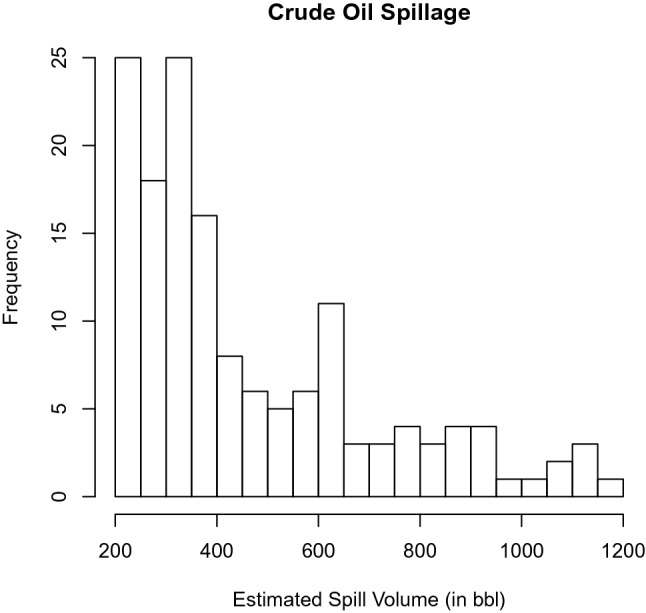
Histogram showing ESV of Crude Oil in Nigeria
Fitting the Models to Oil Spill Data
The estimated spill volume of crude oil can be determined by the Duration of Clean-up (DOC). If the duration of clean-up is known, the spill volume can be estimated from an appropriate model. Thus, the dependent variable is ESV and the independent variable is the DOC.
Table 4 shows the model parameters estimated, their standard errors and their corresponding P-values.
Table 4.
Generalised linear model parameter estimates for Oil Spill model
| Distribution | P-Value | P-Value | ||||
|---|---|---|---|---|---|---|
| NPLD | 1.463495 | 0.000920 | 0.000000 | 0.007670 | 0.000002 | 0.000000 |
| Normal | -87.909300 | 60.111900 | 0.147000 | 4.101300 | 0.807100 | 0.000002 |
| Gamma | 0.019900 | 0.004512 | 0.000029 | -0.000071 | 0.000016 | 0.000042 |
Table 5 shows that the NPLD regression model outperforms the other regression models using all the selection criteria.
Table 5.
Generalised linear model goodness-of-fit criteria for ESV model
| Distribution | AIC | D | A | |||
|---|---|---|---|---|---|---|
| NPLD | 93.97682 | 193.9536 | 0.2809 | 6.0198 | 3.4428 | 43.060 |
| Normal | 663.5405 | 1333.0810 | 0.4157 | 6.0410 | 4.0625 | 1558.443 |
| Gamma | 401.7506 | 809.5012 | 0.6966 | 10.6512 | 8.1603 | 370.830 |
Application 2: Total Research Gate Score
Total Research Gate (TRG) score data is a cross-sectional data collected from Research Gate page of 100 selected researchers in the field of Mathematical Science as of 15th May 2021. The data includes TRG score, Total Research Interest (TRI), Citations, Recommendations, Reads and Research Items (RI). The independent variables are citations and RI (Fig. 3).
Fig. 3.
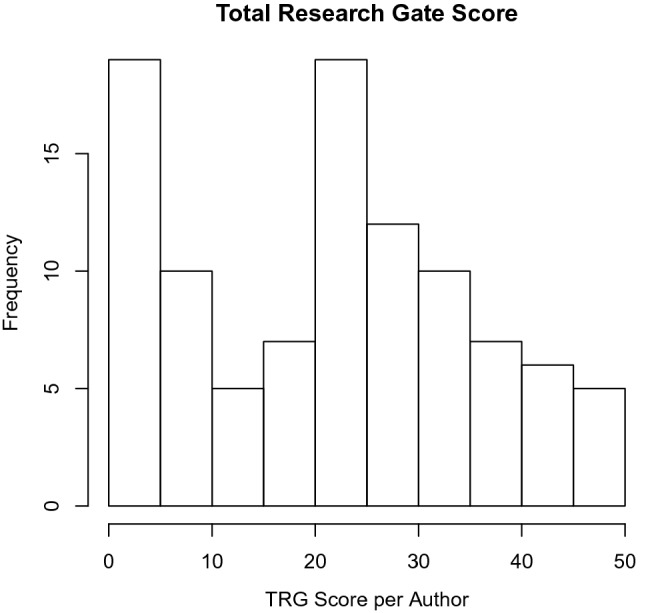
Histogram showing TRG Score of some selected researchers
Figure 3 shows that the TRG score data is bimodal with positive skewness of 0.1595 and kurtosis of 1.9747.
Fitting the Models to Research Gate Data
The TRG score can be predicted by Citations and Research Items. If citations and research items increased, the TRG score will also increase. Thus, the dependent variable is TRG score, while the independent variables are citations and research items.
Table 6 shows the model parameters estimated using MLE, their standard error and their corresponding P-values. The fitted NPLD regression model shows that the estimates and are significant at 5 level of error. This is also true for gamma and normal regression models.
Table 6.
Generalised linear model parameter estimates for TRG Score model
| Distribution | P-Value | P-Value | ||||
|---|---|---|---|---|---|---|
| NPLD | 0.00212 | 0.00000 | 0.00015 | 0.05554 | 0.00000 | 0.00000 |
| Normal | 0.00117 | 0.00036 | 0.00151 | 0.04910 | 0.00857 | 0.00000 |
| Gamma | -0.00002 | 0.00000 | 0.00022 | -0.00003 | 0.00000 | 0.00030 |
Table 7 shows that the NPLD regression model outperforms the other regression models using all the goodness-of-fit criteria.
Table 7.
Generalised linear model goodness-of-fit criteria for TRG Score model
| Distribution | AIC | D | A | |||
|---|---|---|---|---|---|---|
| NPLD | 280.5727 | 565.1455 | 0.2145 | 9.0244 | 1.5532 | 10.5850 |
| Normal | 379.0210 | 762.0421 | 0.2305 | 10.5501 | 1.9402 | 94.1980 |
| Gamma | 344.9956 | 693.9912 | 0.3247 | 17.9003 | 3.6227 | 58.6690 |
Application 3: Gross Domestics Product per Capita per COVID-19 Cases
The data used here are daily data collected from World Health Organisation (WHO) from 1st June 2020 to 31st December 2020, spanning 214 datasets, used by Iluno et al. (2021). The independent variable is a measure of COVID-19, termed COVID-19 Mortality per 1 million persons in the population (CMP), while the dependent variable is the GDP per capita per COVID-19 laboratory-confirmed cases (RGDPC). The CMP is a proxy to measure COVID-19 mortality, while RGDPC is a proxy to measure the economic wellbeing of a country.
Figure 4 shows that the RGDPC data has a positive skewness of 2.317554 and kurtosis of 7.896267. This data is highly skewed and very peaked (leptokurtic).
Fig. 4.

Histogram showing RGDPC of Nigeria
Fitting the Models to COVID-19 Data
The RGDPC can be predicted by the CMP. If COVID-19 Mortality per Population is high, it can affect the GDP per Capita of a country negatively. Thus, the dependent variable is RGDPC and the independent variable is the CMP. Four competing distributions are used to fit the GLM. The performance of the three competing models are presented in Table 8 to show the performance of the models when fitted to the RGDPC data (Table 9).
Table 8.
Generalised linear model parameter estimates for RGDPC model
| Distribution | P-Value | P-Value | ||||
|---|---|---|---|---|---|---|
| NPLD | 3.01647 | 0.00080 | 0.00000 | −0.53761 | 0.00058 | 0.00000 |
| Normal | 0.45155 | 0.00890 | 0.00000 | −0.06810 | 0.00184 | 0.00000 |
| Gamma | −1.92291 | 0.06327 | 0.00000 | 2.44210 | 0.02002 | 0.00000 |
Table 9.
Generalised linear model goodness-of-fit criteria for RGDPC model
| Distribution | D | χ2 | ||||
|---|---|---|---|---|---|---|
| NPLD | 280.5727 | 565.1455 | 0.2145 | 9.0244 | 1.5532 | 10.5850 |
| Normal | 379.0210 | 762.0421 | 0.2305 | 10.5501 | 1.9402 | 94.1980 |
| Gamma | 344.9956 | 693.9912 | 0.3247 | 17.9003 | 3.6227 | 58.6690 |
Table 8 shows the model parameters estimated, their standard errors and their corresponding P-values.
Table 9 shows that the NPLD regression modeloutperforms the other regression models using all the selection criteria.
Conclusions
This study developed a novel NPLD model, using the T-Powerlogistic family of distributions. The cdf, pdf, survival function, hazard rate, cumulative hazard function, reverse hazard function, useful transformation, quantile functions, mode, robust skewness, robust kurtosis, series expansion and moment are derived. The maximum likelihood estimation of the parameters of the distribution were derived and that of its generalized regression model. The NPLD regression model was applied to three real-life data namely, Estimated Spill Volume (ESV) of crude oil in Niger Delta area of Nigeria, Total Research Gate (TRG) score of some selected researchers in research gate and GDP per Capita per COVID-19 cases (RGDPC; and the results of its performance was compared favourably with normal and Gamma regression models.
The goodness of fit statistics showed that the NPLD regression model outperforms the other regression models using all the selection criteria. Also, the goodness of fit statistics also show that the NPLD regression model outperforms the other regression models using all the criteria for the TRG score model as well as the RGDPC model. Hence, NPLD regression model can be used effectively to analyze and model the crude oil spill volume data, TRG score data, RGDPC and other related data when normal is not good fit.
This research therefore recommends that
NPLD model should be used to estimate spill volume of crude oil, and total research gate score.
It is recommended that the convoluted distribution NPLD should be used when normal is not a good fit to emerging data of interest.
It is recommended based on the applications that clean-up of spilled oil should be carried out immediately and complete it at record time, because it can be used to estimate the spilled volume of crude oil.
It is also recommended that researchers should increase the research items they upload to research gate and write quality papers to increase their citations, in order to increase their total research gate score.
It is also recommended that COVID-19 mortality be reduced, by providing medical response to infected individuals, because, it can affect the economic well-being of the nation.
Acknowledgements
I am very grateful to my PhD supervisors Prof. Muminu Adamu, who is also the pioneer HOD, Department of Statistics, University of Lagos and Dr. Eno Akarawak for their supervisory role during my Ph.D. work. I appreciate Prof. Felix Famoye of Central Michigan University, United States for mentoring me during the beginning of this work in the University of Lagos and for the materials he gave me. I am also grateful to the reviewers for their appropriate and constructive suggestions to improve this work.
Funding
There is no funding for this research.
Declaration
Conflict of interest
The authors declare that they have no conflict of interest.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Akagbue HI, Adamu MO, Anake TA (2017) Solutions of chi-square quantile differential equation. In: Proceedings of the world congress on engineering and computer science, San Francisco, USA
- Akarawak EEE, Adeleke IA, Okafor RO (2013) The Weibull–Rayleigh distribution and its properties. J Eng Res 18(1):61–72 [Google Scholar]
- Akarawak EEE, Adeleke IA, Okafor RO (2017) The Gamma–Rayleigh distribution and applications to survival data. Nigerian J Basic Appl Sci 25(2):130–142 [Google Scholar]
- Aljarrah MA, Lee C, Famoye F (2014) On generating T-X family of distributions using quantile functions. J Stat Distrib Appl 1(2):1–17. 10.1890/13-1452.1 [Google Scholar]
- Almagambetova A, Zakiyeva N, Alzaatreh A, Pya N (2016) On logistic-normal distribution. Department of Mathematics, Nazarbayev University, Kazakhstan [Google Scholar]
- Alzaatreh A, Famoye F, Lee C (2014) The gamma-normal distribution: properties and application. Comput Stat Data Anal 69:67–80 [Google Scholar]
- Alzaatreh A, Lee C, Famoye F, Ghosh I (2016) The generalized Cauchy family of distributions with applications. J Stat Distrib Appl, vol 3, No. 12. 10.1186/s40488-016-0050-3
- Amalare AA, Ogunsanya AS, Ekum MI, Owolabi TO (2020) Lomax–CauchyUniform distribution: properties and application to exceedances of flood peaks of Wheaton River. Benin J Stat 3:128–141 [Google Scholar]
- Arowolo OT, Nurudeen TS, Akinyemi JA, Ogunsanya AS, Ekum MI (2019) Reduced beta skewed Laplace distribution with application to failure-time of electrical component data. Ann Stat Theory Appl (ASTA) 1:31–41 [Google Scholar]
- Arshad MA, Iqbal MZ, Ahmadm M (2020) Exponentiated power function distribution: properties and applications. J Stat Theory Appl 19(2):297–313 [Google Scholar]
- Chen G, Balakrishnan N (1995) A general purpose approximate goodness-of-fit test. J Qual Technol 27:154–161 [Google Scholar]
- Cordeiro GM, de Castro M (2011) A new family of generalized distributions. J Stat Comput Simul 81:883–898 [Google Scholar]
- Dallas AC (1976) Characterization of Pareto and power function distribution. Ann Math Stat 28:491–497 [Google Scholar]
- Deinkuro NS, Knapp CW, Raimi MO, Nanalok NH (2021) Oil Spills in the Niger Delta Region, Nigeria: Environmental Fate of Toxic Volatile Organics. Res Square. 10.21203/rs.3.rs-654453/v1
- Ekum MI, Adamu MO, Akarawak EEE (2020a) T-Dagum: A way of generalizing dagum distribution using Lomax quantile function. J Prob Stat. 10.1155/2020/1641207 [Google Scholar]
- Ekum MI, Adeleke IA, Akarawak EEE (2020b) Lambda upper bound distribution: some properties and applications. Benin J Stat 3:12–40 [Google Scholar]
- Ekum MI, Adamu MO, Akarawak EEE (2021) A class of power function distributions: its properties and applications. Unilag J Math Appl 1(1):35–59 [Google Scholar]
- Eugene N, Lee C (2002) Famoye F Beta-normal distribution and its applications. Commun Stat Theory Methods 31:497–512 [Google Scholar]
- Famoye F, Akarawak E, Ekum M (2018) Weibull-normal distribution and its applications. J Stat Theory Appl 17(4):719–727. 10.2991/jsta.2018.17.4.12 [Google Scholar]
- Gupta RC, Gupta PL, Gupta RD (1998) Modeling failure time data by Lehmann alternatives. Commun Stat Theory Methods 27:887–904 [Google Scholar]
- Iluno C, Taylor J, Akinmoladun O, Ekum Aderele OM (2021) Modelling the effect of Covid-19 mortality on the economy of Nigeria. Res Glob 3(2021):100050 [Google Scholar]
- Jordan K (2015) Exploring the ResearchGate score as an academic metric: reflections and implications for practice. In: Quantifying and Analysing Scholarly Communication on the Web (ASCW-15), Oxford
- Kundu D (2017). Multivariate geometric skew-normal distribution. Stat J Theor Appl Stat 51(6)
- Meniconi M, Barry DM (1996) The power function distribution: a useful and simple distribution to assess electrical component reliability. Micreoelectronics Reliab 36:1207–1212 [Google Scholar]
- O’Brien K (2019) ResearchGate. J Med Library Assoc JMLA 107(2):284–285. 10.5195/jmla.2019.643 [Google Scholar]
- Ogunsanya AS, Sanni OO, Yahya WB (2019) Exploring some properties of odd Lomax-exponential distribution. Ann Stat Theory Appl(ASTA) 1:21–30 [Google Scholar]
- Ogunsanya AS, Akarawak EEE, Ekum MI (2021) On some properties of Rayleigh–Cauchy distribution. J Stat Manage Syst. 10.1080/09720510.2020.1822499 [Google Scholar]
- Okorie IE, Akpanta AC, Ohakwe J, Chikezie DC (2017) The modified Power function distribution. Cogent Math 4:1319592. 10.1080/23311835.2017.1319592
- Pak A, Adegboye OA, Adekunle AI, Rahman KM, McBryde ES, Eisen DP (2020) Economic consequences of the COVID-19 outbreak: the need for epidemic preparedness. Front Public Health 8. 10.3389/fpubh.2020.00241 [DOI] [PMC free article] [PubMed]
- Tahir MH, Alizadeh M, Mansoor M, Cordeiro GM, Zubair M (2016) The Weibull-power function distribution with applications. Hacettepe J Math Stat 45(1):245–265 [Google Scholar]
- Whanda S, Adekola O, Adamu B, Yahaya S, Pandey P (2016) Geo-spatial analysis of oil spill distribution and susceptibility in the Niger Delta Region of Nigeria. J Geogr Inf Syst 8:438–456. 10.4236/jgis.2016.84037 [Google Scholar]
- Zaka A, Akhter AS (2013) Methods for estimating the parameters of power function distribution. Pak J Stat Oper Res 9:213–224 [Google Scholar]
- Zografos K, Balakrishnan N (2009) On families of beta and generalized gamma-generated distributions and associated inference. Stat Methodol 6:344–362 [Google Scholar]
- Zubair M, Alzaatreh A, Cordeiro GM, Tahir MH, Mansoor M (2018) On generalized classes of exponential distribution using T-X family framework. Filomat 32(4):1259–1272 [Google Scholar]