

Abstract
This paper introduces exact permutation methods for use when there are independent clusters of data with arbitrary within-cluster correlation. To eliminate the problem of clustering, we randomly select a data point from each cluster and for this now independent data, and calculate our test statistic and the associated support points for all possible permutations. While clearly valid, this is also inefficient. We repeat this process until all possible independent data sets have been created and use the support points averaged over the randomly created data sets as our reference distribution for the averaged test statistic. This approach uses all of the data and is a permutation extension of within-cluster resampling (WCR). We discuss both exact and Monte Carlo versions of the approach and apply it to several data sets. WCR permutation can be applied in quite general settings when within cluster correlation is a nuisance and exact inference is necessary.
Keywords: Clustering, Correlated data, Multiple outputation, Permutation test, Within-cluster resampling
1. INTRODUCTION
The use of permutation tests is well established and a popular option for statistical inference when exact p values are desired. Permutation tests are typically applied to statistically independent data points. In some settings, however, observations will be clustered and application of permutation methods will not be obvious. In a recent collaboration (Di Mascio et al., 2004), repeated measurements of CD4 cell counts and viral load were obtained on human immunodeficiency virus (HIV)-infected individuals. Many of the viral loads were below the limit of detection; detectable values were called “blips.” The researchers, who were comfortable with permutation tests, wanted to determine whether the relative change in CD4 was the same in consecutive “nonblip, blip” visits as for consecutive “nonblip, nonblip” visits. If each individual provided a single pair of such couples, a permutation t-test or Wilcoxon signed rank test could be performed using the pair of relative changes. However, each individual provided many such couples.
Permutation methods for correlated data have been discussed by a variety of authors in specific settings. Fay and Shih (1998) introduced distribution permutation tests (DPT) for the situation where each cluster provides multiple responses. Their work generalizes Wilcoxon rank sum and permutation t-tests to clustered data. Generalizations of the Wilcoxon rank sum test to clustered data that apply asymptotically have been derived (Datta and Satten, 2005; Rosner et al., 2003). Gail et al. (1996) discuss and evaluate permutation tests for group randomized trials. Braun and Feng (2001) introduce optimal permutation tests for group randomized trials by postulating models for the within-cluster observations. Finally, Cai and Shen (2000) apply permutation tests for clustered survival data by creating test statistics that pretend the data are independent, but then permute cluster labels rather than individual labels.
This paper introduces a general approach to construct permutation tests for clustered data with a common cluster-wide covariate that is to be permuted. The idea extends the within-cluster resampling of Hoffman et al. (2001) (see also Follmann et al., 2003). The basic idea is that if each cluster provided a single data point, standard permutation methods could be used. Thus, we randomly select one data point from each cluster. Based on this now independent data, we form both the test statistic and the b support points of the permutation distribution. We repeat the process for all m possible within-cluster (WC) resamples or ways we can do this, and average the test statistics for each of the b permutations over these m resamples. The b support points of the averaged test statistic provide the null distribution. We call this exhaustive WCR permutation (WCRP). We also describe a Monte Carlo approach where we randomly sample from the set of permutations and resamples. Note that WCR averaging of a test statistic derived from estimating equations has been used by Williamson et al. (2003) and Datta and Satten (2005, 2008) but they relied on asymptotic approximations for inference.
We begin with a review of permutation tests and then define WCRP, showing how it works in simple settings. We next describe Monte Carlo WCRP and show how to come close to the (exhaustive) WCRP result by using an ad hoc “6-tens” algorithm. A small simulation is conducted to illustrate key features of the algorithm. We finish by applying the proposed methods to some data sets that motivated its development.
2. EXHAUSTIVE PERMUTATION
We first review the situation where each of n clusters provides one data point. In this situation, the outcomes are given by the n-vector X = (X1, . . . , Xn). Associated with the ith cluster is a variable Zi, e.g., a group indicator, or the dose of a drug. Under the null hypothesis H0, all permutations of Z = (Z1, . . . , Zn) are equally likely. We form the test statistic on the observed data, t0 = t(X, Z). We calculate t for all permutations of Z, denoting the kth permutation as tk = t{X, Z(πk)}, where πk, k = 1, . . . , b is a listing of all possible nonredundant permutations, with π0 corresponding to the unpermuted data: Z = Z(π0). For example, if Z = 1.1, 2.2, 3.3, 4.4, corresponding to 4 doses of a drug, and πk = (4, 1, 3, 2), then b = 4! and Z(πk) = 4.4, 1.1, 3.3, 2.2. The one-sided lower p value is where I( ) is the indicator function.
As a simple example, consider the made-up data of six clusters with a single response in each cluster: X = [3.3, 3.1, 0.8, 1.1, 1.5, 2.3] and two groups, Z = [0, 0, 0, 1, 1, 1]. We can test equality of the distributions F(x|Z = 0) and F(x|Z = 1) by using the permutation t-test whose test statistic is the mean difference:
Here, and pl = 4/20.
3. WITHIN-CLUSTER RESAMPLING PERMUTATION
3.1. Basic Definition
Now consider the setting where the ith cluster has mi data points, with mi > 1 for some i. Denote the responses by the long vector
where Xij is the jth data point in the ith cluster. Importantly, the covariate of interest Z is not allowed to change within a cluster, so Z has dimension n.
For a single within-cluster resample we randomly select a single data point from each cluster. Table 1 provides a diagram that should aid understanding of this notation. Let the chosen index for cluster i be j(i), where j(i) ∈ {1, . . . , mi}. Let j = {j(1), . . . , j(n)}, define X(j) = X1j(1), . . . , Xnj(n), and set Xi(j) = Xij(i). For the jth WCR, we define our test statistic as tj0 = t{X(jj), Z}. To obtain the exact permutation distribution for this jth resample, we calculate all b possible permutations of Z, Z(π1), . . . , Z(πb), and for each, the associated test statistic. (We generalize this to allow uncountable sets of permutations in section 5.) Define the test statistic based on the jth resample and kth permutation as tjk = t{X(jj), Z(πk)}. As shown in Table 2, exhaustive WCRP then averages each column (unique permutation) of test statistics over all within-cluster resamples (the rows). The exhaustive WCR permutation distribution is given by the final row of Table 2 and a lower p value is given by . Note that there are m = m1 × · · · × mn unique ways to select one observation from each person.
Table 1.
Schematic representation of exhaustive WCR permutation
| Cluster | Covariate | Permutation | Outcome | ||||||
|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||
| 1 | Z1 = 1 | Z 3 | X11 | X12 | X13 | X14 | X15 | X16 | X17 |
| 2 | Z2 = 1 | Z 1 | X21 | ||||||
| 3 | Z3 = 1 | Z 6 | X31 | X32 | X33 | X34 | |||
| 4 | Z4 = 0 | Z 4 | X41 | X42 | X43 | ||||
| 5 | Z5 = 0 | Z 2 | X41 | X52 | X53 | X54 | X55 | X56 | |
| 6 | Z6 = 0 | Z 5 | X71 | X62 | |||||
| j = (3, 1, 2, 3, 6, 1) | |||||||||
| Z (π) = (Z3, Z1, Z6, Z4, Z2, Z5) | |||||||||
| X(j) = (X13, X21, X32, X43, X56, X71) | |||||||||
Note. Within each cluster an outcome is randomly selected and denoted by a box. The indices of the randomly selected outcomes from each cluster are given by j. A permutation of the covariates π is given by Z(π). A WCR is given by X(j). A difference in means test statistic for permutation π and WCR j is provided in the bottom row.
Table 2.
Matrix of test statistics for exhaustive WCR permutation (WCRP)
| Within-cluster resample (j) | Permutation (k) |
Original data | |||
|---|---|---|---|---|---|
| π 1 | π 2 | … | π b | π 0 | |
|
| |||||
| j 1 | t 11 | t 12 | … | t 1b | t 10 |
| j 2 | t 21 | t 22 | … | t 2b | t 20 |
| · | · | · | · | · | |
| · | · | · | · | · | |
| · | · | · | tjk | · | · |
| · | · | · | · | · | |
| j m | t m1 | t m2 | … | t mb | t m0 |
| Average | … | ||||
Note. For each of m within cluster resamples, the test statistic is calculated over the same b permutations. The final row provides the single permutation distribution for the averaged test statistic. The “permutation” π0 denotes the original unpermuted setting.
As another aid to understanding, refer back to the made-up data from the previous section, but now suppose that person 3 gives us an additional data point, say 2.7 in addition to her old 0.8. In this case there are two possible WC resamples j1 = (1, 1, 1, 1, 1, 1) and j2 = (1, 1, 2, 1, 1, 1). As before, for each resample there are 20 permutations so b = 20 and m = 2. The test statistics are given by
for j = 1, 2. For each possible permutation π1, . . . , π20, we can calculate the pair of test statistics for the two WC resamples, say (t11, t21), . . . , (t1,20, t2,20). Figure 1 plots these pairs of test statistics along their projections onto the axes that correspond to the permutation distributions for j = 1(2) for the horizontal (vertical) projections. The associated lower p values for the two WC resamples are 4/20 and 1/20, respectively. So the additional data point gives some additional evidence against the null hypothesis, but it is unclear how to make this precise.
Figure 1.
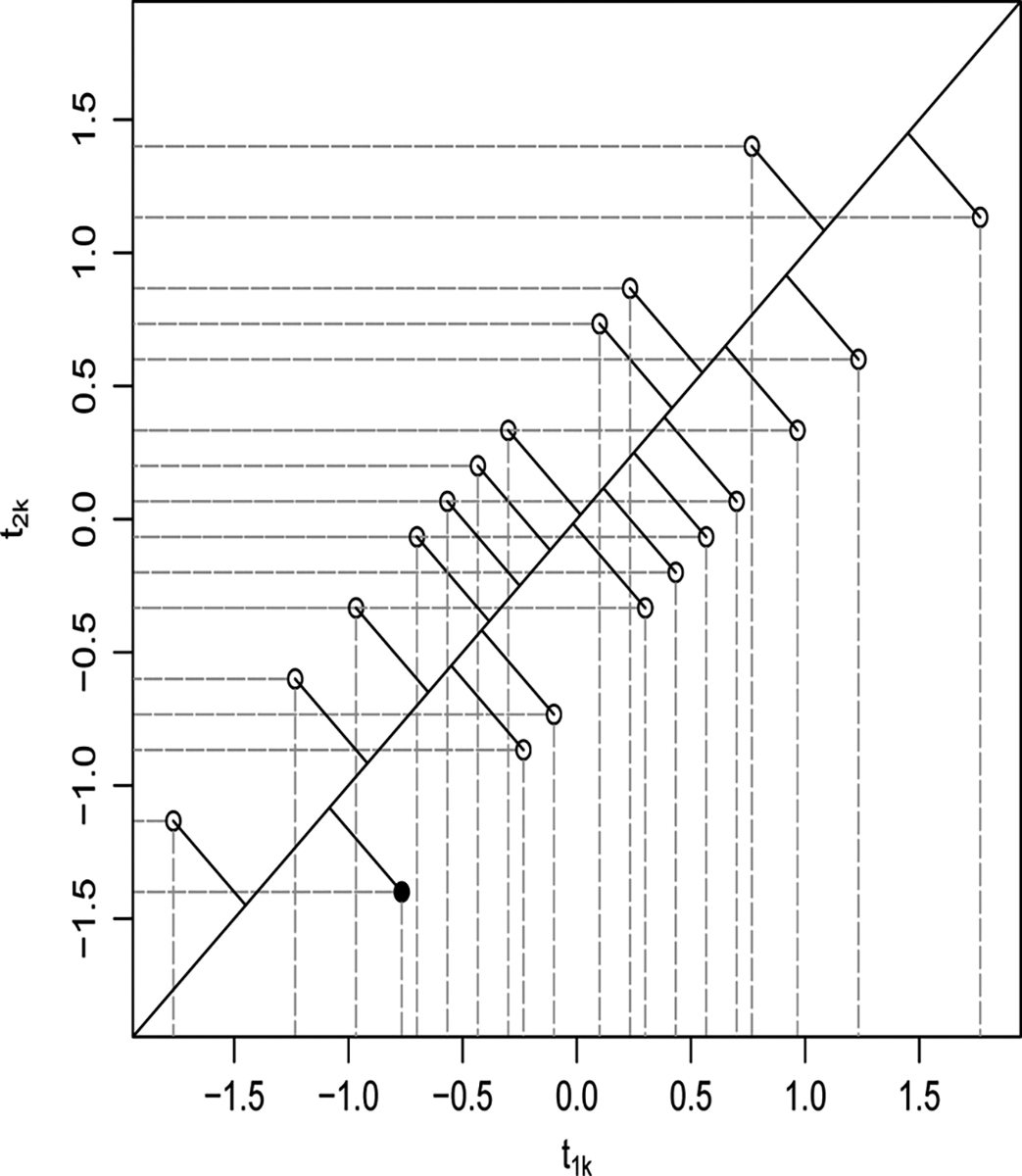
Geometric representation of permutation tests for the data of section 3.1, where everyone provides one measurement except the last person in group 0 who gives 2. Each (x, y) dot corresponds to the pair of test statistics for one of the 20 possible permutations. The x-value (y-value) is based on the first (second) measurement from this last person, the permutation distribution is the horizontal (vertical) projection, and the one-sided p value is 4/20 (1/20). Exhaustive WCR permutation is equivalent to projecting the pair of test statistics onto the 45-degree line. Here, the WCR permutation one-sided p value is 2/20.
Under the null hypothesis that all permutations of Z are equally likely, all two-dimensional points in Fig. 1 are equally likely. We can thus define a rejection region by some shape in two-dimensional space other than the vertical or horizontal lines. A natural test is to take the average of the two test statistics. This test is proportional to the projection of each point onto the 45° line as shown in Fig. 1. The p values are determined by the number of projected support points that are more extreme than the projected test statistic. We see that the lower p value based on this maneuver is pℓ = 2/20.
With standard permutation tests, inference is unaffected by any monotone transformation of the test statistic. However, with WCR permutation, this is not the case. Suppose that instead of using the usual test statistic, say t, we used log(t). With WCR permutation OP we would average either t or log(t) and the p values could differ. To ensure that inference is unaffected by monotone transformations of the test statistic one can use ranks. Specifically, let Rjk be the rank of tjk among tj1, . . . , tjb. For each resample we replace the tjks with these associated ranks. A “rank” WCR permutation p value rank is the the percentile of with respect to the empirical distribution of .
WCR permutation cannot be applied to permutation tests where the permutation set π1, . . . , πb depends on jj. If this happens then we cannot line up the columns of the matrix of Table 2 correctly. For example, in Fisher’s exact test, we condition on the marginal totals, and if these change with different resamples we cannot apply the procedure. Another example where the permutation set can depend on π is when Z changes within a cluster. An example is a crossover study with Z = (0, 1) or (1, 0) denoting the treatment assignment sequence over the two periods for each person (cluster). Here, one might have an WC resample where only Zs = 0 are selected and a test statistic could not even be calculated.
Since WCRP is a permutation test, it is formally testing the strong null hypothesis that z is a meaningless label. This strong null is a composite that the distribution of cluster sizes and the joint distribution of outcomes given a cluster size are both free of z. In symbols, we test
where G( ) is the distribution function of the cluster sizes and Fm( ) is the joint distribution X1, . . . , Xm. Note that this does allow for informative cluster sizes as Fm( ) can depend on m.
3.2. Example: Permutation t-Test
In some simple cases, we can calculate the final row of Table 2 directly. Consider the two-sample t-test setting where Zi = 0(1) identifies the control (treatment) group, and person i gives clustered outcomes Xi1, . . . , Xim(i). One can show that exhaustive WCR permutation corresponds to taking the sample average for each person and using these averages in a permutation t-test. That is, the averaged test statistic is
| (1) |
where is the within-cluster mean. The b support points of the permutation distribution are
for k = 1, . . . , b, where Zi(πk) is the ith element of Z(πk). Note that this does allow for informative cluster sizes as Fm( ) can depend on m.
3.3. Example: Linear Permutation Tests
Suppose the test statistic for WC resample j can be written as
where wX( ) is a function that may depend on the entire vector X and possibly other covariates, but cannot depend on Zi. Then for permutation k we can write
This form covers many tests. The permutation t-test has . An analysis of covariance (ANCOVA) permutation test statistic can be fashioned based on the model
where ϵij are mean 0 random variables free of Zi. We then obtain
where is the slope of the regression of on Wi and . The Wilcoxon rank sum test has , where R{Xi(ji)} is the rank of Xi(jj) among X1(jj), . . . , Xn(jj). Additionally, the distribution permutation tests of Fay and Shih (1998) have , where ϕ( ) is some function and is the empirical distribution function for the responses of cluster i.
4. MONTE CARLO WCR PERMUTATION
4.1. Basic Setup
In many settings, b and m will be too large for exhaustive WCR permutation to be feasible and we must approximate the exact p value by Monte Carlo methods. In this section we discuss how to choose the number of randomly selected Monte Carlo resamples and permutations so that the resultant p value is close to the exhaustive WCR permutation p value.
Let , where k = 1, . . . , b, so that is the exhaustive WCRP upper p value. To approximate the permutation distribution, we randomly draw a large number, say B, of permutations. Denote the associated indicator functions by , where upper case K = 1, . . . , B are the indices of a random (with replacement) sample of the integers 1, . . . , b. Note that these y1, . . . , yB terms are iid Bernoullis with probability pu. By the Central Limit Theorem (CLT) we know that
One could choose B to achieve any desired level of accuracy.
If m = m1 × · · · × mn was small, we could calculate exactly. If m is large, we will need to estimate . Since we only care if , the precision of our estimate of should depend on how far it is from . Thus we will allow MK, the number of randomly selected WC resamples for permutation ПK to vary with K. Let JJ be the Jth Monte Carlo draw from the full set of possible resamples, j1, . . . , jm. Also let ПK be the Kth Monte Carlo draw from the full set of possible permutations, π1, . . . , πb . We write the test statistic associated with the Jth resample and Kth permutation as TJK = T{X(JJ), Z(MK)}. We use upper case T, J, J, П, K to emphasize that they are random variables and not fixed constants as for the exhaustive case. For the Kth selected permutation, we estimate yK by first drawing MK WC resamples for this permutation, say, . We then form , and also estimate for these same resamples, . We then form . Note that for each support point we reestimate . If we used a common estimate for all resamples, then Y1, . . . , YB would not be independent. Although inefficient, using a different for each response ensures that the Y1, . . . , YB are independent and thus allows easy approximation of .
We define the (upper) Monte Carlo WCRP permutation p value as . In practice, we will often use the asymptotically (on B) equivalent form because it bounds the p value away from zero and ensures proper size (Fay and Follmann, 2002). We want to select each MK so that each YK has a high probability of equaling yK.
Note that for a fixed K we can think of as a sample mean based on MK random draws from the column of Table 2 where π = ПK. That is, from the discrete distribution with support points t1K, . . . , tmK. This also applies to . Without loss of generality, let ПK = πk. By the CLT, as MK → ∞, is approximately normal with mean and variance , where .
For each K we only need to know if is positive or negative. To achieve this with high probability, we propose the 6-tens algorithm, an ad hoc procedure that chooses MK so that
is large, and thus the sign of equals that of with high probability.
4.2. 6-Tens Algorithm
- Set MK = 10 for K = 1, . . . , B. For each of the B selected permutations П1, . . . , ПB, randomly draw 10 resamples, say JK1, . . . , JK10, and calculate
for ℓ = 1, . . . , 10. Calculate the mean and sample variance of the Ds, say and , and form
Let be the set of Ks for which |ZK| < 6. - For each set MK = MK × 10, randomly generate MK differences DKℓ, and form
Again let be the set of Ks for which |ZK| < 6. Repeat step 2 until either is empty, or MK > Mmax, some prespecified maximum value.
Let YK = I(ZK > 0), where ZK is the final value from step 3, and estimate the p value as .
One can show that the expected Monte Carlo p value does not equal the exact p value or , so bias can be a problem in principle. With the 6-tens algorithm we try to essentially eliminate bias by making each YK a very good estimate of yK. In the Appendix the bias of is explored in more detail, along with a more formal justification of the 6-tens algorithm.
4.3. Evaluation of the 6-Tens Algorithm
To empirically evaluate the 6-tens algorithm, we conducted a simple simulation. We assumed that the true support points followed a normal(0,τ2) distribution and that the variance of was σ2. We fixed so the WCRP upper p value was . We pretended that σ2 was known and did not estimate it. We randomly selected B = 1000 permutations (true support points) and calculated , the “true” p value for that choice of permutations/support points. Note that . This approximation becomes exact as B → ∞. We fixed this set of support points/permutations and then repeated the 6-tens algorithm 10,000 times. For each of these 10,000 repeats, we calculated and . The objective was to see whether the 6-tens algorithm worked well in terms of bias, mean squared error (MSE), and accuracy of the variance approximation (10), for a specific set of permutations.
Table 3 shows an unsurprising decrease in bias as max MK increases. Importantly, the average estimated variance appears quite close to the actual sample variance, suggesting the approximation of (10) will be useful in setting sample size. While the scenarios here are limited, a maximum of 10, 000 seems to be a reasonable choice for the 6-tens algorithm.
Table 3.
Simulated performance of the 6-tens algorithm
| σ | max(MK) | %|ZK|s < 6 | bias | MSE | ||||
|---|---|---|---|---|---|---|---|---|
|
| ||||||||
| 1 | 1 | 100 | .144 | .415 | 4.2 × 10−3 | 3.5 × 10−5 | 1.9 × 10−5 | 1.8 × 10−5 |
| 1 | 1 | 10000 | .161 | .040 | −5.0 × 10−5 | 1.9 × 10−6 | 1.7 × 10−6 | 1.6 × 10−6 |
| 1 | 1 | 1000000 | .156 | .003 | −2.6 × 10−5 | 2.6 × 10−8 | 6.2 × 10−8 | 2.5 × 10−8 |
| 1 | 2 | 100 | .020 | .133 | 2.5 × 10−3 | 1.1 × 10−5 | 4.6 × 10−6 | 4.8 × 10−6 |
| 1 | 2 | 10000 | .019 | .006 | 6.6 × 10−4 | 9.3 × 10−7 | 4.0 × 10−7 | 4.9 × 10−7 |
| 1 | 2 | 1000000 | .017 | .000 | 0 | 0 | 2.6 × 10−14 | 0 |
| .1 | 1 | 100 | .174 | .040 | −1.5 × 10−3 | 3.4 × 10−6 | 1.5 × 10−6 | 1.2 × 10−6 |
| .1 | 1 | 10000 | .175 | .004 | −1.7 × 10−6 | 9.3 × 10−9 | 5.2 × 10−8 | 9.3 × 10−9 |
| .1 | 1 | 1000000 | .158 | .0 | 0 | 0 | 4.7 × 10−15 | 0 |
| .1 | 2 | 100 | .022 | .009 | −1.9 × 10−4 | 3.8 × 10−7 | 3.7 × 10−7 | 3.4 × 10−7 |
| .1 | 2 | 10000 | .023 | 0 | 0 | 0 | 1.1 × 10−15 | 1.2 × 10−35 |
| .1 | 2 | 1000000 | .020 | 0 | 0 | 0 | 1.8 × 10−15 | 0 |
Note. Each line represents a summary of 10,000 estimates () of a single WCR permutation p value based on a specific set of 1000 permutations (support points). Bias is the average of the 10,000 differences . MSE is the average of the 10,000 squared differences . is the sample variance of the .
5. A MORE GENERAL FORM OF THE TEST
Although we have spoken only about conditional permutation tests, we can generalize to other tests that are permutation-like. In this section, Z denotes a random vector from a distribution fZ(z) where z is a realization of this variable. First we write the permutation tests in a form that will be easily generalized. Let , so that . Then we generalize the lower WCRP p value by writing it as
| (2) |
where EZ represents expectation over the n-dimensional random vector Z, and z0 is the observed value of z. In the usual setting, the distribution of Z has b equally likely support points, and fZ is the permutation distribution on Z, such that
In that case we condition on the observed value Z = z0 and consider permutations of that observed value. We can generalize to unconditional tests by allowing the null hypothesis distribution of Z to not be conditional on z0. For example, one could let fZ be an n-dimensional continuous distribution with an infinite number of support points. In section 7.3 we give an example where z0 is an n-dimensional zero vector, and fZ is continuous with
where π ≈ 3.14 . . . is the irrational number, not a permutation. The lower p value is still represented by Eq. (2).
6. SIMULATION
To evaluate the performance of different tests for clustered data, we conducted a small simulation for the two-sample setting. We generated data under a normal mixture model: Xij = μZi + bi + ϵij, where i = 1, . . . , 2n indexes clusters, j = 1, . . . , mi indexes observations within clusters, Zi = 0, 1 is the treatment group indicator for cluster i, mZ the cluster sizes for group Z = 0, 1, and there are n clusters per group. We generated and with all b’s and ϵ’s independent. We considered 36 different situations as follows:
= (0, 1), (1, 1), and (1, 0). These correspond to within-cluster correlations of 0, 0.5, and 1.
μ = 0 or a where a was chosen to so that EOP had approximately 80% power.
Three types of cluster sizes were considered: rectangular: mi = 5, triangular: mi = i, and informative: mi = 1 × I(bi ≤ 0) + 10 × I(bi > 0)
Number of clusters per group = 5 or 15.
We evaluated three tests, single WCR permutation (SWCRP), exhaustive WCR permutation (EWCRP), and the Wilcoxon rank sum test of Datta and Satten (2005) (DS). For SWCRP the test statistic is the difference means of the first observation in each cluster;
while for EWCRP the test statistic is the difference in cluster means,
The test of Datta and Satten is a WCR version of the Wilcoxon test and is based on
the sum of the ranks for a randomly selected WCR, J. The test is based on forming , where the expectation is over J, and then standardizing and comparing the standardized test statistic to an asymptotically valid standard normal null distribution.
For all permutation-based test statistics, we simulated the permutation distribution by scrambling the Zis 299 times and rejected the one-sided null at α = .05 if the simulated p value was smaller than .05, where Tp is the pth permuted test statistic. Note that exhausts all within-cluster resamples, but uses Monte Carlo approximation for the permutation distribution.
From Table 4, we see that both EWCRP and SWCRP always control the type I error rate, as they must. For Datta and Satten, there is some minor inflation for n = 15 and more substantial inflation with n = 5. This is entirely expected as Datta and Satten’s null distribution is based on an asymptotic argument. Thus, as always, if control of the type I error rate is a major concern, exact methods such as EWCRP have appeal. For n = 15, the power of Datta and Satten’s test is quite similar to EWCRP under rectangular and triangular data structure for the mis. Under an informative cluster size, EWCRP is more powerful for ρ = .5 and 1. For n = 5, the EWCRP has similar or somewhat less power than Datta and Satten for the rectangular and triangular data structures—presumably a consequence of the coarseness of the permutation distribution for small n, and the modest type I error rate inflation of Datta and Satten. For the informative cluster size setting, the EWCRP has better power for ρ = .5 and 1.
Table 4.
Proportion of rejections for different tests of equality of two distributions
| mis | μ | ρ | SWCRP | EWCRP | DS | n/2 |
|---|---|---|---|---|---|---|
|
| ||||||
| Rectangular | 0 | 0 | 0.0510 | 0.0505 | 0.0538 | 15 |
| Rectangular | 0 | .5 | 0.0504 | 0.0495 | 0.0529 | 15 |
| Rectangular | 0 | 1 | 0.0519 | 0.0519 | 0.0545 | 15 |
| Rectangular | a | 0 | 0.3080 | 0.8180 | 0.8164 | 15 |
| Rectangular | a | .5 | 0.5466 | 0.7341 | 0.7451 | 15 |
| Rectangular | a | 1 | 0.7299 | 0.7299 | 0.7260 | 15 |
| Triangular | 0 | 0 | 0.0504 | 0.0508 | 0.0540 | 15 |
| Triangular | 0 | .5 | 0.0498 | 0.0503 | 0.0532 | 15 |
| Triangular | 0 | 1 | 0.0505 | 0.0505 | 0.0526 | 15 |
| Triangular | a | 0 | 0.3045 | 0.7874 | 0.7719 | 15 |
| Triangular | a | .5 | 0.5456 | 0.7278 | 0.7338 | 15 |
| Triangular | a | 1 | 0.7272 | 0.7272 | 0.7165 | 15 |
| Informative | 0 | 0 | 0.0503 | 0.0503 | 0.0539 | 15 |
| Informative | 0 | .5 | 0.0501 | 0.0504 | 0.0375 | 15 |
| Informative | 0 | 1 | 0.0499 | 0.0499 | 0.0180 | 15 |
| Informative | a | 0 | 0.5819 | 0.8061 | 0.7924 | 15 |
| Informative | a | .5 | 0.6471 | 0.7438 | 0.6858 | 15 |
| Informative | a | 1 | 0.7307 | 0.7307 | 0.5751 | 15 |
| Rectangular | 0 | 0 | 0.0472 | 0.0487 | 0.0615 | 5 |
| Rectangular | 0 | .5 | 0.0486 | 0.0478 | 0.0621 | 5 |
| Rectangular | 0 | 1 | 0.0478 | 0.0478 | 0.0471 | 5 |
| Rectangular | a | 0 | 0.2736 | 0.7547 | 0.7943 | 5 |
| Rectangular | a | .5 | 0.6651 | 0.6651 | 0.6512 | 5 |
| Rectangular | a | 1 | 0.4932 | 0.6723 | 0.7313 | 5 |
| Triangular | 0 | 0 | 0.2744 | 0.4847 | 0.5148 | 5 |
| Triangular | 0 | .5 | 0.4900 | 0.6008 | 0.6474 | 5 |
| Triangular | 0 | 1 | 0.6667 | 0.6667 | 0.6797 | 5 |
| Triangular | a | 0 | 0.0468 | 0.0463 | 0.0624 | 5 |
| Triangular | a | .5 | 0.0487 | 0.0465 | 0.0607 | 5 |
| Triangular | a | 1 | 0.0480 | 0.0480 | 0.0558 | 5 |
| Informative | 0 | 0 | 0.0484 | 0.0483 | 0.0653 | 5 |
| Informative | 0 | .5 | 0.0471 | 0.0481 | 0.0436 | 5 |
| Informative | 0 | 1 | 0.0484 | 0.0484 | 0.0187 | 5 |
| Informative | a | 0 | 0.5223 | 0.7567 | 0.7518 | 5 |
| Informative | a | .5 | 0.5838 | 0.6813 | 0.6572 | 5 |
| Informative | a | 1 | 0.6653 | 0.6653 | 0.5437 | 5 |
Note. Within clusters, data are multivariate normal with correlation ρ. The mean cluster difference between groups is μ and varies for different scenarios. Cluster sizes and tests are described in the text.
7. EXAMPLES
7.1. Viral Blips and HIV Infection
The introduction of highly active antiretroviral therapy (HAART) has had a profound impact on the treatment of patients with HIV. Potent combinations of drugs can often render the load of virus (VL) circulating in the blood below the limit of detection of common assays, currently 50 copies/ml. However, even during periods of sustained viral suppression, sometimes “blips” occur—occasions when the amount of virus is above the limit of detection. The meaning of such blips is controversial and under investigation (Di Mascio et al., 2004). Part of their investigation focused on whether the occurrence of blips was associated with a change in the number of CD4 cells, cells of the adaptive immune system that both fight and are infected by HIV.
One approach to this problem would be to build a fairly complicated model for the repeated CD4 and VL data. If such a model could be correctly specified it could then be used to draw conclusions about various hypotheses, including the effect of blips on CD4 and CD8 cells. A different approach is to test specific hypotheses using simple statistics that are easily described and understood by a medical audience.
If the increase in virions during a blip impairs the recovery of CD4 cells, the relative change in CD4 counts on two successive visits starting with a nonblip and ending with a blip, say, R01 = (CD4i − CD4i−1)/CD4i−1, should tend to be lower than the analogous relative change ending in a nonblip, say, R00. If each patient provided a single pair R01, R00, then one could form D = R01 − R00. The associated D1, . . . , Dn could be the data for a paired difference t-test. However, patients generally have sustained periods of viral suppression and thus many R00s and several R01s. In our dataset there are 44 patients with acute HIV infection with both 00 and 01 couples. The total number of couples was 1094 and the mean (SD) number of couples per person was 24.5 (9.9). The mean (SD) number of 01 couples was 2.5 (1.9).
Here exhaustive WCR permutation corresponds to taking the sample average for each patient and using these averages in a permutation test. Thus we form for each patient and then take the average of these average differences to form our test statistic:
where Zi = ±1 and Z(π1), . . . , Z(πb) enumerates the b = 2n possible signs of an n-vector. There were 44 patients who had both 00 and 01 couples during acute infection. The exact upper p value here is .1793, and took about 30 s to calculate on a desktop computer.
A random effects model could also be fit to these data, where
where bi, ϵij are independent normals with mean zero and variances τ2 and σ2, respectively, Rij is the relative change in CD4 count for patient i for the jth couple, and Zij is the indicator for whether this couple started with a blip in viremia. This approach makes parametric assumptions and the p value for testing Δ = 0 is .14.
7.2. Heart Function in HIV-Infected Children
A retrospective study of 133 HIV-infected children was conducted at the National Institutes of Health to assess the contributions of progressive HIV disease (as measured by CD4 counts and percentages), vertical transmission, and azidothymidine (AZT) on cardiac function (Domanski et al., 1995). Cardiac function was measured by the fractional shortening of the left ventricle, which is essentially the fractional decrease in volume during a heartbeat, and larger values are desirable. Table 5 provides some descriptive statistics for the variables of interest, including averages of all the measurements and averages of each patient’s values.
Table 5.
Descriptive statistics for the study of factors on the fractional shortening of the left ventricle in children with AIDS (Domanski et al., 1995)
| Variable | Σmi = 486 measurements |
Mean of n cluster averages | ||
|---|---|---|---|---|
| Mean | Minimum | Maximum | ||
|
| ||||
| Fractional shortening | 0.34 | 0.05 | 0.59 | 0.34 |
| CD4 cells | 455.6 | 0 | 3421 | 544.8 |
| Percent CD4 cells | 16.1 | 0 | 63 | 18.1 |
| I (AZT) | 0.53 | 0 | 1 | 0.53 |
| I (vertical) | 0.51 | 0 | 1 | 0.60 |
| Age | 7.2 | .33 | 17.11 | 6.4 |
Of primary interest was the effect of the covariates on fractional shortening:
| (3) |
where i = 1, . . . , n = 133 and j = 1, . . . , mi. Thus i, j is the jth visit of the ith patient and ageij, CD4ij are the age and CD4 count, % CD4ij is the percentage of CD4 cells among the white blood cells, I(AZT)ij is 1 if on AZT, and I(vertical)i is 1 if infected by the mother.
For regression, there are different approaches to permutation analysis (see Edgington, 1995; Kennedy and Cade, 1996; Manly, 1997). We use “permutation under the reduced model” (Freedman and Lane, 1983) as recommended by Anderson and Legendre (1999) to evaluate the effect of I(vertical). Permutation methods can be more powerful than the normal t-test approach if the errors are non-normal (Anderson and Legendre, 1999). Using an obvious notation, we write the regression model of Eq. (3), for a single resample J of n independent data points as
| (4) |
for i = 1, . . . , n, where Z is I(vertical), and ϵJ(i) is an error term. As a test statistic, we use the usual t-statistic for testing Δ = 0 based on least-squares regression of X on W, Z:
| (5) |
To obtain a permutation distribution for this test, we randomly select a permutation П and perform an initial regression without Z:
| (6) |
The permuted residuals, are added to the predicted Xs from this regression to form X*
| (7) |
where П(i) is the ith element of the permutation vector П. Then the newly created X* is regressed on the original W, Z:
| (8) |
and based on this regression, the usual t-statistic for testing Δ = 0 is formed: T{X(J), Z(П)} from Eq. (5). For Monte Carlo WCR with the 6-tens algorithm, the preceding steps (6), (7), and (8) are repeated MK times for both ПK and П0. One can show that the T{X(J), Z(П0)} as defined in Eq. (5) based on Eq. (4) also obtains from the procedure defined by Eqs. (6), (7), and (8) with П = П0.
Using the preceding methods we tested the relationship between fractional shortening and vertical transmission while controlling for the effects of the four confounders. We used the 6-tens algorithms with B = 1999 and MMax = 105 and obtained a lower p value of p = .4745 with standard error of 0.011, where 99.8% of the variance estimate is due to the second term of (10):. This calculation took approximately 13 h on a PC.
One can also analyze these data using GEE (Liang and Zeger, 1986). We postulate a working independence correlation matrix and calculate a Wald statistic for Δ of −.32, which corresponds to a p value of .37. This method uses an asymptotic null distribution in contrast to WCRP, which can be liberal if the number of clusters is small or the covariates are not balanced (Fay and Graubard, 2001).
7.3. Correlated Angular Measurements
Follmann and Proschan (1999) discuss the problem of testing uniformity with correlated angular data. Of interest was whether times of seizures have a circadian pattern, or whether they are uniformly distributed on the 24-hour clock. Data from 12 patients were provided; one patient had one seizure, while another had 36 with a cluster of seizures a little before midnight.
Follmann and Proschan (1999) introduced a definition of uniformity called rotation invariance and provided several tests for rotation invariance that explicitly allowed for arbitrary clustering/correlation of angles within a cluster. Developing new methodology can be time-consuming, and it is also nice to have simple tools to attack complicated problems. The basic data here is the long vector
where Xij is the jth seizure time on the 24-hour clock (in radians) for individual i. A seizure at 6:00 a.m. = 0 radians and a seizure at noon = 3π/2 radians.
A standard test of uniformity for angular data is the Rayleigh test. For a single “resample” J, the Rayleigh test statistic is
If T{X(J)} is close to 0, the angles are scattered, while if T{X(J)} is close to 1, the angles have a definite preferred direction. Mardia (1972) provides the exact null distribution of R and argues that for large n, 2nT{X(J)}2 is approximately chi-square with 2 degrees of freedom. Though unnecessary here since the null distribution is known (Mardia, 1972), one could simulate the null distribution of T{X(J)} by forming
where Z = (Z1, . . . , Zn), and the Zi are independent and uniform (0, 2π). One would generate many such Zs and the associated Ts would comprise a simulated null reference distribution.
We apply the idea of Monte Carlo WCR permutation using the general setup described in Section 5. We randomly generate B n-vectors, Z1, . . . , ZB, where ZK = (ZK1, . . . , ZKn) and each ZKi is uniform (0, 2π). For each ZK, we form
We applied the 6-tens algorithm with B = 1999 and MMax = 105 and obtained an upper p value of 1528/2000. The estimate of the standard deviation, from Eq. (10), of that p value is .011, with 98.7% of the variance estimate due to the second term of Eq. (10):. This calculation took approximately 10 h on a personal computer (PC). The tests of Follmann and Proschan for the null hypothesis of rotation invariance all provide p values greater than .40.
8. SUMMARY
This paper has introduced a general method for obtaining exact permutation results in the presence of arbitrary within cluster correlation by using within cluster resampling. A fixed set of permutations is selected, and then for each cluster a single outcome is randomly selected and a test statistic calculated for each permutation. The procedure of drawing a single outcome from each cluster is repeated many times, and the test statistics for each specific permutation are averaged over all WC resamples. These averaged test statistics are used as the null reference distribution for the averaged test statistic. In practice, Monte Carlo methods to approximate the permutation distribution may be required. An algorithm is proposed where computational effort is focused to determine whether the support points of the null distribution fall to the left or right of the test statistic, thus ensuring an accurate approximate p value. Different examples are used to illustrate the broad application of WCR permutation. WCR permutation is a handy and simple way to apply permutation methods when within-cluster correlation is a nuisance.
Acknowledgments
We thank Michael Proschan and Zonghui Hu for providing helpful comments on an earlier draft of this article.
APPENDIX: BIAS OF
It is instructive to explore how bias becomes a substantial problem if one uses a small number of Monte Carlo resamples. This analysis also demonstrates how the easy approach of doing single resamples and averaging the p values over many resamples is generally conservative.
For this section, suppose that MK = M for all K, and define as the p value based on B random permutations and M random resamples. For a fixed dataset, p(B, M) is still a random variable dependent on the specific resamples and permutations that were selected. Since E[p(B, M)] is free of B, we use to denote the expected Monte Carlo WCR p value based on M resamples. To see the problem for small samples, consider again the made-up data of section 3.1. Suppose that we set M = 1 but enumerate the 20 permutations. Thus the p value is either 1/20 or 4/20 and both occur with equal probability. Formally we can write
which is larger than p(∞, ∞) = 2/20. If we set M = 2, then E[p(∞, 2)] = 9/80, which is still larger than p(∞, ∞). One can show that E[p(∞, M)] is not monotone for this small dataset, and one can produce datasets where . Thus, the bias can go in either direction.
To get a handle on the form of the bias in large samples, we worked out some asymptotics for the two-group test statistic of Eq. (1). By the CLT, where . As n → ∞ the distribution of , based on the difference in means statistic, approaches that of a normal distribution with mean 0 and some variance, say τ2, by the permutational CLT (Sen, 1985). One can also show that for the difference in means statistic. Thus, if we knew we would have the following approximation for the expected p value based on M WC resamples:
| (9) |
where the second expectation is over K, the random permutation index.
With Eq. (9), we see that the approximate asymptotic bias decreases with M and increases with σ2/τ2. To graphically appreciate this point, consider Fig. 2, which is a plot of the exhaustive and Monte Carlo WCR p values for a large dataset assuming normality of the , normality of and knowledge of . The area to the right of based on the is approximately E{p(∞, M)}, and this is larger than the area to the right of based on the , which is p(∞, ∞). Thus, the average of single WC resample p values should be larger than the exhaustive WCR p value.
Figure 2.
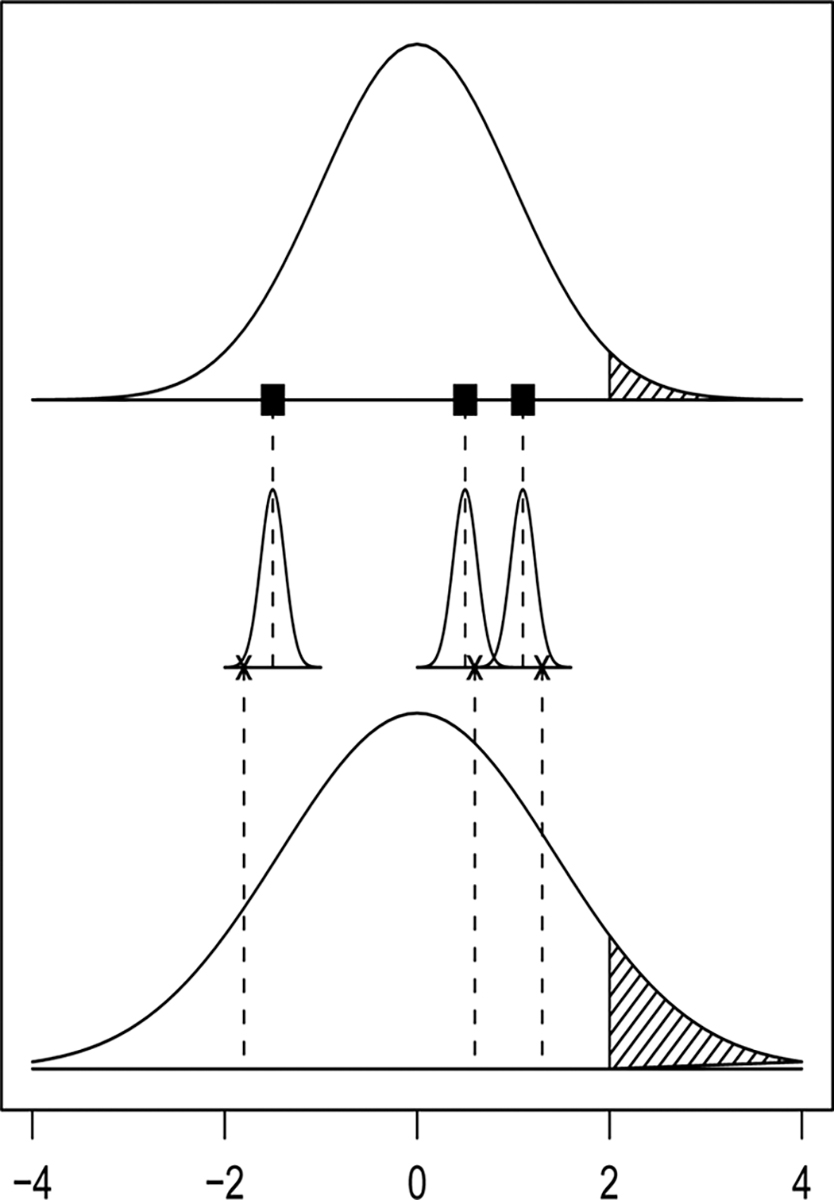
Illustration of the sources of variability in the averaged permutation distribution for the difference in means statistic. The top panel shows the approximate Gaussian (0, τ2) distribution of the , i.e., exhaustive WCR permutation distribution. Conditional on , has an approximate Gaussian distribution. Thus unconditionally, the Monte Carlo WCR permutation distribution (bottom panel) is more spread out than the exhaustive permutation distribution. The shaded area of the bottom panel is larger than for the top panel, illustrating that the Monte Carlo p value is likely to be larger than the exhaustive p value.
APPENDIX: JUSTIFICATION OF THE 6-TEN’S ALGORITHM
Note that for the fixed permutations П1, . . . , ПB, we have YK as independent Bernoullis with
In the preceding, the first approximation is by the CLT and the second one is because we replace the parameters , , and with estimates. This approximation works because for each K (except those with ), |ZK| → ∞ as MK → ∞. We thus can approximate the variance of for this set of permutations:
The overall variance estimate for our p value is
| (10) |
The second line approximation is because we approximate P(YK = 1) by Ф(ZK). The third line approximation is because we replace the expectation of a random variable with a realization of that random variable and we use to estimate the exhaustive WCR p value . Note that with the 6-tens algorithm, most |ZK|s are large so is the dominant term of Eq. (10).
REFERENCES
- Anderson M, Legendre P (1999). An empirical comparison of permutation methods for tests of partial regression coefficients in a linear model. Journal of Statistical Computation and Simulation 62:271–303. [Google Scholar]
- Braun T, Feng Z (2001). Optimal permutation tests for the analysis of group randomized trials. Journal of the American Statistical Association 96:1424–1432. [Google Scholar]
- Cai J, Shen Y (2000). Permutation tests for comparing marginal survival functions with clustered failure time data. Statistics in Medicine 19:2963–2973. [DOI] [PubMed] [Google Scholar]
- Datta S, Satten G (2005). Rank tests for clustered data. Journal of the American Statistical Association 100:908–915. [Google Scholar]
- Datta S, Satten G (2008). A signed-rank test for for clustered data. Biometrics Association 64:501–507. [DOI] [PubMed] [Google Scholar]
- Di Mascio M, Markowitz M, Louie M, Hurley A, Hogan C, Simon V, Follmann D, Ho DD, Perelson AS (2004). Dynamics of intermittent viremia during highly active antiretroviral therapy in patients who initiate therapy during chronic versus acute and early human immunodeficiency virus type 1 infection. Journal of Virology 78(19):10566–10573. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Domanski M, Sloas M, Follmann DA, Scallise PP, Tucker EE, Egan D, Pizzo P (1995). Effect of zidovudine and didanosine treatment on cardiac function in human immunodeficiency virus infected children. Journal of Pediatrics 127:137–146. [DOI] [PubMed] [Google Scholar]
- Edgington ES (1995). Randomization Test. 3rd ed. New York: Marcel Dekker. [Google Scholar]
- Fay MP, Follmann D (2002). Designing Monte Carlo implementations of permutation or bootstrap hypothesis tests. American Statistician 56:63–70. [Google Scholar]
- Fay MP, Graubard BI (2001). Small-sample adjustments for Wald-type tests using sandwich estimators. Biometrics 57(4):1198–1206. [DOI] [PubMed] [Google Scholar]
- Fay MP, Shih JH (1998). Permutation tests using estimated distribution functions. Journal of the American Statistical Association 93:387–396. [Google Scholar]
- Follmann DA, Proschan MA, Leifer E (2003). Multiple outputation: Inference for complex multivariate data by averaging analyses from univariate data. Biometrics 59:420–429. [DOI] [PubMed] [Google Scholar]
- Follmann DA, Proschan MA (1999). A simple permutation-type method for testing circular uniformity with correlated angular measurements. Biometrics 55:782–791. [DOI] [PubMed] [Google Scholar]
- Freedman D, Lane D (1983). A nonstochastic interpretation of reported significance levels. Journal of Business and Economic Statistics 1:292–298. [Google Scholar]
- Gail M, Mark S, Carroll R, Green S, Pee D (1996). On design considerations and randomization-based inference for community intervention trials. Statistics in Medicine 15:1069–1092. [DOI] [PubMed] [Google Scholar]
- Hoffman EB, Sen PK, Weinberg C (2001). Within-cluster resampling. Biometrika 88:1121–1134. [Google Scholar]
- Kennedy PE, Cade BS (1996). Randomization tests for multiple regression. Communications in Statistics: Simulation and Computation 25:923–936. [Google Scholar]
- Liang K-Y, Zeger S (1986). Longitudinal analysis using generalized linear models. Biometrika 73:13–22. [Google Scholar]
- Manly BFJ (1997). Randomization and Monte Carlo Methods in Biology. London: Chapman and Hall. [Google Scholar]
- Mardia KV (1972). Statistics of Directional Data. New York: Academic Press. [Google Scholar]
- Rosner B, Glynn R, Lee M-L (2003). Incorporation of clustering effects for the Wilcoxon Rank Sum Test: A large-sample approach. Biometrics 59:1089–1098. [DOI] [PubMed] [Google Scholar]
- Sen PK (1985). Permutational central limit theorem. In: Kotz Balakrishnan, Read Vidakovic, Johnson, eds. Encyclopedia of Statistical Sciences. 2nd ed. pp. 6069–6073. [Google Scholar]
- Williamson J, Datta S, Satten G (2003). Marginal analyses of clustered data when cluster size is informative. Biometrics 59:36–42. [DOI] [PubMed] [Google Scholar]