

Abstract
目的
提出一种融入坐标注意力和高效通道注意力机制的深度学习目标检测模型AM-YOLO。
方法
运用Mosaic图像增强与MixUp混类增强对图像进行预处理,采用One-Stage结构的目标检测模型YOLOv5s,并对该模型的骨干网络与颈部网络进行改进。在该模型的骨干网络中把空间金字塔的最大池化层替换成二维最大池化层,接着将坐标注意力机制和高效通道注意力机制分别融入到YOLOv5s模型的C3模块与该模型的骨干网络中。将改进后的模型与未改进的YOLOv5s模型,YOLOv3模型,YOLOv3-SPP模型,YOLOv3-tiny模型进行相关算法指标的对比实验。
结果
融入了坐标注意力和高效通道注意力机制的AM-YOLO模型能够有效提升对黑色素瘤的识别率,同时也减少了模型权重的大小。AM-YOLO模型在准确率,召回率以及平均精度均值上都要明显优于其他模型,并且对于早期和晚期黑色素瘤的平均精度均值分别达92.8%和87.1%。
结论
本文采用的深度学习目标检测算法模型能够应用于黑色素瘤目标的识别中。
Keywords: 深度学习, 目标检测, 注意力机制, YOLOv5s, 黑色素瘤
Abstract
Objective
To propose a deep learning target detection model AM- YOLO that integrates coordinate attention and efficient attention mechanism.
Methods
Mosaic image enhancement and MixUp mixed-class enhancement were used for image preprocessing. In the target detection model YOLOv5s with One-Stage structure and modified backbone network and neck network, the maximum pooling layer of the spatial pyramid of the backbone network was replaced with a two-dimensional maximum pooling layer, and the coordinate attention mechanism and the efficient channel attention mechanism were integrated into the C3 module and the backbone network of the model, respectively. The improved model was compared with the unmodified YOLOv5s model, YOLOv3 model, YOLOv3-SPP model, and YOLOv3-tiny model for relevant algorithmic indicators in comparative experiments.
Results
The AM-YOLO model incorporating coordinate attention and efficient channel attention mechanism effectively improved the accuracy of melanoma recognition with also a reduced size of the model weight. This model showed significantly better performance than other models in terms of precision, recall rate and mean average precision, and its mean average precision for benign and malignant melanoma reached 92.8% and 87.1%, respectively.
Conclusion
The deep learning-based target object detection algorithm model can be applied in recognition of melanoma targets.
Keywords: deep learning, object detection, attention mechanism, YOLOv5s, melanoma
黑色素瘤是由黑色素细胞高度恶变而来的,是一类恶性程度高,侵袭性强的皮肤恶性肿瘤[1]。根据我国的数据显示,我国每年黑色素瘤新发病例将近2万人,发病率呈现逐年上升的趋势[2]。黑色素瘤多发生于皮肤表层,也可能发生于眼,内脏粘膜等部位,而且极易发生早期转移,非常容易被忽略或误诊为其他疾病[3]。因此,黑色素瘤的早发现和早诊断能够更及时的为患者治疗,有效提升患者的治愈率。为此,对黑色素瘤的目标检测十分关键。
近年来,随着深度学习算法的兴起。目标检测作为计算机视觉领域最重要的分支之一[4],在监控,识别等领域发挥着重要作用。相对于传统机器学习算法通过手工提取特征而言,通过深度学习的目标检测算法训练出来的模型泛化能力更好,精度更高[5]。将深度学习算法应用到黑色素瘤目标的检测上,能够更好的辅助医生诊断[6]。就目前发展的情况来说,计算机视觉的目标检测算法主要分为One-Stage结构和Two-Stage结构这两类[7]。Two-Stage模型算法是将目标检测划分为两个阶段,第一个阶段先产生候选区域,第二阶段对候选区域分类并对位置修正,代表的模型有SPP-Net[5],FastRCNN[8],R-FCN[9]等。由于Two-Stage模型计算量较大,难以实时检测,考虑到Two-Stage模型检测的实用性问题。以One-Stage结构的模型算法在不需要生成候选区域的情况下[10],直接对每个目标类别进行回归预测,极大的降低网络模型的算法时间复杂度,提升了检测速度,代表的模型有SSD[11],EfficientDet[12],YOLO[13]系列等。
目前,YOLO系列是目标检测算法广泛应用的模型之一,YOLO是You Only Look Once的英文缩写。在2016年由Redmon提出的YOLOv1[14]模型开始,经过不断的迭代升级,推出了YOLOv2[15]模型,YOLOv3[16]模型,YOLOv4[17]模型,直至目前最新的YOLOv5[18]模型,以及YOLOX[19],YOLOR[20]等衍生模型,其中YOLOv5模型的综合性能最佳,适用于实际的工程项目应用。
在此之前,有许多学者将YOLO系列的模型应用于黑色素瘤目标检测,其中Nie等[21]提出了基于YOLOv3算法的黑色素瘤目标检测,在对早期黑色素瘤和晚期黑色素瘤的检测中,精确率分别达到了79% 和75%。Bisla等[22]使用YOLOv3算法并通过图像分割技术来检测皮肤病变,但是YOLOv3算法模型对检测小目标定位精度较差,且模型权重较大,召回率较低。
因此,为了更好地解决提升对黑色素瘤的识别精度和降低模型复杂度的问题,本文提出了采用YOLO系列最新的轻量化模型YOLOv5s,模型大小为14MB。通过改进YOLOv5s骨干网络的空间金字塔池化层,并且在YOLOv5s的C3模块里融入坐标注意力机制和在骨干网络中融入高效通道注意力机制。使得模型在不带来额外计算开销的情况下,降低了模型的总体参数量,同时在跨信道交互过程中嵌入特征的坐标信息,并且在确保模型不降维的同时让轻量化网络模型能够捕获更大区域的位置信息,提升了对黑色素瘤的识别率。采用开源数据集和运用两种不同的图像增强方案,对改进后的模型进行对比实验分析,然后对模型关键指标进行评估[23]。实验结果表明,本文改进后的模型能够更有效的识别黑色素瘤。
1. 方法
1.1. YOLOv5模型简介
YOLOv5根据Bottleneck残差结构个数以及卷积核数量划分网络结构的深度与宽度,将其分为YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x 4种主要模型。其中YOLOv5s的网络深度为0.33,网络宽度为0.50,其余3个主要模型均在该网络深度与宽度的基础上不断加深与加宽。YOLOv5的结构主要包含输入端, 骨干网络, 颈部网络以及预测头。YOLOv5s模型随着结构内部所含的残差结构个数的依次增多,网络特征提取与融合能力得到不断加强,同时检测精度得到提高,但是相应运行速度就会变慢,模型所花费的时间也会相应增加。YOLOv5s网络结构如图 1所示。
1.

YOLOv5s网络模型结构图
Structure diagram of YOLOv5s network model.
1.1.1. Input输入端
在YOLOv5s的输入端部分通过自动设定初始锚框的大小自适应缩放图片。同时,还可以采用图像增强的方法对图像数据进行预处理。并且在每次训练时,对标注样本的锚框尺寸采用聚类算法确定最合适的锚框尺寸。
1.1.2. Backbone骨干网络
Backbone骨干网络作用是提取数据集中的指定特征,特征提取能力越强,模型对目标的识别精度就越高。为此,Backbone骨干网络由多种模块构成,包含Conv,C3,SPP这3个组件。
Conv模块是一个标准的卷积模块,是整个骨干网络中最基础的组件,由卷积层,BN层,Activate激活函数组成。而C3模块是CSPBottleneck的改进版本,结构的基本功能均与CSPBottleneck相同,C3模块通过精简只保留了三个CBL。因此,C3模块起到精简模型的网络结构,减少模型的总体参数和降低模型的计算量以及模型推理时间的效果。
为了解决输入图像尺寸不统一的问题,在骨干网络中引入空间金字塔池化层(SPP)。SPP能够对输入到骨干网络中的图像进行卷积运算,然后输出特征映射,再将得到的特征映射分成若干等分用来进行最大池化操作,最后送入到全连接层。SPP对不同大小特征的融合,实现了多重融合感受野,解决了黑色素瘤目标特征大小差异较大的问题。
1.1.3. Neck network颈部网络
颈部网络是由特征金字塔(PAN)组成。通过FPN结构进行上采样,使得底层特征图包含更强的黑色素瘤语义信息。再由PAN进行下采样,加强顶层特征图中黑色素瘤的位置信息。最后将FPN和PAN进行融合,使得特征图中有效包含黑色素瘤的语义信息和特征信息,确保对不同尺寸的黑色素瘤图像能够做到有效识别。
1.1.4. Predict head预测头
为了能够快速检测跨尺度目标,YOLOv5针对不同尺度的特征图采用anchorbased的方法,通过不同尺度的anchor一次性输出预测框的位置和类别置信度。因此,在Predict head中会有20×20,40×40,80×80这3种尺度的输出。其中,20×20尺度代表深层特征图,用于大目标的检测;80×80尺度代表浅层特征图,用于小目标的检测。
在实现了跨尺度目标检测的同时,考虑到预测框与真实框的长宽比例问题。为此,YOLOv5使用CIOU loss函数来衡量锚框的损失。CIOU loss通过对预测框与真实框的距离,长宽比例,重叠率以及尺度参数地计算,使得预测框的回归更加稳定。CIOU计算公式如(1)式所示:
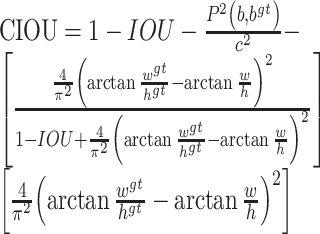 |
1 |
其中,P2(b, bgt)代表预测框与真实框中心点之间的欧式距离,c代表预测框与真实框的最小包围矩形的对角线长。
1.2. 注意力机制
计算机视觉领域的注意力机制是为了在原有的数据上找到数据之间的关系,从而突出数据上的某种重要特征,现以广泛应用到目标检测和图像分割上。目前,注意力机制主要划分为通道注意力机制和空间注意力机制以及两者相结合的混合型注意力机制。一般来讲,虽然混合型注意力机制能够提高模型的精确率,但是不可避免的增加了模型的参数量与计算量。
1.2.1. CoordAtt注意力机制
由新加坡国立大学的Hou等[24]提出了一种专门为轻量级网络设计的注意力机制,称为坐标注意力机制。该注意力机制将空间信息编码成两个并行的一维特征编码, 利用两个一维特征编码插入坐标信息来避免二维全局池化所造成的位置信息损失。CoordAtt注意力机制不仅能够捕获跨通道信息, 还嵌入了空间信息。因此,使得模型能够更准确的定位目标区域,并且抑制了非重要信息的计算,坐标注意力机制具体结构如图 2所示。
2.
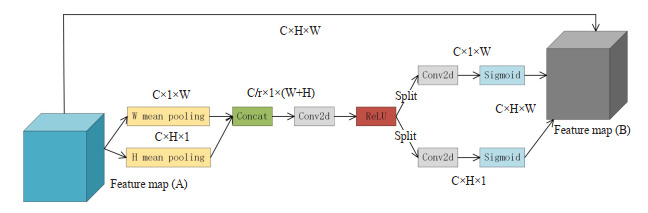
坐标注意力机制结构图
Structure of the coordinate attention module. The coordinate attention module can accurately capture the coordinate information of hyperspectral images.
根据图 2所示,坐标注意力机制模块首先编码高度H和宽度W。在特征图像中,给定位置(i, j),通道C上的像素值为xc(i, j)。
宽度W平均池化的输出定义如(2)式所示:
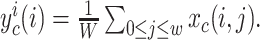 |
2 |
高度H平均池化的输出定义如(3)式所示:
 |
3 |
坐标注意力机制完成连接,卷积和激活函数操作定义如(4)式所示:
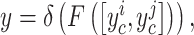 |
4 |
(4)式中F代表1×1卷积运算,δ为ReLU激活函数。y是ReLU层的输出特征图。
经过拆分操作后,y分解为yi和yj。yi与yj通过2D卷积和Sigmod激活函数分别完成对宽度W与高度H平均池化的加权。相关定义如(5)式与(6)式所示:
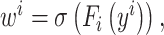 |
5 |
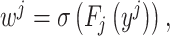 |
6 |
(5)式中,wi是特征图像数据H方向的自适应加权。Fi代表对H的卷积运算,输入值是yi。(6)式中,wj是特征图像数据W方向的自适应加权。Fj代表对W的卷积运算,输入值是yj。σ代表的是Sigmoid激活函数。
因此,坐标注意力机制的特征图像输出定义如(7)式所示:
 |
7 |
(7)式中,通过给定(i, j)坐标位置,确定xc (i, j)特征图像输入的值与fc (i, j)特征图像输出的值。
1.2.2. ECA注意力机制
为了增强网络模型提取跨信道特征的效率,提升黑色素瘤的检测精度。通过改进传统的SE注意力机制(SE)[25],从而得到一种轻量型的高效通道注意力机制(ECA)[26]。ECA注意力机制在给定全局平均池化(GAP)之后,使用1×1卷积层来完成跨通道间的信息交互。同时去除全连接层,避免了权重分配过程中的维度缩减操作。ECA注意力机制旨在跨通道信息交互的覆盖范围内获取通道间的依赖关系,增强目标特征的表达能力。ECA注意力机制具体结构如图 3所示。
3.
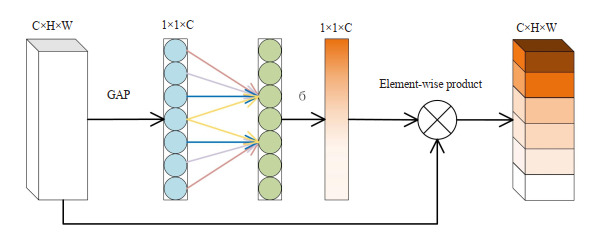
ECA注意力机制结构图
Structure diagram of the efficient channel attention mechanism.
1.3. 改进方法
1.3.1. 改进空间金字塔池化层
为了进一步加快网络模型的训练收敛速度,输出同一长度的池化特征。通过将SPP模块的最大池化层替换成二维最大池化层, 使得模型可以加快提取黑色素瘤的显著特征,剔除目标特征的冗余信息。将改进后的空间金字塔池化层称为SPPFast,SPP-Fast模块结构如图 4所示。
4.

SPP-Fast模块结构图
Struture of SPP-Fast module.
1.3.2. 融入注意力机制
首先在YOLOv5s的C3模块中调控嵌入CoordAtt注意力机制,并将改进后的C3模块调控融入到模型的骨干网络与颈部网络。通过将CoordAtt注意力机制与模型的主要核心模块进行深度调控绑定,确保网络模型能够更加准确地定位感兴趣的目标位置信息。其次,在YOLOv5s骨干网络的中间结构层上调控引入ECA注意力机制,使得模型在提取跨通道的交互信息过程中,提升了由CoordAtt注意力机制所捕获的坐标信息的传递效率,并在骨干网络的深度调控结构中起到承上启下的作用。最后,将改进后的YOLOv5s模型命名为基于注意力机制调控的YOLO网络模型(AM-YOLO)。AM-YOLO的网络模型结构如图 5所示。
5.

AM-YOLO网络模型结构图
Structure diagram of theAM-YOLO network model.
1.3.3. 图像增强
为了弥补训练样本不足和解决图像特征差异不明显的问题,采用Mosaic图像增强方案[27]。Mosaic图像增强能够随机提取黑色素瘤训练集中的四张图片进行拼接,每一张图片都有其对应的预锚框,将四张图片随机裁剪拼接之后便可获得一张新的图片以及图像所对应的预锚框,极大的丰富了训练数据。Mosaic图像增强实例如图 6所示。
6.

Mosaic图像增强实例
Examples of mosaic image enhancement.
于此同时,在Mosaic图像增强的基础上,采用MixUp[28]增强方式对数据集进行混类增强,进一步提升模型的泛化能力,加快了模型的训练速度[29]。除此之外,还对数据集中的图像色调,旋转角度,饱和度,翻转程度以及缩放比例等参数进行改进,以防止模型在训练过程中出现过拟合现象[30]。
1.4. 实验数据集与实验环境
1.4.1. 实验数据集的收集与构建
本文采用的图像数据均来自ISIC Archive,ISIC是国际皮肤成像合作组织的简称,ISIC由斯隆凯特琳癌症中心的资助下运行。ISIC Archive的皮肤图像病变类型出自医学专家的判断,因此能够确保数据的真实性。本实验从ISIC Archive上提取3297张图片,包括早期黑色素瘤图像1800张,晚期黑色素瘤图像1497张,并对该图像数据集严格按照9∶1的比例划分训练集与验证集。然后,使用LabelImg数据标注软件对指定目标进行数据标注[31]。
1.4.2. 实验环境的配置
实验的硬件配置与开发环境均在云服务器上成功部署,主要实验环境配置如表 1所示:
1.
实验环境
Platform for the experiments
| Item | Configuration |
| CPU | Intel(R) Xeon(R) Gold 5218 |
| GPU | Nvidia GeForce RTX 2080ti |
| OS version | Ubuntu 18.04 |
| Cuda version | 11.4 |
| Pytorch version | 1.10.2 |
1.4.3. 实验参数的设置
在实验参数的设置上,模型参数选取主要包括批量大小为16,学习率为0.01,100轮次,动量常数为0.937,权值衰减系数0.0005。
1.5. 算法指标
本文实验选用准确率(P),召回率(R),以及平均精度均值(mAP)作为模型的评价指标。准确率P是评估模型识别的准确程度,R是评估模型对数据集的训练是否全面。其P和R的定义如(8)式与(9)式所示:
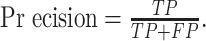 |
8 |
 |
9 |
为此,以P为纵坐标,R为横坐标可以绘制成P-R曲线。通过P-R曲线下方的面积可以计算出单个种类的平均精度(AP),其定义如(10)式所示:
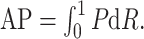 |
10 |
通过对数据集中所有类别AP求和并且除以总的类别数量便可以得到平均精度均值(mAP)。mAP是评估模型在所有类别上训练出来的好坏程度,即mAP就是取所有类别上AP的平均值。AP与mAP的数值越大,表明模型的识别精度越高,检测效果更好,其定义如(11)式所示:
 |
11 |
(11)式中:n代表训练数据集中的检测种类中的总数,i代表当前检测种类的编号。
另外,本文还比较了实验训练之后,网络模型的权重大小。通过模型权重大小的对比,来验证模型改进之后的效果。模型权重越小,模型参数量就越少,模型复杂度就越低,因此说明该模型越轻量。
1.6. 实验所选取的网络模型
为了能够验证本文研究中所提出的AM-YOLO网络模型性能,本文选取Nie等[21]所采用的YOLOv3模型,以及YOLOv3-tiny模型[32],YOLOv3-SPP模型[33]和未改进的YOLOv5s模型进行各项实验,并且通过相关算法指标对综合性能进行对比。
2. 结果
2.1. YOLOv5s基础模型的实验结果
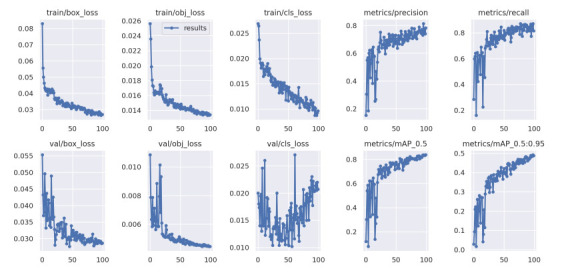
根据实验参数的设置,首先采用未改进的YOLOv5s模型对黑色素瘤数据集进行训练。在迭代训练100次后,未改进的YOLOv5s模型对黑色素瘤的识别精确率达到83.4%,召回率在81%左右,具体实验结果如图 7所示。
7.
YOLOv5s基础模型的各项实验结果
Experimental results of the YOLOv5s base model.
2.2. AM-YOLO模型的对比实验与结果
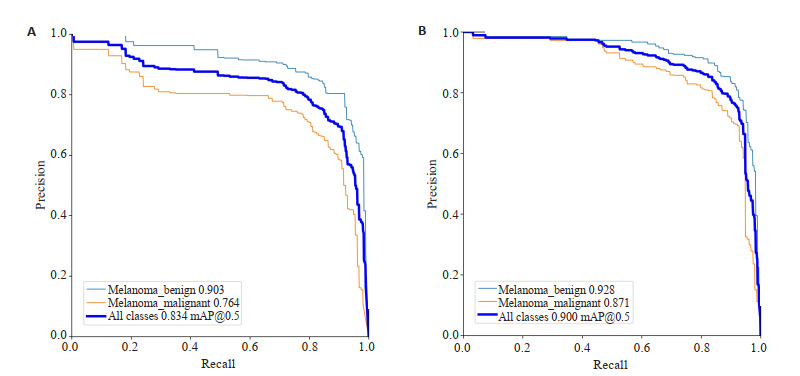
YOLOv5s模型在完成100次训练之后,早期黑色素瘤的AP为90.3%,晚期黑色素瘤的AP为76.4%,黑色素瘤的mAP为83.4%。在实验环境与参数保持一致的情况下,AM-YOLO模型在迭代训练100次之后,早期黑色素瘤的AP达到92.8%,晚期黑色素瘤的AP达到87.1%。黑色素瘤的mAP达到90.0%。实验的对比结果如图 8所示。
8.
YOLOv5s与AM-YOLO结果对比
Comparison of the experimental results with the YOLOv5s (A) andAM-YOLO (B) models.
2.3. 综合性能对比实验
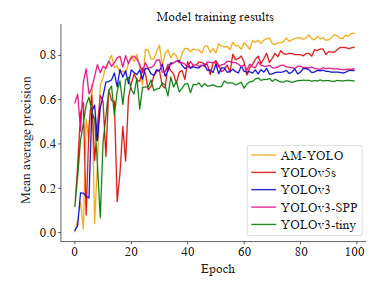
在同样的数据集和统一的环境配置以及相同的实验训练参数下根据本文实验方法中选取的五种网络模型进行模型训练,并且采用Matplotlib数据可视化绘制相关的曲线图与柱状图。实验中五种网络模型的mAP训练曲线结果如图 9所示。
9.
平均精度均值曲线图
Mean Average Precision graph. The yellow curve represents AM-YOLO, the red curve represents YOLOv5s, the purple curve represents YOLOv3-SPP, the blue curve represents YOLOv3, and the green curve represents YOLOv3-tiny.
根据实验所得到的数据,早期黑色素瘤和晚期黑色素瘤的AP、mAP以及各实验模型权重大小如图 10所示。AM-YOLO模型权重大小为10.5 MB,比未改进的模型权重减小4.0 MB。
10.

指标对比
Metric comparison of the models. A: Performance comparison. B: Weight size comparison.
2.4. 验证模型改进后的效果
为了更加直观地检验本文改进后网络模型的实际效果,通过选取能够代表模型改进后的效果图像进行展示和对比分析,如图 11依次显示YOLOv5s和AMYOLO验证集图像可视化的检测结果。图 11A中的第1行第3张图片,YOLOv5s并未识别出黑色素瘤目标。图 11A中的第2行第2张图片,存在多个黑色素瘤目标叠加的情况下,YOLOv5s算法模型存在漏检与错检。图 11A中的第2行第4张图片,在有毛发遮挡物的情况下,虽然能够对早期黑色素瘤进行正确识别,但是受遮挡物的影响,对黑色素瘤的识别精度明显降低。
11.

验证结果
Results of verification of the models.A: YOLOv5s; B: AM-YOLO.
3. 讨论
如何提升对黑色素瘤的识别精度以及降低模型的复杂度,是本文研究的重点与难点。首先,本文通过两种不同的图像增强方案对黑色素瘤数据集进行预处理。其次,采用轻量化的目标检测模型YOLOv5s,通过对该模型的空间金字塔池化层进行改进,加快模型的收敛速度。再次,将CoordAtt注意力机制与模型的基础模块深度调控绑定;同时也将ECA注意力机制调控融入到模型的骨干网络中,增强了模型对于目标的兴趣表示,使得模型能在保持精度不下降的情况下减少模型的总体参数量。最后,将改进后的YOLOv5s模型命名为AM-YOLO。
AM-YOLO模型对早期黑色素瘤以及晚期黑色素瘤的AP相较于YOLOv5s模型分别提升了2.5%和10.7%,mAP提升了6.6%。相较于Yali等[9]提出的基于YOLOv3对早期和晚期黑色素瘤的检测也显著提升了4.5%和20%,mAP也提升了12.3%。与此同时,AM-YOLO模型的权重大小为10.5 MB,比未改进的模型权重减小了4.0 MB。因此,可以说明调控CoordAtt注意力机制与ECA注意力机制对实验的各项指标有较为明显的提升,并且模型的总体参数量有所下降。
YOLOv5s存在着部分漏检的情况。对于部分晚期黑色素瘤的检测中,虽然能够对晚期黑色素瘤进行正确的目标识别,但是对晚期黑色素瘤识别不够准确。通过AM-YOLO检测的结果来看,对于早期和晚期的黑色素瘤都能够正确识别,不存在漏检的情况。对于有毛发遮挡的情况下,AM-YOLO识别率为70%~80%之间,相较于YOLOv5s有较大的提升[34]。
综合图片检测结果可知,AM-YOLO能够正确识别和区分早期黑色素瘤和晚期黑色素瘤,对于多个黑色素瘤目标在正确识别的情况下,有较高的检测准确率。因此,本文提出的基于注意力机制调控的轻型黑色素瘤目标检测网络适合对黑色素瘤目标检测任务。
本文通过改进算法模型,降低模型的权重大小。在真实场景中,如移动端设备或者是嵌入式设备,这些边缘平台普遍存在内存资源少,处理器性能不高,功耗受限等缺点,这使得模型权重较大的算法无法正常进行部署和实时运行。因此,轻量化的网络模型在保持精度不变的情况下,通过精简模型结构以及减少模型参数,将模型转化部署到边缘设备上,从而辅助缺乏经验的医疗人员鉴别黑色素瘤以及提升医生诊断效率[35]。
本次实验虽然说明了AM-YOLO模型能够很好的识别黑色素瘤,但是仍然存在一些需要改进的地方。本文构建的数据集图片数量不多,部分的黑色素瘤特征过于相似,而且受限于当前的硬件环境。对于小目标以及多个特征目标的叠加的情况,未进行实际测试。因此,在后续的工作中通过在线收集或者图像增广的方式逐渐扩充数据集,尝试引入全新的激活函数,增加一个预测头来处理小尺寸目标,进一步提升模型的识别检测能力。
Biography
钟友闻,在读硕士研究生,E-mail: 201482906@qq.com
Funding Statement
国家自然科学基金(61972186,U21B2027);云南高新技术产业发展项目(201606);云南省重大科技专项计划(202103AA080015,202002AD080001-5);云南省基础研究计划(202001AS070014);云南省学术和技术带头人后备人才(202105AC160018)
Supported by National Nature Science Foundation of China (61972186, U21B2027)
Contributor Information
钟 友闻 (Youwen ZHONG), Email: 201482906@qq.com.
车 文刚 (Wengang CHE), Email: goooglethink@gmail.com.
References
- 1.潘 志宏, 毛 家玺, 薛 源, et al. 原发性肝脏黑色素瘤汇总分析. 中华肝脏外科手术学电子杂志. 2021;10(6):612–7. doi: 10.3877/cma.j.issn.2095-3232.2021.06.017. [潘志宏, 毛家玺, 薛源, 等. 原发性肝脏黑色素瘤汇总分析[J]. 中华肝脏外科手术学电子杂志, 2021, 10(6): 612-7.] [DOI] [Google Scholar]
- 2.张 佳冉, 斯 璐. 抗血管生成在黑色素瘤中的基础研究及临床应用. https://www.cnki.com.cn/Article/CJFDTOTAL-ZLZD202201002.htm. 肿瘤综合治疗电子杂志. 2022;8(1):1–7. [张佳冉, 斯璐. 抗血管生成在黑色素瘤中的基础研究及临床应用[J]. 肿瘤综合治疗电子杂志, 2022, 8(1): 1-7.] [Google Scholar]
- 3.李 细媛, 朱 智鑫, 赵 海龙. BRAF突变型黑色素瘤的耐药性机制及治疗最新研究进展. https://www.cnki.com.cn/Article/CJFDTOTAL-TJYZ202202019.htm. 天津医药. 2022;50(2):214–9. [李细媛, 朱智鑫, 赵海龙. BRAF突变型黑色素瘤的耐药性机制及治疗最新研究进展[J]. 天津医药, 2022, 50(2): 214-9.] [Google Scholar]
- 4.Kaczmarek-Śliwińska M. Organisational communication in the age of artificial intelligence development. opportunities and threats. Soc Commun. 2019;5(2):62–8. doi: 10.2478/sc-2019-0010. [Kaczmarek-Śliwińska M. Organisational communication in the age of artificial intelligence development. opportunities and threats[J]. Soc Commun, 2019, 5(2): 62-8.] [DOI] [Google Scholar]
- 5.He KM, Zhang XY, Ren SQ, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans PatternAnal Mach Intell. 2015;37(9):1904–16. doi: 10.1109/TPAMI.2015.2389824. [He KM, Zhang XY, Ren SQ, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans PatternAnal Mach Intell, 2015, 37(9): 1904-16.] [DOI] [PubMed] [Google Scholar]
- 6.Cheryl Guttman Krader. AI has potential to improve melanoma detection. Dermatol Times. 2020;41(9):3. [Cheryl Guttman Krader. AI has potential to improve melanoma detection[J]. Dermatol Times, 2020, 41(9): 3.] [Google Scholar]
- 7.Ren SQ, He KM, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans PatternAnal Mach Intell. 2017;39(6):1137–49. doi: 10.1109/TPAMI.2016.2577031. [Ren SQ, He KM, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans PatternAnal Mach Intell, 2017, 39(6): 1137-49.] [DOI] [PubMed] [Google Scholar]
- 8.Lee YS, Park WH. Diagnosis of depressive disorder model on facial expression based on fast R-CNN. Diagnostics (Basel) 2022;12(2):317. doi: 10.3390/diagnostics12020317. [Lee YS, Park WH. Diagnosis of depressive disorder model on facial expression based on fast R-CNN[J]. Diagnostics (Basel), 2022, 12 (2): 317.] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Harms J, Lei Y, Tian SB, et al. Automatic delineation of cardiac substructures using a region-based fully convolutional network. Med Phys. 2021;48(6):2867–76. doi: 10.1002/mp.14810. [Harms J, Lei Y, Tian SB, et al. Automatic delineation of cardiac substructures using a region-based fully convolutional network[J]. Med Phys, 2021, 48(6): 2867-76.] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Zuo X, Li JJ, Huang J, et al. Pedestrian detection based on one-stage YOLO algorithm. J Phys: Conf Ser. 2021;1871(1):012131. doi: 10.1088/1742-6596/1871/1/012131. [Zuo X, Li JJ, Huang J, et al. Pedestrian detection based on one-stage YOLO algorithm[J]. J Phys: Conf Ser, 2021, 1871(1): 012131.] [DOI] [Google Scholar]
- 11.Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector [C]. European conference on computer vision. Springer, Cham, 2016: 21-37.
- 12.Tan MX, Pang RM, le QV. EfficientDet: scalable and efficient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA. IEEE, : 10778-87.
- 13.Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA. IEEE, : 779- 88.
- 14.Liu KZ, Ye YM, Li XT, et al. A real-time method to estimate speed of object based on object detection and optical flow calculation. J Phys: Conf Ser. 2018;1004:012003. doi: 10.1088/1742-6596/1004/1/012003. [Liu KZ, Ye YM, Li XT, et al. A real-time method to estimate speed of object based on object detection and optical flow calculation[J]. J Phys: Conf Ser, 2018, 1004: 012003.] [DOI] [Google Scholar]
- 15.Sharif MI, Li JP, Amin J, et al. An improved framework for brain tumor analysis using MRI based on YOLOv2 and convolutional neural network. Complex Intell Syst. 2021;7(4):2023–36. doi: 10.1007/s40747-021-00310-3. [Sharif MI, Li JP, Amin J, et al. An improved framework for brain tumor analysis using MRI based on YOLOv2 and convolutional neural network[J]. Complex Intell Syst, 2021, 7(4): 2023-36.] [DOI] [Google Scholar]
- 16.于 哲舟, 刘 岩, 刘 元宁. 基于YOLOV3改进的虹膜定位算法. https://www.cnki.com.cn/Article/CJFDTOTAL-DBDX202204006.htm. 东北大学学报: 自然科学版. 2022;43(4):496-500, 508. [于哲舟, 刘岩, 刘元宁. 基于YOLOV3改进的虹膜定位算法[J]. 东北大学学报: 自然科学版, 2022, 43(4): 496-500, 508.] [Google Scholar]
- 17.Qiu ZB, Zhu X, Liao CB, et al. Detection of transmission line insulator defects based on an improved lightweight YOLOv4 model. Appl Sci. 2022;12(3):1207. doi: 10.3390/app12031207. [Qiu ZB, Zhu X, Liao CB, et al. Detection of transmission line insulator defects based on an improved lightweight YOLOv4 model [J]. Appl Sci, 2022, 12(3): 1207.] [DOI] [Google Scholar]
- 18.Yan B, Fan P, Lei XY, et al. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021;13(9):1619. doi: 10.3390/rs13091619. [Yan B, Fan P, Lei XY, et al. A real-time apple targets detection method for picking robot based on improved YOLOv5[J]. Remote Sens, 2021, 13(9): 1619.] [DOI] [Google Scholar]
- 19.Song JY, Zhao Y, Song WL, et al. Fisheye image detection of trees using improved YOLOX for tree height estimation. Sensors (Basel) 2022;22(10):3636. doi: 10.3390/s22103636. [Song JY, Zhao Y, Song WL, et al. Fisheye image detection of trees using improved YOLOX for tree height estimation[J]. Sensors (Basel), 2022, 22(10): 3636.] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Kizilay E, Aydin &. A YOLOR based visual detection of amateur drones[C]//2022 International Conference on Decision Aid Sciences andApplications (DASA). Chiangrai, Thailand. IEEE, : 1446-9.
- 21.Nie YL, Sommella P, O' Nils M, et al. Automatic detection of melanoma with yolo deep convolutional neural networks[C]//2019 E-Health and Bioengineering Conference (EHB). Iasi, Romania. IEEE, : 1-4.
- 22.Bisla D, Choromanska A, Berman RS, et al. Towards automated melanoma detection with deep learning: data purification and augmentation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Long Beach, CA, USA. IEEE, : 2720-8.
- 23.Xie C, Zhu HY, Fei YQ. Deep coordinate attention network for single image super-resolution. IET Image Process. 2022;16(1):273–84. [Xie C, Zhu HY, Fei YQ. Deep coordinate attention network for single image super-resolution[J]. IET Image Process, 2022, 16(1): 273-84.] [Google Scholar]
- 24.Hou QB, Zhou DQ, Feng JS. Coordinate attention for efficient mobile network design[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA. IEEE, : 13708-17.
- 25.Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA. IEEE, : 7132-41.
- 26.Wang QL, Wu BG, Zhu PF, et al. ECA-net: efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA. IEEE, : 11531-9.
- 27.孙 丰刚, 王 云露, 兰 鹏, et al. 基于改进YOLOv5s和迁移学习的苹果果实病害识别方法. https://www.cnki.com.cn/Article/CJFDTOTAL-NYGU202211019.htm. 农业工程学报. 2022;38(11):171–9. [孙丰刚, 王云露, 兰鹏, 等. 基于改进YOLOv5s和迁移学习的苹果果实病害识别方法[J]. 农业工程学报, 2022, 38(11): 171-9.] [Google Scholar]
- 28.陆 健强, 林 佳翰, 黄 仲强, et al. 基于Mixup算法和卷积神经网络的柑橘黄龙病果实识别研究. https://www.cnki.com.cn/Article/CJFDTOTAL-HNNB202103011.htm. 华南农业大学学报. 2021;42(3):94–101. [陆健强, 林佳翰, 黄仲强, 等. 基于Mixup算法和卷积神经网络的柑橘黄龙病果实识别研究[J]. 华南农业大学学报, 2021, 42(3): 94-101.] [Google Scholar]
- 29.杨 永波, 李 栋. 改进YOLOv5的轻量级安全帽佩戴检测算法. https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG202209021.htm. 计算机工程与应用. 2022;58(9):201–7. [杨永波, 李栋. 改进YOLOv5的轻量级安全帽佩戴检测算法[J]. 计算机工程与应用, 2022, 58(9): 201-7.] [Google Scholar]
- 30.王 书坤, 高 林, 伏 德粟, et al. 改进的轻量型YOLOv5绝缘子缺陷检测算法研究. https://www.cnki.com.cn/Article/CJFDTOTAL-HBXZ202104017.htm. 湖北民族大学学报: 自然科学版. 2021;39(4):456–61. [王书坤, 高林, 伏德粟, 等. 改进的轻量型YOLOv5绝缘子缺陷检测算法研究[J]. 湖北民族大学学报: 自然科学版, 2021, 39(4): 456-61.] [Google Scholar]
- 31.邓 杰航, 何 冬冬, 卓 家鸿, et al. 复杂背景干扰下硅藻图像的深度网络识别与定位. https://www.j-smu.com/CN/10.12122/j.issn.1673-4254.2020.02.03. 南方医科大学学报. 2020;40(2):183–9. doi: 10.12122/j.issn.1673-4254.2020.02.08. [邓杰航, 何冬冬, 卓家鸿, 等. 复杂背景干扰下硅藻图像的深度网络识别与定位[J]. 南方医科大学学报, 2020, 40(2): 183-9.] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Li JC, Guo SY, Kong LL, et al. An improved YOLOv3-tiny method for fire detection in the construction industry. E3S Web Conf. 2021;253:03069. [Li JC, Guo SY, Kong LL, et al. An improved YOLOv3-tiny method for fire detection in the construction industry[J]. E3S Web Conf, 2021, 253: 03069.] [Google Scholar]
- 33.Dong S, Ma YH, Li CM. Implementation of detection system of grassland degradation indicator grass species based on YOLOv3-SPP algorithm. J Phys: Conf Ser. 2021;1738(1):012051. [Dong S, Ma YH, Li CM. Implementation of detection system of grassland degradation indicator grass species based on YOLOv3-SPP algorithm[J]. J Phys: Conf Ser, 2021, 1738(1): 012051.] [Google Scholar]
- 34.王 榆锋, 李 大海. 改进YOLO框架的血细胞检测算法. https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG202212021.htm. 计算机工程与应用. 2022;58(12):191–8. [王榆锋, 李大海. 改进YOLO框架的血细胞检测算法[J]. 计算机工程与应用, 2022, 58(12): 191-8.] [Google Scholar]
- 35.Roy SS, Haque AU, Neubert J. Automatic diagnosis of melanoma from dermoscopic image using real-time object detection[C]//2018 52nd Annual Conference on Information Sciences and Systems (CISS). Princeton, NJ, USA. IEEE, : 1-5.