

Summary
Collecting information on multiple longitudinal outcomes is increasingly common in many clinical settings. In many cases, it is desirable to model these outcomes jointly. However, in large data sets, with many outcomes, computational burden often prevents the simultaneous modeling of multiple outcomes within a single model. We develop a mean field variational Bayes algorithm, to jointly model multiple Gaussian, Poisson, or binary longitudinal markers within a multivariate generalized linear mixed model. Through simulation studies and clinical applications (in the fields of sight threatening diabetic retinopathy and primary biliary cirrhosis), we demonstrate substantial computational savings of our approximate approach when compared to a standard Markov Chain Monte Carlo, while maintaining good levels of accuracy of model parameters.
Keywords: Bayesian computing, Generalized linear mixed model, Markov chain Monte Carlo, Mean field variational Bayes, Multivariate mixed models, Repeated measurements
1. Introduction
Since the random-effects models paper of Laird and Ware (1982), mixed models have become a standard tool for the analysis of longitudinal data in medical studies. The aim is to capture the evolution over time of a marker of interest. Fixed effects describe the influence of covariates on the population mean profile, and random effects describe the group-specific deviations from the population mean.
Mixed models are now so well established that a number of books could introduce the reader to the basic principles and many extensions of methods for analyzing longitudinal data. See for example Verbeke and Molenberghs (2000) for details of the linear mixed model, mainly focusing on continuous longitudinal outcomes, or Molenberghs and Verbeke (2005), McCulloch and others (2008) or Diggle and others (2002) for further details of various extensions including modeling noncontinuous responses with generalized linear mixed models.
Our focus is on the longitudinal analysis of medical data, with measurements of multiple clinical variables collected repeatedly over time. However, at its most basic level, our problem is the analysis of grouped data. Such data are commonly found in a wide range of applications, not limited to medical data, including panel data analysis (Baltagi, 2008), multilevel models (Gelman and Hill, 2007; Goldstein, 2011), and small area estimation (Rao and Molina, 2015).
Extensions have been developed in many directions. We consider the case where multiple longitudinal outcomes are observed on each patient in a clinical study. In such studies, both repeated observations of a marker on the same patient, and observations of different markers on the same patient are likely to be correlated, and modeling strategies should account for the correlation implied by this hierarchical structure. For example, patients with diabetes will routinely have their glycated hemoglobin (HbA1c), cholesterol, blood pressure, and estimated glomerular filtration rate (eGFR) measured (along with potentially many other outcomes, including level of retinopathy collect at retinal screening visits for example), to allow monitoring of a patient’s diabetes severity and assessment of the risk of developing additional complications such as sight threatening diabetic retinopathy.
Many studies that collect longitudinal data on multiple outcomes analyze longitudinal trends separately using univariate mixed models. Depending on the questions of interest this may be a legitimate approach. However, by analyzing outcomes separately we are unable to describe the relationship between outcomes or to assess the simultaneous effect of some covariate on a number of related outcomes. To answer these questions, multivariate mixed models can be used.
Verbeke and others (2014) provide a review of various ways of analyzing multivariate longitudinal data. Our work in this article concerns the conditional models in Section 3 of their review. Constructing multivariate mixed models for longitudinal data involves a trade-off between the information gained in such models and the computational cost of fitting the model. For this reason, most work on multivariate mixed models only considers the inclusion of a small number of longitudinal markers (typically 2–5 markers). A notable exception is a pairwise approach that considers all combinations of bivariate longitudinal models to assess changes over time in 22 hearing threshold frequencies (Fieuws and others, 2007). A key problem is that the inclusion of more longitudinal markers, usually also involves the specification of higher-dimensional random effects distributions. This makes maximum likelihood estimation challenging due to the need to evaluate high-dimensional integrals over random effects distributions. Bayesian estimation through Markov Chain Monte Carlo (MCMC) can also be computationally challenging due to the high-dimensional nature of the problem.
In this article, we propose mean field variational Bayes (MFVB) as an efficient way of fitting multivariate mixed models. MFVB is widely used in computer science (e.g. Bishop, 2006) though is perhaps less familiar in the statistical literature. This situation is changing, thanks in part to two recent reviews of MFVB (Blei and others, 2017) and the related variational message passing (Wand, 2017).
In Section 2, we describe multivariate generalized linear mixed models (MGLMMs) and provide a Bayesian specification of the model of interest in this paper. Section 3 gives a brief overview of MFVB methods and describes in detail the computations necessary to develop an algorithm for MFVB estimation of MGLMMs. We assess the performance of our MFVB algorithm in comparison to popular MCMC routines, in simulated data sets in Section 4, whilst in Section 5, we show the performance of our approach in a relatively small data set of patients with primary biliary cirrhosis and a much larger dataset of patients with diabetes who were screened for sight threatening diabetic retinopathy. Section 6 provides a brief conclusion to the article.
2. Multivariate generalized linear mixed models
2.1. Notation
We begin by first describing the notation used in this article. We consider a study that collects data on 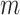 individuals. For each patient, data are collected on up to
individuals. For each patient, data are collected on up to  longitudinal markers of interest. We let
longitudinal markers of interest. We let  denote the
denote the 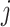 th observation (
th observation (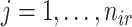 ) of the
) of the  th marker (
th marker ( ) for patient
) for patient 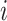 , (
, ( ) and collect all observations of marker
) and collect all observations of marker  on a particular patient into a vector
on a particular patient into a vector  . Further, we collect all observations of the
. Further, we collect all observations of the  markers on a particular patient into a combined vector
markers on a particular patient into a combined vector  , and let
, and let  denote all the longitudinal observations for the study in question. We may specify some covariates that are believed to influence the change over time in each longitudinal marker. The covariates for each marker,
denote all the longitudinal observations for the study in question. We may specify some covariates that are believed to influence the change over time in each longitudinal marker. The covariates for each marker,  , for each individual,
, for each individual, 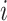 , are stored in a (
, are stored in a ( ) design matrix
) design matrix 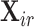 . The overall design matrix for individual
. The overall design matrix for individual 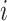 is represented by
is represented by  . Similar design matrices can be constructed for the random effects terms in a mixed model, which are denoted by the
. Similar design matrices can be constructed for the random effects terms in a mixed model, which are denoted by the  matrix
matrix  , where
, where  denotes the total number of random effects included in the model, and
denotes the total number of random effects included in the model, and 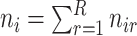 denotes the total number of measurements on individual
denotes the total number of measurements on individual  . These design matrices can be stacked across all individuals, giving
. These design matrices can be stacked across all individuals, giving  and
and 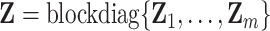 .
.
2.2. Model specification
We now proceed to develop our MGLMM. We assume that each response,  is distributed according to a member of the exponential family, to allow the inclusion of non-continuous responses such as binary and Poisson markers, in addition to continuous markers,
is distributed according to a member of the exponential family, to allow the inclusion of non-continuous responses such as binary and Poisson markers, in addition to continuous markers,
 |
(2.1) |
where for notational convenience we have defined  and
and  , with
, with 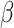 denoting the
denoting the 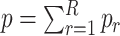 fixed effects in the model, and
fixed effects in the model, and  denoting the
denoting the  vector of individual random effects. The subscript
vector of individual random effects. The subscript  attached to any of these design matrices denotes the parts relating to marker
attached to any of these design matrices denotes the parts relating to marker  . We denote by
. We denote by  a matrix of nuisance parameters which in our case is a diagonal matrix with diagonal entries of
a matrix of nuisance parameters which in our case is a diagonal matrix with diagonal entries of  if the row corresponds to an observation from the
if the row corresponds to an observation from the  th Gaussian marker, and 1 if the row corresponds to an observation of a binary or count longitudinal marker.
th Gaussian marker, and 1 if the row corresponds to an observation of a binary or count longitudinal marker.
In 2.1, we use 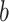 to denote the cumulant function and
to denote the cumulant function and 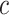 to denote the base measure according to the notation of McCullagh and Nelder (1989), and assume elementwise evaluation of the functions
to denote the base measure according to the notation of McCullagh and Nelder (1989), and assume elementwise evaluation of the functions 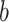 and
and  (i.e., the appropriate function is applied to the appropriate row of input). For example, if
(i.e., the appropriate function is applied to the appropriate row of input). For example, if  is a continuous marker
is a continuous marker  whilst if
whilst if  is binary then
is binary then 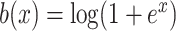 and if Poisson,
and if Poisson,  . To extend this model for our needs in this article to fit a joint model to multiple longitudinal responses, we consider the following density for our stacked response
. To extend this model for our needs in this article to fit a joint model to multiple longitudinal responses, we consider the following density for our stacked response  ,
,
 |
Here, we have abused notation slightly for the sake of neat exposition, and understand  and
and 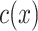 to be elementwise application of whichever transformation is appropriate for the type of outcome corresponding to the row in question. We assume that the random effects terms jointly follow a multivariate normal distribution with mean
to be elementwise application of whichever transformation is appropriate for the type of outcome corresponding to the row in question. We assume that the random effects terms jointly follow a multivariate normal distribution with mean 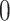 and unstructured covariance matrix
and unstructured covariance matrix  . That is,
. That is,
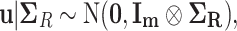 |
with 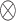 denoting a Kronecker product. The remaining terms in our model are;
denoting a Kronecker product. The remaining terms in our model are;
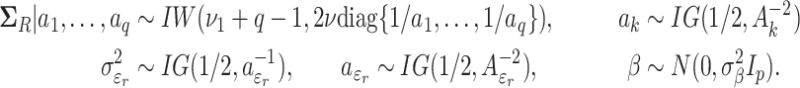 |
(2.2) |
In (2.2), we specify an Inverse-Wishart prior for the random effects covariance matrix  and inverse-gamma priors for the residual variances
and inverse-gamma priors for the residual variances  for the
for the  continuous markers included in the MGLMM. The inclusion of auxiliary variables
continuous markers included in the MGLMM. The inclusion of auxiliary variables 
 , and
, and 
 follows the extension of Huang and Wand (2013) in order to place weakly informative priors on the covariance terms in
follows the extension of Huang and Wand (2013) in order to place weakly informative priors on the covariance terms in  that are equivalent to the Half-Cauchy distributions proposed by Gelman (2006). The choice of
that are equivalent to the Half-Cauchy distributions proposed by Gelman (2006). The choice of  allows the standard deviation terms in
allows the standard deviation terms in  to have Half-t distributions with 2 degrees of freedom, whilst the correlation parameters have uniform distributions over
to have Half-t distributions with 2 degrees of freedom, whilst the correlation parameters have uniform distributions over  . Each auxiliary variable is assumed to independently follow an inverse-gamma distribution as specified in (2.2). A Normal prior with mean
. Each auxiliary variable is assumed to independently follow an inverse-gamma distribution as specified in (2.2). A Normal prior with mean  , and variance
, and variance 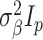 is placed on the fixed effects parameter
is placed on the fixed effects parameter 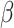 .
.
We desire posterior distributions on  . As mentioned in Section 1, one way to proceed would be to use an MCMC sampling routine. However, as we show in Section 5, this can be very computationally intensive in large data sets that contain data on many longitudinal markers. For this reason, in Section 3, we work towards a mean field variational Bayes solution for fitting MGLMMs in high-dimensional data.
. As mentioned in Section 1, one way to proceed would be to use an MCMC sampling routine. However, as we show in Section 5, this can be very computationally intensive in large data sets that contain data on many longitudinal markers. For this reason, in Section 3, we work towards a mean field variational Bayes solution for fitting MGLMMs in high-dimensional data.
3. Variational inference
Our aim in Bayesian inference is to find the posterior distribution for the parameters of interest in a model, described by 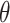 . Mean field variational Bayes aims to provide an approximation to
. Mean field variational Bayes aims to provide an approximation to  in situations where a full MCMC sampling procedure would be computationally expensive. An introduction to MFVB from a statistical perspective is given in Ormerod and Wand (2010). The basic premise is to approximate the complex posterior
in situations where a full MCMC sampling procedure would be computationally expensive. An introduction to MFVB from a statistical perspective is given in Ormerod and Wand (2010). The basic premise is to approximate the complex posterior  (which is challenging to estimate using MCMC), by a simpler density function
(which is challenging to estimate using MCMC), by a simpler density function 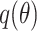 .
.
3.1. Overview of mean field variational Bayes
MFVB achieves substantial computational gains by enforcing a product restriction
 |
This restriction is known as the mean field restriction, hence the optimal solution, 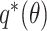 (from all possible distributions
(from all possible distributions  ) is known as the mean field variational Bayes (MFVB) approximation to the actual posterior distribution
) is known as the mean field variational Bayes (MFVB) approximation to the actual posterior distribution  . The challenge of MFVB is to select an optimal
. The challenge of MFVB is to select an optimal 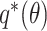 that is as close as possible, in terms of Kullback–Leibler divergence to the true posterior. To justify this approach, first consider the joint posterior of the parameter vector given the observed data,
that is as close as possible, in terms of Kullback–Leibler divergence to the true posterior. To justify this approach, first consider the joint posterior of the parameter vector given the observed data,
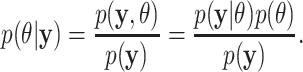 |
As explained in Ormerod and Wand (2010), simple algebraic manipulations show that the logarithm of the marginal likelihood satisfies
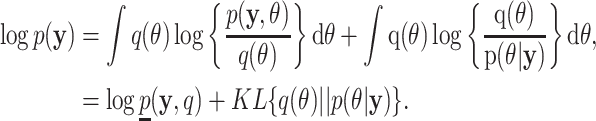 |
Since a KL divergence is always non-negative, we have that 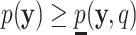 , and so minimizing the KL divergence (which is often intractable) is equivalent to maximizing
, and so minimizing the KL divergence (which is often intractable) is equivalent to maximizing  (which is usually more tractable). Hence, we have that
(which is usually more tractable). Hence, we have that
 |
Under the mean field product restriction, the optimal 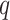 -density functions satisfy
-density functions satisfy
 |
(3.3) |
with 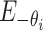 denoting the expectation with respect to all parameters in the model except for those in partition
denoting the expectation with respect to all parameters in the model except for those in partition  (referred to as the rest).
(referred to as the rest).
MFVB proceeds by determining optimal forms for each partition of 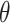 using (3.3), which will result in expression that each depend on other partitions of
using (3.3), which will result in expression that each depend on other partitions of 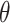 . These expressions can be iteratively updated until there is negligible increase in
. These expressions can be iteratively updated until there is negligible increase in 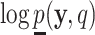 .
.
3.2. Mean field variational Bayes for multiple markers
Having given a sketched outline of the key elements of MFVB approximations, we now develop the MFVB approximation for the MGLMMs described in Section 2. We seek an approximation to the full posterior as follows.
 |
Note that the second restrictions are induced simply due to assumed independencies in the model specified in Section 2, and place no further restriction on the parameter space. That is, the strength of the MFVB approach depends in this case on the amount of information lost by the approximation by two factors.
Optimal 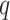 -densities can be calculated according to (3.3). The updates for
-densities can be calculated according to (3.3). The updates for  ,
,  and
and 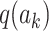 involve only relatively standard calculations and result in optimal densities that are inverse gamma distributions, with arguments according to Algorithm 1. Similarly,
involve only relatively standard calculations and result in optimal densities that are inverse gamma distributions, with arguments according to Algorithm 1. Similarly, 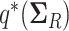 can be shown to be an inverse Wishart distribution. When all of the longitudinal markers are continuous,
can be shown to be an inverse Wishart distribution. When all of the longitudinal markers are continuous,  is a multivariate normal distribution. However, when at least some of the longitudinal markers are Poisson or binary, then evaluation of (3.3) no longer leads to a recognizable distribution. This is caused by the need to evaluate
is a multivariate normal distribution. However, when at least some of the longitudinal markers are Poisson or binary, then evaluation of (3.3) no longer leads to a recognizable distribution. This is caused by the need to evaluate  and
and 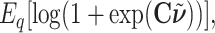 respectively. To overcome this difficulty, we follow the semiparametric MFVB approach outlined by Rohde and Wand (2016) and specify that
respectively. To overcome this difficulty, we follow the semiparametric MFVB approach outlined by Rohde and Wand (2016) and specify that  . We still need to evaluate the logistic term for binary markers. A number of approaches could be taken to deal with this, either through quadrature, or through the tilted bound of Jaakkola and Jordan (2000). However, we follow the approach of Nolan and Wand (2017) who use Knowles–Minka–Wand updates with Monahan–Stefanski updates to approximate the logistic fragment with a scaled mixture of normal distributions (Knowles and Minka, 2011; Wand, 2014; Monahan and Stefanski, 1989). Full derivations of these optimal
. We still need to evaluate the logistic term for binary markers. A number of approaches could be taken to deal with this, either through quadrature, or through the tilted bound of Jaakkola and Jordan (2000). However, we follow the approach of Nolan and Wand (2017) who use Knowles–Minka–Wand updates with Monahan–Stefanski updates to approximate the logistic fragment with a scaled mixture of normal distributions (Knowles and Minka, 2011; Wand, 2014; Monahan and Stefanski, 1989). Full derivations of these optimal 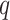 -densities are given in the Supplementary material available at Biostatistics online.
-densities are given in the Supplementary material available at Biostatistics online.
The updates for 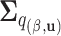 require calculation of the inverse of a potentially large matrix, which causes a huge computational cost, especially when
require calculation of the inverse of a potentially large matrix, which causes a huge computational cost, especially when  is large. However, we can exploit the block-diagonal structure of
is large. However, we can exploit the block-diagonal structure of 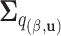 and streamline our MFVB algorithm using the approach of Lee and Wand (2016), in order to substantially improve the computational speed of our algorithm. Further details of the streamlining approach are given in the Supplementary material available at Biostatistics online. The full streamlined MFVB approximation for estimating an MGLMM is given in Algorithm 1. As noted by Rohde and Wand (2016) and Nolan and Wand (2017), the semiparametric MFVB algorithm proposed is not guaranteed to converge, although our empirical work suggests this is not a problem most of the time.
and streamline our MFVB algorithm using the approach of Lee and Wand (2016), in order to substantially improve the computational speed of our algorithm. Further details of the streamlining approach are given in the Supplementary material available at Biostatistics online. The full streamlined MFVB approximation for estimating an MGLMM is given in Algorithm 1. As noted by Rohde and Wand (2016) and Nolan and Wand (2017), the semiparametric MFVB algorithm proposed is not guaranteed to converge, although our empirical work suggests this is not a problem most of the time.
Algorithm 1
Streamlined algorithm for multivariate generalized linear mixed models.
1. Initialize
a
positive definite matrix,
,
, and
;
2. Cycle through updates
3.
4. for
5.
;
6.
7.
;
8.
9.
;
10. for
11.
12.
13.
;
;
14. for
15.
16. If marker
is Gaussian,
;
17. If marker
is Poisson,
;
18. If marker
is binary,
;
29. for
20.
21.
;
;
22. for
;
23.
24.
25. until the increase in
is negligible
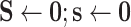


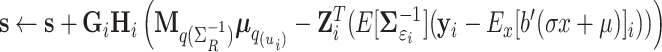
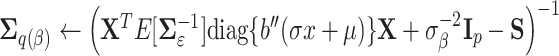
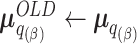





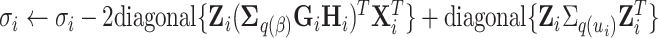



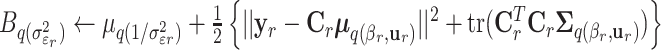

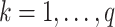
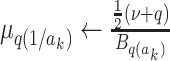


4. Simulation study
In this section, we assess the performance of the MFVB Algorithm 1, through a simulation study. We are interested in two key measures of performance; the accuracy of the MFVB posterior distributions when compared to posteriors derived using MCMC, and the speed gains in using the MFVB algorithm over the MCMC algorithm.
We designed two simulation scenarios. The first considered three continuous longitudinal markers according to model (4.4). The second scenario, considered one continuous, one binary and one Poisson longitudinal marker, according to model 4.5,
 |
(4.4) |
We assumed 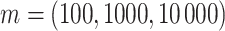 patients and simulated 100 data sets for each sample size. For each individual patient, we simulated between 5 and 10 visits according to a uniform distribution. At each visit, we simulated the three response outcome measurements according to model (4.4) or (4.5),
patients and simulated 100 data sets for each sample size. For each individual patient, we simulated between 5 and 10 visits according to a uniform distribution. At each visit, we simulated the three response outcome measurements according to model (4.4) or (4.5),
 |
(4.5) |
with all other simulation details remaining unchanged. For each of the simulated data sets we first fit a MGLMM using MCMC sampling using the R package mixAK (Komárek and Komárková, 2014). We simulated 10 000 samples after a burn in of 5000 and thinned by 10. Convergence of the MCMC samples was assessed by trace plots and autocorrelation functions. We also fit a MGLMM using our streamlined MFVB algorithm. The stopping criteria for our algorithm was the relative change in the log lower bound, 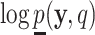 falling below
falling below 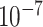 or a maximum of 500 iterations. Each simulated data set was submitted to the University of Liverpool cluster computing system, Condor, and the computations were performed on Windows 10 computers with a 3.4 gigahertz Intel Core i7-6700 processor and 16 gigabytes of random access memory.
or a maximum of 500 iterations. Each simulated data set was submitted to the University of Liverpool cluster computing system, Condor, and the computations were performed on Windows 10 computers with a 3.4 gigahertz Intel Core i7-6700 processor and 16 gigabytes of random access memory.
4.1. Comparison of accuracy
To compare the accuracy of the MFVB algorithm to the MCMC sample, we calculated the accuracy score based on the integrated absolute error as proposed by Faes and others (2011).
 |
(4.6) |
We used a kernel density estimate with plug-in bandwidth to estimate 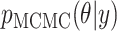 using the R package KernSmooth, (Wand and Ripley, 2009).
using the R package KernSmooth, (Wand and Ripley, 2009).
Figure 1 shows boxplots of the accuracy for each parameter in simulation scenarios 1 and 2, in the case where there were 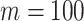 individuals. Similar plots for
individuals. Similar plots for  and
and  individuals are shown in the Figures S1 and S2 of the Supplementary material available at Biostatistics online. When all the markers are continuous, the MFVB algorithm estimates the posterior distribution with very good accuracy. The fixed effects are estimated very well, as are the estimates of residual standard deviations, with very little difference between the MCMC and MFVB posteriors. The random effects covariance matrix is slightly less accurate, but the MFVB posteriors are still very similar to the MCMC posteriors. When some of the markers are non-Gaussian, the MFVB estimates are less accurate. The fixed effects are still generally well estimated although the random effects covariances less so. This is a well-known feature of MFVB algorithms (see e.g., Luts and Wand, 2015). However, an inspection of Figures S3 and S4 of the Supplementary material available at Biostatistics online, which show the posterior density functions for scenarios 1 and 2, respectively for a single simulated data set, shows that the means of the posterior distributions are usually very similar for both the MFVB and MCMC approaches and also that the true parameter value was usually within MFVB credible intervals. The accuracy of posterior distribution estimation does not appear to be influenced by sample size very much.
individuals are shown in the Figures S1 and S2 of the Supplementary material available at Biostatistics online. When all the markers are continuous, the MFVB algorithm estimates the posterior distribution with very good accuracy. The fixed effects are estimated very well, as are the estimates of residual standard deviations, with very little difference between the MCMC and MFVB posteriors. The random effects covariance matrix is slightly less accurate, but the MFVB posteriors are still very similar to the MCMC posteriors. When some of the markers are non-Gaussian, the MFVB estimates are less accurate. The fixed effects are still generally well estimated although the random effects covariances less so. This is a well-known feature of MFVB algorithms (see e.g., Luts and Wand, 2015). However, an inspection of Figures S3 and S4 of the Supplementary material available at Biostatistics online, which show the posterior density functions for scenarios 1 and 2, respectively for a single simulated data set, shows that the means of the posterior distributions are usually very similar for both the MFVB and MCMC approaches and also that the true parameter value was usually within MFVB credible intervals. The accuracy of posterior distribution estimation does not appear to be influenced by sample size very much.
Fig. 1.

Accuracy scores for mean field variational Bayes compared to MCMC for simulated data sets with three continuous longitudinal markers (top panel) and three types of markers (bottom panel) in the simulation with  individuals.
individuals.
4.2. Comparison of computational speed
We also quantified the difference in computational time between the MFVB and MCMC approaches. The average time taken to fit each model in the simulated data sets is shown in Table 1. The MFVB routine is clearly substantially faster than the MCMC procedure. When all markers in an MGLMM are continuous, the speed gains are particularly noticeable. For example, in the model with 10 000 patients, the MCMC model takes more than 6 hours to fit, whilst the MFVB takes less than 7 min. The speed gains are less substantial in these simulations where the markers are not all continuous, although even in this case, when there are 10 000 patients, the MCMC model takes over 10.5 h to fit, whilst the MFVB model fits in just over an hour. The convergence of the MFVB algorithm is slower when adjustments need to be made for the Poisson and binary markers.
Table 1.
Average (standard deviation) computing time in seconds, for MFVB and MCMC approaches in simulated data sets.
| MCMC | MFVB | Ratio | |
|---|---|---|---|
| Three Gaussian markers | |||

|
267.32 (63.97) | 3.79 (1.46) | 70.49 |
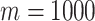
|
2029.57 (497.02) | 31.28 (11.70) | 64.88 |
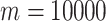
|
23 264.57 (5029.08) | 400.54 (125.54) | 58.08 |
| One Gaussian, Poisson, and Bernoulli marker | |||

|
430.26 (167.45) | 35.07 (17.35) | 12.27 |
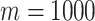
|
4717.34 (1222.18) | 635.45 (225.35) | 7.42 |
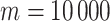
|
38 121.47 (15 647.86) | 4009.55 (2566.41) | 9.51 |
A comparison of speeds is to some extent subjective. Both approaches to fitting a MGLMM have different stopping criteria, which we have described at the beginning of this section. We have used freely available code to estimate our MCMC models. More efficient software could perhaps be written although, in our testing, the mixAK package was quicker than the more flexible rstan package for fitting MGLMMs using MCMC (in terms of obtaining the same number of samples with the same burn-in and thinning settings). We note too that other packages within R, such as the stan_mvmer function in rstanarmGoodrich and others (2018) or the brms package Bürkner (2017) could fit the models considered in this article, and bespoke codes may indeed produce MCMC estimates faster. Nevertheless, our aim in comparing speeds in this article is to show that MFVB models are substantially quicker than off-the-shelf software for MCMC.
To summarize our simulation results, we have shown that MFVB algorithms offer substantial time gains in fitting MGLMMs. These gains needs to be balanced against the reduced accuracy in some of the posterior distribution estimates, especially when not all of the markers are continuous. However, depending on which parameters are of interest to the researcher, the MFVB algorithm gives estimates of the means of the posterior distributions that are very similar to those obtained by MCMC, but in a much shorter time frame.
5. Real data examples
We now demonstrate the use of the MFVB algorithm to fit MGLMMs in two real data applications. The first is the well known, but relatively small primary biliary cirrhosis (PBC) data set. This data is publicly available within the mixAK package in R (and also in Appendix D of Fleming and Harrington (1991) and at http://lib.stat.cmu.edu/datasets/pbcseq). It contains measurements of seven continuous (bilirubin, albumin, alkaline phosphatase, cholesterol, serum glutamic-oxaloacetic transaminase, platelet count, and prothrombosis time) and three binary longitudinal markers (presence of ascites, hepatomegaly, and blood vessel malformations (spiders)) on 312 patients.
The second data set is a much larger data set coming from the Individualised Screening for Diabetic Retinopathy (ISDR) Cohort Study at the University of Liverpool. This study collected biomarker information on a number of risk factors for diabetic retinopathy in patients with diabetes who attended screening programs in the Merseyside region. For the purposes of this illustration, we will consider data on 17 682 patients, for whom we have repeated measurements of 10 continuous markers (HbA1c (mmol/mol), cholesterol (mmol/L), diastolic blood pressure (mm/Hg), systolic blood pressure (mm/Hg), high-density lipoprotein cholesterol (mmol/L), low-density lipoprotein cholesterol (mmol/L), eGFR (mL/min/1.73 m ), Albumin-Creatinine Ratio (mg/mmol), triglycerides (mmol/L), and body mass index (kg/m
), Albumin-Creatinine Ratio (mg/mmol), triglycerides (mmol/L), and body mass index (kg/m ) and two binary markers (retinopathy gradings in left and right eyes). A patient had a retinopathy grading of 0 if they were graded R0 (no retinopathy) in the eye being examined, and 1 if they were graded R1 (mild non-proliferative/background retinopathy). We have not considered any observations where the gradings showed more serious retinopathy, and so this analysis considers the longitudinal trajectories before sight threatening diabetic retinopathy is diagnosed. More details on this cohort can be found in García-Fiñana and others (2019) and Eleuteri and others (2017). Note that in both examples not all markers were collected at every time point for each patient. For each continuous marker, we considered a model with a random intercept and random slope, and a random intercept model for each binary marker. In addition, each marker had a fixed intercept and time slope. The values for the hyperparameters,
) and two binary markers (retinopathy gradings in left and right eyes). A patient had a retinopathy grading of 0 if they were graded R0 (no retinopathy) in the eye being examined, and 1 if they were graded R1 (mild non-proliferative/background retinopathy). We have not considered any observations where the gradings showed more serious retinopathy, and so this analysis considers the longitudinal trajectories before sight threatening diabetic retinopathy is diagnosed. More details on this cohort can be found in García-Fiñana and others (2019) and Eleuteri and others (2017). Note that in both examples not all markers were collected at every time point for each patient. For each continuous marker, we considered a model with a random intercept and random slope, and a random intercept model for each binary marker. In addition, each marker had a fixed intercept and time slope. The values for the hyperparameters,  ,
,  , and
, and  are each set to 10 000 and
are each set to 10 000 and  . In this analysis, all continuous markers except for systolic/diastolic blood pressure, body mass index, and eGFR were log transformed. All continuous markers were then scaled prior to the analysis.
. In this analysis, all continuous markers except for systolic/diastolic blood pressure, body mass index, and eGFR were log transformed. All continuous markers were then scaled prior to the analysis.
We compared the time taken to fit MGLMMs, and the accuracy of the posterior distributions for increasing numbers of markers in each data set. As before we assessed the accuracy using the integrated absolute error (4.6). All computations were performed on a personal computer with Windows 10 operating system and a 3.5 gigahertz Intel Xeon E5-1620 processor and 16 gigabyte of random access memory.
5.1. Primary biliary cirrhosis
We first assessed the MFVB algorithm in the PBC data which is small enough for MCMC sampling to be computationally feasible, even in the 10 marker model. Our aim was to provide proof-of-concept in a small data set where comparison to MCMC was relatively easy, in order to justify the use of the MFVB algorithm in much larger data sets where MCMC would be computationally challenging.
Table 2 shows the time taken to fit MGLMMs with increasing numbers of markers. In general, the MFVB approach was substantially faster than MCMC sampling. As more markers were included in the model, the improvement by using the MFVB approach was even more noticeable. Notice that even in a relatively small data set, the full 10-marker MGLMM took around 48 min to fit using MCMC, but only 14 s using our MFVB algorithm. An example of the failure to converge of the MFVB model can be seen in the 8-marker model. Nevertheless, after 500 iterations, the results, although not technically converged, still gave good accuracy estimates (results not shown, but are comparable to those presented in the 10-marker model in Figure S5 of the Supplementary material available at Biostatistics online.
Table 2.
Average computing time for MFVB and MCMC approaches in primary biliary cirrhosis data (in seconds) and in the diabetic retinopathy data (in hours).
| Number of markers | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Primary biliary cirrhosis computation times (in seconds) | ||||||||||||
| MCMC | 84.20 | 134.65 | 219.19 | 342.17 | 483.93 | 665.26 | 895.80 | 1983.25 | 2409.01 | 2890.92 | ||
| MFVB | 1.30 | 2.88 | 3.14 | 5.95 | 6.64 | 6.55 | 6.87 | 27.73 | 13.73 | 14.75 | ||
| Ratio | 64.77 | 46.80 | 69.74 | 57.53 | 72.92 | 101.58 | 130.39 | 71.52 | 175.43 | 196.05 | ||
| Diabetic retinopathy computation times (in hours) | ||||||||||||
| MCMC | 1.14 | 1.71 | 2.90 | 4.44 | 6.41 | 8.90 | 11.99 | 15.84 | 19.78 | 24.80 | 53.22 | 62.19 |
| MFVB | 0.04 | 0.07 | 0.12 | 0.32 | 0.33 | 0.47 | 0.48 | 0.51 | 0.64 | 0.69 | 0.77 | 0.92 |
| Ratio | 27.56 | 25.22 | 24.08 | 13.66 | 19.59 | 18.97 | 24.89 | 31.16 | 30.77 | 35.68 | 69.02 | 67.57 |
In terms of accuracy, we present here the results for the most complicated model with 10 longitudinal markers. Figure S5 of the Supplementary material available at Biostatistics online shows heat maps showing the accuracy for the model parameters and the implied correlations between longitudinal markers. Only two random effects variances score lower than 50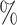 accuracy, whilst the majority of parameters are estimated with good to excellent accuracy, showing that very similar results can be obtained in the 14 s required for the MFVB algorithm, and the MCMC sampling that required 48 min. As in the simulation studies, the fixed effects were estimated with very high accuracy.
accuracy, whilst the majority of parameters are estimated with good to excellent accuracy, showing that very similar results can be obtained in the 14 s required for the MFVB algorithm, and the MCMC sampling that required 48 min. As in the simulation studies, the fixed effects were estimated with very high accuracy.
5.2. Individualized screening for diabetic retinopathy
The diabetic retinopathy application demonstrates the performance of MFVB in a much larger data set and gives a greater indication of the speed gains possible with MFVB. The times in hours of models with increasing numbers of longitudinal markers are shown in Table 2. The full 12-marker model was fit in less than one hour using MFVB whilst the MCMC fit required more than 2.5 days. Figure 2 reports the accuracy of this model. Again the fixed effects estimates are generally very well estimated, and most of the random effects covariance matrix parameters are reasonably accurately estimated, and clearly in a much shorter time frame than the MCMC model. The random effects for the two binary intercepts are poorly estimated in this case.
Fig. 2.

Model results for a 12 marker multivariate generalized linear mixed model in the diabetic retinopathy. Panel (a) shows the accuracy heat maps of the MFVB fixed effects estimates and residual standard deviations (compared to the MCMC estimates), (b) shows the accuracy of the MFVB random effects covariance matrix (compared to the MCMC estimates), and (c) shows the implied matrix of correlations between the 12 longitudinal markers calculated using MFVB.
The correlation plot in panel (c) of Figure 2 reveals markers that are highly correlated, and shows why one may wish to model longitudinal markers simultaneously. We are able to identify reasonably strong positive correlations between changes over time in a patient’s triglycerides values and their HbA1c, cholesterol, and low-density lipoprotein cholesterol values. We also note negative correlations between triglycerides and high-density lipoprotein cholesterol both in terms of initial value and changes over time.
Figure 3 shows the fitted models for each of the 12 diabetic retinopathy markers for three patients. There is very little difference between the fitted regression lines obtained by MCMC and MFVB. Even when accuracy scores (compared to MCMC) are not as high as one might desire, many of the results extracted from a model fit are almost identical to those that would be obtained with MCMC. The lower accuracy is largely caused by the known problem of poor covariance estimation for some parameters.
Fig. 3.

Fitted longitudinal markers for mean field variational Bayes (dashed lines) compared to MCMC (solid lines) for the 12 markers in the diabetic retinopathy data, for three patients. The orange stars, green dots, and blue triangles show the observed values for three different patients, with the respectively colored lines showing the fitted models for each individual. All continuous values, including time, have been scaled prior to analysis and the results plotted here are in terms of the scaled variables. The y-axis of each plot shows the scale version of the variable noted in the title of each panel. The original units for each variable can be found in the description at the start of Section 5.
6. Summary
In this article, we present an approach for fast approximate Bayesian inference for multivariate longitudinal data. We have described how mean field variational Bayes can be used to obtain fast accurate results, that are very similar to those obtained by the much slower MCMC routines. Our article adds to the growing literature showing that MFVB is a promising avenue for fast inference in Bayesian models and demonstrates that this usefulness extends to multivariate generalized linear mixed models.
We have demonstrated through simulation studies and through application to clinical data sets that MFVB offers significant time gains over MCMC, although sometimes with the cost of less accurate estimation of covariance. This could be of use in early exploration of model fits, where assessing multiple competing models is prohibitive if models take days rather than minutes/hours to fit. MFVB could also be used to obtain good starting points for MCMC based inference, in an attempt to speed up MCMC procedures. However, we believe our article demonstrates that for many outputs of interest, MFVB provides good estimates in its own right.
Future work should investigate ways to improve the speed of MFVB algorithms further, without losing accuracy in the estimation of posterior distributions. One possible avenue for pursuing this could be through model reparameterization which Tan (2021) shows can improve both accuracy and speed of convergence.
We have demonstrated our MFVB approach in two clinical data sets. Although the diabetic retinopathy data consists of data on 12 longitudinal markers for 17 682 patients, this number is potentially small in comparison to the data increasingly available form sources such as electronic health records, where data may be held on hundreds of thousands of patients, with many more than 12 longitudinal markers. Although MCMC is slow in the diabetic retinopathy application (with the 12-marker model taking more than 2.5 days to fit), it is still at least feasible. This would not be the case in the much larger data sets available through electronic health records.
In this article, we have shown that MFVB can give accurate parameter estimates in much faster times, which gives confidence that they could do so in settings where MCMC was computationally infeasible. In this case, it is desirable to have some indication about how good an MFVB approximation is. Two promising post hoc diagnostic tools have been proposed to assess goodness of fit by Yao and others (2018). The first assesses the goodness of fit of the joint distribution (i.e., how close is  to the true
to the true  ), interpreting the shape parameter from Pareto smoothed importance sampling as the Renyi divergence between
), interpreting the shape parameter from Pareto smoothed importance sampling as the Renyi divergence between  and
and  , with small divergences indicating good fit. This approach offers the interesting prospect of correcting MFVB estimates post analysis and would be a profitable avenue for further research. The second diagnostic proposed is a variational simulation based calibration diagnostic that assesses the average performance of point estimates from an MFVB approximation.
, with small divergences indicating good fit. This approach offers the interesting prospect of correcting MFVB estimates post analysis and would be a profitable avenue for further research. The second diagnostic proposed is a variational simulation based calibration diagnostic that assesses the average performance of point estimates from an MFVB approximation.
The applications to primary biliary cirrhosis and diabetic retinopathy data in this article were for the purposes of illustration. One may also wish to consider the influence of many other covariates on the longitudinal profiles of various markers. This is perfectly possible within the algorithm presented in this article. Similarly, as not all markers are measured at each time point, there could well be information simply in the fact that a marker was measured. Additional work could be done to model this informative observation. This was outside the scope of this article and would be an interesting avenue for future work.
The problem of poorly estimated covariance matrices observed in this article is a well-known problem with MFVB algorithms. How much of a problem this is depends on what a researcher wants from a model. If estimates of posterior means are required then MFVB can provide very good estimates. Equally, if the MGLMM is to be used for prediction or classification (e.g., Hughes and others, 2018) then fast and accurate estimate of posterior means may be sufficient. If a more accurate assessment of variability is required, then more work is required. One promising area we are currently investigating is the use of linear response variational Bayes to correct MFVB variance estimates (Giordano and others, 2015).
Although we have shown in this article that MFVB can provide a very useful modelling tool in complex longitudinal models, there is no guarantee that MFVB will always provide a good solution. Much depends on how much correlation is ignored in the mean field product restriction. Additionally, Nolan and Wand (2017) show that the amount of posterior correlation between regression parameters can affect the performance of MFVB. Other features of a problem, unrelated to MFVB specifically, such as the number of repeated measurements per individual, and the sample size in general will likely contribute to the quality of a MFVB approximation.
Overall, MFVB offers a fast and useful alternative to MCMC for scalable Bayesian inference in complex longitudinal data.
7. Software
Software in the form of R code, together with a sample input data set and complete documentation is available on request from the corresponding author (dmhughes@liverpool.ac.uk). Code to reproduce the PBC analysis is available on GitHub at https://github.com/dmhughesLiv/VariationalBayes
Supplementary Material
Acknowledgments
We are grateful to Professor Simon Harding for permission to use the Individualised Screening for diabetic retinopathy data set, and Dr Chris Cheyne for helpful discussions about this data. We thank Dr Ian Smith for help using the University of Liverpool Condor system. Conflict of Interest: None declared.
Contributor Information
David M Hughes, Department of Health Data Science, Waterhouse Building, Block F, University of Liverpool, 1-5 Brownlow Street, Liverpool, L69 3GL, UK.
Marta García-Fiñana, Department of Health Data Science, Waterhouse Building, Block F, University of Liverpool, 1-5 Brownlow Street, Liverpool, L69 3GL, UK.
Matt P Wand, School of Mathematical and Physical Sciences, University of Technology Sydney, P.O. Box 123, Broadway, NSW 2007, AUSTRALIA.
Supplementary material
Supplementary material is available at http://biostatistics.oxfordjournals.org.
Funding
UK Research & Innovation, Innovation Fellowship, funded by the Medical Research Council (Research Project MR/R024847/1 to D.M.H.); Australian Research Council Discovery Project (DP140100441), in part.
References
- Baltagi, B. (2008). Econometric Analysis of Panel Data. Chichester, UK: Wiley. [Google Scholar]
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. New York: Springer. [Google Scholar]
- Blei, D. M., Kucukelbir, A. and McAuliffe, J. D. (2017). Variational inference: a review for statisticians. Journal of the American Statistical Association 112, 859–877. [Google Scholar]
- Bürkner, P.-C. (2017). brms: an R package for Bayesian multilevel models using stan. Journal of Statistical Software 80, 1–28. [Google Scholar]
- Diggle, P. J., Heagerty, P., Liang, K.-Y., Heagerty, P. J. and Zeger, S. (2002). Analysis of Longitudinal Data. Oxford, UK: Oxford University Press. [Google Scholar]
- Eleuteri, A., Fisher, A. C., Broadbent, D. M., García-Fiñana, M., Cheyne, C. P., Wang, A., Stratton, I. M., Gabbay, M., Seddon, D. and Harding, S. P. (2017). Individualised variable-interval risk-based screening for sight-threatening diabetic retinopathy: the Liverpool Risk Calculation Engine. Diabetologia 60, 2174–2182. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Faes, C., Ormerod, J. T. and Wand, M. P. (2011). Variational Bayesian inference for parametric and nonparametric regression with missing data. Journal of the American Statistical Association 106, 959–971. [Google Scholar]
- Fieuws, S., Verbeke, G. and Molenberghs, G. (2007). Random-effects models for multivariate repeated measures. Statistical Methods in Medical Research 16, 387–397. [DOI] [PubMed] [Google Scholar]
- Fleming, T. R. and Harrington, D. P. (1991). Counting Processes and Survival Analysis. New York: Wiley. [Google Scholar]
- García-Fiñana, M., Hughes, D. M., Cheyne, C. P., Broadbent, D. M., Wang, A., Komárek, A., Stratton, I. M., Mobayen-Rahni, M., Alshukri, A., Vora, J. P.. and others. (2019). Personalized risk-based screening for diabetic retinopathy: a multivariate approach versus the use of stratification rules. Diabetes, Obesity and Metabolism 21, 560–568. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gelman, A. (2006). Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Analysis 1, 515–534. [Google Scholar]
- Gelman, A. and Hill, J. (2007). Data Analysis using Regression and Multilevel/Hierarchical Models. New York: Cambridge University Press. [Google Scholar]
- Giordano, R. J., Broderick, T. and Jordan, M. I. (2015). Linear response methods for accurate covariance estimates from mean field variational Bayes. In: Advances in Neural Information Processing Systems. pp. 1441–1449. [Google Scholar]
- Goldstein, H. (2011). Multilevel Statistical Models. Chichester, UK: Wiley. [Google Scholar]
- Goodrich, B., Gabry, J., Ali, I. and Brilleman, S. (2018). rstanarm: Bayesian applied regression modeling via stan. R package version 2, 1758. [Google Scholar]
- Huang, A. and Wand, M. P. (2013). Simple marginally noninformative prior distributions for covariance matrices. Bayesian Analysis 8, 439–452. [Google Scholar]
- Hughes, D. M., Komárek, A., Czanner, G. and Garcia-Finana, M. (2018). Dynamic longitudinal discriminant analysis using multiple longitudinal markers of different types. Statistical Methods in Medical Research 27, 2060–2080. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jaakkola, T. S. and Jordan, M. I. (2000). Bayesian parameter estimation via variational methods. Statistics and Computing 10, 25–37. [Google Scholar]
- Knowles, D. A. and Minka, T. (2011). Non-conjugate variational message passing for multinomial and binary regression. In: Shawe-Taylor, J., Zamel, R. S., Bartlett, P., Pereira, F. and Weinberger, K. Q. (editors), Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, pp. 1701–1709. [Google Scholar]
- Komárek, A. and Komárková, L. (2014). Capabilities of R package mixAK for clustering based on multivariate continuous and discrete longitudinal data. Journal of Statistical Software 59, 1–38.26917999 [Google Scholar]
- Laird, N. M. and Ware, J. H. (1982). Random-effects models for longitudinal data. Biometrics 38, 963–974. [PubMed] [Google Scholar]
- Lee, C. Y. Y. and Wand, M. P. (2016). Streamlined mean field variational Bayes for longitudinal and multilevel data analysis. Biometrical Journal 58, 868–895. [DOI] [PubMed] [Google Scholar]
- Luts, J. and Wand, M. P. (2015). Variational inference for count response semiparametric regression. Bayesian Analysis 10, 991–1023. [Google Scholar]
- McCullagh, P. and Nelder, J. (1989). Generalized Linear Models, 2nd edition. London: Chapman & Hall. [Google Scholar]
- McCulloch, C. E., Searle, S. R. and Neuhaus, J. M. (2008). Generalized, Linear, and Mixed Models. New York: Wiley. [Google Scholar]
- Molenberghs, G. and Verbeke, G. (2005). Models for Discrete Longitudinal Data. New York: Springer. [Google Scholar]
-
Monahan, J. F. and Stefanski, L. A. (1989). Normal scale mixture approximations to
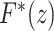 and computation of the logistic-normal integral. In: Balakrishnan, N. (editor), Handbook of the Logistic Distribution. New York: Marcel Dekker, pp. 529–540. [Google Scholar]
and computation of the logistic-normal integral. In: Balakrishnan, N. (editor), Handbook of the Logistic Distribution. New York: Marcel Dekker, pp. 529–540. [Google Scholar] - Nolan, T. H. and Wand, M. P. (2017). Accurate logistic variational message passing: algebraic and numerical details. Stat 6, 102–112. [Google Scholar]
- Ormerod, J. T. and Wand, M. P. (2010). Explaining variational approximations. The American Statistician 64, 140–153. [Google Scholar]
- Rao, J. N. K. and Molina, I. (2015). Small Area Estimation. New York: Wiley-Blackwell. [Google Scholar]
- Rohde, D. and Wand, M. P. (2016). Semiparametric mean field variational Bayes: general principles and numerical issues. The Journal of Machine Learning Research 17, 5975–6021. [Google Scholar]
- Tan, L. S. L. (2021). Use of model reparametrization to improve variational Bayes. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 83, 30–57. [Google Scholar]
- Verbeke, G., Fieuws, S., Molenberghs, G. and Davidian, M. (2014). The analysis of multivariate longitudinal data: a review. Statistical Methods in Medical Research 23, 42–59. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Verbeke, G. and Molenberghs, G. (2000). Linear Mixed Models for Longitudinal Data. New York: Springer. [Google Scholar]
- Wand, M. P. (2014). Fully simplified multivariate normal updates in non-conjugate variational message passing. Journal of Machine Learning Research 15, 1351–1369. [Google Scholar]
- Wand, M. P. (2017). Fast approximate inference for arbitrarily large semiparametric regression models via message passing. Journal of the American Statistical Association 112, 137–168. [Google Scholar]
- Wand, M. P. and Ripley, B. D. (2009). KernSmooth: Functions for Kernel Smoothing Corresponding to the Book: Wand, M.P. & Jones, M.C. (1995) Kernel Smoothing. R package. R package version 2.23. [Google Scholar]
- Yao, Y., Vehtari, A., Simpson, D. and Gelman, A. (2018). Yes, but did it work?: Evaluating variational inference. In: International Conference on Machine Learning. PMLR. pp. 5581–5590. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.