

Abstract
Using event-related potentials (ERPs), this study investigated how the brains of Chinese children of different ages extract and encode relational patterns contained in orthographic input. Ninety-nine Chinese children in Grades 1-3 performed an artificial orthography statistical learning task that comprised logographic components embedded in characters with high (100%), moderate (80%), and low (60%) positional consistency. The behavioral results indicated that across grades, participants more accurately recognized characters with high rather than low consistency. The neurophysiological results revealed that in each grade, the amplitude of some ERP components differed, with a larger P1 effect in the high consistency condition and a larger N170 and left-lateralized P300 effect in the low consistency condition. A smaller N170 effect occurred in Grade 3 than in Grade 1, and a larger P300 effect occurred in Grade 1 than in either Grade 2 or 3. These findings suggest the dynamic nature of statistical learning by showing that neural adaptation associated with N170, and attention and working memory related to P1 and P300, regulate different types of structural input, and that children’s abilities to prioritize these mechanisms vary with context and age.
Keywords: Statistical learning, Orthographic regularity, P1-N170-P300 pattern, Neural adaptation, Attention and working memory
Highlights
-
•
How multiple mechanisms regulate statistical learning remains unknown.
-
•
EEG recorded children’s learning of high-, moderate- and low-positional consistencies.
-
•
An attenuated N170 for high-consistency reflects neural adaptation.
-
•
An enhanced P1 and P300 for low-consistency indicate attention and working memory.
-
•
Statistical learning is supported by adaptation, attention and working memory.
Previous behavioral studies have demonstrated that statistical learning—the ability to involuntarily extract and encode relational patterns of environmental input—plays a critical role in reading acquisition (for a review, see Lee et al., 2022). This is partly because many orthographies contain myriad statistical patterns that can be detected and learned by young children through mere repeated exposure (e.g., Frost et al., 2013; Treiman and Kessler, 2022). Also, individual's implicit orthographic processing, defined as sensitivity to the untaught distribution of print patterns (e.g., the co-occurring frequency of letters or letter clusters in English, and the position of occurrence of radicals/stroke patterns in Chinese), determines initial reading success (e.g., Apel, 2011; Tong et al., 2019, Tong et al., 2020a). For example, using sperate measures of statistical learning and implicit orthographic processing, a recent study has suggested a potential direct link between visual statistical learning and the acquisition of orthographic regularities (e.g., Tong et al., 2019). However, due to the constraints of behavioral approach and the lack of a unified paradigm for tapping directly into the processes of statistical learning of orthographic regularities, what the neural mechanisms underpin, and the possible developmental changes affecting statistical learning of orthographic regularities remain less well understood. Thus, by employing event-related potentials (ERPs) to record continuous neural signals evoked by cognitive processes before the behavioral response (e.g., Sommer et al., 2022), this study synergized statistical learning with orthographic regularity acquisition in an artificial logography learning paradigm to examine the neural correlates of statistical learning of orthographic regularities and the possible developmental changes at the neural level of Chinese first-, second-, and third-graders.
As a logographic script, Chinese compound characters exhibit orthographic regularities by the position and function of radicals and stroke patterns, which are the constituent components of characters. For example, the left-right structured, semantic-phonetic compound character 情/qing2/ (affection) comprises a left-sided phonetic radical 青 /qing1/ providing a sound cue and a right-sided semantic radical 忄(heart-related) indicating a clue to meaning. Positional consistency refers to the probability of a radical appearing at a given position within characters (Tong et al., 2020a). Since the radical 忄always appears on the left, its left positional consistency is 100%, but zero for other locations. However, unlike 忄, the positional regularities of radicals and stroke patterns are not exclusively regular/rule-basedbut more quasi-regular. For example, among a corpus of 3,764 characters learned by Chinese primary school students, 42 contain the component "目", which appears on the left in 29 (e.g., 瞇, 睫, 瞅, 瞞, 瞄, 盯, 瞎, 睜, 瞼, 瞪, 睡, 眼, 睛. 眨, 睹, 瞧, 盼, 瞭, 眠, 眺, 瞻, 瞰, 睬, 矚, 瞬, 眶, 眈, 瞌, 睦), on the right in one (i.e., 相), at the top in one (e.g., 鼎), at the bottom in 10 (e.g., 看, 督, 眉, 冒, 盲, 省, 盾, 瞥, 眷, 着), and in the middle in one (i.e., 算). Thus, the distribution of the occurrence frequency of "目" is 69.05%, 2.38%, 2.38%, 23.81%, and 2.38% for left, right, top, bottom, and middle, respectively.
In fact, several behavioral studies have demonstrated that Chinese children are sensitive to the untaught distributional patterns of positional regularities of radicals and stroke patterns. For example, using an implicit orthographic regularity elicitation paradigm, Tong and McBride (2014) showed that even 5-year-old Chinese kindergarteners were sensitive to the distributional patterns of character components. Similarly, Yin and McBride (2015) found that Chinese kindergartners’ accuracy was higher when reading pseudocharacters with phonetic cues or with radicals in their legal, rather than illegal, position. A recent study corroborated these findings by showing that Chinese children with dyslexia can statistically extract positional regularities of radicals, but were influenced by distributional patterns of left-right and top-bottom structured characters (Tong et al., 2020b). Together, these behavioral studies indicate that Chinese children can extract statistical regularities at a very young age and manifest them in their reading behavior. However, none of these studies elucidate the neural processes that enable these children to cope with quasi-regularity of the positional occurrence of radicals, and establish the representation for further learning and reading.
Recently, Conway (2020) proposed a multicomponent model encompassing two primary cortical systems, with the first comprising a set of implicit, unconscious learning mechanisms based on the general principle of cortical plasticity, while the second is an explicit, conscious process mediated by attentional and working memory networks. In the implicit system, statistical learning’s plasticity of processing reflects the adaptation of neural networks to statistical structures (Reber, 2013), which is associated with reduced neural activity (Grill-Spector et al., 2006). According to the second system, statistical learning also involves consciousness, including attention and working memory, to learn complex regularities through accumulated experience (e.g., Daltrozzo and Conway, 2014; Hendricks et al., 2013). Similarly, Mano (2016) assumed sensitivity to orthographic regularities as a two-process framework involving statistical learning, task-driven attentional control, and their dynamic interplay in sublexical processing, that mainly activated the posterior occipitotemporal sulcal region (i.e., visual word form area; Cohen and Dehaene, 2004).
Aligning with the multicomponent views, several ERP studies provided initial evidence for the possible involvement of multiple cognitive processes during statistical learning. For example, using a short interstimulus interval adaptation paradigm, Cao et al. (2014) compared the N170 effects elicited by two adaptor-test pairs and found that test characters with the same adaptor (vs. a foil adaptor) produced a smaller N170, reflecting an increased efficiency in neural adaptation (Reber, 2013). Meanwhile, Turk-Browne et al. (2005) found that while statistical regularities could be automatically and implicitly learned, this process was controlled by selective attention as evidenced by slower responses in the attended stream condition but not in the unattended condition.
Indeed, past studies suggested that attentional levels affected all ERP components corresponding to statistical learning (Daltrozzo and Conway, 2014). For example, P300 reflects the extent of attentional resource allocation and the depth of input processing (Peisch et al., 2021) and is a neural indicator of working memory load during conscious visual processing (Koivisto et al., 2018). Also, P1, a positive ERP component recorded at 90–130 ms after stimulus onset in occipital sites, is related to children’s visual processing and spatial location (e.g., Taylor et al., 2003). Baldwin and Kutas (1997) demonstrated that P300 effects were evoked by sequence violations in both explicit and implicit statistical learning. Neural imaging studies further revealed that implicit learning tasks triggered the caudate nucleus, a brain area that was activated in explicit rule learning and working memory (e.g., Lieberman et al., 2004; Seger and Cincotta, 2002). Together, these prior neuroscience studies reinforce our hypothesis that statistical learning of orthographic regularities may be supported by multiple neural mechanisms operating at different stages of learning. We tested this hypothesis with developing Chinese children.
Our second aim is to address another unresolved issue concerning a developmental change in statistical learning: namely, how age affects neural mechanisms of statistical learning (Daltrozzo and Conway, 2014). The developmental invariance model assumes that implicit statistical learning is an age-independent cognitive process (Reber, 1993). An ERP study using a predictor-target task on adults, older children (aged 9–12), and younger children (aged 6–8) showed that high predictors evoked a similar P300 effect across all three groups, indicating no age difference for visual statistical learning (Jost et al., 2015). However, the age-variant model claims that children’s performance improves as they age (e.g., Arciuli and Simpson, 2011). Employing the visual triplet statistical learning paradigm on 5- to 12-year-olds, Arciuli and Simpson (2011) demonstrated that older children outperformed younger children. Furthermore, Raviv and Arnon (2018) found that the age effect was modality-specific such that visual but not auditory statistical learning improved with age. Subsequently, Shufaniya and Arnon (2018) reported that both learning patterns in different perceptual modalities improved with age, resulting in age invariance for the input’s linguistic feature.
In sum, our study examined 1) when and to what extent children’s brains were activated during statistical learning of orthographic regularities, and 2) the developmental differences of this process in first-, second-, and third- graders. Specifically, by detecting the temporal course of each ERP indicator and comparing the activated ERP differences among three position consistency levels (i.e., high, moderate, and low), we clarified the neural mechanism underpinning statistical learning of orthographic regularities in children from 7 to 9. As in study of Tong et al. (2020a) showing N170 as the ERP indicator of adults’ statistical learning of positional consistency, we hypothesize a larger N170 effect in low versus high condition. Furthermore, since younger children’s processing is less automatic than older children's, their statistical learning of orthographic regularities demands more explicit attention and working memory. We thus hypothesize the attenuated N170 response elicited by high condition relative to moderate and low conditions (reflecting implicit process), and that the P300 becomes smaller as age increases (indicating explicit process).
1. Method
1.1. Participants
One hundred healthy native Chinese first- (17 boys, 15 girls; Mean age = 7 years, 2 months, SD = 4.69 months), second- (17 boys, 19 girls; Mean age = 8 years, 3 months, SD = 4.12 months), and third-graders (13 boys, 19 girls; Mean age = 9 years, 6 months, SD = 7.68 months) participated in this study. One second-grader whose accuracy rate in the learning phase was 2.5 standard deviations below the individual mean was removed from the final analysis. Data for two second-graders in the recognition test were non-existent since they completed the EEG recording in the learning phase only. Therefore, 99 children’s EEG data were used for final EEG data analysis and 97 children’s data were used for the recognition data analysis. All participants had normal or corrected-to-normal vision and were right-handed. Ethical approval for this study was obtained from the Research Ethics Committee of the corresponding author’s university.
1.2. Materials
Stimuli were adopted and modified from a past study (He and Tong, 2017). For the learning phase, stimuli consisted of 30 artificial pseudocharacters combining six target radicals with five control radicals adopted from Geba and Dongba characters used by the Naxi minority in Western China. Participants in this study were unfamiliar with these two scripts. The target radicals appeared in two positions (i.e., half at the top, half at the bottom) and were manipulated to carry different levels of positional consistency: high (100%), moderate (80%), and low (60%), according to orthographic regularity in Chinese radicals. The high consistency radicals (e.g.,  ) were manipulated to appear in the same top or bottom position in all five pseudocharacters (e.g.,
) were manipulated to appear in the same top or bottom position in all five pseudocharacters (e.g., 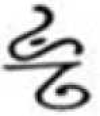 ,
, ,
, ,
, ,
, ). The moderate radicals (e.g.,
). The moderate radicals (e.g.,  ) were manipulated to appear at the top or bottom in four pseudocharacters with 20% in the opposite position (e.g.,
) were manipulated to appear at the top or bottom in four pseudocharacters with 20% in the opposite position (e.g.,  ,
, ,
, ,
, ,
, ). The low consistency radicals (e.g.,
). The low consistency radicals (e.g.,  ) were manipulated to appear at the top or bottom in three pseudocharacters with 40% in the opposite position (e.g.,
) were manipulated to appear at the top or bottom in three pseudocharacters with 40% in the opposite position (e.g.,  ,
, ,
, ,
, ,
, ). The control radical carried no positional preference among items. Thirty pseudocharacters (10 for each condition) were ultimately created in the learning phase.
). The control radical carried no positional preference among items. Thirty pseudocharacters (10 for each condition) were ultimately created in the learning phase.
The visual complexity of all pseudocharacters was matched through cosine similarity to control for visual difference among items in the three conditions. Widely used in machine learning to extract critical words from a text to show high sensitivity between two characters, cosine similarity assesses similarity according to the cosine of the angle between the vectors of two items (Korenius et al., 2007, Xia et al., 2015). The similarity between two characters, c1 and c2, is defined as:
where c1 and c2 are the value of pixels on the binary images of character c1 and c2, respectively. The similarity score between two characters ranges from zero to one, with higher scores indicating higher levels of similarity. Using the cosine similarity measure, three 10 × 10 matrixes for every two consistency levels (each contains 10 items) were obtained in this study. Results show that the averaged visual similarities for every two consistency levels are matched (high vs. moderate: M = 0.911; high vs. low: M = 0.912; moderate vs. low: M = 0.912). Fig. 1 displays the averaged similarity scores of 100 paired comparisons for every two conditions.
Fig. 1.

The similarity scores of 100 paired comparisons for every two conditions. The averaged similarities are in the lower left.
1.3. Procedure
All participants were involved in the learning and recognition phases. During the learning phase, participants were exposed to a continuous sequence of pseudocharacters in a fixed pseudo-randomized order at the center of the monitor (e.g., He and Tong, 2017). Stimuli were displayed using E-Prime 2.0 software (Psychology Software Tools, Pittsburgh, PA). For each trial, a fixation “+ ” was shown at the center of the monitor for 500 ms, followed by a blank screen for 500 ms. Then, a pseudocharacter appeared for 800 ms, followed by a blank screen for 1000 ms. Participants were required to press the SPACEBAR key when two identical stimuli appeared continuously. Each stimulus was repeated 24 times resulting in 720 trials.
The recognition phase contained 30 stimuli, half of which were original stimuli used in the learning phase, and the other half novel stimuli created by reversing the positions of target and control radicals. Participants were required to press corresponding keys if they recognized stimuli from the learning phase. Items remained visible until the participants responded. Children’s reaction time and accuracy rate were recorded for both the learning and recognition phases. The experiment lasted approximately 40 minutes.
1.4. EEG recording and data analysis
While children performed the statistical learning task in the learning phase, the Brain Product 32-channel Ag/AgCl system (Brain Products Inc) recorded EEG at a sample rate of 500 Hz with the FCz electrode as the online reference. Electrode impedances were kept below 15 kΩ. EEG data were preprocessed with EEGLAB (Delorme and Makeig, 2004) and re-referenced to the average reference with ICA employed to correct for eye-blink artifacts. The continuous EEG was segmented into epochs from − 100–600 ms and time-locked to the target stimuli with a 2–30 Hz band-pass filter. The baseline of each epoch was corrected from − 100–0 ms, and ERPs were averaged within each condition.
Using Global Field Power (GFP), ERP components were identified based on their peak. Within each grade, peaks were similar for each component. Thus, the average GFP in all participants determined the time window of each component. As shown in Fig. 2, a large positive waveform, i.e., the P1 component, was observed at 146 ms. A large negative waveform, i.e., the N170 component, was found at 230 ms. Another large positive waveform, the P300 component, was observed at 344 ms. Therefore, three ERP components, i.e., P1 (120–180 ms), N170 (210–250 ms), and P300 (320–370 ms), were identified. Past studies have suggested that orthographic processing is located in the occipital-temporal area (Tong et al., 2020a, Tong et al., 2020b). We thus selected four electrodes (i.e., P7, P8, O1, and O2) in the occipital-temporal areas based on the topographic maxima over both hemispheres across different conditions. We averaged the ERPs within the left (LOT) and right (ROT) occipital-temporal areas in order to increase the signal-to-noise ratio. Bonferroni correction was applied to protect from Type-I error in multiple comparisons. Finally, we applied Greenhouse-Geisser correction to overcome the effect when the assumption of sphericity in repeated measures analysis of variance (ANOVA) was violated.
Fig. 2.

GFP for the whole process across the entire group. The vertical gray columns indicate three microstates reflecting P1, N170, and P300. Note. GFP is defined as the spatial standard deviation quantifying the amount of neural activity from all electrodes at each time point (Skrandies, 1990). Therefore, the peak of N170 here is positive.
2. Results
2.1. Behavioral results
Table 1 shows the reaction times and accuracy rates from the learning phase and recognition test for three conditions among the three grades. Trials with incorrect response and 2.5 standard deviations more than the individual mean were removed from the final analysis in the recognition test. For the learning phase, children’s mean response accuracy was 61.6%, 61.4%, and 58.2% for Grades 1, 2, and 3, respectively.
Table 1.
Reaction Time and Accuracy Rate in the Learning Phase and Recognition Test for Three Conditions among Three Grades.
| Conditions | Learning phase |
Recognition test |
||
|---|---|---|---|---|
| Reaction time | Accuracy rate | Reaction time | Accuracy rate | |
| Grade 1 | ||||
| High | 967.813(140.122) | 0.624(0.205) | 2015.462(640.588) | 0.681(0.133) |
| Moderate | 960.874(144.827) | 0.608(0.193) | 1776.324(808.110) | 0.531(0.120) |
| Low | 928.534(104.640) | 0.616(0.180) | 1760.964(607.180) | 0.613(0.186) |
| Grade 2 | ||||
| High | 889.591(142.697) | 0.598(0.201) | 1824.167(586.519) | 0.682(0.155) |
| Moderate | 881.843(134.280) | 0.626(0.218) | 1609.469(641.614) | 0.536(0.156) |
| Low | 855.420(127.432) | 0.619(0.178) | 1841.021(767.402) | 0.570(0.133) |
| Grade 3 | ||||
| High | 855.321(161.235) | 0.584(0.217) | 1484.867(601.916) | 0.716(0.176) |
| Moderate | 863.070(188.855) | 0.560(0.213) | 1426.795(556.112) | 0.581(0.142) |
| Low | 826.994(179.431) | 0.602(0.192) | 1460.593(643.145) | 0.572(0.130) |
Note: Standard deviations are in parentheses. The reaction time and accuracy rate in the learning phase are based on children’s performance of filler trials in the cover task. As the cover task is to ensure participants’ pay attention to learning stimuli, we did not interpret the behavioral results in the learning phase.
For the recognition test in Grade 1, the mean recognition accuracy was 60.8%, significantly higher than chance (50%; t(31) = 7.35, p < 0.001). One-sample t-tests revealed significant differences between recognition accuracy and chance for the high-consistency condition (Mean = 68.12%; t(31) = 7.71, p < 0.001) and the low-consistency condition (Mean = 61.25%; t(31) = 3.42, p = 0.002). However, no significant difference between recognition accuracy and chance occurred for the moderate-consistency condition (Mean = 53.13%; t(31) = 1.47, p = 0.152).
For the recognition test in Grade 2, the mean recognition accuracy was 59.6%, significantly higher than chance (50%; t(32) = 5.70, p < 0.001). One-sample t-tests revealed significant differences between recognition accuracy and chance for the high consistency condition (Mean = 68.18%; t(32) = 6.74, p < 0.001) and the low-consistency condition (Mean = 56.97%; t(32) = 3.00, p = 0.005). However, no significant difference between recognition accuracy and chance occurred for the moderate-consistency condition (Mean = 53.64%; t(32) = 1.34, p = 0.189).
For the recognition test in Grade 3, the mean recognition accuracy was 62.3%, significantly higher than chance (50%; t(31) = 7.71, p < 0.001). One-sample t-tests revealed significant differences between recognition accuracy and chance for the high-consistency condition (Mean = 71.56%; t(31) = 6.92, p < 0.001), the moderate-consistency condition (Mean = 58.12%; t(31) = 3.23, p = 0.003), and the low-consistency condition (Mean = 57.19%; t(31) = 3.13, p = 0.004).
Two separate mixed ANOVAs with consistency (high, moderate, and low conditions) as a within-factor and grade (1, 2, and 3) as a between-factor were performed on accuracy rate and response time for the recognition test. For accuracy rate, the main effect of consistency was significant (F(2, 188) = 25.41, p < 0.001, = 0.213). Follow-up comparisons showed that children were more accurate in the high-consistency condition than in the moderate- and low-consistency conditions (ps < 0.001). However, no statistically significant difference occurred between the moderate and low conditions (p = 0.301). For reaction time, the effect of consistency was significant (F(2, 188) = 5.17, p = 0.008, = 0.052). Follow-up comparisons showed that children showed faster responses in the moderate-consistency condition than in the high-consistency condition (p = 0.010). However, no statistical difference occurred between the high and low conditions (p = 0.360), nor between the moderate and low conditions (p = 0.219). The effect of grade was significant (F(2, 94) = 4.01, p = 0.021, = 0.079). Follow-up comparisons showed that third-graders had a shorter reaction time than first-graders (p = 0.024). However, no statistical difference occurred between the first- and second-graders (p = 1.0), nor between the second- and third-graders (p = 0.119). No other main effects and interactions were found to be significant (ps > 0.05).
2.2. ERP results
The mean amplitude and comparisons across conditions in both LOT and ROT are shown in Table 2 and Fig. 3. Topographical maps of different conditions for three grade groups in each time window are shown in Fig. 4, Fig. 5, Fig. 6. The results of the statistical analyses in three ERP components are summarized in Table 1s (see Supplemental Tables).
Table 2.
Mean Amplitudes of Three ERP Components (P1, N170, and P300) for Each Consistency Condition in the Left Occipital-temporal (LOT) and Right Occipital-temporal (ROT) Regions.
| ROI |
||
|---|---|---|
| LOT | ROT | |
| P1 | ||
| High | 6.343(3.970) | 6.409(3.695) |
| Moderate | 6.193(3.752) | 6.149(3.578) |
| Low | 5.913(3.675) | 5.922(3.598) |
| N170 | ||
| High | -2.631(3.803) | -4.003(3.820) |
| Moderate | -3.190(3.695) | -4.745(3.486) |
| Low | -3.126(3.839) | -4.510(3.846) |
| P300 | ||
| High | 7.378(3.699) | 7.251(3.452) |
| Moderate | 7.611(3.626) | 7.056(3.451) |
| Low | 7.721(3.511) | 7.302(3.498) |
Note: Standard deviations are in parentheses.
Fig. 3.

Grand averaged ERP waveforms of high-, moderate-, and low-consistency conditions at LOT and ROT for three grade groups.
Fig. 4.

Topographical maps of different conditions in the 120–180 ms time windows for three Grade groups. H-L: the voltage difference between high and low consistency conditions; H-M: the voltage difference o between high and moderate consistency conditions; M-L: the voltage difference between moderate and low consistency conditions.
Fig. 5.

Topographical maps of different conditions in the 210–250 ms time windows for three Grade groups. M-H: the voltage difference between moderate and high consistency conditions; M-L: the voltage difference between moderate and low consistency conditions; L-H: the voltage difference between low and high consistency conditions.
Fig. 6.

Topographical maps of different conditions in the 320–370 ms time windows for three Grade groups. L-H: the voltage difference between low and high consistency conditions; L-M: the voltage difference between low and moderate consistency conditions; M-H: the voltage difference between moderate and high consistency conditions.
2.2.1. P1 (120–180 ms time window)
A mixed ANOVA with consistency (high, moderate, and low conditions) and ROI (LOT and ROT) as within-subject factors, and grade (1, 2, and 3) as a between-subject factor revealed that the main effect of consistency was significant (F(2, 192) = 9.04, p < 0.001, = 0.086). Follow-up comparisons showed that the mean amplitude for the high-consistency condition was more positive than for the low-consistency condition (p < 0.001). However, the difference between high- and moderate-consistency conditions (p = 0.110 ) and between moderate- and low-consistency conditions (p = 0.074) was not significant. No other main effects and interactions were found to be significant (ps > 0.1).
2.2.2. N170 (210–250 ms time window)
A mixed ANOVA with consistency (high, moderate, and low conditions) and ROI (LOT and ROT) as within-subject factors, and grade (1, 2, and 3) as a between-subject factor showed that the main effect of consistency was significant (F(2, 192) = 18.41, p < 0.001, = 0.161). Follow-up comparisons showed that the mean amplitude for the low-consistency condition was more negative than for the high-consistency condition (p < 0.001), and the mean amplitude for the moderate-consistency condition was more negative than for the high-consistency condition (p < 0.001). However, the difference between the moderate-consistency condition and the low-consistency condition was not significant (p = 0.628). The main effect of ROI was significant (F(1, 96) = 22.52, p < 0.001, = 0.190). The following comparison showed that the mean amplitude for ROT was more negative than for LOT (p < 0.001). Moreover, the main effect of Grade was significant (F(2, 96) = 3.18, p = 0.046, = 0.062). The mean amplitude for Grade 1 was marginally more negative than for Grade 3 (p = 0.050); however, the difference was not significant between Grade 1 and Grade 2 (p = 1.0), nor between Grade 2 and Grade 3 (p = 0.224). No other interaction was observed in our analysis (ps > 0.1).
2.2.3. P300 (320–370 ms time window)
A mixed ANOVA with consistency (high, moderate, and low conditions) and ROI (LOT and ROT) as within-subject factors, and grade (1, 2, and 3) as a between-subject factor revealed that the main effect of grade was significant (F(2, 96) = 10.57, p < 0.001, = 0.180). Follow-up comparisons showed that the mean amplitude for Grade 1 was more positive than for Grade 3 (p < 0.001), and the mean amplitude for Grade 1 was more positive than for Grade 2 (p = 0.017). However, the difference between Grade 2 and 3 was not significant (p = 0.211). The interaction of consistency by ROI was significant (F(2, 192) = 5.36, p = 0.005, = 0.053). Further analysis showed a significant effect of consistency at LOT (F(2, 192) = 4.16, p = 0.017, = 0.042). The mean amplitude for the low consistency condition was more positive than for the high-consistency condition (p = 0.014). However, no significant difference occurred between the moderate- and high-consistency conditions (p = 0.199) or between the low- and moderate-consistency conditions (p = 1.0). The effect of consistency was not significant at ROT (F(2, 192) = 2.45, p = 0.089, = 0.025). No other main effects and interactions were significant (ps > 0.1).
2.2.4. Time-point-wise TANOVA analysis
To compare the consistent difference of scalp fields among the three conditions, a time-point-wise Topographic Analysis of Variance (TANOVA) was conducted by computing a nonparametric randomization test based on the GFP of difference maps. The time-point-wise TANOVA analyses for ERP effects of consistency are shown in Fig. 7. T-map series across three grade groups are summarized in Table 5s (see supplemental analysis). Results revealed a significant difference of orthographic statistical learning between the low- and high-consistency conditions in four time windows: N170 with a P1/N170 transition (164–242 ms), P300 time range (260–356 ms), and two small time windows (402–434 ms, and 446–500 ms). Process differed between the moderate- and high-consistency conditions during two time ranges: a P1 and N170 duration (116–250 ms) and a time window of P300 (268–414 ms). The comparison of the moderate and low conditions suggested process differences in a brief time window within the N170 duration (214–218 ms) and P300 time range (276–342 ms). Each t-map for the significant TANOVA time windows is displayed on the right of Fig. 7. The t-maps of both the low-high and moderate-high comparisons were significant in the P1-N170 segment at the occipital-temporal and parietal electrodes. A contrast of low- versus high-consistency conditions was observed at the left occipital-temporal electrodes in the time window of 402–434 ms, and at the right occipital-temporal electrodes in the time window of 446–500 ms.
Fig. 7.

Time-point-wise ERP effects of consistency. The TANOVA results of low versus high and moderate versus high contrasts showed differences in the P1-N170 component and the other two time ranges (dark grey frames are from 164 to 242 ms, 402–434 ms, and 446–500 ms, respectively. T-maps are displayed on the right).
Fig. 8 displays the time-point-wise TANOVA analyses of grade effects. Results revealed that grade effects significantly differed during statistical learning of orthographic regularities between first- and third-graders, and between first- and second-graders in three time windows: P1 (116–188 ms), N170 (206–260 ms), and P300 (300–490 ms). However, no statistically significant difference occurred in the three time windows between second- and third-graders.
Fig. 8.

Time-point-wise ERP effects of grade. The TANOVA results of Grade 1 versus Grade 3 and Grade 1 versus Grade 2 contrasts showed differences in the P1, N170, and P300 components (dark grey frames are from 116 to 188 ms, 206–260 ms, and 300–490 ms, respectively. T-maps are displayed on the right).
3. Discussion
Many studies have demonstrated that the human brain can detect orthographic regularities in a language through statistical learning (e.g., Gingras and Sénéchal, 2019; He and Tong, 2017; Samara and Caravolas, 2014). However, the neural mechanisms underlying, and the developmental patterns affecting this learning process, remain largely unknown. Using the ERP technique with an artifical orthographic statistical learning paradigm, this study investigated neurophysiological correlates and developmental patterns of statistical learning of orthographic regularities in Chinese first-, second-, and third-graders. In conjunction with behavioral results, the ERP data demonstrated that children from all three grades could extract positional regularities of radicals embedded in artificial pseudocharacters using statistical learning. The statistical learning process of orthographic regularities is accompanied by rapid changes in neural activation, indicated by three ERP components (i.e., P1, N170, and P300). Specifically, in each grade, the amplitude of some ERP components differed, with a larger P1 effect in the high consistency condition and a larger N170 and left-lateralized P300 effect in the low consistency condition. Also, a smaller N170 amplitude occurred in Grade 3 than in Grade 1, and a larger P300 amplitude occurred in Grade 1 than in either Grade 2 or 3. These findings suggest statistical learning is subserved by at least two mechanisms: a neural adaptation triggered by high consistency inputs, and a cognitive control process (i.e., attention or working memory) triggered by low consistency inputs.
Consistent with previous behavioral studies, all first-, second-, and third-graders were able to extract and learn the orthographic regularities (i.e., the position of radicals) through occurance frequency patterns embedded in the artificial pseudocharacters (e.g., He and Tong, 2017; Tong et al., 2020a, Tong et al., 2020b; Yin & McBride, 2015). This finding supports the experience-dependent mechanism (e.g., Canale, 2022; Saffran et al., 1996), which might be domain-general (Thiessen and Saffran, 2007) since it applies to a broad range of learning processes, including visual perception (e.g., Turk-Browne et al., 2010), motor skill learning (e.g., Robertson, 2007), speech segmentation (e.g., Saffran et al., 1996), and even social intuition (Lieberman, 2000). Our finding extends previous studies by demonstrating that this mechanism may be essential for learning quasi-regularities of Chinese character orthography.
Regarding the neural mechanisms related to children’s statistical learning, this study demonstrated a larger P1 amplitude in the high-consistency condition compared to the low-consistency condition. As the P1 effect is sensitive to the violation of radical positions in Chinese characters (Lo et al., 2019, Yum et al., 2015), the P1 activation produced by high-consistency condition in the current study may indicate that children were unaware of the legality of the artificial radicals embedded in the pseudocharacters; thus, the P1 effect was entirely attributed to visual statistical learning. Additionally, the effect of positional consistency can be explained by top-down attentional modulation (Taylor et al., 2003) in which the larger P1 effect elicited by stimuli in the high-consistency condition reflects stronger attentional control from top-down modulatory processing associated with more consistent features in orthographic regularities.
However, the peak between low- and high-consistency conditions shifted in the N170 component. That is, an attenuated N170 effect was found for the high-consistency level compared to the low-consistency level, suggesting a neural adaptation to familiar and consistent statistical input (e.g., Peter et al., 2019; Taylor et al., 2003) in which the neurocognitive processes of perceiving, encoding, and acting upon a given stimulus change adaptively as the experience of external input increases (Conway, 2020). This is exemplified by neuronal activity decay during the repetition of identical or similar stimuli (Benda, 2021). Of relevance to our study is that the high-, moderate-, and low-consistency conditions for radicals embedded in artificial pseudocharacters were manipulated by varying the frequency of same-position target radicals across different pseudocharacters. High consistency meant that the same radical appeared in the same position across stimuli every time. With the accumulation of repeated exposure to the stimuli, participants became more familiar with the position of the radicals in the high-consistency condition than in the low- consistency condition. This greater familiarity leads to a decreased neuronal response to radicals appearing in the same position—hence, the observed attenuated N170 effect.
The orthographic regularity hypothesis offers an alternative explanation: namely, that stimuli carrying greater orthographic regularity should be associated with less negative N170 responses (McCandliss et al., 1997, Tong et al., 2020a, Tong et al., 2020b). In this study, orthographic regularity was the positional consistency of target radicals appearing in artificial pseudocharacters. The more consistently a target radical appeared in more learned materials, the greater the orthographic regularity of that radical. Thus, a less negative N170 effect was found for the high-consistency condition than for the low-consistency condition (see item analysis in Supplemental Analyses), suggesting that during a long-term learning process, children more efficiently extract and encode high condition orthographic regularities and more rapidly distinguish low positional consistency. However, in the moderate condition, detecting regularities was puzzling for the children, leading to larger N170 amplitudes, lower accuracy, and shorter reaction times. Our results extend this hypothesis to artificial orthography learning by showing that N170 is not specific to a real orthography but applies to visual materials encoding regularity information. Future research needs to further verify this hypothesis using different sets of artificial materials.
Furthermore, this study detected an enhanced P300 amplitude in the low-consistency condition compared to the high-consistency condition. P300 in the learning phase suggested that children need to focus their attention on encoding the artificial stimuli and allocate attentional resources to acquire statistical patterns of artificial orthography. The enhanced P300 effect indicates that increased attentional control is triggered by the inconsistent inputs with higher uncertainty (Carrión and Bly, 2007, Johnson, 1986), which might be attributed to the limitation of young learners’ attentional resources for the more complicated regularities extracted from the low-consistency condition (Forest et al., 2021). This explanation is supported by Mano’s (2016) two-process framework in which attention control interacts with statistical learning during the orthographic learning process. The two-process framework assumed that, in addition to the need for statistical learning, the processing of certain types of orthographic regularities might require unique amounts of attention and cognitive control. Conway (2020) further explained that some aspects of statistical learning, especially for rule-based information, reflect conscious processes that rely on attention and working memory.
An alternative explanation for the P300 effect is the working memory load hypothesis. As suggested by Koivisto et al. (2018), P300 indicates that visual consciousness and working memory share resources at the relatively late maintenance stage. Consistent with this hypothesis, children need to constantly encode while consolidating the extracted orthographic regularities. As each positional consistency condition occupies different working memory resources, a significant difference in P300 amplitudes was observed between the low- and high-consistency conditions over the left occipitotemporal scalp. However, working memory load was associated more with maintenance than the encoding process (Shucard et al., 2009). As the current experimental design cannot distinguish the encoding and maintenance processes, future research is needed to investigate how and to what extent working memory load influences the process of encoding and long-term maintenance during orthographic statistical learning. The results of all three ERP components indicate that young children can acquire complex regularities from domain-general statistical learning and language recoding mechanisms (Rey et al., 2019).
Our study observed a developmental progression among children from 7 to 9 years old, with first-graders evoking larger N170 and P300 effects than third-graders. More specifically, the analysis of time-point-wise TANOVA indicated a developmental profile of children’s first few years of primary school: at the start of learning to read, children required more effort to process statistical patterns of orthographic regularity, as indicated by larger P1, N170, and P300 responses. After more reading training, children from at least 8 years old improved during the entire stage of orthographic processing, as manifested by each ERP indicator. These findings were consistent with previous studies (Ho et al., 2003, Tong and McBride, 2014) showing a gradual development in children’s ability to acquire orthographic regularities. Thus, first-graders acquired the orthographic information of radicals (Ho et al., 2003), which produced further improvement after one year of maturation and training (Anderson et al., 2013, Pacton et al., 2001).
Additionally, the absence of interaction between consistency and grade at the behavioral and neural levels suggested that developmental difference in statistical learning is not apparent enough for children during the first three years of primary school. This finding corroborated the claim by Reber (1993) and other statistical learning studies (e.g., Amso and Davidow, 2012; Jost et al., 2015; Janacsek et al., 2012), suggesting that statistical learning of orthographic regularities is age invariant from the start of reading development. However, since our study manipulated only positional regularities, further reserach is needed to determine whether statistical learning of other types of orthographic regularities, such as semantic or phonetic consistency of radicals, relies on the same sets of mechanism. In fact, past behavioral developmental studies have demonstrated that Chinese children acquire positional regularities of radicals earlier than the functional regularities (e.g., Ho et al., 2003; Tong et al., 2016). Moreover, considering that the children’s age range was only 7–9 years old, further studies on primary school children, as well as testing the difference of functional connections based on activation of brain regions among three age groups, would be of value.
Notably, a discrepancy exists between the behavioral results and ERP results. Specifically, first- and second-graders' accuracy rates for the behavioral recognition test did not exceed the chance level though a significant difference between high and moderate conditions was observed at N170. One explanation is the nature of the measurement with ERPs reflecting the neural activities that occurred during learning phase, while the accuracy for the recognition task occurred during the retrieval process of learning outcomes. Furthermore, as orthographic statistical learning might occur after only a few minutes of exposure (Chetail, 2017), the behavioral performance could results from a combination of learning and memory consolidation. These results may indicate that ERPs are moresensitive than behavioral measures for online statistical learning process.
Additionally, the the first- and second- graders' chace-level behavioral recognition accuracy in moderate, but above chance-level in high- and low-consistency conditions, could reflect that the recognition of high- and low-consistency items is dominated by a single mechanism while the retrieval of moderate consistency items may activate two competing mechanisms. Specifically, during the learning phase, two types of representation are formed: an abstract statistical structure representation of the target radicals' positional regularities, and an item-specific pseudocharacter representation. Although both representations are available during the testing phase, abstract statistical structure representation dominates the retrieval of high-consistency condition items (100%), while item-specific representation is more active in the retrieval of low-consistency items due to more violated position items in low than moderate conditions. In contrast, two types of representations are equally active in the moderate consistency-condition and compete for cognitive resources, resulting in a lower recognition accuracy rate than high- and low-consistency conditions (see results of item regularity analysis in supplementary material). Future research is needed to further warrant this explanation.
Nevertheless, our ERP results of N170, P1 and P300 align well with the multicomponent view of statistical learning, suggesting that high and low consistency inputs elicit two learning systems (see developmental difference analysis in supplemental analyses). Specifically, the attenuated N170 could be a neural index of the adaptation of familiar and repeated input, and the effects under high consistency condition (i.e., the target radical always appears in one position) are qualitatively different from moderate and low conditions (i.e., the target radical can appear in two positions). In contrast, the P1 and P300 components reflect the attentional processing triggered by items with various distributional statistics. One possibility is that the difference between 100% and 80% consistency is not large enough to elicit attentional effects, but between 100% and 60% consistency is.
Despite the robust results showing the neural activities of statistical learning of positional regularities of target radicals, it should be noted that the target radicals were not counterbalanced across low, moderate, and high conditions. However, becuase our experimental stimuli were created from Dongba and Geba characters and not exposed to our particiants before, we were able to more effectively eliminate the influence of individuals’ preference and prior knowledge. Thus, it is unlikely that the strong effect observed in the present study is related to the repeated visual features of the stimuli.
In sum, this study advances our understanding of the neurophysiological markers of statistical learning of orthographic regularities and the associated developmental patterns. Specifically, the P1, N170, and P300 components of ERPs can be used in conjunction with reaction time to identify the cognitive process of statistical learning of orthographic regularities in Chinese children. N170 reflects the extraction and encoding of orthographic regularities in the occipitotemporal region with neural adaptation, while P1 and P300 relate to multiple cognitive mechanisms underlying the process of statistical learning. The grade effect was significant, i.e., the smaller N170 amplitude in Grade 3 than Grade 1 and the larger P300 amplitude in Grade 1 than either Grade 2 or 3. These findings underscore the multiple mechanisms underlying statistical learning and indicate the developmental invariance of statistical learning of orthographic regularities in Chinese children.
CRediT authorship contribution statement
Conceptualization and experimental design: S-XT and XT; Data collection: RD and YY; Formal data analysis: RD and XT; Final writing and revision: S-XT, RD and XT; Equipment and Resources: WS and ST. Supervision of the Investigation: XT. Shelley Xiuli Tong and Rujun Duan contributed equally to this paper. All authors approved the final version of the mansucript.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
This research was supported by a grant from the Research Grants Council (RGC) of the Hong Kong Special Administrative Region, China (Project No. 28606419) and by Departmental Research Grant from The Education University of Hong Kong (E0475, 2021–2022) to Xiuhong Tong. This work was also partially supported by Research Fellow Scheme (RFS 2021–7H05) from Hong Kong RGC to Shelley Xiuli Tong. We would like to thank Yongjun Yu for participant recruitmentand Hong Fu, Chi Gao, and Hongmin Wang for data collection,and all children and parents for their participation. Finally, we thank Puyuan Zhang and Mei Zhou for their comments and suggestions on the first draft of our mansucript.
Footnotes
Supplementary data associated with this article can be found in the online version at doi:10.1016/j.dcn.2022.101190.
Contributor Information
Shelley Xiuli Tong, Email: xltong@hku.hk.
Xiuhong Tong, Email: xhtong@eduhk.hk.
Appendix A. Supplementary material
Supplementary material
.
Data availability
Data will be made available on request.
References
- Amso D., Davidow J. The development of implicit learning from infancy to adulthood: Item frequencies, relations, and cognitive flexibility. Dev. Psychobiol. 2012;54(6):664–673. doi: 10.1002/dev.20587. [DOI] [PubMed] [Google Scholar]
- Anderson R.C., Ku Y.M., Li W., Chen X., Wu X., Shu H. Learning to see the patterns in Chinese characters. Sci. Stud. Read. 2013;17(1):41–56. doi: 10.1080/10888438.2012.689789. [DOI] [Google Scholar]
- Apel, K., 2011, What is orthographic knowledge? 〈https://doi.org/10.1044/0161–1461(2011/10–0085)〉.
- Arciuli J., Simpson I.C. Statistical learning in typically developing children: The role of age and speed of stimulus presentation. Dev. Sci. 2011;14(3):464–473. doi: 10.1111/j.1467-7687.2009.00937.x. [DOI] [PubMed] [Google Scholar]
- Baldwin K.B., Kutas M. An ERP analysis of implicit structured sequence learning. Psychophysiology. 1997;34(1):74–86. doi: 10.1111/j.1469-8986.1997.tb02418.x. [DOI] [PubMed] [Google Scholar]
- Benda J. Neural adaptation. Curr. Biol. 2021;31(3):R110–R116. doi: 10.1016/j.cub.2020.11.054. [DOI] [PubMed] [Google Scholar]
- Canale R. The importance of statistical learning. Nat. Rev. Psychol. 2022;1(2):68. doi: 10.1038/s44159-021-00010-2. [DOI] [Google Scholar]
- Cao X.H., Jiang B., Li C., He Z.Q. Rapid adaptation effect of N170 for printed words. Percept. Mot. Skills. 2014;119(1):191–202. doi: 10.2466/24.22.PMS.119c15z6. [DOI] [PubMed] [Google Scholar]
- Carrión R.E., Bly B.M. Event-related potential markers of expectation violation in an artificial grammar learning task. NeuroReport. 2007;18(2):191–195. doi: 10.1097/WNR.0b013e328011b8ae. [DOI] [PubMed] [Google Scholar]
- Chetail F. What do we do with what we learn? Statistical learning of orthographic regularities impacts written word processing. Cognition. 2017;163:103–120. doi: 10.1016/j.cognition.2017.02.015. [DOI] [PubMed] [Google Scholar]
- Cohen L., Dehaene S. Specialization within the ventral stream: The case for the visual word form area. NeuroImage. 2004;22(1):466–476. doi: 10.1016/j.neuroimage.2003.12.049. [DOI] [PubMed] [Google Scholar]
- Conway C.M. How does the brain learn environmental structure? Ten core principles for understanding the neurocognitive mechanisms of statistical learning. Neurosci. Biobehav. Rev. 2020;112:279–299. doi: 10.1016/j.neubiorev.2020.01.032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Daltrozzo J., Conway C.M. Neurocognitive mechanisms of statistical-sequential learning: What do event-related potentials tell us. Front. Hum. Neurosci. 2014;8:1–22. doi: 10.3389/fnhum.2014.00437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Delorme A., Makeig S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods. 2004;134(1):9–21. doi: 10.1016/j.jneumeth.2003.10.009. [DOI] [PubMed] [Google Scholar]
- Forest, T., Siegelman, N., & Finn, A., 2021, Attention shifts to more complex locations with experience. 〈https://doi.org/10.31234/osf.io/kr5a9〉.
- Frost R., Siegelman N., Narkiss A., Afek L. What predicts successful literacy acquisition in a second language. Psychol. Sci. 2013;24(7):1243–1252. doi: 10.1177/0956797612472207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gingras M., Sénéchal M. Evidence of statistical learning of orthographic representations in grades 1–5: The case of silent letters and double consonants in French. Sci. Stud. Read. 2019;23(1):37–48. doi: 10.1080/10888438.2018.1482303. [DOI] [Google Scholar]
- Grill-Spector K., Henson R., Martin A. Repetition and the brain: Neural models of stimulus-specific effects. Trends Cogn. Sci. 2006;10(1):14–23. doi: 10.1016/j.tics.2005.11.006. [DOI] [PubMed] [Google Scholar]
- He X., Tong X. Statistical learning as a key to cracking Chinese orthographic codes. Sci. Stud. Read. 2017;21(1):60–75. doi: 10.1080/10888438.2016.1243541. [DOI] [Google Scholar]
- Hendricks M.A., Conway C.M., Kellogg R.T. Using dual-task methodology to dissociate automatic from nonautomatic processes involved in artificial grammar learning. J. Exp. Psychol. Learn. Mem. Cogn. 2013;39(5):1491–1500. doi: 10.1037/a0032974. [DOI] [PubMed] [Google Scholar]
- Ho C.S.H., Ng T.T., Ng W.K. A “radical” approach to reading development in Chinese: The role of semantic radicals and phonetic radicals. J. Lit. Res. 2003;35(3):849–878. doi: 10.1207/s15548430jlr3503_3. [DOI] [Google Scholar]
- Janacsek K., Fiser J., Nemeth D. The best time to acquire new skills: Age-related differences in implicit sequence learning across the human lifespan. Dev. Sci. 2012;15(4):496–505. doi: 10.1111/j.1467-7687.2012.01150.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson R. A triarchic model of P300 amplitude. Psychophysiology. 1986;23(4):367–384. doi: 10.1111/j.1469-8986.1986.tb00649.x. [DOI] [PubMed] [Google Scholar]
- Jost E., Conway C.M., Purdy J.D., Walk A.M., Hendricks M.A. Exploring the neurodevelopment of visual statistical learning using event-related brain potentials. Brain Res. 2015;1597:95–107. doi: 10.1016/j.brainres.2014.10.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Koivisto M., Ruohola M., Vahtera A., Lehmusvuo T., Intaite M. The effects of working memory load on visual awareness and its electrophysiological correlates. Neuropsychologia. 2018;120:86–96. doi: 10.1016/j.neuropsychologia.2018.10.011. [DOI] [PubMed] [Google Scholar]
- Korenius T., Laurikkala J., Juhola M. On principal component analysis, cosine and Euclidean measures in information retrieval. Inf. Sci. 2007;177(22):4893–4905. doi: 10.1016/j.ins.2007.05.027. [DOI] [Google Scholar]
- Lee S.M.K., Cui Y., Tong S.X. Toward a model of statistical learning and reading: Evidence from a meta-analysis. Rev. Educ. Res. 2022 doi: 10.3102/00346543211073188. [DOI] [Google Scholar]
- Lieberman M.D. Intuition: A social cognitive neuroscience approach. Psychol. Bull. 2000;126(1):109–136. doi: 10.1037/0033-2909.126.1.109. [DOI] [PubMed] [Google Scholar]
- Lieberman M.D., Chang G.Y., Chiao J., Bookheimer S.Y., Knowlton B.J. An event-related fMRI study of artificial grammar learning in a balanced chunk strength design. J. Cogn. Neurosci. 2004;16(3):427–438. doi: 10.1162/089892904322926764. [DOI] [PubMed] [Google Scholar]
- Lo J.C.M., McBride C., Ho C.S. han, Maurer U. Event-related potentials during Chinese single-character and two-character word reading in children. Brain Cogn. 2019;136 doi: 10.1016/j.bandc.2019.103589. [DOI] [PubMed] [Google Scholar]
- Mano Q.R. Developing sensitivity to subword combinatorial orthographic regularity (SCORe): A two-process framework. Sci. Stud. Read. 2016;20(3):231–247. doi: 10.1080/10888438.2016.1141210. [DOI] [Google Scholar]
- McCandliss B.D., Posner M.I., Givón T. Brain plasticity in learning visual words. Cogn. Psychol. 1997;33(1):88–110. doi: 10.1006/cogp.1997.0661. [DOI] [Google Scholar]
- Pacton S., Perruchet P., Fayol M., Cleeremans A. Implicit learning out of the lab: The case of orthographic regularities. J. Exp. Psychol. Gen. 2001;130(3):401–426. doi: 10.1037//0096-3445.130.3.401. [DOI] [PubMed] [Google Scholar]
- Peisch V., Rutter T., Wilkinson C.L., Arnett A.B. Sensory processing and P300 event-related potential correlates of stimulant response in children with attention-deficit/hyperactivity disorder: A critical review. Clin. Neurophysiol. 2021;132(4):953–966. doi: 10.1016/j.clinph.2021.01.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peter B., McCollum H., Daliri A., Panagiotides H. Auditory gating in adults with dyslexia: An ERP account of diminished rapid neural adaptation. Clin. Neurophysiol. 2019;130(11):2182–2192. doi: 10.1016/j.clinph.2019.07.028. [DOI] [PubMed] [Google Scholar]
- Raviv L., Arnon I. The developmental trajectory of children’s auditory and visual statistical learning abilities: Modality-based differences in the effect of age. Dev. Sci. 2018;21(4):1–13. doi: 10.1111/desc.12593. [DOI] [PubMed] [Google Scholar]
- Reber P.J. The neural basis of implicit learning and memory: A review of neuropsychological and neuroimaging research. Neuropsychologia. 2013;51(10):2026–2042. doi: 10.1016/j.neuropsychologia.2013.06.019. [DOI] [PubMed] [Google Scholar]
- Reber, S., 1993, Implicit learning and tacit knowledge: An essay on the cognitive unconscious, New York.
- Rey A., Minier L., Malassis R., Bogaerts L., Fagot J. Regularity extraction across species: Associative learning mechanisms shared by human and non‐human primates. Top. Cogn. Sci. 2019;11(3):573–586. doi: 10.1111/tops.12343. [DOI] [PubMed] [Google Scholar]
- Robertson E.M. The serial reaction time task: Implicit motor skill learning? J. Neurosci. 2007;27(38):10073–10075. doi: 10.1523/JNEUROSCI.2747-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Saffran J.R., Aslin R.N., Newport E.L. Statistical learning by 8-month-old infants. Science. 1996;274(5294):1926–1928. doi: 10.1126/science.274.5294.1926. 〈http://www.ncbi.nlm.nih.gov/pubmed/8943209〉 [DOI] [PubMed] [Google Scholar]
- Samara A., Caravolas M. Statistical learning of novel graphotactic constraints in children and adults. J. Exp. Child Psychol. 2014;121(1):137–155. doi: 10.1016/j.jecp.2013.11.009. [DOI] [PubMed] [Google Scholar]
- Seger C.A., Cincotta C.M. Striatal activity in concept learning. Cogn. Affect. Behav. Neurosci. 2002;2(2):149–161. doi: 10.3758/CABN.2.2.149. [DOI] [PubMed] [Google Scholar]
- Shucard J.L., Tekok-Kilic A., Shiels K., Shucard D.W. Stage and load effects on ERP topography during verbal and spatial working memory. Brain Res. 2009;1254(2006):49–62. doi: 10.1016/j.brainres.2008.11.063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shufaniya A., Arnon I. Statistical learning is not age-invariant during childhood: Performance improves with age across modality. Cogn. Sci. 2018;42(8):3100–3115. doi: 10.1111/cogs.12692. [DOI] [PubMed] [Google Scholar]
- Skrandies W. Global field power and topographic similarity. Brain Topogr. 1990;3(1):137–141. doi: 10.1007/BF01128870. [DOI] [PubMed] [Google Scholar]
- Sommer V.R., Mount L., Weigelt S., Werkle-Bergner M., Sander M.C. Spectral pattern similarity analysis: Tutorial and application in developmental cognitive neuroscience. Dev. Cogn. Neurosci. 2022;54 doi: 10.1016/j.dcn.2022.101071. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor M.J., Chevalier H., Lobaugh N.J. Discrimination of single features and conjunctions by children. Int. J. Psychophysiol. 2003;51(1):85–95. doi: 10.1016/S0167-8760(03)00155-7. [DOI] [PubMed] [Google Scholar]
- Thiessen E.D., Saffran J.R. Learning to learn: Infants’ acquisition of stress-based strategies for word segmentation. Lang. Learn. Dev. 2007;3(1):73–100. doi: 10.1080/15475440709337001. [DOI] [Google Scholar]
- Tong S., Zhang P., He X. Statistical learning of orthographic regularities in Chinese children with and without dyslexia. Child Dev. 2020;91(6):1953–1969. doi: 10.1111/cdev.13384. [DOI] [PubMed] [Google Scholar]
- Tong X., Leung W.W.S., Tong X. Visual statistical learning and orthographic awareness in Chinese children with and without developmental dyslexia. Res. Dev. Disabil. 2019;92 doi: 10.1016/j.ridd.2019.103443. [DOI] [PubMed] [Google Scholar]
- Tong Xiuhong, Lo J.C.M., McBride C., Ho C.S., Waye M.M.Y., Chung K.K.H., Wong S.W.L., Chow B.W.Y. Coarse and fine N1 tuning for print in younger and older Chinese children: Orthography, phonology, or semantics driven? Neuropsychologia. 2016;91:109–119. doi: 10.1016/j.neuropsychologia.2016.08.006. [DOI] [PubMed] [Google Scholar]
- Tong Xiuhong, Wang Y., Tong S.X. The neural signature of statistical learning of orthography. Front. Hum. Neurosci. 2020;14:1–7. doi: 10.3389/fnhum.2020.00026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tong Xiuli, McBride C. Chinese children’s statistical learning of orthographic regularities: Positional constraints and character structure. Sci. Stud. Read. 2014;18(4):291–308. doi: 10.1080/10888438.2014.884098. [DOI] [Google Scholar]
- Treiman R., Kessler B. Statistical learning in word reading and spelling across languages and writing systems. Sci. Stud. Read. 2022;26(2):139–149. doi: 10.1080/10888438.2021.1920951. [DOI] [Google Scholar]
- Turk-Browne N.B., Jungé J.A., Scholl B.J. The automaticity of visual statistical learning. J. Exp. Psychol. Gen. 2005;134(4):552–564. doi: 10.1037/0096-3445.134.4.552. [DOI] [PubMed] [Google Scholar]
- Turk-Browne N.B., Scholl B.J., Johnson M.K., Chun M.M. Implicit perceptual anticipation triggered by statistical learning. J. Neurosci. 2010;30(33):11177–11187. doi: 10.1523/JNEUROSCI.0858-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xia P., Zhang L., Li F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015;307:39–52. doi: 10.1016/j.ins.2015.02.024. [DOI] [Google Scholar]
- Yum Y.N., Su I.-F., Law S.P. Early effects of radical position legality in Chinese: An ERP study. Sci. Stud. Read. 2015;19(6):456–467. doi: 10.1080/10888438.2015.1081204. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material
Data Availability Statement
Data will be made available on request.